L1FilterPruner is a general structured pruning algorithm for pruning filters in the convolutional layers.
In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), authors Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet and Hans Peter Graf.

> L1Filter Pruner prunes filters in the **convolution layers**
>
> The procedure of pruning m filters from the ith convolutional layer is as follows:
>
> 1. For each filter , calculate the sum of its absolute kernel weights
> 2. Sort the filters by 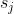.
> 3. Prune 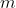 filters with the smallest sum values and their corresponding feature maps. The
> kernels in the next convolutional layer corresponding to the pruned feature maps are also
> removed.
> 4. A new kernel matrix is created for both the th and 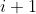th layers, and the remaining kernel
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**op_types:** Only Conv2d is supported in L1Filter Pruner
## 3. Experiment
We implemented one of the experiments in ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), we pruned **VGG-16** for CIFAR-10 to **VGG-16-pruned-A** in the paper, in which $64\%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |
@@ -12,6 +12,8 @@ We have provided two naive compression algorithms and three popular ones for use
|---|---|
| [Level Pruner](./Pruner.md#level-pruner) | Pruning the specified ratio on each weight based on absolute values of weights |
| [AGP Pruner](./Pruner.md#agp-pruner) | Automated gradual pruning (To prune, or not to prune: exploring the efficacy of pruning for model compression) [Reference Paper](https://arxiv.org/abs/1710.01878)|
| [L1Filter Pruner](./Pruner.md#l1filter-pruner) | Pruning least important filters in convolution layers(PRUNING FILTERS FOR EFFICIENT CONVNETS)[Reference Paper](https://arxiv.org/abs/1608.08710) |
| [Slim Pruner](./Pruner.md#slim-pruner) | Pruning channels in convolution layers by pruning scaling factors in BN layers(Learning Efficient Convolutional Networks through Network Slimming)[Reference Paper](https://arxiv.org/abs/1708.06519) |
| [Lottery Ticket Pruner](./Pruner.md#agp-pruner) | The pruning process used by "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks". It prunes a model iteratively. [Reference Paper](https://arxiv.org/abs/1803.03635)|
| [FPGM Pruner](./Pruner.md#fpgm-pruner) | Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration [Reference Paper](https://arxiv.org/pdf/1811.00250.pdf)|
This is one basic pruner: you can set a target sparsity level (expressed as a fraction, 0.6 means we will prune 60%).
This is one basic one-shot pruner: you can set a target sparsity level (expressed as a fraction, 0.6 means we will prune 60%).
We first sort the weights in the specified layer by their absolute values. And then mask to zero the smallest magnitude weights until the desired sparsity level is reached.
...
...
@@ -31,7 +31,7 @@ pruner.compress()
***
## AGP Pruner
In [To prune, or not to prune: exploring the efficacy of pruning for model compression](https://arxiv.org/abs/1710.01878), authors Michael Zhu and Suyog Gupta provide an algorithm to prune the weight gradually.
This is an iterative pruner, In [To prune, or not to prune: exploring the efficacy of pruning for model compression](https://arxiv.org/abs/1710.01878), authors Michael Zhu and Suyog Gupta provide an algorithm to prune the weight gradually.
>We introduce a new automated gradual pruning algorithm in which the sparsity is increased from an initial sparsity value si (usually 0) to a final sparsity value sf over a span of n pruning steps, starting at training step t0 and with pruning frequency ∆t:

...
...
@@ -65,7 +65,7 @@ config_list = [{
'start_epoch':0,
'end_epoch':10,
'frequency':1,
'op_types':'default'
'op_types':['default']
}]
pruner=AGP_Pruner(model,config_list)
pruner.compress()
...
...
@@ -134,7 +134,7 @@ The above configuration means that there are 5 times of iterative pruning. As th
***
## FPGM Pruner
FPGM Pruner is an implementation of paper [Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration](https://arxiv.org/pdf/1811.00250.pdf)
This is an one-shot pruner, FPGM Pruner is an implementation of paper [Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration](https://arxiv.org/pdf/1811.00250.pdf)
>Previous works utilized “smaller-norm-less-important” criterion to prune filters with smaller norm values in a convolutional neural network. In this paper, we analyze this norm-based criterion and point out that its effectiveness depends on two requirements that are not always met: (1) the norm deviation of the filters should be large; (2) the minimum norm of the filters should be small. To solve this problem, we propose a novel filter pruning method, namely Filter Pruning via Geometric Median (FPGM), to compress the model regardless of those two requirements. Unlike previous methods, FPGM compresses CNN models by pruning filters with redundancy, rather than those with “relatively less” importance.
...
...
@@ -179,3 +179,57 @@ You can view example for more information
***sparsity:** How much percentage of convolutional filters are to be pruned.
***
## L1Filter Pruner
This is an one-shot pruner, In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), authors Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet and Hans Peter Graf.

> L1Filter Pruner prunes filters in the **convolution layers**
>
> The procedure of pruning m filters from the ith convolutional layer is as follows:
>
> 1. For each filter , calculate the sum of its absolute kernel weights
> 2. Sort the filters by 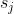.
> 3. Prune 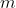 filters with the smallest sum values and their corresponding feature maps. The
> kernels in the next convolutional layer corresponding to the pruned feature maps are also
> removed.
> 4. A new kernel matrix is created for both the th and 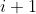th layers, and the remaining kernel
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**op_types:** Only Conv2d is supported in L1Filter Pruner
## Slim Pruner
This is an one-shot pruner, In ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf), authors Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan and Changshui Zhang.

> Slim Pruner **prunes channels in the convolution layers by masking corresponding scaling factors in the later BN layers**, L1 regularization on the scaling factors should be applied in batch normalization (BN) layers while training, scaling factors of BN layers are **globally ranked** while pruning, so the sparse model can be automatically found given sparsity.
SlimPruner is a structured pruning algorithm for pruning channels in the convolutional layers by pruning corresponding scaling factors in the later BN layers.
In ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf), authors Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan and Changshui Zhang.

> Slim Pruner **prunes channels in the convolution layers by masking corresponding scaling factors in the later BN layers**, L1 regularization on the scaling factors should be applied in batch normalization (BN) layers while training, scaling factors of BN layers are **globally ranked** while pruning, so the sparse model can be automatically found given sparsity.
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**op_types:** Only BatchNorm2d is supported in Slim Pruner
## 3. Experiment
We implemented one of the experiments in ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf), we pruned $70\%$ channels in the **VGGNet** for CIFAR-10 in the paper, in which $88.5\%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |

{kind=link}

{kind=link}
