
Merge branch 'ds-v0.9.2-rocm' into 'main'
Ds v0.9.2 rocm See merge request dcutoolkit/deeplearing/deepspeed!2
Showing
Too many changes to show.
To preserve performance only 553 of 553+ files are displayed.
{kind=link}
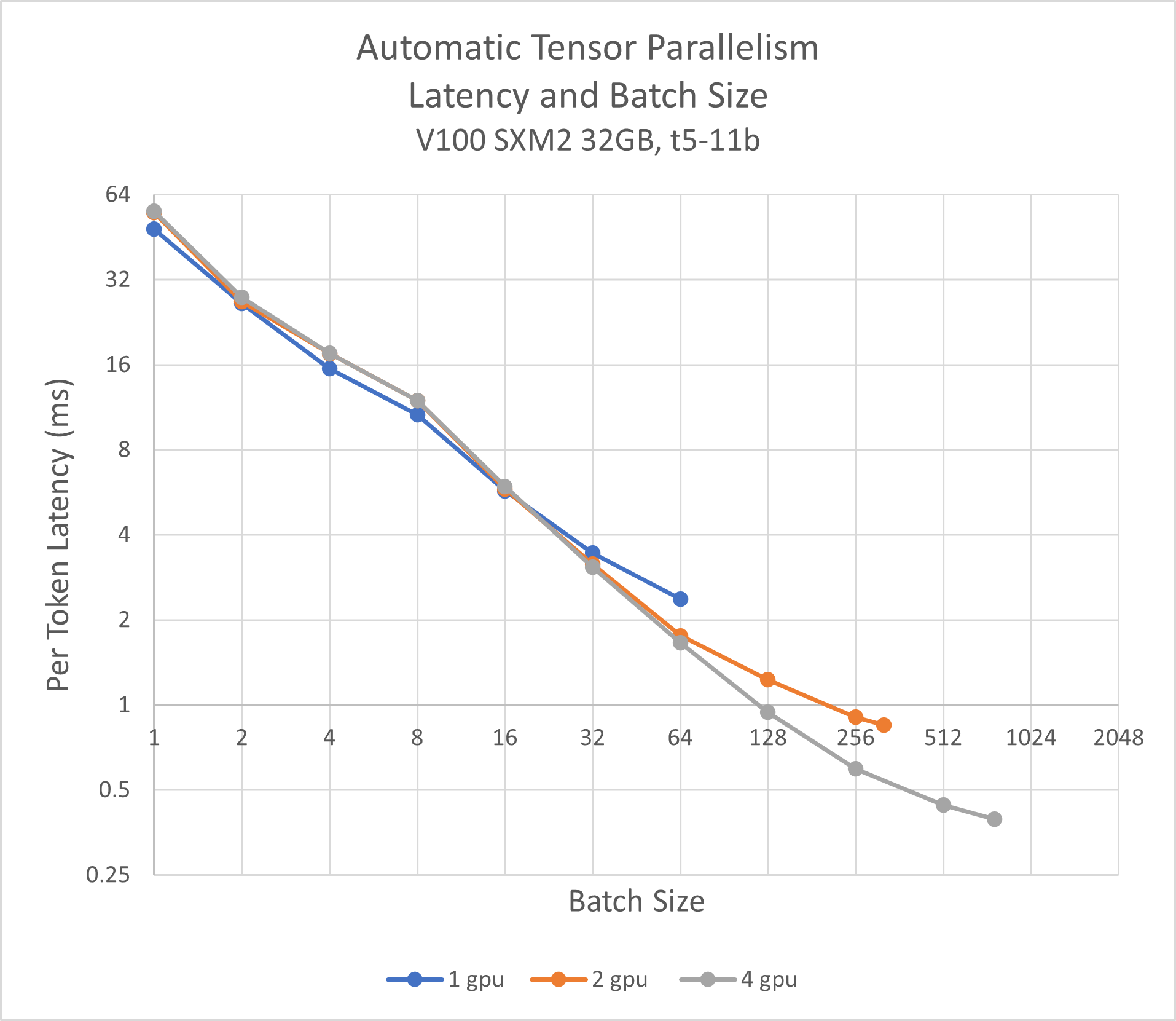
134 KB
{kind=link}
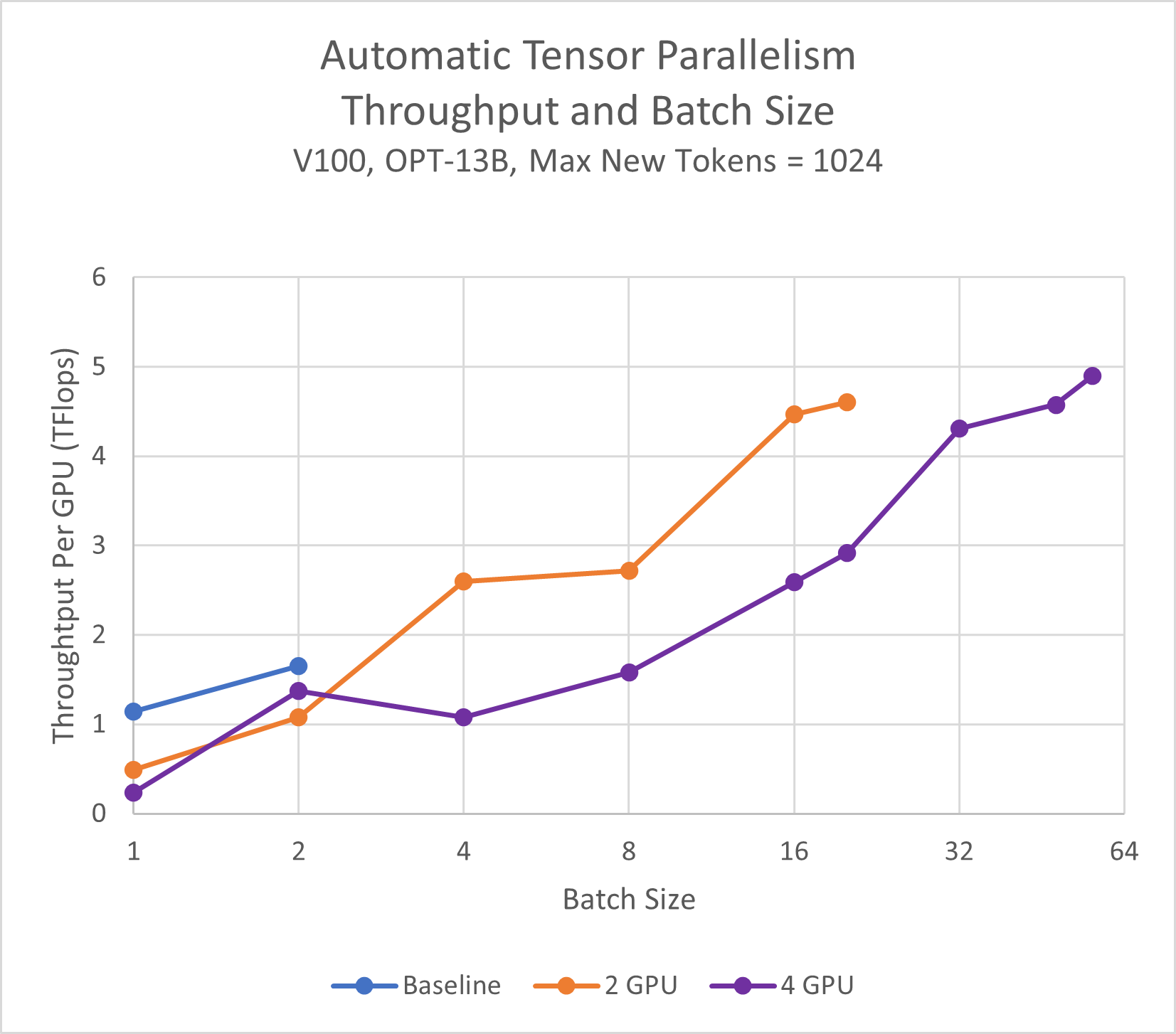
101 KB
{kind=link}
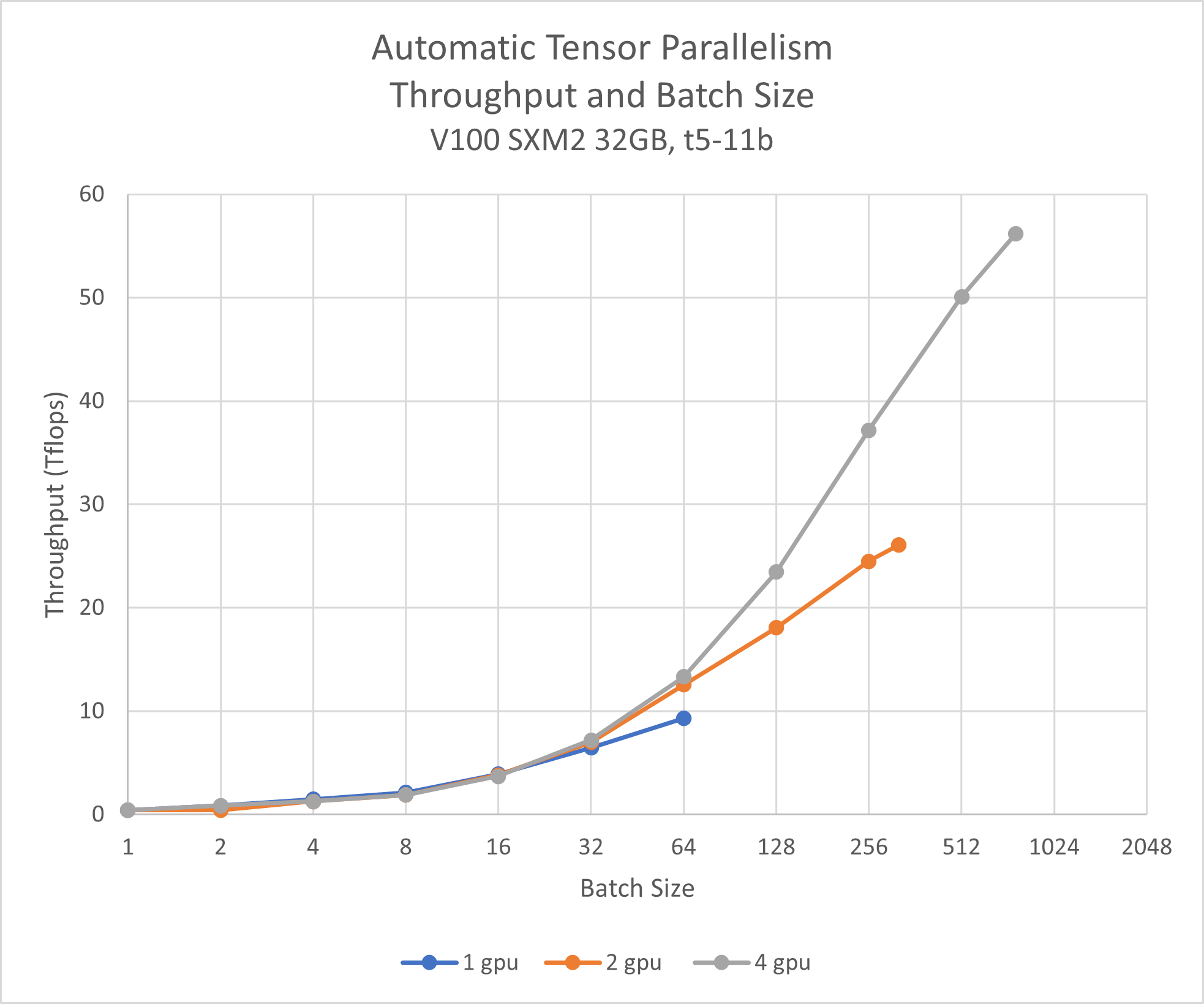
124 KB
{kind=link}
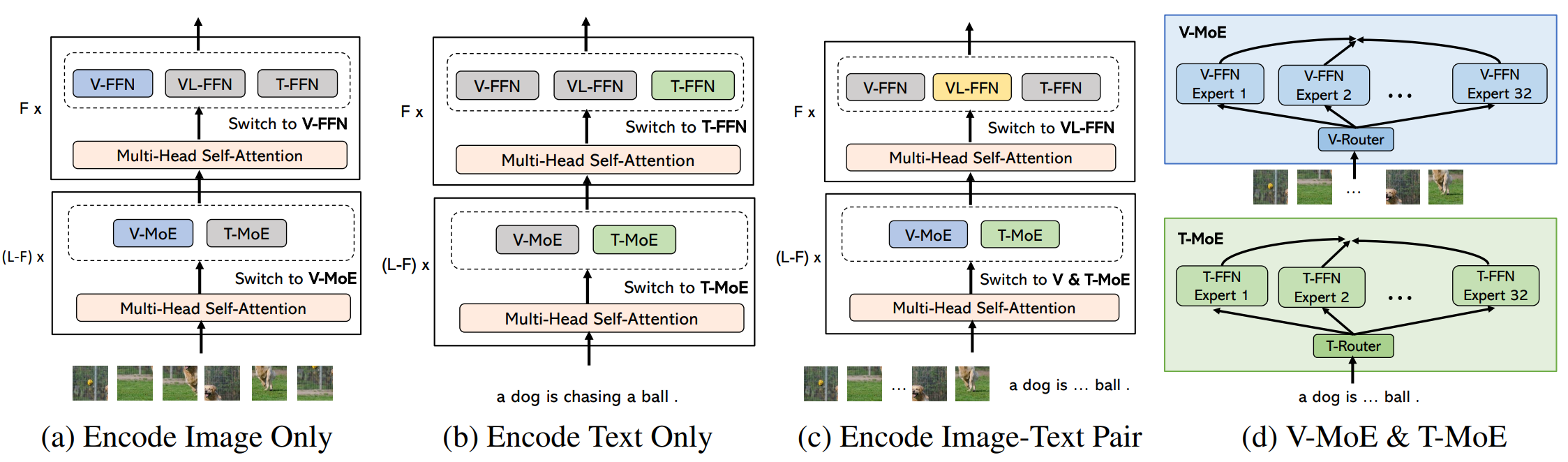
334 KB
docs/news/index.html
deleted
100644 → 0
env.sh
deleted
100644 → 0