[English Version]
# 书生2.5 - 多模态多任务通用大模型
[](https://paperswithcode.com/sota/object-detection-on-coco?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/object-detection-on-coco-minival?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/object-detection-on-lvis-v1-0-minival?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/object-detection-on-lvis-v1-0-val?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/object-detection-on-pascal-voc-2007?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/object-detection-on-pascal-voc-2012?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/object-detection-on-openimages-v6?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/object-detection-on-crowdhuman-full-body?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/2d-object-detection-on-bdd100k-val?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/semantic-segmentation-on-ade20k?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/semantic-segmentation-on-cityscapes?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/semantic-segmentation-on-cityscapes-val?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/semantic-segmentation-on-pascal-context?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/semantic-segmentation-on-coco-stuff-test?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/3d-object-detection-on-nuscenes-camera-only?p=bevformer-v2-adapting-modern-image-backbones)
[](https://paperswithcode.com/sota/image-classification-on-inaturalist-2018?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/image-classification-on-places365?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/image-classification-on-places205?p=internimage-exploring-large-scale-vision)
[](https://paperswithcode.com/sota/image-classification-on-imagenet?p=internimage-exploring-large-scale-vision)
这个代码仓库是[InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions](https://arxiv.org/abs/2211.05778)的官方实现。
[论文](https://arxiv.org/abs/2211.05778) \| [知乎专栏](https://zhuanlan.zhihu.com/p/610772005) | [文档](./docs/)
## 简介
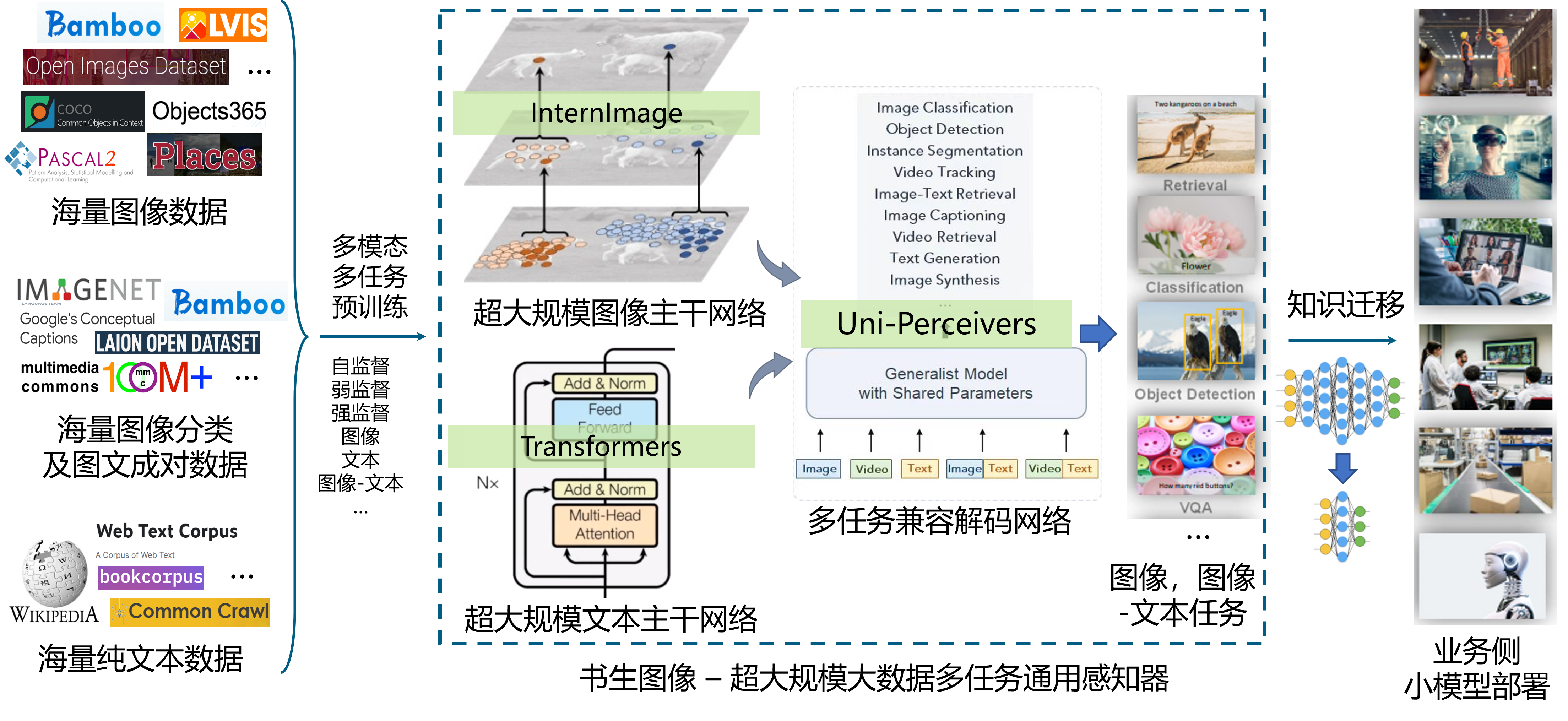
商汤科技与上海人工智能实验室在2023年3月14日联合发布多模态多任务通用大模型“书生2.5”。“书生2.5”在多模态多任务处理能力中斩获多项全新突破,其卓越的图文跨模态任务处理能力可为自动驾驶等通用场景任务提供高效精准的感知和理解能力支持。“书生2.5”致力于多模态多任务通用模型的构建,旨在接收处理各种不同模态的输入,并采用统一的模型架构和参数处理各种不同的任务,促进不同模态和任务之间在表示学习方面的协作,逐步实现通用人工智能领域的融会贯通。
## 概览图
## 亮点
- :thumbsup: **高达30亿参数的最强视觉通用主干模型**
- 🏆 **图像分类标杆数据集ImageNet `90.1% Top1`准确率,开源模型中准确度最高**
- 🏆 **物体检测标杆数据集COCO `65.5 mAP`,唯一超过`65 mAP`的模型**
## 最新进展
- 2023年3月14日: 🚀 “书生2.5”发布!
- 2023年2月28日: 🚀 InternImage 被CVPR 2023接收!
- 2022年11月18日: 🚀 基于 InternImage-XL 主干网络,[BEVFormer v2](https://arxiv.org/abs/2211.10439) 在nuScenes的纯视觉3D检测任务上取得了最佳性能 `63.4 NDS` !
- 2022年11月10日: 🚀 InternImage-H 在COCO目标检测任务上以 `65.4 mAP` 斩获冠军,是唯一突破 `65.0 mAP` 的超强物体检测模型!
- 2022年11月10日: 🚀 InternImage-H 在ADE20K语义分割数据集上取得 `62.9 mIoU` 的SOTA性能!
## “书生2.5”的应用
### 1. 图像模态任务性能
- 在图像分类标杆数据集ImageNet上,“书生2.5”仅基于公开数据便达到了 90.1% 的Top-1准确率。这是除谷歌与微软两个未公开模型及额外数据集外,唯一准确率超过90.0%的模型,同时也是世界上开源模型中ImageNet准确度最高,规模最大的模型;
- 在物体检测标杆数据集COCO上,“书生2.5” 取得了 65.5 的 mAP,是世界上唯一超过65 mAP的模型;
- 在另外16个重要的视觉基础数据集(覆盖分类、检测和分割任务)上取得世界最好性能。
**分类任务**
| 图像分类 | 场景分类 | 长尾分类 |
| ImageNet | Places365 | Places 205 | iNaturalist 2018 |
| 90.1 | 61.2 | 71.7 | 92.3 |
**检测任务**
| 常规物体检测 | 长尾物体检测 | 自动驾驶物体检测 | 密集物体检测 |
| COCO | VOC 2007 | VOC 2012 | OpenImage | LVIS minival | LVIS val | BDD100K | nuScenes | CrowdHuman |
| 65.5 | 94.0 | 97.2 | 74.1 | 65.8 | 63.2 | 38.8 | 64.8 | 97.2 |
**分割任务**
| 语义分割 | 街景分割 | RGBD分割 |
| ADE20K | COCO Stuff-10K | Pascal Context | CityScapes | NYU Depth V2 |
| 62.9 | 59.6 | 70.3 | 86.1 | 69.7 |
### 2. 图文跨模态任务性能
- 图文检索
“书生2.5”可根据文本内容需求快速定位检索出语义最相关的图像。这一能力既可应用于视频和图像集合,也可进一步结合物体检测框,具有丰富的应用模式,帮助用户更便捷、快速地找到所需图像资源, 例如可在相册中返回文本所指定的相关图像。
- 以图生文
“书生2.5”的“以图生文”在图像描述、视觉问答、视觉推理和文字识别等多个方面均拥有强大的理解能力。例如在自动驾驶场景下,可以提升场景感知理解能力,辅助车辆判断交通信号灯状态、道路标志牌等信息,为车辆的决策规划提供有效的感知信息支持。
**图文多模态任务**
| 图像描述 | 微调图文检索 | 零样本图文检索 |
| COCO Caption | COCO Caption | Flickr30k | Flickr30k |
| 148.2 | 76.4 | 94.8 | 89.1 |
## 核心技术
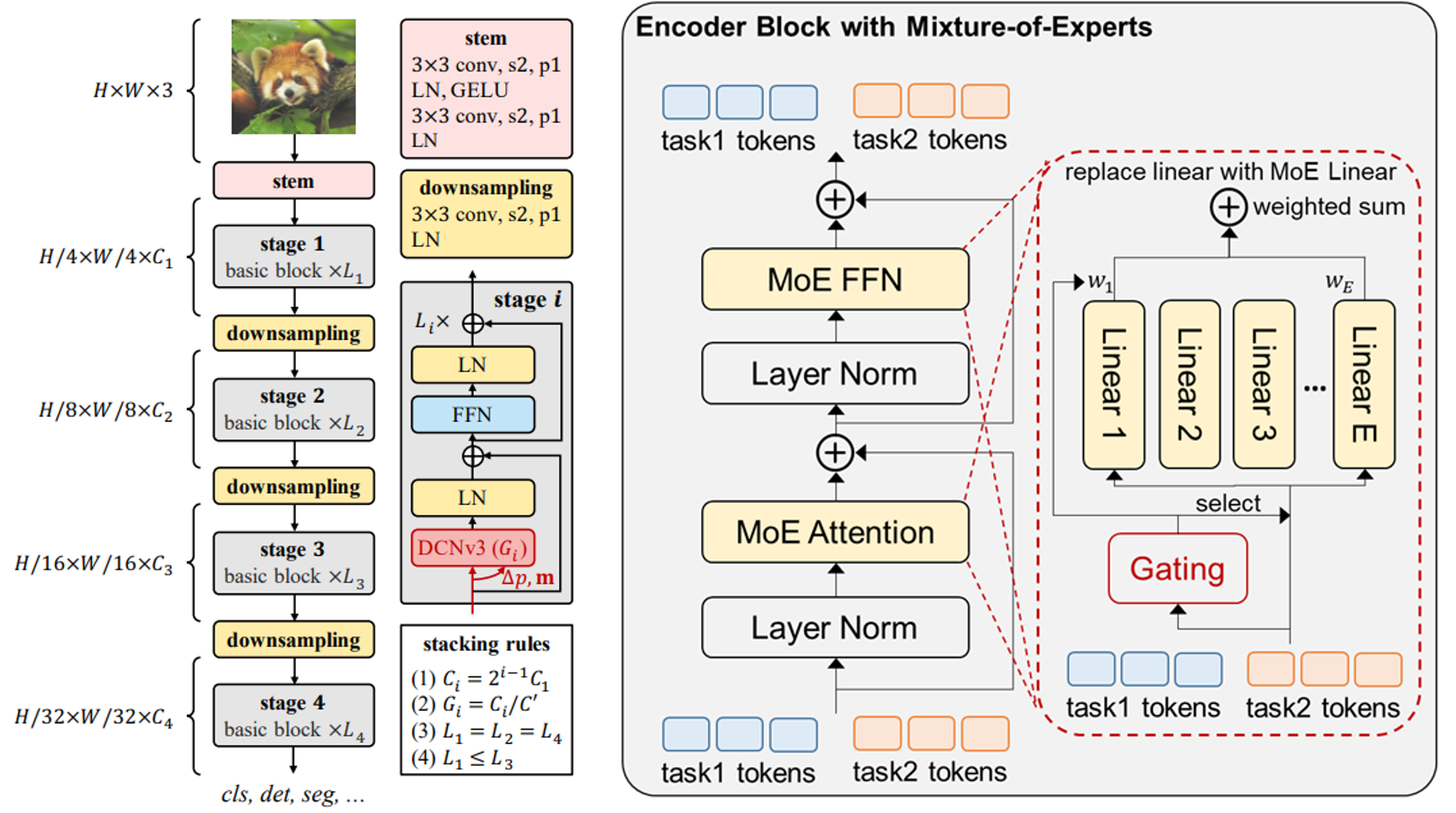
“书生2.5”在图文跨模态领域卓越的性能表现,源自于在多模态多任务通用模型技术核心方面的多项创新,实现了视觉核心视觉感知大模型主干网络(InternImage)、用于文本核心的超大规模文本预训练网络(LLM)和用于多任务的兼容解码建模(Uni-Perceiver)的创新组合。 视觉主干网络InternImage参数量高达30亿,能够基于动态稀疏卷积算子自适应地调整卷积的位置和组合方式,从而为多功能视觉感知提供强大的表示。Uni-Perceiver通才任务解码建模通过将不同模态的数据编码到统一的表示空间,并将不同任务统一为相同的任务范式,从而能够以相同的任务架构和共享的模型参数同时处理各种模态和任务。
## 项目功能
- [ ] 各类下游任务
- [x] InternImage-H(1B)/G(3B)
- [x] TensorRT 推理
- [x] InternImage 系列分类代码
- [x] InternImage-T/S/B/L/XL ImageNet-1K 预训练模型
- [x] InternImage-L/XL ImageNet-22K 预训练模型
- [x] InternImage-T/S/B/L/XL 检测和实例分割模型
- [x] InternImage-T/S/B/L/XL 语义分割模型
## 开源模型
- 目标检测和实例分割: [COCO](detection/configs/coco/)
- 语义分割: [ADE20K](segmentation/configs/ade20k/), [Cityscapes](segmentation/configs/cityscapes/)
- 图文检索、图像描述和视觉问答: [Uni-Perceiver](https://github.com/fundamentalvision/Uni-Perceiver)
- 3D感知: [BEVFormer](https://github.com/fundamentalvision/BEVFormer)
## 经典视觉任务性能
**ImageNet图像分类**
| name | pretrain | resolution | acc@1 | #param | FLOPs | 22K model | 1K model |
| :------------: | :----------: | :--------: | :---: | :-----: | :---: | :-----------------: | :-----------------: |
| InternImage-T | ImageNet-1K | 224x224 | 83.5 | 30M | 5G | - | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_t_1k_224.pth) \| [cfg](classification/configs/internimage_t_1k_224.yaml) |
| InternImage-S | ImageNet-1K | 224x224 | 84.2 | 50M | 8G | - | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_s_1k_224.pth) \| [cfg](classification/configs/internimage_s_1k_224.yaml) |
| InternImage-B | ImageNet-1K | 224x224 | 84.9 | 97M | 16G | - | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_b_1k_224.pth) \| [cfg](classification/configs/internimage_b_1k_224.yaml) |
| InternImage-L | ImageNet-22K | 384x384 | 87.7 | 223M | 108G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_l_22k_192to384.pth) | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_l_22kto1k_384.pth) \| [cfg](classification/configs/internimage_l_22kto1k_384.yaml) |
| InternImage-XL | ImageNet-22K | 384x384 | 88.0 | 335M | 163G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_xl_22k_192to384.pth) | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_xl_22kto1k_384.pth) \| [cfg](classification/configs/internimage_xl_22kto1k_384.yaml) |
| InternImage-H | Joint 427M | 640x640 | 89.6 | 1.08B | 1478G | TODO | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_h_jointto1k_640.pth) \| [cfg](classification/configs/internimage_h_jointto1k_640.yaml) |
| InternImage-G | Joint 427M | 512x512 | 90.1 | 3B | TODO | TODO | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/internimage_g_jointto1k_512.pth) \| [cfg](classification/configs/internimage_g_jointto1k_512.yaml) |
**COCO目标检测和实例分割**
| backbone | method | schd | box mAP | mask mAP | #param | FLOPs | Download |
| :------------: | :----------------: | :---------: | :-----: | :------: | :-----: | :---: | :---: |
| InternImage-T | Mask R-CNN | 1x | 47.2 | 42.5 | 49M | 270G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_t_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_t_fpn_1x_coco.py) |
| InternImage-T | Mask R-CNN | 3x | 49.1 | 43.7 | 49M | 270G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_t_fpn_3x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_t_fpn_3x_coco.py) |
| InternImage-S | Mask R-CNN | 1x | 47.8 | 43.3 | 69M | 340G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_s_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_s_fpn_1x_coco.py) |
| InternImage-S | Mask R-CNN | 3x | 49.7 | 44.5 | 69M | 340G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_s_fpn_3x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_s_fpn_3x_coco.py) |
| InternImage-B | Mask R-CNN | 1x | 48.8 | 44.0 | 115M | 501G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_b_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_b_fpn_1x_coco.py) |
| InternImage-B | Mask R-CNN | 3x | 50.3 | 44.8 | 115M | 501G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/mask_rcnn_internimage_b_fpn_3x_coco.pth) \| [cfg](detection/configs/coco/mask_rcnn_internimage_b_fpn_3x_coco.py) |
| InternImage-L | Cascade | 1x | 54.9 | 47.7 | 277M | 1399G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/cascade_internimage_l_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/cascade_internimage_l_fpn_1x_coco.py) |
| InternImage-L | Cascade | 3x | 56.1 | 48.5 | 277M | 1399G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/cascade_internimage_l_fpn_3x_coco.pth) \| [cfg](detection/configs/coco/cascade_internimage_l_fpn_3x_coco.py) |
| InternImage-XL | Cascade | 1x | 55.3 | 48.1 | 387M | 1782G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/cascade_internimage_xl_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/cascade_internimage_xl_fpn_1x_coco.py) |
| InternImage-XL | Cascade | 3x | 56.2 | 48.8 | 387M | 1782G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/cascade_internimage_xl_fpn_1x_coco.pth) \| [cfg](detection/configs/coco/cascade_internimage_xl_fpn_3x_coco.py) |
| backbone | method | box mAP (val/test) | #param | FLOPs | Download |
| :------------: | :----------------: | :---------: | :------: | :-----: | :---: |
| InternImage-H | DINO (TTA) | 65.0 / 65.4 | 2.18B | TODO | TODO |
| InternImage-G | DINO (TTA) | 65.3 / 65.5 | 3B | TODO | TODO |
**ADE20K语义分割**
| backbone | method | resolution | mIoU (ss/ms) | #param | FLOPs | Download |
| :------------: | :--------: | :--------: | :----------: | :-----: | :---: | :---: |
| InternImage-T | UperNet | 512x512 | 47.9 / 48.1 | 59M | 944G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_t_512_160k_ade20k.pth) \| [cfg](segmentation/configs/ade20k/upernet_internimage_t_512_160k_ade20k.py) |
| InternImage-S | UperNet | 512x512 | 50.1 / 50.9 | 80M | 1017G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_s_512_160k_ade20k.pth) \| [cfg](segmentation/configs/ade20k/upernet_internimage_s_512_160k_ade20k.py) |
| InternImage-B | UperNet | 512x512 | 50.8 / 51.3 | 128M | 1185G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_b_512_160k_ade20k.pth) \| [cfg](segmentation/configs/ade20k/upernet_internimage_b_512_160k_ade20k.py) |
| InternImage-L | UperNet | 640x640 | 53.9 / 54.1 | 256M | 2526G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_l_640_160k_ade20k.pth) \| [cfg](segmentation/configs/ade20k/upernet_internimage_l_640_160k_ade20k.py) |
| InternImage-XL | UperNet | 640x640 | 55.0 / 55.3 | 368M | 3142G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_xl_640_160k_ade20k.pth) \| [cfg](segmentation/configs/ade20k/upernet_internimage_xl_640_160k_ade20k.py) |
| InternImage-H | UperNet | 896x896 | 59.9 / 60.3 | 1.12B | 3566G | [ckpt](https://huggingface.co/OpenGVLab/InternImage/resolve/main/upernet_internimage_h_896_160k_ade20k.pth) \| [cfg](segmentation/configs/ade20k/upernet_internimage_h_896_160k_ade20k.py) |
| InternImage-H | Mask2Former | 896x896 | 62.5 / 62.9 | 1.31B | 4635G | ckpt \| cfg |
**模型推理速度**
| name | resolution | #param | FLOPs | Batch 1 FPS(TensorRT) |
| :------------: | :--------: | :-----: | :---: | :-------------------: |
| InternImage-T | 224x224 | 30M | 5G | 156 |
| InternImage-S | 224x224 | 50M | 8G | 129 |
| InternImage-B | 224x224 | 97M | 16G | 116 |
| InternImage-L | 384x384 | 223M | 108G | 56 |
| InternImage-XL | 384x384 | 335M | 163G | 47 |
## 引用
若“书生2.5”对您的研究工作有帮助,请参考如下bibtex对我们的工作进行引用。
```
@article{wang2022internimage,
title={InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions},
author={Wang, Wenhai and Dai, Jifeng and Chen, Zhe and Huang, Zhenhang and Li, Zhiqi and Zhu, Xizhou and Hu, Xiaowei and Lu, Tong and Lu, Lewei and Li, Hongsheng and others},
journal={arXiv preprint arXiv:2211.05778},
year={2022}
}
@inproceedings{zhu2022uni,
title={Uni-perceiver: Pre-training unified architecture for generic perception for zero-shot and few-shot tasks},
author={Zhu, Xizhou and Zhu, Jinguo and Li, Hao and Wu, Xiaoshi and Li, Hongsheng and Wang, Xiaohua and Dai, Jifeng},
booktitle={CVPR},
pages={16804--16815},
year={2022}
}
@article{zhu2022uni,
title={Uni-perceiver-moe: Learning sparse generalist models with conditional moes},
author={Zhu, Jinguo and Zhu, Xizhou and Wang, Wenhai and Wang, Xiaohua and Li, Hongsheng and Wang, Xiaogang and Dai, Jifeng},
journal={arXiv preprint arXiv:2206.04674},
year={2022}
}
@article{li2022uni,
title={Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks},
author={Li, Hao and Zhu, Jinguo and Jiang, Xiaohu and Zhu, Xizhou and Li, Hongsheng and Yuan, Chun and Wang, Xiaohua and Qiao, Yu and Wang, Xiaogang and Wang, Wenhai and others},
journal={arXiv preprint arXiv:2211.09808},
year={2022}
}
@article{yang2022bevformer,
title={BEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision},
author={Yang, Chenyu and Chen, Yuntao and Tian, Hao and Tao, Chenxin and Zhu, Xizhou and Zhang, Zhaoxiang and Huang, Gao and Li, Hongyang and Qiao, Yu and Lu, Lewei and others},
journal={arXiv preprint arXiv:2211.10439},
year={2022}
}
@article{su2022towards,
title={Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information},
author={Su, Weijie and Zhu, Xizhou and Tao, Chenxin and Lu, Lewei and Li, Bin and Huang, Gao and Qiao, Yu and Wang, Xiaogang and Zhou, Jie and Dai, Jifeng},
journal={arXiv preprint arXiv:2211.09807},
year={2022}
}
@inproceedings{li2022bevformer,
title={Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers},
author={Li, Zhiqi and Wang, Wenhai and Li, Hongyang and Xie, Enze and Sima, Chonghao and Lu, Tong and Qiao, Yu and Dai, Jifeng},
booktitle={ECCV},
pages={1--18},
year={2022},
}
```