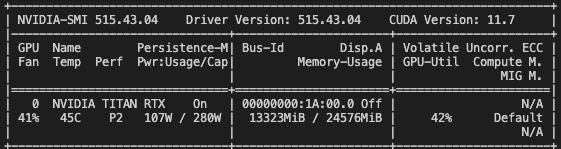
@@ -116,19 +116,10 @@ In `nerfacc`, this is implemented via the :class:`nerfacc.PropNetEstimator` clas
...
@@ -116,19 +116,10 @@ In `nerfacc`, this is implemented via the :class:`nerfacc.PropNetEstimator` clas
Which Estimator to use?
Which Estimator to use?
-----------------------
-----------------------
- :class:`nerfacc.OccGridEstimator` is a generally more efficient when most of the space in the scene is empty, such as in the case of `NeRF-Synthetic`_ dataset. But but it still places samples within occupied but occluded areas that contribute little to the final rendering (e.g., the last sample in the above illustration).
- :class:`nerfacc.OccGridEstimator` is a generally more efficient when most of the space in the scene is empty, such as in the case of `NeRF-Synthetic`_ dataset. But it still places samples within occluded areas that contribute little to the final rendering (e.g., the last sample in the above illustration).
- :class:`nerfacc.PropNetEstimator` generally provide more accurate transmittance estimation, enabling samples to concentrate more on high-contribution areas (e.g., surfaces) and to be more spread out in both empty and occluded regions. Also this method works nicely on unbouned scenes as it does not require a preset bounding box of the scene. Thus datasets like `Mip-NeRF 360`_ are better suited with this estimator.
- :class:`nerfacc.PropNetEstimator` generally provide more accurate transmittance estimation, enabling samples to concentrate more on high-contribution areas (e.g., surfaces) and to be more spread out in both empty and occluded regions. Also this method works nicely on unbouned scenes as it does not require a preset bounding box of the scene. Thus datasets like `Mip-NeRF 360`_ are better suited with this estimator.
.. .. currentmodule:: nerfacc
.. .. autoclass:: OccGridEstimator
.. :members:
.. .. autoclass:: PropNetEstimator
.. :members:
.. _`SIGGRAPH 2017 Course: Production Volume Rendering`: https://graphics.pixar.com/library/ProductionVolumeRendering/paper.pdf
.. _`SIGGRAPH 2017 Course: Production Volume Rendering`: https://graphics.pixar.com/library/ProductionVolumeRendering/paper.pdf
")
{kind=link}