Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in
Toggle navigation
Menu
Open sidebar
OpenDAS
nni
Commits
e9f3cddf
Unverified
Commit
e9f3cddf
authored
Aug 12, 2020
by
chicm-ms
Committed by
GitHub
Aug 12, 2020
Browse files
AutoML for model compression (#2573)
parent
3757cf27
Changes
22
Show whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
2741 additions
and
11 deletions
+2741
-11
azure-pipelines.yml
azure-pipelines.yml
+4
-0
docs/en_US/Compressor/Pruner.md
docs/en_US/Compressor/Pruner.md
+34
-0
docs/img/amc_pruner.jpg
docs/img/amc_pruner.jpg
+0
-0
examples/model_compress/amc/amc_search.py
examples/model_compress/amc/amc_search.py
+136
-0
examples/model_compress/amc/amc_train.py
examples/model_compress/amc/amc_train.py
+234
-0
examples/model_compress/amc/data.py
examples/model_compress/amc/data.py
+156
-0
examples/model_compress/amc/utils.py
examples/model_compress/amc/utils.py
+138
-0
examples/model_compress/models/mobilenet.py
examples/model_compress/models/mobilenet.py
+83
-0
examples/model_compress/models/mobilenet_v2.py
examples/model_compress/models/mobilenet_v2.py
+128
-0
src/sdk/pynni/nni/compression/torch/compressor.py
src/sdk/pynni/nni/compression/torch/compressor.py
+21
-7
src/sdk/pynni/nni/compression/torch/pruning/__init__.py
src/sdk/pynni/nni/compression/torch/pruning/__init__.py
+2
-0
src/sdk/pynni/nni/compression/torch/pruning/amc/__init__.py
src/sdk/pynni/nni/compression/torch/pruning/amc/__init__.py
+4
-0
src/sdk/pynni/nni/compression/torch/pruning/amc/amc_pruner.py
...sdk/pynni/nni/compression/torch/pruning/amc/amc_pruner.py
+329
-0
src/sdk/pynni/nni/compression/torch/pruning/amc/channel_pruning_env.py
.../nni/compression/torch/pruning/amc/channel_pruning_env.py
+602
-0
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/__init__.py
...k/pynni/nni/compression/torch/pruning/amc/lib/__init__.py
+0
-0
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/agent.py
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/agent.py
+232
-0
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/memory.py
...sdk/pynni/nni/compression/torch/pruning/amc/lib/memory.py
+227
-0
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/net_measure.py
...ynni/nni/compression/torch/pruning/amc/lib/net_measure.py
+123
-0
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/utils.py
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/utils.py
+124
-0
src/sdk/pynni/nni/compression/torch/pruning/structured_pruning.py
...pynni/nni/compression/torch/pruning/structured_pruning.py
+164
-4
No files found.
azure-pipelines.yml
View file @
e9f3cddf
...
...
@@ -28,6 +28,7 @@ jobs:
set -e
sudo apt-get install -y pandoc
python3 -m pip install torch==1.5.0+cpu torchvision==0.6.0+cpu -f https://download.pytorch.org/whl/torch_stable.html --user
python3 -m pip install tensorboardX==1.9
python3 -m pip install tensorflow==2.2.0 --user
python3 -m pip install keras==2.4.2 --user
python3 -m pip install gym onnx peewee thop --user
...
...
@@ -68,6 +69,7 @@ jobs:
-
script
:
|
set -e
python3 -m pip install torch==1.3.1+cpu torchvision==0.4.2+cpu -f https://download.pytorch.org/whl/torch_stable.html --user
python3 -m pip install tensorboardX==1.9
python3 -m pip install tensorflow==1.15.2 --user
python3 -m pip install keras==2.1.6 --user
python3 -m pip install gym onnx peewee --user
...
...
@@ -117,6 +119,7 @@ jobs:
set -e
# pytorch Mac binary does not support CUDA, default is cpu version
python3 -m pip install torchvision==0.6.0 torch==1.5.0 --user
python3 -m pip install tensorboardX==1.9
python3 -m pip install tensorflow==1.15.2 --user
brew install swig@3
rm -f /usr/local/bin/swig
...
...
@@ -144,6 +147,7 @@ jobs:
python -m pip install scikit-learn==0.23.2 --user
python -m pip install keras==2.1.6 --user
python -m pip install torch==1.5.0+cpu torchvision==0.6.0+cpu -f https://download.pytorch.org/whl/torch_stable.html --user
python -m pip install tensorboardX==1.9
python -m pip install tensorflow==1.15.2 --user
displayName
:
'
Install
dependencies'
-
script
:
|
...
...
docs/en_US/Compressor/Pruner.md
View file @
e9f3cddf
...
...
@@ -20,6 +20,7 @@ We provide several pruning algorithms that support fine-grained weight pruning a
*
[
NetAdapt Pruner
](
#netadapt-pruner
)
*
[
SimulatedAnnealing Pruner
](
#simulatedannealing-pruner
)
*
[
AutoCompress Pruner
](
#autocompress-pruner
)
*
[
AutoML for Model Compression Pruner
](
#automl-for-model-compression-pruner
)
*
[
Sensitivity Pruner
](
#sensitivity-pruner
)
**Others**
...
...
@@ -476,6 +477,39 @@ You can view [example](https://github.com/microsoft/nni/blob/master/examples/mod
.. autoclass:: nni.compression.torch.AutoCompressPruner
```
## AutoML for Model Compression Pruner
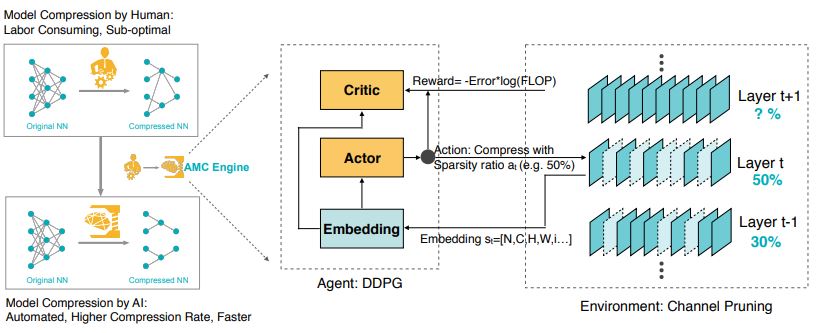
AutoML for Model Compression Pruner (AMCPruner) leverages reinforcement learning to provide the model compression policy.
This learning-based compression policy outperforms conventional rule-based compression policy by having higher compression ratio,
better preserving the accuracy and freeing human labor.

For more details, please refer to
[
AMC: AutoML for Model Compression and Acceleration on Mobile Devices
](
https://arxiv.org/pdf/1802.03494.pdf
)
.
#### Usage
PyTorch code
```
python
from
nni.compression.torch
import
AMCPruner
config_list
=
[{
'op_types'
:
[
'Conv2d'
,
'Linear'
]
}]
pruner
=
AMCPruner
(
model
,
config_list
,
evaluator
,
val_loader
,
flops_ratio
=
0.5
)
pruner
.
compress
()
```
You can view
[
example
](
https://github.com/microsoft/nni/blob/master/examples/model_compress/amc/
)
for more information.
#### User configuration for AutoCompress Pruner
##### PyTorch
```
eval_rst
.. autoclass:: nni.compression.torch.AMCPruner
```
## ADMM Pruner
Alternating Direction Method of Multipliers (ADMM) is a mathematical optimization technique,
...
...
docs/img/amc_pruner.jpg
0 → 100644
View file @
e9f3cddf
58.5 KB
examples/model_compress/amc/amc_search.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
sys
import
argparse
import
time
import
torch
import
torch.nn
as
nn
from
nni.compression.torch
import
AMCPruner
from
data
import
get_split_dataset
from
utils
import
AverageMeter
,
accuracy
sys
.
path
.
append
(
'../models'
)
def
parse_args
():
parser
=
argparse
.
ArgumentParser
(
description
=
'AMC search script'
)
parser
.
add_argument
(
'--model_type'
,
default
=
'mobilenet'
,
type
=
str
,
choices
=
[
'mobilenet'
,
'mobilenetv2'
],
help
=
'model to prune'
)
parser
.
add_argument
(
'--dataset'
,
default
=
'cifar10'
,
type
=
str
,
choices
=
[
'cifar10'
,
'imagenet'
],
help
=
'dataset to use (cifar/imagenet)'
)
parser
.
add_argument
(
'--batch_size'
,
default
=
50
,
type
=
int
,
help
=
'number of data batch size'
)
parser
.
add_argument
(
'--data_root'
,
default
=
'./cifar10'
,
type
=
str
,
help
=
'dataset path'
)
parser
.
add_argument
(
'--flops_ratio'
,
default
=
0.5
,
type
=
float
,
help
=
'target flops ratio to preserve of the model'
)
parser
.
add_argument
(
'--lbound'
,
default
=
0.2
,
type
=
float
,
help
=
'minimum sparsity'
)
parser
.
add_argument
(
'--rbound'
,
default
=
1.
,
type
=
float
,
help
=
'maximum sparsity'
)
parser
.
add_argument
(
'--ckpt_path'
,
default
=
None
,
type
=
str
,
help
=
'manual path of checkpoint'
)
parser
.
add_argument
(
'--train_episode'
,
default
=
800
,
type
=
int
,
help
=
'number of training episode'
)
parser
.
add_argument
(
'--n_gpu'
,
default
=
1
,
type
=
int
,
help
=
'number of gpu to use'
)
parser
.
add_argument
(
'--n_worker'
,
default
=
16
,
type
=
int
,
help
=
'number of data loader worker'
)
parser
.
add_argument
(
'--job'
,
default
=
'train_export'
,
type
=
str
,
choices
=
[
'train_export'
,
'export_only'
],
help
=
'search best pruning policy and export or just export model with searched policy'
)
parser
.
add_argument
(
'--export_path'
,
default
=
None
,
type
=
str
,
help
=
'path for exporting models'
)
parser
.
add_argument
(
'--searched_model_path'
,
default
=
None
,
type
=
str
,
help
=
'path for searched best wrapped model'
)
return
parser
.
parse_args
()
def
get_model_and_checkpoint
(
model
,
dataset
,
checkpoint_path
,
n_gpu
=
1
):
if
model
==
'mobilenet'
and
dataset
==
'imagenet'
:
from
mobilenet
import
MobileNet
net
=
MobileNet
(
n_class
=
1000
)
elif
model
==
'mobilenetv2'
and
dataset
==
'imagenet'
:
from
mobilenet_v2
import
MobileNetV2
net
=
MobileNetV2
(
n_class
=
1000
)
elif
model
==
'mobilenet'
and
dataset
==
'cifar10'
:
from
mobilenet
import
MobileNet
net
=
MobileNet
(
n_class
=
10
)
elif
model
==
'mobilenetv2'
and
dataset
==
'cifar10'
:
from
mobilenet_v2
import
MobileNetV2
net
=
MobileNetV2
(
n_class
=
10
)
else
:
raise
NotImplementedError
if
checkpoint_path
:
print
(
'loading {}...'
.
format
(
checkpoint_path
))
sd
=
torch
.
load
(
checkpoint_path
,
map_location
=
torch
.
device
(
'cpu'
))
if
'state_dict'
in
sd
:
# a checkpoint but not a state_dict
sd
=
sd
[
'state_dict'
]
sd
=
{
k
.
replace
(
'module.'
,
''
):
v
for
k
,
v
in
sd
.
items
()}
net
.
load_state_dict
(
sd
)
if
torch
.
cuda
.
is_available
()
and
n_gpu
>
0
:
net
=
net
.
cuda
()
if
n_gpu
>
1
:
net
=
torch
.
nn
.
DataParallel
(
net
,
range
(
n_gpu
))
return
net
def
init_data
(
args
):
# split the train set into train + val
# for CIFAR, split 5k for val
# for ImageNet, split 3k for val
val_size
=
5000
if
'cifar'
in
args
.
dataset
else
3000
train_loader
,
val_loader
,
_
=
get_split_dataset
(
args
.
dataset
,
args
.
batch_size
,
args
.
n_worker
,
val_size
,
data_root
=
args
.
data_root
,
shuffle
=
False
)
# same sampling
return
train_loader
,
val_loader
def
validate
(
val_loader
,
model
,
verbose
=
False
):
batch_time
=
AverageMeter
()
losses
=
AverageMeter
()
top1
=
AverageMeter
()
top5
=
AverageMeter
()
criterion
=
nn
.
CrossEntropyLoss
().
cuda
()
# switch to evaluate mode
model
.
eval
()
end
=
time
.
time
()
t1
=
time
.
time
()
with
torch
.
no_grad
():
for
i
,
(
input
,
target
)
in
enumerate
(
val_loader
):
target
=
target
.
to
(
device
)
input_var
=
torch
.
autograd
.
Variable
(
input
).
to
(
device
)
target_var
=
torch
.
autograd
.
Variable
(
target
).
to
(
device
)
# compute output
output
=
model
(
input_var
)
loss
=
criterion
(
output
,
target_var
)
# measure accuracy and record loss
prec1
,
prec5
=
accuracy
(
output
.
data
,
target
,
topk
=
(
1
,
5
))
losses
.
update
(
loss
.
item
(),
input
.
size
(
0
))
top1
.
update
(
prec1
.
item
(),
input
.
size
(
0
))
top5
.
update
(
prec5
.
item
(),
input
.
size
(
0
))
# measure elapsed time
batch_time
.
update
(
time
.
time
()
-
end
)
end
=
time
.
time
()
t2
=
time
.
time
()
if
verbose
:
print
(
'* Test loss: %.3f top1: %.3f top5: %.3f time: %.3f'
%
(
losses
.
avg
,
top1
.
avg
,
top5
.
avg
,
t2
-
t1
))
return
top5
.
avg
if
__name__
==
"__main__"
:
args
=
parse_args
()
device
=
torch
.
device
(
'cuda'
)
if
torch
.
cuda
.
is_available
()
and
args
.
n_gpu
>
0
else
torch
.
device
(
'cpu'
)
model
=
get_model_and_checkpoint
(
args
.
model_type
,
args
.
dataset
,
checkpoint_path
=
args
.
ckpt_path
,
n_gpu
=
args
.
n_gpu
)
_
,
val_loader
=
init_data
(
args
)
config_list
=
[{
'op_types'
:
[
'Conv2d'
,
'Linear'
]
}]
pruner
=
AMCPruner
(
model
,
config_list
,
validate
,
val_loader
,
model_type
=
args
.
model_type
,
dataset
=
args
.
dataset
,
train_episode
=
args
.
train_episode
,
job
=
args
.
job
,
export_path
=
args
.
export_path
,
searched_model_path
=
args
.
searched_model_path
,
flops_ratio
=
args
.
flops_ratio
,
lbound
=
args
.
lbound
,
rbound
=
args
.
rbound
)
pruner
.
compress
()
examples/model_compress/amc/amc_train.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
sys
import
os
import
time
import
argparse
import
shutil
import
math
import
numpy
as
np
import
torch
import
torch.nn
as
nn
import
torch.optim
as
optim
from
tensorboardX
import
SummaryWriter
from
nni.compression.torch.pruning.amc.lib.net_measure
import
measure_model
from
nni.compression.torch.pruning.amc.lib.utils
import
get_output_folder
from
data
import
get_dataset
from
utils
import
AverageMeter
,
accuracy
,
progress_bar
sys
.
path
.
append
(
'../models'
)
from
mobilenet
import
MobileNet
from
mobilenet_v2
import
MobileNetV2
def
parse_args
():
parser
=
argparse
.
ArgumentParser
(
description
=
'AMC train / fine-tune script'
)
parser
.
add_argument
(
'--model_type'
,
default
=
'mobilenet'
,
type
=
str
,
help
=
'name of the model to train'
)
parser
.
add_argument
(
'--dataset'
,
default
=
'cifar10'
,
type
=
str
,
help
=
'name of the dataset to train'
)
parser
.
add_argument
(
'--lr'
,
default
=
0.1
,
type
=
float
,
help
=
'learning rate'
)
parser
.
add_argument
(
'--n_gpu'
,
default
=
1
,
type
=
int
,
help
=
'number of GPUs to use'
)
parser
.
add_argument
(
'--batch_size'
,
default
=
128
,
type
=
int
,
help
=
'batch size'
)
parser
.
add_argument
(
'--n_worker'
,
default
=
4
,
type
=
int
,
help
=
'number of data loader worker'
)
parser
.
add_argument
(
'--lr_type'
,
default
=
'exp'
,
type
=
str
,
help
=
'lr scheduler (exp/cos/step3/fixed)'
)
parser
.
add_argument
(
'--n_epoch'
,
default
=
50
,
type
=
int
,
help
=
'number of epochs to train'
)
parser
.
add_argument
(
'--wd'
,
default
=
4e-5
,
type
=
float
,
help
=
'weight decay'
)
parser
.
add_argument
(
'--seed'
,
default
=
None
,
type
=
int
,
help
=
'random seed to set'
)
parser
.
add_argument
(
'--data_root'
,
default
=
'./data'
,
type
=
str
,
help
=
'dataset path'
)
# resume
parser
.
add_argument
(
'--ckpt_path'
,
default
=
None
,
type
=
str
,
help
=
'checkpoint path to fine tune'
)
# run eval
parser
.
add_argument
(
'--eval'
,
action
=
'store_true'
,
help
=
'Simply run eval'
)
parser
.
add_argument
(
'--calc_flops'
,
action
=
'store_true'
,
help
=
'Calculate flops'
)
return
parser
.
parse_args
()
def
get_model
(
args
):
print
(
'=> Building model..'
)
if
args
.
dataset
==
'imagenet'
:
n_class
=
1000
elif
args
.
dataset
==
'cifar10'
:
n_class
=
10
else
:
raise
NotImplementedError
if
args
.
model_type
==
'mobilenet'
:
net
=
MobileNet
(
n_class
=
n_class
).
cuda
()
elif
args
.
model_type
==
'mobilenetv2'
:
net
=
MobileNetV2
(
n_class
=
n_class
).
cuda
()
else
:
raise
NotImplementedError
if
args
.
ckpt_path
is
not
None
:
# the checkpoint can be a saved whole model object exported by amc_search.py, or a state_dict
print
(
'=> Loading checkpoint {} ..'
.
format
(
args
.
ckpt_path
))
ckpt
=
torch
.
load
(
args
.
ckpt_path
)
if
type
(
ckpt
)
==
dict
:
net
.
load_state_dict
(
ckpt
[
'state_dict'
])
else
:
net
=
ckpt
net
.
to
(
args
.
device
)
if
torch
.
cuda
.
is_available
()
and
args
.
n_gpu
>
1
:
net
=
torch
.
nn
.
DataParallel
(
net
,
list
(
range
(
args
.
n_gpu
)))
return
net
def
train
(
epoch
,
train_loader
,
device
):
print
(
'
\n
Epoch: %d'
%
epoch
)
net
.
train
()
batch_time
=
AverageMeter
()
losses
=
AverageMeter
()
top1
=
AverageMeter
()
top5
=
AverageMeter
()
end
=
time
.
time
()
for
batch_idx
,
(
inputs
,
targets
)
in
enumerate
(
train_loader
):
inputs
,
targets
=
inputs
.
to
(
device
),
targets
.
to
(
device
)
optimizer
.
zero_grad
()
outputs
=
net
(
inputs
)
loss
=
criterion
(
outputs
,
targets
)
loss
.
backward
()
optimizer
.
step
()
# measure accuracy and record loss
prec1
,
prec5
=
accuracy
(
outputs
.
data
,
targets
.
data
,
topk
=
(
1
,
5
))
losses
.
update
(
loss
.
item
(),
inputs
.
size
(
0
))
top1
.
update
(
prec1
.
item
(),
inputs
.
size
(
0
))
top5
.
update
(
prec5
.
item
(),
inputs
.
size
(
0
))
# timing
batch_time
.
update
(
time
.
time
()
-
end
)
end
=
time
.
time
()
progress_bar
(
batch_idx
,
len
(
train_loader
),
'Loss: {:.3f} | Acc1: {:.3f}% | Acc5: {:.3f}%'
.
format
(
losses
.
avg
,
top1
.
avg
,
top5
.
avg
))
writer
.
add_scalar
(
'loss/train'
,
losses
.
avg
,
epoch
)
writer
.
add_scalar
(
'acc/train_top1'
,
top1
.
avg
,
epoch
)
writer
.
add_scalar
(
'acc/train_top5'
,
top5
.
avg
,
epoch
)
def
test
(
epoch
,
test_loader
,
device
,
save
=
True
):
global
best_acc
net
.
eval
()
batch_time
=
AverageMeter
()
losses
=
AverageMeter
()
top1
=
AverageMeter
()
top5
=
AverageMeter
()
end
=
time
.
time
()
with
torch
.
no_grad
():
for
batch_idx
,
(
inputs
,
targets
)
in
enumerate
(
test_loader
):
inputs
,
targets
=
inputs
.
to
(
device
),
targets
.
to
(
device
)
outputs
=
net
(
inputs
)
loss
=
criterion
(
outputs
,
targets
)
# measure accuracy and record loss
prec1
,
prec5
=
accuracy
(
outputs
.
data
,
targets
.
data
,
topk
=
(
1
,
5
))
losses
.
update
(
loss
.
item
(),
inputs
.
size
(
0
))
top1
.
update
(
prec1
.
item
(),
inputs
.
size
(
0
))
top5
.
update
(
prec5
.
item
(),
inputs
.
size
(
0
))
# timing
batch_time
.
update
(
time
.
time
()
-
end
)
end
=
time
.
time
()
progress_bar
(
batch_idx
,
len
(
test_loader
),
'Loss: {:.3f} | Acc1: {:.3f}% | Acc5: {:.3f}%'
.
format
(
losses
.
avg
,
top1
.
avg
,
top5
.
avg
))
if
save
:
writer
.
add_scalar
(
'loss/test'
,
losses
.
avg
,
epoch
)
writer
.
add_scalar
(
'acc/test_top1'
,
top1
.
avg
,
epoch
)
writer
.
add_scalar
(
'acc/test_top5'
,
top5
.
avg
,
epoch
)
is_best
=
False
if
top1
.
avg
>
best_acc
:
best_acc
=
top1
.
avg
is_best
=
True
print
(
'Current best acc: {}'
.
format
(
best_acc
))
save_checkpoint
({
'epoch'
:
epoch
,
'model'
:
args
.
model_type
,
'dataset'
:
args
.
dataset
,
'state_dict'
:
net
.
module
.
state_dict
()
if
isinstance
(
net
,
nn
.
DataParallel
)
else
net
.
state_dict
(),
'acc'
:
top1
.
avg
,
'optimizer'
:
optimizer
.
state_dict
(),
},
is_best
,
checkpoint_dir
=
log_dir
)
def
adjust_learning_rate
(
optimizer
,
epoch
):
if
args
.
lr_type
==
'cos'
:
# cos without warm-up
lr
=
0.5
*
args
.
lr
*
(
1
+
math
.
cos
(
math
.
pi
*
epoch
/
args
.
n_epoch
))
elif
args
.
lr_type
==
'exp'
:
step
=
1
decay
=
0.96
lr
=
args
.
lr
*
(
decay
**
(
epoch
//
step
))
elif
args
.
lr_type
==
'fixed'
:
lr
=
args
.
lr
else
:
raise
NotImplementedError
print
(
'=> lr: {}'
.
format
(
lr
))
for
param_group
in
optimizer
.
param_groups
:
param_group
[
'lr'
]
=
lr
return
lr
def
save_checkpoint
(
state
,
is_best
,
checkpoint_dir
=
'.'
):
filename
=
os
.
path
.
join
(
checkpoint_dir
,
'ckpt.pth.tar'
)
print
(
'=> Saving checkpoint to {}'
.
format
(
filename
))
torch
.
save
(
state
,
filename
)
if
is_best
:
shutil
.
copyfile
(
filename
,
filename
.
replace
(
'.pth.tar'
,
'.best.pth.tar'
))
if
__name__
==
'__main__'
:
args
=
parse_args
()
if
torch
.
cuda
.
is_available
():
torch
.
backends
.
cudnn
.
benchmark
=
True
args
.
device
=
torch
.
device
(
'cuda'
)
if
torch
.
cuda
.
is_available
()
and
args
.
n_gpu
>
0
else
torch
.
device
(
'cpu'
)
best_acc
=
0
# best test accuracy
start_epoch
=
0
# start from epoch 0 or last checkpoint epoch
if
args
.
seed
is
not
None
:
np
.
random
.
seed
(
args
.
seed
)
torch
.
manual_seed
(
args
.
seed
)
torch
.
cuda
.
manual_seed
(
args
.
seed
)
print
(
'=> Preparing data..'
)
train_loader
,
val_loader
,
n_class
=
get_dataset
(
args
.
dataset
,
args
.
batch_size
,
args
.
n_worker
,
data_root
=
args
.
data_root
)
net
=
get_model
(
args
)
# for measure
if
args
.
calc_flops
:
IMAGE_SIZE
=
224
if
args
.
dataset
==
'imagenet'
else
32
n_flops
,
n_params
=
measure_model
(
net
,
IMAGE_SIZE
,
IMAGE_SIZE
)
print
(
'=> Model Parameter: {:.3f} M, FLOPs: {:.3f}M'
.
format
(
n_params
/
1e6
,
n_flops
/
1e6
))
exit
(
0
)
criterion
=
nn
.
CrossEntropyLoss
()
print
(
'Using SGD...'
)
print
(
'weight decay = {}'
.
format
(
args
.
wd
))
optimizer
=
optim
.
SGD
(
net
.
parameters
(),
lr
=
args
.
lr
,
momentum
=
0.9
,
weight_decay
=
args
.
wd
)
if
args
.
eval
:
# just run eval
print
(
'=> Start evaluation...'
)
test
(
0
,
val_loader
,
args
.
device
,
save
=
False
)
else
:
# train
print
(
'=> Start training...'
)
print
(
'Training {} on {}...'
.
format
(
args
.
model_type
,
args
.
dataset
))
train_type
=
'train'
if
args
.
ckpt_path
is
None
else
'finetune'
log_dir
=
get_output_folder
(
'./logs'
,
'{}_{}_{}'
.
format
(
args
.
model_type
,
args
.
dataset
,
train_type
))
print
(
'=> Saving logs to {}'
.
format
(
log_dir
))
# tf writer
writer
=
SummaryWriter
(
logdir
=
log_dir
)
for
epoch
in
range
(
start_epoch
,
start_epoch
+
args
.
n_epoch
):
lr
=
adjust_learning_rate
(
optimizer
,
epoch
)
train
(
epoch
,
train_loader
,
args
.
device
)
test
(
epoch
,
val_loader
,
args
.
device
)
writer
.
close
()
print
(
'=> Best top-1 acc: {}%'
.
format
(
best_acc
))
examples/model_compress/amc/data.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
torch
import
torch.nn.parallel
import
torch.optim
import
torch.utils.data
import
torchvision
import
torchvision.transforms
as
transforms
import
torchvision.datasets
as
datasets
from
torch.utils.data.sampler
import
SubsetRandomSampler
import
numpy
as
np
import
os
def
get_dataset
(
dset_name
,
batch_size
,
n_worker
,
data_root
=
'../../data'
):
cifar_tran_train
=
[
transforms
.
RandomCrop
(
32
,
padding
=
4
),
transforms
.
RandomHorizontalFlip
(),
transforms
.
ToTensor
(),
transforms
.
Normalize
((
0.4914
,
0.4822
,
0.4465
),
(
0.2023
,
0.1994
,
0.2010
)),
]
cifar_tran_test
=
[
transforms
.
ToTensor
(),
transforms
.
Normalize
((
0.4914
,
0.4822
,
0.4465
),
(
0.2023
,
0.1994
,
0.2010
)),
]
print
(
'=> Preparing data..'
)
if
dset_name
==
'cifar10'
:
transform_train
=
transforms
.
Compose
(
cifar_tran_train
)
transform_test
=
transforms
.
Compose
(
cifar_tran_test
)
trainset
=
torchvision
.
datasets
.
CIFAR10
(
root
=
data_root
,
train
=
True
,
download
=
True
,
transform
=
transform_train
)
train_loader
=
torch
.
utils
.
data
.
DataLoader
(
trainset
,
batch_size
=
batch_size
,
shuffle
=
True
,
num_workers
=
n_worker
,
pin_memory
=
True
,
sampler
=
None
)
testset
=
torchvision
.
datasets
.
CIFAR10
(
root
=
data_root
,
train
=
False
,
download
=
True
,
transform
=
transform_test
)
val_loader
=
torch
.
utils
.
data
.
DataLoader
(
testset
,
batch_size
=
batch_size
,
shuffle
=
False
,
num_workers
=
n_worker
,
pin_memory
=
True
)
n_class
=
10
elif
dset_name
==
'imagenet'
:
# get dir
traindir
=
os
.
path
.
join
(
data_root
,
'train'
)
valdir
=
os
.
path
.
join
(
data_root
,
'val'
)
# preprocessing
input_size
=
224
imagenet_tran_train
=
[
transforms
.
RandomResizedCrop
(
input_size
,
scale
=
(
0.2
,
1.0
)),
transforms
.
RandomHorizontalFlip
(),
transforms
.
ToTensor
(),
transforms
.
Normalize
(
mean
=
[
0.485
,
0.456
,
0.406
],
std
=
[
0.229
,
0.224
,
0.225
]),
]
imagenet_tran_test
=
[
transforms
.
Resize
(
int
(
input_size
/
0.875
)),
transforms
.
CenterCrop
(
input_size
),
transforms
.
ToTensor
(),
transforms
.
Normalize
(
mean
=
[
0.485
,
0.456
,
0.406
],
std
=
[
0.229
,
0.224
,
0.225
]),
]
train_loader
=
torch
.
utils
.
data
.
DataLoader
(
datasets
.
ImageFolder
(
traindir
,
transforms
.
Compose
(
imagenet_tran_train
)),
batch_size
=
batch_size
,
shuffle
=
True
,
num_workers
=
n_worker
,
pin_memory
=
True
,
sampler
=
None
)
val_loader
=
torch
.
utils
.
data
.
DataLoader
(
datasets
.
ImageFolder
(
valdir
,
transforms
.
Compose
(
imagenet_tran_test
)),
batch_size
=
batch_size
,
shuffle
=
False
,
num_workers
=
n_worker
,
pin_memory
=
True
)
n_class
=
1000
else
:
raise
NotImplementedError
return
train_loader
,
val_loader
,
n_class
def
get_split_dataset
(
dset_name
,
batch_size
,
n_worker
,
val_size
,
data_root
=
'../data'
,
shuffle
=
True
):
'''
split the train set into train / val for rl search
'''
if
shuffle
:
index_sampler
=
SubsetRandomSampler
else
:
# every time we use the same order for the split subset
class
SubsetSequentialSampler
(
SubsetRandomSampler
):
def
__iter__
(
self
):
return
(
self
.
indices
[
i
]
for
i
in
torch
.
arange
(
len
(
self
.
indices
)).
int
())
index_sampler
=
SubsetSequentialSampler
print
(
'=> Preparing data: {}...'
.
format
(
dset_name
))
if
dset_name
==
'cifar10'
:
transform_train
=
transforms
.
Compose
([
transforms
.
RandomCrop
(
32
,
padding
=
4
),
transforms
.
RandomHorizontalFlip
(),
transforms
.
ToTensor
(),
transforms
.
Normalize
((
0.4914
,
0.4822
,
0.4465
),
(
0.2023
,
0.1994
,
0.2010
)),
])
transform_test
=
transforms
.
Compose
([
transforms
.
ToTensor
(),
transforms
.
Normalize
((
0.4914
,
0.4822
,
0.4465
),
(
0.2023
,
0.1994
,
0.2010
)),
])
trainset
=
torchvision
.
datasets
.
CIFAR100
(
root
=
data_root
,
train
=
True
,
download
=
True
,
transform
=
transform_train
)
valset
=
torchvision
.
datasets
.
CIFAR10
(
root
=
data_root
,
train
=
True
,
download
=
True
,
transform
=
transform_test
)
n_train
=
len
(
trainset
)
indices
=
list
(
range
(
n_train
))
# now shuffle the indices
#np.random.shuffle(indices)
assert
val_size
<
n_train
train_idx
,
val_idx
=
indices
[
val_size
:],
indices
[:
val_size
]
train_sampler
=
index_sampler
(
train_idx
)
val_sampler
=
index_sampler
(
val_idx
)
train_loader
=
torch
.
utils
.
data
.
DataLoader
(
trainset
,
batch_size
=
batch_size
,
shuffle
=
False
,
sampler
=
train_sampler
,
num_workers
=
n_worker
,
pin_memory
=
True
)
val_loader
=
torch
.
utils
.
data
.
DataLoader
(
valset
,
batch_size
=
batch_size
,
shuffle
=
False
,
sampler
=
val_sampler
,
num_workers
=
n_worker
,
pin_memory
=
True
)
n_class
=
10
elif
dset_name
==
'imagenet'
:
train_dir
=
os
.
path
.
join
(
data_root
,
'train'
)
val_dir
=
os
.
path
.
join
(
data_root
,
'val'
)
normalize
=
transforms
.
Normalize
(
mean
=
[
0.485
,
0.456
,
0.406
],
std
=
[
0.229
,
0.224
,
0.225
])
input_size
=
224
train_transform
=
transforms
.
Compose
([
transforms
.
RandomResizedCrop
(
input_size
),
transforms
.
RandomHorizontalFlip
(),
transforms
.
ToTensor
(),
normalize
,
])
test_transform
=
transforms
.
Compose
([
transforms
.
Resize
(
int
(
input_size
/
0.875
)),
transforms
.
CenterCrop
(
input_size
),
transforms
.
ToTensor
(),
normalize
,
])
trainset
=
datasets
.
ImageFolder
(
train_dir
,
train_transform
)
valset
=
datasets
.
ImageFolder
(
train_dir
,
test_transform
)
n_train
=
len
(
trainset
)
indices
=
list
(
range
(
n_train
))
np
.
random
.
shuffle
(
indices
)
assert
val_size
<
n_train
train_idx
,
val_idx
=
indices
[
val_size
:],
indices
[:
val_size
]
train_sampler
=
index_sampler
(
train_idx
)
val_sampler
=
index_sampler
(
val_idx
)
train_loader
=
torch
.
utils
.
data
.
DataLoader
(
trainset
,
batch_size
=
batch_size
,
sampler
=
train_sampler
,
num_workers
=
n_worker
,
pin_memory
=
True
)
val_loader
=
torch
.
utils
.
data
.
DataLoader
(
valset
,
batch_size
=
batch_size
,
sampler
=
val_sampler
,
num_workers
=
n_worker
,
pin_memory
=
True
)
n_class
=
1000
else
:
raise
NotImplementedError
return
train_loader
,
val_loader
,
n_class
examples/model_compress/amc/utils.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
sys
import
os
import
time
class
AverageMeter
(
object
):
"""Computes and stores the average and current value"""
def
__init__
(
self
):
self
.
reset
()
def
reset
(
self
):
self
.
val
=
0
self
.
avg
=
0
self
.
sum
=
0
self
.
count
=
0
def
update
(
self
,
val
,
n
=
1
):
self
.
val
=
val
self
.
sum
+=
val
*
n
self
.
count
+=
n
if
self
.
count
>
0
:
self
.
avg
=
self
.
sum
/
self
.
count
def
accumulate
(
self
,
val
,
n
=
1
):
self
.
sum
+=
val
self
.
count
+=
n
if
self
.
count
>
0
:
self
.
avg
=
self
.
sum
/
self
.
count
def
accuracy
(
output
,
target
,
topk
=
(
1
,
5
)):
"""Computes the precision@k for the specified values of k"""
batch_size
=
target
.
size
(
0
)
num
=
output
.
size
(
1
)
target_topk
=
[]
appendices
=
[]
for
k
in
topk
:
if
k
<=
num
:
target_topk
.
append
(
k
)
else
:
appendices
.
append
([
0.0
])
topk
=
target_topk
maxk
=
max
(
topk
)
_
,
pred
=
output
.
topk
(
maxk
,
1
,
True
,
True
)
pred
=
pred
.
t
()
correct
=
pred
.
eq
(
target
.
view
(
1
,
-
1
).
expand_as
(
pred
))
res
=
[]
for
k
in
topk
:
correct_k
=
correct
[:
k
].
view
(
-
1
).
float
().
sum
(
0
)
res
.
append
(
correct_k
.
mul_
(
100.0
/
batch_size
))
return
res
+
appendices
# Custom progress bar
_
,
term_width
=
os
.
popen
(
'stty size'
,
'r'
).
read
().
split
()
term_width
=
int
(
term_width
)
TOTAL_BAR_LENGTH
=
40.
last_time
=
time
.
time
()
begin_time
=
last_time
def
progress_bar
(
current
,
total
,
msg
=
None
):
def
format_time
(
seconds
):
days
=
int
(
seconds
/
3600
/
24
)
seconds
=
seconds
-
days
*
3600
*
24
hours
=
int
(
seconds
/
3600
)
seconds
=
seconds
-
hours
*
3600
minutes
=
int
(
seconds
/
60
)
seconds
=
seconds
-
minutes
*
60
secondsf
=
int
(
seconds
)
seconds
=
seconds
-
secondsf
millis
=
int
(
seconds
*
1000
)
f
=
''
i
=
1
if
days
>
0
:
f
+=
str
(
days
)
+
'D'
i
+=
1
if
hours
>
0
and
i
<=
2
:
f
+=
str
(
hours
)
+
'h'
i
+=
1
if
minutes
>
0
and
i
<=
2
:
f
+=
str
(
minutes
)
+
'm'
i
+=
1
if
secondsf
>
0
and
i
<=
2
:
f
+=
str
(
secondsf
)
+
's'
i
+=
1
if
millis
>
0
and
i
<=
2
:
f
+=
str
(
millis
)
+
'ms'
i
+=
1
if
f
==
''
:
f
=
'0ms'
return
f
global
last_time
,
begin_time
if
current
==
0
:
begin_time
=
time
.
time
()
# Reset for new bar.
cur_len
=
int
(
TOTAL_BAR_LENGTH
*
current
/
total
)
rest_len
=
int
(
TOTAL_BAR_LENGTH
-
cur_len
)
-
1
sys
.
stdout
.
write
(
' ['
)
for
i
in
range
(
cur_len
):
sys
.
stdout
.
write
(
'='
)
sys
.
stdout
.
write
(
'>'
)
for
i
in
range
(
rest_len
):
sys
.
stdout
.
write
(
'.'
)
sys
.
stdout
.
write
(
']'
)
cur_time
=
time
.
time
()
step_time
=
cur_time
-
last_time
last_time
=
cur_time
tot_time
=
cur_time
-
begin_time
L
=
[]
L
.
append
(
' Step: %s'
%
format_time
(
step_time
))
L
.
append
(
' | Tot: %s'
%
format_time
(
tot_time
))
if
msg
:
L
.
append
(
' | '
+
msg
)
msg
=
''
.
join
(
L
)
sys
.
stdout
.
write
(
msg
)
for
i
in
range
(
term_width
-
int
(
TOTAL_BAR_LENGTH
)
-
len
(
msg
)
-
3
):
sys
.
stdout
.
write
(
' '
)
# Go back to the center of the bar.
for
i
in
range
(
term_width
-
int
(
TOTAL_BAR_LENGTH
/
2
)
+
2
):
sys
.
stdout
.
write
(
'
\b
'
)
sys
.
stdout
.
write
(
' %d/%d '
%
(
current
+
1
,
total
))
if
current
<
total
-
1
:
sys
.
stdout
.
write
(
'
\r
'
)
else
:
sys
.
stdout
.
write
(
'
\n
'
)
sys
.
stdout
.
flush
()
examples/model_compress/models/mobilenet.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
torch.nn
as
nn
import
math
def
conv_bn
(
inp
,
oup
,
stride
):
return
nn
.
Sequential
(
nn
.
Conv2d
(
inp
,
oup
,
3
,
stride
,
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup
),
nn
.
ReLU
(
inplace
=
True
)
)
def
conv_dw
(
inp
,
oup
,
stride
):
return
nn
.
Sequential
(
nn
.
Conv2d
(
inp
,
inp
,
3
,
stride
,
1
,
groups
=
inp
,
bias
=
False
),
nn
.
BatchNorm2d
(
inp
),
nn
.
ReLU
(
inplace
=
True
),
nn
.
Conv2d
(
inp
,
oup
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup
),
nn
.
ReLU
(
inplace
=
True
),
)
class
MobileNet
(
nn
.
Module
):
def
__init__
(
self
,
n_class
,
profile
=
'normal'
):
super
(
MobileNet
,
self
).
__init__
()
# original
if
profile
==
'normal'
:
in_planes
=
32
cfg
=
[
64
,
(
128
,
2
),
128
,
(
256
,
2
),
256
,
(
512
,
2
),
512
,
512
,
512
,
512
,
512
,
(
1024
,
2
),
1024
]
# 0.5 AMC
elif
profile
==
'0.5flops'
:
in_planes
=
24
cfg
=
[
48
,
(
96
,
2
),
80
,
(
192
,
2
),
200
,
(
328
,
2
),
352
,
368
,
360
,
328
,
400
,
(
736
,
2
),
752
]
else
:
raise
NotImplementedError
self
.
conv1
=
conv_bn
(
3
,
in_planes
,
stride
=
2
)
self
.
features
=
self
.
_make_layers
(
in_planes
,
cfg
,
conv_dw
)
self
.
classifier
=
nn
.
Sequential
(
nn
.
Linear
(
cfg
[
-
1
],
n_class
),
)
self
.
_initialize_weights
()
def
forward
(
self
,
x
):
x
=
self
.
conv1
(
x
)
x
=
self
.
features
(
x
)
x
=
x
.
mean
(
3
).
mean
(
2
)
# global average pooling
x
=
self
.
classifier
(
x
)
return
x
def
_make_layers
(
self
,
in_planes
,
cfg
,
layer
):
layers
=
[]
for
x
in
cfg
:
out_planes
=
x
if
isinstance
(
x
,
int
)
else
x
[
0
]
stride
=
1
if
isinstance
(
x
,
int
)
else
x
[
1
]
layers
.
append
(
layer
(
in_planes
,
out_planes
,
stride
))
in_planes
=
out_planes
return
nn
.
Sequential
(
*
layers
)
def
_initialize_weights
(
self
):
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
n
=
m
.
kernel_size
[
0
]
*
m
.
kernel_size
[
1
]
*
m
.
out_channels
m
.
weight
.
data
.
normal_
(
0
,
math
.
sqrt
(
2.
/
n
))
if
m
.
bias
is
not
None
:
m
.
bias
.
data
.
zero_
()
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
m
.
weight
.
data
.
fill_
(
1
)
m
.
bias
.
data
.
zero_
()
elif
isinstance
(
m
,
nn
.
Linear
):
n
=
m
.
weight
.
size
(
1
)
m
.
weight
.
data
.
normal_
(
0
,
0.01
)
m
.
bias
.
data
.
zero_
()
examples/model_compress/models/mobilenet_v2.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
torch.nn
as
nn
import
math
def
conv_bn
(
inp
,
oup
,
stride
):
return
nn
.
Sequential
(
nn
.
Conv2d
(
inp
,
oup
,
3
,
stride
,
1
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup
),
nn
.
ReLU6
(
inplace
=
True
)
)
def
conv_1x1_bn
(
inp
,
oup
):
return
nn
.
Sequential
(
nn
.
Conv2d
(
inp
,
oup
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup
),
nn
.
ReLU6
(
inplace
=
True
)
)
class
InvertedResidual
(
nn
.
Module
):
def
__init__
(
self
,
inp
,
oup
,
stride
,
expand_ratio
):
super
(
InvertedResidual
,
self
).
__init__
()
self
.
stride
=
stride
assert
stride
in
[
1
,
2
]
hidden_dim
=
round
(
inp
*
expand_ratio
)
self
.
use_res_connect
=
self
.
stride
==
1
and
inp
==
oup
if
expand_ratio
==
1
:
self
.
conv
=
nn
.
Sequential
(
# dw
nn
.
Conv2d
(
hidden_dim
,
hidden_dim
,
3
,
stride
,
1
,
groups
=
hidden_dim
,
bias
=
False
),
nn
.
BatchNorm2d
(
hidden_dim
),
nn
.
ReLU6
(
inplace
=
True
),
# pw-linear
nn
.
Conv2d
(
hidden_dim
,
oup
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup
),
)
else
:
self
.
conv
=
nn
.
Sequential
(
# pw
nn
.
Conv2d
(
inp
,
hidden_dim
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
hidden_dim
),
nn
.
ReLU6
(
inplace
=
True
),
# dw
nn
.
Conv2d
(
hidden_dim
,
hidden_dim
,
3
,
stride
,
1
,
groups
=
hidden_dim
,
bias
=
False
),
nn
.
BatchNorm2d
(
hidden_dim
),
nn
.
ReLU6
(
inplace
=
True
),
# pw-linear
nn
.
Conv2d
(
hidden_dim
,
oup
,
1
,
1
,
0
,
bias
=
False
),
nn
.
BatchNorm2d
(
oup
),
)
def
forward
(
self
,
x
):
if
self
.
use_res_connect
:
return
x
+
self
.
conv
(
x
)
else
:
return
self
.
conv
(
x
)
class
MobileNetV2
(
nn
.
Module
):
def
__init__
(
self
,
n_class
=
1000
,
input_size
=
224
,
width_mult
=
1.
):
super
(
MobileNetV2
,
self
).
__init__
()
block
=
InvertedResidual
input_channel
=
32
last_channel
=
1280
interverted_residual_setting
=
[
# t, c, n, s
[
1
,
16
,
1
,
1
],
[
6
,
24
,
2
,
2
],
[
6
,
32
,
3
,
2
],
[
6
,
64
,
4
,
2
],
[
6
,
96
,
3
,
1
],
[
6
,
160
,
3
,
2
],
[
6
,
320
,
1
,
1
],
]
# building first layer
assert
input_size
%
32
==
0
input_channel
=
int
(
input_channel
*
width_mult
)
self
.
last_channel
=
int
(
last_channel
*
width_mult
)
if
width_mult
>
1.0
else
last_channel
self
.
features
=
[
conv_bn
(
3
,
input_channel
,
2
)]
# building inverted residual blocks
for
t
,
c
,
n
,
s
in
interverted_residual_setting
:
output_channel
=
int
(
c
*
width_mult
)
for
i
in
range
(
n
):
if
i
==
0
:
self
.
features
.
append
(
block
(
input_channel
,
output_channel
,
s
,
expand_ratio
=
t
))
else
:
self
.
features
.
append
(
block
(
input_channel
,
output_channel
,
1
,
expand_ratio
=
t
))
input_channel
=
output_channel
# building last several layers
self
.
features
.
append
(
conv_1x1_bn
(
input_channel
,
self
.
last_channel
))
# make it nn.Sequential
self
.
features
=
nn
.
Sequential
(
*
self
.
features
)
# building classifier
self
.
classifier
=
nn
.
Sequential
(
nn
.
Dropout
(
0.2
),
nn
.
Linear
(
self
.
last_channel
,
n_class
),
)
self
.
_initialize_weights
()
def
forward
(
self
,
x
):
x
=
self
.
features
(
x
)
x
=
x
.
mean
(
3
).
mean
(
2
)
x
=
self
.
classifier
(
x
)
return
x
def
_initialize_weights
(
self
):
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
n
=
m
.
kernel_size
[
0
]
*
m
.
kernel_size
[
1
]
*
m
.
out_channels
m
.
weight
.
data
.
normal_
(
0
,
math
.
sqrt
(
2.
/
n
))
if
m
.
bias
is
not
None
:
m
.
bias
.
data
.
zero_
()
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
m
.
weight
.
data
.
fill_
(
1
)
m
.
bias
.
data
.
zero_
()
elif
isinstance
(
m
,
nn
.
Linear
):
n
=
m
.
weight
.
size
(
1
)
m
.
weight
.
data
.
normal_
(
0
,
0.01
)
m
.
bias
.
data
.
zero_
()
src/sdk/pynni/nni/compression/torch/compressor.py
View file @
e9f3cddf
...
...
@@ -54,20 +54,34 @@ class Compressor:
self
.
_fwd_hook_handles
=
{}
self
.
_fwd_hook_id
=
0
for
layer
,
config
in
self
.
_detect_modules_to_compress
():
wrapper
=
self
.
_wrap_modules
(
layer
,
config
)
self
.
modules_wrapper
.
append
(
wrapper
)
self
.
reset
()
if
not
self
.
modules_wrapper
:
_logger
.
warning
(
'Nothing is configured to compress, please check your model and config_list'
)
self
.
_wrap_model
()
def
validate_config
(
self
,
model
,
config_list
):
"""
subclass can optionally implement this method to check if config_list if valid
"""
pass
def
reset
(
self
,
checkpoint
=
None
):
"""
reset model state dict and model wrapper
"""
self
.
_unwrap_model
()
if
checkpoint
is
not
None
:
self
.
bound_model
.
load_state_dict
(
checkpoint
)
self
.
modules_to_compress
=
None
self
.
modules_wrapper
=
[]
for
layer
,
config
in
self
.
_detect_modules_to_compress
():
wrapper
=
self
.
_wrap_modules
(
layer
,
config
)
self
.
modules_wrapper
.
append
(
wrapper
)
self
.
_wrap_model
()
def
_detect_modules_to_compress
(
self
):
"""
detect all modules should be compressed, and save the result in `self.modules_to_compress`.
...
...
@@ -346,7 +360,7 @@ class Pruner(Compressor):
config : dict
the configuration for generating the mask
"""
_logger
.
info
(
"Module detected to compress : %s."
,
layer
.
name
)
_logger
.
debug
(
"Module detected to compress : %s."
,
layer
.
name
)
wrapper
=
PrunerModuleWrapper
(
layer
.
module
,
layer
.
name
,
layer
.
type
,
config
,
self
)
assert
hasattr
(
layer
.
module
,
'weight'
),
"module %s does not have 'weight' attribute"
%
layer
.
name
# move newly registered buffers to the same device of weight
...
...
@@ -381,7 +395,7 @@ class Pruner(Compressor):
if
weight_mask
is
not
None
:
mask_sum
=
weight_mask
.
sum
().
item
()
mask_num
=
weight_mask
.
numel
()
_logger
.
info
(
'Layer: %s Sparsity: %.4f'
,
wrapper
.
name
,
1
-
mask_sum
/
mask_num
)
_logger
.
debug
(
'Layer: %s Sparsity: %.4f'
,
wrapper
.
name
,
1
-
mask_sum
/
mask_num
)
wrapper
.
module
.
weight
.
data
=
wrapper
.
module
.
weight
.
data
.
mul
(
weight_mask
)
if
bias_mask
is
not
None
:
wrapper
.
module
.
bias
.
data
=
wrapper
.
module
.
bias
.
data
.
mul
(
bias_mask
)
...
...
src/sdk/pynni/nni/compression/torch/pruning/__init__.py
View file @
e9f3cddf
...
...
@@ -12,3 +12,5 @@ from .net_adapt_pruner import NetAdaptPruner
from
.admm_pruner
import
ADMMPruner
from
.auto_compress_pruner
import
AutoCompressPruner
from
.sensitivity_pruner
import
SensitivityPruner
from
.amc
import
AMCPruner
src/sdk/pynni/nni/compression/torch/pruning/amc/__init__.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
from
.amc_pruner
import
AMCPruner
src/sdk/pynni/nni/compression/torch/pruning/amc/amc_pruner.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
os
from
copy
import
deepcopy
from
argparse
import
Namespace
import
numpy
as
np
import
torch
from
nni.compression.torch.compressor
import
Pruner
from
.channel_pruning_env
import
ChannelPruningEnv
from
.lib.agent
import
DDPG
from
.lib.utils
import
get_output_folder
torch
.
backends
.
cudnn
.
deterministic
=
True
class
AMCPruner
(
Pruner
):
"""
A pytorch implementation of AMC: AutoML for Model Compression and Acceleration on Mobile Devices.
(https://arxiv.org/pdf/1802.03494.pdf)
Parameters:
model: nn.Module
The model to be pruned.
config_list: list
Configuration list to configure layer pruning.
Supported keys:
- op_types: operation type to be pruned
- op_names: operation name to be pruned
evaluator: function
function to evaluate the pruned model.
The prototype of the function:
>>> def evaluator(val_loader, model):
>>> ...
>>> return acc
val_loader: torch.utils.data.DataLoader
Data loader of validation dataset.
suffix: str
suffix to help you remember what experiment you ran. Default: None.
job: str
train_export: search best pruned model and export after search.
export_only: export a searched model, searched_model_path and export_path must be specified.
searched_model_path: str
when job == export_only, use searched_model_path to specify the path of the searched model.
export_path: str
path for exporting models
# parameters for pruning environment
model_type: str
model type to prune, currently 'mobilenet' and 'mobilenetv2' are supported. Default: mobilenet
flops_ratio: float
preserve flops ratio. Default: 0.5
lbound: float
minimum weight preserve ratio for each layer. Default: 0.2
rbound: float
maximum weight preserve ratio for each layer. Default: 1.0
reward: function
reward function type:
- acc_reward: accuracy * 0.01
- acc_flops_reward: - (100 - accuracy) * 0.01 * np.log(flops)
Default: acc_reward
# parameters for channel pruning
n_calibration_batches: int
number of batches to extract layer information. Default: 60
n_points_per_layer: int
number of feature points per layer. Default: 10
channel_round: int
round channel to multiple of channel_round. Default: 8
# parameters for ddpg agent
hidden1: int
hidden num of first fully connect layer. Default: 300
hidden2: int
hidden num of second fully connect layer. Default: 300
lr_c: float
learning rate for critic. Default: 1e-3
lr_a: float
learning rate for actor. Default: 1e-4
warmup: int
number of episodes without training but only filling the replay memory. During warmup episodes,
random actions ares used for pruning. Default: 100
discount: float
next Q value discount for deep Q value target. Default: 0.99
bsize: int
minibatch size for training DDPG agent. Default: 64
rmsize: int
memory size for each layer. Default: 100
window_length: int
replay buffer window length. Default: 1
tau: float
moving average for target network being used by soft_update. Default: 0.99
# noise
init_delta: float
initial variance of truncated normal distribution
delta_decay: float
delta decay during exploration
# parameters for training ddpg agent
max_episode_length: int
maximum episode length
output_dir: str
output directory to save log files and model files. Default: ./logs
debug: boolean
debug mode
train_episode: int
train iters each timestep. Default: 800
epsilon: int
linear decay of exploration policy. Default: 50000
seed: int
random seed to set for reproduce experiment. Default: None
"""
def
__init__
(
self
,
model
,
config_list
,
evaluator
,
val_loader
,
suffix
=
None
,
job
=
'train_export'
,
export_path
=
None
,
searched_model_path
=
None
,
model_type
=
'mobilenet'
,
dataset
=
'cifar10'
,
flops_ratio
=
0.5
,
lbound
=
0.2
,
rbound
=
1.
,
reward
=
'acc_reward'
,
n_calibration_batches
=
60
,
n_points_per_layer
=
10
,
channel_round
=
8
,
hidden1
=
300
,
hidden2
=
300
,
lr_c
=
1e-3
,
lr_a
=
1e-4
,
warmup
=
100
,
discount
=
1.
,
bsize
=
64
,
rmsize
=
100
,
window_length
=
1
,
tau
=
0.01
,
init_delta
=
0.5
,
delta_decay
=
0.99
,
max_episode_length
=
1e9
,
output_dir
=
'./logs'
,
debug
=
False
,
train_episode
=
800
,
epsilon
=
50000
,
seed
=
None
):
from
tensorboardX
import
SummaryWriter
self
.
job
=
job
self
.
searched_model_path
=
searched_model_path
self
.
export_path
=
export_path
if
seed
is
not
None
:
np
.
random
.
seed
(
seed
)
torch
.
manual_seed
(
seed
)
torch
.
cuda
.
manual_seed
(
seed
)
checkpoint
=
deepcopy
(
model
.
state_dict
())
super
().
__init__
(
model
,
config_list
,
optimizer
=
None
)
# build folder and logs
base_folder_name
=
'{}_{}_r{}_search'
.
format
(
model_type
,
dataset
,
flops_ratio
)
if
suffix
is
not
None
:
base_folder_name
=
base_folder_name
+
'_'
+
suffix
self
.
output_dir
=
get_output_folder
(
output_dir
,
base_folder_name
)
if
self
.
export_path
is
None
:
self
.
export_path
=
os
.
path
.
join
(
self
.
output_dir
,
'{}_r{}_exported.pth'
.
format
(
model_type
,
flops_ratio
))
self
.
env_args
=
Namespace
(
model_type
=
model_type
,
preserve_ratio
=
flops_ratio
,
lbound
=
lbound
,
rbound
=
rbound
,
reward
=
reward
,
n_calibration_batches
=
n_calibration_batches
,
n_points_per_layer
=
n_points_per_layer
,
channel_round
=
channel_round
,
output
=
self
.
output_dir
)
self
.
env
=
ChannelPruningEnv
(
self
,
evaluator
,
val_loader
,
checkpoint
,
args
=
self
.
env_args
)
if
self
.
job
==
'train_export'
:
print
(
'=> Saving logs to {}'
.
format
(
self
.
output_dir
))
self
.
tfwriter
=
SummaryWriter
(
logdir
=
self
.
output_dir
)
self
.
text_writer
=
open
(
os
.
path
.
join
(
self
.
output_dir
,
'log.txt'
),
'w'
)
print
(
'=> Output path: {}...'
.
format
(
self
.
output_dir
))
nb_states
=
self
.
env
.
layer_embedding
.
shape
[
1
]
nb_actions
=
1
# just 1 action here
rmsize
=
rmsize
*
len
(
self
.
env
.
prunable_idx
)
# for each layer
print
(
'** Actual replay buffer size: {}'
.
format
(
rmsize
))
self
.
ddpg_args
=
Namespace
(
hidden1
=
hidden1
,
hidden2
=
hidden2
,
lr_c
=
lr_c
,
lr_a
=
lr_a
,
warmup
=
warmup
,
discount
=
discount
,
bsize
=
bsize
,
rmsize
=
rmsize
,
window_length
=
window_length
,
tau
=
tau
,
init_delta
=
init_delta
,
delta_decay
=
delta_decay
,
max_episode_length
=
max_episode_length
,
debug
=
debug
,
train_episode
=
train_episode
,
epsilon
=
epsilon
)
self
.
agent
=
DDPG
(
nb_states
,
nb_actions
,
self
.
ddpg_args
)
def
compress
(
self
):
if
self
.
job
==
'train_export'
:
self
.
train
(
self
.
ddpg_args
.
train_episode
,
self
.
agent
,
self
.
env
,
self
.
output_dir
)
self
.
export_pruned_model
()
def
train
(
self
,
num_episode
,
agent
,
env
,
output_dir
):
agent
.
is_training
=
True
step
=
episode
=
episode_steps
=
0
episode_reward
=
0.
observation
=
None
T
=
[]
# trajectory
while
episode
<
num_episode
:
# counting based on episode
# reset if it is the start of episode
if
observation
is
None
:
observation
=
deepcopy
(
env
.
reset
())
agent
.
reset
(
observation
)
# agent pick action ...
if
episode
<=
self
.
ddpg_args
.
warmup
:
action
=
agent
.
random_action
()
# action = sample_from_truncated_normal_distribution(lower=0., upper=1., mu=env.preserve_ratio, sigma=0.5)
else
:
action
=
agent
.
select_action
(
observation
,
episode
=
episode
)
# env response with next_observation, reward, terminate_info
observation2
,
reward
,
done
,
info
=
env
.
step
(
action
)
T
.
append
([
reward
,
deepcopy
(
observation
),
deepcopy
(
observation2
),
action
,
done
])
# fix-length, never reach here
# if max_episode_length and episode_steps >= max_episode_length - 1:
# done = True
# [optional] save intermideate model
if
num_episode
/
3
<=
1
or
episode
%
int
(
num_episode
/
3
)
==
0
:
agent
.
save_model
(
output_dir
)
# update
step
+=
1
episode_steps
+=
1
episode_reward
+=
reward
observation
=
deepcopy
(
observation2
)
if
done
:
# end of episode
print
(
'#{}: episode_reward:{:.4f} acc: {:.4f}, ratio: {:.4f}'
.
format
(
episode
,
episode_reward
,
info
[
'accuracy'
],
info
[
'compress_ratio'
]
)
)
self
.
text_writer
.
write
(
'#{}: episode_reward:{:.4f} acc: {:.4f}, ratio: {:.4f}
\n
'
.
format
(
episode
,
episode_reward
,
info
[
'accuracy'
],
info
[
'compress_ratio'
]
)
)
final_reward
=
T
[
-
1
][
0
]
# print('final_reward: {}'.format(final_reward))
# agent observe and update policy
for
_
,
s_t
,
s_t1
,
a_t
,
done
in
T
:
agent
.
observe
(
final_reward
,
s_t
,
s_t1
,
a_t
,
done
)
if
episode
>
self
.
ddpg_args
.
warmup
:
agent
.
update_policy
()
#agent.memory.append(
# observation,
# agent.select_action(observation, episode=episode),
# 0., False
#)
# reset
observation
=
None
episode_steps
=
0
episode_reward
=
0.
episode
+=
1
T
=
[]
self
.
tfwriter
.
add_scalar
(
'reward/last'
,
final_reward
,
episode
)
self
.
tfwriter
.
add_scalar
(
'reward/best'
,
env
.
best_reward
,
episode
)
self
.
tfwriter
.
add_scalar
(
'info/accuracy'
,
info
[
'accuracy'
],
episode
)
self
.
tfwriter
.
add_scalar
(
'info/compress_ratio'
,
info
[
'compress_ratio'
],
episode
)
self
.
tfwriter
.
add_text
(
'info/best_policy'
,
str
(
env
.
best_strategy
),
episode
)
# record the preserve rate for each layer
for
i
,
preserve_rate
in
enumerate
(
env
.
strategy
):
self
.
tfwriter
.
add_scalar
(
'preserve_rate/{}'
.
format
(
i
),
preserve_rate
,
episode
)
self
.
text_writer
.
write
(
'best reward: {}
\n
'
.
format
(
env
.
best_reward
))
self
.
text_writer
.
write
(
'best policy: {}
\n
'
.
format
(
env
.
best_strategy
))
self
.
text_writer
.
close
()
def
export_pruned_model
(
self
):
if
self
.
searched_model_path
is
None
:
wrapper_model_ckpt
=
os
.
path
.
join
(
self
.
output_dir
,
'best_wrapped_model.pth'
)
else
:
wrapper_model_ckpt
=
self
.
searched_model_path
self
.
env
.
reset
()
self
.
bound_model
.
load_state_dict
(
torch
.
load
(
wrapper_model_ckpt
))
print
(
'validate searched model:'
,
self
.
env
.
_validate
(
self
.
env
.
_val_loader
,
self
.
env
.
model
))
self
.
env
.
export_model
()
self
.
_unwrap_model
()
print
(
'validate exported model:'
,
self
.
env
.
_validate
(
self
.
env
.
_val_loader
,
self
.
env
.
model
))
torch
.
save
(
self
.
bound_model
,
self
.
export_path
)
print
(
'exported model saved to: {}'
.
format
(
self
.
export_path
))
src/sdk/pynni/nni/compression/torch/pruning/amc/channel_pruning_env.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
os
import
time
import
math
import
copy
import
numpy
as
np
import
torch
import
torch.nn
as
nn
from
nni.compression.torch.compressor
import
PrunerModuleWrapper
from
.lib.utils
import
prGreen
from
..
import
AMCWeightMasker
# for pruning
def
acc_reward
(
net
,
acc
,
flops
):
return
acc
*
0.01
def
acc_flops_reward
(
net
,
acc
,
flops
):
error
=
(
100
-
acc
)
*
0.01
return
-
error
*
np
.
log
(
flops
)
class
ChannelPruningEnv
:
"""
Env for channel pruning search.
This class is used to prune model using specified pruner. It prunes one layer when
step() is called. When the last layer is pruned, it evaluate the pruned model using
evaluator, and use the returned value of evaluator as reward of the episode.
Usage:
env = ChannelPruningEnv(pruner, evaluator, val_loader, checkpoint, env_args)
episode = 0
T = []
while episode < num_episode:
action = agent.select_action(observation)
observation2, reward, done, info = env.step(action)
T.append([reward, deepcopy(observation), deepcopy(observation2), action, done])
if done: # end of episode, last layer pruned
episode += 1
# train agent with episode data
for _, s_t, s_t1, a_t, done in T:
agent.observe(final_reward, s_t, s_t1, a_t, done)
agent.update_policy()
T = []
Attributes:
prunable_idx: layer indices for pruable layers, the index values are the index
of list(self.model.modules()). Pruable layers are pointwise Conv2d layers and Linear
layers.
buffer_idx: layer indices for buffer layers which refers the depthwise layers.
Each depthwise layer is always followd by a pointwise layer for both mobilenet and
mobilenetv2. The depthwise layer's filters are pruned when its next pointwise layer's
corresponding input channels are pruned.
shared_idx: layer indices for layers which share input.
For example: [[1,4], [8, 10, 15]] means layer 1 and 4 share same input, and layer
8, 10 and 15 share another input.
layer_embedding: embeddings for each prunable layers, the embedding is used as
observation for DDPG agent.
layer_info_dict: flops and number of parameters of each layer.
min_strategy_dict: key is layer index, value is a tuple, the first value is the minimum
action of input channel, the second value is the minimum action value of output channel.
strategy_dict: key is layer index, value is a tuple, the first value is the action of input
channel, the second value is the action of output channel.
Parameters:
pruner: Pruner
NNI Pruner instance used to prune model.
evaluator: function
function to evaluate the pruned model.
The prototype of the function:
>>> def evaluator(val_loader, model):
>>> ...
>>> return acc
val_loader: torch.utils.data.DataLoader
Data loader of validation dataset.
checkpoint: dict
checkpoint of the model to be pruned. It is used to reset model at beginning of each
episode.
args:
A Namespace object containing following arguments:
model_type: str
model type to prune, currently 'mobilenet' and 'mobilenetv2' are supported.
flops_ratio: float
preserve flops ratio.
lbound: float
minimum weight preserve ratio for each layer.
rbound: float
maximum weight preserve ratio for each layer.
reward: function
reward function type
# parameters for channel pruning
n_calibration_batches: int
number of batches to extract layer information.
n_points_per_layer: int
number of feature points per layer.
channel_round: int
round channel to multiple of channel_round.
"""
def
__init__
(
self
,
pruner
,
evaluator
,
val_loader
,
checkpoint
,
args
):
self
.
pruner
=
pruner
self
.
model
=
pruner
.
bound_model
self
.
checkpoint
=
checkpoint
self
.
batch_size
=
val_loader
.
batch_size
self
.
preserve_ratio
=
args
.
preserve_ratio
self
.
channel_prune_masker
=
AMCWeightMasker
(
self
.
model
,
self
.
pruner
,
args
.
channel_round
)
# options from args
self
.
args
=
args
self
.
lbound
=
args
.
lbound
self
.
rbound
=
args
.
rbound
self
.
n_calibration_batches
=
args
.
n_calibration_batches
self
.
n_points_per_layer
=
args
.
n_points_per_layer
self
.
channel_round
=
args
.
channel_round
# sanity check
assert
self
.
preserve_ratio
>
self
.
lbound
,
'Error! You can not achieve preserve_ratio smaller than lbound!'
# prepare data
self
.
_val_loader
=
val_loader
self
.
_validate
=
evaluator
# build indexs
self
.
_build_index
()
self
.
n_prunable_layer
=
len
(
self
.
prunable_idx
)
# extract information for preparing
self
.
_extract_layer_information
()
# build embedding (static part)
self
.
_build_state_embedding
()
# build reward
self
.
reset
()
# restore weight
self
.
org_acc
=
self
.
_validate
(
self
.
_val_loader
,
self
.
model
)
print
(
'=> original acc: {:.3f}%'
.
format
(
self
.
org_acc
))
self
.
org_model_size
=
sum
(
self
.
wsize_list
)
print
(
'=> original weight size: {:.4f} M param'
.
format
(
self
.
org_model_size
*
1.
/
1e6
))
self
.
org_flops
=
sum
(
self
.
flops_list
)
print
(
'=> FLOPs:'
)
print
([
self
.
layer_info_dict
[
idx
][
'flops'
]
/
1e6
for
idx
in
sorted
(
self
.
layer_info_dict
.
keys
())])
print
(
'=> original FLOPs: {:.4f} M'
.
format
(
self
.
org_flops
*
1.
/
1e6
))
self
.
expected_preserve_computation
=
self
.
preserve_ratio
*
self
.
org_flops
self
.
reward
=
eval
(
args
.
reward
)
self
.
best_reward
=
-
math
.
inf
self
.
best_strategy
=
None
self
.
best_d_prime_list
=
None
self
.
best_masks
=
None
self
.
org_w_size
=
sum
(
self
.
wsize_list
)
def
step
(
self
,
action
):
# Pseudo prune and get the corresponding statistics. The real pruning happens till the end of all pseudo pruning
if
self
.
visited
[
self
.
cur_ind
]:
action
=
self
.
strategy_dict
[
self
.
prunable_idx
[
self
.
cur_ind
]][
0
]
preserve_idx
=
self
.
index_buffer
[
self
.
cur_ind
]
else
:
action
=
self
.
_action_wall
(
action
)
# percentage to preserve
preserve_idx
=
None
# prune and update action
action
,
d_prime
,
preserve_idx
=
self
.
prune_kernel
(
self
.
prunable_idx
[
self
.
cur_ind
],
action
,
preserve_idx
)
if
not
self
.
visited
[
self
.
cur_ind
]:
for
group
in
self
.
shared_idx
:
if
self
.
cur_ind
in
group
:
# set the shared ones
for
g_idx
in
group
:
self
.
strategy_dict
[
self
.
prunable_idx
[
g_idx
]][
0
]
=
action
self
.
strategy_dict
[
self
.
prunable_idx
[
g_idx
-
1
]][
1
]
=
action
self
.
visited
[
g_idx
]
=
True
self
.
index_buffer
[
g_idx
]
=
preserve_idx
.
copy
()
self
.
strategy
.
append
(
action
)
# save action to strategy
self
.
d_prime_list
.
append
(
d_prime
)
self
.
strategy_dict
[
self
.
prunable_idx
[
self
.
cur_ind
]][
0
]
=
action
if
self
.
cur_ind
>
0
:
self
.
strategy_dict
[
self
.
prunable_idx
[
self
.
cur_ind
-
1
]][
1
]
=
action
# all the actions are made
if
self
.
_is_final_layer
():
assert
len
(
self
.
strategy
)
==
len
(
self
.
prunable_idx
)
current_flops
=
self
.
_cur_flops
()
acc_t1
=
time
.
time
()
acc
=
self
.
_validate
(
self
.
_val_loader
,
self
.
model
)
acc_t2
=
time
.
time
()
self
.
val_time
=
acc_t2
-
acc_t1
compress_ratio
=
current_flops
*
1.
/
self
.
org_flops
info_set
=
{
'compress_ratio'
:
compress_ratio
,
'accuracy'
:
acc
,
'strategy'
:
self
.
strategy
.
copy
()}
reward
=
self
.
reward
(
self
,
acc
,
current_flops
)
if
reward
>
self
.
best_reward
:
self
.
best_reward
=
reward
self
.
best_strategy
=
self
.
strategy
.
copy
()
self
.
best_d_prime_list
=
self
.
d_prime_list
.
copy
()
torch
.
save
(
self
.
model
.
state_dict
(),
os
.
path
.
join
(
self
.
args
.
output
,
'best_wrapped_model.pth'
))
prGreen
(
'New best reward: {:.4f}, acc: {:.4f}, compress: {:.4f}'
.
format
(
self
.
best_reward
,
acc
,
compress_ratio
))
prGreen
(
'New best policy: {}'
.
format
(
self
.
best_strategy
))
prGreen
(
'New best d primes: {}'
.
format
(
self
.
best_d_prime_list
))
obs
=
self
.
layer_embedding
[
self
.
cur_ind
,
:].
copy
()
# actually the same as the last state
done
=
True
return
obs
,
reward
,
done
,
info_set
info_set
=
None
reward
=
0
done
=
False
self
.
visited
[
self
.
cur_ind
]
=
True
# set to visited
self
.
cur_ind
+=
1
# the index of next layer
# build next state (in-place modify)
self
.
layer_embedding
[
self
.
cur_ind
][
-
3
]
=
self
.
_cur_reduced
()
*
1.
/
self
.
org_flops
# reduced
self
.
layer_embedding
[
self
.
cur_ind
][
-
2
]
=
sum
(
self
.
flops_list
[
self
.
cur_ind
+
1
:])
*
1.
/
self
.
org_flops
# rest
self
.
layer_embedding
[
self
.
cur_ind
][
-
1
]
=
self
.
strategy
[
-
1
]
# last action
obs
=
self
.
layer_embedding
[
self
.
cur_ind
,
:].
copy
()
return
obs
,
reward
,
done
,
info_set
def
reset
(
self
):
# restore env by loading the checkpoint
self
.
pruner
.
reset
(
self
.
checkpoint
)
self
.
cur_ind
=
0
self
.
strategy
=
[]
# pruning strategy
self
.
d_prime_list
=
[]
self
.
strategy_dict
=
copy
.
deepcopy
(
self
.
min_strategy_dict
)
# reset layer embeddings
self
.
layer_embedding
[:,
-
1
]
=
1.
self
.
layer_embedding
[:,
-
2
]
=
0.
self
.
layer_embedding
[:,
-
3
]
=
0.
obs
=
self
.
layer_embedding
[
0
].
copy
()
obs
[
-
2
]
=
sum
(
self
.
wsize_list
[
1
:])
*
1.
/
sum
(
self
.
wsize_list
)
self
.
extract_time
=
0
self
.
fit_time
=
0
self
.
val_time
=
0
# for share index
self
.
visited
=
[
False
]
*
len
(
self
.
prunable_idx
)
self
.
index_buffer
=
{}
return
obs
def
set_export_path
(
self
,
path
):
self
.
export_path
=
path
def
prune_kernel
(
self
,
op_idx
,
preserve_ratio
,
preserve_idx
=
None
):
m_list
=
list
(
self
.
model
.
modules
())
op
=
m_list
[
op_idx
]
assert
(
0.
<
preserve_ratio
<=
1.
)
assert
type
(
op
)
==
PrunerModuleWrapper
if
preserve_ratio
==
1
:
# do not prune
if
(
preserve_idx
is
None
)
or
(
len
(
preserve_idx
)
==
op
.
module
.
weight
.
size
(
1
)):
return
1.
,
op
.
module
.
weight
.
size
(
1
),
None
# should be a full index
op
.
input_feat
=
self
.
layer_info_dict
[
op_idx
][
'input_feat'
]
op
.
output_feat
=
self
.
layer_info_dict
[
op_idx
][
'output_feat'
]
masks
=
self
.
channel_prune_masker
.
calc_mask
(
sparsity
=
1
-
preserve_ratio
,
wrapper
=
op
,
preserve_idx
=
preserve_idx
)
m
=
masks
[
'weight_mask'
].
cpu
().
data
if
type
(
op
.
module
)
==
nn
.
Conv2d
:
d_prime
=
(
m
.
sum
((
0
,
2
,
3
))
>
0
).
sum
().
item
()
preserve_idx
=
np
.
nonzero
((
m
.
sum
((
0
,
2
,
3
))
>
0
).
numpy
())[
0
]
else
:
assert
type
(
op
.
module
)
==
nn
.
Linear
d_prime
=
(
m
.
sum
(
1
)
>
0
).
sum
().
item
()
preserve_idx
=
np
.
nonzero
((
m
.
sum
(
1
)
>
0
).
numpy
())[
0
]
op
.
weight_mask
=
masks
[
'weight_mask'
]
if
hasattr
(
op
.
module
,
'bias'
)
and
op
.
module
.
bias
is
not
None
and
'bias_mask'
in
masks
:
op
.
bias_mask
=
masks
[
'bias_mask'
]
action
=
(
m
==
1
).
sum
().
item
()
/
m
.
numel
()
return
action
,
d_prime
,
preserve_idx
def
export_model
(
self
):
while
True
:
self
.
export_layer
(
self
.
prunable_idx
[
self
.
cur_ind
])
if
self
.
_is_final_layer
():
break
self
.
cur_ind
+=
1
#TODO replace this speedup implementation with nni.compression.torch.ModelSpeedup
def
export_layer
(
self
,
op_idx
):
m_list
=
list
(
self
.
model
.
modules
())
op
=
m_list
[
op_idx
]
assert
type
(
op
)
==
PrunerModuleWrapper
w
=
op
.
module
.
weight
.
cpu
().
data
m
=
op
.
weight_mask
.
cpu
().
data
if
type
(
op
.
module
)
==
nn
.
Linear
:
w
=
w
.
unsqueeze
(
-
1
).
unsqueeze
(
-
1
)
m
=
m
.
unsqueeze
(
-
1
).
unsqueeze
(
-
1
)
d_prime
=
(
m
.
sum
((
0
,
2
,
3
))
>
0
).
sum
().
item
()
preserve_idx
=
np
.
nonzero
((
m
.
sum
((
0
,
2
,
3
))
>
0
).
numpy
())[
0
]
assert
d_prime
<=
w
.
size
(
1
)
if
d_prime
==
w
.
size
(
1
):
return
mask
=
np
.
zeros
(
w
.
size
(
1
),
bool
)
mask
[
preserve_idx
]
=
True
rec_weight
=
torch
.
zeros
((
w
.
size
(
0
),
d_prime
,
w
.
size
(
2
),
w
.
size
(
3
)))
rec_weight
=
w
[:,
preserve_idx
,
:,
:]
if
type
(
op
.
module
)
==
nn
.
Linear
:
rec_weight
=
rec_weight
.
squeeze
()
# no need to provide bias mask for channel pruning
rec_mask
=
torch
.
ones_like
(
rec_weight
)
# assign new weight and mask
device
=
op
.
module
.
weight
.
device
op
.
module
.
weight
.
data
=
rec_weight
.
to
(
device
)
op
.
weight_mask
=
rec_mask
.
to
(
device
)
if
type
(
op
.
module
)
==
nn
.
Conv2d
:
op
.
module
.
in_channels
=
d_prime
else
:
# Linear
op
.
module
.
in_features
=
d_prime
# export prev layers
prev_idx
=
self
.
prunable_idx
[
self
.
prunable_idx
.
index
(
op_idx
)
-
1
]
for
idx
in
range
(
prev_idx
,
op_idx
):
m
=
m_list
[
idx
]
if
type
(
m
)
==
nn
.
Conv2d
:
# depthwise
m
.
weight
.
data
=
m
.
weight
.
data
[
mask
,
:,
:,
:]
if
m
.
groups
==
m
.
in_channels
:
m
.
groups
=
int
(
np
.
sum
(
mask
))
m
.
out_channels
=
d_prime
elif
type
(
m
)
==
nn
.
BatchNorm2d
:
m
.
weight
.
data
=
m
.
weight
.
data
[
mask
]
m
.
bias
.
data
=
m
.
bias
.
data
[
mask
]
m
.
running_mean
.
data
=
m
.
running_mean
.
data
[
mask
]
m
.
running_var
.
data
=
m
.
running_var
.
data
[
mask
]
m
.
num_features
=
d_prime
def
_is_final_layer
(
self
):
return
self
.
cur_ind
==
len
(
self
.
prunable_idx
)
-
1
def
_action_wall
(
self
,
action
):
"""
Limit the action generated by DDPG for this layer by two constraints:
1. The total flops must meet the flops reduce target.
For example: the original flops of entire model is 1000, target flops ratio is 0.5, target flops
is 1000*0.5 = 500. The reduced flops of other layers is 400, so the remaining flops quota is 500-400=100,
if the total original flops of this layer is 250, then the maximum ratio is 100/250 = 0.4. So the
action of this layer can not be greater than 0.4.
2. The action must be greater than lbound which is stored in self.strategy_dict.
"""
assert
len
(
self
.
strategy
)
==
self
.
cur_ind
action
=
float
(
action
)
action
=
np
.
clip
(
action
,
0
,
1
)
other_comp
=
0
this_comp
=
0
for
i
,
idx
in
enumerate
(
self
.
prunable_idx
):
flop
=
self
.
layer_info_dict
[
idx
][
'flops'
]
buffer_flop
=
self
.
_get_buffer_flops
(
idx
)
if
i
==
self
.
cur_ind
-
1
:
# TODO: add other member in the set
this_comp
+=
flop
*
self
.
strategy_dict
[
idx
][
0
]
# add buffer (but not influenced by ratio)
other_comp
+=
buffer_flop
*
self
.
strategy_dict
[
idx
][
0
]
elif
i
==
self
.
cur_ind
:
this_comp
+=
flop
*
self
.
strategy_dict
[
idx
][
1
]
# also add buffer here (influenced by ratio)
this_comp
+=
buffer_flop
else
:
other_comp
+=
flop
*
self
.
strategy_dict
[
idx
][
0
]
*
self
.
strategy_dict
[
idx
][
1
]
# add buffer
other_comp
+=
buffer_flop
*
self
.
strategy_dict
[
idx
][
0
]
# only consider input reduction
self
.
expected_min_preserve
=
other_comp
+
this_comp
*
action
max_preserve_ratio
=
(
self
.
expected_preserve_computation
-
other_comp
)
*
1.
/
this_comp
action
=
np
.
minimum
(
action
,
max_preserve_ratio
)
action
=
np
.
maximum
(
action
,
self
.
strategy_dict
[
self
.
prunable_idx
[
self
.
cur_ind
]][
0
])
# impossible (should be)
return
action
def
_get_buffer_flops
(
self
,
idx
):
buffer_idx
=
self
.
buffer_dict
[
idx
]
buffer_flop
=
sum
([
self
.
layer_info_dict
[
_
][
'flops'
]
for
_
in
buffer_idx
])
return
buffer_flop
def
_cur_flops
(
self
):
flops
=
0
for
idx
in
self
.
prunable_idx
:
c
,
n
=
self
.
strategy_dict
[
idx
]
# input, output pruning ratio
flops
+=
self
.
layer_info_dict
[
idx
][
'flops'
]
*
c
*
n
# add buffer computation
flops
+=
self
.
_get_buffer_flops
(
idx
)
*
c
# only related to input channel reduction
return
flops
def
_cur_reduced
(
self
):
# return the reduced weight
reduced
=
self
.
org_flops
-
self
.
_cur_flops
()
return
reduced
def
_build_index
(
self
):
"""
Build following information/data for later pruning:
self.prunable_idx: layer indices for pruable layers, the index values are the index
of list(self.model.modules()). Pruable layers are pointwise Conv2d layers and Linear
layers.
self.prunable_ops: prunable modules
self.buffer_idx: layer indices for buffer layers which refers the depthwise layers.
Each depthwise layer is always followd by a pointwise layer for both mobilenet and
mobilenetv2. The depthwise layer's filters are pruned when its next pointwise layer's
corresponding input channels are pruned.
self.shared_idx: layer indices for layers which share input.
For example: [[1,4], [8, 10, 15]] means layer 1 and 4 share same input, and layer
8, 10 and 15 share another input.
self.org_channels: number of input channels for each layer
self.min_strategy_dict: key is layer index, value is a tuple, the first value is the minimum
action of input channel, the second value is the minimum action value of output channel.
self.strategy_dict: same as self.min_strategy_dict, but it will be updated later.
"""
self
.
prunable_idx
=
[]
self
.
prunable_ops
=
[]
self
.
layer_type_dict
=
{}
self
.
strategy_dict
=
{}
self
.
buffer_dict
=
{}
this_buffer_list
=
[]
self
.
org_channels
=
[]
# build index and the min strategy dict
for
i
,
m
in
enumerate
(
self
.
model
.
modules
()):
if
isinstance
(
m
,
PrunerModuleWrapper
):
m
=
m
.
module
if
type
(
m
)
==
nn
.
Conv2d
and
m
.
groups
==
m
.
in_channels
:
# depth-wise conv, buffer
this_buffer_list
.
append
(
i
)
else
:
# really prunable
self
.
prunable_idx
.
append
(
i
)
self
.
prunable_ops
.
append
(
m
)
self
.
layer_type_dict
[
i
]
=
type
(
m
)
self
.
buffer_dict
[
i
]
=
this_buffer_list
this_buffer_list
=
[]
# empty
self
.
org_channels
.
append
(
m
.
in_channels
if
type
(
m
)
==
nn
.
Conv2d
else
m
.
in_features
)
self
.
strategy_dict
[
i
]
=
[
self
.
lbound
,
self
.
lbound
]
self
.
strategy_dict
[
self
.
prunable_idx
[
0
]][
0
]
=
1
# modify the input
self
.
strategy_dict
[
self
.
prunable_idx
[
-
1
]][
1
]
=
1
# modify the output
self
.
shared_idx
=
[]
if
self
.
args
.
model_type
==
'mobilenetv2'
:
# TODO: to be tested! Share index for residual connection
connected_idx
=
[
4
,
6
,
8
,
10
,
12
,
14
,
16
,
18
,
20
,
22
,
24
,
26
,
28
,
30
,
32
]
# to be partitioned
last_ch
=
-
1
share_group
=
None
for
c_idx
in
connected_idx
:
if
self
.
prunable_ops
[
c_idx
].
in_channels
!=
last_ch
:
# new group
last_ch
=
self
.
prunable_ops
[
c_idx
].
in_channels
if
share_group
is
not
None
:
self
.
shared_idx
.
append
(
share_group
)
share_group
=
[
c_idx
]
else
:
# same group
share_group
.
append
(
c_idx
)
self
.
shared_idx
.
append
(
share_group
)
print
(
'=> Conv layers to share channels: {}'
.
format
(
self
.
shared_idx
))
self
.
min_strategy_dict
=
copy
.
deepcopy
(
self
.
strategy_dict
)
self
.
buffer_idx
=
[]
for
_
,
v
in
self
.
buffer_dict
.
items
():
self
.
buffer_idx
+=
v
print
(
'=> Prunable layer idx: {}'
.
format
(
self
.
prunable_idx
))
print
(
'=> Buffer layer idx: {}'
.
format
(
self
.
buffer_idx
))
print
(
'=> Shared idx: {}'
.
format
(
self
.
shared_idx
))
print
(
'=> Initial min strategy dict: {}'
.
format
(
self
.
min_strategy_dict
))
# added for supporting residual connections during pruning
self
.
visited
=
[
False
]
*
len
(
self
.
prunable_idx
)
self
.
index_buffer
=
{}
def
_extract_layer_information
(
self
):
m_list
=
list
(
self
.
model
.
modules
())
self
.
data_saver
=
[]
self
.
layer_info_dict
=
dict
()
self
.
wsize_list
=
[]
self
.
flops_list
=
[]
from
.lib.utils
import
measure_layer_for_pruning
# extend the forward fn to record layer info
def
new_forward
(
m
):
def
lambda_forward
(
x
):
m
.
input_feat
=
x
.
clone
()
#TODO replace this flops counter with nni.compression.torch.utils.counter.count_flops_params
measure_layer_for_pruning
(
m
,
x
)
y
=
m
.
old_forward
(
x
)
m
.
output_feat
=
y
.
clone
()
return
y
return
lambda_forward
device
=
None
for
idx
in
self
.
prunable_idx
+
self
.
buffer_idx
:
# get all
m
=
m_list
[
idx
]
m
.
old_forward
=
m
.
forward
m
.
forward
=
new_forward
(
m
)
if
device
is
None
and
type
(
m
)
==
PrunerModuleWrapper
:
device
=
m
.
module
.
weight
.
device
# now let the image flow
print
(
'=> Extracting information...'
)
with
torch
.
no_grad
():
for
i_b
,
(
inputs
,
target
)
in
enumerate
(
self
.
_val_loader
):
# use image from train set
if
i_b
==
self
.
n_calibration_batches
:
break
self
.
data_saver
.
append
((
inputs
.
clone
(),
target
.
clone
()))
input_var
=
torch
.
autograd
.
Variable
(
inputs
).
to
(
device
)
# inference and collect stats
_
=
self
.
model
(
input_var
)
if
i_b
==
0
:
# first batch
for
idx
in
self
.
prunable_idx
+
self
.
buffer_idx
:
self
.
layer_info_dict
[
idx
]
=
dict
()
self
.
layer_info_dict
[
idx
][
'params'
]
=
m_list
[
idx
].
params
self
.
layer_info_dict
[
idx
][
'flops'
]
=
m_list
[
idx
].
flops
self
.
wsize_list
.
append
(
m_list
[
idx
].
params
)
self
.
flops_list
.
append
(
m_list
[
idx
].
flops
)
print
(
'flops:'
,
self
.
flops_list
)
for
idx
in
self
.
prunable_idx
:
f_in_np
=
m_list
[
idx
].
input_feat
.
data
.
cpu
().
numpy
()
f_out_np
=
m_list
[
idx
].
output_feat
.
data
.
cpu
().
numpy
()
if
len
(
f_in_np
.
shape
)
==
4
:
# conv
if
self
.
prunable_idx
.
index
(
idx
)
==
0
:
# first conv
f_in2save
,
f_out2save
=
None
,
None
elif
m_list
[
idx
].
module
.
weight
.
size
(
3
)
>
1
:
# normal conv
f_in2save
,
f_out2save
=
f_in_np
,
f_out_np
else
:
# 1x1 conv
# assert f_out_np.shape[2] == f_in_np.shape[2] # now support k=3
randx
=
np
.
random
.
randint
(
0
,
f_out_np
.
shape
[
2
]
-
0
,
self
.
n_points_per_layer
)
randy
=
np
.
random
.
randint
(
0
,
f_out_np
.
shape
[
3
]
-
0
,
self
.
n_points_per_layer
)
# input: [N, C, H, W]
self
.
layer_info_dict
[
idx
][(
i_b
,
'randx'
)]
=
randx
.
copy
()
self
.
layer_info_dict
[
idx
][(
i_b
,
'randy'
)]
=
randy
.
copy
()
f_in2save
=
f_in_np
[:,
:,
randx
,
randy
].
copy
().
transpose
(
0
,
2
,
1
)
\
.
reshape
(
self
.
batch_size
*
self
.
n_points_per_layer
,
-
1
)
f_out2save
=
f_out_np
[:,
:,
randx
,
randy
].
copy
().
transpose
(
0
,
2
,
1
)
\
.
reshape
(
self
.
batch_size
*
self
.
n_points_per_layer
,
-
1
)
else
:
assert
len
(
f_in_np
.
shape
)
==
2
f_in2save
=
f_in_np
.
copy
()
f_out2save
=
f_out_np
.
copy
()
if
'input_feat'
not
in
self
.
layer_info_dict
[
idx
]:
self
.
layer_info_dict
[
idx
][
'input_feat'
]
=
f_in2save
self
.
layer_info_dict
[
idx
][
'output_feat'
]
=
f_out2save
else
:
self
.
layer_info_dict
[
idx
][
'input_feat'
]
=
np
.
vstack
(
(
self
.
layer_info_dict
[
idx
][
'input_feat'
],
f_in2save
))
self
.
layer_info_dict
[
idx
][
'output_feat'
]
=
np
.
vstack
(
(
self
.
layer_info_dict
[
idx
][
'output_feat'
],
f_out2save
))
def
_build_state_embedding
(
self
):
# build the static part of the state embedding
print
(
'Building state embedding...'
)
layer_embedding
=
[]
module_list
=
list
(
self
.
model
.
modules
())
for
i
,
ind
in
enumerate
(
self
.
prunable_idx
):
m
=
module_list
[
ind
].
module
this_state
=
[]
if
type
(
m
)
==
nn
.
Conv2d
:
this_state
.
append
(
i
)
# index
this_state
.
append
(
0
)
# layer type, 0 for conv
this_state
.
append
(
m
.
in_channels
)
# in channels
this_state
.
append
(
m
.
out_channels
)
# out channels
this_state
.
append
(
m
.
stride
[
0
])
# stride
this_state
.
append
(
m
.
kernel_size
[
0
])
# kernel size
this_state
.
append
(
np
.
prod
(
m
.
weight
.
size
()))
# weight size
elif
type
(
m
)
==
nn
.
Linear
:
this_state
.
append
(
i
)
# index
this_state
.
append
(
1
)
# layer type, 1 for fc
this_state
.
append
(
m
.
in_features
)
# in channels
this_state
.
append
(
m
.
out_features
)
# out channels
this_state
.
append
(
0
)
# stride
this_state
.
append
(
1
)
# kernel size
this_state
.
append
(
np
.
prod
(
m
.
weight
.
size
()))
# weight size
# this 3 features need to be changed later
this_state
.
append
(
0.
)
# reduced
this_state
.
append
(
0.
)
# rest
this_state
.
append
(
1.
)
# a_{t-1}
layer_embedding
.
append
(
np
.
array
(
this_state
))
# normalize the state
layer_embedding
=
np
.
array
(
layer_embedding
,
'float'
)
print
(
'=> shape of embedding (n_layer * n_dim): {}'
.
format
(
layer_embedding
.
shape
))
assert
len
(
layer_embedding
.
shape
)
==
2
,
layer_embedding
.
shape
for
i
in
range
(
layer_embedding
.
shape
[
1
]):
fmin
=
min
(
layer_embedding
[:,
i
])
fmax
=
max
(
layer_embedding
[:,
i
])
if
fmax
-
fmin
>
0
:
layer_embedding
[:,
i
]
=
(
layer_embedding
[:,
i
]
-
fmin
)
/
(
fmax
-
fmin
)
self
.
layer_embedding
=
layer_embedding
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/__init__.py
0 → 100644
View file @
e9f3cddf
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/agent.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
numpy
as
np
import
torch
import
torch.nn
as
nn
from
torch.optim
import
Adam
from
.memory
import
SequentialMemory
from
.utils
import
to_numpy
,
to_tensor
criterion
=
nn
.
MSELoss
()
USE_CUDA
=
torch
.
cuda
.
is_available
()
class
Actor
(
nn
.
Module
):
def
__init__
(
self
,
nb_states
,
nb_actions
,
hidden1
=
400
,
hidden2
=
300
):
super
(
Actor
,
self
).
__init__
()
self
.
fc1
=
nn
.
Linear
(
nb_states
,
hidden1
)
self
.
fc2
=
nn
.
Linear
(
hidden1
,
hidden2
)
self
.
fc3
=
nn
.
Linear
(
hidden2
,
nb_actions
)
self
.
relu
=
nn
.
ReLU
()
self
.
sigmoid
=
nn
.
Sigmoid
()
def
forward
(
self
,
x
):
out
=
self
.
fc1
(
x
)
out
=
self
.
relu
(
out
)
out
=
self
.
fc2
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
fc3
(
out
)
out
=
self
.
sigmoid
(
out
)
return
out
class
Critic
(
nn
.
Module
):
def
__init__
(
self
,
nb_states
,
nb_actions
,
hidden1
=
400
,
hidden2
=
300
):
super
(
Critic
,
self
).
__init__
()
self
.
fc11
=
nn
.
Linear
(
nb_states
,
hidden1
)
self
.
fc12
=
nn
.
Linear
(
nb_actions
,
hidden1
)
self
.
fc2
=
nn
.
Linear
(
hidden1
,
hidden2
)
self
.
fc3
=
nn
.
Linear
(
hidden2
,
1
)
self
.
relu
=
nn
.
ReLU
()
def
forward
(
self
,
xs
):
x
,
a
=
xs
out
=
self
.
fc11
(
x
)
+
self
.
fc12
(
a
)
out
=
self
.
relu
(
out
)
out
=
self
.
fc2
(
out
)
out
=
self
.
relu
(
out
)
out
=
self
.
fc3
(
out
)
return
out
class
DDPG
(
object
):
def
__init__
(
self
,
nb_states
,
nb_actions
,
args
):
self
.
nb_states
=
nb_states
self
.
nb_actions
=
nb_actions
# Create Actor and Critic Network
net_cfg
=
{
'hidden1'
:
args
.
hidden1
,
'hidden2'
:
args
.
hidden2
,
# 'init_w': args.init_w
}
self
.
actor
=
Actor
(
self
.
nb_states
,
self
.
nb_actions
,
**
net_cfg
)
self
.
actor_target
=
Actor
(
self
.
nb_states
,
self
.
nb_actions
,
**
net_cfg
)
self
.
actor_optim
=
Adam
(
self
.
actor
.
parameters
(),
lr
=
args
.
lr_a
)
self
.
critic
=
Critic
(
self
.
nb_states
,
self
.
nb_actions
,
**
net_cfg
)
self
.
critic_target
=
Critic
(
self
.
nb_states
,
self
.
nb_actions
,
**
net_cfg
)
self
.
critic_optim
=
Adam
(
self
.
critic
.
parameters
(),
lr
=
args
.
lr_c
)
self
.
hard_update
(
self
.
actor_target
,
self
.
actor
)
# Make sure target is with the same weight
self
.
hard_update
(
self
.
critic_target
,
self
.
critic
)
# Create replay buffer
self
.
memory
=
SequentialMemory
(
limit
=
args
.
rmsize
,
window_length
=
args
.
window_length
)
# self.random_process = OrnsteinUhlenbeckProcess(size=nb_actions, theta=args.ou_theta, mu=args.ou_mu,
# sigma=args.ou_sigma)
# Hyper-parameters
self
.
batch_size
=
args
.
bsize
self
.
tau
=
args
.
tau
self
.
discount
=
args
.
discount
self
.
depsilon
=
1.0
/
args
.
epsilon
self
.
lbound
=
0.
# args.lbound
self
.
rbound
=
1.
# args.rbound
# noise
self
.
init_delta
=
args
.
init_delta
self
.
delta_decay
=
args
.
delta_decay
self
.
warmup
=
args
.
warmup
#
self
.
epsilon
=
1.0
# self.s_t = None # Most recent state
# self.a_t = None # Most recent action
self
.
is_training
=
True
#
if
USE_CUDA
:
self
.
cuda
()
# moving average baseline
self
.
moving_average
=
None
self
.
moving_alpha
=
0.5
# based on batch, so small
def
update_policy
(
self
):
# Sample batch
state_batch
,
action_batch
,
reward_batch
,
\
next_state_batch
,
terminal_batch
=
self
.
memory
.
sample_and_split
(
self
.
batch_size
)
# normalize the reward
batch_mean_reward
=
np
.
mean
(
reward_batch
)
if
self
.
moving_average
is
None
:
self
.
moving_average
=
batch_mean_reward
else
:
self
.
moving_average
+=
self
.
moving_alpha
*
(
batch_mean_reward
-
self
.
moving_average
)
reward_batch
-=
self
.
moving_average
# if reward_batch.std() > 0:
# reward_batch /= reward_batch.std()
# Prepare for the target q batch
with
torch
.
no_grad
():
next_q_values
=
self
.
critic_target
([
to_tensor
(
next_state_batch
),
self
.
actor_target
(
to_tensor
(
next_state_batch
)),
])
target_q_batch
=
to_tensor
(
reward_batch
)
+
\
self
.
discount
*
to_tensor
(
terminal_batch
.
astype
(
np
.
float
))
*
next_q_values
# Critic update
self
.
critic
.
zero_grad
()
q_batch
=
self
.
critic
([
to_tensor
(
state_batch
),
to_tensor
(
action_batch
)])
value_loss
=
criterion
(
q_batch
,
target_q_batch
)
value_loss
.
backward
()
self
.
critic_optim
.
step
()
# Actor update
self
.
actor
.
zero_grad
()
policy_loss
=
-
self
.
critic
([
# pylint: disable=all
to_tensor
(
state_batch
),
self
.
actor
(
to_tensor
(
state_batch
))
])
policy_loss
=
policy_loss
.
mean
()
policy_loss
.
backward
()
self
.
actor_optim
.
step
()
# Target update
self
.
soft_update
(
self
.
actor_target
,
self
.
actor
)
self
.
soft_update
(
self
.
critic_target
,
self
.
critic
)
def
eval
(
self
):
self
.
actor
.
eval
()
self
.
actor_target
.
eval
()
self
.
critic
.
eval
()
self
.
critic_target
.
eval
()
def
cuda
(
self
):
self
.
actor
.
cuda
()
self
.
actor_target
.
cuda
()
self
.
critic
.
cuda
()
self
.
critic_target
.
cuda
()
def
observe
(
self
,
r_t
,
s_t
,
s_t1
,
a_t
,
done
):
if
self
.
is_training
:
self
.
memory
.
append
(
s_t
,
a_t
,
r_t
,
done
)
# save to memory
# self.s_t = s_t1
def
random_action
(
self
):
action
=
np
.
random
.
uniform
(
self
.
lbound
,
self
.
rbound
,
self
.
nb_actions
)
# self.a_t = action
return
action
def
select_action
(
self
,
s_t
,
episode
):
# assert episode >= self.warmup, 'Episode: {} warmup: {}'.format(episode, self.warmup)
action
=
to_numpy
(
self
.
actor
(
to_tensor
(
np
.
array
(
s_t
).
reshape
(
1
,
-
1
)))).
squeeze
(
0
)
delta
=
self
.
init_delta
*
(
self
.
delta_decay
**
(
episode
-
self
.
warmup
))
# action += self.is_training * max(self.epsilon, 0) * self.random_process.sample()
action
=
self
.
sample_from_truncated_normal_distribution
(
lower
=
self
.
lbound
,
upper
=
self
.
rbound
,
mu
=
action
,
sigma
=
delta
)
action
=
np
.
clip
(
action
,
self
.
lbound
,
self
.
rbound
)
# self.a_t = action
return
action
def
reset
(
self
,
obs
):
pass
# self.s_t = obs
# self.random_process.reset_states()
def
load_weights
(
self
,
output
):
if
output
is
None
:
return
self
.
actor
.
load_state_dict
(
torch
.
load
(
'{}/actor.pkl'
.
format
(
output
))
)
self
.
critic
.
load_state_dict
(
torch
.
load
(
'{}/critic.pkl'
.
format
(
output
))
)
def
save_model
(
self
,
output
):
torch
.
save
(
self
.
actor
.
state_dict
(),
'{}/actor.pkl'
.
format
(
output
)
)
torch
.
save
(
self
.
critic
.
state_dict
(),
'{}/critic.pkl'
.
format
(
output
)
)
def
soft_update
(
self
,
target
,
source
):
for
target_param
,
param
in
zip
(
target
.
parameters
(),
source
.
parameters
()):
target_param
.
data
.
copy_
(
target_param
.
data
*
(
1.0
-
self
.
tau
)
+
param
.
data
*
self
.
tau
)
def
hard_update
(
self
,
target
,
source
):
for
target_param
,
param
in
zip
(
target
.
parameters
(),
source
.
parameters
()):
target_param
.
data
.
copy_
(
param
.
data
)
def
sample_from_truncated_normal_distribution
(
self
,
lower
,
upper
,
mu
,
sigma
,
size
=
1
):
from
scipy
import
stats
return
stats
.
truncnorm
.
rvs
((
lower
-
mu
)
/
sigma
,
(
upper
-
mu
)
/
sigma
,
loc
=
mu
,
scale
=
sigma
,
size
=
size
)
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/memory.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
from
__future__
import
absolute_import
from
collections
import
deque
,
namedtuple
import
warnings
import
random
import
numpy
as
np
# [reference] https://github.com/matthiasplappert/keras-rl/blob/master/rl/memory.py
# This is to be understood as a transition: Given `state0`, performing `action`
# yields `reward` and results in `state1`, which might be `terminal`.
Experience
=
namedtuple
(
'Experience'
,
'state0, action, reward, state1, terminal1'
)
def
sample_batch_indexes
(
low
,
high
,
size
):
if
high
-
low
>=
size
:
# We have enough data. Draw without replacement, that is each index is unique in the
# batch. We cannot use `np.random.choice` here because it is horribly inefficient as
# the memory grows. See https://github.com/numpy/numpy/issues/2764 for a discussion.
# `random.sample` does the same thing (drawing without replacement) and is way faster.
r
=
range
(
low
,
high
)
batch_idxs
=
random
.
sample
(
r
,
size
)
else
:
# Not enough data. Help ourselves with sampling from the range, but the same index
# can occur multiple times. This is not good and should be avoided by picking a
# large enough warm-up phase.
warnings
.
warn
(
'Not enough entries to sample without replacement. '
'Consider increasing your warm-up phase to avoid oversampling!'
)
batch_idxs
=
np
.
random
.
random_integers
(
low
,
high
-
1
,
size
=
size
)
assert
len
(
batch_idxs
)
==
size
return
batch_idxs
class
RingBuffer
(
object
):
def
__init__
(
self
,
maxlen
):
self
.
maxlen
=
maxlen
self
.
start
=
0
self
.
length
=
0
self
.
data
=
[
None
for
_
in
range
(
maxlen
)]
def
__len__
(
self
):
return
self
.
length
def
__getitem__
(
self
,
idx
):
if
idx
<
0
or
idx
>=
self
.
length
:
raise
KeyError
()
return
self
.
data
[(
self
.
start
+
idx
)
%
self
.
maxlen
]
def
append
(
self
,
v
):
if
self
.
length
<
self
.
maxlen
:
# We have space, simply increase the length.
self
.
length
+=
1
elif
self
.
length
==
self
.
maxlen
:
# No space, "remove" the first item.
self
.
start
=
(
self
.
start
+
1
)
%
self
.
maxlen
else
:
# This should never happen.
raise
RuntimeError
()
self
.
data
[(
self
.
start
+
self
.
length
-
1
)
%
self
.
maxlen
]
=
v
def
zeroed_observation
(
observation
):
if
hasattr
(
observation
,
'shape'
):
return
np
.
zeros
(
observation
.
shape
)
elif
hasattr
(
observation
,
'__iter__'
):
out
=
[]
for
x
in
observation
:
out
.
append
(
zeroed_observation
(
x
))
return
out
else
:
return
0.
class
Memory
(
object
):
def
__init__
(
self
,
window_length
,
ignore_episode_boundaries
=
False
):
self
.
window_length
=
window_length
self
.
ignore_episode_boundaries
=
ignore_episode_boundaries
self
.
recent_observations
=
deque
(
maxlen
=
window_length
)
self
.
recent_terminals
=
deque
(
maxlen
=
window_length
)
def
sample
(
self
,
batch_size
,
batch_idxs
=
None
):
raise
NotImplementedError
()
def
append
(
self
,
observation
,
action
,
reward
,
terminal
,
training
=
True
):
self
.
recent_observations
.
append
(
observation
)
self
.
recent_terminals
.
append
(
terminal
)
def
get_recent_state
(
self
,
current_observation
):
# This code is slightly complicated by the fact that subsequent observations might be
# from different episodes. We ensure that an experience never spans multiple episodes.
# This is probably not that important in practice but it seems cleaner.
state
=
[
current_observation
]
idx
=
len
(
self
.
recent_observations
)
-
1
for
offset
in
range
(
0
,
self
.
window_length
-
1
):
current_idx
=
idx
-
offset
current_terminal
=
self
.
recent_terminals
[
current_idx
-
1
]
if
current_idx
-
1
>=
0
else
False
if
current_idx
<
0
or
(
not
self
.
ignore_episode_boundaries
and
current_terminal
):
# The previously handled observation was terminal, don't add the current one.
# Otherwise we would leak into a different episode.
break
state
.
insert
(
0
,
self
.
recent_observations
[
current_idx
])
while
len
(
state
)
<
self
.
window_length
:
state
.
insert
(
0
,
zeroed_observation
(
state
[
0
]))
return
state
def
get_config
(
self
):
config
=
{
'window_length'
:
self
.
window_length
,
'ignore_episode_boundaries'
:
self
.
ignore_episode_boundaries
,
}
return
config
class
SequentialMemory
(
Memory
):
def
__init__
(
self
,
limit
,
**
kwargs
):
super
(
SequentialMemory
,
self
).
__init__
(
**
kwargs
)
self
.
limit
=
limit
# Do not use deque to implement the memory. This data structure may seem convenient but
# it is way too slow on random access. Instead, we use our own ring buffer implementation.
self
.
actions
=
RingBuffer
(
limit
)
self
.
rewards
=
RingBuffer
(
limit
)
self
.
terminals
=
RingBuffer
(
limit
)
self
.
observations
=
RingBuffer
(
limit
)
def
sample
(
self
,
batch_size
,
batch_idxs
=
None
):
if
batch_idxs
is
None
:
# Draw random indexes such that we have at least a single entry before each
# index.
batch_idxs
=
sample_batch_indexes
(
0
,
self
.
nb_entries
-
1
,
size
=
batch_size
)
batch_idxs
=
np
.
array
(
batch_idxs
)
+
1
assert
np
.
min
(
batch_idxs
)
>=
1
assert
np
.
max
(
batch_idxs
)
<
self
.
nb_entries
assert
len
(
batch_idxs
)
==
batch_size
# Create experiences
experiences
=
[]
for
idx
in
batch_idxs
:
terminal0
=
self
.
terminals
[
idx
-
2
]
if
idx
>=
2
else
False
while
terminal0
:
# Skip this transition because the environment was reset here. Select a new, random
# transition and use this instead. This may cause the batch to contain the same
# transition twice.
idx
=
sample_batch_indexes
(
1
,
self
.
nb_entries
,
size
=
1
)[
0
]
terminal0
=
self
.
terminals
[
idx
-
2
]
if
idx
>=
2
else
False
assert
1
<=
idx
<
self
.
nb_entries
# This code is slightly complicated by the fact that subsequent observations might be
# from different episodes. We ensure that an experience never spans multiple episodes.
# This is probably not that important in practice but it seems cleaner.
state0
=
[
self
.
observations
[
idx
-
1
]]
for
offset
in
range
(
0
,
self
.
window_length
-
1
):
current_idx
=
idx
-
2
-
offset
current_terminal
=
self
.
terminals
[
current_idx
-
1
]
if
current_idx
-
1
>
0
else
False
if
current_idx
<
0
or
(
not
self
.
ignore_episode_boundaries
and
current_terminal
):
# The previously handled observation was terminal, don't add the current one.
# Otherwise we would leak into a different episode.
break
state0
.
insert
(
0
,
self
.
observations
[
current_idx
])
while
len
(
state0
)
<
self
.
window_length
:
state0
.
insert
(
0
,
zeroed_observation
(
state0
[
0
]))
action
=
self
.
actions
[
idx
-
1
]
reward
=
self
.
rewards
[
idx
-
1
]
terminal1
=
self
.
terminals
[
idx
-
1
]
# Okay, now we need to create the follow-up state. This is state0 shifted on timestep
# to the right. Again, we need to be careful to not include an observation from the next
# episode if the last state is terminal.
state1
=
[
np
.
copy
(
x
)
for
x
in
state0
[
1
:]]
state1
.
append
(
self
.
observations
[
idx
])
assert
len
(
state0
)
==
self
.
window_length
assert
len
(
state1
)
==
len
(
state0
)
experiences
.
append
(
Experience
(
state0
=
state0
,
action
=
action
,
reward
=
reward
,
state1
=
state1
,
terminal1
=
terminal1
))
assert
len
(
experiences
)
==
batch_size
return
experiences
def
sample_and_split
(
self
,
batch_size
,
batch_idxs
=
None
):
experiences
=
self
.
sample
(
batch_size
,
batch_idxs
)
state0_batch
=
[]
reward_batch
=
[]
action_batch
=
[]
terminal1_batch
=
[]
state1_batch
=
[]
for
e
in
experiences
:
state0_batch
.
append
(
e
.
state0
)
state1_batch
.
append
(
e
.
state1
)
reward_batch
.
append
(
e
.
reward
)
action_batch
.
append
(
e
.
action
)
terminal1_batch
.
append
(
0.
if
e
.
terminal1
else
1.
)
# Prepare and validate parameters.
state0_batch
=
np
.
array
(
state0_batch
,
'double'
).
reshape
(
batch_size
,
-
1
)
state1_batch
=
np
.
array
(
state1_batch
,
'double'
).
reshape
(
batch_size
,
-
1
)
terminal1_batch
=
np
.
array
(
terminal1_batch
,
'double'
).
reshape
(
batch_size
,
-
1
)
reward_batch
=
np
.
array
(
reward_batch
,
'double'
).
reshape
(
batch_size
,
-
1
)
action_batch
=
np
.
array
(
action_batch
,
'double'
).
reshape
(
batch_size
,
-
1
)
return
state0_batch
,
action_batch
,
reward_batch
,
state1_batch
,
terminal1_batch
def
append
(
self
,
observation
,
action
,
reward
,
terminal
,
training
=
True
):
super
(
SequentialMemory
,
self
).
append
(
observation
,
action
,
reward
,
terminal
,
training
=
training
)
# This needs to be understood as follows: in `observation`, take `action`, obtain `reward`
# and weather the next state is `terminal` or not.
if
training
:
self
.
observations
.
append
(
observation
)
self
.
actions
.
append
(
action
)
self
.
rewards
.
append
(
reward
)
self
.
terminals
.
append
(
terminal
)
@
property
def
nb_entries
(
self
):
return
len
(
self
.
observations
)
def
get_config
(
self
):
config
=
super
(
SequentialMemory
,
self
).
get_config
()
config
[
'limit'
]
=
self
.
limit
return
config
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/net_measure.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
torch
# [reference] https://github.com/ShichenLiu/CondenseNet/blob/master/utils.py
def
get_num_gen
(
gen
):
return
sum
(
1
for
_
in
gen
)
def
is_leaf
(
model
):
return
get_num_gen
(
model
.
children
())
==
0
def
get_layer_info
(
layer
):
layer_str
=
str
(
layer
)
type_name
=
layer_str
[:
layer_str
.
find
(
'('
)].
strip
()
return
type_name
def
get_layer_param
(
model
):
import
operator
import
functools
return
sum
([
functools
.
reduce
(
operator
.
mul
,
i
.
size
(),
1
)
for
i
in
model
.
parameters
()])
count_ops
=
0
count_params
=
0
def
measure_layer
(
layer
,
x
):
global
count_ops
,
count_params
delta_ops
=
0
delta_params
=
0
multi_add
=
1
type_name
=
get_layer_info
(
layer
)
# ops_conv
if
type_name
in
[
'Conv2d'
]:
out_h
=
int
((
x
.
size
()[
2
]
+
2
*
layer
.
padding
[
0
]
-
layer
.
kernel_size
[
0
])
/
layer
.
stride
[
0
]
+
1
)
out_w
=
int
((
x
.
size
()[
3
]
+
2
*
layer
.
padding
[
1
]
-
layer
.
kernel_size
[
1
])
/
layer
.
stride
[
1
]
+
1
)
delta_ops
=
layer
.
in_channels
*
layer
.
out_channels
*
layer
.
kernel_size
[
0
]
*
\
layer
.
kernel_size
[
1
]
*
out_h
*
out_w
/
layer
.
groups
*
multi_add
delta_params
=
get_layer_param
(
layer
)
# ops_nonlinearity
elif
type_name
in
[
'ReLU'
]:
delta_ops
=
x
.
numel
()
/
x
.
size
(
0
)
delta_params
=
get_layer_param
(
layer
)
# ops_pooling
elif
type_name
in
[
'AvgPool2d'
]:
in_w
=
x
.
size
()[
2
]
kernel_ops
=
layer
.
kernel_size
*
layer
.
kernel_size
out_w
=
int
((
in_w
+
2
*
layer
.
padding
-
layer
.
kernel_size
)
/
layer
.
stride
+
1
)
out_h
=
int
((
in_w
+
2
*
layer
.
padding
-
layer
.
kernel_size
)
/
layer
.
stride
+
1
)
delta_ops
=
x
.
size
()[
1
]
*
out_w
*
out_h
*
kernel_ops
delta_params
=
get_layer_param
(
layer
)
elif
type_name
in
[
'AdaptiveAvgPool2d'
]:
delta_ops
=
x
.
size
()[
1
]
*
x
.
size
()[
2
]
*
x
.
size
()[
3
]
delta_params
=
get_layer_param
(
layer
)
# ops_linear
elif
type_name
in
[
'Linear'
]:
weight_ops
=
layer
.
weight
.
numel
()
*
multi_add
bias_ops
=
layer
.
bias
.
numel
()
delta_ops
=
weight_ops
+
bias_ops
delta_params
=
get_layer_param
(
layer
)
# ops_nothing
elif
type_name
in
[
'BatchNorm2d'
,
'Dropout2d'
,
'DropChannel'
,
'Dropout'
]:
delta_params
=
get_layer_param
(
layer
)
# unknown layer type
else
:
delta_params
=
get_layer_param
(
layer
)
count_ops
+=
delta_ops
count_params
+=
delta_params
return
def
measure_model
(
model
,
H
,
W
):
global
count_ops
,
count_params
count_ops
=
0
count_params
=
0
data
=
torch
.
zeros
(
2
,
3
,
H
,
W
).
cuda
()
def
should_measure
(
x
):
return
is_leaf
(
x
)
def
modify_forward
(
model
):
for
child
in
model
.
children
():
if
should_measure
(
child
):
def
new_forward
(
m
):
def
lambda_forward
(
x
):
measure_layer
(
m
,
x
)
return
m
.
old_forward
(
x
)
return
lambda_forward
child
.
old_forward
=
child
.
forward
child
.
forward
=
new_forward
(
child
)
else
:
modify_forward
(
child
)
def
restore_forward
(
model
):
for
child
in
model
.
children
():
# leaf node
if
is_leaf
(
child
)
and
hasattr
(
child
,
'old_forward'
):
child
.
forward
=
child
.
old_forward
child
.
old_forward
=
None
else
:
restore_forward
(
child
)
modify_forward
(
model
)
model
.
forward
(
data
)
restore_forward
(
model
)
return
count_ops
,
count_params
src/sdk/pynni/nni/compression/torch/pruning/amc/lib/utils.py
0 → 100644
View file @
e9f3cddf
# Copyright (c) Microsoft Corporation.
# Licensed under the MIT license.
import
os
import
torch
class
TextLogger
(
object
):
"""Write log immediately to the disk"""
def
__init__
(
self
,
filepath
):
self
.
f
=
open
(
filepath
,
'w'
)
self
.
fid
=
self
.
f
.
fileno
()
self
.
filepath
=
filepath
def
close
(
self
):
self
.
f
.
close
()
def
write
(
self
,
content
):
self
.
f
.
write
(
content
)
self
.
f
.
flush
()
os
.
fsync
(
self
.
fid
)
def
write_buf
(
self
,
content
):
self
.
f
.
write
(
content
)
def
print_and_write
(
self
,
content
):
print
(
content
)
self
.
write
(
content
+
'
\n
'
)
def
to_numpy
(
var
):
use_cuda
=
torch
.
cuda
.
is_available
()
return
var
.
cpu
().
data
.
numpy
()
if
use_cuda
else
var
.
data
.
numpy
()
def
to_tensor
(
ndarray
,
requires_grad
=
False
):
# return a float tensor by default
tensor
=
torch
.
from_numpy
(
ndarray
).
float
()
# by default does not require grad
if
requires_grad
:
tensor
.
requires_grad_
()
return
tensor
.
cuda
()
if
torch
.
cuda
.
is_available
()
else
tensor
def
measure_layer_for_pruning
(
wrapper
,
x
):
def
get_layer_type
(
layer
):
layer_str
=
str
(
layer
)
return
layer_str
[:
layer_str
.
find
(
'('
)].
strip
()
def
get_layer_param
(
model
):
import
operator
import
functools
return
sum
([
functools
.
reduce
(
operator
.
mul
,
i
.
size
(),
1
)
for
i
in
model
.
parameters
()])
multi_add
=
1
layer
=
wrapper
.
module
type_name
=
get_layer_type
(
layer
)
# ops_conv
if
type_name
in
[
'Conv2d'
]:
out_h
=
int
((
x
.
size
()[
2
]
+
2
*
layer
.
padding
[
0
]
-
layer
.
kernel_size
[
0
])
/
layer
.
stride
[
0
]
+
1
)
out_w
=
int
((
x
.
size
()[
3
]
+
2
*
layer
.
padding
[
1
]
-
layer
.
kernel_size
[
1
])
/
layer
.
stride
[
1
]
+
1
)
wrapper
.
flops
=
layer
.
in_channels
*
layer
.
out_channels
*
layer
.
kernel_size
[
0
]
*
\
layer
.
kernel_size
[
1
]
*
out_h
*
out_w
/
layer
.
groups
*
multi_add
wrapper
.
params
=
get_layer_param
(
layer
)
# ops_linear
elif
type_name
in
[
'Linear'
]:
weight_ops
=
layer
.
weight
.
numel
()
*
multi_add
bias_ops
=
layer
.
bias
.
numel
()
wrapper
.
flops
=
weight_ops
+
bias_ops
wrapper
.
params
=
get_layer_param
(
layer
)
return
def
least_square_sklearn
(
X
,
Y
):
from
sklearn.linear_model
import
LinearRegression
reg
=
LinearRegression
(
fit_intercept
=
False
)
reg
.
fit
(
X
,
Y
)
return
reg
.
coef_
def
get_output_folder
(
parent_dir
,
env_name
):
"""Return save folder.
Assumes folders in the parent_dir have suffix -run{run
number}. Finds the highest run number and sets the output folder
to that number + 1. This is just convenient so that if you run the
same script multiple times tensorboard can plot all of the results
on the same plots with different names.
Parameters
----------
parent_dir: str
Path of the directory containing all experiment runs.
Returns
-------
parent_dir/run_dir
Path to this run's save directory.
"""
os
.
makedirs
(
parent_dir
,
exist_ok
=
True
)
experiment_id
=
0
for
folder_name
in
os
.
listdir
(
parent_dir
):
if
not
os
.
path
.
isdir
(
os
.
path
.
join
(
parent_dir
,
folder_name
)):
continue
try
:
folder_name
=
int
(
folder_name
.
split
(
'-run'
)[
-
1
])
if
folder_name
>
experiment_id
:
experiment_id
=
folder_name
except
:
pass
experiment_id
+=
1
parent_dir
=
os
.
path
.
join
(
parent_dir
,
env_name
)
parent_dir
=
parent_dir
+
'-run{}'
.
format
(
experiment_id
)
os
.
makedirs
(
parent_dir
,
exist_ok
=
True
)
return
parent_dir
# logging
def
prRed
(
prt
):
print
(
"
\033
[91m {}
\033
[00m"
.
format
(
prt
))
def
prGreen
(
prt
):
print
(
"
\033
[92m {}
\033
[00m"
.
format
(
prt
))
def
prYellow
(
prt
):
print
(
"
\033
[93m {}
\033
[00m"
.
format
(
prt
))
def
prLightPurple
(
prt
):
print
(
"
\033
[94m {}
\033
[00m"
.
format
(
prt
))
def
prPurple
(
prt
):
print
(
"
\033
[95m {}
\033
[00m"
.
format
(
prt
))
def
prCyan
(
prt
):
print
(
"
\033
[96m {}
\033
[00m"
.
format
(
prt
))
def
prLightGray
(
prt
):
print
(
"
\033
[97m {}
\033
[00m"
.
format
(
prt
))
def
prBlack
(
prt
):
print
(
"
\033
[98m {}
\033
[00m"
.
format
(
prt
))
src/sdk/pynni/nni/compression/torch/pruning/structured_pruning.py
View file @
e9f3cddf
...
...
@@ -2,19 +2,40 @@
# Licensed under the MIT license.
import
logging
import
math
import
numpy
as
np
import
torch
from
.weight_masker
import
WeightMasker
__all__
=
[
'L1FilterPrunerMasker'
,
'L2FilterPrunerMasker'
,
'FPGMPrunerMasker'
,
\
'TaylorFOWeightFilterPrunerMasker'
,
'ActivationAPoZRankFilterPrunerMasker'
,
\
'ActivationMeanRankFilterPrunerMasker'
,
'SlimPrunerMasker'
]
'ActivationMeanRankFilterPrunerMasker'
,
'SlimPrunerMasker'
,
'AMCWeightMasker'
]
logger
=
logging
.
getLogger
(
'torch filter pruners'
)
class
StructuredWeightMasker
(
WeightMasker
):
"""
A structured pruning masker base class that prunes convolutional layer filters.
Parameters
----------
model: nn.Module
model to be pruned
pruner: Pruner
A Pruner instance used to prune the model
preserve_round: int
after pruning, preserve filters/channels round to `preserve_round`, for example:
for a Conv2d layer, output channel is 32, sparsity is 0.2, if preserve_round is
1 (no preserve round), then there will be int(32 * 0.2) = 6 filters pruned, and
32 - 6 = 26 filters are preserved. If preserve_round is 4, preserved filters will
be round up to 28 (which can be divided by 4) and only 4 filters are pruned.
"""
def
__init__
(
self
,
model
,
pruner
,
preserve_round
=
1
):
self
.
model
=
model
self
.
pruner
=
pruner
self
.
preserve_round
=
preserve_round
def
calc_mask
(
self
,
sparsity
,
wrapper
,
wrapper_idx
=
None
):
"""
Calculate the mask of given layer.
...
...
@@ -53,9 +74,16 @@ class StructuredWeightMasker(WeightMasker):
mask_bias
=
None
mask
=
{
'weight_mask'
:
mask_weight
,
'bias_mask'
:
mask_bias
}
filters
=
weight
.
size
(
0
)
num_prune
=
int
(
filters
*
sparsity
)
if
filters
<
2
or
num_prune
<
1
:
num_total
=
weight
.
size
(
0
)
num_prune
=
int
(
num_total
*
sparsity
)
if
self
.
preserve_round
>
1
:
num_preserve
=
num_total
-
num_prune
num_preserve
=
int
(
math
.
ceil
(
num_preserve
*
1.
/
self
.
preserve_round
)
*
self
.
preserve_round
)
if
num_preserve
>
num_total
:
num_preserve
=
int
(
math
.
floor
(
num_total
*
1.
/
self
.
preserve_round
)
*
self
.
preserve_round
)
num_prune
=
num_total
-
num_preserve
if
num_total
<
2
or
num_prune
<
1
:
return
mask
# weight*mask_weight: apply base mask for iterative pruning
return
self
.
get_mask
(
mask
,
weight
*
mask_weight
,
num_prune
,
wrapper
,
wrapper_idx
)
...
...
@@ -365,3 +393,135 @@ class SlimPrunerMasker(WeightMasker):
mask_bias
=
mask_weight
.
clone
()
mask
=
{
'weight_mask'
:
mask_weight
.
detach
(),
'bias_mask'
:
mask_bias
.
detach
()}
return
mask
def
least_square_sklearn
(
X
,
Y
):
from
sklearn.linear_model
import
LinearRegression
reg
=
LinearRegression
(
fit_intercept
=
False
)
reg
.
fit
(
X
,
Y
)
return
reg
.
coef_
class
AMCWeightMasker
(
WeightMasker
):
"""
Weight maskser class for AMC pruner. Currently, AMCPruner only supports pruning kernel
size 1x1 pointwise Conv2d layer. Before using this class to prune kernels, AMCPruner
collected input and output feature maps for each layer, the features maps are flattened
and save into wrapper.input_feat and wrapper.output_feat.
Parameters
----------
model: nn.Module
model to be pruned
pruner: Pruner
A Pruner instance used to prune the model
preserve_round: int
after pruning, preserve filters/channels round to `preserve_round`, for example:
for a Conv2d layer, output channel is 32, sparsity is 0.2, if preserve_round is
1 (no preserve round), then there will be int(32 * 0.2) = 6 filters pruned, and
32 - 6 = 26 filters are preserved. If preserve_round is 4, preserved filters will
be round up to 28 (which can be divided by 4) and only 4 filters are pruned.
"""
def
__init__
(
self
,
model
,
pruner
,
preserve_round
=
1
):
self
.
model
=
model
self
.
pruner
=
pruner
self
.
preserve_round
=
preserve_round
def
calc_mask
(
self
,
sparsity
,
wrapper
,
wrapper_idx
=
None
,
preserve_idx
=
None
):
"""
Calculate the mask of given layer.
Parameters
----------
sparsity: float
pruning ratio, preserved weight ratio is `1 - sparsity`
wrapper: PrunerModuleWrapper
layer wrapper of this layer
wrapper_idx: int
index of this wrapper in pruner's all wrappers
Returns
-------
dict
dictionary for storing masks, keys of the dict:
'weight_mask': weight mask tensor
'bias_mask': bias mask tensor (optional)
"""
msg
=
'module type {} is not supported!'
.
format
(
wrapper
.
type
)
assert
wrapper
.
type
in
[
'Conv2d'
,
'Linear'
],
msg
weight
=
wrapper
.
module
.
weight
.
data
bias
=
None
if
hasattr
(
wrapper
.
module
,
'bias'
)
and
wrapper
.
module
.
bias
is
not
None
:
bias
=
wrapper
.
module
.
bias
.
data
if
wrapper
.
weight_mask
is
None
:
mask_weight
=
torch
.
ones
(
weight
.
size
()).
type_as
(
weight
).
detach
()
else
:
mask_weight
=
wrapper
.
weight_mask
.
clone
()
if
bias
is
not
None
:
if
wrapper
.
bias_mask
is
None
:
mask_bias
=
torch
.
ones
(
bias
.
size
()).
type_as
(
bias
).
detach
()
else
:
mask_bias
=
wrapper
.
bias_mask
.
clone
()
else
:
mask_bias
=
None
mask
=
{
'weight_mask'
:
mask_weight
,
'bias_mask'
:
mask_bias
}
num_total
=
weight
.
size
(
1
)
num_prune
=
int
(
num_total
*
sparsity
)
if
self
.
preserve_round
>
1
:
num_preserve
=
num_total
-
num_prune
num_preserve
=
int
(
math
.
ceil
(
num_preserve
*
1.
/
self
.
preserve_round
)
*
self
.
preserve_round
)
if
num_preserve
>
num_total
:
num_preserve
=
num_total
num_prune
=
num_total
-
num_preserve
if
(
num_total
<
2
or
num_prune
<
1
)
and
preserve_idx
is
None
:
return
mask
return
self
.
get_mask
(
mask
,
weight
,
num_preserve
,
wrapper
,
wrapper_idx
,
preserve_idx
)
def
get_mask
(
self
,
base_mask
,
weight
,
num_preserve
,
wrapper
,
wrapper_idx
,
preserve_idx
):
w
=
weight
.
data
.
cpu
().
numpy
()
if
wrapper
.
type
==
'Linear'
:
w
=
w
[:,
:,
None
,
None
]
if
preserve_idx
is
None
:
importance
=
np
.
abs
(
w
).
sum
((
0
,
2
,
3
))
sorted_idx
=
np
.
argsort
(
-
importance
)
# sum magnitude along C_in, sort descend
d_prime
=
num_preserve
preserve_idx
=
sorted_idx
[:
d_prime
]
# to preserve index
else
:
d_prime
=
len
(
preserve_idx
)
assert
len
(
preserve_idx
)
==
d_prime
mask
=
np
.
zeros
(
w
.
shape
[
1
],
bool
)
mask
[
preserve_idx
]
=
True
# reconstruct, X, Y <= [N, C]
X
,
Y
=
wrapper
.
input_feat
,
wrapper
.
output_feat
masked_X
=
X
[:,
mask
]
if
w
.
shape
[
2
]
==
1
:
# 1x1 conv or fc
rec_weight
=
least_square_sklearn
(
X
=
masked_X
,
Y
=
Y
)
rec_weight
=
rec_weight
.
reshape
(
-
1
,
1
,
1
,
d_prime
)
# (C_out, K_h, K_w, C_in')
rec_weight
=
np
.
transpose
(
rec_weight
,
(
0
,
3
,
1
,
2
))
# (C_out, C_in', K_h, K_w)
else
:
raise
NotImplementedError
(
'Current code only supports 1x1 conv now!'
)
rec_weight_pad
=
np
.
zeros_like
(
w
)
# pylint: disable=all
rec_weight_pad
[:,
mask
,
:,
:]
=
rec_weight
rec_weight
=
rec_weight_pad
if
wrapper
.
type
==
'Linear'
:
rec_weight
=
rec_weight
.
squeeze
()
assert
len
(
rec_weight
.
shape
)
==
2
# now assign
wrapper
.
module
.
weight
.
data
=
torch
.
from_numpy
(
rec_weight
).
to
(
weight
.
device
)
mask_weight
=
torch
.
zeros_like
(
weight
)
if
wrapper
.
type
==
'Linear'
:
mask_weight
[:,
preserve_idx
]
=
1.
if
base_mask
[
'bias_mask'
]
is
not
None
and
wrapper
.
module
.
bias
is
not
None
:
mask_bias
=
torch
.
ones_like
(
wrapper
.
module
.
bias
)
else
:
mask_weight
[:,
preserve_idx
,
:,
:]
=
1.
mask_bias
=
None
return
{
'weight_mask'
:
mask_weight
.
detach
(),
'bias_mask'
:
mask_bias
}
Prev
1
2
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}