
Merge branch 'lmcafee/distrib-opt-nodupe' into 'main'
Distributed optimizer See merge request ADLR/megatron-lm!408
Showing
docs/distrib_optimizer.md
0 → 100644
{kind=link}
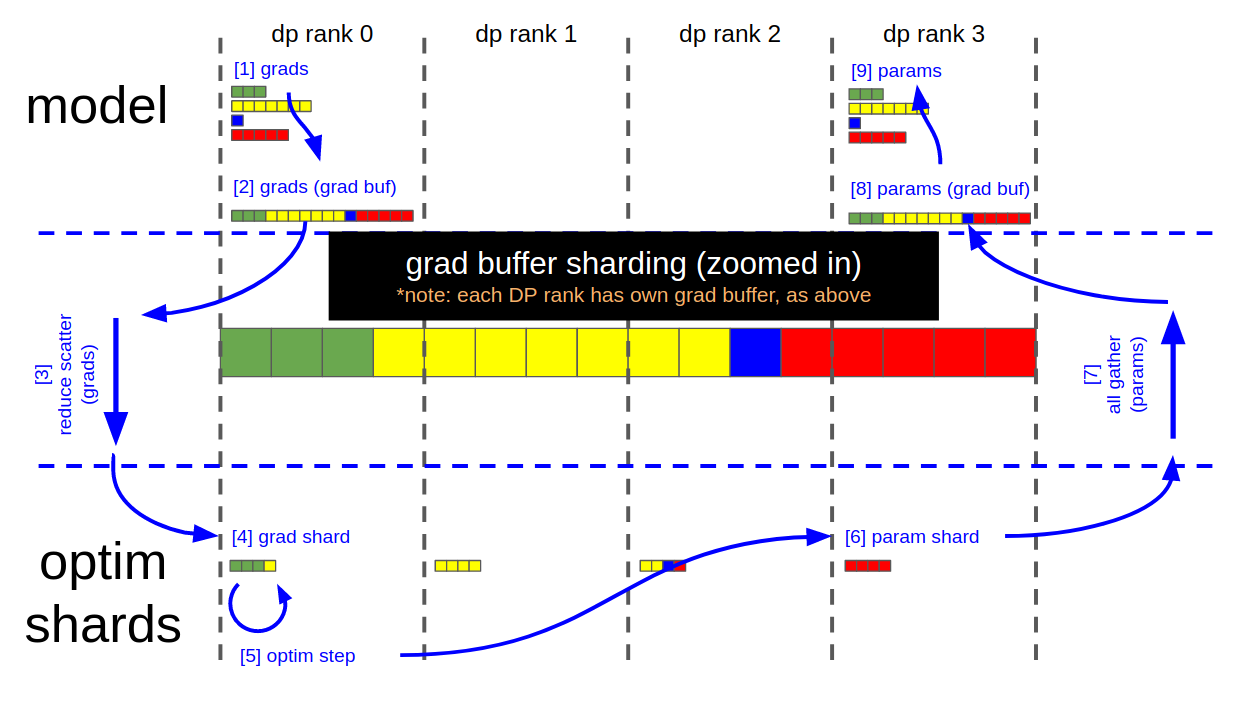
87.9 KB
{kind=link}
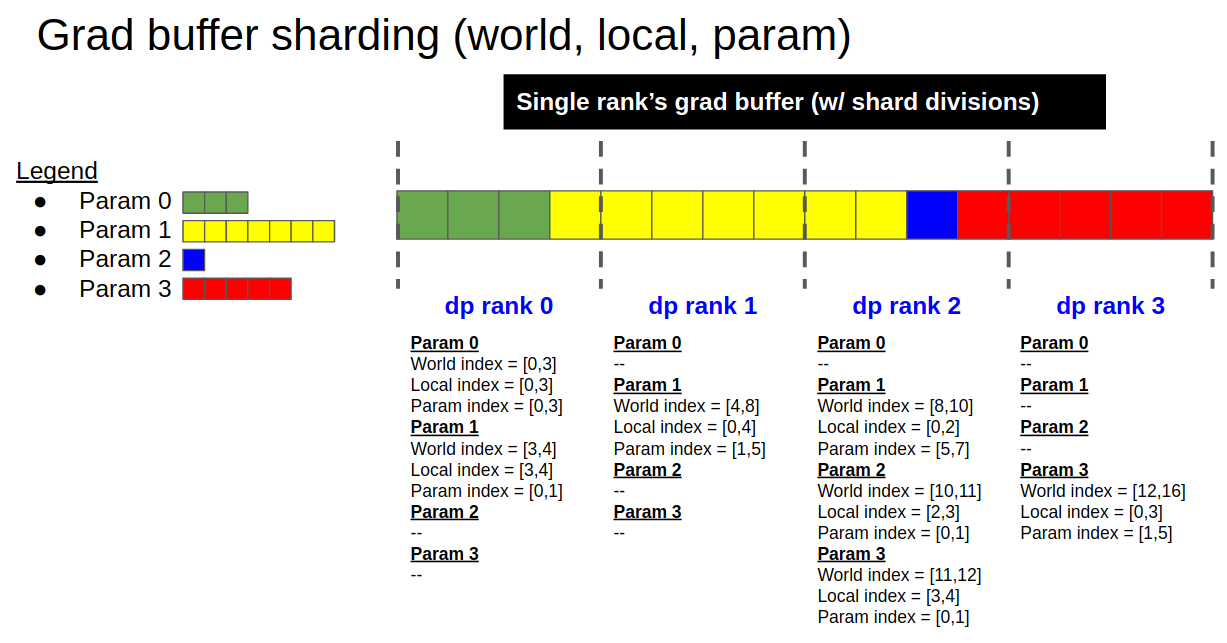
96.8 KB
Distributed optimizer See merge request ADLR/megatron-lm!408
87.9 KB
96.8 KB