1. Update the code by considering that :code:`input_ids` and :code:`positions` are now flattened tensors.
2. Replace the attention operation with either :code:`PagedAttention`, :code:`PagedAttentionWithRoPE`, or :code:`PagedAttentionWithALiBi` depending on the model's architecture.
To ensure compatibility with vLLM, your model must meet the following requirements:
Initialization Code
^^^^^^^^^^^^^^^^^^^
All vLLM modules within the model must include a ``prefix`` argument in their constructor. This ``prefix`` is typically the full name of the module in the model's state dictionary and is crucial for:
* Runtime support: vLLM's attention operators are registered in a model's state by their full names. Each attention operator must have a unique prefix as its layer name to avoid conflicts.
* Non-uniform quantization support: A quantized checkpoint can selectively quantize certain layers while keeping others in full precision. By providing the ``prefix`` during initialization, vLLM can match the current layer's ``prefix`` with the quantization configuration to determine if the layer should be initialized in quantized mode.
Rewrite the :meth:`~torch.nn.Module.forward` method of your model to remove any unnecessary code, such as training-specific code. Modify the input parameters to treat ``input_ids`` and ``positions`` as flattened tensors with a single batch size dimension, without a max-sequence length dimension.
.. code-block:: python
def forward(
self,
input_ids: torch.Tensor,
positions: torch.Tensor,
kv_caches: List[torch.Tensor],
attn_metadata: AttentionMetadata,
) -> torch.Tensor:
...
.. note::
Currently, vLLM supports the basic multi-head attention mechanism and its variant with rotary positional embeddings.
If your model employs a different attention mechanism, you will need to implement a new attention layer in vLLM.
For reference, check out the `LLAMA model <https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/llama.py>`__. vLLM already supports a large number of models. It is recommended to find a model similar to yours and adapt it to your model's architecture. Check out the `vLLM models <https://github.com/vllm-project/vllm/tree/main/vllm/model_executor/models>`__ directory for more examples.
3. (Optional) Implement tensor parallelism and quantization support
@@ -85,28 +114,28 @@ When it comes to the linear layers, we provide the following options to parallel
* :code:`ReplicatedLinear`: Replicates the inputs and weights across multiple GPUs. No memory saving.
* :code:`RowParallelLinear`: The input tensor is partitioned along the hidden dimension. The weight matrix is partitioned along the rows (input dimension). An *all-reduce* operation is performed after the matrix multiplication to reduce the results. Typically used for the second FFN layer and the output linear transformation of the attention layer.
* :code:`ColumnParallelLinear`: The input tensor is replicated. The weight matrix is partitioned along the columns (output dimension). The result is partitioned along the column dimension. Typically used for the first FFN layer and the separated QKV transformation of the attention layer in the original Transformer.
* :code:`MergedColumnParallelLinear`: Column-parallel linear that merges multiple `ColumnParallelLinear` operators. Typically used for the first FFN layer with weighted activation functions (e.g., SiLU). This class handles the sharded weight loading logic of multiple weight matrices.
* :code:`MergedColumnParallelLinear`: Column-parallel linear that merges multiple :code:`ColumnParallelLinear` operators. Typically used for the first FFN layer with weighted activation functions (e.g., SiLU). This class handles the sharded weight loading logic of multiple weight matrices.
* :code:`QKVParallelLinear`: Parallel linear layer for the query, key, and value projections of the multi-head and grouped-query attention mechanisms. When number of key/value heads are less than the world size, this class replicates the key/value heads properly. This class handles the weight loading and replication of the weight matrices.
Note that all the linear layers above take `linear_method` as an input. vLLM will set this parameter according to different quantization schemes to support weight quantization.
Note that all the linear layers above take :code:`linear_method` as an input. vLLM will set this parameter according to different quantization schemes to support weight quantization.
4. Implement the weight loading logic
-------------------------------------
You now need to implement the :code:`load_weights` method in your :code:`*ForCausalLM` class.
This method should load the weights from the HuggingFace's checkpoint file and assign them to the corresponding layers in your model. Specifically, for `MergedColumnParallelLinear` and `QKVParallelLinear` layers, if the original model has separated weight matrices, you need to load the different parts separately.
This method should load the weights from the HuggingFace's checkpoint file and assign them to the corresponding layers in your model. Specifically, for :code:`MergedColumnParallelLinear` and :code:`QKVParallelLinear` layers, if the original model has separated weight matrices, you need to load the different parts separately.
5. Register your model
----------------------
Finally, register your :code:`*ForCausalLM` class to the :code:`_MODELS` in `vllm/model_executor/models/__init__.py <https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/__init__.py>`_.
Finally, register your :code:`*ForCausalLM` class to the :code:`_VLLM_MODELS` in `vllm/model_executor/models/registry.py <https://github.com/vllm-project/vllm/blob/main/vllm/model_executor/models/registry.py>`_.
6. Out-of-Tree Model Integration
--------------------------------------------
--------------------------------
We also provide a way to integrate a model without modifying the vLLM codebase. Step 2, 3, 4 are still required, but you can skip step 1 and 5.
You can integrate a model without modifying the vLLM codebase. Steps 2, 3, and 4 are still required, but you can skip steps 1 and 5. Instead, write a plugin to register your model. For general introduction of the plugin system, see :ref:`plugin_system`.
Just add the following lines in your code:
To register the model, use the following code:
.. code-block:: python
...
...
@@ -114,14 +143,17 @@ Just add the following lines in your code:
If you are running api server with :code:`vllm serve <args>`, you can wrap the entrypoint with the following code:
If your model imports modules that initialize CUDA, consider lazy-importing it to avoid errors like :code:`RuntimeError: Cannot re-initialize CUDA in forked subprocess`:
If your model is a multimodal model, ensure the model class implements the :class:`~vllm.model_executor.models.interfaces.SupportsMultiModal` interface.
Read more about that :ref:`here <enabling_multimodal_inputs>`.
.. note::
Although you can directly put these code snippets in your script using ``vllm.LLM``, the recommended way is to place these snippets in a vLLM plugin. This ensures compatibility with various vLLM features like distributed inference and the API server.
vLLM provides first-class support for generative models, which covers most of LLMs.
In vLLM, generative models implement the :class:`~vllm.model_executor.models.VllmModelForTextGeneration` interface.
Based on the final hidden states of the input, these models output log probabilities of the tokens to generate,
which are then passed through :class:`~vllm.model_executor.layers.Sampler` to obtain the final text.
Offline Inference
-----------------
The :class:`~vllm.LLM` class provides various methods for offline inference.
See :ref:`Engine Arguments <engine_args>` for a list of options when initializing the model.
For generative models, the only supported :code:`task` option is :code:`"generate"`.
Usually, this is automatically inferred so you don't have to specify it.
``LLM.generate``
^^^^^^^^^^^^^^^^
The :class:`~vllm.LLM.generate` method is available to all generative models in vLLM.
It is similar to `its counterpart in HF Transformers <https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.GenerationMixin.generate>`__,
except that tokenization and detokenization are also performed automatically.
A code example can be found in `examples/offline_inference.py <https://github.com/vllm-project/vllm/blob/main/examples/offline_inference.py>`_.
``LLM.beam_search``
^^^^^^^^^^^^^^^^^^^
The :class:`~vllm.LLM.beam_search` method implements `beam search <https://huggingface.co/docs/transformers/en/generation_strategies#beam-search-decoding>`__ on top of :class:`~vllm.LLM.generate`.
For example, to search using 5 beams and output at most 50 tokens:
A code example can be found in `examples/offline_inference_chat.py <https://github.com/vllm-project/vllm/blob/main/examples/offline_inference_chat.py>`_.
If the model doesn't have a chat template or you want to specify another one,
you can explicitly pass a chat template:
.. code-block:: python
from vllm.entrypoints.chat_utils import load_chat_template
# You can find a list of existing chat templates under `examples/`
Our `OpenAI Compatible Server <../serving/openai_compatible_server>`__ can be used for online inference.
Please click on the above link for more details on how to launch the server.
Completions API
^^^^^^^^^^^^^^^
Our Completions API is similar to ``LLM.generate`` but only accepts text.
It is compatible with `OpenAI Completions API <https://platform.openai.com/docs/api-reference/completions>`__
so that you can use OpenAI client to interact with it.
A code example can be found in `examples/openai_completion_client.py <https://github.com/vllm-project/vllm/blob/main/examples/openai_completion_client.py>`_.
Chat API
^^^^^^^^
Our Chat API is similar to ``LLM.chat``, accepting both text and :ref:`multi-modal inputs <multimodal_inputs>`.
It is compatible with `OpenAI Chat Completions API <https://platform.openai.com/docs/api-reference/chat>`__
so that you can use OpenAI client to interact with it.
A code example can be found in `examples/openai_chat_completion_client.py <https://github.com/vllm-project/vllm/blob/main/examples/openai_chat_completion_client.py>`_.
A code example can be found in `examples/offline_inference_embedding.py <https://github.com/vllm-project/vllm/blob/main/examples/offline_inference_embedding.py>`_.
``LLM.classify``
^^^^^^^^^^^^^^^^
The :class:`~vllm.LLM.classify` method outputs a probability vector for each prompt.
It is primarily designed for classification models.
A code example can be found in `examples/offline_inference_classification.py <https://github.com/vllm-project/vllm/blob/main/examples/offline_inference_classification.py>`_.
``LLM.score``
^^^^^^^^^^^^^
The :class:`~vllm.LLM.score` method outputs similarity scores between sentence pairs.
It is primarily designed for `cross-encoder models <https://www.sbert.net/examples/applications/cross-encoder/README.html>`__.
These types of models serve as rerankers between candidate query-document pairs in RAG systems.
.. note::
vLLM can only perform the model inference component (e.g. embedding, reranking) of RAG.
To handle RAG at a higher level, you should use integration frameworks such as `LangChain <https://github.com/langchain-ai/langchain>`_.
(output,) = llm.score("What is the capital of France?",
"The capital of Brazil is Brasilia.")
score = output.outputs.score
print(f"Score: {score}")
A code example can be found in `examples/offline_inference_scoring.py <https://github.com/vllm-project/vllm/blob/main/examples/offline_inference_scoring.py>`_.
Online Inference
----------------
Our `OpenAI Compatible Server <../serving/openai_compatible_server>`__ can be used for online inference.
Please click on the above link for more details on how to launch the server.
Embeddings API
^^^^^^^^^^^^^^
Our Embeddings API is similar to ``LLM.embed``, accepting both text and :ref:`multi-modal inputs <multimodal_inputs>`.
The text-only API is compatible with `OpenAI Embeddings API <https://platform.openai.com/docs/api-reference/embeddings>`__
so that you can use OpenAI client to interact with it.
A code example can be found in `examples/openai_embedding_client.py <https://github.com/vllm-project/vllm/blob/main/examples/openai_embedding_client.py>`_.
The multi-modal API is an extension of the `OpenAI Embeddings API <https://platform.openai.com/docs/api-reference/embeddings>`__
that incorporates `OpenAI Chat Completions API <https://platform.openai.com/docs/api-reference/chat>`__,
so it is not part of the OpenAI standard. Please see :ref:`this page <multimodal_inputs>` for more details on how to use it.
Score API
^^^^^^^^^
Our Score API is similar to ``LLM.score``.
Please see `this page <../serving/openai_compatible_server.html#score-api-for-cross-encoder-models>`__ for more details on how to use it.
vLLM currently only supports adding LoRA to the language backbone of multimodal models.
llm = LLM(model=...) # Name or path of your model
output = llm.generate("Hello, my name is")
print(output)
.. note::
To use :code:`TIGER-Lab/Mantis-8B-siglip-llama3`, you have to install their GitHub repo (:code:`pip install git+https://github.com/TIGER-AI-Lab/Mantis.git`)
and pass :code:`--hf_overrides '{"architectures": ["MantisForConditionalGeneration"]}'` when running vLLM.
If vLLM successfully generates text, it indicates that your model is supported.
.. note::
The official :code:`openbmb/MiniCPM-V-2` doesn't work yet, so we need to use a fork (:code:`HwwwH/MiniCPM-V-2`) for now.
For more details, please see: https://github.com/vllm-project/vllm/pull/4087#issuecomment-2250397630
.. tip::
To use models from `ModelScope <https://www.modelscope.cn>`_ instead of HuggingFace Hub, set an environment variable:
Pooling Models
++++++++++++++
.. code-block:: shell
See :ref:`this page <pooling_models>` for more information on how to use pooling models.
$ export VLLM_USE_MODELSCOPE=True
.. important::
Since some model architectures support both generative and pooling tasks,
you should explicitly specify the task type to ensure that the model is used in pooling mode instead of generative mode.
And use with :code:`trust_remote_code=True`.
Text Embedding (``--task embed``)
---------------------------------
.. code-block:: python
Any text generation model can be converted into an embedding model by passing :code:`--task embed`.
from vllm import LLM
.. note::
To get the best results, you should use pooling models that are specifically trained as such.
llm = LLM(model=..., revision=..., trust_remote_code=True) # Name or path of your model
output = llm.generate("Hello, my name is")
print(output)
The following table lists those that are tested in vLLM.
.. list-table::
:widths: 25 25 15 25 5 5
:header-rows: 1
* - Architecture
- Models
- Inputs
- Example HF Models
- :ref:`LoRA <lora>`
- :ref:`PP <distributed_serving>`
* - :code:`LlavaNextForConditionalGeneration`
- LLaVA-NeXT-based
- T / I
- :code:`royokong/e5-v`
-
- ✅︎
* - :code:`Phi3VForCausalLM`
- Phi-3-Vision-based
- T + I
- :code:`TIGER-Lab/VLM2Vec-Full`
- 🚧
- ✅︎
* - :code:`Qwen2VLForConditionalGeneration`
- Qwen2-VL-based
- T + I
- :code:`MrLight/dse-qwen2-2b-mrl-v1`
-
- ✅︎
----
Model Support Policy
=====================
...
...
@@ -354,6 +801,9 @@ At vLLM, we are committed to facilitating the integration and support of third-p
2. **Best-Effort Consistency**: While we aim to maintain a level of consistency between the models implemented in vLLM and other frameworks like transformers, complete alignment is not always feasible. Factors like acceleration techniques and the use of low-precision computations can introduce discrepancies. Our commitment is to ensure that the implemented models are functional and produce sensible results.
.. tip::
When comparing the output of :code:`model.generate` from HuggingFace Transformers with the output of :code:`llm.generate` from vLLM, note that the former reads the model's generation config file (i.e., `generation_config.json <https://github.com/huggingface/transformers/blob/19dabe96362803fb0a9ae7073d03533966598b17/src/transformers/generation/utils.py#L1945>`__) and applies the default parameters for generation, while the latter only uses the parameters passed to the function. Ensure all sampling parameters are identical when comparing outputs.
3. **Issue Resolution and Model Updates**: Users are encouraged to report any bugs or issues they encounter with third-party models. Proposed fixes should be submitted via PRs, with a clear explanation of the problem and the rationale behind the proposed solution. If a fix for one model impacts another, we rely on the community to highlight and address these cross-model dependencies. Note: for bugfix PRs, it is good etiquette to inform the original author to seek their feedback.
4. **Monitoring and Updates**: Users interested in specific models should monitor the commit history for those models (e.g., by tracking changes in the main/vllm/model_executor/models directory). This proactive approach helps users stay informed about updates and changes that may affect the models they use.
...
...
@@ -369,4 +819,4 @@ We have the following levels of testing for models:
1. **Strict Consistency**: We compare the output of the model with the output of the model in the HuggingFace Transformers library under greedy decoding. This is the most stringent test. Please refer to `models tests <https://github.com/vllm-project/vllm/blob/main/tests/models>`_ for the models that have passed this test.
2. **Output Sensibility**: We check if the output of the model is sensible and coherent, by measuring the perplexity of the output and checking for any obvious errors. This is a less stringent test.
3. **Runtime Functionality**: We check if the model can be loaded and run without errors. This is the least stringent test. Please refer to `functionality tests <https://github.com/vllm-project/vllm/tree/main/tests>`_ and `examples <https://github.com/vllm-project/vllm/tree/main/examples>`_ for the models that have passed this test.
4. **Community Feedback**: We rely on the community to provide feedback on the models. If a model is broken or not working as expected, we encourage users to raise issues to report it or open pull requests to fix it. The rest of the models fall under this category.
4. **Community Feedback**: We rely on the community to provide feedback on the models. If a model is broken or not working as expected, we encourage users to raise issues to report it or open pull requests to fix it. The rest of the models fall under this category.
vLLM provides experimental support for Vision Language Models (VLMs). See the :ref:`list of supported VLMs here <supported_vlms>`.
This document shows you how to run and serve these models using vLLM.
.. important::
We are actively iterating on VLM support. Expect breaking changes to VLM usage and development in upcoming releases without prior deprecation.
We are continuously improving user & developer experience for VLMs. Please `open an issue on GitHub <https://github.com/vllm-project/vllm/issues/new/choose>`_ if you have any feedback or feature requests.
Offline Inference
-----------------
Single-image input
^^^^^^^^^^^^^^^^^^
The :class:`~vllm.LLM` class can be instantiated in much the same way as language-only models.
.. code-block:: python
llm = LLM(model="llava-hf/llava-1.5-7b-hf")
.. note::
We have removed all vision language related CLI args in the ``0.5.1`` release. **This is a breaking change**, so please update your code to follow
the above snippet. Specifically, ``image_feature_size`` can no longer be specified as we now calculate that internally for each model.
To pass an image to the model, note the following in :class:`vllm.inputs.PromptInputs`:
* ``prompt``: The prompt should follow the format that is documented on HuggingFace.
* ``multi_modal_data``: This is a dictionary that follows the schema defined in :class:`vllm.multimodal.MultiModalDataDict`.
.. code-block:: python
# Refer to the HuggingFace repo for the correct format to use
prompt = "USER: <image>\nWhat is the content of this image?\nASSISTANT:"
# Load the image using PIL.Image
image = PIL.Image.open(...)
# Single prompt inference
outputs = llm.generate({
"prompt": prompt,
"multi_modal_data": {"image": image},
})
for o in outputs:
generated_text = o.outputs[0].text
print(generated_text)
# Inference with image embeddings as input
image_embeds = torch.load(...) # torch.Tensor of shape (1, image_feature_size, hidden_size of LM)
outputs = llm.generate({
"prompt": prompt,
"multi_modal_data": {"image": image_embeds},
})
for o in outputs:
generated_text = o.outputs[0].text
print(generated_text)
# Batch inference
image_1 = PIL.Image.open(...)
image_2 = PIL.Image.open(...)
outputs = llm.generate(
[
{
"prompt": "USER: <image>\nWhat is the content of this image?\nASSISTANT:",
"multi_modal_data": {"image": image_1},
},
{
"prompt": "USER: <image>\nWhat's the color of this image?\nASSISTANT:",
"multi_modal_data": {"image": image_2},
}
]
)
for o in outputs:
generated_text = o.outputs[0].text
print(generated_text)
A code example can be found in `examples/offline_inference_vision_language.py <https://github.com/vllm-project/vllm/blob/main/examples/offline_inference_vision_language.py>`_.
Multi-image input
^^^^^^^^^^^^^^^^^
Multi-image input is only supported for a subset of VLMs, as shown :ref:`here <supported_vlms>`.
To enable multiple multi-modal items per text prompt, you have to set ``limit_mm_per_prompt`` for the :class:`~vllm.LLM` class.
.. code-block:: python
llm = LLM(
model="microsoft/Phi-3.5-vision-instruct",
trust_remote_code=True, # Required to load Phi-3.5-vision
max_model_len=4096, # Otherwise, it may not fit in smaller GPUs
limit_mm_per_prompt={"image": 2}, # The maximum number to accept
)
Instead of passing in a single image, you can pass in a list of images.
.. code-block:: python
# Refer to the HuggingFace repo for the correct format to use
prompt = "<|user|>\n<image_1>\n<image_2>\nWhat is the content of each image?<|end|>\n<|assistant|>\n"
# Load the images using PIL.Image
image1 = PIL.Image.open(...)
image2 = PIL.Image.open(...)
outputs = llm.generate({
"prompt": prompt,
"multi_modal_data": {
"image": [image1, image2]
},
})
for o in outputs:
generated_text = o.outputs[0].text
print(generated_text)
A code example can be found in `examples/offline_inference_vision_language_multi_image.py <https://github.com/vllm-project/vllm/blob/main/examples/offline_inference_vision_language_multi_image.py>`_.
Online Inference
----------------
OpenAI Vision API
^^^^^^^^^^^^^^^^^
You can serve vision language models with vLLM's HTTP server that is compatible with `OpenAI Vision API <https://platform.openai.com/docs/guides/vision>`_.
Below is an example on how to launch the same ``microsoft/Phi-3.5-vision-instruct`` with vLLM's OpenAI-compatible API server.
Since OpenAI Vision API is based on `Chat Completions <https://platform.openai.com/docs/api-reference/chat>`_ API,
a chat template is **required** to launch the API server.
Although Phi-3.5-Vision comes with a chat template, for other models you may have to provide one if the model's tokenizer does not come with it.
The chat template can be inferred based on the documentation on the model's HuggingFace repo.
For example, LLaVA-1.5 (``llava-hf/llava-1.5-7b-hf``) requires a chat template that can be found `here <https://github.com/vllm-project/vllm/blob/main/examples/template_llava.jinja>`_.
To consume the server, you can use the OpenAI client like in the example below:
A full code example can be found in `examples/openai_vision_api_client.py <https://github.com/vllm-project/vllm/blob/main/examples/openai_vision_api_client.py>`_.
.. note::
By default, the timeout for fetching images through http url is ``5`` seconds. You can override this by setting the environment variable:
.. code-block:: shell
export VLLM_IMAGE_FETCH_TIMEOUT=<timeout>
.. note::
There is no need to format the prompt in the API request since it will be handled by the server.
The performance benchmarks are used for development to confirm whether new changes improve performance under various workloads. They are triggered on every commit with both the ``perf-benchmarks`` and ``ready`` labels, and when a PR is merged into vLLM.
The latest performance results are hosted on the public `vLLM Performance Dashboard <https://perf.vllm.ai>`_.
More information on the performance benchmarks and their parameters can be found `here <https://github.com/vllm-project/vllm/blob/main/.buildkite/nightly-benchmarks/performance-benchmarks-descriptions.md>`__.
.. _nightly_benchmarks:
Nightly Benchmarks
------------------
These compare vLLM's performance against alternatives (``tgi``, ``trt-llm``, and ``lmdeploy``) when there are major updates of vLLM (e.g., bumping up to a new version). They are primarily intended for consumers to evaluate when to choose vLLM over other options and are triggered on every commit with both the ``perf-benchmarks`` and ``nightly-benchmarks`` labels.
The latest nightly benchmark results are shared in major release blog posts such as `vLLM v0.6.0 <https://blog.vllm.ai/2024/09/05/perf-update.html>`_.
More information on the nightly benchmarks and their parameters can be found `here <https://github.com/vllm-project/vllm/blob/main/.buildkite/nightly-benchmarks/nightly-descriptions.md>`__.
+ **Performance benchmarks**: benchmark vLLM's performance under various workloads at a high frequency (when a pull request (PR for short) of vLLM is being merged). See `vLLM performance dashboard <https://perf.vllm.ai>`_ for the latest performance results.
+ **Nightly benchmarks**: compare vLLM's performance against alternatives (tgi, trt-llm, and lmdeploy) when there are major updates of vLLM (e.g., bumping up to a new version). The latest results are available in the `vLLM GitHub README <https://github.com/vllm-project/vllm/blob/main/README.md>`_.
Trigger a benchmark
-------------------
The performance benchmarks and nightly benchmarks can be triggered by submitting a PR to vLLM, and label the PR with `perf-benchmarks` and `nightly-benchmarks`.
.. note::
Please refer to `vLLM performance benchmark descriptions <https://github.com/vllm-project/vllm/blob/main/.buildkite/nightly-benchmarks/performance-benchmarks-descriptions.md>`_ and `vLLM nightly benchmark descriptions <https://github.com/vllm-project/vllm/blob/main/.buildkite/nightly-benchmarks/nightly-descriptions.md>`_ for detailed descriptions on benchmark environment, workload and metrics.
@@ -27,8 +27,8 @@ The table below shows the compatibility of various quantization implementations
- ✅︎
- ✅︎
- ✗
- ✗
- ✗
- ✅︎
- ✅︎
- ✗
- ✗
* - GPTQ
...
...
@@ -38,8 +38,8 @@ The table below shows the compatibility of various quantization implementations
- ✅︎
- ✅︎
- ✗
- ✗
- ✗
- ✅︎
- ✅︎
- ✗
- ✗
* - Marlin (GPTQ/AWQ/FP8)
...
...
@@ -61,7 +61,7 @@ The table below shows the compatibility of various quantization implementations
- ✅︎
- ✗
- ✗
- ✗
- ✅︎
- ✗
- ✗
* - FP8 (W8A8)
...
...
@@ -129,4 +129,4 @@ Notes:
Please note that this compatibility chart may be subject to change as vLLM continues to evolve and expand its support for different hardware platforms and quantization methods.
For the most up-to-date information on hardware support and quantization methods, please check the `quantization directory <https://github.com/vllm-project/vllm/tree/main/vllm/model_executor/layers/quantization>`_ or consult with the vLLM development team.
\ No newline at end of file
For the most up-to-date information on hardware support and quantization methods, please check the `quantization directory <https://github.com/vllm-project/vllm/tree/main/vllm/model_executor/layers/quantization>`_ or consult with the vLLM development team.
Helm is a package manager for Kubernetes. It will help you to deploy vLLM on k8s and automate the deployment of vLLMm Kubernetes applications. With Helm, you can deploy the same framework architecture with different configurations to multiple namespaces by overriding variables values.
This guide will walk you through the process of deploying vLLM with Helm, including the necessary prerequisites, steps for helm install and documentation on architecture and values file.
Prerequisites
-------------
Before you begin, ensure that you have the following:
- A running Kubernetes cluster
- NVIDIA Kubernetes Device Plugin (``k8s-device-plugin``): This can be found at `https://github.com/NVIDIA/k8s-device-plugin <https://github.com/NVIDIA/k8s-device-plugin>`__
- Available GPU resources in your cluster
- S3 with the model which will be deployed
Installing the chart
--------------------
To install the chart with the release name ``test-vllm``:
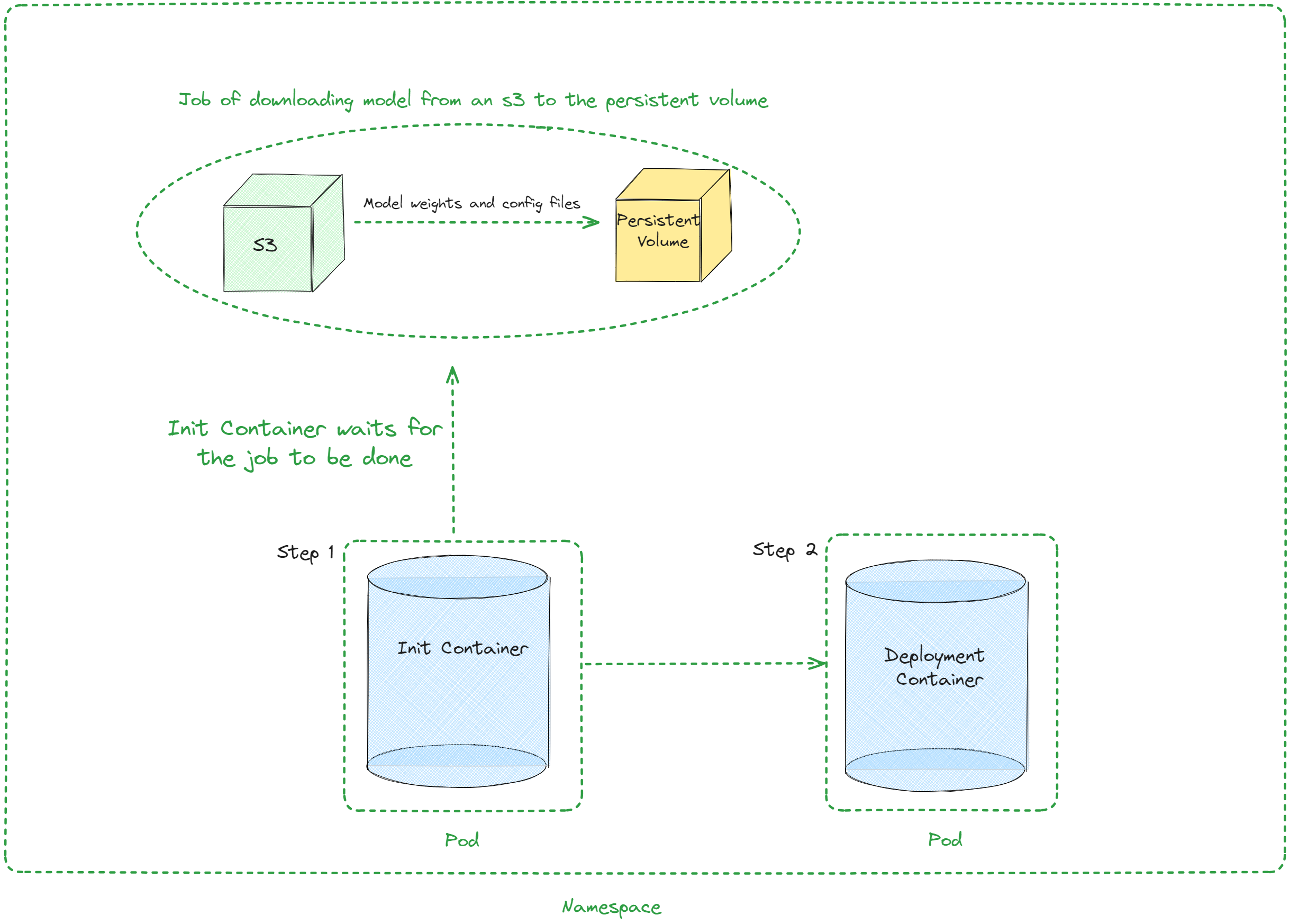
Using Kubernetes to deploy vLLM is a scalable and efficient way to serve machine learning models. This guide will walk you through the process of deploying vLLM with Kubernetes, including the necessary prerequisites, steps for deployment, and testing.
Prerequisites
-------------
Before you begin, ensure that you have the following:
- A running Kubernetes cluster
- NVIDIA Kubernetes Device Plugin (`k8s-device-plugin`): This can be found at `https://github.com/NVIDIA/k8s-device-plugin/`
- Available GPU resources in your cluster
Deployment Steps
----------------
1. **Create a PVC , Secret and Deployment for vLLM**
PVC is used to store the model cache and it is optional, you can use hostPath or other storage options
.. code-block:: yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mistral-7b
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
storageClassName: default
volumeMode: Filesystem
Secret is optional and only required for accessing gated models, you can skip this step if you are not using gated models
.. code-block:: yaml
apiVersion: v1
kind: Secret
metadata:
name: hf-token-secret
namespace: default
type: Opaque
data:
token: "REPLACE_WITH_TOKEN"
Create a deployment file for vLLM to run the model server. The following example deploys the `Mistral-7B-Instruct-v0.3` model:
.. code-block:: yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: mistral-7b
namespace: default
labels:
app: mistral-7b
spec:
replicas: 1
selector:
matchLabels:
app: mistral-7b
template:
metadata:
labels:
app: mistral-7b
spec:
volumes:
- name: cache-volume
persistentVolumeClaim:
claimName: mistral-7b
# vLLM needs to access the host's shared memory for tensor parallel inference.
If the service is correctly deployed, you should receive a response from the vLLM model.
Conclusion
----------
Deploying vLLM with Kubernetes allows for efficient scaling and management of ML models leveraging GPU resources. By following the steps outlined above, you should be able to set up and test a vLLM deployment within your Kubernetes cluster. If you encounter any issues or have suggestions, please feel free to contribute to the documentation.
`KubeAI <https://github.com/substratusai/kubeai>`_ is a Kubernetes operator that enables you to deploy and manage AI models on Kubernetes. It provides a simple and scalable way to deploy vLLM in production. Functionality such as scale-from-zero, load based autoscaling, model caching, and much more is provided out of the box with zero external dependencies.
Please see the Installation Guides for environment specific instructions:

{kind=link}