diff --git a/CITATION.cff b/CITATION.cff
new file mode 100644
index 0000000000000000000000000000000000000000..81ea8f792645b1904e792918590eb215c62dd323
--- /dev/null
+++ b/CITATION.cff
@@ -0,0 +1,9 @@
+cff-version: 1.2.0
+message: "If you use this software, please cite it as below."
+title: "OpenMMLab's Pre-training Toolbox and Benchmark"
+authors:
+ - name: "MMPreTrain Contributors"
+version: 0.15.0
+date-released: 2023-04-06
+repository-code: "https://github.com/open-mmlab/mmpretrain"
+license: Apache-2.0
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..ce84c2a09f59785d3220a722b8ba1282c97a8030
--- /dev/null
+++ b/CONTRIBUTING.md
@@ -0,0 +1,73 @@
+# Contributing to MMPreTrain
+
+- [Contributing to MMPreTrain](#contributing-to-mmpretrain)
+ - [Workflow](#workflow)
+ - [Code style](#code-style)
+ - [Python](#python)
+ - [C++ and CUDA](#c-and-cuda)
+ - [Pre-commit Hook](#pre-commit-hook)
+
+Thanks for your interest in contributing to MMPreTrain! All kinds of contributions are welcome, including but not limited to the following.
+
+- Fix typo or bugs
+- Add documentation or translate the documentation into other languages
+- Add new features and components
+
+## Workflow
+
+We recommend the potential contributors follow this workflow for contribution.
+
+1. Fork and pull the latest MMPreTrain repository, follow [get started](https://mmpretrain.readthedocs.io/en/latest/get_started.html) to setup the environment.
+2. Checkout a new branch (**do not use the master or dev branch** for PRs)
+
+```bash
+git checkout -b xxxx # xxxx is the name of new branch
+```
+
+3. Edit the related files follow the code style mentioned below
+4. Use [pre-commit hook](https://pre-commit.com/) to check and format your changes.
+5. Commit your changes
+6. Create a PR with related information
+
+## Code style
+
+### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](https://github.com/open-mmlab/mmpretrain/blob/main/setup.cfg).
+
+### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+## Pre-commit Hook
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](https://github.com/open-mmlab/mmpretrain/blob/main/.pre-commit-config.yaml).
+
+After you clone the repository, you will need to install initialize pre-commit hook.
+
+```shell
+pip install -U pre-commit
+```
+
+From the repository folder
+
+```shell
+pre-commit install
+```
+
+After this on every commit check code linters and formatter will be enforced.
+
+> Before you create a PR, make sure that your code lints and is formatted by yapf.
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..ae87343779455c4c4b43e10a27d1657142666726
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,203 @@
+Copyright (c) OpenMMLab. All rights reserved
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright 2020 MMPreTrain Authors.
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..ad4d8dafbdeb31327429c94430a8338e5f024acb
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1,5 @@
+include requirements/*.txt
+include mmpretrain/.mim/model-index.yml
+include mmpretrain/.mim/dataset-index.yml
+recursive-include mmpretrain/.mim/configs *.py *.yml
+recursive-include mmpretrain/.mim/tools *.py *.sh
diff --git a/README.md b/README.md
index a67d4b0aa6efa336d0b9be3f0244c77fc3f00c98..5318df5b958b8f54dcba1896776eebfb04ba9871 100644
--- a/README.md
+++ b/README.md
@@ -1,2 +1,339 @@
-# mmpretrain
+
+

+
+
+
+
+[](https://pypi.org/project/mmpretrain)
+[](https://mmpretrain.readthedocs.io/en/latest/)
+[](https://github.com/open-mmlab/mmpretrain/actions)
+[](https://codecov.io/gh/open-mmlab/mmpretrain)
+[](https://github.com/open-mmlab/mmpretrain/blob/main/LICENSE)
+[](https://github.com/open-mmlab/mmpretrain/issues)
+[](https://github.com/open-mmlab/mmpretrain/issues)
+
+[📘 Documentation](https://mmpretrain.readthedocs.io/en/latest/) |
+[🛠️ Installation](https://mmpretrain.readthedocs.io/en/latest/get_started.html#installation) |
+[👀 Model Zoo](https://mmpretrain.readthedocs.io/en/latest/modelzoo_statistics.html) |
+[🆕 Update News](https://mmpretrain.readthedocs.io/en/latest/notes/changelog.html) |
+[🤔 Reporting Issues](https://github.com/open-mmlab/mmpretrain/issues/new/choose)
+
+

+
+English | [简体中文](/README_zh-CN.md)
+
+
+
+ 
+

+
+ 
+
+
+ 
+
+
+ 
+
+
+ 
+
+
+ 
+
+ Overview
+
+
+
+
+ |
+ Supported Backbones
+ |
+
+ Self-supervised Learning
+ |
+
+ Multi-Modality Algorithms
+ |
+
+ Others
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+ |
+
+ Image Retrieval Task:
+
+ Training&Test Tips:
+
+ |
+
+
+
+## Contributing
+
+We appreciate all contributions to improve MMPreTrain.
+Please refer to [CONTRUBUTING](https://mmpretrain.readthedocs.io/en/latest/notes/contribution_guide.html) for the contributing guideline.
+
+## Acknowledgement
+
+MMPreTrain is an open source project that is contributed by researchers and engineers from various colleges and companies. We appreciate all the contributors who implement their methods or add new features, as well as users who give valuable feedbacks.
+We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and supporting their own academic research.
+
+## Citation
+
+If you find this project useful in your research, please consider cite:
+
+```BibTeX
+@misc{2023mmpretrain,
+ title={OpenMMLab's Pre-training Toolbox and Benchmark},
+ author={MMPreTrain Contributors},
+ howpublished = {\url{https://github.com/open-mmlab/mmpretrain}},
+ year={2023}
+}
+```
+
+## License
+
+This project is released under the [Apache 2.0 license](LICENSE).
+
+## Projects in OpenMMLab
+
+- [MMEngine](https://github.com/open-mmlab/mmengine): OpenMMLab foundational library for training deep learning models.
+- [MMCV](https://github.com/open-mmlab/mmcv): OpenMMLab foundational library for computer vision.
+- [MIM](https://github.com/open-mmlab/mim): MIM installs OpenMMLab packages.
+- [MMEval](https://github.com/open-mmlab/mmeval): A unified evaluation library for multiple machine learning libraries.
+- [MMPreTrain](https://github.com/open-mmlab/mmpretrain): OpenMMLab pre-training toolbox and benchmark.
+- [MMDetection](https://github.com/open-mmlab/mmdetection): OpenMMLab detection toolbox and benchmark.
+- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): OpenMMLab's next-generation platform for general 3D object detection.
+- [MMRotate](https://github.com/open-mmlab/mmrotate): OpenMMLab rotated object detection toolbox and benchmark.
+- [MMYOLO](https://github.com/open-mmlab/mmyolo): OpenMMLab YOLO series toolbox and benchmark.
+- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation): OpenMMLab semantic segmentation toolbox and benchmark.
+- [MMOCR](https://github.com/open-mmlab/mmocr): OpenMMLab text detection, recognition, and understanding toolbox.
+- [MMPose](https://github.com/open-mmlab/mmpose): OpenMMLab pose estimation toolbox and benchmark.
+- [MMHuman3D](https://github.com/open-mmlab/mmhuman3d): OpenMMLab 3D human parametric model toolbox and benchmark.
+- [MMSelfSup](https://github.com/open-mmlab/mmselfsup): OpenMMLab self-supervised learning toolbox and benchmark.
+- [MMRazor](https://github.com/open-mmlab/mmrazor): OpenMMLab model compression toolbox and benchmark.
+- [MMFewShot](https://github.com/open-mmlab/mmfewshot): OpenMMLab fewshot learning toolbox and benchmark.
+- [MMAction2](https://github.com/open-mmlab/mmaction2): OpenMMLab's next-generation action understanding toolbox and benchmark.
+- [MMTracking](https://github.com/open-mmlab/mmtracking): OpenMMLab video perception toolbox and benchmark.
+- [MMFlow](https://github.com/open-mmlab/mmflow): OpenMMLab optical flow toolbox and benchmark.
+- [MMagic](https://github.com/open-mmlab/mmagic): Open**MM**Lab **A**dvanced, **G**enerative and **I**ntelligent **C**reation toolbox.
+- [MMGeneration](https://github.com/open-mmlab/mmgeneration): OpenMMLab image and video generative models toolbox.
+- [MMDeploy](https://github.com/open-mmlab/mmdeploy): OpenMMLab model deployment framework.
+- [Playground](https://github.com/open-mmlab/playground): A central hub for gathering and showcasing amazing projects built upon OpenMMLab.
diff --git a/README_zh-CN.md b/README_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..9ee8dffc401d414c0c2b7135ba2a4887f80608a4
--- /dev/null
+++ b/README_zh-CN.md
@@ -0,0 +1,353 @@
+
+
+
+
+
+
+
+[](https://pypi.org/project/mmpretrain)
+[](https://mmpretrain.readthedocs.io/zh_CN/latest/)
+[](https://github.com/open-mmlab/mmpretrain/actions)
+[](https://codecov.io/gh/open-mmlab/mmpretrain)
+[](https://github.com/open-mmlab/mmpretrain/blob/main/LICENSE)
+[](https://github.com/open-mmlab/mmpretrain/issues)
+[](https://github.com/open-mmlab/mmpretrain/issues)
+
+[📘 中文文档](https://mmpretrain.readthedocs.io/zh_CN/latest/) |
+[🛠️ 安装教程](https://mmpretrain.readthedocs.io/zh_CN/latest/get_started.html) |
+[👀 模型库](https://mmpretrain.readthedocs.io/zh_CN/latest/modelzoo_statistics.html) |
+[🆕 更新日志](https://mmpretrain.readthedocs.io/zh_CN/latest/notes/changelog.html) |
+[🤔 报告问题](https://github.com/open-mmlab/mmpretrain/issues/new/choose)
+
+
+
+[English](/README.md) | 简体中文
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ 概览
+
+
+
+
+ |
+ 支持的主干网络
+ |
+
+ 自监督学习
+ |
+
+ 多模态算法
+ |
+
+ 其它
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+ |
+
+ 图像检索任务:
+
+ 训练和测试 Tips:
+
+ |
+
+
+
+## 参与贡献
+
+我们非常欢迎任何有助于提升 MMPreTrain 的贡献,请参考 [贡献指南](https://mmpretrain.readthedocs.io/zh_CN/latest/notes/contribution_guide.html) 来了解如何参与贡献。
+
+## 致谢
+
+MMPreTrain 是一款由不同学校和公司共同贡献的开源项目。我们感谢所有为项目提供算法复现和新功能支持的贡献者,以及提供宝贵反馈的用户。
+我们希望该工具箱和基准测试可以为社区提供灵活的代码工具,供用户复现现有算法并开发自己的新模型,从而不断为开源社区提供贡献。
+
+## 引用
+
+如果你在研究中使用了本项目的代码或者性能基准,请参考如下 bibtex 引用 MMPreTrain。
+
+```BibTeX
+@misc{2023mmpretrain,
+ title={OpenMMLab's Pre-training Toolbox and Benchmark},
+ author={MMPreTrain Contributors},
+ howpublished = {\url{https://github.com/open-mmlab/mmpretrain}},
+ year={2023}
+}
+```
+
+## 许可证
+
+该项目开源自 [Apache 2.0 license](LICENSE).
+
+## OpenMMLab 的其他项目
+
+- [MMEngine](https://github.com/open-mmlab/mmengine): OpenMMLab 深度学习模型训练基础库
+- [MMCV](https://github.com/open-mmlab/mmcv): OpenMMLab 计算机视觉基础库
+- [MIM](https://github.com/open-mmlab/mim): MIM 是 OpenMMlab 项目、算法、模型的统一入口
+- [MMEval](https://github.com/open-mmlab/mmeval): 统一开放的跨框架算法评测库
+- [MMPreTrain](https://github.com/open-mmlab/mmpretrain): OpenMMLab 深度学习预训练工具箱
+- [MMDetection](https://github.com/open-mmlab/mmdetection): OpenMMLab 目标检测工具箱
+- [MMDetection3D](https://github.com/open-mmlab/mmdetection3d): OpenMMLab 新一代通用 3D 目标检测平台
+- [MMRotate](https://github.com/open-mmlab/mmrotate): OpenMMLab 旋转框检测工具箱与测试基准
+- [MMYOLO](https://github.com/open-mmlab/mmyolo): OpenMMLab YOLO 系列工具箱与测试基准
+- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation): OpenMMLab 语义分割工具箱
+- [MMOCR](https://github.com/open-mmlab/mmocr): OpenMMLab 全流程文字检测识别理解工具包
+- [MMPose](https://github.com/open-mmlab/mmpose): OpenMMLab 姿态估计工具箱
+- [MMHuman3D](https://github.com/open-mmlab/mmhuman3d): OpenMMLab 人体参数化模型工具箱与测试基准
+- [MMSelfSup](https://github.com/open-mmlab/mmselfsup): OpenMMLab 自监督学习工具箱与测试基准
+- [MMRazor](https://github.com/open-mmlab/mmrazor): OpenMMLab 模型压缩工具箱与测试基准
+- [MMFewShot](https://github.com/open-mmlab/mmfewshot): OpenMMLab 少样本学习工具箱与测试基准
+- [MMAction2](https://github.com/open-mmlab/mmaction2): OpenMMLab 新一代视频理解工具箱
+- [MMTracking](https://github.com/open-mmlab/mmtracking): OpenMMLab 一体化视频目标感知平台
+- [MMFlow](https://github.com/open-mmlab/mmflow): OpenMMLab 光流估计工具箱与测试基准
+- [MMagic](https://github.com/open-mmlab/mmagic): OpenMMLab 新一代人工智能内容生成(AIGC)工具箱
+- [MMGeneration](https://github.com/open-mmlab/mmgeneration): OpenMMLab 图片视频生成模型工具箱
+- [MMDeploy](https://github.com/open-mmlab/mmdeploy): OpenMMLab 模型部署框架
+- [Playground](https://github.com/open-mmlab/playground): 收集和展示 OpenMMLab 相关的前沿、有趣的社区项目
+
+## 欢迎加入 OpenMMLab 社区
+
+扫描下方的二维码可关注 OpenMMLab 团队的 [知乎官方账号](https://www.zhihu.com/people/openmmlab),扫描下方微信二维码添加喵喵好友,进入 MMPretrain 微信交流社群。【加好友申请格式:研究方向+地区+学校/公司+姓名】
+
+
+


+
+

+
+
+
+

+
+

+
+
+
+
+
+

+
+

+
+

+
+
+
+

+
+

+
+
+
+
+Show the paper's abstract
+
+
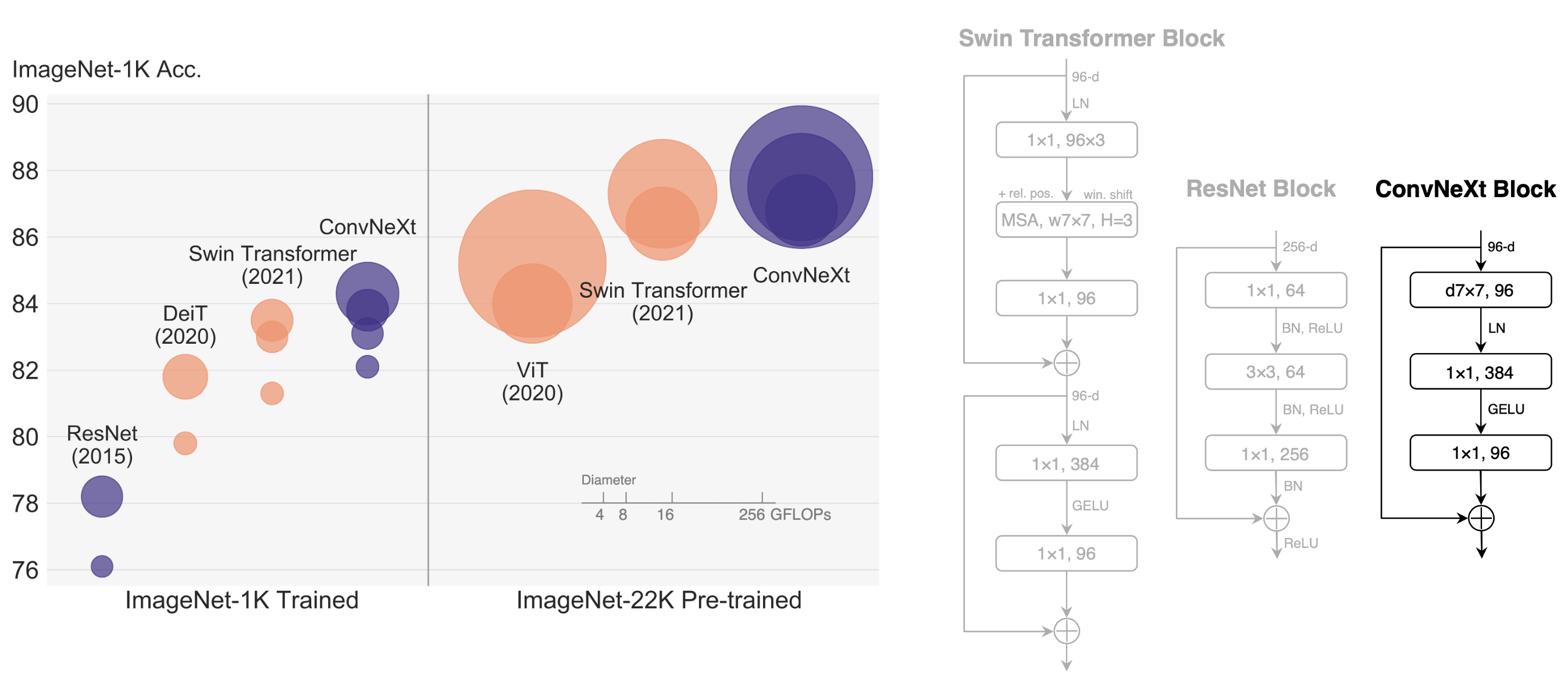
+The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('convnext-tiny_32xb128_in1k', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('convnext-tiny_32xb128_in1k', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Train/Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Train:
+
+```shell
+python tools/train.py configs/convnext/convnext-tiny_32xb128_in1k.py
+```
+
+Test:
+
+```shell
+python tools/test.py configs/convnext/convnext-tiny_32xb128_in1k.py https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_32xb128_in1k_20221207-998cf3e9.pth
+```
+
+
+
+## Models and results
+
+### Pretrained models
+
+| Model | Params (M) | Flops (G) | Config | Download |
+| :--------------------------------- | :--------: | :-------: | :---------------------------------------: | :--------------------------------------------------------------------------------------------------------: |
+| `convnext-base_3rdparty_in21k`\* | 88.59 | 15.36 | [config](convnext-base_32xb128_in21k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_3rdparty_in21k_20220124-13b83eec.pth) |
+| `convnext-large_3rdparty_in21k`\* | 197.77 | 34.37 | [config](convnext-large_64xb64_in21k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-large_3rdparty_in21k_20220124-41b5a79f.pth) |
+| `convnext-xlarge_3rdparty_in21k`\* | 350.20 | 60.93 | [config](convnext-xlarge_64xb64_in21k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-xlarge_3rdparty_in21k_20220124-f909bad7.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/facebookresearch/ConvNeXt). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :------------------------------------------------ | :----------: | :--------: | :-------: | :-------: | :-------: | :--------------------------------------------: | :------------------------------------------------------: |
+| `convnext-tiny_32xb128_in1k` | From scratch | 28.59 | 4.46 | 82.14 | 96.06 | [config](convnext-tiny_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_32xb128_in1k_20221207-998cf3e9.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_32xb128_in1k_20221207-998cf3e9.json) |
+| `convnext-tiny_32xb128-noema_in1k` | From scratch | 28.59 | 4.46 | 81.95 | 95.89 | [config](convnext-tiny_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_32xb128-noema_in1k_20221208-5d4509c7.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_32xb128_in1k_20221207-998cf3e9.json) |
+| `convnext-tiny_in21k-pre_3rdparty_in1k`\* | ImageNet-21k | 28.59 | 4.46 | 82.90 | 96.62 | [config](convnext-tiny_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_in21k-pre_3rdparty_in1k_20221219-7501e534.pth) |
+| `convnext-tiny_in21k-pre_3rdparty_in1k-384px`\* | ImageNet-21k | 28.59 | 13.14 | 84.11 | 97.14 | [config](convnext-tiny_32xb128_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_in21k-pre_3rdparty_in1k-384px_20221219-c1182362.pth) |
+| `convnext-small_32xb128_in1k` | From scratch | 50.22 | 8.69 | 83.16 | 96.56 | [config](convnext-small_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-small_32xb128_in1k_20221207-4ab7052c.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-small_32xb128_in1k_20221207-4ab7052c.json) |
+| `convnext-small_32xb128-noema_in1k` | From scratch | 50.22 | 8.69 | 83.21 | 96.48 | [config](convnext-small_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-small_32xb128-noema_in1k_20221208-4a618995.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-small_32xb128_in1k_20221207-4ab7052c.json) |
+| `convnext-small_in21k-pre_3rdparty_in1k`\* | ImageNet-21k | 50.22 | 8.69 | 84.59 | 97.41 | [config](convnext-small_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-small_in21k-pre_3rdparty_in1k_20221219-aeca4c93.pth) |
+| `convnext-small_in21k-pre_3rdparty_in1k-384px`\* | ImageNet-21k | 50.22 | 25.58 | 85.75 | 97.88 | [config](convnext-small_32xb128_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-small_in21k-pre_3rdparty_in1k-384px_20221219-96f0bb87.pth) |
+| `convnext-base_32xb128_in1k` | From scratch | 88.59 | 15.36 | 83.66 | 96.74 | [config](convnext-base_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_32xb128_in1k_20221207-fbdb5eb9.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_32xb128_in1k_20221207-fbdb5eb9.json) |
+| `convnext-base_32xb128-noema_in1k` | From scratch | 88.59 | 15.36 | 83.64 | 96.61 | [config](convnext-base_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_32xb128-noema_in1k_20221208-f8182678.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_32xb128_in1k_20221207-fbdb5eb9.json) |
+| `convnext-base_3rdparty_in1k`\* | From scratch | 88.59 | 15.36 | 83.85 | 96.74 | [config](convnext-base_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_3rdparty_32xb128_in1k_20220124-d0915162.pth) |
+| `convnext-base_3rdparty-noema_in1k`\* | From scratch | 88.59 | 15.36 | 83.71 | 96.60 | [config](convnext-base_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_3rdparty_32xb128-noema_in1k_20220222-dba4f95f.pth) |
+| `convnext-base_3rdparty_in1k-384px`\* | From scratch | 88.59 | 45.21 | 85.10 | 97.34 | [config](convnext-base_32xb128_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_3rdparty_in1k-384px_20221219-c8f1dc2b.pth) |
+| `convnext-base_in21k-pre_3rdparty_in1k`\* | ImageNet-21k | 88.59 | 15.36 | 85.81 | 97.86 | [config](convnext-base_32xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_in21k-pre-3rdparty_32xb128_in1k_20220124-eb2d6ada.pth) |
+| `convnext-base_in21k-pre-3rdparty_in1k-384px`\* | From scratch | 88.59 | 45.21 | 86.82 | 98.25 | [config](convnext-base_32xb128_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_in21k-pre-3rdparty_in1k-384px_20221219-4570f792.pth) |
+| `convnext-large_3rdparty_in1k`\* | From scratch | 197.77 | 34.37 | 84.30 | 96.89 | [config](convnext-large_64xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-large_3rdparty_64xb64_in1k_20220124-f8a0ded0.pth) |
+| `convnext-large_3rdparty_in1k-384px`\* | From scratch | 197.77 | 101.10 | 85.50 | 97.59 | [config](convnext-large_64xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-large_3rdparty_in1k-384px_20221219-6dd29d10.pth) |
+| `convnext-large_in21k-pre_3rdparty_in1k`\* | ImageNet-21k | 197.77 | 34.37 | 86.61 | 98.04 | [config](convnext-large_64xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-large_in21k-pre-3rdparty_64xb64_in1k_20220124-2412403d.pth) |
+| `convnext-large_in21k-pre-3rdparty_in1k-384px`\* | From scratch | 197.77 | 101.10 | 87.46 | 98.37 | [config](convnext-large_64xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-large_in21k-pre-3rdparty_in1k-384px_20221219-6d38dd66.pth) |
+| `convnext-xlarge_in21k-pre_3rdparty_in1k`\* | ImageNet-21k | 350.20 | 60.93 | 86.97 | 98.20 | [config](convnext-xlarge_64xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-xlarge_in21k-pre-3rdparty_64xb64_in1k_20220124-76b6863d.pth) |
+| `convnext-xlarge_in21k-pre-3rdparty_in1k-384px`\* | From scratch | 350.20 | 179.20 | 87.76 | 98.55 | [config](convnext-xlarge_64xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/convnext/convnext-xlarge_in21k-pre-3rdparty_in1k-384px_20221219-b161bc14.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/facebookresearch/ConvNeXt). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+## Citation
+
+```bibtex
+@Article{liu2022convnet,
+ author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
+ title = {A ConvNet for the 2020s},
+ journal = {arXiv preprint arXiv:2201.03545},
+ year = {2022},
+}
+```
diff --git a/configs/convnext/convnext-base_32xb128_in1k-384px.py b/configs/convnext/convnext-base_32xb128_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..65546942562ac17b3d4510c78d3090aa8b87a831
--- /dev/null
+++ b/configs/convnext/convnext-base_32xb128_in1k-384px.py
@@ -0,0 +1,23 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-base.py',
+ '../_base_/datasets/imagenet_bs64_swin_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset setting
+train_dataloader = dict(batch_size=128)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# runtime setting
+custom_hooks = [dict(type='EMAHook', momentum=4e-5, priority='ABOVE_NORMAL')]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-base_32xb128_in1k.py b/configs/convnext/convnext-base_32xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ae8ec47c4c7ac3f22712c97dbad315c7a798e6f
--- /dev/null
+++ b/configs/convnext/convnext-base_32xb128_in1k.py
@@ -0,0 +1,23 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-base.py',
+ '../_base_/datasets/imagenet_bs64_swin_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset setting
+train_dataloader = dict(batch_size=128)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=None,
+)
+
+# runtime setting
+custom_hooks = [dict(type='EMAHook', momentum=1e-4, priority='ABOVE_NORMAL')]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-base_32xb128_in21k.py b/configs/convnext/convnext-base_32xb128_in21k.py
new file mode 100644
index 0000000000000000000000000000000000000000..c343526c7f084501fc3651c1581752209f5019a4
--- /dev/null
+++ b/configs/convnext/convnext-base_32xb128_in21k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-base.py',
+ '../_base_/datasets/imagenet21k_bs128.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# model setting
+model = dict(head=dict(num_classes=21841))
+
+# dataset setting
+data_preprocessor = dict(num_classes=21841)
+train_dataloader = dict(batch_size=128)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-large_64xb64_in1k-384px.py b/configs/convnext/convnext-large_64xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..6698b9edcdae463d6d1cf943237efbaf236cd71c
--- /dev/null
+++ b/configs/convnext/convnext-large_64xb64_in1k-384px.py
@@ -0,0 +1,23 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-large.py',
+ '../_base_/datasets/imagenet_bs64_swin_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset setting
+train_dataloader = dict(batch_size=64)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# runtime setting
+custom_hooks = [dict(type='EMAHook', momentum=4e-5, priority='ABOVE_NORMAL')]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (64 GPUs) x (64 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-large_64xb64_in1k.py b/configs/convnext/convnext-large_64xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a78c58bc3d85e0e08083d339378886f870388bc
--- /dev/null
+++ b/configs/convnext/convnext-large_64xb64_in1k.py
@@ -0,0 +1,23 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-large.py',
+ '../_base_/datasets/imagenet_bs64_swin_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset setting
+train_dataloader = dict(batch_size=64)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=None,
+)
+
+# runtime setting
+custom_hooks = [dict(type='EMAHook', momentum=1e-4, priority='ABOVE_NORMAL')]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (64 GPUs) x (64 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-large_64xb64_in21k.py b/configs/convnext/convnext-large_64xb64_in21k.py
new file mode 100644
index 0000000000000000000000000000000000000000..420edab67b1dc094f08b4a3810af522b2a988b62
--- /dev/null
+++ b/configs/convnext/convnext-large_64xb64_in21k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-base.py',
+ '../_base_/datasets/imagenet21k_bs128.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# model setting
+model = dict(head=dict(num_classes=21841))
+
+# dataset setting
+data_preprocessor = dict(num_classes=21841)
+train_dataloader = dict(batch_size=64)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-small_32xb128_in1k-384px.py b/configs/convnext/convnext-small_32xb128_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..729f00ad2fdf53943ffae9de165e2e9985e733c7
--- /dev/null
+++ b/configs/convnext/convnext-small_32xb128_in1k-384px.py
@@ -0,0 +1,23 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-small.py',
+ '../_base_/datasets/imagenet_bs64_swin_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset setting
+train_dataloader = dict(batch_size=128)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# runtime setting
+custom_hooks = [dict(type='EMAHook', momentum=4e-5, priority='ABOVE_NORMAL')]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-small_32xb128_in1k.py b/configs/convnext/convnext-small_32xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..b623e900f830fbea7891b61c737398c0dee1076e
--- /dev/null
+++ b/configs/convnext/convnext-small_32xb128_in1k.py
@@ -0,0 +1,23 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-small.py',
+ '../_base_/datasets/imagenet_bs64_swin_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset setting
+train_dataloader = dict(batch_size=128)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=None,
+)
+
+# runtime setting
+custom_hooks = [dict(type='EMAHook', momentum=1e-4, priority='ABOVE_NORMAL')]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-tiny_32xb128_in1k-384px.py b/configs/convnext/convnext-tiny_32xb128_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..6513ad8dfa41714ecb5c9de5992496716337c596
--- /dev/null
+++ b/configs/convnext/convnext-tiny_32xb128_in1k-384px.py
@@ -0,0 +1,23 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-tiny.py',
+ '../_base_/datasets/imagenet_bs64_swin_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset setting
+train_dataloader = dict(batch_size=128)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# runtime setting
+custom_hooks = [dict(type='EMAHook', momentum=4e-5, priority='ABOVE_NORMAL')]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-tiny_32xb128_in1k.py b/configs/convnext/convnext-tiny_32xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..59d3004bde89510b5c44110c8a6513957c0cbba0
--- /dev/null
+++ b/configs/convnext/convnext-tiny_32xb128_in1k.py
@@ -0,0 +1,23 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-tiny.py',
+ '../_base_/datasets/imagenet_bs64_swin_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset setting
+train_dataloader = dict(batch_size=128)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=None,
+)
+
+# runtime setting
+custom_hooks = [dict(type='EMAHook', momentum=1e-4, priority='ABOVE_NORMAL')]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-xlarge_64xb64_in1k-384px.py b/configs/convnext/convnext-xlarge_64xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..6edc94d2448157fc82bf38a988bf4393f192a89f
--- /dev/null
+++ b/configs/convnext/convnext-xlarge_64xb64_in1k-384px.py
@@ -0,0 +1,23 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-xlarge.py',
+ '../_base_/datasets/imagenet_bs64_swin_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset setting
+train_dataloader = dict(batch_size=64)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# runtime setting
+custom_hooks = [dict(type='EMAHook', momentum=4e-5, priority='ABOVE_NORMAL')]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (64 GPUs) x (64 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-xlarge_64xb64_in1k.py b/configs/convnext/convnext-xlarge_64xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..528894e808b7085ee66d8be89cf84f860ddec979
--- /dev/null
+++ b/configs/convnext/convnext-xlarge_64xb64_in1k.py
@@ -0,0 +1,23 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-xlarge.py',
+ '../_base_/datasets/imagenet_bs64_swin_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset setting
+train_dataloader = dict(batch_size=64)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=None,
+)
+
+# runtime setting
+custom_hooks = [dict(type='EMAHook', momentum=1e-4, priority='ABOVE_NORMAL')]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (64 GPUs) x (64 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/convnext-xlarge_64xb64_in21k.py b/configs/convnext/convnext-xlarge_64xb64_in21k.py
new file mode 100644
index 0000000000000000000000000000000000000000..420edab67b1dc094f08b4a3810af522b2a988b62
--- /dev/null
+++ b/configs/convnext/convnext-xlarge_64xb64_in21k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/convnext/convnext-base.py',
+ '../_base_/datasets/imagenet21k_bs128.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# model setting
+model = dict(head=dict(num_classes=21841))
+
+# dataset setting
+data_preprocessor = dict(num_classes=21841)
+train_dataloader = dict(batch_size=64)
+
+# schedule setting
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/convnext/metafile.yml b/configs/convnext/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..16896629f07ffadd5313a6e38bc1532ddc3c08f2
--- /dev/null
+++ b/configs/convnext/metafile.yml
@@ -0,0 +1,410 @@
+Collections:
+ - Name: ConvNeXt
+ Metadata:
+ Training Data: ImageNet-1k
+ Architecture:
+ - 1x1 Convolution
+ - LayerScale
+ Paper:
+ URL: https://arxiv.org/abs/2201.03545v1
+ Title: A ConvNet for the 2020s
+ README: configs/convnext/README.md
+ Code:
+ Version: v0.20.1
+ URL: https://github.com/open-mmlab/mmpretrain/blob/v0.20.1/mmcls/models/backbones/convnext.py
+
+Models:
+ - Name: convnext-tiny_32xb128_in1k
+ Metadata:
+ FLOPs: 4457472768
+ Parameters: 28589128
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 82.14
+ Top 5 Accuracy: 96.06
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_32xb128_in1k_20221207-998cf3e9.pth
+ Config: configs/convnext/convnext-tiny_32xb128_in1k.py
+ - Name: convnext-tiny_32xb128-noema_in1k
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 4457472768
+ Parameters: 28589128
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.95
+ Top 5 Accuracy: 95.89
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_32xb128-noema_in1k_20221208-5d4509c7.pth
+ Config: configs/convnext/convnext-tiny_32xb128_in1k.py
+ - Name: convnext-tiny_in21k-pre_3rdparty_in1k
+ Metadata:
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ FLOPs: 4457472768
+ Parameters: 28589128
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 82.90
+ Top 5 Accuracy: 96.62
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_in21k-pre_3rdparty_in1k_20221219-7501e534.pth
+ Config: configs/convnext/convnext-tiny_32xb128_in1k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_tiny_22k_1k_224.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-tiny_in21k-pre_3rdparty_in1k-384px
+ Metadata:
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ FLOPs: 13135236864
+ Parameters: 28589128
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.11
+ Top 5 Accuracy: 97.14
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-tiny_in21k-pre_3rdparty_in1k-384px_20221219-c1182362.pth
+ Config: configs/convnext/convnext-tiny_32xb128_in1k-384px.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_tiny_22k_1k_384.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-small_32xb128_in1k
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 8687008512
+ Parameters: 50223688
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.16
+ Top 5 Accuracy: 96.56
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-small_32xb128_in1k_20221207-4ab7052c.pth
+ Config: configs/convnext/convnext-small_32xb128_in1k.py
+ - Name: convnext-small_32xb128-noema_in1k
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 8687008512
+ Parameters: 50223688
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.21
+ Top 5 Accuracy: 96.48
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-small_32xb128-noema_in1k_20221208-4a618995.pth
+ Config: configs/convnext/convnext-small_32xb128_in1k.py
+ - Name: convnext-small_in21k-pre_3rdparty_in1k
+ Metadata:
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ FLOPs: 8687008512
+ Parameters: 50223688
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.59
+ Top 5 Accuracy: 97.41
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-small_in21k-pre_3rdparty_in1k_20221219-aeca4c93.pth
+ Config: configs/convnext/convnext-small_32xb128_in1k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_small_22k_1k_224.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-small_in21k-pre_3rdparty_in1k-384px
+ Metadata:
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ FLOPs: 25580818176
+ Parameters: 50223688
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 85.75
+ Top 5 Accuracy: 97.88
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-small_in21k-pre_3rdparty_in1k-384px_20221219-96f0bb87.pth
+ Config: configs/convnext/convnext-small_32xb128_in1k-384px.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_small_22k_1k_384.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-base_32xb128_in1k
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 15359124480
+ Parameters: 88591464
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.66
+ Top 5 Accuracy: 96.74
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_32xb128_in1k_20221207-fbdb5eb9.pth
+ Config: configs/convnext/convnext-base_32xb128_in1k.py
+ - Name: convnext-base_32xb128-noema_in1k
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 15359124480
+ Parameters: 88591464
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.64
+ Top 5 Accuracy: 96.61
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_32xb128-noema_in1k_20221208-f8182678.pth
+ Config: configs/convnext/convnext-base_32xb128_in1k.py
+ - Name: convnext-base_3rdparty_in1k
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 15359124480
+ Parameters: 88591464
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.85
+ Top 5 Accuracy: 96.74
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_3rdparty_32xb128_in1k_20220124-d0915162.pth
+ Config: configs/convnext/convnext-base_32xb128_in1k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224_ema.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-base_3rdparty-noema_in1k
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 15359124480
+ Parameters: 88591464
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.71
+ Top 5 Accuracy: 96.60
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_3rdparty_32xb128-noema_in1k_20220222-dba4f95f.pth
+ Config: configs/convnext/convnext-base_32xb128_in1k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-base_3rdparty_in1k-384px
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 45205885952
+ Parameters: 88591464
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 85.10
+ Top 5 Accuracy: 97.34
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_3rdparty_in1k-384px_20221219-c8f1dc2b.pth
+ Config: configs/convnext/convnext-base_32xb128_in1k-384px.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_384.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-base_3rdparty_in21k
+ Metadata:
+ Training Data: ImageNet-21k
+ FLOPs: 15359124480
+ Parameters: 88591464
+ In Collection: ConvNeXt
+ Results: null
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_3rdparty_in21k_20220124-13b83eec.pth
+ Config: configs/convnext/convnext-base_32xb128_in21k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-base_in21k-pre_3rdparty_in1k
+ Metadata:
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ FLOPs: 15359124480
+ Parameters: 88591464
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 85.81
+ Top 5 Accuracy: 97.86
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_in21k-pre-3rdparty_32xb128_in1k_20220124-eb2d6ada.pth
+ Config: configs/convnext/convnext-base_32xb128_in1k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_224.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-base_in21k-pre-3rdparty_in1k-384px
+ Metadata:
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ FLOPs: 45205885952
+ Parameters: 88591464
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 86.82
+ Top 5 Accuracy: 98.25
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-base_in21k-pre-3rdparty_in1k-384px_20221219-4570f792.pth
+ Config: configs/convnext/convnext-base_32xb128_in1k-384px.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_384.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-large_3rdparty_in1k
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 34368026112
+ Parameters: 197767336
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.30
+ Top 5 Accuracy: 96.89
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-large_3rdparty_64xb64_in1k_20220124-f8a0ded0.pth
+ Config: configs/convnext/convnext-large_64xb64_in1k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_224_ema.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-large_3rdparty_in1k-384px
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 101103214080
+ Parameters: 197767336
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 85.50
+ Top 5 Accuracy: 97.59
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-large_3rdparty_in1k-384px_20221219-6dd29d10.pth
+ Config: configs/convnext/convnext-large_64xb64_in1k-384px.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_384.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-large_3rdparty_in21k
+ Metadata:
+ Training Data: ImageNet-21k
+ FLOPs: 34368026112
+ Parameters: 197767336
+ In Collection: ConvNeXt
+ Results: null
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-large_3rdparty_in21k_20220124-41b5a79f.pth
+ Config: configs/convnext/convnext-large_64xb64_in21k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_224.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-large_in21k-pre_3rdparty_in1k
+ Metadata:
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ FLOPs: 34368026112
+ Parameters: 197767336
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 86.61
+ Top 5 Accuracy: 98.04
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-large_in21k-pre-3rdparty_64xb64_in1k_20220124-2412403d.pth
+ Config: configs/convnext/convnext-large_64xb64_in1k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_1k_224.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-large_in21k-pre-3rdparty_in1k-384px
+ Metadata:
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ FLOPs: 101103214080
+ Parameters: 197767336
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 87.46
+ Top 5 Accuracy: 98.37
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-large_in21k-pre-3rdparty_in1k-384px_20221219-6d38dd66.pth
+ Config: configs/convnext/convnext-large_64xb64_in1k-384px.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_1k_384.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-xlarge_3rdparty_in21k
+ Metadata:
+ Training Data: ImageNet-21k
+ FLOPs: 60929820672
+ Parameters: 350196968
+ In Collection: ConvNeXt
+ Results: null
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-xlarge_3rdparty_in21k_20220124-f909bad7.pth
+ Config: configs/convnext/convnext-xlarge_64xb64_in21k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_224.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-xlarge_in21k-pre_3rdparty_in1k
+ Metadata:
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ FLOPs: 60929820672
+ Parameters: 350196968
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 86.97
+ Top 5 Accuracy: 98.20
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-xlarge_in21k-pre-3rdparty_64xb64_in1k_20220124-76b6863d.pth
+ Config: configs/convnext/convnext-xlarge_64xb64_in1k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_1k_224_ema.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
+ - Name: convnext-xlarge_in21k-pre-3rdparty_in1k-384px
+ Metadata:
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ FLOPs: 179196798976
+ Parameters: 350196968
+ In Collection: ConvNeXt
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 87.76
+ Top 5 Accuracy: 98.55
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/convnext/convnext-xlarge_in21k-pre-3rdparty_in1k-384px_20221219-b161bc14.pth
+ Config: configs/convnext/convnext-xlarge_64xb64_in1k-384px.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_1k_384_ema.pth
+ Code: https://github.com/facebookresearch/ConvNeXt
diff --git a/configs/convnext_v2/README.md b/configs/convnext_v2/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..e561387412aa3a8e088cb7d015e7b98dba8e50c1
--- /dev/null
+++ b/configs/convnext_v2/README.md
@@ -0,0 +1,107 @@
+# ConvNeXt V2
+
+> [Co-designing and Scaling ConvNets with Masked Autoencoders](http://arxiv.org/abs/2301.00808)
+
+
+
+## Abstract
+
+Driven by improved architectures and better representation learning frameworks, the field of visual recognition has enjoyed rapid modernization and performance boost in the early 2020s. For example, modern ConvNets, represented by ConvNeXt, have demonstrated strong performance in various scenarios. While these models were originally designed for supervised learning with ImageNet labels, they can also potentially benefit from self-supervised learning techniques such as masked autoencoders (MAE). However, we found that simply combining these two approaches leads to subpar performance. In this paper, we propose a fully convolutional masked autoencoder framework and a new Global Response Normalization (GRN) layer that can be added to the ConvNeXt architecture to enhance inter-channel feature competition. This co-design of self-supervised learning techniques and architectural improvement results in a new model family called ConvNeXt V2, which significantly improves the performance of pure ConvNets on various recognition benchmarks, including ImageNet classification, COCO detection, and ADE20K segmentation. We also provide pre-trained ConvNeXt V2 models of various sizes, ranging from an efficient 3.7M-parameter Atto model with 76.7% top-1 accuracy on ImageNet, to a 650M Huge model that achieves a state-of-the-art 88.9% accuracy using only public training data.
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+Click to show the detailed Abstract
+
+
+Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet. To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters.
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('efficientnet-b0_3rdparty_8xb32_in1k', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('efficientnet-b0_3rdparty_8xb32_in1k', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Test:
+
+```shell
+python tools/test.py configs/efficientnet/efficientnet-b0_8xb32_in1k.py https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b0_3rdparty_8xb32_in1k_20220119-a7e2a0b1.pth
+```
+
+
+
+## Models and results
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :-------------------------------------------------- | :----------: | :--------: | :-------: | :-------: | :-------: | :--------------------------------------------: | :----------------------------------------------------: |
+| `efficientnet-b0_3rdparty_8xb32_in1k`\* | From scratch | 5.29 | 0.42 | 76.74 | 93.17 | [config](efficientnet-b0_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b0_3rdparty_8xb32_in1k_20220119-a7e2a0b1.pth) |
+| `efficientnet-b0_3rdparty_8xb32-aa_in1k`\* | From scratch | 5.29 | 0.42 | 77.26 | 93.41 | [config](efficientnet-b0_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b0_3rdparty_8xb32-aa_in1k_20220119-8d939117.pth) |
+| `efficientnet-b0_3rdparty_8xb32-aa-advprop_in1k`\* | From scratch | 5.29 | 0.42 | 77.53 | 93.61 | [config](efficientnet-b0_8xb32-01norm_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b0_3rdparty_8xb32-aa-advprop_in1k_20220119-26434485.pth) |
+| `efficientnet-b0_3rdparty-ra-noisystudent_in1k`\* | From scratch | 5.29 | 0.42 | 77.63 | 94.00 | [config](efficientnet-b0_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b0_3rdparty-ra-noisystudent_in1k_20221103-75cd08d3.pth) |
+| `efficientnet-b1_3rdparty_8xb32_in1k`\* | From scratch | 7.79 | 0.74 | 78.68 | 94.28 | [config](efficientnet-b1_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b1_3rdparty_8xb32_in1k_20220119-002556d9.pth) |
+| `efficientnet-b1_3rdparty_8xb32-aa_in1k`\* | From scratch | 7.79 | 0.74 | 79.20 | 94.42 | [config](efficientnet-b1_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b1_3rdparty_8xb32-aa_in1k_20220119-619d8ae3.pth) |
+| `efficientnet-b1_3rdparty_8xb32-aa-advprop_in1k`\* | From scratch | 7.79 | 0.74 | 79.52 | 94.43 | [config](efficientnet-b1_8xb32-01norm_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b1_3rdparty_8xb32-aa-advprop_in1k_20220119-5715267d.pth) |
+| `efficientnet-b1_3rdparty-ra-noisystudent_in1k`\* | From scratch | 7.79 | 0.74 | 81.44 | 95.83 | [config](efficientnet-b1_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b1_3rdparty-ra-noisystudent_in1k_20221103-756bcbc0.pth) |
+| `efficientnet-b2_3rdparty_8xb32_in1k`\* | From scratch | 9.11 | 1.07 | 79.64 | 94.80 | [config](efficientnet-b2_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b2_3rdparty_8xb32_in1k_20220119-ea374a30.pth) |
+| `efficientnet-b2_3rdparty_8xb32-aa_in1k`\* | From scratch | 9.11 | 1.07 | 80.21 | 94.96 | [config](efficientnet-b2_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b2_3rdparty_8xb32-aa_in1k_20220119-dd61e80b.pth) |
+| `efficientnet-b2_3rdparty_8xb32-aa-advprop_in1k`\* | From scratch | 9.11 | 1.07 | 80.45 | 95.07 | [config](efficientnet-b2_8xb32-01norm_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b2_3rdparty_8xb32-aa-advprop_in1k_20220119-1655338a.pth) |
+| `efficientnet-b2_3rdparty-ra-noisystudent_in1k`\* | From scratch | 9.11 | 1.07 | 82.47 | 96.23 | [config](efficientnet-b2_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b2_3rdparty-ra-noisystudent_in1k_20221103-301ed299.pth) |
+| `efficientnet-b3_3rdparty_8xb32_in1k`\* | From scratch | 12.23 | 1.95 | 81.01 | 95.34 | [config](efficientnet-b3_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b3_3rdparty_8xb32_in1k_20220119-4b4d7487.pth) |
+| `efficientnet-b3_3rdparty_8xb32-aa_in1k`\* | From scratch | 12.23 | 1.95 | 81.58 | 95.67 | [config](efficientnet-b3_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b3_3rdparty_8xb32-aa_in1k_20220119-5b4887a0.pth) |
+| `efficientnet-b3_3rdparty_8xb32-aa-advprop_in1k`\* | From scratch | 12.23 | 1.95 | 81.81 | 95.69 | [config](efficientnet-b3_8xb32-01norm_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b3_3rdparty_8xb32-aa-advprop_in1k_20220119-53b41118.pth) |
+| `efficientnet-b3_3rdparty-ra-noisystudent_in1k`\* | From scratch | 12.23 | 1.95 | 84.02 | 96.89 | [config](efficientnet-b3_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b3_3rdparty-ra-noisystudent_in1k_20221103-a4ab5fd6.pth) |
+| `efficientnet-b4_3rdparty_8xb32_in1k`\* | From scratch | 19.34 | 4.66 | 82.57 | 96.09 | [config](efficientnet-b4_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b4_3rdparty_8xb32_in1k_20220119-81fd4077.pth) |
+| `efficientnet-b4_3rdparty_8xb32-aa_in1k`\* | From scratch | 19.34 | 4.66 | 82.95 | 96.26 | [config](efficientnet-b4_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b4_3rdparty_8xb32-aa_in1k_20220119-45b8bd2b.pth) |
+| `efficientnet-b4_3rdparty_8xb32-aa-advprop_in1k`\* | From scratch | 19.34 | 4.66 | 83.25 | 96.44 | [config](efficientnet-b4_8xb32-01norm_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b4_3rdparty_8xb32-aa-advprop_in1k_20220119-38c2238c.pth) |
+| `efficientnet-b4_3rdparty-ra-noisystudent_in1k`\* | From scratch | 19.34 | 4.66 | 85.25 | 97.52 | [config](efficientnet-b4_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b4_3rdparty-ra-noisystudent_in1k_20221103-16ba8a2d.pth) |
+| `efficientnet-b5_3rdparty_8xb32_in1k`\* | From scratch | 30.39 | 10.80 | 83.18 | 96.47 | [config](efficientnet-b5_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b5_3rdparty_8xb32_in1k_20220119-e9814430.pth) |
+| `efficientnet-b5_3rdparty_8xb32-aa_in1k`\* | From scratch | 30.39 | 10.80 | 83.82 | 96.76 | [config](efficientnet-b5_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b5_3rdparty_8xb32-aa_in1k_20220119-2cab8b78.pth) |
+| `efficientnet-b5_3rdparty_8xb32-aa-advprop_in1k`\* | From scratch | 30.39 | 10.80 | 84.21 | 96.98 | [config](efficientnet-b5_8xb32-01norm_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b5_3rdparty_8xb32-aa-advprop_in1k_20220119-f57a895a.pth) |
+| `efficientnet-b5_3rdparty-ra-noisystudent_in1k`\* | From scratch | 30.39 | 10.80 | 86.08 | 97.75 | [config](efficientnet-b5_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b5_3rdparty-ra-noisystudent_in1k_20221103-111a185f.pth) |
+| `efficientnet-b6_3rdparty_8xb32-aa_in1k`\* | From scratch | 43.04 | 19.97 | 84.05 | 96.82 | [config](efficientnet-b6_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b6_3rdparty_8xb32-aa_in1k_20220119-45b03310.pth) |
+| `efficientnet-b6_3rdparty_8xb32-aa-advprop_in1k`\* | From scratch | 43.04 | 19.97 | 84.74 | 97.14 | [config](efficientnet-b6_8xb32-01norm_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b6_3rdparty_8xb32-aa-advprop_in1k_20220119-bfe3485e.pth) |
+| `efficientnet-b6_3rdparty-ra-noisystudent_in1k`\* | From scratch | 43.04 | 19.97 | 86.47 | 97.87 | [config](efficientnet-b6_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b6_3rdparty-ra-noisystudent_in1k_20221103-7de7d2cc.pth) |
+| `efficientnet-b7_3rdparty_8xb32-aa_in1k`\* | From scratch | 66.35 | 39.32 | 84.38 | 96.88 | [config](efficientnet-b7_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b7_3rdparty_8xb32-aa_in1k_20220119-bf03951c.pth) |
+| `efficientnet-b7_3rdparty_8xb32-aa-advprop_in1k`\* | From scratch | 66.35 | 39.32 | 85.14 | 97.23 | [config](efficientnet-b7_8xb32-01norm_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b7_3rdparty_8xb32-aa-advprop_in1k_20220119-c6dbff10.pth) |
+| `efficientnet-b7_3rdparty-ra-noisystudent_in1k`\* | From scratch | 66.35 | 39.32 | 86.83 | 98.08 | [config](efficientnet-b7_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b7_3rdparty-ra-noisystudent_in1k_20221103-a82894bc.pth) |
+| `efficientnet-b8_3rdparty_8xb32-aa-advprop_in1k`\* | From scratch | 87.41 | 65.00 | 85.38 | 97.28 | [config](efficientnet-b8_8xb32-01norm_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b8_3rdparty_8xb32-aa-advprop_in1k_20220119-297ce1b7.pth) |
+| `efficientnet-l2_3rdparty-ra-noisystudent_in1k-800px`\* | From scratch | 480.31 | 174.20 | 88.33 | 98.65 | [config](efficientnet-l2_8xb8_in1k-800px.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-l2_3rdparty-ra-noisystudent_in1k_20221103-be73be13.pth) |
+| `efficientnet-l2_3rdparty-ra-noisystudent_in1k-475px`\* | From scratch | 480.31 | 484.98 | 88.18 | 98.55 | [config](efficientnet-l2_8xb32_in1k-475px.py) | [model](https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-l2_3rdparty-ra-noisystudent_in1k-475px_20221103-5a0d8058.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+## Citation
+
+```bibtex
+@inproceedings{tan2019efficientnet,
+ title={Efficientnet: Rethinking model scaling for convolutional neural networks},
+ author={Tan, Mingxing and Le, Quoc},
+ booktitle={International Conference on Machine Learning},
+ pages={6105--6114},
+ year={2019},
+ organization={PMLR}
+}
+```
diff --git a/configs/efficientnet/efficientnet-b0_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-b0_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..369d0a43d1950de5da47789d0f28465c95fdaae5
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b0_8xb32-01norm_in1k.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../_base_/models/efficientnet_b0.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=224),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=224),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b0_8xb32_in1k.py b/configs/efficientnet/efficientnet-b0_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4263da196430b310fae4da3273d13bb66e89075
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b0_8xb32_in1k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_b0.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=224),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=224),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b1_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-b1_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..0405cf5f84eeedf0a2e761670bc600d9f82401af
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b1_8xb32-01norm_in1k.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../_base_/models/efficientnet_b1.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=240),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=240),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b1_8xb32_in1k.py b/configs/efficientnet/efficientnet-b1_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..e5bf2e8076d81c97adb4d1883cfbdb5f645b6b93
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b1_8xb32_in1k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_b1.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=240),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=240),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b2_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-b2_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..da3f23b84c6f7fc8b5d415b90ca2f69f4d6e58c4
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b2_8xb32-01norm_in1k.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../_base_/models/efficientnet_b2.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=260),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=260),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b2_8xb32_in1k.py b/configs/efficientnet/efficientnet-b2_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..060a2ad3ea9247131c4207d738dce0bfacd16a16
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b2_8xb32_in1k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_b2.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=260),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=260),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b3_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-b3_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..55729a9c2258352a6ed981dff25777b0acaaae85
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b3_8xb32-01norm_in1k.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../_base_/models/efficientnet_b3.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=300),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=300),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b3_8xb32_in1k.py b/configs/efficientnet/efficientnet-b3_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..d84de5a79316ab6d7f73e45f266fbaec43ed9629
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b3_8xb32_in1k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_b3.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=300),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=300),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b4_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-b4_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4dbfb212fd03d508b678a684f4d8b6854f648c6
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b4_8xb32-01norm_in1k.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../_base_/models/efficientnet_b4.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=380),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=380),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b4_8xb32_in1k.py b/configs/efficientnet/efficientnet-b4_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..08e246c3851d12ee067469d9afb10fc7f0933de7
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b4_8xb32_in1k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_b4.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=380),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=380),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b5_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-b5_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c646da43d4baf23cebfc6835ec400dba6d5bd35
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b5_8xb32-01norm_in1k.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../_base_/models/efficientnet_b5.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=456),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=456),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b5_8xb32_in1k.py b/configs/efficientnet/efficientnet-b5_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..af4fa4b8fcbce99ae1ac163c72cec11789109482
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b5_8xb32_in1k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_b5.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=456),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=456),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b6_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-b6_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..dd15054928b56bdae2c3a2ef479e96826824fe2b
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b6_8xb32-01norm_in1k.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../_base_/models/efficientnet_b6.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=528),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=528),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b6_8xb32_in1k.py b/configs/efficientnet/efficientnet-b6_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..fae02aed6dd5b8fbb1b42140856333b771c927d1
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b6_8xb32_in1k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_b6.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=528),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=528),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b7_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-b7_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..687dfd261d73d84061b289c955cb0260059999b2
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b7_8xb32-01norm_in1k.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../_base_/models/efficientnet_b7.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=600),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=600),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b7_8xb32_in1k.py b/configs/efficientnet/efficientnet-b7_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..5d783bb30bf1939aa1c8c9a010e5733ae7b1342b
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b7_8xb32_in1k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_b7.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=600),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=600),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b8_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-b8_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..07d3692baa9b9f3d10109e63d1da5e74cc62ee26
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b8_8xb32-01norm_in1k.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../_base_/models/efficientnet_b8.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=672),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=672),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-b8_8xb32_in1k.py b/configs/efficientnet/efficientnet-b8_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..868986f52488233b36631c13d66d8da2aac8c348
--- /dev/null
+++ b/configs/efficientnet/efficientnet-b8_8xb32_in1k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_b8.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=672),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=672),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-em_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-em_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..9de3b27fb31a1382c08a646987b7cf4d996e77f4
--- /dev/null
+++ b/configs/efficientnet/efficientnet-em_8xb32-01norm_in1k.py
@@ -0,0 +1,31 @@
+_base_ = [
+ '../_base_/models/efficientnet_em.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=240),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=240),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-es_8xb32-01norm_in1k.py b/configs/efficientnet/efficientnet-es_8xb32-01norm_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..e643d55089b932732d47c5dbe5734c2085a2fb3e
--- /dev/null
+++ b/configs/efficientnet/efficientnet-es_8xb32-01norm_in1k.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_es.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=224),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=224),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-l2_8xb32_in1k-475px.py b/configs/efficientnet/efficientnet-l2_8xb32_in1k-475px.py
new file mode 100644
index 0000000000000000000000000000000000000000..560695144f50194c00bc78707c8ddf7288e4cd52
--- /dev/null
+++ b/configs/efficientnet/efficientnet-l2_8xb32_in1k-475px.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_l2.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=475),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=475),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/efficientnet-l2_8xb8_in1k-800px.py b/configs/efficientnet/efficientnet-l2_8xb8_in1k-800px.py
new file mode 100644
index 0000000000000000000000000000000000000000..61bddfa735117db68377a224f72c1160a046ae1c
--- /dev/null
+++ b/configs/efficientnet/efficientnet-l2_8xb8_in1k-800px.py
@@ -0,0 +1,24 @@
+_base_ = [
+ '../_base_/models/efficientnet_l2.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetRandomCrop', scale=800),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='EfficientNetCenterCrop', crop_size=800),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(batch_size=8, dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(batch_size=8, dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(batch_size=8, dataset=dict(pipeline=test_pipeline))
diff --git a/configs/efficientnet/metafile.yml b/configs/efficientnet/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..21130c4ff1d64895295372acac18961a4f90bd7c
--- /dev/null
+++ b/configs/efficientnet/metafile.yml
@@ -0,0 +1,551 @@
+Collections:
+ - Name: EfficientNet
+ Metadata:
+ Training Data: ImageNet-1k
+ Architecture:
+ - 1x1 Convolution
+ - Average Pooling
+ - Convolution
+ - Dense Connections
+ - Dropout
+ - Inverted Residual Block
+ - RMSProp
+ - Squeeze-and-Excitation Block
+ - Swish
+ Paper:
+ URL: https://arxiv.org/abs/1905.11946v5
+ Title: "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks"
+ README: configs/efficientnet/README.md
+ Code:
+ Version: v0.20.1
+ URL: https://github.com/open-mmlab/mmpretrain/blob/v0.20.1/mmcls/models/backbones/efficientnet.py
+
+Models:
+ - Name: efficientnet-b0_3rdparty_8xb32_in1k
+ Metadata:
+ FLOPs: 420592480
+ Parameters: 5288548
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 76.74
+ Top 5 Accuracy: 93.17
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b0_3rdparty_8xb32_in1k_20220119-a7e2a0b1.pth
+ Config: configs/efficientnet/efficientnet-b0_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckpts/efficientnet-b0.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b0_3rdparty_8xb32-aa_in1k
+ Metadata:
+ FLOPs: 420592480
+ Parameters: 5288548
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 77.26
+ Top 5 Accuracy: 93.41
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b0_3rdparty_8xb32-aa_in1k_20220119-8d939117.pth
+ Config: configs/efficientnet/efficientnet-b0_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckptsaug/efficientnet-b0.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b0_3rdparty_8xb32-aa-advprop_in1k
+ Metadata:
+ FLOPs: 420592480
+ Parameters: 5288548
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 77.53
+ Top 5 Accuracy: 93.61
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b0_3rdparty_8xb32-aa-advprop_in1k_20220119-26434485.pth
+ Config: configs/efficientnet/efficientnet-b0_8xb32-01norm_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/advprop/efficientnet-b0.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b0_3rdparty-ra-noisystudent_in1k
+ Metadata:
+ FLOPs: 420592480
+ Parameters: 5288548
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 77.63
+ Top 5 Accuracy: 94.00
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b0_3rdparty-ra-noisystudent_in1k_20221103-75cd08d3.pth
+ Config: configs/efficientnet/efficientnet-b0_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/noisystudent/noisy_student_efficientnet-b0.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b1_3rdparty_8xb32_in1k
+ Metadata:
+ FLOPs: 744059920
+ Parameters: 7794184
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 78.68
+ Top 5 Accuracy: 94.28
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b1_3rdparty_8xb32_in1k_20220119-002556d9.pth
+ Config: configs/efficientnet/efficientnet-b1_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckpts/efficientnet-b1.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b1_3rdparty_8xb32-aa_in1k
+ Metadata:
+ FLOPs: 744059920
+ Parameters: 7794184
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 79.20
+ Top 5 Accuracy: 94.42
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b1_3rdparty_8xb32-aa_in1k_20220119-619d8ae3.pth
+ Config: configs/efficientnet/efficientnet-b1_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckptsaug/efficientnet-b1.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b1_3rdparty_8xb32-aa-advprop_in1k
+ Metadata:
+ FLOPs: 744059920
+ Parameters: 7794184
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 79.52
+ Top 5 Accuracy: 94.43
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b1_3rdparty_8xb32-aa-advprop_in1k_20220119-5715267d.pth
+ Config: configs/efficientnet/efficientnet-b1_8xb32-01norm_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/advprop/efficientnet-b1.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b1_3rdparty-ra-noisystudent_in1k
+ Metadata:
+ FLOPs: 744059920
+ Parameters: 7794184
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.44
+ Top 5 Accuracy: 95.83
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b1_3rdparty-ra-noisystudent_in1k_20221103-756bcbc0.pth
+ Config: configs/efficientnet/efficientnet-b1_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/noisystudent/noisy_student_efficientnet-b1.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b2_3rdparty_8xb32_in1k
+ Metadata:
+ FLOPs: 1066620392
+ Parameters: 9109994
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 79.64
+ Top 5 Accuracy: 94.80
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b2_3rdparty_8xb32_in1k_20220119-ea374a30.pth
+ Config: configs/efficientnet/efficientnet-b2_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckpts/efficientnet-b2.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b2_3rdparty_8xb32-aa_in1k
+ Metadata:
+ FLOPs: 1066620392
+ Parameters: 9109994
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 80.21
+ Top 5 Accuracy: 94.96
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b2_3rdparty_8xb32-aa_in1k_20220119-dd61e80b.pth
+ Config: configs/efficientnet/efficientnet-b2_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckptsaug/efficientnet-b2.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b2_3rdparty_8xb32-aa-advprop_in1k
+ Metadata:
+ FLOPs: 1066620392
+ Parameters: 9109994
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 80.45
+ Top 5 Accuracy: 95.07
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b2_3rdparty_8xb32-aa-advprop_in1k_20220119-1655338a.pth
+ Config: configs/efficientnet/efficientnet-b2_8xb32-01norm_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/advprop/efficientnet-b2.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b2_3rdparty-ra-noisystudent_in1k
+ Metadata:
+ FLOPs: 1066620392
+ Parameters: 9109994
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 82.47
+ Top 5 Accuracy: 96.23
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b2_3rdparty-ra-noisystudent_in1k_20221103-301ed299.pth
+ Config: configs/efficientnet/efficientnet-b2_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/noisystudent/noisy_student_efficientnet-b2.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b3_3rdparty_8xb32_in1k
+ Metadata:
+ FLOPs: 1953798216
+ Parameters: 12233232
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.01
+ Top 5 Accuracy: 95.34
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b3_3rdparty_8xb32_in1k_20220119-4b4d7487.pth
+ Config: configs/efficientnet/efficientnet-b3_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckpts/efficientnet-b3.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b3_3rdparty_8xb32-aa_in1k
+ Metadata:
+ FLOPs: 1953798216
+ Parameters: 12233232
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.58
+ Top 5 Accuracy: 95.67
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b3_3rdparty_8xb32-aa_in1k_20220119-5b4887a0.pth
+ Config: configs/efficientnet/efficientnet-b3_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckptsaug/efficientnet-b3.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b3_3rdparty_8xb32-aa-advprop_in1k
+ Metadata:
+ FLOPs: 1953798216
+ Parameters: 12233232
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.81
+ Top 5 Accuracy: 95.69
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b3_3rdparty_8xb32-aa-advprop_in1k_20220119-53b41118.pth
+ Config: configs/efficientnet/efficientnet-b3_8xb32-01norm_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/advprop/efficientnet-b3.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b3_3rdparty-ra-noisystudent_in1k
+ Metadata:
+ FLOPs: 1953798216
+ Parameters: 12233232
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.02
+ Top 5 Accuracy: 96.89
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b3_3rdparty-ra-noisystudent_in1k_20221103-a4ab5fd6.pth
+ Config: configs/efficientnet/efficientnet-b3_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/noisystudent/noisy_student_efficientnet-b3.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b4_3rdparty_8xb32_in1k
+ Metadata:
+ FLOPs: 4659080176
+ Parameters: 19341616
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 82.57
+ Top 5 Accuracy: 96.09
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b4_3rdparty_8xb32_in1k_20220119-81fd4077.pth
+ Config: configs/efficientnet/efficientnet-b4_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckpts/efficientnet-b4.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b4_3rdparty_8xb32-aa_in1k
+ Metadata:
+ FLOPs: 4659080176
+ Parameters: 19341616
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 82.95
+ Top 5 Accuracy: 96.26
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b4_3rdparty_8xb32-aa_in1k_20220119-45b8bd2b.pth
+ Config: configs/efficientnet/efficientnet-b4_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckptsaug/efficientnet-b4.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b4_3rdparty_8xb32-aa-advprop_in1k
+ Metadata:
+ FLOPs: 4659080176
+ Parameters: 19341616
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.25
+ Top 5 Accuracy: 96.44
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b4_3rdparty_8xb32-aa-advprop_in1k_20220119-38c2238c.pth
+ Config: configs/efficientnet/efficientnet-b4_8xb32-01norm_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/advprop/efficientnet-b4.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b4_3rdparty-ra-noisystudent_in1k
+ Metadata:
+ FLOPs: 4659080176
+ Parameters: 19341616
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 85.25
+ Top 5 Accuracy: 97.52
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b4_3rdparty-ra-noisystudent_in1k_20221103-16ba8a2d.pth
+ Config: configs/efficientnet/efficientnet-b4_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/noisystudent/noisy_student_efficientnet-b4.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b5_3rdparty_8xb32_in1k
+ Metadata:
+ FLOPs: 10799472560
+ Parameters: 30389784
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.18
+ Top 5 Accuracy: 96.47
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b5_3rdparty_8xb32_in1k_20220119-e9814430.pth
+ Config: configs/efficientnet/efficientnet-b5_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckpts/efficientnet-b5.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b5_3rdparty_8xb32-aa_in1k
+ Metadata:
+ FLOPs: 10799472560
+ Parameters: 30389784
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.82
+ Top 5 Accuracy: 96.76
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b5_3rdparty_8xb32-aa_in1k_20220119-2cab8b78.pth
+ Config: configs/efficientnet/efficientnet-b5_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckptsaug/efficientnet-b5.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b5_3rdparty_8xb32-aa-advprop_in1k
+ Metadata:
+ FLOPs: 10799472560
+ Parameters: 30389784
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.21
+ Top 5 Accuracy: 96.98
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b5_3rdparty_8xb32-aa-advprop_in1k_20220119-f57a895a.pth
+ Config: configs/efficientnet/efficientnet-b5_8xb32-01norm_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/advprop/efficientnet-b5.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b5_3rdparty-ra-noisystudent_in1k
+ Metadata:
+ FLOPs: 10799472560
+ Parameters: 30389784
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 86.08
+ Top 5 Accuracy: 97.75
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b5_3rdparty-ra-noisystudent_in1k_20221103-111a185f.pth
+ Config: configs/efficientnet/efficientnet-b5_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/noisystudent/noisy_student_efficientnet-b5.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b6_3rdparty_8xb32-aa_in1k
+ Metadata:
+ FLOPs: 19971777560
+ Parameters: 43040704
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.05
+ Top 5 Accuracy: 96.82
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b6_3rdparty_8xb32-aa_in1k_20220119-45b03310.pth
+ Config: configs/efficientnet/efficientnet-b6_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckptsaug/efficientnet-b6.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b6_3rdparty_8xb32-aa-advprop_in1k
+ Metadata:
+ FLOPs: 19971777560
+ Parameters: 43040704
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.74
+ Top 5 Accuracy: 97.14
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b6_3rdparty_8xb32-aa-advprop_in1k_20220119-bfe3485e.pth
+ Config: configs/efficientnet/efficientnet-b6_8xb32-01norm_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/advprop/efficientnet-b6.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b6_3rdparty-ra-noisystudent_in1k
+ Metadata:
+ FLOPs: 19971777560
+ Parameters: 43040704
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 86.47
+ Top 5 Accuracy: 97.87
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b6_3rdparty-ra-noisystudent_in1k_20221103-7de7d2cc.pth
+ Config: configs/efficientnet/efficientnet-b6_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/noisystudent/noisy_student_efficientnet-b6.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b7_3rdparty_8xb32-aa_in1k
+ Metadata:
+ FLOPs: 39316473392
+ Parameters: 66347960
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.38
+ Top 5 Accuracy: 96.88
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b7_3rdparty_8xb32-aa_in1k_20220119-bf03951c.pth
+ Config: configs/efficientnet/efficientnet-b7_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/ckptsaug/efficientnet-b7.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b7_3rdparty_8xb32-aa-advprop_in1k
+ Metadata:
+ FLOPs: 39316473392
+ Parameters: 66347960
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 85.14
+ Top 5 Accuracy: 97.23
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b7_3rdparty_8xb32-aa-advprop_in1k_20220119-c6dbff10.pth
+ Config: configs/efficientnet/efficientnet-b7_8xb32-01norm_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/advprop/efficientnet-b7.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b7_3rdparty-ra-noisystudent_in1k
+ Metadata:
+ FLOPs: 39316473392
+ Parameters: 66347960
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 86.83
+ Top 5 Accuracy: 98.08
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b7_3rdparty-ra-noisystudent_in1k_20221103-a82894bc.pth
+ Config: configs/efficientnet/efficientnet-b7_8xb32_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/noisystudent/noisy_student_efficientnet-b7.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-b8_3rdparty_8xb32-aa-advprop_in1k
+ Metadata:
+ FLOPs: 64999827816
+ Parameters: 87413142
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 85.38
+ Top 5 Accuracy: 97.28
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-b8_3rdparty_8xb32-aa-advprop_in1k_20220119-297ce1b7.pth
+ Config: configs/efficientnet/efficientnet-b8_8xb32-01norm_in1k.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/advprop/efficientnet-b8.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-l2_3rdparty-ra-noisystudent_in1k-800px
+ Metadata:
+ FLOPs: 174203533416
+ Parameters: 480309308
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 88.33
+ Top 5 Accuracy: 98.65
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-l2_3rdparty-ra-noisystudent_in1k_20221103-be73be13.pth
+ Config: configs/efficientnet/efficientnet-l2_8xb8_in1k-800px.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/noisystudent/noisy_student_efficientnet-l2.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
+ - Name: efficientnet-l2_3rdparty-ra-noisystudent_in1k-475px
+ Metadata:
+ FLOPs: 484984099280
+ Parameters: 480309308
+ In Collection: EfficientNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 88.18
+ Top 5 Accuracy: 98.55
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/efficientnet/efficientnet-l2_3rdparty-ra-noisystudent_in1k-475px_20221103-5a0d8058.pth
+ Config: configs/efficientnet/efficientnet-l2_8xb32_in1k-475px.py
+ Converted From:
+ Weights: https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/noisystudent/noisy_student_efficientnet-l2_475.tar.gz
+ Code: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
diff --git a/configs/efficientnet_v2/README.md b/configs/efficientnet_v2/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..965421823e7fe3e6cf8504d717864bf8a499ab2e
--- /dev/null
+++ b/configs/efficientnet_v2/README.md
@@ -0,0 +1,98 @@
+# EfficientNetV2
+
+> [EfficientNetV2: Smaller Models and Faster Training](https://arxiv.org/abs/2104.00298)
+
+
+
+## Abstract
+
+This paper introduces EfficientNetV2, a new family of convolutional networks that have faster training speed and better parameter efficiency than previous models. To develop this family of models, we use a combination of training-aware neural architecture search and scaling, to jointly optimize training speed and parameter efficiency. The models were searched from the search space enriched with new ops such as Fused-MBConv. Our experiments show that EfficientNetV2 models train much faster than state-of-the-art models while being up to 6.8x smaller. Our training can be further sped up by progressively increasing the image size during training, but it often causes a drop in accuracy. To compensate for this accuracy drop, we propose to adaptively adjust regularization (e.g., dropout and data augmentation) as well, such that we can achieve both fast training and good accuracy. With progressive learning, our EfficientNetV2 significantly outperforms previous models on ImageNet and CIFAR/Cars/Flowers datasets. By pretraining on the same ImageNet21k, our EfficientNetV2 achieves 87.3% top-1 accuracy on ImageNet ILSVRC2012, outperforming the recent ViT by 2.0% accuracy while training 5x-11x faster using the same computing resources. Code will be available at https://github.com/google/automl/tree/master/efficientnetv2.
+
+
+

+
+

+
+

+
+
+
+

+
+

+
+

+
+

+
+

+
+
+
+

+
+
+
+

+
+

+
+

+
+

+
+

+
+

+
![]() '
+ 'Describe this image in detail.'),
+ ('
'
+ 'Describe this image in detail.'),
+ ('![]() '
+ 'Take a look at this image and describe what you notice.'),
+ ('
'
+ 'Take a look at this image and describe what you notice.'),
+ ('![]() '
+ 'Please provide a detailed description of the picture.'),
+ ('
'
+ 'Please provide a detailed description of the picture.'),
+ ('![]() '
+ 'Could you describe the contents of this image for me?')]),
+ ('zh', [('
'
+ 'Could you describe the contents of this image for me?')]),
+ ('zh', [('![]() '
+ '详细描述这张图片。'), ('
'
+ '详细描述这张图片。'), ('![]() '
+ '浏览这张图片并描述你注意到什么。'),
+ ('
'
+ '浏览这张图片并描述你注意到什么。'),
+ ('![]() '
+ '请对这张图片进行详细的描述。'),
+ ('
'
+ '请对这张图片进行详细的描述。'),
+ ('![]() '
+ '你能为我描述这张图片的内容吗?')])
+ ]),
+ max_txt_len=160,
+ end_sym='###')
+
+strategy = dict(
+ type='DeepSpeedStrategy',
+ fp16=dict(
+ enabled=True,
+ auto_cast=False,
+ fp16_master_weights_and_grads=False,
+ loss_scale=0,
+ loss_scale_window=1000,
+ hysteresis=1,
+ min_loss_scale=1,
+ initial_scale_power=16,
+ ),
+ inputs_to_half=[0],
+ zero_optimization=dict(
+ stage=2,
+ allgather_partitions=True,
+ allgather_bucket_size=2e8,
+ reduce_scatter=True,
+ reduce_bucket_size='auto',
+ overlap_comm=True,
+ contiguous_gradients=True,
+ ),
+)
+
+# schedule settings
+optim_wrapper = dict(
+ type='DeepSpeedOptimWrapper',
+ optimizer=dict(type='AdamW', lr=1e-3, weight_decay=0.05))
+
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1e-3 / 500,
+ by_epoch=False,
+ begin=0,
+ end=500,
+ ),
+ dict(
+ type='CosineAnnealingLR',
+ eta_min=2e-4,
+ by_epoch=False,
+ begin=500,
+ ),
+]
+
+train_cfg = dict(by_epoch=True, max_epochs=6)
+test_cfg = dict()
+
+runner_type = 'FlexibleRunner'
+
+default_hooks = dict(
+ checkpoint=dict(
+ type='CheckpointHook',
+ interval=1,
+ by_epoch=True,
+ save_last=True,
+ max_keep_ckpts=1,
+ ))
diff --git a/configs/minigpt4/minigpt-4_vicuna-7b_caption.py b/configs/minigpt4/minigpt-4_vicuna-7b_caption.py
new file mode 100644
index 0000000000000000000000000000000000000000..f468e2d8fac7ce46871801c9cc490acb97db683d
--- /dev/null
+++ b/configs/minigpt4/minigpt-4_vicuna-7b_caption.py
@@ -0,0 +1,94 @@
+_base_ = [
+ '../_base_/datasets/coco_caption.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='Resize',
+ scale=(224, 224),
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(type='PackInputs', meta_keys=['image_id']),
+]
+
+val_dataloader = dict(batch_size=1, dataset=dict(pipeline=test_pipeline))
+test_dataloader = val_dataloader
+
+# model settings
+model = dict(
+ type='MiniGPT4',
+ vision_encoder=dict(
+ type='BEiTViT',
+ # eva-g without the final layer
+ arch=dict(
+ embed_dims=1408,
+ num_layers=39,
+ num_heads=16,
+ feedforward_channels=6144,
+ ),
+ img_size=224,
+ patch_size=14,
+ layer_scale_init_value=0.0,
+ frozen_stages=39,
+ use_abs_pos_emb=True,
+ use_rel_pos_bias=False,
+ final_norm=False,
+ use_shared_rel_pos_bias=False,
+ out_type='raw',
+ pretrained= # noqa
+ 'https://download.openmmlab.com/mmpretrain/v1.0/minigpt4/minigpt-4_eva-g-p14_20230615-e908c021.pth' # noqa
+ ),
+ q_former_model=dict(
+ type='Qformer',
+ model_style='bert-base-uncased',
+ vision_model_width=1408,
+ add_cross_attention=True,
+ cross_attention_freq=2,
+ num_query_token=32,
+ pretrained= # noqa
+ 'https://download.openmmlab.com/mmpretrain/v1.0/minigpt4/minigpt-4_qformer_20230615-1dfa889c.pth' # noqa
+ ),
+ lang_encoder=dict(
+ type='AutoModelForCausalLM', name_or_path='YOUR_PATH_TO_VICUNA'),
+ tokenizer=dict(type='LlamaTokenizer', name_or_path='YOUR_PATH_TO_VICUNA'),
+ task='caption',
+ prompt_template=dict([('en', '###Ask: {} ###Answer: '),
+ ('zh', '###问:{} ###答:')]),
+ raw_prompts=dict([
+ ('en', [('
'
+ '你能为我描述这张图片的内容吗?')])
+ ]),
+ max_txt_len=160,
+ end_sym='###')
+
+strategy = dict(
+ type='DeepSpeedStrategy',
+ fp16=dict(
+ enabled=True,
+ auto_cast=False,
+ fp16_master_weights_and_grads=False,
+ loss_scale=0,
+ loss_scale_window=1000,
+ hysteresis=1,
+ min_loss_scale=1,
+ initial_scale_power=16,
+ ),
+ inputs_to_half=[0],
+ zero_optimization=dict(
+ stage=2,
+ allgather_partitions=True,
+ allgather_bucket_size=2e8,
+ reduce_scatter=True,
+ reduce_bucket_size='auto',
+ overlap_comm=True,
+ contiguous_gradients=True,
+ ),
+)
+
+# schedule settings
+optim_wrapper = dict(
+ type='DeepSpeedOptimWrapper',
+ optimizer=dict(type='AdamW', lr=1e-3, weight_decay=0.05))
+
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1e-3 / 500,
+ by_epoch=False,
+ begin=0,
+ end=500,
+ ),
+ dict(
+ type='CosineAnnealingLR',
+ eta_min=2e-4,
+ by_epoch=False,
+ begin=500,
+ ),
+]
+
+train_cfg = dict(by_epoch=True, max_epochs=6)
+test_cfg = dict()
+
+runner_type = 'FlexibleRunner'
+
+default_hooks = dict(
+ checkpoint=dict(
+ type='CheckpointHook',
+ interval=1,
+ by_epoch=True,
+ save_last=True,
+ max_keep_ckpts=1,
+ ))
diff --git a/configs/minigpt4/minigpt-4_vicuna-7b_caption.py b/configs/minigpt4/minigpt-4_vicuna-7b_caption.py
new file mode 100644
index 0000000000000000000000000000000000000000..f468e2d8fac7ce46871801c9cc490acb97db683d
--- /dev/null
+++ b/configs/minigpt4/minigpt-4_vicuna-7b_caption.py
@@ -0,0 +1,94 @@
+_base_ = [
+ '../_base_/datasets/coco_caption.py',
+ '../_base_/default_runtime.py',
+]
+
+# dataset settings
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='Resize',
+ scale=(224, 224),
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(type='PackInputs', meta_keys=['image_id']),
+]
+
+val_dataloader = dict(batch_size=1, dataset=dict(pipeline=test_pipeline))
+test_dataloader = val_dataloader
+
+# model settings
+model = dict(
+ type='MiniGPT4',
+ vision_encoder=dict(
+ type='BEiTViT',
+ # eva-g without the final layer
+ arch=dict(
+ embed_dims=1408,
+ num_layers=39,
+ num_heads=16,
+ feedforward_channels=6144,
+ ),
+ img_size=224,
+ patch_size=14,
+ layer_scale_init_value=0.0,
+ frozen_stages=39,
+ use_abs_pos_emb=True,
+ use_rel_pos_bias=False,
+ final_norm=False,
+ use_shared_rel_pos_bias=False,
+ out_type='raw',
+ pretrained= # noqa
+ 'https://download.openmmlab.com/mmpretrain/v1.0/minigpt4/minigpt-4_eva-g-p14_20230615-e908c021.pth' # noqa
+ ),
+ q_former_model=dict(
+ type='Qformer',
+ model_style='bert-base-uncased',
+ vision_model_width=1408,
+ add_cross_attention=True,
+ cross_attention_freq=2,
+ num_query_token=32,
+ pretrained= # noqa
+ 'https://download.openmmlab.com/mmpretrain/v1.0/minigpt4/minigpt-4_qformer_20230615-1dfa889c.pth' # noqa
+ ),
+ lang_encoder=dict(
+ type='AutoModelForCausalLM', name_or_path='YOUR_PATH_TO_VICUNA'),
+ tokenizer=dict(type='LlamaTokenizer', name_or_path='YOUR_PATH_TO_VICUNA'),
+ task='caption',
+ prompt_template=dict([('en', '###Ask: {} ###Answer: '),
+ ('zh', '###问:{} ###答:')]),
+ raw_prompts=dict([
+ ('en', [('![]() '
+ 'Describe this image in detail.'),
+ ('
'
+ 'Describe this image in detail.'),
+ ('![]() '
+ 'Take a look at this image and describe what you notice.'),
+ ('
'
+ 'Take a look at this image and describe what you notice.'),
+ ('![]() '
+ 'Please provide a detailed description of the picture.'),
+ ('
'
+ 'Please provide a detailed description of the picture.'),
+ ('![]() '
+ 'Could you describe the contents of this image for me?')]),
+ ('zh', [('
'
+ 'Could you describe the contents of this image for me?')]),
+ ('zh', [('![]() '
+ '详细描述这张图片。'), ('
'
+ '详细描述这张图片。'), ('![]() '
+ '浏览这张图片并描述你注意到什么。'),
+ ('
'
+ '浏览这张图片并描述你注意到什么。'),
+ ('![]() '
+ '请对这张图片进行详细的描述。'),
+ ('
'
+ '请对这张图片进行详细的描述。'),
+ ('![]() '
+ '你能为我描述这张图片的内容吗?')])
+ ]),
+ max_txt_len=160,
+ end_sym='###')
+
+# schedule settings
+optim_wrapper = dict(optimizer=dict(type='AdamW', lr=1e-5, weight_decay=0.05))
+
+param_scheduler = [
+ dict(
+ type='CosineAnnealingLR',
+ by_epoch=True,
+ begin=0,
+ end=5,
+ )
+]
+
+train_cfg = dict(by_epoch=True, max_epochs=5)
+val_cfg = dict()
+test_cfg = dict()
diff --git a/configs/mixmim/README.md b/configs/mixmim/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..e07f5011b32463a7be65d2cbe285148e88a6b3fc
--- /dev/null
+++ b/configs/mixmim/README.md
@@ -0,0 +1,102 @@
+# MixMIM
+
+> [MixMIM: Mixed and Masked Image Modeling for Efficient Visual Representation Learning](https://arxiv.org/abs/2205.13137)
+
+
+
+## Abstract
+
+In this study, we propose Mixed and Masked Image Modeling (MixMIM), a
+simple but efficient MIM method that is applicable to various hierarchical Vision
+Transformers. Existing MIM methods replace a random subset of input tokens with
+a special [MASK] symbol and aim at reconstructing original image tokens from
+the corrupted image. However, we find that using the [MASK] symbol greatly
+slows down the training and causes training-finetuning inconsistency, due to the
+large masking ratio (e.g., 40% in BEiT). In contrast, we replace the masked tokens
+of one image with visible tokens of another image, i.e., creating a mixed image.
+We then conduct dual reconstruction to reconstruct the original two images from
+the mixed input, which significantly improves efficiency. While MixMIM can
+be applied to various architectures, this paper explores a simpler but stronger
+hierarchical Transformer, and scales with MixMIM-B, -L, and -H. Empirical
+results demonstrate that MixMIM can learn high-quality visual representations
+efficiently. Notably, MixMIM-B with 88M parameters achieves 85.1% top-1
+accuracy on ImageNet-1K by pretraining for 600 epochs, setting a new record for
+neural networks with comparable model sizes (e.g., ViT-B) among MIM methods.
+Besides, its transferring performances on the other 6 datasets show MixMIM has
+better FLOPs / performance tradeoff than previous MIM methods
+
+
'
+ '你能为我描述这张图片的内容吗?')])
+ ]),
+ max_txt_len=160,
+ end_sym='###')
+
+# schedule settings
+optim_wrapper = dict(optimizer=dict(type='AdamW', lr=1e-5, weight_decay=0.05))
+
+param_scheduler = [
+ dict(
+ type='CosineAnnealingLR',
+ by_epoch=True,
+ begin=0,
+ end=5,
+ )
+]
+
+train_cfg = dict(by_epoch=True, max_epochs=5)
+val_cfg = dict()
+test_cfg = dict()
diff --git a/configs/mixmim/README.md b/configs/mixmim/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..e07f5011b32463a7be65d2cbe285148e88a6b3fc
--- /dev/null
+++ b/configs/mixmim/README.md
@@ -0,0 +1,102 @@
+# MixMIM
+
+> [MixMIM: Mixed and Masked Image Modeling for Efficient Visual Representation Learning](https://arxiv.org/abs/2205.13137)
+
+
+
+## Abstract
+
+In this study, we propose Mixed and Masked Image Modeling (MixMIM), a
+simple but efficient MIM method that is applicable to various hierarchical Vision
+Transformers. Existing MIM methods replace a random subset of input tokens with
+a special [MASK] symbol and aim at reconstructing original image tokens from
+the corrupted image. However, we find that using the [MASK] symbol greatly
+slows down the training and causes training-finetuning inconsistency, due to the
+large masking ratio (e.g., 40% in BEiT). In contrast, we replace the masked tokens
+of one image with visible tokens of another image, i.e., creating a mixed image.
+We then conduct dual reconstruction to reconstruct the original two images from
+the mixed input, which significantly improves efficiency. While MixMIM can
+be applied to various architectures, this paper explores a simpler but stronger
+hierarchical Transformer, and scales with MixMIM-B, -L, and -H. Empirical
+results demonstrate that MixMIM can learn high-quality visual representations
+efficiently. Notably, MixMIM-B with 88M parameters achieves 85.1% top-1
+accuracy on ImageNet-1K by pretraining for 600 epochs, setting a new record for
+neural networks with comparable model sizes (e.g., ViT-B) among MIM methods.
+Besides, its transferring performances on the other 6 datasets show MixMIM has
+better FLOPs / performance tradeoff than previous MIM methods
+
+
+

+
+

+
+
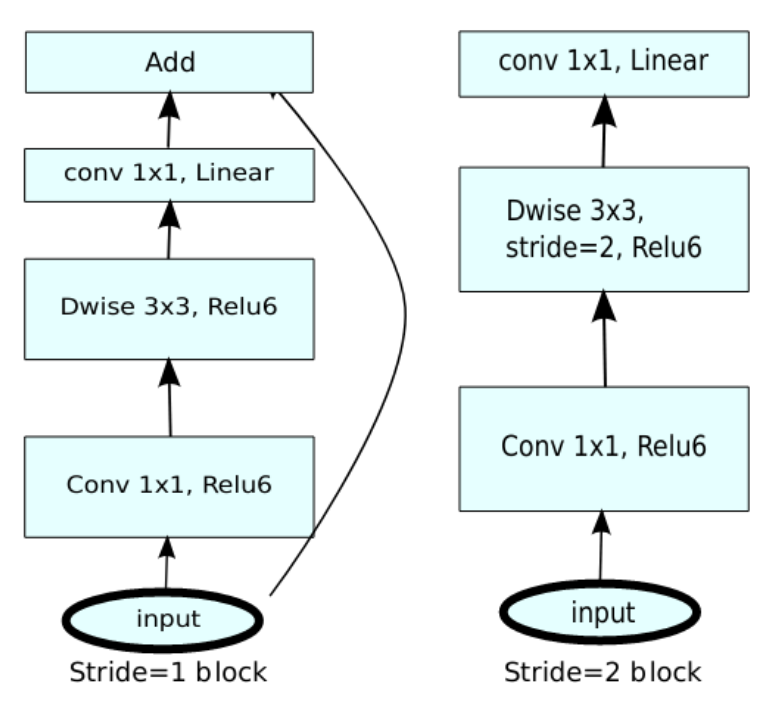
+
+
+Show the paper's abstract
+
+
+In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3.
+
+The MobileNetV2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input an MobileNetV2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on Imagenet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as the number of parameters.
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('mobilenet-v2_8xb32_in1k', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('mobilenet-v2_8xb32_in1k', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Train/Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Train:
+
+```shell
+python tools/train.py configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py
+```
+
+Test:
+
+```shell
+python tools/test.py configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py https://download.openmmlab.com/mmclassification/v0/mobilenet_v2/mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth
+```
+
+
+
+## Models and results
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :------------------------ | :----------: | :--------: | :-------: | :-------: | :-------: | :----------------------------------: | :----------------------------------------------------------------------------------------: |
+| `mobilenet-v2_8xb32_in1k` | From scratch | 3.50 | 0.32 | 71.86 | 90.42 | [config](mobilenet-v2_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobilenet_v2/mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/mobilenet_v2/mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.json) |
+
+## Citation
+
+```bibtex
+@INPROCEEDINGS{8578572,
+ author={M. {Sandler} and A. {Howard} and M. {Zhu} and A. {Zhmoginov} and L. {Chen}},
+ booktitle={2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ title={MobileNetV2: Inverted Residuals and Linear Bottlenecks},
+ year={2018},
+ volume={},
+ number={},
+ pages={4510-4520},
+ doi={10.1109/CVPR.2018.00474}}
+}
+```
diff --git a/configs/mobilenet_v2/metafile.yml b/configs/mobilenet_v2/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..aaa490ae485e87c3965f946f3fe25aa52919830b
--- /dev/null
+++ b/configs/mobilenet_v2/metafile.yml
@@ -0,0 +1,34 @@
+Collections:
+ - Name: MobileNet V2
+ Metadata:
+ Training Data: ImageNet-1k
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Epochs: 300
+ Batch Size: 256
+ Architecture:
+ - MobileNet V2
+ Paper:
+ URL: https://arxiv.org/abs/1801.04381
+ Title: "MobileNetV2: Inverted Residuals and Linear Bottlenecks"
+ README: configs/mobilenet_v2/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmpretrain/blob/v0.15.0/mmcls/models/backbones/mobilenet_v2.py#L101
+ Version: v0.15.0
+
+Models:
+ - Name: mobilenet-v2_8xb32_in1k
+ Metadata:
+ FLOPs: 319000000
+ Parameters: 3500000
+ In Collection: MobileNet V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 71.86
+ Top 5 Accuracy: 90.42
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobilenet_v2/mobilenet_v2_batch256_imagenet_20200708-3b2dc3af.pth
+ Config: configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py
diff --git a/configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py b/configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..afd2d9795af601010833ba239465c3e2c5abdf20
--- /dev/null
+++ b/configs/mobilenet_v2/mobilenet-v2_8xb32_in1k.py
@@ -0,0 +1,6 @@
+_base_ = [
+ '../_base_/models/mobilenet_v2_1x.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256_epochstep.py',
+ '../_base_/default_runtime.py'
+]
diff --git a/configs/mobilenet_v3/README.md b/configs/mobilenet_v3/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..833de5b25aae9a8af43f5e086e6e2fd212669d03
--- /dev/null
+++ b/configs/mobilenet_v3/README.md
@@ -0,0 +1,99 @@
+# MobileNet V3
+
+> [Searching for MobileNetV3](https://arxiv.org/abs/1905.02244)
+
+
+
+## Introduction
+
+**MobileNet V3** is initially described in [the paper](https://arxiv.org/pdf/1905.02244.pdf). MobileNetV3 parameters are obtained by NAS (network architecture search) search, and some practical results of V1 and V2 are inherited, and the attention mechanism of SE channel is attracted, which can be considered as a masterpiece. The author create two new MobileNet models for release: MobileNetV3-Large and MobileNetV3-Small which are targeted for high and low resource use cases. These models are then adapted and applied to the tasks of object detection and semantic segmentation. The author of MobileNet V3 measure its performance on Imagenet classification, COCO object detection, and Cityscapes segmentation.
+
+
+
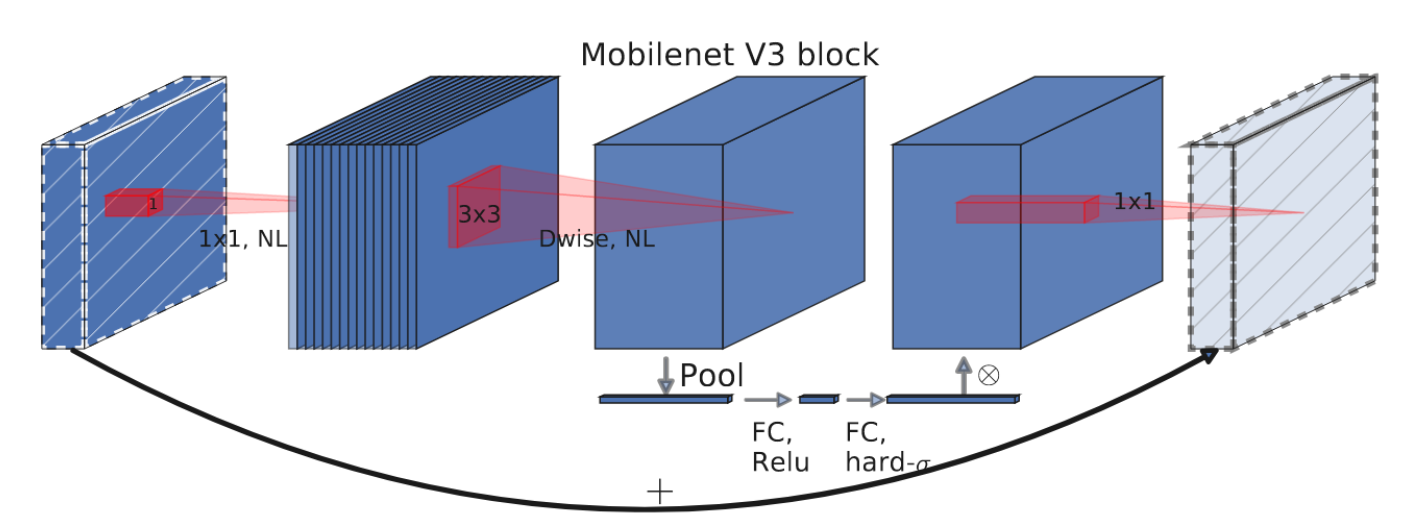
+
+
+Show the paper's abstract
+
+
+We present the next generation of MobileNets based on a combination of complementary search techniques as well as a novel architecture design. MobileNetV3 is tuned to mobile phone CPUs through a combination of hardware-aware network architecture search (NAS) complemented by the NetAdapt algorithm and then subsequently improved through novel architecture advances. This paper starts the exploration of how automated search algorithms and network design can work together to harness complementary approaches improving the overall state of the art. Through this process we create two new MobileNet models for release: MobileNetV3-Large and MobileNetV3-Small which are targeted for high and low resource use cases. These models are then adapted and applied to the tasks of object detection and semantic segmentation. For the task of semantic segmentation (or any dense pixel prediction), we propose a new efficient segmentation decoder Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP). We achieve new state of the art results for mobile classification, detection and segmentation. MobileNetV3-Large is 3.2% more accurate on ImageNet classification while reducing latency by 15% compared to MobileNetV2. MobileNetV3-Small is 4.6% more accurate while reducing latency by 5% compared to MobileNetV2. MobileNetV3-Large detection is 25% faster at roughly the same accuracy as MobileNetV2 on COCO detection. MobileNetV3-Large LR-ASPP is 30% faster than MobileNetV2 R-ASPP at similar accuracy for Cityscapes segmentation.
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('mobilenet-v3-small-050_3rdparty_in1k', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('mobilenet-v3-small-050_3rdparty_in1k', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Train/Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Train:
+
+```shell
+python tools/train.py configs/mobilenet_v3/mobilenet-v3-small_8xb128_in1k.py
+```
+
+Test:
+
+```shell
+python tools/test.py configs/mobilenet_v3/mobilenet-v3-small-050_8xb128_in1k.py https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-small-050_3rdparty_in1k_20221114-e0b86be1.pth
+```
+
+
+
+## Models and results
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :--------------------------------------- | :----------: | :--------: | :-------: | :-------: | :-------: | :---------------------------------------------: | :--------------------------------------------------------------: |
+| `mobilenet-v3-small-050_3rdparty_in1k`\* | From scratch | 1.59 | 0.02 | 57.91 | 80.19 | [config](mobilenet-v3-small-050_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-small-050_3rdparty_in1k_20221114-e0b86be1.pth) |
+| `mobilenet-v3-small-075_3rdparty_in1k`\* | From scratch | 2.04 | 0.04 | 65.23 | 85.44 | [config](mobilenet-v3-small-075_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-small-075_3rdparty_in1k_20221114-2011fa76.pth) |
+| `mobilenet-v3-small_8xb128_in1k` | From scratch | 2.54 | 0.06 | 66.68 | 86.74 | [config](mobilenet-v3-small_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-small_8xb128_in1k_20221114-bd1bfcde.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-small_8xb128_in1k_20221114-bd1bfcde.json) |
+| `mobilenet-v3-small_3rdparty_in1k`\* | From scratch | 2.54 | 0.06 | 67.66 | 87.41 | [config](mobilenet-v3-small_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_small-8427ecf0.pth) |
+| `mobilenet-v3-large_8xb128_in1k` | From scratch | 5.48 | 0.23 | 73.49 | 91.31 | [config](mobilenet-v3-large_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-large_8xb128_in1k_20221114-0ed9ed9a.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-large_8xb128_in1k_20221114-0ed9ed9a.json) |
+| `mobilenet-v3-large_3rdparty_in1k`\* | From scratch | 5.48 | 0.23 | 74.04 | 91.34 | [config](mobilenet-v3-large_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_large-3ea3c186.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/pytorch/vision/blob/main/torchvision/models/mobilenetv3.py). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+## Citation
+
+```bibtex
+@inproceedings{Howard_2019_ICCV,
+ author = {Howard, Andrew and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and Le, Quoc V. and Adam, Hartwig},
+ title = {Searching for MobileNetV3},
+ booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
+ month = {October},
+ year = {2019}
+}
+```
diff --git a/configs/mobilenet_v3/metafile.yml b/configs/mobilenet_v3/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..53f1653682fa2af2155b786ee5a8f0be9c98698e
--- /dev/null
+++ b/configs/mobilenet_v3/metafile.yml
@@ -0,0 +1,111 @@
+Collections:
+ - Name: MobileNet V3
+ Metadata:
+ Training Data: ImageNet-1k
+ Training Techniques:
+ - RMSprop with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Epochs: 600
+ Batch Size: 1024
+ Architecture:
+ - MobileNet V3
+ Paper:
+ URL: https://arxiv.org/abs/1905.02244
+ Title: Searching for MobileNetV3
+ README: configs/mobilenet_v3/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmpretrain/blob/v0.15.0/mmcls/models/backbones/mobilenet_v3.py
+ Version: v0.15.0
+
+Models:
+ - Name: mobilenet-v3-small-050_3rdparty_in1k
+ Metadata:
+ FLOPs: 24895000
+ Parameters: 1590000
+ In Collection: MobileNet V3
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 57.91
+ Top 5 Accuracy: 80.19
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-small-050_3rdparty_in1k_20221114-e0b86be1.pth
+ Config: configs/mobilenet_v3/mobilenet-v3-small-050_8xb128_in1k.py
+ Converted From:
+ Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_small_050_lambc-4b7bbe87.pth
+ Code: https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/mobilenetv3.py
+ - Name: mobilenet-v3-small-075_3rdparty_in1k
+ Metadata:
+ FLOPs: 44791000
+ Parameters: 2040000
+ In Collection: MobileNet V3
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 65.23
+ Top 5 Accuracy: 85.44
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-small-075_3rdparty_in1k_20221114-2011fa76.pth
+ Config: configs/mobilenet_v3/mobilenet-v3-small-075_8xb128_in1k.py
+ Converted From:
+ Weights: https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_small_075_lambc-384766db.pth
+ Code: https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/mobilenetv3.py
+ - Name: mobilenet-v3-small_8xb128_in1k
+ Metadata:
+ FLOPs: 60000000
+ Parameters: 2540000
+ In Collection: MobileNet V3
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 66.68
+ Top 5 Accuracy: 86.74
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-small_8xb128_in1k_20221114-bd1bfcde.pth
+ Config: configs/mobilenet_v3/mobilenet-v3-small_8xb128_in1k.py
+ - Name: mobilenet-v3-small_3rdparty_in1k
+ Metadata:
+ FLOPs: 60000000
+ Parameters: 2540000
+ In Collection: MobileNet V3
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 67.66
+ Top 5 Accuracy: 87.41
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_small-8427ecf0.pth
+ Config: configs/mobilenet_v3/mobilenet-v3-small_8xb128_in1k.py
+ Converted From:
+ Weights: https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pth
+ Code: https://github.com/pytorch/vision/blob/main/torchvision/models/mobilenetv3.py
+ - Name: mobilenet-v3-large_8xb128_in1k
+ Metadata:
+ FLOPs: 230000000
+ Parameters: 5480000
+ In Collection: MobileNet V3
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 73.49
+ Top 5 Accuracy: 91.31
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/mobilenet-v3-large_8xb128_in1k_20221114-0ed9ed9a.pth
+ Config: configs/mobilenet_v3/mobilenet-v3-large_8xb128_in1k.py
+ - Name: mobilenet-v3-large_3rdparty_in1k
+ Metadata:
+ FLOPs: 230000000
+ Parameters: 5480000
+ In Collection: MobileNet V3
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 74.04
+ Top 5 Accuracy: 91.34
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobilenet_v3/convert/mobilenet_v3_large-3ea3c186.pth
+ Config: configs/mobilenet_v3/mobilenet-v3-large_8xb128_in1k.py
+ Converted From:
+ Weights: https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth
+ Code: https://github.com/pytorch/vision/blob/main/torchvision/models/mobilenetv3.py
diff --git a/configs/mobilenet_v3/mobilenet-v3-large_8xb128_in1k.py b/configs/mobilenet_v3/mobilenet-v3-large_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5c05baf39f1cffdb9610d41b1603119a2edc727
--- /dev/null
+++ b/configs/mobilenet_v3/mobilenet-v3-large_8xb128_in1k.py
@@ -0,0 +1,28 @@
+# Refers to https://pytorch.org/blog/ml-models-torchvision-v0.9/#classification
+
+_base_ = [
+ '../_base_/models/mobilenet_v3/mobilenet_v3_large_imagenet.py',
+ '../_base_/datasets/imagenet_bs128_mbv3.py',
+ '../_base_/default_runtime.py',
+]
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(
+ type='RMSprop',
+ lr=0.064,
+ alpha=0.9,
+ momentum=0.9,
+ eps=0.0316,
+ weight_decay=1e-5))
+
+param_scheduler = dict(type='StepLR', by_epoch=True, step_size=2, gamma=0.973)
+
+train_cfg = dict(by_epoch=True, max_epochs=600, val_interval=1)
+val_cfg = dict()
+test_cfg = dict()
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (8 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=1024)
diff --git a/configs/mobilenet_v3/mobilenet-v3-small-050_8xb128_in1k.py b/configs/mobilenet_v3/mobilenet-v3-small-050_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc145625ca22f44ff48a6f4684589ab6833313e3
--- /dev/null
+++ b/configs/mobilenet_v3/mobilenet-v3-small-050_8xb128_in1k.py
@@ -0,0 +1,70 @@
+_base_ = [
+ '../_base_/models/mobilenet_v3/mobilenet_v3_small_050_imagenet.py',
+ '../_base_/datasets/imagenet_bs128_mbv3.py',
+ '../_base_/default_runtime.py',
+]
+
+# model settings
+model = dict(backbone=dict(norm_cfg=dict(type='BN', eps=1e-5, momentum=0.1)))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='RandomResizedCrop',
+ scale=224,
+ backend='pillow',
+ interpolation='bicubic'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='AutoAugment',
+ policies='imagenet',
+ hparams=dict(pad_val=[round(x) for x in [103.53, 116.28, 123.675]])),
+ dict(
+ type='RandomErasing',
+ erase_prob=0.2,
+ mode='rand',
+ min_area_ratio=0.02,
+ max_area_ratio=1 / 3,
+ fill_color=[103.53, 116.28, 123.675],
+ fill_std=[57.375, 57.12, 58.395]),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='ResizeEdge',
+ scale=256,
+ edge='short',
+ backend='pillow',
+ interpolation='bicubic'),
+ dict(type='CenterCrop', crop_size=224),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+# If you want standard test, please manually configure the test dataset
+test_dataloader = val_dataloader
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(
+ type='RMSprop',
+ lr=0.064,
+ alpha=0.9,
+ momentum=0.9,
+ eps=0.0316,
+ weight_decay=1e-5))
+
+param_scheduler = dict(type='StepLR', by_epoch=True, step_size=2, gamma=0.973)
+
+train_cfg = dict(by_epoch=True, max_epochs=600, val_interval=10)
+val_cfg = dict()
+test_cfg = dict()
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (8 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=1024)
diff --git a/configs/mobilenet_v3/mobilenet-v3-small-075_8xb128_in1k.py b/configs/mobilenet_v3/mobilenet-v3-small-075_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..464b7cbd60e8b741f9765df091bfdadbfe1712a3
--- /dev/null
+++ b/configs/mobilenet_v3/mobilenet-v3-small-075_8xb128_in1k.py
@@ -0,0 +1,68 @@
+_base_ = [
+ '../_base_/models/mobilenet_v3/mobilenet_v3_small_075_imagenet.py',
+ '../_base_/datasets/imagenet_bs128_mbv3.py',
+ '../_base_/default_runtime.py',
+]
+
+# model settings
+model = dict(backbone=dict(norm_cfg=dict(type='BN', eps=1e-5, momentum=0.1)))
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='RandomResizedCrop',
+ scale=224,
+ backend='pillow',
+ interpolation='bicubic'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='AutoAugment',
+ policies='imagenet',
+ hparams=dict(pad_val=[round(x) for x in [103.53, 116.28, 123.675]])),
+ dict(
+ type='RandomErasing',
+ erase_prob=0.2,
+ mode='rand',
+ min_area_ratio=0.02,
+ max_area_ratio=1 / 3,
+ fill_color=[103.53, 116.28, 123.675],
+ fill_std=[57.375, 57.12, 58.395]),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='ResizeEdge',
+ scale=256,
+ edge='short',
+ backend='pillow',
+ interpolation='bicubic'),
+ dict(type='CenterCrop', crop_size=224),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = val_dataloader
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(
+ type='RMSprop',
+ lr=0.064,
+ alpha=0.9,
+ momentum=0.9,
+ eps=0.0316,
+ weight_decay=1e-5))
+
+param_scheduler = dict(type='StepLR', by_epoch=True, step_size=2, gamma=0.973)
+
+train_cfg = dict(by_epoch=True, max_epochs=600, val_interval=10)
+val_cfg = dict()
+test_cfg = dict()
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (8 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=1024)
diff --git a/configs/mobilenet_v3/mobilenet-v3-small_8xb128_in1k.py b/configs/mobilenet_v3/mobilenet-v3-small_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..06b0a328106611ced7ede94c0439f3e39d12f306
--- /dev/null
+++ b/configs/mobilenet_v3/mobilenet-v3-small_8xb128_in1k.py
@@ -0,0 +1,28 @@
+# Refers to https://pytorch.org/blog/ml-models-torchvision-v0.9/#classification
+
+_base_ = [
+ '../_base_/models/mobilenet_v3/mobilenet_v3_small_imagenet.py',
+ '../_base_/datasets/imagenet_bs128_mbv3.py',
+ '../_base_/default_runtime.py',
+]
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(
+ type='RMSprop',
+ lr=0.064,
+ alpha=0.9,
+ momentum=0.9,
+ eps=0.0316,
+ weight_decay=1e-5))
+
+param_scheduler = dict(type='StepLR', by_epoch=True, step_size=2, gamma=0.973)
+
+train_cfg = dict(by_epoch=True, max_epochs=600, val_interval=1)
+val_cfg = dict()
+test_cfg = dict()
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (8 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=1024)
diff --git a/configs/mobilenet_v3/mobilenet-v3-small_8xb16_cifar10.py b/configs/mobilenet_v3/mobilenet-v3-small_8xb16_cifar10.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cfaa2f629523ad66966d3e70c9ca084644e1f8d
--- /dev/null
+++ b/configs/mobilenet_v3/mobilenet-v3-small_8xb16_cifar10.py
@@ -0,0 +1,15 @@
+_base_ = [
+ '../_base_/models/mobilenet_v3/mobilenet_v3_small_cifar.py',
+ '../_base_/datasets/cifar10_bs16.py',
+ '../_base_/schedules/cifar10_bs128.py', '../_base_/default_runtime.py'
+]
+
+# schedule settings
+param_scheduler = dict(
+ type='MultiStepLR',
+ by_epoch=True,
+ milestones=[120, 170],
+ gamma=0.1,
+)
+
+train_cfg = dict(by_epoch=True, max_epochs=200)
diff --git a/configs/mobileone/README.md b/configs/mobileone/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..e753aff9089fe30700f6db4313fd337f73f7d47d
--- /dev/null
+++ b/configs/mobileone/README.md
@@ -0,0 +1,98 @@
+# MobileOne
+
+> [An Improved One millisecond Mobile Backbone](https://arxiv.org/abs/2206.04040)
+
+
+
+## Introduction
+
+Mobileone is proposed by apple and based on reparameterization. On the apple chips, the accuracy of the model is close to 0.76 on the ImageNet dataset when the latency is less than 1ms. Its main improvements based on [RepVGG](../repvgg) are fllowing:
+
+- Reparameterization using Depthwise convolution and Pointwise convolution instead of normal convolution.
+- Removal of the residual structure which is not friendly to access memory.
+
+
+

+
+
+Show the paper's abstract
+
+
+Efficient neural network backbones for mobile devices are often optimized for metrics such as FLOPs or parameter count. However, these metrics may not correlate well with latency of the network when deployed on a mobile device. Therefore, we perform extensive analysis of different metrics by deploying several mobile-friendly networks on a mobile device. We identify and analyze architectural and optimization bottlenecks in recent efficient neural networks and provide ways to mitigate these bottlenecks. To this end, we design an efficient backbone MobileOne, with variants achieving an inference time under 1 ms on an iPhone12 with 75.9% top-1 accuracy on ImageNet. We show that MobileOne achieves state-of-the-art performance within the efficient architectures while being many times faster on mobile. Our best model obtains similar performance on ImageNet as MobileFormer while being 38x faster. Our model obtains 2.3% better top-1 accuracy on ImageNet than EfficientNet at similar latency. Furthermore, we show that our model generalizes to multiple tasks - image classification, object detection, and semantic segmentation with significant improvements in latency and accuracy as compared to existing efficient architectures when deployed on a mobile device.
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('mobileone-s0_8xb32_in1k', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('mobileone-s0_8xb32_in1k', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Train/Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Train:
+
+```shell
+python tools/train.py configs/mobileone/mobileone-s0_8xb32_in1k.py
+```
+
+Test:
+
+```shell
+python tools/test.py configs/mobileone/mobileone-s0_8xb32_in1k.py https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s0_8xb32_in1k_20221110-0bc94952.pth
+```
+
+
+
+## Models and results
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :------------------------ | :----------: | :--------: | :-------: | :-------: | :-------: | :----------------------------------: | :----------------------------------------------------------------------------------------: |
+| `mobileone-s0_8xb32_in1k` | From scratch | 2.08 | 0.27 | 71.34 | 89.87 | [config](mobileone-s0_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s0_8xb32_in1k_20221110-0bc94952.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s0_8xb32_in1k_20221110-0bc94952.json) |
+| `mobileone-s1_8xb32_in1k` | From scratch | 4.76 | 0.82 | 75.72 | 92.54 | [config](mobileone-s1_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s1_8xb32_in1k_20221110-ceeef467.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s1_8xb32_in1k_20221110-ceeef467.json) |
+| `mobileone-s2_8xb32_in1k` | From scratch | 7.81 | 1.30 | 77.37 | 93.34 | [config](mobileone-s2_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s2_8xb32_in1k_20221110-9c7ecb97.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s2_8xb32_in1k_20221110-9c7ecb97.json) |
+| `mobileone-s3_8xb32_in1k` | From scratch | 10.08 | 1.89 | 78.06 | 93.83 | [config](mobileone-s3_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s3_8xb32_in1k_20221110-c95eb3bf.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s3_8xb32_in1k_20221110-c95eb3bf.json) |
+| `mobileone-s4_8xb32_in1k` | From scratch | 14.84 | 2.98 | 79.69 | 94.46 | [config](mobileone-s4_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s4_8xb32_in1k_20221110-28d888cb.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s4_8xb32_in1k_20221110-28d888cb.json) |
+
+## Citation
+
+```bibtex
+@article{mobileone2022,
+ title={An Improved One millisecond Mobile Backbone},
+ author={Vasu, Pavan Kumar Anasosalu and Gabriel, James and Zhu, Jeff and Tuzel, Oncel and Ranjan, Anurag},
+ journal={arXiv preprint arXiv:2206.04040},
+ year={2022}
+}
+```
diff --git a/configs/mobileone/deploy/mobileone-s0_deploy_8xb32_in1k.py b/configs/mobileone/deploy/mobileone-s0_deploy_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..145f3f4ec90f643a056177a7d7c0b8fc370539cc
--- /dev/null
+++ b/configs/mobileone/deploy/mobileone-s0_deploy_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = ['../mobileone-s0_8xb32_in1k.py']
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/mobileone/deploy/mobileone-s1_deploy_8xb32_in1k.py b/configs/mobileone/deploy/mobileone-s1_deploy_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..8602c31ce6c7c3115e3f45313b687816f0854ddb
--- /dev/null
+++ b/configs/mobileone/deploy/mobileone-s1_deploy_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = ['../mobileone-s1_8xb32_in1k.py']
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/mobileone/deploy/mobileone-s2_deploy_8xb32_in1k.py b/configs/mobileone/deploy/mobileone-s2_deploy_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..97aaddd0740b0a005ecab5b08d3459b0da6c474c
--- /dev/null
+++ b/configs/mobileone/deploy/mobileone-s2_deploy_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = ['../mobileone-s2_8xb32_in1k.py']
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/mobileone/deploy/mobileone-s3_deploy_8xb32_in1k.py b/configs/mobileone/deploy/mobileone-s3_deploy_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..0d335a7ba9300f8d6d35a288dab02baf0adabdb2
--- /dev/null
+++ b/configs/mobileone/deploy/mobileone-s3_deploy_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = ['../mobileone-s3_8xb32_in1k.py']
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/mobileone/deploy/mobileone-s4_deploy_8xb32_in1k.py b/configs/mobileone/deploy/mobileone-s4_deploy_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..b82f5a9ac7ecd6c5fc84369083c66d6dae0afd51
--- /dev/null
+++ b/configs/mobileone/deploy/mobileone-s4_deploy_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = ['../mobileone-s4_8xb32_in1k.py']
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/mobileone/metafile.yml b/configs/mobileone/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..70370da0e8d56baf8001ddaff1f78110462ad86a
--- /dev/null
+++ b/configs/mobileone/metafile.yml
@@ -0,0 +1,83 @@
+Collections:
+ - Name: MobileOne
+ Metadata:
+ Training Data: ImageNet-1k
+ Architecture:
+ - re-parameterization Convolution
+ - VGG-style Neural Network
+ - Depthwise Convolution
+ - Pointwise Convolution
+ Paper:
+ URL: https://arxiv.org/abs/2206.04040
+ Title: 'An Improved One millisecond Mobile Backbone'
+ README: configs/mobileone/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmpretrain/blob/v1.0.0rc1/configs/mobileone/metafile.yml
+ Version: v1.0.0rc1
+
+Models:
+ - Name: mobileone-s0_8xb32_in1k
+ In Collection: MobileOne
+ Config: configs/mobileone/mobileone-s0_8xb32_in1k.py
+ Metadata:
+ FLOPs: 274136576 # 0.27G
+ Parameters: 2078504 # 2.08M
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 71.34
+ Top 5 Accuracy: 89.87
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s0_8xb32_in1k_20221110-0bc94952.pth
+ - Name: mobileone-s1_8xb32_in1k
+ In Collection: MobileOne
+ Config: configs/mobileone/mobileone-s1_8xb32_in1k.py
+ Metadata:
+ FLOPs: 823839744 # 8.6G
+ Parameters: 4764840 # 4.82M
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 75.72
+ Top 5 Accuracy: 92.54
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s1_8xb32_in1k_20221110-ceeef467.pth
+ - Name: mobileone-s2_8xb32_in1k
+ In Collection: MobileOne
+ Config: configs/mobileone/mobileone-s2_8xb32_in1k.py
+ Metadata:
+ FLOPs: 1296478848
+ Parameters: 7808168
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 77.37
+ Top 5 Accuracy: 93.34
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s2_8xb32_in1k_20221110-9c7ecb97.pth
+ - Name: mobileone-s3_8xb32_in1k
+ In Collection: MobileOne
+ Config: configs/mobileone/mobileone-s3_8xb32_in1k.py
+ Metadata:
+ FLOPs: 1893842944
+ Parameters: 10078312
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 78.06
+ Top 5 Accuracy: 93.83
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s3_8xb32_in1k_20221110-c95eb3bf.pth
+ - Name: mobileone-s4_8xb32_in1k
+ In Collection: MobileOne
+ Config: configs/mobileone/mobileone-s4_8xb32_in1k.py
+ Metadata:
+ FLOPs: 2979222528
+ Parameters: 14838352
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 79.69
+ Top 5 Accuracy: 94.46
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobileone/mobileone-s4_8xb32_in1k_20221110-28d888cb.pth
diff --git a/configs/mobileone/mobileone-s0_8xb32_in1k.py b/configs/mobileone/mobileone-s0_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..be56b86c3ce4afc3cc61995efa60830be98050e0
--- /dev/null
+++ b/configs/mobileone/mobileone-s0_8xb32_in1k.py
@@ -0,0 +1,20 @@
+_base_ = [
+ '../_base_/models/mobileone/mobileone_s0.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256_coslr_coswd_300e.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(paramwise_cfg=dict(norm_decay_mult=0.))
+
+val_dataloader = dict(batch_size=256)
+test_dataloader = dict(batch_size=256)
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ momentum=5e-4,
+ priority='ABOVE_NORMAL',
+ update_buffers=True)
+]
diff --git a/configs/mobileone/mobileone-s1_8xb32_in1k.py b/configs/mobileone/mobileone-s1_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..0bc3fb08922e0c87ad681e79c378d2b5404b696f
--- /dev/null
+++ b/configs/mobileone/mobileone-s1_8xb32_in1k.py
@@ -0,0 +1,60 @@
+_base_ = [
+ '../_base_/models/mobileone/mobileone_s1.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256_coslr_coswd_300e.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(paramwise_cfg=dict(norm_decay_mult=0.))
+
+val_dataloader = dict(batch_size=256)
+test_dataloader = dict(batch_size=256)
+
+bgr_mean = _base_.data_preprocessor['mean'][::-1]
+base_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=224, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='RandAugment',
+ policies='timm_increasing',
+ num_policies=2,
+ total_level=10,
+ magnitude_level=7,
+ magnitude_std=0.5,
+ hparams=dict(pad_val=[round(x) for x in bgr_mean])),
+ dict(type='PackInputs')
+]
+
+import copy # noqa: E402
+
+# modify start epoch's RandomResizedCrop.scale to 160
+train_pipeline_1e = copy.deepcopy(base_train_pipeline)
+train_pipeline_1e[1]['scale'] = 160
+train_pipeline_1e[3]['magnitude_level'] *= 0.1
+_base_.train_dataloader.dataset.pipeline = train_pipeline_1e
+
+# modify 37 epoch's RandomResizedCrop.scale to 192
+train_pipeline_37e = copy.deepcopy(base_train_pipeline)
+train_pipeline_37e[1]['scale'] = 192
+train_pipeline_1e[3]['magnitude_level'] *= 0.2
+
+# modify 112 epoch's RandomResizedCrop.scale to 224
+train_pipeline_112e = copy.deepcopy(base_train_pipeline)
+train_pipeline_112e[1]['scale'] = 224
+train_pipeline_1e[3]['magnitude_level'] *= 0.3
+
+custom_hooks = [
+ dict(
+ type='SwitchRecipeHook',
+ schedule=[
+ dict(action_epoch=37, pipeline=train_pipeline_37e),
+ dict(action_epoch=112, pipeline=train_pipeline_112e),
+ ]),
+ dict(
+ type='EMAHook',
+ momentum=5e-4,
+ priority='ABOVE_NORMAL',
+ update_buffers=True)
+]
diff --git a/configs/mobileone/mobileone-s2_8xb32_in1k.py b/configs/mobileone/mobileone-s2_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..a7d4aae074952538d5d037b33438172f4c283613
--- /dev/null
+++ b/configs/mobileone/mobileone-s2_8xb32_in1k.py
@@ -0,0 +1,65 @@
+_base_ = [
+ '../_base_/models/mobileone/mobileone_s2.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256_coslr_coswd_300e.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(paramwise_cfg=dict(norm_decay_mult=0.))
+
+val_dataloader = dict(batch_size=256)
+test_dataloader = dict(batch_size=256)
+
+import copy # noqa: E402
+
+bgr_mean = _base_.data_preprocessor['mean'][::-1]
+base_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=224, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='RandAugment',
+ policies='timm_increasing',
+ num_policies=2,
+ total_level=10,
+ magnitude_level=7,
+ magnitude_std=0.5,
+ hparams=dict(pad_val=[round(x) for x in bgr_mean])),
+ dict(type='PackInputs')
+]
+
+# modify start epoch RandomResizedCrop.scale to 160
+# and RA.magnitude_level * 0.3
+train_pipeline_1e = copy.deepcopy(base_train_pipeline)
+train_pipeline_1e[1]['scale'] = 160
+train_pipeline_1e[3]['magnitude_level'] *= 0.3
+_base_.train_dataloader.dataset.pipeline = train_pipeline_1e
+
+import copy # noqa: E402
+
+# modify 137 epoch's RandomResizedCrop.scale to 192
+# and RA.magnitude_level * 0.7
+train_pipeline_37e = copy.deepcopy(base_train_pipeline)
+train_pipeline_37e[1]['scale'] = 192
+train_pipeline_37e[3]['magnitude_level'] *= 0.7
+
+# modify 112 epoch's RandomResizedCrop.scale to 224
+# and RA.magnitude_level * 1.0
+train_pipeline_112e = copy.deepcopy(base_train_pipeline)
+train_pipeline_112e[1]['scale'] = 224
+train_pipeline_112e[3]['magnitude_level'] *= 1.0
+
+custom_hooks = [
+ dict(
+ type='SwitchRecipeHook',
+ schedule=[
+ dict(action_epoch=37, pipeline=train_pipeline_37e),
+ dict(action_epoch=112, pipeline=train_pipeline_112e),
+ ]),
+ dict(
+ type='EMAHook',
+ momentum=5e-4,
+ priority='ABOVE_NORMAL',
+ update_buffers=True)
+]
diff --git a/configs/mobileone/mobileone-s3_8xb32_in1k.py b/configs/mobileone/mobileone-s3_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..2be0dc7e814c4e5a28369ae8888221f3e26ec657
--- /dev/null
+++ b/configs/mobileone/mobileone-s3_8xb32_in1k.py
@@ -0,0 +1,65 @@
+_base_ = [
+ '../_base_/models/mobileone/mobileone_s3.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256_coslr_coswd_300e.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(paramwise_cfg=dict(norm_decay_mult=0.))
+
+val_dataloader = dict(batch_size=256)
+test_dataloader = dict(batch_size=256)
+
+import copy # noqa: E402
+
+bgr_mean = _base_.data_preprocessor['mean'][::-1]
+base_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=224, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='RandAugment',
+ policies='timm_increasing',
+ num_policies=2,
+ total_level=10,
+ magnitude_level=7,
+ magnitude_std=0.5,
+ hparams=dict(pad_val=[round(x) for x in bgr_mean])),
+ dict(type='PackInputs')
+]
+
+# modify start epoch RandomResizedCrop.scale to 160
+# and RA.magnitude_level * 0.3
+train_pipeline_1e = copy.deepcopy(base_train_pipeline)
+train_pipeline_1e[1]['scale'] = 160
+train_pipeline_1e[3]['magnitude_level'] *= 0.3
+_base_.train_dataloader.dataset.pipeline = train_pipeline_1e
+
+import copy # noqa: E402
+
+# modify 137 epoch's RandomResizedCrop.scale to 192
+# and RA.magnitude_level * 0.7
+train_pipeline_37e = copy.deepcopy(base_train_pipeline)
+train_pipeline_37e[1]['scale'] = 192
+train_pipeline_37e[3]['magnitude_level'] *= 0.7
+
+# modify 112 epoch's RandomResizedCrop.scale to 224
+# and RA.magnitude_level * 1.0
+train_pipeline_112e = copy.deepcopy(base_train_pipeline)
+train_pipeline_112e[1]['scale'] = 224
+train_pipeline_112e[3]['magnitude_level'] *= 1.0
+
+custom_hooks = [
+ dict(
+ type='SwitchRecipeHook',
+ schedule=[
+ dict(action_epoch=37, pipeline=train_pipeline_37e),
+ dict(action_epoch=112, pipeline=train_pipeline_112e),
+ ]),
+ dict(
+ type='EMAHook',
+ momentum=5e-4,
+ priority='ABOVE_NORMAL',
+ update_buffers=True)
+]
diff --git a/configs/mobileone/mobileone-s4_8xb32_in1k.py b/configs/mobileone/mobileone-s4_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..49356f05f9574f90192dc32d5b14c3b74a5cd459
--- /dev/null
+++ b/configs/mobileone/mobileone-s4_8xb32_in1k.py
@@ -0,0 +1,63 @@
+_base_ = [
+ '../_base_/models/mobileone/mobileone_s4.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256_coslr_coswd_300e.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(paramwise_cfg=dict(norm_decay_mult=0.))
+
+val_dataloader = dict(batch_size=256)
+test_dataloader = dict(batch_size=256)
+
+bgr_mean = _base_.data_preprocessor['mean'][::-1]
+base_train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=224, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='RandAugment',
+ policies='timm_increasing',
+ num_policies=2,
+ total_level=10,
+ magnitude_level=7,
+ magnitude_std=0.5,
+ hparams=dict(pad_val=[round(x) for x in bgr_mean])),
+ dict(type='PackInputs')
+]
+
+import copy # noqa: E402
+
+# modify start epoch RandomResizedCrop.scale to 160
+# and RA.magnitude_level * 0.3
+train_pipeline_1e = copy.deepcopy(base_train_pipeline)
+train_pipeline_1e[1]['scale'] = 160
+train_pipeline_1e[3]['magnitude_level'] *= 0.3
+_base_.train_dataloader.dataset.pipeline = train_pipeline_1e
+
+# modify 137 epoch's RandomResizedCrop.scale to 192
+# and RA.magnitude_level * 0.7
+train_pipeline_37e = copy.deepcopy(base_train_pipeline)
+train_pipeline_37e[1]['scale'] = 192
+train_pipeline_37e[3]['magnitude_level'] *= 0.7
+
+# modify 112 epoch's RandomResizedCrop.scale to 224
+# and RA.magnitude_level * 1.0
+train_pipeline_112e = copy.deepcopy(base_train_pipeline)
+train_pipeline_112e[1]['scale'] = 224
+train_pipeline_112e[3]['magnitude_level'] *= 1.0
+
+custom_hooks = [
+ dict(
+ type='SwitchRecipeHook',
+ schedule=[
+ dict(action_epoch=37, pipeline=train_pipeline_37e),
+ dict(action_epoch=112, pipeline=train_pipeline_112e),
+ ]),
+ dict(
+ type='EMAHook',
+ momentum=5e-4,
+ priority='ABOVE_NORMAL',
+ update_buffers=True)
+]
diff --git a/configs/mobilevit/README.md b/configs/mobilevit/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..fa0960d123aed6eae6fee1155fd99d0955355280
--- /dev/null
+++ b/configs/mobilevit/README.md
@@ -0,0 +1,96 @@
+# MobileViT
+
+> [MobileViT Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178)
+
+
+
+## Introduction
+
+**MobileViT** aims at introducing a light-weight network, which takes the advantages of both ViTs and CNNs, uses the `InvertedResidual` blocks in [MobileNetV2](../mobilenet_v2/README.md) and `MobileViTBlock` which refers to [ViT](../vision_transformer/README.md) transformer blocks to build a standard 5-stage model structure.
+
+The MobileViTBlock reckons transformers as convolutions to perform a global representation, meanwhile conbined with original convolution layers for local representation to build a block with global receptive field. This is different from ViT, which adds an extra class token and position embeddings for learning relative relationship. Without any position embeddings, MobileViT can benfit from multi-scale inputs during training.
+
+Also, this paper puts forward a strategy for multi-scale training to dynamically adjust batch size based on the image size to both improve training efficiency and final performance.
+
+It is also proven effective in downstream tasks such as object detection and segmentation.
+
+
+

+
+
+Show the paper's abstract
+
+
+
+Light-weight convolutional neural networks (CNNs) are the de-facto for mobile vision tasks. Their spatial inductive biases allow them to learn representations with fewer parameters across different vision tasks. However, these networks are spatially local. To learn global representations, self-attention-based vision trans-formers (ViTs) have been adopted. Unlike CNNs, ViTs are heavy-weight. In this paper, we ask the following question: is it possible to combine the strengths of CNNs and ViTs to build a light-weight and low latency network for mobile vision tasks? Towards this end, we introduce MobileViT, a light-weight and general-purpose vision transformer for mobile devices. MobileViT presents a different perspective for the global processing of information with transformers, i.e., transformers as convolutions. Our results show that MobileViT significantly outperforms CNN- and ViT-based networks across different tasks and datasets. On the ImageNet-1k dataset, MobileViT achieves top-1 accuracy of 78.4% with about 6 million parameters, which is 3.2% and 6.2% more accurate than MobileNetv3 (CNN-based) and DeIT (ViT-based) for a similar number of parameters. On the MS-COCO object detection task, MobileViT is 5.7% more accurate than MobileNetv3 for a similar number of parameters.
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('mobilevit-small_3rdparty_in1k', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('mobilevit-small_3rdparty_in1k', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Test:
+
+```shell
+python tools/test.py configs/mobilevit/mobilevit-small_8xb128_in1k.py https://download.openmmlab.com/mmclassification/v0/mobilevit/mobilevit-small_3rdparty_in1k_20221018-cb4f741c.pth
+```
+
+
+
+## Models and results
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :---------------------------------- | :----------: | :--------: | :-------: | :-------: | :-------: | :----------------------------------------: | :------------------------------------------------------------------------: |
+| `mobilevit-small_3rdparty_in1k`\* | From scratch | 5.58 | 2.03 | 78.25 | 94.09 | [config](mobilevit-small_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobilevit/mobilevit-small_3rdparty_in1k_20221018-cb4f741c.pth) |
+| `mobilevit-xsmall_3rdparty_in1k`\* | From scratch | 2.32 | 1.05 | 74.75 | 92.32 | [config](mobilevit-xsmall_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobilevit/mobilevit-xsmall_3rdparty_in1k_20221018-be39a6e7.pth) |
+| `mobilevit-xxsmall_3rdparty_in1k`\* | From scratch | 1.27 | 0.42 | 69.02 | 88.91 | [config](mobilevit-xxsmall_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/mobilevit/mobilevit-xxsmall_3rdparty_in1k_20221018-77835605.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/apple/ml-cvnets). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+## Citation
+
+```bibtex
+@article{mehta2021mobilevit,
+ title={MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer},
+ author={Mehta, Sachin and Rastegari, Mohammad},
+ journal={arXiv preprint arXiv:2110.02178},
+ year={2021}
+}
+```
diff --git a/configs/mobilevit/metafile.yml b/configs/mobilevit/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..15fd84ad54cacf0c7c0337b5139ba891d14c22f5
--- /dev/null
+++ b/configs/mobilevit/metafile.yml
@@ -0,0 +1,60 @@
+Collections:
+ - Name: MobileViT
+ Metadata:
+ Training Data: ImageNet-1k
+ Architecture:
+ - MobileViT Block
+ Paper:
+ URL: https://arxiv.org/abs/2110.02178
+ Title: MobileViT Light-weight, General-purpose, and Mobile-friendly Vision Transformer
+ README: configs/mobilevit/README.md
+
+Models:
+ - Name: mobilevit-small_3rdparty_in1k
+ Metadata:
+ FLOPs: 2030000000
+ Parameters: 5580000
+ In Collection: MobileViT
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 78.25
+ Top 5 Accuracy: 94.09
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobilevit/mobilevit-small_3rdparty_in1k_20221018-cb4f741c.pth
+ Config: configs/mobilevit/mobilevit-small_8xb128_in1k.py
+ Converted From:
+ Weights: https://docs-assets.developer.apple.com/ml-research/models/cvnets/classification/mobilevit_s.pt
+ Code: https://github.com/apple/ml-cvnets
+ - Name: mobilevit-xsmall_3rdparty_in1k
+ Metadata:
+ FLOPs: 1050000000
+ Parameters: 2320000
+ In Collection: MobileViT
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 74.75
+ Top 5 Accuracy: 92.32
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobilevit/mobilevit-xsmall_3rdparty_in1k_20221018-be39a6e7.pth
+ Config: configs/mobilevit/mobilevit-xsmall_8xb128_in1k.py
+ Converted From:
+ Weights: https://docs-assets.developer.apple.com/ml-research/models/cvnets/classification/mobilevit_xs.pt
+ Code: https://github.com/apple/ml-cvnets
+ - Name: mobilevit-xxsmall_3rdparty_in1k
+ Metadata:
+ FLOPs: 420000000
+ Parameters: 1270000
+ In Collection: MobileViT
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 69.02
+ Top 5 Accuracy: 88.91
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/mobilevit/mobilevit-xxsmall_3rdparty_in1k_20221018-77835605.pth
+ Config: configs/mobilevit/mobilevit-xxsmall_8xb128_in1k.py
+ Converted From:
+ Weights: https://docs-assets.developer.apple.com/ml-research/models/cvnets/classification/mobilevit_xxs.pt
+ Code: https://github.com/apple/ml-cvnets
diff --git a/configs/mobilevit/mobilevit-small_8xb128_in1k.py b/configs/mobilevit/mobilevit-small_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..596939631c0520e67d480a37669704556719f2dc
--- /dev/null
+++ b/configs/mobilevit/mobilevit-small_8xb128_in1k.py
@@ -0,0 +1,30 @@
+_base_ = [
+ '../_base_/models/mobilevit/mobilevit_s.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/default_runtime.py',
+ '../_base_/schedules/imagenet_bs256.py',
+]
+
+# no normalize for original implements
+data_preprocessor = dict(
+ # RGB format normalization parameters
+ mean=[0, 0, 0],
+ std=[255, 255, 255],
+ # use bgr directly
+ to_rgb=False,
+)
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='ResizeEdge', scale=288, edge='short'),
+ dict(type='CenterCrop', crop_size=256),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(batch_size=128)
+
+val_dataloader = dict(
+ batch_size=128,
+ dataset=dict(pipeline=test_pipeline),
+)
+test_dataloader = val_dataloader
diff --git a/configs/mobilevit/mobilevit-xsmall_8xb128_in1k.py b/configs/mobilevit/mobilevit-xsmall_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..557892bcc4911912d7e5d585cb0d27235cf08cd5
--- /dev/null
+++ b/configs/mobilevit/mobilevit-xsmall_8xb128_in1k.py
@@ -0,0 +1,30 @@
+_base_ = [
+ '../_base_/models/mobilevit/mobilevit_xs.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/default_runtime.py',
+ '../_base_/schedules/imagenet_bs256.py',
+]
+
+# no normalize for original implements
+data_preprocessor = dict(
+ # RGB format normalization parameters
+ mean=[0, 0, 0],
+ std=[255, 255, 255],
+ # use bgr directly
+ to_rgb=False,
+)
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='ResizeEdge', scale=288, edge='short'),
+ dict(type='CenterCrop', crop_size=256),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(batch_size=128)
+
+val_dataloader = dict(
+ batch_size=128,
+ dataset=dict(pipeline=test_pipeline),
+)
+test_dataloader = val_dataloader
diff --git a/configs/mobilevit/mobilevit-xxsmall_8xb128_in1k.py b/configs/mobilevit/mobilevit-xxsmall_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..74aea82f32bd65fd71962c588384e4a1e6ab43ea
--- /dev/null
+++ b/configs/mobilevit/mobilevit-xxsmall_8xb128_in1k.py
@@ -0,0 +1,30 @@
+_base_ = [
+ '../_base_/models/mobilevit/mobilevit_xxs.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/default_runtime.py',
+ '../_base_/schedules/imagenet_bs256.py',
+]
+
+# no normalize for original implements
+data_preprocessor = dict(
+ # RGB format normalization parameters
+ mean=[0, 0, 0],
+ std=[255, 255, 255],
+ # use bgr directly
+ to_rgb=False,
+)
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='ResizeEdge', scale=288, edge='short'),
+ dict(type='CenterCrop', crop_size=256),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(batch_size=128)
+
+val_dataloader = dict(
+ batch_size=128,
+ dataset=dict(pipeline=test_pipeline),
+)
+test_dataloader = val_dataloader
diff --git a/configs/mocov2/README.md b/configs/mocov2/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..cb0ae4ee7468f3294b28157eafb32cb04b63814d
--- /dev/null
+++ b/configs/mocov2/README.md
@@ -0,0 +1,85 @@
+# MoCoV2
+
+> [Improved Baselines with Momentum Contrastive Learning](https://arxiv.org/abs/2003.04297)
+
+
+
+## Abstract
+
+Contrastive unsupervised learning has recently shown encouraging progress, e.g., in Momentum Contrast (MoCo) and SimCLR. In this note, we verify the effectiveness of two of SimCLR’s design improvements by implementing them in the MoCo framework. With simple modifications to MoCo—namely, using an MLP projection head and more data augmentation—we establish stronger baselines that outperform SimCLR and do not require large training batches. We hope this will make state-of-the-art unsupervised learning research more accessible.
+
+
+

+
+

+
+

+
+
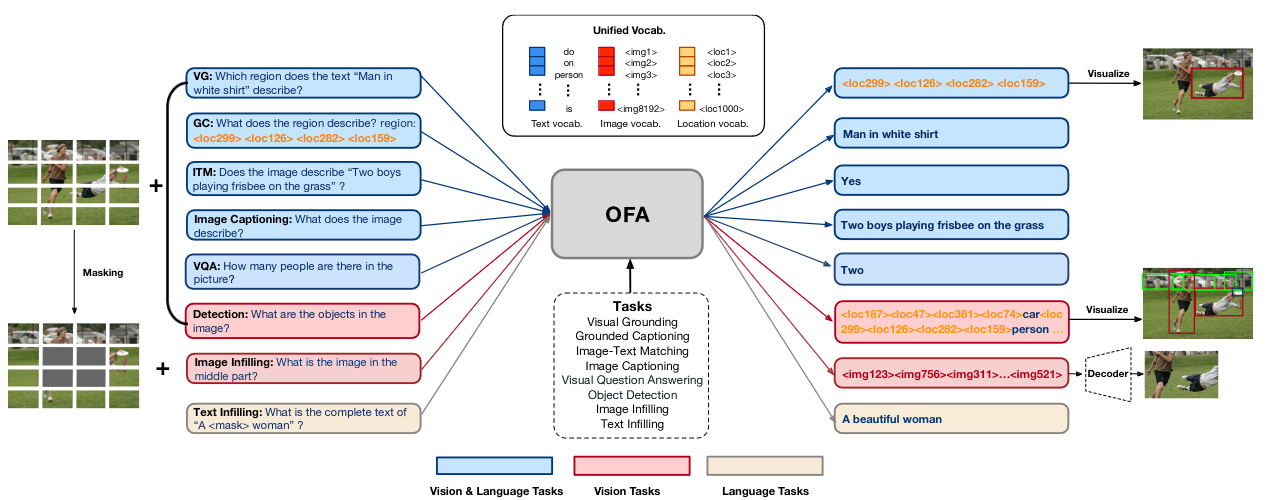
+
+

+
+
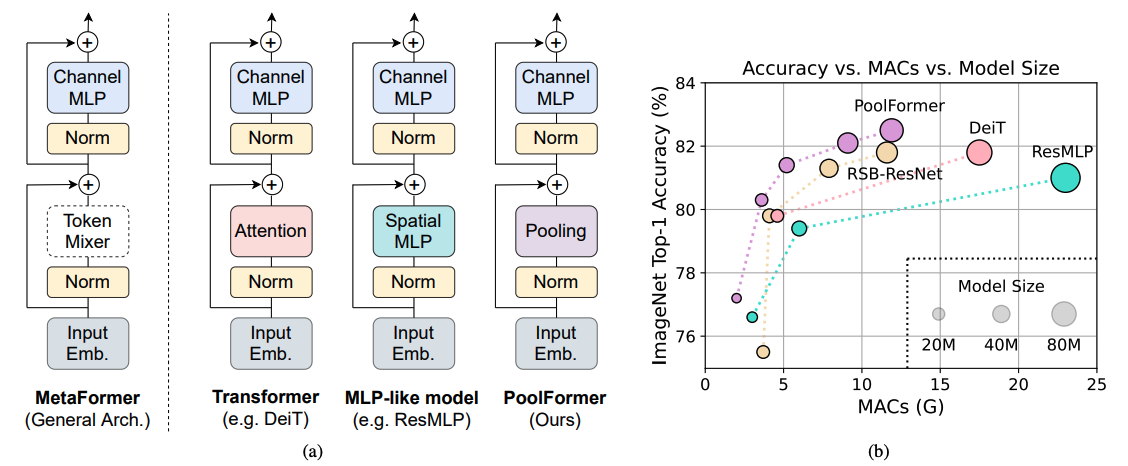
+
+

+
+

+
+

+
+

+
+
+Show the paper's abstract
+
+
+We present a simple but powerful architecture of convolutional neural network, which has a VGG-like inference-time body composed of nothing but a stack of 3x3 convolution and ReLU, while the training-time model has a multi-branch topology. Such decoupling of the training-time and inference-time architecture is realized by a structural re-parameterization technique so that the model is named RepVGG. On ImageNet, RepVGG reaches over 80% top-1 accuracy, which is the first time for a plain model, to the best of our knowledge. On NVIDIA 1080Ti GPU, RepVGG models run 83% faster than ResNet-50 or 101% faster than ResNet-101 with higher accuracy and show favorable accuracy-speed trade-off compared to the state-of-the-art models like EfficientNet and RegNet.
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model, get_model
+
+model = get_model('repvgg-A0_8xb32_in1k', pretrained=True)
+model.backbone.switch_to_deploy()
+predict = inference_model(model, 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('repvgg-A0_8xb32_in1k', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Train/Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Train:
+
+```shell
+python tools/train.py configs/repvgg/repvgg-A0_8xb32_in1k.py
+```
+
+Test:
+
+```shell
+python tools/test.py configs/repvgg/repvgg-A0_8xb32_in1k.py https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-A0_8xb32_in1k_20221213-60ae8e23.pth
+```
+
+Test with reparameterized model:
+
+```shell
+python tools/test.py configs/repvgg/repvgg-A0_8xb32_in1k.py repvgg_A0_deploy.pth --cfg-options model.backbone.deploy=True
+```
+
+**Reparameterization**
+
+The checkpoints provided are all `training-time` models. Use the reparameterize tool to switch them to more efficient `inference-time` architecture, which not only has fewer parameters but also less calculations.
+
+```bash
+python tools/convert_models/reparameterize_model.py ${CFG_PATH} ${SRC_CKPT_PATH} ${TARGET_CKPT_PATH}
+```
+
+`${CFG_PATH}` is the config file, `${SRC_CKPT_PATH}` is the source chenpoint file, `${TARGET_CKPT_PATH}` is the target deploy weight file path.
+
+To use reparameterized weights, the config file must switch to the deploy config files.
+
+```bash
+python tools/test.py ${deploy_cfg} ${deploy_checkpoint} --metrics accuracy
+```
+
+You can also use `backbone.switch_to_deploy()` to switch to the deploy mode in Python code. For example:
+
+```python
+from mmpretrain.models import RepVGG
+
+backbone = RepVGG(arch='A0')
+backbone.switch_to_deploy()
+```
+
+
+
+## Models and results
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :---------------------------- | :----------: | :--------: | :-------: | :-------: | :-------: | :---------------------------------: | :-------------------------------------------------------------------------------------: |
+| `repvgg-A0_8xb32_in1k` | From scratch | 8.31 | 1.36 | 72.37 | 90.56 | [config](repvgg-A0_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-A0_8xb32_in1k_20221213-60ae8e23.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-A0_8xb32_in1k_20221213-60ae8e23.log) |
+| `repvgg-A1_8xb32_in1k` | From scratch | 12.79 | 2.36 | 74.23 | 91.80 | [config](repvgg-A1_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-A1_8xb32_in1k_20221213-f81bf3df.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-A1_8xb32_in1k_20221213-f81bf3df.log) |
+| `repvgg-A2_8xb32_in1k` | From scratch | 25.50 | 5.12 | 76.49 | 93.09 | [config](repvgg-A2_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-A2_8xb32_in1k_20221213-a8767caf.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-A2_8xb32_in1k_20221213-a8767caf.log) |
+| `repvgg-B0_8xb32_in1k` | From scratch | 3.42 | 15.82 | 75.27 | 92.21 | [config](repvgg-B0_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B0_8xb32_in1k_20221213-5091ecc7.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B0_8xb32_in1k_20221213-5091ecc7.log) |
+| `repvgg-B1_8xb32_in1k` | From scratch | 51.83 | 11.81 | 78.19 | 94.04 | [config](repvgg-B1_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B1_8xb32_in1k_20221213-d17c45e7.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B1_8xb32_in1k_20221213-d17c45e7.log) |
+| `repvgg-B1g2_8xb32_in1k` | From scratch | 41.36 | 8.81 | 77.87 | 93.99 | [config](repvgg-B1g2_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B1g2_8xb32_in1k_20221213-ae6428fd.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B1g2_8xb32_in1k_20221213-ae6428fd.log) |
+| `repvgg-B1g4_8xb32_in1k` | From scratch | 36.13 | 7.30 | 77.81 | 93.77 | [config](repvgg-B1g4_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B1g4_8xb32_in1k_20221213-a7a4aaea.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B1g4_8xb32_in1k_20221213-a7a4aaea.log) |
+| `repvgg-B2_8xb32_in1k` | From scratch | 80.32 | 18.37 | 78.58 | 94.23 | [config](repvgg-B2_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B2_8xb32_in1k_20221213-d8b420ef.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B2_8xb32_in1k_20221213-d8b420ef.log) |
+| `repvgg-B2g4_8xb32_in1k` | From scratch | 55.78 | 11.33 | 79.44 | 94.72 | [config](repvgg-B2g4_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B2g4_8xb32_in1k_20221213-0c1990eb.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B2g4_8xb32_in1k_20221213-0c1990eb.log) |
+| `repvgg-B3_8xb32_in1k` | From scratch | 110.96 | 26.21 | 80.58 | 95.33 | [config](repvgg-B3_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B3_8xb32_in1k_20221213-927a329a.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B3_8xb32_in1k_20221213-927a329a.log) |
+| `repvgg-B3g4_8xb32_in1k` | From scratch | 75.63 | 16.06 | 80.26 | 95.15 | [config](repvgg-B3g4_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B3g4_8xb32_in1k_20221213-e01cb280.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B3g4_8xb32_in1k_20221213-e01cb280.log) |
+| `repvgg-D2se_3rdparty_in1k`\* | From scratch | 120.39 | 32.84 | 81.81 | 95.94 | [config](repvgg-D2se_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-D2se_3rdparty_4xb64-autoaug-lbs-mixup-coslr-200e_in1k_20210909-cf3139b7.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/DingXiaoH/RepVGG/blob/9f272318abfc47a2b702cd0e916fca8d25d683e7/repvgg.py#L250). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+## Citation
+
+```bibtex
+@inproceedings{ding2021repvgg,
+ title={Repvgg: Making vgg-style convnets great again},
+ author={Ding, Xiaohan and Zhang, Xiangyu and Ma, Ningning and Han, Jungong and Ding, Guiguang and Sun, Jian},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={13733--13742},
+ year={2021}
+}
+```
diff --git a/configs/repvgg/metafile.yml b/configs/repvgg/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..e93250ae2288b2ace58081bdcc24fc80c2f3c5b5
--- /dev/null
+++ b/configs/repvgg/metafile.yml
@@ -0,0 +1,175 @@
+Collections:
+ - Name: RepVGG
+ Metadata:
+ Training Data: ImageNet-1k
+ Architecture:
+ - re-parameterization Convolution
+ - VGG-style Neural Network
+ Paper:
+ URL: https://arxiv.org/abs/2101.03697
+ Title: 'RepVGG: Making VGG-style ConvNets Great Again'
+ README: configs/repvgg/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmpretrain/blob/v0.16.0/mmcls/models/backbones/repvgg.py#L257
+ Version: v0.16.0
+
+Models:
+ - Name: repvgg-A0_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-A0_8xb32_in1k.py
+ Metadata:
+ FLOPs: 1360233728
+ Parameters: 8309384
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 72.37
+ Top 5 Accuracy: 90.56
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-A0_8xb32_in1k_20221213-60ae8e23.pth
+ - Name: repvgg-A1_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-A1_8xb32_in1k.py
+ Metadata:
+ FLOPs: 2362750208
+ Parameters: 12789864
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 74.23
+ Top 5 Accuracy: 91.80
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-A1_8xb32_in1k_20221213-f81bf3df.pth
+ - Name: repvgg-A2_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-A2_8xb32_in1k.py
+ Metadata:
+ FLOPs: 5115612544
+ Parameters: 25499944
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 76.49
+ Top 5 Accuracy: 93.09
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-A2_8xb32_in1k_20221213-a8767caf.pth
+ - Name: repvgg-B0_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-B0_8xb32_in1k.py
+ Metadata:
+ FLOPs: 15820000000
+ Parameters: 3420000
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 75.27
+ Top 5 Accuracy: 92.21
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B0_8xb32_in1k_20221213-5091ecc7.pth
+ - Name: repvgg-B1_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-B1_8xb32_in1k.py
+ Metadata:
+ FLOPs: 11813537792
+ Parameters: 51829480
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 78.19
+ Top 5 Accuracy: 94.04
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B1_8xb32_in1k_20221213-d17c45e7.pth
+ - Name: repvgg-B1g2_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-B1g2_8xb32_in1k.py
+ Metadata:
+ FLOPs: 8807794688
+ Parameters: 41360104
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 77.87
+ Top 5 Accuracy: 93.99
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B1g2_8xb32_in1k_20221213-ae6428fd.pth
+ - Name: repvgg-B1g4_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-B1g4_8xb32_in1k.py
+ Metadata:
+ FLOPs: 7304923136
+ Parameters: 36125416
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 77.81
+ Top 5 Accuracy: 93.77
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B1g4_8xb32_in1k_20221213-a7a4aaea.pth
+ - Name: repvgg-B2_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-B2_8xb32_in1k.py
+ Metadata:
+ FLOPs: 18374175232
+ Parameters: 80315112
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 78.58
+ Top 5 Accuracy: 94.23
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B2_8xb32_in1k_20221213-d8b420ef.pth
+ - Name: repvgg-B2g4_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-B2g4_8xb32_in1k.py
+ Metadata:
+ FLOPs: 11329464832
+ Parameters: 55777512
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 79.44
+ Top 5 Accuracy: 94.72
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B2g4_8xb32_in1k_20221213-0c1990eb.pth
+ - Name: repvgg-B3_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-B3_8xb32_in1k.py
+ Metadata:
+ FLOPs: 26206448128
+ Parameters: 110960872
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 80.58
+ Top 5 Accuracy: 95.33
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B3_8xb32_in1k_20221213-927a329a.pth
+ - Name: repvgg-B3g4_8xb32_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-B3g4_8xb32_in1k.py
+ Metadata:
+ FLOPs: 16062065152
+ Parameters: 75626728
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 80.26
+ Top 5 Accuracy: 95.15
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-B3g4_8xb32_in1k_20221213-e01cb280.pth
+ - Name: repvgg-D2se_3rdparty_in1k
+ In Collection: RepVGG
+ Config: configs/repvgg/repvgg-D2se_8xb32_in1k.py
+ Metadata:
+ FLOPs: 32838581760
+ Parameters: 120387572
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 81.81
+ Top 5 Accuracy: 95.94
+ Weights: https://download.openmmlab.com/mmclassification/v0/repvgg/repvgg-D2se_3rdparty_4xb64-autoaug-lbs-mixup-coslr-200e_in1k_20210909-cf3139b7.pth
+ Converted From:
+ Weights: https://drive.google.com/drive/folders/1Avome4KvNp0Lqh2QwhXO6L5URQjzCjUq
+ Code: https://github.com/DingXiaoH/RepVGG/blob/9f272318abfc47a2b702cd0e916fca8d25d683e7/repvgg.py#L250
diff --git a/configs/repvgg/repvgg-A0_8xb32_in1k.py b/configs/repvgg/repvgg-A0_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..b767ae2a3e4062563cec782385baafdf6181baf3
--- /dev/null
+++ b/configs/repvgg/repvgg-A0_8xb32_in1k.py
@@ -0,0 +1,33 @@
+_base_ = [
+ '../_base_/models/repvgg-A0_in1k.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256_coslr.py',
+ '../_base_/default_runtime.py'
+]
+
+val_dataloader = dict(batch_size=256)
+test_dataloader = dict(batch_size=256)
+
+# schedule settings
+optim_wrapper = dict(
+ paramwise_cfg=dict(
+ bias_decay_mult=0.0,
+ custom_keys={
+ 'branch_3x3.norm': dict(decay_mult=0.0),
+ 'branch_1x1.norm': dict(decay_mult=0.0),
+ 'branch_norm.bias': dict(decay_mult=0.0),
+ }))
+
+# schedule settings
+param_scheduler = dict(
+ type='CosineAnnealingLR',
+ T_max=120,
+ by_epoch=True,
+ begin=0,
+ end=120,
+ convert_to_iter_based=True)
+
+train_cfg = dict(by_epoch=True, max_epochs=120)
+
+default_hooks = dict(
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
diff --git a/configs/repvgg/repvgg-A0_deploy_in1k.py b/configs/repvgg/repvgg-A0_deploy_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..897e2bb36e9ad8197b4889f22530a32a79fef055
--- /dev/null
+++ b/configs/repvgg/repvgg-A0_deploy_in1k.py
@@ -0,0 +1,3 @@
+_base_ = './repvgg-A0_8xb32_in1k.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/repvgg/repvgg-A1_8xb32_in1k.py b/configs/repvgg/repvgg-A1_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..fab5e586359370dd59a7ba55b91511541e922a11
--- /dev/null
+++ b/configs/repvgg/repvgg-A1_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = './repvgg-A0_8xb32_in1k.py'
+
+model = dict(backbone=dict(arch='A1'))
diff --git a/configs/repvgg/repvgg-A2_8xb32_in1k.py b/configs/repvgg/repvgg-A2_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..f6196f02fbfedb36e9e498160884eeb7315513f6
--- /dev/null
+++ b/configs/repvgg/repvgg-A2_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = './repvgg-A0_8xb32_in1k.py'
+
+model = dict(backbone=dict(arch='A2'), head=dict(in_channels=1408))
diff --git a/configs/repvgg/repvgg-B0_8xb32_in1k.py b/configs/repvgg/repvgg-B0_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..9bbc4ab2259ccd929eae948cae0f676b7fca4b74
--- /dev/null
+++ b/configs/repvgg/repvgg-B0_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = './repvgg-A0_8xb32_in1k.py'
+
+model = dict(backbone=dict(arch='B0'), head=dict(in_channels=1280))
diff --git a/configs/repvgg/repvgg-B1_8xb32_in1k.py b/configs/repvgg/repvgg-B1_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..e08db3c4b8145cd3141851a7b41bbbe4fbfff776
--- /dev/null
+++ b/configs/repvgg/repvgg-B1_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = './repvgg-A0_8xb32_in1k.py'
+
+model = dict(backbone=dict(arch='B1'), head=dict(in_channels=2048))
diff --git a/configs/repvgg/repvgg-B1g2_8xb32_in1k.py b/configs/repvgg/repvgg-B1g2_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1c53fded4e0ff0c59038fb82ca8cb0ca3e41742
--- /dev/null
+++ b/configs/repvgg/repvgg-B1g2_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = './repvgg-A0_8xb32_in1k.py'
+
+model = dict(backbone=dict(arch='B1g2'), head=dict(in_channels=2048))
diff --git a/configs/repvgg/repvgg-B1g4_8xb32_in1k.py b/configs/repvgg/repvgg-B1g4_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..0757b1e580e5091b9d5c633cd87c856a526ebdf0
--- /dev/null
+++ b/configs/repvgg/repvgg-B1g4_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = './repvgg-A0_8xb32_in1k.py'
+
+model = dict(backbone=dict(arch='B1g4'), head=dict(in_channels=2048))
diff --git a/configs/repvgg/repvgg-B2_8xb32_in1k.py b/configs/repvgg/repvgg-B2_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9a7d4ca5570518f0c4d0b81951e0e97c46606f9
--- /dev/null
+++ b/configs/repvgg/repvgg-B2_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = './repvgg-A0_8xb32_in1k.py'
+
+model = dict(backbone=dict(arch='B2'), head=dict(in_channels=2560))
diff --git a/configs/repvgg/repvgg-B2g4_8xb32_in1k.py b/configs/repvgg/repvgg-B2g4_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b3397881d74785870c266f1212cfee364dab38d
--- /dev/null
+++ b/configs/repvgg/repvgg-B2g4_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = './repvgg-B3_8xb32_in1k.py'
+
+model = dict(backbone=dict(arch='B2g4'), head=dict(in_channels=2560))
diff --git a/configs/repvgg/repvgg-B3_8xb32_in1k.py b/configs/repvgg/repvgg-B3_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..e9d5257838c9e2061dfbe39aa2b1456820009ff3
--- /dev/null
+++ b/configs/repvgg/repvgg-B3_8xb32_in1k.py
@@ -0,0 +1,67 @@
+_base_ = [
+ '../_base_/models/repvgg-B3_lbs-mixup_in1k.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256_coslr.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(
+ paramwise_cfg=dict(
+ bias_decay_mult=0.0,
+ custom_keys={
+ 'branch_3x3.norm': dict(decay_mult=0.0),
+ 'branch_1x1.norm': dict(decay_mult=0.0),
+ 'branch_norm.bias': dict(decay_mult=0.0),
+ }))
+
+data_preprocessor = dict(
+ # RGB format normalization parameters
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+bgr_mean = data_preprocessor['mean'][::-1]
+bgr_std = data_preprocessor['std'][::-1]
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=224, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='RandAugment',
+ policies='timm_increasing',
+ num_policies=2,
+ total_level=10,
+ magnitude_level=7,
+ magnitude_std=0.5,
+ hparams=dict(pad_val=[round(x) for x in bgr_mean])),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='ResizeEdge', scale=256, edge='short', backend='pillow'),
+ dict(type='CenterCrop', crop_size=224),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+
+# schedule settings
+param_scheduler = dict(
+ type='CosineAnnealingLR',
+ T_max=200,
+ by_epoch=True,
+ begin=0,
+ end=200,
+ convert_to_iter_based=True)
+
+train_cfg = dict(by_epoch=True, max_epochs=200)
+
+default_hooks = dict(
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
diff --git a/configs/repvgg/repvgg-B3g4_8xb32_in1k.py b/configs/repvgg/repvgg-B3g4_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0c5c00af845f5e4f02b44105095f78835f35096
--- /dev/null
+++ b/configs/repvgg/repvgg-B3g4_8xb32_in1k.py
@@ -0,0 +1,3 @@
+_base_ = './repvgg-B3_8xb32_in1k.py'
+
+model = dict(backbone=dict(arch='B3g4'))
diff --git a/configs/repvgg/repvgg-D2se_8xb32_in1k.py b/configs/repvgg/repvgg-D2se_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..f532dcd79686a119e1bed528a1e7c36195e70857
--- /dev/null
+++ b/configs/repvgg/repvgg-D2se_8xb32_in1k.py
@@ -0,0 +1,28 @@
+_base_ = './repvgg-B3_8xb32_in1k.py'
+
+model = dict(backbone=dict(arch='D2se'), head=dict(in_channels=2560))
+
+param_scheduler = [
+ # warm up learning rate scheduler
+ dict(
+ type='LinearLR',
+ start_factor=0.0001,
+ by_epoch=True,
+ begin=0,
+ end=5,
+ # update by iter
+ convert_to_iter_based=True),
+ # main learning rate scheduler
+ dict(
+ type='CosineAnnealingLR',
+ T_max=295,
+ eta_min=1.0e-6,
+ by_epoch=True,
+ begin=5,
+ end=300)
+]
+
+train_cfg = dict(by_epoch=True, max_epochs=300)
+
+default_hooks = dict(
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
diff --git a/configs/res2net/README.md b/configs/res2net/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..68b1acce79c18d994d2e310392a75a4b74db6078
--- /dev/null
+++ b/configs/res2net/README.md
@@ -0,0 +1,78 @@
+# Res2Net
+
+> [Res2Net: A New Multi-scale Backbone Architecture](https://arxiv.org/abs/1904.01169)
+
+
+
+## Abstract
+
+Representing features at multiple scales is of great importance for numerous vision tasks. Recent advances in backbone convolutional neural networks (CNNs) continually demonstrate stronger multi-scale representation ability, leading to consistent performance gains on a wide range of applications. However, most existing methods represent the multi-scale features in a layer-wise manner. In this paper, we propose a novel building block for CNNs, namely Res2Net, by constructing hierarchical residual-like connections within one single residual block. The Res2Net represents multi-scale features at a granular level and increases the range of receptive fields for each network layer. The proposed Res2Net block can be plugged into the state-of-the-art backbone CNN models, e.g., ResNet, ResNeXt, and DLA. We evaluate the Res2Net block on all these models and demonstrate consistent performance gains over baseline models on widely-used datasets, e.g., CIFAR-100 and ImageNet. Further ablation studies and experimental results on representative computer vision tasks, i.e., object detection, class activation mapping, and salient object detection, further verify the superiority of the Res2Net over the state-of-the-art baseline methods.
+
+
+

+
+

+
+

+
+
+Show the paper's abstract
+
+
+Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
+
+The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('resnet18_8xb16_cifar10', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('resnet18_8xb16_cifar10', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Train/Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Train:
+
+```shell
+python tools/train.py configs/resnet/resnet18_8xb16_cifar10.py
+```
+
+Test:
+
+```shell
+python tools/test.py configs/resnet/resnet18_8xb16_cifar10.py https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth
+```
+
+
+
+## Models and results
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :--------------------------------- | :----------: | :--------: | :-------: | :-------: | :-------: | :-------------------------------------------: | :----------------------------------------------------------------------: |
+| `resnet18_8xb32_in1k` | From scratch | 11.69 | 1.82 | 69.90 | 89.43 | [config](resnet18_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.json) |
+| `resnet34_8xb32_in1k` | From scratch | 2.18 | 3.68 | 73.62 | 91.59 | [config](resnet34_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet34_8xb32_in1k_20210831-f257d4e6.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet34_8xb32_in1k_20210831-f257d4e6.json) |
+| `resnet50_8xb32_in1k` | From scratch | 25.56 | 4.12 | 76.55 | 93.06 | [config](resnet50_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.json) |
+| `resnet101_8xb32_in1k` | From scratch | 44.55 | 7.85 | 77.97 | 94.06 | [config](resnet101_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet101_8xb32_in1k_20210831-539c63f8.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet101_8xb32_in1k_20210831-539c63f8.json) |
+| `resnet152_8xb32_in1k` | From scratch | 60.19 | 11.58 | 78.48 | 94.13 | [config](resnet152_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet152_8xb32_in1k_20210901-4d7582fa.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet152_8xb32_in1k_20210901-4d7582fa.json) |
+| `resnetv1d50_8xb32_in1k` | From scratch | 25.58 | 4.36 | 77.54 | 93.57 | [config](resnetv1d50_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1d50_b32x8_imagenet_20210531-db14775a.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1d50_b32x8_imagenet_20210531-db14775a.json) |
+| `resnetv1d101_8xb32_in1k` | From scratch | 44.57 | 8.09 | 78.93 | 94.48 | [config](resnetv1d101_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1d101_b32x8_imagenet_20210531-6e13bcd3.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1d101_b32x8_imagenet_20210531-6e13bcd3.json) |
+| `resnetv1d152_8xb32_in1k` | From scratch | 60.21 | 11.82 | 79.41 | 94.70 | [config](resnetv1d152_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1d152_b32x8_imagenet_20210531-278cf22a.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1d152_b32x8_imagenet_20210531-278cf22a.json) |
+| `resnet50_8xb32-fp16_in1k` | From scratch | 25.56 | 4.12 | 76.30 | 93.07 | [config](resnet50_8xb32-fp16_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/fp16/resnet50_batch256_fp16_imagenet_20210320-b3964210.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/fp16/resnet50_batch256_fp16_imagenet_20210320-b3964210.json) |
+| `resnet50_8xb256-rsb-a1-600e_in1k` | From scratch | 25.56 | 4.12 | 80.12 | 94.78 | [config](resnet50_8xb256-rsb-a1-600e_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a1-600e_in1k_20211228-20e21305.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a1-600e_in1k_20211228-20e21305.json) |
+| `resnet50_8xb256-rsb-a2-300e_in1k` | From scratch | 25.56 | 4.12 | 79.55 | 94.37 | [config](resnet50_8xb256-rsb-a2-300e_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a2-300e_in1k_20211228-0fd8be6e.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a2-300e_in1k_20211228-0fd8be6e.json) |
+| `resnet50_8xb256-rsb-a3-100e_in1k` | From scratch | 25.56 | 4.12 | 78.30 | 93.80 | [config](resnet50_8xb256-rsb-a3-100e_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a3-100e_in1k_20211228-3493673c.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a3-100e_in1k_20211228-3493673c.json) |
+| `resnetv1c50_8xb32_in1k` | From scratch | 25.58 | 4.36 | 77.01 | 93.58 | [config](resnetv1c50_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1c50_8xb32_in1k_20220214-3343eccd.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1c50_8xb32_in1k_20220214-3343eccd.json) |
+| `resnetv1c101_8xb32_in1k` | From scratch | 44.57 | 8.09 | 78.30 | 94.27 | [config](resnetv1c101_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1c101_8xb32_in1k_20220214-434fe45f.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1c101_8xb32_in1k_20220214-434fe45f.json) |
+| `resnetv1c152_8xb32_in1k` | From scratch | 60.21 | 11.82 | 78.76 | 94.41 | [config](resnetv1c152_8xb32_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1c152_8xb32_in1k_20220214-c013291f.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1c152_8xb32_in1k_20220214-c013291f.json) |
+
+### Image Classification on CIFAR-10
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Config | Download |
+| :------------------------ | :----------: | :--------: | :-------: | :-------: | :----------------------------------: | :-------------------------------------------------------------------------------------------------: |
+| `resnet18_8xb16_cifar10` | From scratch | 11.17 | 0.56 | 94.82 | [config](resnet18_8xb16_cifar10.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.json) |
+| `resnet34_8xb16_cifar10` | From scratch | 21.28 | 1.16 | 95.34 | [config](resnet34_8xb16_cifar10.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet34_b16x8_cifar10_20210528-a8aa36a6.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet34_b16x8_cifar10_20210528-a8aa36a6.json) |
+| `resnet50_8xb16_cifar10` | From scratch | 23.52 | 1.31 | 95.55 | [config](resnet50_8xb16_cifar10.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_b16x8_cifar10_20210528-f54bfad9.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_b16x8_cifar10_20210528-f54bfad9.json) |
+| `resnet101_8xb16_cifar10` | From scratch | 42.51 | 2.52 | 95.58 | [config](resnet101_8xb16_cifar10.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet101_b16x8_cifar10_20210528-2d29e936.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet101_b16x8_cifar10_20210528-2d29e936.json) |
+| `resnet152_8xb16_cifar10` | From scratch | 58.16 | 3.74 | 95.76 | [config](resnet152_8xb16_cifar10.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet152_b16x8_cifar10_20210528-3e8e9178.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet152_b16x8_cifar10_20210528-3e8e9178.json) |
+
+### Image Classification on CIFAR-100
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :------------------------ | :----------: | :--------: | :-------: | :-------: | :-------: | :----------------------------------: | :----------------------------------------------------------------------------------------: |
+| `resnet50_8xb16_cifar100` | From scratch | 23.71 | 1.31 | 79.90 | 95.19 | [config](resnet50_8xb16_cifar100.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_b16x8_cifar100_20210528-67b58a1b.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_b16x8_cifar100_20210528-67b58a1b.json) |
+
+### Image Classification on CUB-200-2011
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Config | Download |
+| :------------------ | :----------: | :--------: | :-------: | :-------: | :----------------------------: | :-------------------------------------------------------------------------------------------------------------: |
+| `resnet50_8xb8_cub` | From scratch | 23.92 | 16.48 | 88.45 | [config](resnet50_8xb8_cub.py) | [model](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb8_cub_20220307-57840e60.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb8_cub_20220307-57840e60.json) |
+
+## Citation
+
+```bibtex
+@inproceedings{he2016deep,
+ title={Deep residual learning for image recognition},
+ author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
+ booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
+ pages={770--778},
+ year={2016}
+}
+```
diff --git a/configs/resnet/metafile.yml b/configs/resnet/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..16387248c43aea59c5563b4c6c98df8dd8effead
--- /dev/null
+++ b/configs/resnet/metafile.yml
@@ -0,0 +1,352 @@
+Collections:
+ - Name: ResNet
+ Metadata:
+ Training Data: ImageNet-1k
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Epochs: 100
+ Batch Size: 256
+ Architecture:
+ - ResNet
+ Paper:
+ URL: https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
+ Title: "Deep Residual Learning for Image Recognition"
+ README: configs/resnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmpretrain/blob/v0.15.0/mmcls/models/backbones/resnet.py#L383
+ Version: v0.15.0
+
+Models:
+ - Name: resnet18_8xb16_cifar10
+ Metadata:
+ Training Data: CIFAR-10
+ Epochs: 200
+ Batch Size: 128
+ FLOPs: 560000000
+ Parameters: 11170000
+ In Collection: ResNet
+ Results:
+ - Dataset: CIFAR-10
+ Metrics:
+ Top 1 Accuracy: 94.82
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_b16x8_cifar10_20210528-bd6371c8.pth
+ Config: configs/resnet/resnet18_8xb16_cifar10.py
+ - Name: resnet34_8xb16_cifar10
+ Metadata:
+ Training Data: CIFAR-10
+ Epochs: 200
+ Batch Size: 128
+ FLOPs: 1160000000
+ Parameters: 21280000
+ In Collection: ResNet
+ Results:
+ - Dataset: CIFAR-10
+ Metrics:
+ Top 1 Accuracy: 95.34
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet34_b16x8_cifar10_20210528-a8aa36a6.pth
+ Config: configs/resnet/resnet34_8xb16_cifar10.py
+ - Name: resnet50_8xb16_cifar10
+ Metadata:
+ Training Data: CIFAR-10
+ Epochs: 200
+ Batch Size: 128
+ FLOPs: 1310000000
+ Parameters: 23520000
+ In Collection: ResNet
+ Results:
+ - Dataset: CIFAR-10
+ Metrics:
+ Top 1 Accuracy: 95.55
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_b16x8_cifar10_20210528-f54bfad9.pth
+ Config: configs/resnet/resnet50_8xb16_cifar10.py
+ - Name: resnet101_8xb16_cifar10
+ Metadata:
+ Training Data: CIFAR-10
+ Epochs: 200
+ Batch Size: 128
+ FLOPs: 2520000000
+ Parameters: 42510000
+ In Collection: ResNet
+ Results:
+ - Dataset: CIFAR-10
+ Metrics:
+ Top 1 Accuracy: 95.58
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet101_b16x8_cifar10_20210528-2d29e936.pth
+ Config: configs/resnet/resnet101_8xb16_cifar10.py
+ - Name: resnet152_8xb16_cifar10
+ Metadata:
+ Training Data: CIFAR-10
+ Epochs: 200
+ Batch Size: 128
+ FLOPs: 3740000000
+ Parameters: 58160000
+ In Collection: ResNet
+ Results:
+ - Dataset: CIFAR-10
+ Metrics:
+ Top 1 Accuracy: 95.76
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet152_b16x8_cifar10_20210528-3e8e9178.pth
+ Config: configs/resnet/resnet152_8xb16_cifar10.py
+ - Name: resnet50_8xb16_cifar100
+ Metadata:
+ Training Data: CIFAR-100
+ Epochs: 200
+ Batch Size: 128
+ FLOPs: 1310000000
+ Parameters: 23710000
+ In Collection: ResNet
+ Results:
+ - Dataset: CIFAR-100
+ Metrics:
+ Top 1 Accuracy: 79.90
+ Top 5 Accuracy: 95.19
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_b16x8_cifar100_20210528-67b58a1b.pth
+ Config: configs/resnet/resnet50_8xb16_cifar100.py
+ - Name: resnet18_8xb32_in1k
+ Metadata:
+ FLOPs: 1820000000
+ Parameters: 11690000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 69.90
+ Top 5 Accuracy: 89.43
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet18_8xb32_in1k_20210831-fbbb1da6.pth
+ Config: configs/resnet/resnet18_8xb32_in1k.py
+ - Name: resnet34_8xb32_in1k
+ Metadata:
+ FLOPs: 3680000000
+ Parameters: 2180000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 73.62
+ Top 5 Accuracy: 91.59
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet34_8xb32_in1k_20210831-f257d4e6.pth
+ Config: configs/resnet/resnet34_8xb32_in1k.py
+ - Name: resnet50_8xb32_in1k
+ Metadata:
+ FLOPs: 4120000000
+ Parameters: 25560000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 76.55
+ Top 5 Accuracy: 93.06
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth
+ Config: configs/resnet/resnet50_8xb32_in1k.py
+ - Name: resnet101_8xb32_in1k
+ Metadata:
+ FLOPs: 7850000000
+ Parameters: 44550000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 77.97
+ Top 5 Accuracy: 94.06
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet101_8xb32_in1k_20210831-539c63f8.pth
+ Config: configs/resnet/resnet101_8xb32_in1k.py
+ - Name: resnet152_8xb32_in1k
+ Metadata:
+ FLOPs: 11580000000
+ Parameters: 60190000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 78.48
+ Top 5 Accuracy: 94.13
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet152_8xb32_in1k_20210901-4d7582fa.pth
+ Config: configs/resnet/resnet152_8xb32_in1k.py
+ - Name: resnetv1d50_8xb32_in1k
+ Metadata:
+ FLOPs: 4360000000
+ Parameters: 25580000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 77.54
+ Top 5 Accuracy: 93.57
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1d50_b32x8_imagenet_20210531-db14775a.pth
+ Config: configs/resnet/resnetv1d50_8xb32_in1k.py
+ - Name: resnetv1d101_8xb32_in1k
+ Metadata:
+ FLOPs: 8090000000
+ Parameters: 44570000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 78.93
+ Top 5 Accuracy: 94.48
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1d101_b32x8_imagenet_20210531-6e13bcd3.pth
+ Config: configs/resnet/resnetv1d101_8xb32_in1k.py
+ - Name: resnetv1d152_8xb32_in1k
+ Metadata:
+ FLOPs: 11820000000
+ Parameters: 60210000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 79.41
+ Top 5 Accuracy: 94.70
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1d152_b32x8_imagenet_20210531-278cf22a.pth
+ Config: configs/resnet/resnetv1d152_8xb32_in1k.py
+ - Name: resnet50_8xb32-fp16_in1k
+ Metadata:
+ FLOPs: 4120000000
+ Parameters: 25560000
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ - Mixed Precision Training
+ In Collection: ResNet
+ Results:
+ - Task: Image Classification
+ Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 76.30
+ Top 5 Accuracy: 93.07
+ Weights: https://download.openmmlab.com/mmclassification/v0/fp16/resnet50_batch256_fp16_imagenet_20210320-b3964210.pth
+ Config: configs/resnet/resnet50_8xb32-fp16_in1k.py
+ - Name: resnet50_8xb256-rsb-a1-600e_in1k
+ Metadata:
+ FLOPs: 4120000000
+ Parameters: 25560000
+ Training Techniques:
+ - LAMB
+ - Weight Decay
+ - Cosine Annealing
+ - Mixup
+ - CutMix
+ - RepeatAugSampler
+ - RandAugment
+ Epochs: 600
+ Batch Size: 2048
+ In Collection: ResNet
+ Results:
+ - Task: Image Classification
+ Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 80.12
+ Top 5 Accuracy: 94.78
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a1-600e_in1k_20211228-20e21305.pth
+ Config: configs/resnet/resnet50_8xb256-rsb-a1-600e_in1k.py
+ - Name: resnet50_8xb256-rsb-a2-300e_in1k
+ Metadata:
+ FLOPs: 4120000000
+ Parameters: 25560000
+ Training Techniques:
+ - LAMB
+ - Weight Decay
+ - Cosine Annealing
+ - Mixup
+ - CutMix
+ - RepeatAugSampler
+ - RandAugment
+ Epochs: 300
+ Batch Size: 2048
+ In Collection: ResNet
+ Results:
+ - Task: Image Classification
+ Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 79.55
+ Top 5 Accuracy: 94.37
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a2-300e_in1k_20211228-0fd8be6e.pth
+ Config: configs/resnet/resnet50_8xb256-rsb-a2-300e_in1k.py
+ - Name: resnet50_8xb256-rsb-a3-100e_in1k
+ Metadata:
+ FLOPs: 4120000000
+ Parameters: 25560000
+ Training Techniques:
+ - LAMB
+ - Weight Decay
+ - Cosine Annealing
+ - Mixup
+ - CutMix
+ - RandAugment
+ Batch Size: 2048
+ In Collection: ResNet
+ Results:
+ - Task: Image Classification
+ Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 78.30
+ Top 5 Accuracy: 93.80
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb256-rsb-a3-100e_in1k_20211228-3493673c.pth
+ Config: configs/resnet/resnet50_8xb256-rsb-a3-100e_in1k.py
+ - Name: resnetv1c50_8xb32_in1k
+ Metadata:
+ FLOPs: 4360000000
+ Parameters: 25580000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 77.01
+ Top 5 Accuracy: 93.58
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1c50_8xb32_in1k_20220214-3343eccd.pth
+ Config: configs/resnet/resnetv1c50_8xb32_in1k.py
+ - Name: resnetv1c101_8xb32_in1k
+ Metadata:
+ FLOPs: 8090000000
+ Parameters: 44570000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 78.30
+ Top 5 Accuracy: 94.27
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1c101_8xb32_in1k_20220214-434fe45f.pth
+ Config: configs/resnet/resnetv1c101_8xb32_in1k.py
+ - Name: resnetv1c152_8xb32_in1k
+ Metadata:
+ FLOPs: 11820000000
+ Parameters: 60210000
+ In Collection: ResNet
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 78.76
+ Top 5 Accuracy: 94.41
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnetv1c152_8xb32_in1k_20220214-c013291f.pth
+ Config: configs/resnet/resnetv1c152_8xb32_in1k.py
+ - Name: resnet50_8xb8_cub
+ Metadata:
+ FLOPs: 16480000000
+ Parameters: 23920000
+ In Collection: ResNet
+ Results:
+ - Dataset: CUB-200-2011
+ Metrics:
+ Top 1 Accuracy: 88.45
+ Task: Image Classification
+ Pretrain: https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_3rdparty-mill_in21k_20220331-faac000b.pth
+ Weights: https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb8_cub_20220307-57840e60.pth
+ Config: configs/resnet/resnet50_8xb8_cub.py
diff --git a/configs/resnet/resnet101_8xb16_cifar10.py b/configs/resnet/resnet101_8xb16_cifar10.py
new file mode 100644
index 0000000000000000000000000000000000000000..166a1740b09c5fb74462a0672cd5fef54caae8f7
--- /dev/null
+++ b/configs/resnet/resnet101_8xb16_cifar10.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnet101_cifar.py',
+ '../_base_/datasets/cifar10_bs16.py',
+ '../_base_/schedules/cifar10_bs128.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet101_8xb32_in1k.py b/configs/resnet/resnet101_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..388d2cd918ab75ec46346faa0448ef9cf2893fc8
--- /dev/null
+++ b/configs/resnet/resnet101_8xb32_in1k.py
@@ -0,0 +1,4 @@
+_base_ = [
+ '../_base_/models/resnet101.py', '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet152_8xb16_cifar10.py b/configs/resnet/resnet152_8xb16_cifar10.py
new file mode 100644
index 0000000000000000000000000000000000000000..3f307b6aa81661558b8308094de6e8327d08c830
--- /dev/null
+++ b/configs/resnet/resnet152_8xb16_cifar10.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnet152_cifar.py',
+ '../_base_/datasets/cifar10_bs16.py',
+ '../_base_/schedules/cifar10_bs128.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet152_8xb32_in1k.py b/configs/resnet/resnet152_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc9dc2cee4a0fd8a9d47d461b2d5d00bf9962bf5
--- /dev/null
+++ b/configs/resnet/resnet152_8xb32_in1k.py
@@ -0,0 +1,4 @@
+_base_ = [
+ '../_base_/models/resnet152.py', '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet18_8xb16_cifar10.py b/configs/resnet/resnet18_8xb16_cifar10.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7afa397b7b6a01decd0a010816ebe3678ca44aa
--- /dev/null
+++ b/configs/resnet/resnet18_8xb16_cifar10.py
@@ -0,0 +1,4 @@
+_base_ = [
+ '../_base_/models/resnet18_cifar.py', '../_base_/datasets/cifar10_bs16.py',
+ '../_base_/schedules/cifar10_bs128.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet18_8xb32_in1k.py b/configs/resnet/resnet18_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..ac452ff75602464eba84a3eea150b30748122c69
--- /dev/null
+++ b/configs/resnet/resnet18_8xb32_in1k.py
@@ -0,0 +1,4 @@
+_base_ = [
+ '../_base_/models/resnet18.py', '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet34_8xb16_cifar10.py b/configs/resnet/resnet34_8xb16_cifar10.py
new file mode 100644
index 0000000000000000000000000000000000000000..7f5cd517d505ea479b506b6e4756c117c392dabd
--- /dev/null
+++ b/configs/resnet/resnet34_8xb16_cifar10.py
@@ -0,0 +1,4 @@
+_base_ = [
+ '../_base_/models/resnet34_cifar.py', '../_base_/datasets/cifar10_bs16.py',
+ '../_base_/schedules/cifar10_bs128.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet34_8xb32_in1k.py b/configs/resnet/resnet34_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..7749261c80defef7cbf94c4e1284c26382246dc6
--- /dev/null
+++ b/configs/resnet/resnet34_8xb32_in1k.py
@@ -0,0 +1,4 @@
+_base_ = [
+ '../_base_/models/resnet34.py', '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet50_32xb64-warmup-coslr_in1k.py b/configs/resnet/resnet50_32xb64-warmup-coslr_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..c26245ef53a736c22c0ef7d4e9d8b7876509fe2e
--- /dev/null
+++ b/configs/resnet/resnet50_32xb64-warmup-coslr_in1k.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnet50.py', '../_base_/datasets/imagenet_bs64.py',
+ '../_base_/schedules/imagenet_bs2048_coslr.py',
+ '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet50_32xb64-warmup-lbs_in1k.py b/configs/resnet/resnet50_32xb64-warmup-lbs_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f24f9a0f2c54a2bb634c1f374bc1b534d63697f
--- /dev/null
+++ b/configs/resnet/resnet50_32xb64-warmup-lbs_in1k.py
@@ -0,0 +1,12 @@
+_base_ = ['./resnet50_32xb64-warmup_in1k.py']
+model = dict(
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=2048,
+ loss=dict(
+ type='LabelSmoothLoss',
+ loss_weight=1.0,
+ label_smooth_val=0.1,
+ num_classes=1000),
+ ))
diff --git a/configs/resnet/resnet50_32xb64-warmup_in1k.py b/configs/resnet/resnet50_32xb64-warmup_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..34d5288b9d3f9fcf3f0b409dc1c17906654c2170
--- /dev/null
+++ b/configs/resnet/resnet50_32xb64-warmup_in1k.py
@@ -0,0 +1,4 @@
+_base_ = [
+ '../_base_/models/resnet50.py', '../_base_/datasets/imagenet_bs64.py',
+ '../_base_/schedules/imagenet_bs2048.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet50_8xb128_coslr-90e_in21k.py b/configs/resnet/resnet50_8xb128_coslr-90e_in21k.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2cc1ee2830661998505310d8c7074d8ae5da6b4
--- /dev/null
+++ b/configs/resnet/resnet50_8xb128_coslr-90e_in21k.py
@@ -0,0 +1,11 @@
+_base_ = [
+ '../_base_/models/resnet50.py', '../_base_/datasets/imagenet21k_bs128.py',
+ '../_base_/schedules/imagenet_bs1024_coslr.py',
+ '../_base_/default_runtime.py'
+]
+
+# model settings
+model = dict(head=dict(num_classes=21843))
+
+# runtime settings
+train_cfg = dict(by_epoch=True, max_epochs=90)
diff --git a/configs/resnet/resnet50_8xb16-mixup_cifar10.py b/configs/resnet/resnet50_8xb16-mixup_cifar10.py
new file mode 100644
index 0000000000000000000000000000000000000000..2420ebfeb0a34675a4b1b2a69c0b8a39e197ce35
--- /dev/null
+++ b/configs/resnet/resnet50_8xb16-mixup_cifar10.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnet50_cifar_mixup.py',
+ '../_base_/datasets/cifar10_bs16.py',
+ '../_base_/schedules/cifar10_bs128.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet50_8xb16_cifar10.py b/configs/resnet/resnet50_8xb16_cifar10.py
new file mode 100644
index 0000000000000000000000000000000000000000..669e5de27e526dd46d9f06c99e478dce16f0ac9a
--- /dev/null
+++ b/configs/resnet/resnet50_8xb16_cifar10.py
@@ -0,0 +1,4 @@
+_base_ = [
+ '../_base_/models/resnet50_cifar.py', '../_base_/datasets/cifar10_bs16.py',
+ '../_base_/schedules/cifar10_bs128.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet50_8xb16_cifar100.py b/configs/resnet/resnet50_8xb16_cifar100.py
new file mode 100644
index 0000000000000000000000000000000000000000..ebde6c76ecca6d23b58edfb85ebc3b72ce15a2b2
--- /dev/null
+++ b/configs/resnet/resnet50_8xb16_cifar100.py
@@ -0,0 +1,19 @@
+_base_ = [
+ '../_base_/models/resnet50_cifar.py',
+ '../_base_/datasets/cifar100_bs16.py',
+ '../_base_/schedules/cifar10_bs128.py',
+ '../_base_/default_runtime.py',
+]
+
+# model settings
+model = dict(head=dict(num_classes=100))
+
+# schedule settings
+optim_wrapper = dict(optimizer=dict(weight_decay=0.0005))
+
+param_scheduler = dict(
+ type='MultiStepLR',
+ by_epoch=True,
+ milestones=[60, 120, 160],
+ gamma=0.2,
+)
diff --git a/configs/resnet/resnet50_8xb256-rsb-a1-600e_in1k.py b/configs/resnet/resnet50_8xb256-rsb-a1-600e_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4ea15984a0063c06e09eb5063d49b2cf90371cf
--- /dev/null
+++ b/configs/resnet/resnet50_8xb256-rsb-a1-600e_in1k.py
@@ -0,0 +1,56 @@
+_base_ = [
+ '../_base_/models/resnet50.py',
+ '../_base_/datasets/imagenet_bs256_rsb_a12.py',
+ '../_base_/schedules/imagenet_bs2048_rsb.py',
+ '../_base_/default_runtime.py'
+]
+
+# model settings
+model = dict(
+ backbone=dict(
+ norm_cfg=dict(type='SyncBN', requires_grad=True),
+ drop_path_rate=0.05,
+ ),
+ head=dict(
+ loss=dict(
+ type='LabelSmoothLoss',
+ label_smooth_val=0.1,
+ mode='original',
+ use_sigmoid=True,
+ )),
+ train_cfg=dict(augments=[
+ dict(type='Mixup', alpha=0.2),
+ dict(type='CutMix', alpha=1.0)
+ ]),
+)
+
+# dataset settings
+train_dataloader = dict(sampler=dict(type='RepeatAugSampler', shuffle=True))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(weight_decay=0.01),
+ paramwise_cfg=dict(bias_decay_mult=0., norm_decay_mult=0.),
+)
+
+param_scheduler = [
+ # warm up learning rate scheduler
+ dict(
+ type='LinearLR',
+ start_factor=0.0001,
+ by_epoch=True,
+ begin=0,
+ end=5,
+ # update by iter
+ convert_to_iter_based=True),
+ # main learning rate scheduler
+ dict(
+ type='CosineAnnealingLR',
+ T_max=595,
+ eta_min=1.0e-6,
+ by_epoch=True,
+ begin=5,
+ end=600)
+]
+
+train_cfg = dict(by_epoch=True, max_epochs=600)
diff --git a/configs/resnet/resnet50_8xb256-rsb-a2-300e_in1k.py b/configs/resnet/resnet50_8xb256-rsb-a2-300e_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..df8edc0370400a3f3985c33bffae2d04afc55772
--- /dev/null
+++ b/configs/resnet/resnet50_8xb256-rsb-a2-300e_in1k.py
@@ -0,0 +1,46 @@
+_base_ = [
+ '../_base_/models/resnet50.py',
+ '../_base_/datasets/imagenet_bs256_rsb_a12.py',
+ '../_base_/schedules/imagenet_bs2048_rsb.py',
+ '../_base_/default_runtime.py'
+]
+
+# model settings
+model = dict(
+ backbone=dict(
+ norm_cfg=dict(type='SyncBN', requires_grad=True),
+ drop_path_rate=0.05,
+ ),
+ head=dict(loss=dict(use_sigmoid=True)),
+ train_cfg=dict(augments=[
+ dict(type='Mixup', alpha=0.1),
+ dict(type='CutMix', alpha=1.0)
+ ]))
+
+# dataset settings
+train_dataloader = dict(sampler=dict(type='RepeatAugSampler', shuffle=True))
+
+# schedule settings
+optim_wrapper = dict(
+ paramwise_cfg=dict(bias_decay_mult=0., norm_decay_mult=0.))
+
+param_scheduler = [
+ # warm up learning rate scheduler
+ dict(
+ type='LinearLR',
+ start_factor=0.0001,
+ by_epoch=True,
+ begin=0,
+ end=5,
+ # update by iter
+ convert_to_iter_based=True),
+ # main learning rate scheduler
+ dict(
+ type='CosineAnnealingLR',
+ T_max=295,
+ eta_min=1.0e-6,
+ by_epoch=True,
+ begin=5,
+ end=300)
+]
+train_cfg = dict(by_epoch=True, max_epochs=300)
diff --git a/configs/resnet/resnet50_8xb256-rsb-a3-100e_in1k.py b/configs/resnet/resnet50_8xb256-rsb-a3-100e_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a36c5843a69aea20fdb9287561e5c2a96459852
--- /dev/null
+++ b/configs/resnet/resnet50_8xb256-rsb-a3-100e_in1k.py
@@ -0,0 +1,22 @@
+_base_ = [
+ '../_base_/models/resnet50.py',
+ '../_base_/datasets/imagenet_bs256_rsb_a3.py',
+ '../_base_/schedules/imagenet_bs2048_rsb.py',
+ '../_base_/default_runtime.py'
+]
+
+# model settings
+model = dict(
+ backbone=dict(norm_cfg=dict(type='SyncBN', requires_grad=True)),
+ head=dict(loss=dict(use_sigmoid=True)),
+ train_cfg=dict(augments=[
+ dict(type='Mixup', alpha=0.1),
+ dict(type='CutMix', alpha=1.0)
+ ]),
+)
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=0.008),
+ paramwise_cfg=dict(bias_decay_mult=0., norm_decay_mult=0.),
+)
diff --git a/configs/resnet/resnet50_8xb32-coslr-preciseBN_in1k.py b/configs/resnet/resnet50_8xb32-coslr-preciseBN_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..01fefbbf2852eeceddb0ad026fb5098e763e0710
--- /dev/null
+++ b/configs/resnet/resnet50_8xb32-coslr-preciseBN_in1k.py
@@ -0,0 +1,13 @@
+_base_ = 'resnet50_8xb32-coslr_in1k.py'
+
+# Precise BN hook will update the bn stats, so this hook should be executed
+# before CheckpointHook(priority of 'VERY_LOW') and
+# EMAHook(priority of 'NORMAL') So set the priority of PreciseBNHook to
+# 'ABOVENORMAL' here.
+custom_hooks = [
+ dict(
+ type='PreciseBNHook',
+ num_samples=8192,
+ interval=1,
+ priority='ABOVE_NORMAL')
+]
diff --git a/configs/resnet/resnet50_8xb32-coslr_in1k.py b/configs/resnet/resnet50_8xb32-coslr_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..938a114b79696b5ad3442c1dd2a7aea33342b679
--- /dev/null
+++ b/configs/resnet/resnet50_8xb32-coslr_in1k.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnet50.py', '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256_coslr.py',
+ '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet50_8xb32-cutmix_in1k.py b/configs/resnet/resnet50_8xb32-cutmix_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f8d0ca9f3a500344c18b669f25f3cb78393d7dd
--- /dev/null
+++ b/configs/resnet/resnet50_8xb32-cutmix_in1k.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnet50_cutmix.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet50_8xb32-fp16-dynamic_in1k.py b/configs/resnet/resnet50_8xb32-fp16-dynamic_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..58f6fe4cf25e8f0b3d321a7aab4b746552aa4163
--- /dev/null
+++ b/configs/resnet/resnet50_8xb32-fp16-dynamic_in1k.py
@@ -0,0 +1,4 @@
+_base_ = ['./resnet50_8xb32_in1k.py']
+
+# schedule settings
+optim_wrapper = dict(type='AmpOptimWrapper', loss_scale='dynamic')
diff --git a/configs/resnet/resnet50_8xb32-fp16_in1k.py b/configs/resnet/resnet50_8xb32-fp16_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..19ee6ee4f82ec02f34628bdf8dd74a379798cc67
--- /dev/null
+++ b/configs/resnet/resnet50_8xb32-fp16_in1k.py
@@ -0,0 +1,4 @@
+_base_ = ['./resnet50_8xb32_in1k.py']
+
+# schedule settings
+optim_wrapper = dict(type='AmpOptimWrapper', loss_scale=512.)
diff --git a/configs/resnet/resnet50_8xb32-lbs_in1k.py b/configs/resnet/resnet50_8xb32-lbs_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c1aa5a2c4eee10c10159175224d9b77ea57e57b
--- /dev/null
+++ b/configs/resnet/resnet50_8xb32-lbs_in1k.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnet50_label_smooth.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet50_8xb32-mixup_in1k.py b/configs/resnet/resnet50_8xb32-mixup_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a153d0e18f521f72b8beaf4cbea36d41f5b3300
--- /dev/null
+++ b/configs/resnet/resnet50_8xb32-mixup_in1k.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnet50_mixup.py',
+ '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet50_8xb32_in1k.py b/configs/resnet/resnet50_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..c32f333b67c255c6101469323636bf242eebb8da
--- /dev/null
+++ b/configs/resnet/resnet50_8xb32_in1k.py
@@ -0,0 +1,4 @@
+_base_ = [
+ '../_base_/models/resnet50.py', '../_base_/datasets/imagenet_bs32.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnet50_8xb8_cub.py b/configs/resnet/resnet50_8xb8_cub.py
new file mode 100644
index 0000000000000000000000000000000000000000..17054ef536930d74136897f8f25637321a364ce7
--- /dev/null
+++ b/configs/resnet/resnet50_8xb8_cub.py
@@ -0,0 +1,20 @@
+_base_ = [
+ '../_base_/models/resnet50.py',
+ '../_base_/datasets/cub_bs8_448.py',
+ '../_base_/schedules/cub_bs64.py',
+ '../_base_/default_runtime.py',
+]
+
+# model settings
+# use pre-train weight converted from https://github.com/Alibaba-MIIL/ImageNet21K # noqa
+pretrained = 'https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_3rdparty-mill_in21k_20220331-faac000b.pth' # noqa
+
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint=pretrained, prefix='backbone')),
+ head=dict(num_classes=200, ))
+
+# runtime settings
+default_hooks = dict(logger=dict(type='LoggerHook', interval=20))
diff --git a/configs/resnet/resnetv1c101_8xb32_in1k.py b/configs/resnet/resnetv1c101_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..441aff591851f402a176c142c93dc866a77b82c2
--- /dev/null
+++ b/configs/resnet/resnetv1c101_8xb32_in1k.py
@@ -0,0 +1,7 @@
+_base_ = [
+ '../_base_/models/resnetv1c50.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
+
+model = dict(backbone=dict(depth=101))
diff --git a/configs/resnet/resnetv1c152_8xb32_in1k.py b/configs/resnet/resnetv1c152_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9f466f85c8e8c89fb78f53c27eca1d5acaf5221
--- /dev/null
+++ b/configs/resnet/resnetv1c152_8xb32_in1k.py
@@ -0,0 +1,7 @@
+_base_ = [
+ '../_base_/models/resnetv1c50.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
+
+model = dict(backbone=dict(depth=152))
diff --git a/configs/resnet/resnetv1c50_8xb32_in1k.py b/configs/resnet/resnetv1c50_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa1c8b6475ce373f4a35123a72e31419b87027c0
--- /dev/null
+++ b/configs/resnet/resnetv1c50_8xb32_in1k.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnetv1c50.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnetv1d101_8xb32_in1k.py b/configs/resnet/resnetv1d101_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..b16ca863db2c50267764b1b37aa8b2db891ad2c9
--- /dev/null
+++ b/configs/resnet/resnetv1d101_8xb32_in1k.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnetv1d101.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnetv1d152_8xb32_in1k.py b/configs/resnet/resnetv1d152_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..76926ddbb661029b8cff86ad0d98028531235fa1
--- /dev/null
+++ b/configs/resnet/resnetv1d152_8xb32_in1k.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnetv1d152.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnet/resnetv1d50_8xb32_in1k.py b/configs/resnet/resnetv1d50_8xb32_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..208bde470ad12407d7e56eddeddfc88529e3708b
--- /dev/null
+++ b/configs/resnet/resnetv1d50_8xb32_in1k.py
@@ -0,0 +1,5 @@
+_base_ = [
+ '../_base_/models/resnetv1d50.py',
+ '../_base_/datasets/imagenet_bs32_pil_resize.py',
+ '../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
+]
diff --git a/configs/resnext/README.md b/configs/resnext/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b901b31bd5bd3b99bce07cc2454e4b9a12d40bb2
--- /dev/null
+++ b/configs/resnext/README.md
@@ -0,0 +1,83 @@
+# ResNeXt
+
+> [Aggregated Residual Transformations for Deep Neural Networks](https://openaccess.thecvf.com/content_cvpr_2017/html/Xie_Aggregated_Residual_Transformations_CVPR_2017_paper.html)
+
+
+
+## Abstract
+
+We present a simple, highly modularized network architecture for image classification. Our network is constructed by repeating a building block that aggregates a set of transformations with the same topology. Our simple design results in a homogeneous, multi-branch architecture that has only a few hyper-parameters to set. This strategy exposes a new dimension, which we call "cardinality" (the size of the set of transformations), as an essential factor in addition to the dimensions of depth and width. On the ImageNet-1K dataset, we empirically show that even under the restricted condition of maintaining complexity, increasing cardinality is able to improve classification accuracy. Moreover, increasing cardinality is more effective than going deeper or wider when we increase the capacity. Our models, named ResNeXt, are the foundations of our entry to the ILSVRC 2016 classification task in which we secured 2nd place. We further investigate ResNeXt on an ImageNet-5K set and the COCO detection set, also showing better results than its ResNet counterpart. The code and models are publicly available online.
+
+
+

+
+

+
+
+Show the paper's abstract
+
+
+We present Reversible Vision Transformers, a memory efficient architecture design for visual recognition. By decoupling the GPU memory footprint from the depth of the model, Reversible Vision Transformers enable memory efficient scaling of transformer architectures. We adapt two popular models, namely Vision Transformer and Multiscale Vision Transformers, to reversible variants and benchmark extensively across both model sizes and tasks of image classification, object detection and video classification. Reversible Vision Transformers achieve a reduced memory footprint of up to 15.5× at identical model complexity, parameters and accuracy, demonstrating the promise of reversible vision transformers as an efficient backbone for resource limited training regimes. Finally, we find that the additional computational burden of recomputing activations is more than overcome for deeper models, where throughput can increase up to 3.9× over their non-reversible counterparts.
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('revvit-small_3rdparty_in1k', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('revvit-small_3rdparty_in1k', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Test:
+
+```shell
+python tools/test.py configs/revvit/revvit-small_8xb256_in1k.py https://download.openmmlab.com/mmclassification/v0/revvit/revvit-base_3rdparty_in1k_20221213-87a7b0a5.pth
+```
+
+
+
+## Models and results
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :----------------------------- | :----------: | :--------: | :-------: | :-------: | :-------: | :-----------------------------------: | :----------------------------------------------------------------------------------: |
+| `revvit-small_3rdparty_in1k`\* | From scratch | 22.44 | 4.58 | 79.87 | 94.90 | [config](revvit-small_8xb256_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/revvit/revvit-base_3rdparty_in1k_20221213-87a7b0a5.pth) |
+| `revvit-base_3rdparty_in1k`\* | From scratch | 87.34 | 17.49 | 81.81 | 95.56 | [config](revvit-base_8xb256_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/revvit/revvit-small_3rdparty_in1k_20221213-a3a34f5c.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/facebookresearch/SlowFast). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+## Citation
+
+```bibtex
+@inproceedings{mangalam2022reversible,
+ title={Reversible Vision Transformers},
+ author={Mangalam, Karttikeya and Fan, Haoqi and Li, Yanghao and Wu, Chao-Yuan and Xiong, Bo and Feichtenhofer, Christoph and Malik, Jitendra},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={10830--10840},
+ year={2022}
+}
+```
diff --git a/configs/revvit/metafile.yml b/configs/revvit/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..842de071f1b15cc9bc65b1ff85d208b6d7131b9d
--- /dev/null
+++ b/configs/revvit/metafile.yml
@@ -0,0 +1,48 @@
+Collections:
+ - Name: RevViT
+ Metadata:
+ Training Data: ImageNet-1k
+ Architecture:
+ - Vision Transformer
+ - Reversible
+ Paper:
+ URL: https://openaccess.thecvf.com/content/CVPR2022/papers/Mangalam_Reversible_Vision_Transformers_CVPR_2022_paper.pdf
+ Title: Reversible Vision Transformers
+ README: configs/revvit/README.md
+ Code:
+ Version: v1.0.0rc5
+ URL: https://github.com/open-mmlab/mmpretrain/blob/1.0.0rc5/mmcls/models/backbones/revvit.py
+
+Models:
+ - Name: revvit-small_3rdparty_in1k
+ Metadata:
+ FLOPs: 4583427072
+ Parameters: 22435432
+ In Collection: RevViT
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 79.87
+ Top 5 Accuracy: 94.90
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/revvit/revvit-small_3rdparty_in1k_20221213-a3a34f5c.pth
+ Config: configs/revvit/revvit-small_8xb256_in1k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/pyslowfast/rev/REV_VIT_S.pyth
+ Code: https://github.com/facebookresearch/SlowFast
+ - Name: revvit-base_3rdparty_in1k
+ Metadata:
+ FLOPs: 17490450432
+ Parameters: 87337192
+ In Collection: RevViT
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.81
+ Top 5 Accuracy: 95.56
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/revvit/revvit-base_3rdparty_in1k_20221213-87a7b0a5.pth
+ Config: configs/revvit/revvit-base_8xb256_in1k.py
+ Converted From:
+ Weights: https://dl.fbaipublicfiles.com/pyslowfast/rev/REV_VIT_B.pyth
+ Code: https://github.com/facebookresearch/SlowFast
diff --git a/configs/revvit/revvit-base_8xb256_in1k.py b/configs/revvit/revvit-base_8xb256_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4fde5c9487fb675b75c824608f88ba96f27e9aa
--- /dev/null
+++ b/configs/revvit/revvit-base_8xb256_in1k.py
@@ -0,0 +1,6 @@
+_base_ = [
+ '../_base_/models/revvit/revvit-base.py',
+ '../_base_/datasets/imagenet_bs128_revvit_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_revvit.py',
+ '../_base_/default_runtime.py'
+]
diff --git a/configs/revvit/revvit-small_8xb256_in1k.py b/configs/revvit/revvit-small_8xb256_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..ec3904a3da8164f7f69c61e49d9dfee217a6b99b
--- /dev/null
+++ b/configs/revvit/revvit-small_8xb256_in1k.py
@@ -0,0 +1,6 @@
+_base_ = [
+ '../_base_/models/revvit/revvit-small.py',
+ '../_base_/datasets/imagenet_bs128_revvit_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_revvit.py',
+ '../_base_/default_runtime.py'
+]
diff --git a/configs/riformer/README.md b/configs/riformer/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..6be694d1bf72fd7ba5e5bac0c99d33b9338e0893
--- /dev/null
+++ b/configs/riformer/README.md
@@ -0,0 +1,181 @@
+# RIFormer
+
+> [RIFormer: Keep Your Vision Backbone Effective But Removing Token Mixer](https://arxiv.org/abs/2304.05659)
+
+
+
+## Introduction
+
+RIFormer is a way to keep a vision backbone effective while removing token mixers in its basic building blocks. Equipped with our proposed optimization strategy, we are able to build an extremely simple vision backbone with encouraging performance, while enjoying the high efficiency during inference. RIFormer shares nearly the same macro and micro design as MetaFormer, but safely removing all token mixers. The quantitative results show that our networks outperform many prevailing backbones with faster inference speed on ImageNet-1K.
+
+
+

+
+
+Show the paper's abstract
+
+
+This paper studies how to keep a vision backbone effective while removing token mixers in its basic building blocks. Token mixers, as self-attention for vision transformers (ViTs), are intended to perform information communication between different spatial tokens but suffer from considerable computational cost and latency. However, directly removing them will lead to an incomplete model structure prior, and thus brings a significant accuracy drop. To this end, we first develop an RepIdentityFormer base on the re-parameterizing idea, to study the token mixer free model architecture. And we then explore the improved learning paradigm to break the limitation of simple token mixer free backbone, and summarize the empirical practice into 5 guidelines. Equipped with the proposed optimization strategy, we are able to build an extremely simple vision backbone with encouraging performance, while enjoying the high efficiency during inference. Extensive experiments and ablative analysis also demonstrate that the inductive bias of network architecture, can be incorporated into simple network structure with appropriate optimization strategy. We hope this work can serve as a starting point for the exploration of optimization-driven efficient network design.
+
+
+
+
+## How to use
+
+The checkpoints provided are all `training-time` models. Use the reparameterize tool or `switch_to_deploy` interface to switch them to more efficient `inference-time` architecture, which not only has fewer parameters but also less calculations.
+
+
+
+**Predict image**
+
+Use `classifier.backbone.switch_to_deploy()` interface to switch the RIFormer models into inference mode.
+
+```python
+>>> import torch
+>>> from mmpretrain import get_model, inference_model
+>>>
+>>> model = get_model("riformer-s12_in1k", pretrained=True)
+>>> results = inference_model(model, 'demo/demo.JPEG')
+>>> print( (results['pred_class'], results['pred_score']) )
+('sea snake', 0.7827484011650085)
+>>>
+>>> # switch to deploy mode
+>>> model.backbone.switch_to_deploy()
+>>> results = inference_model(model, 'demo/demo.JPEG')
+>>> print( (results['pred_class'], results['pred_score']) )
+('sea snake', 0.7827480435371399)
+```
+
+**Use the model**
+
+```python
+>>> import torch
+>>>
+>>> model = get_model("riformer-s12_in1k", pretrained=True)
+>>> model.eval()
+>>> inputs = torch.rand(1, 3, 224, 224).to(model.data_preprocessor.device)
+>>> # To get classification scores.
+>>> out = model(inputs)
+>>> print(out.shape)
+torch.Size([1, 1000])
+>>> # To extract features.
+>>> outs = model.extract_feat(inputs)
+>>> print(outs[0].shape)
+torch.Size([1, 512])
+>>>
+>>> # switch to deploy mode
+>>> model.backbone.switch_to_deploy()
+>>> out_deploy = model(inputs)
+>>> print(out.shape)
+torch.Size([1, 1000])
+>>> assert torch.allclose(out, out_deploy, rtol=1e-4, atol=1e-5) # pass without error
+```
+
+**Test Command**
+
+Place the ImageNet dataset to the `data/imagenet/` directory, or prepare datasets according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+*224×224*
+
+Download Checkpoint:
+
+```shell
+wget https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s12_32xb128_in1k_20230406-6741ce71.pth
+```
+
+Test use unfused model:
+
+```shell
+python tools/test.py configs/riformer/riformer-s12_8xb128_in1k.py riformer-s12_32xb128_in1k_20230406-6741ce71.pth
+```
+
+Reparameterize checkpoint:
+
+```shell
+python tools/model_converters/reparameterize_model.py configs/riformer/riformer-s12_8xb128_in1k.py riformer-s12_32xb128_in1k_20230406-6741ce71.pth riformer-s12_deploy.pth
+```
+
+Test use fused model:
+
+```shell
+python tools/test.py configs/riformer/deploy/riformer-s12-deploy_8xb128_in1k.py riformer-s12_deploy.pth
+```
+
+
+
+For more configurable parameters, please refer to the [API](https://mmpretrain.readthedocs.io/en/latest/api/generated/mmpretrain.models.backbones.RIFormer.html#mmpretrain.models.backbones.RIFormer).
+
+
+
+How to use the reparameterization tool(click to show)
+
+
+
+Use provided tool to reparameterize the given model and save the checkpoint:
+
+```bash
+python tools/convert_models/reparameterize_model.py ${CFG_PATH} ${SRC_CKPT_PATH} ${TARGET_CKPT_PATH}
+```
+
+`${CFG_PATH}` is the config file path, `${SRC_CKPT_PATH}` is the source chenpoint file path, `${TARGET_CKPT_PATH}` is the target deploy weight file path.
+
+For example:
+
+```shell
+# download the weight
+wget https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s12_32xb128_in1k_20230406-6741ce71.pth
+
+# reparameterize unfused weight to fused weight
+python tools/model_converters/reparameterize_model.py configs/riformer/riformer-s12_8xb128_in1k.py riformer-s12_32xb128_in1k_20230406-6741ce71.pth riformer-s12_deploy.pth
+```
+
+To use reparameterized weights, you can use the deploy model config file such as the [s12_deploy example](./deploy/riformer-s12-deploy_8xb128_in1k.py):
+
+```text
+# in riformer-s12-deploy_8xb128_in1k.py
+_base_ = '../deploy/riformer-s12-deploy_8xb128_in1k.py' # basic s12 config
+
+model = dict(backbone=dict(deploy=True)) # switch model into deploy mode
+```
+
+```shell
+python tools/test.py configs/riformer/deploy/riformer-s12-deploy_8xb128_in1k.py riformer-s12_deploy.pth
+```
+
+
+
+
+
+## Results and models
+
+### ImageNet-1k
+
+| Model | resolution | Params(M) | Flops(G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :-------------------: | :--------: | :-------: | :------: | :-------: | :-------: | :-------------------------------------------: | :---------------------------------------------------------------------------------------: |
+| riformer-s12_in1k | 224x224 | 11.92 | 1.82 | 76.90 | 93.06 | [config](./riformer-s12_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s12_32xb128_in1k_20230406-6741ce71.pth) |
+| riformer-s24_in1k | 224x224 | 21.39 | 3.41 | 80.28 | 94.80 | [config](./riformer-s24_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s24_32xb128_in1k_20230406-fdab072a.pth) |
+| riformer-s36_in1k | 224x224 | 30.86 | 5.00 | 81.29 | 95.41 | [config](./riformer-s36_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s36_32xb128_in1k_20230406-fdfcd3b0.pth) |
+| riformer-m36_in1k | 224x224 | 56.17 | 8.80 | 82.57 | 95.99 | [config](./riformer-m36_8xb128_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v1/riformer/riformer-m36_32xb128_in1k_20230406-2fcb9d9b.pth) |
+| riformer-m48_in1k | 224x224 | 73.47 | 11.59 | 82.75 | 96.11 | [config](./riformer-m48_8xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v1/riformer/riformer-m48_32xb128_in1k_20230406-2b9d1abf.pth) |
+| riformer-s12_384_in1k | 384x384 | 11.92 | 5.36 | 78.29 | 93.93 | [config](./riformer-s12_8xb128_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s12_32xb128_in1k-384px_20230406-145eda4c.pth) |
+| riformer-s24_384_in1k | 384x384 | 21.39 | 10.03 | 81.36 | 95.40 | [config](./riformer-s24_8xb128_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s24_32xb128_in1k-384px_20230406-bafae7ab.pth) |
+| riformer-s36_384_in1k | 384x384 | 30.86 | 14.70 | 82.22 | 95.95 | [config](./riformer-s36_8xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s36_32xb128_in1k-384px_20230406-017ed3c4.pth) |
+| riformer-m36_384_in1k | 384x384 | 56.17 | 25.87 | 83.39 | 96.40 | [config](./riformer-m36_8xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v1/riformer/riformer-m36_32xb128_in1k-384px_20230406-66a6f764.pth) |
+| riformer-m48_384_in1k | 384x384 | 73.47 | 34.06 | 83.70 | 96.60 | [config](./riformer-m48_8xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v1/riformer/riformer-m48_32xb128_in1k-384px_20230406-2e874826.pth) |
+
+The config files of these models are only for inference.
+
+## Citation
+
+```bibtex
+@inproceedings{wang2023riformer,
+ title={RIFormer: Keep Your Vision Backbone Effective But Removing Token Mixer},
+ author={Wang, Jiahao and Zhang, Songyang and Liu, Yong and Wu, Taiqiang and Yang, Yujiu and Liu, Xihui and Chen, Kai and Luo, Ping and Lin, Dahua},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ year={2023}
+}
+```
diff --git a/configs/riformer/deploy/riformer-m36-deploy_8xb128_in1k.py b/configs/riformer/deploy/riformer-m36-deploy_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..fcec41c810849d20c080faa1a710692e4b2bb9a0
--- /dev/null
+++ b/configs/riformer/deploy/riformer-m36-deploy_8xb128_in1k.py
@@ -0,0 +1,3 @@
+_base_ = '../riformer-m36_8xb128_in1k.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/riformer/deploy/riformer-m36-deploy_8xb64_in1k-384px.py b/configs/riformer/deploy/riformer-m36-deploy_8xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..e18f836f89d9057b1d8a1b6d31cd83d6bdca6b3a
--- /dev/null
+++ b/configs/riformer/deploy/riformer-m36-deploy_8xb64_in1k-384px.py
@@ -0,0 +1,3 @@
+_base_ = '../riformer-m36_8xb64_in1k-384px.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/riformer/deploy/riformer-m48-deploy_8xb64_in1k-384px.py b/configs/riformer/deploy/riformer-m48-deploy_8xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..0ab33534e271ccad60a9f6d896fa15238601a4e0
--- /dev/null
+++ b/configs/riformer/deploy/riformer-m48-deploy_8xb64_in1k-384px.py
@@ -0,0 +1,3 @@
+_base_ = '../riformer-m48_8xb64_in1k-384px.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/riformer/deploy/riformer-m48-deploy_8xb64_in1k.py b/configs/riformer/deploy/riformer-m48-deploy_8xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..e32ad328f893aaa0da1a4072315a91f514a594ce
--- /dev/null
+++ b/configs/riformer/deploy/riformer-m48-deploy_8xb64_in1k.py
@@ -0,0 +1,3 @@
+_base_ = '../riformer-m48_8xb64_in1k.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/riformer/deploy/riformer-s12-deploy_8xb128_in1k-384px.py b/configs/riformer/deploy/riformer-s12-deploy_8xb128_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..ffbb4be31d76716432ff283d9d7c2d77370ddbb0
--- /dev/null
+++ b/configs/riformer/deploy/riformer-s12-deploy_8xb128_in1k-384px.py
@@ -0,0 +1,3 @@
+_base_ = '../riformer-s12_8xb128_in1k-384px.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/riformer/deploy/riformer-s12-deploy_8xb128_in1k.py b/configs/riformer/deploy/riformer-s12-deploy_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..70fd8b74342e07ec2e3b4299364681ffbea5ec25
--- /dev/null
+++ b/configs/riformer/deploy/riformer-s12-deploy_8xb128_in1k.py
@@ -0,0 +1,3 @@
+_base_ = '../riformer-s12_8xb128_in1k.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/riformer/deploy/riformer-s24-deploy_8xb128_in1k-384px.py b/configs/riformer/deploy/riformer-s24-deploy_8xb128_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d05e5c1a14afe10e05ae648e47c16d53220f226
--- /dev/null
+++ b/configs/riformer/deploy/riformer-s24-deploy_8xb128_in1k-384px.py
@@ -0,0 +1,3 @@
+_base_ = '../riformer-s24_8xb128_in1k-384px.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/riformer/deploy/riformer-s24-deploy_8xb128_in1k.py b/configs/riformer/deploy/riformer-s24-deploy_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..47f83a08f4f2c6fa6ffc7105265b41c12e30fd2e
--- /dev/null
+++ b/configs/riformer/deploy/riformer-s24-deploy_8xb128_in1k.py
@@ -0,0 +1,3 @@
+_base_ = '../riformer-s24_8xb128_in1k.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/riformer/deploy/riformer-s36-deploy_8xb128_in1k.py b/configs/riformer/deploy/riformer-s36-deploy_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c03bb15106829f22ba959d2a84d0a92ceba4dac
--- /dev/null
+++ b/configs/riformer/deploy/riformer-s36-deploy_8xb128_in1k.py
@@ -0,0 +1,3 @@
+_base_ = '../riformer-s36_8xb128_in1k.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/riformer/deploy/riformer-s36-deploy_8xb64_in1k-384px.py b/configs/riformer/deploy/riformer-s36-deploy_8xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..67b17ee5173e5bef7d2ecdf6d92e09cbb48db482
--- /dev/null
+++ b/configs/riformer/deploy/riformer-s36-deploy_8xb64_in1k-384px.py
@@ -0,0 +1,3 @@
+_base_ = '../riformer-s36_8xb64_in1k-384px.py'
+
+model = dict(backbone=dict(deploy=True))
diff --git a/configs/riformer/metafile.yml b/configs/riformer/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5f3e2ec8773d26cde570bb874d2a45a73a49bc7b
--- /dev/null
+++ b/configs/riformer/metafile.yml
@@ -0,0 +1,152 @@
+Collections:
+ - Name: RIFormer
+ Metadata:
+ Training Data: ImageNet-1k
+ Training Resources: 8x A100 GPUs
+ Architecture:
+ - Affine
+ - 1x1 Convolution
+ - LayerScale
+ Paper:
+ URL: https://arxiv.org/abs/xxxx.xxxxx
+ Title: "RIFormer: Keep Your Vision Backbone Effective But Removing Token Mixer"
+ README: configs/riformer/README.md
+ Code:
+ Version: v1.0.0rc7
+ URL: null
+
+Models:
+ - Name: riformer-s12_in1k
+ Metadata:
+ FLOPs: 1822000000
+ Parameters: 11915000
+ In Collection: RIFormer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 76.90
+ Top 5 Accuracy: 93.06
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s12_32xb128_in1k_20230406-6741ce71.pth
+ Config: configs/riformer/riformer-s12_8xb128_in1k.py
+ - Name: riformer-s24_in1k
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 3412000000
+ Parameters: 21389000
+ In Collection: RIFormer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 80.28
+ Top 5 Accuracy: 94.80
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s24_32xb128_in1k_20230406-fdab072a.pth
+ Config: configs/riformer/riformer-s24_8xb128_in1k.py
+ - Name: riformer-s36_in1k
+ Metadata:
+ FLOPs: 5003000000
+ Parameters: 30863000
+ In Collection: RIFormer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.29
+ Top 5 Accuracy: 95.41
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s36_32xb128_in1k_20230406-fdfcd3b0.pth
+ Config: configs/riformer/riformer-s36_8xb128_in1k.py
+ - Name: riformer-m36_in1k
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 8801000000
+ Parameters: 56173000
+ In Collection: RIFormer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 82.57
+ Top 5 Accuracy: 95.99
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v1/riformer/riformer-m36_32xb128_in1k_20230406-2fcb9d9b.pth
+ Config: configs/riformer/riformer-m36_8xb128_in1k.py
+ - Name: riformer-m48_in1k
+ Metadata:
+ FLOPs: 11590000000
+ Parameters: 73473000
+ In Collection: RIFormer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 82.75
+ Top 5 Accuracy: 96.11
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v1/riformer/riformer-m48_32xb128_in1k_20230406-2b9d1abf.pth
+ Config: configs/riformer/riformer-m48_8xb64_in1k.py
+ - Name: riformer-s12_in1k-384
+ Metadata:
+ FLOPs: 5355000000
+ Parameters: 11915000
+ In Collection: RIFormer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 78.29
+ Top 5 Accuracy: 93.93
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s12_32xb128_in1k-384px_20230406-145eda4c.pth
+ Config: configs/riformer/riformer-s12_8xb128_in1k-384px.py
+ - Name: riformer-s24_in1k-384
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 10028000000
+ Parameters: 21389000
+ In Collection: RIFormer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.36
+ Top 5 Accuracy: 95.40
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s24_32xb128_in1k-384px_20230406-bafae7ab.pth
+ Config: configs/riformer/riformer-s24_8xb128_in1k-384px.py
+ - Name: riformer-s36_in1k-384
+ Metadata:
+ FLOPs: 14702000000
+ Parameters: 30863000
+ In Collection: RIFormer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 82.22
+ Top 5 Accuracy: 95.95
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v1/riformer/riformer-s36_32xb128_in1k-384px_20230406-017ed3c4.pth
+ Config: configs/riformer/riformer-s36_8xb64_in1k-384px.py
+ - Name: riformer-m36_in1k-384
+ Metadata:
+ Training Data: ImageNet-1k
+ FLOPs: 25865000000
+ Parameters: 56173000
+ In Collection: RIFormer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.39
+ Top 5 Accuracy: 96.40
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v1/riformer/riformer-m36_32xb128_in1k-384px_20230406-66a6f764.pth
+ Config: configs/riformer/riformer-m36_8xb64_in1k-384px.py
+ - Name: riformer-m48_in1k-384
+ Metadata:
+ FLOPs: 34060000000
+ Parameters: 73473000
+ In Collection: RIFormer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.70
+ Top 5 Accuracy: 96.60
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v1/riformer/riformer-m48_32xb128_in1k-384px_20230406-2e874826.pth
+ Config: configs/riformer/riformer-m48_8xb64_in1k-384px.py
diff --git a/configs/riformer/riformer-m36_8xb128_in1k.py b/configs/riformer/riformer-m36_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..30e93aa83d0f5c0b379367e2dc9b7a7d038108b4
--- /dev/null
+++ b/configs/riformer/riformer-m36_8xb128_in1k.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs128_poolformer_medium_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='RIFormer',
+ arch='m36',
+ drop_path_rate=0.1,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['GroupNorm'], val=1., bias=0.),
+ ]),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=768,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/riformer/riformer-m36_8xb64_in1k-384px.py b/configs/riformer/riformer-m36_8xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..57f687cd50b60d99978dec7baeec4bf6a67e5de5
--- /dev/null
+++ b/configs/riformer/riformer-m36_8xb64_in1k-384px.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs128_riformer_medium_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='RIFormer',
+ arch='m36',
+ drop_path_rate=0.1,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['GroupNorm'], val=1., bias=0.),
+ ]),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=768,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/riformer/riformer-m48_8xb64_in1k-384px.py b/configs/riformer/riformer-m48_8xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef6f1964624f76e204a5d257ddee2410f21ab456
--- /dev/null
+++ b/configs/riformer/riformer-m48_8xb64_in1k-384px.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs128_riformer_medium_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='RIFormer',
+ arch='m48',
+ drop_path_rate=0.1,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['GroupNorm'], val=1., bias=0.),
+ ]),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=768,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/riformer/riformer-m48_8xb64_in1k.py b/configs/riformer/riformer-m48_8xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..9dc5c3e291f136d40633e05c9c2931d140c532bc
--- /dev/null
+++ b/configs/riformer/riformer-m48_8xb64_in1k.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs128_poolformer_medium_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='RIFormer',
+ arch='m48',
+ drop_path_rate=0.1,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['GroupNorm'], val=1., bias=0.),
+ ]),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=768,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/riformer/riformer-s12_8xb128_in1k-384px.py b/configs/riformer/riformer-s12_8xb128_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d19dae07c811aeb0ca5af3cb92e57903405e49b
--- /dev/null
+++ b/configs/riformer/riformer-s12_8xb128_in1k-384px.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs128_riformer_small_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='RIFormer',
+ arch='s12',
+ drop_path_rate=0.1,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['GroupNorm'], val=1., bias=0.),
+ ]),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=512,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/riformer/riformer-s12_8xb128_in1k.py b/configs/riformer/riformer-s12_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..e85f8fb883de19f1021b8148fc680711149b5a9d
--- /dev/null
+++ b/configs/riformer/riformer-s12_8xb128_in1k.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs128_poolformer_small_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='RIFormer',
+ arch='s12',
+ drop_path_rate=0.1,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['GroupNorm'], val=1., bias=0.),
+ ]),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=512,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/riformer/riformer-s24_8xb128_in1k-384px.py b/configs/riformer/riformer-s24_8xb128_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a1ec7b57385c4910ffaebcd152296bbdee360e1
--- /dev/null
+++ b/configs/riformer/riformer-s24_8xb128_in1k-384px.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs128_riformer_small_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='RIFormer',
+ arch='s24',
+ drop_path_rate=0.1,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['GroupNorm'], val=1., bias=0.),
+ ]),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=512,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/riformer/riformer-s24_8xb128_in1k.py b/configs/riformer/riformer-s24_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..560cddcf8829703d2f1e9aaf4856e947b762b49a
--- /dev/null
+++ b/configs/riformer/riformer-s24_8xb128_in1k.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs128_poolformer_small_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='RIFormer',
+ arch='s24',
+ drop_path_rate=0.1,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['GroupNorm'], val=1., bias=0.),
+ ]),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=512,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/riformer/riformer-s36_8xb128_in1k.py b/configs/riformer/riformer-s36_8xb128_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..28511307a294031301cb425d513844780d199606
--- /dev/null
+++ b/configs/riformer/riformer-s36_8xb128_in1k.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs128_poolformer_small_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='RIFormer',
+ arch='s36',
+ drop_path_rate=0.1,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['GroupNorm'], val=1., bias=0.),
+ ]),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=512,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/riformer/riformer-s36_8xb64_in1k-384px.py b/configs/riformer/riformer-s36_8xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..b3077357051632c81426e5d94322558412430373
--- /dev/null
+++ b/configs/riformer/riformer-s36_8xb64_in1k-384px.py
@@ -0,0 +1,39 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs128_riformer_small_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# Model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='RIFormer',
+ arch='s36',
+ drop_path_rate=0.1,
+ init_cfg=[
+ dict(
+ type='TruncNormal',
+ layer=['Conv2d', 'Linear'],
+ std=.02,
+ bias=0.),
+ dict(type='Constant', layer=['GroupNorm'], val=1., bias=0.),
+ ]),
+ neck=dict(type='GlobalAveragePooling'),
+ head=dict(
+ type='LinearClsHead',
+ num_classes=1000,
+ in_channels=512,
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
+ ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(lr=4e-3),
+ clip_grad=dict(max_norm=5.0),
+)
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/sam/README.md b/configs/sam/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..1a5668a3d0bff5aacac10f26a41714afe3622c78
--- /dev/null
+++ b/configs/sam/README.md
@@ -0,0 +1,57 @@
+# SAM
+
+> [Segment Anything](https://arxiv.org/abs/2304.02643)
+
+
+
+## Abstract
+
+We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billionmasks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive – often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at https://segment-anything.com to foster research into foundation models for computer vision.
+
+
+

+
+
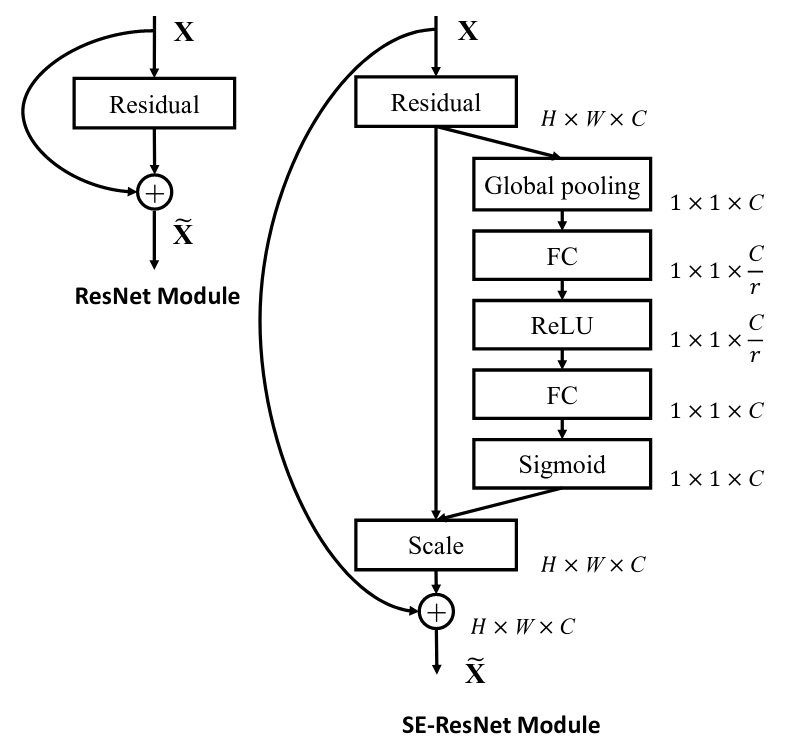
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+Show the paper's abstract
+
+
+This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with **Shifted windows**. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('swin-tiny_16xb64_in1k', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('swin-tiny_16xb64_in1k', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Train/Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Train:
+
+```shell
+python tools/train.py configs/swin_transformer/swin-tiny_16xb64_in1k.py
+```
+
+Test:
+
+```shell
+python tools/test.py configs/swin_transformer/swin-tiny_16xb64_in1k.py https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_tiny_224_b16x64_300e_imagenet_20210616_090925-66df6be6.pth
+```
+
+
+
+## Models and results
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :----------------------------------------- | :----------: | :--------: | :-------: | :-------: | :-------: | :---------------------------------------: | :------------------------------------------------------------------: |
+| `swin-tiny_16xb64_in1k` | From scratch | 28.29 | 4.36 | 81.18 | 95.61 | [config](swin-tiny_16xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_tiny_224_b16x64_300e_imagenet_20210616_090925-66df6be6.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_tiny_224_b16x64_300e_imagenet_20210616_090925.json) |
+| `swin-small_16xb64_in1k` | From scratch | 49.61 | 8.52 | 83.02 | 96.29 | [config](swin-small_16xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_small_224_b16x64_300e_imagenet_20210615_110219-7f9d988b.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_small_224_b16x64_300e_imagenet_20210615_110219.json) |
+| `swin-base_16xb64_in1k` | From scratch | 87.77 | 15.14 | 83.36 | 96.44 | [config](swin-base_16xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_base_224_b16x64_300e_imagenet_20210616_190742-93230b0d.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_base_224_b16x64_300e_imagenet_20210616_190742.json) |
+| `swin-tiny_3rdparty_in1k`\* | From scratch | 28.29 | 4.36 | 81.18 | 95.52 | [config](swin-tiny_16xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_tiny_patch4_window7_224-160bb0a5.pth) |
+| `swin-small_3rdparty_in1k`\* | From scratch | 49.61 | 8.52 | 83.21 | 96.25 | [config](swin-small_16xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_small_patch4_window7_224-cc7a01c9.pth) |
+| `swin-base_3rdparty_in1k`\* | From scratch | 87.77 | 15.14 | 83.42 | 96.44 | [config](swin-base_16xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_base_patch4_window7_224-4670dd19.pth) |
+| `swin-base_3rdparty_in1k-384`\* | From scratch | 87.90 | 44.49 | 84.49 | 96.95 | [config](swin-base_16xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_base_patch4_window12_384-02c598a4.pth) |
+| `swin-base_in21k-pre-3rdparty_in1k`\* | From scratch | 87.77 | 15.14 | 85.16 | 97.50 | [config](swin-base_16xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_base_patch4_window7_224_22kto1k-f967f799.pth) |
+| `swin-base_in21k-pre-3rdparty_in1k-384`\* | From scratch | 87.90 | 44.49 | 86.44 | 98.05 | [config](swin-base_16xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_base_patch4_window12_384_22kto1k-d59b0d1d.pth) |
+| `swin-large_in21k-pre-3rdparty_in1k`\* | From scratch | 196.53 | 34.04 | 86.24 | 97.88 | [config](swin-large_16xb64_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_large_patch4_window7_224_22kto1k-5f0996db.pth) |
+| `swin-large_in21k-pre-3rdparty_in1k-384`\* | From scratch | 196.74 | 100.04 | 87.25 | 98.25 | [config](swin-large_16xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_large_patch4_window12_384_22kto1k-0a40944b.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/microsoft/Swin-Transformer/blob/777f6c66604bb5579086c4447efe3620344d95a9/models/swin_transformer.py#L458). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+### Image Classification on CUB-200-2011
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Config | Download |
+| :-------------------------- | :----------: | :--------: | :-------: | :-------: | :------------------------------------: | :---------------------------------------------------------------------------------------------: |
+| `swin-large_8xb8_cub-384px` | From scratch | 195.51 | 100.04 | 91.87 | [config](swin-large_8xb8_cub-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin-large_8xb8_cub_384px_20220307-1bbaee6a.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin-large_8xb8_cub_384px_20220307-1bbaee6a.json) |
+
+## Citation
+
+```bibtex
+@article{liu2021Swin,
+ title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
+ author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
+ journal={arXiv preprint arXiv:2103.14030},
+ year={2021}
+}
+```
diff --git a/configs/swin_transformer/metafile.yml b/configs/swin_transformer/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8bff599267afe52a0904c106be4fcd8c76f6e4bf
--- /dev/null
+++ b/configs/swin_transformer/metafile.yml
@@ -0,0 +1,201 @@
+Collections:
+ - Name: Swin-Transformer
+ Metadata:
+ Training Data: ImageNet-1k
+ Training Techniques:
+ - AdamW
+ - Weight Decay
+ Training Resources: 16x V100 GPUs
+ Epochs: 300
+ Batch Size: 1024
+ Architecture:
+ - Shift Window Multihead Self Attention
+ Paper:
+ URL: https://arxiv.org/abs/2103.14030
+ Title: "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows"
+ README: configs/swin_transformer/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmpretrain/blob/v0.15.0/mmcls/models/backbones/swin_transformer.py#L176
+ Version: v0.15.0
+
+Models:
+ - Name: swin-tiny_16xb64_in1k
+ Metadata:
+ FLOPs: 4360000000
+ Parameters: 28290000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.18
+ Top 5 Accuracy: 95.61
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_tiny_224_b16x64_300e_imagenet_20210616_090925-66df6be6.pth
+ Config: configs/swin_transformer/swin-tiny_16xb64_in1k.py
+ - Name: swin-small_16xb64_in1k
+ Metadata:
+ FLOPs: 8520000000
+ Parameters: 49610000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.02
+ Top 5 Accuracy: 96.29
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_small_224_b16x64_300e_imagenet_20210615_110219-7f9d988b.pth
+ Config: configs/swin_transformer/swin-small_16xb64_in1k.py
+ - Name: swin-base_16xb64_in1k
+ Metadata:
+ FLOPs: 15140000000
+ Parameters: 87770000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.36
+ Top 5 Accuracy: 96.44
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin_base_224_b16x64_300e_imagenet_20210616_190742-93230b0d.pth
+ Config: configs/swin_transformer/swin-base_16xb64_in1k.py
+ - Name: swin-tiny_3rdparty_in1k
+ Metadata:
+ FLOPs: 4360000000
+ Parameters: 28290000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.18
+ Top 5 Accuracy: 95.52
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_tiny_patch4_window7_224-160bb0a5.pth
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth
+ Code: https://github.com/microsoft/Swin-Transformer/blob/777f6c66604bb5579086c4447efe3620344d95a9/models/swin_transformer.py#L458
+ Config: configs/swin_transformer/swin-tiny_16xb64_in1k.py
+ - Name: swin-small_3rdparty_in1k
+ Metadata:
+ FLOPs: 8520000000
+ Parameters: 49610000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.21
+ Top 5 Accuracy: 96.25
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_small_patch4_window7_224-cc7a01c9.pth
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth
+ Code: https://github.com/microsoft/Swin-Transformer/blob/777f6c66604bb5579086c4447efe3620344d95a9/models/swin_transformer.py#L458
+ Config: configs/swin_transformer/swin-small_16xb64_in1k.py
+ - Name: swin-base_3rdparty_in1k
+ Metadata:
+ FLOPs: 15140000000
+ Parameters: 87770000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.42
+ Top 5 Accuracy: 96.44
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_base_patch4_window7_224-4670dd19.pth
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224.pth
+ Code: https://github.com/microsoft/Swin-Transformer/blob/777f6c66604bb5579086c4447efe3620344d95a9/models/swin_transformer.py#L458
+ Config: configs/swin_transformer/swin-base_16xb64_in1k.py
+ - Name: swin-base_3rdparty_in1k-384
+ Metadata:
+ FLOPs: 44490000000
+ Parameters: 87900000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.49
+ Top 5 Accuracy: 96.95
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_base_patch4_window12_384-02c598a4.pth
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384.pth
+ Code: https://github.com/microsoft/Swin-Transformer/blob/777f6c66604bb5579086c4447efe3620344d95a9/models/swin_transformer.py#L458
+ Config: configs/swin_transformer/swin-base_16xb64_in1k-384px.py
+ - Name: swin-base_in21k-pre-3rdparty_in1k
+ Metadata:
+ FLOPs: 15140000000
+ Parameters: 87770000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 85.16
+ Top 5 Accuracy: 97.50
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_base_patch4_window7_224_22kto1k-f967f799.pth
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22kto1k.pth
+ Code: https://github.com/microsoft/Swin-Transformer/blob/777f6c66604bb5579086c4447efe3620344d95a9/models/swin_transformer.py#L458
+ Config: configs/swin_transformer/swin-base_16xb64_in1k.py
+ - Name: swin-base_in21k-pre-3rdparty_in1k-384
+ Metadata:
+ FLOPs: 44490000000
+ Parameters: 87900000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 86.44
+ Top 5 Accuracy: 98.05
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_base_patch4_window12_384_22kto1k-d59b0d1d.pth
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22kto1k.pth
+ Code: https://github.com/microsoft/Swin-Transformer/blob/777f6c66604bb5579086c4447efe3620344d95a9/models/swin_transformer.py#L458
+ Config: configs/swin_transformer/swin-base_16xb64_in1k-384px.py
+ - Name: swin-large_in21k-pre-3rdparty_in1k
+ Metadata:
+ FLOPs: 34040000000
+ Parameters: 196530000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 86.24
+ Top 5 Accuracy: 97.88
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_large_patch4_window7_224_22kto1k-5f0996db.pth
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22kto1k.pth
+ Code: https://github.com/microsoft/Swin-Transformer/blob/777f6c66604bb5579086c4447efe3620344d95a9/models/swin_transformer.py#L458
+ Config: configs/swin_transformer/swin-large_16xb64_in1k.py
+ - Name: swin-large_in21k-pre-3rdparty_in1k-384
+ Metadata:
+ FLOPs: 100040000000
+ Parameters: 196740000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 87.25
+ Top 5 Accuracy: 98.25
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin_large_patch4_window12_384_22kto1k-0a40944b.pth
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22kto1k.pth
+ Code: https://github.com/microsoft/Swin-Transformer/blob/777f6c66604bb5579086c4447efe3620344d95a9/models/swin_transformer.py#L458
+ Config: configs/swin_transformer/swin-large_16xb64_in1k-384px.py
+ - Name: swin-large_8xb8_cub-384px
+ Metadata:
+ FLOPs: 100040000000
+ Parameters: 195510000
+ In Collection: Swin-Transformer
+ Results:
+ - Dataset: CUB-200-2011
+ Metrics:
+ Top 1 Accuracy: 91.87
+ Task: Image Classification
+ Pretrain: https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin-large_3rdparty_in21k-384px.pth
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-transformer/swin-large_8xb8_cub_384px_20220307-1bbaee6a.pth
+ Config: configs/swin_transformer/swin-large_8xb8_cub-384px.py
diff --git a/configs/swin_transformer/swin-base_16xb64_in1k-384px.py b/configs/swin_transformer/swin-base_16xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..10f89921ff1ec6659509ccdee8e15cfe52395880
--- /dev/null
+++ b/configs/swin_transformer/swin-base_16xb64_in1k-384px.py
@@ -0,0 +1,9 @@
+_base_ = [
+ '../_base_/models/swin_transformer/base_384.py',
+ '../_base_/datasets/imagenet_bs64_swin_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(clip_grad=dict(max_norm=5.0))
diff --git a/configs/swin_transformer/swin-base_16xb64_in1k.py b/configs/swin_transformer/swin-base_16xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..05a95b4483dd3764abbcf9e32b1291334e084099
--- /dev/null
+++ b/configs/swin_transformer/swin-base_16xb64_in1k.py
@@ -0,0 +1,9 @@
+_base_ = [
+ '../_base_/models/swin_transformer/base_224.py',
+ '../_base_/datasets/imagenet_bs64_swin_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(clip_grad=dict(max_norm=5.0))
diff --git a/configs/swin_transformer/swin-large_16xb64_in1k-384px.py b/configs/swin_transformer/swin-large_16xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ba52b3564704acfeb2c40eb39e1d4e5cf5bf573
--- /dev/null
+++ b/configs/swin_transformer/swin-large_16xb64_in1k-384px.py
@@ -0,0 +1,9 @@
+_base_ = [
+ '../_base_/models/swin_transformer/large_384.py',
+ '../_base_/datasets/imagenet_bs64_swin_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(clip_grad=dict(max_norm=5.0))
diff --git a/configs/swin_transformer/swin-large_16xb64_in1k.py b/configs/swin_transformer/swin-large_16xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..36121efca15f951a03d153b614d3e844cc8cad26
--- /dev/null
+++ b/configs/swin_transformer/swin-large_16xb64_in1k.py
@@ -0,0 +1,9 @@
+_base_ = [
+ '../_base_/models/swin_transformer/large_224.py',
+ '../_base_/datasets/imagenet_bs64_swin_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(clip_grad=dict(max_norm=5.0))
diff --git a/configs/swin_transformer/swin-large_8xb8_cub-384px.py b/configs/swin_transformer/swin-large_8xb8_cub-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..a2f10a6a292bc2485085a38c895b635a5944d04c
--- /dev/null
+++ b/configs/swin_transformer/swin-large_8xb8_cub-384px.py
@@ -0,0 +1,40 @@
+_base_ = [
+ '../_base_/models/swin_transformer/large_384.py',
+ '../_base_/datasets/cub_bs8_384.py',
+ '../_base_/schedules/cub_bs64.py',
+ '../_base_/default_runtime.py',
+]
+
+# model settings
+checkpoint = 'https://download.openmmlab.com/mmclassification/v0/swin-transformer/convert/swin-large_3rdparty_in21k-384px.pth' # noqa
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', checkpoint=checkpoint, prefix='backbone')),
+ head=dict(num_classes=200, ))
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(
+ _delete_=True,
+ type='AdamW',
+ lr=5e-6,
+ weight_decay=0.0005,
+ eps=1e-8,
+ betas=(0.9, 0.999)),
+ paramwise_cfg=dict(
+ norm_decay_mult=0.0,
+ bias_decay_mult=0.0,
+ custom_keys={
+ '.absolute_pos_embed': dict(decay_mult=0.0),
+ '.relative_position_bias_table': dict(decay_mult=0.0)
+ }),
+ clip_grad=dict(max_norm=5.0),
+)
+
+default_hooks = dict(
+ # log every 20 intervals
+ logger=dict(type='LoggerHook', interval=20),
+ # save last three checkpoints
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
diff --git a/configs/swin_transformer/swin-small_16xb64_in1k.py b/configs/swin_transformer/swin-small_16xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..7c1a8e21a7f2cbc881cbde43c19af9cd10b7c2ba
--- /dev/null
+++ b/configs/swin_transformer/swin-small_16xb64_in1k.py
@@ -0,0 +1,9 @@
+_base_ = [
+ '../_base_/models/swin_transformer/small_224.py',
+ '../_base_/datasets/imagenet_bs64_swin_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(clip_grad=dict(max_norm=5.0))
diff --git a/configs/swin_transformer/swin-tiny_16xb64_in1k.py b/configs/swin_transformer/swin-tiny_16xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a1ce2508ab603b008640583de78c64d2f178620
--- /dev/null
+++ b/configs/swin_transformer/swin-tiny_16xb64_in1k.py
@@ -0,0 +1,9 @@
+_base_ = [
+ '../_base_/models/swin_transformer/tiny_224.py',
+ '../_base_/datasets/imagenet_bs64_swin_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+# schedule settings
+optim_wrapper = dict(clip_grad=dict(max_norm=5.0))
diff --git a/configs/swin_transformer_v2/README.md b/configs/swin_transformer_v2/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..dd20548ae780ebca6cf0cc982ea71c782e369b52
--- /dev/null
+++ b/configs/swin_transformer_v2/README.md
@@ -0,0 +1,121 @@
+# Swin-Transformer V2
+
+> [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)
+
+
+
+## Introduction
+
+**Swin Transformer V2** is a work on the scale up visual model based on [Swin Transformer](https://github.com/open-mmlab/mmpretrain/tree/main/configs/swin_transformer). In the visual field, We can not increase the performance by just simply scaling up the visual model like NLP models. The possible reasons mentioned in the article are:
+
+- Training instability when increasing the vision model
+- Migrating the model trained at low resolution to a larger scale resolution task
+- Too mush GPU memory
+
+To solve it, The following method improvements are proposed in the paper:
+
+- post normalization: layer normalization after self-attention layer and MLP block
+- scaled cosine attention approach: use cosine similarity to calculate the relationship between token pairs
+- log-spaced continuous position bias: redefine relative position encoding
+
+
+

+
+
+Show the detailed Abstract
+
+
+
+Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in computer vision. We tackle three major issues in training and application of large vision models, including training instability, resolution gaps between pre-training and fine-tuning, and hunger on labelled data. Three main techniques are proposed: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) A log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) A self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images. Through these techniques, this paper successfully trained a 3 billion-parameter Swin Transformer V2 model, which is the largest dense vision model to date, and makes it capable of training with images of up to 1,536×1,536 resolution. It set new performance records on 4 representative vision tasks, including ImageNet-V2 image classification, COCO object detection, ADE20K semantic segmentation, and Kinetics-400 video action classification. Also note our training is much more efficient than that in Google's billion-level visual models, which consumes 40 times less labelled data and 40 times less training time.
+
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('swinv2-tiny-w8_3rdparty_in1k-256px', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('swinv2-tiny-w8_3rdparty_in1k-256px', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Test:
+
+```shell
+python tools/test.py configs/swin_transformer_v2/swinv2-tiny-w8_16xb64_in1k-256px.py https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-tiny-w8_3rdparty_in1k-256px_20220803-e318968f.pth
+```
+
+
+
+## Models and results
+
+### Pretrained models
+
+| Model | Params (M) | Flops (G) | Config | Download |
+| :---------------------------------------- | :--------: | :-------: | :----------------------------------------------: | :------------------------------------------------------------------------------------------: |
+| `swinv2-base-w12_3rdparty_in21k-192px`\* | 87.92 | 8.51 | [config](swinv2-base-w12_8xb128_in21k-192px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/pretrain/swinv2-base-w12_3rdparty_in21k-192px_20220803-f7dc9763.pth) |
+| `swinv2-large-w12_3rdparty_in21k-192px`\* | 196.74 | 19.04 | [config](swinv2-large-w12_8xb128_in21k-192px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/pretrain/swinv2-large-w12_3rdparty_in21k-192px_20220803-d9073fee.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/microsoft/Swin-Transformer). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :------------------------------------------------ | :----------: | :--------: | :-------: | :-------: | :-------: | :------------------------------------------------: | :--------------------------------------------------: |
+| `swinv2-tiny-w8_3rdparty_in1k-256px`\* | From scratch | 28.35 | 4.35 | 81.76 | 95.87 | [config](swinv2-tiny-w8_16xb64_in1k-256px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-tiny-w8_3rdparty_in1k-256px_20220803-e318968f.pth) |
+| `swinv2-tiny-w16_3rdparty_in1k-256px`\* | From scratch | 28.35 | 4.40 | 82.81 | 96.23 | [config](swinv2-tiny-w16_16xb64_in1k-256px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-tiny-w16_3rdparty_in1k-256px_20220803-9651cdd7.pth) |
+| `swinv2-small-w8_3rdparty_in1k-256px`\* | From scratch | 49.73 | 8.45 | 83.74 | 96.60 | [config](swinv2-small-w8_16xb64_in1k-256px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-small-w8_3rdparty_in1k-256px_20220803-b01a4332.pth) |
+| `swinv2-small-w16_3rdparty_in1k-256px`\* | From scratch | 49.73 | 8.57 | 84.13 | 96.83 | [config](swinv2-small-w16_16xb64_in1k-256px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-small-w16_3rdparty_in1k-256px_20220803-b707d206.pth) |
+| `swinv2-base-w8_3rdparty_in1k-256px`\* | From scratch | 87.92 | 14.99 | 84.20 | 96.86 | [config](swinv2-base-w8_16xb64_in1k-256px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-base-w8_3rdparty_in1k-256px_20220803-8ff28f2b.pth) |
+| `swinv2-base-w16_3rdparty_in1k-256px`\* | From scratch | 87.92 | 15.14 | 84.60 | 97.05 | [config](swinv2-base-w16_16xb64_in1k-256px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-base-w16_3rdparty_in1k-256px_20220803-5a1886b7.pth) |
+| `swinv2-base-w16_in21k-pre_3rdparty_in1k-256px`\* | ImageNet-21k | 87.92 | 15.14 | 86.17 | 97.88 | [config](swinv2-base-w16_in21k-pre_16xb64_in1k-256px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-base-w16_in21k-pre_3rdparty_in1k-256px_20220803-8d7aa8ad.pth) |
+| `swinv2-base-w24_in21k-pre_3rdparty_in1k-384px`\* | ImageNet-21k | 87.92 | 34.07 | 87.14 | 98.23 | [config](swinv2-base-w24_in21k-pre_16xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-base-w24_in21k-pre_3rdparty_in1k-384px_20220803-44eb70f8.pth) |
+| `swinv2-large-w16_in21k-pre_3rdparty_in1k-256px`\* | ImageNet-21k | 196.75 | 33.86 | 86.93 | 98.06 | [config](swinv2-large-w16_in21k-pre_16xb64_in1k-256px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-large-w16_in21k-pre_3rdparty_in1k-256px_20220803-c40cbed7.pth) |
+| `swinv2-large-w24_in21k-pre_3rdparty_in1k-384px`\* | ImageNet-21k | 196.75 | 76.20 | 87.59 | 98.27 | [config](swinv2-large-w24_in21k-pre_16xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-large-w24_in21k-pre_3rdparty_in1k-384px_20220803-3b36c165.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/microsoft/Swin-Transformer). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+## Citation
+
+```bibtex
+@article{https://doi.org/10.48550/arxiv.2111.09883,
+ doi = {10.48550/ARXIV.2111.09883},
+ url = {https://arxiv.org/abs/2111.09883},
+ author = {Liu, Ze and Hu, Han and Lin, Yutong and Yao, Zhuliang and Xie, Zhenda and Wei, Yixuan and Ning, Jia and Cao, Yue and Zhang, Zheng and Dong, Li and Wei, Furu and Guo, Baining},
+ keywords = {Computer Vision and Pattern Recognition (cs.CV), FOS: Computer and information sciences, FOS: Computer and information sciences},
+ title = {Swin Transformer V2: Scaling Up Capacity and Resolution},
+ publisher = {arXiv},
+ year = {2021},
+ copyright = {Creative Commons Attribution 4.0 International}
+}
+```
diff --git a/configs/swin_transformer_v2/metafile.yml b/configs/swin_transformer_v2/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..55a14cbab587f037d96583d3b0210ac3008b1118
--- /dev/null
+++ b/configs/swin_transformer_v2/metafile.yml
@@ -0,0 +1,206 @@
+Collections:
+ - Name: Swin-Transformer V2
+ Metadata:
+ Training Data: ImageNet-1k
+ Training Techniques:
+ - AdamW
+ - Weight Decay
+ Training Resources: 16x V100 GPUs
+ Epochs: 300
+ Batch Size: 1024
+ Architecture:
+ - Shift Window Multihead Self Attention
+ Paper:
+ URL: https://arxiv.org/abs/2111.09883
+ Title: "Swin Transformer V2: Scaling Up Capacity and Resolution"
+ README: configs/swin_transformer_v2/README.md
+
+Models:
+ - Name: swinv2-tiny-w8_3rdparty_in1k-256px
+ Metadata:
+ FLOPs: 4350000000
+ Parameters: 28350000
+ In Collection: Swin-Transformer V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 81.76
+ Top 5 Accuracy: 95.87
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-tiny-w8_3rdparty_in1k-256px_20220803-e318968f.pth
+ Config: configs/swin_transformer_v2/swinv2-tiny-w8_16xb64_in1k-256px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_tiny_patch4_window8_256.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-tiny-w16_3rdparty_in1k-256px
+ Metadata:
+ FLOPs: 4400000000
+ Parameters: 28350000
+ In Collection: Swin-Transformer V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 82.81
+ Top 5 Accuracy: 96.23
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-tiny-w16_3rdparty_in1k-256px_20220803-9651cdd7.pth
+ Config: configs/swin_transformer_v2/swinv2-tiny-w16_16xb64_in1k-256px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_tiny_patch4_window16_256.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-small-w8_3rdparty_in1k-256px
+ Metadata:
+ FLOPs: 8450000000
+ Parameters: 49730000
+ In Collection: Swin-Transformer V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 83.74
+ Top 5 Accuracy: 96.6
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-small-w8_3rdparty_in1k-256px_20220803-b01a4332.pth
+ Config: configs/swin_transformer_v2/swinv2-small-w8_16xb64_in1k-256px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_small_patch4_window8_256.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-small-w16_3rdparty_in1k-256px
+ Metadata:
+ FLOPs: 8570000000
+ Parameters: 49730000
+ In Collection: Swin-Transformer V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.13
+ Top 5 Accuracy: 96.83
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-small-w16_3rdparty_in1k-256px_20220803-b707d206.pth
+ Config: configs/swin_transformer_v2/swinv2-small-w16_16xb64_in1k-256px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_small_patch4_window16_256.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-base-w8_3rdparty_in1k-256px
+ Metadata:
+ FLOPs: 14990000000
+ Parameters: 87920000
+ In Collection: Swin-Transformer V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.2
+ Top 5 Accuracy: 96.86
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-base-w8_3rdparty_in1k-256px_20220803-8ff28f2b.pth
+ Config: configs/swin_transformer_v2/swinv2-base-w8_16xb64_in1k-256px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window8_256.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-base-w16_3rdparty_in1k-256px
+ Metadata:
+ FLOPs: 15140000000
+ Parameters: 87920000
+ In Collection: Swin-Transformer V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 84.6
+ Top 5 Accuracy: 97.05
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-base-w16_3rdparty_in1k-256px_20220803-5a1886b7.pth
+ Config: configs/swin_transformer_v2/swinv2-base-w16_16xb64_in1k-256px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window16_256.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-base-w16_in21k-pre_3rdparty_in1k-256px
+ Metadata:
+ Training Data: ImageNet-21k
+ FLOPs: 15140000000
+ Parameters: 87920000
+ In Collection: Swin-Transformer V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 86.17
+ Top 5 Accuracy: 97.88
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-base-w16_in21k-pre_3rdparty_in1k-256px_20220803-8d7aa8ad.pth
+ Config: configs/swin_transformer_v2/swinv2-base-w16_in21k-pre_16xb64_in1k-256px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12to16_192to256_22kto1k_ft.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-base-w24_in21k-pre_3rdparty_in1k-384px
+ Metadata:
+ Training Data: ImageNet-21k
+ FLOPs: 34070000000
+ Parameters: 87920000
+ In Collection: Swin-Transformer V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 87.14
+ Top 5 Accuracy: 98.23
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-base-w24_in21k-pre_3rdparty_in1k-384px_20220803-44eb70f8.pth
+ Config: configs/swin_transformer_v2/swinv2-base-w24_in21k-pre_16xb64_in1k-384px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12to24_192to384_22kto1k_ft.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-large-w16_in21k-pre_3rdparty_in1k-256px
+ Metadata:
+ Training Data: ImageNet-21k
+ FLOPs: 33860000000
+ Parameters: 196750000
+ In Collection: Swin-Transformer V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 86.93
+ Top 5 Accuracy: 98.06
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-large-w16_in21k-pre_3rdparty_in1k-256px_20220803-c40cbed7.pth
+ Config: configs/swin_transformer_v2/swinv2-large-w16_in21k-pre_16xb64_in1k-256px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12to16_192to256_22kto1k_ft.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-large-w24_in21k-pre_3rdparty_in1k-384px
+ Metadata:
+ Training Data: ImageNet-21k
+ FLOPs: 76200000000
+ Parameters: 196750000
+ In Collection: Swin-Transformer V2
+ Results:
+ - Dataset: ImageNet-1k
+ Metrics:
+ Top 1 Accuracy: 87.59
+ Top 5 Accuracy: 98.27
+ Task: Image Classification
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/swinv2-large-w24_in21k-pre_3rdparty_in1k-384px_20220803-3b36c165.pth
+ Config: configs/swin_transformer_v2/swinv2-large-w24_in21k-pre_16xb64_in1k-384px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12to24_192to384_22kto1k_ft.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-base-w12_3rdparty_in21k-192px
+ Metadata:
+ Training Data: ImageNet-21k
+ FLOPs: 8510000000
+ Parameters: 87920000
+ In Collection: Swin-Transformer V2
+ Results: null
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/pretrain/swinv2-base-w12_3rdparty_in21k-192px_20220803-f7dc9763.pth
+ Config: configs/swin_transformer_v2/swinv2-base-w12_8xb128_in21k-192px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12_192_22k.pth
+ Code: https://github.com/microsoft/Swin-Transformer
+ - Name: swinv2-large-w12_3rdparty_in21k-192px
+ Metadata:
+ Training Data: ImageNet-21k
+ FLOPs: 19040000000
+ Parameters: 196740000
+ In Collection: Swin-Transformer V2
+ Results: null
+ Weights: https://download.openmmlab.com/mmclassification/v0/swin-v2/pretrain/swinv2-large-w12_3rdparty_in21k-192px_20220803-d9073fee.pth
+ Config: configs/swin_transformer_v2/swinv2-large-w12_8xb128_in21k-192px.py
+ Converted From:
+ Weights: https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12_192_22k.pth
+ Code: https://github.com/microsoft/Swin-Transformer
diff --git a/configs/swin_transformer_v2/swinv2-base-w12_8xb128_in21k-192px.py b/configs/swin_transformer_v2/swinv2-base-w12_8xb128_in21k-192px.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b01b75d296dae9db97d2d85f73463f6c87c0b1c
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-base-w12_8xb128_in21k-192px.py
@@ -0,0 +1,19 @@
+_base_ = [
+ '../_base_/models/swin_transformer_v2/base_256.py',
+ '../_base_/datasets/imagenet21k_bs128.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# model settings
+model = dict(
+ backbone=dict(img_size=192, window_size=[12, 12, 12, 6]),
+ head=dict(num_classes=21841),
+)
+
+# dataset settings
+data_preprocessor = dict(num_classes=21841)
+
+_base_['train_pipeline'][1]['scale'] = 192 # RandomResizedCrop
+_base_['test_pipeline'][1]['scale'] = 219 # ResizeEdge
+_base_['test_pipeline'][2]['crop_size'] = 192 # CenterCrop
diff --git a/configs/swin_transformer_v2/swinv2-base-w16_16xb64_in1k-256px.py b/configs/swin_transformer_v2/swinv2-base-w16_16xb64_in1k-256px.py
new file mode 100644
index 0000000000000000000000000000000000000000..5f375ee1fc9b10885f8b9d9f4794b8530c1460b5
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-base-w16_16xb64_in1k-256px.py
@@ -0,0 +1,8 @@
+_base_ = [
+ '../_base_/models/swin_transformer_v2/base_256.py',
+ '../_base_/datasets/imagenet_bs64_swin_256.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+model = dict(backbone=dict(window_size=[16, 16, 16, 8]))
diff --git a/configs/swin_transformer_v2/swinv2-base-w16_in21k-pre_16xb64_in1k-256px.py b/configs/swin_transformer_v2/swinv2-base-w16_in21k-pre_16xb64_in1k-256px.py
new file mode 100644
index 0000000000000000000000000000000000000000..0725f9e739a099551a4d5b5f007bcb83708be309
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-base-w16_in21k-pre_16xb64_in1k-256px.py
@@ -0,0 +1,13 @@
+_base_ = [
+ '../_base_/models/swin_transformer_v2/base_256.py',
+ '../_base_/datasets/imagenet_bs64_swin_256.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ window_size=[16, 16, 16, 8],
+ drop_path_rate=0.2,
+ pretrained_window_sizes=[12, 12, 12, 6]))
diff --git a/configs/swin_transformer_v2/swinv2-base-w24_in21k-pre_16xb64_in1k-384px.py b/configs/swin_transformer_v2/swinv2-base-w24_in21k-pre_16xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..3dd4e5fd935a356d29e7790e91d4538c94711062
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-base-w24_in21k-pre_16xb64_in1k-384px.py
@@ -0,0 +1,14 @@
+_base_ = [
+ '../_base_/models/swin_transformer_v2/base_384.py',
+ '../_base_/datasets/imagenet_bs64_swin_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ img_size=384,
+ window_size=[24, 24, 24, 12],
+ drop_path_rate=0.2,
+ pretrained_window_sizes=[12, 12, 12, 6]))
diff --git a/configs/swin_transformer_v2/swinv2-base-w8_16xb64_in1k-256px.py b/configs/swin_transformer_v2/swinv2-base-w8_16xb64_in1k-256px.py
new file mode 100644
index 0000000000000000000000000000000000000000..23fc40701470f8e41252c274072896d1cd811f28
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-base-w8_16xb64_in1k-256px.py
@@ -0,0 +1,6 @@
+_base_ = [
+ '../_base_/models/swin_transformer_v2/base_256.py',
+ '../_base_/datasets/imagenet_bs64_swin_256.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
diff --git a/configs/swin_transformer_v2/swinv2-large-w12_8xb128_in21k-192px.py b/configs/swin_transformer_v2/swinv2-large-w12_8xb128_in21k-192px.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b01b75d296dae9db97d2d85f73463f6c87c0b1c
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-large-w12_8xb128_in21k-192px.py
@@ -0,0 +1,19 @@
+_base_ = [
+ '../_base_/models/swin_transformer_v2/base_256.py',
+ '../_base_/datasets/imagenet21k_bs128.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py',
+]
+
+# model settings
+model = dict(
+ backbone=dict(img_size=192, window_size=[12, 12, 12, 6]),
+ head=dict(num_classes=21841),
+)
+
+# dataset settings
+data_preprocessor = dict(num_classes=21841)
+
+_base_['train_pipeline'][1]['scale'] = 192 # RandomResizedCrop
+_base_['test_pipeline'][1]['scale'] = 219 # ResizeEdge
+_base_['test_pipeline'][2]['crop_size'] = 192 # CenterCrop
diff --git a/configs/swin_transformer_v2/swinv2-large-w16_in21k-pre_16xb64_in1k-256px.py b/configs/swin_transformer_v2/swinv2-large-w16_in21k-pre_16xb64_in1k-256px.py
new file mode 100644
index 0000000000000000000000000000000000000000..62a2a29b843f197c15d8f53a7cbd1029be675fa8
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-large-w16_in21k-pre_16xb64_in1k-256px.py
@@ -0,0 +1,13 @@
+# Only for evaluation
+_base_ = [
+ '../_base_/models/swin_transformer_v2/large_256.py',
+ '../_base_/datasets/imagenet_bs64_swin_256.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ window_size=[16, 16, 16, 8], pretrained_window_sizes=[12, 12, 12, 6]),
+)
diff --git a/configs/swin_transformer_v2/swinv2-large-w24_in21k-pre_16xb64_in1k-384px.py b/configs/swin_transformer_v2/swinv2-large-w24_in21k-pre_16xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..d97d9b2b869c1e0c264910859b6f980387a7b6ab
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-large-w24_in21k-pre_16xb64_in1k-384px.py
@@ -0,0 +1,15 @@
+# Only for evaluation
+_base_ = [
+ '../_base_/models/swin_transformer_v2/large_384.py',
+ '../_base_/datasets/imagenet_bs64_swin_384.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ img_size=384,
+ window_size=[24, 24, 24, 12],
+ pretrained_window_sizes=[12, 12, 12, 6]),
+)
diff --git a/configs/swin_transformer_v2/swinv2-small-w16_16xb64_in1k-256px.py b/configs/swin_transformer_v2/swinv2-small-w16_16xb64_in1k-256px.py
new file mode 100644
index 0000000000000000000000000000000000000000..f87265dd199c712a6442407db852b5d4b6aabd7d
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-small-w16_16xb64_in1k-256px.py
@@ -0,0 +1,8 @@
+_base_ = [
+ '../_base_/models/swin_transformer_v2/small_256.py',
+ '../_base_/datasets/imagenet_bs64_swin_256.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+model = dict(backbone=dict(window_size=[16, 16, 16, 8]))
diff --git a/configs/swin_transformer_v2/swinv2-small-w8_16xb64_in1k-256px.py b/configs/swin_transformer_v2/swinv2-small-w8_16xb64_in1k-256px.py
new file mode 100644
index 0000000000000000000000000000000000000000..f1001f1b6e1978c3706ca6183f863c316b13ade4
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-small-w8_16xb64_in1k-256px.py
@@ -0,0 +1,6 @@
+_base_ = [
+ '../_base_/models/swin_transformer_v2/small_256.py',
+ '../_base_/datasets/imagenet_bs64_swin_256.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
diff --git a/configs/swin_transformer_v2/swinv2-tiny-w16_16xb64_in1k-256px.py b/configs/swin_transformer_v2/swinv2-tiny-w16_16xb64_in1k-256px.py
new file mode 100644
index 0000000000000000000000000000000000000000..7e1f290f371e1b9084f4cd5291e1e638d0ad54e3
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-tiny-w16_16xb64_in1k-256px.py
@@ -0,0 +1,8 @@
+_base_ = [
+ '../_base_/models/swin_transformer_v2/tiny_256.py',
+ '../_base_/datasets/imagenet_bs64_swin_256.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+model = dict(backbone=dict(window_size=[16, 16, 16, 8]))
diff --git a/configs/swin_transformer_v2/swinv2-tiny-w8_16xb64_in1k-256px.py b/configs/swin_transformer_v2/swinv2-tiny-w8_16xb64_in1k-256px.py
new file mode 100644
index 0000000000000000000000000000000000000000..2cdc9a25ae8a64758f8642c079e1ff7fbf0548c3
--- /dev/null
+++ b/configs/swin_transformer_v2/swinv2-tiny-w8_16xb64_in1k-256px.py
@@ -0,0 +1,6 @@
+_base_ = [
+ '../_base_/models/swin_transformer_v2/tiny_256.py',
+ '../_base_/datasets/imagenet_bs64_swin_256.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
diff --git a/configs/t2t_vit/README.md b/configs/t2t_vit/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..bf0967cf27f606788174bc9fc2198cad3dbfced6
--- /dev/null
+++ b/configs/t2t_vit/README.md
@@ -0,0 +1,81 @@
+# Tokens-to-Token ViT
+
+> [Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet](https://arxiv.org/abs/2101.11986)
+
+
+
+## Abstract
+
+Transformers, which are popular for language modeling, have been explored for solving vision tasks recently, e.g., the Vision Transformer (ViT) for image classification. The ViT model splits each image into a sequence of tokens with fixed length and then applies multiple Transformer layers to model their global relation for classification. However, ViT achieves inferior performance to CNNs when trained from scratch on a midsize dataset like ImageNet. We find it is because: 1) the simple tokenization of input images fails to model the important local structure such as edges and lines among neighboring pixels, leading to low training sample efficiency; 2) the redundant attention backbone design of ViT leads to limited feature richness for fixed computation budgets and limited training samples. To overcome such limitations, we propose a new Tokens-To-Token Vision Transformer (T2T-ViT), which incorporates 1) a layer-wise Tokens-to-Token (T2T) transformation to progressively structurize the image to tokens by recursively aggregating neighboring Tokens into one Token (Tokens-to-Token), such that local structure represented by surrounding tokens can be modeled and tokens length can be reduced; 2) an efficient backbone with a deep-narrow structure for vision transformer motivated by CNN architecture design after empirical study. Notably, T2T-ViT reduces the parameter count and MACs of vanilla ViT by half, while achieving more than 3.0% improvement when trained from scratch on ImageNet. It also outperforms ResNets and achieves comparable performance with MobileNets by directly training on ImageNet. For example, T2T-ViT with comparable size to ResNet50 (21.5M parameters) can achieve 83.3% top1 accuracy in image resolution 384×384 on ImageNet.
+
+
+

+
+

+
+

+
+
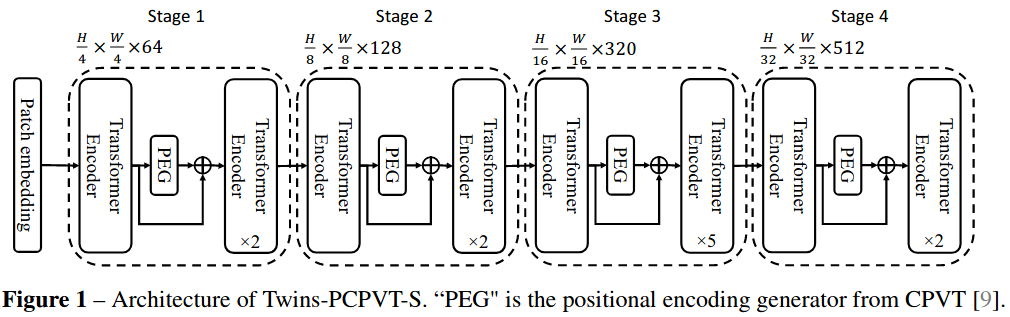
+
+

+
+

+
+

+
+

+
+
+Show the paper's abstract
+
+
+
+While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
+
+
+
+
+## How to use it?
+
+
+
+**Predict image**
+
+```python
+from mmpretrain import inference_model
+
+predict = inference_model('vit-base-p32_in21k-pre_3rdparty_in1k-384px', 'demo/bird.JPEG')
+print(predict['pred_class'])
+print(predict['pred_score'])
+```
+
+**Use the model**
+
+```python
+import torch
+from mmpretrain import get_model
+
+model = get_model('vit-base-p32_in21k-pre_3rdparty_in1k-384px', pretrained=True)
+inputs = torch.rand(1, 3, 224, 224)
+out = model(inputs)
+print(type(out))
+# To extract features.
+feats = model.extract_feat(inputs)
+print(type(feats))
+```
+
+**Train/Test Command**
+
+Prepare your dataset according to the [docs](https://mmpretrain.readthedocs.io/en/latest/user_guides/dataset_prepare.html#prepare-dataset).
+
+Train:
+
+```shell
+python tools/train.py configs/vision_transformer/vit-base-p16_32xb128-mae_in1k.py
+```
+
+Test:
+
+```shell
+python tools/test.py configs/vision_transformer/vit-base-p32_64xb64_in1k-384px.py https://download.openmmlab.com/mmclassification/v0/vit/finetune/vit-base-p32_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-9cea8599.pth
+```
+
+
+
+## Models and results
+
+### Image Classification on ImageNet-1k
+
+| Model | Pretrain | Params (M) | Flops (G) | Top-1 (%) | Top-5 (%) | Config | Download |
+| :---------------------------------------------- | :----------: | :--------: | :-------: | :-------: | :-------: | :------------------------------------------: | :----------------------------------------------------------: |
+| `vit-base-p32_in21k-pre_3rdparty_in1k-384px`\* | ImageNet-21k | 88.30 | 13.06 | 84.01 | 97.08 | [config](vit-base-p32_64xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/vit/finetune/vit-base-p32_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-9cea8599.pth) |
+| `vit-base-p16_32xb128-mae_in1k` | From scratch | 86.57 | 17.58 | 82.37 | 96.15 | [config](vit-base-p16_32xb128-mae_in1k.py) | [model](https://download.openmmlab.com/mmclassification/v0/vit/vit-base-p16_pt-32xb128-mae_in1k_20220623-4c544545.pth) \| [log](https://download.openmmlab.com/mmclassification/v0/vit/vit-base-p16_pt-32xb128-mae_in1k_20220623-4c544545.log) |
+| `vit-base-p16_in21k-pre_3rdparty_in1k-384px`\* | ImageNet-21k | 86.86 | 55.54 | 85.43 | 97.77 | [config](vit-base-p16_64xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/vit/finetune/vit-base-p16_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-98e8652b.pth) |
+| `vit-large-p16_in21k-pre_3rdparty_in1k-384px`\* | ImageNet-21k | 304.72 | 191.21 | 85.63 | 97.63 | [config](vit-large-p16_64xb64_in1k-384px.py) | [model](https://download.openmmlab.com/mmclassification/v0/vit/finetune/vit-large-p16_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-b20ba619.pth) |
+
+*Models with * are converted from the [official repo](https://github.com/google-research/vision_transformer/blob/88a52f8892c80c10de99194990a517b4d80485fd/vit_jax/models.py#L208). The config files of these models are only for inference. We haven't reproduce the training results.*
+
+## Citation
+
+```bibtex
+@inproceedings{
+ dosovitskiy2021an,
+ title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
+ author={Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby},
+ booktitle={International Conference on Learning Representations},
+ year={2021},
+ url={https://openreview.net/forum?id=YicbFdNTTy}
+}
+```
diff --git a/configs/vision_transformer/metafile.yml b/configs/vision_transformer/metafile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..891c413ab6c5b579eb5d404b7b7e7d01fe94b8d8
--- /dev/null
+++ b/configs/vision_transformer/metafile.yml
@@ -0,0 +1,95 @@
+Collections:
+ - Name: Vision Transformer
+ Metadata:
+ Architecture:
+ - Attention Dropout
+ - Convolution
+ - Dense Connections
+ - Dropout
+ - GELU
+ - Layer Normalization
+ - Multi-Head Attention
+ - Scaled Dot-Product Attention
+ - Tanh Activation
+ Paper:
+ Title: 'An Image is Worth 16x16 Words: Transformers for Image Recognition at
+ Scale'
+ URL: https://arxiv.org/abs/2010.11929
+ README: configs/vision_transformer/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmpretrain/blob/v0.17.0/mmcls/models/backbones/vision_transformer.py
+ Version: v0.17.0
+
+Models:
+ - Name: vit-base-p32_in21k-pre_3rdparty_in1k-384px
+ Metadata:
+ FLOPs: 13056716544
+ Parameters: 88297192
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ In Collection: Vision Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 84.01
+ Top 5 Accuracy: 97.08
+ Weights: https://download.openmmlab.com/mmclassification/v0/vit/finetune/vit-base-p32_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-9cea8599.pth
+ Config: configs/vision_transformer/vit-base-p32_64xb64_in1k-384px.py
+ Converted From:
+ Weights: https://console.cloud.google.com/storage/browser/_details/vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz
+ Code: https://github.com/google-research/vision_transformer/blob/88a52f8892c80c10de99194990a517b4d80485fd/vit_jax/models.py#L208
+ - Name: vit-base-p16_32xb128-mae_in1k
+ Metadata:
+ FLOPs: 17581972224
+ Parameters: 86567656
+ Training Data:
+ - ImageNet-1k
+ In Collection: Vision Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 82.37
+ Top 5 Accuracy: 96.15
+ Weights: https://download.openmmlab.com/mmclassification/v0/vit/vit-base-p16_pt-32xb128-mae_in1k_20220623-4c544545.pth
+ Config: configs/vision_transformer/vit-base-p16_32xb128-mae_in1k.py
+ - Name: vit-base-p16_in21k-pre_3rdparty_in1k-384px
+ Metadata:
+ FLOPs: 55538974464
+ Parameters: 86859496
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ In Collection: Vision Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 85.43
+ Top 5 Accuracy: 97.77
+ Weights: https://download.openmmlab.com/mmclassification/v0/vit/finetune/vit-base-p16_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-98e8652b.pth
+ Config: configs/vision_transformer/vit-base-p16_64xb64_in1k-384px.py
+ Converted From:
+ Weights: https://console.cloud.google.com/storage/browser/_details/vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz
+ Code: https://github.com/google-research/vision_transformer/blob/88a52f8892c80c10de99194990a517b4d80485fd/vit_jax/models.py#L208
+ - Name: vit-large-p16_in21k-pre_3rdparty_in1k-384px
+ Metadata:
+ FLOPs: 191210034176
+ Parameters: 304715752
+ Training Data:
+ - ImageNet-21k
+ - ImageNet-1k
+ In Collection: Vision Transformer
+ Results:
+ - Dataset: ImageNet-1k
+ Task: Image Classification
+ Metrics:
+ Top 1 Accuracy: 85.63
+ Top 5 Accuracy: 97.63
+ Weights: https://download.openmmlab.com/mmclassification/v0/vit/finetune/vit-large-p16_in21k-pre-3rdparty_ft-64xb64_in1k-384_20210928-b20ba619.pth
+ Config: configs/vision_transformer/vit-large-p16_64xb64_in1k-384px.py
+ Converted From:
+ Weights: https://console.cloud.google.com/storage/browser/_details/vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz
+ Code: https://github.com/google-research/vision_transformer/blob/88a52f8892c80c10de99194990a517b4d80485fd/vit_jax/models.py#L208
diff --git a/configs/vision_transformer/vit-base-p16_32xb128-mae_in1k.py b/configs/vision_transformer/vit-base-p16_32xb128-mae_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..a46bbb21a99b34f792f277759b4dccb75c88b2ed
--- /dev/null
+++ b/configs/vision_transformer/vit-base-p16_32xb128-mae_in1k.py
@@ -0,0 +1,58 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs64_swin_224.py',
+ '../_base_/schedules/imagenet_bs1024_adamw_swin.py',
+ '../_base_/default_runtime.py'
+]
+
+# model settings
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='VisionTransformer',
+ arch='base',
+ img_size=224,
+ patch_size=16,
+ drop_path_rate=0.1),
+ neck=None,
+ head=dict(
+ type='VisionTransformerClsHead',
+ num_classes=1000,
+ in_channels=768,
+ loss=dict(
+ type='LabelSmoothLoss', label_smooth_val=0.1, mode='original'),
+ ),
+ init_cfg=[
+ dict(type='TruncNormal', layer='Linear', std=.02),
+ dict(type='Constant', layer='LayerNorm', val=1., bias=0.),
+ ],
+ train_cfg=dict(augments=[
+ dict(type='Mixup', alpha=0.8),
+ dict(type='CutMix', alpha=1.0)
+ ]))
+
+# dataset settings
+train_dataloader = dict(batch_size=128)
+
+# schedule settings
+optim_wrapper = dict(
+ optimizer=dict(
+ type='AdamW',
+ lr=1e-4 * 4096 / 256,
+ weight_decay=0.3,
+ eps=1e-8,
+ betas=(0.9, 0.95)),
+ paramwise_cfg=dict(
+ norm_decay_mult=0.0,
+ bias_decay_mult=0.0,
+ custom_keys={
+ '.cls_token': dict(decay_mult=0.0),
+ '.pos_embed': dict(decay_mult=0.0)
+ }))
+
+# runtime settings
+custom_hooks = [dict(type='EMAHook', momentum=1e-4)]
+
+# NOTE: `auto_scale_lr` is for automatically scaling LR
+# based on the actual training batch size.
+# base_batch_size = (32 GPUs) x (128 samples per GPU)
+auto_scale_lr = dict(base_batch_size=4096)
diff --git a/configs/vision_transformer/vit-base-p16_4xb544-ipu_in1k.py b/configs/vision_transformer/vit-base-p16_4xb544-ipu_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..d378b3b265b30b7f3e492dcf22527fed5cd9beb4
--- /dev/null
+++ b/configs/vision_transformer/vit-base-p16_4xb544-ipu_in1k.py
@@ -0,0 +1,114 @@
+_base_ = [
+ '../_base_/models/vit-base-p16.py',
+ '../_base_/datasets/imagenet_bs64_pil_resize_autoaug.py',
+ '../_base_/default_runtime.py'
+]
+
+# specific to vit pretrain
+paramwise_cfg = dict(custom_keys={
+ '.cls_token': dict(decay_mult=0.0),
+ '.pos_embed': dict(decay_mult=0.0)
+})
+
+pretrained = 'https://download.openmmlab.com/mmclassification/v0/vit/pretrain/vit-base-p16_3rdparty_pt-64xb64_in1k-224_20210928-02284250.pth' # noqa
+
+model = dict(
+ head=dict(
+ loss=dict(type='CrossEntropyLoss', loss_weight=1.0, _delete_=True), ),
+ backbone=dict(
+ img_size=224,
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint=pretrained,
+ _delete_=True,
+ prefix='backbone')))
+
+img_norm_cfg = dict(
+ mean=[127.5, 127.5, 127.5], std=[127.5, 127.5, 127.5], to_rgb=True)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=224, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='ToTensor', keys=['gt_label']),
+ dict(type='ToHalf', keys=['img']),
+ dict(type='Collect', keys=['img', 'gt_label'])
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='Resize', scale=(224, -1), keep_ratio=True, backend='pillow'),
+ dict(type='CenterCrop', crop_size=224),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='ToHalf', keys=['img']),
+ dict(type='Collect', keys=['img'])
+]
+
+# change batch size
+data = dict(
+ samples_per_gpu=17,
+ workers_per_gpu=16,
+ drop_last=True,
+ train=dict(pipeline=train_pipeline),
+ train_dataloader=dict(mode='async'),
+ val=dict(pipeline=test_pipeline, ),
+ val_dataloader=dict(samples_per_gpu=4, workers_per_gpu=1),
+ test=dict(pipeline=test_pipeline),
+ test_dataloader=dict(samples_per_gpu=4, workers_per_gpu=1))
+
+# optimizer
+optimizer = dict(
+ type='SGD',
+ lr=0.08,
+ weight_decay=1e-5,
+ momentum=0.9,
+ paramwise_cfg=paramwise_cfg,
+)
+
+# learning policy
+param_scheduler = [
+ dict(type='LinearLR', start_factor=0.02, by_epoch=False, begin=0, end=800),
+ dict(
+ type='CosineAnnealingLR',
+ T_max=4200,
+ by_epoch=False,
+ begin=800,
+ end=5000)
+]
+
+# ipu cfg
+# model partition config
+ipu_model_cfg = dict(
+ train_split_edges=[
+ dict(layer_to_call='backbone.patch_embed', ipu_id=0),
+ dict(layer_to_call='backbone.layers.3', ipu_id=1),
+ dict(layer_to_call='backbone.layers.6', ipu_id=2),
+ dict(layer_to_call='backbone.layers.9', ipu_id=3)
+ ],
+ train_ckpt_nodes=['backbone.layers.{}'.format(i) for i in range(12)])
+
+# device config
+options_cfg = dict(
+ randomSeed=42,
+ partialsType='half',
+ train_cfg=dict(
+ executionStrategy='SameAsIpu',
+ Training=dict(gradientAccumulation=32),
+ availableMemoryProportion=[0.3, 0.3, 0.3, 0.3],
+ ),
+ eval_cfg=dict(deviceIterations=1, ),
+)
+
+# add model partition config and device config to runner
+runner = dict(
+ type='IterBasedRunner',
+ ipu_model_cfg=ipu_model_cfg,
+ options_cfg=options_cfg,
+ max_iters=5000)
+
+default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=1000))
+
+fp16 = dict(loss_scale=256.0, velocity_accum_type='half', accum_type='half')
diff --git a/configs/vision_transformer/vit-base-p16_64xb64_in1k-384px.py b/configs/vision_transformer/vit-base-p16_64xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..e0f745874bcef7e3896cfc694c16bf4e5a235fae
--- /dev/null
+++ b/configs/vision_transformer/vit-base-p16_64xb64_in1k-384px.py
@@ -0,0 +1,38 @@
+_base_ = [
+ '../_base_/models/vit-base-p16.py',
+ '../_base_/datasets/imagenet_bs64_pil_resize.py',
+ '../_base_/schedules/imagenet_bs4096_AdamW.py',
+ '../_base_/default_runtime.py'
+]
+
+# model setting
+model = dict(backbone=dict(img_size=384))
+
+# dataset setting
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=384, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='ResizeEdge', scale=384, edge='short', backend='pillow'),
+ dict(type='CenterCrop', crop_size=384),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+
+# schedule setting
+optim_wrapper = dict(clip_grad=dict(max_norm=1.0))
diff --git a/configs/vision_transformer/vit-base-p16_64xb64_in1k.py b/configs/vision_transformer/vit-base-p16_64xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..07be0e9a373a324f07989476314d391f2fee4f8e
--- /dev/null
+++ b/configs/vision_transformer/vit-base-p16_64xb64_in1k.py
@@ -0,0 +1,15 @@
+_base_ = [
+ '../_base_/models/vit-base-p16.py',
+ '../_base_/datasets/imagenet_bs64_pil_resize_autoaug.py',
+ '../_base_/schedules/imagenet_bs4096_AdamW.py',
+ '../_base_/default_runtime.py'
+]
+
+# model setting
+model = dict(
+ head=dict(hidden_dim=3072),
+ train_cfg=dict(augments=dict(type='Mixup', alpha=0.2)),
+)
+
+# schedule setting
+optim_wrapper = dict(clip_grad=dict(max_norm=1.0))
diff --git a/configs/vision_transformer/vit-base-p16_8xb64-lora_in1k-384px.py b/configs/vision_transformer/vit-base-p16_8xb64-lora_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..ffe1018e5d9c0f724911b782a555cb34d50d6ceb
--- /dev/null
+++ b/configs/vision_transformer/vit-base-p16_8xb64-lora_in1k-384px.py
@@ -0,0 +1,84 @@
+_base_ = [
+ '../_base_/datasets/imagenet_bs64_pil_resize.py',
+ '../_base_/schedules/imagenet_bs4096_AdamW.py',
+ '../_base_/default_runtime.py'
+]
+
+# model setting
+model = dict(
+ type='ImageClassifier',
+ backbone=dict(
+ type='LoRAModel',
+ module=dict(
+ type='VisionTransformer',
+ arch='b',
+ img_size=384,
+ patch_size=16,
+ drop_rate=0.1,
+ init_cfg=dict(type='Pretrained', checkpoint='',
+ prefix='backbone')),
+ alpha=16,
+ rank=16,
+ drop_rate=0.1,
+ targets=[dict(type='qkv')]),
+ neck=None,
+ head=dict(
+ type='VisionTransformerClsHead',
+ num_classes=1000,
+ in_channels=768,
+ loss=dict(
+ type='LabelSmoothLoss', label_smooth_val=0.1,
+ mode='classy_vision'),
+ init_cfg=[dict(type='TruncNormal', layer='Linear', std=2e-5)],
+ ))
+
+# dataset setting
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=384, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='ResizeEdge', scale=384, edge='short', backend='pillow'),
+ dict(type='CenterCrop', crop_size=384),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1e-4,
+ by_epoch=True,
+ begin=0,
+ end=5,
+ convert_to_iter_based=True),
+ dict(
+ type='CosineAnnealingLR',
+ T_max=45,
+ by_epoch=True,
+ begin=5,
+ end=50,
+ eta_min=1e-6,
+ convert_to_iter_based=True)
+]
+
+train_cfg = dict(by_epoch=True, max_epochs=50)
+default_hooks = dict(
+ # save checkpoint per epoch.
+ checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
+
+# schedule setting
+optim_wrapper = dict(clip_grad=dict(max_norm=1.0))
diff --git a/configs/vision_transformer/vit-base-p32_64xb64_in1k-384px.py b/configs/vision_transformer/vit-base-p32_64xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..e5a4d14f4dad0759f70b9b9e29c085ad7eff292c
--- /dev/null
+++ b/configs/vision_transformer/vit-base-p32_64xb64_in1k-384px.py
@@ -0,0 +1,38 @@
+_base_ = [
+ '../_base_/models/vit-base-p32.py',
+ '../_base_/datasets/imagenet_bs64_pil_resize.py',
+ '../_base_/schedules/imagenet_bs4096_AdamW.py',
+ '../_base_/default_runtime.py'
+]
+
+# model setting
+model = dict(backbone=dict(img_size=384))
+
+# dataset setting
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=384, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='ResizeEdge', scale=384, edge='short', backend='pillow'),
+ dict(type='CenterCrop', crop_size=384),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+
+# schedule setting
+optim_wrapper = dict(clip_grad=dict(max_norm=1.0))
diff --git a/configs/vision_transformer/vit-base-p32_64xb64_in1k.py b/configs/vision_transformer/vit-base-p32_64xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..9cfc7c47df0887e4ace1bbaeb59bb5d42e004a83
--- /dev/null
+++ b/configs/vision_transformer/vit-base-p32_64xb64_in1k.py
@@ -0,0 +1,15 @@
+_base_ = [
+ '../_base_/models/vit-base-p32.py',
+ '../_base_/datasets/imagenet_bs64_pil_resize_autoaug.py',
+ '../_base_/schedules/imagenet_bs4096_AdamW.py',
+ '../_base_/default_runtime.py'
+]
+
+# model setting
+model = dict(
+ head=dict(hidden_dim=3072),
+ train_cfg=dict(augments=dict(type='Mixup', alpha=0.2)),
+)
+
+# schedule setting
+optim_wrapper = dict(clip_grad=dict(max_norm=1.0))
diff --git a/configs/vision_transformer/vit-large-p16_64xb64_in1k-384px.py b/configs/vision_transformer/vit-large-p16_64xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..98e96ec68ffdaca2648e1ac2ae5a79db30ec8382
--- /dev/null
+++ b/configs/vision_transformer/vit-large-p16_64xb64_in1k-384px.py
@@ -0,0 +1,38 @@
+_base_ = [
+ '../_base_/models/vit-large-p16.py',
+ '../_base_/datasets/imagenet_bs64_pil_resize.py',
+ '../_base_/schedules/imagenet_bs4096_AdamW.py',
+ '../_base_/default_runtime.py'
+]
+
+# model setting
+model = dict(backbone=dict(img_size=384))
+
+# dataset setting
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=384, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='ResizeEdge', scale=384, edge='short', backend='pillow'),
+ dict(type='CenterCrop', crop_size=384),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+
+# schedule setting
+optim_wrapper = dict(clip_grad=dict(max_norm=1.0))
diff --git a/configs/vision_transformer/vit-large-p16_64xb64_in1k.py b/configs/vision_transformer/vit-large-p16_64xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..0d9bd283b779af36df99574bbdde7701c6b41393
--- /dev/null
+++ b/configs/vision_transformer/vit-large-p16_64xb64_in1k.py
@@ -0,0 +1,15 @@
+_base_ = [
+ '../_base_/models/vit-large-p16.py',
+ '../_base_/datasets/imagenet_bs64_pil_resize_autoaug.py',
+ '../_base_/schedules/imagenet_bs4096_AdamW.py',
+ '../_base_/default_runtime.py'
+]
+
+# model setting
+model = dict(
+ head=dict(hidden_dim=3072),
+ train_cfg=dict(augments=dict(type='Mixup', alpha=0.2)),
+)
+
+# schedule setting
+optim_wrapper = dict(clip_grad=dict(max_norm=1.0))
diff --git a/configs/vision_transformer/vit-large-p32_64xb64_in1k-384px.py b/configs/vision_transformer/vit-large-p32_64xb64_in1k-384px.py
new file mode 100644
index 0000000000000000000000000000000000000000..22320d119890bb80aca47e45322dabeee4d0feb7
--- /dev/null
+++ b/configs/vision_transformer/vit-large-p32_64xb64_in1k-384px.py
@@ -0,0 +1,38 @@
+_base_ = [
+ '../_base_/models/vit-large-p32.py',
+ '../_base_/datasets/imagenet_bs64_pil_resize_autoaug.py',
+ '../_base_/schedules/imagenet_bs4096_AdamW.py',
+ '../_base_/default_runtime.py'
+]
+
+# model setting
+model = dict(backbone=dict(img_size=384))
+
+# dataset setting
+data_preprocessor = dict(
+ mean=[127.5, 127.5, 127.5],
+ std=[127.5, 127.5, 127.5],
+ # convert image from BGR to RGB
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='RandomResizedCrop', scale=384, backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='PackInputs'),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='ResizeEdge', scale=384, edge='short', backend='pillow'),
+ dict(type='CenterCrop', crop_size=384),
+ dict(type='PackInputs'),
+]
+
+train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
+val_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
+
+# schedule setting
+optim_wrapper = dict(clip_grad=dict(max_norm=1.0))
diff --git a/configs/vision_transformer/vit-large-p32_64xb64_in1k.py b/configs/vision_transformer/vit-large-p32_64xb64_in1k.py
new file mode 100644
index 0000000000000000000000000000000000000000..61e179165b84d8aa521426aa992cc2460d7ae0a5
--- /dev/null
+++ b/configs/vision_transformer/vit-large-p32_64xb64_in1k.py
@@ -0,0 +1,15 @@
+_base_ = [
+ '../_base_/models/vit-large-p32.py',
+ '../_base_/datasets/imagenet_bs64_pil_resize_autoaug.py',
+ '../_base_/schedules/imagenet_bs4096_AdamW.py',
+ '../_base_/default_runtime.py'
+]
+
+# model setting
+model = dict(
+ head=dict(hidden_dim=3072),
+ train_cfg=dict(augments=dict(type='Mixup', alpha=0.2)),
+)
+
+# schedule setting
+optim_wrapper = dict(clip_grad=dict(max_norm=1.0))
diff --git a/configs/wrn/README.md b/configs/wrn/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2753307b06699b4235aaf1465f0ce5cf89a30952
--- /dev/null
+++ b/configs/wrn/README.md
@@ -0,0 +1,76 @@
+# Wide-ResNet
+
+> [Wide Residual Networks](https://arxiv.org/abs/1605.07146)
+
+
+
+## Abstract
+
+Deep residual networks were shown to be able to scale up to thousands of layers and still have improving performance. However, each fraction of a percent of improved accuracy costs nearly doubling the number of layers, and so training very deep residual networks has a problem of diminishing feature reuse, which makes these networks very slow to train. To tackle these problems, in this paper we conduct a detailed experimental study on the architecture of ResNet blocks, based on which we propose a novel architecture where we decrease depth and increase width of residual networks. We call the resulting network structures wide residual networks (WRNs) and show that these are far superior over their commonly used thin and very deep counterparts. For example, we demonstrate that even a simple 16-layer-deep wide residual network outperforms in accuracy and efficiency all previous deep residual networks, including thousand-layer-deep networks, achieving new state-of-the-art results on CIFAR, SVHN, COCO, and significant improvements on ImageNet.
+
+
+

+
+

+