
Pipeline parallel training engine. (#392)
Co-authored-by:  Jeff Rasley <jerasley@microsoft.com>
Jeff Rasley <jerasley@microsoft.com>
Showing
{kind=link}

244 KB
{kind=link}
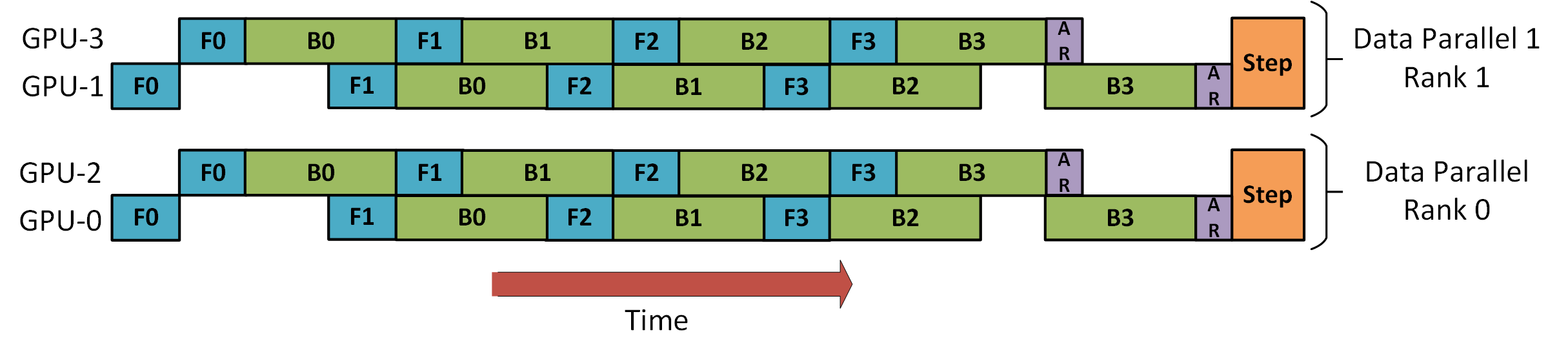
53.7 KB
tests/unit/test_data.py
0 → 100644
tests/unit/test_partition.py
0 → 100644
tests/unit/test_pipe.py
0 → 100644
This diff is collapsed.
tests/unit/test_topology.py
0 → 100644
This diff is collapsed.