
[](https://opensource.org/licenses/Apache-2.0)
[](https://github.com/ai-dynamo/dynamo/releases/latest)
[](https://deepwiki.com/ai-dynamo/dynamo)
[](https://discord.gg/D92uqZRjCZ)  
| **[Roadmap](https://github.com/ai-dynamo/dynamo/issues/5506)** | **[Support Matrix](https://github.com/ai-dynamo/dynamo/blob/main/docs/reference/support-matrix.md)** | **[Docs](https://docs.nvidia.com/dynamo/latest/index.html)** | **[Recipes](https://github.com/ai-dynamo/dynamo/tree/main/recipes)** | **[Examples](https://github.com/ai-dynamo/dynamo/tree/main/examples)** | **[Prebuilt Containers](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ai-dynamo/collections/ai-dynamo)** | **[Design Proposals](https://github.com/ai-dynamo/enhancements)** | **[Blogs](https://developer.nvidia.com/blog/tag/nvidia-dynamo)**
# NVIDIA Dynamo
High-throughput, low-latency inference framework designed for serving generative AI and reasoning models in multi-node distributed environments.
## Why Dynamo
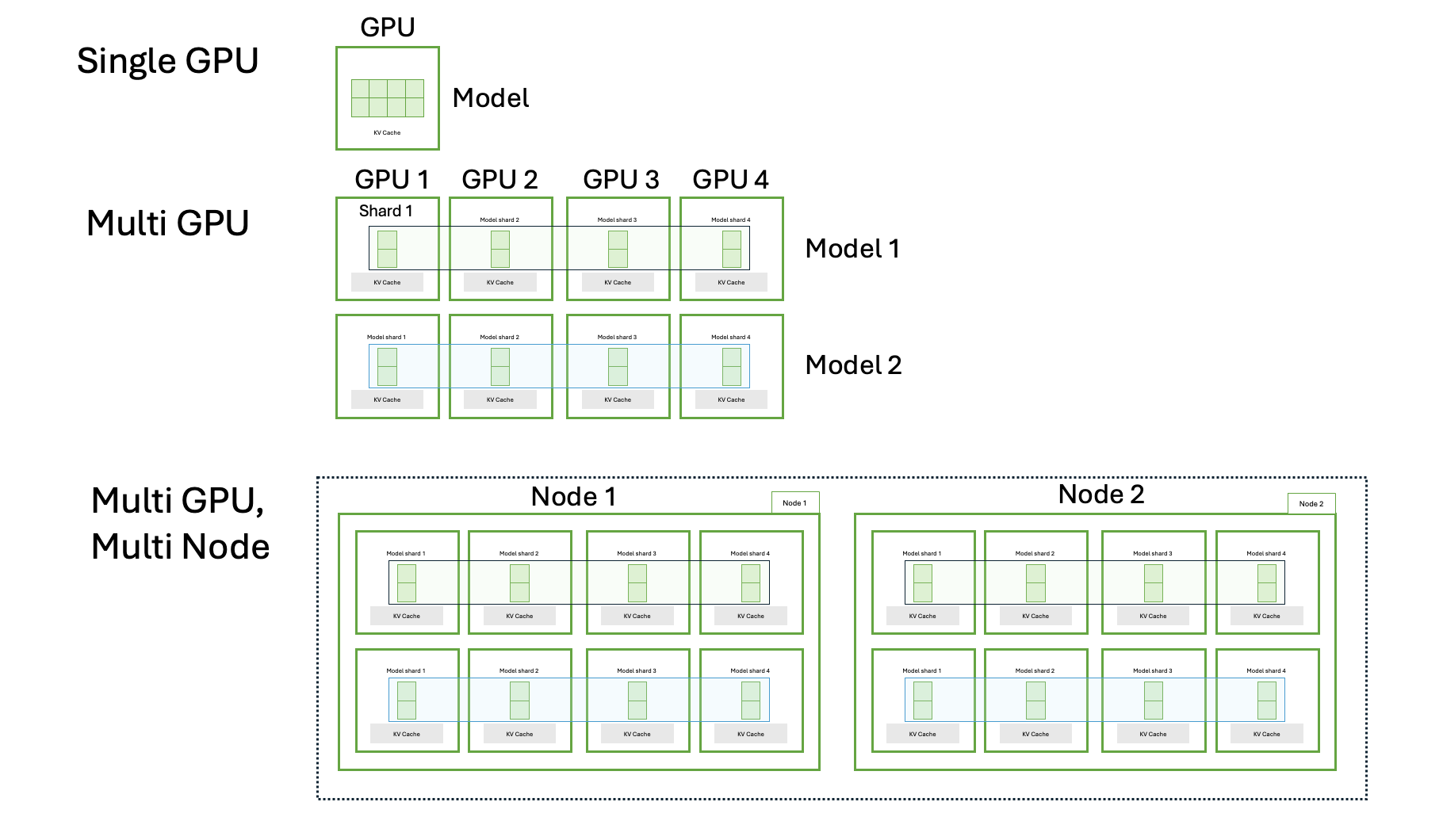
Large language models exceed single-GPU capacity. Tensor parallelism spreads layers across GPUs but creates coordination challenges. Dynamo closes this orchestration gap.
Dynamo is inference engine agnostic (supports TRT-LLM, vLLM, SGLang) and provides:
- **Disaggregated Prefill & Decode** – Maximizes GPU throughput with latency/throughput trade-offs
- **Dynamic GPU Scheduling** – Optimizes performance based on fluctuating demand
- **LLM-Aware Request Routing** – Eliminates unnecessary KV cache re-computation
- **Accelerated Data Transfer** – Reduces inference response time using NIXL
- **KV Cache Offloading** – Leverages multiple memory hierarchies for higher throughput
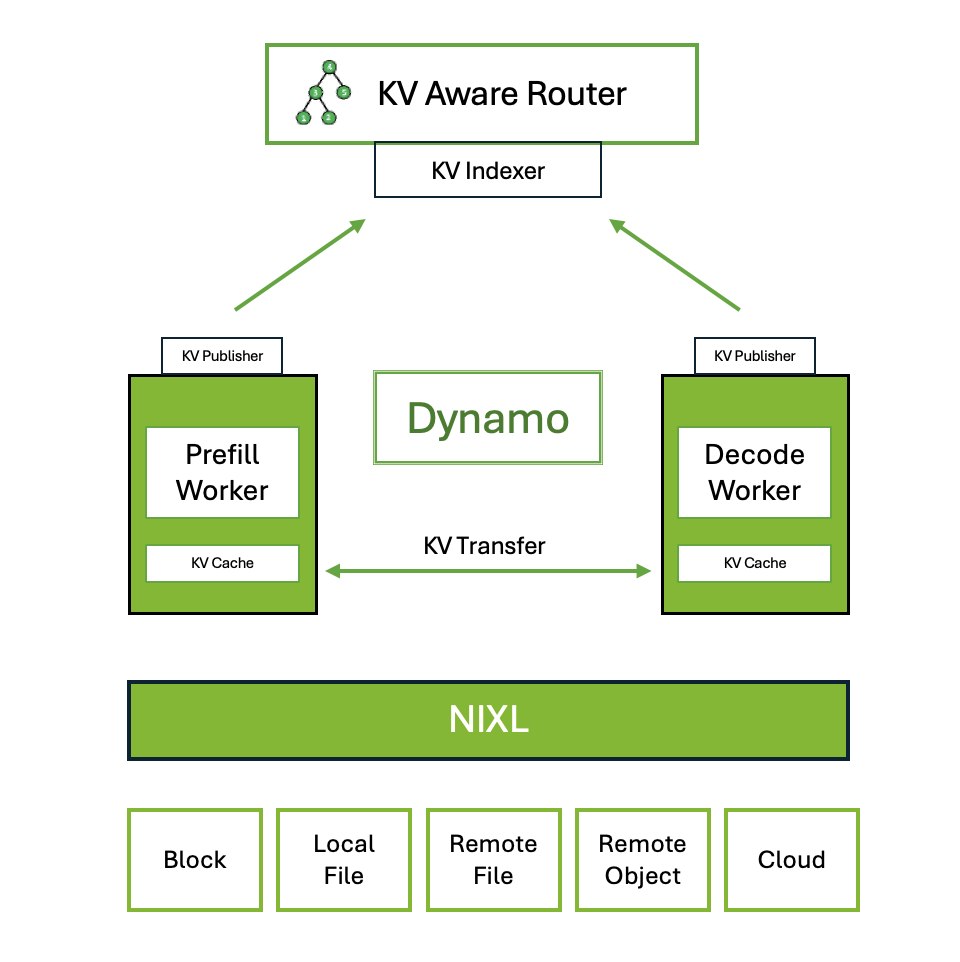
Built in Rust for performance and Python for extensibility, Dynamo is fully open-source with an OSS-first development approach.
## Framework Support Matrix
| Feature | [vLLM](docs/backends/vllm/README.md) | [SGLang](docs/backends/sglang/README.md) | [TensorRT-LLM](docs/backends/trtllm/README.md) |
| -------------------------------------------------------------------- | :--: | :----: | :----------: |
| [**Disaggregated Serving**](docs/design_docs/disagg_serving.md) | ✅ | ✅ | ✅ |
| [**KV-Aware Routing**](docs/router/kv_cache_routing.md) | ✅ | ✅ | ✅ |
| [**SLA-Based Planner**](docs/planner/sla_planner.md) | ✅ | ✅ | ✅ |
| [**KVBM**](docs/kvbm/kvbm_architecture.md) | ✅ | 🚧 | ✅ |
| [**Multimodal**](docs/multimodal/index.md) | ✅ | ✅ | ✅ |
| [**Tool Calling**](docs/agents/tool-calling.md) | ✅ | ✅ | ✅ |
> **[Full Feature Matrix →](feature-matrix.md)** — Detailed compatibility including LoRA, Request Migration, Speculative Decoding, and feature interactions.
## Latest News
- [12/05] [Moonshot AI's Kimi K2 achieves 10x inference speedup with Dynamo on GB200](https://quantumzeitgeist.com/kimi-k2-nvidia-ai-ai-breakthrough/)
- [12/02] [Mistral AI runs Mistral Large 3 with 10x faster inference using Dynamo](https://www.marktechpost.com/2025/12/02/nvidia-and-mistral-ai-bring-10x-faster-inference-for-the-mistral-3-family-on-gb200-nvl72-gpu-systems/)
- [12/01] [InfoQ: NVIDIA Dynamo simplifies Kubernetes deployment for LLM inference](https://www.infoq.com/news/2025/12/nvidia-dynamo-kubernetes/)
- [11/20] [Dell integrates PowerScale with Dynamo's NIXL for 19x faster TTFT](https://www.dell.com/en-us/dt/corporate/newsroom/announcements/detailpage.press-releases~usa~2025~11~dell-technologies-and-nvidia-advance-enterprise-ai-innovation.htm)
- [11/20] [WEKA partners with NVIDIA on KV cache storage for Dynamo](https://siliconangle.com/2025/11/20/nvidia-weka-kv-cache-solution-ai-inferencing-sc25/)
- [11/13] [Dynamo Office Hours Playlist](https://www.youtube.com/playlist?list=PL5B692fm6--tgryKu94h2Zb7jTFM3Go4X)
- [10/16] [How Baseten achieved 2x faster inference with NVIDIA Dynamo](https://www.baseten.co/blog/how-baseten-achieved-2x-faster-inference-with-nvidia-dynamo/)
## Get Started
| Path | Use Case | Time | Requirements |
|------|----------|------|--------------|
| [**Local Quick Start**](#local-quick-start) | Test on a single machine | ~5 min | 1 GPU, Ubuntu 24.04 |
| [**Kubernetes Deployment**](#kubernetes-deployment) | Production multi-node clusters | ~30 min | K8s cluster with GPUs |
## Contributing
Want to help shape the future of distributed LLM inference? We welcome contributors at all levels—from doc fixes to new features.
- **[Contributing Guide](CONTRIBUTING.md)** – How to get started
- **[Report a Bug](https://github.com/ai-dynamo/dynamo/issues/new?template=bug_report.yml)** – Found an issue?
- **[Feature Request](https://github.com/ai-dynamo/dynamo/issues/new?template=feature_request.yml)** – Have an idea?
# Local Quick Start
The following examples require a few system level packages.
Recommended to use Ubuntu 24.04 with a x86_64 CPU. See [docs/reference/support-matrix.md](docs/reference/support-matrix.md)
## 1. Initial Setup
The Dynamo team recommends the `uv` Python package manager, although any way works. Install uv:
```
curl -LsSf https://astral.sh/uv/install.sh | sh
```
### Install Python Development Headers
Backend engines require Python development headers for JIT compilation. Install them with:
```bash
sudo apt install python3-dev
```
## 2. Select an Engine
We publish Python wheels specialized for each of our supported engines: vllm, sglang, and trtllm. The examples that follow use SGLang; continue reading for other engines.
```
uv venv venv
source venv/bin/activate
uv pip install pip
# Choose one
uv pip install "ai-dynamo[sglang]" #replace with [vllm], [trtllm], etc.
```
## 3. Run Dynamo
### Sanity Check (Optional)
Before trying out Dynamo, you can verify your system configuration and dependencies:
```bash
python3 deploy/sanity_check.py
```
This is a quick check for system resources, development tools, LLM frameworks, and Dynamo components.
### Running an LLM API Server
Dynamo provides a simple way to spin up a local set of inference components including:
- **OpenAI Compatible Frontend** – High performance OpenAI compatible http api server written in Rust.
- **Basic and Kv Aware Router** – Route and load balance traffic to a set of workers.
- **Workers** – Set of pre-configured LLM serving engines.
```bash
# Start an OpenAI compatible HTTP server with prompt templating, tokenization, and routing.
# For local dev: --store-kv file avoids etcd (workers and frontend must share a disk)
python3 -m dynamo.frontend --http-port 8000 --store-kv file
# Start the SGLang engine. You can run several of these for the same or different models.
# The frontend will discover them automatically.
python3 -m dynamo.sglang --model-path deepseek-ai/DeepSeek-R1-Distill-Llama-8B --store-kv file
```
> **Note:** vLLM workers publish KV cache events by default, which requires NATS. For dependency-free local development with vLLM, add `--kv-events-config '{"enable_kv_cache_events": false}'`. This keeps local prefix caching enabled while disabling event publishing. See [Service Discovery and Messaging](#service-discovery-and-messaging) for details.
#### Send a Request
```bash
curl localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"messages": [
{
"role": "user",
"content": "Hello, how are you?"
}
],
"stream":false,
"max_tokens": 300
}' | jq
```
Rerun with `curl -N` and change `stream` in the request to `true` to get the responses as soon as the engine issues them.
### What's Next?
- **Scale up**: Deploy on Kubernetes with [Recipes](recipes/)
- **Add features**: Enable [KV-aware routing](docs/router/kv_cache_routing.md), [disaggregated serving](docs/design_docs/disagg_serving.md)
- **Benchmark**: Use [AIPerf](docs/benchmarks/benchmarking.md) to measure performance
- **Try other engines**: [vLLM](docs/backends/vllm/), [SGLang](docs/backends/sglang/), [TensorRT-LLM](docs/backends/trtllm/)
# Kubernetes Deployment
For production deployments on Kubernetes clusters with multiple GPUs.
## Prerequisites
- Kubernetes cluster with GPU nodes
- [Dynamo Platform installed](docs/kubernetes/README.md)
- HuggingFace token for model downloads
## Production Recipes
Pre-built deployment configurations for common models and topologies:
| Model | Framework | Mode | GPUs | Recipe |
|-------|-----------|------|------|--------|
| Llama-3.1-70B | vLLM | Aggregated | 4x H100 | [View](recipes/vllm/llama-3.1-70b/) |
| DeepSeek-R1 | SGLang | Disaggregated | 8x H200 | [View](recipes/sglang/deepseek-r1/) |
| Qwen3-32B | TensorRT-LLM | Disaggregated | 8x GPU | [View](recipes/trtllm/qwen3-32b/) |
See [recipes/README.md](recipes/README.md) for the full list and deployment instructions.
## Cloud Deployment Guides
- [Amazon EKS](examples/deployments/EKS/)
- [Google GKE](examples/deployments/GKE/)
# Concepts
## Engines
Dynamo is inference engine agnostic. Install the wheel for your chosen engine and run with `python3 -m dynamo. --help`.
| Engine | Install | Docs | Best For |
|--------|---------|------|----------|
| vLLM | `uv pip install ai-dynamo[vllm]` | [Guide](docs/backends/vllm/) | Broadest feature coverage |
| SGLang | `uv pip install ai-dynamo[sglang]` | [Guide](docs/backends/sglang/) | High-throughput serving |
| TensorRT-LLM | `pip install --pre --extra-index-url https://pypi.nvidia.com ai-dynamo[trtllm]` | [Guide](docs/backends/trtllm/) | Maximum performance |
> **Note:** TensorRT-LLM requires `pip` (not `uv`) due to URL-based dependencies. See the [TRT-LLM guide](docs/backends/trtllm/) for container setup and prerequisites.
Use `CUDA_VISIBLE_DEVICES` to specify which GPUs to use. Engine-specific options (context length, multi-GPU, etc.) are documented in each backend guide.
## Service Discovery and Messaging
Dynamo uses TCP for inter-component communication. External services are optional for most deployments:
| Deployment | etcd | NATS | Notes |
|------------|------|------|-------|
| **Kubernetes** | ❌ Not required | ❌ Not required | K8s-native discovery; TCP request plane |
| **Local Development** | ❌ Not required | ❌ Not required | Pass `--store-kv file`; vLLM also needs `--kv-events-config '{"enable_kv_cache_events": false}'` |
| **KV-Aware Routing** | — | ✅ Required | Prefix caching enabled by default requires NATS |
For local development without external dependencies, pass `--store-kv file` (avoids etcd) to both the frontend and workers. vLLM users should also pass `--kv-events-config '{"enable_kv_cache_events": false}'` to disable KV event publishing (avoids NATS) while keeping local prefix caching enabled; SGLang and TRT-LLM don't require this flag.
For distributed non-Kubernetes deployments or KV-aware routing:
- [etcd](https://etcd.io/) can be run directly as `./etcd`.
- [nats](https://nats.io/) needs JetStream enabled: `nats-server -js`.
To quickly setup both: `docker compose -f deploy/docker-compose.yml up -d`
# Advanced Topics
## Benchmarking
Dynamo provides comprehensive benchmarking tools:
- **[Benchmarking Guide](docs/benchmarks/benchmarking.md)** – Compare deployment topologies using AIPerf
- **[SLA-Driven Deployments](docs/planner/sla_planner_quickstart.md)** – Optimize deployments to meet SLA requirements
## Frontend OpenAPI Specification
The OpenAI-compatible frontend exposes an OpenAPI 3 spec at `/openapi.json`. To generate without running the server:
```bash
cargo run -p dynamo-llm --bin generate-frontend-openapi
```
This writes to `docs/frontends/openapi.json`.
# Building from Source
For contributors who want to build Dynamo from source rather than installing from PyPI.
## 1. Install Libraries
**Ubuntu:**
```
sudo apt install -y build-essential libhwloc-dev libudev-dev pkg-config libclang-dev protobuf-compiler python3-dev cmake
```
**macOS:**
- [Homebrew](https://brew.sh/)
```
# if brew is not installed on your system, install it
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
```
- [Xcode](https://developer.apple.com/xcode/)
```
brew install cmake protobuf
## Check that Metal is accessible
xcrun -sdk macosx metal
```
If Metal is accessible, you should see an error like `metal: error: no input files`, which confirms it is installed correctly.
## 2. Install Rust
```
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source $HOME/.cargo/env
```
## 3. Create a Python Virtual Environment
Follow the instructions in [uv installation](https://docs.astral.sh/uv/#installation) guide to install uv if you don't have `uv` installed. Once uv is installed, create a virtual environment and activate it.
- Install uv
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
- Create a virtual environment
```bash
uv venv dynamo
source dynamo/bin/activate
```
## 4. Install Build Tools
```
uv pip install pip maturin
```
[Maturin](https://github.com/PyO3/maturin) is the Rust<->Python bindings build tool.
## 5. Build the Rust Bindings
```
cd lib/bindings/python
maturin develop --uv
```
## 6. Install the Wheel
```
cd $PROJECT_ROOT
uv pip install -e .
```
You should now be able to run `python3 -m dynamo.frontend`.
For local development, pass `--store-kv file` to avoid external dependencies (see Service Discovery and Messaging section).
Set the environment variable `DYN_LOG` to adjust the logging level; for example, `export DYN_LOG=debug`. It has the same syntax as `RUST_LOG`.
If you use vscode or cursor, we have a .devcontainer folder built on [Microsofts Extension](https://code.visualstudio.com/docs/devcontainers/containers). For instructions see the [ReadMe](.devcontainer/README.md) for more details.
[disagg]: docs/design_docs/disagg_serving.md
[kv-routing]: docs/router/kv_cache_routing.md
[planner]: docs/planner/sla_planner.md
[kvbm]: docs/kvbm/kvbm_architecture.md
[mm]: examples/multimodal/
[migration]: docs/fault_tolerance/request_migration.md
[lora]: examples/backends/vllm/deploy/lora/README.md
[tools]: docs/agents/tool-calling.md