This guide is specifically designed for hardware resource-constrained environments, particularly configurations with **8GB VRAM + 16/32GB RAM**, providing detailed instructions on how to successfully run Lightx2v 14B models for 480p and 720p video generation.
Lightx2v is a powerful video generation model, but it requires careful optimization to run smoothly in resource-constrained environments. This guide provides a complete solution from hardware selection to software configuration, ensuring you can achieve the best video generation experience under limited hardware conditions.
## 🎯 Target Hardware Configuration
### Recommended Hardware Specifications
**GPU Requirements**:
-**VRAM**: 8GB (RTX 3060/3070/4060/4060Ti, etc.)
-**Architecture**: NVIDIA graphics cards with CUDA support
**System Memory**:
-**Minimum**: 16GB DDR4
-**Recommended**: 32GB DDR4/DDR5
-**Memory Speed**: 3200MHz or higher recommended
**Storage Requirements**:
-**Type**: NVMe SSD strongly recommended
-**Capacity**: At least 50GB available space
-**Speed**: Read speed of 3000MB/s or higher recommended
**CPU Requirements**:
-**Cores**: 8 cores or more recommended
-**Frequency**: 3.0GHz or higher recommended
-**Architecture**: Support for AVX2 instruction set
## ⚙️ Core Optimization Strategies
### 1. Environment Optimization
Before running Lightx2v, it's recommended to set the following environment variables to optimize performance:
-**[14B Model 480p Video Generation Configuration](https://github.com/ModelTC/lightx2v/tree/main/configs/offload/disk/wan_i2v_phase_lazy_load_480p.json)**
-**[14B Model 720p Video Generation Configuration](https://github.com/ModelTC/lightx2v/tree/main/configs/offload/disk/wan_i2v_phase_lazy_load_720p.json)**
-**[1.3B Model 720p Video Generation Configuration](https://github.com/ModelTC/LightX2V/tree/main/configs/offload/block/wan_t2v_1_3b.json)**
- The inference bottleneck for 1.3B models is the T5 encoder, so the configuration file specifically optimizes for T5
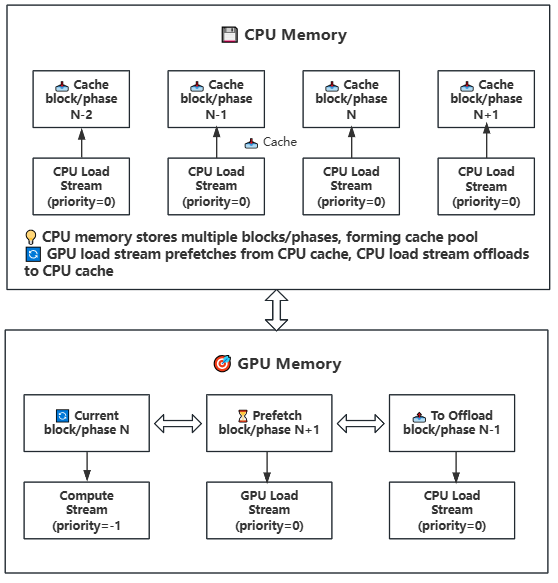
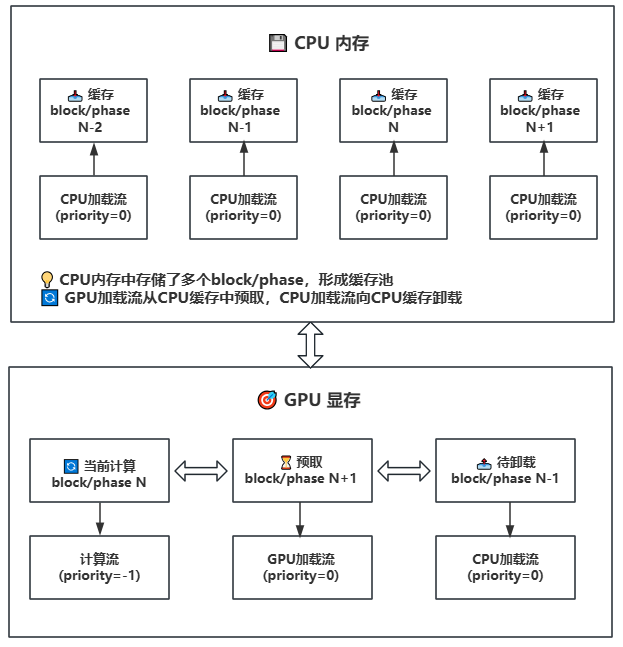
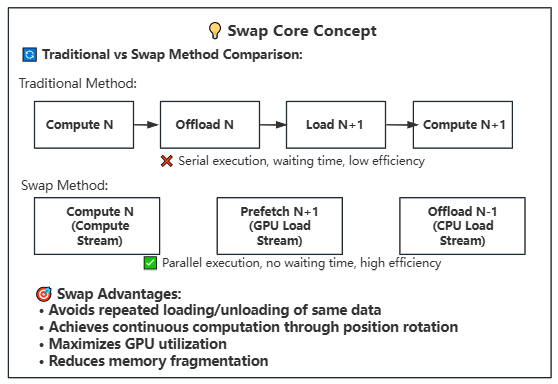
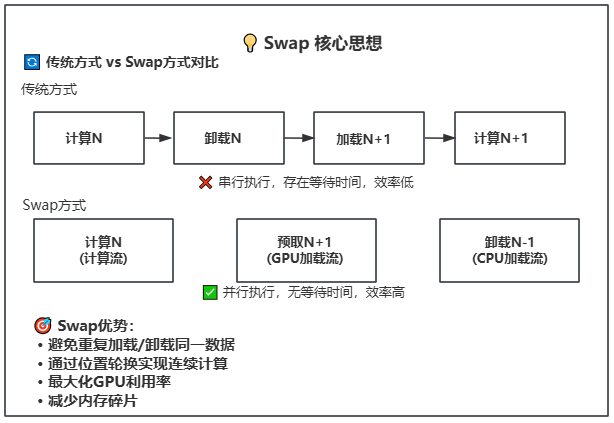
Lightx2v implements an advanced parameter offloading mechanism designed for large model inference under limited hardware resources. This system provides excellent speed-memory balance through intelligent management of model weights across different memory hierarchies.
Lightx2v implements a state-of-the-art parameter offloading mechanism specifically designed for efficient large model inference under limited hardware resources. This system provides excellent speed-memory balance through intelligent management of model weights across different memory hierarchies, enabling dynamic scheduling between GPU, CPU, and disk storage.
**Core Features:**
**Core Features:**
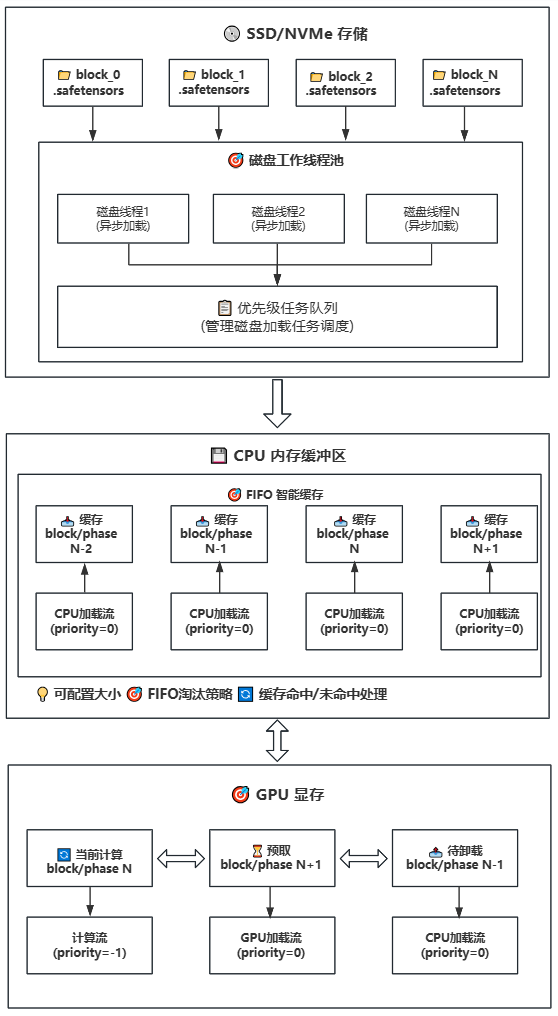
-**Block/Phase Offloading**: Efficiently manages model weights in block/phase units for optimal memory usage
-**Intelligent Granularity Management**: Supports both Block and Phase offloading granularities for flexible memory control
-**Block**: Basic computational unit of Transformer models, containing complete Transformer layers (self-attention, cross-attention, feed-forward networks, etc.), serving as larger memory management units
-**Block Granularity**: Complete Transformer layers as management units, containing self-attention, cross-attention, feed-forward networks, etc., suitable for memory-sufficient environments
-**Phase**: Finer-grained computational stages within blocks, containing individual computational components (such as self-attention, cross-attention, feed-forward networks, etc.), providing more precise memory control
-**Phase Granularity**: Individual computational components as management units, providing finer-grained memory control for memory-constrained deployment scenarios
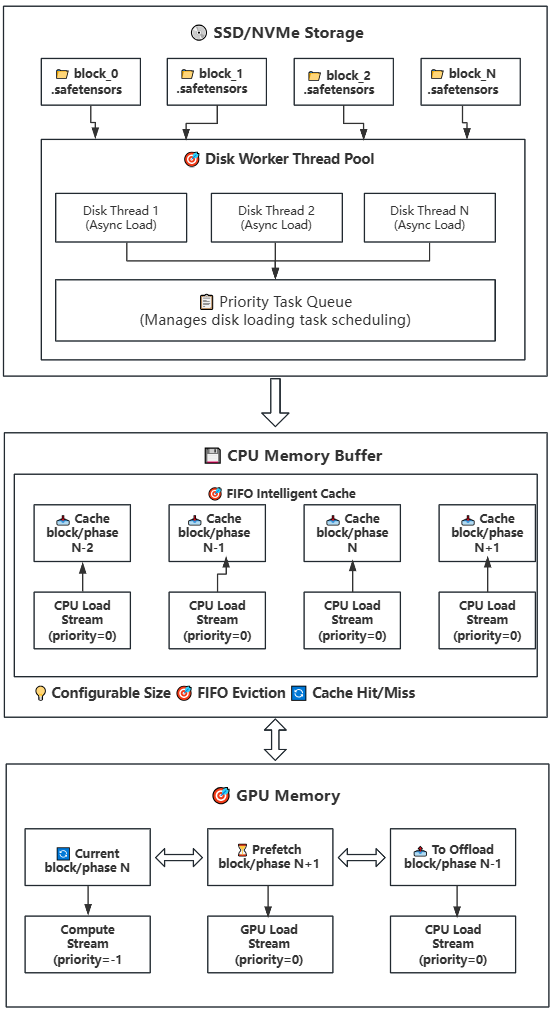
-**Multi-level Storage Support**: GPU → CPU → Disk hierarchy with intelligent caching
-**Multi-level Storage Architecture**: GPU → CPU → Disk three-tier storage hierarchy with intelligent caching strategies
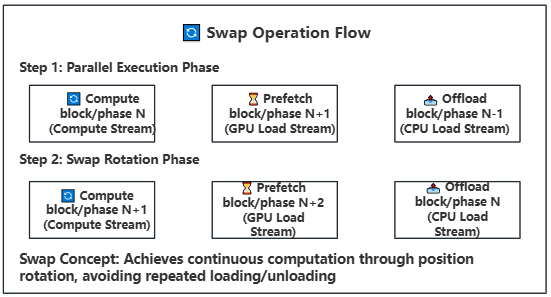
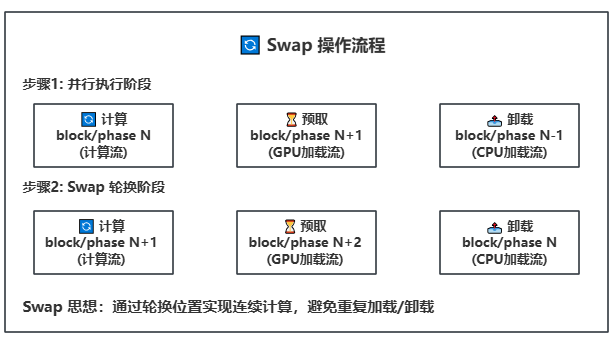
-**Asynchronous Operations**: Uses CUDA streams to overlap computation and data transfer
-**Asynchronous Parallel Processing**: CUDA stream-based asynchronous computation and data transfer for maximum hardware utilization
-**Disk/NVMe Serialization**: Supports secondary storage when memory is insufficient
-**Persistent Storage Support**: SSD/NVMe disk storage support for ultra-large model inference deployment
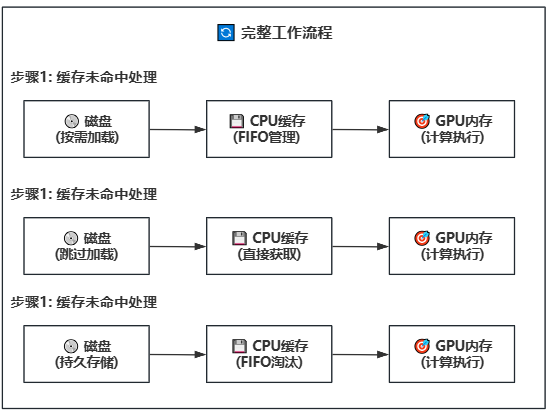
## 🎯 Offloading Strategies
## 🎯 Offloading Strategy Details
### Strategy 1: GPU-CPU Block/Phase Offloading
### Strategy 1: GPU-CPU Granularity Offloading
**Applicable Scenarios**: GPU VRAM insufficient but system memory adequate
**Applicable Scenarios**: GPU VRAM insufficient but system memory resources adequate
**Working Principle**: Manages model weights in block or phase units between GPU and CPU memory, utilizing CUDA streams to overlap computation and data transfer. Blocks contain complete Transformer layers, while phases are individual computational components within blocks.
**Technical Principle**: Establishes efficient weight scheduling mechanism between GPU and CPU memory, managing model weights in Block or Phase units. Leverages CUDA stream asynchronous capabilities to achieve parallel execution of computation and data transfer. Blocks contain complete Transformer layer structures, while Phases correspond to individual computational components within layers.
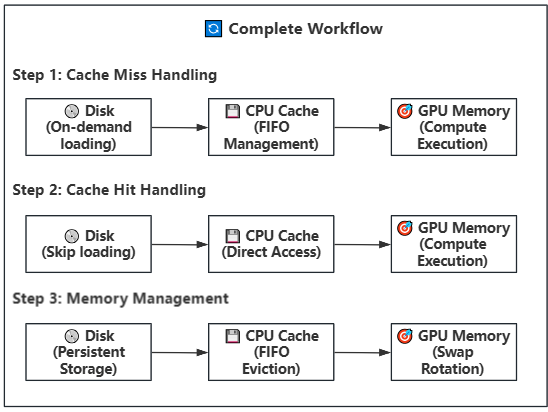
**Working Principle**: Introduces disk storage on top of Strategy 1, implementing a three-level storage hierarchy (Disk → CPU → GPU). CPU continues as a cache pool but with configurable size, suitable for CPU memory-constrained devices.
**Applicable Scenarios**: Both GPU VRAM and system memory resources insufficient in constrained environments
```
**Technical Principle**: Introduces disk storage layer on top of Strategy 1, constructing a Disk→CPU→GPU three-level storage architecture. CPU serves as a configurable intelligent cache pool, suitable for various memory-constrained deployment environments.
- 💾 Disk-CPU-GPU Three-Level Offloading: Suitable for limited GPU VRAM (RTX 3060/4090 8G) and insufficient system memory (16-32G)
- Advantages: Supports ultra-large model inference with lowest hardware threshold
### Common Issues and Solutions
- 🚫 No Offload Mode: Suitable for high-end hardware configurations pursuing optimal inference performance
- Advantages: Maximizes computational efficiency, suitable for latency-sensitive application scenarios
1.**Disk I/O Bottleneck**
## 🔍 Troubleshooting and Solutions
```
Solution: Use NVMe SSD, increase num_disk_workers
```
2.**Memory Buffer Overflow**
### Common Performance Issues and Optimization Strategies
```
Solution: Increase max_memory or decrease num_disk_workers
```
3.**Loading Timeout**
1.**Disk I/O Performance Bottleneck**
```
- Problem Symptoms: Slow model loading speed, high inference latency
Solution: Check disk performance, optimize file system
- Solutions:
```
- Upgrade to NVMe SSD storage devices
- Increase num_disk_workers parameter value
- Optimize file system configuration
**Note**: This offloading mechanism is specifically designed for Lightx2v, fully utilizing modern hardware's asynchronous computing capabilities, significantly reducing the hardware threshold for large model inference.
2.**Memory Buffer Overflow**
- Problem Symptoms: Insufficient system memory, program abnormal exit
- Solutions:
- Increase max_memory parameter value
- Decrease num_disk_workers parameter value
- Adjust offload_granularity to "phase"
3.**Model Loading Timeout**
- Problem Symptoms: Timeout errors during model loading process
- Solutions:
- Check disk read/write performance
- Optimize file system parameters
- Verify storage device health status
## 📚 Technical Summary
Lightx2v's offloading mechanism is specifically designed for modern AI inference scenarios, fully leveraging GPU's asynchronous computing capabilities and multi-level storage architecture advantages. Through intelligent weight management and efficient parallel processing, this mechanism significantly reduces the hardware threshold for large model inference, providing developers with flexible and efficient deployment solutions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}