
Merge pull request #121 from Microsoft/master
merge master
Showing
docs/gbdt_example.md
0 → 100644
docs/img/Assessor.png
0 → 100644
{kind=link}
119 KB
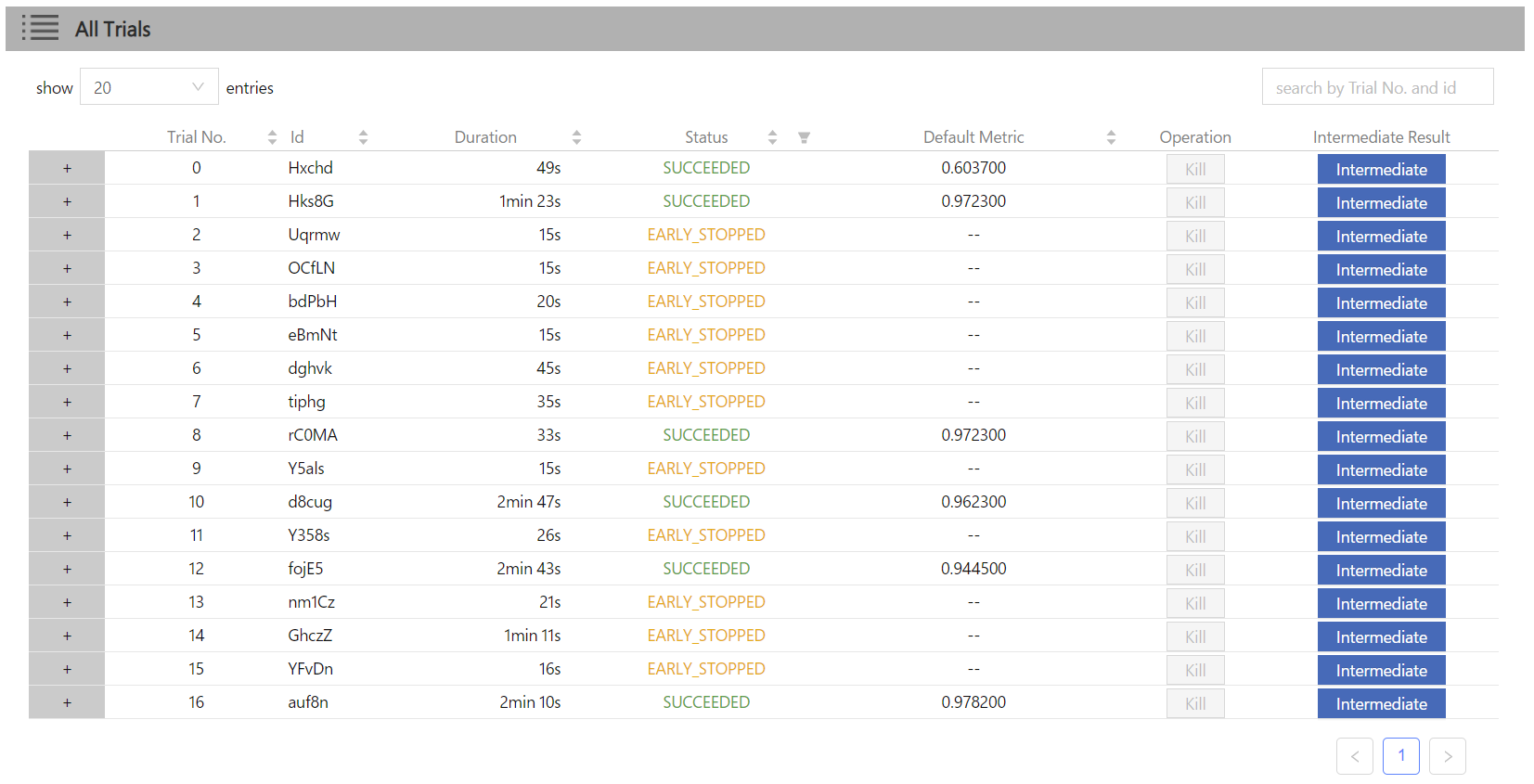
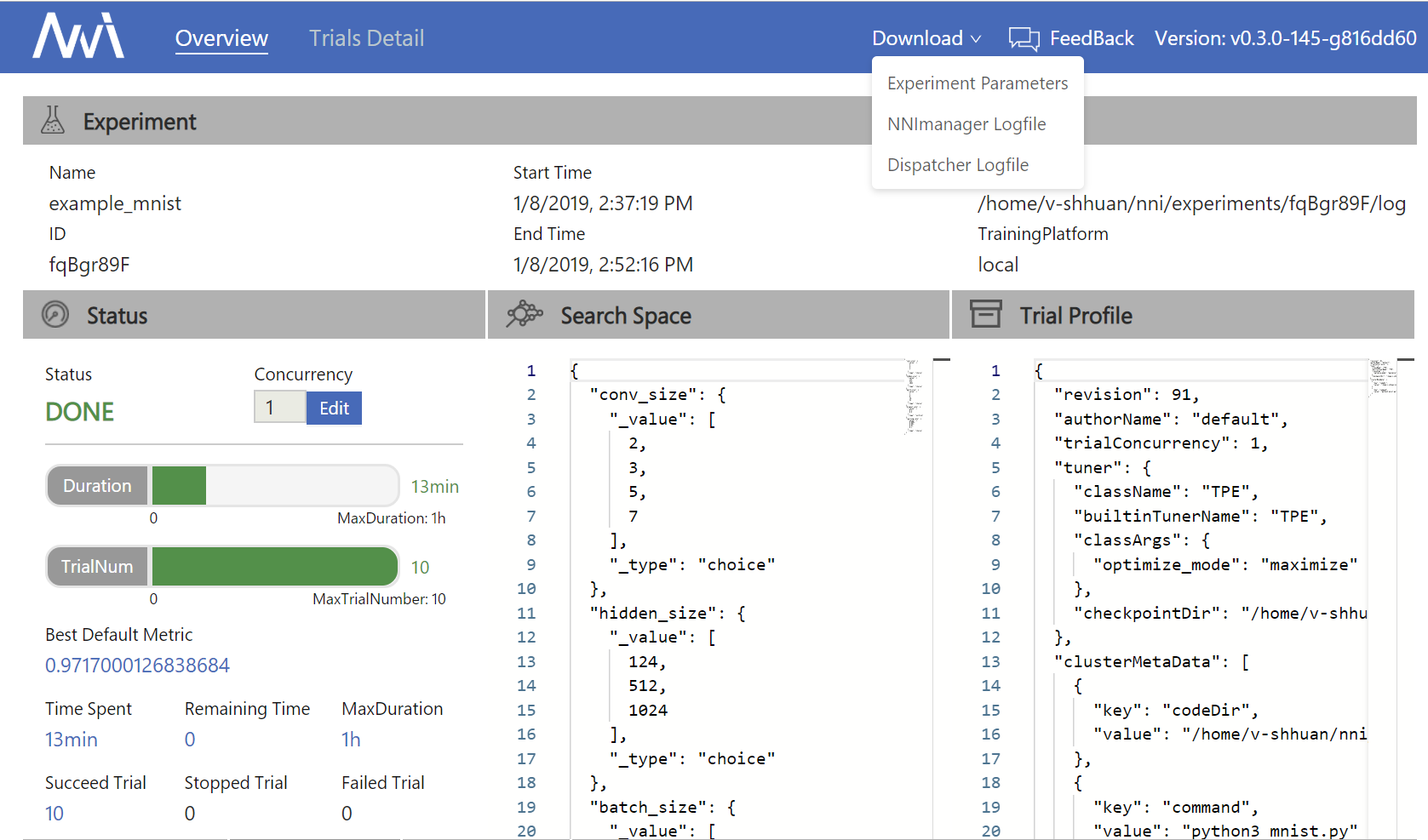
docs/img/QuickStart1.png
0 → 100644
{kind=link}
162 KB
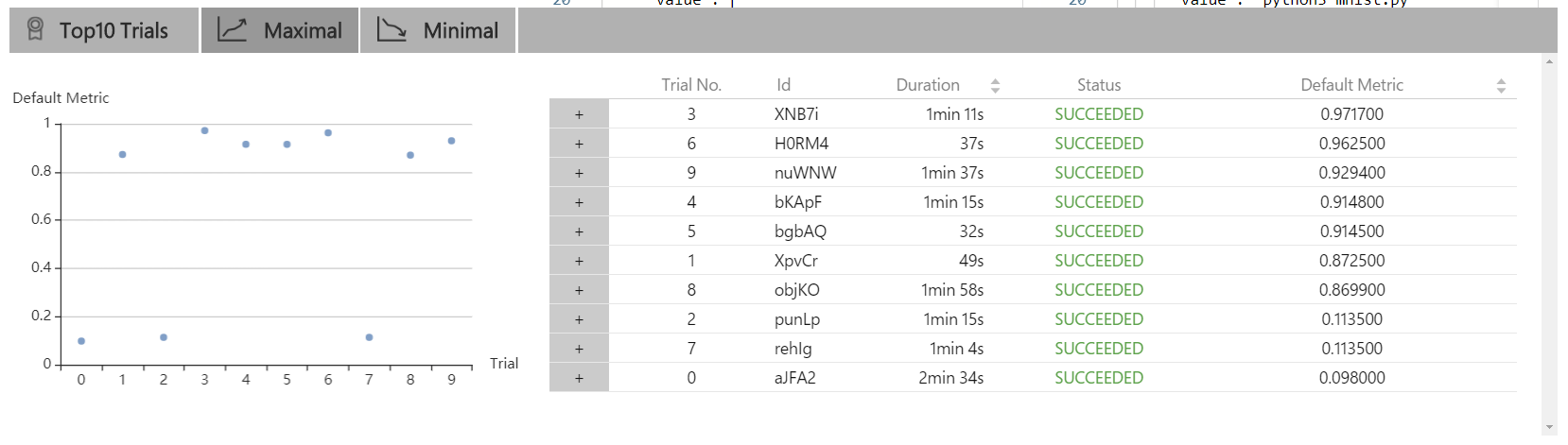
docs/img/QuickStart2.png
0 → 100644
{kind=link}
67.6 KB
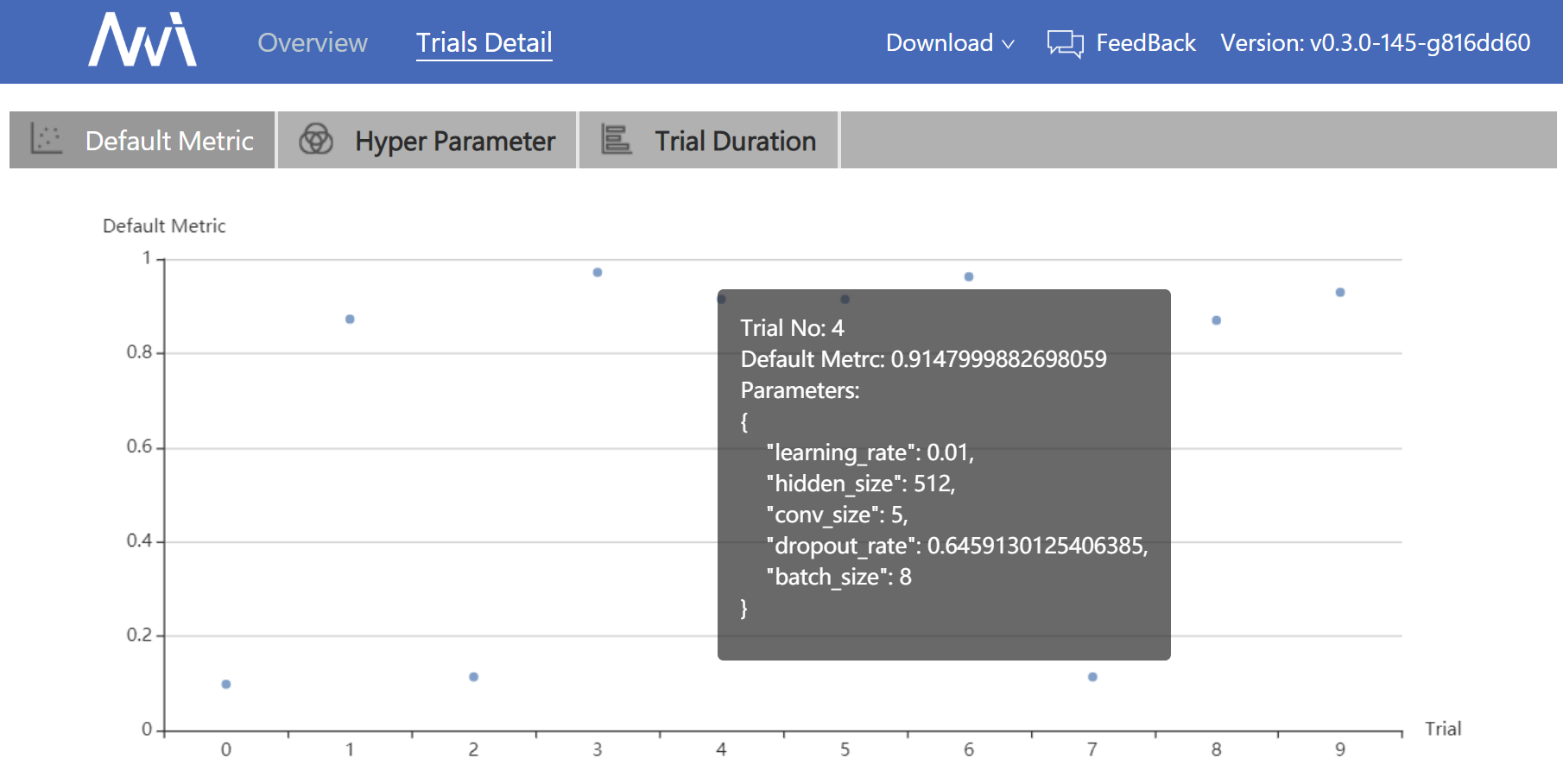
docs/img/QuickStart3.png
0 → 100644
{kind=link}
92.2 KB
docs/img/QuickStart4.png
0 → 100644
{kind=link}
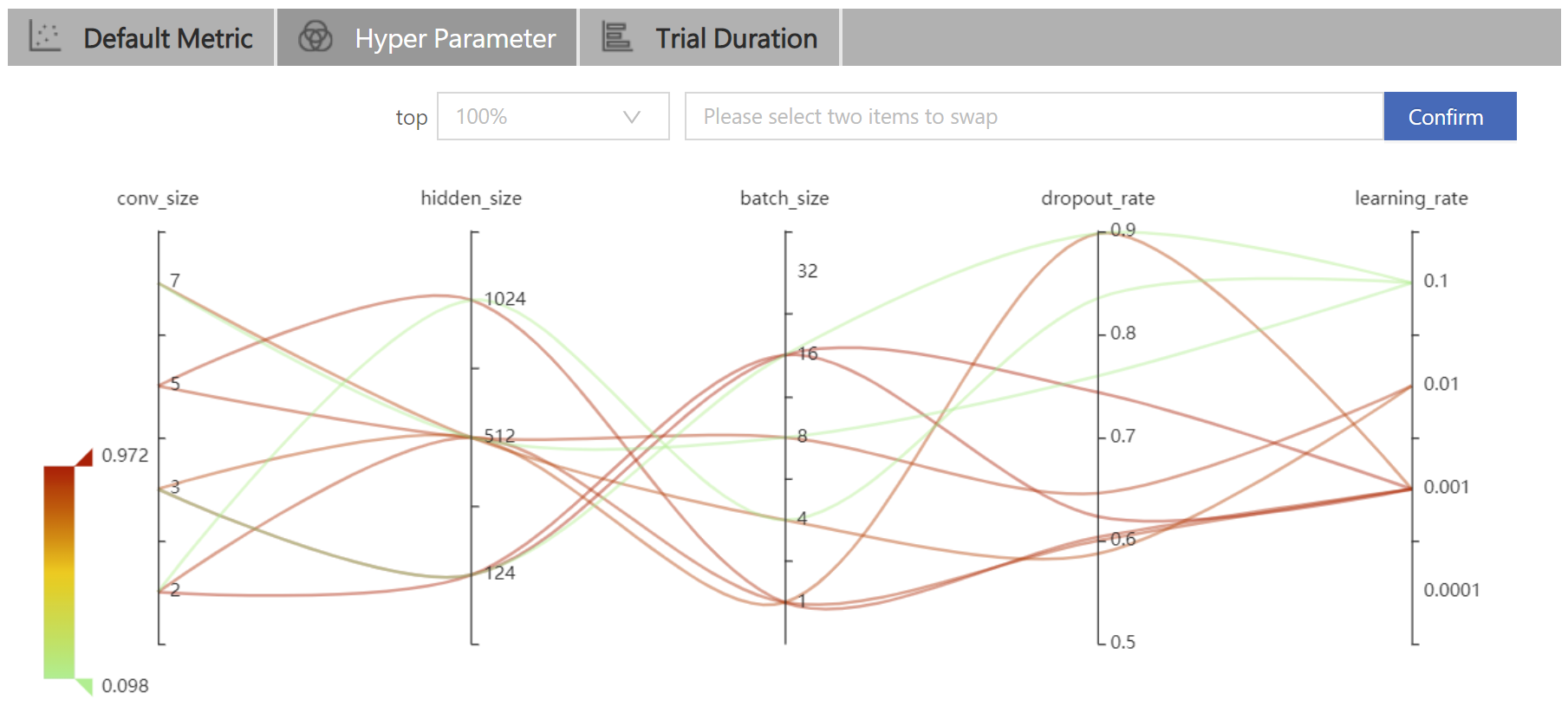
292 KB
docs/img/QuickStart5.png
0 → 100644
{kind=link}
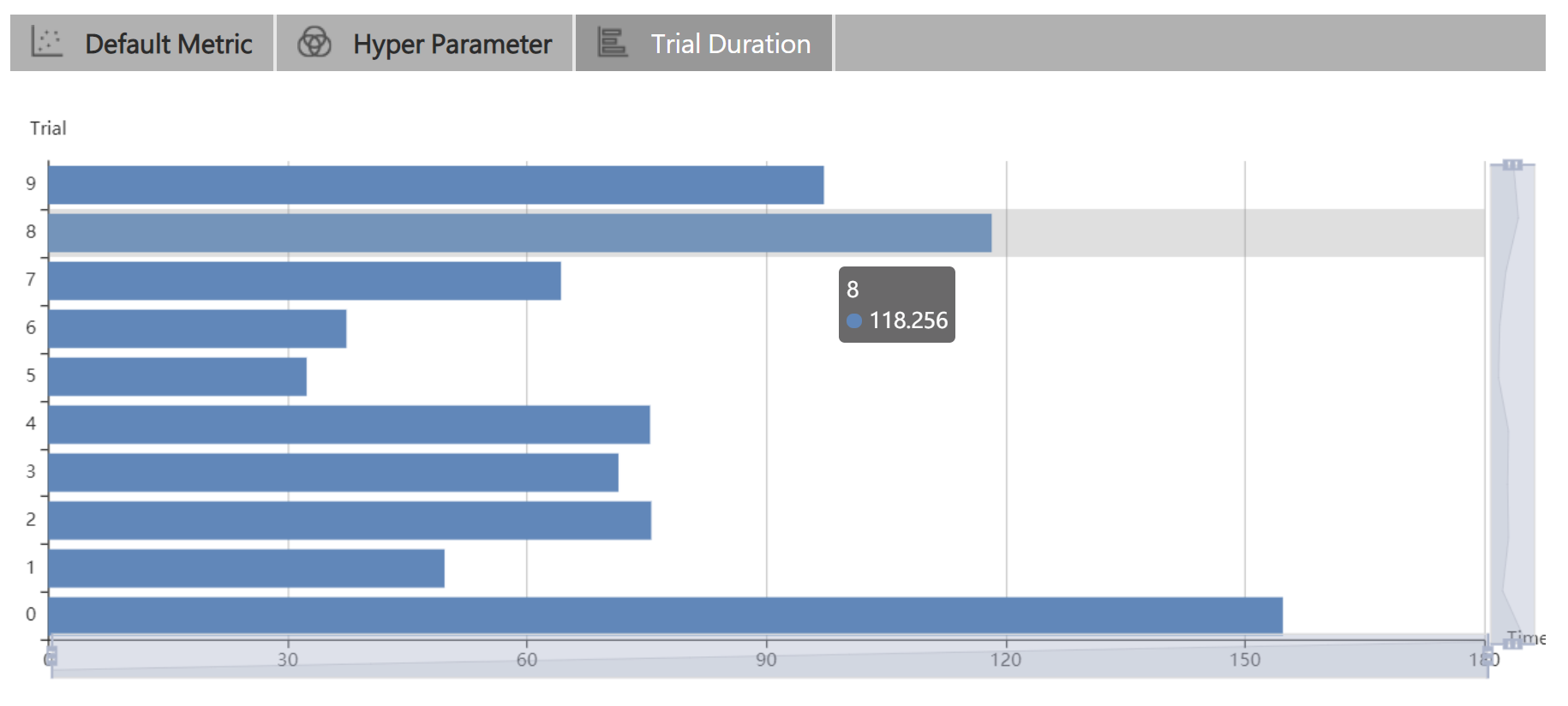
71.5 KB
docs/img/QuickStart6.png
0 → 100644
{kind=link}
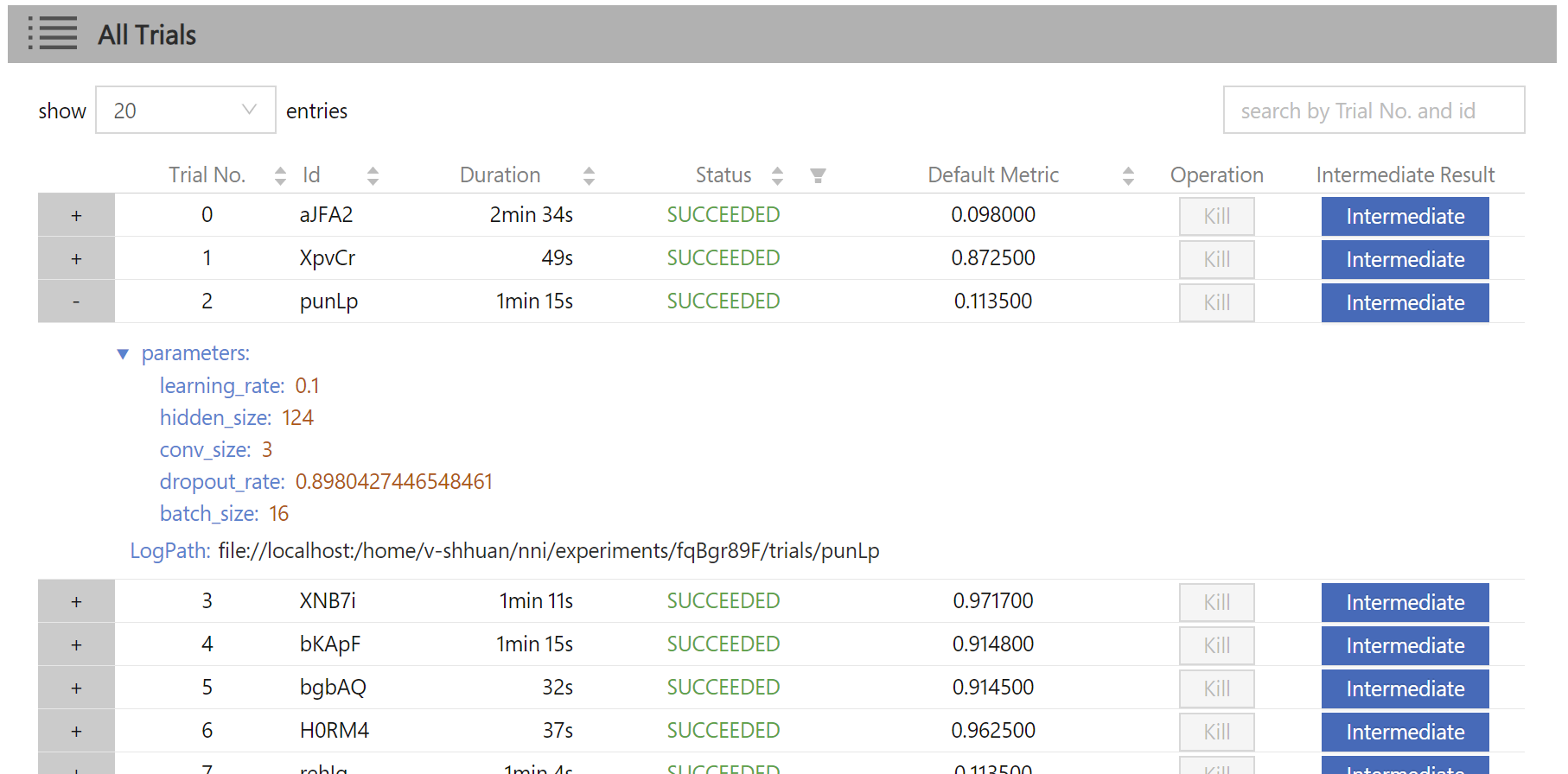
118 KB
docs/img/QuickStart7.png
0 → 100644
{kind=link}
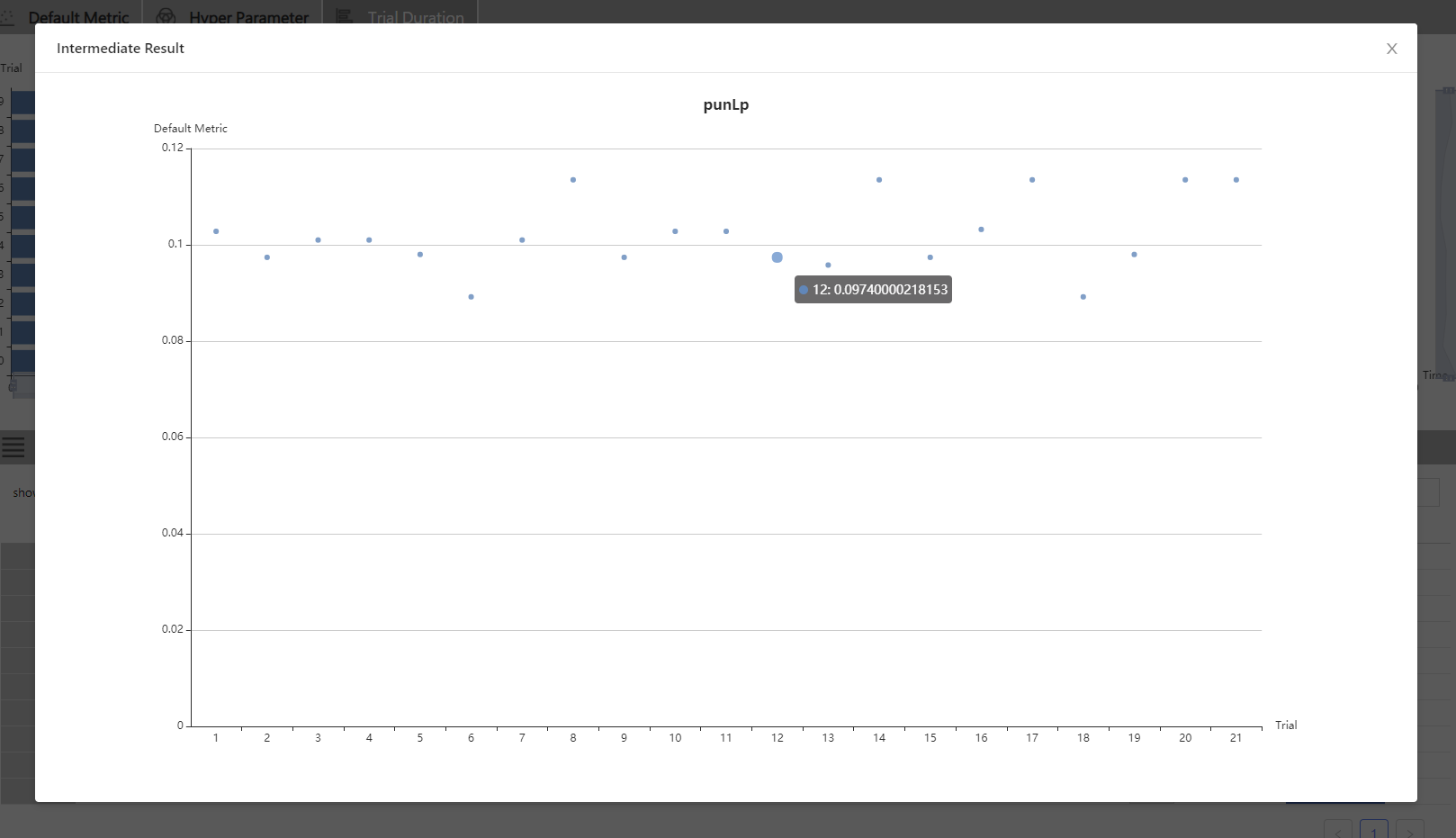
36.7 KB
docs/img/highlevelarchi.png
0 → 100644
{kind=link}
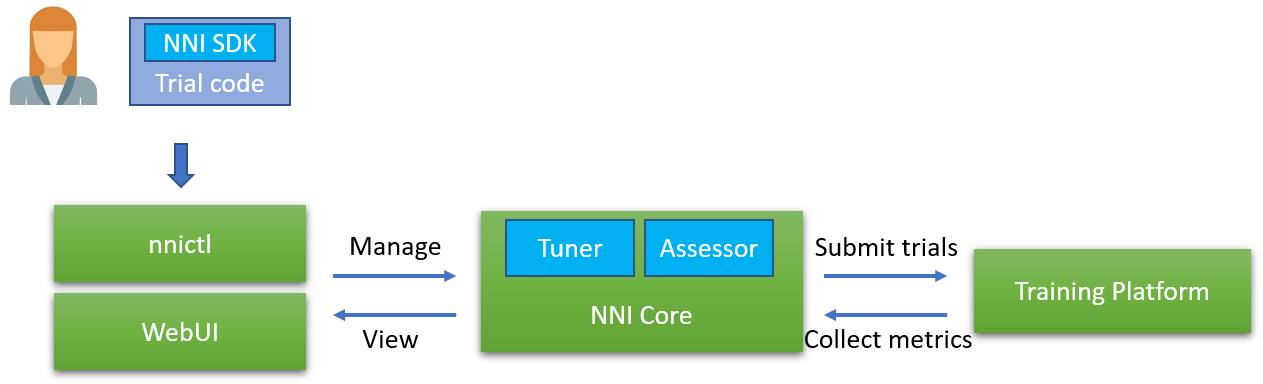
33.2 KB
docs/img/nni_logo_dark.png
0 → 100644
{kind=link}
22.2 KB
docs/index.rst
0 → 100644
docs/mnist_examples.md
0 → 100644
docs/requirements.txt
0 → 100644
docs/sdk_reference.rst
0 → 100644
docs/sklearn_examples.md
0 → 100644
docs/training_services.rst
0 → 100644
docs/tuners.rst
0 → 100644