
Merge branch 'main' into hip
Showing
{kind=link}
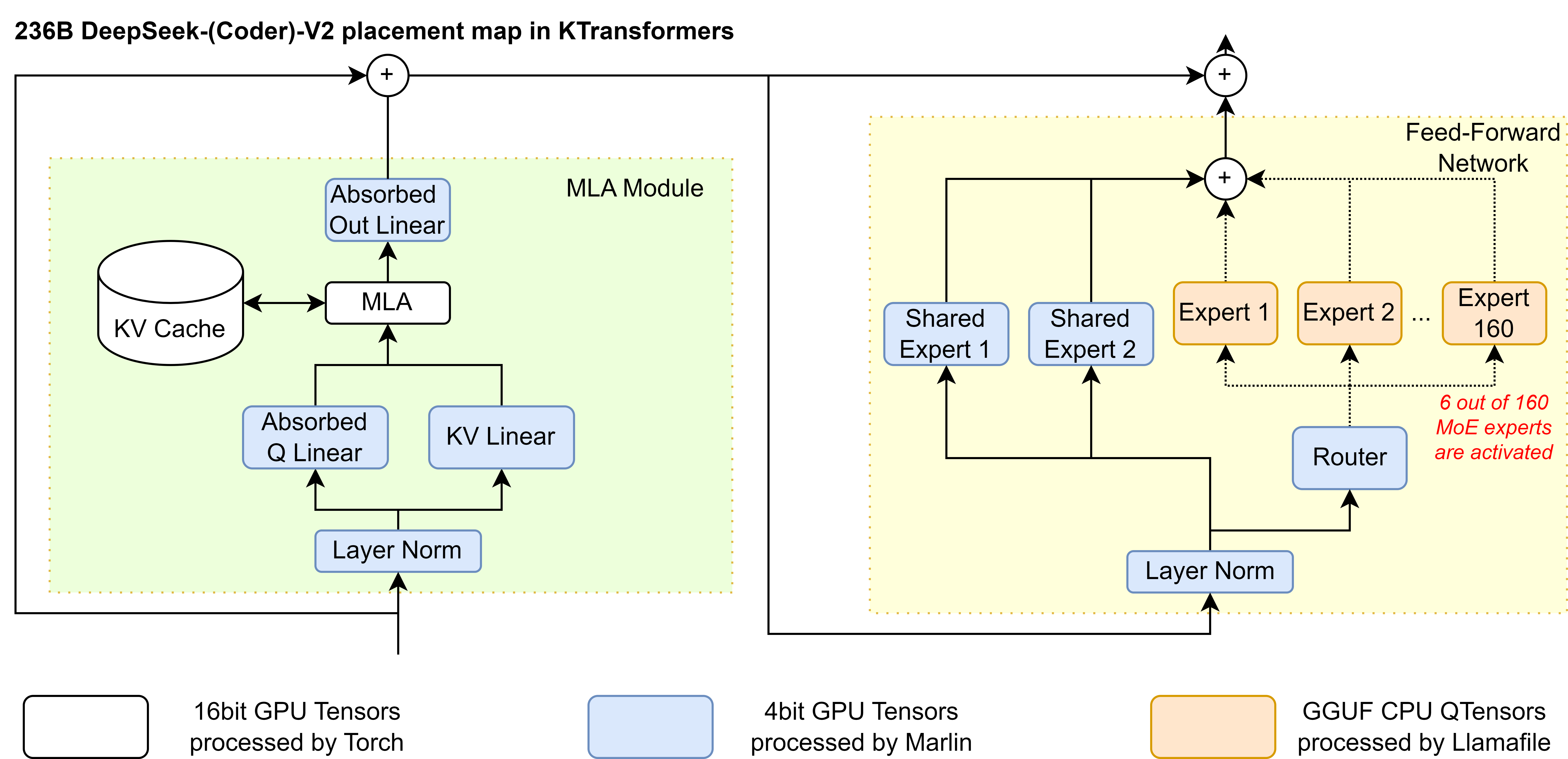
1.23 MB
{kind=link}
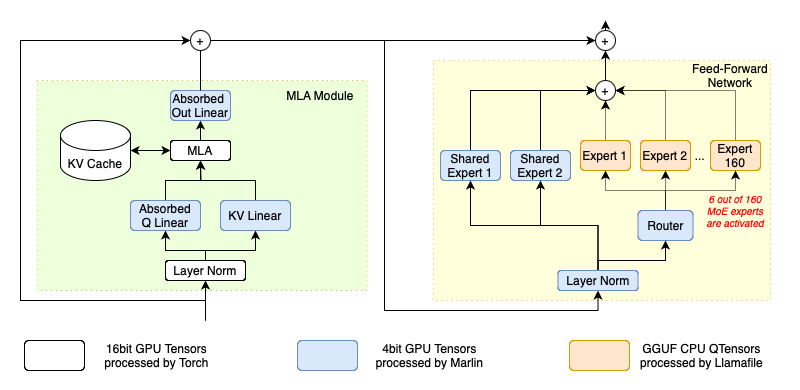
82.9 KB
doc/basic/note1.md
0 → 100644
doc/basic/note2.md
0 → 100644
doc/en/V3-success.md
0 → 100644
doc/en/benchmark.md
0 → 100644
doc/en/fp8_kernel.md
0 → 100644
doc/en/install.md
0 → 100644
doc/en/multi-gpu-tutorial.md
0 → 100644