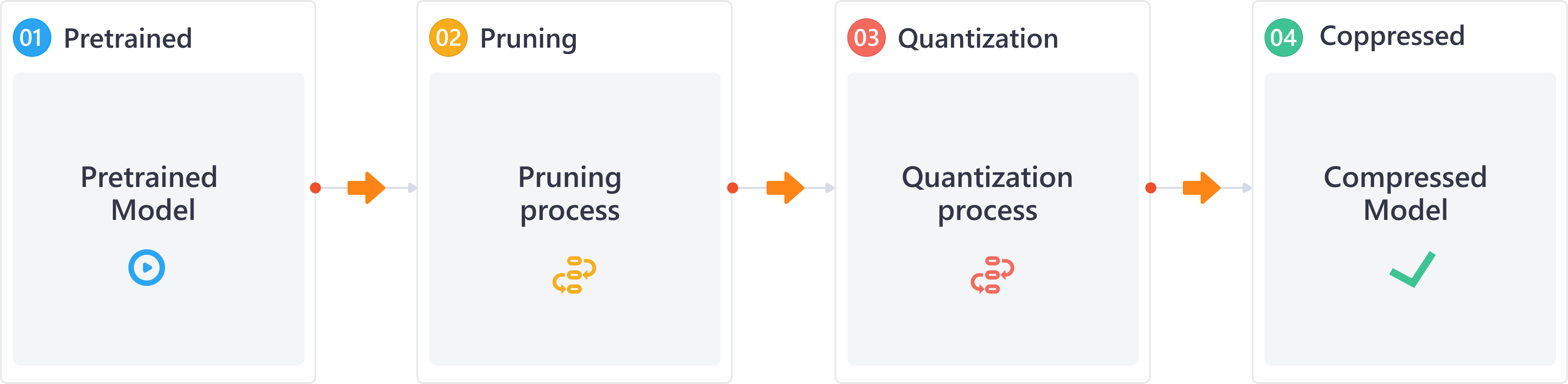
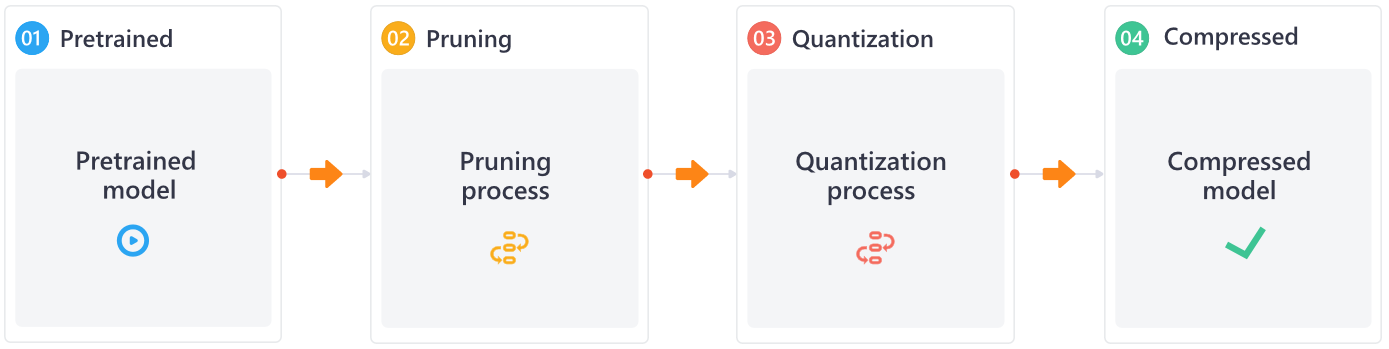
"\n# Pruning Transformer with NNI\n\n## Workable Pruning Process\n\nHere we show an effective transformer pruning process that NNI team has tried, and users can use NNI to discover better processes.\n\nThe entire pruning process can be divided into the following steps:\n\n1. Finetune the pre-trained model on the downstream task. From our experience,\n the final performance of pruning on the finetuned model is better than pruning directly on the pre-trained model.\n At the same time, the finetuned model obtained in this step will also be used as the teacher model for the following\n distillation training.\n2. Pruning the attention layer at first. Here we apply block-sparse on attention layer weight,\n and directly prune the head (condense the weight) if the head was fully masked.\n If the head was partially masked, we will not prune it and recover its weight.\n3. Retrain the head-pruned model with distillation. Recover the model precision before pruning FFN layer.\n4. Pruning the FFN layer. Here we apply the output channels pruning on the 1st FFN layer,\n and the 2nd FFN layer input channels will be pruned due to the pruning of 1st layer output channels.\n5. Retrain the final pruned model with distillation.\n\nDuring the process of pruning transformer, we gained some of the following experiences:\n\n* We using `movement-pruner` in step 2 and `taylor-fo-weight-pruner` in step 4. `movement-pruner` has good performance on attention layers,\n and `taylor-fo-weight-pruner` method has good performance on FFN layers. These two pruners are all some kinds of gradient-based pruning algorithms,\n we also try weight-based pruning algorithms like `l1-norm-pruner`, but it doesn't seem to work well in this scenario.\n* Distillation is a good way to recover model precision. In terms of results, usually 1~2% improvement in accuracy can be achieved when we prune bert on mnli task.\n* It is necessary to gradually increase the sparsity rather than reaching a very high sparsity all at once.\n\n## Experiment\n\n### Preparation\nPlease set ``dev_mode`` to ``False`` to run this tutorial. Here ``dev_mode`` is ``True`` by default is for generating documents.\n\nThe complete pruning process takes about 8 hours on one A100.\n"
"\n# Pruning Bert on Task MNLI\n\n## Workable Pruning Process\n\nHere we show an effective transformer pruning process that NNI team has tried, and users can use NNI to discover better processes.\n\nThe entire pruning process can be divided into the following steps:\n\n1. Finetune the pre-trained model on the downstream task. From our experience,\n the final performance of pruning on the finetuned model is better than pruning directly on the pre-trained model.\n At the same time, the finetuned model obtained in this step will also be used as the teacher model for the following\n distillation training.\n2. Pruning the attention layer at first. Here we apply block-sparse on attention layer weight,\n and directly prune the head (condense the weight) if the head was fully masked.\n If the head was partially masked, we will not prune it and recover its weight.\n3. Retrain the head-pruned model with distillation. Recover the model precision before pruning FFN layer.\n4. Pruning the FFN layer. Here we apply the output channels pruning on the 1st FFN layer,\n and the 2nd FFN layer input channels will be pruned due to the pruning of 1st layer output channels.\n5. Retrain the final pruned model with distillation.\n\nDuring the process of pruning transformer, we gained some of the following experiences:\n\n* We using `movement-pruner` in step 2 and `taylor-fo-weight-pruner` in step 4. `movement-pruner` has good performance on attention layers,\n and `taylor-fo-weight-pruner` method has good performance on FFN layers. These two pruners are all some kinds of gradient-based pruning algorithms,\n we also try weight-based pruning algorithms like `l1-norm-pruner`, but it doesn't seem to work well in this scenario.\n* Distillation is a good way to recover model precision. In terms of results, usually 1~2% improvement in accuracy can be achieved when we prune bert on mnli task.\n* It is necessary to gradually increase the sparsity rather than reaching a very high sparsity all at once.\n\n## Experiment\n\nThe complete pruning process will take about 8 hours on one A100.\n\n### Preparation\n\nThis section is mainly to get a finetuned model on the downstream task.\nIf you are familiar with how to finetune Bert on GLUE dataset, you can skip this section.\n\n<div class=\"alert alert-info\"><h4>Note</h4><p>Please set ``dev_mode`` to ``False`` to run this tutorial. Here ``dev_mode`` is ``True`` by default is for generating documents.</p></div>\n"
]
]
},
},
{
{
...
@@ -44,14 +44,14 @@
...
@@ -44,14 +44,14 @@
},
},
"outputs": [],
"outputs": [],
"source": [
"source": [
"from pathlib import Path\nfrom typing import Callable\n\npretrained_model_name_or_path = 'bert-base-uncased'\ntask_name = 'mnli'\nexperiment_id = 'pruning_bert'\n\n# heads_num and layers_num should align with pretrained_model_name_or_path\nheads_num = 12\nlayers_num = 12\n\n# used to save the experiment log\nlog_dir = Path(f'./pruning_log/{pretrained_model_name_or_path}/{task_name}/{experiment_id}')\nlog_dir.mkdir(parents=True, exist_ok=True)\n\n# used to save the finetuned model and share between different experiemnts with same pretrained_model_name_or_path and task_name\nmodel_dir = Path(f'./models/{pretrained_model_name_or_path}/{task_name}')\nmodel_dir.mkdir(parents=True, exist_ok=True)\n\nfrom transformers import set_seed\nset_seed(1024)\n\nimport torch\ndevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')"
"from pathlib import Path\nfrom typing import Callable, Dict\n\npretrained_model_name_or_path = 'bert-base-uncased'\ntask_name = 'mnli'\nexperiment_id = 'pruning_bert_mnli'\n\n# heads_num and layers_num should align with pretrained_model_name_or_path\nheads_num = 12\nlayers_num = 12\n\n# used to save the experiment log\nlog_dir = Path(f'./pruning_log/{pretrained_model_name_or_path}/{task_name}/{experiment_id}')\nlog_dir.mkdir(parents=True, exist_ok=True)\n\n# used to save the finetuned model and share between different experiemnts with same pretrained_model_name_or_path and task_name\nmodel_dir = Path(f'./models/{pretrained_model_name_or_path}/{task_name}')\nmodel_dir.mkdir(parents=True, exist_ok=True)\n\n# used to save GLUE data\ndata_dir = Path(f'./data')\ndata_dir.mkdir(parents=True, exist_ok=True)\n\n# set seed\nfrom transformers import set_seed\nset_seed(1024)\n\nimport torch\ndevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')"
]
]
},
},
{
{
"cell_type": "markdown",
"cell_type": "markdown",
"metadata": {},
"metadata": {},
"source": [
"source": [
"The function used to create dataloaders, note that 'mnli' has two evaluation dataset.\nIf teacher_model is set, will run all dataset on teacher model to get the 'teacher_logits' for distillation.\n\n"
"Create dataloaders.\n\n"
]
]
},
},
{
{
...
@@ -62,7 +62,7 @@
...
@@ -62,7 +62,7 @@
},
},
"outputs": [],
"outputs": [],
"source": [
"source": [
"from torch.utils.data import DataLoader\n\nfrom datasets import load_dataset\nfrom transformers import BertTokenizerFast, DataCollatorWithPadding\n\ntask_to_keys = {\n 'cola': ('sentence', None),\n 'mnli': ('premise', 'hypothesis'),\n 'mrpc': ('sentence1', 'sentence2'),\n 'qnli': ('question', 'sentence'),\n 'qqp': ('question1', 'question2'),\n 'rte': ('sentence1', 'sentence2'),\n 'sst2': ('sentence', None),\n 'stsb': ('sentence1', 'sentence2'),\n 'wnli': ('sentence1', 'sentence2'),\n}\n\ndef prepare_data(cache_dir='./data', train_batch_size=32, eval_batch_size=32,\n teacher_model: torch.nn.Module = None):\n tokenizer = BertTokenizerFast.from_pretrained(pretrained_model_name_or_path)\n sentence1_key, sentence2_key = task_to_keys[task_name]\n data_collator = DataCollatorWithPadding(tokenizer)\n\n # used to preprocess the raw data\n def preprocess_function(examples):\n # Tokenize the texts\n args = (\n (examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])\n )\n result = tokenizer(*args, padding=False, max_length=128, truncation=True)\n\n if 'label' in examples:\n # In all cases, rename the column to labels because the model will expect that.\n result['labels'] = examples['label']\n return result\n\n raw_datasets = load_dataset('glue', task_name, cache_dir=cache_dir)\n for key in list(raw_datasets.keys()):\n if 'test' in key:\n raw_datasets.pop(key)\n\n processed_datasets = raw_datasets.map(preprocess_function, batched=True,\n remove_columns=raw_datasets['train'].column_names)\n\n # if has teacher model, add 'teacher_logits' to datasets who has 'labels'.\n # 'teacher_logits' is used for distillation and avoid the double counting.\n if teacher_model:\n teacher_model_training = teacher_model.training\n teacher_model.eval()\n model_device = next(teacher_model.parameters()).device\n\n def add_teacher_logits(examples):\n result = {k: v for k, v in examples.items()}\n samples = data_collator(result).to(model_device)\n if 'labels' in samples:\n with torch.no_grad():\n logits = teacher_model(**samples).logits.tolist()\n result['teacher_logits'] = logits\n return result\n\n processed_datasets = processed_datasets.map(add_teacher_logits, batched=True,\n batch_size=train_batch_size)\n teacher_model.train(teacher_model_training)\n\n train_dataset = processed_datasets['train']\n validation_dataset = processed_datasets['validation_matched' if task_name == 'mnli' else 'validation']\n validation_dataset2 = processed_datasets['validation_mismatched'] if task_name == 'mnli' else None\n\n train_dataloader = DataLoader(train_dataset,\n shuffle=True,\n collate_fn=data_collator,\n batch_size=train_batch_size)\n validation_dataloader = DataLoader(validation_dataset,\n collate_fn=data_collator,\n batch_size=eval_batch_size)\n validation_dataloader2 = DataLoader(validation_dataset2,\n collate_fn=data_collator,\n batch_size=eval_batch_size) if task_name == 'mnli' else None\n\n return train_dataloader, validation_dataloader, validation_dataloader2"
"from torch.utils.data import DataLoader\n\nfrom datasets import load_dataset\nfrom transformers import BertTokenizerFast, DataCollatorWithPadding\n\ntask_to_keys = {\n 'cola': ('sentence', None),\n 'mnli': ('premise', 'hypothesis'),\n 'mrpc': ('sentence1', 'sentence2'),\n 'qnli': ('question', 'sentence'),\n 'qqp': ('question1', 'question2'),\n 'rte': ('sentence1', 'sentence2'),\n 'sst2': ('sentence', None),\n 'stsb': ('sentence1', 'sentence2'),\n 'wnli': ('sentence1', 'sentence2'),\n}\n\ndef prepare_dataloaders(cache_dir=data_dir, train_batch_size=32, eval_batch_size=32):\n tokenizer = BertTokenizerFast.from_pretrained(pretrained_model_name_or_path)\n sentence1_key, sentence2_key = task_to_keys[task_name]\n data_collator = DataCollatorWithPadding(tokenizer)\n\n # used to preprocess the raw data\n def preprocess_function(examples):\n # Tokenize the texts\n args = (\n (examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])\n )\n result = tokenizer(*args, padding=False, max_length=128, truncation=True)\n\n if 'label' in examples:\n # In all cases, rename the column to labels because the model will expect that.\n result['labels'] = examples['label']\n return result\n\n raw_datasets = load_dataset('glue', task_name, cache_dir=cache_dir)\n for key in list(raw_datasets.keys()):\n if 'test' in key:\n raw_datasets.pop(key)\n\n processed_datasets = raw_datasets.map(preprocess_function, batched=True,\n remove_columns=raw_datasets['train'].column_names)\n\n train_dataset = processed_datasets['train']\n if task_name == 'mnli':\n validation_datasets = {\n 'validation_matched': processed_datasets['validation_matched'],\n 'validation_mismatched': processed_datasets['validation_mismatched']\n }\n else:\n validation_datasets = {\n 'validation': processed_datasets['validation']\n }\n\n train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=data_collator, batch_size=train_batch_size)\n validation_dataloaders = {\n val_name: DataLoader(val_dataset, collate_fn=data_collator, batch_size=eval_batch_size) \\\n for val_name, val_dataset in validation_datasets.items()\n }\n\n return train_dataloader, validation_dataloaders\n\n\ntrain_dataloader, validation_dataloaders = prepare_dataloaders()"
]
]
},
},
{
{
...
@@ -80,7 +80,7 @@
...
@@ -80,7 +80,7 @@
},
},
"outputs": [],
"outputs": [],
"source": [
"source": [
"import time\nimport torch.nn.functional as F\nfrom datasets import load_metric\n\ndef training(train_dataloader: DataLoader,\n model: torch.nn.Module,\n optimizer: torch.optim.Optimizer,\n criterion: Callable[[torch.Tensor, torch.Tensor], torch.Tensor],\n lr_scheduler: torch.optim.lr_scheduler._LRScheduler = None,\n max_steps: int = None, max_epochs: int = None,\n save_best_model: bool = False, save_path: str = None,\n log_path: str = Path(log_dir) / 'training.log',\n distillation: bool = False,\n evaluation_func=None):\n model.train()\n current_step = 0\n best_result = 0\n\n for current_epoch in range(max_epochs if max_epochs else 1):\n for batch in train_dataloader:\n batch.to(device)\n teacher_logits = batch.pop('teacher_logits', None)\n optimizer.zero_grad()\n outputs = model(**batch)\n loss = outputs.loss\n\n if distillation:\n assert teacher_logits is not None\n distil_loss = F.kl_div(F.log_softmax(outputs.logits / 2, dim=-1),\n F.softmax(teacher_logits / 2, dim=-1), reduction='batchmean') * (2 ** 2)\n loss = 0.1 * loss + 0.9 * distil_loss\n\n loss = criterion(loss, None)\n loss.backward()\n optimizer.step()\n\n if lr_scheduler:\n lr_scheduler.step()\n\n current_step += 1\n\n # evaluation for every 1000 steps\n if current_step % 1000 == 0 or current_step % len(train_dataloader) == 0:\n result = evaluation_func(model) if evaluation_func else None\n with (log_path).open('a+') as f:\n msg = '[{}] Epoch {}, Step {}: {}\\n'.format(time.asctime(time.localtime(time.time())), current_epoch, current_step, result)\n f.write(msg)\n # if it's the best model, save it.\n if save_best_model and best_result < result['default']:\n assert save_path is not None\n torch.save(model.state_dict(), save_path)\n best_result = result['default']\n\n if max_steps and current_step >= max_steps:\n return\n\ndef evaluation(validation_dataloader: DataLoader,\n validation_dataloader2: DataLoader,\n model: torch.nn.Module):\n training = model.training\n model.eval()\n is_regression = task_name == 'stsb'\n metric = load_metric('glue', task_name)\n\n for batch in validation_dataloader:\n batch.pop('teacher_logits', None)\n batch.to(device)\n outputs = model(**batch)\n predictions = outputs.logits.argmax(dim=-1) if not is_regression else outputs.logits.squeeze()\n metric.add_batch(\n predictions=predictions,\n references=batch['labels'],\n )\n result = metric.compute()\n\n if validation_dataloader2:\n for batch in validation_dataloader2:\n batch.pop('teacher_logits', None)\n batch.to(device)\n outputs = model(**batch)\n predictions = outputs.logits.argmax(dim=-1) if not is_regression else outputs.logits.squeeze()\n metric.add_batch(\n predictions=predictions,\n references=batch['labels'],\n )\n result = {'matched': result, 'mismatched': metric.compute()}\n result['default'] = (result['matched']['accuracy'] + result['mismatched']['accuracy']) / 2\n else:\n result['default'] = result.get('f1', result.get('accuracy', None))\n\n model.train(training)\n return result\n\n# using huggingface native loss\ndef fake_criterion(outputs, targets):\n return outputs"
"import functools\nimport time\n\nimport torch.nn.functional as F\nfrom datasets import load_metric\nfrom transformers.modeling_outputs import SequenceClassifierOutput\n\n\ndef training(model: torch.nn.Module,\n optimizer: torch.optim.Optimizer,\n criterion: Callable[[torch.Tensor, torch.Tensor], torch.Tensor],\n lr_scheduler: torch.optim.lr_scheduler._LRScheduler = None,\n max_steps: int = None,\n max_epochs: int = None,\n train_dataloader: DataLoader = None,\n distillation: bool = False,\n teacher_model: torch.nn.Module = None,\n distil_func: Callable = None,\n log_path: str = Path(log_dir) / 'training.log',\n save_best_model: bool = False,\n save_path: str = None,\n evaluation_func: Callable = None,\n eval_per_steps: int = 1000,\n device=None):\n\n assert train_dataloader is not None\n\n model.train()\n if teacher_model is not None:\n teacher_model.eval()\n current_step = 0\n best_result = 0\n\n total_epochs = max_steps // len(train_dataloader) + 1 if max_steps else max_epochs if max_epochs else 3\n total_steps = max_steps if max_steps else total_epochs * len(train_dataloader)\n\n print(f'Training {total_epochs} epochs, {total_steps} steps...')\n\n for current_epoch in range(total_epochs):\n for batch in train_dataloader:\n if current_step >= total_steps:\n return\n batch.to(device)\n outputs = model(**batch)\n loss = outputs.loss\n\n if distillation:\n assert teacher_model is not None\n with torch.no_grad():\n teacher_outputs = teacher_model(**batch)\n distil_loss = distil_func(outputs, teacher_outputs)\n loss = 0.1 * loss + 0.9 * distil_loss\n\n loss = criterion(loss, None)\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n # per step schedule\n if lr_scheduler:\n lr_scheduler.step()\n\n current_step += 1\n\n if current_step % eval_per_steps == 0 or current_step % len(train_dataloader) == 0:\n result = evaluation_func(model) if evaluation_func else None\n with (log_path).open('a+') as f:\n msg = '[{}] Epoch {}, Step {}: {}\\n'.format(time.asctime(time.localtime(time.time())), current_epoch, current_step, result)\n f.write(msg)\n # if it's the best model, save it.\n if save_best_model and (result is None or best_result < result['default']):\n assert save_path is not None\n torch.save(model.state_dict(), save_path)\n best_result = None if result is None else result['default']\n\n\ndef distil_loss_func(stu_outputs: SequenceClassifierOutput, tea_outputs: SequenceClassifierOutput, encoder_layer_idxs=[]):\n encoder_hidden_state_loss = []\n for i, idx in enumerate(encoder_layer_idxs[:-1]):\n encoder_hidden_state_loss.append(F.mse_loss(stu_outputs.hidden_states[i], tea_outputs.hidden_states[idx]))\n logits_loss = F.kl_div(F.log_softmax(stu_outputs.logits / 2, dim=-1), F.softmax(tea_outputs.logits / 2, dim=-1), reduction='batchmean') * (2 ** 2)\n\n distil_loss = 0\n for loss in encoder_hidden_state_loss:\n distil_loss += loss\n distil_loss += logits_loss\n return distil_loss\n\n\ndef evaluation(model: torch.nn.Module, validation_dataloaders: Dict[str, DataLoader] = None, device=None):\n assert validation_dataloaders is not None\n training = model.training\n model.eval()\n\n is_regression = task_name == 'stsb'\n metric = load_metric('glue', task_name)\n\n result = {}\n default_result = 0\n for val_name, validation_dataloader in validation_dataloaders.items():\n for batch in validation_dataloader:\n batch.to(device)\n outputs = model(**batch)\n predictions = outputs.logits.argmax(dim=-1) if not is_regression else outputs.logits.squeeze()\n metric.add_batch(\n predictions=predictions,\n references=batch['labels'],\n )\n result[val_name] = metric.compute()\n default_result += result[val_name].get('f1', result[val_name].get('accuracy', 0))\n result['default'] = default_result / len(result)\n\n model.train(training)\n return result\n\n\nevaluation_func = functools.partial(evaluation, validation_dataloaders=validation_dataloaders, device=device)\n\n\ndef fake_criterion(loss, _):\n return loss"
"Using finetuned model as teacher model to create dataloader.\nAdd 'teacher_logits' to dataset, it is used to do the distillation, it can be seen as a kind of data label.\n\n"
"### Pruning\nAccording to experience, it is easier to achieve good results by pruning the attention part and the FFN part in stages.\nOf course, pruning together can also achieve the similar effect, but more parameter adjustment attempts are required.\nSo in this section, we do pruning in stages.\n\nFirst, we prune the attention layer with MovementPruner.\n\n"
"steps_per_epoch = len(train_dataloader)\n\n# Set training steps/epochs for pruning.\n\nif not dev_mode:\n total_epochs = 4\n total_steps = total_epochs * steps_per_epoch\n warmup_steps = 1 * steps_per_epoch\n cooldown_steps = 1 * steps_per_epoch\nelse:\n total_epochs = 1\n total_steps = 3\n warmup_steps = 1\n cooldown_steps = 1\n\n# Initialize evaluator used by MovementPruner.\n\nimport nni\nfrom nni.algorithms.compression.v2.pytorch import TorchEvaluator\n\nmovement_training = functools.partial(training, train_dataloader=train_dataloader,\n log_path=log_dir / 'movement_pruning.log',\n evaluation_func=evaluation_func, device=device)\ntraced_optimizer = nni.trace(Adam)(finetuned_model.parameters(), lr=3e-5, eps=1e-8)\n\ndef lr_lambda(current_step: int):\n if current_step < warmup_steps:\n return float(current_step) / warmup_steps\n return max(0.0, float(total_steps - current_step) / float(total_steps - warmup_steps))\n\ntraced_scheduler = nni.trace(LambdaLR)(traced_optimizer, lr_lambda)\nevaluator = TorchEvaluator(movement_training, traced_optimizer, fake_criterion, traced_scheduler)\n\n# Apply block-soft-movement pruning on attention layers.\n# Note that block sparse is introduced by `sparse_granularity='auto'`, and only support `bert`, `bart`, `t5` right now.\n\nfrom nni.compression.pytorch.pruning import MovementPruner\n\nconfig_list = [{\n 'op_types': ['Linear'],\n 'op_partial_names': ['bert.encoder.layer.{}.attention'.format(i) for i in range(layers_num)],\n 'sparsity': 0.1\n}]\n\npruner = MovementPruner(model=finetuned_model,\n config_list=config_list,\n evaluator=evaluator,\n training_epochs=total_epochs,\n training_steps=total_steps,\n warm_up_step=warmup_steps,\n cool_down_beginning_step=total_steps - cooldown_steps,\n regular_scale=10,\n movement_mode='soft',\n sparse_granularity='auto')\n_, attention_masks = pruner.compress()\npruner.show_pruned_weights()\n\ntorch.save(attention_masks, Path(log_dir) / 'attention_masks.pth')"
]
]
},
},
{
{
"cell_type": "markdown",
"cell_type": "markdown",
"metadata": {},
"metadata": {},
"source": [
"source": [
"### Pruning\nFirst, using MovementPruner to prune attention head.\n\n"
"Load a new finetuned model to do speedup, you can think of this as using the finetuned state to initialize the pruned model weights.\nNote that nni speedup don't support replacing attention module, so here we manully replace the attention module.\n\nIf the head is entire masked, physically prune it and create config_list for FFN pruning.\n\n"
"attention_pruned_model = create_finetuned_model().to(device)\nattention_masks = torch.load(Path(log_dir) / 'attention_masks.pth')\n\nffn_config_list = []\nlayer_remained_idxs = []\nmodule_list = []\nfor i in range(0, layers_num):\n prefix = f'bert.encoder.layer.{i}.'\n value_mask: torch.Tensor = attention_masks[prefix + 'attention.self.value']['weight']\n head_mask = (value_mask.reshape(heads_num, -1).sum(-1) == 0.)\n head_idxs = torch.arange(len(head_mask))[head_mask].long().tolist()\n print(f'layer {i} prune {len(head_idxs)} head: {head_idxs}')\n if len(head_idxs) != heads_num:\n attention_pruned_model.bert.encoder.layer[i].attention.prune_heads(head_idxs)\n module_list.append(attention_pruned_model.bert.encoder.layer[i])\n # The final ffn weight remaining ratio is the half of the attention weight remaining ratio.\n # This is just an empirical configuration, you can use any other method to determine this sparsity.\n sparsity = 1 - (1 - len(head_idxs) / heads_num) * 0.5\n # here we use a simple sparsity schedule, we will prune ffn in 12 iterations, each iteration prune `sparsity_per_iter`.\n sparsity_per_iter = 1 - (1 - sparsity) ** (1 / 12)\n ffn_config_list.append({\n 'op_names': [f'bert.encoder.layer.{len(layer_remained_idxs)}.intermediate.dense'],\n 'sparsity': sparsity_per_iter\n })\n layer_remained_idxs.append(i)\n\nattention_pruned_model.bert.encoder.layer = torch.nn.ModuleList(module_list)\ndistil_func = functools.partial(distil_loss_func, encoder_layer_idxs=layer_remained_idxs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Load a new finetuned model to do the speedup.\nNote that nni speedup don't support replace attention module, so here we manully replace the attention module.\n\nIf the head is entire masked, physically prune it and create config_list for FFN pruning.\n\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"attention_pruned_model = create_finetuned_model().to(device)\nattention_masks = torch.load(Path(log_dir) / 'attention_masks.pth')\n\nffn_config_list = []\nlayer_count = 0\nmodule_list = []\nfor i in range(0, layers_num):\n prefix = f'bert.encoder.layer.{i}.'\n value_mask: torch.Tensor = attention_masks[prefix + 'attention.self.value']['weight']\n head_mask = (value_mask.reshape(heads_num, -1).sum(-1) == 0.)\n head_idx = torch.arange(len(head_mask))[head_mask].long().tolist()\n print(f'layer {i} pruner {len(head_idx)} head: {head_idx}')\n if len(head_idx) != heads_num:\n attention_pruned_model.bert.encoder.layer[i].attention.prune_heads(head_idx)\n module_list.append(attention_pruned_model.bert.encoder.layer[i])\n # The final ffn weight remaining ratio is the half of the attention weight remaining ratio.\n # This is just an empirical configuration, you can use any other method to determine this sparsity.\n sparsity = 1 - (1 - len(head_idx) / heads_num) * 0.5\n # here we use a simple sparsity schedule, we will prune ffn in 12 iterations, each iteration prune `sparsity_per_iter`.\n sparsity_per_iter = 1 - (1 - sparsity) ** (1 / heads_num)\n ffn_config_list.append({'op_names': [f'bert.encoder.layer.{layer_count}.intermediate.dense'], 'sparsity': sparsity_per_iter})\n layer_count += 1\n\nattention_pruned_model.bert.encoder.layer = torch.nn.ModuleList(module_list)"
"Iterative pruning FFN with TaylorFOWeightPruner in 12 iterations.\nFinetuning 2000 steps after each iteration, then finetuning 2 epochs after pruning finished.\n\nNNI will support per-step-pruning-schedule in the future, then can use an pruner to replace the following code.\n\n"
"Iterative pruning FFN with TaylorFOWeightPruner in 12 iterations.\nFinetuning 3000 steps after each pruning iteration, then finetuning 2 epochs after pruning finished.\n\nNNI will support per-step-pruning-schedule in the future, then can use an pruner to replace the following code.\n\n"
]
]
},
},
{
{
...
@@ -188,14 +170,14 @@
...
@@ -188,14 +170,14 @@
},
},
"outputs": [],
"outputs": [],
"source": [
"source": [
"if not dev_mode:\n total_epochs = 4\n total_steps = None\n taylor_pruner_steps = 1000\n steps_per_iteration = 2000\n total_pruning_steps = 24000\n distillation = True\nelse:\n total_epochs = 1\n total_steps = 6\n taylor_pruner_steps = 2\n steps_per_iteration = 2\n total_pruning_steps = 4\n distillation = False\n\nfrom nni.compression.pytorch.pruning import TaylorFOWeightPruner\nfrom nni.compression.pytorch.speedup import ModelSpeedup\n\ndistil_training = functools.partial(training, train_dataloader, log_path=log_dir / 'taylor_pruning.log',\n distillation=distillation, evaluation_func=evaluation_func)\ntraced_optimizer = nni.trace(Adam)(attention_pruned_model.parameters(), lr=3e-5, eps=1e-8)\nevaluator = TorchEvaluator(distil_training, traced_optimizer, fake_criterion)\n\ncurrent_step = 0\nbest_result = 0\ninit_lr = 3e-5\n\ndummy_input = torch.rand(8, 128, 768).to(device)\n\nattention_pruned_model.train()\nfor current_epoch in range(total_epochs):\n for batch in train_dataloader:\n if total_steps and current_step >= total_steps:\n break\n # pruning 12 times\n if current_step % steps_per_iteration == 0 and current_step < total_pruning_steps:\n check_point = attention_pruned_model.state_dict()\n pruner = TaylorFOWeightPruner(attention_pruned_model, ffn_config_list, evaluator, taylor_pruner_steps)\n _, ffn_masks = pruner.compress()\n renamed_ffn_masks = {}\n # rename the masks keys, because we only speedup the bert.encoder\n for model_name, targets_mask in ffn_masks.items():\n renamed_ffn_masks[model_name.split('bert.encoder.')[1]] = targets_mask\n pruner._unwrap_model()\n attention_pruned_model.load_state_dict(check_point)\n ModelSpeedup(attention_pruned_model.bert.encoder, dummy_input, renamed_ffn_masks).speedup_model()\n optimizer = Adam(attention_pruned_model.parameters(), lr=init_lr)\n\n batch.to(device)\n teacher_logits = batch.pop('teacher_logits', None)\n optimizer.zero_grad()\n\n # manually schedule lr\n for params_group in optimizer.param_groups:\n params_group['lr'] = (1 - current_step / (total_epochs * steps_per_epoch)) * init_lr\n\n outputs = attention_pruned_model(**batch)\n loss = outputs.loss\n\n # distillation\n if teacher_logits is not None:\n distil_loss = F.kl_div(F.log_softmax(outputs.logits / 2, dim=-1),\n F.softmax(teacher_logits / 2, dim=-1), reduction='batchmean') * (2 ** 2)\n loss = 0.1 * loss + 0.9 * distil_loss\n loss.backward()\n optimizer.step()\n\n current_step += 1\n if current_step % 1000 == 0 or current_step % len(train_dataloader) == 0:\n result = evaluation_func(attention_pruned_model)\n with (log_dir / 'ffn_pruning.log').open('a+') as f:\n msg = '[{}] Epoch {}, Step {}: {}\\n'.format(time.asctime(time.localtime(time.time())),\n current_epoch, current_step, result)\n f.write(msg)\n if current_step >= total_pruning_steps and best_result < result['default']:\n torch.save(attention_pruned_model, log_dir / 'best_model.pth')\n best_result = result['default']"
"if not dev_mode:\n total_epochs = 7\n total_steps = None\n taylor_pruner_steps = 1000\n steps_per_iteration = 3000\n total_pruning_steps = 36000\n distillation = True\nelse:\n total_epochs = 1\n total_steps = 6\n taylor_pruner_steps = 2\n steps_per_iteration = 2\n total_pruning_steps = 4\n distillation = False\n\nfrom nni.compression.pytorch.pruning import TaylorFOWeightPruner\nfrom nni.compression.pytorch.speedup import ModelSpeedup\n\ndistil_training = functools.partial(training, train_dataloader=train_dataloader, distillation=distillation,\n teacher_model=teacher_model, distil_func=distil_func, device=device)\ntraced_optimizer = nni.trace(Adam)(attention_pruned_model.parameters(), lr=3e-5, eps=1e-8)\nevaluator = TorchEvaluator(distil_training, traced_optimizer, fake_criterion)\n\ncurrent_step = 0\nbest_result = 0\ninit_lr = 3e-5\n\ndummy_input = torch.rand(8, 128, 768).to(device)\n\nattention_pruned_model.train()\nfor current_epoch in range(total_epochs):\n for batch in train_dataloader:\n if total_steps and current_step >= total_steps:\n break\n # pruning with TaylorFOWeightPruner & reinitialize optimizer\n if current_step % steps_per_iteration == 0 and current_step < total_pruning_steps:\n check_point = attention_pruned_model.state_dict()\n pruner = TaylorFOWeightPruner(attention_pruned_model, ffn_config_list, evaluator, taylor_pruner_steps)\n _, ffn_masks = pruner.compress()\n renamed_ffn_masks = {}\n # rename the masks keys, because we only speedup the bert.encoder\n for model_name, targets_mask in ffn_masks.items():\n renamed_ffn_masks[model_name.split('bert.encoder.')[1]] = targets_mask\n pruner._unwrap_model()\n attention_pruned_model.load_state_dict(check_point)\n ModelSpeedup(attention_pruned_model.bert.encoder, dummy_input, renamed_ffn_masks).speedup_model()\n optimizer = Adam(attention_pruned_model.parameters(), lr=init_lr)\n\n batch.to(device)\n # manually schedule lr\n for params_group in optimizer.param_groups:\n params_group['lr'] = (1 - current_step / (total_epochs * steps_per_epoch)) * init_lr\n\n outputs = attention_pruned_model(**batch)\n loss = outputs.loss\n\n # distillation\n if distillation:\n assert teacher_model is not None\n with torch.no_grad():\n teacher_outputs = teacher_model(**batch)\n distil_loss = distil_func(outputs, teacher_outputs)\n loss = 0.1 * loss + 0.9 * distil_loss\n\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n current_step += 1\n\n if current_step % 1000 == 0 or current_step % len(train_dataloader) == 0:\n result = evaluation_func(attention_pruned_model)\n with (log_dir / 'ffn_pruning.log').open('a+') as f:\n msg = '[{}] Epoch {}, Step {}: {}\\n'.format(time.asctime(time.localtime(time.time())),\n current_epoch, current_step, result)\n f.write(msg)\n if current_step >= total_pruning_steps and best_result < result['default']:\n torch.save(attention_pruned_model, log_dir / 'best_model.pth')\n best_result = result['default']"
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertForSequenceClassification: ['cls.seq_relationship.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.bias', 'cls.predictions.transform.dense.weight']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertForSequenceClassification: ['cls.seq_relationship.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.bias', 'cls.predictions.transform.dense.weight']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
if current_step % 1000 == 0 or current_step % len(train_dataloader) == 0:
if current_step % 1000 == 0 or current_step % len(train_dataloader) == 0:
result = evaluation_func(attention_pruned_model)
result = evaluation_func(attention_pruned_model)
with (log_dir / 'ffn_pruning.log').open('a+') as f:
with (log_dir / 'ffn_pruning.log').open('a+') as f:
...
@@ -707,22 +643,7 @@ NNI will support per-step-pruning-schedule in the future, then can use an pruner
...
@@ -707,22 +643,7 @@ NNI will support per-step-pruning-schedule in the future, then can use an pruner
.. GENERATED FROM PYTHON SOURCE LINES 538-593
.. rst-class:: sphx-glr-script-out
.. code-block:: none
Did not bind any model, no need to unbind model.
no multi-dimension masks found.
/home/nishang/anaconda3/envs/nni-dev/lib/python3.7/site-packages/torch/_tensor.py:1083: UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations. (Triggered internally at aten/src/ATen/core/TensorBody.h:477.)

{kind=link}
{kind=link}