Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in
Toggle navigation
Menu
Open sidebar
OpenDAS
vllm_cscc
Commits
7c4f76e3
Commit
7c4f76e3
authored
Apr 15, 2024
by
zhuwenwen
Browse files
merge v0.4.0
parents
2da0dd3e
51c31bc1
Changes
332
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
399 additions
and
269 deletions
+399
-269
csrc/custom_all_reduce.cuh
csrc/custom_all_reduce.cuh
+75
-152
csrc/custom_all_reduce_test.cu
csrc/custom_all_reduce_test.cu
+108
-76
csrc/moe_align_block_size_kernels.cu
csrc/moe_align_block_size_kernels.cu
+30
-13
csrc/ops.h
csrc/ops.h
+14
-0
csrc/pos_encoding_kernels.cu
csrc/pos_encoding_kernels.cu
+111
-15
csrc/punica/bgmv/bgmv_config.h
csrc/punica/bgmv/bgmv_config.h
+10
-0
csrc/punica/bgmv/generator.py
csrc/punica/bgmv/generator.py
+1
-1
csrc/punica/punica_ops.cc
csrc/punica/punica_ops.cc
+3
-1
csrc/pybind.cpp
csrc/pybind.cpp
+10
-1
csrc/reduction_utils.cuh
csrc/reduction_utils.cuh
+15
-5
docs/requirements-docs.txt
docs/requirements-docs.txt
+7
-0
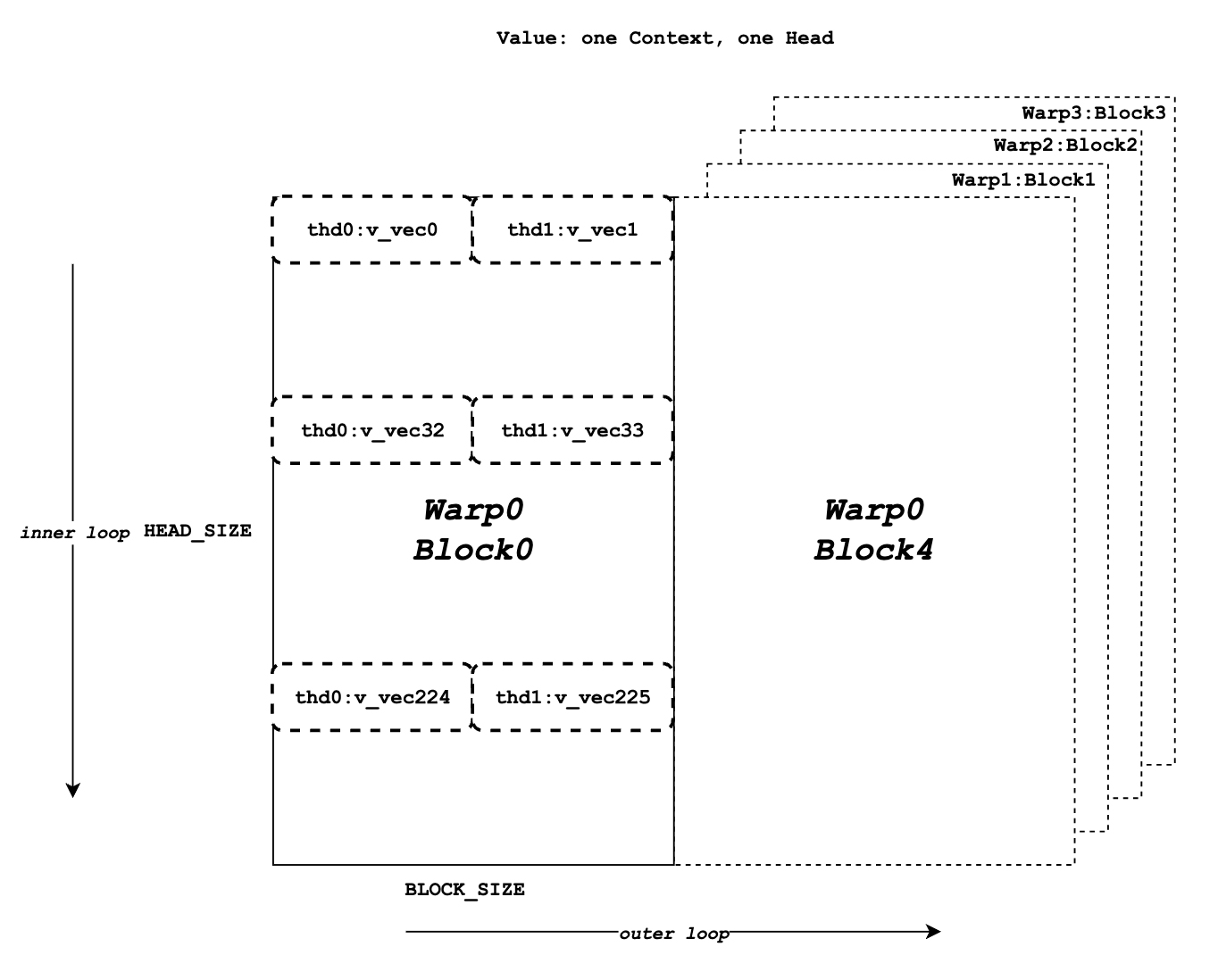
docs/source/assets/kernel/k_vecs.png
docs/source/assets/kernel/k_vecs.png
+0
-0
docs/source/assets/kernel/key.png
docs/source/assets/kernel/key.png
+0
-0
docs/source/assets/kernel/logits_vec.png
docs/source/assets/kernel/logits_vec.png
+0
-0
docs/source/assets/kernel/q_vecs.png
docs/source/assets/kernel/q_vecs.png
+0
-0
docs/source/assets/kernel/query.png
docs/source/assets/kernel/query.png
+0
-0
docs/source/assets/kernel/v_vec.png
docs/source/assets/kernel/v_vec.png
+0
-0
docs/source/assets/kernel/value.png
docs/source/assets/kernel/value.png
+0
-0
docs/source/conf.py
docs/source/conf.py
+14
-4
docs/source/dev/engine/llm_engine.rst
docs/source/dev/engine/llm_engine.rst
+1
-1
No files found.
csrc/custom_all_reduce.cuh
View file @
7c4f76e3
...
@@ -23,29 +23,17 @@
...
@@ -23,29 +23,17 @@
namespace
vllm
{
namespace
vllm
{
constexpr
int
kMaxBlocks
=
64
;
// note: we don't want to use atomics for signals because peer atomics are no
// supported on PCIe links
struct
Signal
{
struct
Signal
{
alignas
(
64
)
union
{
alignas
(
128
)
uint32_t
start
[
kMaxBlocks
][
8
];
uint64_t
flag
;
alignas
(
128
)
uint32_t
end
[
kMaxBlocks
][
8
];
unsigned
char
data
[
8
];
}
start
;
alignas
(
64
)
union
{
uint64_t
flag
;
unsigned
char
data
[
8
];
}
end
;
};
};
struct
Metadata
{
alignas
(
128
)
Signal
sg
;
alignas
(
128
)
int
counter
;
};
static_assert
(
offsetof
(
Metadata
,
counter
)
==
128
);
static_assert
(
sizeof
(
Metadata
)
==
256
);
struct
__align__
(
16
)
RankData
{
const
void
*
__restrict__
ptrs
[
8
];
};
struct
__align__
(
16
)
RankData
{
const
void
*
__restrict__
ptrs
[
8
];
};
struct
RankSignals
{
struct
__align__
(
16
)
RankSignals
{
volatile
Signal
*
signals
[
8
];
};
volatile
Signal
*
signals
[
8
];
};
// like std::array, but aligned
// like std::array, but aligned
template
<
typename
T
,
int
sz
>
template
<
typename
T
,
int
sz
>
...
@@ -135,70 +123,49 @@ DINLINE O downcast(array_t<float, O::size> val) {
...
@@ -135,70 +123,49 @@ DINLINE O downcast(array_t<float, O::size> val) {
}
}
}
}
// compute flag at compile time
// This function is meant to be used as the first synchronization in the all
__host__
__device__
constexpr
uint64_t
compute_flag
(
int
ngpus
)
{
// reduce kernel. Thus, it doesn't need to make any visibility guarantees for
auto
m
=
std
::
numeric_limits
<
uint64_t
>::
max
();
// prior memory accesses. Note: volatile writes will not be reordered against
return
m
>>
((
8
-
ngpus
)
*
8
);
// other volatile writes.
}
template
<
int
ngpus
>
template
<
int
ngpus
>
DINLINE
void
start_sync
(
const
RankSignals
&
sg
,
volatile
Metadata
*
meta
,
DINLINE
void
start_sync
(
const
RankSignals
&
sg
,
volatile
Signal
*
self_sg
,
int
rank
)
{
int
rank
)
{
constexpr
auto
FLAG
=
compute_flag
(
ngpus
);
if
(
threadIdx
.
x
<
ngpus
)
{
if
(
blockIdx
.
x
==
0
)
{
// reset flag for next time
if
(
threadIdx
.
x
<
ngpus
)
self_sg
->
end
[
blockIdx
.
x
][
threadIdx
.
x
]
=
0
;
// simultaneously write to the corresponding byte to all other ranks.
// simultaneously write to the corresponding flag of all ranks.
// Latency = 1 p2p write
// Latency = 1 p2p write
sg
.
signals
[
threadIdx
.
x
]
->
start
.
data
[
rank
]
=
255
;
sg
.
signals
[
threadIdx
.
x
]
->
start
[
blockIdx
.
x
][
rank
]
=
1
;
else
if
(
threadIdx
.
x
==
32
)
// wait until we got true from all ranks
// reset
while
(
!
self_sg
->
start
[
blockIdx
.
x
][
threadIdx
.
x
])
meta
->
sg
.
end
.
flag
=
0
;
}
if
(
threadIdx
.
x
==
0
)
{
while
(
meta
->
sg
.
start
.
flag
!=
FLAG
)
;
;
}
}
__syncthreads
();
__syncthreads
();
}
}
// This function is meant to be used as the second or the final synchronization
// barrier in the all reduce kernel. If it's the final synchronization barrier,
// we don't need to make any visibility guarantees for prior memory accesses.
template
<
int
ngpus
,
bool
final_sync
=
false
>
template
<
int
ngpus
,
bool
final_sync
=
false
>
DINLINE
void
end_sync
(
const
RankSignals
&
sg
,
volatile
Metadata
*
meta
,
DINLINE
void
end_sync
(
const
RankSignals
&
sg
,
volatile
Signal
*
self_sg
,
int
rank
)
{
int
rank
)
{
constexpr
auto
FLAG
=
compute_flag
(
ngpus
);
__syncthreads
();
__syncthreads
();
__shared__
int
num
;
// eliminate the case that prior writes are not visible after signals become
if
(
threadIdx
.
x
==
0
)
num
=
atomicAdd
((
int
*
)
&
meta
->
counter
,
1
);
// visible. Note that I did not managed to make this happen through a lot of
__syncthreads
();
// testing. Might be the case that hardware provides stronger guarantee than
// the memory model.
// Only the last completing block can perform the end synchronization
if
constexpr
(
!
final_sync
)
__threadfence_system
();
// This can ensures when the final busy wait ends, all ranks must have
if
(
threadIdx
.
x
<
ngpus
)
{
// finished reading each other's buffer.
// reset flag for next time
if
(
num
==
gridDim
.
x
-
1
)
{
self_sg
->
start
[
blockIdx
.
x
][
threadIdx
.
x
]
=
0
;
if
(
threadIdx
.
x
==
32
)
{
// simultaneously write to the corresponding flag of all ranks.
// reset in a different warp
// Latency = 1 p2p write
meta
->
counter
=
0
;
sg
.
signals
[
threadIdx
.
x
]
->
end
[
blockIdx
.
x
][
rank
]
=
1
;
meta
->
sg
.
start
.
flag
=
0
;
// wait until we got true from all ranks
}
else
if
(
threadIdx
.
x
<
ngpus
)
{
while
(
!
self_sg
->
end
[
blockIdx
.
x
][
threadIdx
.
x
])
// simultaneously write to the corresponding byte to all other ranks.
;
// Latency = 1 p2p write
sg
.
signals
[
threadIdx
.
x
]
->
end
.
data
[
rank
]
=
255
;
}
// if this is the final sync, only one block needs it
// because kernel exit can serve as sync
if
constexpr
(
final_sync
)
{
if
(
threadIdx
.
x
==
0
)
{
while
(
meta
->
sg
.
end
.
flag
!=
FLAG
)
;
}
}
}
if
constexpr
(
!
final_sync
)
{
if
(
threadIdx
.
x
==
0
)
{
while
(
meta
->
sg
.
end
.
flag
!=
FLAG
)
;
}
__syncthreads
();
}
}
if
constexpr
(
!
final_sync
)
__syncthreads
();
}
}
template
<
typename
P
,
int
ngpus
,
typename
A
>
template
<
typename
P
,
int
ngpus
,
typename
A
>
...
@@ -214,32 +181,32 @@ DINLINE P packed_reduce(const P *ptrs[], int idx) {
...
@@ -214,32 +181,32 @@ DINLINE P packed_reduce(const P *ptrs[], int idx) {
template
<
typename
T
,
int
ngpus
>
template
<
typename
T
,
int
ngpus
>
__global__
void
__launch_bounds__
(
512
,
1
)
__global__
void
__launch_bounds__
(
512
,
1
)
cross_device_reduce_1stage
(
RankData
*
_dp
,
RankSignals
sg
,
cross_device_reduce_1stage
(
RankData
*
_dp
,
RankSignals
sg
,
volatile
Metadata
*
meta
,
T
*
__restrict__
result
,
volatile
Signal
*
self_sg
,
T
*
__restrict__
result
,
int
rank
,
int
size
)
{
int
rank
,
int
size
)
{
using
P
=
typename
packed_t
<
T
>::
P
;
using
P
=
typename
packed_t
<
T
>::
P
;
using
A
=
typename
packed_t
<
T
>::
A
;
using
A
=
typename
packed_t
<
T
>::
A
;
// note: we don't reorder the address so the accumulation order is the same
// note: we don't reorder the address so the accumulation order is the same
// for all ranks, ensuring bitwise identical results
// for all ranks, ensuring bitwise identical results
auto
dp
=
*
_dp
;
auto
dp
=
*
_dp
;
start_sync
<
ngpus
>
(
sg
,
meta
,
rank
);
start_sync
<
ngpus
>
(
sg
,
self_sg
,
rank
);
// do the actual reduction
// do the actual reduction
for
(
int
idx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
idx
<
size
;
for
(
int
idx
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
idx
<
size
;
idx
+=
gridDim
.
x
*
blockDim
.
x
)
{
idx
+=
gridDim
.
x
*
blockDim
.
x
)
{
((
P
*
)
result
)[
idx
]
=
((
P
*
)
result
)[
idx
]
=
packed_reduce
<
P
,
ngpus
,
A
>
((
const
P
**
)
&
dp
.
ptrs
[
0
],
idx
);
packed_reduce
<
P
,
ngpus
,
A
>
((
const
P
**
)
&
dp
.
ptrs
[
0
],
idx
);
}
}
end_sync
<
ngpus
,
true
>
(
sg
,
meta
,
rank
);
end_sync
<
ngpus
,
true
>
(
sg
,
self_sg
,
rank
);
}
}
template
<
typename
P
>
template
<
typename
P
>
DINLINE
P
*
get_tmp_buf
(
volatile
Signal
*
sg
)
{
DINLINE
P
*
get_tmp_buf
(
volatile
Signal
*
sg
)
{
return
(
P
*
)(((
Metadata
*
)
sg
)
+
1
);
return
(
P
*
)(((
Signal
*
)
sg
)
+
1
);
}
}
template
<
typename
T
,
int
ngpus
>
template
<
typename
T
,
int
ngpus
>
__global__
void
__launch_bounds__
(
512
,
1
)
__global__
void
__launch_bounds__
(
512
,
1
)
cross_device_reduce_2stage
(
RankData
*
_dp
,
RankSignals
sg
,
cross_device_reduce_2stage
(
RankData
*
_dp
,
RankSignals
sg
,
volatile
Metadata
*
meta
,
T
*
__restrict__
result
,
volatile
Signal
*
self_sg
,
T
*
__restrict__
result
,
int
rank
,
int
size
)
{
int
rank
,
int
size
)
{
int
tid
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
tid
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
stride
=
gridDim
.
x
*
blockDim
.
x
;
int
stride
=
gridDim
.
x
*
blockDim
.
x
;
...
@@ -248,6 +215,7 @@ __global__ void __launch_bounds__(512, 1)
...
@@ -248,6 +215,7 @@ __global__ void __launch_bounds__(512, 1)
int
part
=
size
/
ngpus
;
int
part
=
size
/
ngpus
;
int
start
=
rank
*
part
;
int
start
=
rank
*
part
;
int
end
=
rank
==
ngpus
-
1
?
size
:
start
+
part
;
int
end
=
rank
==
ngpus
-
1
?
size
:
start
+
part
;
int
largest_part
=
part
+
size
%
ngpus
;
const
P
*
ptrs
[
ngpus
];
const
P
*
ptrs
[
ngpus
];
P
*
tmps
[
ngpus
];
P
*
tmps
[
ngpus
];
#pragma unroll
#pragma unroll
...
@@ -257,75 +225,28 @@ __global__ void __launch_bounds__(512, 1)
...
@@ -257,75 +225,28 @@ __global__ void __launch_bounds__(512, 1)
tmps
[
i
]
=
get_tmp_buf
<
P
>
(
sg
.
signals
[
target
]);
tmps
[
i
]
=
get_tmp_buf
<
P
>
(
sg
.
signals
[
target
]);
}
}
auto
tmp_out
=
tmps
[
0
];
auto
tmp_out
=
tmps
[
0
];
start_sync
<
ngpus
>
(
sg
,
meta
,
rank
);
start_sync
<
ngpus
>
(
sg
,
self_sg
,
rank
);
// stage 1: reduce scatter
// stage 1: reduce scatter
for
(
int
idx
=
start
+
tid
;
idx
<
end
;
idx
+=
stride
)
{
for
(
int
idx
=
start
+
tid
;
idx
<
end
;
idx
+=
stride
)
{
tmp_out
[
idx
-
start
]
=
packed_reduce
<
P
,
ngpus
,
A
>
(
ptrs
,
idx
);
tmp_out
[
idx
-
start
]
=
packed_reduce
<
P
,
ngpus
,
A
>
(
ptrs
,
idx
);
}
}
// Maybe TODO: replace this with per-block release-acquire
end_sync
<
ngpus
>
(
sg
,
self_sg
,
rank
);
// can save about 1-2us (not a lot though)
end_sync
<
ngpus
>
(
sg
,
meta
,
rank
);
// stage 2: allgather. Note: it's important to match the tid between
// the two stages, because visibility across devices is only guaranteed
// stage 2: allgather
// between threads that have the same tid. If thread i computes the sum of
for
(
int
idx
=
tid
;
idx
<
part
;
idx
+=
stride
)
{
// start + i in the first stage, then thread i also gathers start + i from all
// ranks.
for
(
int
idx
=
tid
;
idx
<
largest_part
;
idx
+=
stride
)
{
#pragma unroll
#pragma unroll
for
(
int
i
=
0
;
i
<
ngpus
;
i
++
)
{
for
(
int
i
=
0
;
i
<
ngpus
;
i
++
)
{
int
dst_idx
=
((
rank
+
i
)
%
ngpus
)
*
part
+
idx
;
int
gather_from_rank
=
((
rank
+
i
)
%
ngpus
);
((
P
*
)
result
)[
dst_idx
]
=
tmps
[
i
][
idx
];
if
(
gather_from_rank
==
ngpus
-
1
||
idx
<
part
)
{
}
int
dst_idx
=
gather_from_rank
*
part
+
idx
;
}
((
P
*
)
result
)[
dst_idx
]
=
tmps
[
i
][
idx
];
// process the last larger partition
}
int
remaining
=
size
-
part
*
ngpus
;
if
(
tid
<
remaining
)
{
int
dst_idx
=
tid
+
part
*
ngpus
;
((
P
*
)
result
)[
dst_idx
]
=
get_tmp_buf
<
P
>
(
sg
.
signals
[
ngpus
-
1
])[
part
+
tid
];
}
// faster than this
// for (int idx = tid; idx < size; idx += stride) {
// int target_rank = idx / part;
// if (target_rank == ngpus) target_rank -= 1;
// ((P *)result)[idx] = tmps[target_rank][idx - target_rank * part];
// }
}
template
<
typename
T
,
int
ngpus
>
__global__
void
__launch_bounds__
(
512
,
1
)
cross_device_reduce_half_butterfly
(
RankData
*
_dp
,
RankSignals
sg
,
volatile
Metadata
*
meta
,
T
*
__restrict__
result
,
int
rank
,
int
size
)
{
int
tid
=
blockIdx
.
x
*
blockDim
.
x
+
threadIdx
.
x
;
int
stride
=
gridDim
.
x
*
blockDim
.
x
;
using
P
=
typename
packed_t
<
T
>::
P
;
using
A
=
typename
packed_t
<
T
>::
A
;
auto
tmp_out
=
get_tmp_buf
<
P
>
(
sg
.
signals
[
rank
]);
constexpr
int
hg
=
ngpus
/
2
;
// Actually not quite half butterfly.
// This is an all-to-all within each group containing half of the ranks
// followed by cross-group add. Equivalent to half butterfly when there
// are 4 GPUs, a common case for PCIe cards like T4 and A10.
const
P
*
ptrs
[
hg
];
{
int
start
=
rank
-
rank
%
hg
;
#pragma unroll
for
(
int
i
=
0
;
i
<
hg
;
i
++
)
{
ptrs
[
i
]
=
(
const
P
*
)
_dp
->
ptrs
[
i
+
start
];
}
}
}
}
start_sync
<
ngpus
>
(
sg
,
meta
,
rank
);
for
(
int
idx
=
tid
;
idx
<
size
;
idx
+=
stride
)
{
tmp_out
[
idx
]
=
packed_reduce
<
P
,
hg
,
A
>
(
ptrs
,
idx
);
}
end_sync
<
ngpus
>
(
sg
,
meta
,
rank
);
auto
src
=
get_tmp_buf
<
P
>
(
sg
.
signals
[(
ngpus
-
1
)
-
rank
%
ngpus
]);
// do the cross group reduction
for
(
int
idx
=
tid
;
idx
<
size
;
idx
+=
stride
)
{
auto
tmp
=
tmp_out
[
idx
];
packed_assign_add
(
tmp
,
src
[
idx
]);
((
P
*
)
result
)[
idx
]
=
tmp
;
}
}
}
using
IPC_KEY
=
std
::
array
<
uint8_t
,
sizeof
(
cudaIpcMemHandle_t
)
>
;
using
IPC_KEY
=
std
::
array
<
uint8_t
,
sizeof
(
cudaIpcMemHandle_t
)
>
;
...
@@ -341,7 +262,7 @@ class CustomAllreduce {
...
@@ -341,7 +262,7 @@ class CustomAllreduce {
// below are device pointers
// below are device pointers
RankSignals
sg_
;
RankSignals
sg_
;
std
::
unordered_map
<
void
*
,
RankData
*>
buffers_
;
std
::
unordered_map
<
void
*
,
RankData
*>
buffers_
;
Metadata
*
meta
_
;
Signal
*
self_sg
_
;
// stores the registered device pointers from all ranks
// stores the registered device pointers from all ranks
RankData
*
d_rank_data_base_
,
*
d_rank_data_end_
;
RankData
*
d_rank_data_base_
,
*
d_rank_data_end_
;
...
@@ -352,32 +273,32 @@ class CustomAllreduce {
...
@@ -352,32 +273,32 @@ class CustomAllreduce {
/**
/**
* meta is a pointer to device metadata and temporary buffer for allreduce.
* meta is a pointer to device metadata and temporary buffer for allreduce.
*
*
* There's a total of sizeof(
Metadata
) of prefix before the actual data,
* There's a total of sizeof(
Signal
) of prefix before the actual data,
* so meta + 1 points to actual temporary buffer.
* so meta + 1 points to actual temporary buffer.
*
*
* note: this class does not own any device memory. Any required buffers
* note: this class does not own any device memory. Any required buffers
* are passed in from the constructor
* are passed in from the constructor
*/
*/
CustomAllreduce
(
Metadata
*
meta
,
void
*
rank_data
,
size_t
rank_data_sz
,
CustomAllreduce
(
Signal
*
meta
,
void
*
rank_data
,
size_t
rank_data_sz
,
const
cudaIpcMemHandle_t
*
handles
,
const
cudaIpcMemHandle_t
*
handles
,
const
std
::
vector
<
int64_t
>
&
offsets
,
int
rank
,
const
std
::
vector
<
int64_t
>
&
offsets
,
int
rank
,
bool
full_nvlink
=
true
)
bool
full_nvlink
=
true
)
:
rank_
(
rank
),
:
rank_
(
rank
),
world_size_
(
offsets
.
size
()),
world_size_
(
offsets
.
size
()),
full_nvlink_
(
full_nvlink
),
full_nvlink_
(
full_nvlink
),
meta
_
(
meta
),
self_sg
_
(
meta
),
d_rank_data_base_
(
reinterpret_cast
<
RankData
*>
(
rank_data
)),
d_rank_data_base_
(
reinterpret_cast
<
RankData
*>
(
rank_data
)),
d_rank_data_end_
(
d_rank_data_base_
+
rank_data_sz
/
sizeof
(
RankData
))
{
d_rank_data_end_
(
d_rank_data_base_
+
rank_data_sz
/
sizeof
(
RankData
))
{
for
(
int
i
=
0
;
i
<
world_size_
;
i
++
)
{
for
(
int
i
=
0
;
i
<
world_size_
;
i
++
)
{
Metadata
*
rank_
meta
;
Signal
*
rank_
sg
;
if
(
i
!=
rank_
)
{
if
(
i
!=
rank_
)
{
char
*
handle
=
open_ipc_handle
(
&
handles
[
i
]);
char
*
handle
=
open_ipc_handle
(
&
handles
[
i
]);
handle
+=
offsets
[
i
];
handle
+=
offsets
[
i
];
rank_
meta
=
(
Metadata
*
)
handle
;
rank_
sg
=
(
Signal
*
)
handle
;
}
else
{
}
else
{
rank_
meta
=
meta
_
;
rank_
sg
=
self_sg
_
;
}
}
sg_
.
signals
[
i
]
=
&
rank_
meta
->
sg
;
sg_
.
signals
[
i
]
=
rank_sg
;
}
}
}
}
...
@@ -492,6 +413,10 @@ class CustomAllreduce {
...
@@ -492,6 +413,10 @@ class CustomAllreduce {
"custom allreduce currently requires input length to be multiple "
"custom allreduce currently requires input length to be multiple "
"of "
+
"of "
+
std
::
to_string
(
d
));
std
::
to_string
(
d
));
if
(
block_limit
>
kMaxBlocks
)
throw
std
::
runtime_error
(
"max supported block limit is "
+
std
::
to_string
(
kMaxBlocks
)
+
". Got "
+
std
::
to_string
(
block_limit
));
RankData
*
ptrs
;
RankData
*
ptrs
;
cudaStreamCaptureStatus
status
;
cudaStreamCaptureStatus
status
;
...
@@ -512,9 +437,9 @@ class CustomAllreduce {
...
@@ -512,9 +437,9 @@ class CustomAllreduce {
size
/=
d
;
size
/=
d
;
auto
bytes
=
size
*
sizeof
(
typename
packed_t
<
T
>::
P
);
auto
bytes
=
size
*
sizeof
(
typename
packed_t
<
T
>::
P
);
int
blocks
=
std
::
min
(
block_limit
,
(
size
+
threads
-
1
)
/
threads
);
int
blocks
=
std
::
min
(
block_limit
,
(
size
+
threads
-
1
)
/
threads
);
#define KL(ngpus, name) \
#define KL(ngpus, name)
\
name<T, ngpus>
\
name<T, ngpus>
<<<blocks, threads, 0, stream>>>(ptrs, sg_, self_sg_, output,
\
<<<blocks, threads, 0, stream>>>(ptrs, sg_, meta_, output,
rank_, size);
rank_, size);
#define REDUCE_CASE(ngpus) \
#define REDUCE_CASE(ngpus) \
case ngpus: { \
case ngpus: { \
if (world_size_ == 2) { \
if (world_size_ == 2) { \
...
@@ -526,8 +451,6 @@ class CustomAllreduce {
...
@@ -526,8 +451,6 @@ class CustomAllreduce {
} else { \
} else { \
KL(ngpus, cross_device_reduce_2stage); \
KL(ngpus, cross_device_reduce_2stage); \
} \
} \
} else { \
KL(ngpus, cross_device_reduce_half_butterfly); \
} \
} \
break; \
break; \
}
}
...
@@ -556,7 +479,7 @@ class CustomAllreduce {
...
@@ -556,7 +479,7 @@ class CustomAllreduce {
/**
/**
* To inspect PTX/SASS, copy paste this header file to compiler explorer and add
* To inspect PTX/SASS, copy paste this header file to compiler explorer and add
a template instantiation:
a template instantiation:
* template void CustomAllreduce::allreduce<half>(cudaStream_t, half *,
half *,
* template void
vllm::
CustomAllreduce::allreduce<half>(cudaStream_t, half *,
int, int, int);
half *,
int, int, int);
*/
*/
}
// namespace vllm
}
// namespace vllm
csrc/custom_all_reduce_test.cu
View file @
7c4f76e3
...
@@ -92,7 +92,7 @@ __global__ void gen_data(curandState_t *state, T *data, double *ground_truth,
...
@@ -92,7 +92,7 @@ __global__ void gen_data(curandState_t *state, T *data, double *ground_truth,
template
<
typename
T
>
template
<
typename
T
>
void
run
(
int
myRank
,
int
nRanks
,
ncclComm_t
&
comm
,
int
threads
,
int
block_limit
,
void
run
(
int
myRank
,
int
nRanks
,
ncclComm_t
&
comm
,
int
threads
,
int
block_limit
,
int
data_size
)
{
int
data_size
,
bool
performance_test
)
{
T
*
result
;
T
*
result
;
cudaStream_t
stream
;
cudaStream_t
stream
;
CUDACHECK
(
cudaStreamCreateWithFlags
(
&
stream
,
cudaStreamNonBlocking
));
CUDACHECK
(
cudaStreamCreateWithFlags
(
&
stream
,
cudaStreamNonBlocking
));
...
@@ -101,7 +101,7 @@ void run(int myRank, int nRanks, ncclComm_t &comm, int threads, int block_limit,
...
@@ -101,7 +101,7 @@ void run(int myRank, int nRanks, ncclComm_t &comm, int threads, int block_limit,
cudaIpcMemHandle_t
self_data_handle
;
cudaIpcMemHandle_t
self_data_handle
;
cudaIpcMemHandle_t
data_handles
[
8
];
cudaIpcMemHandle_t
data_handles
[
8
];
vllm
::
Metadata
*
buffer
;
vllm
::
Signal
*
buffer
;
T
*
self_data_copy
;
T
*
self_data_copy
;
/**
/**
* Allocate IPC buffer
* Allocate IPC buffer
...
@@ -115,9 +115,9 @@ void run(int myRank, int nRanks, ncclComm_t &comm, int threads, int block_limit,
...
@@ -115,9 +115,9 @@ void run(int myRank, int nRanks, ncclComm_t &comm, int threads, int block_limit,
* convenience.
* convenience.
*/
*/
CUDACHECK
(
CUDACHECK
(
cudaMalloc
(
&
buffer
,
2
*
data_size
*
sizeof
(
T
)
+
sizeof
(
vllm
::
Metadata
)));
cudaMalloc
(
&
buffer
,
2
*
data_size
*
sizeof
(
T
)
+
sizeof
(
vllm
::
Signal
)));
CUDACHECK
(
cudaMemset
(
buffer
,
0
,
CUDACHECK
(
2
*
data_size
*
sizeof
(
T
)
+
sizeof
(
vllm
::
Metadata
)));
cudaMemset
(
buffer
,
0
,
2
*
data_size
*
sizeof
(
T
)
+
sizeof
(
vllm
::
Signal
)));
CUDACHECK
(
cudaMalloc
(
&
self_data_copy
,
data_size
*
sizeof
(
T
)));
CUDACHECK
(
cudaMalloc
(
&
self_data_copy
,
data_size
*
sizeof
(
T
)));
CUDACHECK
(
cudaIpcGetMemHandle
(
&
self_data_handle
,
buffer
));
CUDACHECK
(
cudaIpcGetMemHandle
(
&
self_data_handle
,
buffer
));
...
@@ -133,7 +133,7 @@ void run(int myRank, int nRanks, ncclComm_t &comm, int threads, int block_limit,
...
@@ -133,7 +133,7 @@ void run(int myRank, int nRanks, ncclComm_t &comm, int threads, int block_limit,
offsets
,
myRank
);
offsets
,
myRank
);
auto
*
self_data
=
auto
*
self_data
=
reinterpret_cast
<
T
*>
(
reinterpret_cast
<
char
*>
(
buffer
)
+
reinterpret_cast
<
T
*>
(
reinterpret_cast
<
char
*>
(
buffer
)
+
sizeof
(
vllm
::
Metadata
)
+
data_size
*
sizeof
(
T
));
sizeof
(
vllm
::
Signal
)
+
data_size
*
sizeof
(
T
));
// hack buffer registration
// hack buffer registration
{
{
std
::
vector
<
std
::
string
>
handles
;
std
::
vector
<
std
::
string
>
handles
;
...
@@ -143,8 +143,8 @@ void run(int myRank, int nRanks, ncclComm_t &comm, int threads, int block_limit,
...
@@ -143,8 +143,8 @@ void run(int myRank, int nRanks, ncclComm_t &comm, int threads, int block_limit,
char
*
end
=
(
char
*
)
&
data_handles
[
i
+
1
];
char
*
end
=
(
char
*
)
&
data_handles
[
i
+
1
];
handles
.
emplace_back
(
begin
,
end
);
handles
.
emplace_back
(
begin
,
end
);
}
}
std
::
vector
<
int64_t
>
offsets
(
std
::
vector
<
int64_t
>
offsets
(
nRanks
,
nRanks
,
sizeof
(
vllm
::
Metadata
)
+
data_size
*
sizeof
(
T
));
sizeof
(
vllm
::
Signal
)
+
data_size
*
sizeof
(
T
));
fa
.
register_buffer
(
handles
,
offsets
,
self_data
);
fa
.
register_buffer
(
handles
,
offsets
,
self_data
);
}
}
...
@@ -169,81 +169,112 @@ void run(int myRank, int nRanks, ncclComm_t &comm, int threads, int block_limit,
...
@@ -169,81 +169,112 @@ void run(int myRank, int nRanks, ncclComm_t &comm, int threads, int block_limit,
}
else
{
}
else
{
ncclDtype
=
ncclFloat
;
ncclDtype
=
ncclFloat
;
}
}
double
*
nccl_result
,
*
my_result
;
CUDACHECK
(
cudaMallocHost
(
&
nccl_result
,
data_size
*
sizeof
(
double
)));
CUDACHECK
(
cudaMallocHost
(
&
my_result
,
data_size
*
sizeof
(
double
)));
if
(
performance_test
)
{
dummy_kernel
<<<
1
,
1
,
0
,
stream
>>>
();
constexpr
int
warmup_iters
=
5
;
constexpr
int
num_iters
=
100
;
// warmup
for
(
int
i
=
0
;
i
<
warmup_iters
;
i
++
)
{
NCCLCHECK
(
ncclAllReduce
(
result
,
result
,
data_size
,
ncclDtype
,
ncclSum
,
comm
,
stream
));
}
CUDACHECK
(
cudaEventRecord
(
start
,
stream
));
for
(
int
i
=
0
;
i
<
num_iters
;
i
++
)
{
NCCLCHECK
(
ncclAllReduce
(
result
,
result
,
data_size
,
ncclDtype
,
ncclSum
,
comm
,
stream
));
}
CUDACHECK
(
cudaEventRecord
(
stop
,
stream
));
CUDACHECK
(
cudaStreamSynchronize
(
stream
));
float
allreduce_ms
=
0
;
cudaEventElapsedTime
(
&
allreduce_ms
,
start
,
stop
);
dummy_kernel
<<<
1
,
1
,
0
,
stream
>>>
();
dummy_kernel
<<<
1
,
1
,
0
,
stream
>>>
();
constexpr
int
warmup_iters
=
5
;
// warm up
constexpr
int
num_iters
=
25
;
for
(
int
i
=
0
;
i
<
warmup_iters
;
i
++
)
{
// warmup
fa
.
allreduce
<
T
>
(
stream
,
self_data
,
result
,
data_size
,
threads
,
for
(
int
i
=
0
;
i
<
warmup_iters
;
i
++
)
{
block_limit
);
NCCLCHECK
(
ncclAllReduce
(
result
,
result
,
data_size
,
ncclDtype
,
ncclSum
,
comm
,
}
stream
));
CUDACHECK
(
cudaEventRecord
(
start
,
stream
));
}
for
(
int
i
=
0
;
i
<
num_iters
;
i
++
)
{
CUDACHECK
(
cudaEventRecord
(
start
,
stream
));
fa
.
allreduce
<
T
>
(
stream
,
self_data
,
result
,
data_size
,
threads
,
for
(
int
i
=
0
;
i
<
num_iters
;
i
++
)
{
block_limit
);
NCCLCHECK
(
ncclAllReduce
(
result
,
result
,
data_size
,
ncclDtype
,
ncclSum
,
comm
,
}
stream
));
CUDACHECK
(
cudaEventRecord
(
stop
,
stream
));
}
CUDACHECK
(
cudaStreamSynchronize
(
stream
));
CUDACHECK
(
cudaEventRecord
(
stop
,
stream
));
CUDACHECK
(
cudaStreamSynchronize
(
stream
));
float
allreduce_ms
=
0
;
cudaEventElapsedTime
(
&
allreduce_ms
,
start
,
stop
);
// if (myRank == 1) dummy_kernel<<<1, 1, 0, stream>>>();
// set_data<T><<<16, 1024, 0, stream>>>(self_data, data_size, myRank);
dummy_kernel
<<<
1
,
1
,
0
,
stream
>>>
();
// warm up
for
(
int
i
=
0
;
i
<
warmup_iters
;
i
++
)
{
fa
.
allreduce
<
T
>
(
stream
,
self_data
,
result
,
data_size
,
threads
,
block_limit
);
}
CUDACHECK
(
cudaEventRecord
(
start
,
stream
));
for
(
int
i
=
0
;
i
<
num_iters
;
i
++
)
{
fa
.
allreduce
<
T
>
(
stream
,
self_data
,
result
,
data_size
,
threads
,
block_limit
);
}
CUDACHECK
(
cudaEventRecord
(
stop
,
stream
));
CUDACHECK
(
cudaStreamSynchronize
(
stream
));
float
duration_ms
=
0
;
cudaEventElapsedTime
(
&
duration_ms
,
start
,
stop
);
if
(
myRank
==
0
)
printf
(
"Rank %d done, nGPUs:%d, sz (kb): %d, %d, %d, my time:%.2fus, nccl "
"time:%.2fus
\n
"
,
myRank
,
nRanks
,
data_size
*
sizeof
(
T
)
/
1024
,
threads
,
block_limit
,
duration_ms
*
1e3
/
num_iters
,
allreduce_ms
*
1e3
/
num_iters
);
// And wait for all the queued up work to complete
float
duration_ms
=
0
;
CUDACHECK
(
cudaStreamSynchronize
(
stream
));
cudaEventElapsedTime
(
&
duration_ms
,
start
,
stop
);
if
(
myRank
==
0
)
printf
(
"Rank %d done, nGPUs:%d, sz (kb): %d, %d, %d, my time:%.2fus, nccl "
"time:%.2fus
\n
"
,
myRank
,
nRanks
,
data_size
*
sizeof
(
T
)
/
1024
,
threads
,
block_limit
,
duration_ms
*
1e3
/
num_iters
,
allreduce_ms
*
1e3
/
num_iters
);
NCCLCHECK
(
ncclAllReduce
(
self_data_copy
,
self_data
,
data_size
,
ncclDtype
,
// And wait for all the queued up work to complete
ncclSum
,
comm
,
stream
));
CUDACHECK
(
cudaStreamSynchronize
(
stream
));
double
*
nccl_result
,
*
my_result
;
NCCLCHECK
(
ncclAllReduce
(
self_data_copy
,
self_data
,
data_size
,
ncclDtype
,
CUDACHECK
(
cudaMallocHost
(
&
nccl_result
,
data_size
*
sizeof
(
double
)));
ncclSum
,
comm
,
stream
));
CUDACHECK
(
cudaMallocHost
(
&
my_result
,
data_size
*
sizeof
(
double
)));
convert_data
<
T
><<<
108
,
1024
,
0
,
stream
>>>
(
self_data
,
result
,
nccl_result
,
convert_data
<
T
><<<
108
,
1024
,
0
,
stream
>>>
(
self_data
,
result
,
nccl_result
,
my_result
,
data_size
);
my_result
,
data_size
);
CUDACHECK
(
cudaStreamSynchronize
(
stream
));
CUDACHECK
(
cudaStreamSynchronize
(
stream
));
for
(
unsigned
long
j
=
0
;
j
<
data_size
;
j
++
)
{
for
(
unsigned
long
j
=
0
;
j
<
data_size
;
j
++
)
{
auto
diff
=
abs
(
nccl_result
[
j
]
-
my_result
[
j
]);
auto
diff
=
abs
(
nccl_result
[
j
]
-
my_result
[
j
]);
if
(
diff
>=
1e-2
)
{
if
(
diff
>=
4e-2
)
{
printf
(
"Rank %d: Verification mismatch at %lld: %f != (my) %f, gt=%f
\n
"
,
printf
(
"Rank %d: Verification mismatch at %lld: %f != (my) %f, gt=%f
\n
"
,
myRank
,
j
,
nccl_result
[
j
],
my_result
[
j
],
ground_truth
[
j
]);
myRank
,
j
,
nccl_result
[
j
],
my_result
[
j
],
ground_truth
[
j
]);
break
;
break
;
}
}
}
}
long
double
nccl_diffs
=
0.0
;
long
double
my_diffs
=
0.0
;
for
(
int
j
=
0
;
j
<
data_size
;
j
++
)
{
nccl_diffs
+=
abs
(
nccl_result
[
j
]
-
ground_truth
[
j
]);
my_diffs
+=
abs
(
my_result
[
j
]
-
ground_truth
[
j
]);
}
if
(
myRank
==
0
)
std
::
cout
<<
"average abs diffs: nccl: "
<<
nccl_diffs
/
data_size
<<
" me: "
<<
my_diffs
/
data_size
<<
std
::
endl
;
}
else
{
for
(
int
i
=
0
;
i
<
100
;
i
++
)
{
fa
.
allreduce
<
T
>
(
stream
,
self_data
,
result
,
data_size
,
threads
,
block_limit
);
CUDACHECK
(
cudaStreamSynchronize
(
stream
));
NCCLCHECK
(
ncclAllReduce
(
self_data
,
self_data_copy
,
data_size
,
ncclDtype
,
ncclSum
,
comm
,
stream
));
convert_data
<
T
><<<
108
,
1024
,
0
,
stream
>>>
(
self_data_copy
,
result
,
nccl_result
,
my_result
,
data_size
);
CUDACHECK
(
cudaStreamSynchronize
(
stream
));
long
double
nccl_diffs
=
0.0
;
for
(
unsigned
long
j
=
0
;
j
<
data_size
;
j
++
)
{
long
double
my_diffs
=
0.0
;
auto
diff
=
abs
(
nccl_result
[
j
]
-
my_result
[
j
]);
for
(
int
j
=
0
;
j
<
data_size
;
j
++
)
{
if
(
diff
>=
4e-2
)
{
nccl_diffs
+=
abs
(
nccl_result
[
j
]
-
ground_truth
[
j
]);
printf
(
my_diffs
+=
abs
(
my_result
[
j
]
-
ground_truth
[
j
]);
"Rank %d: Verification mismatch at %lld: %f != (my) %f, gt=%f
\n
"
,
myRank
,
j
,
nccl_result
[
j
],
my_result
[
j
],
ground_truth
[
j
]);
break
;
}
}
}
if
(
myRank
==
0
)
printf
(
"Test passed: nGPUs:%d, sz (kb): %d, %d, %d
\n
"
,
nRanks
,
data_size
*
sizeof
(
T
)
/
1024
,
threads
,
block_limit
);
// long double nccl_diffs = 0.0;
// long double my_diffs = 0.0;
// for (int j = 0; j < data_size; j++) {
// nccl_diffs += abs(nccl_result[j] - ground_truth[j]);
// my_diffs += abs(my_result[j] - ground_truth[j]);
// }
// if (myRank == 0)
// std::cout << "average abs diffs: nccl: " << nccl_diffs / data_size
// << " me: " << my_diffs / data_size << std::endl;
}
}
if
(
myRank
==
0
)
std
::
cout
<<
"average abs diffs: nccl: "
<<
nccl_diffs
/
data_size
<<
" me: "
<<
my_diffs
/
data_size
<<
std
::
endl
;
CUDACHECK
(
cudaFree
(
result
));
CUDACHECK
(
cudaFree
(
result
));
CUDACHECK
(
cudaFree
(
self_data_copy
));
CUDACHECK
(
cudaFree
(
self_data_copy
));
...
@@ -269,14 +300,15 @@ int main(int argc, char **argv) {
...
@@ -269,14 +300,15 @@ int main(int argc, char **argv) {
MPI_COMM_WORLD
));
MPI_COMM_WORLD
));
NCCLCHECK
(
ncclCommInitRank
(
&
comm
,
nRanks
,
id
,
myRank
));
NCCLCHECK
(
ncclCommInitRank
(
&
comm
,
nRanks
,
id
,
myRank
));
bool
performance_test
=
true
;
cudaProfilerStart
();
cudaProfilerStart
();
// for (int threads : {256, 512}) {
// for (int threads : {256, 512}) {
// for (int block_limit = 16; block_limit < 112; block_limit += 4) {
// for (int block_limit = 16; block_limit < 112; block_limit += 4) {
// run<half>(myRank, nRanks, comm, threads, block_limit, 4096 * 1024);
// run<half>(myRank, nRanks, comm, threads, block_limit, 4096 * 1024);
// }
// }
// }
// }
for
(
int
sz
=
512
;
sz
<=
(
32
<<
20
);
sz
*=
2
)
{
for
(
int
sz
=
512
;
sz
<=
(
8
<<
20
);
sz
*=
2
)
{
run
<
half
>
(
myRank
,
nRanks
,
comm
,
512
,
36
,
sz
+
8
*
50
);
run
<
half
>
(
myRank
,
nRanks
,
comm
,
512
,
36
,
sz
+
8
*
47
,
performance_test
);
}
}
cudaProfilerStop
();
cudaProfilerStop
();
...
...
csrc/moe_align_block_size_kernels.cu
View file @
7c4f76e3
...
@@ -7,10 +7,17 @@
...
@@ -7,10 +7,17 @@
#include "cuda_compat.h"
#include "cuda_compat.h"
#include "dispatch_utils.h"
#include "dispatch_utils.h"
const
static
size_t
NUM_MAX_EXPERTS
=
64
;
#define CEILDIV(x,y) (((x) + (y) - 1) / (y))
#define CEILDIV(x,y) (((x) + (y) - 1) / (y))
namespace
vllm
{
namespace
vllm
{
namespace
{
__device__
__forceinline__
int32_t
index
(
int32_t
total_col
,
int32_t
row
,
int32_t
col
)
{
// don't worry about overflow because num_experts is relatively small
return
row
*
total_col
+
col
;
}
}
template
<
typename
scalar_t
>
template
<
typename
scalar_t
>
__global__
void
moe_align_block_size_kernel
(
scalar_t
*
__restrict__
topk_ids
,
__global__
void
moe_align_block_size_kernel
(
scalar_t
*
__restrict__
topk_ids
,
int32_t
*
sorted_token_ids
,
int32_t
*
sorted_token_ids
,
...
@@ -21,10 +28,14 @@ __global__ void moe_align_block_size_kernel(scalar_t *__restrict__ topk_ids,
...
@@ -21,10 +28,14 @@ __global__ void moe_align_block_size_kernel(scalar_t *__restrict__ topk_ids,
size_t
numel
)
{
size_t
numel
)
{
const
size_t
tokens_per_thread
=
CEILDIV
(
numel
,
blockDim
.
x
);
const
size_t
tokens_per_thread
=
CEILDIV
(
numel
,
blockDim
.
x
);
const
size_t
start_idx
=
threadIdx
.
x
*
tokens_per_thread
;
const
size_t
start_idx
=
threadIdx
.
x
*
tokens_per_thread
;
__shared__
int32_t
tokens_cnts
[
NUM_MAX_EXPERTS
+
1
][
NUM_MAX_EXPERTS
];
__shared__
int32_t
cumsum
[
NUM_MAX_EXPERTS
+
1
];
extern
__shared__
int32_t
shared_mem
[];
int32_t
*
tokens_cnts
=
shared_mem
;
// 2d tensor with shape (num_experts + 1, num_experts)
int32_t
*
cumsum
=
shared_mem
+
(
num_experts
+
1
)
*
num_experts
;
// 1d tensor with shape (num_experts + 1)
for
(
int
i
=
0
;
i
<
num_experts
;
++
i
)
{
for
(
int
i
=
0
;
i
<
num_experts
;
++
i
)
{
tokens_cnts
[
threadIdx
.
x
+
1
][
i
]
=
0
;
tokens_cnts
[
index
(
num_experts
,
threadIdx
.
x
+
1
,
i
)
]
=
0
;
}
}
/**
/**
...
@@ -33,15 +44,15 @@ __global__ void moe_align_block_size_kernel(scalar_t *__restrict__ topk_ids,
...
@@ -33,15 +44,15 @@ __global__ void moe_align_block_size_kernel(scalar_t *__restrict__ topk_ids,
* to expert expert_index.
* to expert expert_index.
*/
*/
for
(
int
i
=
start_idx
;
i
<
numel
&&
i
<
start_idx
+
tokens_per_thread
;
++
i
)
{
for
(
int
i
=
start_idx
;
i
<
numel
&&
i
<
start_idx
+
tokens_per_thread
;
++
i
)
{
++
tokens_cnts
[
threadIdx
.
x
+
1
][
topk_ids
[
i
]];
++
tokens_cnts
[
index
(
num_experts
,
threadIdx
.
x
+
1
,
topk_ids
[
i
]
)
];
}
}
__syncthreads
();
__syncthreads
();
// For each expert we accumulate the token counts from the different threads.
// For each expert we accumulate the token counts from the different threads.
tokens_cnts
[
0
][
threadIdx
.
x
]
=
0
;
tokens_cnts
[
index
(
num_experts
,
0
,
threadIdx
.
x
)
]
=
0
;
for
(
int
i
=
1
;
i
<=
blockDim
.
x
;
++
i
)
{
for
(
int
i
=
1
;
i
<=
blockDim
.
x
;
++
i
)
{
tokens_cnts
[
i
][
threadIdx
.
x
]
+=
tokens_cnts
[
i
-
1
][
threadIdx
.
x
];
tokens_cnts
[
i
ndex
(
num_experts
,
i
,
threadIdx
.
x
)
]
+=
tokens_cnts
[
i
ndex
(
num_experts
,
i
-
1
,
threadIdx
.
x
)
];
}
}
__syncthreads
();
__syncthreads
();
...
@@ -50,7 +61,7 @@ __global__ void moe_align_block_size_kernel(scalar_t *__restrict__ topk_ids,
...
@@ -50,7 +61,7 @@ __global__ void moe_align_block_size_kernel(scalar_t *__restrict__ topk_ids,
if
(
threadIdx
.
x
==
0
)
{
if
(
threadIdx
.
x
==
0
)
{
cumsum
[
0
]
=
0
;
cumsum
[
0
]
=
0
;
for
(
int
i
=
1
;
i
<=
num_experts
;
++
i
)
{
for
(
int
i
=
1
;
i
<=
num_experts
;
++
i
)
{
cumsum
[
i
]
=
cumsum
[
i
-
1
]
+
CEILDIV
(
tokens_cnts
[
blockDim
.
x
][
i
-
1
],
block_size
)
*
block_size
;
cumsum
[
i
]
=
cumsum
[
i
-
1
]
+
CEILDIV
(
tokens_cnts
[
index
(
num_experts
,
blockDim
.
x
,
i
-
1
)
],
block_size
)
*
block_size
;
}
}
*
total_tokens_post_pad
=
cumsum
[
num_experts
];
*
total_tokens_post_pad
=
cumsum
[
num_experts
];
}
}
...
@@ -78,9 +89,9 @@ __global__ void moe_align_block_size_kernel(scalar_t *__restrict__ topk_ids,
...
@@ -78,9 +89,9 @@ __global__ void moe_align_block_size_kernel(scalar_t *__restrict__ topk_ids,
* stores the indices of the tokens processed by the expert with expert_id within
* stores the indices of the tokens processed by the expert with expert_id within
* the current thread's token shard.
* the current thread's token shard.
*/
*/
int32_t
rank_post_pad
=
tokens_cnts
[
threadIdx
.
x
][
expert_id
]
+
cumsum
[
expert_id
];
int32_t
rank_post_pad
=
tokens_cnts
[
index
(
num_experts
,
threadIdx
.
x
,
expert_id
)
]
+
cumsum
[
expert_id
];
sorted_token_ids
[
rank_post_pad
]
=
i
;
sorted_token_ids
[
rank_post_pad
]
=
i
;
++
tokens_cnts
[
threadIdx
.
x
][
expert_id
];
++
tokens_cnts
[
index
(
num_experts
,
threadIdx
.
x
,
expert_id
)
];
}
}
}
}
}
}
...
@@ -93,11 +104,17 @@ void moe_align_block_size(
...
@@ -93,11 +104,17 @@ void moe_align_block_size(
torch
::
Tensor
experts_ids
,
torch
::
Tensor
experts_ids
,
torch
::
Tensor
num_tokens_post_pad
)
{
torch
::
Tensor
num_tokens_post_pad
)
{
const
cudaStream_t
stream
=
at
::
cuda
::
getCurrentCUDAStream
();
const
cudaStream_t
stream
=
at
::
cuda
::
getCurrentCUDAStream
();
assert
(
num_experts
<=
NUM_MAX_EXPERTS
);
VLLM_DISPATCH_INTEGRAL_TYPES
(
VLLM_DISPATCH_INTEGRAL_TYPES
(
topk_ids
.
scalar_type
(),
"moe_align_block_size_kernel"
,
[
&
]
{
topk_ids
.
scalar_type
(),
"moe_align_block_size_kernel"
,
[
&
]
{
vllm
::
moe_align_block_size_kernel
<
scalar_t
><<<
1
,
num_experts
,
0
,
stream
>>>
(
// calc needed amount of shared mem for `tokens_cnts` and `cumsum` tensors
topk_ids
.
data_ptr
<
scalar_t
>
(),
const
int32_t
shared_mem
=
((
num_experts
+
1
)
*
num_experts
+
(
num_experts
+
1
))
*
sizeof
(
int32_t
);
// set dynamic shared mem
auto
kernel
=
vllm
::
moe_align_block_size_kernel
<
scalar_t
>
;
AT_CUDA_CHECK
(
VLLM_DevFuncAttribute_SET_MaxDynamicSharedMemorySize
((
void
*
)
kernel
,
shared_mem
));
kernel
<<<
1
,
num_experts
,
shared_mem
,
stream
>>>
(
topk_ids
.
data_ptr
<
scalar_t
>
(),
sorted_token_ids
.
data_ptr
<
int32_t
>
(),
sorted_token_ids
.
data_ptr
<
int32_t
>
(),
experts_ids
.
data_ptr
<
int32_t
>
(),
experts_ids
.
data_ptr
<
int32_t
>
(),
num_tokens_post_pad
.
data_ptr
<
int32_t
>
(),
num_tokens_post_pad
.
data_ptr
<
int32_t
>
(),
...
...
csrc/ops.h
View file @
7c4f76e3
...
@@ -53,6 +53,16 @@ void rotary_embedding(
...
@@ -53,6 +53,16 @@ void rotary_embedding(
torch
::
Tensor
&
cos_sin_cache
,
torch
::
Tensor
&
cos_sin_cache
,
bool
is_neox
);
bool
is_neox
);
void
batched_rotary_embedding
(
torch
::
Tensor
&
positions
,
torch
::
Tensor
&
query
,
torch
::
Tensor
&
key
,
int
head_size
,
torch
::
Tensor
&
cos_sin_cache
,
bool
is_neox
,
int
rot_dim
,
torch
::
Tensor
&
cos_sin_cache_offsets
);
void
silu_and_mul
(
void
silu_and_mul
(
torch
::
Tensor
&
out
,
torch
::
Tensor
&
out
,
torch
::
Tensor
&
input
);
torch
::
Tensor
&
input
);
...
@@ -61,6 +71,10 @@ void gelu_and_mul(
...
@@ -61,6 +71,10 @@ void gelu_and_mul(
torch
::
Tensor
&
out
,
torch
::
Tensor
&
out
,
torch
::
Tensor
&
input
);
torch
::
Tensor
&
input
);
void
gelu_tanh_and_mul
(
torch
::
Tensor
&
out
,
torch
::
Tensor
&
input
);
void
gelu_new
(
void
gelu_new
(
torch
::
Tensor
&
out
,
torch
::
Tensor
&
out
,
torch
::
Tensor
&
input
);
torch
::
Tensor
&
input
);
...
...
csrc/pos_encoding_kernels.cu
View file @
7c4f76e3
...
@@ -8,7 +8,7 @@
...
@@ -8,7 +8,7 @@
namespace
vllm
{
namespace
vllm
{
template
<
typename
scalar_t
,
bool
IS_NEOX
>
template
<
typename
scalar_t
,
bool
IS_NEOX
>
inline
__device__
void
apply_rotary_embedding
(
inline
__device__
void
apply_
token_
rotary_embedding
(
scalar_t
*
__restrict__
arr
,
scalar_t
*
__restrict__
arr
,
const
scalar_t
*
__restrict__
cos_ptr
,
const
scalar_t
*
__restrict__
cos_ptr
,
const
scalar_t
*
__restrict__
sin_ptr
,
const
scalar_t
*
__restrict__
sin_ptr
,
...
@@ -38,22 +38,18 @@ inline __device__ void apply_rotary_embedding(
...
@@ -38,22 +38,18 @@ inline __device__ void apply_rotary_embedding(
}
}
template
<
typename
scalar_t
,
bool
IS_NEOX
>
template
<
typename
scalar_t
,
bool
IS_NEOX
>
__global__
void
rotary_embedding_kernel
(
inline
__device__
void
apply_rotary_embedding
(
const
int64_t
*
__restrict__
positions
,
// [batch_size, seq_len] or [num_tokens]
scalar_t
*
__restrict__
query
,
// [batch_size, seq_len, num_heads, head_size] or [num_tokens, num_heads, head_size]
scalar_t
*
__restrict__
query
,
// [batch_size, seq_len, num_heads, head_size] or [num_tokens, num_heads, head_size]
scalar_t
*
__restrict__
key
,
// [batch_size, seq_len, num_kv_heads, head_size] or [num_tokens, num_kv_heads, head_size]
scalar_t
*
__restrict__
key
,
// [batch_size, seq_len, num_kv_heads, head_size] or [num_tokens, num_kv_heads, head_size]
const
scalar_t
*
__restrict__
cos_sin_cache
,
// [max_position, 2, rot_dim // 2]
const
scalar_t
*
cache_ptr
,
const
int
rot_dim
,
const
int
head_size
,
const
int64_t
query_stride
,
const
int64_t
key_stride
,
const
int
num_heads
,
const
int
num_heads
,
const
int
num_kv_heads
,
const
int
num_kv_heads
,
const
int
head_size
)
{
const
int
rot_dim
,
// Each thread block is responsible for one token.
const
int
token_idx
,
const
int
token_idx
=
blockIdx
.
x
;
const
int64_t
query_stride
,
int64_t
pos
=
positions
[
token_idx
];
const
int64_t
key_stride
)
const
scalar_t
*
cache_ptr
=
cos_sin_cache
+
pos
*
rot_dim
;
{
const
int
embed_dim
=
rot_dim
/
2
;
const
int
embed_dim
=
rot_dim
/
2
;
const
scalar_t
*
cos_ptr
=
cache_ptr
;
const
scalar_t
*
cos_ptr
=
cache_ptr
;
const
scalar_t
*
sin_ptr
=
cache_ptr
+
embed_dim
;
const
scalar_t
*
sin_ptr
=
cache_ptr
+
embed_dim
;
...
@@ -63,7 +59,7 @@ __global__ void rotary_embedding_kernel(
...
@@ -63,7 +59,7 @@ __global__ void rotary_embedding_kernel(
const
int
head_idx
=
i
/
embed_dim
;
const
int
head_idx
=
i
/
embed_dim
;
const
int64_t
token_head
=
token_idx
*
query_stride
+
head_idx
*
head_size
;
const
int64_t
token_head
=
token_idx
*
query_stride
+
head_idx
*
head_size
;
const
int
rot_offset
=
i
%
embed_dim
;
const
int
rot_offset
=
i
%
embed_dim
;
apply_rotary_embedding
<
scalar_t
,
IS_NEOX
>
(
query
+
token_head
,
cos_ptr
,
apply_
token_
rotary_embedding
<
scalar_t
,
IS_NEOX
>
(
query
+
token_head
,
cos_ptr
,
sin_ptr
,
rot_offset
,
embed_dim
);
sin_ptr
,
rot_offset
,
embed_dim
);
}
}
...
@@ -72,11 +68,53 @@ __global__ void rotary_embedding_kernel(
...
@@ -72,11 +68,53 @@ __global__ void rotary_embedding_kernel(
const
int
head_idx
=
i
/
embed_dim
;
const
int
head_idx
=
i
/
embed_dim
;
const
int64_t
token_head
=
token_idx
*
key_stride
+
head_idx
*
head_size
;
const
int64_t
token_head
=
token_idx
*
key_stride
+
head_idx
*
head_size
;
const
int
rot_offset
=
i
%
embed_dim
;
const
int
rot_offset
=
i
%
embed_dim
;
apply_rotary_embedding
<
scalar_t
,
IS_NEOX
>
(
key
+
token_head
,
cos_ptr
,
apply_
token_
rotary_embedding
<
scalar_t
,
IS_NEOX
>
(
key
+
token_head
,
cos_ptr
,
sin_ptr
,
rot_offset
,
embed_dim
);
sin_ptr
,
rot_offset
,
embed_dim
);
}
}
}
}
template
<
typename
scalar_t
,
bool
IS_NEOX
>
__global__
void
rotary_embedding_kernel
(
const
int64_t
*
__restrict__
positions
,
// [batch_size, seq_len] or [num_tokens]
scalar_t
*
__restrict__
query
,
// [batch_size, seq_len, num_heads, head_size] or [num_tokens, num_heads, head_size]
scalar_t
*
__restrict__
key
,
// [batch_size, seq_len, num_kv_heads, head_size] or [num_tokens, num_kv_heads, head_size]
const
scalar_t
*
__restrict__
cos_sin_cache
,
// [max_position, 2, rot_dim // 2]
const
int
rot_dim
,
const
int64_t
query_stride
,
const
int64_t
key_stride
,
const
int
num_heads
,
const
int
num_kv_heads
,
const
int
head_size
)
{
// Each thread block is responsible for one token.
const
int
token_idx
=
blockIdx
.
x
;
int64_t
pos
=
positions
[
token_idx
];
const
scalar_t
*
cache_ptr
=
cos_sin_cache
+
pos
*
rot_dim
;
apply_rotary_embedding
<
scalar_t
,
IS_NEOX
>
(
query
,
key
,
cache_ptr
,
head_size
,
num_heads
,
num_kv_heads
,
rot_dim
,
token_idx
,
query_stride
,
key_stride
);
}
template
<
typename
scalar_t
,
bool
IS_NEOX
>
__global__
void
batched_rotary_embedding_kernel
(
const
int64_t
*
__restrict__
positions
,
// [batch_size, seq_len] or [num_tokens]
scalar_t
*
__restrict__
query
,
// [batch_size, seq_len, num_heads, head_size] or [num_tokens, num_heads, head_size]
scalar_t
*
__restrict__
key
,
// [batch_size, seq_len, num_kv_heads, head_size] or [num_tokens, num_kv_heads, head_size]
const
scalar_t
*
__restrict__
cos_sin_cache
,
// [max_position, 2, rot_dim // 2]
const
int64_t
*
__restrict__
cos_sin_cache_offsets
,
// [batch_size, seq_len] or [num_tokens]
const
int
rot_dim
,
const
int64_t
query_stride
,
const
int64_t
key_stride
,
const
int
num_heads
,
const
int
num_kv_heads
,
const
int
head_size
)
{
// Each thread block is responsible for one token.
const
int
token_idx
=
blockIdx
.
x
;
int64_t
pos
=
positions
[
token_idx
];
int64_t
cos_sin_cache_offset
=
cos_sin_cache_offsets
[
token_idx
];
const
scalar_t
*
cache_ptr
=
cos_sin_cache
+
(
cos_sin_cache_offset
+
pos
)
*
rot_dim
;
apply_rotary_embedding
<
scalar_t
,
IS_NEOX
>
(
query
,
key
,
cache_ptr
,
head_size
,
num_heads
,
num_kv_heads
,
rot_dim
,
token_idx
,
query_stride
,
key_stride
);
}
}
// namespace vllm
}
// namespace vllm
void
rotary_embedding
(
void
rotary_embedding
(
...
@@ -128,3 +166,61 @@ void rotary_embedding(
...
@@ -128,3 +166,61 @@ void rotary_embedding(
}
}
});
});
}
}
/*
Batched version of rotary embedding, pack multiple LoRAs together
and process in batched manner.
*/
void
batched_rotary_embedding
(
torch
::
Tensor
&
positions
,
// [batch_size, seq_len] or [num_tokens]
torch
::
Tensor
&
query
,
// [batch_size, seq_len, num_heads * head_size] or [num_tokens, num_heads * head_size]
torch
::
Tensor
&
key
,
// [batch_size, seq_len, num_kv_heads * head_size] or [num_tokens, num_kv_heads * head_size]
int
head_size
,
torch
::
Tensor
&
cos_sin_cache
,
// [max_position, rot_dim]
bool
is_neox
,
int
rot_dim
,
torch
::
Tensor
&
cos_sin_cache_offsets
// [num_tokens]
)
{
int64_t
num_tokens
=
cos_sin_cache_offsets
.
size
(
0
);
int
num_heads
=
query
.
size
(
-
1
)
/
head_size
;
int
num_kv_heads
=
key
.
size
(
-
1
)
/
head_size
;
int64_t
query_stride
=
query
.
stride
(
-
2
);
int64_t
key_stride
=
key
.
stride
(
-
2
);
dim3
grid
(
num_tokens
);
dim3
block
(
std
::
min
(
num_heads
*
rot_dim
/
2
,
512
));
const
at
::
cuda
::
OptionalCUDAGuard
device_guard
(
device_of
(
query
));
const
cudaStream_t
stream
=
at
::
cuda
::
getCurrentCUDAStream
();
VLLM_DISPATCH_FLOATING_TYPES
(
query
.
scalar_type
(),
"rotary_embedding"
,
[
&
]
{
if
(
is_neox
)
{
vllm
::
batched_rotary_embedding_kernel
<
scalar_t
,
true
><<<
grid
,
block
,
0
,
stream
>>>
(
positions
.
data_ptr
<
int64_t
>
(),
query
.
data_ptr
<
scalar_t
>
(),
key
.
data_ptr
<
scalar_t
>
(),
cos_sin_cache
.
data_ptr
<
scalar_t
>
(),
cos_sin_cache_offsets
.
data_ptr
<
int64_t
>
(),
rot_dim
,
query_stride
,
key_stride
,
num_heads
,
num_kv_heads
,
head_size
);
}
else
{
vllm
::
batched_rotary_embedding_kernel
<
scalar_t
,
false
><<<
grid
,
block
,
0
,
stream
>>>
(
positions
.
data_ptr
<
int64_t
>
(),
query
.
data_ptr
<
scalar_t
>
(),
key
.
data_ptr
<
scalar_t
>
(),
cos_sin_cache
.
data_ptr
<
scalar_t
>
(),
cos_sin_cache_offsets
.
data_ptr
<
int64_t
>
(),
rot_dim
,
query_stride
,
key_stride
,
num_heads
,
num_kv_heads
,
head_size
);
}
});
}
csrc/punica/bgmv/bgmv_config.h
View file @
7c4f76e3
...
@@ -14,21 +14,28 @@ void bgmv_kernel(out_T *__restrict__ Y, const in_T *__restrict__ X,
...
@@ -14,21 +14,28 @@ void bgmv_kernel(out_T *__restrict__ Y, const in_T *__restrict__ X,
f(in_T, out_T, W_T, narrow, 128) \
f(in_T, out_T, W_T, narrow, 128) \
f(in_T, out_T, W_T, narrow, 256) \
f(in_T, out_T, W_T, narrow, 256) \
f(in_T, out_T, W_T, narrow, 512) \
f(in_T, out_T, W_T, narrow, 512) \
f(in_T, out_T, W_T, narrow, 768) \
f(in_T, out_T, W_T, narrow, 1024) \
f(in_T, out_T, W_T, narrow, 1024) \
f(in_T, out_T, W_T, narrow, 1152) \
f(in_T, out_T, W_T, narrow, 1280) \
f(in_T, out_T, W_T, narrow, 1280) \
f(in_T, out_T, W_T, narrow, 1536) \
f(in_T, out_T, W_T, narrow, 1728) \
f(in_T, out_T, W_T, narrow, 1728) \
f(in_T, out_T, W_T, narrow, 1792) \
f(in_T, out_T, W_T, narrow, 1792) \
f(in_T, out_T, W_T, narrow, 2048) \
f(in_T, out_T, W_T, narrow, 2048) \
f(in_T, out_T, W_T, narrow, 2304) \
f(in_T, out_T, W_T, narrow, 2560) \
f(in_T, out_T, W_T, narrow, 2560) \
f(in_T, out_T, W_T, narrow, 2752) \
f(in_T, out_T, W_T, narrow, 2752) \
f(in_T, out_T, W_T, narrow, 2816) \
f(in_T, out_T, W_T, narrow, 3072) \
f(in_T, out_T, W_T, narrow, 3072) \
f(in_T, out_T, W_T, narrow, 3456) \
f(in_T, out_T, W_T, narrow, 3456) \
f(in_T, out_T, W_T, narrow, 3584) \
f(in_T, out_T, W_T, narrow, 3584) \
f(in_T, out_T, W_T, narrow, 4096) \
f(in_T, out_T, W_T, narrow, 4096) \
f(in_T, out_T, W_T, narrow, 4608) \
f(in_T, out_T, W_T, narrow, 5120) \
f(in_T, out_T, W_T, narrow, 5120) \
f(in_T, out_T, W_T, narrow, 5504) \
f(in_T, out_T, W_T, narrow, 5504) \
f(in_T, out_T, W_T, narrow, 5632) \
f(in_T, out_T, W_T, narrow, 5632) \
f(in_T, out_T, W_T, narrow, 6144) \
f(in_T, out_T, W_T, narrow, 6144) \
f(in_T, out_T, W_T, narrow, 6848) \
f(in_T, out_T, W_T, narrow, 6912) \
f(in_T, out_T, W_T, narrow, 6912) \
f(in_T, out_T, W_T, narrow, 7168) \
f(in_T, out_T, W_T, narrow, 7168) \
f(in_T, out_T, W_T, narrow, 8192) \
f(in_T, out_T, W_T, narrow, 8192) \
...
@@ -36,11 +43,14 @@ void bgmv_kernel(out_T *__restrict__ Y, const in_T *__restrict__ X,
...
@@ -36,11 +43,14 @@ void bgmv_kernel(out_T *__restrict__ Y, const in_T *__restrict__ X,
f(in_T, out_T, W_T, narrow, 10240) \
f(in_T, out_T, W_T, narrow, 10240) \
f(in_T, out_T, W_T, narrow, 11008) \
f(in_T, out_T, W_T, narrow, 11008) \
f(in_T, out_T, W_T, narrow, 12288) \
f(in_T, out_T, W_T, narrow, 12288) \
f(in_T, out_T, W_T, narrow, 13696) \
f(in_T, out_T, W_T, narrow, 13824) \
f(in_T, out_T, W_T, narrow, 13824) \
f(in_T, out_T, W_T, narrow, 14336) \
f(in_T, out_T, W_T, narrow, 14336) \
f(in_T, out_T, W_T, narrow, 16384) \
f(in_T, out_T, W_T, narrow, 16384) \
f(in_T, out_T, W_T, narrow, 20480) \
f(in_T, out_T, W_T, narrow, 20480) \
f(in_T, out_T, W_T, narrow, 22016) \
f(in_T, out_T, W_T, narrow, 24576) \
f(in_T, out_T, W_T, narrow, 24576) \
f(in_T, out_T, W_T, narrow, 27392) \
f(in_T, out_T, W_T, narrow, 28672) \
f(in_T, out_T, W_T, narrow, 28672) \
f(in_T, out_T, W_T, narrow, 32000) \
f(in_T, out_T, W_T, narrow, 32000) \
f(in_T, out_T, W_T, narrow, 32256) \
f(in_T, out_T, W_T, narrow, 32256) \
...
...
csrc/punica/bgmv/generator.py
View file @
7c4f76e3
...
@@ -10,7 +10,7 @@ TEMPLATE = """
...
@@ -10,7 +10,7 @@ TEMPLATE = """
#include "bgmv_impl.cuh"
#include "bgmv_impl.cuh"
FOR_BGMV_WIDE_NARROW(INST_BGMV_TWOSIDE, {input_dtype}, {output_dtype}, {weight_dtype})
FOR_BGMV_WIDE_NARROW(INST_BGMV_TWOSIDE, {input_dtype}, {output_dtype}, {weight_dtype})
"""
.
lstrip
()
"""
.
lstrip
()
# noqa: E501
for
input_dtype
in
DTYPES
:
for
input_dtype
in
DTYPES
:
for
output_dtype
in
DTYPES
:
for
output_dtype
in
DTYPES
:
...
...
csrc/punica/punica_ops.cc
View file @
7c4f76e3
#include <cuda_bf16.h>
#include <cuda_bf16.h>
#include <cuda_fp16.h>
#include <cuda_fp16.h>
#include <torch/extension.h>
#include <torch/extension.h>
#include <c10/cuda/CUDAGuard.h>
#include <cstdint>
#include <cstdint>
#include "bgmv/bgmv_config.h"
#include "bgmv/bgmv_config.h"
...
@@ -91,6 +91,7 @@ void dispatch_bgmv(torch::Tensor y, torch::Tensor x, torch::Tensor w,
...
@@ -91,6 +91,7 @@ void dispatch_bgmv(torch::Tensor y, torch::Tensor x, torch::Tensor w,
CHECK_EQ
(
w
.
size
(
2
),
h_out
);
CHECK_EQ
(
w
.
size
(
2
),
h_out
);
CHECK_EQ
(
indicies
.
size
(
0
),
x
.
size
(
0
));
CHECK_EQ
(
indicies
.
size
(
0
),
x
.
size
(
0
));
CHECK_EQ
(
y
.
size
(
0
),
x
.
size
(
0
));
CHECK_EQ
(
y
.
size
(
0
),
x
.
size
(
0
));
const
at
::
cuda
::
OptionalCUDAGuard
device_guard
(
device_of
(
x
));
bool
ok
=
false
;
bool
ok
=
false
;
if
(
h_in
<
65536
&&
h_out
<
65536
)
{
if
(
h_in
<
65536
&&
h_out
<
65536
)
{
// TODO: See if we can get rid of this massive nested switch
// TODO: See if we can get rid of this massive nested switch
...
@@ -322,6 +323,7 @@ void dispatch_bgmv_low_level(torch::Tensor y, torch::Tensor x, torch::Tensor w,
...
@@ -322,6 +323,7 @@ void dispatch_bgmv_low_level(torch::Tensor y, torch::Tensor x, torch::Tensor w,
CHECK_EQ
(
w
.
size
(
2
),
h_out
);
CHECK_EQ
(
w
.
size
(
2
),
h_out
);
CHECK_EQ
(
indicies
.
size
(
0
),
x
.
size
(
0
));
CHECK_EQ
(
indicies
.
size
(
0
),
x
.
size
(
0
));
CHECK_EQ
(
y
.
size
(
0
),
x
.
size
(
0
));
CHECK_EQ
(
y
.
size
(
0
),
x
.
size
(
0
));
const
at
::
cuda
::
OptionalCUDAGuard
device_guard
(
device_of
(
x
));
bool
ok
=
false
;
bool
ok
=
false
;
if
(
h_in
<
65536
&&
h_out
<
65536
)
{
if
(
h_in
<
65536
&&
h_out
<
65536
)
{
// TODO: See if we can get rid of this massive nested switch
// TODO: See if we can get rid of this massive nested switch
...
...
csrc/pybind.cpp
View file @
7c4f76e3
...
@@ -25,7 +25,11 @@ PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
...
@@ -25,7 +25,11 @@ PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
ops
.
def
(
ops
.
def
(
"gelu_and_mul"
,
"gelu_and_mul"
,
&
gelu_and_mul
,
&
gelu_and_mul
,
"Activation function used in GeGLU."
);
"Activation function used in GeGLU with `none` approximation."
);
ops
.
def
(
"gelu_tanh_and_mul"
,
&
gelu_tanh_and_mul
,
"Activation function used in GeGLU with `tanh` approximation."
);
ops
.
def
(
ops
.
def
(
"gelu_new"
,
"gelu_new"
,
&
gelu_new
,
&
gelu_new
,
...
@@ -52,6 +56,11 @@ PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
...
@@ -52,6 +56,11 @@ PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
&
rotary_embedding
,
&
rotary_embedding
,
"Apply GPT-NeoX or GPT-J style rotary embedding to query and key"
);
"Apply GPT-NeoX or GPT-J style rotary embedding to query and key"
);
ops
.
def
(
"batched_rotary_embedding"
,
&
batched_rotary_embedding
,
"Apply GPT-NeoX or GPT-J style rotary embedding to query and key (supports multiple loras)"
);
// Quantization ops
// Quantization ops
#ifndef USE_ROCM
#ifndef USE_ROCM
ops
.
def
(
"awq_gemm"
,
&
awq_gemm
,
"Quantized GEMM for AWQ"
);
ops
.
def
(
"awq_gemm"
,
&
awq_gemm
,
"Quantized GEMM for AWQ"
);
...
...
csrc/reduction_utils.cuh
View file @
7c4f76e3
...
@@ -24,17 +24,27 @@ namespace vllm {
...
@@ -24,17 +24,27 @@ namespace vllm {
template
<
typename
T
>
template
<
typename
T
>
__inline__
__device__
T
warpReduceSum
(
T
val
)
{
__inline__
__device__
T
warpReduceSum
(
T
val
)
{
#pragma unroll
#pragma unroll
for
(
int
mask
=
16
;
mask
>
0
;
mask
>>=
1
)
for
(
int
mask
=
WARP_SIZE
/
2
;
mask
>
0
;
mask
>>=
1
)
val
+=
VLLM_SHFL_XOR_SYNC
(
val
,
mask
);
val
+=
VLLM_SHFL_XOR_SYNC
(
val
,
mask
);
return
val
;
return
val
;
}
}
__inline__
__device__
constexpr
int
_calculateLaneMask
(
int
warp_size
)
{
return
warp_size
-
1
;
}
__inline__
__device__
constexpr
int
_calculateWidShift
(
int
warp_size
)
{
return
5
+
(
warp_size
>>
6
);
}
/* Calculate the sum of all elements in a block */
/* Calculate the sum of all elements in a block */
template
<
typename
T
>
template
<
typename
T
>
__inline__
__device__
T
blockReduceSum
(
T
val
)
{
__inline__
__device__
T
blockReduceSum
(
T
val
)
{
static
__shared__
T
shared
[
32
];
static
__shared__
T
shared
[
WARP_SIZE
];
int
lane
=
threadIdx
.
x
&
0x1f
;
constexpr
auto
LANE_MASK
=
_calculateLaneMask
(
WARP_SIZE
);
int
wid
=
threadIdx
.
x
>>
5
;
constexpr
auto
WID_SHIFT
=
_calculateWidShift
(
WARP_SIZE
);
int
lane
=
threadIdx
.
x
&
LANE_MASK
;
int
wid
=
threadIdx
.
x
>>
WID_SHIFT
;
val
=
warpReduceSum
<
T
>
(
val
);
val
=
warpReduceSum
<
T
>
(
val
);
...
@@ -45,7 +55,7 @@ __inline__ __device__ T blockReduceSum(T val) {
...
@@ -45,7 +55,7 @@ __inline__ __device__ T blockReduceSum(T val) {
// Modify from blockDim.x << 5 to blockDim.x / 32. to prevent
// Modify from blockDim.x << 5 to blockDim.x / 32. to prevent
// blockDim.x is not divided by 32
// blockDim.x is not divided by 32
val
=
(
threadIdx
.
x
<
(
blockDim
.
x
/
32.
f
))
?
shared
[
lane
]
:
(
T
)(
0.0
f
);
val
=
(
threadIdx
.
x
<
(
blockDim
.
x
/
(
WARP_SIZE
*
1.0
f
)
))
?
shared
[
lane
]
:
(
T
)(
0.0
f
);
val
=
warpReduceSum
<
T
>
(
val
);
val
=
warpReduceSum
<
T
>
(
val
);
return
val
;
return
val
;
}
}
...
...
docs/requirements-docs.txt
View file @
7c4f76e3
sphinx == 6.2.1
sphinx == 6.2.1
sphinx-book-theme == 1.0.1
sphinx-book-theme == 1.0.1
sphinx-copybutton == 0.5.2
sphinx-copybutton == 0.5.2
myst-parser == 2.0.0
sphinx-argparse
# packages to install to build the documentation
pydantic
-f https://download.pytorch.org/whl/cpu
torch
\ No newline at end of file
docs/source/assets/kernel/k_vecs.png
0 → 100644
View file @
7c4f76e3
27 KB
docs/source/assets/kernel/key.png
0 → 100644
View file @
7c4f76e3
109 KB
docs/source/assets/kernel/logits_vec.png
0 → 100644
View file @
7c4f76e3
17.1 KB
docs/source/assets/kernel/q_vecs.png
0 → 100644
View file @
7c4f76e3
41.1 KB
docs/source/assets/kernel/query.png
0 → 100644
View file @
7c4f76e3
31.9 KB
docs/source/assets/kernel/v_vec.png
0 → 100644
View file @
7c4f76e3
41.5 KB
docs/source/assets/kernel/value.png
0 → 100644
View file @
7c4f76e3
167 KB
docs/source/conf.py
View file @
7c4f76e3
...
@@ -10,10 +10,11 @@
...
@@ -10,10 +10,11 @@
# add these directories to sys.path here. If the directory is relative to the
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
# documentation root, use os.path.abspath to make it absolute, like shown here.
import
logging
import
os
import
os
import
sys
import
sys
from
sphinx.ext
import
autodoc
from
sphinx.ext
import
autodoc
import
logging
sys
.
path
.
insert
(
0
,
os
.
path
.
abspath
(
os
.
path
.
join
(
'..'
,
'..'
)))
sys
.
path
.
insert
(
0
,
os
.
path
.
abspath
(
os
.
path
.
join
(
'..'
,
'..'
)))
...
@@ -22,7 +23,7 @@ logger = logging.getLogger(__name__)
...
@@ -22,7 +23,7 @@ logger = logging.getLogger(__name__)
# -- Project information -----------------------------------------------------
# -- Project information -----------------------------------------------------
project
=
'vLLM'
project
=
'vLLM'
copyright
=
'202
3
, vLLM Team'
copyright
=
'202
4
, vLLM Team'
author
=
'the vLLM Team'
author
=
'the vLLM Team'
# -- General configuration ---------------------------------------------------
# -- General configuration ---------------------------------------------------
...
@@ -37,6 +38,8 @@ extensions = [
...
@@ -37,6 +38,8 @@ extensions = [
"sphinx_copybutton"
,
"sphinx_copybutton"
,
"sphinx.ext.autodoc"
,
"sphinx.ext.autodoc"
,
"sphinx.ext.autosummary"
,
"sphinx.ext.autosummary"
,
"myst_parser"
,
"sphinxarg.ext"
,
]
]
# Add any paths that contain templates here, relative to this directory.
# Add any paths that contain templates here, relative to this directory.
...
@@ -72,8 +75,15 @@ html_theme_options = {
...
@@ -72,8 +75,15 @@ html_theme_options = {
# Mock out external dependencies here.
# Mock out external dependencies here.
autodoc_mock_imports
=
[
autodoc_mock_imports
=
[
"torch"
,
"transformers"
,
"psutil"
,
"prometheus_client"
,
"sentencepiece"
,
"torch"
,
"vllm.cuda_utils"
,
"vllm._C"
"transformers"
,
"psutil"
,
"prometheus_client"
,
"sentencepiece"
,
"vllm.cuda_utils"
,
"vllm._C"
,
"numpy"
,
"tqdm"
,
]
]
for
mock_target
in
autodoc_mock_imports
:
for
mock_target
in
autodoc_mock_imports
:
...
...
docs/source/dev/engine/llm_engine.rst
View file @
7c4f76e3
...
@@ -2,5 +2,5 @@ LLMEngine
...
@@ -2,5 +2,5 @@ LLMEngine
=================================
=================================
.. autoclass:: vllm.engine.llm_engine.LLMEngine
.. autoclass:: vllm.engine.llm_engine.LLMEngine
:members: add_request, abort_request, step
, _init_cache
:members: add_request, abort_request, step
:show-inheritance:
:show-inheritance:
\ No newline at end of file
Prev
1
2
3
4
5
6
7
…
17
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}

{kind=link}
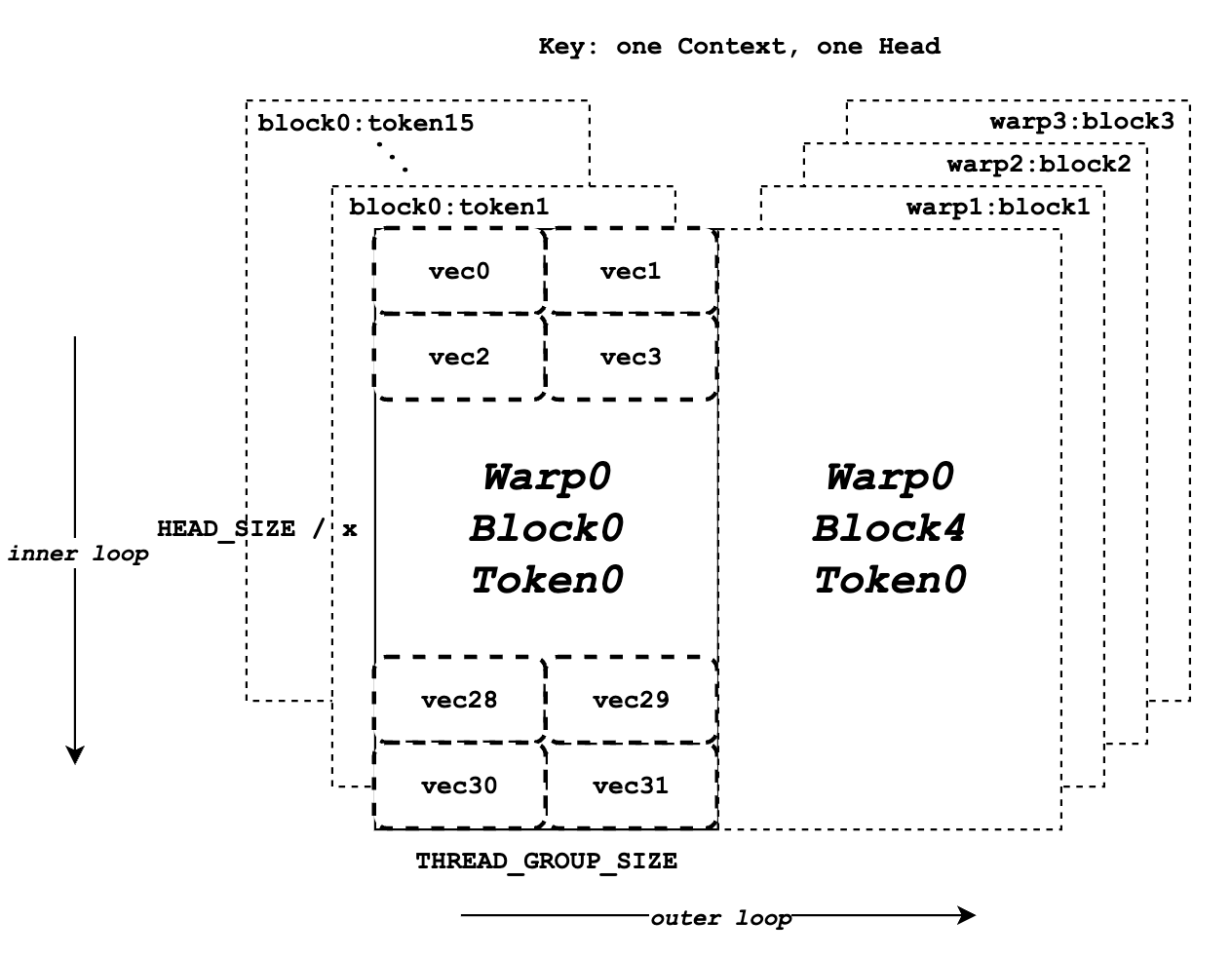
{kind=link}

{kind=link}

{kind=link}

{kind=link}
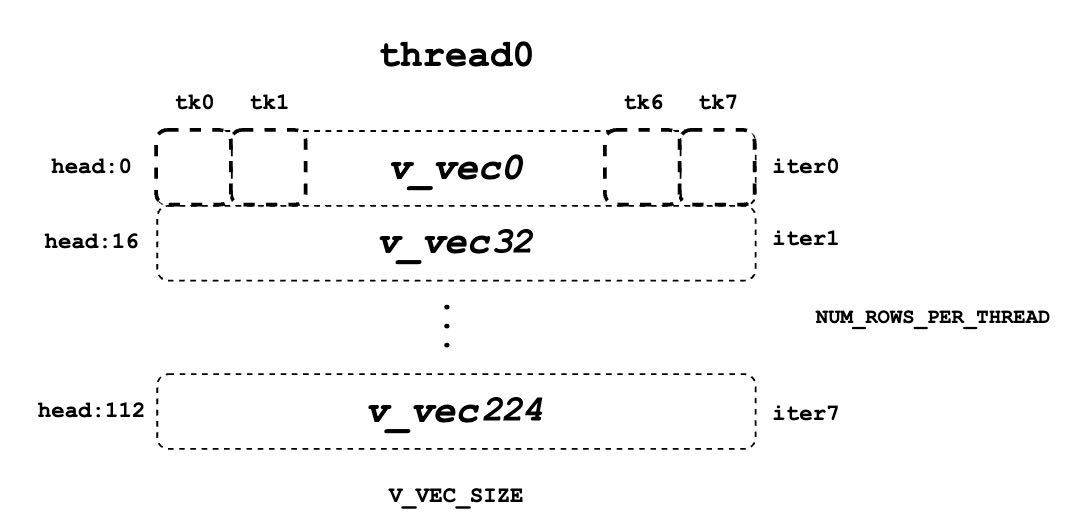
{kind=link}