
Merge tag 'v0.8.3' into v0.8.3-ori
Showing
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}
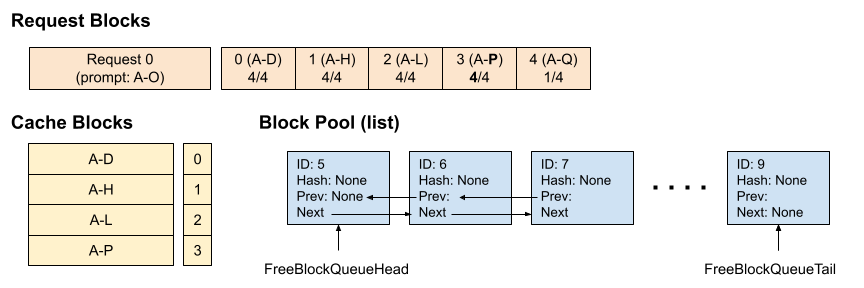
| W: | H:

| W: | H:
{kind=link}
{kind=link}
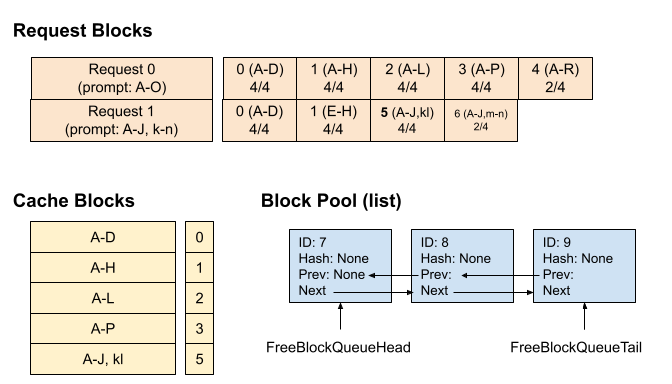
| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}
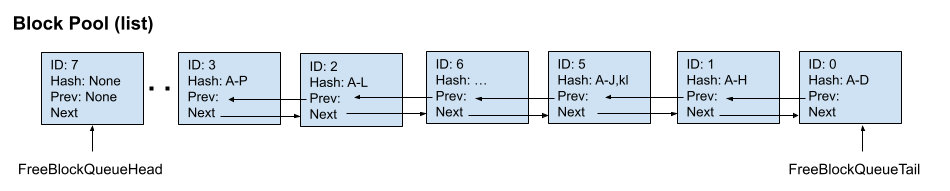
| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
34 KB | W: | H:
46.8 KB | W: | H:
36.2 KB | W: | H:
50 KB | W: | H:
40.6 KB | W: | H:
59.2 KB | W: | H:
38.8 KB | W: | H:
54.1 KB | W: | H:
24.9 KB | W: | H:
53.5 KB | W: | H:
32.4 KB | W: | H:
54.6 KB | W: | H: