
first commit
Showing
Too many changes to show.
To preserve performance only 261 of 261+ files are displayed.
{kind=link}
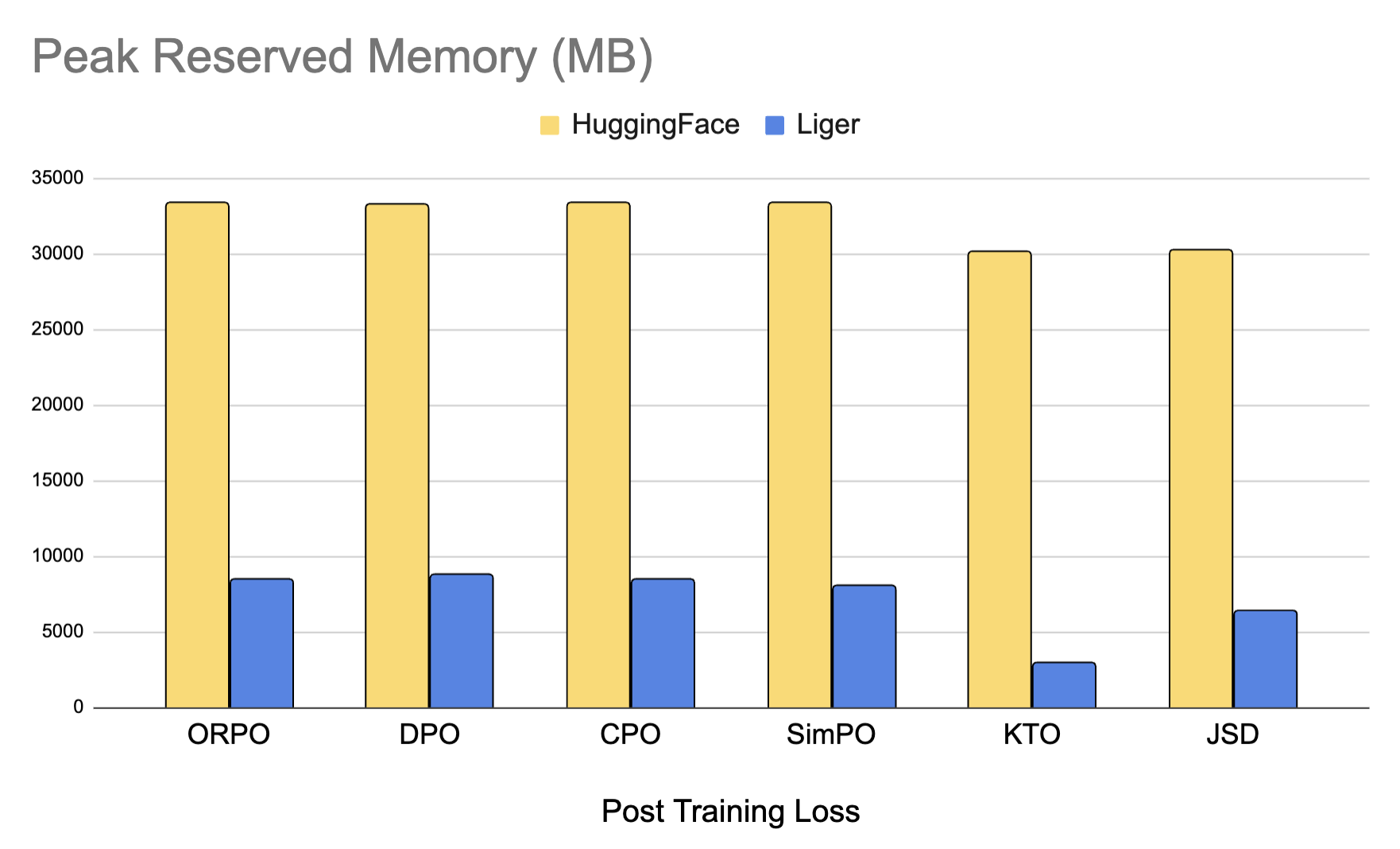
145 KB
docs/index.md
0 → 100755
docs/license.md
0 → 100755
{kind=link}

12.1 KB
{kind=link}
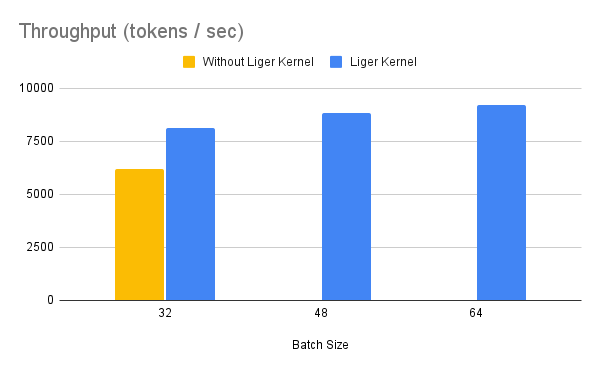
11.8 KB
{kind=link}
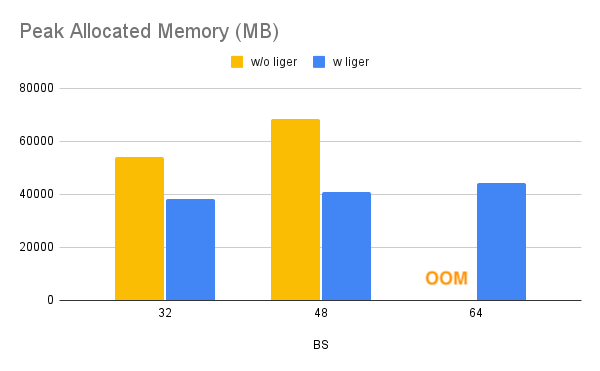
15.1 KB
{kind=link}

15.7 KB
{kind=link}
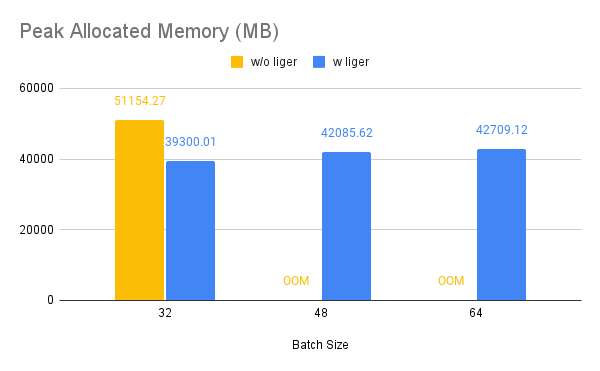
13.7 KB
{kind=link}

15 KB