| The effective training batch size. This is the amount of data samples that leads to one step of model update. ***train\_batch\_size*** is aggregated by the batch size that a single GPU processes in one forward/backward pass (a.k.a., ***train\_step\_batch\_size***), the gradient accumulation steps (a.k.a., ***gradient\_accumulation\_steps***), and the number of GPUs. | `32` |
| Batch size to be processed by one GPU in one step (without gradient accumulation). When specified, ***gradient\_accumulation\_steps*** is automatically calculated using ***train\_batch\_size*** and number of GPUs. Should not be concurrently specified with ***gradient\_accumulation\_steps*** in the configuration JSON. | ***train\_batch\_size*** value |
| Number of training steps to accumulate gradients before averaging and applying them. This feature is sometimes useful to improve scalability since it results in less frequent communication of gradients between steps. Another impact of this feature is the ability to train with larger batch sizes per GPU. When specified, ***train\_step\_batch\_size*** is automatically calculated using ***train\_batch\_size*** and number of GPUs. Should not be concurrently specified with ***train\_step\_batch\_size*** in the configuration JSON. | `1` |
| type | The optimizer name. DeepSpeed natively supports Adam and LAMB optimizers and will import other optimizers from [torch](https://pytorch.org/docs/stable/optim.html). | `"Adam"` |
| params | Dictionary of parameters to instantiate optimizer. The parameter names must match the optimizer constructor signature (e.g., for [Adam](https://pytorch.org/docs/stable/optim.html#torch.optim.Adam)). | `{"lr": 0.001, "eps": 1e-8}` |
| type | The scheduler name. See [here](https://microsoft.github.io/DeepSpeed/docs/htmlfiles/api/full/pt/deepspeed_lr_schedules.m.html) for list of support schedulers. | `"1Cycle"` |
| params | Dictionary of parameters to instantiate scheduler. The parameter names should match scheduler constructor signature. | `{"lr": 0.001, "eps": 1e-8}` |
| Configuration for using mixed precision/FP16 training that leverages [NVIDIA's Apex package](https://nvidia.github.io/apex/). An example, including the available dictionary keys is illustrated below. | None |
| ***loss\_scale*** is a ***fp16*** parameter representing the loss scaling value for FP16 training. The default value of 0.0 results in dynamic loss scaling, otherwise the value will be used for static fixed loss scaling. | `0.0` |
| ***initial\_loss\_scale\_power*** is a **fp16** parameter representing the power of the initial dynamic loss scale value. The actual loss scale is computed as 2<sup>***initial\_loss\_scale\_power***</sup>. | `32` |
<em>The figure depicts system throughput improvements of DeepSpeed (combining ZeRO-powered data parallelism with model parallelism of NVIDIA Megatron-LM) over using Megatron-LM alone.</em>
</p>
## Fast convergence for effectiveness
DeepSpeed supports advanced hyperparameter tuning and large batch size
optimizers such as [LAMB](https://arxiv.org/abs/1904.00962). These improve the
effectiveness of model training and reduce the number of samples required to
Only a few lines of code changes are needed to enable a PyTorch model to use DeepSpeed and ZeRO. Compared to current model parallelism libraries, DeepSpeed does not require a code redesign or model refactoring. It also does not put limitations on model dimensions (such as number of attention heads, hidden sizes, and others), batch size, or any other training parameters. For models of up to six billion parameters, you can use ZeRO-powered data parallelism conveniently without requiring model parallelism, while in contrast, standard data parallelism will run out of memory for models with more than 1.3 billion parameters. In addition, DeepSpeed conveniently supports flexible combination of ZeRO-powered data parallelism with custom model parallelisms, such as tensor slicing of NVIDIA's Megatron-LM.
## Features
Below we provide a brief feature list, see our detailed [feature
overview](features) for descriptions and usage.
*[Distributed Training with Mixed Precision](features.md#distributed-training-with-mixed-precision)
*[Simplified Data Loader](features.md#simplified-data-loader)
*[Performance Analysis and Debugging](features.md#performance-analysis-and-debugging)
# Getting Started
## Installation
* Please see our [Azure tutorial](docs/azure.md) to get started with DeepSpeed on Azure!
* If you're not on Azure, we recommend using our docker image via `docker pull deepspeed/deepspeed:latest` which contains a pre-installed version of DeepSpeed and all the necessary dependencies.
* If you want to install DeepSpeed manually, we provide an install script [install.sh](install.sh) to help install on a local machine or across an entire cluster.
## Writing DeepSpeed Models
DeepSpeed model training is accomplished using the DeepSpeed engine. The engine
can wrap any arbitrary model of type `torch.nn.module` and has a minimal set of APIs
for training and checkpointing the model. Please see the tutorials for detailed
| [API Documentation](/code-docs/) | Generated DeepSpeed API documentation |
| [CIFAR-10 Tutorial](./docs/tutorials/CIFAR-10.md) | Getting started with CIFAR-10 and DeepSpeed |
| [Megatron-LM Tutorial](./docs/tutorials/MegatronGPT2Tutorial.md) | Train GPT2 with DeepSpeed and Megatron-LM |
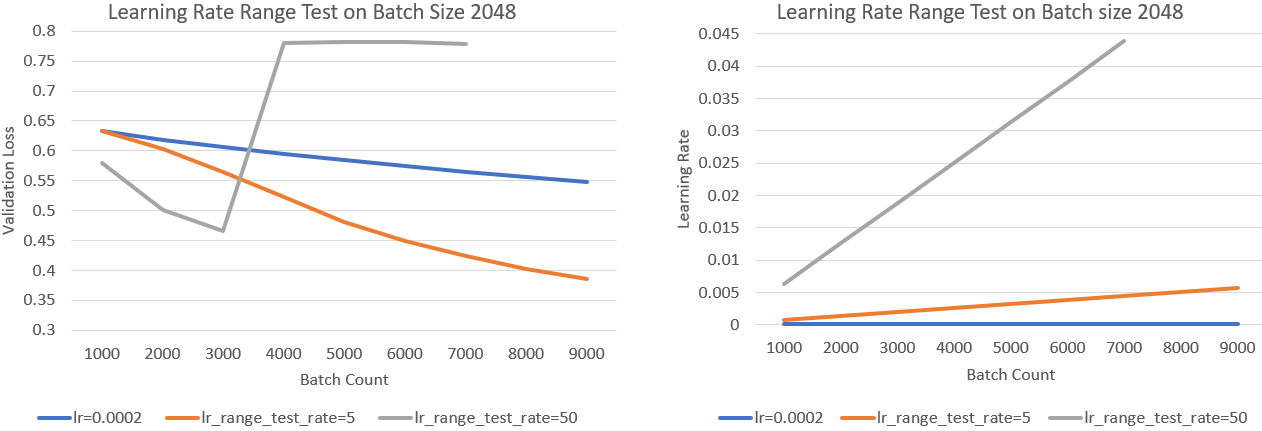
| [Learning Rate Range Test Tutorial](./docs/tutorials/lrrt.md) | Faster training with large learning rates |
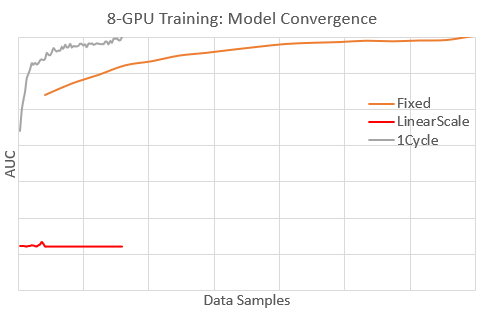
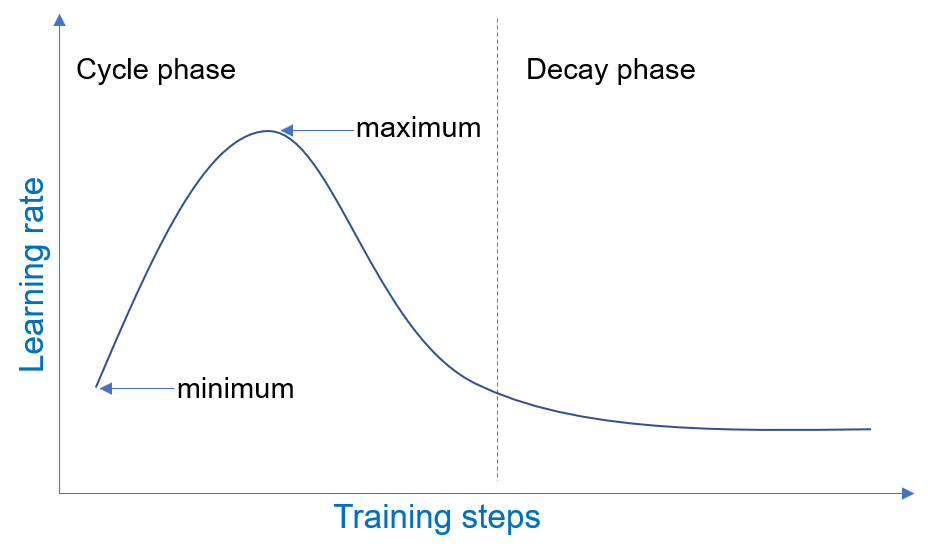
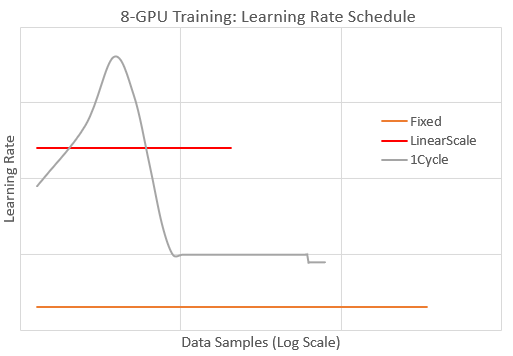
| [1Cycle Tutorial](./docs/tutorials/1Cycle.md) | SOTA learning schedule in DeepSpeed |
# Contributing
DeepSpeed welcomes your contributions! Please see our
[contributing](CONTRIBUTING.md) guide for more details on formatting, testing,
etc.
## Contributor License Agreement
This project welcomes contributions and suggestions. Most contributions require you to
agree to a Contributor License Agreement (CLA) declaring that you have the right to, and
actually do, grant us the rights to use your contribution. For details, visit
https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need
to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply
follow the instructions provided by the bot. You will only need to do this once across
all repos using our CLA.
## Code of Conduct
This project has adopted the [Microsoft Open Source Code of
Conduct](https://opensource.microsoft.com/codeofconduct/). For more information see the
[Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/) or contact
[opencode@microsoft.com](mailto:opencode@microsoft.com) with any additional questions or
comments.
# Publications
1. Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. (2019) ZeRO: Memory Optimization Towards Training A Trillion Parameter Models. [ArXiv:1910.02054](https://arxiv.org/abs/1910.02054)
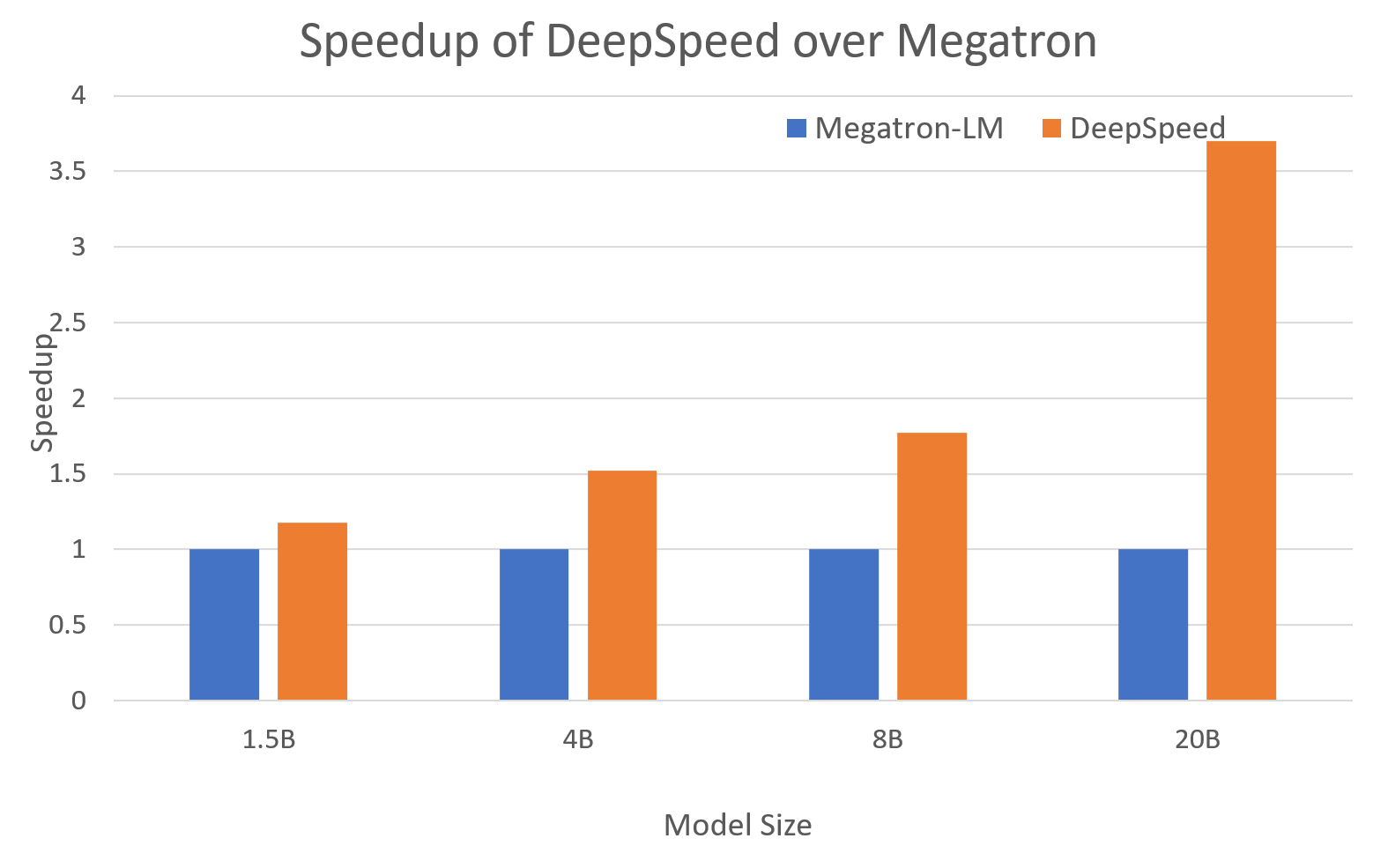
<em>The figure depicts system throughput improvements of DeepSpeed (combining ZeRO-powered data parallelism with model parallelism of Nvidia Megatron-LM) over using Megatron-LM alone.</em>
</p>
### 3.1 On Low Bandwidth GPU Cluster
The figure above shows that training 1.5B parameter model with DeepSpeed is
nearly 4x faster than without DeepSpeed on a cluster with 4 nodes, 4 GPU per
node, and 16 GPUs total. These GPUs have 16GB of memory each, and PCI-E
interconnects GPUs within a node, and 40 Gbps infiniband across nodes.
The performance improvement comes from lower model parallelism degree and
larger batch size as discussed earlier. Training 1.5B parameter model with
Megatron-LM alone requires 4-way model parallelism, and can only fit an effective
batch size of 32 using all 16 GPUs. On the other hand, DeepSpeed does not
require any model-parallelism to train this model, and can support an
effective batch size of 128 without running out of memory, resulting in
significantly higher performance.
### 3.2 On High bandwidth DGX-2 GPU Cluster
Each GPU on the DGX-2 cluster has 32 GB of memory, and GPUs inside a box is connected via
the high-bandwidth NVSwitch. DGX-2 nodes are connected to each other via 800 Gbps (8 x 100Gbps) infiniband interconnect. As such, running a 1.5B model on DGX-2 requires less model
parallelism, and the performance improvement from DeepSpeed for this model size is less
significant. However, at larger model sizes, Megatron still requires significantly larger
model parallelism degree, and can only run much smaller batch sizes than DeepSpeed.
Therefore, as the model sizes get larger, DeepSpeed, by coming ZeRO with Megatron model parallelism, starts to significantly outperform
using Megatron-LM alone.
### 3.3 Performance Improvements with Configuration Details
The figure below compares DeepSpeed with Megatron on a 64 GPU cluster with 4
DGX-2 nodes. To give the readers a clear idea of source of the performance
improvements, we also present the configuration table for both Megatron and
DeepSpeed. It shows the smallest model parallelism degree and the largest batch
size that can be used to train these models without running out of memory. As
discussed above, the tables demonstrate that DeepSpeed runs with smaller model parallelism degree
<em>The figure depicts system throughput improvements of DeepSpeed (combining ZeRO-powered data parallelism with model parallelism of Nvidia Megatron-LM) over using Megatron-LM alone.</em>

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}