
[Docs] Fix pdf build (#1266)
* [Fix] Fix pdf error when building docs * fix docs * fix pdf * fix pdf * fix pdf
Showing
{kind=link}
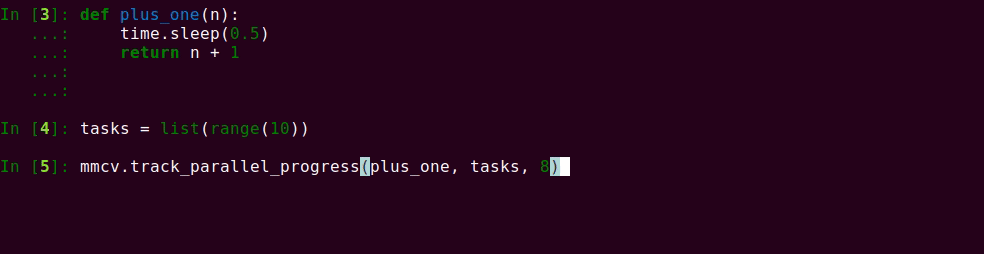
9.5 KB
docs/_static/progress.png
0 → 100644
{kind=link}
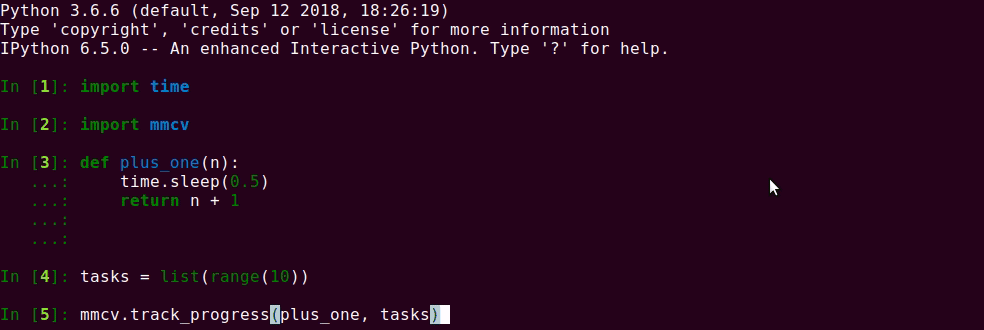
20.4 KB
* [Fix] Fix pdf error when building docs * fix docs * fix pdf * fix pdf * fix pdf
9.5 KB
20.4 KB