
create branch for v2.9
parents
Showing
Too many changes to show.
To preserve performance only 633 of 633+ files are displayed.
This source diff could not be displayed because it is too large. You can view the blob instead.
{kind=link}

78.5 KB
{kind=link}
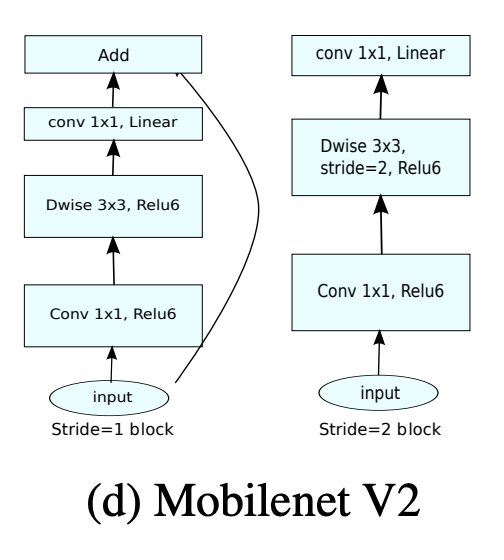
57.3 KB
{kind=link}
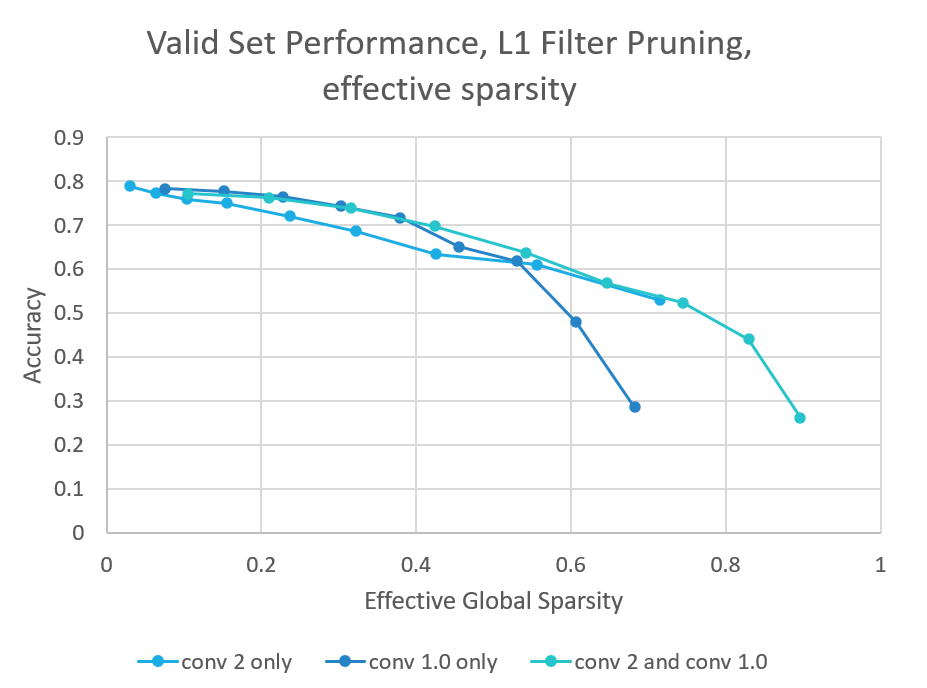
49.8 KB
{kind=link}
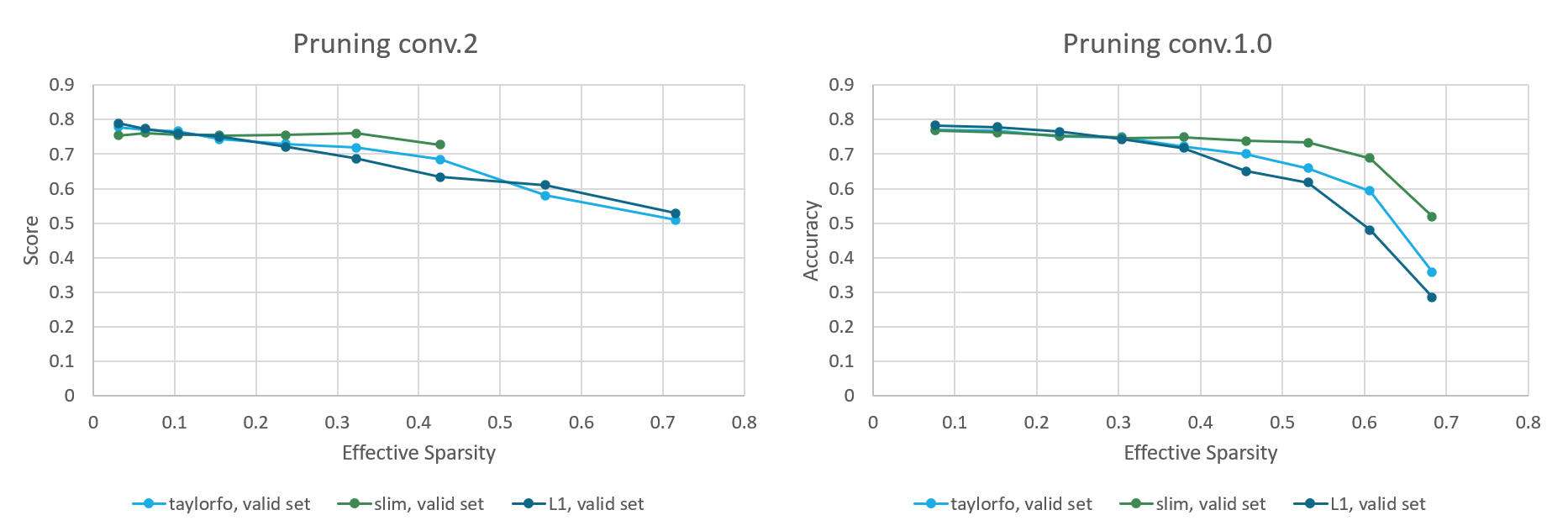
73.3 KB
{kind=link}
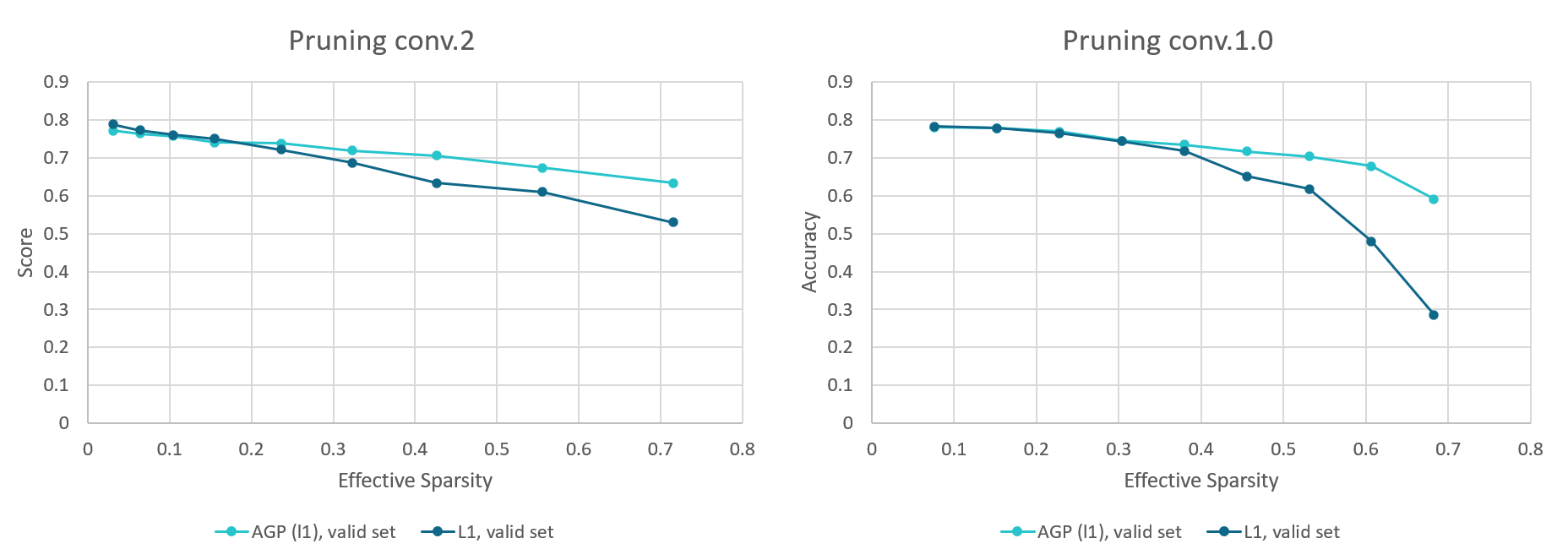
63 KB
{kind=link}
96.6 KB
{kind=link}
72.4 KB