"vscode:/vscode.git/clone" did not exist on "36ede4598949092be3b61418a5141cbe730d1098"

Merge tag 'v0.12.0' into v0.12.0-dev
Showing
Too many changes to show.
To preserve performance only 380 of 380+ files are displayed.

350 KB
814 KB

267 KB
354 KB

781 KB

51.1 KB
359 KB
81.7 KB

70.3 KB
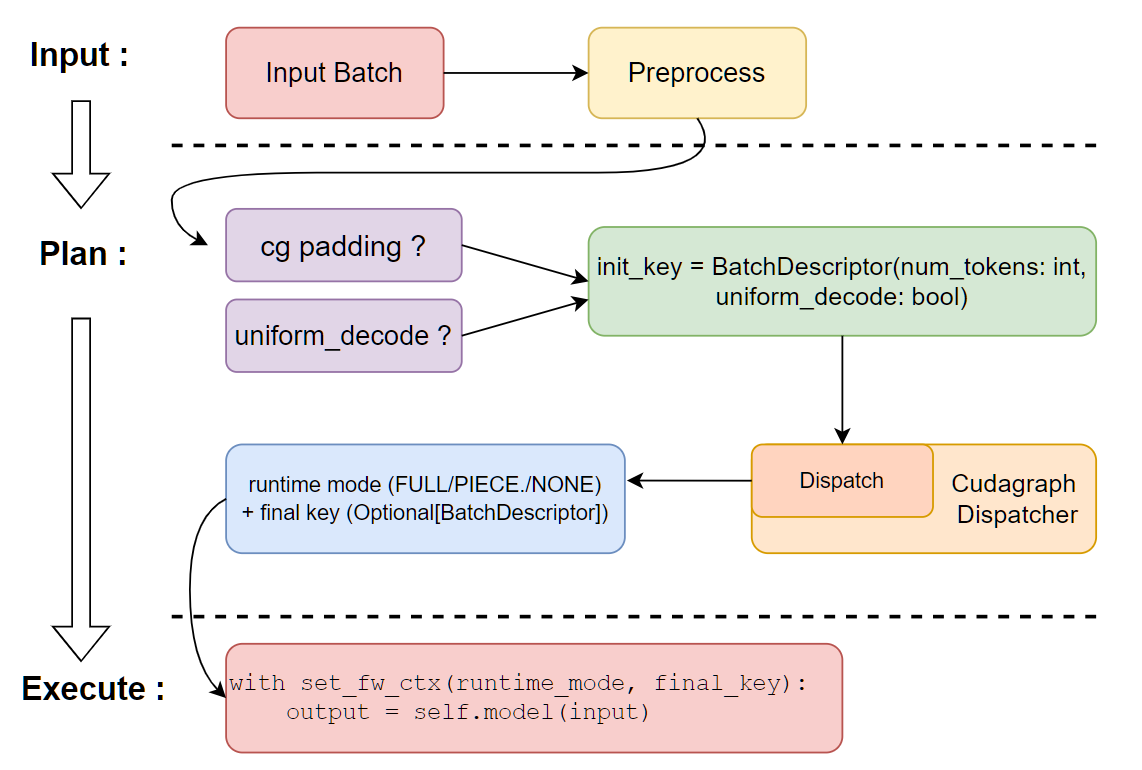
60.5 KB

43.9 KB
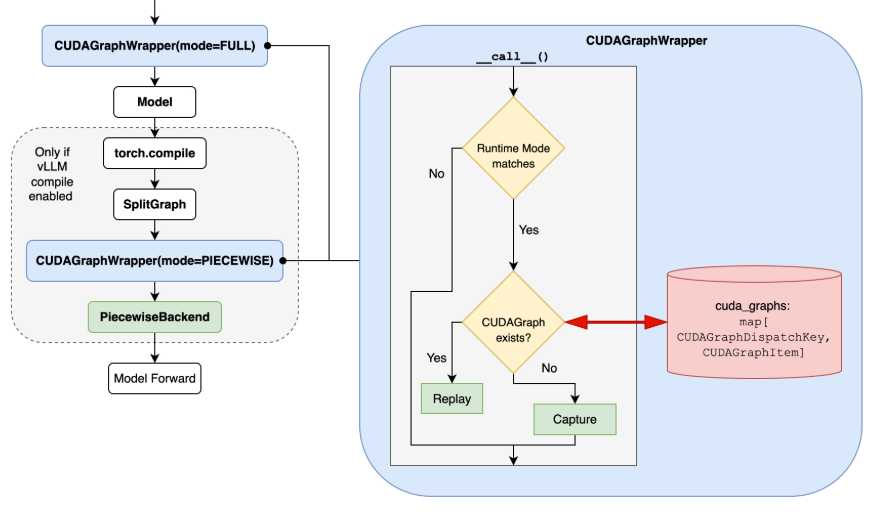
87.2 KB

315 KB

359 KB

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

83.9 KB
docs/benchmarking/README.md
0 → 100644
docs/benchmarking/sweeps.md
0 → 100644