
draft documentation
Showing
docs/Makefile
0 → 100644
{kind=link}
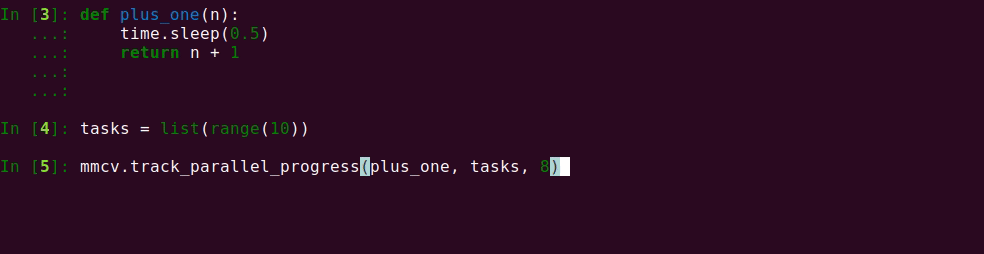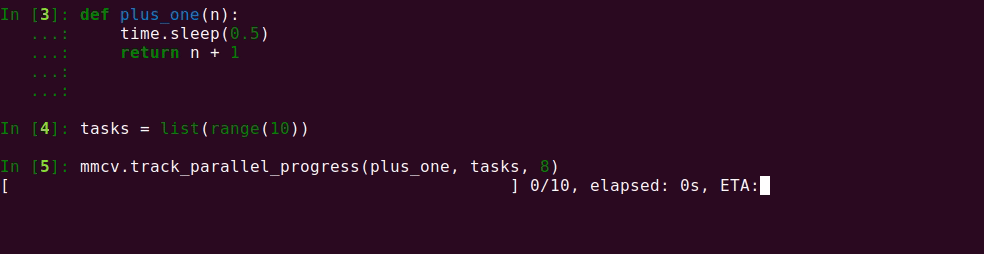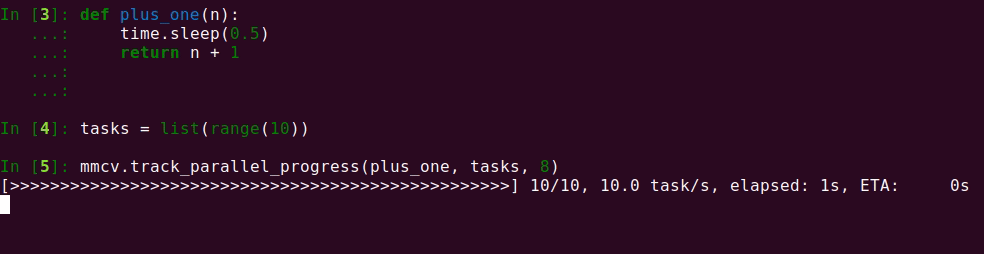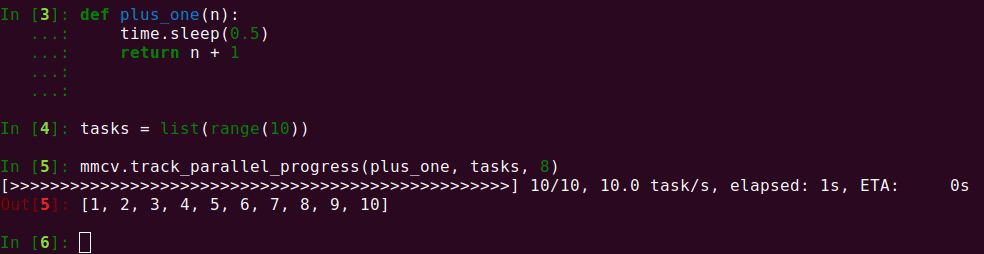
27 KB
docs/_static/progress.gif
0 → 100644
{kind=link}
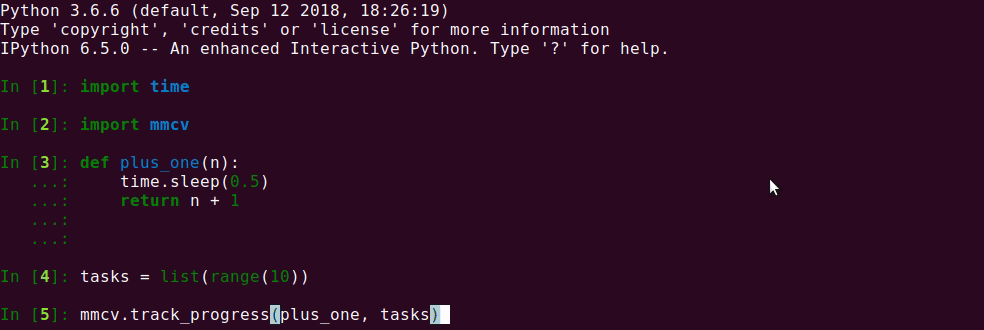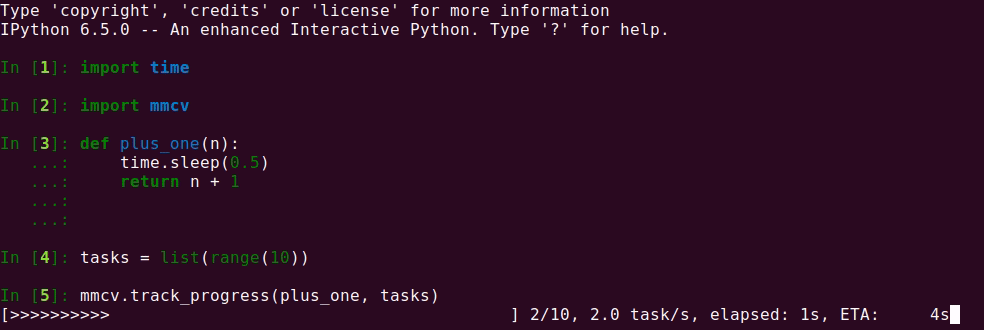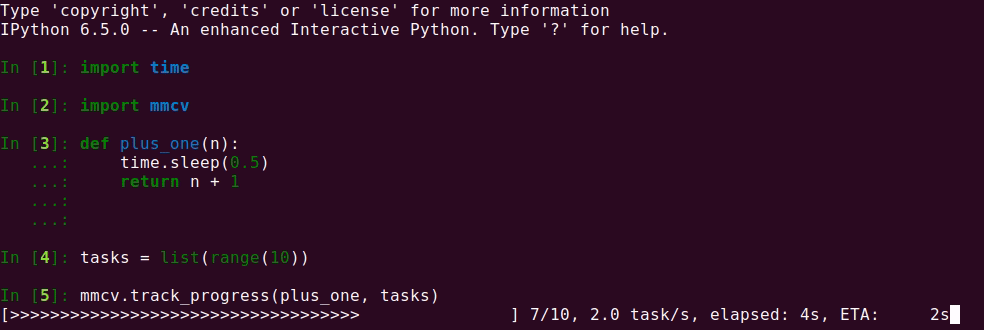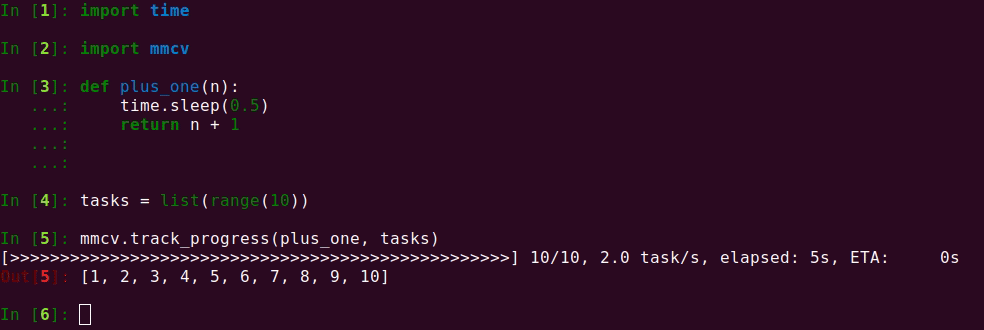
98.4 KB
docs/api.rst
0 → 100644
docs/conf.py
0 → 100644
docs/image.md
0 → 100644
docs/index.rst
0 → 100644
docs/intro.md
0 → 100644
docs/io.md
0 → 100644
docs/make.bat
0 → 100644
docs/runner.md
0 → 100644
docs/utils.md
0 → 100644
docs/video.md
0 → 100644
docs/visualization.md
0 → 100644