# Tutorial for Advanced Neural Architecture Search
Currently many of the NAS algorithms leverage the technique of **weight sharing** among trials to accelerate its training process. For example, [ENAS][1] delivers 1000x effiency with '_parameter sharing between child models_', compared with the previous [NASNet][2] algorithm. Other NAS algorithms such as [DARTS][3], [Network Morphism][4], and [Evolution][5] is also leveraging, or has the potential to leverage weight sharing.
This is a tutorial on how to enable weight sharing in NNI.
## Weight Sharing among trials
Currently we recommend sharing weights through NFS (Network File System), which supports sharing files across machines, and is light-weighted, (relatively) efficient. We also welcome contributions from the community on more efficient techniques.
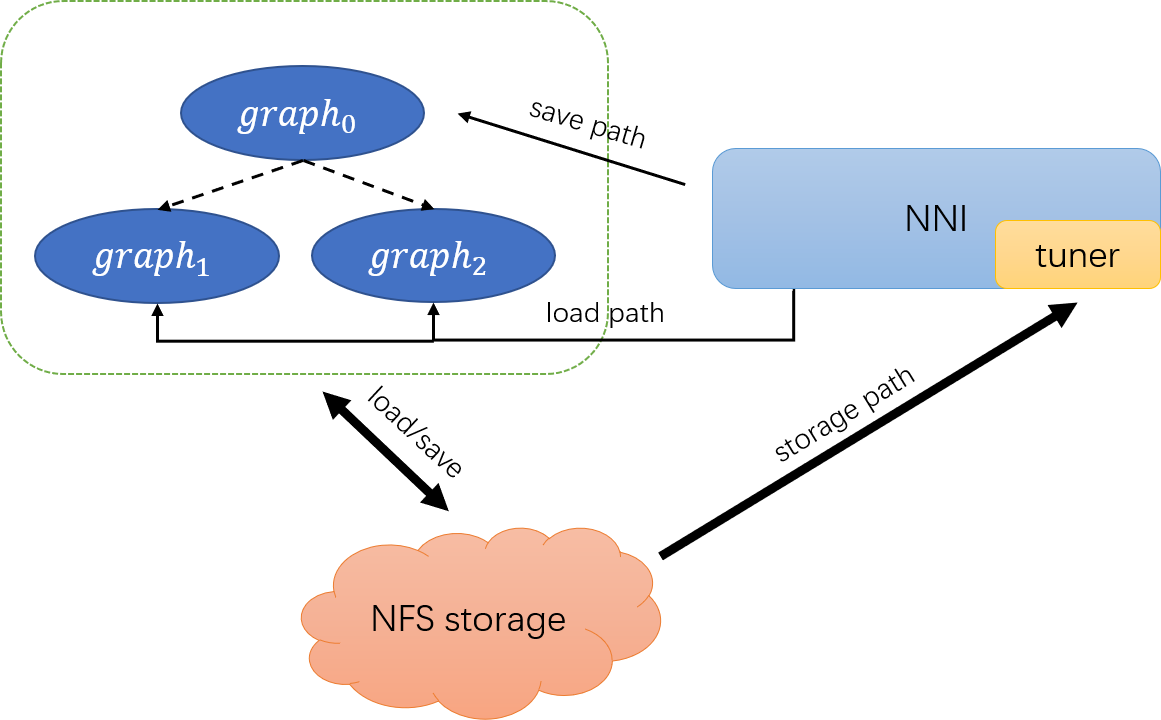
### Weight Sharing through NFS file
With the NFS setup (see below), trial code can share model weight through loading & saving files. Here we recommend that user feed the tuner with the storage path:
```yaml
tuner:
codeDir:path/to/customer_tuner
classFileName:customer_tuner.py
className:CustomerTuner
classArgs:
...
save_dir_root:/nfs/storage/path/
```
And let tuner decide where to save & load weights and feed the paths to trials through `nni.get_next_parameters()`:
where `'save_path'` and `'restore_path'` in hyper-parameter can be managed by the tuner.
### NFS Setup
In NFS, files are physically stored on a server machine, and trials on the client machine can read/write those files in the same way that they access local files.
#### Install NFS on server machine
First, install NFS server:
```bash
sudo apt-get install nfs-kernel-server
```
Suppose `/tmp/nni/shared` is used as the physical storage, then run:
You can check if the above directory is successfully exported by NFS using `sudo showmount -e localhost`
#### Install NFS on client machine
First, install NFS client:
```bash
sudo apt-get install nfs-common
```
Then create & mount the mounted directory of shared files:
```bash
sudo mkdir-p /mnt/nfs/nni/
sudo mount -t nfs 10.10.10.10:/tmp/nni/shared /mnt/nfs/nni
```
where `10.10.10.10` should be replaced by the real IP of NFS server machine in practice.
## Asynchornous Dispatcher Mode for trial dependency control
The feature of weight sharing enables trials from different machines, in which most of the time **read after write** consistency must be assured. After all, the child model should not load parent model before parent trial finishes training. To deal with this, users can enable **asynchronous dispatcher mode** with `multiThread: true` in `config.yml` in NNI, where the dispatcher assign a tuner thread each time a `NEW_TRIAL` request comes in, and the tuner thread can decide when to submit a new trial by blocking and unblocking the thread itself. For example:
For details, please refer to this [simple weight sharing example](../test/async_sharing_test). We also provided a [practice example](../examples/trials/weight_sharing/ga_squad) for reading comprehension, based on previous [ga_squad](../examples/trials/ga_squad) example.

{kind=link}