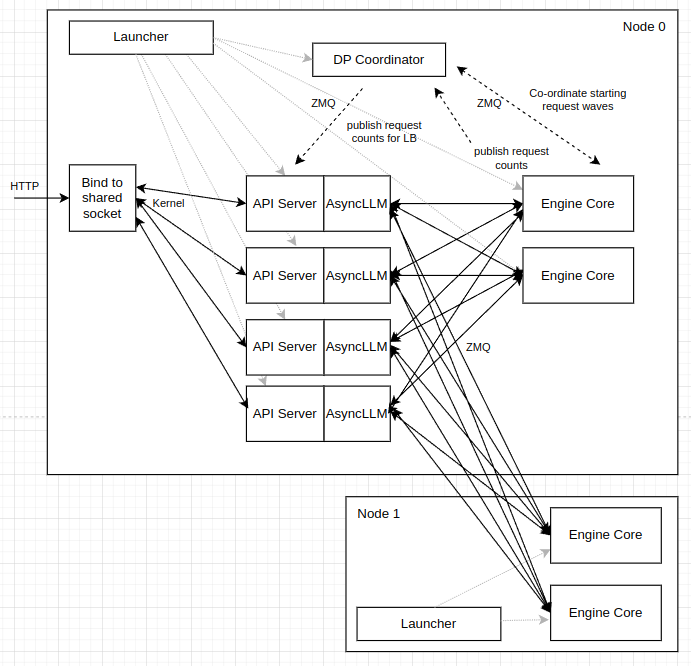
#################### DEV IMAGE ####################
#################### DEV IMAGE ####################
FROM base as dev
FROM base AS dev
ARG PIP_INDEX_URL UV_INDEX_URL
ARG PIP_INDEX_URL UV_INDEX_URL
ARG PIP_EXTRA_INDEX_URL UV_EXTRA_INDEX_URL
ARG PIP_EXTRA_INDEX_URL UV_EXTRA_INDEX_URL
...
@@ -375,48 +388,33 @@ RUN --mount=type=bind,from=build,src=/workspace/dist,target=/vllm-workspace/dist
...
@@ -375,48 +388,33 @@ RUN --mount=type=bind,from=build,src=/workspace/dist,target=/vllm-workspace/dist
# -rw-rw-r-- 1 mgoin mgoin 205M Jun 9 18:03 flashinfer_python-0.2.6.post1-cp39-abi3-linux_x86_64.whl
# -rw-rw-r-- 1 mgoin mgoin 205M Jun 9 18:03 flashinfer_python-0.2.6.post1-cp39-abi3-linux_x86_64.whl
# $ # upload the wheel to a public location, e.g. https://wheels.vllm.ai/flashinfer/v0.2.6.post1/flashinfer_python-0.2.6.post1-cp39-abi3-linux_x86_64.whl
# $ # upload the wheel to a public location, e.g. https://wheels.vllm.ai/flashinfer/v0.2.6.post1/flashinfer_python-0.2.6.post1-cp39-abi3-linux_x86_64.whl
# Allow specifying a version, Git revision or local .whl file
-[How continuous batching enables 23x throughput in LLM inference while reducing p50 latency](https://www.anyscale.com/blog/continuous-batching-llm-inference) by Cade Daniel et al.
-[How continuous batching enables 23x throughput in LLM inference while reducing p50 latency](https://www.anyscale.com/blog/continuous-batching-llm-inference) by Cade Daniel et al.

{kind=link}
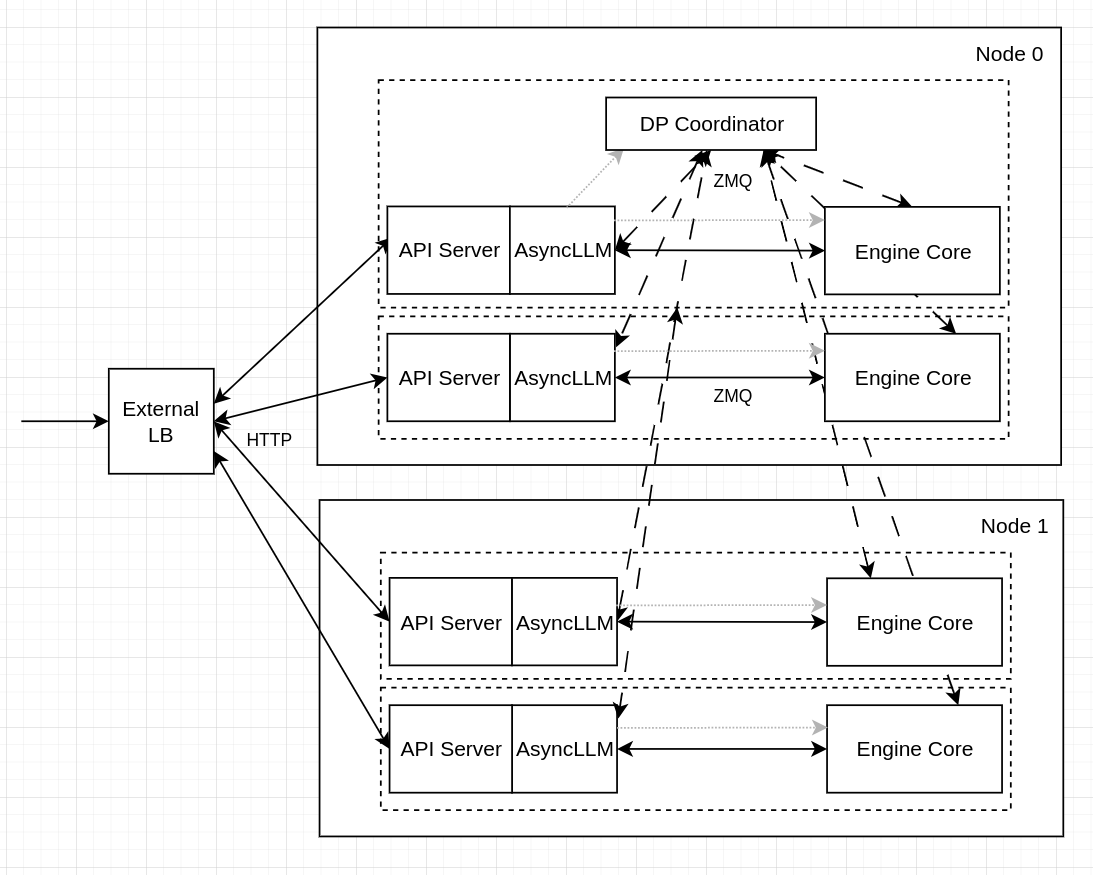
{kind=link}