
Ported Megatron tutorial. (#30)
* Ported DeepSpeed overview.
* Renamed subsection
* Formatting table of contents
* initial import of Megatron tutorial
* Grammatical edits, formatting, and paths.
* formatting and data download instructions
* formatting tutorial
* formatting tutorial
* formatting tutorial
* formatting tutorial
* formatting tutorial
* formatting tutorial
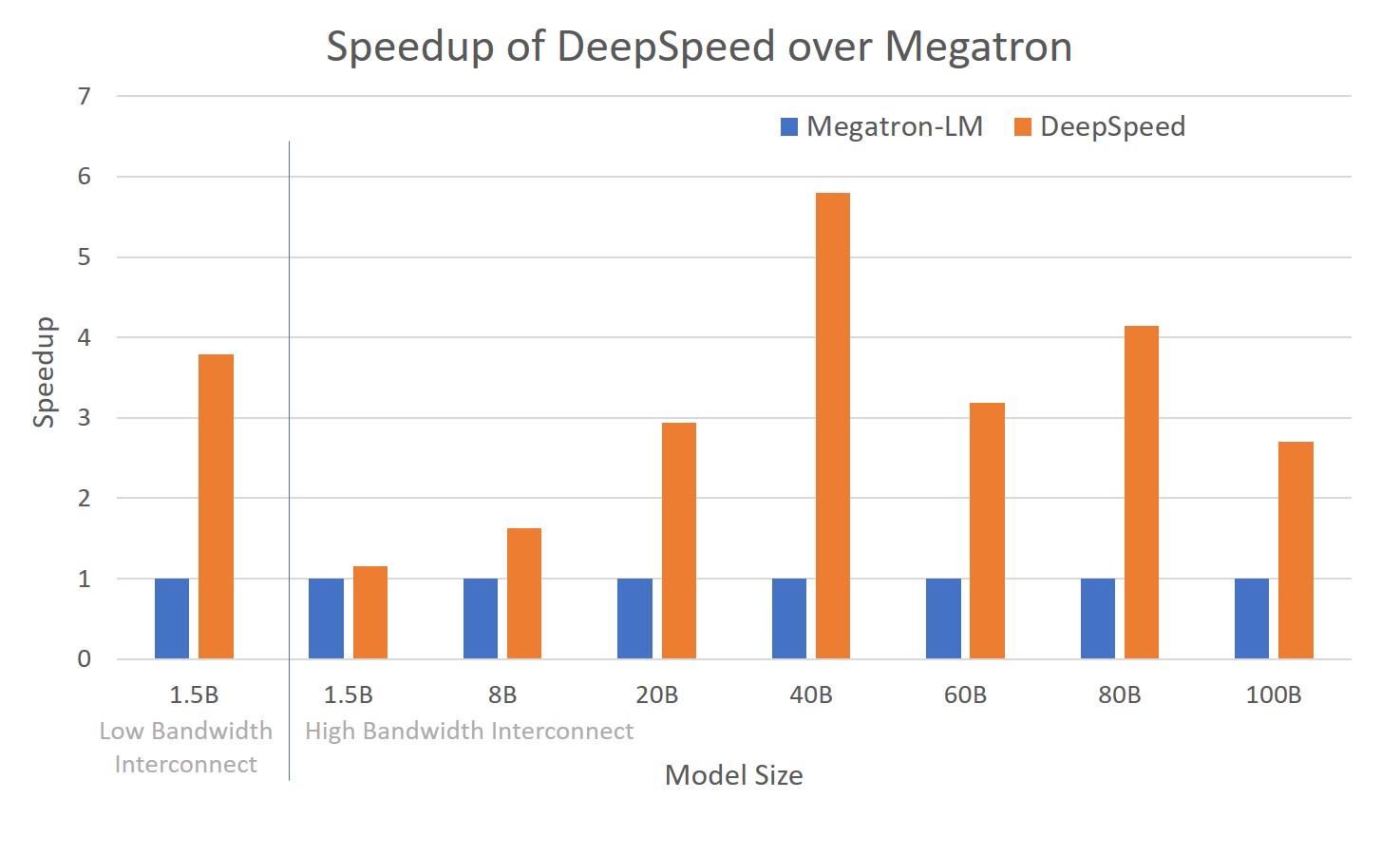
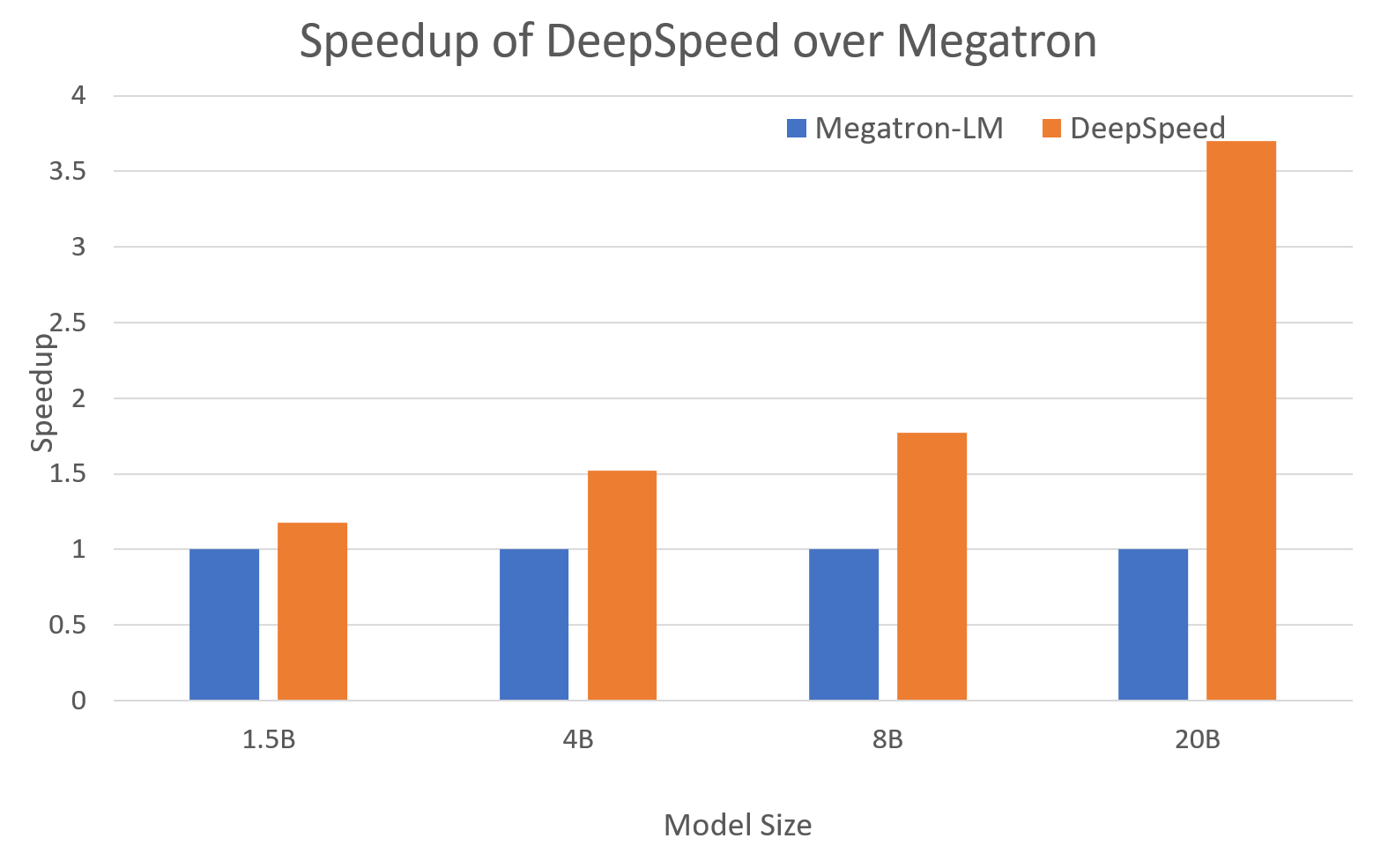
* new perf chart
* removing TODO
* adding pointer to tutorial
* edits
* azure to low bandwidth
Co-authored-by:  Samyam Rajbhandari <samyamr@microsoft.com>
Samyam Rajbhandari <samyamr@microsoft.com>
Showing
README.md
100644 → 100755
{kind=link}
95.6 KB
{kind=link}
41.1 KB