
Merge tag 'v0.8.5' into v0.8.5-dev
Showing
csrc/rocm/skinny_gemms.cu
0 → 100644
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
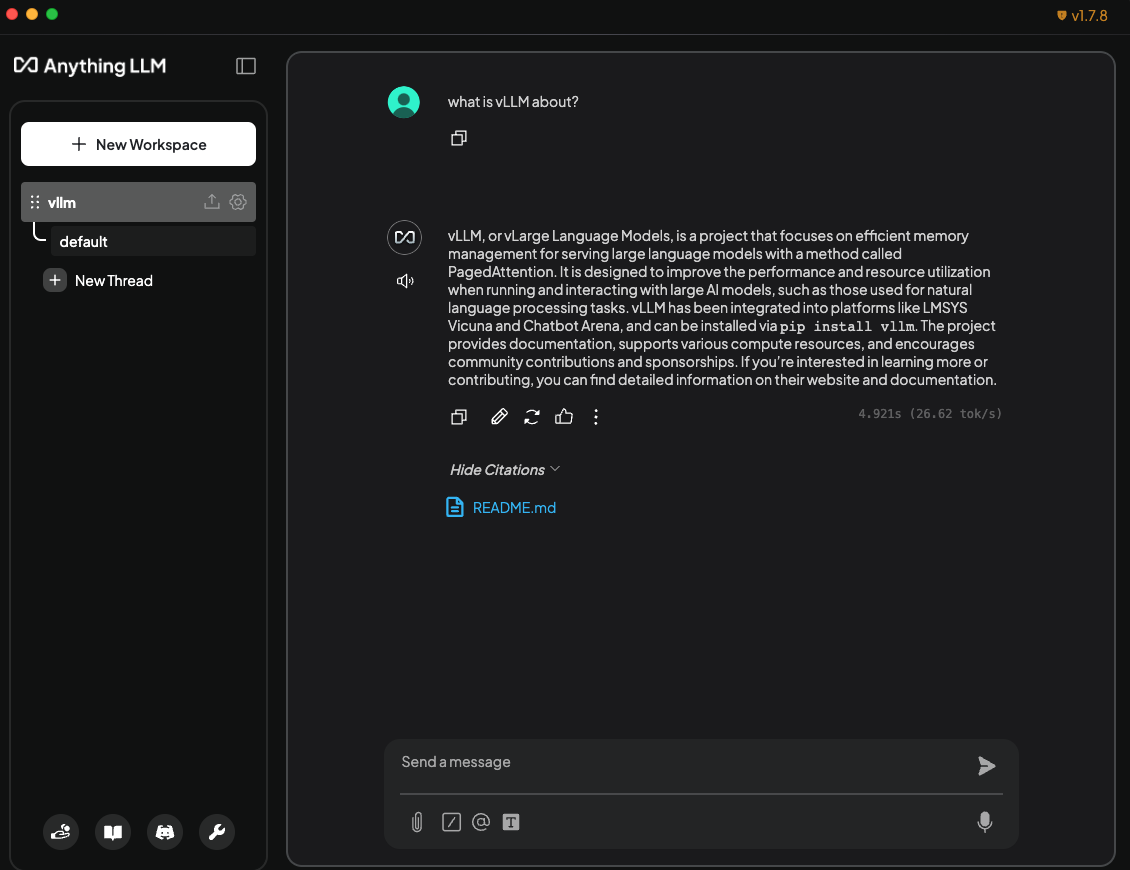
{kind=link}
{kind=link}
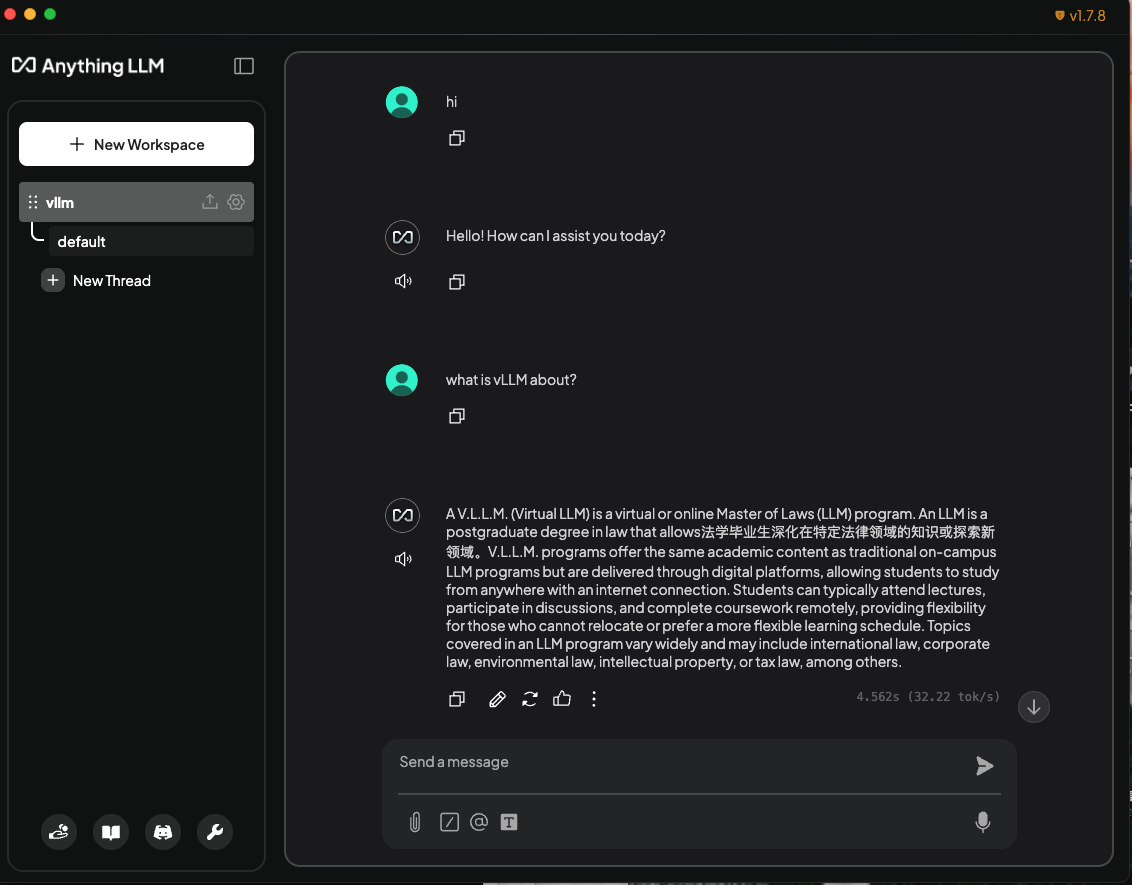
136 KB
{kind=link}
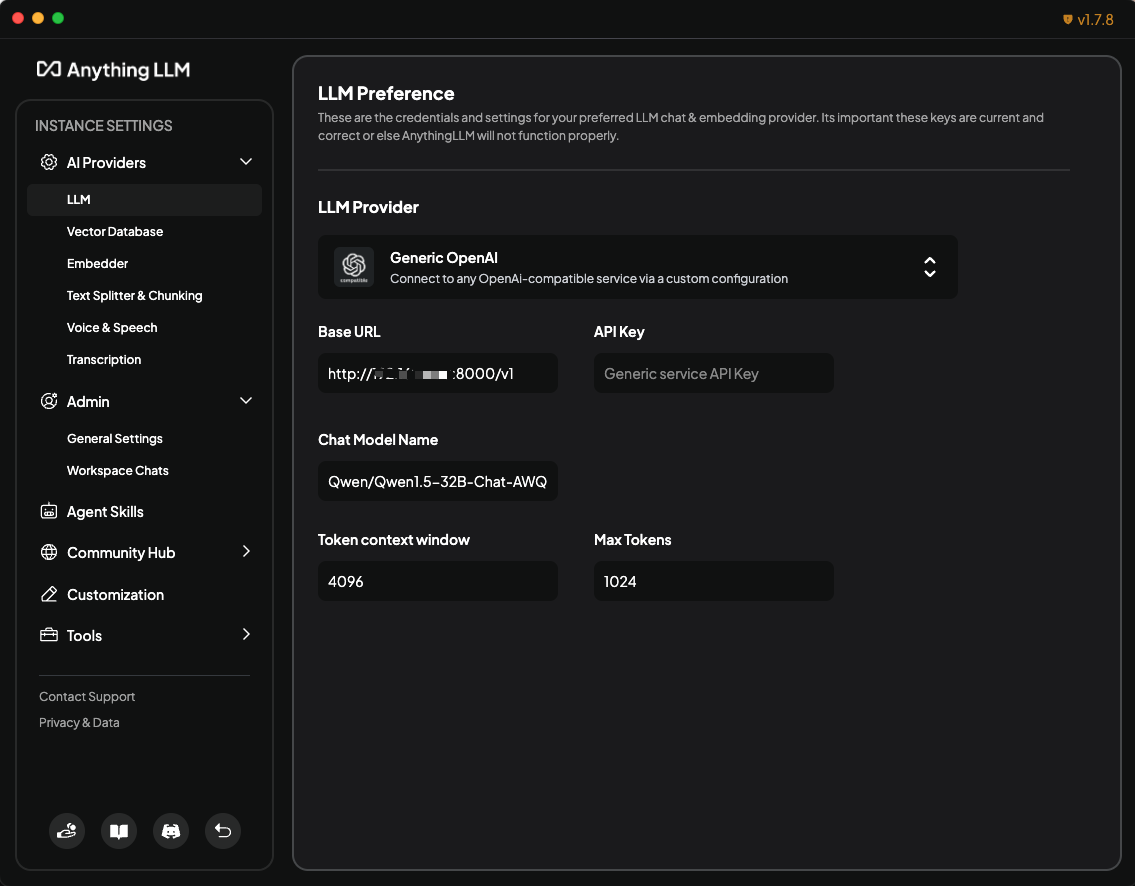
110 KB
136 KB
110 KB