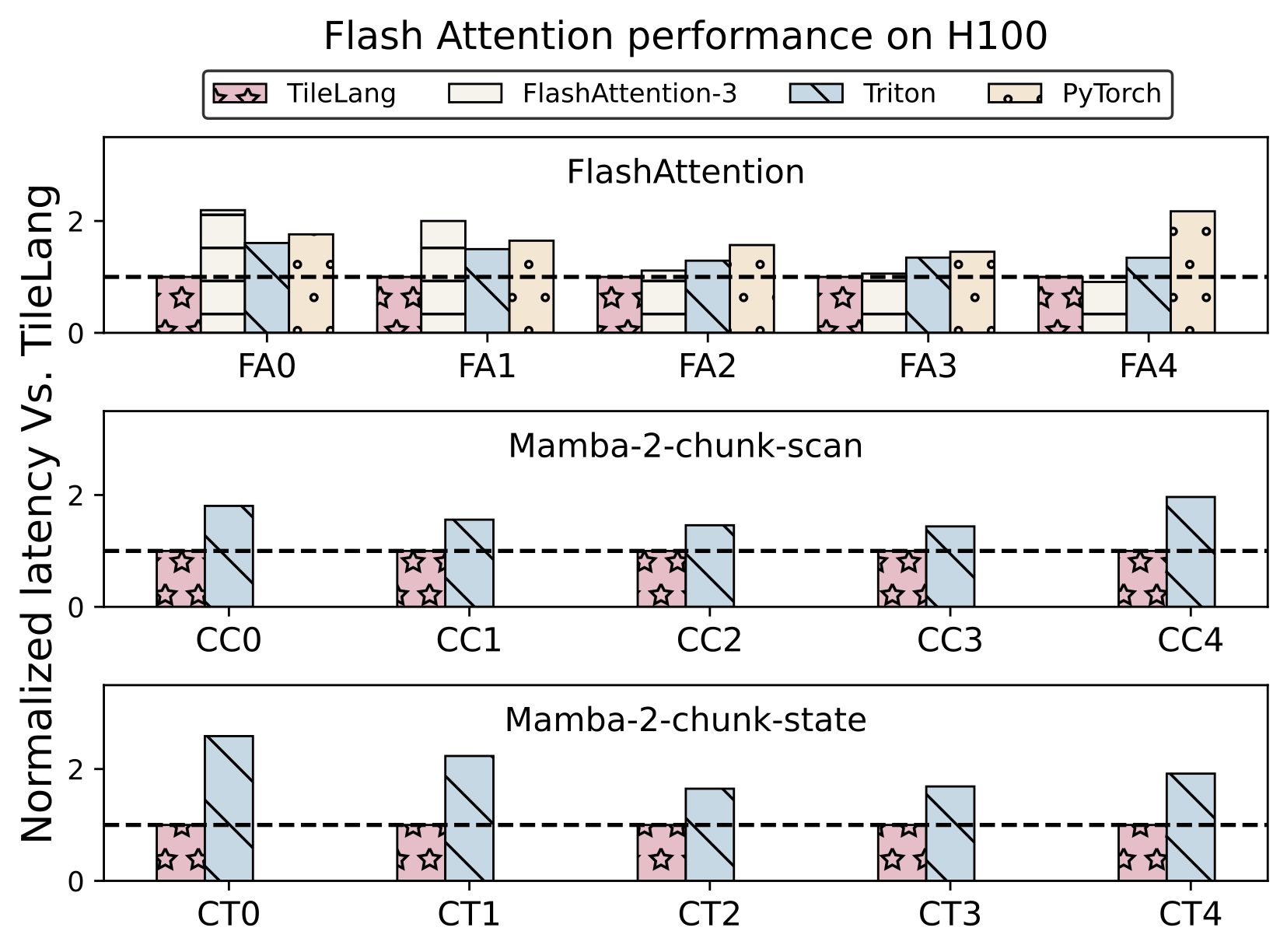
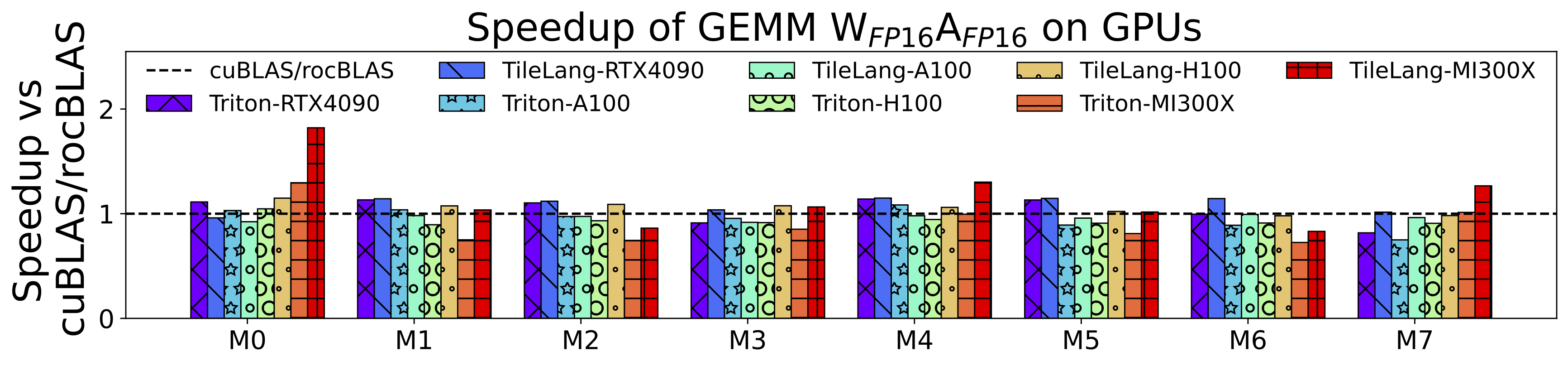
# Tile Language