
更新代码
Showing
Too many changes to show.
To preserve performance only 172 of 172+ files are displayed.
GPT_pretraining.sh
deleted
100644 → 0
Llama_pretraining.sh
deleted
100644 → 0
{kind=link}
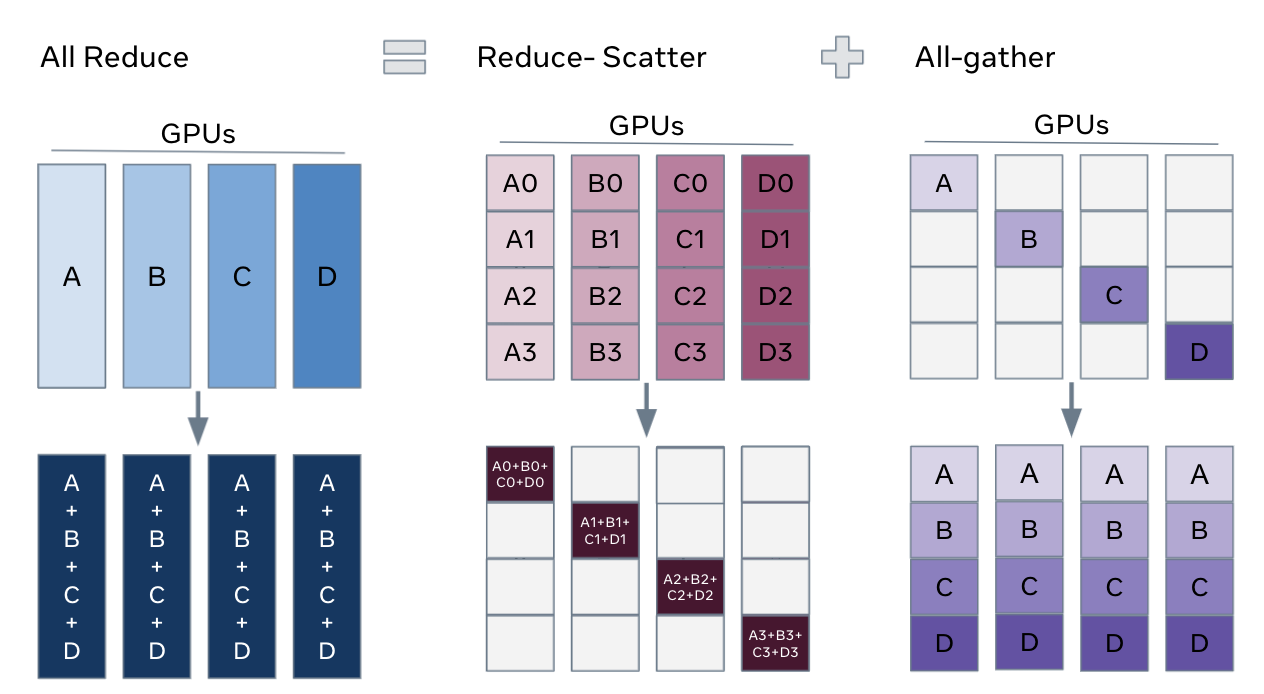
84.5 KB
{kind=link}
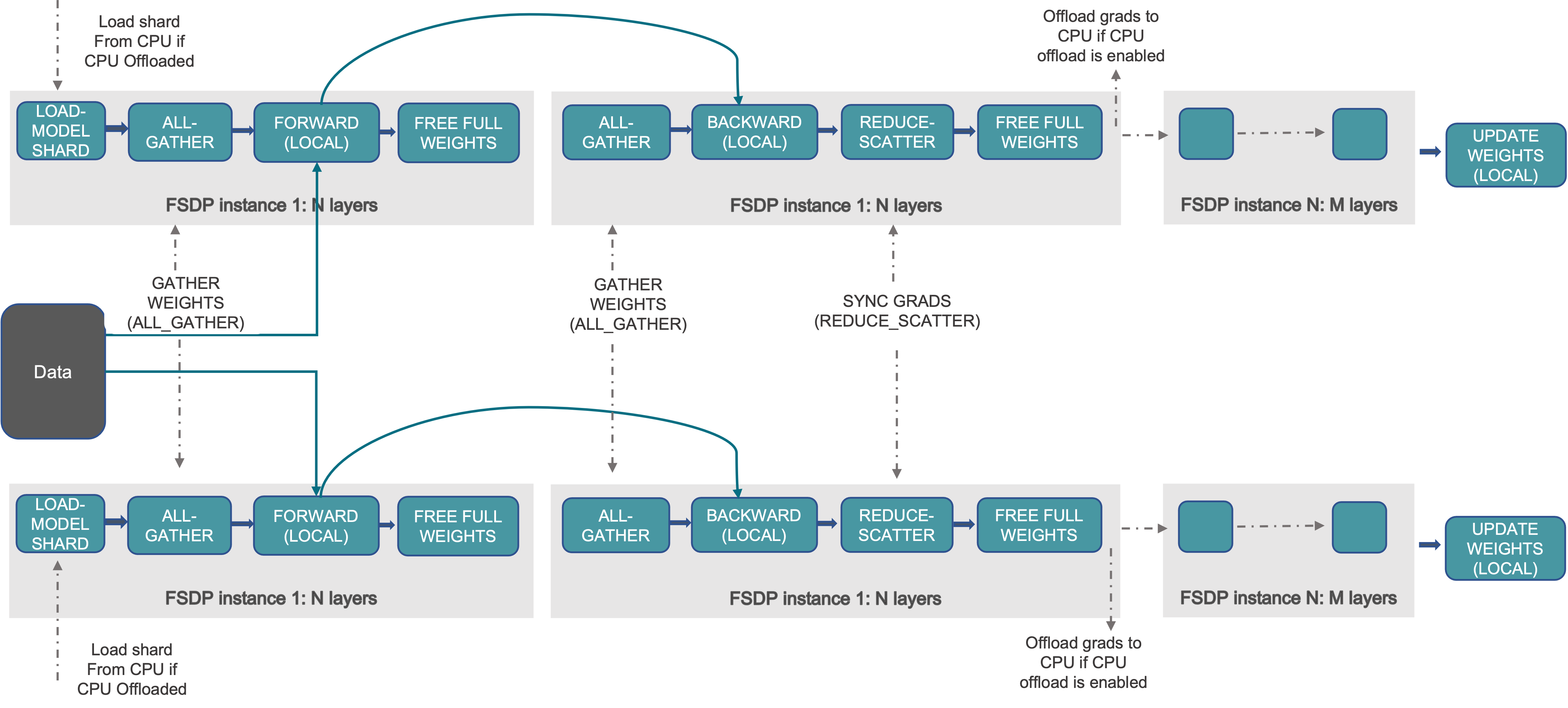
555 KB
{kind=link}

499 KB
File mode changed from 100644 to 100755
File mode changed from 100644 to 100755