Deep neural networks (DNNs) have achieved great success in many tasks.
Deep neural networks (DNNs) have achieved great success in many tasks like embedded development and scenarios that needs rapid feedbacks.
However, typical neural networks are both computationally expensive and energy-intensive,
can be difficult to be deployed on devices with low computation resources or with strict latency requirements.
which can be difficult to be deployed on devices with low computation resources or with strict latency requirements.
Therefore, a natural thought is to perform model compression to reduce model size and accelerate model training/inference without losing performance significantly.
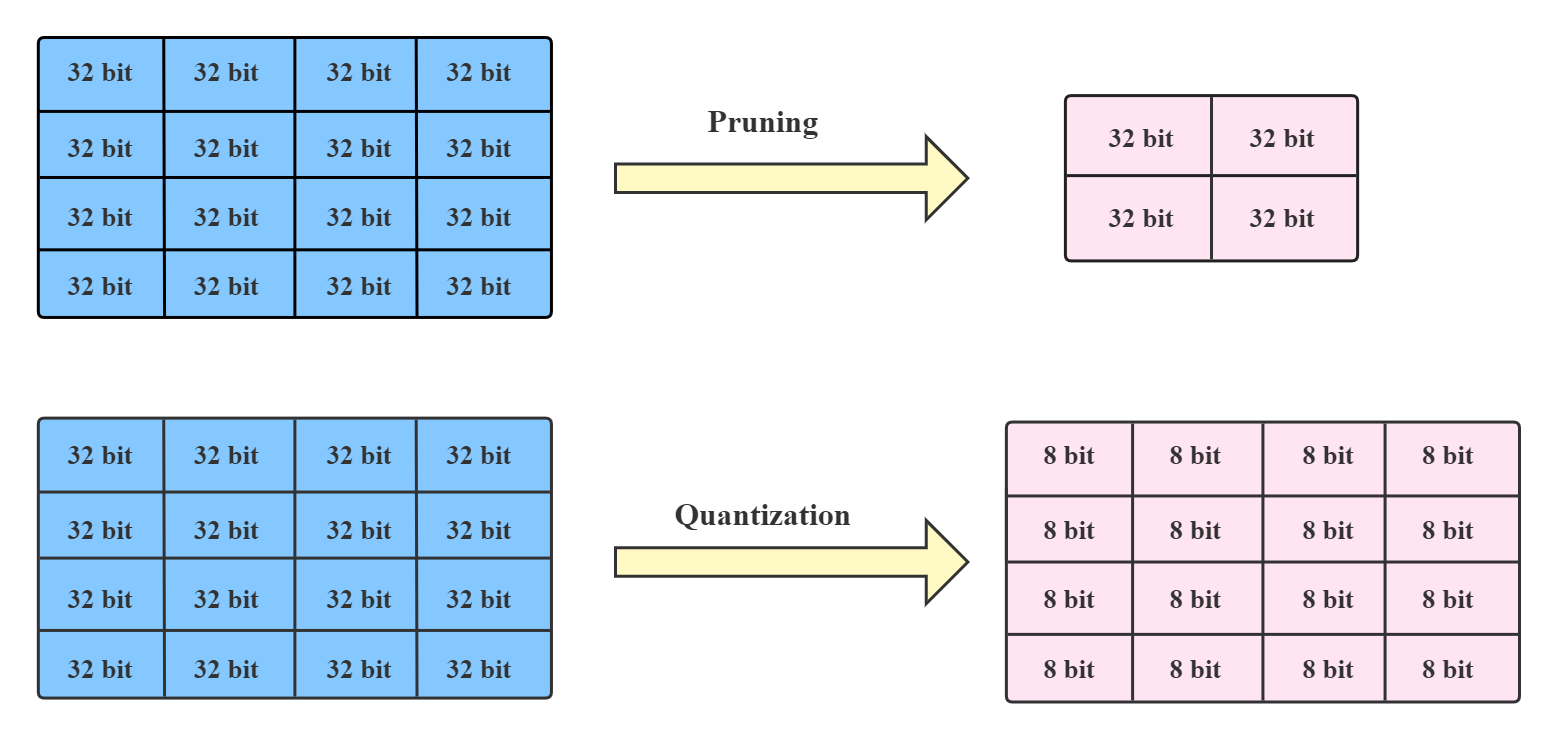
Model compression techniques can be divided into two categories: pruning and quantization.
The pruning methods explore the redundancy in the model weights and try to remove/prune the redundant and uncritical weights.
Quantization refers to compressing models by reducing the number of bits required to represent weights or activations.
Quantization refers to compressing models by reducing the number of bits required to represent weights or activations functions.
We further elaborate on the two methods, pruning and quantization, in the following chapters. Besides, the figure below visualizes the difference between these two methods.
.. image:: ../../img/prune_quant.jpg
:target: ../../img/prune_quant.jpg
:scale: 40%
:alt:
NNI provides an easy-to-use toolkit to help users design and use model pruning and quantization algorithms.
For users to compress their models, they only need to add several lines in their code.
There are some popular model compression algorithms built-in in NNI.
Users could further use NNI’s auto-tuning power to find the bestcompressed model, which is detailed in Auto Model Compression.
Users could further use NNI’s auto-tuning power to find the best-compressed model, which is detailed in Auto Model Compression.
On the other hand, users could easily customize their new compression algorithms using NNI’s interface.
There are several core features supported by NNI model compression:
* Support many popular pruning and quantization algorithms.
* Automate model pruning and quantization process with state-of-the-art strategies and NNI's auto tuning power.
* Speed up a compressed model to make it have lower inference latency and also make it become smaller.
* Speed up a compressed model to make it have lower inference latency and also make it smaller.
* Provide friendly and easy-to-use compression utilities for users to dive into the compression process and results.
* Concise interface for users to customize their own compression algorithms.
...
...
@@ -31,18 +40,19 @@ Compression Pipeline
:target: ../../img/compression_flow.jpg
:alt:
The overall compression pipeline in NNI. For compressing a pretrained model, pruning and quantization can be used alone or in combination.
The overall compression pipeline in NNI is shown above. For compressing a pretrained model, pruning and quantization can be used alone or in combination.
If users want to apply both, a sequential mode is recommended as common practise.
.. note::
Since NNI compression algorithms are not meant to compress model while NNI speedup tool can truly compress model and reduce latency.
To obtain a truly compact model, users should conduct :doc:`model speedup <../tutorials/pruning_speed_up>`.
The interface and APIs are unified for both PyTorch and TensorFlow, currently only PyTorch version has been supported, TensorFlow version will be supported in future.
Note that NNI pruners or quantizers are not meant to physically compact the model but for simulating the compression effect. Whereas NNI speedup tool can truly compress model by changing the network architecture and therefore reduce latency.
To obtain a truly compact model, users should conduct :doc:`pruning speedup <../tutorials/pruning_speed_up>` or :doc:`quantizaiton speedup <../tutorials/quantization_speed_up>`.
The interface and APIs are unified for both PyTorch and TensorFlow. Currently only PyTorch version has been supported, and TensorFlow version will be supported in future.
Supported Algorithms
--------------------
The algorithms include pruning algorithms and quantization algorithms.
The supported model compression algorithms include pruning algorithms and quantization algorithms.
Pruning Algorithms
^^^^^^^^^^^^^^^^^^
...
...
@@ -120,6 +130,15 @@ Model Speedup
The final goal of model compression is to reduce inference latency and model size.
However, existing model compression algorithms mainly use simulation to check the performance (e.g., accuracy) of compressed model.
For example, using masks for pruning algorithms, and storing quantized values still in float32 for quantization algorithms.
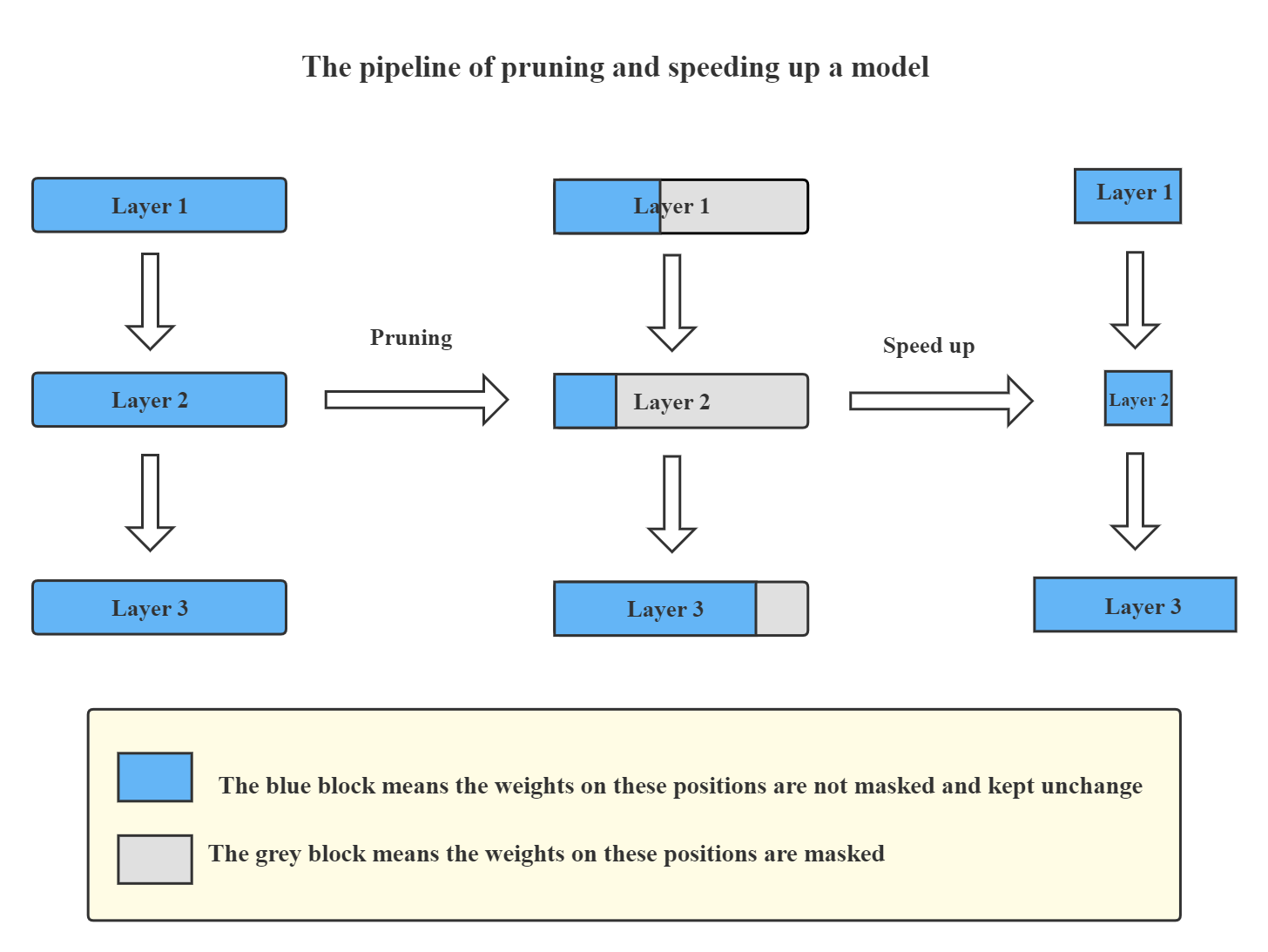
Given the output masks and quantization bits produced by those algorithms, NNI can really speed up the model.
Given the output masks and quantization bits produced by those algorithms, NNI can really speed up the model. The following figure shows how NNI prunes and speeds up your models.
.. image:: ../../img/pipeline_compress.jpg
:target: ../../img/pipeline_compress.jpg
:scale: 40%
:alt:
The detailed tutorial of Speed Up Model with Mask can be found :doc:`here <../tutorials/pruning_speed_up>`.
The detailed tutorial of Speed Up Model with Calibration Config can be found :doc:`here <../tutorials/quantization_speed_up>`.

{kind=link}
{kind=link}