
vllm-omni_0.15.0.rc1+fix1 first commit
Showing
Too many changes to show.
To preserve performance only 306 of 306+ files are displayed.
{kind=link}
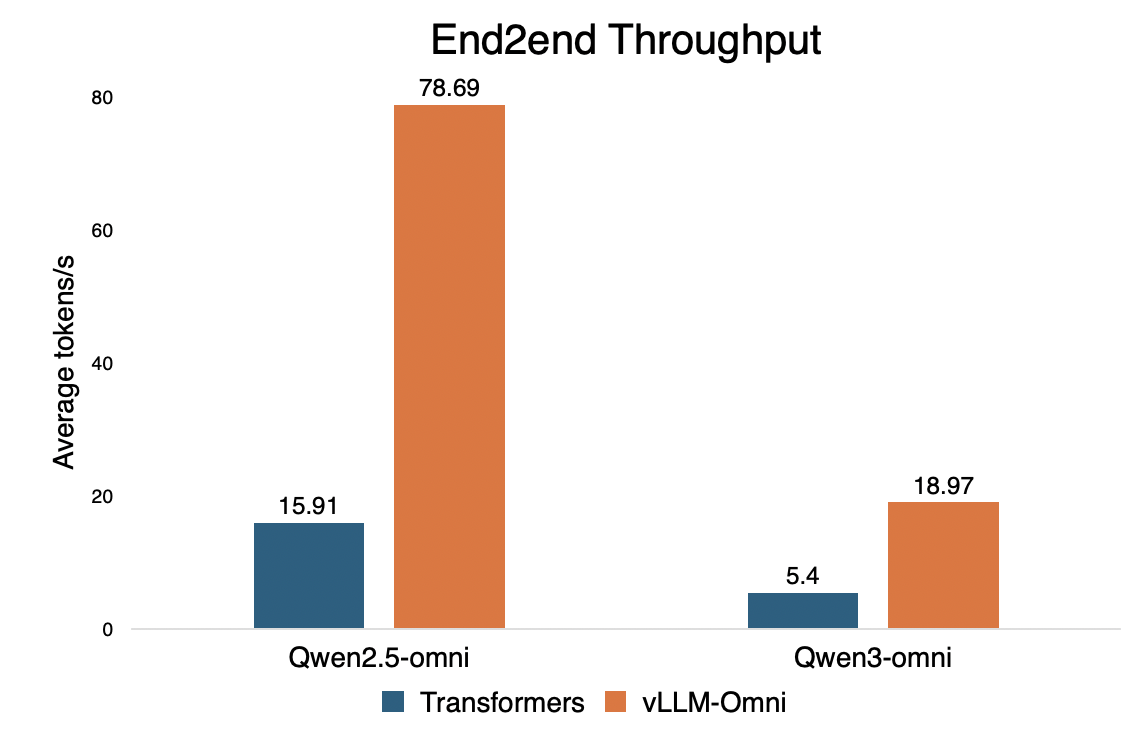
115 KB
collect_env.py
0 → 100644
docker/Dockerfile.ci
0 → 100644
docker/Dockerfile.ci.npu
0 → 100644
docker/Dockerfile.rocm
0 → 100644
docs/.nav.yml
0 → 100644
docs/README.md
0 → 100644
docs/api/README.md
0 → 100644
docs/assets/WeChat.jpg
0 → 100644
{kind=link}

124 KB
docs/cli/README.md
0 → 100644
docs/cli/bench/serve.md
0 → 100644
docs/community/contact_us.md
0 → 100644
docs/community/meetups.md
0 → 100644
docs/community/volunteers.md
0 → 100644
docs/configuration/README.md
0 → 100644