ActivationRankFilterPruner is a series of pruners which prune filters according to some importance criterion calculated from the filters' output activations.
| Pruner | Importance criterion | Reference paper |
| ActivationAPoZRankFilterPruner | APoZ(average percentage of zeros) | [Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures](https://arxiv.org/abs/1607.03250) |
| ActivationMeanRankFilterPruner | mean value of output activations | [Pruning Convolutional Neural Networks for Resource Efficient Inference](https://arxiv.org/abs/1611.06440) |
## 2. Pruners
### ActivationAPoZRankFilterPruner
Hengyuan Hu, Rui Peng, Yu-Wing Tai and Chi-Keung Tang,
"[Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures](https://arxiv.org/abs/1607.03250)", ICLR 2016.
ActivationAPoZRankFilterPruner prunes the filters with the smallest APoZ(average percentage of zeros) of output activations.
The APoZ is defined as:

### ActivationMeanRankFilterPruner
Pavlo Molchanov, Stephen Tyree, Tero Karras, Timo Aila and Jan Kautz,
"[Pruning Convolutional Neural Networks for Resource Efficient Inference](https://arxiv.org/abs/1611.06440)", ICLR 2017.
ActivationMeanRankFilterPruner prunes the filters with the smallest mean value of output activations
@@ -14,10 +14,14 @@ We have provided several compression algorithms, including several pruning and q
|---|---|
| [Level Pruner](./Pruner.md#level-pruner) | Pruning the specified ratio on each weight based on absolute values of weights |
| [AGP Pruner](./Pruner.md#agp-pruner) | Automated gradual pruning (To prune, or not to prune: exploring the efficacy of pruning for model compression) [Reference Paper](https://arxiv.org/abs/1710.01878)|
| [L1Filter Pruner](./Pruner.md#l1filter-pruner) | Pruning least important filters in convolution layers(PRUNING FILTERS FOR EFFICIENT CONVNETS)[Reference Paper](https://arxiv.org/abs/1608.08710) |
| [Slim Pruner](./Pruner.md#slim-pruner) | Pruning channels in convolution layers by pruning scaling factors in BN layers(Learning Efficient Convolutional Networks through Network Slimming)[Reference Paper](https://arxiv.org/abs/1708.06519) |
| [Lottery Ticket Pruner](./Pruner.md#agp-pruner) | The pruning process used by "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks". It prunes a model iteratively. [Reference Paper](https://arxiv.org/abs/1803.03635)|
| [FPGM Pruner](./Pruner.md#fpgm-pruner) | Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration [Reference Paper](https://arxiv.org/pdf/1811.00250.pdf)|
| [L1Filter Pruner](./Pruner.md#l1filter-pruner) | Pruning filters with the smallest L1 norm of weights in convolution layers(PRUNING FILTERS FOR EFFICIENT CONVNETS)[Reference Paper](https://arxiv.org/abs/1608.08710) |
| [L2Filter Pruner](./Pruner.md#l2filter-pruner) | Pruning filters with the smallest L2 norm of weights in convolution layers |
| [ActivationAPoZRankFilterPruner](./Pruner.md#ActivationAPoZRankFilterPruner) | Pruning filters prunes the filters with the smallest APoZ(average percentage of zeros) of output activations(Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures)[Reference Paper](https://arxiv.org/abs/1607.03250) |
| [ActivationMeanRankFilterPruner](./Pruner.md#ActivationMeanRankFilterPruner) | Pruning filters prunes the filters with the smallest mean value of output activations(Pruning Convolutional Neural Networks for Resource Efficient Inference)[Reference Paper](https://arxiv.org/abs/1611.06440) |
| [Slim Pruner](./Pruner.md#slim-pruner) | Pruning channels in convolution layers by pruning scaling factors in BN layers(Learning Efficient Convolutional Networks through Network Slimming)[Reference Paper](https://arxiv.org/abs/1708.06519) |
Second, you should add code below to update epoch number when you finish one epoch in your training code.
you should add code below to update epoch number when you finish one epoch in your training code.
Tensorflow code
```python
...
...
@@ -133,13 +131,16 @@ The above configuration means that there are 5 times of iterative pruning. As th
***sparsity:** The final sparsity when the compression is done.
***
## FPGM Pruner
## WeightRankFilterPruner
WeightRankFilterPruner is a series of pruners which prune the filters with the smallest importance criterion calculated from the weights in convolution layers to achieve a preset level of network sparsity
### 1, FPGM Pruner
This is an one-shot pruner, FPGM Pruner is an implementation of paper [Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration](https://arxiv.org/pdf/1811.00250.pdf)
>Previous works utilized “smaller-norm-less-important” criterion to prune filters with smaller norm values in a convolutional neural network. In this paper, we analyze this norm-based criterion and point out that its effectiveness depends on two requirements that are not always met: (1) the norm deviation of the filters should be large; (2) the minimum norm of the filters should be small. To solve this problem, we propose a novel filter pruning method, namely Filter Pruning via Geometric Median (FPGM), to compress the model regardless of those two requirements. Unlike previous methods, FPGM compresses CNN models by pruning filters with redundancy, rather than those with “relatively less” importance.
### Usage
First, you should import pruner and add mask to model.
#### Usage
Tensorflow code
```python
...
...
@@ -163,7 +164,7 @@ pruner.compress()
```
Note: FPGM Pruner is used to prune convolutional layers within deep neural networks, therefore the `op_types` field supports only convolutional layers.
Second, you should add code below to update epoch number at beginning of each epoch.
you should add code below to update epoch number at beginning of each epoch.
Tensorflow code
```python
...
...
@@ -180,7 +181,7 @@ You can view example for more information
***
## L1Filter Pruner
### 2, L1Filter Pruner
This is an one-shot pruner, In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), authors Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet and Hans Peter Graf.
...
...
@@ -198,7 +199,11 @@ This is an one-shot pruner, In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https:
> 4. A new kernel matrix is created for both the th and 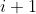th layers, and the remaining kernel
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**op_types:** Only Conv1d and Conv2d is supported in L2Filter Pruner
## ActivationRankFilterPruner
ActivationRankFilterPruner is a series of pruners which prune the filters with the smallest importance criterion calculated from the output activations of convolution layers to achieve a preset level of network sparsity
### 1, ActivationAPoZRankFilterPruner
This is an one-shot pruner, ActivationAPoZRankFilterPruner is an implementation of paper [Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures](https://arxiv.org/abs/1607.03250)
Note: ActivationAPoZRankFilterPruner is used to prune convolutional layers within deep neural networks, therefore the `op_types` field supports only convolutional layers.
You can view example for more information
#### User configuration for ActivationAPoZRankFilterPruner
-**sparsity:** How much percentage of convolutional filters are to be pruned.
-**op_types:** Only Conv2d is supported in ActivationAPoZRankFilterPruner
***
### 2, ActivationMeanRankFilterPruner
This is an one-shot pruner, ActivationMeanRankFilterPruner is an implementation of paper [Pruning Convolutional Neural Networks for Resource Efficient Inference](https://arxiv.org/abs/1611.06440)
Note: ActivationMeanRankFilterPruner is used to prune convolutional layers within deep neural networks, therefore the `op_types` field supports only convolutional layers.
You can view example for more information
#### User configuration for ActivationMeanRankFilterPruner
-**sparsity:** How much percentage of convolutional filters are to be pruned.
-**op_types:** Only Conv2d is supported in ActivationMeanRankFilterPruner
***
## Slim Pruner
...
...
@@ -222,7 +310,7 @@ This is an one-shot pruner, In ['Learning Efficient Convolutional Networks throu
| L1FilterPruner | L1 norm of weights | [PRUNING FILTERS FOR EFFICIENT CONVNETS](https://arxiv.org/abs/1608.08710) |
| L2FilterPruner | L2 norm of weights | |
| FPGMPruner | Geometric Median of weights | [Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration](https://arxiv.org/pdf/1811.00250.pdf) |
## 2. Pruners
### L1FilterPruner
L1FilterPruner is a general structured pruning algorithm for pruning filters in the convolutional layers.
In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), authors Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet and Hans Peter Graf.
...
...
@@ -21,7 +33,21 @@ In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710),
> 4. A new kernel matrix is created for both the th and 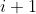th layers, and the remaining kernel
> weights are copied to the new model.
## 2. Usage
### L2FilterPruner
L2FilterPruner is similar to L1FilterPruner, but only replace the importance criterion from L1 norm to L2 norm
### FPGMPruner
Yang He, Ping Liu, Ziwei Wang, Zhilan Hu, Yi Yang
"[Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration](https://arxiv.org/abs/1811.00250)", CVPR 2019.
FPGMPruner prune filters with the smallest geometric median

## 3. Usage
PyTorch code
...
...
@@ -37,9 +63,9 @@ pruner.compress()
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**op_types:** Only Conv2d is supported in L1Filter Pruner
## 3. Experiment
## 4. Experiment
We implemented one of the experiments in ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), we pruned **VGG-16** for CIFAR-10 to **VGG-16-pruned-A** in the paper, in which $64\%$ parameters are pruned. Our experiments results are as follows:
We implemented one of the experiments in ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710) with **L1FilterPruner**, we pruned **VGG-16** for CIFAR-10 to **VGG-16-pruned-A** in the paper, in which $64\%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |

{kind=link}

{kind=link}
