Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in
Toggle navigation
Menu
Open sidebar
OpenDAS
vllm_cscc
Commits
081057de
Commit
081057de
authored
Apr 29, 2025
by
zhuwenwen
Browse files
Merge tag 'v0.8.5' into v0.8.5-ori
parents
7cf5d5c4
ba41cc90
Changes
689
Expand all
Show whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
2020 additions
and
17 deletions
+2020
-17
csrc/quantization/cutlass_w8a8/moe/moe_data.cu
csrc/quantization/cutlass_w8a8/moe/moe_data.cu
+15
-2
csrc/quantization/cutlass_w8a8/scaled_mm_c2x_sm89_fp8_dispatch.cuh
...tization/cutlass_w8a8/scaled_mm_c2x_sm89_fp8_dispatch.cuh
+1
-1
csrc/quantization/cutlass_w8a8/scaled_mm_c2x_sm89_int8_dispatch.cuh
...ization/cutlass_w8a8/scaled_mm_c2x_sm89_int8_dispatch.cuh
+1
-1
csrc/quantization/fp4/nvfp4_scaled_mm_kernels.cu
csrc/quantization/fp4/nvfp4_scaled_mm_kernels.cu
+1
-1
csrc/quantization/gptq_marlin/marlin.cuh
csrc/quantization/gptq_marlin/marlin.cuh
+7
-2
csrc/quantization/gptq_marlin/marlin_dtypes.cuh
csrc/quantization/gptq_marlin/marlin_dtypes.cuh
+7
-3
csrc/rocm/ops.h
csrc/rocm/ops.h
+9
-0
csrc/rocm/skinny_gemms.cu
csrc/rocm/skinny_gemms.cu
+1600
-0
csrc/rocm/torch_bindings.cpp
csrc/rocm/torch_bindings.cpp
+18
-0
csrc/torch_bindings.cpp
csrc/torch_bindings.cpp
+7
-0
docker/Dockerfile
docker/Dockerfile
+9
-0
docker/Dockerfile.cpu
docker/Dockerfile.cpu
+1
-0
docker/Dockerfile.nightly_torch
docker/Dockerfile.nightly_torch
+307
-0
docker/Dockerfile.ppc64le
docker/Dockerfile.ppc64le
+14
-4
docker/Dockerfile.rocm_base
docker/Dockerfile.rocm_base
+1
-1
docker/Dockerfile.s390x
docker/Dockerfile.s390x
+22
-2
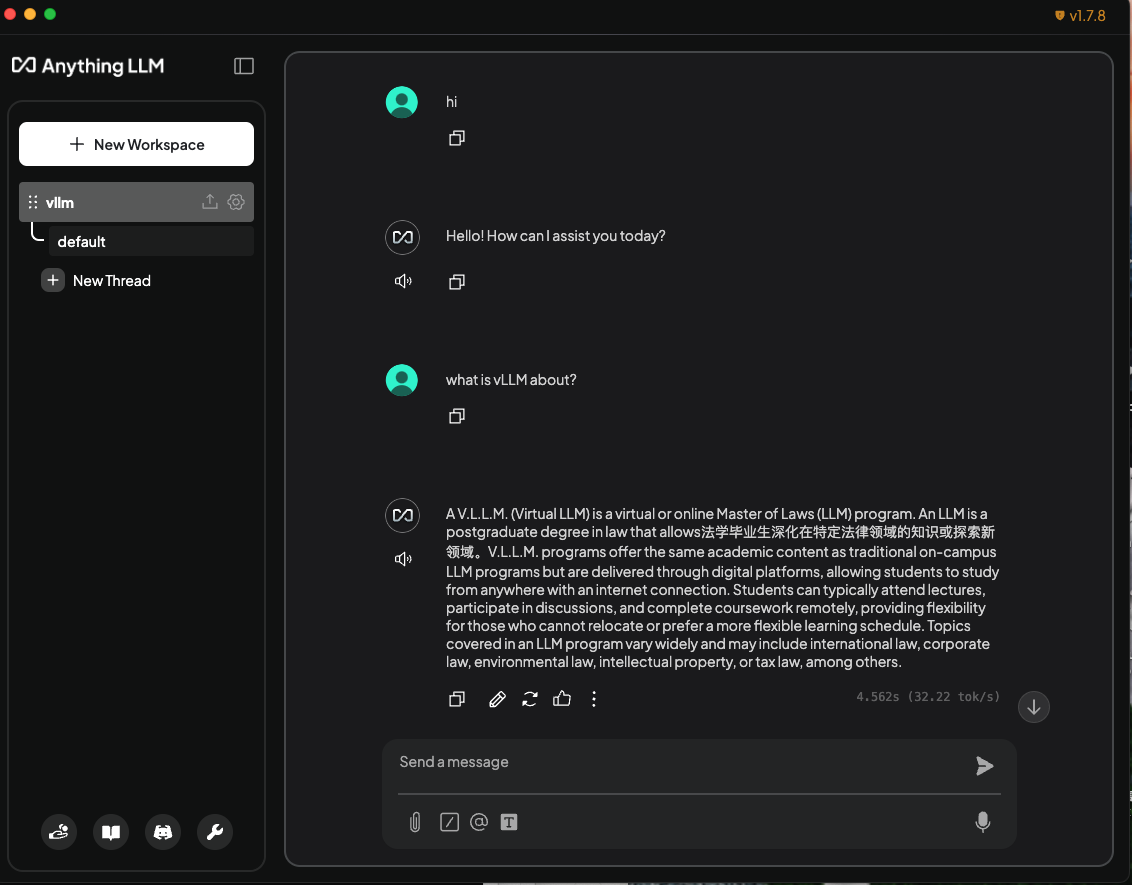
docs/source/assets/deployment/anything-llm-chat-with-doc.png
docs/source/assets/deployment/anything-llm-chat-with-doc.png
+0
-0
docs/source/assets/deployment/anything-llm-chat-without-doc.png
...ource/assets/deployment/anything-llm-chat-without-doc.png
+0
-0
docs/source/assets/deployment/anything-llm-provider.png
docs/source/assets/deployment/anything-llm-provider.png
+0
-0
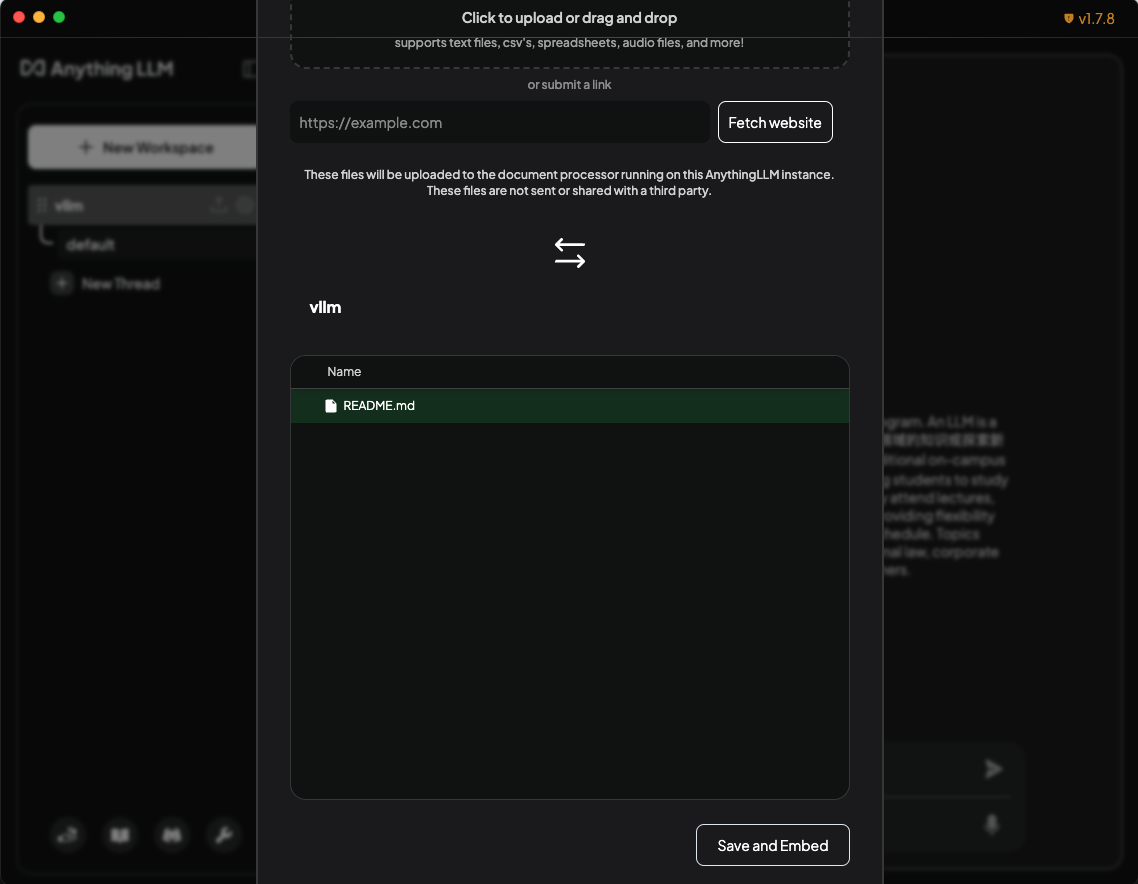
docs/source/assets/deployment/anything-llm-upload-doc.png
docs/source/assets/deployment/anything-llm-upload-doc.png
+0
-0
No files found.
csrc/quantization/cutlass_w8a8/moe/moe_data.cu
View file @
081057de
...
...
@@ -46,14 +46,26 @@ __global__ void compute_expert_offsets(
}
__global__
void
compute_arg_sorts
(
const
int
*
__restrict__
topk_ids
,
const
int32_t
*
__restrict__
expert_offsets
,
int32_t
*
input_permutation
,
int32_t
*
output_permutation
,
int32_t
*
atomic_buffer
,
const
int
topk_length
,
const
int
topk
)
{
int
expert_id
=
blockIdx
.
x
;
int
const
blk_expert_id
=
blockIdx
.
x
;
int
const
num_experts
=
gridDim
.
x
;
int32_t
const
num_tokens
=
expert_offsets
[
num_experts
];
for
(
int
i
=
threadIdx
.
x
;
i
<
topk_length
;
i
+=
THREADS_PER_EXPERT
)
{
if
(
topk_ids
[
i
]
==
expert_id
)
{
int
const
expert_id
=
topk_ids
[
i
];
if
(
expert_id
==
-
1
&&
blockIdx
.
x
==
0
)
{
// output_permutation is used to re-order the moe outputs. It is
// used as c2 = c2[c_map], where c2 is a torch.tensor that is the
// output of the cutlass kernels and c_map is the output_permutation.
// c2 is initialized to zeros, therefore by setting the output_permutation
// to num_tokens, we are guaranteed to fill the moe outputs to zero
// for "invalid" topk_ids.
output_permutation
[
i
]
=
num_tokens
;
}
else
if
(
expert_id
==
blk_expert_id
)
{
int
start
=
atomicAdd
(
&
atomic_buffer
[
expert_id
],
1
);
input_permutation
[
start
]
=
i
/
topk
;
output_permutation
[
i
]
=
start
;
...
...
@@ -83,6 +95,7 @@ void get_cutlass_moe_mm_data_caller(
static_cast
<
int32_t
*>
(
atomic_buffer
.
data_ptr
()),
num_experts
);
compute_arg_sorts
<<<
num_experts
,
num_threads
,
0
,
stream
>>>
(
static_cast
<
const
int32_t
*>
(
topk_ids
.
data_ptr
()),
static_cast
<
const
int32_t
*>
(
expert_offsets
.
data_ptr
()),
static_cast
<
int32_t
*>
(
input_permutation
.
data_ptr
()),
static_cast
<
int32_t
*>
(
output_permutation
.
data_ptr
()),
static_cast
<
int32_t
*>
(
atomic_buffer
.
data_ptr
()),
topk_ids
.
numel
(),
...
...
csrc/quantization/cutlass_w8a8/scaled_mm_c2x_sm89_fp8_dispatch.cuh
View file @
081057de
...
...
@@ -336,7 +336,7 @@ inline void cutlass_gemm_sm89_fp8_dispatch(torch::Tensor& out,
uint32_t
const
m
=
a
.
size
(
0
);
uint32_t
const
mp2
=
std
::
max
(
static_cast
<
uint32_t
>
(
32
),
next_pow_2
(
m
));
// next power of 2
std
::
max
(
static_cast
<
uint32_t
>
(
16
),
next_pow_2
(
m
));
// next power of 2
if
(
mp2
<=
16
)
{
// M in [1, 16]
...
...
csrc/quantization/cutlass_w8a8/scaled_mm_c2x_sm89_int8_dispatch.cuh
View file @
081057de
...
...
@@ -321,7 +321,7 @@ inline void cutlass_gemm_sm89_int8_dispatch(torch::Tensor& out,
uint32_t
const
m
=
a
.
size
(
0
);
uint32_t
const
mp2
=
std
::
max
(
static_cast
<
uint32_t
>
(
32
),
next_pow_2
(
m
));
// next power of 2
std
::
max
(
static_cast
<
uint32_t
>
(
16
),
next_pow_2
(
m
));
// next power of 2
if
(
mp2
<=
16
)
{
// M in [1, 16]
...
...
csrc/quantization/fp4/nvfp4_scaled_mm_kernels.cu
View file @
081057de
...
...
@@ -134,7 +134,7 @@ typename T::Gemm::Arguments args_from_options(
using
StrideB
=
typename
T
::
StrideB
;
using
StrideD
=
typename
T
::
StrideD
;
using
Sm100BlkScaledConfig
=
typename
T
::
Gemm
::
GemmKernel
::
CollectiveMainloop
::
Sm1
00
BlkScaledConfig
;
typename
T
::
Gemm
::
GemmKernel
::
CollectiveMainloop
::
Sm1
xx
BlkScaledConfig
;
int
m
=
static_cast
<
int
>
(
M
);
int
n
=
static_cast
<
int
>
(
N
);
...
...
csrc/quantization/gptq_marlin/marlin.cuh
View file @
081057de
...
...
@@ -9,7 +9,11 @@
#include <cuda_runtime.h>
#include <iostream>
namespace
marlin
{
#ifndef MARLIN_NAMESPACE_NAME
#define MARLIN_NAMESPACE_NAME marlin
#endif
namespace
MARLIN_NAMESPACE_NAME
{
// Marlin params
...
...
@@ -23,6 +27,7 @@ static constexpr int pipe_stages =
static
constexpr
int
min_thread_n
=
64
;
static
constexpr
int
min_thread_k
=
64
;
static
constexpr
int
max_thread_n
=
256
;
static
constexpr
int
tile_size
=
16
;
static
constexpr
int
max_par
=
16
;
...
...
@@ -84,4 +89,4 @@ __device__ inline void cp_async_wait() {
#endif
}
// namespace
marlin
}
// namespace
MARLIN_NAMESPACE_NAME
csrc/quantization/gptq_marlin/marlin_dtypes.cuh
View file @
081057de
...
...
@@ -5,7 +5,11 @@
#include <cuda_fp16.h>
#include <cuda_bf16.h>
namespace
marlin
{
#ifndef MARLIN_NAMESPACE_NAME
#define MARLIN_NAMESPACE_NAME marlin
#endif
namespace
MARLIN_NAMESPACE_NAME
{
template
<
typename
scalar_t
>
class
ScalarType
{};
...
...
@@ -54,7 +58,7 @@ class ScalarType<nv_bfloat16> {
using
FragS
=
Vec
<
nv_bfloat162
,
1
>
;
using
FragZP
=
Vec
<
nv_bfloat162
,
4
>
;
#if defined(__CUDA_ARCH__)
&&
__CUDA_ARCH__ >= 800
#if
!
defined(__CUDA_ARCH__)
||
__CUDA_ARCH__ >= 800
static
__device__
float
inline
num2float
(
const
nv_bfloat16
x
)
{
return
__bfloat162float
(
x
);
}
...
...
@@ -74,6 +78,6 @@ class ScalarType<nv_bfloat16> {
#endif
};
}
// namespace
marlin
}
// namespace
MARLIN_NAMESPACE_NAME
#endif
csrc/rocm/ops.h
View file @
081057de
...
...
@@ -2,6 +2,15 @@
#include <torch/all.h>
torch
::
Tensor
LLMM1
(
at
::
Tensor
&
in_a
,
at
::
Tensor
&
in_b
,
const
int64_t
rows_per_block
);
torch
::
Tensor
wvSplitK
(
at
::
Tensor
&
in_a
,
at
::
Tensor
&
in_b
,
const
int64_t
CuCount
);
void
wvSplitKQ
(
at
::
Tensor
&
in_a
,
at
::
Tensor
&
in_b
,
at
::
Tensor
&
out_c
,
at
::
Tensor
&
scale_a
,
at
::
Tensor
&
scale_b
,
const
int64_t
CuCount
);
void
paged_attention
(
torch
::
Tensor
&
out
,
torch
::
Tensor
&
exp_sums
,
torch
::
Tensor
&
max_logits
,
torch
::
Tensor
&
tmp_out
,
torch
::
Tensor
&
query
,
torch
::
Tensor
&
key_cache
,
...
...
csrc/rocm/skinny_gemms.cu
0 → 100644
View file @
081057de
This diff is collapsed.
Click to expand it.
csrc/rocm/torch_bindings.cpp
View file @
081057de
...
...
@@ -14,6 +14,24 @@
TORCH_LIBRARY_EXPAND
(
TORCH_EXTENSION_NAME
,
rocm_ops
)
{
// vLLM custom ops for rocm
// Custom gemm op for matrix-vector multiplication
rocm_ops
.
def
(
"LLMM1(Tensor in_a, Tensor in_b, int rows_per_block) -> "
"Tensor"
);
rocm_ops
.
impl
(
"LLMM1"
,
torch
::
kCUDA
,
&
LLMM1
);
// Custom gemm op for skinny matrix-matrix multiplication
rocm_ops
.
def
(
"wvSplitK(Tensor in_a, Tensor in_b, int CuCount) -> "
"Tensor"
);
rocm_ops
.
impl
(
"wvSplitK"
,
torch
::
kCUDA
,
&
wvSplitK
);
// wvSplitK for fp8
rocm_ops
.
def
(
"wvSplitKQ(Tensor in_a, Tensor in_b, Tensor! out_c, Tensor scale_a, "
" Tensor scale_b, int CuCount) -> ()"
);
rocm_ops
.
impl
(
"wvSplitKQ"
,
torch
::
kCUDA
,
&
wvSplitKQ
);
// Custom attention op
// Compute the attention between an input query and the cached
// keys/values using PagedAttention.
...
...
csrc/torch_bindings.cpp
View file @
081057de
...
...
@@ -130,6 +130,13 @@ TORCH_LIBRARY_EXPAND(TORCH_EXTENSION_NAME, ops) {
") -> ()"
);
ops
.
impl
(
"advance_step_flashinfer"
,
torch
::
kCUDA
,
&
advance_step_flashinfer
);
// Compute MLA decode using cutlass.
ops
.
def
(
"cutlass_mla_decode(Tensor! out, Tensor q_nope, Tensor q_pe,"
" Tensor kv_c_and_k_pe_cache, Tensor seq_lens,"
" Tensor page_table, float scale) -> ()"
);
ops
.
impl
(
"cutlass_mla_decode"
,
torch
::
kCUDA
,
&
cutlass_mla_decode
);
// Layernorm
// Apply Root Mean Square (RMS) Normalization to the input tensor.
ops
.
def
(
...
...
docker/Dockerfile
View file @
081057de
...
...
@@ -162,6 +162,9 @@ ENV UV_HTTP_TIMEOUT=500
COPY
requirements/lint.txt requirements/lint.txt
COPY
requirements/test.txt requirements/test.txt
COPY
requirements/dev.txt requirements/dev.txt
# Workaround for #17068
RUN
--mount
=
type
=
cache,target
=
/root/.cache/uv
\
uv pip
install
--system
mamba-ssm
==
2.2.4
--no-build-isolation
RUN
--mount
=
type
=
cache,target
=
/root/.cache/uv
\
uv pip
install
--system
-r
requirements/dev.txt
#################### DEV IMAGE ####################
...
...
@@ -240,6 +243,8 @@ if [ "$TARGETPLATFORM" != "linux/arm64" ]; then \
uv pip
install
--system
https://github.com/flashinfer-ai/flashinfer/releases/download/v0.2.1.post2/flashinfer_python-0.2.1.post2+cu124torch2.6-cp38-abi3-linux_x86_64.whl
;
\
fi
COPY
examples examples
COPY
benchmarks benchmarks
COPY
./vllm/collect_env.py .
# Although we build Flashinfer with AOT mode, there's still
# some issues w.r.t. JIT compilation. Therefore we need to
...
...
@@ -263,6 +268,9 @@ ADD . /vllm-workspace/
ENV
UV_HTTP_TIMEOUT=500
# install development dependencies (for testing)
# Workaround for #17068
RUN
--mount
=
type
=
cache,target
=
/root/.cache/uv
\
uv pip
install
--system
mamba-ssm
==
2.2.4
--no-build-isolation
RUN
--mount
=
type
=
cache,target
=
/root/.cache/uv
\
uv pip
install
--system
-r
requirements/dev.txt
...
...
@@ -289,6 +297,7 @@ RUN mv vllm test_docs/
#################### OPENAI API SERVER ####################
# base openai image with additional requirements, for any subsequent openai-style images
FROM
vllm-base AS vllm-openai-base
ARG
TARGETPLATFORM
# This timeout (in seconds) is necessary when installing some dependencies via uv since it's likely to time out
# Reference: https://github.com/astral-sh/uv/pull/1694
...
...
docker/Dockerfile.cpu
View file @
081057de
...
...
@@ -121,6 +121,7 @@ RUN --mount=type=cache,target=/root/.cache/uv \
ADD ./tests/ ./tests/
ADD ./examples/ ./examples/
ADD ./benchmarks/ ./benchmarks/
ADD ./vllm/collect_env.py .
# install development dependencies (for testing)
RUN --mount=type=cache,target=/root/.cache/uv \
...
...
docker/Dockerfile.nightly_torch
0 → 100644
View file @
081057de
This diff is collapsed.
Click to expand it.
docker/Dockerfile.ppc64le
View file @
081057de
...
...
@@ -126,13 +126,16 @@ RUN --mount=type=cache,target=/root/.cache/uv \
FROM base-builder AS cv-builder
ARG MAX_JOBS
ARG OPENCV_VERSION=84
ARG OPENCV_VERSION=86
# patch for version 4.11.0.86
ARG OPENCV_PATCH=97f3f39
ARG ENABLE_HEADLESS=1
RUN --mount=type=cache,target=/root/.cache/uv \
source /opt/rh/gcc-toolset-13/enable && \
git clone --recursive https://github.com/opencv/opencv-python.git -b ${OPENCV_VERSION} && \
cd opencv-python && \
sed -i 's/"setuptools==59.2.0",/"setuptools<70.0",/g' pyproject.toml && \
sed -i -E -e 's/"setuptools.+",/"setuptools",/g' pyproject.toml && \
cd opencv && git cherry-pick --no-commit $OPENCV_PATCH && cd .. && \
python -m build --wheel --installer=uv --outdir /opencvwheels/
###############################################################
...
...
@@ -148,9 +151,15 @@ COPY --from=arrow-builder /tmp/control /dev/null
COPY --from=cv-builder /tmp/control /dev/null
ARG VLLM_TARGET_DEVICE=cpu
ARG GRPC_PYTHON_BUILD_SYSTEM_OPENSSL=1
# this step installs vllm and populates uv cache
# with all the transitive dependencies
RUN --mount=type=cache,target=/root/.cache/uv \
source /opt/rh/gcc-toolset-13/enable && \
git clone https://github.com/huggingface/xet-core.git && cd xet-core/hf_xet/ && \
uv pip install maturin && \
uv build --wheel --out-dir /hf_wheels/
RUN --mount=type=cache,target=/root/.cache/uv \
--mount=type=bind,from=torch-builder,source=/torchwheels/,target=/torchwheels/,ro \
--mount=type=bind,from=arrow-builder,source=/arrowwheels/,target=/arrowwheels/,ro \
...
...
@@ -159,7 +168,7 @@ RUN --mount=type=cache,target=/root/.cache/uv \
source /opt/rh/gcc-toolset-13/enable && \
uv pip install /opencvwheels/*.whl /arrowwheels/*.whl /torchwheels/*.whl && \
sed -i -e 's/.*torch.*//g' /src/pyproject.toml /src/requirements/*.txt && \
uv pip install pandas pythran pybind11 && \
uv pip install pandas pythran pybind11
/hf_wheels/*.whl
&& \
# sentencepiece.pc is in some pkgconfig inside uv cache
export PKG_CONFIG_PATH=$(find / -type d -name "pkgconfig" 2>/dev/null | tr '\n' ':') && \
uv pip install -r /src/requirements/common.txt -r /src/requirements/cpu.txt -r /src/requirements/build.txt --no-build-isolation && \
...
...
@@ -247,8 +256,9 @@ RUN --mount=type=cache,target=/root/.cache/uv \
--mount=type=bind,from=torch-builder,source=/torchwheels/,target=/torchwheels/,ro \
--mount=type=bind,from=arrow-builder,source=/arrowwheels/,target=/arrowwheels/,ro \
--mount=type=bind,from=cv-builder,source=/opencvwheels/,target=/opencvwheels/,ro \
--mount=type=bind,from=vllmcache-builder,source=/hf_wheels/,target=/hf_wheels/,ro \
--mount=type=bind,from=vllmcache-builder,source=/vllmwheel/,target=/vllmwheel/,ro \
HOME=/root uv pip install /opencvwheels/*.whl /arrowwheels/*.whl /torchwheels/*.whl /vllmwheel/*.whl
HOME=/root uv pip install /opencvwheels/*.whl /arrowwheels/*.whl /torchwheels/*.whl
/hf_wheels/*.whl
/vllmwheel/*.whl
COPY ./ /workspace/vllm
WORKDIR /workspace/vllm
...
...
docker/Dockerfile.rocm_base
View file @
081057de
...
...
@@ -12,7 +12,7 @@ ARG PYTORCH_REPO="https://github.com/pytorch/pytorch.git"
ARG PYTORCH_VISION_REPO="https://github.com/pytorch/vision.git"
ARG FA_BRANCH="1a7f4dfa"
ARG FA_REPO="https://github.com/Dao-AILab/flash-attention.git"
ARG AITER_BRANCH="
8970b25b
"
ARG AITER_BRANCH="
7e1ed08
"
ARG AITER_REPO="https://github.com/ROCm/aiter.git"
FROM ${BASE_IMAGE} AS base
...
...
docker/Dockerfile.s390x
View file @
081057de
This diff is collapsed.
Click to expand it.
docs/source/assets/deployment/anything-llm-chat-with-doc.png
0 → 100644
View file @
081057de
118 KB
docs/source/assets/deployment/anything-llm-chat-without-doc.png
0 → 100644
View file @
081057de
136 KB
docs/source/assets/deployment/anything-llm-provider.png
0 → 100644
View file @
081057de
110 KB
docs/source/assets/deployment/anything-llm-upload-doc.png
0 → 100644
View file @
081057de
111 KB
Prev
1
2
3
4
5
6
7
8
…
35
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment



{kind=link}
{kind=link}
{kind=link}
{kind=link}