
Sparse attn + ops/runtime refactor + v0.3.0 (#343)
* Sparse attn + ops/runtime refactor + v0.3.0 Co-authored-by:Arash Ashari <arashari@microsoft.com> Co-authored-by:
Showing
{kind=link}
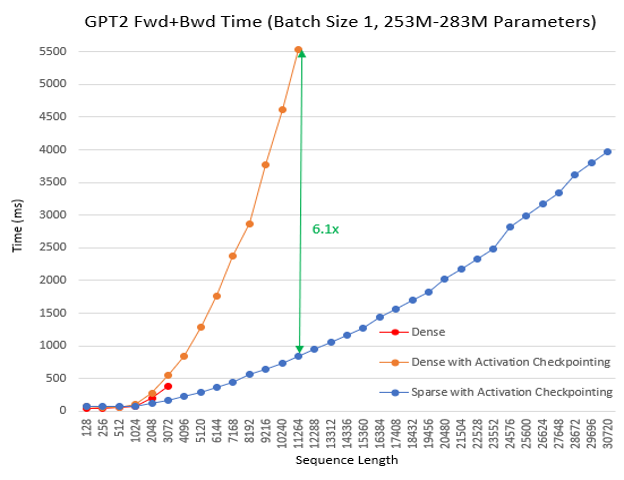
60.6 KB
{kind=link}
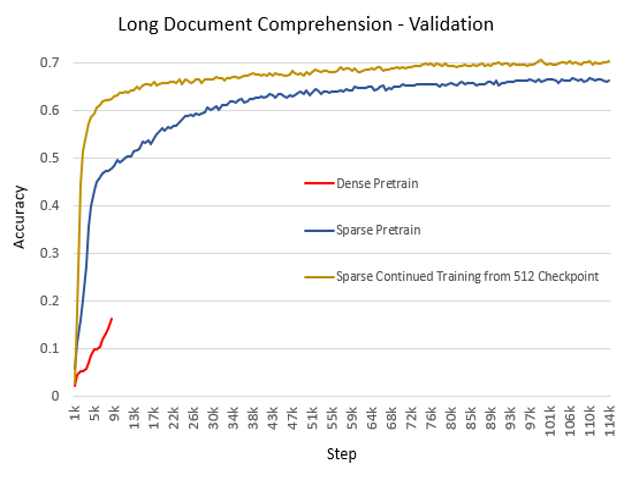
57.6 KB
{kind=link}

33.2 KB
{kind=link}
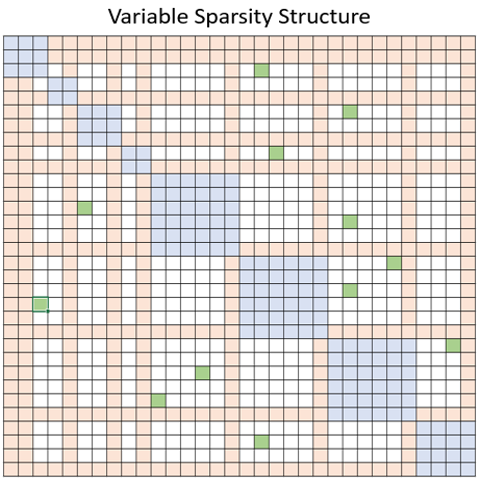
98.7 KB
{kind=link}
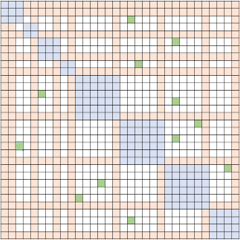
41.7 KB
| ... | ... | @@ -3,7 +3,3 @@ torchvision>=0.4.0 |
| tqdm | ||
| psutil | ||
| tensorboardX==1.8 | ||
| pytest | ||
| pytest-forked | ||
| pre-commit | ||
| clang-format |