For the mobile application of facial landmark, based on the basic architecture of PFLD model, we have applied the FBNet (Block-wise DNAS) to design an concise model with the trade-off between latency and accuracy. References are listed as below:
* `PFLD: A Practical Facial Landmark Detector <https://arxiv.org/abs/1902.10859>`__
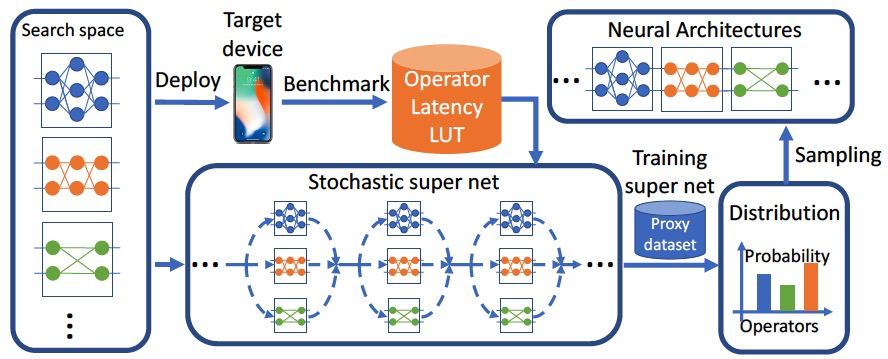
FBNet is a block-wise differentiable NAS method (Block-wise DNAS), where the best candidate building blocks can be chosen by using Gumbel Softmax random sampling and differentiable training. At each layer (or stage) to be searched, the diverse candidate blocks are side by side planned (just like the effectiveness of structural re-parameterization), leading to sufficient pre-training of the supernet. The pre-trained supernet is further sampled for finetuning of the subnet, to achieve better performance.
.. image:: ../../img/fbnet.png
:target: ../../img/fbnet.png
:alt:
PFLD is a lightweight facial landmark model for realtime application. The architecture of PLFD is firstly simplified for acceleration, by using the stem block of PeleeNet, average pooling with depthwise convolution and eSE module.
To achieve better trade-off between latency and accuracy, the FBNet is further applied on the simplified PFLD for searching the best block at each specific layer. The search space is based on the FBNet space, and optimized for mobile deployment by using the average pooling with depthwise convolution and eSE module etc.
Experiments
------------
To verify the effectiveness of FBNet applied on PFLD, we choose the open source dataset with 106 landmark points as the benchmark:
* `Grand Challenge of 106-Point Facial Landmark Localization <https://arxiv.org/abs/1905.03469>`__
The baseline model is denoted as MobileNet-V3 PFLD (`Reference baseline <https://github.com/Hsintao/pfld_106_face_landmarks>`__), and the searched model is denoted as Subnet. The experimental results are listed as below, where the latency is tested on Qualcomm 625 CPU (ARMv8):
Please run the following scripts at the example directory.
The Python dependencies used here are listed as below:
.. code-block:: bash
numpy==1.18.5
opencv-python==4.5.1.48
torch==1.6.0
torchvision==0.7.0
onnx==1.8.1
onnx-simplifier==0.3.5
onnxruntime==1.7.0
Data Preparation
-----------------
Firstly, you should download the dataset `106points dataset <https://drive.google.com/file/d/1I7QdnLxAlyG2Tq3L66QYzGhiBEoVfzKo/view?usp=sharing>`__ to the path ``./data/106points`` . The dataset includes the train-set and test-set:
.. code-block:: bash
./data/106points/train_data/imgs
./data/106points/train_data/list.txt
./data/106points/test_data/imgs
./data/106points/test_data/list.txt
Quik Start
-----------
1. Search
^^^^^^^^^^
Based on the architecture of simplified PFLD, the setting of multi-stage search space and hyper-parameters for searching should be firstly configured to construct the supernet, as an example:
.. code-block:: bash
from lib.builder import search_space
from lib.ops import PRIMITIVES
from lib.supernet import PFLDInference, AuxiliaryNet
from nni.algorithms.nas.pytorch.fbnet import LookUpTable, NASConfig,
# configuration of hyper-parameters
# search_space defines the multi-stage search space
After creation of the supernet with the specification of search space and hyper-parameters, we can run below command to start searching and training of the supernet:
ONNX model is saved as ``./output/subnet.onnx``, which can be further converted to the mobile inference engine by using `MNN <https://github.com/alibaba/MNN>`__ .
The checkpoints of pre-trained supernet and subnet are offered as below:
@@ -58,6 +58,8 @@ NNI currently supports the one-shot NAS algorithms listed below and is adding mo
...
@@ -58,6 +58,8 @@ NNI currently supports the one-shot NAS algorithms listed below and is adding mo
- `Cyclic Differentiable Architecture Search <https://arxiv.org/pdf/2006.10724.pdf>`__ builds a cyclic feedback mechanism between the search and evaluation networks. It introduces a cyclic differentiable architecture search framework which integrates the two networks into a unified architecture.
- `Cyclic Differentiable Architecture Search <https://arxiv.org/pdf/2006.10724.pdf>`__ builds a cyclic feedback mechanism between the search and evaluation networks. It introduces a cyclic differentiable architecture search framework which integrates the two networks into a unified architecture.
* - `ProxylessNAS <Proxylessnas.rst>`__
* - `ProxylessNAS <Proxylessnas.rst>`__
- `ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware <https://arxiv.org/abs/1812.00332>`__. It removes proxy, directly learns the architectures for large-scale target tasks and target hardware platforms.
- `ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware <https://arxiv.org/abs/1812.00332>`__. It removes proxy, directly learns the architectures for large-scale target tasks and target hardware platforms.
* - `FBNet <FBNet.rst>`__
- `FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search <https://arxiv.org/abs/1812.03443>`__. It is a block-wise differentiable neural network architecture search method with the hardware-aware constraint.
* - `TextNAS <TextNAS.rst>`__
* - `TextNAS <TextNAS.rst>`__
- `TextNAS: A Neural Architecture Search Space tailored for Text Representation <https://arxiv.org/pdf/1912.10729.pdf>`__. It is a neural architecture search algorithm tailored for text representation.
- `TextNAS: A Neural Architecture Search Space tailored for Text Representation <https://arxiv.org/pdf/1912.10729.pdf>`__. It is a neural architecture search algorithm tailored for text representation.

{kind=link}