# Architecture Overview
This document outlines the architectural design for vLLM-Omni.
# Goals
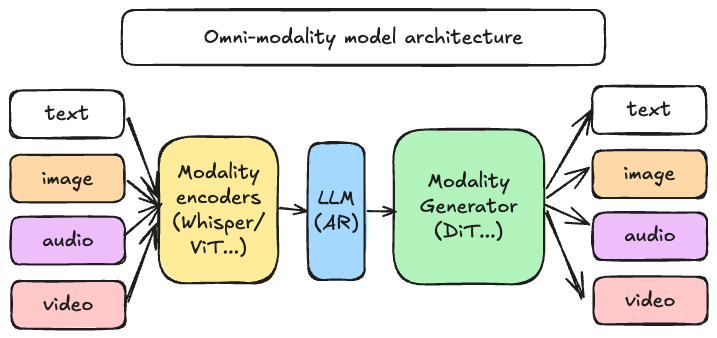
The primary goal of the vLLM-Omni project is to build the fastest and easiest-to-use open-source Omni-Modality model inference & serving engine. vLLM-Omni extends the original vLLM, which was created to support large language models for text-based autoregressive (AR) generation tasks. vLLM-Omni is designed to support:
* **Non-textual Output:** Enables the integration, efficient processing and output of various data types, including but not limited to, images, audio, and video, alongside text.
* **Non-Autoregressive Structure:** Support model structure beyond autoregressive, especially Diffusion Transformer (DiT), which is widely used in visual and audio generation.
* **Integration with vLLM Core:** Maintain compatibility and leverage existing vLLM key modules and optimizations where applicable.
* **Extensibility:** Design a modular and flexible architecture that can easily accommodate new modalities, model architectures, and output formats.
# Representative omni-modality models
According to analysis for current popular open-source models, most of them have the combination of AR+DiT. Specifically, they can be further categorized into 3 types below:
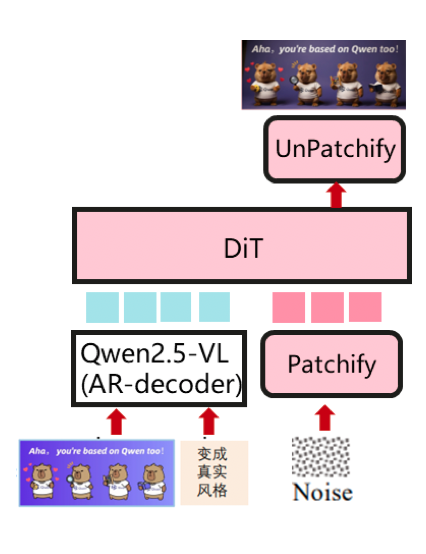
**DiT as a main structure, with AR as text encoder (e.g.: Qwen-Image)**
A powerful image generation foundation model capable of complex text rendering and precise image editing.
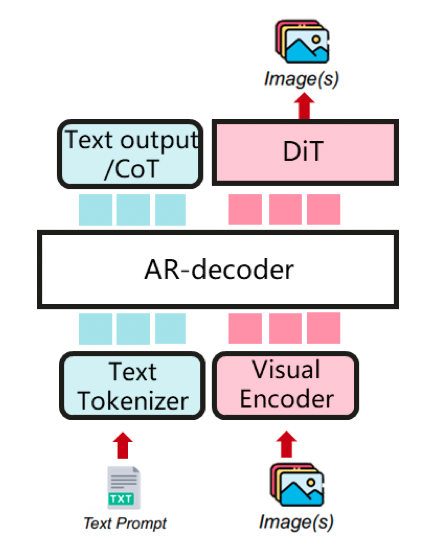
**AR as a main structure, with DiT as multi-modal generator (e.g. BAGEL)**
A unified multimodal comprehension and generation model, with cot text output and visual generation.
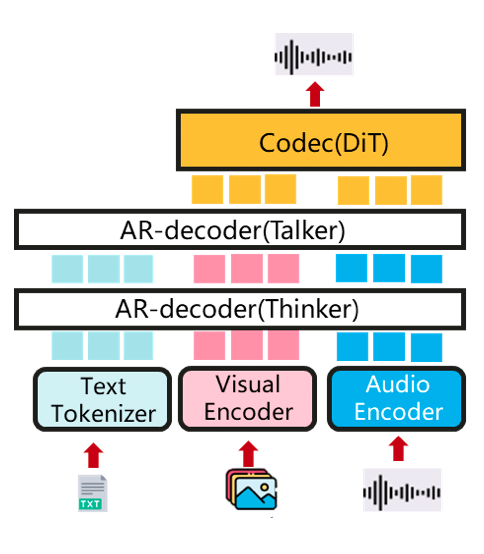
**AR+DiT (e.g. Qwen-Omni)**
A natively end-to-end omni-modal LLM for multimodal inputs (text/image/audio/video...) and outputs (text/audio...).
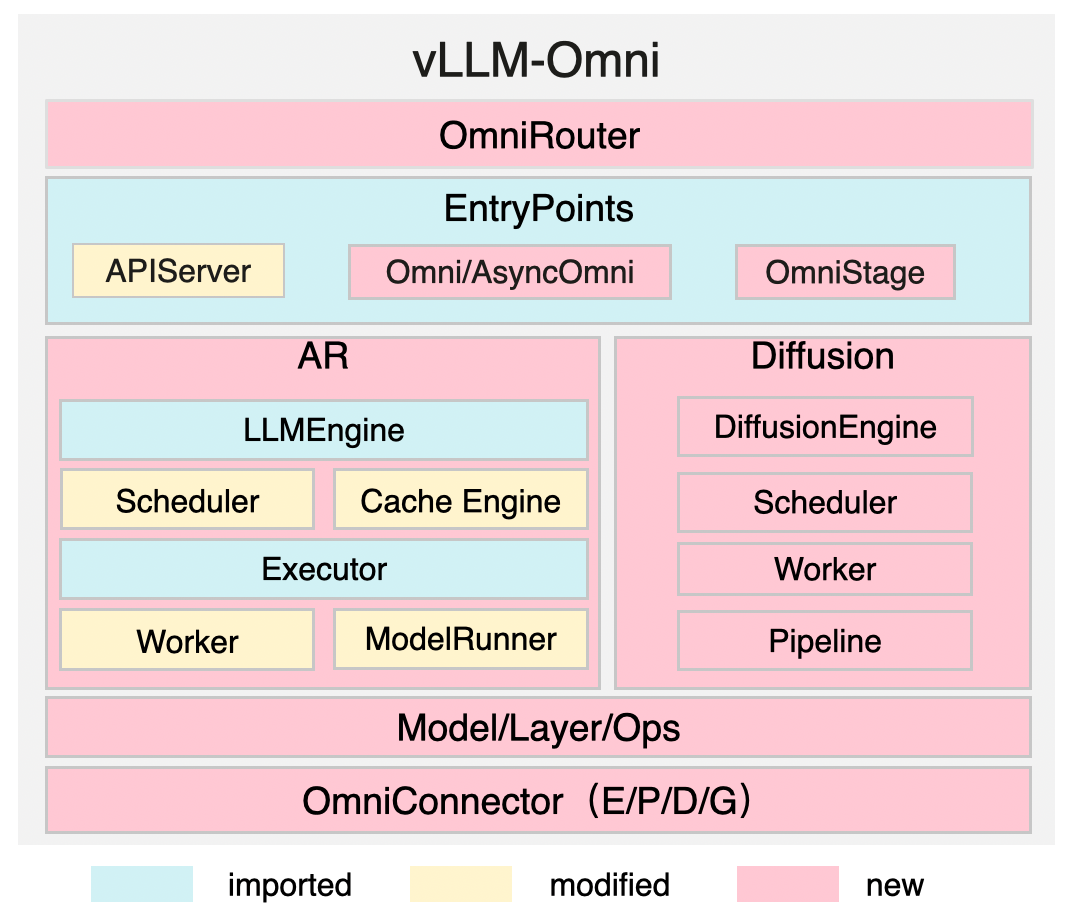
# vLLM-Omni main architecture
## Key Components
| Component | Description |
| ----------------- | ---------------------------------------------------------------------------------------------------------------------------------------- |
| **OmniRouter** | provide an intelligent router for Omni-modality requests dispatch |
| **EntryPoints** | define the APIs for offline/online serving (APIServer, Omni/AsyncOmni) and provide the OmniStage abstraction for different AR/DiT stages |
| **AR** | adapted for omni-modality models while inheriting efficient features from vLLM, such as cache management |
| **Diffusion** | natively implemented and optimized using acceleration components |
| **OmniConnector** | supports fully disaggregation based on E/P/D/G (Encoding/Processing/Decoding/Generation) disaggregation across stages |
Disaggregated stages are managed through configuration, such as in the Qwen3-Omni example, where stages like Thinker, Talker, and Code2wav are defined as separate OmniStage instances with specific resources and input/output type.
## Main features
vLLM-Omni aims to be fast, flexible, and easy to use with the following features:
### Performance and Acceleration
The framework achieves high performance through several optimization techniques:
* **Efficient AR Support:** Leverages efficient KV cache management inherited from vLLM.
* **Pipelined Execution:** Uses pipelined stage execution overlapping to ensure high throughput.
* **Full Disaggregation:** Relies on the OmniConnector and dynamic resource allocation across stages.
* **Diffusion Acceleration:** Includes integrated support for diffusion acceleration. This is managed by the acceleration layer, which handles:
* **Cache:** Includes DBCache, TeaCache and third-party integration(e.g., [cache-dit](https://github.com/vipshop/cache-dit)).
* **Parallelism:** Supports TP, CP, USP, and CFG.
* **Attention:** Provides an interface for third-party integration (e.g., FA3, SAGE, MindIE-SD).
* **Quantization:** Supports various quantization implementations including FP8 and AWQ.
* **FusedOps:** Allows for custom and third-party integration.
### Flexibility and Usability
vLLM-Omni is designed to be flexible and straightforward for users:
* **Heterogeneous Pipeline Abstraction:** Manages complex model workflows effectively.
* **Hugging Face Integration:** Offers seamless integration with popular Hugging Face models.
* **Distributed Inference:** Supports tensor, pipeline, data, and expert parallelism.
* **Streaming Outputs:** Supports streaming outputs.
* **Unified API:** Provides a consistent and unified API interface compatible with vLLM.
* **OpenAI-compatible API Server:** Includes a FastAPI-based server for online serving that is compatible with the OpenAI API.
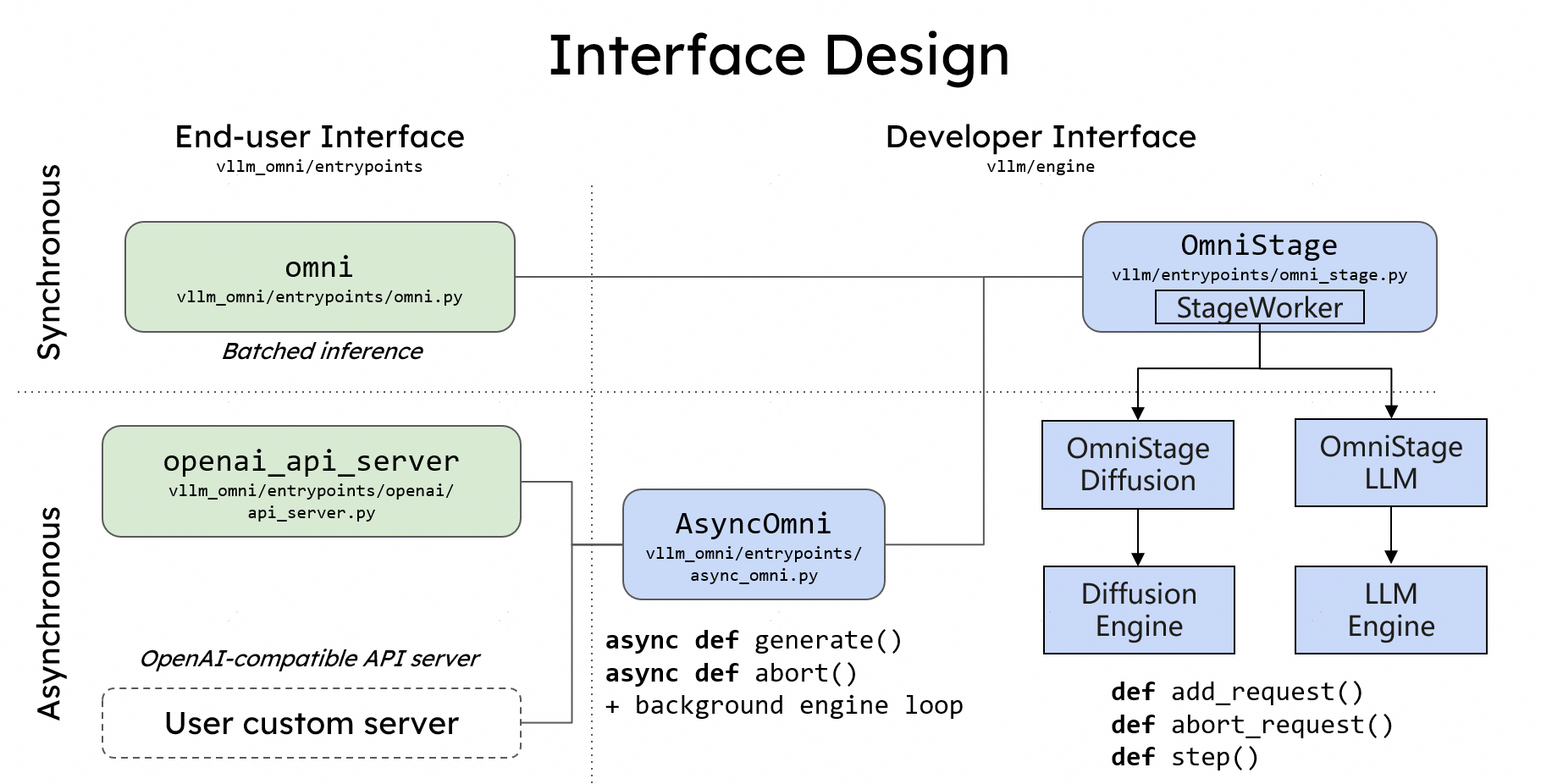
# Interface design
If you use vLLM, then you know how to use vLLM-Omni from Day 0:
Taking **Qwen3-Omni** as an example:
## Offline Inference
The **Omni** class provides a Python interface for offline batched inference. Users initialize the Omni class with a Hugging Face model name and use the generate method, passing inputs that include both text prompts and multi-modal data:
```
# Create an omni_lm with HF model name.
from vllm_omni.entrypoints.omni import Omni
omni_lm = Omni(model="Qwen/Qwen3-Omni-30B-A3B-Instruct")
# Example prompts.
om_inputs = {"prompt": prompt,
"multi_modal_data": {
"video": video_frames,
"audio": audio_signal,
}}
# Generate texts and audio from the multi-modality inputs.
outputs = omni_lm.generate(om_inputs, sampling_params_list)
```
## Online Serving
Similar to vLLM, vLLM-Omni also provides a FastAPI-based server for online serving. Users can launch the server using the vllm serve command with the `--omni` flag:
```
vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
```
Users can send requests to the server using curl:
```
# prepare user content
user_content='[
{
"type": "video_url",
"video_url": {
"url": "'"$SAMPLE_VIDEO_URL"'"
}
},
{
"type": "text",
"text": "Why is this video funny?"
}
]'
sampling_params_list='[
'"$thinker_sampling_params"',
'"$talker_sampling_params"',
'"$code2wav_sampling_params"'
]'
mm_processor_kwargs="{}"
# send the request
curl -sS -X POST http://localhost:8091/v1/chat/completions \
-H "Content-Type: application/json" \
-d @- <