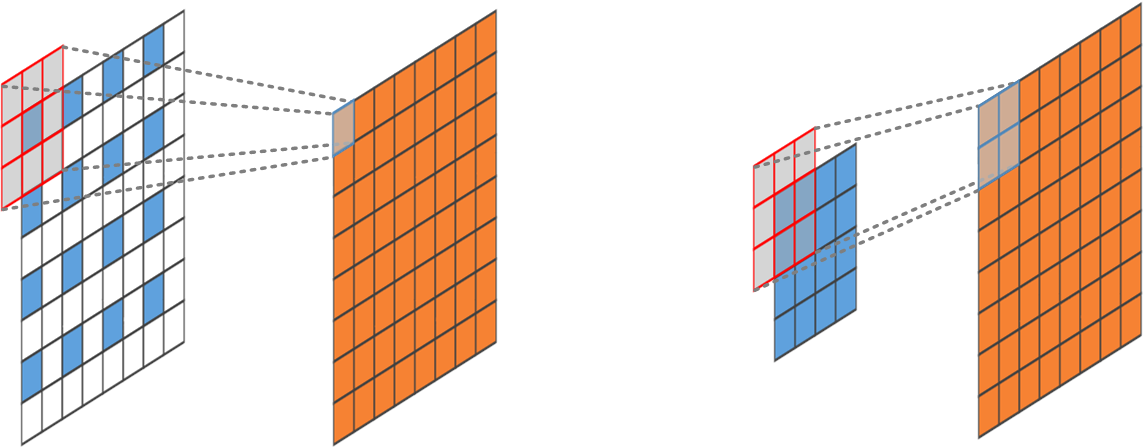
We provide correct dilated pre-trained ResNet and DenseNet for semantic segmentation.
For dilation of ResNet, we replace the stride of 2 Conv3x3 at begining of certain stage and update the dilation of the conv layers afterwards.
For dilation of DenseNet, we provide DilatedAvgPool2d that handles the dilation of the transition layers, then update the dilation of the conv layers afterwards.
For dilation of DenseNet, we provide :class:`encoding.nn.DilatedAvgPool2d` that handles the dilation of the transition layers, then update the dilation of the conv layers afterwards.
`Image Style Transfer Using Convolutional Neural Networks <http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf>`_ by Leon A. Gatys, Alexander S. Ecker, and Matthias Bethge::
PyTorch-Encoding is an optimized PyTorch package with CUDA backend, including Encoding Layer, Multi-GPU Synchronized Batch Normalization and useful util functions. Example systems are also provided in `experiments section <experiments/texture.html>`_. We hope this software will accelerate your research, please cite our `papers <notes/compile.html>`_.
- An optimized PyTorch package with CUDA backend, including Encoding Layer :class:`encoding.nn.Encoding`, Multi-GPU Synchronized Batch Normalization :class:`encoding.nn.BatchNorm2d` and other customized modules and functions.
- **Example Systems** for Semantic Segmentation (coming), CIFAR-10 Classification, `Texture Recognition <experiments/texture.html>`_ and `Style Transfer <experiments/style.html>`_ are provided in experiments section.
- Install PyTorch from Source to the ``$HOME`` directory:
* Please follow the `PyTorch instructions <https://github.com/pytorch/pytorch#from-source>`_ (recommended).
* Or you can simply clone a copy to ``$HOME`` directory::
Install from Source
-------------------
* Please follow the `PyTorch instructions <https://github.com/pytorch/pytorch#from-source>`_ to install PyTorch from Source to the ``$HOME`` directory (recommended). Or you can simply clone a copy to ``$HOME`` directory::
We will release the implementation detail of Multi-GPU Batch Normalization in later version.
Why Synchronize?
----------------
In this tutorial, we discuss the implementation detail of Multi-GPU Batch Normalization (BN) :class:`encoding.nn.BatchNorm2d` and compatible :class:`encoding.parallel.SelfDataParallel`. We will provide the training example in a later version.
- Standard Implementation
How BN works?
-------------
BN layer was introduced in the paper `Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift <https://arxiv.org/abs/1502.03167>`_, which dramatically speed up the training process of the network (enables larger learning rate) and makes the network less sensitive to the weight initialization.
- Forward Pass:
For the input data :math:`X={x_1, ...x_N}`, the data are normalized to be zero-mean and unit-variance, then scale and shit:
.. math::
y_i = \gamma\cdot\frac{x_i-\mu}{\sigma} + \beta ,
where :math:`\mu=\frac{\sum_i^N x_i}{N} , \sigma = \sqrt{\frac{\sum_i^N (x_i-\mu)^2}{N}+\epsilon}` and :math:`\gamma, \beta` are the learnable parameters.
- Backward Pass:
For calculating the gradient :math:`\frac{d_\ell}{d_{x_i}}`, we need to consider the gradient from :math:`\frac{d_\ell}{d_y}` and the gradients from :math:`\frac{d_\ell}{d_\mu}` and :math:`\frac{d_\ell}{d_\sigma}`, since the :math:`\mu \text{ and } \sigma` are the function of the input :math:`x_i`. We use patial direvative in the notations:
where :math:`\frac{d_\ell}{d_{x_i}}=\frac{\gamma}{\sigma}, \frac{d_\ell}{d_\mu}=-\frac{\gamma}{\sigma}\sum_i^N\frac{d_\ell}{d_{y_i}}
\text{ and } \frac{d_\sigma}{d_{x_i}}=-\frac{1}{\sigma}(\frac{x_i-\mu}{N})`.
Why Synchronize BN?
-------------------
- Standard Implementations of BN in public frameworks (suck as Caffe, MXNet, Torch, TF, PyTorch) are unsynchronized, which means that the data are normalized within each GPU. Therefore the `working batch-size` of the BN layer is `BatchSize/nGPU` (batch-size in each GPU).
- Since the `working batch-size` is typically large enough for standard vision tasks, such as classification and detection, there is no need to synchronize BN layer during the training. The synchronization will slow down the training.
- However, for the Semantic Segmentation task, the state-of-the-art approaches typically adopt dilated convoluton, which is very memory consuming. The `working bath-size` can be too small for BN layers (2 or 4 in each GPU) when using larger/deeper pre-trained networks, such as :class:`encoding.dilated.ResNet` or :class:`encoding.dilated.DenseNet`.
How to Synchronize?
-------------------
- Forward and Backward Pass
Suppose we have :math:`K` number of GPUs, :math:`sum(x)_k` and :math:`sum(x^2)_k` denotes the sum of elements and sum of element squares in :math:`k^{th}` GPU.
- Forward Pass:
We can calculate the sum of elements :math:`sum(x)=\sum x_i \text{ and sum of squares } sum(x^2)=\sum x_i^2` in each GPU, then apply :class:`encoding.parallel.AllReduce` operation to sum accross GPUs. Then calculate the global mean :math:`\mu=\frac{sum(x)}{N} \text{ and global variance } \sigma=\sqrt{\frac{sum(x^2)}{N}-\mu^2+\epsilon}`.
- Backward Pass:
* :math:`\frac{d_\ell}{d_{x_i}}=\frac{\gamma}{\sigma}` can be calculated locally in each GPU.
* Calculate the gradient of :math:`sum(x)` and :math:`sum(x^2)` individually in each GPU :math:`\frac{d_\ell}{d_{sum(x)_k}}` and :math:`\frac{d_\ell}{d_{sum(x^2)_k}}`.
* Then Sync the gradient (automatically handled by :class:`encoding.parallel.AllReduce`) and continue the backward.
- Synchronized DataParallel:
Standard DataParallel pipeline of public frameworks (MXNet, PyTorch...) in each training iters:
* duplicate the network (weights) to all the GPUs,
* split the training batch to each GPU,
* forward and backward to calculate gradient,
* update network parameters (weights) then go to next iter.
- Synchronized DataParallel
Therefore, communicattion accross different GPUs are not supported. To address this problem, we introduce a :class:`encoding.parallel.SelfDataParallel` mode, which enables each layer to accept mutli-GPU inputs directly. Those self-parallel layers are provide in :class:`encoding.nn`.
- Cross GPU Autograd
- Cross GPU Autograd:
Due to the BN layers are frequently used in the networks, the PyTorch autograd engine will be messed up by such a complicated backward graph. To address this problem, we provide an aotograd function :class:`encoding.parallel.AllReduce` to handle the cross GPU gradient calculation.
Comparing Performance
---------------------
- Training Time:
- Segmentation Performance:
Citation
--------
.. note::
This code is provided together with the paper (coming soon), please cite our work.
Current PyTorch DataParallel Table is not supporting mutl-gpu loss calculation, which makes the gpu memory usage very in-efficient. We address this issue here by doing CriterionDataParallel.
The DataParallel compatible with SyncBN will be released later.
- Current PyTorch DataParallel Table is not supporting mutl-gpu loss calculation, which makes the gpu memory usage very in-efficient. We address this issue here by doing CriterionDataParallel.
- :class:`encoding.parallel.SelfDataParallel` is compatible with Synchronized Batch Normalization :class:`encoding.nn.BatchNorm2d`.
The current BN is implementated insynchronized accross the gpus, which is a big problem for memory consuming tasks such as Semantic Segmenation, since the mini-batch is very small.
To synchronize the batchnorm accross multiple gpus is not easy to implment within the current Dataparallel framework. We address this difficulty by making each layer 'self-parallel', that is accepting the inputs from multi-gpus. Therefore, we can handle different layers seperately for synchronizing it across gpus.
We will release the whole SyncBN Module and compatible DataParallel later.
To synchronize the batchnorm accross multiple gpus is not easy to implment within the current Dataparallel framework. We address this difficulty by making each layer 'self-parallel' :class:`encoding.parallel.SelfDataParallel`, that is accepting the inputs from multi-gpus. Therefore, we can handle the synchronizing across gpus.

{kind=link}
{kind=link}

{kind=link}
{kind=link}