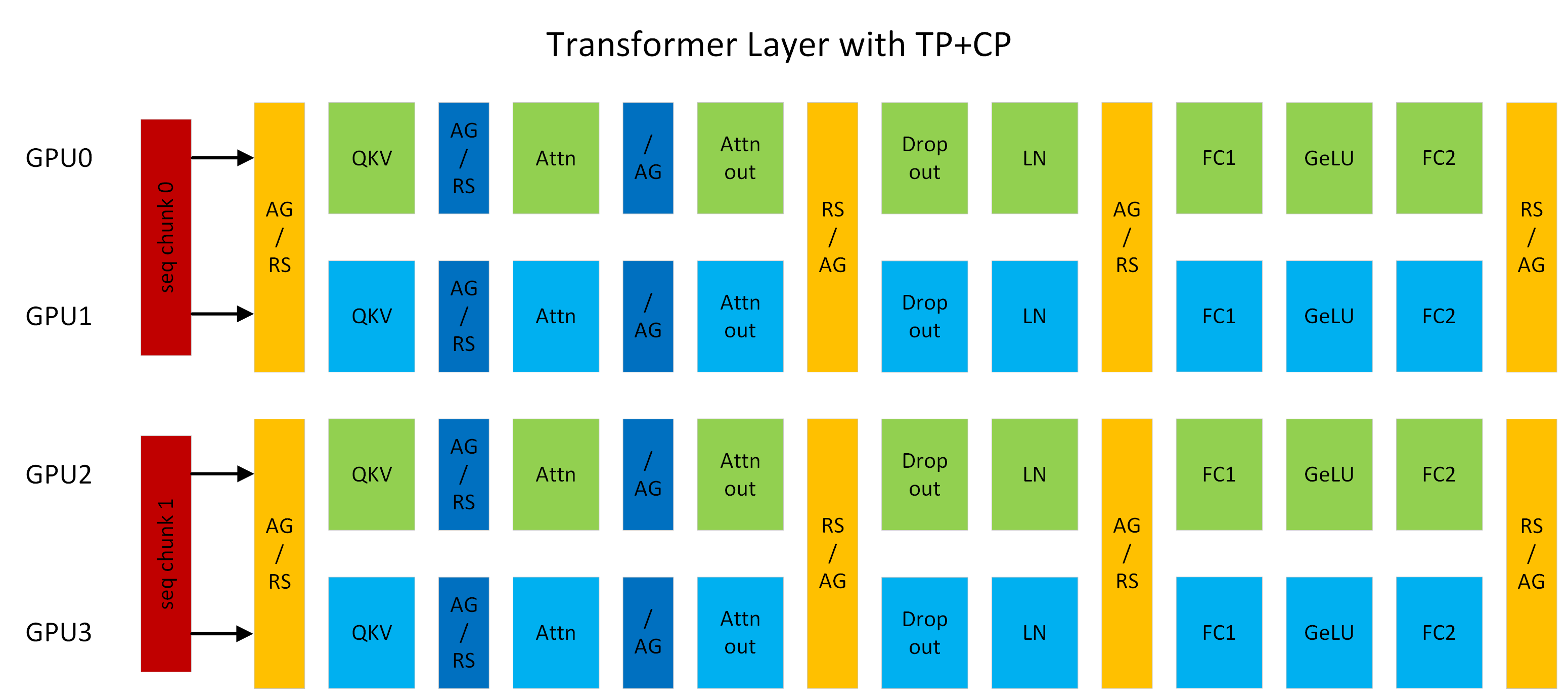
Figure 1: A transformer layer running with TP2CP2. Communications next to Attention are for CP, others are for TP. (AG/RS: all-gather in forward and reduce-scatter in backward, RS/AG: reduce-scatter in forward and all-gather in backward, /AG: no-op in forward and all-gather in backward).
Context Parallelism ("CP") is a parallelization scheme on the dimension of sequence length. Unlike prior SP (sequence parallelism) which only splits the sequence of Dropout and LayerNorm activations, CP partitions the network inputs and all activations along sequence dimension. With CP, all modules except attention (e.g., Linear, LayerNorm, etc.) can work as usual without any changes, because they do not have inter-token operations. As for attention, the Q (query) of each token needs to compute with the KV (key and value) of all tokens in the same sequence. Hence, CP requires additional all-gather across GPUs to collect the full sequence of KV. Correspondingly, reduce-scatter should be applied to the activation gradients of KV in backward propagation. To reduce activation memory footprint, each GPU only stores the KV of a sequence chunk in forward and gathers KV again in backward. KV communication happens between a GPU and its counterparts in other TP groups. The all-gather and reduce-scatter are transformed to point-to-point communications in ring topology under the hood. Exchanging KV also can leverage MQA/GQA to reduce communication volumes, as they only have one or few attention heads for KV.
For example, in Figure 1, assuming sequence length is 8K, each GPU processes 4K tokens. GPU0 and GPU2 compose a CP group, they exchange KV with each other. Same thing also happens between GPU1 and GPU3. CP is similar to `Ring Attention <https://arxiv.org/abs/2310.01889>`_ but provides better performance by (1) leveraging the latest OSS and cuDNN flash attention kernels; (2) removing unnecessary computation resulted from low-triangle causal masking and achieving optimal load balance among GPUs.
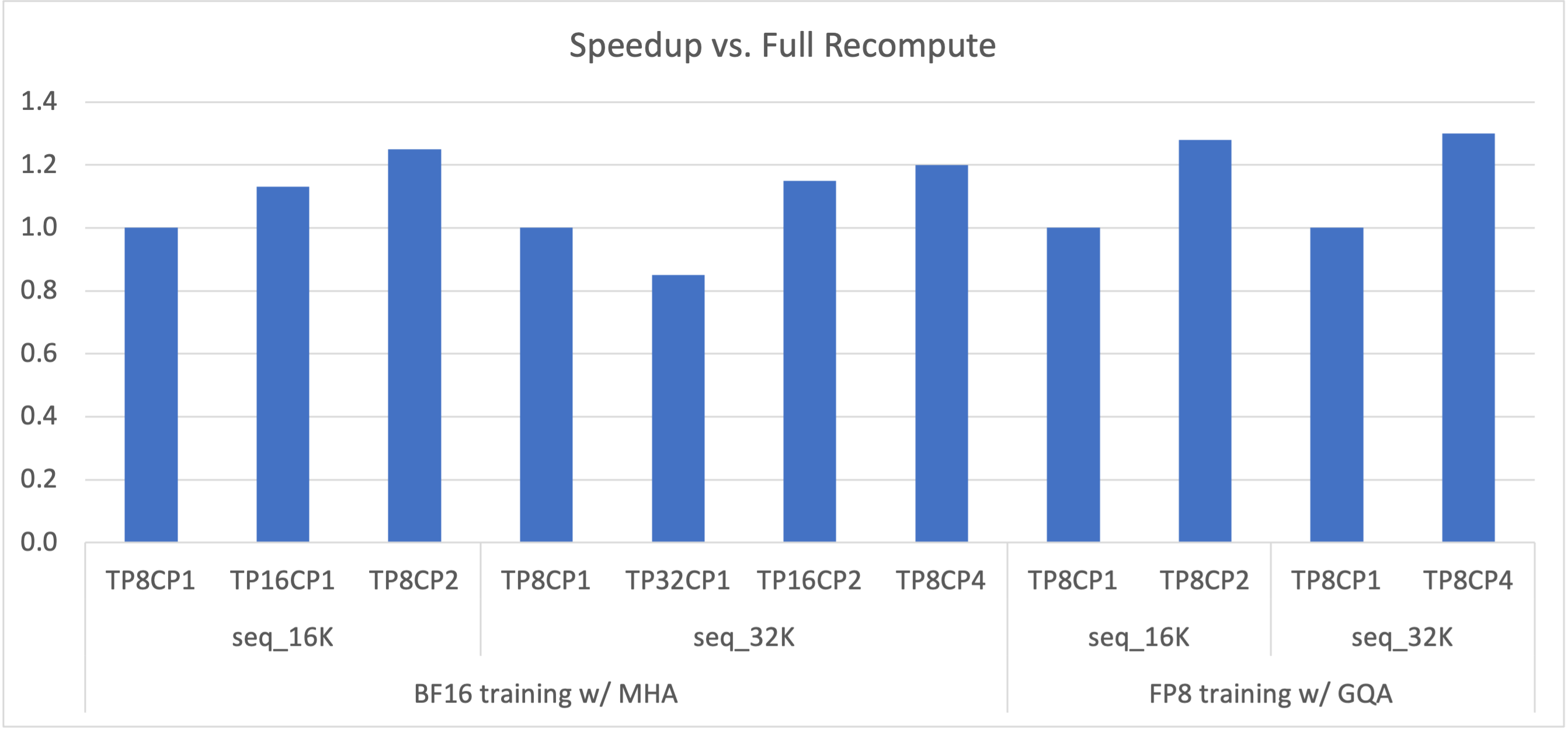
Figure 2: Speedup of 175B GPT with various TP+CP combinations vs. full recompute (i.e., TP8CP1).
LLM encounters OOM (out of memory) issue with long context (i.e., long sequence length) because of linearly increasing memory footprint of activations. Recomputing activations in backward can avoid OOM but also introduce significant overheads (~30% with full recompute). Enlarging TP (tensor model parallelism) can fix the OOM issue as well, but it potentially makes compute (e.g., Linear) too short to overlap communication latencies. To be clear, scaling out to more GPUs with bigger TP can hit the overlapping problem no matter if OOM happens.
CP can better address the issues. With CP, each GPU only computes on a part of the sequence, which reduces both computation and communication by CP times. Therefore, there are no concerns about the overlapping between them. The activation memory footprint per GPU is also CP times smaller, hence no OOM issue any more. As Figure 2 shows, the combinations of TP and CP can achieve optimal performance by eliminating recompute overheads and making the best tradeoff between computation and communications.
Enabling context parallelism
----------------------------
CP support has been added to GPT. All models that share GPT code path also should be able to benefit from CP, such as Llama. CP can work with TP (tensor model parallelism), PP (pipeline model parallelism), and DP (data parallelism), where the total number of GPUs equals TPxCPxPPxDP. CP also can work with different attention variants, including MHA/MQA/GQA, uni-directional and bi-directional masking.
CP is enabled by simply setting context_parallel_size=<CP_SIZE> in command line. Default context_parallel_size is 1, which means CP is disabled. Running with CP requires Megatron-Core (>=0.5.0) and Transformer Engine (>=1.1).
Package defining different checkpoint formats (backends) and saving/loading algorithms (strategies).
Strategies can be used for implementing new checkpoint formats or implementing new (more optimal for a given use case) ways of saving/loading of existing formats.
Strategies are passed to `dist_checkpointing.load` and `dist_checkpointing.save` functions and control the actual saving/loading procedure.
This package provides modules that provide commonly fused
operations. Fusing operations improves compute efficiency by
increasing the amount of work done each time a tensor is read from
memory. To perform the fusion, modules in this either rely on PyTorch
functionality for doing just-in-time compilation
(i.e. `torch.jit.script` in older PyTorch versions of `torch.compile`
in recent versions), or call into custom kernels in external libraries
such as Apex or TransformerEngine.
Submodules
----------
fusions.fused\_bias\_dropout module
-----------------------------------
This module uses PyTorch JIT to fuse the bias add and dropout operations. Since dropout is not used during inference, different functions are used when in train mode and when in inference mode.
.. automodule:: core.fusions.fused_bias_dropout
:members:
:undoc-members:
:show-inheritance:
fusions.fused\_bias\_gelu module
--------------------------------
This module uses PyTorch JIT to fuse the bias add and GeLU nonlinearity operations.
.. automodule:: core.fusions.fused_bias_gelu
:members:
:undoc-members:
:show-inheritance:
fusions.fused\_layer\_norm module
---------------------------------
This module provides a wrapper around various fused LayerNorm implementation in Apex.
.. automodule:: core.fusions.fused_layer_norm
:members:
:undoc-members:
:show-inheritance:
fusions.fused\_softmax module
-----------------------------
This module provides wrappers around variations of Softmax in Apex.
.. automodule:: core.fusions.fused_softmax
:members:
:undoc-members:
:show-inheritance:
fusions.fused\_cross\_entropy\_loss module
------------------------------------------
This module uses PyTorch JIT to fuse the cross entropy loss calculation and batches communication calls.
This is the implementation of the popular GPT model. It supports several features like model parallelization (Tensor Parallel, Pipeline Parallel, Data Parallel) , mixture of experts, FP8 , Distributed optimizer etc. We are constantly adding new features. So be on the lookout or raise an issue if you want to have something added.
This package contains most of the popular LLMs . Currently we have support for GPT, Bert, T5 and Retro . This is an ever growing list so keep an eye out.
The motivation for the distributed optimizer is to save memory by distributing the optimizer state evenly across data parallel ranks, versus the current method of replicating the optimizer state across data parallel ranks. As described in https://arxiv.org/abs/1910.02054, this branch specifically implements the following:
- [yes] distribute all 'non-overlapping' optimizer state (i.e., model params already in fp32 are NOT distributed)
- [no] distribute model gradients
- [no] distribute model parameters
Theoretical memory savings vary depending on the combination of the model's param dtype and grad dtype. In the current implementation, the theoretical number of bytes per parameter is (where 'd' is the data parallel size):
| | Non-distributed optim | Distributed optim |
| ------ | ------ | ------ |
| float16 param, float16 grads | 20 | 4 + 16/d |
| float16 param, fp32 grads | 18 | 6 + 12/d |
| fp32 param, fp32 grads | 16 | 8 + 8/d |
The implementation of the distributed optimizer is centered on using the contiguous grad buffer for communicating grads & params between the model state and the optimizer state. The grad buffer at any given moment either holds:
1. all model grads
2. a 1/d size _copy_ of the main grads (before copying to the optimizer state)
3. a 1/d size _copy_ of the main params (after copying from the optimizer state)
4. all model params
5. zeros (or None), between iterations
The grad buffer is used for performing reduce-scatter and all-gather operations, for passing grads & params between the model state and optimizer state. With this implementation, no dynamic buffers are allocated.
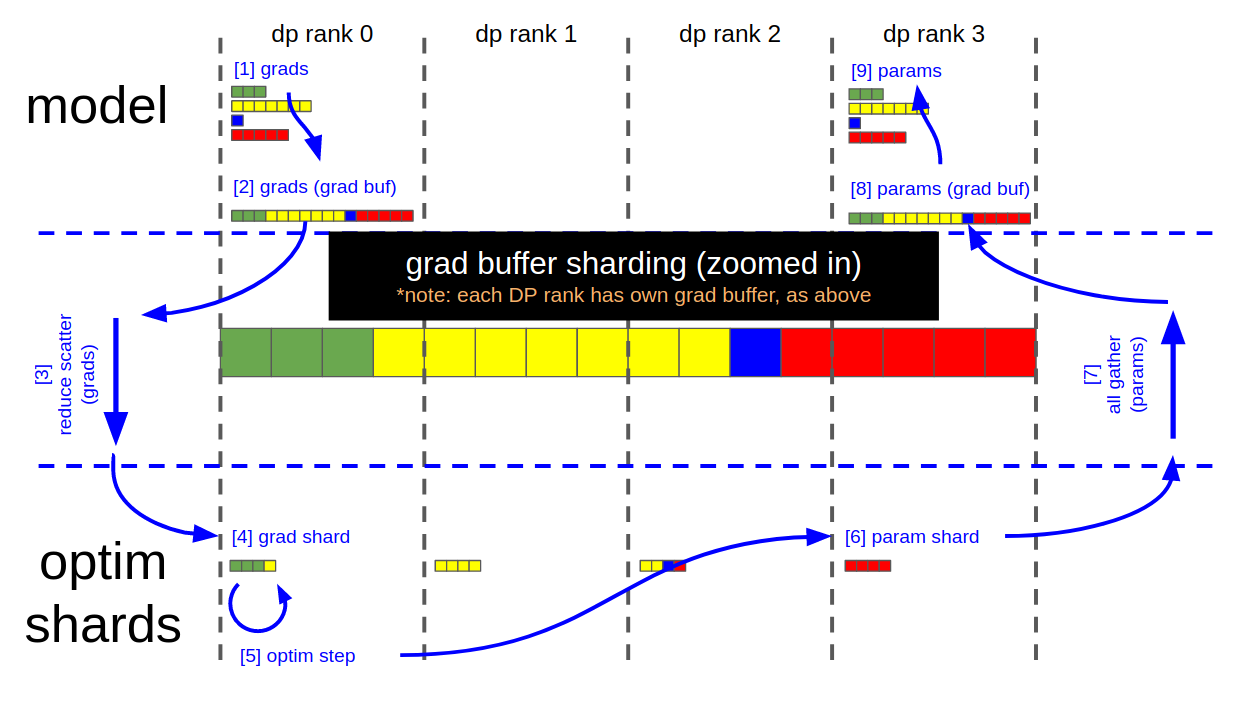
The figures below illustrate the grad buffer's sharding scheme, and the key steps of the distributed optimizer's param update:
- Each DP rank now has 4 elements within the grad buffer that are fully reduced (remaining 12 elements are garbage)
- Each DP rank copies its relevant 4 fp16 grad elements from the grad buffer into 4 fp32 main grad elements (separate buffer, owned by the optimizer); i.e.
- DP rank 0 copies elements [0:4]
- DP rank 1 copies elements [4:8]
- DP rank 2 copies elements [8:12]
- DP rank 3 copies elements [12:16]
- Optimizer.step()
- Each DP rank copies its 4 fp32 main (/optimizer) param elements into the corresponding 4 fp16 elements in the grad buffer
- Call all-gather on each DP rank
- Grad buffer now contains all 16, fully updated, fp16 model param elements
- Copy updated model params from grad buffer into their respective param tensors
- (At this point, grad buffer is ready to be zero'd for the next iteration)

{kind=link}
{kind=link}
{kind=link}