Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in
Toggle navigation
Menu
Open sidebar
OpenDAS
flash-attention
Commits
34e67b1e
Commit
34e67b1e
authored
May 09, 2026
by
zhangshao
Browse files
first commit
parents
Pipeline
#3582
failed with stages
in 0 seconds
Changes
819
Pipelines
1
Expand all
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
3365 additions
and
0 deletions
+3365
-0
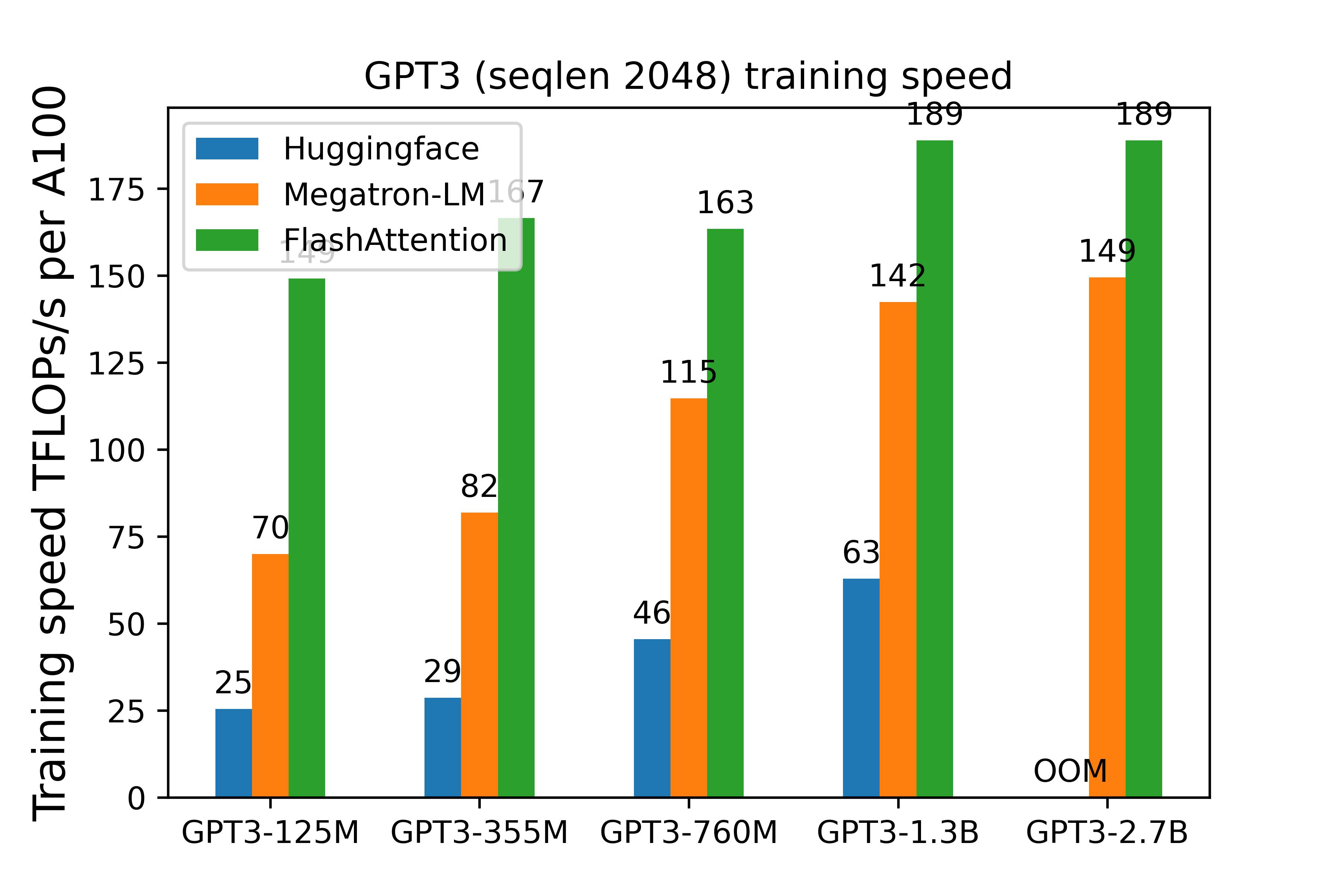
assets/gpt3_training_curve.jpg
assets/gpt3_training_curve.jpg
+0
-0
assets/gpt3_training_efficiency.jpg
assets/gpt3_training_efficiency.jpg
+0
-0
benchmarks/benchmark_alibi.py
benchmarks/benchmark_alibi.py
+275
-0
benchmarks/benchmark_attnmask.py
benchmarks/benchmark_attnmask.py
+226
-0
benchmarks/benchmark_causal.py
benchmarks/benchmark_causal.py
+225
-0
benchmarks/benchmark_fa_varlen.py
benchmarks/benchmark_fa_varlen.py
+116
-0
benchmarks/benchmark_fa_varlen_mla_test_fp8.py
benchmarks/benchmark_fa_varlen_mla_test_fp8.py
+165
-0
benchmarks/benchmark_fa_varlen_test.py
benchmarks/benchmark_fa_varlen_test.py
+148
-0
benchmarks/benchmark_fa_varlen_test_fp8.py
benchmarks/benchmark_fa_varlen_test_fp8.py
+165
-0
benchmarks/benchmark_flash_attention.py
benchmarks/benchmark_flash_attention.py
+195
-0
benchmarks/benchmark_flash_attention_padding.py
benchmarks/benchmark_flash_attention_padding.py
+216
-0
benchmarks/benchmark_hg_test.py
benchmarks/benchmark_hg_test.py
+178
-0
benchmarks/benchmark_kvcache.py
benchmarks/benchmark_kvcache.py
+152
-0
benchmarks/benchmark_ours.py
benchmarks/benchmark_ours.py
+174
-0
benchmarks/benchmark_prefix_cache.py
benchmarks/benchmark_prefix_cache.py
+156
-0
benchmarks/fa_bwd_benchmark.py
benchmarks/fa_bwd_benchmark.py
+147
-0
benchmarks/hy/test_flash_attn.py
benchmarks/hy/test_flash_attn.py
+437
-0
benchmarks/test_prefix_kvcache.py
benchmarks/test_prefix_kvcache.py
+390
-0
csrc/flash_attn/flash_api.cpp
csrc/flash_attn/flash_api.cpp
+0
-0
csrc/flash_attn/flash_api_attnmask.cpp
csrc/flash_attn/flash_api_attnmask.cpp
+0
-0
No files found.
assets/gpt3_training_curve.jpg
0 → 100644
View file @
34e67b1e
183 KB
assets/gpt3_training_efficiency.jpg
0 → 100644
View file @
34e67b1e
382 KB
benchmarks/benchmark_alibi.py
0 → 100644
View file @
34e67b1e
# Copyright (c) 2024, Sanghun Cho, Tri Dao.
import
pickle
import
math
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
from
einops
import
rearrange
,
repeat
from
flash_attn.layers.rotary
import
apply_rotary_emb
from
flash_attn.utils.benchmark
import
benchmark_all
,
benchmark_forward
,
benchmark_backward
from
flash_attn.utils.benchmark
import
benchmark_fwd_bwd
,
benchmark_combined
from
flash_attn
import
flash_attn_qkvpacked_func
,
flash_attn_func
try
:
import
xformers.ops
as
xops
except
ImportError
:
xops
=
None
def
generate_cos_sin
(
seqlen
,
rotary_dim
,
device
,
dtype
):
assert
rotary_dim
%
2
==
0
angle
=
torch
.
rand
(
seqlen
*
2
,
rotary_dim
//
2
,
device
=
device
)
*
2
*
math
.
pi
cos
=
torch
.
cos
(
angle
).
to
(
dtype
=
dtype
)
sin
=
torch
.
sin
(
angle
).
to
(
dtype
=
dtype
)
return
cos
,
sin
def
flash_rotary
(
q
,
k
,
v
,
cos
,
sin
,
causal
=
False
):
# corrected by @tridao comments
q
=
apply_rotary_emb
(
q
,
cos
,
sin
,
seqlen_offsets
=
0
,
interleaved
=
False
,
inplace
=
True
)
k
=
apply_rotary_emb
(
k
,
cos
,
sin
,
seqlen_offsets
=
0
,
interleaved
=
False
,
inplace
=
True
)
return
flash_attn_func
(
q
,
k
,
v
,
causal
=
causal
)
def
attn_bias_from_alibi_slopes
(
slopes
,
seqlen_q
,
seqlen_k
,
query_padding_mask
=
None
,
key_padding_mask
=
None
,
causal
=
False
):
batch
,
nheads
=
slopes
.
shape
device
=
slopes
.
device
slopes
=
rearrange
(
slopes
,
"b h -> b h 1 1"
)
if
causal
:
return
torch
.
arange
(
-
seqlen_k
+
1
,
1
,
device
=
device
,
dtype
=
torch
.
float32
)
*
slopes
else
:
row_idx
=
rearrange
(
torch
.
arange
(
seqlen_q
,
device
=
device
,
dtype
=
torch
.
long
),
"s -> s 1"
)
col_idx
=
torch
.
arange
(
seqlen_k
,
device
=
device
,
dtype
=
torch
.
long
)
sk
=
(
seqlen_k
if
key_padding_mask
is
None
else
rearrange
(
key_padding_mask
.
sum
(
-
1
),
"b -> b 1 1 1"
)
)
sq
=
(
seqlen_q
if
query_padding_mask
is
None
else
rearrange
(
query_padding_mask
.
sum
(
-
1
),
"b -> b 1 1 1"
)
)
relative_pos
=
torch
.
abs
(
row_idx
+
sk
-
sq
-
col_idx
)
return
-
slopes
*
relative_pos
.
to
(
dtype
=
slopes
.
dtype
)
def
flops
(
batch
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
f
=
4
*
batch
*
seqlen
**
2
*
nheads
*
headdim
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
if
not
math
.
isnan
(
time
)
else
0.0
def
attention_pytorch
(
q
,
k
,
v
,
dropout_p
=
0.0
,
causal
=
True
,
attn_bias
=
None
):
"""
Arguments:
q, k, v: (batch_size, seqlen, nheads, head_dim)
dropout_p: float
attn_bias: (batch_size, nheads, seqlen, seqlen) or (1, nheads, seqlen, seqlen)
Output:
output: (batch_size, seqlen, nheads, head_dim)
"""
batch_size
,
seqlen
,
nheads
,
d
=
q
.
shape
q
=
rearrange
(
q
,
'b t h d -> (b h) t d'
)
k
=
rearrange
(
k
,
'b s h d -> (b h) d s'
)
softmax_scale
=
1.0
/
math
.
sqrt
(
d
)
# Preallocate attn_weights for `baddbmm`
if
attn_bias
is
not
None
:
scores
=
rearrange
(
attn_bias
,
'b h t s -> (b h) t s'
)
else
:
scores
=
torch
.
empty
(
batch_size
*
nheads
,
seqlen
,
seqlen
,
dtype
=
q
.
dtype
,
device
=
q
.
device
)
scores
=
rearrange
(
torch
.
baddbmm
(
scores
,
q
,
k
,
beta
=
1.0
,
alpha
=
softmax_scale
),
'(b h) t s -> b h t s'
,
h
=
nheads
)
if
causal
:
# "triu_tril_cuda_template" not implemented for 'BFloat16'
# So we have to construct the mask in float
causal_mask
=
torch
.
triu
(
torch
.
full
((
seqlen
,
seqlen
),
-
10000.0
,
device
=
scores
.
device
),
1
)
# TD [2022-09-30]: Adding is faster than masked_fill_ (idk why, just better kernel I guess)
scores
=
scores
+
causal_mask
.
to
(
dtype
=
scores
.
dtype
)
attention
=
torch
.
softmax
(
scores
,
dim
=-
1
)
attention_drop
=
F
.
dropout
(
attention
,
dropout_p
)
output
=
torch
.
einsum
(
'bhts,bshd->bthd'
,
attention_drop
,
v
)
return
output
.
to
(
dtype
=
q
.
dtype
)
def
time_fwd_bwd
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_fwd_bwd
(
func
,
*
args
,
**
kwargs
)
return
time_f
[
1
].
mean
,
time_b
[
1
].
mean
repeats
=
30
device
=
'cuda'
dtype
=
torch
.
float16
bs_seqlen_vals
=
[(
32
,
512
),
(
16
,
1024
),
(
8
,
2048
),
(
4
,
4096
),
(
2
,
8192
),
(
1
,
16384
)]
causal_vals
=
[
False
,
True
]
headdim_vals
=
[
64
,
128
]
dim
=
2048
dropout_p
=
0.0
methods
=
([
"fa2_alibi"
,
"torch"
]
+
([
"xformers"
]
if
xops
is
not
None
else
[])
+
[
"sdpa"
]
+
[
"fa2_baseline"
]
+
[
"fa2_rotary"
])
time_f
=
{}
time_b
=
{}
time_f_b
=
{}
speed_f
=
{}
speed_b
=
{}
speed_f_b
=
{}
for
causal
in
causal_vals
:
for
headdim
in
headdim_vals
:
for
batch_size
,
seqlen
in
bs_seqlen_vals
:
config
=
(
causal
,
headdim
,
batch_size
,
seqlen
)
nheads
=
dim
//
headdim
q
,
k
,
v
=
[
torch
.
randn
(
batch_size
,
seqlen
,
nheads
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
for
_
in
range
(
3
)]
# alibi_slopes = torch.rand(batch_size, nheads, device=device, dtype=torch.float32) * 0.3
alibi_slopes
=
torch
.
rand
(
1
,
nheads
,
device
=
device
,
dtype
=
torch
.
float32
)
*
0.3
attn_bias
=
attn_bias_from_alibi_slopes
(
alibi_slopes
,
seqlen
,
seqlen
,
causal
=
causal
).
to
(
dtype
)
attn_bias
=
repeat
(
attn_bias
,
"1 ... -> b ..."
,
b
=
batch_size
)
f
,
b
=
time_fwd_bwd
(
flash_attn_func
,
q
,
k
,
v
,
dropout_p
,
causal
=
causal
,
# alibi_slopes=alibi_slopes,
alibi_slopes
=
None
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"fa2_baseline"
]
=
f
time_b
[
config
,
"fa2_baseline"
]
=
b
q
=
q
.
detach
().
requires_grad_
(
True
)
k
=
k
.
detach
().
requires_grad_
(
True
)
v
=
v
.
detach
().
requires_grad_
(
True
)
f
,
b
=
time_fwd_bwd
(
flash_attn_func
,
q
,
k
,
v
,
dropout_p
,
causal
=
causal
,
alibi_slopes
=
rearrange
(
alibi_slopes
,
"1 h -> h"
),
# alibi_slopes=None,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"fa2_alibi"
]
=
f
time_b
[
config
,
"fa2_alibi"
]
=
b
try
:
q
=
q
.
detach
().
requires_grad_
(
True
)
k
=
k
.
detach
().
requires_grad_
(
True
)
v
=
v
.
detach
().
requires_grad_
(
True
)
f
,
b
=
time_fwd_bwd
(
attention_pytorch
,
q
,
k
,
v
,
dropout_p
,
causal
=
causal
,
attn_bias
=
attn_bias
,
repeats
=
repeats
,
verbose
=
False
)
except
:
# Skip if OOM
f
,
b
=
float
(
'nan'
),
float
(
'nan'
)
time_f
[
config
,
"torch"
]
=
f
time_b
[
config
,
"torch"
]
=
b
# F.sdpa doesn't currently (torch 2.1) dispatch to flash-attn but just to be safe
with
torch
.
backends
.
cuda
.
sdp_kernel
(
enable_flash
=
False
):
q_pt
=
q
.
detach
().
requires_grad_
(
True
).
transpose
(
1
,
2
)
k_pt
=
k
.
detach
().
requires_grad_
(
True
).
transpose
(
1
,
2
)
v_pt
=
v
.
detach
().
requires_grad_
(
True
).
transpose
(
1
,
2
)
f
,
b
=
time_fwd_bwd
(
F
.
scaled_dot_product_attention
,
q_pt
,
k_pt
,
v_pt
,
attn_mask
=
attn_bias
,
dropout_p
=
dropout_p
,
is_causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"sdpa"
]
=
f
time_b
[
config
,
"sdpa"
]
=
b
if
xops
is
not
None
:
q
=
q
.
detach
().
requires_grad_
(
True
)
k
=
k
.
detach
().
requires_grad_
(
True
)
v
=
v
.
detach
().
requires_grad_
(
True
)
if
causal
:
attn_bias_xops
=
xops
.
LowerTriangularMask
().
add_bias
(
attn_bias
.
expand
(
-
1
,
-
1
,
seqlen
,
-
1
).
to
(
dtype
=
q
.
dtype
))
# NotImplementedError: No operator found for `memory_efficient_attention_backward` with inputs:
# `flshattB@v2.3.6` is not supported because:
# attn_bias type is <class 'xformers.ops.fmha.attn_bias.LowerTriangularMaskWithTensorBias'>
# `cutlassB` is not supported because:
# attn_bias type is <class 'xformers.ops.fmha.attn_bias.LowerTriangularMaskWithTensorBias'>
attn_bias_xops
=
attn_bias_xops
.
materialize
((
batch_size
,
nheads
,
seqlen
,
seqlen
),
dtype
=
q
.
dtype
,
device
=
device
)
else
:
attn_bias_xops
=
attn_bias
.
to
(
dtype
=
q
.
dtype
)
f
,
b
=
time_fwd_bwd
(
xops
.
memory_efficient_attention
,
q
,
k
,
v
,
attn_bias_xops
,
dropout_p
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"xformers"
]
=
f
time_b
[
config
,
"xformers"
]
=
b
q
=
q
.
detach
().
requires_grad_
(
True
)
k
=
k
.
detach
().
requires_grad_
(
True
)
v
=
v
.
detach
().
requires_grad_
(
True
)
cos
,
sin
=
generate_cos_sin
(
seqlen
,
headdim
,
device
,
dtype
)
f
,
b
=
time_fwd_bwd
(
flash_rotary
,
q
,
k
,
v
,
cos
,
sin
,
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"fa2_rotary"
]
=
f
time_b
[
config
,
"fa2_rotary"
]
=
b
print
(
f
"### causal=
{
causal
}
, headdim=
{
headdim
}
, batch_size=
{
batch_size
}
, seqlen=
{
seqlen
}
###"
)
csv_output
=
""
csv_output
+=
f
"
{
causal
}
,
{
headdim
}
,
{
batch_size
}
,
{
seqlen
}
,"
for
method
in
methods
:
time_f_b
[
config
,
method
]
=
time_f
[
config
,
method
]
+
time_b
[
config
,
method
]
speed_f
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"fwd"
),
time_f
[
config
,
method
]
)
speed_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"bwd"
),
time_b
[
config
,
method
]
)
speed_f_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"fwd_bwd"
),
time_f_b
[
config
,
method
]
)
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s, "
f
"bwd:
{
speed_b
[
config
,
method
]:.
2
f
}
TFLOPs/s, "
f
"fwd + bwd:
{
speed_f_b
[
config
,
method
]:.
2
f
}
TFLOPs/s"
)
csv_output
+=
f
"
{
speed_f
[
config
,
method
]:.
2
f
}
,
{
speed_b
[
config
,
method
]:.
2
f
}
,
{
speed_f_b
[
config
,
method
]:.
2
f
}
,"
print
(
csv_output
)
benchmarks/benchmark_attnmask.py
0 → 100644
View file @
34e67b1e
#!/usr/bin/env python
# Benchmark: 不同 size 下 FlashAttention 无 attnmask vs 有 attnmask 的延时与速度比。
#
# 直接运行(无参数)一次性输出 4 张表:fwd causal=True、fwd causal=False、bwd causal=True、bwd causal=False
# python benchmarks/benchmark_attnmask.py
# 仅 forward:python benchmarks/benchmark_attnmask.py --no-backward
# 仅 causal=True:python benchmarks/benchmark_attnmask.py --no-causal --causal (或只 --no-both-causal)
# 详细对比(非表格):python benchmarks/benchmark_attnmask.py --no-table
import
argparse
import
sys
# 需要与常见 benchmark 表格同尺寸时,可传:--sizes "1,1024 1,2048 1,4096 1,8192 1,16384 1,32768 8,1024 ..."
import
math
import
torch
from
flash_attn
import
flash_attn_func
,
flash_attn_with_mask_func
from
flash_attn.utils.benchmark
import
benchmark_forward
,
benchmark_fwd_bwd
def
flops
(
batch
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"fwd"
):
"""FLOPs 与 benchmark_flash_attention.py / fa_bwd_benchmark.py 一致。
fwd: 4*B*S²*H*d // (2 if causal else 1);bwd: 2.5*f;fwd_bwd: 3.5*f。
"""
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
f
=
4
*
batch
*
seqlen
**
2
*
nheads
*
headdim
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
efficiency
(
flop
,
time_sec
):
"""TFLOPs/s = flop / time_sec / 1e12,与 benchmark_flash_attention / fa_bwd_benchmark 一致。"""
return
(
flop
/
time_sec
/
10
**
12
)
if
not
math
.
isnan
(
time_sec
)
and
time_sec
>
0
else
0.0
def
attn_mask_bytes
(
batch
,
nheads_q
,
seqlen
):
"""attn_mask (batch, nheads_q, seqlen, seqlen) bool 的字节数。"""
return
batch
*
nheads_q
*
seqlen
*
seqlen
# 1 byte per bool
def
_time_forward_ms
(
fn
,
*
args
,
repeats
=
30
,
**
kwargs
):
_
,
m
=
benchmark_forward
(
fn
,
*
args
,
repeats
=
repeats
,
verbose
=
False
,
**
kwargs
)
return
m
.
mean
*
1000.0
def
_time_fwd_bwd_ms
(
fn
,
*
args
,
repeats
=
30
,
**
kwargs
):
(
_
,
m_fwd
),
(
_
,
m_bwd
)
=
benchmark_fwd_bwd
(
fn
,
*
args
,
repeats
=
repeats
,
verbose
=
False
,
**
kwargs
)
return
m_fwd
.
mean
*
1000.0
,
m_bwd
.
mean
*
1000.0
def
main
():
parser
=
argparse
.
ArgumentParser
(
description
=
"Benchmark: 无 attnmask vs 有 attnmask 延时与速度比。默认直接打表。"
)
parser
.
add_argument
(
"--table"
,
action
=
"store_true"
,
default
=
True
,
help
=
"打印表格(默认开启)"
)
parser
.
add_argument
(
"--no-table"
,
action
=
"store_false"
,
dest
=
"table"
,
help
=
"不打印表格,改为详细对比格式"
)
parser
.
add_argument
(
"--batch"
,
type
=
int
,
nargs
=
"+"
,
default
=
[
128
],
help
=
"batch sizes(未指定 --sizes 时)"
)
parser
.
add_argument
(
"--seqlen"
,
type
=
int
,
nargs
=
"+"
,
default
=
[
512
,
1024
,
1280
,
1536
,
2048
],
help
=
"sequence lengths(未指定 --sizes 时)"
)
parser
.
add_argument
(
"--sizes"
,
type
=
str
,
default
=
None
,
help
=
"(batch,seqlen) 对,空格分隔;不传则用 --batch 与 --seqlen 的笛卡尔积"
)
parser
.
add_argument
(
"--nheads"
,
type
=
int
,
default
=
28
,
help
=
"nheads_q 默认值(未指定 --nheads-q 时)"
)
parser
.
add_argument
(
"--nheads-q"
,
type
=
int
,
default
=
None
,
help
=
"query 头数,默认 28"
)
parser
.
add_argument
(
"--num-heads-kv"
,
type
=
int
,
default
=
4
,
help
=
"kv 头数,默认 4(GQA)"
)
parser
.
add_argument
(
"--headdim"
,
type
=
int
,
nargs
=
"+"
,
default
=
[
64
,
128
],
help
=
"head 维度,默认 64,128"
)
parser
.
add_argument
(
"--repeats"
,
type
=
int
,
default
=
30
)
parser
.
add_argument
(
"--causal"
,
action
=
"store_true"
,
default
=
True
,
help
=
"causal=True(默认)"
)
parser
.
add_argument
(
"--no-causal"
,
action
=
"store_false"
,
dest
=
"causal"
,
help
=
"causal=False"
)
parser
.
add_argument
(
"--both-causal"
,
action
=
"store_true"
,
default
=
True
,
help
=
"同时跑 causal True 与 False(默认开启,无参时出 4 张表)"
)
parser
.
add_argument
(
"--no-both-causal"
,
action
=
"store_false"
,
dest
=
"both_causal"
,
help
=
"只跑当前 --causal 一种"
)
parser
.
add_argument
(
"--backward"
,
action
=
"store_true"
,
default
=
True
,
help
=
"是否测 backward(默认开启,无参时出 4 张表)"
)
parser
.
add_argument
(
"--no-backward"
,
action
=
"store_false"
,
dest
=
"backward"
)
parser
.
add_argument
(
"--dtype"
,
choices
=
[
"fp16"
,
"bf16"
],
default
=
"fp16"
)
parser
.
add_argument
(
"--max-mask-gb"
,
type
=
float
,
default
=
24.0
,
help
=
"attn_mask 显存超过此值(GiB)时跳过该尺寸,避免 OOM;0 表示不限制"
)
args
=
parser
.
parse_args
()
nheads_q
=
args
.
nheads_q
if
args
.
nheads_q
is
not
None
else
args
.
nheads
num_heads_kv
=
args
.
num_heads_kv
if
args
.
num_heads_kv
is
not
None
else
nheads_q
assert
nheads_q
%
num_heads_kv
==
0
,
"nheads_q must be divisible by num_heads_kv (GQA)"
device
=
"cuda"
dtype
=
torch
.
float16
if
args
.
dtype
==
"fp16"
else
torch
.
bfloat16
dtype_str
=
"float16"
if
args
.
dtype
==
"fp16"
else
"bfloat16"
if
args
.
sizes
:
batch_sizes
,
seqlens
=
[],
[]
for
pair
in
args
.
sizes
.
split
():
b
,
s
=
pair
.
split
(
","
)
batch_sizes
.
append
(
int
(
b
))
seqlens
.
append
(
int
(
s
))
size_pairs
=
list
(
zip
(
batch_sizes
,
seqlens
))
else
:
size_pairs
=
None
batch_sizes
=
args
.
batch
seqlens
=
args
.
seqlen
headdims
=
args
.
headdim
repeats
=
args
.
repeats
causal_vals
=
[
True
,
False
]
if
args
.
both_causal
else
[
args
.
causal
]
fwd_header
=
"batch_size
\t
seqlen
\t
seqlen
\t
nheads_q
\t
num_heads_kv
\t
causal
\t
dim
\t
dtype
\t
tflops_attnmask_fwd
\t
time_attnmask_fwd(ms)
\t
tflops_no_fwd
\t
time_no_fwd(ms)
\t
fwd(%)"
bwd_header
=
"batch_size
\t
seqlen
\t
seqlen
\t
nheads_q
\t
num_heads_kv
\t
causal
\t
dim
\t
dtype
\t
tflops_attnmask_bwd
\t
time_attnmask_bwd(ms)
\t
tflops_no_bwd
\t
time_no_bwd(ms)
\t
bwd(%)"
for
headdim
in
headdims
:
run_bwd
=
args
.
backward
and
headdim
in
(
64
,
128
)
if
args
.
table
:
print
(
f
"
\n
=== dim=
{
headdim
}
==="
,
flush
=
True
)
for
causal
in
causal_vals
:
rows_bwd
=
[]
if
args
.
table
:
if
run_bwd
:
print
(
fwd_header
,
flush
=
True
)
else
:
print
(
"batch_size
\t
seqlen
\t
seqlen
\t
nheads_q
\t
num_heads_kv
\t
causal
\t
dim
\t
dtype
\t
tflops_attnmask
\t
time_attnmask(ms)
\t
tflops_no
\t
time_no(ms)
\t
tflops_attnmask/no_attnmask(%)"
,
flush
=
True
)
else
:
print
(
"
\n
"
+
"="
*
90
)
print
(
"Benchmark: 无 attnmask vs 有 attnmask — 各 size 延时 (ms) 与速度比 (attnmask/no_attnmask)"
)
print
(
"="
*
90
)
print
(
f
" dtype=
{
args
.
dtype
}
, nheads_q=
{
nheads_q
}
, num_heads_kv=
{
num_heads_kv
}
, headdim=
{
headdim
}
, causal=
{
causal
}
, repeats=
{
repeats
}
"
)
if
args
.
backward
and
headdim
not
in
(
64
,
128
):
print
(
" backward 对比仅在 headdim=64/128 时执行,当前 dim 只统计 forward。"
)
if
run_bwd
:
print
(
f
"
{
'batch'
:
>
5
}
{
'seqlen'
:
>
7
}
│
{
'no_attnmask_fwd'
:
>
12
}
{
'attnmask_fwd'
:
>
12
}
{
'ratio_fwd'
:
>
9
}
│ "
f
"
{
'no_attnmask_bwd'
:
>
12
}
{
'attnmask_bwd'
:
>
12
}
{
'ratio_bwd'
:
>
9
}
"
)
else
:
print
(
f
"
{
'batch'
:
>
5
}
{
'seqlen'
:
>
7
}
│
{
'no_attnmask(ms)'
:
>
14
}
{
'attnmask(ms)'
:
>
14
}
│
{
'speed_ratio'
:
>
10
}
(attnmask/no_attnmask, >1 表示 attnmask 更慢)"
)
print
(
"-"
*
90
)
for
batch
,
seqlen
in
(
size_pairs
if
size_pairs
else
((
b
,
s
)
for
b
in
batch_sizes
for
s
in
seqlens
)):
mask_gb
=
attn_mask_bytes
(
batch
,
nheads_q
,
seqlen
)
/
(
1024
**
3
)
if
args
.
max_mask_gb
>
0
and
mask_gb
>
args
.
max_mask_gb
:
if
args
.
table
:
skip_row
=
f
"
{
batch
}
\t
{
seqlen
}
\t
{
seqlen
}
\t
{
nheads_q
}
\t
{
num_heads_kv
}
\t
{
causal
}
\t
{
headdim
}
\t
{
dtype_str
}
\t
-
\t
-
\t
skip(OOM)
\t
{
mask_gb
:.
1
f
}
GiB_mask
\t
-"
print
(
skip_row
,
flush
=
True
)
if
run_bwd
:
rows_bwd
.
append
(
skip_row
)
else
:
print
(
f
"
{
batch
:
>
5
}
{
seqlen
:
>
7
}
│ skip (attn_mask 约
{
mask_gb
:.
1
f
}
GiB > --max-mask-gb
{
args
.
max_mask_gb
}
)"
)
continue
try
:
q
=
torch
.
randn
(
batch
,
seqlen
,
nheads_q
,
headdim
,
dtype
=
dtype
,
device
=
device
)
k
=
torch
.
randn
(
batch
,
seqlen
,
num_heads_kv
,
headdim
,
dtype
=
dtype
,
device
=
device
)
v
=
torch
.
randn
(
batch
,
seqlen
,
num_heads_kv
,
headdim
,
dtype
=
dtype
,
device
=
device
)
attn_mask
=
torch
.
ones
(
batch
,
nheads_q
,
seqlen
,
seqlen
,
dtype
=
torch
.
bool
,
device
=
device
)
except
torch
.
cuda
.
OutOfMemoryError
:
if
args
.
table
:
oom_row
=
f
"
{
batch
}
\t
{
seqlen
}
\t
{
seqlen
}
\t
{
nheads_q
}
\t
{
num_heads_kv
}
\t
{
causal
}
\t
{
headdim
}
\t
{
dtype_str
}
\t
OOM
\t
-
\t
OOM
\t
-
\t
-"
print
(
oom_row
,
flush
=
True
)
if
run_bwd
:
rows_bwd
.
append
(
oom_row
)
else
:
print
(
f
"
{
batch
:
>
5
}
{
seqlen
:
>
7
}
│ OOM (attn_mask 约
{
mask_gb
:.
1
f
}
GiB)"
)
torch
.
cuda
.
empty_cache
()
continue
try
:
t_no
=
_time_forward_ms
(
flash_attn_func
,
q
,
k
,
v
,
causal
=
causal
,
repeats
=
repeats
)
t_mask
=
_time_forward_ms
(
flash_attn_with_mask_func
,
q
,
k
,
v
,
attn_mask
,
causal
=
causal
,
repeats
=
repeats
)
except
torch
.
cuda
.
OutOfMemoryError
:
if
args
.
table
:
oom_row
=
f
"
{
batch
}
\t
{
seqlen
}
\t
{
seqlen
}
\t
{
nheads_q
}
\t
{
num_heads_kv
}
\t
{
causal
}
\t
{
headdim
}
\t
{
dtype_str
}
\t
OOM
\t
-
\t
OOM
\t
-
\t
-"
print
(
oom_row
,
flush
=
True
)
if
run_bwd
:
rows_bwd
.
append
(
oom_row
)
else
:
print
(
f
"
{
batch
:
>
5
}
{
seqlen
:
>
7
}
│ OOM (forward)"
)
del
q
,
k
,
v
,
attn_mask
torch
.
cuda
.
empty_cache
()
continue
ratio_fwd
=
t_mask
/
t_no
if
t_no
>
0
else
0.0
if
args
.
table
:
flop_fwd
=
flops
(
batch
,
seqlen
,
headdim
,
nheads_q
,
causal
,
mode
=
"fwd"
)
tflops_no_fwd
=
efficiency
(
flop_fwd
,
t_no
/
1000.0
)
tflops_attnmask_fwd
=
efficiency
(
flop_fwd
,
t_mask
/
1000.0
)
fwd_pct
=
(
tflops_attnmask_fwd
/
tflops_no_fwd
*
100.0
)
if
tflops_no_fwd
>
0
else
0.0
if
run_bwd
:
q
.
requires_grad_
(
True
)
k
.
requires_grad_
(
True
)
v
.
requires_grad_
(
True
)
try
:
(
no_fwd
,
no_bwd
)
=
_time_fwd_bwd_ms
(
flash_attn_func
,
q
,
k
,
v
,
causal
=
causal
,
repeats
=
repeats
)
q2
=
q
.
detach
().
clone
().
requires_grad_
(
True
)
k2
=
k
.
detach
().
clone
().
requires_grad_
(
True
)
v2
=
v
.
detach
().
clone
().
requires_grad_
(
True
)
(
mask_fwd
,
mask_bwd
)
=
_time_fwd_bwd_ms
(
flash_attn_with_mask_func
,
q2
,
k2
,
v2
,
attn_mask
,
causal
=
causal
,
repeats
=
repeats
)
except
torch
.
cuda
.
OutOfMemoryError
:
print
(
f
"
{
batch
}
\t
{
seqlen
}
\t
{
seqlen
}
\t
{
nheads_q
}
\t
{
num_heads_kv
}
\t
{
causal
}
\t
{
headdim
}
\t
{
dtype_str
}
\t
{
tflops_attnmask_fwd
:.
2
f
}
\t
{
t_mask
:.
2
f
}
\t
{
tflops_no_fwd
:.
2
f
}
\t
{
t_no
:.
2
f
}
\t
{
fwd_pct
:.
1
f
}
%"
,
flush
=
True
)
rows_bwd
.
append
(
f
"
{
batch
}
\t
{
seqlen
}
\t
{
seqlen
}
\t
{
nheads_q
}
\t
{
num_heads_kv
}
\t
{
causal
}
\t
{
headdim
}
\t
{
dtype_str
}
\t
OOM
\t
-
\t
OOM
\t
-
\t
-"
)
torch
.
cuda
.
empty_cache
()
continue
flop_bwd
=
flops
(
batch
,
seqlen
,
headdim
,
nheads_q
,
causal
,
mode
=
"bwd"
)
tflops_no_bwd
=
efficiency
(
flop_bwd
,
no_bwd
/
1000.0
)
tflops_attnmask_bwd
=
efficiency
(
flop_bwd
,
mask_bwd
/
1000.0
)
bwd_pct
=
(
tflops_attnmask_bwd
/
tflops_no_bwd
*
100.0
)
if
tflops_no_bwd
>
0
else
0.0
print
(
f
"
{
batch
}
\t
{
seqlen
}
\t
{
seqlen
}
\t
{
nheads_q
}
\t
{
num_heads_kv
}
\t
{
causal
}
\t
{
headdim
}
\t
{
dtype_str
}
\t
{
tflops_attnmask_fwd
:.
2
f
}
\t
{
mask_fwd
:.
2
f
}
\t
{
tflops_no_fwd
:.
2
f
}
\t
{
no_fwd
:.
2
f
}
\t
{
fwd_pct
:.
1
f
}
%"
,
flush
=
True
)
rows_bwd
.
append
(
f
"
{
batch
}
\t
{
seqlen
}
\t
{
seqlen
}
\t
{
nheads_q
}
\t
{
num_heads_kv
}
\t
{
causal
}
\t
{
headdim
}
\t
{
dtype_str
}
\t
{
tflops_attnmask_bwd
:.
2
f
}
\t
{
mask_bwd
:.
2
f
}
\t
{
tflops_no_bwd
:.
2
f
}
\t
{
no_bwd
:.
2
f
}
\t
{
bwd_pct
:.
1
f
}
%"
)
else
:
print
(
f
"
{
batch
}
\t
{
seqlen
}
\t
{
seqlen
}
\t
{
nheads_q
}
\t
{
num_heads_kv
}
\t
{
causal
}
\t
{
headdim
}
\t
{
dtype_str
}
\t
{
tflops_attnmask_fwd
:.
2
f
}
\t
{
t_mask
:.
2
f
}
\t
{
tflops_no_fwd
:.
2
f
}
\t
{
t_no
:.
2
f
}
\t
{
fwd_pct
:.
1
f
}
%"
,
flush
=
True
)
continue
if
run_bwd
:
q
.
requires_grad_
(
True
)
k
.
requires_grad_
(
True
)
v
.
requires_grad_
(
True
)
(
no_fwd
,
no_bwd
)
=
_time_fwd_bwd_ms
(
flash_attn_func
,
q
,
k
,
v
,
causal
=
causal
,
repeats
=
repeats
)
q2
=
q
.
detach
().
clone
().
requires_grad_
(
True
)
k2
=
k
.
detach
().
clone
().
requires_grad_
(
True
)
v2
=
v
.
detach
().
clone
().
requires_grad_
(
True
)
(
mask_fwd
,
mask_bwd
)
=
_time_fwd_bwd_ms
(
flash_attn_with_mask_func
,
q2
,
k2
,
v2
,
attn_mask
,
causal
=
causal
,
repeats
=
repeats
)
ratio_fwd
=
mask_fwd
/
no_fwd
if
no_fwd
>
0
else
0.0
ratio_bwd
=
mask_bwd
/
no_bwd
if
no_bwd
>
0
else
0.0
print
(
f
"
{
batch
:
>
5
}
{
seqlen
:
>
7
}
│
{
no_fwd
:
>
12.3
f
}
{
mask_fwd
:
>
12.3
f
}
{
ratio_fwd
:
>
8.2
f
}
x │ "
f
"
{
no_bwd
:
>
12.3
f
}
{
mask_bwd
:
>
12.3
f
}
{
ratio_bwd
:
>
8.2
f
}
x"
)
else
:
print
(
f
"
{
batch
:
>
5
}
{
seqlen
:
>
7
}
│
{
t_no
:
>
14.3
f
}
{
t_mask
:
>
14.3
f
}
│
{
ratio_fwd
:
>
9.2
f
}
x"
)
if
args
.
table
and
run_bwd
and
rows_bwd
:
print
(
bwd_header
,
flush
=
True
)
for
r
in
rows_bwd
:
print
(
r
,
flush
=
True
)
if
not
args
.
table
:
print
(
"="
*
90
)
print
(
"speed_ratio = attnmask_time / no_attnmask_time (>1 表示 attnmask 更慢)"
)
print
()
if
__name__
==
"__main__"
:
main
()
benchmarks/benchmark_causal.py
0 → 100644
View file @
34e67b1e
from
functools
import
partial
import
math
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
from
einops
import
rearrange
,
repeat
# from flash_attn.utils.benchmark import benchmark_forward, benchmark_backward, benchmark_combined, benchmark_all, benchmark_fwd_bwd, pytorch_profiler
from
flash_attn.utils.benchmark
import
benchmark_forward
,
benchmark_backward
,
benchmark_combined
,
benchmark_all
,
benchmark_fwd_bwd
,
pytorch_profiler
from
flash_attn.flash_attn_interface
import
flash_attn_varlen_qkvpacked_func
# # from flash_attn.triton.fused_attention import attention as attention
# from flash_attn.flash_attn_triton import flash_attn_qkvpacked_func
# from flash_attn.flash_attn_triton_og import attention as attention_og
# from triton.ops.flash_attention import attention as attention_triton
from
flash_attn
import
flash_attn_qkvpacked_func
,
flash_attn_kvpacked_func
try
:
from
flash_attn.fused_softmax
import
scaled_upper_triang_masked_softmax
except
ImportError
:
scaled_upper_triang_masked_softmax
=
None
def
attention_pytorch
(
qkv
,
dropout_p
=
0.0
,
causal
=
True
):
"""
Arguments:
qkv: (batch_size, seqlen, 3, nheads, head_dim)
dropout_p: float
Output:
output: (batch_size, seqlen, nheads, head_dim)
"""
batch_size
,
seqlen
,
_
,
nheads
,
d
=
qkv
.
shape
q
,
k
,
v
=
qkv
.
unbind
(
dim
=
2
)
q
=
rearrange
(
q
,
'b t h d -> (b h) t d'
)
k
=
rearrange
(
k
,
'b s h d -> (b h) d s'
)
softmax_scale
=
1.0
/
math
.
sqrt
(
d
)
# Preallocate attn_weights for `baddbmm`
scores
=
torch
.
empty
(
batch_size
*
nheads
,
seqlen
,
seqlen
,
dtype
=
qkv
.
dtype
,
device
=
qkv
.
device
)
scores
=
rearrange
(
torch
.
baddbmm
(
scores
,
q
,
k
,
beta
=
0
,
alpha
=
softmax_scale
),
'(b h) t s -> b h t s'
,
h
=
nheads
)
if
causal
:
# "triu_tril_cuda_template" not implemented for 'BFloat16'
# So we have to construct the mask in float
causal_mask
=
torch
.
triu
(
torch
.
full
((
seqlen
,
seqlen
),
-
10000.0
,
device
=
scores
.
device
),
1
)
# TD [2022-09-30]: Adding is faster than masked_fill_ (idk why, just better kernel I guess)
scores
=
scores
+
causal_mask
.
to
(
dtype
=
scores
.
dtype
)
attention
=
torch
.
softmax
(
scores
,
dim
=-
1
)
attention_drop
=
F
.
dropout
(
attention
,
dropout_p
)
output
=
torch
.
einsum
(
'bhts,bshd->bthd'
,
attention_drop
,
v
)
return
output
.
to
(
dtype
=
qkv
.
dtype
)
def
attention_megatron
(
qkv
):
"""
Arguments:
qkv: (batch_size, seqlen, 3, nheads, head_dim)
Output:
output: (batch_size, seqlen, nheads, head_dim)
"""
batch_size
,
seqlen
,
_
,
nheads
,
d
=
qkv
.
shape
q
,
k
,
v
=
qkv
.
unbind
(
dim
=
2
)
q
=
rearrange
(
q
,
'b t h d -> (b h) t d'
)
k
=
rearrange
(
k
,
'b s h d -> (b h) d s'
)
softmax_scale
=
1.0
/
math
.
sqrt
(
d
)
# Preallocate attn_weights for `baddbmm`
scores
=
torch
.
empty
(
batch_size
*
nheads
,
seqlen
,
seqlen
,
dtype
=
qkv
.
dtype
,
device
=
qkv
.
device
)
scores
=
rearrange
(
torch
.
baddbmm
(
scores
,
q
,
k
,
beta
=
0
,
alpha
=
softmax_scale
),
'(b h) t s -> b h t s'
,
h
=
nheads
)
attention
=
scaled_upper_triang_masked_softmax
(
scores
,
None
,
scale
=
1.0
)
output
=
torch
.
einsum
(
'bhts,bshd->bthd'
,
attention
,
v
)
return
output
.
to
(
dtype
=
qkv
.
dtype
)
torch
.
manual_seed
(
0
)
repeats
=
30
batch_size
=
8
seqlen
=
2048
nheads
=
12
headdim
=
128
# nheads = 24
# headdim = 64
# batch_size = 64
# seqlen = 512
# nheads = 8
# headdim = 128
dropout_p
=
0.0
causal
=
True
dtype
=
torch
.
float16
device
=
'cuda'
qkv
=
torch
.
randn
(
batch_size
,
seqlen
,
3
,
nheads
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
cu_seqlens
=
torch
.
arange
(
0
,
(
batch_size
+
1
)
*
seqlen
,
step
=
seqlen
,
dtype
=
torch
.
int32
,
device
=
qkv
.
device
)
qkv_unpad
=
rearrange
(
qkv
,
'b s ... -> (b s) ...'
).
detach
().
requires_grad_
(
True
)
# benchmark_all(flash_attn_varlen_qkvpacked_func, qkv_unpad,
# cu_seqlens, seqlen, dropout_p, causal=causal, repeats=repeats, desc='FlashAttention')
# pytorch_profiler(flash_attn_varlen_qkvpacked_func, qkv_unpad,
# cu_seqlens, seqlen, dropout_p, causal=causal, backward=True)
benchmark_forward
(
flash_attn_qkvpacked_func
,
qkv
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
desc
=
'Fav2'
)
pytorch_profiler
(
flash_attn_qkvpacked_func
,
qkv
,
dropout_p
,
causal
=
causal
,
backward
=
False
)
# for dropout_p in [0.1, 0.0]:
# for causal in [False, True]:
# print(f"### {dropout_p = }, {causal = } ###")
# pytorch_profiler(fav2_qkvpacked_func, qkv, dropout_p, causal=causal, backward=True)
# nheads_k = 2
# q = torch.randn(batch_size, seqlen, nheads, headdim, device=device, dtype=dtype, requires_grad=True)
# kv = torch.randn(batch_size, seqlen, 2, nheads_k, headdim, device=device, dtype=dtype,
# requires_grad=True)
# if fav2_kvpacked_func is not None:
# benchmark_all(fav2_kvpacked_func, q, kv, dropout_p, causal=causal, repeats=repeats, desc='Fav2')
# pytorch_profiler(fav2_kvpacked_func, q, kv, dropout_p, causal=causal, backward=True)
# dropout_p = 0.0
# causal = False
# benchmark_all(attention_pytorch, qkv, dropout_p, causal=causal,
# repeats=repeats, desc='PyTorch Attention')
# benchmark_all(flash_attn_qkvpacked_func, qkv, None, causal, repeats=repeats, desc='FlashAttention Triton')
# pytorch_profiler(flash_attn_qkvpacked_func, qkv, None, causal, backward=True)
# q, k, v = [torch.randn(batch_size, nheads, seqlen, headdim, device=device, dtype=dtype,
# requires_grad=True) for _ in range(3)]
# benchmark_all(attention_og, q, k, v, 1.0, repeats=repeats, desc='FlashAttention Triton OG')
# # pytorch_profiler(attention, q, k, v, 1.0, backward=True)
# if scaled_upper_triang_masked_softmax is not None:
# benchmark_all(attention_megatron, qkv, repeats=repeats, desc='Megatron Attention')
# from src.ops.fftconv import fftconv_func
# dim = nheads * headdim
# u = torch.randn(batch_size, dim, seqlen, device=device, dtype=dtype, requires_grad=True)
# k = torch.randn(dim, seqlen, device=device, requires_grad=True)
# D = torch.randn(dim, device=device, requires_grad=True)
# benchmark_all(fftconv_func, u, k, D, repeats=repeats, desc='FFTConv')
# pytorch_profiler(fftconv_func, u, k, D, backward=True)
# pytorch_profiler(torch.fft.rfft, u.float())
flops
=
4
*
batch_size
*
seqlen
**
2
*
nheads
*
headdim
ideal_a100_time
=
flops
/
312
/
1e9
print
(
f
"Ideal A100 fwd time:
{
ideal_a100_time
:.
3
f
}
ms, bwd time:
{
ideal_a100_time
*
2.5
:.
3
f
}
ms"
)
exit
(
0
)
def
time_fwd_bwd
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_fwd_bwd
(
func
,
*
args
,
**
kwargs
)
return
time_f
[
1
].
mean
,
time_b
[
1
].
mean
bs_seqlen_vals
=
[(
32
,
512
),
(
16
,
1024
),
(
8
,
2048
),
(
4
,
4096
),
(
2
,
8192
),
(
1
,
16384
)]
causal_vals
=
[
False
,
True
]
headdim_vals
=
[
64
,
128
]
dim
=
2048
dropout_p
=
0.0
time_f
=
{}
time_b
=
{}
for
causal
in
causal_vals
:
for
headdim
in
headdim_vals
:
for
batch_size
,
seqlen
in
bs_seqlen_vals
:
nheads
=
dim
//
headdim
qkv
=
torch
.
randn
(
batch_size
,
seqlen
,
3
,
nheads
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
cu_seqlens
=
torch
.
arange
(
0
,
(
batch_size
+
1
)
*
seqlen
,
step
=
seqlen
,
dtype
=
torch
.
int32
,
device
=
qkv
.
device
)
qkv_unpad
=
rearrange
(
qkv
,
'b s ... -> (b s) ...'
).
detach
().
requires_grad_
(
True
)
f
,
b
=
time_fwd_bwd
(
flash_attn_varlen_qkvpacked_func
,
qkv_unpad
,
cu_seqlens
,
seqlen
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[(
causal
,
headdim
,
batch_size
,
seqlen
),
"Flash"
]
=
f
time_b
[(
causal
,
headdim
,
batch_size
,
seqlen
),
"Flash"
]
=
b
qkv
=
qkv
.
detach
().
requires_grad_
(
True
)
f
,
b
=
time_fwd_bwd
(
fav2_qkvpacked_func
,
qkv
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[(
causal
,
headdim
,
batch_size
,
seqlen
),
"Flash2"
]
=
f
time_b
[(
causal
,
headdim
,
batch_size
,
seqlen
),
"Flash2"
]
=
b
# q, k, v = [torch.randn(batch_size, nheads, seqlen, headdim, device=device, dtype=dtype,
# requires_grad=True) for _ in range(3)]
# # Try both values of sequence_parallel and pick the faster one
# f, b = time_fwd_bwd(
# attention_triton, q, k, v, causal, headdim**(-0.5),
# False, repeats=repeats, verbose=False
# )
# _, b0 = time_fwd_bwd(
# attention_triton, q, k, v, causal, headdim**(-0.5),
# True, repeats=repeats, verbose=False
# )
# time_f[(causal, headdim, batch_size, seqlen), "Triton"] = f
# time_b[(causal, headdim, batch_size, seqlen), "Triton"] = min(b, b0)
if
seqlen
<=
8
*
1024
:
qkv
=
qkv
.
detach
().
requires_grad_
(
True
)
f
,
b
=
time_fwd_bwd
(
attention_pytorch
,
qkv
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
else
:
f
,
b
=
float
(
'nan'
),
float
(
'nan'
)
time_f
[(
causal
,
headdim
,
batch_size
,
seqlen
),
"Pytorch"
]
=
f
time_b
[(
causal
,
headdim
,
batch_size
,
seqlen
),
"Pytorch"
]
=
b
# q, k, v = [torch.randn(batch_size, seqlen, nheads, headdim, device=device, dtype=dtype,
# requires_grad=True) for _ in range(3)]
# import xformers.ops as xops
# f, b = time_fwd_bwd(
# xops.memory_efficient_attention, q, k, v,
# attn_bias=xops.LowerTriangularMask() if causal else None,
# op=(xops.fmha.cutlass.FwOp, xops.fmha.cutlass.BwOp)
# )
# time_f[(causal, headdim, batch_size, seqlen), "xformers"] = f
# time_b[(causal, headdim, batch_size, seqlen), "xformers"] = b
import
pickle
with
open
(
'flash2_attn_time_h100.plk'
,
'wb'
)
as
fp
:
pickle
.
dump
((
time_f
,
time_b
),
fp
,
protocol
=
pickle
.
HIGHEST_PROTOCOL
)
benchmarks/benchmark_fa_varlen.py
0 → 100644
View file @
34e67b1e
import
pickle
import
math
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
# from openpyxl import Workbook
from
einops
import
rearrange
,
repeat
from
flash_attn.utils.benchmark
import
benchmark_all
,
benchmark_forward
,
benchmark_backward
from
flash_attn.utils.benchmark
import
benchmark_fwd_bwd
,
benchmark_combined
from
flash_attn
import
flash_attn_qkvpacked_func
,
flash_attn_func
from
flash_attn
import
flash_attn_varlen_func
wb
=
Workbook
()
ws
=
wb
.
active
def
flops
(
batch
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
f
=
4
*
batch
*
seqlen
**
2
*
nheads
*
headdim
if
causal
:
f
=
f
/
2
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
if
not
math
.
isnan
(
time
)
else
0.0
def
time_forward
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_forward
(
func
,
*
args
,
**
kwargs
)
return
time_b
.
mean
def
padding_bmhk
(
t
):
# BMHK
# print(f"padding..")
batch
,
seqlen
,
nheads
,
dim
=
t
.
shape
t_tmp
=
torch
.
nn
.
functional
.
pad
(
t
.
reshape
(
batch
,
seqlen
,
nheads
*
dim
),
(
0
,
32
),
'constant'
,
0
)[:,:,:
-
32
].
reshape
(
batch
,
seqlen
,
nheads
,
dim
)
# print(f"{t_tmp.shape=}, {t_tmp.stride()=}")
return
t_tmp
repeats
=
30
device
=
'cuda'
dtype
=
torch
.
float16
bs_seqlen_vals
=
[(
1
,
128
),
(
1
,
1024
),
(
1
,
2048
),
(
1
,
4096
),
(
1
,
6144
),
(
1
,
8192
),
(
1
,
10
*
1024
),
(
1
,
12
*
1024
),
(
1
,
16
*
1024
),
(
1
,
32
*
1024
),
(
1
,
64
*
1024
)]
# bs_seqlen_vals = [(1, 1024), (1, 2048), (1, 4096), (1, 8192), (1, 16*1024), (1, 32*1024)]
# bs_seqlen_vals += [(8, 1024), (8, 2048), (8, 4096), (8, 8192), (8, 16*1024), (8, 32*1024)]
# bs_seqlen_vals += [(16, 2049), (32, 1024), (64, 512), (128, 256), (256, 128)]
causal_vals
=
[
True
]
headdim_vals
=
[
128
]
nheads_vals
=
[(
32
,
2
),
(
16
,
1
),
(
8
,
1
),
(
32
,
8
),
(
32
,
32
),
(
16
,
16
),
(
8
,
8
),
(
4
,
4
),
(
40
,
40
),
(
20
,
20
),
(
10
,
10
),
(
5
,
5
),
(
32
,
4
),
(
16
,
2
),
(
16
,
16
),
(
14
,
2
),
(
7
,
1
),
(
20
,
4
),
(
10
,
2
),
(
5
,
1
)]
# nheads_vals=[(28,4)]
dropout_p
=
0.0
pad
=
0
methods
=
([
"Flash2"
])
time_f
=
{}
time_b
=
{}
time_f_b
=
{}
speed_f
=
{}
speed_b
=
{}
speed_f_b
=
{}
# ws.append(['batch_size', 'total_q', 'total_kv', 'nheads_q', 'num_heads_kv', 'causal', 'dim', 'dtype', 'tflops', 'time(ms)'])
for
batch_size
,
seqlen
in
bs_seqlen_vals
:
for
causal
in
causal_vals
:
for
headdim
in
headdim_vals
:
for
nheads_q
,
nheads_k
in
nheads_vals
:
config
=
(
causal
,
headdim
,
batch_size
,
seqlen
,
nheads_q
,
nheads_k
)
q
=
torch
.
randn
(
batch_size
,
seqlen
,
nheads_q
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
k
=
torch
.
randn
(
batch_size
,
seqlen
,
nheads_k
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
v
=
torch
.
randn
(
batch_size
,
seqlen
,
nheads_k
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
q
=
padding_bmhk
(
q
)
k
=
padding_bmhk
(
k
)
v
=
padding_bmhk
(
v
)
# # print(q.shape)
# print(q.stride())
q
=
q
.
reshape
(
batch_size
*
seqlen
,
nheads_q
,
headdim
)
k
=
k
.
reshape
(
batch_size
*
seqlen
,
nheads_k
,
headdim
)
v
=
v
.
reshape
(
batch_size
*
seqlen
,
nheads_k
,
headdim
)
# print(q.shape)
# print(q.stride())
# print(k.shape)
# print(k.stride())
# print(v.shape)
# exit(-1)
cu_seqlens
=
torch
.
arange
(
0
,
(
batch_size
+
1
)
*
seqlen
,
step
=
seqlen
,
dtype
=
torch
.
int32
,
device
=
device
)
f
=
time_forward
(
flash_attn_varlen_func
,
q
,
k
,
v
,
cu_seqlens
,
cu_seqlens
,
seqlen
,
seqlen
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
print
(
f
"### causal=
{
causal
}
, headdim=
{
headdim
}
, batch_size=
{
batch_size
}
, nheads_q=
{
nheads_q
}
, nheads_k=
{
nheads_k
}
, seqlen=
{
seqlen
}
###"
)
for
method
in
methods
:
# time_f_b[config, method] = time_f[config, method] + time_b[config, method]
speed_f
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
seqlen
,
headdim
,
nheads_q
,
causal
,
mode
=
"fwd"
),
time_f
[
config
,
method
]
)
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms"
# f"bwd: {speed_b[config, method]:.2f} TFLOPs/s, "
# f"fwd + bwd: {speed_f_b[config, method]:.2f} TFLOPs/s"
)
# ws.append([batch_size, seqlen, seqlen, nheads_q, nheads_k, causal, headdim, "float16", round(speed_f[config, method], 2), round(time_f[config, method]*1000, 2)])
# exit(0)
# wb.save("varlen_64_32_4_018a7dd_waq.xlsx")
benchmarks/benchmark_fa_varlen_mla_test_fp8.py
0 → 100644
View file @
34e67b1e
import
pickle
import
math
import
argparse
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
# from openpyxl import Workbook
from
einops
import
rearrange
,
repeat
from
flash_attn.utils.benchmark
import
benchmark_all
,
benchmark_forward
,
benchmark_backward
from
flash_attn.utils.benchmark
import
benchmark_fwd_bwd
,
benchmark_combined
from
flash_attn
import
flash_attn_qkvpacked_func
,
flash_attn_func
from
flash_attn
import
flash_attn_varlen_func
# wb = Workbook()
# ws = wb.active
parser
=
argparse
.
ArgumentParser
(
description
=
'test'
)
parser
.
add_argument
(
'--prof'
,
default
=
False
,
action
=
'store_true'
,
help
=
'prof or not'
)
parser
.
add_argument
(
'--fwd'
,
default
=
False
,
action
=
'store_true'
,
help
=
'only run fwd'
)
args
=
parser
.
parse_args
()
def
flops
(
batch
,
seqlen
,
nheads
,
seqlen_k
,
nheads_kv
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
# f = 4 * batch * seqlen**2 * nheads * headdim // (2 if causal else 1)
f
=
2
*
batch
*
seqlen
*
seqlen_k
*
nheads
*
(
headdim
+
headdimv
)
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
bytegb
(
batch
,
seqlen
,
nheads
,
seqlen_k
,
nheads_kv
,
headdim
,
headdimv
,
causal
):
b
=
((
batch
*
seqlen
*
nheads
*
headdim
+
batch
*
seqlen_k
*
nheads_kv
*
headdim
+
batch
*
seqlen_k
*
nheads_kv
*
headdimv
)
*
(
torch
.
finfo
(
torch
.
float8_e4m3fn
).
bits
//
8
)
+
(
batch
*
seqlen
*
nheads
*
headdimv
)
*
(
torch
.
finfo
(
torch
.
float16
).
bits
//
8
))
//
(
2
if
causal
else
1
)
return
b
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
if
not
math
.
isnan
(
time
)
else
0.0
def
efficiency_bytes
(
byte
,
time
):
return
(
byte
/
time
/
10
**
9
)
if
not
math
.
isnan
(
time
)
else
0.0
def
time_forward
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_forward
(
func
,
*
args
,
**
kwargs
)
return
time_b
.
mean
def
time_fwd_bwd
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_fwd_bwd
(
func
,
*
args
,
**
kwargs
)
return
time_f
[
1
].
mean
,
time_b
[
1
].
mean
def
padding_bmhk
(
t
):
# BMHK
# print(f"padding..")
batch
,
seqlen
,
nheads
,
dim
=
t
.
shape
t_tmp
=
torch
.
nn
.
functional
.
pad
(
t
.
reshape
(
batch
,
seqlen
,
nheads
*
dim
),
(
0
,
32
),
'constant'
,
0
)[:,:,:
-
32
].
reshape
(
batch
,
seqlen
,
nheads
,
dim
)
# print(f"{t_tmp.shape=}, {t_tmp.stride()=}")
return
t_tmp
repeats
=
30
device
=
'cuda'
dtype
=
torch
.
float8_e4m3fn
dropout_p
=
0.0
pad
=
0
methods
=
([
"Flash2"
])
time_f
=
{}
time_b
=
{}
time_f_b
=
{}
speed_f
=
{}
speed_b
=
{}
speed_f_b
=
{}
gb_s
=
{}
fwdOnly
=
True
# ws.append(['batch_size', 'total_q', 'total_kv', 'nheads_q', 'num_heads_kv', 'causal', 'dim', 'dimv', 'dtype', 'tflops', 'time(ms)'])
test_size
=
[
(
32
,
512
,
16
,
512
,
16
,
192
,
128
,
False
),
(
16
,
1024
,
16
,
1024
,
16
,
192
,
128
,
False
),
(
8
,
2048
,
16
,
2048
,
16
,
192
,
128
,
False
),
(
4
,
4096
,
16
,
4096
,
16
,
192
,
128
,
False
),
(
2
,
8192
,
16
,
8192
,
16
,
192
,
128
,
False
),
(
1
,
16384
,
16
,
16384
,
16
,
192
,
128
,
False
),
(
32
,
512
,
16
,
512
,
16
,
192
,
128
,
True
),
(
16
,
1024
,
16
,
1024
,
16
,
192
,
128
,
True
),
(
8
,
2048
,
16
,
2048
,
16
,
192
,
128
,
True
),
(
4
,
4096
,
16
,
4096
,
16
,
192
,
128
,
True
),
(
2
,
8192
,
16
,
8192
,
16
,
192
,
128
,
True
),
(
1
,
16384
,
16
,
16384
,
16
,
192
,
128
,
True
),
]
if
args
.
prof
:
repeats
=
1
test_size
=
[
test_size
[
-
3
]]
for
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
in
test_size
:
config
=
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
)
q
=
torch
.
randn
(
batch_size
,
total_q
,
nheads_q
,
headdim
,
device
=
device
,
dtype
=
torch
.
bfloat16
,
requires_grad
=
True
)
k
=
torch
.
randn
(
batch_size
,
total_kv
,
nheads_k
,
headdim
,
device
=
device
,
dtype
=
torch
.
bfloat16
,
requires_grad
=
True
)
v
=
torch
.
randn
(
batch_size
,
total_kv
,
nheads_k
,
headdimv
,
device
=
device
,
dtype
=
torch
.
bfloat16
,
requires_grad
=
True
)
# q = padding_bmhk(q)
# k = padding_bmhk(k)
# v = padding_bmhk(v)
# # print(q.shape)
# print(q.stride())
q
=
q
.
reshape
(
batch_size
*
total_q
,
nheads_q
,
headdim
)
k
=
k
.
reshape
(
batch_size
*
total_kv
,
nheads_k
,
headdim
)
v
=
v
.
reshape
(
batch_size
*
total_kv
,
nheads_k
,
headdimv
)
q
,
k
,
v
=
q
.
to
(
dtype
),
k
.
to
(
dtype
),
v
.
to
(
dtype
)
q_descale
,
k_descale
,
v_descale
=
[
torch
.
ones
(
batch_size
,
nheads_k
,
device
=
device
,
dtype
=
torch
.
float32
)
for
_
in
range
(
3
)]
# print(q.shape)
# print(q.stride())
# print(k.shape)
# print(k.stride())
# print(v.shape)
# exit(-1)
cu_seqlens
=
torch
.
arange
(
0
,
(
batch_size
+
1
)
*
total_q
,
step
=
total_q
,
dtype
=
torch
.
int32
,
device
=
device
)
if
fwdOnly
:
f
=
time_forward
(
flash_attn_varlen_func
,
q
,
k
,
v
,
cu_seqlens
,
cu_seqlens
,
total_q
,
total_kv
,
dropout_p
,
causal
=
causal
,
q_descale
=
q_descale
,
k_descale
=
k_descale
,
v_descale
=
v_descale
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
else
:
f
,
b
=
time_fwd_bwd
(
flash_attn_varlen_func
,
q
,
k
,
v
,
cu_seqlens
,
cu_seqlens
,
total_q
,
total_kv
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
time_b
[
config
,
"Flash2"
]
=
b
print
(
f
"### causal=
{
causal
}
, headdim=
{
headdim
}
, headdimv=
{
headdimv
}
, batch_size=
{
batch_size
}
, nheads_q=
{
nheads_q
}
, nheads_k=
{
nheads_k
}
, total_q=
{
total_q
}
, total_kv=
{
total_kv
}
###"
)
for
method
in
methods
:
# time_f_b[config, method] = time_f[config, method] + time_b[config, method]
speed_f
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd"
),
time_f
[
config
,
method
]
)
gb_s
[
config
,
method
]
=
efficiency_bytes
(
bytegb
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
),
time_f
[
config
,
method
]
)
if
fwdOnly
:
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
gb_s
[
config
,
method
]:.
2
f
}
GB/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
)
else
:
time_f_b
[
config
,
method
]
=
time_f
[
config
,
method
]
+
time_b
[
config
,
method
]
speed_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"bwd"
),
time_b
[
config
,
method
]
)
speed_f_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd_bwd"
),
time_f_b
[
config
,
method
]
)
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
f
"bwd:
{
speed_b
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_b
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
f
"fwd + bwd:
{
speed_f_b
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f_b
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
)
# ws.append([batch_size, seqlen, seqlen, nheads_q, nheads_k, causal, headdim, "float16", round(speed_f[config, method], 2), round(time_f[config, method]*1000, 2)])
# exit(0)
# wb.save("varlen_64_32_4_018a7dd_waq.xlsx")
benchmarks/benchmark_fa_varlen_test.py
0 → 100644
View file @
34e67b1e
import
pickle
import
math
import
argparse
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
# from openpyxl import Workbook
from
einops
import
rearrange
,
repeat
from
flash_attn.utils.benchmark
import
benchmark_all
,
benchmark_forward
,
benchmark_backward
from
flash_attn.utils.benchmark
import
benchmark_fwd_bwd
,
benchmark_combined
from
flash_attn
import
flash_attn_qkvpacked_func
,
flash_attn_func
from
flash_attn
import
flash_attn_varlen_func
# wb = Workbook()
# ws = wb.active
parser
=
argparse
.
ArgumentParser
(
description
=
'test'
)
parser
.
add_argument
(
'--prof'
,
default
=
False
,
action
=
'store_true'
,
help
=
'prof or not'
)
parser
.
add_argument
(
'--fwd'
,
default
=
False
,
action
=
'store_true'
,
help
=
'only run fwd'
)
args
=
parser
.
parse_args
()
def
flops
(
batch
,
seqlen
,
nheads
,
seqlen_k
,
nheads_kv
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
# f = 4 * batch * seqlen**2 * nheads * headdim // (2 if causal else 1)
f
=
2
*
batch
*
seqlen
*
seqlen_k
*
nheads
*
(
headdim
+
headdimv
)
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
if
not
math
.
isnan
(
time
)
else
0.0
def
time_forward
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_forward
(
func
,
*
args
,
**
kwargs
)
return
time_b
.
mean
def
time_fwd_bwd
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_fwd_bwd
(
func
,
*
args
,
**
kwargs
)
return
time_f
[
1
].
mean
,
time_b
[
1
].
mean
def
padding_bmhk
(
t
):
# BMHK
# print(f"padding..")
batch
,
seqlen
,
nheads
,
dim
=
t
.
shape
t_tmp
=
torch
.
nn
.
functional
.
pad
(
t
.
reshape
(
batch
,
seqlen
,
nheads
*
dim
),
(
0
,
32
),
'constant'
,
0
)[:,:,:
-
32
].
reshape
(
batch
,
seqlen
,
nheads
,
dim
)
# print(f"{t_tmp.shape=}, {t_tmp.stride()=}")
return
t_tmp
repeats
=
30
device
=
'cuda'
dtype
=
torch
.
float16
dropout_p
=
0.0
pad
=
0
methods
=
([
"Flash2"
])
time_f
=
{}
time_b
=
{}
time_f_b
=
{}
speed_f
=
{}
speed_b
=
{}
speed_f_b
=
{}
fwdOnly
=
args
.
fwd
# ws.append(['batch_size', 'total_q', 'total_kv', 'nheads_q', 'num_heads_kv', 'causal', 'dim', 'dimv', 'dtype', 'tflops', 'time(ms)'])
test_size
=
[
(
32
,
512
,
16
,
512
,
16
,
192
,
128
,
False
),
(
16
,
1024
,
16
,
1024
,
16
,
192
,
128
,
False
),
(
8
,
2048
,
16
,
2048
,
16
,
192
,
128
,
False
),
(
4
,
4096
,
16
,
4096
,
16
,
192
,
128
,
False
),
(
2
,
8192
,
16
,
8192
,
16
,
192
,
128
,
False
),
(
1
,
16384
,
16
,
16384
,
16
,
192
,
128
,
False
),
(
32
,
512
,
16
,
512
,
16
,
192
,
128
,
True
),
(
16
,
1024
,
16
,
1024
,
16
,
192
,
128
,
True
),
(
8
,
2048
,
16
,
2048
,
16
,
192
,
128
,
True
),
(
4
,
4096
,
16
,
4096
,
16
,
192
,
128
,
True
),
(
2
,
8192
,
16
,
8192
,
16
,
192
,
128
,
True
),
(
1
,
16384
,
16
,
16384
,
16
,
192
,
128
,
True
),
]
if
args
.
prof
:
repeats
=
1
test_size
=
[
test_size
[
-
3
]]
for
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
in
test_size
:
config
=
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
)
q
=
torch
.
randn
(
batch_size
,
total_q
,
nheads_q
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
k
=
torch
.
randn
(
batch_size
,
total_kv
,
nheads_k
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
v
=
torch
.
randn
(
batch_size
,
total_kv
,
nheads_k
,
headdimv
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
# q = padding_bmhk(q)
# k = padding_bmhk(k)
# v = padding_bmhk(v)
# # print(q.shape)
# print(q.stride())
q
=
q
.
reshape
(
batch_size
*
total_q
,
nheads_q
,
headdim
)
k
=
k
.
reshape
(
batch_size
*
total_kv
,
nheads_k
,
headdim
)
v
=
v
.
reshape
(
batch_size
*
total_kv
,
nheads_k
,
headdimv
)
# print(q.shape)
# print(q.stride())
# print(k.shape)
# print(k.stride())
# print(v.shape)
# exit(-1)
cu_seqlens
=
torch
.
arange
(
0
,
(
batch_size
+
1
)
*
total_q
,
step
=
total_q
,
dtype
=
torch
.
int32
,
device
=
device
)
if
fwdOnly
:
f
=
time_forward
(
flash_attn_varlen_func
,
q
,
k
,
v
,
cu_seqlens
,
cu_seqlens
,
total_q
,
total_kv
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
else
:
f
,
b
=
time_fwd_bwd
(
flash_attn_varlen_func
,
q
,
k
,
v
,
cu_seqlens
,
cu_seqlens
,
total_q
,
total_kv
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
time_b
[
config
,
"Flash2"
]
=
b
print
(
f
"### causal=
{
causal
}
, headdim=
{
headdim
}
, headdimv=
{
headdimv
}
, batch_size=
{
batch_size
}
, nheads_q=
{
nheads_q
}
, nheads_k=
{
nheads_k
}
, total_q=
{
total_q
}
, total_kv=
{
total_kv
}
###"
)
for
method
in
methods
:
# time_f_b[config, method] = time_f[config, method] + time_b[config, method]
speed_f
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd"
),
time_f
[
config
,
method
]
)
if
fwdOnly
:
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
)
else
:
time_f_b
[
config
,
method
]
=
time_f
[
config
,
method
]
+
time_b
[
config
,
method
]
speed_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"bwd"
),
time_b
[
config
,
method
]
)
speed_f_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd_bwd"
),
time_f_b
[
config
,
method
]
)
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
f
"bwd:
{
speed_b
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_b
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
f
"fwd + bwd:
{
speed_f_b
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f_b
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
)
# ws.append([batch_size, seqlen, seqlen, nheads_q, nheads_k, causal, headdim, "float16", round(speed_f[config, method], 2), round(time_f[config, method]*1000, 2)])
# exit(0)
# wb.save("varlen_64_32_4_018a7dd_waq.xlsx")
benchmarks/benchmark_fa_varlen_test_fp8.py
0 → 100644
View file @
34e67b1e
import
pickle
import
math
import
argparse
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
# from openpyxl import Workbook
from
einops
import
rearrange
,
repeat
from
flash_attn.utils.benchmark
import
benchmark_all
,
benchmark_forward
,
benchmark_backward
from
flash_attn.utils.benchmark
import
benchmark_fwd_bwd
,
benchmark_combined
from
flash_attn
import
flash_attn_qkvpacked_func
,
flash_attn_func
from
flash_attn
import
flash_attn_varlen_func
# wb = Workbook()
# ws = wb.active
parser
=
argparse
.
ArgumentParser
(
description
=
'test'
)
parser
.
add_argument
(
'--prof'
,
default
=
False
,
action
=
'store_true'
,
help
=
'prof or not'
)
parser
.
add_argument
(
'--fwd'
,
default
=
False
,
action
=
'store_true'
,
help
=
'only run fwd'
)
args
=
parser
.
parse_args
()
def
flops
(
batch
,
seqlen
,
nheads
,
seqlen_k
,
nheads_kv
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
# f = 4 * batch * seqlen**2 * nheads * headdim // (2 if causal else 1)
f
=
2
*
batch
*
seqlen
*
seqlen_k
*
nheads
*
(
headdim
+
headdimv
)
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
bytegb
(
batch
,
seqlen
,
nheads
,
seqlen_k
,
nheads_kv
,
headdim
,
headdimv
,
causal
):
b
=
((
batch
*
seqlen
*
nheads
*
headdim
+
batch
*
seqlen_k
*
nheads_kv
*
headdim
+
batch
*
seqlen_k
*
nheads_kv
*
headdimv
)
*
(
torch
.
finfo
(
torch
.
float8_e4m3fn
).
bits
//
8
)
+
(
batch
*
seqlen
*
nheads
*
headdimv
)
*
(
torch
.
finfo
(
torch
.
float16
).
bits
//
8
))
//
(
2
if
causal
else
1
)
return
b
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
if
not
math
.
isnan
(
time
)
else
0.0
def
efficiency_bytes
(
byte
,
time
):
return
(
byte
/
time
/
10
**
9
)
if
not
math
.
isnan
(
time
)
else
0.0
def
time_forward
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_forward
(
func
,
*
args
,
**
kwargs
)
return
time_b
.
mean
def
time_fwd_bwd
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_fwd_bwd
(
func
,
*
args
,
**
kwargs
)
return
time_f
[
1
].
mean
,
time_b
[
1
].
mean
def
padding_bmhk
(
t
):
# BMHK
# print(f"padding..")
batch
,
seqlen
,
nheads
,
dim
=
t
.
shape
t_tmp
=
torch
.
nn
.
functional
.
pad
(
t
.
reshape
(
batch
,
seqlen
,
nheads
*
dim
),
(
0
,
32
),
'constant'
,
0
)[:,:,:
-
32
].
reshape
(
batch
,
seqlen
,
nheads
,
dim
)
# print(f"{t_tmp.shape=}, {t_tmp.stride()=}")
return
t_tmp
repeats
=
30
device
=
'cuda'
dtype
=
torch
.
float8_e4m3fn
dropout_p
=
0.0
pad
=
0
methods
=
([
"Flash2"
])
time_f
=
{}
time_b
=
{}
time_f_b
=
{}
speed_f
=
{}
speed_b
=
{}
speed_f_b
=
{}
gb_s
=
{}
fwdOnly
=
True
# ws.append(['batch_size', 'total_q', 'total_kv', 'nheads_q', 'num_heads_kv', 'causal', 'dim', 'dimv', 'dtype', 'tflops', 'time(ms)'])
test_size
=
[
(
32
,
512
,
16
,
512
,
16
,
128
,
128
,
False
),
(
16
,
1024
,
16
,
1024
,
16
,
128
,
128
,
False
),
(
8
,
2048
,
16
,
2048
,
16
,
128
,
128
,
False
),
(
4
,
4096
,
16
,
4096
,
16
,
128
,
128
,
False
),
(
2
,
8192
,
16
,
8192
,
16
,
128
,
128
,
False
),
(
1
,
16384
,
16
,
16384
,
16
,
128
,
128
,
False
),
(
32
,
512
,
16
,
512
,
16
,
128
,
128
,
True
),
(
16
,
1024
,
16
,
1024
,
16
,
128
,
128
,
True
),
(
8
,
2048
,
16
,
2048
,
16
,
128
,
128
,
True
),
(
4
,
4096
,
16
,
4096
,
16
,
128
,
128
,
True
),
(
2
,
8192
,
16
,
8192
,
16
,
128
,
128
,
True
),
(
1
,
16384
,
16
,
16384
,
16
,
128
,
128
,
True
),
]
if
args
.
prof
:
repeats
=
1
test_size
=
[
test_size
[
-
3
]]
for
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
in
test_size
:
config
=
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
)
q
=
torch
.
randn
(
batch_size
,
total_q
,
nheads_q
,
headdim
,
device
=
device
,
dtype
=
torch
.
bfloat16
,
requires_grad
=
True
)
k
=
torch
.
randn
(
batch_size
,
total_kv
,
nheads_k
,
headdim
,
device
=
device
,
dtype
=
torch
.
bfloat16
,
requires_grad
=
True
)
v
=
torch
.
randn
(
batch_size
,
total_kv
,
nheads_k
,
headdimv
,
device
=
device
,
dtype
=
torch
.
bfloat16
,
requires_grad
=
True
)
# q = padding_bmhk(q)
# k = padding_bmhk(k)
# v = padding_bmhk(v)
# # print(q.shape)
# print(q.stride())
q
=
q
.
reshape
(
batch_size
*
total_q
,
nheads_q
,
headdim
)
k
=
k
.
reshape
(
batch_size
*
total_kv
,
nheads_k
,
headdim
)
v
=
v
.
reshape
(
batch_size
*
total_kv
,
nheads_k
,
headdimv
)
q
,
k
,
v
=
q
.
to
(
dtype
),
k
.
to
(
dtype
),
v
.
to
(
dtype
)
q_descale
,
k_descale
,
v_descale
=
[
torch
.
ones
(
batch_size
,
nheads_k
,
device
=
device
,
dtype
=
torch
.
float32
)
for
_
in
range
(
3
)]
# print(q.shape)
# print(q.stride())
# print(k.shape)
# print(k.stride())
# print(v.shape)
# exit(-1)
cu_seqlens
=
torch
.
arange
(
0
,
(
batch_size
+
1
)
*
total_q
,
step
=
total_q
,
dtype
=
torch
.
int32
,
device
=
device
)
if
fwdOnly
:
f
=
time_forward
(
flash_attn_varlen_func
,
q
,
k
,
v
,
cu_seqlens
,
cu_seqlens
,
total_q
,
total_kv
,
dropout_p
,
causal
=
causal
,
q_descale
=
q_descale
,
k_descale
=
k_descale
,
v_descale
=
v_descale
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
else
:
f
,
b
=
time_fwd_bwd
(
flash_attn_varlen_func
,
q
,
k
,
v
,
cu_seqlens
,
cu_seqlens
,
total_q
,
total_kv
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
time_b
[
config
,
"Flash2"
]
=
b
print
(
f
"### causal=
{
causal
}
, headdim=
{
headdim
}
, headdimv=
{
headdimv
}
, batch_size=
{
batch_size
}
, nheads_q=
{
nheads_q
}
, nheads_k=
{
nheads_k
}
, total_q=
{
total_q
}
, total_kv=
{
total_kv
}
###"
)
for
method
in
methods
:
# time_f_b[config, method] = time_f[config, method] + time_b[config, method]
speed_f
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd"
),
time_f
[
config
,
method
]
)
gb_s
[
config
,
method
]
=
efficiency_bytes
(
bytegb
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
),
time_f
[
config
,
method
]
)
if
fwdOnly
:
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
gb_s
[
config
,
method
]:.
2
f
}
GB/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
)
else
:
time_f_b
[
config
,
method
]
=
time_f
[
config
,
method
]
+
time_b
[
config
,
method
]
speed_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"bwd"
),
time_b
[
config
,
method
]
)
speed_f_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd_bwd"
),
time_f_b
[
config
,
method
]
)
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
f
"bwd:
{
speed_b
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_b
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
f
"fwd + bwd:
{
speed_f_b
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f_b
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
)
# ws.append([batch_size, seqlen, seqlen, nheads_q, nheads_k, causal, headdim, "float16", round(speed_f[config, method], 2), round(time_f[config, method]*1000, 2)])
# exit(0)
# wb.save("varlen_64_32_4_018a7dd_waq.xlsx")
benchmarks/benchmark_flash_attention.py
0 → 100644
View file @
34e67b1e
# Install the newest triton version with
# pip install "git+https://github.com/openai/triton.git#egg=triton&subdirectory=python"
import
sys
import
pickle
import
math
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
from
einops
import
rearrange
,
repeat
from
flash_attn.utils.benchmark
import
benchmark_all
,
benchmark_forward
,
benchmark_backward
from
flash_attn.utils.benchmark
import
benchmark_fwd_bwd
,
benchmark_combined
from
flash_attn
import
flash_attn_qkvpacked_func
try
:
from
triton.ops.flash_attention
import
attention
as
attention_triton
except
ImportError
:
attention_triton
=
None
try
:
import
xformers.ops
as
xops
except
ImportError
:
xops
=
None
xops
=
None
def
flops
(
batch
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
f
=
4
*
batch
*
seqlen
**
2
*
nheads
*
headdim
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
if
not
math
.
isnan
(
time
)
else
0.0
def
attention_pytorch
(
qkv
,
dropout_p
=
0.0
,
causal
=
True
):
"""
Arguments:
qkv: (batch_size, seqlen, 3, nheads, head_dim)
dropout_p: float
Output:
output: (batch_size, seqlen, nheads, head_dim)
"""
batch_size
,
seqlen
,
_
,
nheads
,
d
=
qkv
.
shape
q
,
k
,
v
=
qkv
.
unbind
(
dim
=
2
)
q
=
rearrange
(
q
,
'b t h d -> (b h) t d'
)
k
=
rearrange
(
k
,
'b s h d -> (b h) d s'
)
softmax_scale
=
1.0
/
math
.
sqrt
(
d
)
# Preallocate attn_weights for `baddbmm`
scores
=
torch
.
empty
(
batch_size
*
nheads
,
seqlen
,
seqlen
,
dtype
=
qkv
.
dtype
,
device
=
qkv
.
device
)
scores
=
rearrange
(
torch
.
baddbmm
(
scores
,
q
,
k
,
beta
=
0
,
alpha
=
softmax_scale
),
'(b h) t s -> b h t s'
,
h
=
nheads
)
if
causal
:
# "triu_tril_cuda_template" not implemented for 'BFloat16'
# So we have to construct the mask in float
causal_mask
=
torch
.
triu
(
torch
.
full
((
seqlen
,
seqlen
),
-
10000.0
,
device
=
scores
.
device
),
1
)
# TD [2022-09-30]: Adding is faster than masked_fill_ (idk why, just better kernel I guess)
scores
=
scores
+
causal_mask
.
to
(
dtype
=
scores
.
dtype
)
attention
=
torch
.
softmax
(
scores
,
dim
=-
1
)
attention_drop
=
F
.
dropout
(
attention
,
dropout_p
)
output
=
torch
.
einsum
(
'bhts,bshd->bthd'
,
attention_drop
,
v
)
return
output
.
to
(
dtype
=
qkv
.
dtype
)
def
time_fwd_bwd
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_fwd_bwd
(
func
,
*
args
,
**
kwargs
)
return
time_f
[
1
].
mean
,
time_b
[
1
].
mean
def
time_fwd
(
func
,
*
args
,
**
kwargs
):
time_f
=
benchmark_forward
(
func
,
*
args
,
**
kwargs
)
# print(time_f)
return
time_f
[
1
].
mean
repeats
=
30
device
=
'cuda'
dtype
=
torch
.
float16
bs_seqlen_vals
=
[(
32
,
512
),
(
16
,
1024
),
(
8
,
2048
),
(
4
,
4096
),
(
2
,
8192
),
(
1
,
16384
)]
causal_vals
=
[
False
,
True
]
if
len
(
sys
.
argv
)
>
1
and
sys
.
argv
[
1
]
==
'prof'
:
repeats
=
1
bs_seqlen_vals
=
[
bs_seqlen_vals
[
-
2
]]
causal_vals
=
[
causal_vals
[
-
1
]]
headdim_vals
=
[
128
]
# headdim_vals = [32, 64, 96]
# dim = 2048
# dim = 128 * 17
dropout_p
=
0.0
# methods = (["Flash2", "Pytorch"]
# + (["Triton"] if attention_triton is not None else [])
# + (["xformers.c"] if xops is not None else [])
# + (["xformers.f"] if xops is not None else [])
# )
methods
=
([
"Flash2"
])
time_f
=
{}
time_b
=
{}
time_f_b
=
{}
speed_f
=
{}
speed_b
=
{}
speed_f_b
=
{}
for
causal
in
causal_vals
:
for
headdim
in
headdim_vals
:
for
batch_size
,
seqlen
in
bs_seqlen_vals
:
config
=
(
causal
,
headdim
,
batch_size
,
seqlen
)
# nheads = dim // headdim
nheads
=
16
qkv
=
torch
.
randn
(
batch_size
,
seqlen
,
3
,
nheads
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
f
,
b
=
time_fwd_bwd
(
flash_attn_qkvpacked_func
,
qkv
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
time_b
[
config
,
"Flash2"
]
=
b
try
:
qkv
=
qkv
.
detach
().
requires_grad_
(
True
)
f
,
b
=
time_fwd_bwd
(
attention_pytorch
,
qkv
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
except
:
# Skip if OOM
f
,
b
=
float
(
'nan'
),
float
(
'nan'
)
time_f
[
config
,
"Pytorch"
]
=
f
time_b
[
config
,
"Pytorch"
]
=
b
if
attention_triton
is
not
None
:
q
,
k
,
v
=
[
torch
.
randn
(
batch_size
,
nheads
,
seqlen
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
for
_
in
range
(
3
)]
# Try both values of sequence_parallel and pick the faster one
try
:
f
,
b
=
time_fwd_bwd
(
attention_triton
,
q
,
k
,
v
,
causal
,
headdim
**
(
-
0.5
),
False
,
repeats
=
repeats
,
verbose
=
False
)
except
:
f
,
b
=
float
(
'nan'
),
float
(
'inf'
)
try
:
_
,
b0
=
time_fwd_bwd
(
attention_triton
,
q
,
k
,
v
,
causal
,
headdim
**
(
-
0.5
),
True
,
repeats
=
repeats
,
verbose
=
False
)
except
:
b0
=
float
(
'inf'
)
time_f
[
config
,
"Triton"
]
=
f
time_b
[
config
,
"Triton"
]
=
min
(
b
,
b0
)
if
min
(
b
,
b0
)
<
float
(
'inf'
)
else
float
(
'nan'
)
if
xops
is
not
None
:
q
,
k
,
v
=
[
torch
.
randn
(
batch_size
,
seqlen
,
nheads
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
for
_
in
range
(
3
)]
f
,
b
=
time_fwd_bwd
(
xops
.
memory_efficient_attention
,
q
,
k
,
v
,
attn_bias
=
xops
.
LowerTriangularMask
()
if
causal
else
None
,
op
=
(
xops
.
fmha
.
cutlass
.
FwOp
,
xops
.
fmha
.
cutlass
.
BwOp
)
)
time_f
[
config
,
"xformers.c"
]
=
f
time_b
[
config
,
"xformers.c"
]
=
b
if
xops
is
not
None
:
q
,
k
,
v
=
[
torch
.
randn
(
batch_size
,
seqlen
,
nheads
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
for
_
in
range
(
3
)]
f
,
b
=
time_fwd_bwd
(
xops
.
memory_efficient_attention
,
q
,
k
,
v
,
attn_bias
=
xops
.
LowerTriangularMask
()
if
causal
else
None
,
op
=
(
xops
.
fmha
.
flash
.
FwOp
,
xops
.
fmha
.
flash
.
BwOp
)
)
time_f
[
config
,
"xformers.f"
]
=
f
time_b
[
config
,
"xformers.f"
]
=
b
print
(
f
"### causal=
{
causal
}
, headdim=
{
headdim
}
, batch_size=
{
batch_size
}
,nheads=
{
nheads
}
, seqlen=
{
seqlen
}
###"
)
for
method
in
methods
:
time_f_b
[
config
,
method
]
=
time_f
[
config
,
method
]
+
time_b
[
config
,
method
]
speed_f
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"fwd"
),
time_f
[
config
,
method
]
)
speed_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"bwd"
),
time_b
[
config
,
method
]
)
speed_f_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"fwd_bwd"
),
time_f_b
[
config
,
method
]
)
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms, "
f
"bwd:
{
speed_b
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_b
[
config
,
method
]
*
1000
:.
2
f
}
ms, "
f
"fwd + bwd:
{
speed_f_b
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f_b
[
config
,
method
]
*
1000
:.
2
f
}
ms"
)
# with open('flash2_attn_time.plk', 'wb') as fp:
# pickle.dump((speed_f, speed_b, speed_f_b), fp, protocol=pickle.HIGHEST_PROTOCOL)
benchmarks/benchmark_flash_attention_padding.py
0 → 100644
View file @
34e67b1e
# Install the newest triton version with
# pip install "git+https://github.com/openai/triton.git#egg=triton&subdirectory=python"
import
pickle
import
math
import
sys
import
argparse
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
from
einops
import
rearrange
,
repeat
from
flash_attn.utils.benchmark
import
benchmark_all
,
benchmark_forward
,
benchmark_backward
from
flash_attn.utils.benchmark
import
benchmark_fwd_bwd
,
benchmark_combined
from
flash_attn
import
flash_attn_qkvpacked_func
,
flash_attn_func
# from flash_attn import flash_attn_func_blasst as flash_attn_func
try
:
from
triton.ops.flash_attention
import
attention
as
attention_triton
except
ImportError
:
attention_triton
=
None
try
:
import
xformers.ops
as
xops
except
ImportError
:
xops
=
None
parser
=
argparse
.
ArgumentParser
(
description
=
'test'
)
parser
.
add_argument
(
'--prof'
,
default
=
False
,
action
=
'store_true'
,
help
=
'prof or not'
)
parser
.
add_argument
(
'--bhsd'
,
default
=
False
,
action
=
'store_true'
,
help
=
'bhsd or not'
)
parser
.
add_argument
(
'--hy'
,
default
=
False
,
action
=
'store_true'
,
help
=
'hy code or not'
)
parser
.
add_argument
(
'--ali'
,
default
=
False
,
action
=
'store_true'
,
help
=
'alibaba size or not'
)
parser
.
add_argument
(
'--qwen'
,
default
=
False
,
action
=
'store_true'
,
help
=
'qwen size or not'
)
parser
.
add_argument
(
'--xf'
,
default
=
False
,
action
=
'store_true'
,
help
=
'xunfei size or not'
)
parser
.
add_argument
(
'--fwd'
,
default
=
False
,
action
=
'store_true'
,
help
=
'only run fwd'
)
args
=
parser
.
parse_args
()
# def flops(batch, seqlen, headdim, nheads, causal, mode="fwd"):
# assert mode in ["fwd", "bwd", "fwd_bwd"]
# f = 4 * batch * seqlen ** 2 * nheads * headdim
# if causal:
# f = f / 2
# return f if mode == "fwd" else (2.5 * f if mode == "bwd" else 3.5 * f)
def
flops
(
batch
,
seqlen
,
headdim
,
headdimv
,
nheads
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
# f = 4 * batch * seqlen**2 * nheads * headdim // (2 if causal else 1)
f
=
2
*
batch
*
seqlen
**
2
*
nheads
*
(
headdim
+
headdimv
)
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
if
not
math
.
isnan
(
time
)
else
0.0
def
attention_pytorch
(
qkv
,
dropout_p
=
0.0
,
causal
=
True
):
"""
Arguments:
qkv: (batch_size, seqlen, 3, nheads, head_dim)
dropout_p: float
Output:
output: (batch_size, seqlen, nheads, head_dim)
"""
batch_size
,
seqlen
,
_
,
nheads
,
d
=
qkv
.
shape
q
,
k
,
v
=
qkv
.
unbind
(
dim
=
2
)
q
=
rearrange
(
q
,
'b t h d -> (b h) t d'
)
k
=
rearrange
(
k
,
'b s h d -> (b h) d s'
)
softmax_scale
=
1.0
/
math
.
sqrt
(
d
)
# Preallocate attn_weights for `baddbmm`
scores
=
torch
.
empty
(
batch_size
*
nheads
,
seqlen
,
seqlen
,
dtype
=
qkv
.
dtype
,
device
=
qkv
.
device
)
scores
=
rearrange
(
torch
.
baddbmm
(
scores
,
q
,
k
,
beta
=
0
,
alpha
=
softmax_scale
),
'(b h) t s -> b h t s'
,
h
=
nheads
)
if
causal
:
# "triu_tril_cuda_template" not implemented for 'BFloat16'
# So we have to construct the mask in float
causal_mask
=
torch
.
triu
(
torch
.
full
((
seqlen
,
seqlen
),
-
10000.0
,
device
=
scores
.
device
),
1
)
# TD [2022-09-30]: Adding is faster than masked_fill_ (idk why, just better kernel I guess)
scores
=
scores
+
causal_mask
.
to
(
dtype
=
scores
.
dtype
)
attention
=
torch
.
softmax
(
scores
,
dim
=-
1
)
attention_drop
=
F
.
dropout
(
attention
,
dropout_p
)
output
=
torch
.
einsum
(
'bhts,bshd->bthd'
,
attention_drop
,
v
)
return
output
.
to
(
dtype
=
qkv
.
dtype
)
def
time_fwd_bwd
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_fwd_bwd
(
func
,
*
args
,
**
kwargs
)
return
time_f
[
1
].
mean
,
time_b
[
1
].
mean
def
time_forward
(
func
,
*
args
,
**
kwargs
):
_
,
time_b
=
benchmark_forward
(
func
,
*
args
,
**
kwargs
)
return
time_b
.
mean
def
padding_bmhk
(
t
):
# BMHK
# print(f"padding..")
batch
,
seqlen
,
nheads
,
dim
=
t
.
shape
t_tmp
=
torch
.
nn
.
functional
.
pad
(
t
.
reshape
(
batch
,
seqlen
,
nheads
*
dim
),
(
0
,
32
),
'constant'
,
0
)[:,
:,
:
-
32
].
reshape
(
batch
,
seqlen
,
nheads
,
dim
)
# print(f"{t_tmp.shape=}, {t_tmp.stride()=}")
return
t_tmp
repeats
=
30
device
=
'cuda'
dtype
=
torch
.
bfloat16
bs_seqlen_vals
=
[(
32
,
512
),
(
16
,
1024
),
(
8
,
2048
),
(
4
,
4096
),
(
2
,
8192
),
(
1
,
16384
)]
causal_vals
=
[
False
,
True
]
headdim_vals
=
[(
128
,
128
)]
# headdim_vals = [160, 192, 224, 256]
nheads_vals
=
[(
16
,
16
)]
window_size
=
(
-
1
,
-
1
)
if
args
.
qwen
:
bs_seqlen_vals
=
[(
2
,
256
),
(
2
,
384
),
(
2
,
1024
),
(
2
,
1152
),
(
2
,
1280
),
(
2
,
1408
),
(
2
,
1536
),
(
2
,
1664
),
(
2
,
1792
),
(
2
,
1920
),
(
2
,
2048
),
(
2
,
2304
),
(
2
,
2432
),
(
2
,
2944
),
(
2
,
3456
),
(
2
,
3584
),
(
2
,
3712
),
(
2
,
3968
),
(
2
,
4096
)]
causal_vals
=
[
causal_vals
[
-
1
]]
nheads_vals
=
[(
32
,
32
)]
if
args
.
ali
:
bs_seqlen_vals
=
[(
1
,
8192
)]
causal_vals
=
[
causal_vals
[
-
1
]]
nheads_vals
=
[(
16
,
16
),
(
32
,
32
),
(
32
,
4
),
(
52
,
4
),
(
16
,
2
),
(
26
,
2
),
(
8
,
1
),
(
13
,
1
)]
if
args
.
xf
:
bs_seqlen_vals
=
bs_seqlen_vals
# [(2, 8192)]
causal_vals
=
[
causal_vals
[
-
1
]]
nheads_vals
=
[(
8
,
2
)]
window_size
=
(
8191
,
0
)
if
args
.
prof
:
repeats
=
1
bs_seqlen_vals
=
[
bs_seqlen_vals
[
-
1
]]
causal_vals
=
[
causal_vals
[
-
2
]]
bhsd
=
False
if
args
.
bhsd
or
args
.
hy
:
bhsd
=
True
dropout_p
=
0.0
pad
=
0
methods
=
([
"Flash2"
])
fwdOnly
=
args
.
fwd
time_f
=
{}
time_b
=
{}
time_f_b
=
{}
speed_f
=
{}
speed_b
=
{}
speed_f_b
=
{}
for
nheads_q
,
nheads_k
in
nheads_vals
:
for
causal
in
causal_vals
:
for
headdim
,
headdimv
in
headdim_vals
:
for
batch_size
,
seqlen
in
bs_seqlen_vals
:
config
=
(
causal
,
headdim
,
headdimv
,
batch_size
,
seqlen
)
if
not
bhsd
:
q
=
torch
.
randn
(
batch_size
,
seqlen
,
nheads_q
,
headdim
+
pad
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
k
=
torch
.
randn
(
batch_size
,
seqlen
,
nheads_k
,
headdim
+
pad
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
v
=
torch
.
randn
(
batch_size
,
seqlen
,
nheads_k
,
headdimv
+
pad
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
# q = q[:, :, :, :headdim]
# k = k[:, :, :, :headdim]
# v = v[:, :, :, :headdim]
# q = q.as_strided(q.size(), [seqlen * nheads_q * headdim, headdim, headdim * nheads_q, 1])
# k = k.as_strided(k.size(), [seqlen * nheads_k * headdim, headdim, headdim * nheads_k, 1])
# v = v.as_strided(k.size(), [seqlen * nheads_k * headdim, headdim, headdim * nheads_k, 1])
else
:
q
=
torch
.
randn
(
batch_size
,
nheads_q
,
seqlen
,
headdim
+
pad
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
k
=
torch
.
randn
(
batch_size
,
nheads_k
,
seqlen
,
headdim
+
pad
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
v
=
torch
.
randn
(
batch_size
,
nheads_k
,
seqlen
,
headdimv
+
pad
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
if
fwdOnly
:
if
args
.
hy
:
f
=
time_forward
(
flash_attn_func
,
q
,
k
,
v
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
else
:
f
=
time_forward
(
flash_attn_func
,
q
,
k
,
v
,
dropout_p
,
causal
=
causal
,
bhsd
=
bhsd
,
window_size
=
window_size
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
else
:
if
args
.
hy
:
f
,
b
=
time_fwd_bwd
(
flash_attn_func
,
q
,
k
,
v
,
dropout_p
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
else
:
f
,
b
=
time_fwd_bwd
(
flash_attn_func
,
q
,
k
,
v
,
dropout_p
,
causal
=
causal
,
bhsd
=
bhsd
,
window_size
=
window_size
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
time_b
[
config
,
"Flash2"
]
=
b
print
(
f
"### causal=
{
causal
}
, headdim=
{
headdim
}
, headdim=
{
headdimv
}
, batch_size=
{
batch_size
}
,nheads=
{
nheads_q
}
, seqlen=
{
seqlen
}
###"
)
nheads
=
nheads_q
for
method
in
methods
:
speed_f
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
seqlen
,
headdim
,
headdimv
,
nheads_q
,
causal
,
mode
=
"fwd"
),
time_f
[
config
,
method
]
)
if
fwdOnly
:
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
)
else
:
time_f_b
[
config
,
method
]
=
time_f
[
config
,
method
]
+
time_b
[
config
,
method
]
speed_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
seqlen
,
headdim
,
headdimv
,
nheads
,
causal
,
mode
=
"bwd"
),
time_b
[
config
,
method
]
)
speed_f_b
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
seqlen
,
headdim
,
headdimv
,
nheads
,
causal
,
mode
=
"fwd_bwd"
),
time_f_b
[
config
,
method
]
)
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
f
"bwd:
{
speed_b
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_b
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
f
"fwd + bwd:
{
speed_f_b
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f_b
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
)
benchmarks/benchmark_hg_test.py
0 → 100644
View file @
34e67b1e
import
os
import
math
import
numpy
import
torch
import
torch.utils.benchmark
as
benchmark
from
collections
import
namedtuple
import
argparse
def
flops
(
batch
,
seq_len
,
headdim
,
qheads
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
if
(
isinstance
(
seq_len
,
int
)):
f
=
4
*
batch
*
seq_len
**
2
*
qheads
*
headdim
//
(
2
if
causal
else
1
)
else
:
tmp
=
sum
([(
seq_len
[
k
+
1
]
-
seq_len
[
k
])
**
2
for
k
in
range
(
len
(
seq_len
)
-
1
)])
f
=
4
*
tmp
*
qheads
*
headdim
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
benchmark_forward
(
fn
,
*
inputs
,
repeats
=
100
,
desc
=
""
,
verbose
=
True
,
amp
=
False
,
amp_dtype
=
torch
.
float16
,
**
kwinputs
):
"""Use Pytorch Benchmark on the forward pass of an arbitrary function."""
if
verbose
:
print
(
desc
,
"- Forward pass"
)
def
amp_wrapper
(
*
inputs
,
**
kwinputs
):
with
torch
.
autocast
(
device_type
=
"cuda"
,
dtype
=
amp_dtype
,
enabled
=
amp
):
fn
(
*
inputs
,
**
kwinputs
)
t
=
benchmark
.
Timer
(
stmt
=
"fn_amp(*inputs, **kwinputs)"
,
globals
=
{
"fn_amp"
:
amp_wrapper
,
"inputs"
:
inputs
,
"kwinputs"
:
kwinputs
},
num_threads
=
torch
.
get_num_threads
(),
)
m
=
t
.
timeit
(
repeats
)
if
verbose
:
print
(
m
)
return
t
,
m
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
def
warp_tensor
(
tensor
,
gpu_is_ours
,
is_varlen
=
False
,
num_head
=
None
):
if
(
not
is_varlen
):
return
tensor
if
(
gpu_is_ours
)
else
tensor
.
transpose
(
1
,
2
).
contiguous
()
else
:
return
tensor
if
(
gpu_is_ours
)
else
tensor
.
view
(
-
1
,
num_head
,
tensor
.
shape
[
-
1
])
parser
=
argparse
.
ArgumentParser
(
description
=
'test'
)
parser
.
add_argument
(
'--repeats'
,
default
=
1
,
type
=
int
,
help
=
'run times during once benchmark'
)
parser
.
add_argument
(
'--iterations'
,
default
=
6
,
type
=
int
,
help
=
'times of benchmark'
)
parser
.
add_argument
(
'--compare'
,
default
=
None
,
type
=
str
,
help
=
'competitor card name'
)
parser
.
add_argument
(
'--ratio'
,
default
=
False
,
action
=
'store_true'
,
help
=
'whether compute ratio of ours/nvidia'
)
args
=
parser
.
parse_args
()
# prepare testing cases
params
=
namedtuple
(
'param'
,
[
'causal'
,
'batch_size'
,
'qheads'
,
'kvheads'
,
'seq_len'
,
'head_size'
,
'window_size'
])
params_list
=
[
# params(batch_size=4, qheads=32, kvheads=32, seq_len=(0, 1000, 2000, 3000, 4000), head_size=128, causal=True, window_size=[-1,-1]),
# params(batch_size=2, qheads=32, kvheads=32, seq_len=(0, 2000, 4000), head_size=128, causal=True, window_size=[-1,-1]),
# params(batch_size=4, qheads=16, kvheads=2, seq_len=(0, 1000, 2000, 3000, 4000), head_size=128, causal=True, window_size=[-1,-1]),
# params(batch_size=2, qheads=16, kvheads=2, seq_len=(0, 2000, 4000), head_size=128, causal=True, window_size=[-1,-1]),
# params(batch_size=1, qheads=16, kvheads=2, seq_len=(0, 20000), head_size=128, causal=True, window_size=[-1,-1]),
# params(batch_size=1, qheads=16, kvheads=2, seq_len=(0, 20305), head_size=128, causal=True, window_size=[-1,-1]),
params
(
batch_size
=
1
,
qheads
=
16
,
kvheads
=
16
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
32
,
kvheads
=
32
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
32
,
kvheads
=
4
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
52
,
kvheads
=
4
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
16
,
kvheads
=
2
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
26
,
kvheads
=
2
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
8
,
kvheads
=
1
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
13
,
kvheads
=
1
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
]
import
flash_attn
import
flash_attn_2_cuda
as
_C_flashattention
print
(
"load flash_attn from package"
)
# gpu_card_info = torch.cuda.get_device_properties(0)
# gpu_is_ours = bool("NVIDIA" not in gpu_card_info.name)
gpu_is_ours
=
False
speed_on_this_gpu
=
[]
for
idx
,
params
in
enumerate
(
params_list
):
torch
.
cuda
.
empty_cache
()
cost_time
=
[]
device
=
"cuda"
causal
=
params
.
causal
batch_size
=
params
.
batch_size
qheads
=
params
.
qheads
kvheads
=
params
.
kvheads
seq_len
=
params
.
seq_len
head_size
=
params
.
head_size
window_size
=
params
.
window_size
flops_count
=
flops
(
batch_size
,
seq_len
,
head_size
,
qheads
,
causal
)
repeats
=
args
.
repeats
iterations
=
args
.
iterations
is_varlen
=
isinstance
(
seq_len
,
tuple
)
for
i
in
range
(
iterations
):
torch
.
cuda
.
empty_cache
()
if
(
is_varlen
):
max_seqlen_q
=
max
([
seq_len
[
k
+
1
]
-
seq_len
[
k
]
for
k
in
range
(
len
(
seq_len
)
-
1
)])
seq_len
=
torch
.
tensor
(
list
(
seq_len
),
dtype
=
torch
.
int32
).
cuda
()
total_seqlen_q
=
seq_len
[
-
1
].
item
()
q
=
warp_tensor
(
torch
.
randn
(
qheads
*
total_seqlen_q
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
),
gpu_is_ours
,
is_varlen
,
qheads
)
k
=
warp_tensor
(
torch
.
randn
(
kvheads
*
total_seqlen_q
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
),
gpu_is_ours
,
is_varlen
,
kvheads
)
v
=
warp_tensor
(
torch
.
randn
(
kvheads
*
total_seqlen_q
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
),
gpu_is_ours
,
is_varlen
,
kvheads
)
if
(
"2.6"
in
str
(
flash_attn
.
__version__
)):
fa_varlen_args
=
(
q
,
k
,
v
,
None
,
seq_len
,
seq_len
,
None
,
None
,
None
,
None
,
max_seqlen_q
,
max_seqlen_q
,
0.0
,
1.0
/
math
.
sqrt
(
head_size
),
False
,
causal
,
window_size
[
0
],
window_size
[
1
],
0.0
,
False
,
None
)
else
:
fa_varlen_args
=
(
q
,
k
,
v
,
None
,
seq_len
,
seq_len
,
None
,
None
,
max_seqlen_q
,
max_seqlen_q
,
0.0
,
1.0
/
math
.
sqrt
(
head_size
),
False
,
causal
,
window_size
[
0
],
window_size
[
1
],
False
,
None
)
t
=
benchmark_forward
(
_C_flashattention
.
varlen_fwd
,
*
fa_varlen_args
,
repeats
=
repeats
,
verbose
=
False
)[
1
].
times
[
0
]
else
:
q
=
warp_tensor
(
torch
.
randn
(
batch_size
,
qheads
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
),
gpu_is_ours
)
k
=
warp_tensor
(
torch
.
randn
(
batch_size
,
kvheads
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
),
gpu_is_ours
)
v
=
warp_tensor
(
torch
.
randn
(
batch_size
,
kvheads
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
),
gpu_is_ours
)
t
=
benchmark_forward
(
flash_attn
.
flash_attn_interface
.
flash_attn_func
,
q
,
k
,
v
,
0.0
,
causal
=
causal
,
window_size
=
window_size
,
repeats
=
repeats
,
verbose
=
False
)[
1
].
times
[
0
]
if
(
i
>
0
):
cost_time
.
append
(
t
)
# print("{:.9f} {:.9f}".format(t, efficiency(flops_count, t)))
# delete the data each time to avoid detecting the cache
del
q
,
k
,
v
cost_time
=
numpy
.
array
(
cost_time
)
cost_time_mean
=
cost_time
.
mean
()
# remove bursts of dirty data
cost_time
=
numpy
.
delete
(
cost_time
,
numpy
.
where
(
cost_time
<
(
0.8
*
cost_time_mean
)))
cost_time_mean
=
cost_time
.
mean
()
speed
=
efficiency
(
flops_count
,
cost_time_mean
)
speed_on_this_gpu
.
append
(
speed
)
# if (gpu_is_ours):
if
True
:
if
(
args
.
ratio
):
for
it
in
speed_on_this_gpu
:
print
(
it
)
exit
()
# prepare performance sheet for comparison
nvidia_performance
=
{
# for L20, the numerical value of "repeat" has very little effect, and thus only one piece of data. "repeats" of 100 is adopted
# "L20": [81.95, 89.90, 74.01, 81.75, 108.61, 108.59, 101.95, 106.80, 106.89, 108.62, 102.55, 105.85, 94.71, 100.60],
"L20"
:
[
101.95
,
106.80
,
106.89
,
108.62
,
102.55
,
105.85
,
94.71
,
100.60
],
# for A800, the numerical value of "repeat" has very significant effect, and thus several pieces of data.
# "A800": [103.01, 130.44, 78.70, 99.94, 203.21, 203.51, 191.49, 204.63, 207.69, 213.23, 192.70, 204.25, 163.50, 185.51],
"A800"
:
[
205.8
,
200.9
,
202.2
,
207.7
,
186.5
,
198.1
,
160.9
,
163.7
],
}
# acquire corresponding card
if
(
args
.
compare
is
not
None
):
nvidia_competitor
=
args
.
compare
if
(
nvidia_competitor
not
in
nvidia_performance
.
keys
()):
print
(
"
\033
[1;31mPerformance of competitor is not recorded yet!
\033
[0m"
.
format
(
nvidia_competitor
))
nvidia_speed
=
nvidia_performance
[
nvidia_competitor
]
else
:
nvidia_competitor
=
"A800"
nvidia_speed
=
nvidia_performance
[
nvidia_competitor
]
# check data alignment
if
(
len
(
nvidia_speed
)
!=
len
(
speed_on_this_gpu
)):
print
(
"
\x1b
[31mPerformance data of ours and {} is not correct
\x1b
[0m
\n\n
"
.
format
(
nvidia_competitor
))
exit
()
# output info
speed_ratio
=
[]
print
(
"ours {} Ratio"
.
format
(
nvidia_competitor
))
for
i
,
(
ours
,
nvidia
)
in
enumerate
(
zip
(
speed_on_this_gpu
,
nvidia_speed
)):
print
(
"{:.9f}
\t
{:.9f}
\t
{:.2f}%"
.
format
(
ours
,
nvidia
,
ours
/
nvidia
*
100
))
speed_ratio
.
append
(
ours
/
nvidia
)
speed_on_this_gpu
=
numpy
.
array
(
speed_on_this_gpu
)
nvidia_speed
=
numpy
.
array
(
nvidia_speed
)
speed_ratio
=
numpy
.
array
(
speed_ratio
)
print
(
"============================================"
)
print
(
"{:.9f}
\t
{:.9f}
\t
{:.2f}%"
.
format
(
speed_on_this_gpu
.
mean
(),
nvidia_speed
.
mean
(),
speed_ratio
.
mean
()
*
100
))
print
(
"Mean of ours : {:.9f}"
.
format
(
speed_on_this_gpu
.
mean
()))
print
(
"Mean of NVIDIA {}: {:.9f}"
.
format
(
nvidia_competitor
,
nvidia_speed
.
mean
()))
print
(
"Ratio to NVIDIA {}:
\x1b
[32m{:.2f}%
\x1b
[0m
\n\n
"
.
format
(
nvidia_competitor
,
100
*
speed_ratio
.
mean
()))
else
:
for
it
in
speed_on_this_gpu
:
print
(
it
)
\ No newline at end of file
benchmarks/benchmark_kvcache.py
0 → 100644
View file @
34e67b1e
import
pickle
import
math
import
argparse
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
# from openpyxl import Workbook
from
einops
import
rearrange
,
repeat
from
flash_attn.utils.benchmark
import
benchmark_all
,
benchmark_forward
,
benchmark_backward
from
flash_attn.utils.benchmark
import
benchmark_fwd_bwd
,
benchmark_combined
from
flash_attn
import
flash_attn_qkvpacked_func
,
flash_attn_func
from
flash_attn
import
flash_attn_varlen_func
# wb = Workbook()
# ws = wb.active
parser
=
argparse
.
ArgumentParser
(
description
=
'test'
)
parser
.
add_argument
(
'--prof'
,
default
=
False
,
action
=
'store_true'
,
help
=
'prof or not'
)
parser
.
add_argument
(
'--fwd'
,
default
=
False
,
action
=
'store_true'
,
help
=
'only run fwd'
)
args
=
parser
.
parse_args
()
def
flops
(
batch
,
seqlen
,
nheads
,
seqlen_k
,
nheads_kv
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
# f = 4 * batch * seqlen**2 * nheads * headdim // (2 if causal else 1)
f
=
2
*
batch
*
seqlen
*
seqlen_k
*
nheads
*
(
headdim
+
headdimv
)
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
if
not
math
.
isnan
(
time
)
else
0.0
def
time_forward
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_forward
(
func
,
*
args
,
**
kwargs
)
return
time_b
.
mean
def
time_fwd_bwd
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_fwd_bwd
(
func
,
*
args
,
**
kwargs
)
return
time_f
[
1
].
mean
,
time_b
[
1
].
mean
def
padding_bmhk
(
t
):
# BMHK
# print(f"padding..")
batch
,
seqlen
,
nheads
,
dim
=
t
.
shape
t_tmp
=
torch
.
nn
.
functional
.
pad
(
t
.
reshape
(
batch
,
seqlen
,
nheads
*
dim
),
(
0
,
32
),
'constant'
,
0
)[:,:,:
-
32
].
reshape
(
batch
,
seqlen
,
nheads
,
dim
)
# print(f"{t_tmp.shape=}, {t_tmp.stride()=}")
return
t_tmp
repeats
=
30
device
=
'cuda'
dtype
=
torch
.
float16
dropout_p
=
0.0
pad
=
0
methods
=
([
"Flash2"
])
time_f
=
{}
time_b
=
{}
time_f_b
=
{}
speed_f
=
{}
speed_b
=
{}
speed_f_b
=
{}
fwdOnly
=
args
.
fwd
# ws.append(['batch_size', 'total_q', 'total_kv', 'nheads_q', 'num_heads_kv', 'causal', 'dim', 'dimv', 'dtype', 'tflops', 'time(ms)'])
test_size
=
[
(
32
,
512
,
32
,
512
,
8
,
128
,
128
,
True
),
(
16
,
1024
,
32
,
1024
,
8
,
128
,
128
,
True
),
(
8
,
2048
,
32
,
2048
,
8
,
128
,
128
,
True
),
(
4
,
4096
,
32
,
4096
,
8
,
128
,
128
,
True
),
(
2
,
8192
,
32
,
8192
,
8
,
128
,
128
,
True
),
(
1
,
16384
,
32
,
16384
,
8
,
128
,
128
,
True
),
]
if
args
.
prof
:
repeats
=
1
test_size
=
[
test_size
[
-
1
]]
for
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
in
test_size
:
config
=
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
)
q
=
torch
.
randn
(
batch_size
,
total_q
,
nheads_q
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
False
)
# k = torch.randn(batch_size, total_kv, nheads_k, headdim, device=device, dtype=dtype, requires_grad=True)
# v = torch.randn(batch_size, total_kv, nheads_k, headdimv, device=device, dtype=dtype, requires_grad=True)
# q = padding_bmhk(q)
# k = padding_bmhk(k)
# v = padding_bmhk(v)
# # print(q.shape)
# print(q.stride())
block_size
=
64
q
=
q
.
reshape
(
batch_size
*
total_q
,
nheads_q
,
headdim
)
# 初始化KV Cache和块表
num_blocks
=
math
.
ceil
(
total_kv
/
block_size
)
*
batch_size
# num_blocks = (total_kv + block_size - 1) // block_size
k_cache
=
torch
.
randn
(
num_blocks
,
block_size
,
nheads_k
,
headdim
,
device
=
device
,
dtype
=
dtype
)
v_cache
=
torch
.
randn
(
num_blocks
,
block_size
,
nheads_k
,
headdimv
,
device
=
device
,
dtype
=
dtype
)
# k_cache = padding_bmhk(k_cache)
# v_cache = padding_bmhk(v_cache)
# block_table = torch.zeros(batch_size, num_blocks, dtype=torch.int32, device=device)
block_table
=
rearrange
(
torch
.
randperm
(
num_blocks
,
dtype
=
torch
.
int32
,
device
=
device
),
"(b nblocks) -> b nblocks"
,
b
=
batch_size
,
)
# k = k.reshape(batch_size*total_kv, nheads_k, headdim)
# v = v.reshape(batch_size*total_kv, nheads_k, headdimv)
# q=query,
# k=key_cache,
# v=value_cache,
# cu_seqlens_q=cu_query_lens,
# cu_seqlens_k=cu_kv_lens,
# max_seqlen_q=max_query_len,
# max_seqlen_k=max_kv_len,
# softmax_scale=scale,
# causal=True,
# window_size=window_size,
# block_table=block_tables,
# softcap=soft_cap if soft_cap is not None else 0,
cu_seqlens
=
torch
.
arange
(
0
,
(
batch_size
+
1
)
*
total_kv
,
step
=
total_q
,
dtype
=
torch
.
int32
,
device
=
device
)
# if fwdOnly:
f
=
time_forward
(
flash_attn_varlen_func
,
q
,
k_cache
,
v_cache
,
cu_seqlens
,
cu_seqlens
,
total_q
,
total_kv
,
dropout_p
,
block_table
=
block_table
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
# else:
# f, b = time_fwd_bwd(flash_attn_varlen_func, q, k, v, cu_seqlens, cu_seqlens, total_q, total_kv, dropout_p,
# causal=causal, repeats=repeats, verbose=False)
# time_f[config, "Flash2"] = f
# time_b[config, "Flash2"] = b
print
(
f
"### causal=
{
causal
}
, headdim=
{
headdim
}
, headdimv=
{
headdimv
}
, batch_size=
{
batch_size
}
, nheads_q=
{
nheads_q
}
, nheads_k=
{
nheads_k
}
, total_q=
{
total_q
}
, total_kv=
{
total_kv
}
###"
)
for
method
in
methods
:
# time_f_b[config, method] = time_f[config, method] + time_b[config, method]
speed_f
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd"
),
time_f
[
config
,
method
]
)
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
)
# ws.append([batch_size, seqlen, seqlen, nheads_q, nheads_k, causal, headdim, "float16", round(speed_f[config, method], 2), round(time_f[config, method]*1000, 2)])
# exit(0)
# wb.save("varlen_64_32_4_018a7dd_waq.xlsx")
benchmarks/benchmark_ours.py
0 → 100644
View file @
34e67b1e
import
os
import
math
import
numpy
import
torch
import
torch.utils.benchmark
as
benchmark
from
collections
import
namedtuple
import
argparse
def
flops
(
batch
,
seq_len
,
headdim
,
qheads
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
if
(
isinstance
(
seq_len
,
int
)):
f
=
4
*
batch
*
seq_len
**
2
*
qheads
*
headdim
//
(
2
if
causal
else
1
)
else
:
tmp
=
sum
([(
seq_len
[
k
+
1
]
-
seq_len
[
k
])
**
2
for
k
in
range
(
len
(
seq_len
)
-
1
)])
f
=
4
*
tmp
*
qheads
*
headdim
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
benchmark_forward
(
fn
,
*
inputs
,
repeats
=
100
,
desc
=
""
,
verbose
=
True
,
amp
=
False
,
amp_dtype
=
torch
.
float16
,
**
kwinputs
):
"""Use Pytorch Benchmark on the forward pass of an arbitrary function."""
if
verbose
:
print
(
desc
,
"- Forward pass"
)
def
amp_wrapper
(
*
inputs
,
**
kwinputs
):
with
torch
.
autocast
(
device_type
=
"cuda"
,
dtype
=
amp_dtype
,
enabled
=
amp
):
fn
(
*
inputs
,
**
kwinputs
)
t
=
benchmark
.
Timer
(
stmt
=
"fn_amp(*inputs, **kwinputs)"
,
globals
=
{
"fn_amp"
:
amp_wrapper
,
"inputs"
:
inputs
,
"kwinputs"
:
kwinputs
},
num_threads
=
torch
.
get_num_threads
(),
)
m
=
t
.
timeit
(
repeats
)
if
verbose
:
print
(
m
)
return
t
,
m
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
def
warp_tensor
(
tensor
,
gpu_is_ours
,
is_varlen
=
False
,
num_head
=
None
):
if
(
not
is_varlen
):
return
tensor
if
(
gpu_is_ours
)
else
tensor
.
transpose
(
1
,
2
).
contiguous
()
else
:
return
tensor
if
(
gpu_is_ours
)
else
tensor
.
view
(
-
1
,
num_head
,
tensor
.
shape
[
-
1
])
parser
=
argparse
.
ArgumentParser
(
description
=
'test'
)
parser
.
add_argument
(
'--repeats'
,
default
=
1
,
type
=
int
,
help
=
'run times during once benchmark'
)
parser
.
add_argument
(
'--iterations'
,
default
=
6
,
type
=
int
,
help
=
'times of benchmark'
)
parser
.
add_argument
(
'--compare'
,
default
=
None
,
type
=
str
,
help
=
'competitor card name'
)
parser
.
add_argument
(
'--ratio'
,
default
=
False
,
action
=
'store_true'
,
help
=
'whether compute ratio of ours/nvidia'
)
args
=
parser
.
parse_args
()
# prepare testing cases
params
=
namedtuple
(
'param'
,
[
'causal'
,
'batch_size'
,
'qheads'
,
'kvheads'
,
'seq_len'
,
'head_size'
,
'window_size'
])
params_list
=
[
params
(
batch_size
=
4
,
qheads
=
32
,
kvheads
=
32
,
seq_len
=
(
0
,
1000
,
2000
,
3000
,
4000
),
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
2
,
qheads
=
32
,
kvheads
=
32
,
seq_len
=
(
0
,
2000
,
4000
),
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
4
,
qheads
=
16
,
kvheads
=
2
,
seq_len
=
(
0
,
1000
,
2000
,
3000
,
4000
),
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
2
,
qheads
=
16
,
kvheads
=
2
,
seq_len
=
(
0
,
2000
,
4000
),
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
16
,
kvheads
=
2
,
seq_len
=
(
0
,
20000
),
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
16
,
kvheads
=
2
,
seq_len
=
(
0
,
20305
),
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
16
,
kvheads
=
16
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
32
,
kvheads
=
32
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
32
,
kvheads
=
4
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
52
,
kvheads
=
4
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
16
,
kvheads
=
2
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
26
,
kvheads
=
2
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
8
,
kvheads
=
1
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
params
(
batch_size
=
1
,
qheads
=
13
,
kvheads
=
1
,
seq_len
=
8192
,
head_size
=
128
,
causal
=
True
,
window_size
=
[
-
1
,
-
1
]),
]
import
flash_attn
import
flash_attn_2_cuda
as
_C_flashattention
print
(
"load flash_attn from package"
)
gpu_card_info
=
torch
.
cuda
.
get_device_properties
(
0
)
gpu_is_ours
=
bool
(
"NVIDIA"
not
in
gpu_card_info
.
name
)
speed_on_this_gpu
=
[]
for
idx
,
params
in
enumerate
(
params_list
):
torch
.
cuda
.
empty_cache
()
cost_time
=
[]
device
=
"cuda"
causal
=
params
.
causal
batch_size
=
params
.
batch_size
qheads
=
params
.
qheads
kvheads
=
params
.
kvheads
seq_len
=
params
.
seq_len
head_size
=
params
.
head_size
window_size
=
params
.
window_size
flops_count
=
flops
(
batch_size
,
seq_len
,
head_size
,
qheads
,
causal
)
repeats
=
args
.
repeats
iterations
=
args
.
iterations
is_varlen
=
isinstance
(
seq_len
,
tuple
)
for
i
in
range
(
iterations
):
torch
.
cuda
.
empty_cache
()
if
(
is_varlen
):
max_seqlen_q
=
max
([
seq_len
[
k
+
1
]
-
seq_len
[
k
]
for
k
in
range
(
len
(
seq_len
)
-
1
)])
seq_len
=
torch
.
tensor
(
list
(
seq_len
),
dtype
=
torch
.
int32
).
cuda
()
total_seqlen_q
=
seq_len
[
-
1
].
item
()
q
=
warp_tensor
(
torch
.
randn
(
qheads
*
total_seqlen_q
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
),
gpu_is_ours
,
is_varlen
,
qheads
)
k
=
warp_tensor
(
torch
.
randn
(
kvheads
*
total_seqlen_q
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
),
gpu_is_ours
,
is_varlen
,
kvheads
)
v
=
warp_tensor
(
torch
.
randn
(
kvheads
*
total_seqlen_q
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
),
gpu_is_ours
,
is_varlen
,
kvheads
)
if
(
"2.6"
in
str
(
flash_attn
.
__version__
)):
fa_varlen_args
=
(
q
,
k
,
v
,
None
,
seq_len
,
seq_len
,
None
,
None
,
max_seqlen_q
,
max_seqlen_q
,
0.0
,
1.0
/
math
.
sqrt
(
head_size
),
False
,
causal
,
window_size
[
0
],
window_size
[
1
],
0.0
,
False
,
None
)
else
:
fa_varlen_args
=
(
q
,
k
,
v
,
None
,
seq_len
,
seq_len
,
None
,
None
,
max_seqlen_q
,
max_seqlen_q
,
0.0
,
1.0
/
math
.
sqrt
(
head_size
),
False
,
causal
,
window_size
[
0
],
window_size
[
1
],
False
,
None
)
t
=
benchmark_forward
(
_C_flashattention
.
varlen_fwd
,
*
fa_varlen_args
,
repeats
=
repeats
,
verbose
=
False
)[
1
].
times
[
0
]
else
:
q
=
warp_tensor
(
torch
.
randn
(
batch_size
,
qheads
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
),
gpu_is_ours
)
k
=
warp_tensor
(
torch
.
randn
(
batch_size
,
kvheads
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
),
gpu_is_ours
)
v
=
warp_tensor
(
torch
.
randn
(
batch_size
,
kvheads
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
),
gpu_is_ours
)
t
=
benchmark_forward
(
flash_attn
.
flash_attn_interface
.
flash_attn_func
,
q
,
k
,
v
,
0.0
,
causal
=
causal
,
window_size
=
window_size
,
repeats
=
repeats
,
verbose
=
False
)[
1
].
times
[
0
]
if
(
i
>
0
):
cost_time
.
append
(
t
)
# print("{:.9f} {:.9f}".format(t, efficiency(flops_count, t)))
# delete the data each time to avoid detecting the cache
del
q
,
k
,
v
cost_time
=
numpy
.
array
(
cost_time
)
cost_time_mean
=
cost_time
.
mean
()
# remove bursts of dirty data
cost_time
=
numpy
.
delete
(
cost_time
,
numpy
.
where
(
cost_time
<
(
0.8
*
cost_time_mean
)))
cost_time_mean
=
cost_time
.
mean
()
speed
=
efficiency
(
flops_count
,
cost_time_mean
)
speed_on_this_gpu
.
append
(
speed
)
if
(
gpu_is_ours
):
if
(
args
.
ratio
):
for
it
in
speed_on_this_gpu
:
print
(
it
)
exit
()
# prepare performance sheet for comparison
nvidia_performance
=
{
# for L20, the numerical value of "repeat" has very little effect, and thus only one piece of data. "repeats" of 100 is adopted
"L20"
:
[
81.95
,
89.90
,
74.01
,
81.75
,
108.61
,
108.59
,
101.95
,
106.80
,
106.89
,
108.62
,
102.55
,
105.85
,
94.71
,
100.60
],
# for A800, the numerical value of "repeat" has very significant effect, and thus several pieces of data.
"A800"
:
[
103.01
,
130.44
,
78.70
,
99.94
,
203.21
,
203.51
,
191.49
,
204.63
,
207.69
,
213.23
,
192.70
,
204.25
,
163.50
,
185.51
],
}
# acquire corresponding card
if
(
args
.
compare
is
not
None
):
nvidia_competitor
=
args
.
compare
if
(
nvidia_competitor
not
in
nvidia_performance
.
keys
()):
print
(
"
\033
[1;31mPerformance of competitor is not recorded yet!
\033
[0m"
.
format
(
nvidia_competitor
))
nvidia_speed
=
nvidia_performance
[
nvidia_competitor
]
else
:
nvidia_competitor
=
"A800"
nvidia_speed
=
nvidia_performance
[
nvidia_competitor
]
# check data alignment
if
(
len
(
nvidia_speed
)
!=
len
(
speed_on_this_gpu
)):
print
(
"
\x1b
[31mPerformance data of ours and {} is not correct
\x1b
[0m
\n\n
"
.
format
(
nvidia_competitor
))
exit
()
# output info
speed_ratio
=
[]
print
(
"ours {} Ratio"
.
format
(
nvidia_competitor
))
for
i
,
(
ours
,
nvidia
)
in
enumerate
(
zip
(
speed_on_this_gpu
,
nvidia_speed
)):
print
(
"{:.9f}
\t
{:.9f}
\t
{:.2f}%"
.
format
(
ours
,
nvidia
,
ours
/
nvidia
*
100
))
speed_ratio
.
append
(
ours
/
nvidia
)
speed_on_this_gpu
=
numpy
.
array
(
speed_on_this_gpu
)
nvidia_speed
=
numpy
.
array
(
nvidia_speed
)
speed_ratio
=
numpy
.
array
(
speed_ratio
)
print
(
"============================================"
)
print
(
"{:.9f}
\t
{:.9f}
\t
{:.2f}%"
.
format
(
speed_on_this_gpu
.
mean
(),
nvidia_speed
.
mean
(),
speed_ratio
.
mean
()
*
100
))
print
(
"Mean of ours : {:.9f}"
.
format
(
speed_on_this_gpu
.
mean
()))
print
(
"Mean of NVIDIA {}: {:.9f}"
.
format
(
nvidia_competitor
,
nvidia_speed
.
mean
()))
print
(
"Ratio to NVIDIA {}:
\x1b
[32m{:.2f}%
\x1b
[0m
\n\n
"
.
format
(
nvidia_competitor
,
100
*
speed_ratio
.
mean
()))
else
:
for
it
in
speed_on_this_gpu
:
print
(
it
)
\ No newline at end of file
benchmarks/benchmark_prefix_cache.py
0 → 100644
View file @
34e67b1e
import
pickle
import
math
import
argparse
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
# from openpyxl import Workbook
from
einops
import
rearrange
,
repeat
from
flash_attn.utils.benchmark
import
benchmark_all
,
benchmark_forward
,
benchmark_backward
from
flash_attn.utils.benchmark
import
benchmark_fwd_bwd
,
benchmark_combined
from
flash_attn
import
flash_attn_qkvpacked_func
,
flash_attn_func
from
flash_attn
import
vllm_flash_attn_varlen_func
# wb = Workbook()
# ws = wb.active
parser
=
argparse
.
ArgumentParser
(
description
=
'test'
)
parser
.
add_argument
(
'--prof'
,
default
=
False
,
action
=
'store_true'
,
help
=
'prof or not'
)
parser
.
add_argument
(
'--fwd'
,
default
=
False
,
action
=
'store_true'
,
help
=
'only run fwd'
)
args
=
parser
.
parse_args
()
def
flops
(
batch
,
seqlen
,
nheads
,
seqlen_k
,
nheads_kv
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
# f = 4 * batch * seqlen**2 * nheads * headdim // (2 if causal else 1)
f
=
2
*
batch
*
seqlen
*
seqlen_k
*
nheads
*
(
headdim
+
headdimv
)
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
if
not
math
.
isnan
(
time
)
else
0.0
def
time_forward
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_forward
(
func
,
*
args
,
**
kwargs
)
return
time_b
.
mean
def
time_fwd_bwd
(
func
,
*
args
,
**
kwargs
):
time_f
,
time_b
=
benchmark_fwd_bwd
(
func
,
*
args
,
**
kwargs
)
return
time_f
[
1
].
mean
,
time_b
[
1
].
mean
def
padding_bmhk
(
t
):
# BMHK
# print(f"padding..")
batch
,
seqlen
,
nheads
,
dim
=
t
.
shape
t_tmp
=
torch
.
nn
.
functional
.
pad
(
t
.
reshape
(
batch
,
seqlen
,
nheads
*
dim
),
(
0
,
32
),
'constant'
,
0
)[:,:,:
-
32
].
reshape
(
batch
,
seqlen
,
nheads
,
dim
)
# print(f"{t_tmp.shape=}, {t_tmp.stride()=}")
return
t_tmp
repeats
=
30
device
=
'cuda'
dtype
=
torch
.
bfloat16
dropout_p
=
0.0
pad
=
0
methods
=
([
"Flash2"
])
time_f
=
{}
time_b
=
{}
time_f_b
=
{}
speed_f
=
{}
speed_b
=
{}
speed_f_b
=
{}
fwdOnly
=
args
.
fwd
# ws.append(['batch_size', 'total_q', 'total_kv', 'nheads_q', 'num_heads_kv', 'causal', 'dim', 'dimv', 'dtype', 'tflops', 'time(ms)'])
test_size
=
[
(
32
,
512
,
32
,
512
,
8
,
128
,
128
,
True
),
(
16
,
1024
,
32
,
1024
,
8
,
128
,
128
,
True
),
(
8
,
2048
,
32
,
2048
,
8
,
128
,
128
,
True
),
(
4
,
4096
,
32
,
4096
,
8
,
128
,
128
,
True
),
(
2
,
8192
,
32
,
8192
,
8
,
128
,
128
,
True
),
(
1
,
16384
,
32
,
16384
,
8
,
128
,
128
,
True
),
]
if
args
.
prof
:
repeats
=
1
test_size
=
[
test_size
[
-
1
]]
for
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
in
test_size
:
config
=
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
)
q
=
torch
.
randn
(
batch_size
,
total_q
,
nheads_q
,
headdim
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
False
)
# k = torch.randn(batch_size, total_kv, nheads_k, headdim, device=device, dtype=dtype, requires_grad=True)
# v = torch.randn(batch_size, total_kv, nheads_k, headdimv, device=device, dtype=dtype, requires_grad=True)
# q = padding_bmhk(q)
# k = padding_bmhk(k)
# v = padding_bmhk(v)
# # print(q.shape)
# print(q.stride())
block_size
=
64
q
=
q
.
reshape
(
batch_size
*
total_q
,
nheads_q
,
headdim
)
# 初始化KV Cache和块表
num_blocks
=
math
.
ceil
(
total_kv
/
block_size
)
*
batch_size
# num_blocks = (total_kv + block_size - 1) // block_size
k_cache
=
torch
.
randn
(
num_blocks
,
nheads_k
,
block_size
,
headdim
,
device
=
device
,
dtype
=
dtype
)
v_cache
=
torch
.
randn
(
num_blocks
,
nheads_k
,
headdimv
,
block_size
,
device
=
device
,
dtype
=
dtype
)
cache_seqlens
=
torch
.
full
((
batch_size
,),
total_kv
,
dtype
=
torch
.
int32
,
device
=
device
)
# k_cache = padding_bmhk(k_cache)
# v_cache = padding_bmhk(v_cache)
# block_table = torch.zeros(batch_size, num_blocks, dtype=torch.int32, device=device)
block_table
=
rearrange
(
torch
.
randperm
(
num_blocks
,
dtype
=
torch
.
int32
,
device
=
device
),
"(b nblocks) -> b nblocks"
,
b
=
batch_size
,
)
# k = k.reshape(batch_size*total_kv, nheads_k, headdim)
# v = v.reshape(batch_size*total_kv, nheads_k, headdimv)
# q=query,
# k=key_cache,
# v=value_cache,
# cu_seqlens_q=cu_query_lens,
# cu_seqlens_k=cu_kv_lens,
# max_seqlen_q=max_query_len,
# max_seqlen_k=max_kv_len,
# softmax_scale=scale,
# causal=True,
# window_size=window_size,
# block_table=block_tables,
# softcap=soft_cap if soft_cap is not None else 0,
cu_seqlens
=
torch
.
arange
(
0
,
(
batch_size
+
1
)
*
total_kv
,
step
=
total_q
,
dtype
=
torch
.
int32
,
device
=
device
)
# if fwdOnly:
f
=
time_forward
(
vllm_flash_attn_varlen_func
,
q
=
q
,
k
=
k_cache
,
v
=
v_cache
,
cu_seqlens_q
=
cu_seqlens
,
max_seqlen_q
=
total_q
,
seqused_k
=
cache_seqlens
,
max_seqlen_k
=
total_kv
,
block_table
=
block_table
,
causal
=
causal
,
repeats
=
repeats
,
verbose
=
False
)
time_f
[
config
,
"Flash2"
]
=
f
# else:
# f, b = time_fwd_bwd(flash_attn_varlen_func, q, k, v, cu_seqlens, cu_seqlens, total_q, total_kv, dropout_p,
# causal=causal, repeats=repeats, verbose=False)
# time_f[config, "Flash2"] = f
# time_b[config, "Flash2"] = b
print
(
f
"### causal=
{
causal
}
, headdim=
{
headdim
}
, headdimv=
{
headdimv
}
, batch_size=
{
batch_size
}
, nheads_q=
{
nheads_q
}
, nheads_k=
{
nheads_k
}
, total_q=
{
total_q
}
, total_kv=
{
total_kv
}
###"
)
for
method
in
methods
:
# time_f_b[config, method] = time_f[config, method] + time_b[config, method]
speed_f
[
config
,
method
]
=
efficiency
(
flops
(
batch_size
,
total_q
,
nheads_q
,
total_kv
,
nheads_k
,
headdim
,
headdimv
,
causal
,
mode
=
"fwd"
),
time_f
[
config
,
method
]
)
print
(
f
"
{
method
}
fwd:
{
speed_f
[
config
,
method
]:.
2
f
}
TFLOPs/s,
{
time_f
[
config
,
method
]
*
1000
:.
2
f
}
ms. "
)
# ws.append([batch_size, seqlen, seqlen, nheads_q, nheads_k, causal, headdim, "float16", round(speed_f[config, method], 2), round(time_f[config, method]*1000, 2)])
# exit(0)
# wb.save("varlen_64_32_4_018a7dd_waq.xlsx")
benchmarks/fa_bwd_benchmark.py
0 → 100644
View file @
34e67b1e
import
torch
import
torch.utils.benchmark
as
benchmark
from
collections
import
namedtuple
import
math
import
importlib.util
import
csv
# 加载动态库
path_to_so
=
'../build/flash-attention.so'
print
(
"load from {}"
.
format
(
path_to_so
))
spec
=
importlib
.
util
.
spec_from_file_location
(
"flash_attn_2_cuda"
,
path_to_so
)
flash_attn_2_cuda
=
importlib
.
util
.
module_from_spec
(
spec
)
spec
.
loader
.
exec_module
(
flash_attn_2_cuda
)
import
flash_attn_2_cuda
as
_C_flashattention
def
benchmark_backward
(
fn
,
*
inputs
,
repeats
=
1
,
desc
=
""
,
verbose
=
False
,
amp
=
False
,
amp_dtype
=
torch
.
float16
,
**
kwinputs
):
if
verbose
:
print
(
desc
,
"- Backward pass"
)
def
amp_wrapper
(
*
inputs
,
**
kwinputs
):
with
torch
.
autocast
(
device_type
=
"cuda"
,
dtype
=
amp_dtype
,
enabled
=
amp
):
fn
(
*
inputs
,
**
kwinputs
)
t
=
benchmark
.
Timer
(
stmt
=
"fn_amp(*inputs, **kwinputs)"
,
globals
=
{
"fn_amp"
:
amp_wrapper
,
"inputs"
:
inputs
,
"kwinputs"
:
kwinputs
},
num_threads
=
torch
.
get_num_threads
(),
)
m
=
t
.
timeit
(
repeats
)
if
verbose
:
print
(
m
)
return
m
.
times
[
0
]
def
flops
(
batch
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
f
=
4
*
batch
*
seqlen
**
2
*
nheads
*
headdim
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
12
)
params_list
=
[
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
16
,
'nheads_k'
:
16
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
32
,
'nheads_k'
:
32
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
32
,
'nheads_k'
:
4
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
52
,
'nheads_k'
:
4
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
16
,
'nheads_k'
:
2
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
26
,
'nheads_k'
:
2
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
8
,
'nheads_k'
:
1
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
13
,
'nheads_k'
:
1
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
32
,
'nheads_k'
:
32
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
16
,
'nheads_k'
:
16
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
8
,
'nheads_k'
:
8
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
4
,
'nheads_k'
:
4
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
40
,
'nheads_k'
:
40
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
20
,
'nheads_k'
:
20
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
10
,
'nheads_k'
:
10
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
5
,
'nheads_k'
:
5
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
32
,
'nheads_k'
:
8
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
16
,
'nheads_k'
:
4
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
8
,
'nheads_k'
:
2
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
4
,
'nheads_k'
:
1
,
'seq_len'
:
8192
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
28
,
'nheads_k'
:
4
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
14
,
'nheads_k'
:
2
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
{
'causal'
:
True
,
'batch_size'
:
1
,
'nheads'
:
7
,
'nheads_k'
:
1
,
'seq_len'
:
4096
,
'head_size'
:
128
,
'window_size'
:
[
-
1
,
-
1
]},
]
csv_file_name
=
"bwd_results.csv"
fieldnames
=
[
"batch_size"
,
"seq_len"
,
"head_size"
,
"nheads"
,
"nheads_k"
,
"causal"
,
"bwd_speed"
]
results
=
[]
for
params
in
params_list
:
batch_size
=
params
[
'batch_size'
]
nheads
=
params
[
'nheads'
]
nheads_k
=
params
[
'nheads_k'
]
head_size
=
params
[
'head_size'
]
seq_len
=
params
[
'seq_len'
]
nheads_k
=
params
[
'nheads_k'
]
causal
=
params
[
'causal'
]
window_size_left
=
params
[
'window_size'
][
0
]
window_size_right
=
params
[
'window_size'
][
1
]
device
=
torch
.
device
(
"cuda"
if
torch
.
cuda
.
is_available
()
else
"cpu"
)
softmax_scale
=
1.0
/
math
.
sqrt
(
head_size
)
dropout_p
=
0
q
=
torch
.
randn
(
batch_size
,
nheads
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
)
k
=
torch
.
randn
(
batch_size
,
nheads_k
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
)
v
=
torch
.
randn
(
batch_size
,
nheads_k
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
)
o
=
torch
.
randn
(
batch_size
,
nheads
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
)
do
=
torch
.
randn
(
batch_size
,
nheads
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
,
requires_grad
=
True
)
dq
=
torch
.
empty
(
batch_size
,
nheads
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
)
dk
=
torch
.
empty
(
batch_size
,
nheads_k
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
)
dv
=
torch
.
empty
(
batch_size
,
nheads_k
,
seq_len
,
head_size
,
device
=
device
,
dtype
=
torch
.
float16
)
lse
=
torch
.
randn
(
batch_size
,
nheads_k
,
seq_len
,
device
=
device
,
dtype
=
torch
.
float16
)
input_params
=
(
do
,
q
,
k
,
v
,
o
,
lse
,
dq
,
dk
,
dv
,
None
,
dropout_p
,
softmax_scale
,
causal
,
window_size_left
,
window_size_right
,
0.0
,
False
,
None
,
None
)
fa_average_cost
=
0
# benchmark 多次取平均值
iterations
=
12
warmup
=
2
cost_time_list
=
[]
for
i
in
range
(
iterations
):
cost_time
=
benchmark_backward
(
_C_flashattention
.
bwd
,
*
input_params
,
repeats
=
1
)
if
i
>=
warmup
:
cost_time_list
.
append
(
cost_time
)
torch
.
cuda
.
synchronize
()
torch
.
cuda
.
empty_cache
()
# print(float(cost_time))
max_cost_time
=
max
(
cost_time_list
)
cost_time_list
.
remove
(
max_cost_time
)
fa_average_cost
=
sum
(
cost_time_list
)
/
(
iterations
-
warmup
-
1
)
calculation_amount_bwd
=
flops
(
batch_size
,
seq_len
,
head_size
,
nheads
,
causal
,
"bwd"
)
speed_bwd
=
efficiency
(
calculation_amount_bwd
,
fa_average_cost
)
results
.
append
({
"batch_size"
:
batch_size
,
"seq_len"
:
seq_len
,
"head_size"
:
head_size
,
"nheads"
:
nheads
,
"nheads_k"
:
nheads_k
,
"causal"
:
causal
,
"bwd_speed"
:
speed_bwd
})
print
(
"bs= {}, seq_len={}, head_size={}, nheads={}, nheads_k={}, causal={}, bwd speed={} tflops"
.
format
(
batch_size
,
seq_len
,
head_size
,
nheads
,
nheads_k
,
causal
,
speed_bwd
))
with
open
(
csv_file_name
,
'w'
,
newline
=
''
)
as
csvfile
:
writer
=
csv
.
DictWriter
(
csvfile
,
fieldnames
=
fieldnames
)
writer
.
writeheader
()
# 写入表头
for
result
in
results
:
writer
.
writerow
(
result
)
\ No newline at end of file
benchmarks/hy/test_flash_attn.py
0 → 100644
View file @
34e67b1e
import
torch
from
flash_attn
import
flash_attn_func
,
flash_attn_with_kvcache
,
flash_attn_varlen_func
import
math
import
torch.nn.functional
as
F
import
os
import
pytest
from
einops
import
rearrange
,
repeat
def
native_multi_head_attention_2
(
q
,
k
,
v
,
mask
=
None
,
mask_type
=
None
,
upcast
=
True
,
reorder_ops
=
False
):
original_device
=
q
.
device
original_dtype
=
q
.
dtype
d
=
q
.
size
(
-
1
)
groups
=
q
.
size
(
1
)
//
k
.
size
(
1
)
if
groups
!=
1
:
k
=
torch
.
repeat_interleave
(
k
,
repeats
=
groups
,
dim
=
1
)
v
=
torch
.
repeat_interleave
(
v
,
repeats
=
groups
,
dim
=
1
)
if
upcast
:
q
,
k
,
v
=
q
.
float
(),
k
.
float
(),
v
.
float
()
if
not
reorder_ops
:
q
=
q
/
math
.
sqrt
(
d
)
else
:
k
=
k
/
math
.
sqrt
(
d
)
k1
=
k
.
transpose
(
-
2
,
-
1
)
qkt
=
torch
.
matmul
(
q
,
k1
)
qkt
=
qkt
.
type
(
torch
.
float32
)
if
mask_type
==
0
and
mask
is
not
None
:
qkt
.
masked_fill_
(
mask
,
-
float
(
'inf'
))
# Apply the mask
qkt_max
=
qkt
.
max
(
dim
=-
1
)[
0
].
unsqueeze
(
-
1
)
qkt_exp
=
torch
.
exp
((
qkt
-
qkt_max
))
qkt_sum
=
qkt_exp
.
sum
(
-
1
).
unsqueeze
(
-
1
)
qkt_softmax
=
qkt_exp
/
qkt_sum
# qkt_softmax = qkt_softmax.type(original_dtype)
v
=
v
.
float
()
# print("sum: {:.12f} | max: {:.12f}".format(qkt_sum.item(), qkt_max.item()))
pv
=
torch
.
matmul
(
qkt_softmax
,
v
)
return
pv
.
to
(
original_device
).
to
(
original_dtype
)
def
_generate_block_kvcache
(
seqlen_k
,
paged_kv_block_size
,
batch_size
,
nheads_k
,
d
,
device
,
dtype
):
num_blocks
=
math
.
ceil
(
seqlen_k
/
paged_kv_block_size
)
*
batch_size
*
3
k_cache_paged
=
torch
.
randn
(
num_blocks
,
paged_kv_block_size
,
nheads_k
,
d
,
device
=
device
,
dtype
=
dtype
)
v_cache_paged
=
torch
.
randn
(
num_blocks
,
paged_kv_block_size
,
nheads_k
,
d
,
device
=
device
,
dtype
=
dtype
)
block_table
=
rearrange
(
torch
.
randperm
(
num_blocks
,
dtype
=
torch
.
int32
,
device
=
device
),
"(b nblocks) -> b nblocks"
,
b
=
batch_size
,
)
k_cache
=
rearrange
(
# pytorch 1.12 doesn't have indexing with int32
k_cache_paged
[
block_table
.
to
(
dtype
=
torch
.
long
).
flatten
()],
"(b nblocks) block_size ... -> b (nblocks block_size) ..."
,
b
=
batch_size
,
)[:,
:
seqlen_k
]
v_cache
=
rearrange
(
v_cache_paged
[
block_table
.
to
(
dtype
=
torch
.
long
).
flatten
()],
"(b nblocks) block_size ... -> b (nblocks block_size) ..."
,
b
=
batch_size
,
)[:,
:
seqlen_k
]
k_cache
=
k_cache
.
permute
(
0
,
2
,
1
,
3
).
contiguous
()
v_cache
=
v_cache
.
permute
(
0
,
2
,
1
,
3
).
contiguous
()
k_cache_paged
=
k_cache_paged
.
permute
(
0
,
2
,
1
,
3
).
contiguous
()
v_cache_paged
=
v_cache_paged
.
permute
(
0
,
2
,
1
,
3
).
contiguous
()
return
k_cache
,
v_cache
,
block_table
,
k_cache_paged
,
v_cache_paged
,
num_blocks
def
get_partition
(
batch_size
,
seq_q_len
,
max_seqlen_k
,
nheads_q
,
nheads_k
,
head_size
,
input_dtype
,
input_device
,
device_cu
=
100
):
# 计算一下划分大小和划分策略
partition_size
=
0
scores_raw
=
None
tmp_output
=
None
threshold
=
device_cu
*
0.75
n_group
=
int
(
nheads_q
/
nheads_k
)
use_regroup
=
all
(
n_group
%
it
!=
0
for
it
in
[
16
,
8
,
4
,
2
,
9
,
7
,
5
,
3
])
if
(
use_regroup
):
n_group
=
1
if
((
batch_size
*
seq_q_len
*
n_group
<
threshold
and
max_seqlen_k
>=
1024
)
or
(
max_seqlen_k
>=
8192
)):
# 根据最大的 seqKV 长度, 决定相应的划分 size
if
(
max_seqlen_k
<=
1024
):
partition_size
=
128
elif
(
max_seqlen_k
<=
2048
):
partition_size
=
256
elif
(
max_seqlen_k
<=
32768
):
partition_size
=
512
else
:
partition_size
=
1024
if
(
nheads_q
==
nheads_k
):
partition_size
=
1024
while
((
nheads_q
>
nheads_k
)
and
(
batch_size
*
seq_q_len
*
n_group
*
(
max_seqlen_k
/
partition_size
))
<
threshold
):
# 目前支持的最小 partition size 是 128
if
(
partition_size
<
256
):
break
partition_size
=
int
(
partition_size
/
2
)
num_splits
=
math
.
ceil
(
max_seqlen_k
*
1.0
/
partition_size
)
scores_raw
=
torch
.
empty
(
size
=
(
2
,
num_splits
,
batch_size
,
nheads_q
),
dtype
=
torch
.
float32
,
device
=
input_device
)
tmp_output
=
torch
.
empty
(
size
=
(
num_splits
,
batch_size
,
nheads_q
,
head_size
),
dtype
=
input_dtype
,
device
=
input_device
)
return
partition_size
,
scores_raw
,
tmp_output
os
.
environ
[
'USE_FA_CUDA_BWD'
]
=
'1'
#设置使用我们的hip版的fa_bwd
@
pytest
.
mark
.
parametrize
(
"dtype"
,
[
torch
.
float16
,
torch
.
bfloat16
])
# @pytest.mark.parametrize('dtype', [torch.bfloat16])
@
pytest
.
mark
.
parametrize
(
"nheads,nheads_k"
,
[
(
16
,
16
),
(
32
,
32
),
(
32
,
4
),
(
52
,
4
),
(
16
,
2
),
(
26
,
2
),
(
8
,
1
),
(
13
,
1
)
])
@
pytest
.
mark
.
parametrize
(
"causal"
,
[
False
,
True
])
# @pytest.mark.parametrize('causal', [False])
# @pytest.mark.parametrize('d', [32, 64, 96, 128, 160, 192])
@
pytest
.
mark
.
parametrize
(
'd'
,
[
128
])
@
pytest
.
mark
.
parametrize
(
"seqlen_q,seqlen_kv"
,
[
(
128
,
128
),
(
1024
,
1024
),
(
2048
,
2048
),
# (8192, 8192),
],
)
# @pytest.mark.parametrize('seqlen_q,seqlen_kv', [(128, 128)])
# @pytest.mark.parametrize("dropout_p", [0.0, 0.17])
# @pytest.mark.parametrize('dropout_p', [0.0])
def
test_flash_attn_output
(
seqlen_q
,
seqlen_kv
,
nheads
,
nheads_k
,
d
,
causal
,
dtype
):
if
(
max
(
seqlen_q
,
seqlen_kv
)
>=
2048
and
torch
.
cuda
.
get_device_properties
(
"cuda"
).
total_memory
<=
16
*
2
**
30
):
pytest
.
skip
()
# Reference implementation OOM
device
=
"cuda"
# set seed
torch
.
random
.
manual_seed
(
0
)
batch_size
=
1
assert
nheads
%
nheads_k
==
0
q
=
torch
.
randn
(
batch_size
,
nheads
,
seqlen_q
,
d
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
k
=
torch
.
randn
(
batch_size
,
nheads_k
,
seqlen_kv
,
d
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
,
)
v
=
torch
.
randn
(
batch_size
,
nheads_k
,
seqlen_kv
,
d
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
,
)
q_flash
=
q
.
detach
().
clone
().
requires_grad_
(
True
)
k_flash
=
k
.
detach
().
clone
().
requires_grad_
(
True
)
v_flash
=
v
.
detach
().
clone
().
requires_grad_
(
True
)
out_flash
,
lse
,
S_dmask
=
flash_attn_func
(
q_flash
,
k_flash
,
v_flash
,
return_attn_probs
=
True
,
causal
=
causal
)
q_ref
=
q
.
detach
().
clone
().
requires_grad_
(
True
)
k_ref
=
k
.
detach
().
clone
().
requires_grad_
(
True
)
v_ref
=
v
.
detach
().
clone
().
requires_grad_
(
True
)
q_pt
=
q
.
detach
().
clone
().
requires_grad_
(
True
)
k_pt
=
k
.
detach
().
clone
().
requires_grad_
(
True
)
v_pt
=
v
.
detach
().
clone
().
requires_grad_
(
True
)
mask
=
torch
.
ones
(
q
.
size
(
-
2
),
k
.
size
(
-
2
),
dtype
=
torch
.
bool
,
device
=
q
.
device
).
tril
().
logical_not
()
if
causal
else
None
mask_type
=
0
if
causal
else
None
out_ref
=
native_multi_head_attention_2
(
q_ref
,
k_ref
,
v_ref
,
mask
,
mask_type
)
# out_ref,_ = attention_ref(q_ref, k_ref, v_ref)
# out_pt,_ = attention_ref(q_pt, k_pt, v_pt, upcast=False,reorder_ops=True)
out_pt
=
native_multi_head_attention_2
(
q_pt
,
k_pt
,
v_pt
,
mask
,
mask_type
,
upcast
=
False
,
reorder_ops
=
True
)
print
(
f
"Output max diff:
{
(
out_flash
-
out_ref
).
abs
().
max
().
item
()
}
"
)
print
(
f
"Output mean diff:
{
(
out_flash
-
out_ref
).
abs
().
mean
().
item
()
}
"
)
print
(
f
"Pytorch max diff:
{
(
out_pt
-
out_ref
).
abs
().
max
().
item
()
}
"
)
print
(
f
"Pytorch mean diff:
{
(
out_pt
-
out_ref
).
abs
().
mean
().
item
()
}
"
)
# if dropout_p > 0.0:
# print(f'Attention max diff: {(attn - attn_ref).abs().max().item()}')
# print(f'Attention Pytorch max diff: {(attn_pt - attn_ref).abs().max().item()}')
dO
=
torch
.
randn
(
batch_size
,
nheads
,
seqlen_q
,
d
).
to
(
dtype
).
to
(
device
)
out_flash
.
backward
(
dO
)
out_ref
.
backward
(
dO
)
out_pt
.
backward
(
dO
)
print
(
f
"dQ max diff:
{
(
q_flash
.
grad
-
q_ref
.
grad
).
abs
().
max
().
item
()
}
"
)
print
(
f
"dK max diff:
{
(
k_flash
.
grad
-
k_ref
.
grad
).
abs
().
max
().
item
()
}
"
)
print
(
f
"dV max diff:
{
(
v_flash
.
grad
-
v_ref
.
grad
).
abs
().
max
().
item
()
}
"
)
print
(
f
"dQ mean diff:
{
(
q_flash
.
grad
-
q_ref
.
grad
).
abs
().
mean
().
item
()
}
"
)
print
(
f
"dK mean diff:
{
(
k_flash
.
grad
-
k_ref
.
grad
).
abs
().
mean
().
item
()
}
"
)
print
(
f
"dV mean diff:
{
(
v_flash
.
grad
-
v_ref
.
grad
).
abs
().
mean
().
item
()
}
"
)
print
(
f
"dQ Pytorch max diff:
{
(
q_pt
.
grad
-
q_ref
.
grad
).
abs
().
max
().
item
()
}
"
)
print
(
f
"dK Pytorch max diff:
{
(
k_pt
.
grad
-
k_ref
.
grad
).
abs
().
max
().
item
()
}
"
)
print
(
f
"dV Pytorch max diff:
{
(
v_pt
.
grad
-
v_ref
.
grad
).
abs
().
max
().
item
()
}
"
)
print
(
f
"dQ Pytorch mean diff:
{
(
q_pt
.
grad
-
q_ref
.
grad
).
abs
().
mean
().
item
()
}
"
)
print
(
f
"dK Pytorch mean diff:
{
(
k_pt
.
grad
-
k_ref
.
grad
).
abs
().
mean
().
item
()
}
"
)
print
(
f
"dV Pytorch mean diff:
{
(
v_pt
.
grad
-
v_ref
.
grad
).
abs
().
mean
().
item
()
}
"
)
# Check that FlashAttention's numerical error is at most twice the numerical error
# of a Pytorch implementation.
assert
(
out_flash
-
out_ref
).
abs
().
max
().
item
()
<=
2
*
(
out_pt
-
out_ref
).
abs
().
max
().
item
()
assert
(
q_flash
.
grad
-
q_ref
.
grad
).
abs
().
max
().
item
()
<=
3
*
(
q_pt
.
grad
-
q_ref
.
grad
).
abs
().
max
().
item
()
assert
(
k_flash
.
grad
-
k_ref
.
grad
).
abs
().
max
().
item
()
<=
3
*
(
k_pt
.
grad
-
k_ref
.
grad
).
abs
().
max
().
item
()
assert
(
v_flash
.
grad
-
v_ref
.
grad
).
abs
().
max
().
item
()
<=
3
*
(
v_pt
.
grad
-
v_ref
.
grad
).
abs
().
max
().
item
()
@
pytest
.
mark
.
parametrize
(
"dtype"
,
[
torch
.
float16
,
torch
.
bfloat16
])
# @pytest.mark.parametrize("num_splits", [1])
# @pytest.mark.parametrize("alibi", [False, True])
@
pytest
.
mark
.
parametrize
(
"alibi"
,
[
False
])
# @pytest.mark.parametrize("local", [False, True])
@
pytest
.
mark
.
parametrize
(
"local"
,
[
False
])
# @pytest.mark.parametrize("causal", [False, True])
@
pytest
.
mark
.
parametrize
(
"causal"
,
[
False
])
@
pytest
.
mark
.
parametrize
(
"paged_kv_block_size"
,
[
128
])
# @pytest.mark.parametrize("paged_kv_block_size", [256, 512])
# @pytest.mark.parametrize("paged_kv_block_size", [None])
# @pytest.mark.parametrize("d", [32, 64, 96, 128, 160, 192, 224, 256])
# @pytest.mark.parametrize('d', [32, 40, 64, 80, 96, 128, 160, 192])
# @pytest.mark.parametrize('d', [56, 80])
@
pytest
.
mark
.
parametrize
(
"d"
,
[
128
])
@
pytest
.
mark
.
parametrize
(
"nheads,nheads_k"
,
[
(
16
,
16
),
(
32
,
32
),
(
32
,
4
),
(
52
,
4
),
(
16
,
2
),
(
26
,
2
),
(
8
,
1
),
(
13
,
1
)
])
@
pytest
.
mark
.
parametrize
(
"seqlen_q,seqlen_k"
,
[
(
1
,
1024
),
(
1
,
339
),
(
1
,
128
),
(
1
,
8192
),
(
1
,
8192
*
2
)
],
)
# @pytest.mark.parametrize('seqlen_q,seqlen_k', [(256, 128)])
def
test_flash_attn_kvcache
(
seqlen_q
,
seqlen_k
,
nheads
,
nheads_k
,
d
,
paged_kv_block_size
,
causal
,
local
,
alibi
,
dtype
,
):
device
=
"cuda"
# set seed
torch
.
random
.
manual_seed
(
0
)
batch_size
=
1
assert
nheads
%
nheads_k
==
0
window_size
=
(
-
1
,
-
1
)
if
not
local
else
torch
.
randint
(
0
,
seqlen_k
,
(
2
,))
q
=
torch
.
randn
(
batch_size
,
nheads
,
seqlen_q
,
d
,
device
=
device
,
dtype
=
dtype
)
if
paged_kv_block_size
is
None
:
k_cache
=
torch
.
randn
(
batch_size
,
seqlen_k
,
nheads_k
,
d
,
device
=
device
,
dtype
=
dtype
)
v_cache
=
torch
.
randn
(
batch_size
,
seqlen_k
,
nheads_k
,
d
,
device
=
device
,
dtype
=
dtype
)
block_table
=
None
else
:
(
k_cache
,
v_cache
,
block_table
,
k_cache_paged
,
v_cache_paged
,
num_blocks
,
)
=
_generate_block_kvcache
(
seqlen_k
,
paged_kv_block_size
,
batch_size
,
nheads_k
,
d
,
device
,
dtype
)
# if alibi:
# alibi_slopes = torch.rand(batch_size, nheads, device=device, dtype=torch.float32) * 0.3
# attn_bias = attn_bias_from_alibi_slopes(
# alibi_slopes, seqlen_q, seqlen_k, None, key_padding_mask, causal=causal, key_leftpad=cache_leftpad
# )
# else:
# alibi_slopes, attn_bias = None, None
cu_seq_lens_q
=
torch
.
ones
(
batch_size
*
seqlen_q
,
dtype
=
torch
.
int32
).
to
(
"cuda"
)
cu_seq_lens_k
=
(
torch
.
ones
(
batch_size
*
seqlen_q
,
dtype
=
torch
.
int32
,
device
=
device
)
*
seqlen_k
)
# k_cache[:, 64:] = -1
k_cache_ref
=
k_cache
.
clone
()
v_cache_ref
=
v_cache
.
clone
()
partition_size
,
scores_raw
,
tmp_output
=
get_partition
(
batch_size
,
seqlen_q
,
cu_seq_lens_k
.
max
().
item
(),
nheads
,
nheads_k
,
d
,
dtype
,
device
,
device_cu
=
100
)
out
=
flash_attn_with_kvcache
(
q
,
k_cache
if
paged_kv_block_size
is
None
else
k_cache_paged
,
v_cache
if
paged_kv_block_size
is
None
else
v_cache_paged
,
None
,
None
,
rotary_cos
=
None
,
rotary_sin
=
None
,
cu_seqlens_q
=
cu_seq_lens_q
,
cache_seqlens
=
cu_seq_lens_k
,
cache_batch_idx
=
None
,
cache_leftpad
=
None
,
block_table
=
block_table
,
causal
=
causal
,
window_size
=
window_size
,
alibi_slopes
=
None
,
num_splits
=
partition_size
,
scores_raw
=
scores_raw
,
tmp_output
=
tmp_output
)
out_ref
=
native_multi_head_attention_2
(
q
,
k_cache_ref
,
v_cache_ref
)
out_pt
=
native_multi_head_attention_2
(
q
,
k_cache_ref
,
v_cache_ref
,
upcast
=
False
,
reorder_ops
=
True
)
print
(
f
"Output max diff:
{
(
out
-
out_ref
).
abs
().
max
().
item
()
}
"
)
print
(
f
"Output mean diff:
{
(
out
-
out_ref
).
abs
().
mean
().
item
()
}
"
)
print
(
f
"Output mean rel diff:
{
(
out
/
out_ref
).
abs
().
mean
().
item
()
}
"
)
print
(
f
"Pytorch max diff:
{
(
out_pt
-
out_ref
).
abs
().
max
().
item
()
}
"
)
print
(
f
"Pytorch mean diff:
{
(
out_pt
-
out_ref
).
abs
().
mean
().
item
()
}
"
)
# Check that FlashAttention's numerical error is at most twice the numerical error
# of a Pytorch implementation.
mult
=
3
if
not
alibi
else
5
assert
(
out
-
out_ref
).
abs
().
max
().
item
()
<=
mult
*
(
out_pt
-
out_ref
).
abs
().
max
().
item
()
+
1e-5
@
pytest
.
mark
.
parametrize
(
"dtype"
,
[
torch
.
float16
,
torch
.
bfloat16
])
@
pytest
.
mark
.
parametrize
(
"causal"
,
[
False
,
True
])
# @pytest.mark.parametrize('d', [32, 64, 96, 128, 160, 192, 224, 256])
@
pytest
.
mark
.
parametrize
(
'd'
,
[
128
])
@
pytest
.
mark
.
parametrize
(
"seqlen_q,seqlen_kv"
,
[
(
1024
,
1024
),
(
128
,
128
),
(
339
,
339
),
],
)
@
pytest
.
mark
.
parametrize
(
"nheads,nheads_k"
,
[
(
16
,
16
),
(
32
,
32
),
(
32
,
4
),
(
52
,
4
),
(
16
,
2
),
(
26
,
2
),
(
8
,
1
),
(
13
,
1
)
])
def
test_flash_attn_varlen_output
(
seqlen_q
,
seqlen_kv
,
d
,
nheads
,
nheads_k
,
causal
,
dtype
):
if
(
max
(
seqlen_q
,
seqlen_kv
)
>=
2048
and
torch
.
cuda
.
get_device_properties
(
"cuda"
).
total_memory
<=
16
*
2
**
30
):
pytest
.
skip
()
# Reference implementation OOM
device
=
"cuda"
# set seed
torch
.
random
.
manual_seed
(
0
)
batch_size
=
4
nheads
=
8
nheads_k
=
8
assert
nheads
%
nheads_k
==
0
q
=
torch
.
randn
(
batch_size
,
nheads
,
seqlen_q
,
d
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
k
=
torch
.
randn
(
batch_size
,
nheads_k
,
seqlen_kv
,
d
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
v
=
torch
.
randn
(
batch_size
,
nheads_k
,
seqlen_kv
,
d
,
device
=
device
,
dtype
=
dtype
,
requires_grad
=
True
)
q_fa
=
q
.
view
(
batch_size
*
nheads
*
seqlen_q
,
d
)
k_fa
=
k
.
view
(
batch_size
*
nheads_k
*
seqlen_q
,
d
)
v_fa
=
v
.
view
(
batch_size
*
nheads_k
*
seqlen_q
,
d
)
cu_seqlens_q
=
torch
.
arange
(
0
,
seqlen_q
*
(
batch_size
+
1
),
seqlen_q
,
dtype
=
torch
.
int32
,
device
=
device
)
cu_seqlens_k
=
torch
.
arange
(
0
,
seqlen_kv
*
(
batch_size
+
1
),
seqlen_kv
,
dtype
=
torch
.
int32
,
device
=
device
)
out
,
sm_lse
,
S_dmask
=
flash_attn_varlen_func
(
q_fa
,
k_fa
,
v_fa
,
cu_seqlens_q
,
cu_seqlens_k
,
seqlen_q
,
seqlen_kv
,
0.0
,
return_attn_probs
=
True
,
causal
=
causal
,
)
# out = output_pad_fn(out_unpad)
split_sizes
=
[
cu_seqlens_q
[
i
+
1
]
-
cu_seqlens_q
[
i
]
for
i
in
range
(
len
(
cu_seqlens_q
)
-
1
)]
out_split
=
torch
.
split
(
out
,
[
i
*
nheads
for
i
in
split_sizes
],
dim
=
0
)
o_tmp
=
out_split
[
0
].
view
(
nheads
,
-
1
,
d
)
for
i
in
range
(
1
,
len
(
out_split
)):
o_tmp
=
torch
.
cat
((
o_tmp
,
out_split
[
i
].
view
(
nheads
,
-
1
,
d
)),
dim
=
0
)
out_fa
=
o_tmp
.
view
(
batch_size
,
nheads
,
seqlen_q
,
d
)
mask
=
torch
.
ones
(
q
.
size
(
-
2
),
k
.
size
(
-
2
),
dtype
=
torch
.
bool
,
device
=
q
.
device
).
tril
().
logical_not
()
if
causal
else
None
mask_type
=
0
if
causal
else
None
out_ref
=
native_multi_head_attention_2
(
q
,
k
,
v
,
mask
,
mask_type
)
out_pt
=
native_multi_head_attention_2
(
q
,
k
,
v
,
mask
,
mask_type
,
upcast
=
False
,
reorder_ops
=
True
)
print
(
f
"Output max diff:
{
(
out_fa
-
out_ref
).
abs
().
max
().
item
()
}
"
)
print
(
f
"Output mean diff:
{
(
out_fa
-
out_ref
).
abs
().
mean
().
item
()
}
"
)
print
(
f
"Pytorch max diff:
{
(
out_pt
-
out_ref
).
abs
().
max
().
item
()
}
"
)
print
(
f
"Pytorch mean diff:
{
(
out_pt
-
out_ref
).
abs
().
mean
().
item
()
}
"
)
# if dropout_p > 0.0:
# print(f'Attention max diff: {(attn - attn_ref).abs().max().item()}')
# print(f'Attention Pytorch max diff: {(attn_pt - attn_ref).abs().max().item()}')
# Check that FlashAttention's numerical error is at most twice the numerical error
# of a Pytorch implementation.
assert
(
out_fa
-
out_ref
).
abs
().
max
().
item
()
<=
2
*
(
out_pt
-
out_ref
).
abs
().
max
().
item
()
\ No newline at end of file
benchmarks/test_prefix_kvcache.py
0 → 100644
View file @
34e67b1e
import
argparse
import
math
import
random
import
torch
import
triton
import
pdb
# import flash_attn_2_cuda as flash_attn_cuda
from
flash_attn
import
vllm_flash_attn_with_kvcache
torch
.
set_printoptions
(
precision
=
4
,
profile
=
"default"
,
sci_mode
=
False
)
def
scaled_dot_product_attention
(
query
,
key
,
value
,
h_q
,
h_kv
,
is_causal
=
False
):
query
=
query
.
float
()
key
=
key
.
float
()
value
=
value
.
float
()
key
=
key
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
value
=
value
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
tmp
=
query
@
key
.
transpose
(
-
2
,
-
1
)
# print("attn_weight ", tmp[0, 0, :10])
attn_weight
=
query
@
key
.
transpose
(
-
2
,
-
1
)
/
math
.
sqrt
(
query
.
size
(
-
1
))
if
is_causal
:
s_q
=
query
.
shape
[
-
2
]
s_k
=
key
.
shape
[
-
2
]
attn_bias
=
torch
.
zeros
(
s_q
,
s_k
,
dtype
=
query
.
dtype
)
temp_mask
=
torch
.
ones
(
s_q
,
s_k
,
dtype
=
torch
.
bool
).
tril
(
diagonal
=
s_k
-
s_q
)
attn_bias
.
masked_fill_
(
temp_mask
.
logical_not
(),
float
(
"-inf"
))
attn_bias
.
to
(
query
.
dtype
)
attn_weight
+=
attn_bias
lse
=
attn_weight
.
logsumexp
(
dim
=-
1
)
attn_weight
=
torch
.
softmax
(
attn_weight
,
dim
=-
1
,
dtype
=
torch
.
float32
)
return
attn_weight
@
value
,
lse
def
scaled_dot_product_attention_int8
(
query
,
key
,
value
,
h_q
,
h_kv
,
k_scale
,
v_scale
,
is_causal
=
False
):
query
=
query
.
float
()
key
=
key
.
float
()
value
=
value
.
float
()
# print(" ", key[0])
# print("k_scale ", k_scale[0, :8])
# print(" key k_scale ", key.shape, k_scale.shape)
# print(" key ", key.shape)
# key = key * k_scale
# print("key ", key[0, 0:2, :8])
# value = value * v_scale
# print("k_scale ", k_scale[0:2, :8])
for
i
in
range
(
key
.
shape
[
0
]):
key
[
i
]
=
key
[
i
]
*
k_scale
[
i
]
value
[
i
]
=
value
[
i
]
*
v_scale
[
i
]
# print("key ", key[0:2, 0, :8])
key
=
key
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
value
=
value
.
repeat_interleave
(
h_q
//
h_kv
,
dim
=
0
)
# k_scale = k_scale.repeat_interleave(h_q // h_kv, dim=0)
# v_scale = v_scale.repeat_interleave(h_q // h_kv, dim=0)
attn_weight_temp
=
query
@
key
.
transpose
(
-
2
,
-
1
)
# print(" attn_weight_temp ", attn_weight_temp[0, :3, :4])
attn_weight
=
query
@
key
.
transpose
(
-
2
,
-
1
)
/
math
.
sqrt
(
query
.
size
(
-
1
))
if
is_causal
:
s_q
=
query
.
shape
[
-
2
]
s_k
=
key
.
shape
[
-
2
]
attn_bias
=
torch
.
zeros
(
s_q
,
s_k
,
dtype
=
query
.
dtype
)
temp_mask
=
torch
.
ones
(
s_q
,
s_k
,
dtype
=
torch
.
bool
).
tril
(
diagonal
=
s_k
-
s_q
)
attn_bias
.
masked_fill_
(
temp_mask
.
logical_not
(),
float
(
"-inf"
))
attn_bias
.
to
(
query
.
dtype
)
attn_weight
+=
attn_bias
lse
=
attn_weight
.
logsumexp
(
dim
=-
1
)
attn_weight
=
torch
.
softmax
(
attn_weight
,
dim
=-
1
,
dtype
=
torch
.
float32
)
return
attn_weight
@
value
,
lse
def
cal_diff
(
x
:
torch
.
Tensor
,
y
:
torch
.
Tensor
,
name
:
str
)
->
None
:
torch_dtype
=
x
.
dtype
x
,
y
=
x
.
double
(),
y
.
double
()
RMSE
=
((
x
-
y
)
*
(
x
-
y
)).
mean
().
sqrt
().
item
()
cos_diff
=
1
-
2
*
(
x
*
y
).
sum
().
item
()
/
max
((
x
*
x
+
y
*
y
).
sum
().
item
(),
1e-12
)
amax_diff
=
(
x
-
y
).
abs
().
max
().
item
()
print
(
f
"
{
name
}
:
{
cos_diff
=
}
,
{
RMSE
=
}
,
{
amax_diff
=
}
"
)
assert
cos_diff
<
(
1e-4
if
torch_dtype
==
torch
.
bfloat16
else
1e-5
)
@
torch
.
inference_mode
()
def
test_flash_kvcache
(
b
,
s_q
,
mean_sk
,
h_q
,
h_kv
,
d
,
causal
,
varlen
,
is_prof
=
False
):
print
(
f
"
{
b
=
}
,
{
s_q
=
}
,
{
mean_sk
=
}
,
{
h_q
=
}
,
{
h_kv
=
}
,
{
d
=
}
,
{
causal
=
}
,
{
varlen
=
}
"
)
cache_seqlens
=
torch
.
full
((
b
,),
mean_sk
,
dtype
=
torch
.
int32
)
if
varlen
:
for
i
in
range
(
b
):
cache_seqlens
[
i
]
=
max
(
random
.
normalvariate
(
mean_sk
,
mean_sk
/
2
),
s_q
)
# cache_seqlens[0] = 127
# print(" cache_seqlens[i] ", cache_seqlens)
total_seqlens
=
cache_seqlens
.
sum
().
item
()
mean_seqlens
=
cache_seqlens
.
float
().
mean
().
int
().
item
()
max_seqlen
=
cache_seqlens
.
max
().
item
()
max_seqlen_pad
=
triton
.
cdiv
(
max_seqlen
,
64
)
*
64
print
(
f
"
{
total_seqlens
=
}
,
{
mean_seqlens
=
}
,
{
max_seqlen
=
}
,
{
max_seqlen_pad
=
}
"
)
q
=
torch
.
randn
(
b
,
s_q
,
h_q
,
d
)
# q[0, 0, 0, 0] = 2
# q[:, :, :, 0:32] = 0
# q[:, :, :, 32:64] = 0
# q[:, :, :, 64:96] = 0
# q[:, :, :, 96:128] = 0
# for j in range(d):
# q[0, :, 0, j] = j
block_size
=
64
block_table
=
torch
.
arange
(
b
*
max_seqlen_pad
//
block_size
,
dtype
=
torch
.
int32
).
view
(
b
,
max_seqlen_pad
//
block_size
)
blocked_k
=
torch
.
randn
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
)
# blocked_k[0, 0, 0, 0] = 1
blocked_v
=
torch
.
randn
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
)
# pad = 0
# blocked_k = torch.nn.functional.pad(
# blocked_k.reshape(
# block_table.numel(), block_size, h_kv*d),
# (0, pad), 'constant', 0)[:,:,:-pad].reshape(block_table.numel(), block_size, h_kv, d)
# for i in range(b):
# blocked_k.view(b, max_seqlen_pad, h_kv, d)[i, cache_seqlens[i].item():] = (
# # float("nan")
# 0
# )
# blocked_v.view(b, max_seqlen_pad, h_kv, d)[i, cache_seqlens[i].item():] = (
# # float("nan")
# 0
# )
for
i
in
range
(
b
):
blocked_k
.
view
(
b
,
max_seqlen_pad
,
h_kv
,
d
)[
i
,
cache_seqlens
[
i
].
item
():]
=
(
float
(
"nan"
)
)
blocked_v
.
view
(
b
,
max_seqlen_pad
,
h_kv
,
d
)[
i
,
cache_seqlens
[
i
].
item
():]
=
(
float
(
"nan"
)
)
blocked_k_
=
blocked_k
.
permute
(
0
,
2
,
1
,
3
).
contiguous
()
blocked_v_
=
blocked_v
.
permute
(
0
,
2
,
3
,
1
).
contiguous
()
def
flash_kvcache
():
return
vllm_flash_attn_with_kvcache
(
q
=
q
,
k_cache
=
blocked_k_
,
v_cache
=
blocked_v_
,
block_table
=
block_table
,
cache_seqlens
=
cache_seqlens
,
causal
=
causal
,
return_softmax_lse
=
True
,
num_splits
=
0
,
)
def
ref_kvcache
():
out
=
torch
.
empty
(
b
,
s_q
,
h_q
,
d
,
dtype
=
torch
.
float32
)
lse
=
torch
.
empty
(
b
,
h_q
,
s_q
,
dtype
=
torch
.
float32
)
for
i
in
range
(
b
):
begin
=
i
*
max_seqlen_pad
end
=
begin
+
cache_seqlens
[
i
]
O
,
LSE
=
scaled_dot_product_attention
(
q
[
i
].
transpose
(
0
,
1
),
blocked_k
.
view
(
-
1
,
h_kv
,
d
)[
begin
:
end
].
transpose
(
0
,
1
),
blocked_v
.
view
(
-
1
,
h_kv
,
d
)[
begin
:
end
].
transpose
(
0
,
1
),
h_q
=
h_q
,
h_kv
=
h_kv
,
is_causal
=
causal
,
)
out
[
i
]
=
O
.
transpose
(
0
,
1
)
lse
[
i
]
=
LSE
return
out
,
lse
# # out_flash = flash_kvcache()
out_flash
,
lse_flash
=
flash_kvcache
()
# if is_prof: return
out_torch
,
lse_torch
=
ref_kvcache
()
# print("lse_flash:", lse_flash[0, 0, :16])
# print("lse_torch:", lse_torch[0, 0, :16])
# print("out_flash:", out_flash[0, 0, 0, :16])
# print("out_torch:", out_torch[0, 0, 0, :16])
# indexs = torch.nonzero((out_flash - out_torch).abs() > 0.01)
# # print("indexs ", indexs)
# print("nan ", torch.nonzero(torch.isnan(out_flash)))
# # pdb.set_trace()
print
(
"lse_flash - lse_torch"
,
(
lse_torch
-
lse_flash
).
abs
().
max
())
print
(
"out_torch - out_flash"
,
(
out_flash
-
out_torch
).
abs
().
max
())
cal_diff
(
lse_flash
,
lse_torch
,
"lse"
)
cal_diff
(
out_flash
,
out_torch
,
"out"
)
# cal_diff(lse_flash, lse_torch, "lse")
t
=
triton
.
testing
.
do_bench
(
flash_kvcache
)
print
(
f
"
{
t
:.
3
f
}
ms"
)
@
torch
.
inference_mode
()
def
test_flash_kvcache_int8
(
b
,
s_q
,
mean_sk
,
h_q
,
h_kv
,
d
,
causal
,
varlen
,
is_prof
=
False
):
print
(
f
"
{
b
=
}
,
{
s_q
=
}
,
{
mean_sk
=
}
,
{
h_q
=
}
,
{
h_kv
=
}
,
{
d
=
}
,
{
causal
=
}
,
{
varlen
=
}
"
)
cache_seqlens
=
torch
.
full
((
b
,),
mean_sk
,
dtype
=
torch
.
int32
)
if
varlen
:
for
i
in
range
(
b
):
cache_seqlens
[
i
]
=
max
(
random
.
normalvariate
(
mean_sk
,
mean_sk
/
2
),
s_q
)
total_seqlens
=
cache_seqlens
.
sum
().
item
()
mean_seqlens
=
cache_seqlens
.
float
().
mean
().
int
().
item
()
max_seqlen
=
cache_seqlens
.
max
().
item
()
max_seqlen_pad
=
triton
.
cdiv
(
max_seqlen
,
64
)
*
64
print
(
f
"
{
total_seqlens
=
}
,
{
mean_seqlens
=
}
,
{
max_seqlen
=
}
,
{
max_seqlen_pad
=
}
"
)
q
=
torch
.
randn
(
b
,
s_q
,
h_q
,
d
)
# q = torch.ones(b, s_q, h_q, d)
# for i in range(s_q):
# for j in range(d):
# q[0, i, 0, j] = i
# q[0, 0, 0, 0] = 1
block_size
=
64
block_table
=
torch
.
arange
(
b
*
max_seqlen_pad
//
block_size
,
dtype
=
torch
.
int32
).
view
(
b
,
max_seqlen_pad
//
block_size
)
blocked_k
=
torch
.
randint
(
low
=-
10
,
high
=
10
,
size
=
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
),
dtype
=
torch
.
int8
).
to
(
torch
.
int8
)
blocked_v
=
torch
.
randint
(
low
=-
10
,
high
=
10
,
size
=
(
block_table
.
numel
(),
block_size
,
h_kv
,
d
),
dtype
=
torch
.
int8
).
to
(
torch
.
int8
)
# blocked_k = torch.ones(size = (block_table.numel(), block_size, h_kv, d), dtype = torch.int8).to(torch.int8) * 1
# blocked_v = torch.ones(size = (block_table.numel(), block_size, h_kv, d), dtype = torch.int8).to(torch.int8)
# blocked_k[0, 0, 0, 0] = 1
# blocked_k[0, 1, 0, 0] = 2
# blocked_k[0, 2, 0, 0] = 3
# blocked_k[0, 3, 0, 0] = 4
# blocked_k[0, 4, 0, 0] = 5
# print(blocked_k[0, 0, 0, :3])
# for i in range(64):
# for j in range(128):
# blocked_k[:, i, :, j] = i
k_scale
=
torch
.
randn
(
h_kv
,
d
,
dtype
=
torch
.
float
)
v_scale
=
torch
.
randn
(
h_kv
,
d
,
dtype
=
torch
.
float
)
# k_scale = torch.ones(h_kv, d, dtype = torch.float)
# v_scale = torch.ones(h_kv, d, dtype = torch.float)
# for i in range(128):
# v_scale[:, i] = i
# k_scale[0]
# for i in range(128):
# k_scale[:, i] = i
# print("k_scale ", k_scale)
# pad = 0
# blocked_k = torch.nn.functional.pad(
# blocked_k.reshape(
# block_table.numel(), block_size, h_kv*d),
# (0, pad), 'constant', 0)[:,:,:-pad].reshape(block_table.numel(), block_size, h_kv, d)
for
i
in
range
(
b
):
blocked_k
.
view
(
b
,
max_seqlen_pad
,
h_kv
,
d
)[
i
,
cache_seqlens
[
i
].
item
():]
=
(
-
128
)
blocked_v
.
view
(
b
,
max_seqlen_pad
,
h_kv
,
d
)[
i
,
cache_seqlens
[
i
].
item
():]
=
(
-
128
)
blocked_k_
=
blocked_k
.
permute
(
0
,
2
,
1
,
3
).
contiguous
()
blocked_v_
=
blocked_v
.
permute
(
0
,
2
,
3
,
1
).
contiguous
()
# print("blocked_k_ ", blocked_k_[0, 0, :4, 0])
def
flash_kvcache
():
return
vllm_flash_attn_with_kvcache
(
q
=
q
,
k_cache
=
blocked_k_
,
v_cache
=
blocked_v_
,
block_table
=
block_table
,
cache_seqlens
=
cache_seqlens
,
causal
=
causal
,
return_softmax_lse
=
True
,
k_scale
=
k_scale
,
v_scale
=
v_scale
,
num_splits
=
0
,
# softmax_scale = 0.3,
)
# print(" key k_scale ", blocked_k.view(-1, h_kv, d)[1:4].transpose(0, 1).shape, k_scale.shape)
# def ref_kvcache():
# out = torch.empty(b, s_q, h_q, d, dtype=torch.float32)
# lse = torch.empty(b, h_q, s_q, dtype=torch.float32)
# for i in range(b):
# begin = i * max_seqlen_pad
# end = begin + cache_seqlens[i]
# O, LSE = scaled_dot_product_attention_int8(
# q[i].transpose(0, 1),
# blocked_k.view(-1, h_kv, d)[begin:end].transpose(0, 1),
# blocked_v.view(-1, h_kv, d)[begin:end].transpose(0, 1),
# h_q=h_q,
# h_kv=h_kv,
# k_scale = k_scale,
# v_scale = v_scale,
# is_causal=causal,
# )
# out[i] = O.transpose(0, 1)
# lse[i] = LSE
# return out, lse
# out_flash, lse_flash = flash_kvcache()
# if is_prof: return
# out_torch, lse_torch = ref_kvcache()
# print("out_torch ", out_torch[0, 0, 0, :10])
# print("out_flash ", out_flash[0, 0, 0, :10])
# print("lse_torch ", lse_torch[0, 0, :10])
# print("lse_flash ", lse_flash[0, 0, :10])
# # # print("out_flash:", out_flash)
# # # print("out_torch:", out_torch)
# # print("lse flash diff ", torch.nonzero((lse_flash - lse_torch).abs() > 0.01))
# print(torch.nonzero((out_flash - out_torch).abs() > 1))
# # pdb.set_trace()
# print("out_flash diff", (out_flash - out_torch).max().item())
# print("lse_flash diff", (lse_flash - lse_torch).max().item())
# cal_diff(lse_flash, lse_torch, "lse")
# cal_diff(out_flash, out_torch, "out")
def
flops
(
batch
,
seqlen
,
headdim
,
nheads
,
causal
,
mode
=
"fwd"
):
assert
mode
in
[
"fwd"
,
"bwd"
,
"fwd_bwd"
]
f
=
4
*
batch
*
seqlen
**
2
*
nheads
*
headdim
//
(
2
if
causal
else
1
)
return
f
if
mode
==
"fwd"
else
(
2.5
*
f
if
mode
==
"bwd"
else
3.5
*
f
)
def
efficiency
(
flop
,
time
):
return
(
flop
/
time
/
10
**
9
)
if
not
math
.
isnan
(
time
)
else
0.0
t
=
triton
.
testing
.
do_bench
(
flash_kvcache
)
FLOPS
=
s_q
*
total_seqlens
*
h_q
*
(
d
+
d
)
*
2
# FLOPS = FLOPS // 2 if causal else FLOPS
bytes
=
(
total_seqlens
*
h_kv
*
d
+
b
*
s_q
*
h_q
*
d
+
b
*
s_q
*
h_q
*
d
)
*
(
torch
.
finfo
(
q
.
dtype
).
bits
//
8
)
# print(
# f"{t:.3f} ms, {FLOPS / 10 ** 9 / t:.0f} TFLOPS, {bytes / 10 ** 6 / t:.0f} GB/s"
# )
print
(
f
"
{
t
:.
3
f
}
ms"
)
def
main
(
torch_dtype
,
is_prof
=
False
):
device
=
torch
.
device
(
"cuda:0"
)
torch
.
set_default_dtype
(
torch_dtype
)
torch
.
set_default_device
(
device
)
torch
.
cuda
.
set_device
(
device
)
torch
.
manual_seed
(
0
)
random
.
seed
(
0
)
'''
h_kv = 1
d, dv = 576, 512
causal = True
for b in [128]:
for s in [4096, 8192]:
for h_q in [16, 32, 64, 128]: # TP = 8, 4, 2, 1
for s_q in [1, 2]: # MTP = 1, 2
for varlen in [False, True]:
test_flash_mla(b, s_q, s, h_q, h_kv, d, dv, causal, varlen)
# b, s_q, s, h_q, h_kv, d, dv, causal, varlen'''
test_flash_kvcache
(
32
,
512
,
512
,
32
,
8
,
128
,
True
,
True
,
is_prof
=
is_prof
)
test_flash_kvcache
(
16
,
1024
,
1024
,
32
,
8
,
128
,
True
,
True
,
is_prof
=
is_prof
)
test_flash_kvcache
(
8
,
2048
,
2048
,
32
,
8
,
128
,
True
,
True
,
is_prof
=
is_prof
)
test_flash_kvcache
(
4
,
4096
,
4096
,
32
,
8
,
128
,
True
,
True
,
is_prof
=
is_prof
)
test_flash_kvcache
(
2
,
8192
,
8192
,
32
,
8
,
128
,
True
,
True
,
is_prof
=
is_prof
)
# test_flash_kvcache( 1, 16384, 16384, 16, 16, 128, True, True, is_prof=is_prof)
'''
h_kv = 1
d, dv = 128, 128
causal = True
for b in [1, 32]:
for s in [200, 1002, 2002, 1024, 2000, 4000, 32768, 65536]:
for h_q in [4]:
for s_q in [1]: # MTP = 1, 2
for varlen in [True]:
test_flash_kvcache(b, s_q, s, h_q, h_kv, d, causal, varlen)
'''
if
__name__
==
"__main__"
:
parser
=
argparse
.
ArgumentParser
()
parser
.
add_argument
(
"--dtype"
,
type
=
str
,
choices
=
[
"bf16"
,
"fp16"
],
default
=
"bf16"
,
help
=
"Data type to use for testing (bf16 or fp16)"
,
)
parser
.
add_argument
(
'--prof'
,
default
=
False
,
action
=
'store_true'
,
help
=
'prof or not'
)
args
=
parser
.
parse_args
()
torch_dtype
=
torch
.
bfloat16
if
args
.
dtype
==
"fp16"
:
torch_dtype
=
torch
.
float16
main
(
torch_dtype
,
args
.
prof
)
csrc/flash_attn/flash_api.cpp
0 → 100644
View file @
34e67b1e
This diff is collapsed.
Click to expand it.
csrc/flash_attn/flash_api_attnmask.cpp
0 → 100644
View file @
34e67b1e
This diff is collapsed.
Click to expand it.
Prev
1
2
3
4
5
6
…
41
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
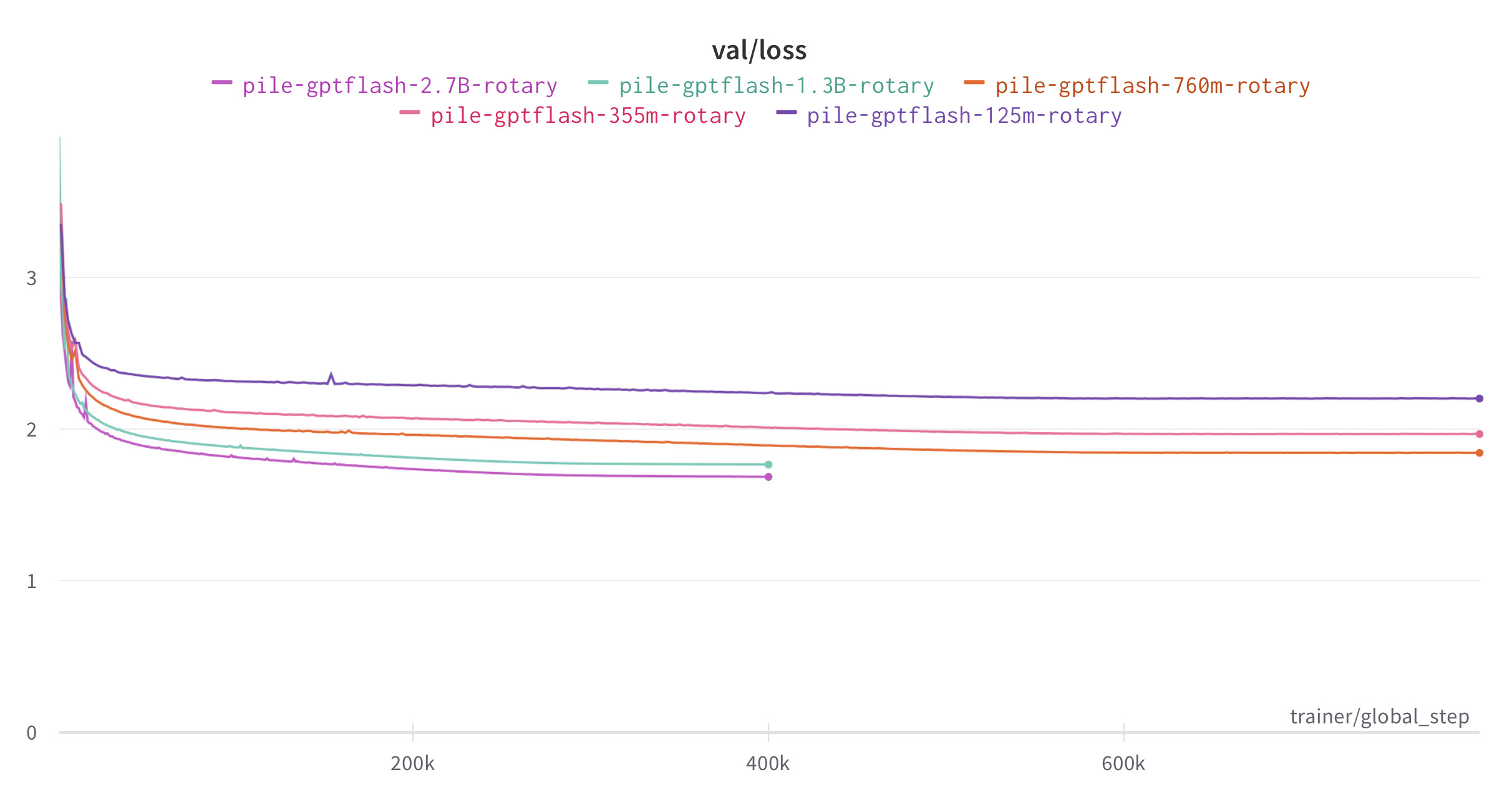
{kind=link}