
Merge tag 'v0.9.0' into v0.9.0-ori
Showing
Too many changes to show.
To preserve performance only 486 of 486+ files are displayed.
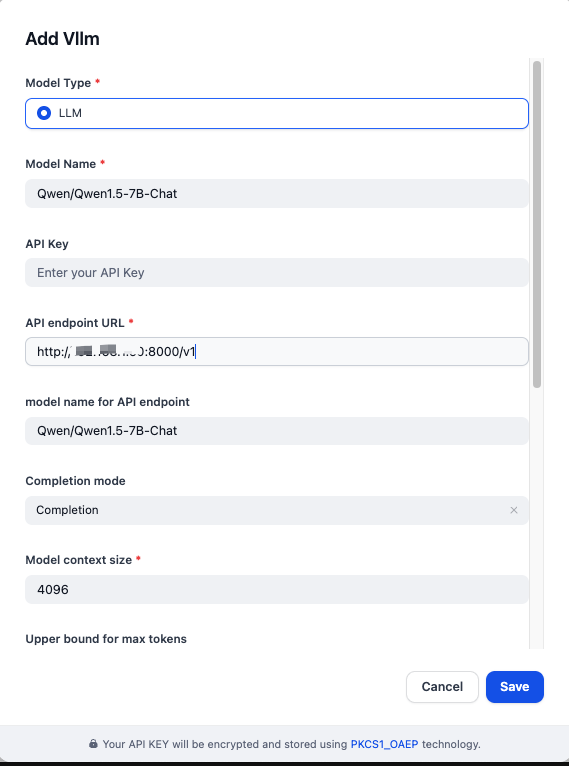
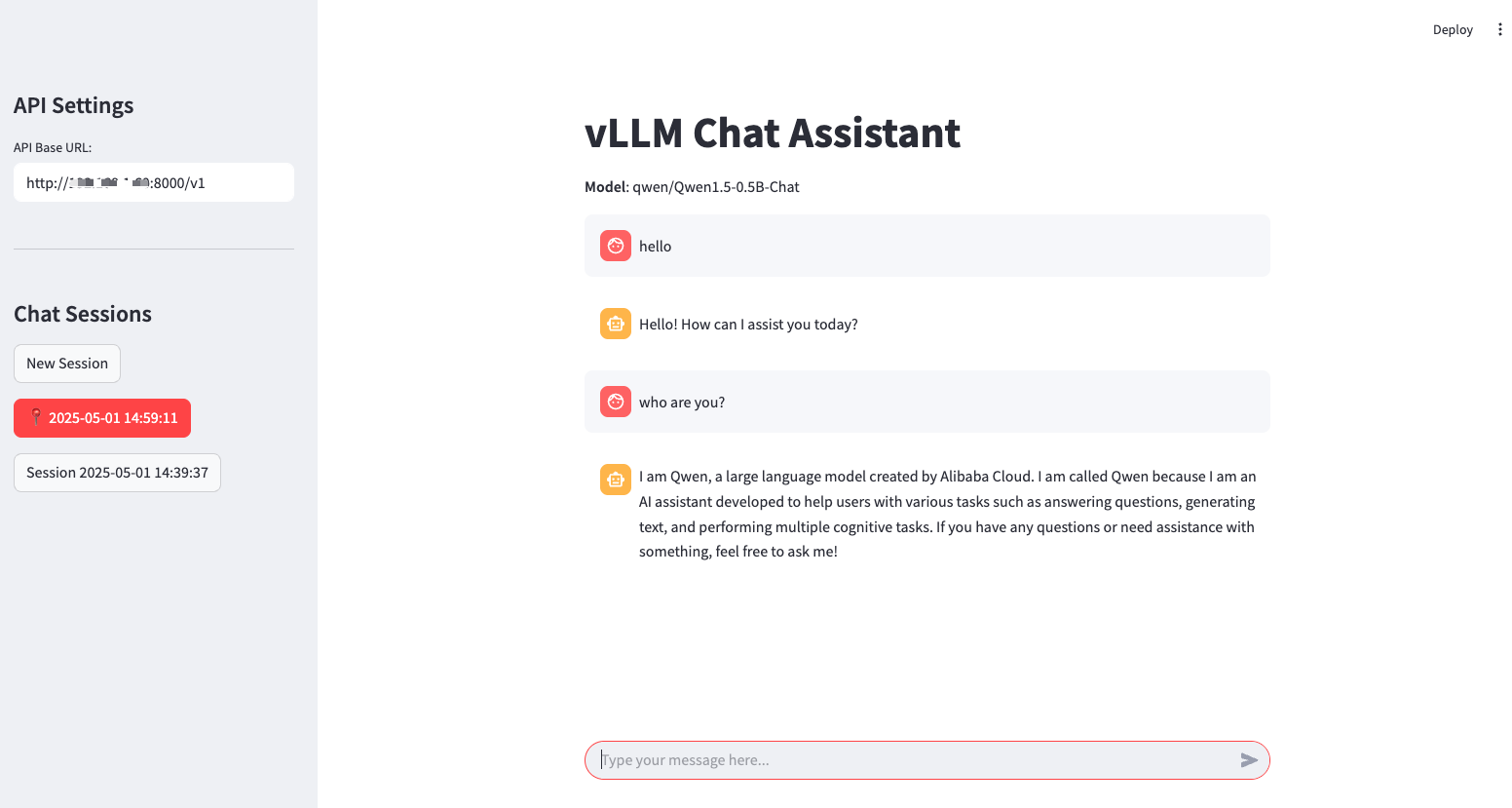
docs/source/api/summary.md
0 → 100644
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
107 KB
{kind=link}
94.9 KB
{kind=link}
143 KB
{kind=link}
265 KB
{kind=link}
51.8 KB
{kind=link}
106 KB