
[](https://opensource.org/licenses/Apache-2.0)
[](https://github.com/ai-dynamo/dynamo/releases/latest)
[](https://discord.gg/D92uqZRjCZ)
[](https://deepwiki.com/ai-dynamo/dynamo)
| **[Roadmap](https://github.com/ai-dynamo/dynamo/issues/762)** | **[Documentation](https://docs.nvidia.com/dynamo/latest/index.html)** | **[Examples](https://github.com/ai-dynamo/dynamo/tree/main/examples)** | **[Design Proposals](https://github.com/ai-dynamo/enhancements)** |
# NVIDIA Dynamo
High-throughput, low-latency inference framework designed for serving generative AI and reasoning models in multi-node distributed environments.
## Latest News
* [08/05] Deploy `openai/gpt-oss-120b` with disaggregated serving on NVIDIA Blackwell GPUs using Dynamo [➡️ link](./components/backends/trtllm/gpt-oss.md)
## The Era of Multi-GPU, Multi-Node
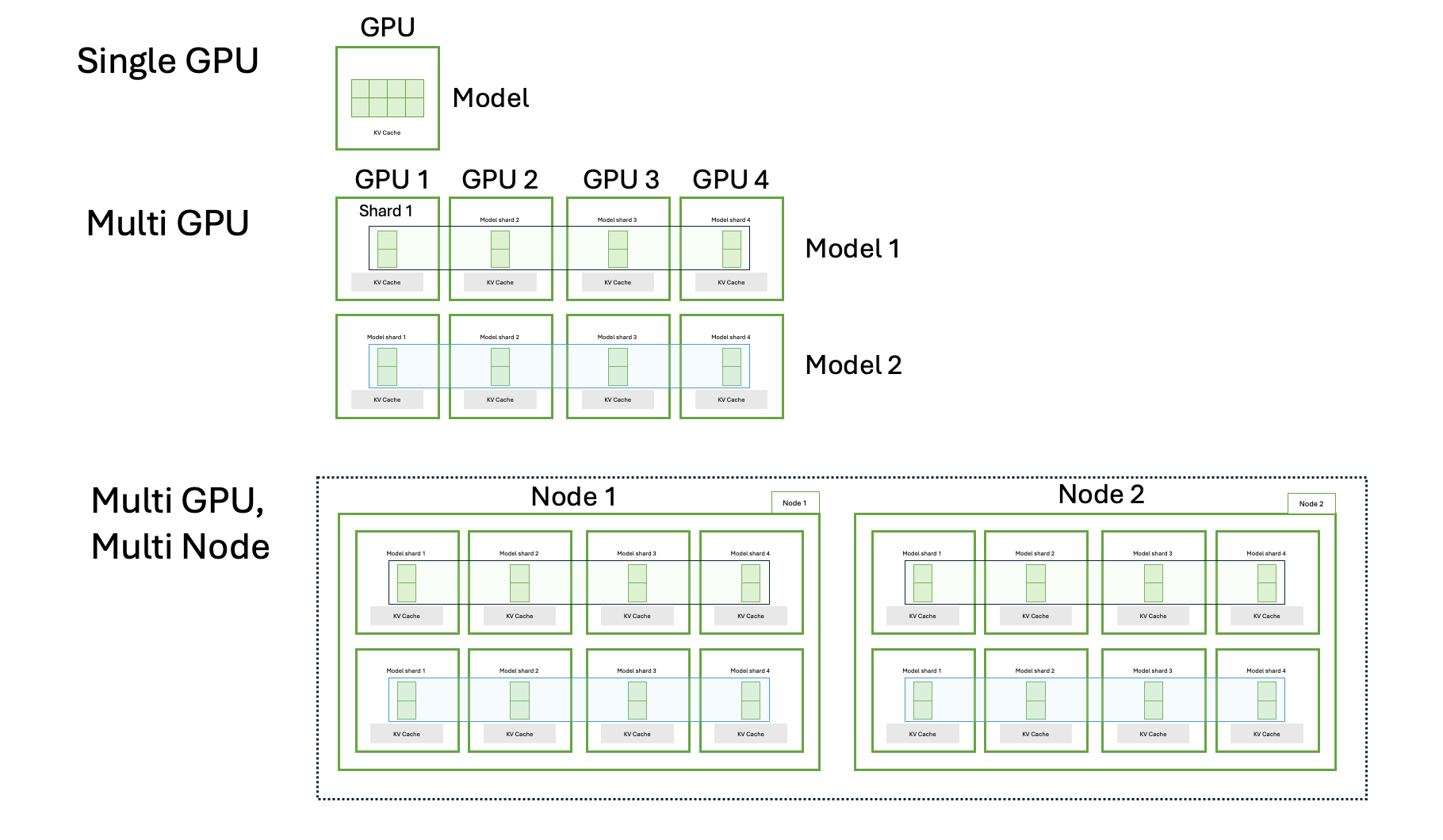
Large language models are quickly outgrowing the memory and compute budget of any single GPU. Tensor-parallelism solves the capacity problem by spreading each layer across many GPUs—and sometimes many servers—but it creates a new one: how do you coordinate those shards, route requests, and share KV cache fast enough to feel like one accelerator? This orchestration gap is exactly what NVIDIA Dynamo is built to close.
Dynamo is designed to be inference engine agnostic (supports TRT-LLM, vLLM, SGLang or others) and captures LLM-specific capabilities such as:
- **Disaggregated prefill & decode inference** – Maximizes GPU throughput and facilitates trade off between throughput and latency.
- **Dynamic GPU scheduling** – Optimizes performance based on fluctuating demand
- **LLM-aware request routing** – Eliminates unnecessary KV cache re-computation
- **Accelerated data transfer** – Reduces inference response time using NIXL.
- **KV cache offloading** – Leverages multiple memory hierarchies for higher system throughput
## Framework Support Matrix
| Feature | vLLM | SGLang | TensorRT-LLM |
|---------|----------------------|----------------------------|----------------------------------------|
| [**Disaggregated Serving**](/docs/architecture/disagg_serving.md) | ✅ | ✅ | ✅ |
| [**Conditional Disaggregation**](/docs/architecture/disagg_serving.md#conditional-disaggregation) | 🚧 | 🚧 | 🚧 |
| [**KV-Aware Routing**](/docs/architecture/kv_cache_routing.md) | ✅ | ✅ | ✅ |
| [**Load Based Planner**](/docs/architecture/load_planner.md) | 🚧 | 🚧 | 🚧 |
| [**SLA-Based Planner**](/docs/architecture/sla_planner.md) | ✅ | ✅ | 🚧 |
| [**KVBM**](/docs/architecture/kvbm_architecture.md) | 🚧 | 🚧 | 🚧 |
To learn more about each framework and their capabilities, check out each framework's README!
- **[vLLM](components/backends/vllm/README.md)**
- **[SGLang](components/backends/sglang/README.md)**
- **[TensorRT-LLM](components/backends/trtllm/README.md)**
Built in Rust for performance and in Python for extensibility, Dynamo is fully open-source and driven by a transparent, OSS (Open Source Software) first development approach.
# Installation
The following examples require a few system level packages.
Recommended to use Ubuntu 24.04 with a x86_64 CPU. See [docs/support_matrix.md](docs/support_matrix.md)
## 1. Initial setup
The Dynamo team recommends the `uv` Python package manager, although any way works. Install uv:
```
curl -LsSf https://astral.sh/uv/install.sh | sh
```
### Install etcd and NATS (required)
To coordinate across a data center, Dynamo relies on etcd and NATS. To run Dynamo locally, these need to be available.
- [etcd](https://etcd.io/) can be run directly as `./etcd`.
- [nats](https://nats.io/) needs jetstream enabled: `nats-server -js`.
To quickly setup etcd & NATS, you can also run:
```
# At the root of the repository:
docker compose -f deploy/docker-compose.yml up -d
```
## 2. Select an engine
We publish Python wheels specialized for each of our supported engines: vllm, sglang, trtllm, and llama.cpp. The examples that follow use SGLang; continue reading for other engines.
```
uv venv venv
source venv/bin/activate
uv pip install pip
# Choose one
uv pip install "ai-dynamo[sglang]" #replace with [vllm], [trtllm], etc.
```
## 3. Run Dynamo
### Running an LLM API server
Dynamo provides a simple way to spin up a local set of inference components including:
- **OpenAI Compatible Frontend** – High performance OpenAI compatible http api server written in Rust.
- **Basic and Kv Aware Router** – Route and load balance traffic to a set of workers.
- **Workers** – Set of pre-configured LLM serving engines.
```
# Start an OpenAI compatible HTTP server, a pre-processor (prompt templating and tokenization) and a router:
python -m dynamo.frontend --http-port 8080
# Start the SGLang engine, connecting to NATS and etcd to receive requests. You can run several of these,
# both for the same model and for multiple models. The frontend node will discover them.
python -m dynamo.sglang.worker --model deepseek-ai/DeepSeek-R1-Distill-Llama-8B --skip-tokenizer-init
```
#### Send a Request
```bash
curl localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"messages": [
{
"role": "user",
"content": "Hello, how are you?"
}
],
"stream":false,
"max_tokens": 300
}' | jq
```
Rerun with `curl -N` and change `stream` in the request to `true` to get the responses as soon as the engine issues them.
### Deploying Dynamo
- Follow the [Quickstart Guide](docs/guides/dynamo_deploy/README.md) to deploy on Kubernetes.
- Check out [Backends](components/backends) to deploy various workflow configurations (e.g. SGLang with router, vLLM with disaggregated serving, etc.)
- Run some [Examples](examples) to learn about building components in Dynamo and exploring various integrations.
# Engines
Dynamo is designed to be inference engine agnostic. To use any engine with Dynamo, NATS and etcd need to be installed, along with a Dynamo frontend (`python -m dynamo.frontend [--interactive]`).
## vLLM
```
uv pip install ai-dynamo[vllm]
```
Run the backend/worker like this:
```
python -m dynamo.vllm --help
```
vLLM attempts to allocate enough KV cache for the full context length at startup. If that does not fit in your available memory pass `--context-length `.
To specify which GPUs to use set environment variable `CUDA_VISIBLE_DEVICES`.
## SGLang
```
# Install libnuma
apt install -y libnuma-dev
uv pip install ai-dynamo[sglang]
```
Run the backend/worker like this:
```
python -m dynamo.sglang.worker --help
```
You can pass any sglang flags directly to this worker, see https://docs.sglang.ai/backend/server_arguments.html . See there to use multiple GPUs.
## TensorRT-LLM
It is recommended to use [NGC PyTorch Container](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch) for running the TensorRT-LLM engine.
> [!Note]
> Ensure that you select a PyTorch container image version that matches the version of TensorRT-LLM you are using.
> For example, if you are using `tensorrt-llm==1.0.0rc4`, use the PyTorch container image version `25.05`.
> To find the correct PyTorch container version for your desired `tensorrt-llm` release, visit the [TensorRT-LLM Dockerfile.multi](https://github.com/NVIDIA/TensorRT-LLM/blob/main/docker/Dockerfile.multi) on GitHub. Switch to the branch that matches your `tensorrt-llm` version, and look for the `BASE_TAG` line to identify the recommended PyTorch container tag.
> [!Important]
> Launch container with the following additional settings `--shm-size=1g --ulimit memlock=-1`
### Install prerequisites
```
# Optional step: Only required for Blackwell and Grace Hopper
pip3 install torch==2.7.1 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
sudo apt-get -y install libopenmpi-dev
```
> [!Tip]
> You can learn more about these prequisites and known issues with TensorRT-LLM pip based installation [here](https://nvidia.github.io/TensorRT-LLM/installation/linux.html).
### After installing the pre-requisites above, install Dynamo
```
uv pip install ai-dynamo[trtllm]
```
Run the backend/worker like this:
```
python -m dynamo.trtllm --help
```
To specify which GPUs to use set environment variable `CUDA_VISIBLE_DEVICES`.
# Developing Locally
## 1. Install libraries
**Ubuntu:**
```
sudo apt install -y build-essential libhwloc-dev libudev-dev pkg-config libclang-dev protobuf-compiler python3-dev cmake
```
**macOS:**
- [Homebrew](https://brew.sh/)
```
# if brew is not installed on your system, install it
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
```
- [Xcode](https://developer.apple.com/xcode/)
```
brew install cmake protobuf
## Check that Metal is accessible
xcrun -sdk macosx metal
```
If Metal is accessible, you should see an error like `metal: error: no input files`, which confirms it is installed correctly.
## 2. Install Rust
```
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source $HOME/.cargo/env
```
## 3. Create a Python virtual env:
Follow the instructions in [uv installation](https://docs.astral.sh/uv/#installation) guide to install uv if you don't have `uv` installed. Once uv is installed, create a virtual environment and activate it.
- Install uv
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
```
- Create a virtual environment
```bash
uv venv dynamo
source dynamo/bin/activate
```
## 4. Install build tools
```
uv pip install pip maturin
```
[Maturin](https://github.com/PyO3/maturin) is the Rust<->Python bindings build tool.
## 5. Build the Rust bindings
```
cd lib/bindings/python
maturin develop --uv
```
## 6. Install the wheel
```
cd $PROJECT_ROOT
uv pip install .
# For development, use
export PYTHONPATH="${PYTHONPATH}:$(pwd)/components/frontend/src:$(pwd)/components/planner/src:$(pwd)/components/backends/vllm/src:$(pwd)/components/backends/sglang/src:$(pwd)/components/backends/trtllm/src:$(pwd)/components/backends/llama_cpp/src:$(pwd)/components/backends/mocker/src"
```
> [!Note]
> Editable (`-e`) does not work because the `dynamo` package is split over multiple directories, one per backend.
You should now be able to run `python -m dynamo.frontend`.
Remember that nats and etcd must be running (see earlier).
Set the environment variable `DYN_LOG` to adjust the logging level; for example, `export DYN_LOG=debug`. It has the same syntax as `RUST_LOG`.
If you use vscode or cursor, we have a .devcontainer folder built on [Microsofts Extension](https://code.visualstudio.com/docs/devcontainers/containers). For instructions see the [ReadMe](.devcontainer/README.md) for more details.