
add dtk24.04 code
Showing
Too many changes to show.
To preserve performance only 520 of 520+ files are displayed.
{kind=link}
74.5 KB
{kind=link}

9.13 KB
{kind=link}

9.46 KB
{kind=link}
{kind=link}

| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}

24.4 KB
{kind=link}
22.1 KB
{kind=link}
{kind=link}
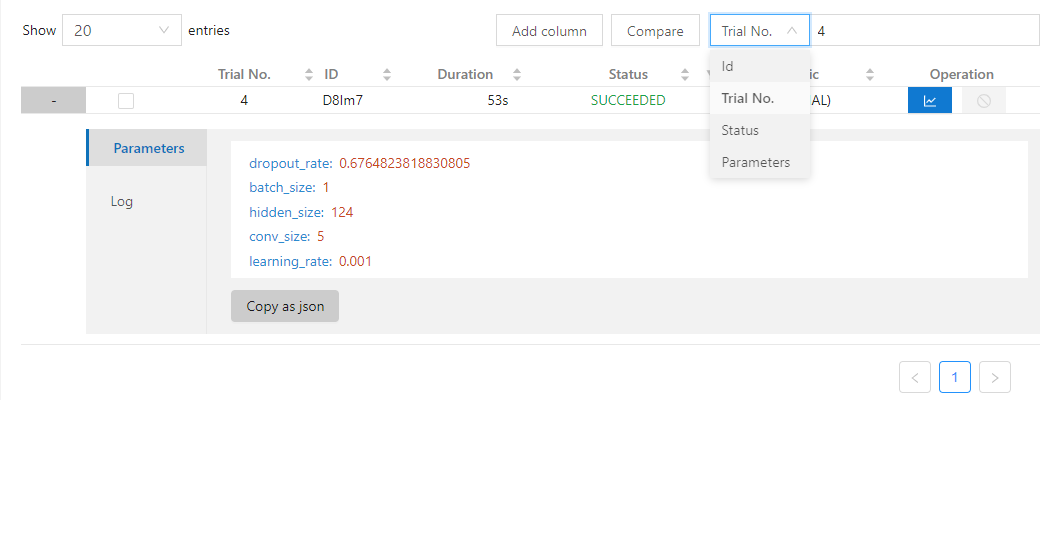
| W: | H:
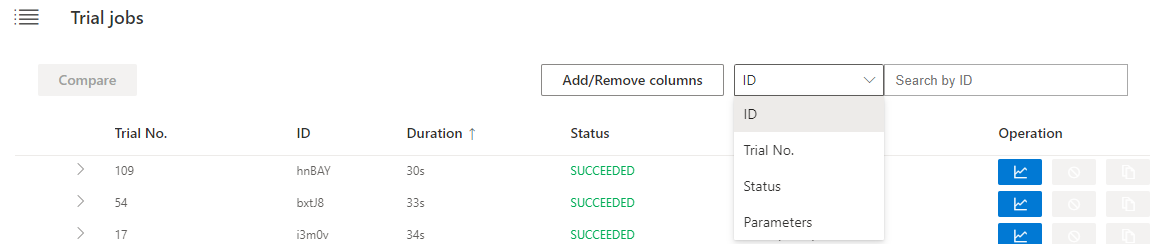
| W: | H:
{kind=link}
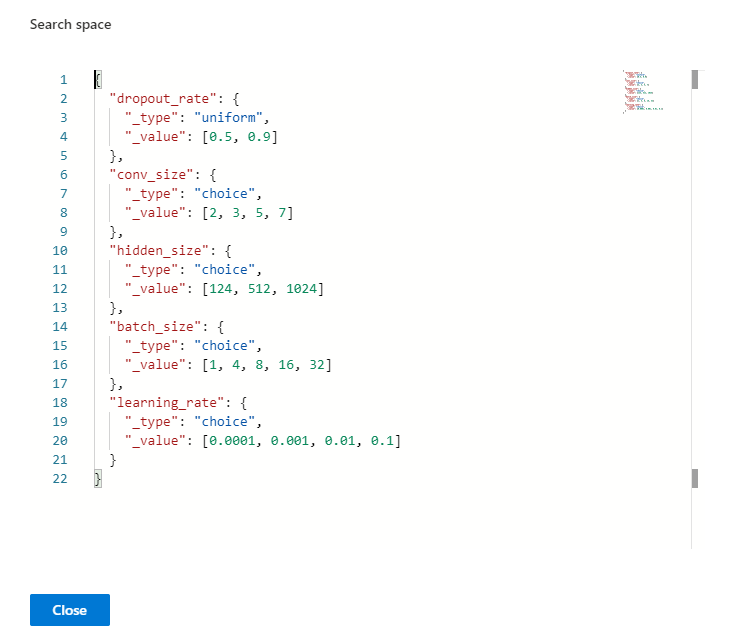
33.3 KB
{kind=link}
{kind=link}
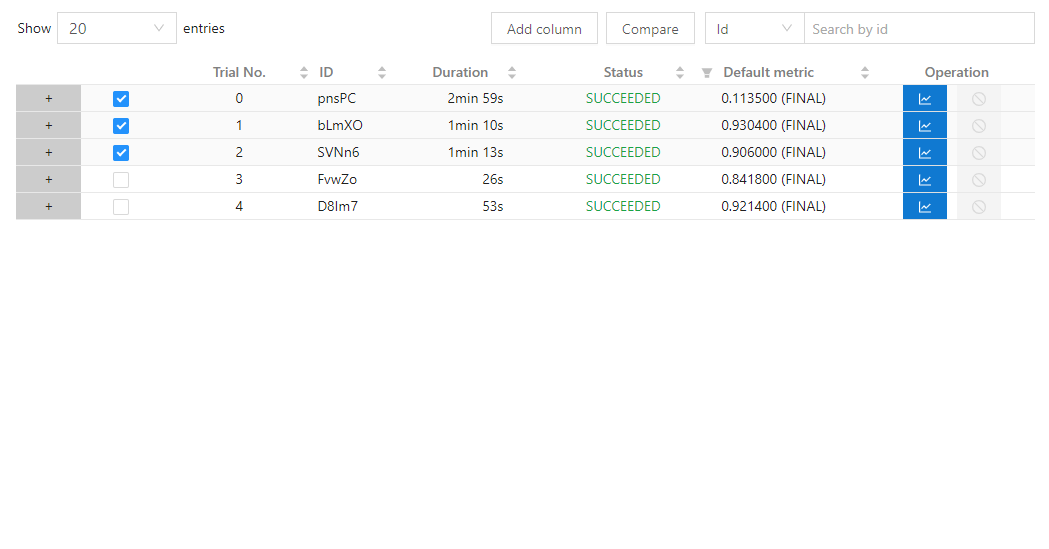
| W: | H:

| W: | H:
{kind=link}
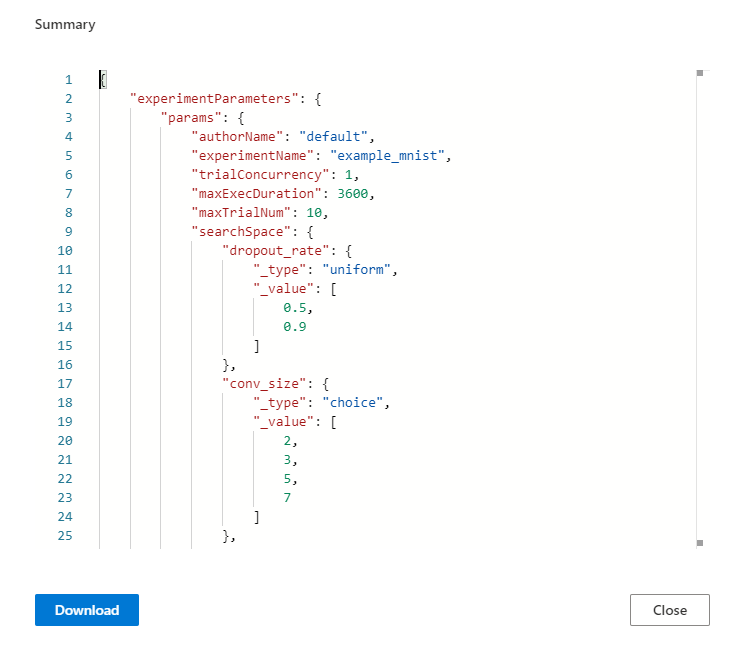
38.7 KB
{kind=link}
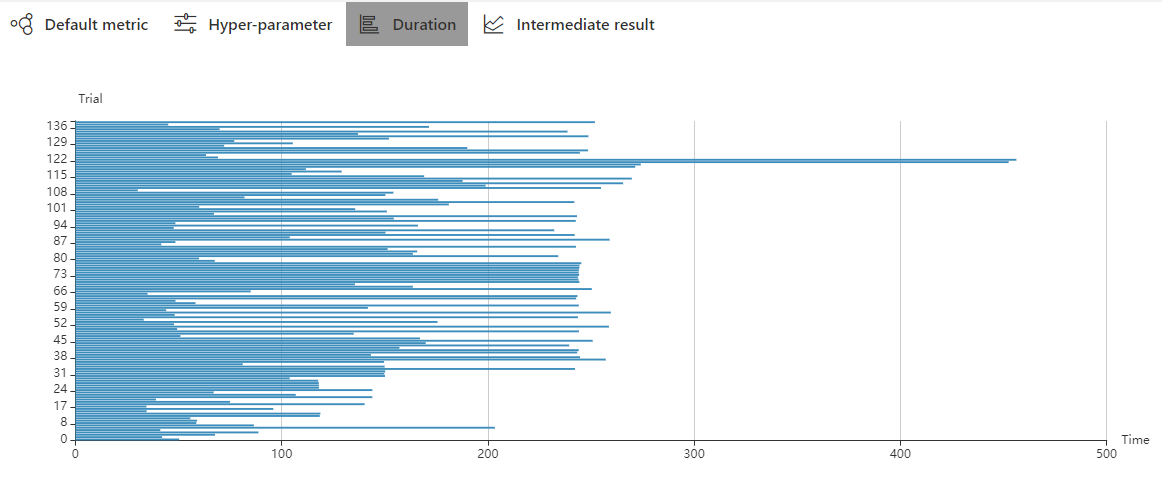
22 KB
{kind=link}
{kind=link}
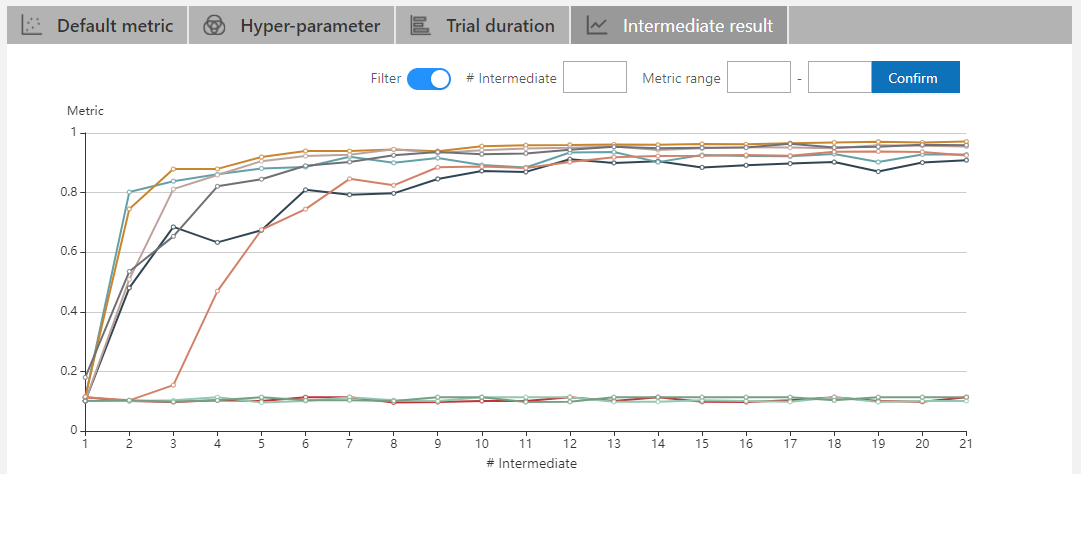
| W: | H:
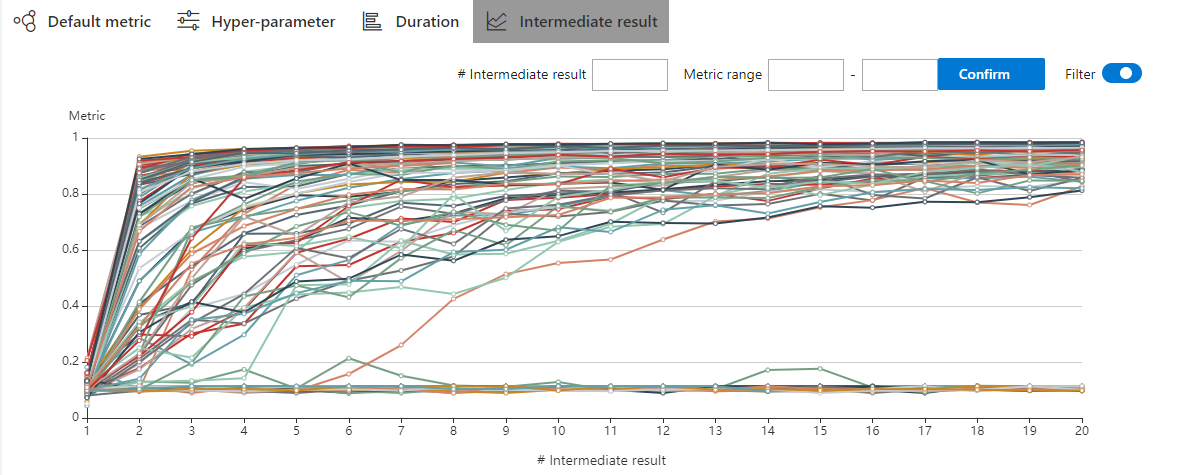
| W: | H: