
Bump version to V1.0.0rc0
Bump version to V1.0.0rc0
Showing
mmdet3d/utils/setup_env.py
0 → 100644
resources/coord_sys_all.png
0 → 100644
{kind=link}
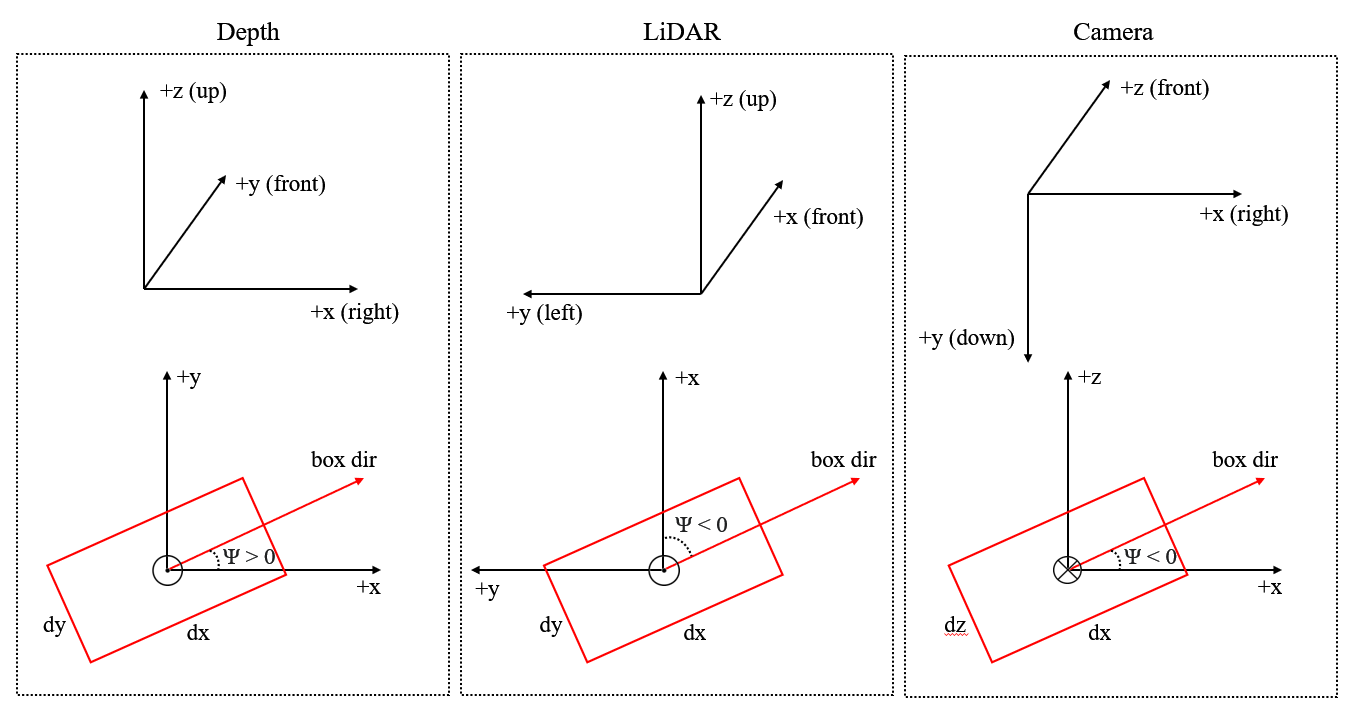
59.5 KB
No preview for this file type
No preview for this file type