
Merge branch 'ds-v0.9.2-rocm' into 'main'
Ds v0.9.2 rocm See merge request dcutoolkit/deeplearing/deepspeed!2
Showing
{kind=link}
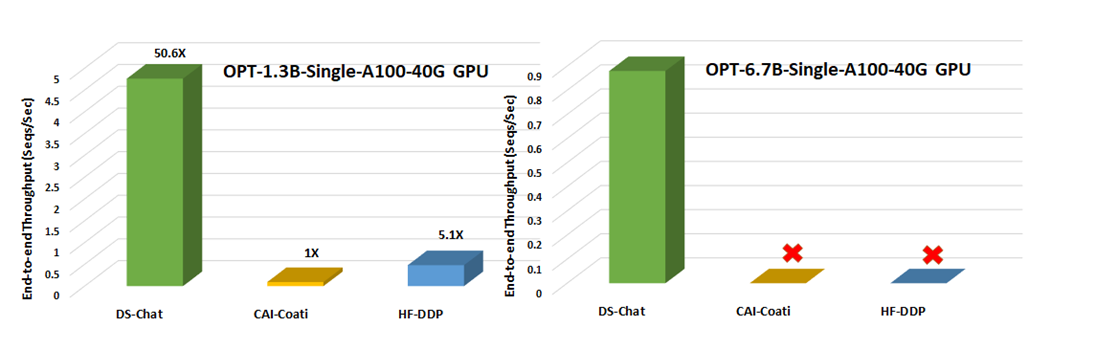
65.7 KB
{kind=link}
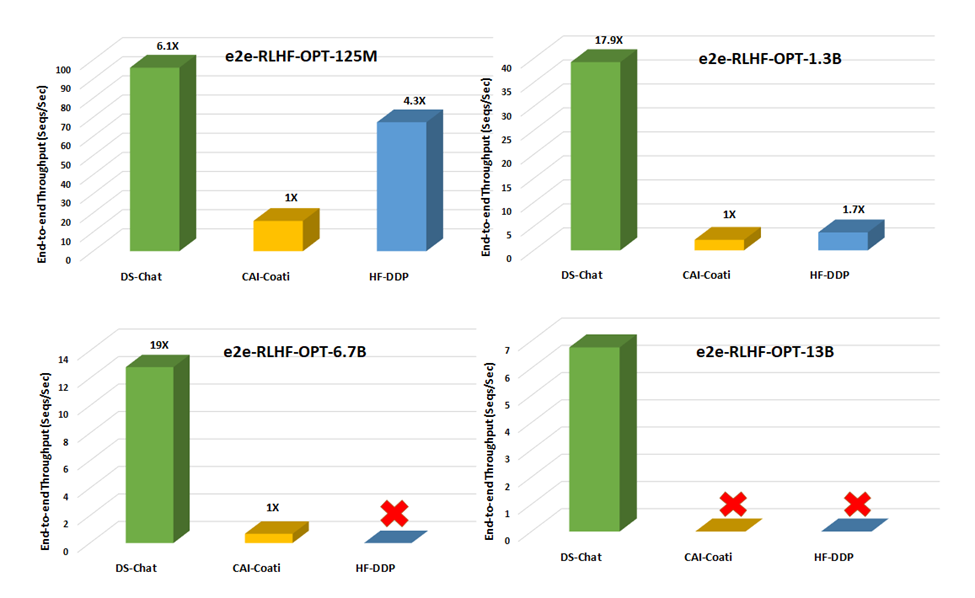
95.7 KB
{kind=link}
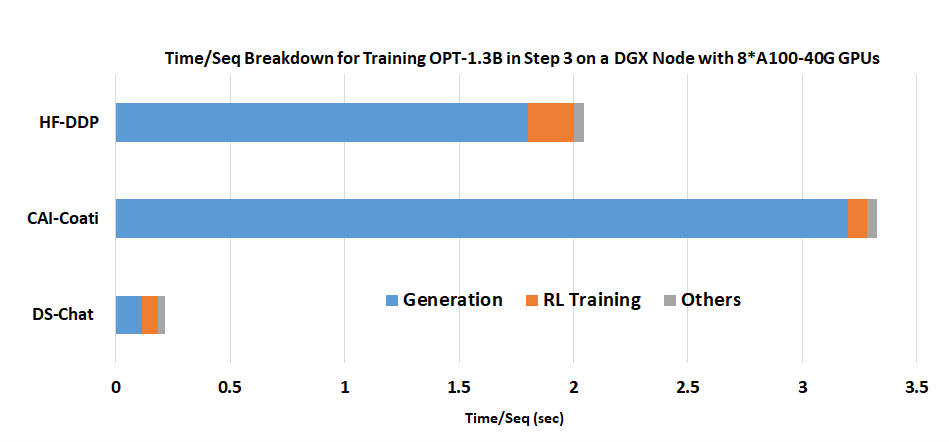
20 KB
{kind=link}
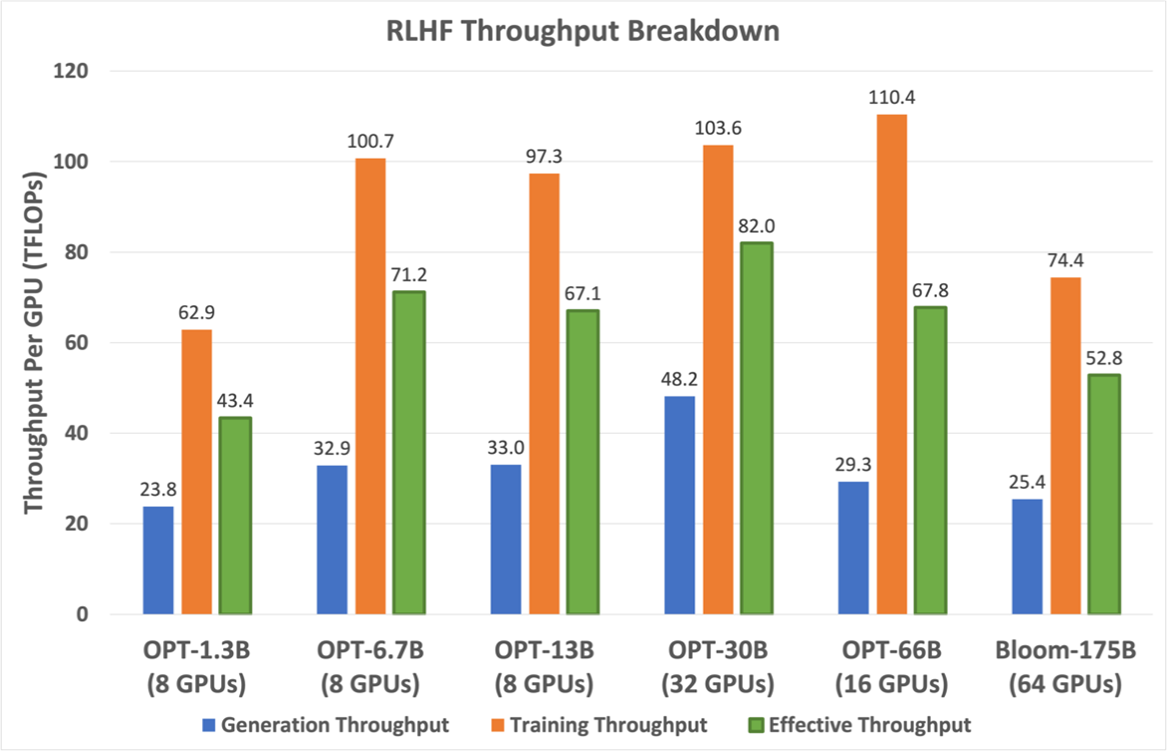
120 KB
{kind=link}
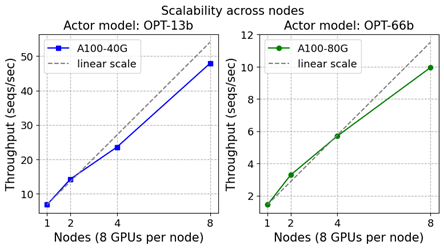
38 KB
{kind=link}
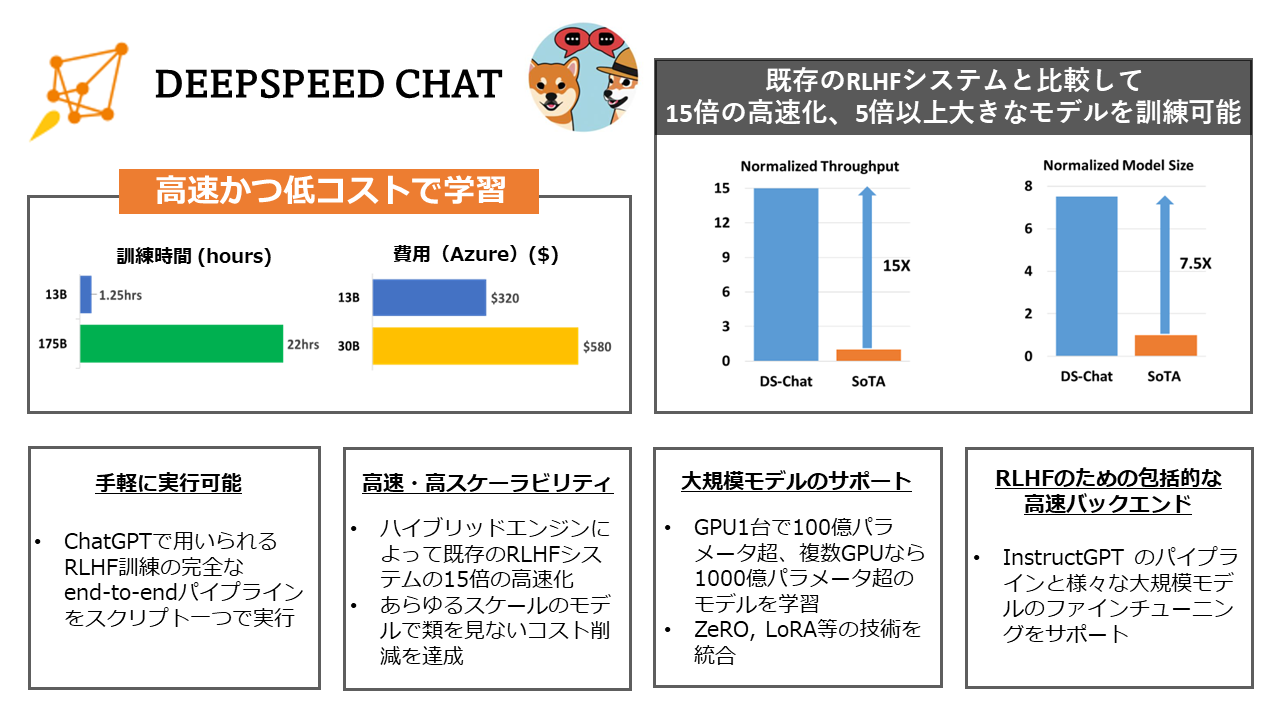
125 KB
{kind=link}
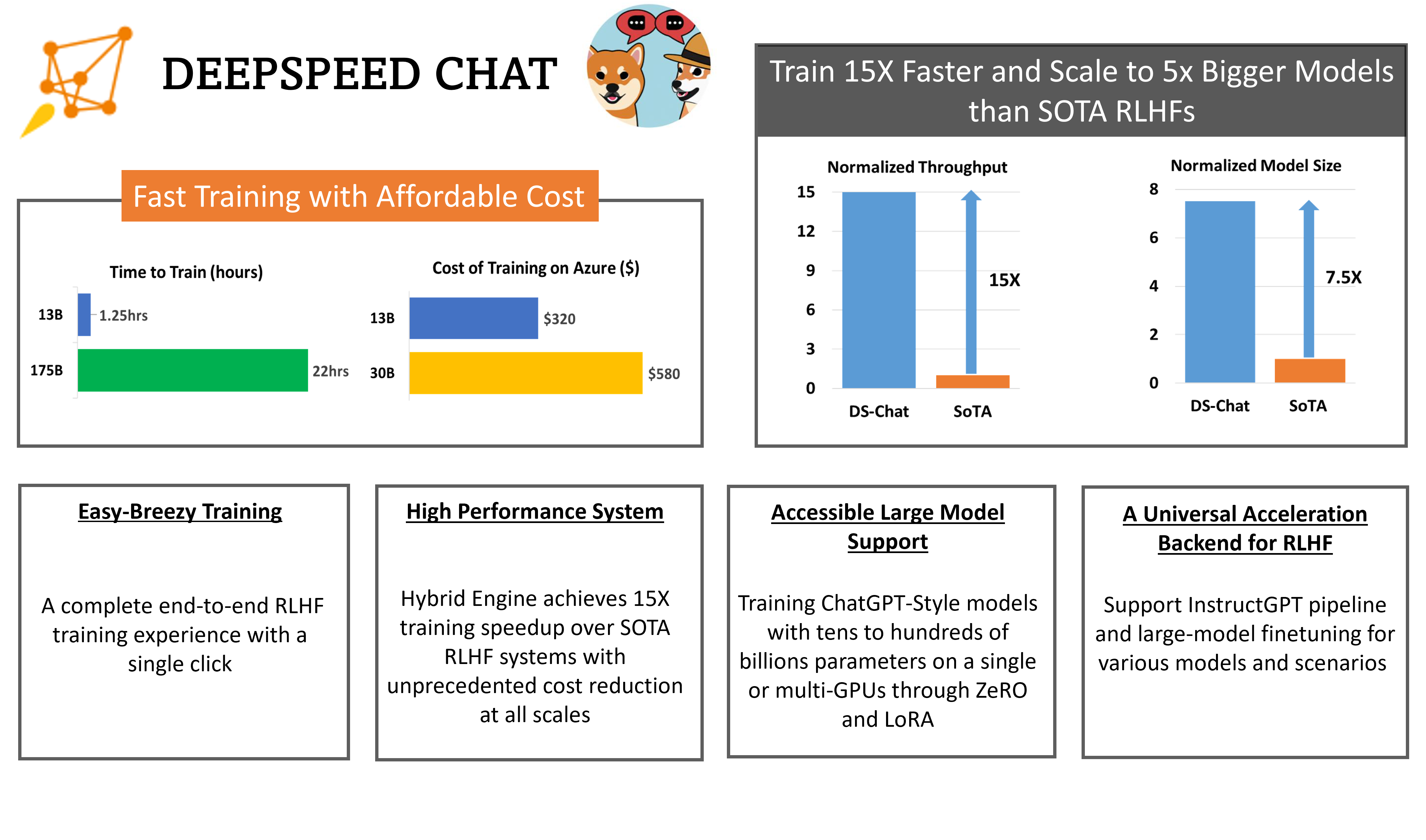
845 KB
{kind=link}

23.6 KB
{kind=link}

82.1 KB
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
csrc/adam/compat.h
deleted
100644 → 0