
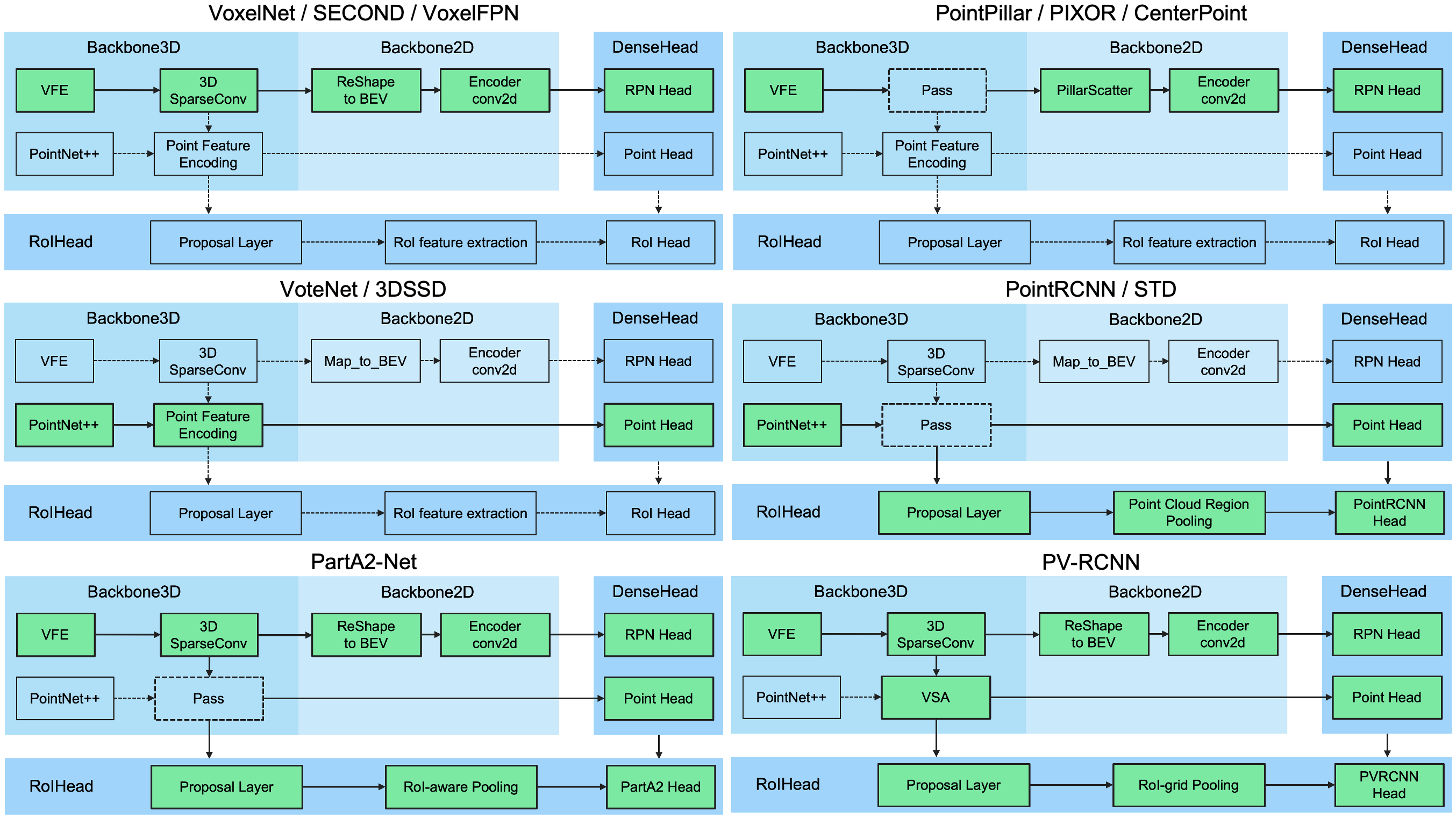
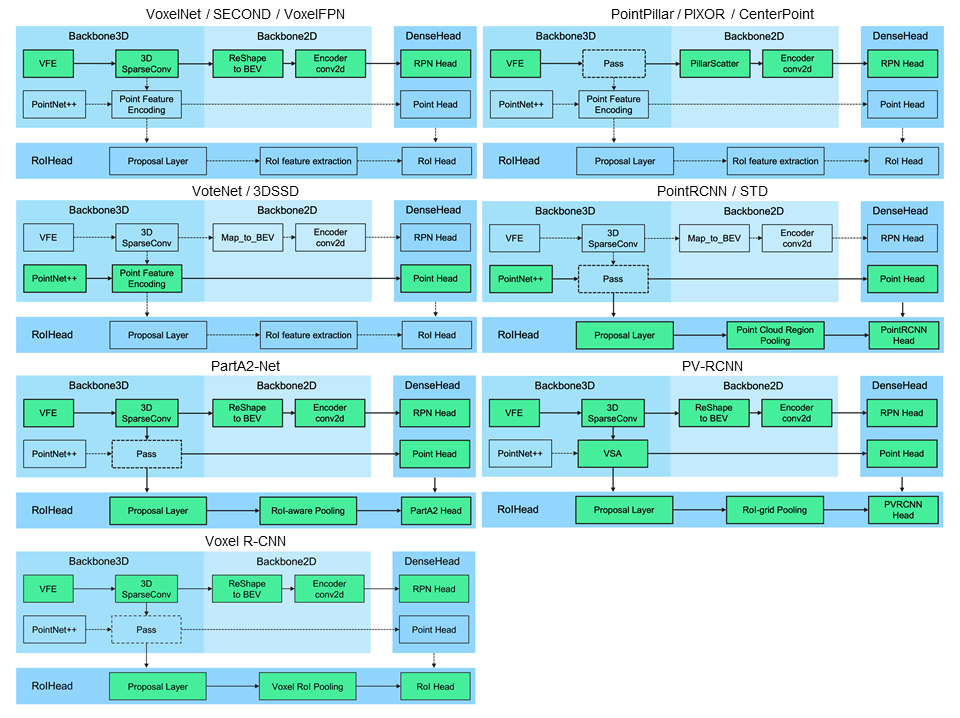
Add Voxel R-CNN (#555)
* add voxel roi pooling
* add voxel r-cnn head
* add voxel query
* add voxel r-cnn
* add Voxel R-CNN
* add infos about Voxel R-CNN
* add voxel_rcnn_car.yaml
* add infos about Voxel R-CNN
Co-authored-by:  Shaoshuai Shi <shaoshuaics@gmail.com>
Shaoshuai Shi <shaoshuaics@gmail.com>
Showing
{kind=link}
{kind=link}
| W: | H:
| W: | H: