{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Capsule Network\n",
"================\n",
"**Author**: `Jinjing Zhou`\n",
"\n",
"This tutorial explains how to use DGL library and its language to implement the [capsule network](http://arxiv.org/abs/1710.09829) proposed by Geoffrey Hinton and his team. The algorithm aims to provide a better alternative to current neural network structures. By using DGL library, users can implement the algorithm in a more intuitive way."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Model Overview\n",
"\n",
"### Introduction\n",
"Capsule Network were first introduced in 2011 by Geoffrey Hinton, et al., in a paper called [Transforming Autoencoders](https://www.cs.toronto.edu/~fritz/absps/transauto6.pdf), but it was only a few months ago, in November 2017, that Sara Sabour, Nicholas Frosst, and Geoffrey Hinton published a paper called Dynamic Routing between Capsules, where they introduced a CapsNet architecture that reached state-of-the-art performance on MNIST.\n",
"\n",
"### What's a capsule?\n",
"> A capsule is a group of neurons whose activity vector represents the instantiation parameters of a specific type of entity such as an object or an object part. \n",
"\n",
"Generally Speaking, the idea of capsule is to encode all the information about the features into a vector form, by substituting scalars in traditional neural network with vectors. And use the norm of the vector to represents the meaning of original scalars. \n",
"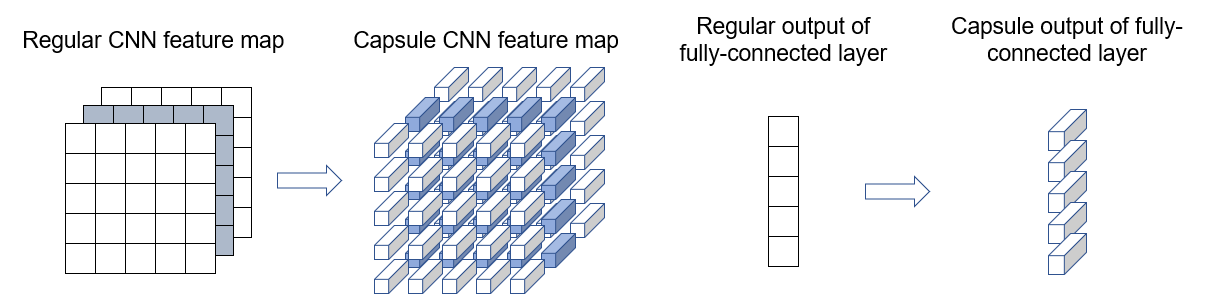\n",
"\n",
"### Dynamic Routing Algorithm\n",
"Due to the different structure of network, capsules network has different operations to calculate results. This figure shows the comparison, drawn by [Max Pechyonkin](https://medium.com/ai%C2%B3-theory-practice-business/understanding-hintons-capsule-networks-part-ii-how-capsules-work-153b6ade9f66O). \n",
"
\n",
"\n",
"The key idea is that the output of each capsule is the sum of weighted input vectors. We will go into details in the later section with code implementations.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Model Implementations\n",
"\n",
"### 1. Consider capsule routing as a graph structure\n",
"\n",
"We can consider each capsule as a node in a graph, and connect all the nodes between layers.\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def construct_graph(self):\n",
" g = dgl.DGLGraph()\n",
" g.add_nodes(self.input_capsule_num + self.output_capsule_num)\n",
" input_nodes = list(range(self.input_capsule_num))\n",
" output_nodes = list(range(self.input_capsule_num, self.input_capsule_num + self.output_capsule_num))\n",
" u, v = [], []\n",
" for i in input_nodes:\n",
" for j in output_nodes:\n",
" u.append(i)\n",
" v.append(j)\n",
" g.add_edges(u, v)\n",
" return g, input_nodes, output_nodes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2. Initialization & Affine Transformation\n",
"- Pre-compute $\\hat{u}_{j|i}$, initialize $b_{ij}$ and store them as edge attribute\n",
"- Initialize node features as zero\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def construct_graph(self):\n",
" g = dgl.DGLGraph()\n",
" g.add_nodes(self.input_capsule_num + self.output_capsule_num)\n",
" input_nodes = list(range(self.input_capsule_num))\n",
" output_nodes = list(range(self.input_capsule_num, self.input_capsule_num + self.output_capsule_num))\n",
" u, v = [], []\n",
" for i in input_nodes:\n",
" for j in output_nodes:\n",
" u.append(i)\n",
" v.append(j)\n",
" g.add_edges(u, v)\n",
" return g, input_nodes, output_nodes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2. Initialization & Affine Transformation\n",
"- Pre-compute $\\hat{u}_{j|i}$, initialize $b_{ij}$ and store them as edge attribute\n",
"- Initialize node features as zero\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# x is the input vextor with shape [batch_size, input_capsule_dim, input_num]\n",
"# Transpose x to [batch_size, input_num, input_capsule_dim] \n",
"x = x.transpose(1, 2)\n",
"# Expand x to [batch_size, input_num, output_num, input_capsule_dim, 1]\n",
"x = torch.stack([x] * self.output_capsule_num, dim=2).unsqueeze(4)\n",
"# Expand W from [input_num, output_num, input_capsule_dim, output_capsule_dim] \n",
"# to [batch_size, input_num, output_num, output_capsule_dim, input_capsule_dim] \n",
"W = self.weight.expand(self.batch_size, *self.weight.size())\n",
"# u_hat's shape is [input_num, output_num, batch_size, output_capsule_dim]\n",
"u_hat = torch.matmul(W, x).permute(1, 2, 0, 3, 4).squeeze().contiguous()\n",
"\n",
"b_ij = torch.zeros(self.input_capsule_num, self.output_capsule_num).to(self.device)\n",
"\n",
"self.g.set_e_repr({'b_ij': b_ij.view(-1)})\n",
"self.g.set_e_repr({'u_hat': u_hat.view(-1, self.batch_size, self.unit_size)})\n",
"\n",
"# Initialize all node features as zero\n",
"node_features = torch.zeros(self.input_capsule_num + self.output_capsule_num, self.batch_size,\n",
" self.output_capsule_dim).to(self.device)\n",
"self.g.set_n_repr({'h': node_features})"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3. Write Message Passing functions and Squash function"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 3.1 Squash function\n",
"Squashing function is to ensure that short vectors get shrunk to almost zero length and long vectors get shrunk to a length slightly below 1.\n",
""
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"def squash(s):\n",
" msg_sq = torch.sum(s ** 2, dim=2, keepdim=True)\n",
" msg = torch.sqrt(msg_sq)\n",
" s = (msg_sq / (1.0 + msg_sq)) * (s / msg)\n",
" return s"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 3.2 Message Functions\n",
"At first stage, we need to define a message function to get all the attributes we need in the further computations."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def capsule_msg(src, edge):\n",
" return {'b_ij': edge['b_ij'], 'h': src['h'], 'u_hat': edge['u_hat']}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 3.3 Reduce Functions\n",
"At this stage, we need to define a reduce function to aggregate all the information we get from message function into node features.\n",
"This step implements the line 4 and line 5 in routing algorithms, which softmax over $b_{ij}$ and calculate weighted sum of input features. Note that softmax operation is over dimension $j$ instead of $i$. \n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# x is the input vextor with shape [batch_size, input_capsule_dim, input_num]\n",
"# Transpose x to [batch_size, input_num, input_capsule_dim] \n",
"x = x.transpose(1, 2)\n",
"# Expand x to [batch_size, input_num, output_num, input_capsule_dim, 1]\n",
"x = torch.stack([x] * self.output_capsule_num, dim=2).unsqueeze(4)\n",
"# Expand W from [input_num, output_num, input_capsule_dim, output_capsule_dim] \n",
"# to [batch_size, input_num, output_num, output_capsule_dim, input_capsule_dim] \n",
"W = self.weight.expand(self.batch_size, *self.weight.size())\n",
"# u_hat's shape is [input_num, output_num, batch_size, output_capsule_dim]\n",
"u_hat = torch.matmul(W, x).permute(1, 2, 0, 3, 4).squeeze().contiguous()\n",
"\n",
"b_ij = torch.zeros(self.input_capsule_num, self.output_capsule_num).to(self.device)\n",
"\n",
"self.g.set_e_repr({'b_ij': b_ij.view(-1)})\n",
"self.g.set_e_repr({'u_hat': u_hat.view(-1, self.batch_size, self.unit_size)})\n",
"\n",
"# Initialize all node features as zero\n",
"node_features = torch.zeros(self.input_capsule_num + self.output_capsule_num, self.batch_size,\n",
" self.output_capsule_dim).to(self.device)\n",
"self.g.set_n_repr({'h': node_features})"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3. Write Message Passing functions and Squash function"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 3.1 Squash function\n",
"Squashing function is to ensure that short vectors get shrunk to almost zero length and long vectors get shrunk to a length slightly below 1.\n",
""
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"def squash(s):\n",
" msg_sq = torch.sum(s ** 2, dim=2, keepdim=True)\n",
" msg = torch.sqrt(msg_sq)\n",
" s = (msg_sq / (1.0 + msg_sq)) * (s / msg)\n",
" return s"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 3.2 Message Functions\n",
"At first stage, we need to define a message function to get all the attributes we need in the further computations."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def capsule_msg(src, edge):\n",
" return {'b_ij': edge['b_ij'], 'h': src['h'], 'u_hat': edge['u_hat']}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 3.3 Reduce Functions\n",
"At this stage, we need to define a reduce function to aggregate all the information we get from message function into node features.\n",
"This step implements the line 4 and line 5 in routing algorithms, which softmax over $b_{ij}$ and calculate weighted sum of input features. Note that softmax operation is over dimension $j$ instead of $i$. \n",
" "
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"def capsule_reduce(node, msg):\n",
" b_ij_c, u_hat = msg['b_ij'], msg['u_hat']\n",
" # line 4\n",
" c_i = F.softmax(b_ij_c, dim=0)\n",
" # line 5\n",
" s_j = (c_i.unsqueeze(2).unsqueeze(3) * u_hat).sum(dim=1)\n",
" return {'h': s_j}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 3.4 Node Update Functions\n",
"Squash the intermidiate representations into node features $v_j$\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def capsule_update(msg):\n",
" # line 6\n",
" v_j = squash(msg['h'])\n",
" return {'h': v_j}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 3.5 Edge Update Functions\n",
"Update the routing parameters\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def update_edge(self, u, v, edge):\n",
" return {'b_ij': edge['b_ij'] + (v['h'] * edge['u_hat']).mean(dim=1).sum(dim=1)}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4. Executing algorithm\n",
"Call `update_all` and `update_edge` functions to execute the algorithms"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"for i in range(self.num_routing):\n",
" self.g.update_all(self.capsule_msg, self.capsule_reduce, self.capsule_update)\n",
" self.g.update_edge(edge_func=self.update_edge)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3.6",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.1"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"def capsule_reduce(node, msg):\n",
" b_ij_c, u_hat = msg['b_ij'], msg['u_hat']\n",
" # line 4\n",
" c_i = F.softmax(b_ij_c, dim=0)\n",
" # line 5\n",
" s_j = (c_i.unsqueeze(2).unsqueeze(3) * u_hat).sum(dim=1)\n",
" return {'h': s_j}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 3.4 Node Update Functions\n",
"Squash the intermidiate representations into node features $v_j$\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def capsule_update(msg):\n",
" # line 6\n",
" v_j = squash(msg['h'])\n",
" return {'h': v_j}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### 3.5 Edge Update Functions\n",
"Update the routing parameters\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def update_edge(self, u, v, edge):\n",
" return {'b_ij': edge['b_ij'] + (v['h'] * edge['u_hat']).mean(dim=1).sum(dim=1)}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4. Executing algorithm\n",
"Call `update_all` and `update_edge` functions to execute the algorithms"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"for i in range(self.num_routing):\n",
" self.g.update_all(self.capsule_msg, self.capsule_reduce, self.capsule_update)\n",
" self.g.update_edge(edge_func=self.update_edge)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3.6",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.1"
}
},
"nbformat": 4,
"nbformat_minor": 2
}