
Merge pull request #121 from Microsoft/master
merge master
Showing
{kind=link}
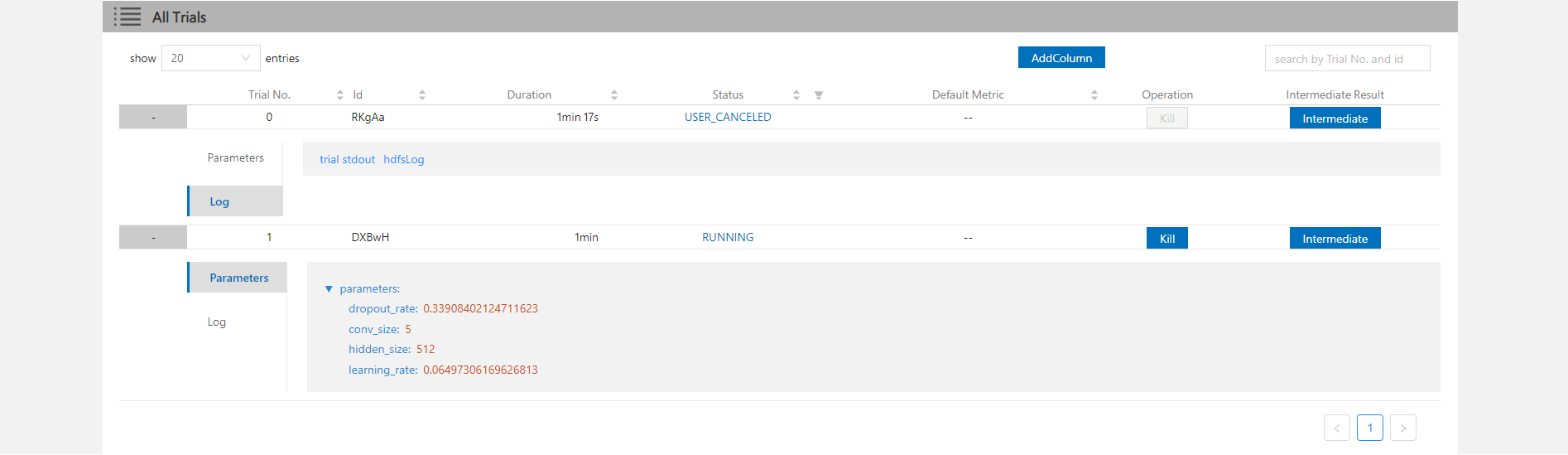
28.9 KB
{kind=link}
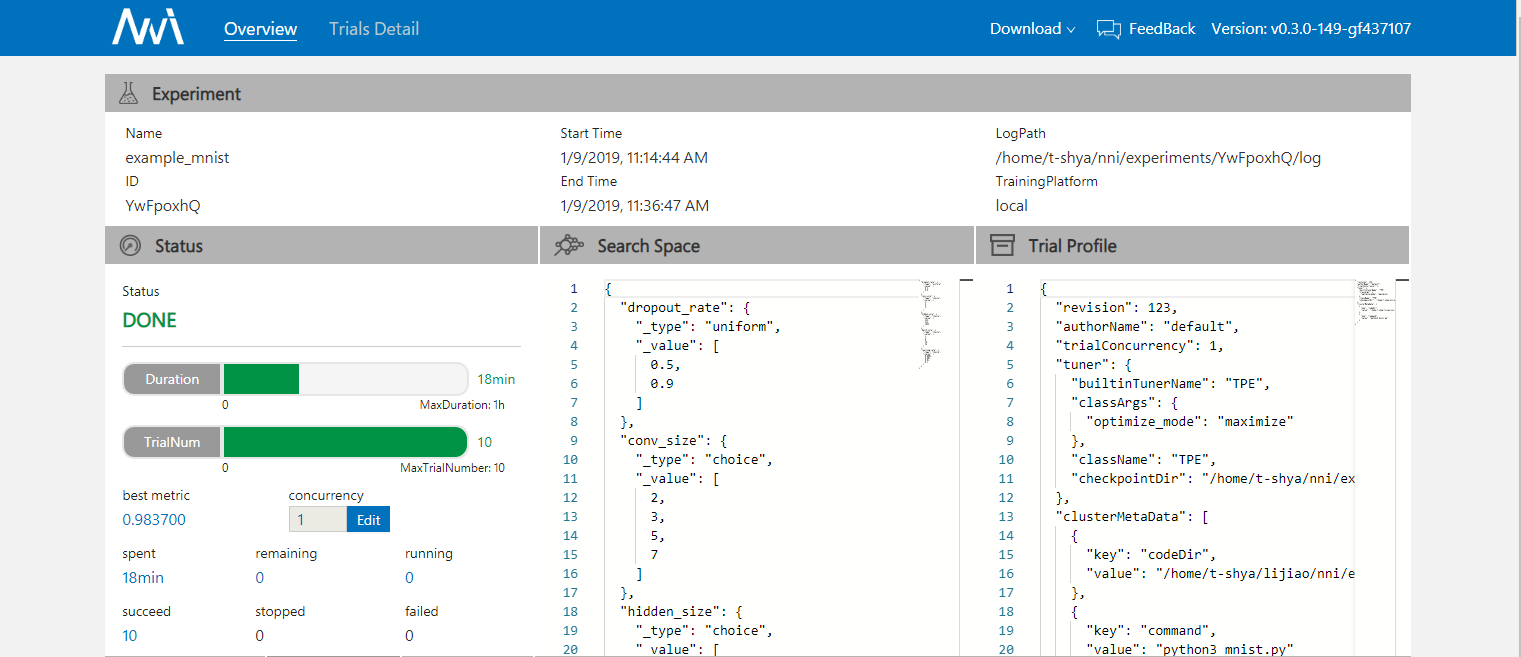
67.1 KB
{kind=link}

35.3 KB
{kind=link}
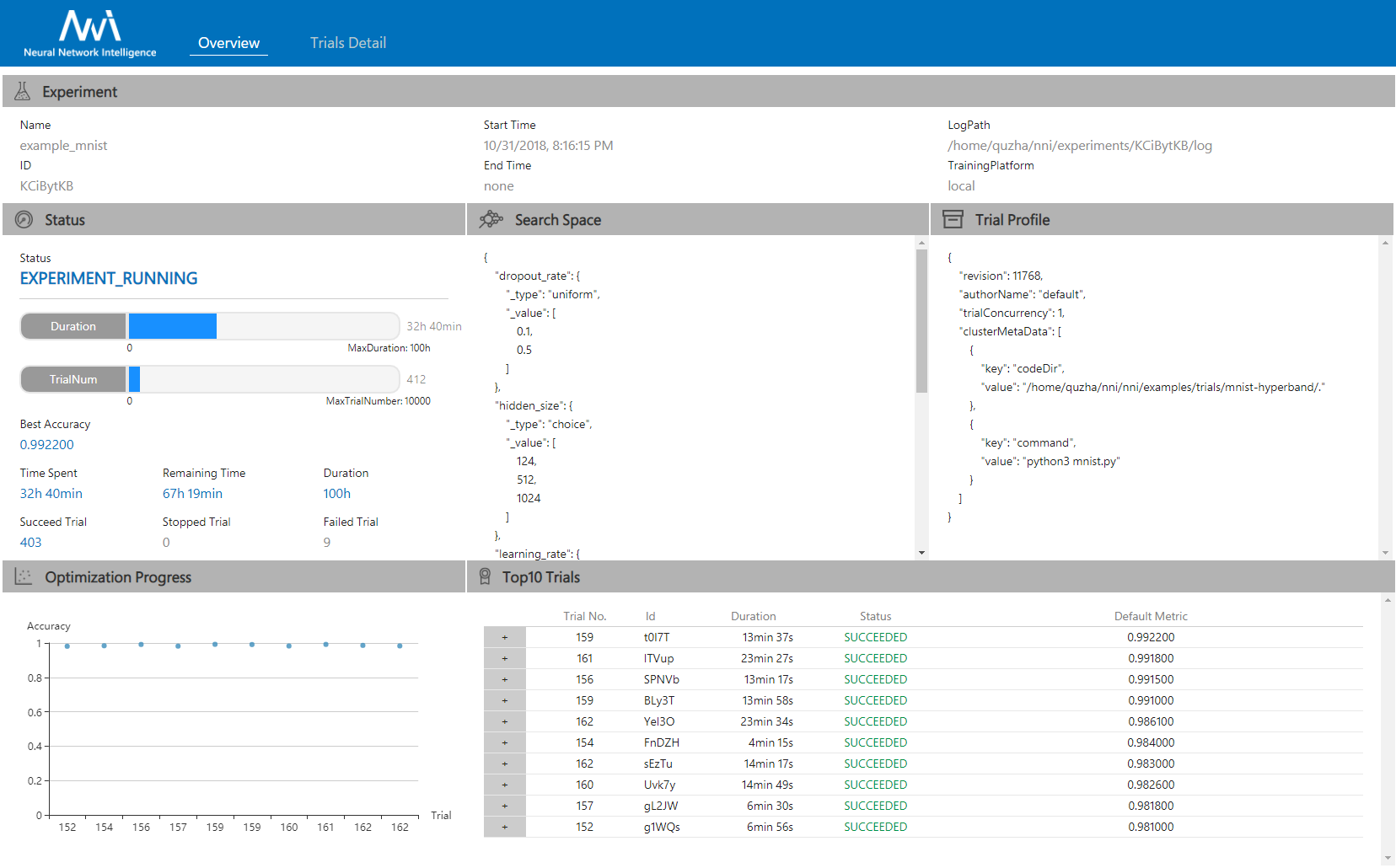
88.2 KB
{kind=link}

93.8 KB
{kind=link}
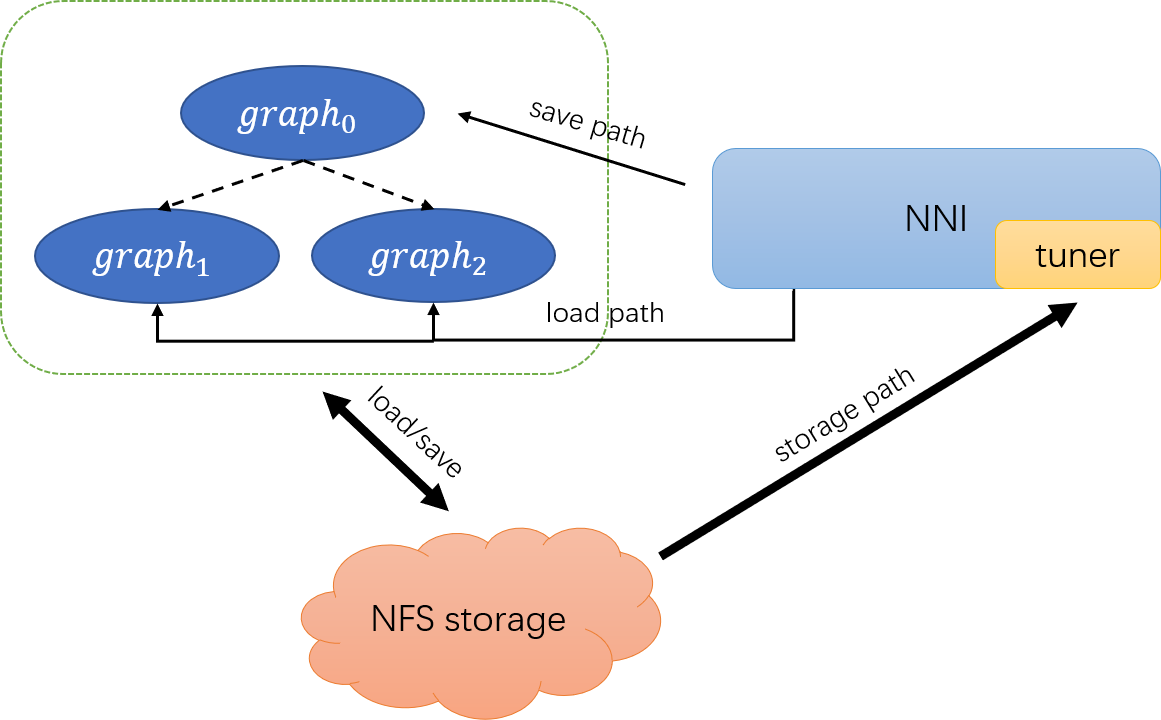
69.7 KB
zh_CN/docs/index.rst
0 → 100644
zh_CN/docs/mnist_examples.md
0 → 100644
zh_CN/docs/multiPhase.md
0 → 100644
zh_CN/docs/requirements.txt
0 → 100644
zh_CN/docs/sdk_reference.rst
0 → 100644
zh_CN/docs/tuners.rst
0 → 100644
{kind=link}
29.6 KB