
first commit
Showing
Too many changes to show.
To preserve performance only 261 of 261+ files are displayed.
benchmark/scripts/utils.py
0 → 100755
dev/fmt-requirements.txt
0 → 100755
dev/modal/benchmarks.py
0 → 100755
dev/modal/tests.py
0 → 100755
docs/Examples.md
0 → 100755
docs/Getting-Started.md
0 → 100755
docs/High-Level-APIs.md
0 → 100755
docs/Low-Level-APIs.md
0 → 100755
docs/acknowledgement.md
0 → 100755
docs/contributing.md
0 → 100755
docs/images/banner.GIF
0 → 100755
{kind=link}
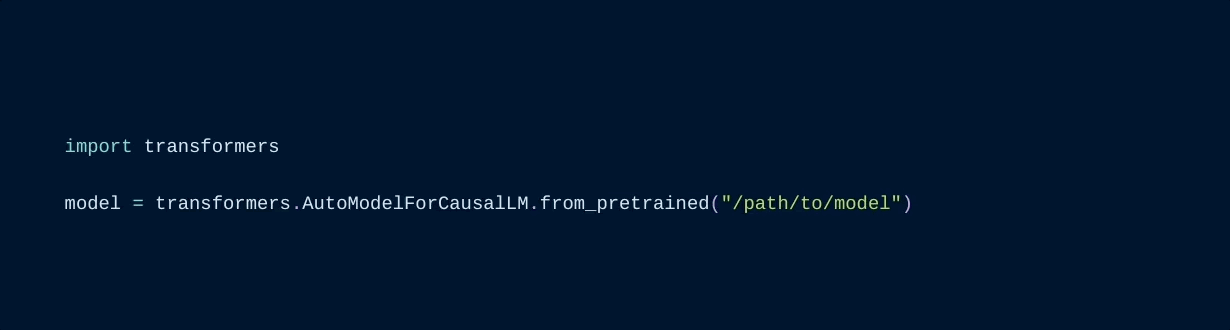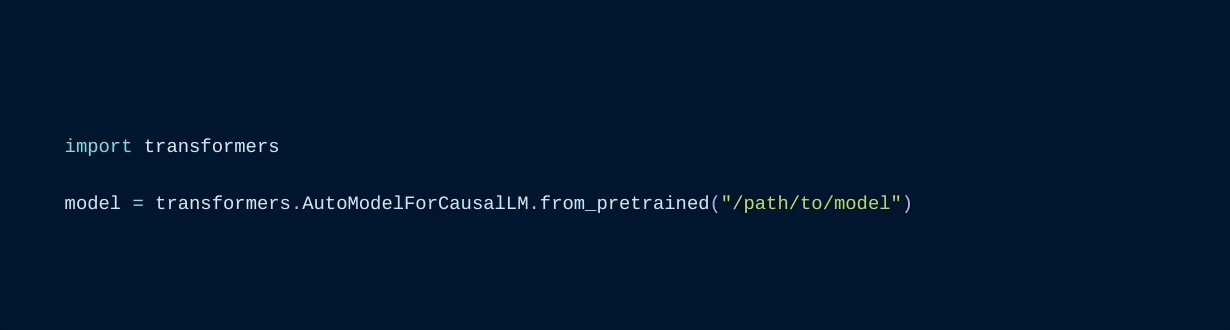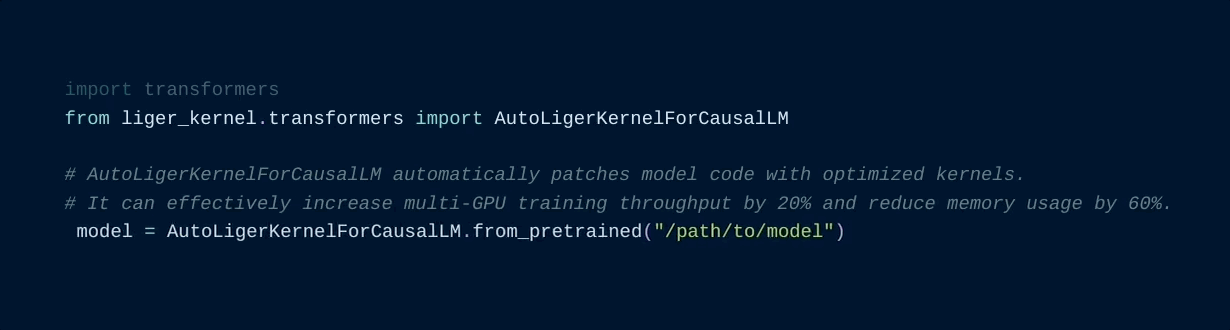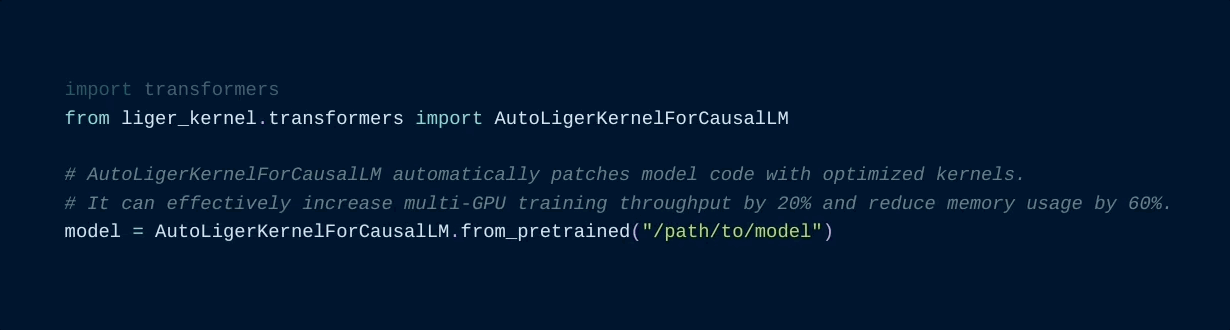
700 KB
docs/images/compose.gif
0 → 100755
{kind=link}

510 KB
docs/images/e2e-memory.png
0 → 100755
{kind=link}

16.7 KB
docs/images/e2e-tps.png
0 → 100755
{kind=link}
15.7 KB
docs/images/logo-banner.png
0 → 100755
{kind=link}
136 KB
docs/images/patch.gif
0 → 100755
{kind=link}

405 KB