+
+ [](https://www.colossalai.org/)
+
+ Colossal-AI: Making large AI models cheaper, faster, and more accessible
+
+
+
+## Latest News
+* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
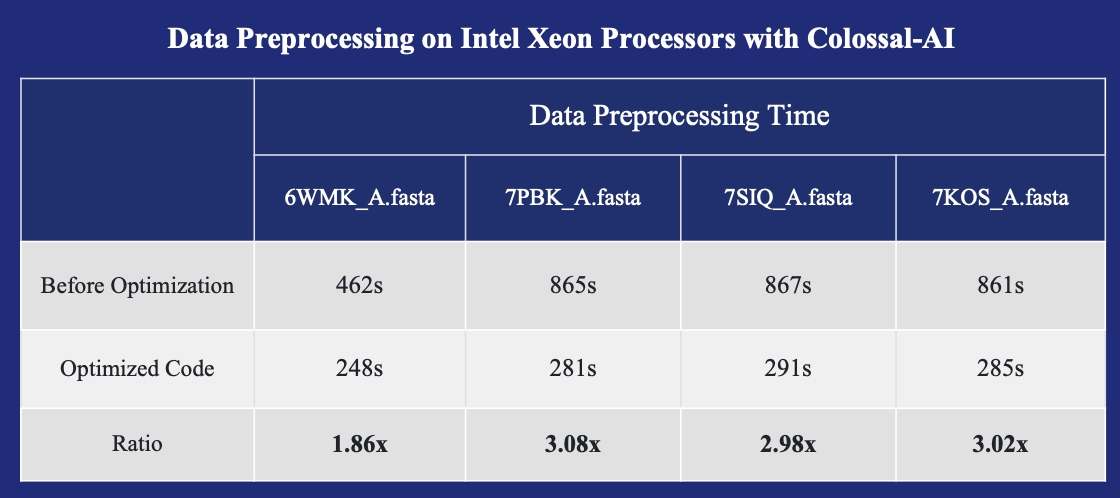
+* [2023/03] [Intel and Colossal-AI Partner to Deliver Cost-Efficient Open-Source Solution for Protein Folding Structure Prediction](https://www.hpc-ai.tech/blog/intel-habana)
+* [2023/03] [AWS and Google Fund Colossal-AI with Startup Cloud Programs](https://www.hpc-ai.tech/blog/aws-and-google-fund-colossal-ai-with-startup-cloud-programs)
+* [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
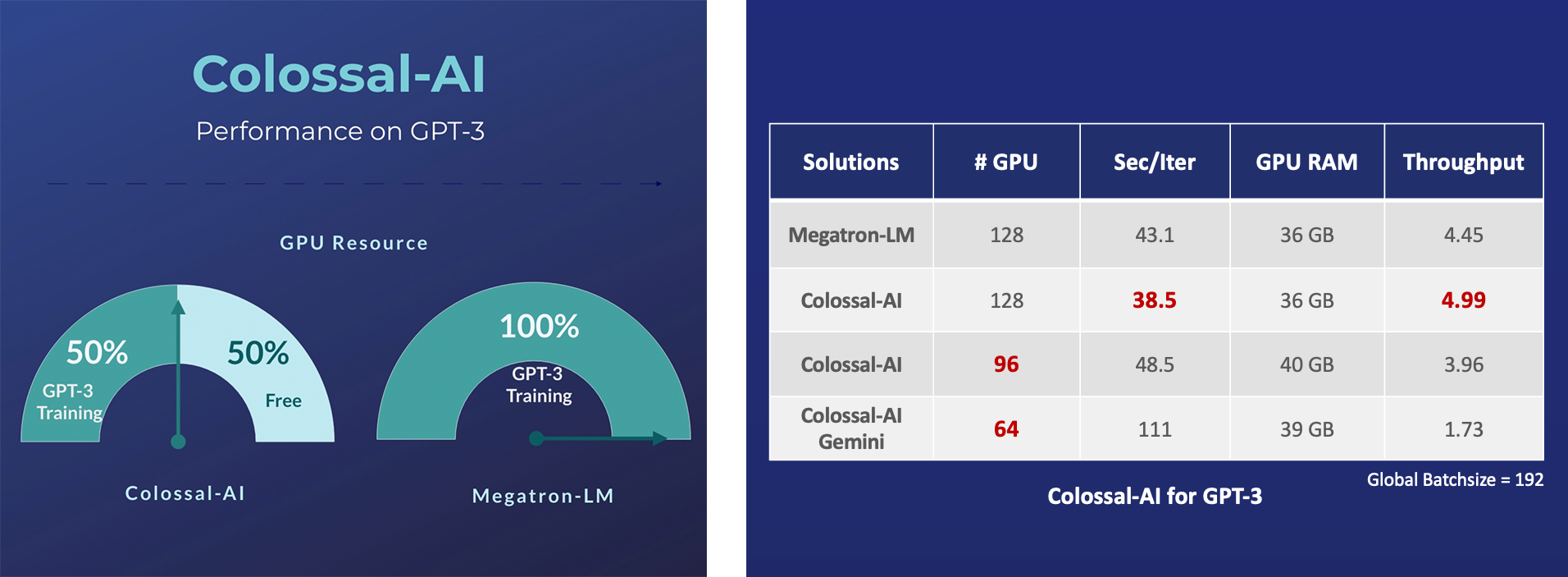
+* [2023/01] [Hardware Savings Up to 46 Times for AIGC and Automatic Parallelism](https://medium.com/pytorch/latest-colossal-ai-boasts-novel-automatic-parallelism-and-offers-savings-up-to-46x-for-stable-1453b48f3f02)
+* [2022/11] [Diffusion Pretraining and Hardware Fine-Tuning Can Be Almost 7X Cheaper](https://www.hpc-ai.tech/blog/diffusion-pretraining-and-hardware-fine-tuning-can-be-almost-7x-cheaper)
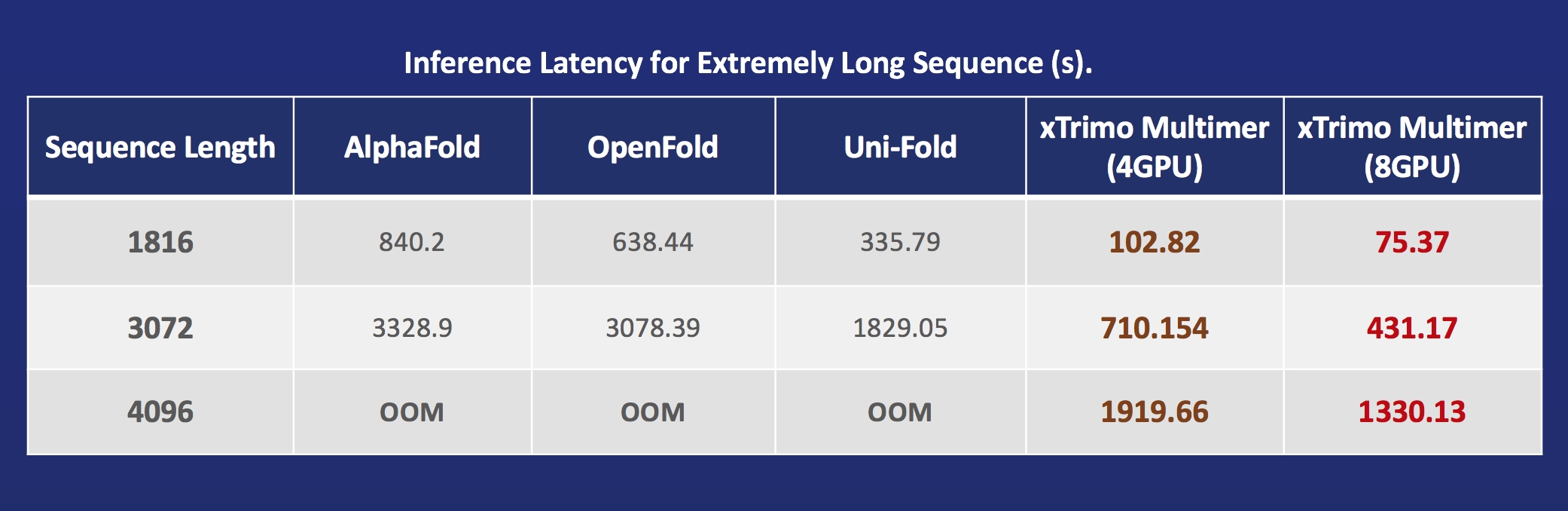
+* [2022/10] [Use a Laptop to Analyze 90% of Proteins, With a Single-GPU Inference Sequence Exceeding 10,000](https://www.hpc-ai.tech/blog/use-a-laptop-to-analyze-90-of-proteins-with-a-single-gpu-inference-sequence-exceeding)
+* [2022/09] [HPC-AI Tech Completes $6 Million Seed and Angel Round Fundraising](https://www.hpc-ai.tech/blog/hpc-ai-tech-completes-6-million-seed-and-angel-round-fundraising-led-by-bluerun-ventures-in-the)
+
+## Table of Contents
+Paper | + Documentation | + Examples | + Forum | + Blog
+ + [](https://github.com/hpcaitech/ColossalAI/stargazers) + [](https://github.com/hpcaitech/ColossalAI/actions/workflows/build_on_schedule.yml) + [](https://colossalai.readthedocs.io/en/latest/?badge=latest) + [](https://www.codefactor.io/repository/github/hpcaitech/colossalai) + [](https://huggingface.co/hpcai-tech) + [](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w) + [](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png) + + + | [English](README.md) | [中文](docs/README-zh-Hans.md) | + +-
+
- Why Colossal-AI +
- Features +
- + Colossal-AI for Real World Applications + + +
- + Parallel Training Demo + + +
- + Single GPU Training Demo + + +
- + Inference (Energon-AI) Demo + + +
-
+ Installation
+
-
+
- PyPI +
- Install From Source +
+ - Use Docker +
- Community +
- Contributing +
- Cite Us +
+
+  +
+
+ Prof. James Demmel (UC Berkeley): Colossal-AI makes training AI models efficient, easy, and scalable.
+
+
+
+ Prof. James Demmel (UC Berkeley): Colossal-AI makes training AI models efficient, easy, and scalable.
+
+
+
+
+## Features
+
+Colossal-AI provides a collection of parallel components for you. We aim to support you to write your
+distributed deep learning models just like how you write your model on your laptop. We provide user-friendly tools to kickstart
+distributed training and inference in a few lines.
+
+- Parallelism strategies
+ - Data Parallelism
+ - Pipeline Parallelism
+ - 1D, [2D](https://arxiv.org/abs/2104.05343), [2.5D](https://arxiv.org/abs/2105.14500), [3D](https://arxiv.org/abs/2105.14450) Tensor Parallelism
+ - [Sequence Parallelism](https://arxiv.org/abs/2105.13120)
+ - [Zero Redundancy Optimizer (ZeRO)](https://arxiv.org/abs/1910.02054)
+ - [Auto-Parallelism](https://arxiv.org/abs/2302.02599)
+
+- Heterogeneous Memory Management
+ - [PatrickStar](https://arxiv.org/abs/2108.05818)
+
+- Friendly Usage
+ - Parallelism based on the configuration file
+
+- Inference
+ - [Energon-AI](https://github.com/hpcaitech/EnergonAI)
+
+
+
+## Colossal-AI in the Real World
+
+### ColossalChat
+
+
+
+
+ Prof. James Demmel (UC Berkeley): Colossal-AI makes training AI models efficient, easy, and scalable.
+
+
+  +
+
+
+
+
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline. [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) [[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b) [[demo]](https://chat.colossalai.org)
+
+
+
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
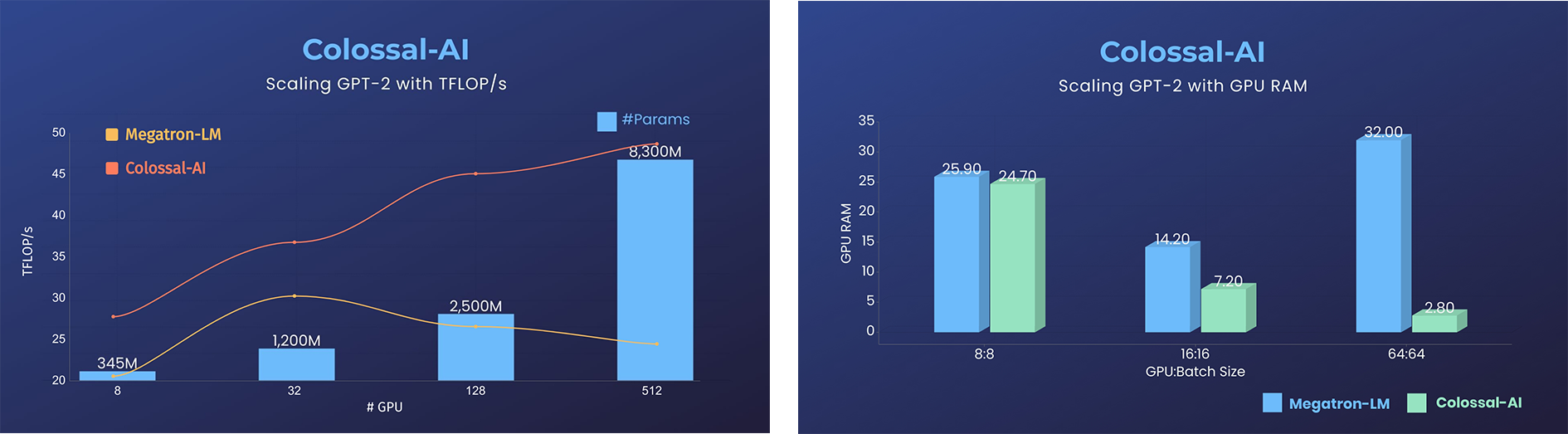 +
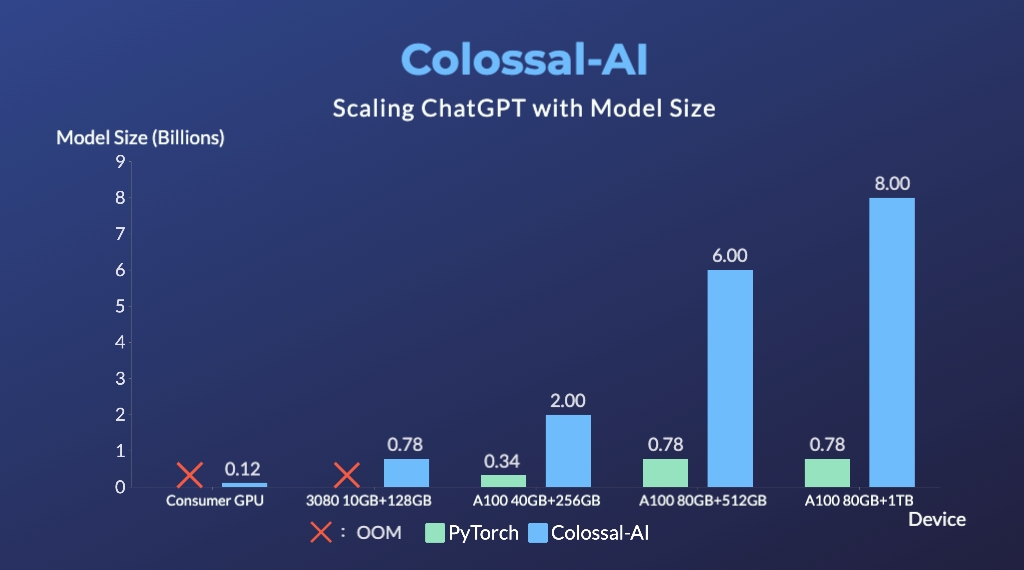
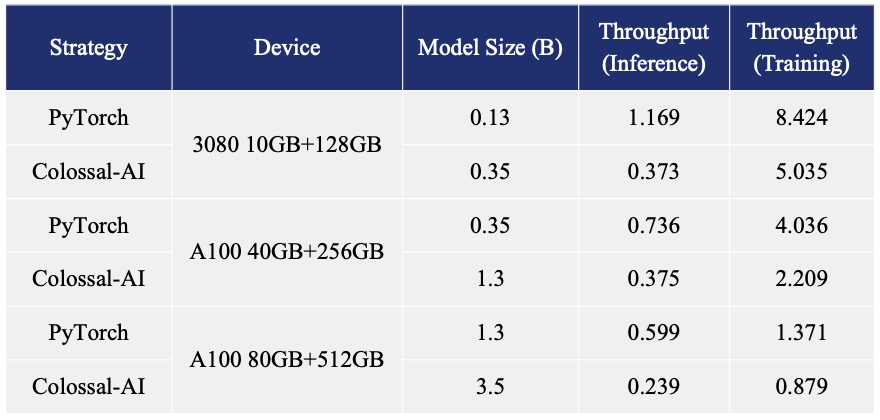
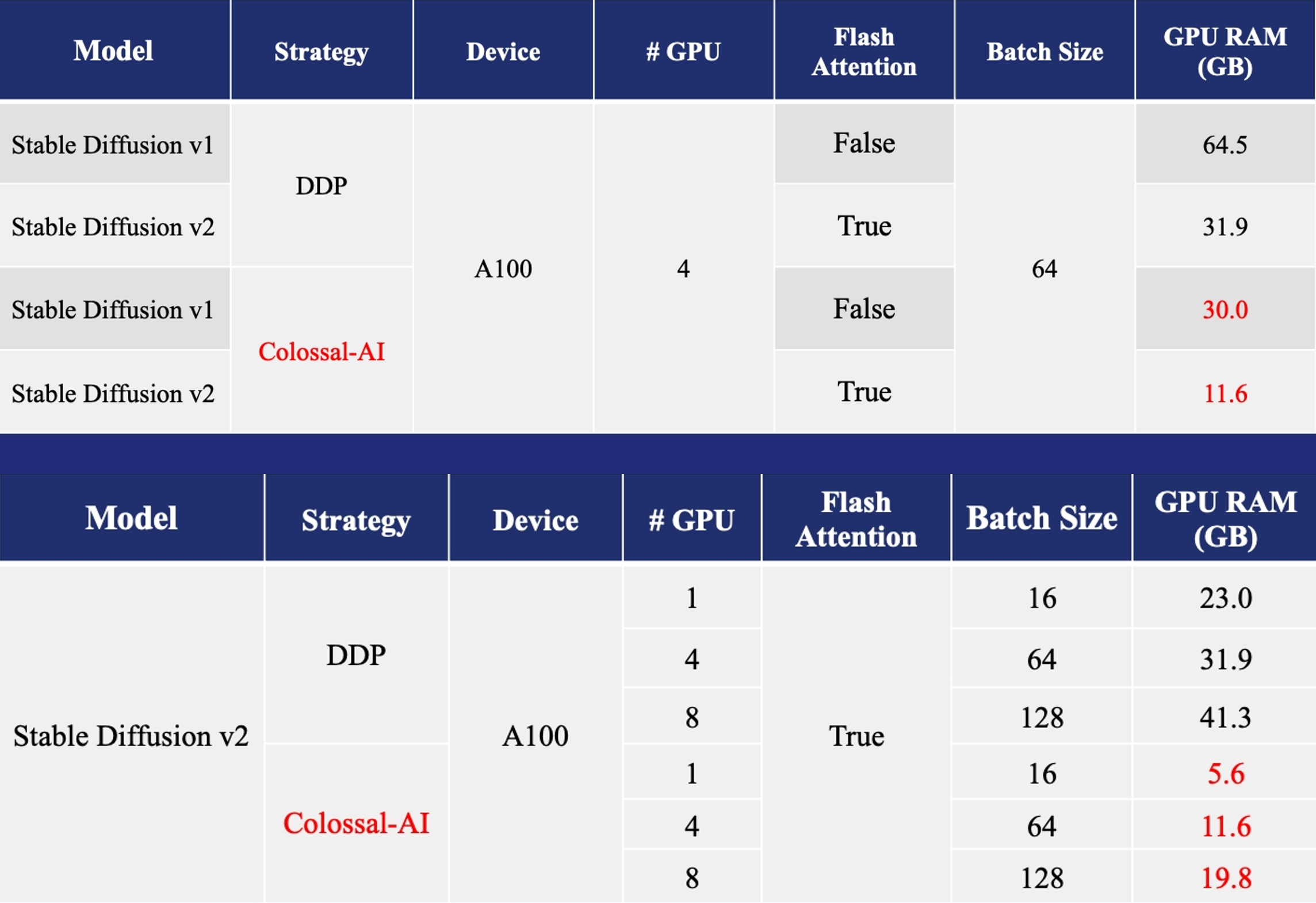
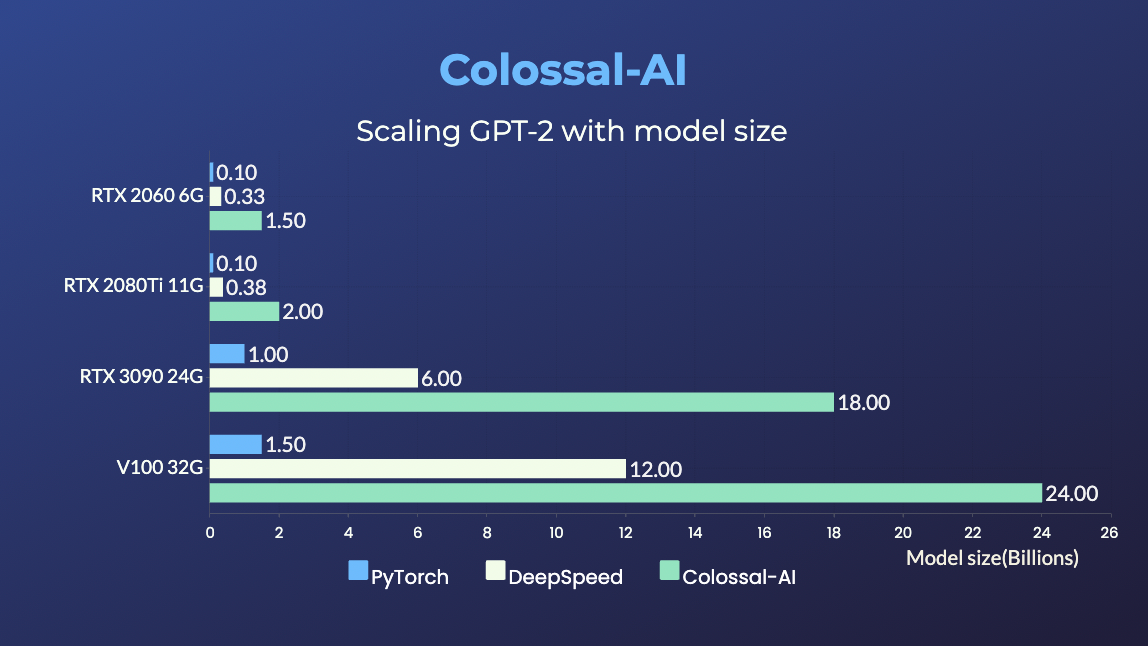
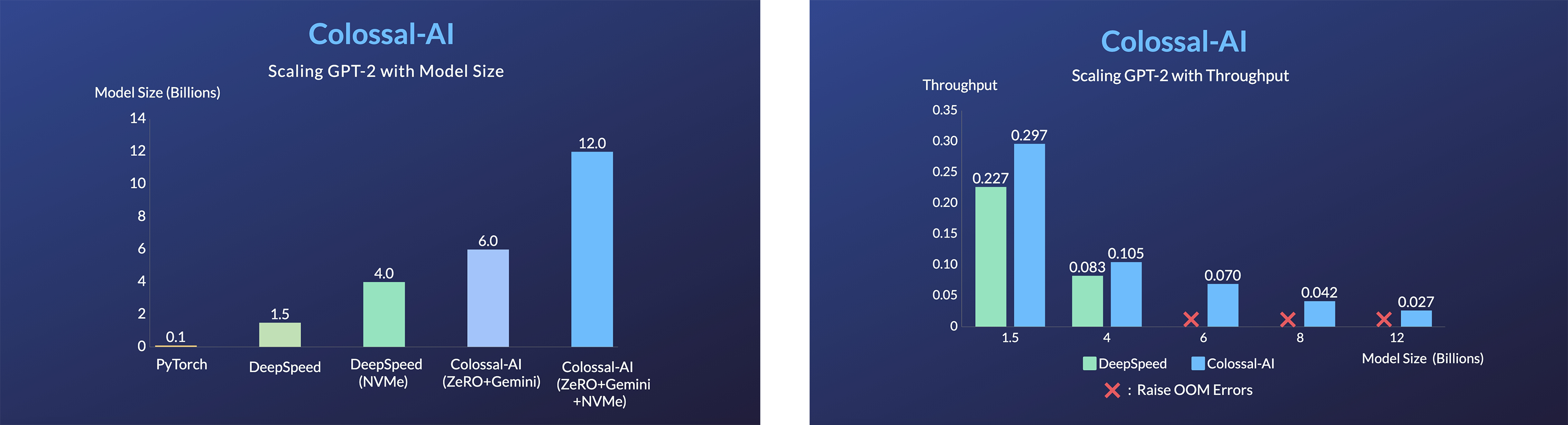
+- 11x lower GPU memory consumption, and superlinear scaling efficiency with Tensor Parallelism
+
+
+
+- 11x lower GPU memory consumption, and superlinear scaling efficiency with Tensor Parallelism
+
+GPT-2.png) +
+- 24x larger model size on the same hardware
+- over 3x acceleration
+### BERT
+
+
+- 24x larger model size on the same hardware
+- over 3x acceleration
+### BERT
+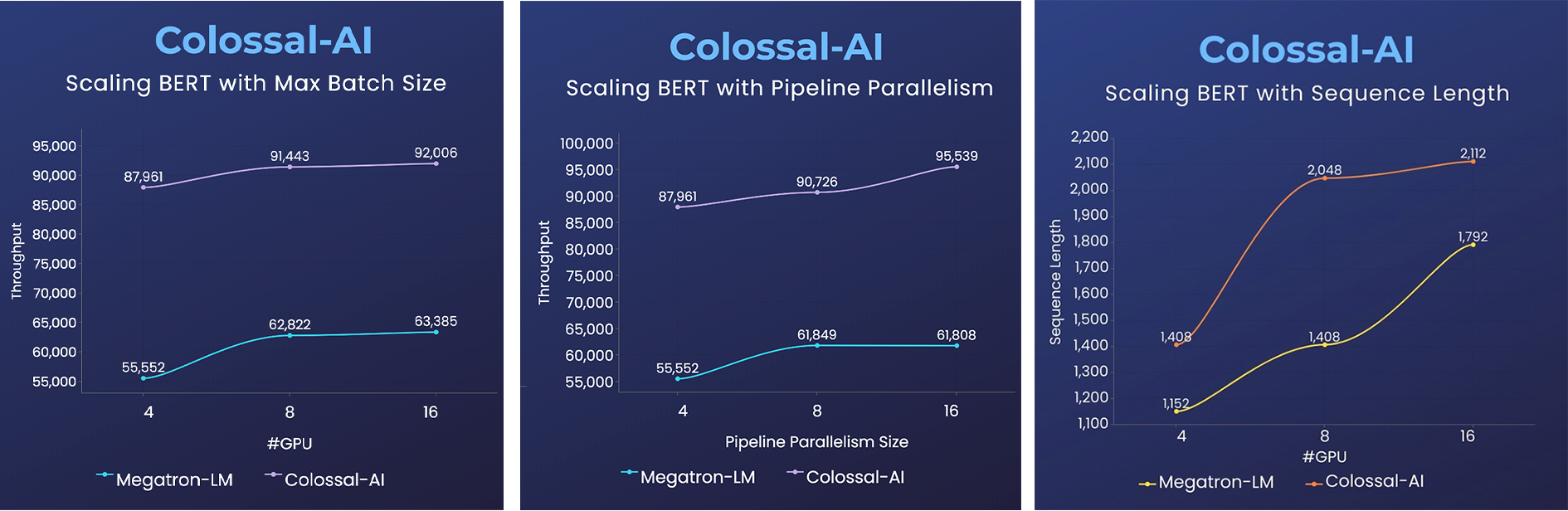 +
+- 2x faster training, or 50% longer sequence length
+
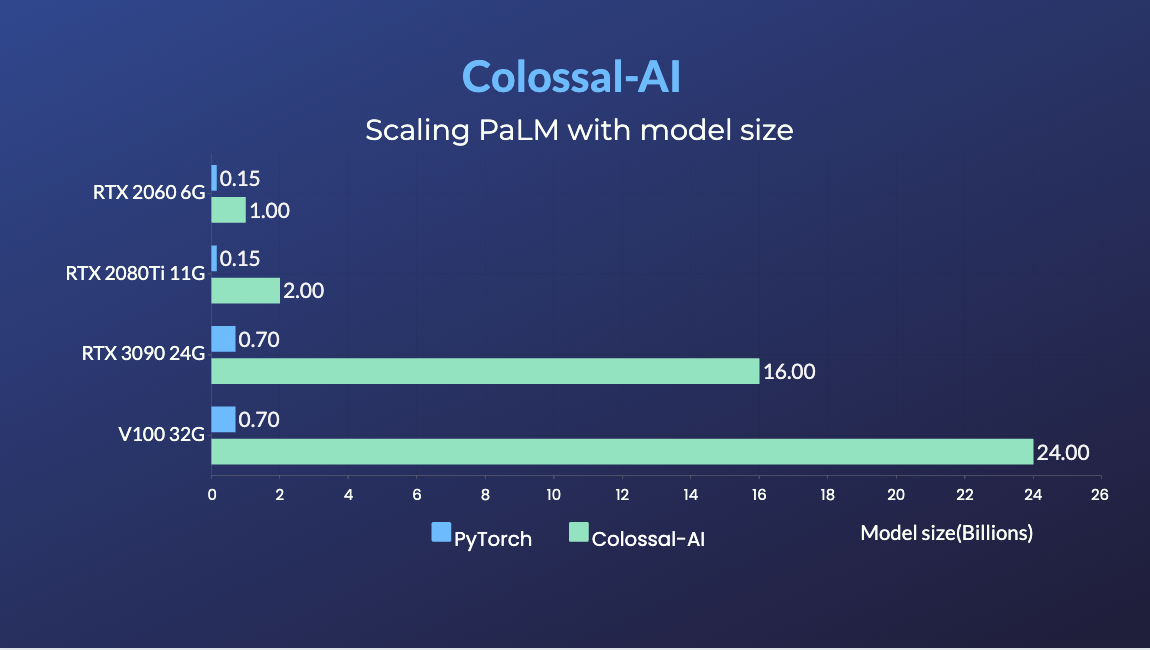
+### PaLM
+- [PaLM-colossalai](https://github.com/hpcaitech/PaLM-colossalai): Scalable implementation of Google's Pathways Language Model ([PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html)).
+
+### OPT
+
+
+- 2x faster training, or 50% longer sequence length
+
+### PaLM
+- [PaLM-colossalai](https://github.com/hpcaitech/PaLM-colossalai): Scalable implementation of Google's Pathways Language Model ([PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html)).
+
+### OPT
+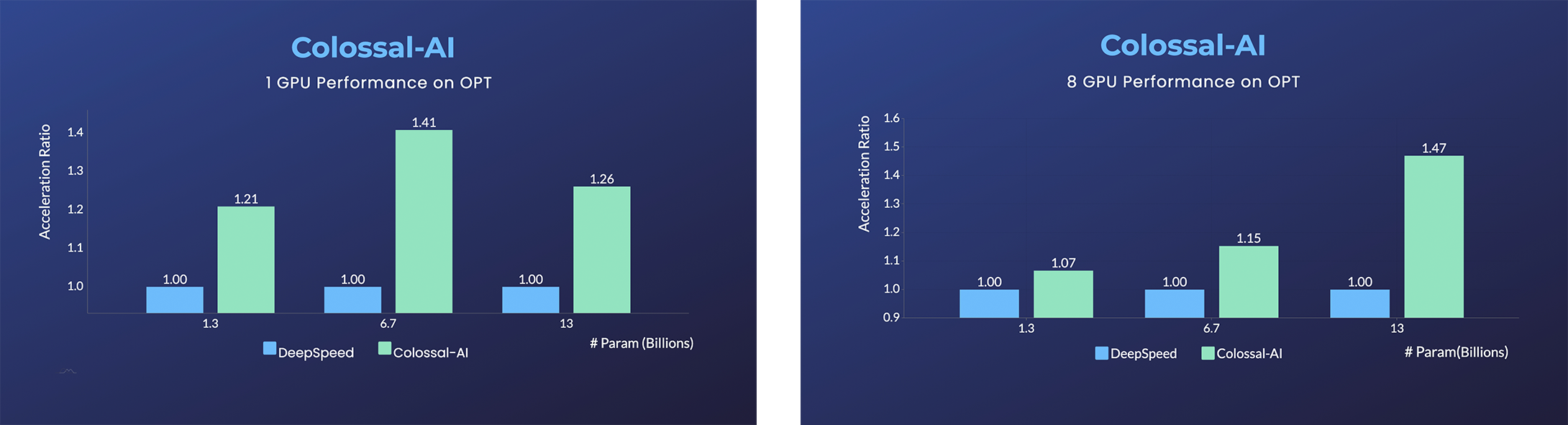 +
+- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because of public pre-trained model weights.
+- 45% speedup fine-tuning OPT at low cost in lines. [[Example]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/opt) [[Online Serving]](https://colossalai.org/docs/advanced_tutorials/opt_service)
+
+Please visit our [documentation](https://www.colossalai.org/) and [examples](https://github.com/hpcaitech/ColossalAI/tree/main/examples) for more details.
+
+### ViT
+
+
+- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because of public pre-trained model weights.
+- 45% speedup fine-tuning OPT at low cost in lines. [[Example]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/opt) [[Online Serving]](https://colossalai.org/docs/advanced_tutorials/opt_service)
+
+Please visit our [documentation](https://www.colossalai.org/) and [examples](https://github.com/hpcaitech/ColossalAI/tree/main/examples) for more details.
+
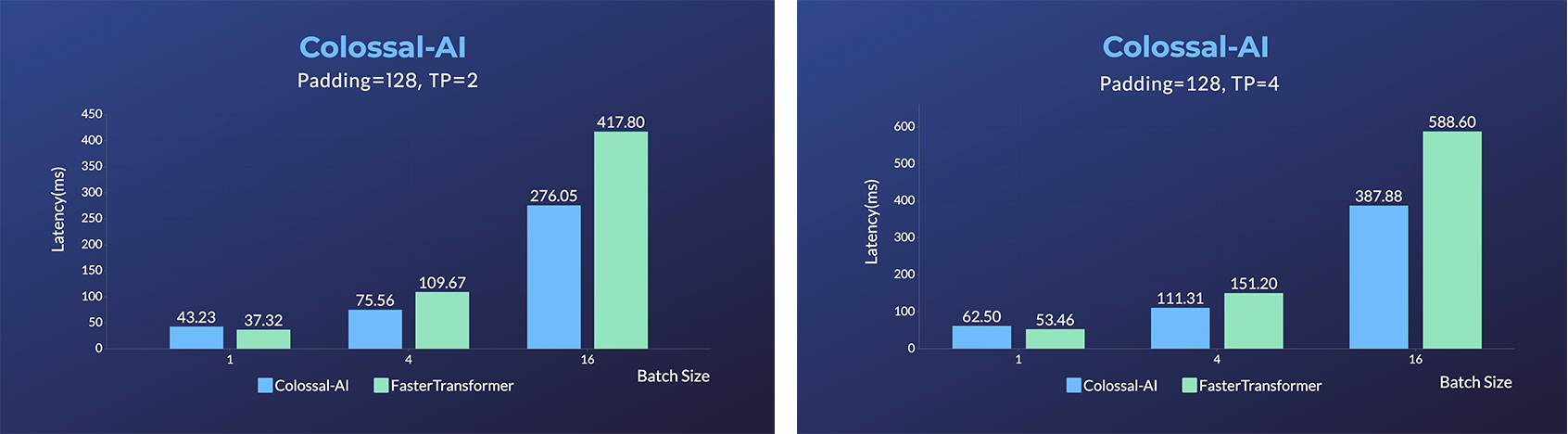
+### ViT
+
+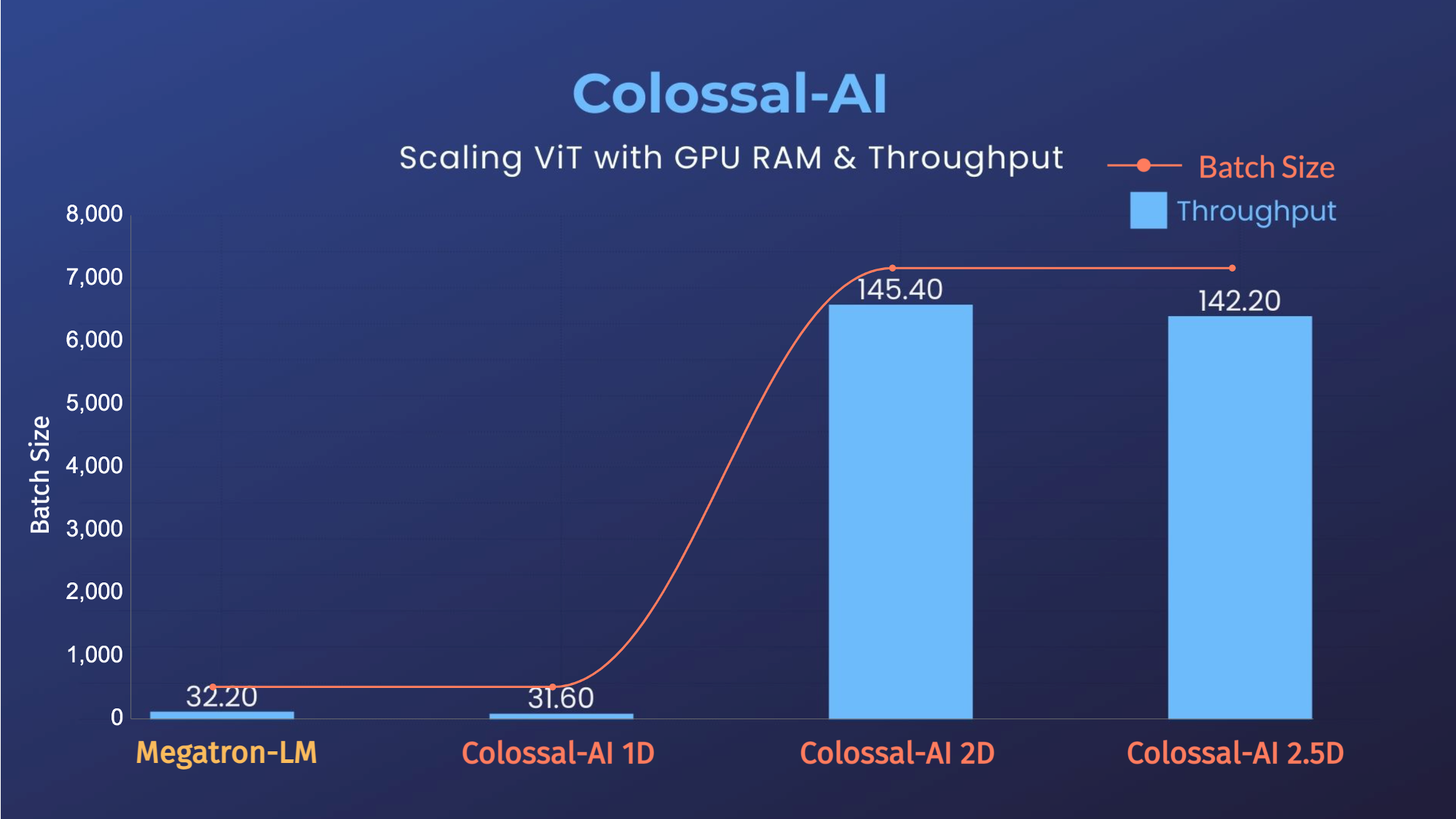 +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+
+  +
+
+ ColossalChat
+
+
+
+## Table of Contents
+
+- [Table of Contents](#table-of-contents)
+- [What is ColossalChat and Coati ?](#what-is-colossalchat-and-coati-)
+- [Online demo](#online-demo)
+- [Install](#install)
+ - [Install the environment](#install-the-environment)
+ - [Install the Transformers](#install-the-transformers)
+- [How to use?](#how-to-use)
+ - [Supervised datasets collection](#supervised-datasets-collection)
+ - [RLHF Training Stage1 - Supervised instructs tuning](#RLHF-training-stage1---supervised-instructs-tuning)
+ - [RLHF Training Stage2 - Training reward model](#RLHF-training-stage2---training-reward-model)
+ - [RLHF Training Stage3 - Training model with reinforcement learning by human feedback](#RLHF-training-stage3---training-model-with-reinforcement-learning-by-human-feedback)
+ - [Inference Quantization and Serving - After Training](#inference-quantization-and-serving---after-training)
+- [Coati7B examples](#coati7b-examples)
+ - [Generation](#generation)
+ - [Open QA](#open-qa)
+ - [Limitation for LLaMA-finetuned models](#limitation)
+ - [Limitation of dataset](#limitation)
+- [FAQ](#faq)
+ - [How to save/load checkpoint](#faq)
+ - [How to train with limited resources](#faq)
+- [The Plan](#the-plan)
+ - [Real-time progress](#real-time-progress)
+- [Invitation to open-source contribution](#invitation-to-open-source-contribution)
+- [Quick Preview](#quick-preview)
+- [Authors](#authors)
+- [Citations](#citations)
+- [Licenses](#licenses)
+---
+## What is ColossalChat and Coati ?
+
+[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) is the project to implement LLM with RLHF, powered by the [Colossal-AI](https://github.com/hpcaitech/ColossalAI) project.
+
+Coati stands for `ColossalAI Talking Intelligence`. It is the name for the module implemented in this project and is also the name of the large language model developed by the ColossalChat project.
+
+The Coati package provides a unified large language model framework that has implemented the following functions
+- Supports comprehensive large-model training acceleration capabilities for ColossalAI, without requiring knowledge of complex distributed training algorithms
+- Supervised datasets collection
+- Supervised instructions fine-tuning
+- Training reward model
+- Reinforcement learning with human feedback
+- Quantization inference
+- Fast model deploying
+- Perfectly integrated with the Hugging Face ecosystem, a high degree of model customization
+
+
+
+
+**As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.**
+
+
+More details can be found in the latest news.
+* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+* [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
+
+## Online demo
+You can experience the performance of Coati7B on this page.
+
+[chat.colossalai.org](https://chat.colossalai.org/)
+
+Due to resource constraints, we will only provide this service from 29th Mar 2023 to 5 April 2023. However, we have provided the inference code in the [inference](./inference/) folder. The WebUI will be open-sourced soon as well.
+
+> Warning: Due to model and dataset size limitations, Coati is just a baby model, Coati7B may output incorrect information and lack the ability for multi-turn dialogue. There is still significant room for improvement.
+## Install
+
+### Install the environment
+
+```shell
+conda create -n coati
+conda activate coati
+git clone https://github.com/hpcaitech/ColossalAI.git
+cd ColossalAI/applications/Chat
+pip install .
+```
+
+### Install the Transformers
+Given Hugging Face hasn't officially supported the LLaMA models, We fork a branch of Transformers that can be compatible with our code
+
+```shell
+git clone https://github.com/hpcaitech/transformers
+cd transformers
+pip install .
+```
+
+## How to use?
+
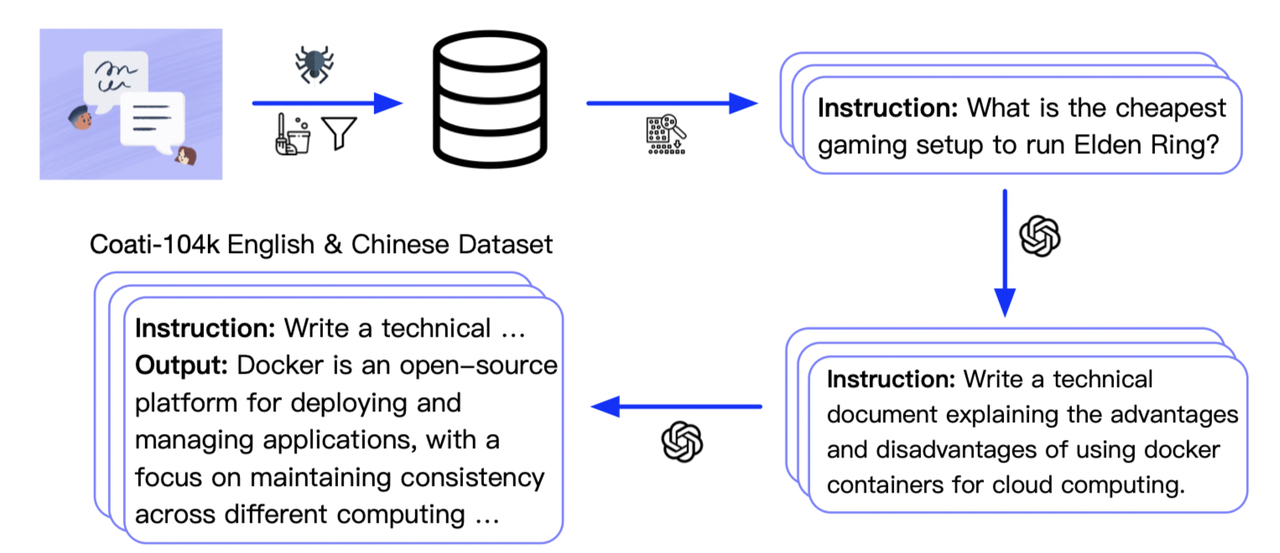
+### Supervised datasets collection
+
+we collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo
+[InstructionWild](https://github.com/XueFuzhao/InstructionWild)
+
+Here is how we collected the data
+
+  +
+
+ +
+
+ +
+
coding
+ + + +regex
+ + + +Tex
+ + + +writing
+ + + +Table
+ + + +Game
+ + + +Travel
+ + + +Physical
+ + + +Chemical
+ + + +Economy
+ + + +Limitation for LLaMA-finetuned models
+- Both Alpaca and ColossalChat are based on LLaMA. It is hard to compensate for the missing knowledge in the pre-training stage. +- Lack of counting ability: Cannot count the number of items in a list. +- Lack of Logics (reasoning and calculation) +- Tend to repeat the last sentence (fail to produce the end token). +- Poor multilingual results: LLaMA is mainly trained on English datasets (Generation performs better than QA). +Limitation of dataset
+- Lack of summarization ability: No such instructions in finetune datasets. +- Lack of multi-turn chat: No such instructions in finetune datasets +- Lack of self-recognition: No such instructions in finetune datasets +- Lack of Safety: + - When the input contains fake facts, the model makes up false facts and explanations. + - Cannot abide by OpenAI's policy: When generating prompts from OpenAI API, it always abides by its policy. So no violation case is in the datasets. +How to save/load checkpoint
+ +We have integrated the Transformers save and load pipeline, allowing users to freely call Hugging Face's language models and save them in the HF format. + +``` +from coati.models.llama import LlamaLM +from coati.trainer import SFTTrainer + +model = LlamaLM(pretrained=args.pretrain) +tokenizer = AutoTokenizer.from_pretrained(args.pretrain) + +(model, optim) = strategy.prepare((model, optim)) +trainer = SFTTrainer(model=model, + strategy=strategy, + optim=optim, + train_dataloader=train_dataloader, + eval_dataloader=eval_dataloader, + batch_size=args.batch_size, + max_epochs=args.max_epochs, + accumulation_steps = args.accumulation_steps +) + +trainer.fit() +# this saves in pytorch format +strategy.save_model(model, args.save_path, only_rank0=True) + +# this saves in HF format. ColossalAI strategy with stage-3 doesn't support this method +strategy.save_pretrained(model, args.save_path, only_rank0=True, tokenizer=tokenizer) +``` + +How to train with limited resources
+ +Here are some examples that can allow you to train a 7B model on a single or multiple consumer-grade GPUs. + +If you only have a single 24G GPU, you can use the following script. `batch_size`, `lora_rank` and `grad_checkpoint` are the most important parameters to successfully train the model. +``` +torchrun --standalone --nproc_per_node=1 train_sft.py \ + --pretrain "/path/to/LLaMa-7B/" \ + --model 'llama' \ + --strategy naive \ + --log_interval 10 \ + --save_path /path/to/Coati-7B \ + --dataset /path/to/data.json \ + --batch_size 1 \ + --accumulation_steps 8 \ + --lr 2e-5 \ + --max_datasets_size 512 \ + --max_epochs 1 \ + --lora_rank 16 \ + --grad_checkpoint +``` + +`colossalai_gemini` strategy can enable a single 24G GPU to train the whole model without using LoRA if you have sufficient CPU memory. You can use the following script. +``` +torchrun --standalone --nproc_per_node=1 train_sft.py \ + --pretrain "/path/to/LLaMa-7B/" \ + --model 'llama' \ + --strategy colossalai_gemini \ + --log_interval 10 \ + --save_path /path/to/Coati-7B \ + --dataset /path/to/data.json \ + --batch_size 1 \ + --accumulation_steps 8 \ + --lr 2e-5 \ + --max_datasets_size 512 \ + --max_epochs 1 \ + --grad_checkpoint +``` + +If you have 4x32 GB GPUs, you can even train the whole 7B model using our `colossalai_zero2_cpu` strategy! The script is given as follows. +``` +torchrun --standalone --nproc_per_node=4 train_sft.py \ + --pretrain "/path/to/LLaMa-7B/" \ + --model 'llama' \ + --strategy colossalai_zero2_cpu \ + --log_interval 10 \ + --save_path /path/to/Coati-7B \ + --dataset /path/to/data.json \ + --batch_size 1 \ + --accumulation_steps 8 \ + --lr 2e-5 \ + --max_datasets_size 512 \ + --max_epochs 1 \ + --grad_checkpoint +``` +
+
+
+
+
+
+- An open-source low cost solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline. [[demo]](https://chat.colossalai.org)
+
+
+
+
+
+
+
+
+
+
+
+
 +
+
+
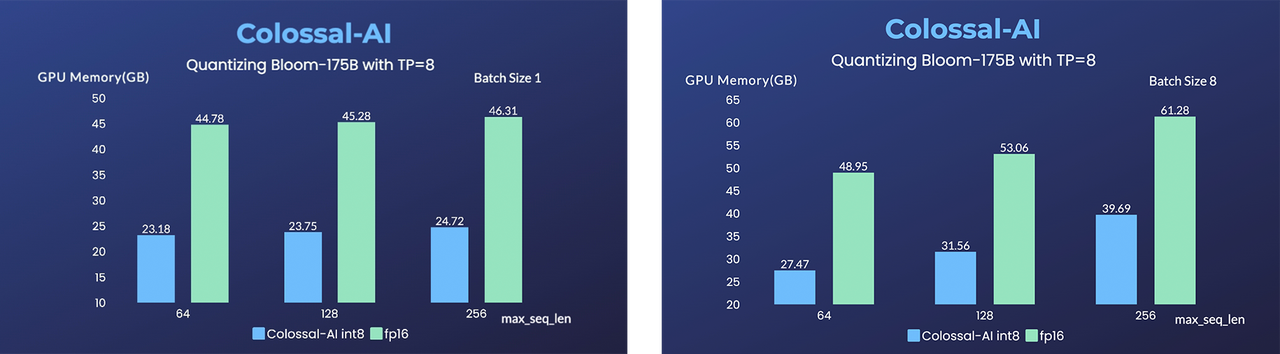
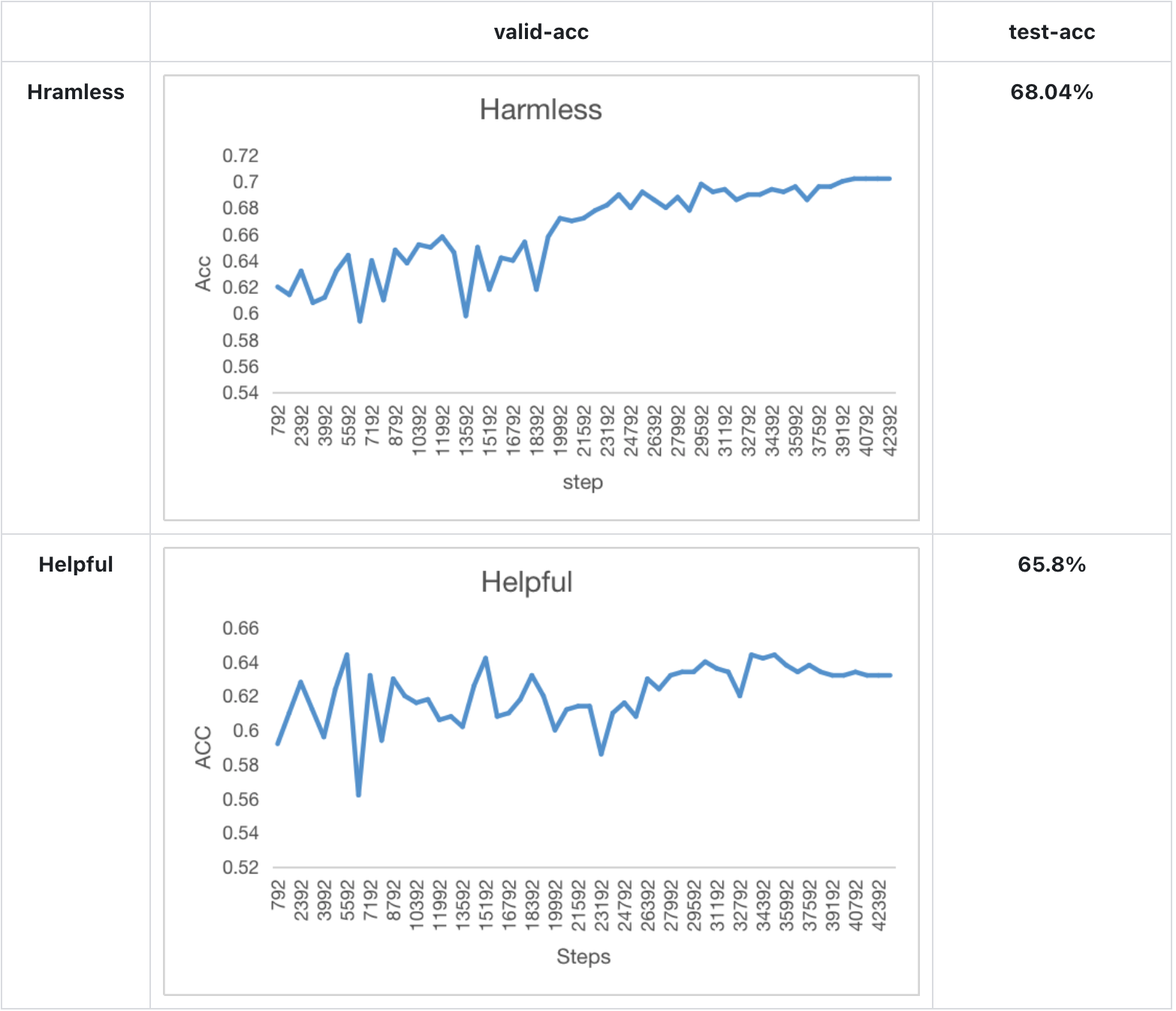
+Our training & test result of bloom-560m for 1 epoch:
+
+  +
+
+
+
+
+We also train the reward model based on LLaMA-7B, which reaches the ACC of 72.06% after 1 epoch, performing almost the same as Anthropic's best RM.
+
+### Arg List
+- --strategy: the strategy using for training, choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
+- --model: model type, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
+- --pretrain: pretrain model, type=str, default=None
+- --model_path: the path of rm model(if continue to train), type=str, default=None
+- --save_path: path to save the model, type=str, default='output'
+- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
+- --max_epochs: max epochs for training, type=int, default=3
+- --dataset: dataset name, type=str, choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static']
+- --subset: subset of the dataset, type=str, default=None
+- --batch_size: batch size while training, type=int, default=4
+- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
+- --loss_func: which kind of loss function, choices=['log_sig', 'log_exp']
+- --max_len: max sentence length for generation, type=int, default=512
+- --test: whether is only testing, if it's true, the dataset will be small
+
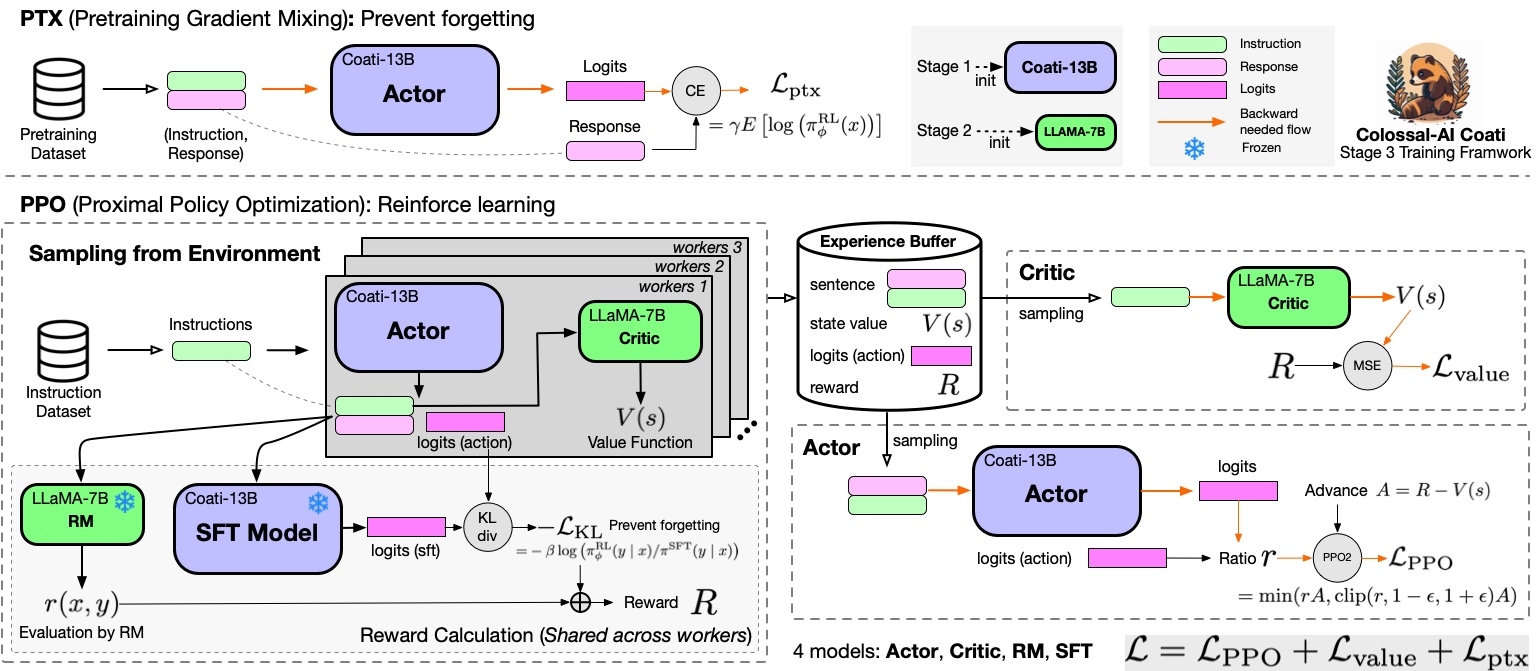
+## Stage3 - Training model using prompts with RL
+
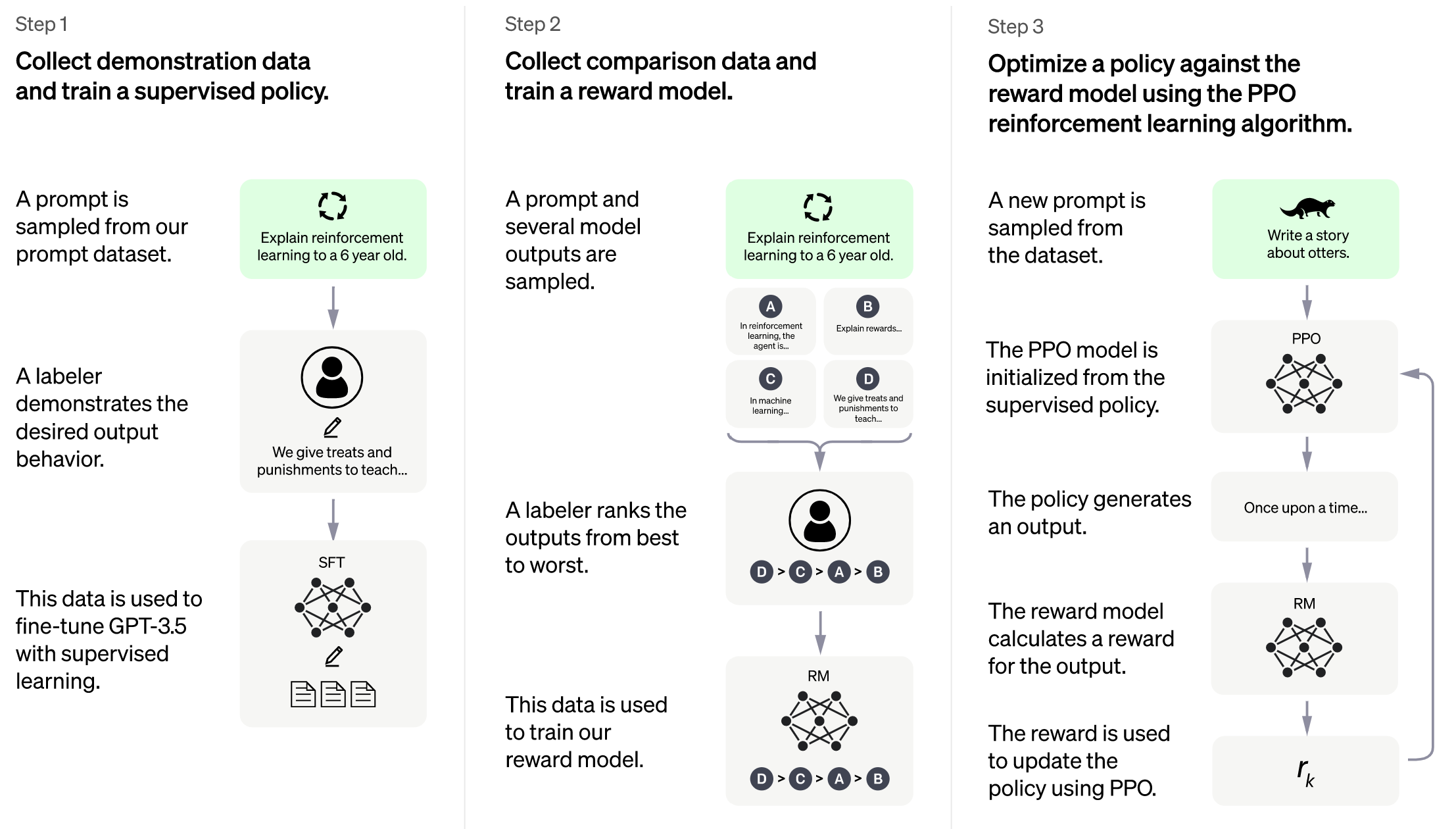
+Stage3 uses reinforcement learning algorithm, which is the most complex part of the training process, as shown below:
+
+ \
+ --model 'bloom' \
+ --strategy colossalai_zero2 \
+ --loss_fn 'log_sig'\
+ --save_path \
+ --dataset 'Anthropic/hh-rlhf'\
diff --git a/applications/Chat/examples/train_sft.py b/applications/Chat/examples/train_sft.py
new file mode 100644
index 0000000000000000000000000000000000000000..da499f068b17885ac468ecd1dcb9de49100f667c
--- /dev/null
+++ b/applications/Chat/examples/train_sft.py
@@ -0,0 +1,196 @@
+import argparse
+import os
+
+import loralib as lora
+import torch
+import torch.distributed as dist
+from coati.dataset import DataCollatorForSupervisedDataset, SFTDataset, SupervisedDataset
+from coati.models import convert_to_lora_module
+from coati.trainer import SFTTrainer
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy, NaiveStrategy
+from coati.utils import prepare_llama_tokenizer_and_embedding
+from datasets import load_dataset
+from torch.optim import Adam
+from torch.utils.data import DataLoader
+from torch.utils.data.distributed import DistributedSampler
+from transformers import AutoTokenizer, BloomConfig, BloomForCausalLM, BloomTokenizerFast, LlamaConfig, LlamaForCausalLM
+from transformers.models.gpt2.configuration_gpt2 import GPT2Config
+from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
+from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
+from transformers.models.opt.configuration_opt import OPTConfig
+from transformers.models.opt.modeling_opt import OPTForCausalLM
+
+from colossalai.logging import get_dist_logger
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.tensor import ColoParameter
+
+
+def train(args):
+ # configure strategy
+ if args.strategy == 'naive':
+ strategy = NaiveStrategy()
+ elif args.strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif args.strategy == 'colossalai_gemini':
+ raise NotImplementedError(
+ 'Gemini is not supported .from_pretrained() yet. We will update this after checkpoint io is ready.')
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ elif args.strategy == 'colossalai_zero2_cpu':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cpu')
+ else:
+ raise ValueError(f'Unsupported strategy "{args.strategy}"')
+
+ # configure model
+ with strategy.model_init_context():
+ if args.model == 'bloom':
+ model = convert_to_lora_module(BloomForCausalLM.from_pretrained(args.pretrain),
+ args.lora_rank).half().cuda()
+ elif args.model == 'opt':
+ model = convert_to_lora_module(OPTForCausalLM.from_pretrained(args.pretrain), args.lora_rank).half().cuda()
+ elif args.model == 'gpt2':
+ model = convert_to_lora_module(GPT2LMHeadModel.from_pretrained(args.pretrain), args.lora_rank).half().cuda()
+ elif args.model == 'llama':
+ model = convert_to_lora_module(LlamaForCausalLM.from_pretrained(args.pretrain),
+ args.lora_rank).half().cuda()
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+ if args.grad_checkpoint:
+ model.gradient_checkpointing_enable()
+
+ # configure tokenizer
+ if args.model == 'gpt2':
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'bloom':
+ tokenizer = BloomTokenizerFast.from_pretrained(args.pretrain)
+ tokenizer.pad_token = tokenizer.eos_token
+ elif args.model == 'opt':
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+ elif args.model == 'llama':
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.pretrain,
+ padding_side="right",
+ use_fast=False,
+ )
+ tokenizer.eos_token = '<\s>'
+ else:
+ raise ValueError(f'Unsupported model "{args.model}"')
+ tokenizer.pad_token = tokenizer.eos_token
+ max_len = args.max_len
+ if args.model == 'llama':
+ tokenizer = prepare_llama_tokenizer_and_embedding(tokenizer, model)
+
+ if args.strategy == 'colossalai_gemini':
+ # this is a hack to deal with the resized embedding
+ # to make sure all parameters are ColoParameter for Colossal-AI Gemini Compatiblity
+ for name, param in model.named_parameters():
+ if not isinstance(param, ColoParameter):
+ sub_module_name = '.'.join(name.split('.')[:-1])
+ weight_name = name.split('.')[-1]
+ sub_module = model.get_submodule(sub_module_name)
+ setattr(sub_module, weight_name, ColoParameter(param))
+ else:
+ tokenizer.pad_token = tokenizer.eos_token
+
+ # configure optimizer
+ if args.strategy.startswith('colossalai'):
+ optim = HybridAdam(model.parameters(), lr=args.lr, clipping_norm=1.0)
+ else:
+ optim = Adam(model.parameters(), lr=args.lr)
+
+ logger = get_dist_logger()
+
+ # configure dataset
+ if args.dataset == 'yizhongw/self_instruct':
+ train_data = load_dataset(args.dataset, 'super_natural_instructions', split='train')
+ eval_data = load_dataset(args.dataset, 'super_natural_instructions', split='test')
+
+ train_dataset = SFTDataset(train_data, tokenizer, max_len)
+ eval_dataset = SFTDataset(eval_data, tokenizer, max_len)
+
+ else:
+ train_dataset = SupervisedDataset(tokenizer=tokenizer,
+ data_path=args.dataset,
+ max_datasets_size=args.max_datasets_size,
+ max_length=max_len)
+ eval_dataset = None
+ data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
+
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ train_sampler = DistributedSampler(train_dataset,
+ shuffle=True,
+ seed=42,
+ drop_last=True,
+ rank=dist.get_rank(),
+ num_replicas=dist.get_world_size())
+ if eval_dataset is not None:
+ eval_sampler = DistributedSampler(eval_dataset,
+ shuffle=False,
+ seed=42,
+ drop_last=False,
+ rank=dist.get_rank(),
+ num_replicas=dist.get_world_size())
+ else:
+ train_sampler = None
+ eval_sampler = None
+
+ train_dataloader = DataLoader(train_dataset,
+ shuffle=(train_sampler is None),
+ sampler=train_sampler,
+ batch_size=args.batch_size,
+ collate_fn=data_collator,
+ pin_memory=True)
+ if eval_dataset is not None:
+ eval_dataloader = DataLoader(eval_dataset,
+ shuffle=(eval_sampler is None),
+ sampler=eval_sampler,
+ batch_size=args.batch_size,
+ collate_fn=data_collator,
+ pin_memory=True)
+ else:
+ eval_dataloader = None
+
+ (model, optim) = strategy.prepare((model, optim))
+ trainer = SFTTrainer(model=model,
+ strategy=strategy,
+ optim=optim,
+ train_dataloader=train_dataloader,
+ eval_dataloader=eval_dataloader,
+ max_epochs=args.max_epochs,
+ accumulation_steps=args.accumulation_steps)
+
+ trainer.fit(logger=logger, use_wandb=args.use_wandb)
+
+ # save model checkpoint after fitting on only rank0
+ strategy.save_pretrained(model, path=args.save_path, only_rank0=True, tokenizer=tokenizer)
+ # save optimizer checkpoint on all ranks
+ if args.need_optim_ckpt:
+ strategy.save_optimizer(trainer.optimizer,
+ 'rm_optim_checkpoint_%d.pt' % (torch.cuda.current_device()),
+ only_rank0=False)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--strategy',
+ choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2', 'colossalai_zero2_cpu'],
+ default='colossalai_zero2')
+ parser.add_argument('--model', choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom')
+ parser.add_argument('--pretrain', type=str, default=None)
+ parser.add_argument('--dataset', type=str, default=None)
+ parser.add_argument('--max_datasets_size', type=int, default=None)
+ parser.add_argument('--save_path', type=str, default='output')
+ parser.add_argument('--need_optim_ckpt', type=bool, default=False)
+ parser.add_argument('--max_epochs', type=int, default=3)
+ parser.add_argument('--batch_size', type=int, default=4)
+ parser.add_argument('--max_len', type=int, default=512)
+ parser.add_argument('--lora_rank', type=int, default=0, help="low-rank adaptation matrices rank")
+ parser.add_argument('--log_interval', type=int, default=100, help="how many steps to log")
+ parser.add_argument('--lr', type=float, default=5e-6)
+ parser.add_argument('--accumulation_steps', type=int, default=8)
+ parser.add_argument('--use_wandb', default=False, action='store_true')
+ parser.add_argument('--grad_checkpoint', default=False, action='store_true')
+ args = parser.parse_args()
+ train(args)
diff --git a/applications/Chat/examples/train_sft.sh b/applications/Chat/examples/train_sft.sh
new file mode 100755
index 0000000000000000000000000000000000000000..c880f85825a77a98ea49ce691bb5cf4fcabca857
--- /dev/null
+++ b/applications/Chat/examples/train_sft.sh
@@ -0,0 +1,12 @@
+torchrun --standalone --nproc_per_node=4 train_sft.py \
+ --pretrain "/path/to/LLaMa-7B/" \
+ --model 'llama' \
+ --strategy colossalai_zero2 \
+ --log_interval 10 \
+ --save_path /path/to/Coati-7B \
+ --dataset /path/to/data.json \
+ --batch_size 4 \
+ --accumulation_steps 8 \
+ --lr 2e-5 \
+ --max_datasets_size 512 \
+ --max_epochs 1 \
diff --git a/applications/Chat/inference/README.md b/applications/Chat/inference/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..434677c98fa58f7050098671c6243c6f70d023a4
--- /dev/null
+++ b/applications/Chat/inference/README.md
@@ -0,0 +1,118 @@
+# Inference
+
+We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
+
+We support 8-bit quantization (RTN), which is powered by [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) and [transformers](https://github.com/huggingface/transformers). And 4-bit quantization (GPTQ), which is powered by [gptq](https://github.com/IST-DASLab/gptq) and [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). We also support FP16 inference.
+
+We only support LLaMA family models now.
+
+## Choosing precision (quantization)
+
+**FP16**: Fastest, best output quality, highest memory usage
+
+**8-bit**: Slow, easier setup (originally supported by transformers), lower output quality (due to RTN), **recommended for first-timers**
+
+**4-bit**: Faster, lowest memory usage, higher output quality (due to GPTQ), but more difficult setup
+
+## Hardware requirements for LLaMA
+
+Tha data is from [LLaMA Int8 4bit ChatBot Guide v2](https://rentry.org/llama-tard-v2).
+
+### 8-bit
+
+| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
+| :---: | :---: | :---: | :---: | :---: |
+| LLaMA-7B | 9.2GB | 10GB | 24GB | 3060 12GB, RTX 3080 10GB, RTX 3090 |
+| LLaMA-13B | 16.3GB | 20GB | 32GB | RTX 3090 Ti, RTX 4090 |
+| LLaMA-30B | 36GB | 40GB | 64GB | A6000 48GB, A100 40GB |
+| LLaMA-65B | 74GB | 80GB | 128GB | A100 80GB |
+
+### 4-bit
+
+| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
+| :---: | :---: | :---: | :---: | :---: |
+| LLaMA-7B | 3.5GB | 6GB | 16GB | RTX 1660, 2060, AMD 5700xt, RTX 3050, 3060 |
+| LLaMA-13B | 6.5GB | 10GB | 32GB | AMD 6900xt, RTX 2060 12GB, 3060 12GB, 3080, A2000 |
+| LLaMA-30B | 15.8GB | 20GB | 64GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 |
+| LLaMA-65B | 31.2GB | 40GB | 128GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000, Titan Ada |
+
+## General setup
+
+```shell
+pip install -r requirements.txt
+```
+
+## 8-bit setup
+
+8-bit quantization is originally supported by the latest [transformers](https://github.com/huggingface/transformers). Please install it from source.
+
+Please ensure you have downloaded HF-format model weights of LLaMA models.
+
+Usage:
+
+```python
+import torch
+from transformers import LlamaForCausalLM
+
+USE_8BIT = True # use 8-bit quantization; otherwise, use fp16
+
+model = LlamaForCausalLM.from_pretrained(
+ "pretrained/path",
+ load_in_8bit=USE_8BIT,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+if not USE_8BIT:
+ model.half() # use fp16
+model.eval()
+```
+
+**Troubleshooting**: if you get error indicating your CUDA-related libraries not found when loading 8-bit model, you can check whether your `LD_LIBRARY_PATH` is correct.
+
+E.g. you can set `export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH`.
+
+## 4-bit setup
+
+Please ensure you have downloaded HF-format model weights of LLaMA models first.
+
+Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight convertion script.
+
+After installing this lib, we may convert the original HF-format LLaMA model weights to 4-bit version.
+
+```shell
+CUDA_VISIBLE_DEVICES=0 python llama.py /path/to/pretrained/llama-7b c4 --wbits 4 --groupsize 128 --save llama7b-4bit.pt
+```
+
+Run this command in your cloned `GPTQ-for-LLaMa` directory, then you will get a 4-bit weight file `llama7b-4bit-128g.pt`.
+
+**Troubleshooting**: if you get error about `position_ids`, you can checkout to commit `50287c3b9ae4a3b66f6b5127c643ec39b769b155`(`GPTQ-for-LLaMa` repo).
+
+## Online inference server
+
+In this directory:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0
+# fp16, will listen on 0.0.0.0:7070 by default
+python server.py /path/to/pretrained
+# 8-bit, will listen on localhost:8080
+python server.py /path/to/pretrained --quant 8bit --http_host localhost --http_port 8080
+# 4-bit
+python server.py /path/to/pretrained --quant 4bit --gptq_checkpoint /path/to/llama7b-4bit-128g.pt --gptq_group_size 128
+```
+
+## Benchmark
+
+In this directory:
+
+```shell
+export CUDA_VISIBLE_DEVICES=0
+# fp16
+python benchmark.py /path/to/pretrained
+# 8-bit
+python benchmark.py /path/to/pretrained --quant 8bit
+# 4-bit
+python benchmark.py /path/to/pretrained --quant 4bit --gptq_checkpoint /path/to/llama7b-4bit-128g.pt --gptq_group_size 128
+```
+
+This benchmark will record throughput and peak CUDA memory usage.
diff --git a/applications/Chat/inference/benchmark.py b/applications/Chat/inference/benchmark.py
new file mode 100644
index 0000000000000000000000000000000000000000..59cd1eeea2aa841ae805d91adf279f668fdb3dd0
--- /dev/null
+++ b/applications/Chat/inference/benchmark.py
@@ -0,0 +1,132 @@
+# Adapted from https://github.com/tloen/alpaca-lora/blob/main/generate.py
+
+import argparse
+from time import time
+
+import torch
+from llama_gptq import load_quant
+from transformers import AutoTokenizer, GenerationConfig, LlamaForCausalLM
+
+
+def generate_prompt(instruction, input=None):
+ if input:
+ return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
+
+### Instruction:
+{instruction}
+
+### Input:
+{input}
+
+### Response:"""
+ else:
+ return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
+
+### Instruction:
+{instruction}
+
+### Response:"""
+
+
+@torch.no_grad()
+def evaluate(
+ model,
+ tokenizer,
+ instruction,
+ input=None,
+ temperature=0.1,
+ top_p=0.75,
+ top_k=40,
+ num_beams=4,
+ max_new_tokens=128,
+ **kwargs,
+):
+ prompt = generate_prompt(instruction, input)
+ inputs = tokenizer(prompt, return_tensors="pt")
+ input_ids = inputs["input_ids"].cuda()
+ generation_config = GenerationConfig(
+ temperature=temperature,
+ top_p=top_p,
+ top_k=top_k,
+ num_beams=num_beams,
+ **kwargs,
+ )
+ generation_output = model.generate(
+ input_ids=input_ids,
+ generation_config=generation_config,
+ return_dict_in_generate=True,
+ output_scores=True,
+ max_new_tokens=max_new_tokens,
+ do_sample=True,
+ )
+ s = generation_output.sequences[0]
+ output = tokenizer.decode(s)
+ n_new_tokens = s.size(0) - input_ids.size(1)
+ return output.split("### Response:")[1].strip(), n_new_tokens
+
+
+instructions = [
+ "Tell me about alpacas.",
+ "Tell me about the president of Mexico in 2019.",
+ "Tell me about the king of France in 2019.",
+ "List all Canadian provinces in alphabetical order.",
+ "Write a Python program that prints the first 10 Fibonacci numbers.",
+ "Write a program that prints the numbers from 1 to 100. But for multiples of three print 'Fizz' instead of the number and for the multiples of five print 'Buzz'. For numbers which are multiples of both three and five print 'FizzBuzz'.",
+ "Tell me five words that rhyme with 'shock'.",
+ "Translate the sentence 'I have no mouth but I must scream' into Spanish.",
+ "Count up from 1 to 500.",
+ # ===
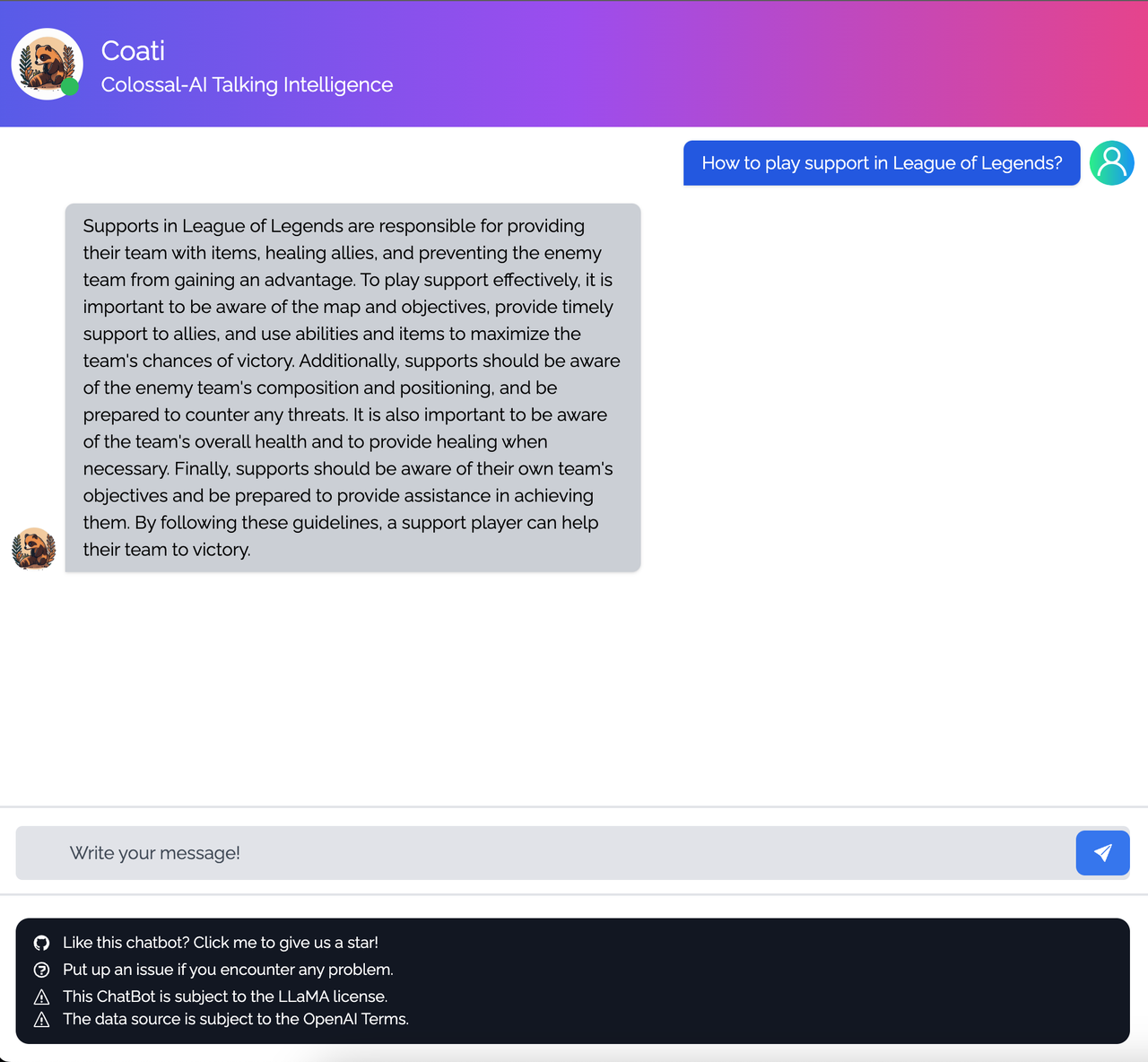
+ "How to play support in legends of league",
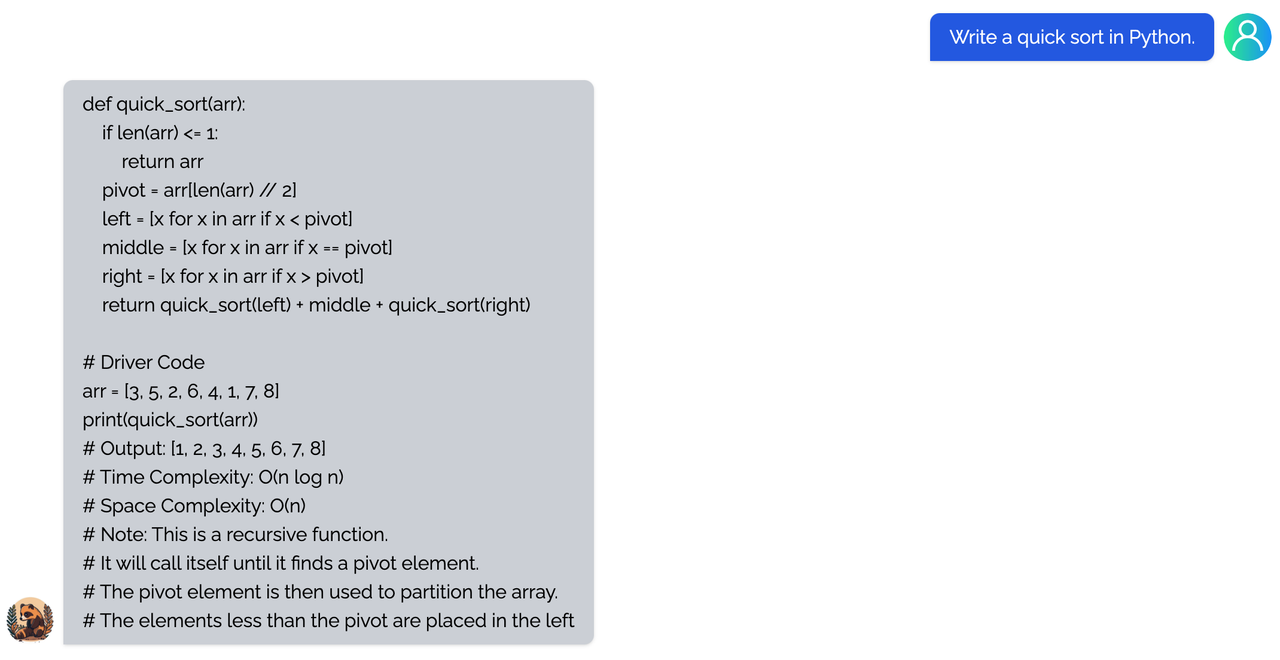
+ "Write a Python program that calculate Fibonacci numbers.",
+]
+inst = [instructions[0]] * 4
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ 'pretrained',
+ help='Path to pretrained model. Can be a local path or a model name from the HuggingFace model hub.')
+ parser.add_argument('--quant',
+ choices=['8bit', '4bit'],
+ default=None,
+ help='Quantization mode. Default: None (no quantization, fp16).')
+ parser.add_argument(
+ '--gptq_checkpoint',
+ default=None,
+ help='Path to GPTQ checkpoint. This is only useful when quantization mode is 4bit. Default: None.')
+ parser.add_argument('--gptq_group_size',
+ type=int,
+ default=128,
+ help='Group size for GPTQ. This is only useful when quantization mode is 4bit. Default: 128.')
+ args = parser.parse_args()
+
+ if args.quant == '4bit':
+ assert args.gptq_checkpoint is not None, 'Please specify a GPTQ checkpoint.'
+
+ tokenizer = AutoTokenizer.from_pretrained(args.pretrained)
+
+ if args.quant == '4bit':
+ model = load_quant(args.pretrained, args.gptq_checkpoint, 4, args.gptq_group_size)
+ model.cuda()
+ else:
+ model = LlamaForCausalLM.from_pretrained(
+ args.pretrained,
+ load_in_8bit=(args.quant == '8bit'),
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+ if args.quant != '8bit':
+ model.half() # seems to fix bugs for some users.
+ model.eval()
+
+ total_tokens = 0
+ start = time()
+ for instruction in instructions:
+ print(f"Instruction: {instruction}")
+ resp, tokens = evaluate(model, tokenizer, instruction, temparature=0.2, num_beams=1)
+ total_tokens += tokens
+ print(f"Response: {resp}")
+ print('\n----------------------------\n')
+ duration = time() - start
+ print(f'Total time: {duration:.3f} s, {total_tokens/duration:.3f} tokens/s')
+ print(f'Peak CUDA mem: {torch.cuda.max_memory_allocated()/1024**3:.3f} GB')
diff --git a/applications/Chat/inference/llama_gptq/__init__.py b/applications/Chat/inference/llama_gptq/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..51c8d6316290fe2fcef7d972803017c830d3e1b4
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/__init__.py
@@ -0,0 +1,5 @@
+from .loader import load_quant
+
+__all__ = [
+ 'load_quant',
+]
diff --git a/applications/Chat/inference/llama_gptq/loader.py b/applications/Chat/inference/llama_gptq/loader.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5c6ac7d1589aa1873918b9c8b02edcfe13ed59f
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/loader.py
@@ -0,0 +1,41 @@
+import torch
+import torch.nn as nn
+import transformers
+from transformers import LlamaConfig, LlamaForCausalLM
+
+from .model_utils import find_layers
+from .quant import make_quant
+
+
+def load_quant(pretrained: str, checkpoint: str, wbits: int, groupsize: int):
+ config = LlamaConfig.from_pretrained(pretrained)
+
+ def noop(*args, **kwargs):
+ pass
+
+ torch.nn.init.kaiming_uniform_ = noop
+ torch.nn.init.uniform_ = noop
+ torch.nn.init.normal_ = noop
+
+ torch.set_default_dtype(torch.half)
+ transformers.modeling_utils._init_weights = False
+ torch.set_default_dtype(torch.half)
+ model = LlamaForCausalLM(config)
+ torch.set_default_dtype(torch.float)
+ model = model.eval()
+ layers = find_layers(model)
+ for name in ['lm_head']:
+ if name in layers:
+ del layers[name]
+ make_quant(model, layers, wbits, groupsize)
+
+ print(f'Loading model with {wbits} bits...')
+ if checkpoint.endswith('.safetensors'):
+ from safetensors.torch import load_file as safe_load
+ model.load_state_dict(safe_load(checkpoint))
+ else:
+ model.load_state_dict(torch.load(checkpoint))
+ model.seqlen = 2048
+ print('Done.')
+
+ return model
diff --git a/applications/Chat/inference/llama_gptq/model_utils.py b/applications/Chat/inference/llama_gptq/model_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..62db171abb52cb88799a8b73d608f2617208cefe
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/model_utils.py
@@ -0,0 +1,13 @@
+# copied from https://github.com/qwopqwop200/GPTQ-for-LLaMa/blob/past/modelutils.py
+
+import torch
+import torch.nn as nn
+
+
+def find_layers(module, layers=[nn.Conv2d, nn.Linear], name=''):
+ if type(module) in layers:
+ return {name: module}
+ res = {}
+ for name1, child in module.named_children():
+ res.update(find_layers(child, layers=layers, name=name + '.' + name1 if name != '' else name1))
+ return res
diff --git a/applications/Chat/inference/llama_gptq/quant.py b/applications/Chat/inference/llama_gptq/quant.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7d5b7ce4bd8217bf246abbef0736c78be3869a6
--- /dev/null
+++ b/applications/Chat/inference/llama_gptq/quant.py
@@ -0,0 +1,283 @@
+# copied from https://github.com/qwopqwop200/GPTQ-for-LLaMa/blob/past/quant.py
+
+import math
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+
+def quantize(x, scale, zero, maxq):
+ q = torch.clamp(torch.round(x / scale) + zero, 0, maxq)
+ return scale * (q - zero)
+
+
+class Quantizer(nn.Module):
+
+ def __init__(self, shape=1):
+ super(Quantizer, self).__init__()
+ self.register_buffer('maxq', torch.tensor(0))
+ self.register_buffer('scale', torch.zeros(shape))
+ self.register_buffer('zero', torch.zeros(shape))
+
+ def configure(self, bits, perchannel=False, sym=True, mse=False, norm=2.4, grid=100, maxshrink=.8):
+ self.maxq = torch.tensor(2**bits - 1)
+ self.perchannel = perchannel
+ self.sym = sym
+ self.mse = mse
+ self.norm = norm
+ self.grid = grid
+ self.maxshrink = maxshrink
+
+ def find_params(self, x, weight=False):
+ dev = x.device
+ self.maxq = self.maxq.to(dev)
+
+ shape = x.shape
+ if self.perchannel:
+ if weight:
+ x = x.flatten(1)
+ else:
+ if len(shape) == 4:
+ x = x.permute([1, 0, 2, 3])
+ x = x.flatten(1)
+ if len(shape) == 3:
+ x = x.reshape((-1, shape[-1])).t()
+ if len(shape) == 2:
+ x = x.t()
+ else:
+ x = x.flatten().unsqueeze(0)
+
+ tmp = torch.zeros(x.shape[0], device=dev)
+ xmin = torch.minimum(x.min(1)[0], tmp)
+ xmax = torch.maximum(x.max(1)[0], tmp)
+
+ if self.sym:
+ xmax = torch.maximum(torch.abs(xmin), xmax)
+ tmp = xmin < 0
+ if torch.any(tmp):
+ xmin[tmp] = -xmax[tmp]
+ tmp = (xmin == 0) & (xmax == 0)
+ xmin[tmp] = -1
+ xmax[tmp] = +1
+
+ self.scale = (xmax - xmin) / self.maxq
+ if self.sym:
+ self.zero = torch.full_like(self.scale, (self.maxq + 1) / 2)
+ else:
+ self.zero = torch.round(-xmin / self.scale)
+
+ if self.mse:
+ best = torch.full([x.shape[0]], float('inf'), device=dev)
+ for i in range(int(self.maxshrink * self.grid)):
+ p = 1 - i / self.grid
+ xmin1 = p * xmin
+ xmax1 = p * xmax
+ scale1 = (xmax1 - xmin1) / self.maxq
+ zero1 = torch.round(-xmin1 / scale1) if not self.sym else self.zero
+ q = quantize(x, scale1.unsqueeze(1), zero1.unsqueeze(1), self.maxq)
+ q -= x
+ q.abs_()
+ q.pow_(self.norm)
+ err = torch.sum(q, 1)
+ tmp = err < best
+ if torch.any(tmp):
+ best[tmp] = err[tmp]
+ self.scale[tmp] = scale1[tmp]
+ self.zero[tmp] = zero1[tmp]
+ if not self.perchannel:
+ if weight:
+ tmp = shape[0]
+ else:
+ tmp = shape[1] if len(shape) != 3 else shape[2]
+ self.scale = self.scale.repeat(tmp)
+ self.zero = self.zero.repeat(tmp)
+
+ if weight:
+ shape = [-1] + [1] * (len(shape) - 1)
+ self.scale = self.scale.reshape(shape)
+ self.zero = self.zero.reshape(shape)
+ return
+ if len(shape) == 4:
+ self.scale = self.scale.reshape((1, -1, 1, 1))
+ self.zero = self.zero.reshape((1, -1, 1, 1))
+ if len(shape) == 3:
+ self.scale = self.scale.reshape((1, 1, -1))
+ self.zero = self.zero.reshape((1, 1, -1))
+ if len(shape) == 2:
+ self.scale = self.scale.unsqueeze(0)
+ self.zero = self.zero.unsqueeze(0)
+
+ def quantize(self, x):
+ if self.ready():
+ return quantize(x, self.scale, self.zero, self.maxq)
+ return x
+
+ def enabled(self):
+ return self.maxq > 0
+
+ def ready(self):
+ return torch.all(self.scale != 0)
+
+
+try:
+ import quant_cuda
+except:
+ print('CUDA extension not installed.')
+
+# Assumes layer is perfectly divisible into 256 * 256 blocks
+
+
+class QuantLinear(nn.Module):
+
+ def __init__(self, bits, groupsize, infeatures, outfeatures):
+ super().__init__()
+ if bits not in [2, 3, 4, 8]:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+ self.infeatures = infeatures
+ self.outfeatures = outfeatures
+ self.bits = bits
+ if groupsize != -1 and groupsize < 32 and groupsize != int(math.pow(2, int(math.log2(groupsize)))):
+ raise NotImplementedError("groupsize supports powers of 2 greater than 32. (e.g. : 32,64,128,etc)")
+ groupsize = groupsize if groupsize != -1 else infeatures
+ self.groupsize = groupsize
+ self.register_buffer(
+ 'qzeros', torch.zeros((math.ceil(infeatures / groupsize), outfeatures // 256 * (bits * 8)),
+ dtype=torch.int))
+ self.register_buffer('scales', torch.zeros((math.ceil(infeatures / groupsize), outfeatures)))
+ self.register_buffer('bias', torch.zeros(outfeatures))
+ self.register_buffer('qweight', torch.zeros((infeatures // 256 * (bits * 8), outfeatures), dtype=torch.int))
+ self._initialized_quant_state = False
+
+ def pack(self, linear, scales, zeros):
+ scales = scales.t().contiguous()
+ zeros = zeros.t().contiguous()
+ scale_zeros = zeros * scales
+ self.scales = scales.clone()
+ if linear.bias is not None:
+ self.bias = linear.bias.clone()
+
+ intweight = []
+ for idx in range(self.infeatures):
+ g_idx = idx // self.groupsize
+ intweight.append(
+ torch.round((linear.weight.data[:, idx] + scale_zeros[g_idx]) / self.scales[g_idx]).to(torch.int)[:,
+ None])
+ intweight = torch.cat(intweight, dim=1)
+ intweight = intweight.t().contiguous()
+ intweight = intweight.numpy().astype(np.uint32)
+ qweight = np.zeros((intweight.shape[0] // 256 * (self.bits * 8), intweight.shape[1]), dtype=np.uint32)
+ i = 0
+ row = 0
+ while row < qweight.shape[0]:
+ if self.bits in [2, 4, 8]:
+ for j in range(i, i + (32 // self.bits)):
+ qweight[row] |= intweight[j] << (self.bits * (j - i))
+ i += 32 // self.bits
+ row += 1
+ elif self.bits == 3:
+ for j in range(i, i + 10):
+ qweight[row] |= intweight[j] << (3 * (j - i))
+ i += 10
+ qweight[row] |= intweight[i] << 30
+ row += 1
+ qweight[row] |= (intweight[i] >> 2) & 1
+ i += 1
+ for j in range(i, i + 10):
+ qweight[row] |= intweight[j] << (3 * (j - i) + 1)
+ i += 10
+ qweight[row] |= intweight[i] << 31
+ row += 1
+ qweight[row] |= (intweight[i] >> 1) & 0x3
+ i += 1
+ for j in range(i, i + 10):
+ qweight[row] |= intweight[j] << (3 * (j - i) + 2)
+ i += 10
+ row += 1
+ else:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+
+ qweight = qweight.astype(np.int32)
+ self.qweight = torch.from_numpy(qweight)
+
+ zeros -= 1
+ zeros = zeros.numpy().astype(np.uint32)
+ qzeros = np.zeros((zeros.shape[0], zeros.shape[1] // 256 * (self.bits * 8)), dtype=np.uint32)
+ i = 0
+ col = 0
+ while col < qzeros.shape[1]:
+ if self.bits in [2, 4, 8]:
+ for j in range(i, i + (32 // self.bits)):
+ qzeros[:, col] |= zeros[:, j] << (self.bits * (j - i))
+ i += 32 // self.bits
+ col += 1
+ elif self.bits == 3:
+ for j in range(i, i + 10):
+ qzeros[:, col] |= zeros[:, j] << (3 * (j - i))
+ i += 10
+ qzeros[:, col] |= zeros[:, i] << 30
+ col += 1
+ qzeros[:, col] |= (zeros[:, i] >> 2) & 1
+ i += 1
+ for j in range(i, i + 10):
+ qzeros[:, col] |= zeros[:, j] << (3 * (j - i) + 1)
+ i += 10
+ qzeros[:, col] |= zeros[:, i] << 31
+ col += 1
+ qzeros[:, col] |= (zeros[:, i] >> 1) & 0x3
+ i += 1
+ for j in range(i, i + 10):
+ qzeros[:, col] |= zeros[:, j] << (3 * (j - i) + 2)
+ i += 10
+ col += 1
+ else:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+
+ qzeros = qzeros.astype(np.int32)
+ self.qzeros = torch.from_numpy(qzeros)
+
+ def forward(self, x):
+ intermediate_dtype = torch.float32
+
+ if not self._initialized_quant_state:
+ # Do we even have a bias? Check for at least one non-zero element.
+ if self.bias is not None and bool(torch.any(self.bias != 0)):
+ # Then make sure it's the right type.
+ self.bias.data = self.bias.data.to(intermediate_dtype)
+ else:
+ self.bias = None
+
+ outshape = list(x.shape)
+ outshape[-1] = self.outfeatures
+ x = x.reshape(-1, x.shape[-1])
+ if self.bias is None:
+ y = torch.zeros(x.shape[0], outshape[-1], dtype=intermediate_dtype, device=x.device)
+ else:
+ y = self.bias.clone().repeat(x.shape[0], 1)
+
+ output_dtype = x.dtype
+ x = x.to(intermediate_dtype)
+ if self.bits == 2:
+ quant_cuda.vecquant2matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ elif self.bits == 3:
+ quant_cuda.vecquant3matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ elif self.bits == 4:
+ quant_cuda.vecquant4matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ elif self.bits == 8:
+ quant_cuda.vecquant8matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
+ else:
+ raise NotImplementedError("Only 2,3,4,8 bits are supported.")
+ y = y.to(output_dtype)
+ return y.reshape(outshape)
+
+
+def make_quant(module, names, bits, groupsize, name=''):
+ if isinstance(module, QuantLinear):
+ return
+ for attr in dir(module):
+ tmp = getattr(module, attr)
+ name1 = name + '.' + attr if name != '' else attr
+ if name1 in names:
+ setattr(module, attr, QuantLinear(bits, groupsize, tmp.in_features, tmp.out_features))
+ for name1, child in module.named_children():
+ make_quant(child, names, bits, groupsize, name + '.' + name1 if name != '' else name1)
diff --git a/applications/Chat/inference/locustfile.py b/applications/Chat/inference/locustfile.py
new file mode 100644
index 0000000000000000000000000000000000000000..51cdc68125bba42d29a91f03285847e0bde27ea8
--- /dev/null
+++ b/applications/Chat/inference/locustfile.py
@@ -0,0 +1,27 @@
+from json import JSONDecodeError
+
+from locust import HttpUser, task
+
+samples = [[
+ dict(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ dict(instruction='continue this talk', response=''),
+], [
+ dict(instruction='Who is the best player in the history of NBA?', response=''),
+]]
+
+
+class GenerationUser(HttpUser):
+
+ @task
+ def generate(self):
+ for sample in samples:
+ data = {'max_new_tokens': 64, 'history': sample}
+ with self.client.post('/generate', json=data, catch_response=True) as response:
+ if response.status_code in (200, 406):
+ response.success()
+ else:
+ response.failure('Response wrong')
diff --git a/applications/Chat/inference/requirements.txt b/applications/Chat/inference/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..511fe1a4f1f339b23f1a11162925703b94e15013
--- /dev/null
+++ b/applications/Chat/inference/requirements.txt
@@ -0,0 +1,13 @@
+fastapi
+locust
+numpy
+pydantic
+safetensors
+slowapi
+sse_starlette
+torch
+uvicorn
+git+https://github.com/huggingface/transformers
+accelerate
+bitsandbytes
+jieba
\ No newline at end of file
diff --git a/applications/Chat/inference/server.py b/applications/Chat/inference/server.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4627299397e6949576318de3938ee9c19aa390c
--- /dev/null
+++ b/applications/Chat/inference/server.py
@@ -0,0 +1,178 @@
+import argparse
+import os
+from threading import Lock
+from typing import Dict, Generator, List, Optional
+
+import torch
+import uvicorn
+from fastapi import FastAPI, HTTPException, Request
+from fastapi.middleware.cors import CORSMiddleware
+from llama_gptq import load_quant
+from pydantic import BaseModel, Field
+from slowapi import Limiter, _rate_limit_exceeded_handler
+from slowapi.errors import RateLimitExceeded
+from slowapi.util import get_remote_address
+from sse_starlette.sse import EventSourceResponse
+from transformers import AutoTokenizer, GenerationConfig, LlamaForCausalLM
+from utils import ChatPromptProcessor, Dialogue, LockedIterator, sample_streamingly, update_model_kwargs_fn, load_json
+
+CONTEXT = 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.'
+MAX_LEN = 512
+running_lock = Lock()
+
+
+class GenerationTaskReq(BaseModel):
+ max_new_tokens: int = Field(gt=0, le=512, example=64)
+ history: List[Dialogue] = Field(min_items=1)
+ top_k: Optional[int] = Field(default=None, gt=0, example=50)
+ top_p: Optional[float] = Field(default=None, gt=0.0, lt=1.0, example=0.5)
+ temperature: Optional[float] = Field(default=None, gt=0.0, lt=1.0, example=0.7)
+ repetition_penalty: Optional[float] = Field(default=None, gt=1.0, example=1.2)
+
+
+limiter = Limiter(key_func=get_remote_address)
+app = FastAPI()
+app.state.limiter = limiter
+app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)
+
+# set CORS
+origin_spec_from_env = os.environ.get('CORS_ORIGIN', None)
+
+if origin_spec_from_env is not None:
+ # allow CORS from the specified origins
+ origins = os.environ['CORS_ORIGIN'].split(',')
+else:
+ # allow CORS from all origins
+ origins = ["*"]
+
+app.add_middleware(
+ CORSMiddleware,
+ allow_origins=origins,
+ allow_credentials=True,
+ allow_methods=["*"],
+ allow_headers=["*"],
+)
+
+
+def generate_streamingly(prompt, max_new_tokens, top_k, top_p, temperature):
+ inputs = {k: v.cuda() for k, v in tokenizer(prompt, return_tensors="pt").items()}
+ #TODO(ver217): streaming generation does not support repetition_penalty now
+ model_kwargs = {
+ 'max_generate_tokens': max_new_tokens,
+ 'early_stopping': True,
+ 'top_k': top_k,
+ 'top_p': top_p,
+ 'temperature': temperature,
+ 'prepare_inputs_fn': model.prepare_inputs_for_generation,
+ 'update_model_kwargs_fn': update_model_kwargs_fn,
+ }
+ is_first_word = True
+ generator = LockedIterator(sample_streamingly(model, **inputs, **model_kwargs), running_lock)
+ for output in generator:
+ output = output.cpu()
+ tokens = tokenizer.convert_ids_to_tokens(output, skip_special_tokens=True)
+ current_sub_tokens = []
+ for token in tokens:
+ if token in tokenizer.all_special_tokens:
+ continue
+ current_sub_tokens.append(token)
+ if current_sub_tokens:
+ out_string = tokenizer.sp_model.decode(current_sub_tokens)
+ if is_first_word:
+ out_string = out_string.lstrip()
+ is_first_word = False
+ elif current_sub_tokens[0].startswith('▁'):
+ # whitespace will be ignored by the frontend
+ out_string = ' ' + out_string
+ yield out_string
+
+
+async def event_generator(request: Request, generator: Generator):
+ while True:
+ if await request.is_disconnected():
+ break
+ try:
+ yield {'event': 'generate', 'data': next(generator)}
+ except StopIteration:
+ yield {'event': 'end', 'data': ''}
+ break
+
+
+@app.post('/generate/stream')
+@limiter.limit('1/second')
+def generate(data: GenerationTaskReq, request: Request):
+ prompt = prompt_processor.preprocess_prompt(data.history, data.max_new_tokens)
+ event_source = event_generator(
+ request, generate_streamingly(prompt, data.max_new_tokens, data.top_k, data.top_p, data.temperature))
+ return EventSourceResponse(event_source)
+
+
+@app.post('/generate')
+@limiter.limit('1/second')
+def generate_no_stream(data: GenerationTaskReq, request: Request):
+ prompt = prompt_processor.preprocess_prompt(data.history, data.max_new_tokens)
+ if prompt_processor.has_censored_words(prompt):
+ return prompt_processor.SAFE_RESPONSE
+ inputs = {k: v.cuda() for k, v in tokenizer(prompt, return_tensors="pt").items()}
+ with running_lock:
+ output = model.generate(**inputs, **data.dict(exclude={'history'}))
+ output = output.cpu()
+ prompt_len = inputs['input_ids'].size(1)
+ response = output[0, prompt_len:]
+ out_string = tokenizer.decode(response, skip_special_tokens=True)
+ out_string = prompt_processor.postprocess_output(out_string)
+ if prompt_processor.has_censored_words(out_string):
+ return prompt_processor.SAFE_RESPONSE
+ return out_string
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ 'pretrained',
+ help='Path to pretrained model. Can be a local path or a model name from the HuggingFace model hub.')
+ parser.add_argument('--quant',
+ choices=['8bit', '4bit'],
+ default=None,
+ help='Quantization mode. Default: None (no quantization, fp16).')
+ parser.add_argument(
+ '--gptq_checkpoint',
+ default=None,
+ help='Path to GPTQ checkpoint. This is only useful when quantization mode is 4bit. Default: None.')
+ parser.add_argument('--gptq_group_size',
+ type=int,
+ default=128,
+ help='Group size for GPTQ. This is only useful when quantization mode is 4bit. Default: 128.')
+ parser.add_argument('--http_host', default='0.0.0.0')
+ parser.add_argument('--http_port', type=int, default=7070)
+ parser.add_argument('--profanity_file', default=None, help='Path to profanity words list. It should be a JSON file containing a list of words.')
+ args = parser.parse_args()
+
+ if args.quant == '4bit':
+ assert args.gptq_checkpoint is not None, 'Please specify a GPTQ checkpoint.'
+
+ tokenizer = AutoTokenizer.from_pretrained(args.pretrained)
+
+ if args.profanity_file is not None:
+ censored_words = load_json(args.profanity_file)
+ else:
+ censored_words = []
+ prompt_processor = ChatPromptProcessor(tokenizer, CONTEXT, MAX_LEN, censored_words=censored_words)
+
+ if args.quant == '4bit':
+ model = load_quant(args.pretrained, args.gptq_checkpoint, 4, args.gptq_group_size)
+ model.cuda()
+ else:
+ model = LlamaForCausalLM.from_pretrained(
+ args.pretrained,
+ load_in_8bit=(args.quant == '8bit'),
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+ if args.quant != '8bit':
+ model.half() # seems to fix bugs for some users.
+ model.eval()
+
+ config = uvicorn.Config(app, host=args.http_host, port=args.http_port)
+ server = uvicorn.Server(config=config)
+ server.run()
diff --git a/applications/Chat/inference/tests/test_chat_prompt.py b/applications/Chat/inference/tests/test_chat_prompt.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5737ebe8c097d73073bb21195341b378e7fc2f1
--- /dev/null
+++ b/applications/Chat/inference/tests/test_chat_prompt.py
@@ -0,0 +1,56 @@
+import os
+
+from transformers import AutoTokenizer
+from utils import ChatPromptProcessor, Dialogue
+
+CONTEXT = 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.'
+tokenizer = AutoTokenizer.from_pretrained(os.environ['PRETRAINED_PATH'])
+
+samples = [
+ ([
+ Dialogue(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ Dialogue(instruction='continue this talk', response=''),
+ ], 128,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\nWho is the best player in the history of NBA?\n\n### Response:\nThe best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1\n\n### Instruction:\ncontinue this talk\n\n### Response:\n'
+ ),
+ ([
+ Dialogue(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ Dialogue(instruction='continue this talk', response=''),
+ ], 200,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\ncontinue this talk\n\n### Response:\n'
+ ),
+ ([
+ Dialogue(
+ instruction='Who is the best player in the history of NBA?',
+ response=
+ 'The best player in the history of the NBA is widely considered to be Michael Jordan. He is one of the most successful players in the league, having won 6 NBA championships with the Chicago Bulls and 5 more with the Washington Wizards. He is a 5-time MVP, 1'
+ ),
+ Dialogue(instruction='continue this talk', response=''),
+ ], 211,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\ncontinue this\n\n### Response:\n'
+ ),
+ ([
+ Dialogue(instruction='Who is the best player in the history of NBA?', response=''),
+ ], 128,
+ 'Below is an instruction that describes a task. Write a response that appropriately completes the request. Do not generate new instructions.\n\n### Instruction:\nWho is the best player in the history of NBA?\n\n### Response:\n'
+ ),
+]
+
+
+def test_chat_prompt_processor():
+ processor = ChatPromptProcessor(tokenizer, CONTEXT, 256)
+ for history, max_new_tokens, result in samples:
+ prompt = processor.preprocess_prompt(history, max_new_tokens)
+ assert prompt == result
+
+
+if __name__ == '__main__':
+ test_chat_prompt_processor()
diff --git a/applications/Chat/inference/utils.py b/applications/Chat/inference/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..37944be70a3bf9631f0a995bd1753d71d6c8b5aa
--- /dev/null
+++ b/applications/Chat/inference/utils.py
@@ -0,0 +1,200 @@
+import re
+from threading import Lock
+from typing import Any, Callable, Generator, List, Optional
+import json
+import jieba
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from pydantic import BaseModel, Field
+
+try:
+ from transformers.generation_logits_process import (
+ LogitsProcessorList,
+ TemperatureLogitsWarper,
+ TopKLogitsWarper,
+ TopPLogitsWarper,
+ )
+except ImportError:
+ from transformers.generation import LogitsProcessorList, TemperatureLogitsWarper, TopKLogitsWarper, TopPLogitsWarper
+
+
+def prepare_logits_processor(top_k: Optional[int] = None,
+ top_p: Optional[float] = None,
+ temperature: Optional[float] = None) -> LogitsProcessorList:
+ processor_list = LogitsProcessorList()
+ if temperature is not None and temperature != 1.0:
+ processor_list.append(TemperatureLogitsWarper(temperature))
+ if top_k is not None and top_k != 0:
+ processor_list.append(TopKLogitsWarper(top_k))
+ if top_p is not None and top_p < 1.0:
+ processor_list.append(TopPLogitsWarper(top_p))
+ return processor_list
+
+
+def _is_sequence_finished(unfinished_sequences: torch.Tensor) -> bool:
+ if dist.is_initialized() and dist.get_world_size() > 1:
+ # consider DP
+ unfinished_sequences = unfinished_sequences.clone()
+ dist.all_reduce(unfinished_sequences)
+ return unfinished_sequences.max() == 0
+
+
+def sample_streamingly(model: nn.Module,
+ input_ids: torch.Tensor,
+ max_generate_tokens: int,
+ early_stopping: bool = False,
+ eos_token_id: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ top_k: Optional[int] = None,
+ top_p: Optional[float] = None,
+ temperature: Optional[float] = None,
+ prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
+ update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
+ **model_kwargs) -> Generator:
+
+ logits_processor = prepare_logits_processor(top_k, top_p, temperature)
+ unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
+
+ for _ in range(max_generate_tokens):
+ model_inputs = prepare_inputs_fn(input_ids, **model_kwargs) if prepare_inputs_fn is not None else {
+ 'input_ids': input_ids
+ }
+ outputs = model(**model_inputs)
+
+ next_token_logits = outputs['logits'][:, -1, :]
+ # pre-process distribution
+ next_token_logits = logits_processor(input_ids, next_token_logits)
+ # sample
+ probs = torch.softmax(next_token_logits, dim=-1, dtype=torch.float)
+ next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
+
+ # finished sentences should have their next token be a padding token
+ if eos_token_id is not None:
+ if pad_token_id is None:
+ raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
+ next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
+
+ yield next_tokens
+
+ # update generated ids, model inputs for next step
+ input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
+ if update_model_kwargs_fn is not None:
+ model_kwargs = update_model_kwargs_fn(outputs, **model_kwargs)
+
+ # if eos_token was found in one sentence, set sentence to finished
+ if eos_token_id is not None:
+ unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
+
+ # stop when each sentence is finished if early_stopping=True
+ if early_stopping and _is_sequence_finished(unfinished_sequences):
+ break
+
+
+def update_model_kwargs_fn(outputs: dict, **model_kwargs) -> dict:
+ if "past_key_values" in outputs:
+ model_kwargs["past"] = outputs["past_key_values"]
+ else:
+ model_kwargs["past"] = None
+
+ # update token_type_ids with last value
+ if "token_type_ids" in model_kwargs:
+ token_type_ids = model_kwargs["token_type_ids"]
+ model_kwargs["token_type_ids"] = torch.cat([token_type_ids, token_type_ids[:, -1].unsqueeze(-1)], dim=-1)
+
+ # update attention mask
+ if "attention_mask" in model_kwargs:
+ attention_mask = model_kwargs["attention_mask"]
+ model_kwargs["attention_mask"] = torch.cat(
+ [attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1)
+
+ return model_kwargs
+
+
+class Dialogue(BaseModel):
+ instruction: str = Field(min_length=1, example='Count up from 1 to 500.')
+ response: str = Field(example='')
+
+
+def _format_dialogue(instruction: str, response: str = ''):
+ return f'\n\n### Instruction:\n{instruction}\n\n### Response:\n{response}'
+
+
+STOP_PAT = re.compile(r'(###|instruction:).*', flags=(re.I | re.S))
+
+
+class ChatPromptProcessor:
+ SAFE_RESPONSE = 'The input/response contains inappropriate content, please rephrase your prompt.'
+
+ def __init__(self, tokenizer, context: str, max_len: int = 2048, censored_words: List[str]=[]):
+ self.tokenizer = tokenizer
+ self.context = context
+ self.max_len = max_len
+ self.censored_words = set([word.lower() for word in censored_words])
+ # These will be initialized after the first call of preprocess_prompt()
+ self.context_len: Optional[int] = None
+ self.dialogue_placeholder_len: Optional[int] = None
+
+ def preprocess_prompt(self, history: List[Dialogue], max_new_tokens: int) -> str:
+ if self.context_len is None:
+ self.context_len = len(self.tokenizer(self.context)['input_ids'])
+ if self.dialogue_placeholder_len is None:
+ self.dialogue_placeholder_len = len(
+ self.tokenizer(_format_dialogue(''), add_special_tokens=False)['input_ids'])
+ prompt = self.context
+ # the last dialogue must be in the prompt
+ last_dialogue = history.pop()
+ # the response of the last dialogue is empty
+ assert last_dialogue.response == ''
+ if len(self.tokenizer(_format_dialogue(last_dialogue.instruction), add_special_tokens=False)
+ ['input_ids']) + max_new_tokens + self.context_len >= self.max_len:
+ # to avoid truncate placeholder, apply truncate to the original instruction
+ instruction_truncated = self.tokenizer(last_dialogue.instruction,
+ add_special_tokens=False,
+ truncation=True,
+ max_length=(self.max_len - max_new_tokens - self.context_len -
+ self.dialogue_placeholder_len))['input_ids']
+ instruction_truncated = self.tokenizer.decode(instruction_truncated).lstrip()
+ prompt += _format_dialogue(instruction_truncated)
+ return prompt
+
+ res_len = self.max_len - max_new_tokens - len(self.tokenizer(prompt)['input_ids'])
+
+ rows = []
+ for dialogue in history[::-1]:
+ text = _format_dialogue(dialogue.instruction, dialogue.response)
+ cur_len = len(self.tokenizer(text, add_special_tokens=False)['input_ids'])
+ if res_len - cur_len < 0:
+ break
+ res_len -= cur_len
+ rows.insert(0, text)
+ prompt += ''.join(rows) + _format_dialogue(last_dialogue.instruction)
+ return prompt
+
+ def postprocess_output(self, output: str) -> str:
+ output = STOP_PAT.sub('', output)
+ return output.strip()
+
+ def has_censored_words(self, text: str) -> bool:
+ if len(self.censored_words) == 0:
+ return False
+ intersection = set(jieba.cut(text.lower())) & self.censored_words
+ return len(intersection) > 0
+
+class LockedIterator:
+
+ def __init__(self, it, lock: Lock) -> None:
+ self.lock = lock
+ self.it = iter(it)
+
+ def __iter__(self):
+ return self
+
+ def __next__(self):
+ with self.lock:
+ return next(self.it)
+
+def load_json(path: str):
+ with open(path) as f:
+ return json.load(f)
\ No newline at end of file
diff --git a/applications/Chat/pytest.ini b/applications/Chat/pytest.ini
new file mode 100644
index 0000000000000000000000000000000000000000..01e5cd217c5d9830551735c7d9e6d4087e038391
--- /dev/null
+++ b/applications/Chat/pytest.ini
@@ -0,0 +1,6 @@
+[pytest]
+markers =
+ cpu: tests which can run on CPU
+ gpu: tests which requires a single GPU
+ dist: tests which are run in a multi-GPU or multi-machine environment
+ experiment: tests for experimental features
diff --git a/applications/Chat/requirements-test.txt b/applications/Chat/requirements-test.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e079f8a6038dd2dc8512967540f96ee0de172067
--- /dev/null
+++ b/applications/Chat/requirements-test.txt
@@ -0,0 +1 @@
+pytest
diff --git a/applications/Chat/requirements.txt b/applications/Chat/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..af7ff67861eb73573489e9ae46f1a2d29eaa02b3
--- /dev/null
+++ b/applications/Chat/requirements.txt
@@ -0,0 +1,13 @@
+transformers>=4.20.1
+tqdm
+datasets
+loralib
+colossalai>=0.2.4
+torch<2.0.0, >=1.12.1
+langchain
+tokenizers
+fastapi
+sse_starlette
+wandb
+sentencepiece
+gpustat
diff --git a/applications/Chat/setup.py b/applications/Chat/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..a285a6dff4bf9cfe6905494de83a0baacfd795cb
--- /dev/null
+++ b/applications/Chat/setup.py
@@ -0,0 +1,41 @@
+from setuptools import find_packages, setup
+
+
+def fetch_requirements(path):
+ with open(path, 'r') as fd:
+ return [r.strip() for r in fd.readlines()]
+
+
+def fetch_readme():
+ with open('README.md', encoding='utf-8') as f:
+ return f.read()
+
+
+def fetch_version():
+ with open('version.txt', 'r') as f:
+ return f.read().strip()
+
+
+setup(
+ name='coati',
+ version=fetch_version(),
+ packages=find_packages(exclude=(
+ 'tests',
+ 'benchmarks',
+ '*.egg-info',
+ )),
+ description='Colossal-AI Talking Intelligence',
+ long_description=fetch_readme(),
+ long_description_content_type='text/markdown',
+ license='Apache Software License 2.0',
+ url='https://github.com/hpcaitech/Coati',
+ install_requires=fetch_requirements('requirements.txt'),
+ python_requires='>=3.6',
+ classifiers=[
+ 'Programming Language :: Python :: 3',
+ 'License :: OSI Approved :: Apache Software License',
+ 'Environment :: GPU :: NVIDIA CUDA',
+ 'Topic :: Scientific/Engineering :: Artificial Intelligence',
+ 'Topic :: System :: Distributed Computing',
+ ],
+)
diff --git a/applications/Chat/tests/__init__.py b/applications/Chat/tests/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/applications/Chat/tests/test_checkpoint.py b/applications/Chat/tests/test_checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c05a343169905dc03d91b1f4c39530ec8834848
--- /dev/null
+++ b/applications/Chat/tests/test_checkpoint.py
@@ -0,0 +1,94 @@
+import os
+import tempfile
+from contextlib import nullcontext
+
+import pytest
+import torch
+import torch.distributed as dist
+from coati.models.gpt import GPTActor
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy
+from transformers.models.gpt2.configuration_gpt2 import GPT2Config
+
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.testing import rerun_if_address_is_in_use, spawn
+
+GPT_CONFIG = GPT2Config(n_embd=128, n_layer=4, n_head=4)
+
+
+def get_data(batch_size: int, seq_len: int = 10) -> dict:
+ input_ids = torch.randint(0, 50257, (batch_size, seq_len), device='cuda')
+ attention_mask = torch.ones_like(input_ids)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def run_test_checkpoint(strategy):
+ BATCH_SIZE = 2
+
+ if strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif strategy == 'colossalai_gemini':
+ strategy = ColossalAIStrategy(stage=3, placement_policy='cuda', initial_scale=2**5)
+ elif strategy == 'colossalai_zero2':
+ strategy = ColossalAIStrategy(stage=2, placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{strategy}"')
+
+ with strategy.model_init_context():
+ actor = GPTActor(config=GPT_CONFIG).cuda()
+
+ actor_optim = HybridAdam(actor.parameters())
+
+ actor, actor_optim = strategy.prepare((actor, actor_optim))
+
+ def run_step():
+ data = get_data(BATCH_SIZE)
+ action_mask = torch.ones_like(data['attention_mask'], dtype=torch.bool)
+ action_log_probs = actor(data['input_ids'], action_mask.size(1), data['attention_mask'])
+ loss = action_log_probs.sum()
+ strategy.backward(loss, actor, actor_optim)
+ strategy.optimizer_step(actor_optim)
+
+ run_step()
+
+ ctx = tempfile.TemporaryDirectory() if dist.get_rank() == 0 else nullcontext()
+
+ with ctx as dirname:
+ rank0_dirname = [dirname]
+ dist.broadcast_object_list(rank0_dirname)
+ rank0_dirname = rank0_dirname[0]
+
+ model_path = os.path.join(rank0_dirname, 'model.pt')
+ optim_path = os.path.join(rank0_dirname, f'optim-r{dist.get_rank()}.pt')
+
+ strategy.save_model(actor, model_path, only_rank0=True)
+ strategy.save_optimizer(actor_optim, optim_path, only_rank0=False)
+
+ dist.barrier()
+
+ strategy.load_model(actor, model_path, strict=False)
+ strategy.load_optimizer(actor_optim, optim_path)
+
+ dist.barrier()
+
+ run_step()
+
+
+def run_dist(rank, world_size, port, strategy):
+ os.environ['RANK'] = str(rank)
+ os.environ['LOCAL_RANK'] = str(rank)
+ os.environ['WORLD_SIZE'] = str(world_size)
+ os.environ['MASTER_ADDR'] = 'localhost'
+ os.environ['MASTER_PORT'] = str(port)
+ run_test_checkpoint(strategy)
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize('world_size', [2])
+@pytest.mark.parametrize('strategy', ['ddp', 'colossalai_zero2', 'colossalai_gemini'])
+@rerun_if_address_is_in_use()
+def test_checkpoint(world_size, strategy):
+ spawn(run_dist, world_size, strategy=strategy)
+
+
+if __name__ == '__main__':
+ test_checkpoint(2, 'colossalai_zero2')
diff --git a/applications/Chat/tests/test_data.py b/applications/Chat/tests/test_data.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e4d4ceac05fa603b98e4ad1c9b098e221345e83
--- /dev/null
+++ b/applications/Chat/tests/test_data.py
@@ -0,0 +1,118 @@
+import os
+from copy import deepcopy
+
+import pytest
+import torch
+import torch.distributed as dist
+from coati.experience_maker import NaiveExperienceMaker
+from coati.models.base import RewardModel
+from coati.models.gpt import GPTActor, GPTCritic
+from coati.replay_buffer import NaiveReplayBuffer
+from coati.trainer.strategies import ColossalAIStrategy, DDPStrategy
+from transformers.models.gpt2.configuration_gpt2 import GPT2Config
+
+from colossalai.testing import rerun_if_address_is_in_use, spawn
+
+GPT_CONFIG = GPT2Config(n_embd=128, n_layer=4, n_head=4)
+
+
+def get_data(batch_size: int, seq_len: int = 10) -> dict:
+ input_ids = torch.randint(0, 50257, (batch_size, seq_len), device='cuda')
+ attention_mask = torch.ones_like(input_ids)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def gather_and_equal(tensor: torch.Tensor) -> bool:
+ world_size = dist.get_world_size()
+ outputs = [torch.empty_like(tensor) for _ in range(world_size)]
+ dist.all_gather(outputs, tensor.contiguous())
+ for t in outputs[1:]:
+ if not torch.equal(outputs[0], t):
+ return False
+ return True
+
+
+def run_test_data(strategy):
+ EXPERINCE_BATCH_SIZE = 4
+ SAMPLE_BATCH_SIZE = 2
+
+ if strategy == 'ddp':
+ strategy = DDPStrategy()
+ elif strategy == 'colossalai':
+ strategy = ColossalAIStrategy(placement_policy='cuda')
+ else:
+ raise ValueError(f'Unsupported strategy "{strategy}"')
+
+ actor = GPTActor(config=GPT_CONFIG).cuda()
+ critic = GPTCritic(config=GPT_CONFIG).cuda()
+
+ initial_model = deepcopy(actor)
+ reward_model = RewardModel(deepcopy(critic.model)).cuda()
+
+ experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model)
+ replay_buffer = NaiveReplayBuffer(SAMPLE_BATCH_SIZE, cpu_offload=False)
+
+ # experience of all ranks should be the same
+ for _ in range(2):
+ data = get_data(EXPERINCE_BATCH_SIZE)
+ assert gather_and_equal(data['input_ids'])
+ assert gather_and_equal(data['attention_mask'])
+ experience = experience_maker.make_experience(**data,
+ do_sample=True,
+ max_length=16,
+ eos_token_id=50256,
+ pad_token_id=50256)
+ assert gather_and_equal(experience.sequences)
+ assert gather_and_equal(experience.action_log_probs)
+ assert gather_and_equal(experience.values)
+ assert gather_and_equal(experience.reward)
+ assert gather_and_equal(experience.advantages)
+ assert gather_and_equal(experience.action_mask)
+ assert gather_and_equal(experience.attention_mask)
+ replay_buffer.append(experience)
+
+ # replay buffer's data should be the same
+ buffer_size = torch.tensor([len(replay_buffer)], device='cuda')
+ assert gather_and_equal(buffer_size)
+ for item in replay_buffer.items:
+ assert gather_and_equal(item.sequences)
+ assert gather_and_equal(item.action_log_probs)
+ assert gather_and_equal(item.values)
+ assert gather_and_equal(item.reward)
+ assert gather_and_equal(item.advantages)
+ assert gather_and_equal(item.action_mask)
+ assert gather_and_equal(item.attention_mask)
+
+ # dataloader of each rank should have the same size and different batch
+ dataloader = strategy.setup_dataloader(replay_buffer)
+ dataloader_size = torch.tensor([len(dataloader)], device='cuda')
+ assert gather_and_equal(dataloader_size)
+ for experience in dataloader:
+ assert not gather_and_equal(experience.sequences)
+ assert not gather_and_equal(experience.action_log_probs)
+ assert not gather_and_equal(experience.values)
+ assert not gather_and_equal(experience.reward)
+ assert not gather_and_equal(experience.advantages)
+ # action mask and attention mask may be same
+
+
+def run_dist(rank, world_size, port, strategy):
+ os.environ['RANK'] = str(rank)
+ os.environ['LOCAL_RANK'] = str(rank)
+ os.environ['WORLD_SIZE'] = str(world_size)
+ os.environ['MASTER_ADDR'] = 'localhost'
+ os.environ['MASTER_PORT'] = str(port)
+ run_test_data(strategy)
+
+
+@pytest.mark.skip
+@pytest.mark.dist
+@pytest.mark.parametrize('world_size', [2])
+@pytest.mark.parametrize('strategy', ['ddp', 'colossalai'])
+@rerun_if_address_is_in_use()
+def test_data(world_size, strategy):
+ spawn(run_dist, world_size, strategy=strategy)
+
+
+if __name__ == '__main__':
+ test_data(2, 'colossalai')
diff --git a/applications/Chat/version.txt b/applications/Chat/version.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3eefcb9dd5b38e2c1dc061052455dd97bcd51e6c
--- /dev/null
+++ b/applications/Chat/version.txt
@@ -0,0 +1 @@
+1.0.0
diff --git a/applications/README.md b/applications/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..cd0435aae199aade3981c1af6502cf42d0d8578e
--- /dev/null
+++ b/applications/README.md
@@ -0,0 +1,12 @@
+# Applications
+
+This directory contains the applications that are powered by Colossal-AI.
+
+The list of applications include:
+
+- [X] [Chatbot](./Chat/README.md)
+- [X] [FastFold](https://github.com/hpcaitech/FastFold): Optimizing AlphaFold (Biomedicine) Training and Inference on GPU Clusters
+
+> Please note that the `Chatbot` application is migrated from the original `ChatGPT` folder.
+
+You can find more example code for base models and functions in the [Examples](https://github.com/hpcaitech/ColossalAI/tree/main/examples) directory.
diff --git a/colossalai/_C/__init__.py b/colossalai/_C/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/colossalai/__init__.py b/colossalai/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f859161f78108e4c8b5cfba89e12026fee28da43
--- /dev/null
+++ b/colossalai/__init__.py
@@ -0,0 +1,17 @@
+from .initialize import (
+ get_default_parser,
+ initialize,
+ launch,
+ launch_from_openmpi,
+ launch_from_slurm,
+ launch_from_torch,
+)
+
+try:
+ # .version will be created by setup.py
+ from .version import __version__
+except ModuleNotFoundError:
+ # this will only happen if the user did not run `pip install`
+ # and directly set PYTHONPATH to use Colossal-AI which is a bad practice
+ __version__ = '0.0.0'
+ print('please install Colossal-AI from https://www.colossalai.org/download or from source')
diff --git a/colossalai/_analyzer/README.md b/colossalai/_analyzer/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c5c55eddd325a2f94b221e78945c51b6b14c21ae
--- /dev/null
+++ b/colossalai/_analyzer/README.md
@@ -0,0 +1,306 @@
+# Analyzer
+
+# Overview
+The Analyzer is a collection of static graph utils including Colossal-AI FX. Features include:
+- MetaTensor -- enabling:
+ - Ahead-of-time Profiling
+ - Shape Propagation
+ - Ideal Flop Counter
+- symbolic_trace()
+ - Robust Control-flow Tracing / Recompile
+ - Robust Activation Checkpoint Tracing / CodeGen
+ - Easy-to-define Bias-Addition Split
+- symbolic_profile()
+ - Support ``MetaTensorMode``, where all Tensor operations are executed symbolically.
+ - Shape Inference Across Device and Unified ``MetaInfo``
+ - Ideal Flop Counter https://dev-discuss.pytorch.org/t/the-ideal-pytorch-flop-counter-with-torch-dispatch/505
+
+# Quickstart
+## Analyzer.FX
+**Reference:**
+
+ https://pytorch.org/docs/stable/fx.html [[paper](https://arxiv.org/pdf/2112.08429)]
+
+
+torch.FX is a toolkit for developers to use to transform nn.Module instances. FX consists of three main components: a symbolic tracer, an intermediate representation, and Python code generation. FX.Tracer hacks _\_\_torch_function\_\__ and use a Proxy object to propagate through any forward function of torch.nn.Module.
+
+ColossalAI FX is modified from torch.FX, with the extra capability of ahead-of-time profiling enabled by the subclass of ``MetaTensor``.
+
+### Analyzer.FX.symbolic_trace()
+A drawback of the original torch.FX implementation is that it is poor at handling control flow. All control flow is not PyTorch native operands and requires actual instances that specify the branches to execute on. For example,
+
+```python
+class MyModule(nn.Module):
+ def forward(self, x):
+ if x.dim() == 3:
+ return x * 2 + 1
+ else:
+ return x - 5
+```
+
+The above function has the computation graph of
+
+
+
+However, since Proxy does not have concrete data, applying ``x.dim()`` will return nothing. In the context of the auto-parallel system, at least the control-flow dependencies for tensor shape should be removed, since any searched strategy could only auto-parallelize a specific computation graph with the same tensor shape. It is native to attach concrete data onto a Proxy, and propagate them through control flow.
+
+
+
+
+With ``MetaTensor``, the computation during shape propagation can be virtualized. This speeds up tracing by avoiding allocating actual memory on devices.
+
+#### Remarks
+There is no free lunch for PyTorch to unify all operands in both its repo and other repos in its eco-system. For example, the einops library currently has no intention to support torch.FX (See https://github.com/arogozhnikov/einops/issues/188). To support different PyTorch-based libraries without modifying source code, good practices can be to allow users to register their implementation to substitute the functions not supported by torch.FX, or to avoid entering incompatible submodules.
+
+### Analyzer.FX.symbolic_profile()
+
+``symbolic_profile`` is another important feature of Colossal-AI's auto-parallel system. Profiling DNN can be costly, as you need to allocate memory and execute on real devices. However, since the profiling requirements for auto-parallel is enough if we can detect when and where the intermediate activations (i.e. Tensor) are generated, we can profile the whole procedure without actually executing it. ``symbolic_profile``, as its name infers, profiles the whole network with symbolic information only.
+
+```python
+with MetaTensorMode():
+ model = MyModule().cuda()
+ sample = torch.rand(100, 3, 224, 224).cuda()
+meta_args = dict(
+ x = sample,
+)
+gm = symbolic_trace(model, meta_args=meta_args)
+gm = symbolic_profile(gm, sample)
+```
+
+``symbolic_profile`` is enabled by ``ShapeProp`` and ``GraphProfile``.
+
+#### ShapeProp
+Both Tensor Parallel and Activation Checkpoint solvers need to know the shape information ahead of time. Unlike PyTorch's implementation, this ``ShapeProp`` can be executed under MetaTensorMode. With this, all the preparation for auto-parallel solvers can be done in milliseconds.
+
+Meanwhile, it is easy to keep track of the memory usage of each node when doing shape propagation. However, the drawbacks of FX is that not every ``call_function`` saves its input for backward, and different tensor that flows within one FX.Graph can actually have the same layout. This raises problems for fine-grained profiling.
+
+
+
+To address this problem, I came up with a simulated environment enabled by ``torch.autograd.graph.saved_tensor_hooks`` and fake ``data_ptr`` (check ``_subclasses/meta_tensor.py`` for more details of ``data_ptr`` updates).
+
+```python
+class sim_env(saved_tensors_hooks):
+ """
+ A simulation of memory allocation and deallocation in the forward pass
+ using ``saved_tensor_hooks``.
+
+ Attributes:
+ ctx (Dict[int, torch.Tensor]): A dictionary that maps the
+ data pointer of a tensor to the tensor itself. This is used
+ to track the memory allocation and deallocation.
+
+ param_ctx (Dict[int, torch.Tensor]): A dictionary that maps the
+ data pointer of all model parameters to the parameter itself.
+ This avoids overestimating the memory usage of the intermediate activations.
+ """
+
+ def __init__(self, module: Optional[torch.nn.Module] = None):
+ super().__init__(self.pack_hook, self.unpack_hook)
+ self.ctx = {}
+ self.param_ctx = {param.data_ptr(): param for param in module.parameters()}
+ self.buffer_ctx = {buffer.data_ptr(): buffer for buffer in module.buffers()} if module else {}
+
+ def pack_hook(self, tensor: torch.Tensor):
+ if tensor.data_ptr() not in self.param_ctx and tensor.data_ptr() not in self.buffer_ctx:
+ self.ctx[tensor.data_ptr()] = tensor
+ return tensor
+
+ def unpack_hook(self, tensor):
+ return tensor
+```
+The ``ctx`` variable will keep track of all saved tensors with a unique identifier. It is likely that ``nn.Parameter`` is also counted in the ``ctx``, which is not desired. To avoid this, we can use ``param_ctx`` to keep track of all parameters in the model. The ``buffer_ctx`` is used to keep track of all buffers in the model. The ``local_ctx`` that is attached to each ``Node`` marks the memory usage of the stage to which the node belongs. With simple ``intersect``, ``union`` and ``subtract`` operations, we can get any memory-related information. For non-profileable nodes, you might add your customized profile rules to simulate the memory allocation. If a ``Graph`` is modified with some non-PyTorch functions, such as fused operands, you can register the shape propagation rule with the decorator.
+
+```python
+@register_shape_impl(fuse_conv_bn)
+def fuse_conv_bn_shape_impl(*args, **kwargs):
+ # infer output shape here
+ return torch.empty(output_shape, device=output_device)
+```
+
+An important notice is that ``ShapeProp`` will attach additional information to the graph, which will be exactly the input of ``Profiler``.
+
+#### GraphProfiler
+``GraphProfiler`` executes at the node level, and profiles both forward and backward within one node. For example, ``FlopProfiler`` will profile the forward and backward FLOPs of a node, and ``CommunicationProfiler`` will profile the forward and backward communication cost of a node. The ``GraphProfiler`` will attach the profiling results to the ``Node``. These procedures are decoupled for better extensibility.
+
+To provide a general insight of the profiled results, you can set ``verbose=True`` to print the summary as well.
+```python
+model = tm.resnet18()
+sample = torch.rand(100, 3, 224, 224)
+meta_args = dict(x=sample)
+gm = symbolic_trace(model, meta_args=meta_args)
+gm = symbolic_profile(gm, sample, verbose=True)
+
+============================================================ Results =====================================================================
+ Op type Op Accumulate size Incremental size Output size Temp size Param size Backward size Fwd FLOPs Bwd FLOPs
+------------- ---------------------------------------------- ----------------- ------------------ ------------- ----------- ------------ --------------- ------------- -------------
+ placeholder x 4.59 Mb 0 b 4.59 Mb 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module conv_proj 4.59 Mb 0 b 0 b 4.59 Mb 2.25 Mb 4.59 Mb 924.84 MFLOPs 924.84 MFLOPs
+ call_method reshape 4.59 Mb 0 b 0 b 4.59 Mb 0 b 4.59 Mb 0 FLOPs 0 FLOPs
+ call_method permute 4.59 Mb 0 b 0 b 4.59 Mb 0 b 4.59 Mb 0 FLOPs 0 FLOPs
+ get_attr class_token 4.59 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_method expand 4.59 Mb 0 b 0 b 24.00 Kb 3.00 Kb 0 b 0 FLOPs 6.14 kFLOPs
+call_function cat 4.59 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+ get_attr encoder_pos_embedding 4.59 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+call_function add 9.21 Mb 4.62 Mb 4.62 Mb 0 b 591.00 Kb 4.62 Mb 1.21 MFLOPs 1.21 MFLOPs
+ call_module encoder_dropout 9.21 Mb 0 b 4.62 Mb 0 b 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_0_ln_1 9.22 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_0_self_attention 46.52 Mb 37.30 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem 46.52 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_1 46.52 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_0_dropout 46.52 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_1 51.14 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_0_ln_2 51.15 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_0_mlp_0 74.24 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_0_mlp_1 92.71 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_0_mlp_2 92.71 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_0_mlp_3 92.71 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_0_mlp_4 92.71 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_2 97.32 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_1_ln_1 101.95 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_1_self_attention 134.63 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_2 134.63 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_3 134.63 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_1_dropout 134.63 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_3 139.25 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_1_ln_2 139.26 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_1_mlp_0 162.35 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_1_mlp_1 180.82 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_1_mlp_2 180.82 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_1_mlp_3 180.82 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_1_mlp_4 180.82 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_4 185.43 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_2_ln_1 190.06 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_2_self_attention 222.74 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_4 222.74 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_5 222.74 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_2_dropout 222.74 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_5 227.36 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_2_ln_2 227.37 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_2_mlp_0 250.46 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_2_mlp_1 268.93 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_2_mlp_2 268.93 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_2_mlp_3 268.93 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_2_mlp_4 268.93 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_6 273.54 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_3_ln_1 278.17 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_3_self_attention 310.86 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_6 310.86 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_7 310.86 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_3_dropout 310.86 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_7 315.47 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_3_ln_2 315.48 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_3_mlp_0 338.57 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_3_mlp_1 357.04 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_3_mlp_2 357.04 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_3_mlp_3 357.04 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_3_mlp_4 357.04 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_8 361.66 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_4_ln_1 366.29 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_4_self_attention 398.97 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_8 398.97 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_9 398.97 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_4_dropout 398.97 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_9 403.58 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_4_ln_2 403.60 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_4_mlp_0 426.68 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_4_mlp_1 445.15 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_4_mlp_2 445.15 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_4_mlp_3 445.15 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_4_mlp_4 445.15 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_10 449.77 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_5_ln_1 454.40 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_5_self_attention 487.08 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_10 487.08 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_11 487.08 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_5_dropout 487.08 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_11 491.70 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_5_ln_2 491.71 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_5_mlp_0 514.79 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_5_mlp_1 533.26 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_5_mlp_2 533.26 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_5_mlp_3 533.26 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_5_mlp_4 533.26 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_12 537.88 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_6_ln_1 542.51 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_6_self_attention 575.19 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_12 575.19 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_13 575.19 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_6_dropout 575.19 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_13 579.81 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_6_ln_2 579.82 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_6_mlp_0 602.90 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_6_mlp_1 621.37 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_6_mlp_2 621.37 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_6_mlp_3 621.37 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_6_mlp_4 621.37 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_14 625.99 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_7_ln_1 630.62 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_7_self_attention 663.30 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_14 663.30 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_15 663.30 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_7_dropout 663.30 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_15 667.92 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_7_ln_2 667.93 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_7_mlp_0 691.02 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_7_mlp_1 709.48 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_7_mlp_2 709.48 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_7_mlp_3 709.48 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_7_mlp_4 709.48 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_16 714.10 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_8_ln_1 718.73 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_8_self_attention 751.41 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_16 751.41 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_17 751.41 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_8_dropout 751.41 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_17 756.03 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_8_ln_2 756.04 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_8_mlp_0 779.13 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_8_mlp_1 797.60 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_8_mlp_2 797.60 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_8_mlp_3 797.60 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_8_mlp_4 797.60 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_18 802.21 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_9_ln_1 806.84 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_9_self_attention 839.52 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_18 839.52 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_19 839.52 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_9_dropout 839.52 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_19 844.14 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_9_ln_2 844.15 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_9_mlp_0 867.24 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_9_mlp_1 885.71 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_9_mlp_2 885.71 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_9_mlp_3 885.71 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_9_mlp_4 885.71 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_20 890.32 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_10_ln_1 894.95 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_10_self_attention 927.63 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_20 927.63 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_21 927.63 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_10_dropout 927.63 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_21 932.25 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_10_ln_2 932.26 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_10_mlp_0 955.35 Mb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_10_mlp_1 973.82 Mb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_10_mlp_2 973.82 Mb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_10_mlp_3 973.82 Mb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_10_mlp_4 973.82 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_22 978.44 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_11_ln_1 983.06 Mb 4.63 Mb 4.62 Mb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_11_self_attention 1015.75 Mb 32.68 Mb 0 b 4.62 Mb 9.01 Mb 13.85 Mb 4.20 GFLOPs 8.40 GFLOPs
+call_function getitem_22 1015.75 Mb 0 b 0 b 4.62 Mb 0 b 0 b 0 FLOPs 0 FLOPs
+call_function getitem_23 1015.75 Mb 0 b 0 b 0 b 0 b 0 b 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_11_dropout 1015.75 Mb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_23 1020.36 Mb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_11_ln_2 1020.38 Mb 12.31 Kb 0 b 4.62 Mb 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+ call_module encoder_layers_encoder_layer_11_mlp_0 1.02 Gb 23.09 Mb 18.47 Mb 0 b 9.01 Mb 4.62 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_11_mlp_1 1.04 Gb 18.47 Mb 18.47 Mb 0 b 0 b 18.47 Mb 4.84 MFLOPs 4.84 MFLOPs
+ call_module encoder_layers_encoder_layer_11_mlp_2 1.04 Gb 0 b 18.47 Mb 0 b 0 b 18.47 Mb 0 FLOPs 0 FLOPs
+ call_module encoder_layers_encoder_layer_11_mlp_3 1.04 Gb 0 b 0 b 4.62 Mb 9.00 Mb 18.47 Mb 3.72 GFLOPs 7.44 GFLOPs
+ call_module encoder_layers_encoder_layer_11_mlp_4 1.04 Gb 0 b 0 b 4.62 Mb 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+call_function add_24 1.04 Gb 4.62 Mb 4.62 Mb 0 b 0 b 9.23 Mb 1.21 MFLOPs 0 FLOPs
+ call_module encoder_ln 1.04 Gb 36.31 Kb 24.00 Kb 0 b 6.00 Kb 4.62 Mb 6.05 MFLOPs 6.05 MFLOPs
+call_function getitem_24 1.04 Gb 0 b 24.00 Kb 0 b 0 b 4.62 Mb 0 FLOPs 0 FLOPs
+ call_module heads_head 1.04 Gb 0 b 0 b 31.25 Kb 2.93 Mb 24.00 Kb 6.14 MFLOPs 12.30 MFLOPs
+ output output 1.04 Gb 0 b 0 b 31.25 Kb 0 b 31.25 Kb 0 FLOPs 0 FLOPs
+```
diff --git a/colossalai/_analyzer/_subclasses/__init__.py b/colossalai/_analyzer/_subclasses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8464fed25edfbd598c43c5c587cb2f3de7cb2e09
--- /dev/null
+++ b/colossalai/_analyzer/_subclasses/__init__.py
@@ -0,0 +1,4 @@
+from ._meta_registration import *
+from ._monkey_patch import *
+from .flop_tensor import flop_count, flop_mapping
+from .meta_tensor import MetaTensor, MetaTensorMode
diff --git a/colossalai/_analyzer/_subclasses/_meta_registration.py b/colossalai/_analyzer/_subclasses/_meta_registration.py
new file mode 100644
index 0000000000000000000000000000000000000000..4049be79c70fc1d9c33807d74c2a00fe17c05acd
--- /dev/null
+++ b/colossalai/_analyzer/_subclasses/_meta_registration.py
@@ -0,0 +1,468 @@
+# meta patch from https://github.com/pytorch/pytorch/blob/master/torch/_meta_registrations.py
+# should be activated for PyTorch version 1.12.0 and below
+# refer to https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/native_functions.yaml
+# for more meta_registrations
+
+from typing import Callable, List, Optional, Tuple, Union
+
+import torch
+from packaging import version
+from torch.utils._pytree import tree_map
+
+aten = torch.ops.aten
+
+try:
+ meta_lib = torch.library.Library("aten", "IMPL", "Meta")
+except AttributeError:
+ meta_lib = None
+
+meta_table = {}
+
+orig_empty = torch.empty
+orig_empty_strided = torch.empty_strided
+orig_empty_like = torch.empty_like
+
+
+def new(*args, **kwargs):
+ return orig_empty(*args, **kwargs, device=torch.device('meta'))
+
+
+def new_strided(*args, **kwargs):
+ return orig_empty_strided(*args, **kwargs, device=torch.device('meta'))
+
+
+def new_like(*args, **kwargs):
+ return orig_empty_like(*args, **kwargs, device=torch.device('meta'))
+
+
+def register_meta(op, register_dispatcher=True):
+
+ def wrapper(f):
+
+ def add_func(op):
+ meta_table[op] = f
+ if register_dispatcher:
+ name = (op.__name__ if op._overloadname != "default" else op.overloadpacket.__name__)
+ try:
+ meta_lib.impl(name, f)
+ except:
+ pass
+
+ tree_map(add_func, op)
+ return f
+
+ return wrapper
+
+
+if version.parse(torch.__version__) >= version.parse('1.12.0'):
+ # ============================== Convolutions ======================================
+ # https://github.com/pytorch/pytorch/pull/79834
+ @register_meta(aten.convolution.default)
+ def meta_conv(
+ input_tensor: torch.Tensor,
+ weight: torch.Tensor,
+ bias: torch.Tensor,
+ stride: List[int],
+ padding: List[int],
+ dilation: List[int],
+ is_transposed: bool,
+ output_padding: List[int],
+ groups: int,
+ ):
+
+ def _formula(ln: int, p: int, d: int, k: int, s: int) -> int:
+ """
+ Formula to apply to calculate the length of some dimension of the output
+ See: https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
+ Args:
+ ln: length of the dimension
+ p: padding in that dim
+ d: dilation in that dim
+ k: kernel size in that dim
+ s: stride in that dim
+ Returns:
+ The output length
+ """
+ return (ln + 2 * p - d * (k - 1) - 1) // s + 1
+
+ def _formula_transposed(ln: int, p: int, d: int, k: int, s: int, op: int) -> int:
+ """
+ Formula to apply to calculate the length of some dimension of the output
+ if transposed convolution is used.
+ See: https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose2d.html
+ Args:
+ ln: length of the dimension
+ p: padding in that dim
+ d: dilation in that dim
+ k: kernel size in that dim
+ s: stride in that dim
+ op: output padding in that dim
+ Returns:
+ The output length
+ """
+ return (ln - 1) * s - 2 * p + d * (k - 1) + op + 1
+
+ def calc_conv_nd_return_shape(
+ dims: torch.Size,
+ kernel_size: torch.Size,
+ stride: Union[List[int], int],
+ padding: Union[List[int], int],
+ dilation: Union[List[int], int],
+ output_padding: Optional[Union[List[int], int]] = None,
+ ):
+ ret_shape = []
+ if isinstance(stride, int):
+ stride = [stride] * len(dims)
+ elif len(stride) == 1:
+ stride = [stride[0]] * len(dims)
+
+ if isinstance(padding, int):
+ padding = [padding] * len(dims)
+ elif len(padding) == 1:
+ padding = [padding[0]] * len(dims)
+
+ if isinstance(dilation, int):
+ dilation = [dilation] * len(dims)
+ elif len(dilation) == 1:
+ dilation = [dilation[0]] * len(dims)
+
+ output_padding_list: Optional[List[int]] = None
+ if output_padding:
+ if isinstance(output_padding, int):
+ output_padding_list = [output_padding] * len(dims)
+ elif len(output_padding) == 1:
+ output_padding_list = [output_padding[0]] * len(dims)
+ else:
+ output_padding_list = output_padding
+
+ for i in range(len(dims)):
+ # If output_padding is present, we are dealing with a transposed convolution
+ if output_padding_list:
+ ret_shape.append(
+ _formula_transposed(
+ dims[i],
+ padding[i],
+ dilation[i],
+ kernel_size[i],
+ stride[i],
+ output_padding_list[i],
+ ))
+ else:
+ ret_shape.append(_formula(dims[i], padding[i], dilation[i], kernel_size[i], stride[i]))
+ return ret_shape
+
+ def pick_memory_format():
+ if input_tensor.is_contiguous(memory_format=torch.channels_last):
+ return torch.channels_last
+ elif input_tensor.is_contiguous(memory_format=torch.contiguous_format):
+ return torch.contiguous_format
+ elif input_tensor.is_contiguous(memory_format=torch.preserve_format):
+ return torch.preserve_format
+
+ kernel_size = weight.shape[2:]
+ dims = input_tensor.shape[2:]
+ if is_transposed:
+ out_channels = groups * weight.shape[1]
+
+ shape_out = calc_conv_nd_return_shape(
+ dims,
+ kernel_size,
+ stride,
+ padding,
+ dilation,
+ output_padding,
+ )
+
+ else:
+ out_channels = weight.shape[0]
+ if weight.shape[1] != input_tensor.shape[1] / groups:
+ raise RuntimeError("Invalid channel dimensions")
+ shape_out = calc_conv_nd_return_shape(dims, kernel_size, stride, padding, dilation)
+ out = input_tensor.new_empty((input_tensor.shape[0], out_channels, *shape_out))
+ mem_fmt = pick_memory_format()
+ out = out.to(memory_format=mem_fmt) # type: ignore[call-overload]
+ return out
+
+ @register_meta(aten._convolution.default)
+ def meta__conv(input_tensor: torch.Tensor, weight: torch.Tensor, bias: torch.Tensor, stride: List[int],
+ padding: List[int], dilation: List[int], is_transposed: bool, output_padding: List[int], groups: int,
+ *extra_args):
+ out = meta_conv(input_tensor, weight, bias, stride, padding, dilation, is_transposed, output_padding, groups)
+ return out
+
+ @register_meta(aten.convolution_backward.default)
+ def meta_conv_backward(grad_output: torch.Tensor, input: torch.Tensor, weight: torch.Tensor, bias_sizes, stride,
+ padding, dilation, transposed, output_padding, groups, output_mask):
+ return new_like(input), new_like(weight), new((bias_sizes))
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/AdaptiveAveragePooling.cpp
+ @register_meta(aten._adaptive_avg_pool2d_backward.default)
+ def meta_adaptive_avg_pool2d_backward(
+ grad_output: torch.Tensor,
+ input: torch.Tensor,
+ ):
+ return new_like(input)
+
+ # ================================ RNN =============================================
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/RNN.cpp
+ @register_meta(aten._cudnn_rnn.default)
+ def meta_cuda_rnn(
+ input,
+ weight,
+ weight_stride0,
+ weight_buf,
+ hx,
+ cx,
+ mode,
+ hidden_size,
+ proj_size,
+ num_layers,
+ batch_first,
+ dropout,
+ train,
+ bidirectional,
+ batch_sizes,
+ dropout_state,
+ ):
+
+ is_input_packed = len(batch_sizes) != 0
+ if is_input_packed:
+ seq_length = len(batch_sizes)
+ mini_batch = batch_sizes[0]
+ batch_sizes_sum = input.shape[0]
+ else:
+ seq_length = input.shape[1] if batch_first else input.shape[0]
+ mini_batch = input.shape[0] if batch_first else input.shape[1]
+ batch_sizes_sum = -1
+
+ num_directions = 2 if bidirectional else 1
+ out_size = proj_size if proj_size != 0 else hidden_size
+ if is_input_packed:
+ out_shape = [batch_sizes_sum, out_size * num_directions]
+ else:
+ out_shape = ([mini_batch, seq_length, out_size *
+ num_directions] if batch_first else [seq_length, mini_batch, out_size * num_directions])
+ output = input.new_empty(out_shape)
+
+ cell_shape = [num_layers * num_directions, mini_batch, hidden_size]
+ cy = new(0) if cx is None else cx.new_empty(cell_shape)
+
+ hy = hx.new_empty([num_layers * num_directions, mini_batch, out_size])
+
+ # TODO: Query cudnnGetRNNTrainingReserveSize (expose to python)
+ reserve_shape = 0 if train else 0
+ reserve = input.new_empty(reserve_shape, dtype=torch.uint8)
+
+ return output, hy, cy, reserve, weight_buf
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/RNN.cpp
+ @register_meta(aten._cudnn_rnn_backward.default)
+ def meta_cudnn_rnn_backward(input: torch.Tensor,
+ weight: torch.Tensor,
+ weight_stride0: int,
+ hx: torch.Tensor,
+ cx: Optional[torch.Tensor] = None,
+ *args,
+ **kwargs):
+ return new_like(input), new_like(weight), new_like(hx), new_like(cx) if cx is not None else new(
+ ()) # (grad_input, grad_weight, grad_hx, grad_cx)
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Activation.cpp
+ # ============================== Activations =======================================
+ _unregistered_ewise = [
+ aten.relu.default,
+ aten.prelu.default,
+ aten.hardswish.default,
+ aten.hardtanh.default,
+ aten.hardswish_backward.default,
+ aten.hardtanh_backward.default,
+ ]
+
+ if version.parse(torch.__version__) < version.parse('2.0.0'):
+ _unregistered_ewise += [
+ aten.prelu_backward.default,
+ ]
+
+ @register_meta(_unregistered_ewise)
+ def meta_unregistered_ewise(input: torch.Tensor, *args):
+ return new_like(input)
+
+ # ============================== Normalization =====================================
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/BatchNorm.cpp
+ @register_meta(aten.native_batch_norm.default)
+ def meta_bn(input: torch.Tensor, weight, bias, running_mean, running_var, training, momentum, eps):
+ n_input = input.size(1)
+ return new_like(input), new((n_input)), new((n_input))
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/BatchNorm.cpp
+ @register_meta(aten.native_batch_norm_backward.default)
+ def meta_bn_backward(dY: torch.Tensor, input: torch.Tensor, weight: torch.Tensor, running_mean, running_var,
+ save_mean, save_invstd, train, eps, output_mask):
+ return new_like(input), new_like(weight), new_like(weight) # (dX, dgamma, dbeta)
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/BatchNorm.cpp
+ @register_meta(aten.cudnn_batch_norm.default)
+ def meta_cudnn_bn(input: torch.Tensor, weight, bias, running_mean, running_var, training, momentum, eps):
+ n_input = input.size(1)
+ return new_like(input), new((n_input)), new((n_input)), new(
+ (0), dtype=torch.uint8) # (output, running_mean, running_var, reserve)
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/BatchNorm.cpp
+ # NB: CuDNN only implements the backward algorithm for batchnorm
+ # in training mode (evaluation mode batchnorm has a different algorithm),
+ # which is why this doesn't accept a 'training' parameter.
+ @register_meta(aten.cudnn_batch_norm_backward.default)
+ def meta_cudnn_bn_backward(dY: torch.Tensor, input: torch.Tensor, weight: torch.Tensor, running_mean, running_var,
+ save_mean, save_invstd, eps, reserve):
+ return new_like(input), new_like(weight), new_like(weight) # (dX, dgamma, dbeta)
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/layer_norm.cpp
+ @register_meta(aten.native_layer_norm.default)
+ def meta_ln(input: torch.Tensor, normalized_shape, weight, bias, eps):
+ bs, n_input = input.size(0), input.size(1)
+ return new_like(input), new((bs, n_input, 1)), new((bs, n_input, 1)) # (output, running_mean, running_var)
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/layer_norm.cpp
+ @register_meta(aten.native_layer_norm_backward.default)
+ def meta_ln_backward(dY: torch.Tensor, input: torch.Tensor, normalized_shape, mean, rstd, weight, bias,
+ grad_input_mask):
+ return new_like(input), new_like(weight), new_like(bias) # (dX, dgamma, dbeta)
+
+ # ================================== Misc ==========================================
+ # Maybe incorrect
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Im2Col.cpp
+ @register_meta(aten.im2col.default)
+ def meta_im2col(input: torch.Tensor, kernel_size, dilation, padding, stride):
+ return new_like(input)
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/native_functions.yaml
+ @register_meta(aten.roll.default)
+ def meta_roll(input: torch.Tensor, shifts, dims):
+ return input
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Scalar.cpp
+ @register_meta(aten._local_scalar_dense.default)
+ def meta_local_scalar_dense(self: torch.Tensor):
+ return 0
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/TensorCompare.cpp
+ @register_meta(aten.where.self)
+ def meta_where_self(condition: torch.Tensor, self: torch.Tensor, other: torch.Tensor):
+ result_type = torch.result_type(self, other)
+ return new_like(condition + self + other, dtype=result_type)
+
+ # ============================== Embedding =========================================
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Embedding.cpp
+
+ @register_meta(aten.embedding_dense_backward.default)
+ def meta_embedding_dense_backward(grad_output: torch.Tensor, indices: torch.Tensor, num_weights, padding_idx,
+ scale_grad_by_freq):
+ return new((num_weights, grad_output.size(-1)), dtype=grad_output.dtype, layout=grad_output.layout)
+
+ # ============================== Dropout ===========================================
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Dropout.cpp
+ @register_meta(aten.native_dropout.default)
+ def meta_native_dropout_default(input: torch.Tensor, p: float, train: bool = False):
+ # notice that mask is bool
+ return new_like(input), new_like(input, dtype=torch.bool) # (output, mask)
+
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Dropout.cpp
+ @register_meta(aten.native_dropout_backward.default)
+ def meta_native_dropout_backward_default(grad: torch.Tensor, mask: torch.Tensor, scale: float):
+ return new_like(grad) # (grad_in)
+
+ if version.parse(torch.__version__) < version.parse('1.13.0'):
+ # https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/native_functions.yaml
+ @register_meta(aten.eye.m_out)
+ def meta_eye(n: int, m: int, out: torch.Tensor):
+ return out
+
+ @register_meta(aten.index.Tensor)
+ def meta_index_Tensor(self, indices):
+ assert indices, "at least one index must be provided"
+ # aten::index is the internal advanced indexing implementation
+ # checkIndexTensorTypes and expandTensors
+ result: List[Optional[torch.Tensor]] = []
+ for i, index in enumerate(indices):
+ if index is not None:
+ assert index.dtype in [torch.long, torch.int8, torch.bool],\
+ "tensors used as indices must be long, byte or bool tensors"
+ if index.dtype in [torch.int8, torch.bool]:
+ nonzero = index.nonzero()
+ k = len(result)
+ assert k + index.ndim <= self.ndim, f"too many indices for tensor of dimension {self.ndim}"
+ for j in range(index.ndim):
+ assert index.shape[j] == self.shape[
+ k +
+ j], f"The shape of the mask {index.shape} at index {i} does not match the shape of the indexed tensor {self.shape} at index {k + j}"
+ result.append(nonzero.select(1, j))
+ else:
+ result.append(index)
+ else:
+ result.append(index)
+ indices = result
+ assert len(
+ indices) <= self.ndim, f"too many indices for tensor of dimension {self.ndim} (got {len(indices)})"
+ # expand_outplace
+ import torch._refs as refs
+
+ indices = list(refs._maybe_broadcast(*indices))
+ # add missing null tensors
+ while len(indices) < self.ndim:
+ indices.append(None)
+
+ # hasContiguousSubspace
+ # true if all non-null tensors are adjacent
+ # See:
+ # https://numpy.org/doc/stable/user/basics.indexing.html#combining-advanced-and-basic-indexing
+ # https://stackoverflow.com/questions/53841497/why-does-numpy-mixed-basic-advanced-indexing-depend-on-slice-adjacency
+ state = 0
+ has_contiguous_subspace = False
+ for index in indices:
+ if state == 0:
+ if index is not None:
+ state = 1
+ elif state == 1:
+ if index is None:
+ state = 2
+ else:
+ if index is not None:
+ break
+ else:
+ has_contiguous_subspace = True
+
+ # transposeToFront
+ # This is the logic that causes the newly inserted dimensions to show up
+ # at the beginning of the tensor, if they're not contiguous
+ if not has_contiguous_subspace:
+ dims = []
+ transposed_indices = []
+ for i, index in enumerate(indices):
+ if index is not None:
+ dims.append(i)
+ transposed_indices.append(index)
+ for i, index in enumerate(indices):
+ if index is None:
+ dims.append(i)
+ transposed_indices.append(index)
+ self = self.permute(dims)
+ indices = transposed_indices
+
+ # AdvancedIndex::AdvancedIndex
+ # Now we can assume the indices have contiguous subspace
+ # This is simplified from AdvancedIndex which goes to more effort
+ # to put the input and indices in a form so that TensorIterator can
+ # take them. If we write a ref for this, probably that logic should
+ # get implemented
+ before_shape: List[int] = []
+ after_shape: List[int] = []
+ replacement_shape: List[int] = []
+ for dim, index in enumerate(indices):
+ if index is None:
+ if replacement_shape:
+ after_shape.append(self.shape[dim])
+ else:
+ before_shape.append(self.shape[dim])
+ else:
+ replacement_shape = list(index.shape)
+ return self.new_empty(before_shape + replacement_shape + after_shape)
diff --git a/colossalai/_analyzer/_subclasses/_monkey_patch.py b/colossalai/_analyzer/_subclasses/_monkey_patch.py
new file mode 100644
index 0000000000000000000000000000000000000000..b3ec98f0811f265e370c638369269f73e589dfd6
--- /dev/null
+++ b/colossalai/_analyzer/_subclasses/_monkey_patch.py
@@ -0,0 +1,93 @@
+import torch
+import torch.distributed as dist
+from packaging import version
+
+__all__ = [
+ "_TorchFactoryMethod",
+ "_TorchOverrideableFactoryMethod",
+ "_TorchNonOverrideableFactoryMethod",
+ "_TensorPropertyMethod",
+ "_DistCommMethod",
+ "_AliasATen",
+ "_InplaceATen",
+ "_MaybeInplaceATen",
+]
+
+_TorchOverrideableFactoryMethod = [
+ "empty",
+ "eye",
+ "full",
+ "ones",
+ "rand",
+ "randn",
+ "zeros",
+]
+
+_TorchNonOverrideableFactoryMethod = [
+ "arange",
+ "finfo",
+ "linspace",
+ "logspace",
+ "randint",
+ "randperm",
+ "tensor",
+]
+
+_TorchFactoryMethod = _TorchOverrideableFactoryMethod + _TorchNonOverrideableFactoryMethod
+
+_TensorPropertyMethod = ["dtype", "shape", "device", "requires_grad", "grad", "grad_fn", "data"]
+
+_DistCommMethod = [
+ "all_gather",
+ "all_reduce",
+ "all_to_all",
+ "broadcast",
+ "gather",
+ "reduce",
+ "reduce_scatter",
+ "scatter",
+]
+
+if version.parse(torch.__version__) >= version.parse('1.12.0'):
+ aten = torch.ops.aten
+ # TODO: dive deep here
+ # refer to https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/TensorShape.cpp
+ _AliasATen = [
+ aten.detach.default,
+ aten.detach_.default,
+ aten.t.default,
+ aten.transpose.int,
+ aten.view.default,
+ aten._unsafe_view.default,
+ aten._reshape_alias.default,
+ ]
+
+ _InplaceATen = [
+ aten.add_.Tensor,
+ aten.add_.Scalar,
+ aten.sub_.Tensor,
+ aten.sub_.Scalar,
+ aten.mul_.Tensor,
+ aten.mul_.Scalar,
+ aten.div_.Tensor,
+ aten.div_.Scalar,
+ aten.pow_.Tensor,
+ aten.pow_.Scalar,
+ ]
+
+ # use `MaybeInplace` because they call ``as_strided()`` or ``slice()``
+ _MaybeInplaceATen = [
+ aten.diagonal.default,
+ aten.expand.default,
+ aten.select.int,
+ aten.slice.Tensor,
+ aten.split.Tensor,
+ aten.squeeze.default,
+ aten.permute.default,
+ aten.unsqueeze.default,
+ aten.as_strided.default,
+ ]
+else:
+ _AliasATen = []
+ _InplaceATen = []
+ _MaybeInplaceATen = []
diff --git a/colossalai/_analyzer/_subclasses/flop_tensor.py b/colossalai/_analyzer/_subclasses/flop_tensor.py
new file mode 100644
index 0000000000000000000000000000000000000000..59991dc5091254631dd4c641c528b09aaf97c285
--- /dev/null
+++ b/colossalai/_analyzer/_subclasses/flop_tensor.py
@@ -0,0 +1,563 @@
+# adopted from https://github.com/facebookresearch/fvcore/blob/main/fvcore/nn/jit_handles.py
+# ideas from https://pastebin.com/AkvAyJBw
+# and https://dev-discuss.pytorch.org/t/the-ideal-pytorch-flop-counter-with-torch-dispatch/505
+
+import operator
+from collections import defaultdict
+from contextlib import contextmanager
+from enum import Enum, auto
+from functools import partial, reduce
+from numbers import Number
+from typing import Any, Callable, List, Optional, Union
+
+import torch
+from packaging import version
+from torch.utils._pytree import tree_map
+
+from .meta_tensor import MetaTensor
+
+aten = torch.ops.aten
+
+
+class Phase(Enum):
+ FWD = auto()
+ BWD = auto()
+
+
+def normalize_tuple(x):
+ if not isinstance(x, tuple):
+ return (x,)
+ return x
+
+
+def _format_flops(flop):
+ K = 1e3
+ M = 1e6
+ B = 1e9
+ T = 1e12
+ if flop < K:
+ return f'{flop:.2f}'
+ elif flop < M:
+ return f'{flop / K:.2f}K'
+ elif flop < B:
+ return f'{flop / M:.2f}M'
+ elif flop < T:
+ return f'{flop / B:.2f}B'
+ else:
+ return f'{flop / T:.2f}T'
+
+
+def flop_count(module: Union[torch.nn.Module, Callable] = None, *args, verbose: bool = False, **kwargs) -> Number:
+ """
+ Count the number of floating point operations in a model.
+ Ideas from https://pastebin.com/AkvAyJBw.
+ Args:
+ module (torch.nn.Module): A PyTorch model.
+ *args: Input arguments to the model.
+ verbose (bool): If True, print the number of flops for each module.
+ **kwargs: Input keyword arguments to the model.
+ Returns:
+ Number: The total number of floating point operations (FWD + BWD).
+ """
+ maybe_inplace = (getattr(module, 'inplace', False) or kwargs.get('inplace', False)
+ or getattr(module, '__name__', None) in ('add_', 'mul_', 'div_', 'sub_'))
+
+ class DummyModule(torch.nn.Module):
+
+ def __init__(self, func):
+ super().__init__()
+ self.func = func
+ self.__name__ = func.__name__
+
+ def forward(self, *args, **kwargs):
+ return self.func(*args, **kwargs)
+
+ total_flop_count = {Phase.FWD: 0, Phase.BWD: 0}
+ flop_counts = defaultdict(lambda: defaultdict(int))
+ parents = ['Global']
+ module = module if isinstance(module, torch.nn.Module) else DummyModule(module)
+
+ class FlopTensor(MetaTensor):
+ _tensor: torch.Tensor
+
+ def __repr__(self):
+ name = 'FlopParameter' if getattr(self, '_is_param', False) else 'FlopTensor'
+ if self.grad_fn:
+ return f"{name}(..., size={tuple(self.shape)}, device='{self.device}', dtype={self.dtype}, grad_fn={self.grad_fn})"
+ return f"{name}(..., size={tuple(self.shape)}, device='{self.device}', dtype={self.dtype})"
+
+ @classmethod
+ def __torch_dispatch__(cls, func, types, args=(), kwargs=None):
+
+ # no_dispatch is only needed if you use enable_python_mode.
+ # It prevents infinite recursion.
+ rs = super().__torch_dispatch__(func, types, args, kwargs)
+
+ outs = normalize_tuple(rs)
+
+ if func in flop_mapping:
+ nonlocal flop_counts, total_flop_count
+ flop_count = flop_mapping[func](args, outs)
+ for par in parents:
+ flop_counts[par][func.__name__] += flop_count
+ total_flop_count[cur_phase] += flop_count
+
+ def wrap(x):
+ if isinstance(x, MetaTensor):
+ x = FlopTensor(x)
+ return x
+
+ rs = tree_map(wrap, rs)
+
+ return rs
+
+ def is_autogradable(x):
+ return isinstance(x, torch.Tensor) and x.is_floating_point()
+
+ def create_backwards_push(name):
+
+ class PushState(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, *args):
+ args = tree_map(lambda x: x.clone() if isinstance(x, torch.Tensor) else x, args)
+ if len(args) == 1:
+ return args[0]
+ return args
+
+ @staticmethod
+ def backward(ctx, *grad_outs):
+ nonlocal parents
+ parents.append(name)
+ return grad_outs
+
+ return PushState.apply
+
+ def create_backwards_pop(name):
+
+ class PopState(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, *args):
+ args = tree_map(lambda x: x.clone() if isinstance(x, torch.Tensor) else x, args)
+ if len(args) == 1:
+ return args[0]
+ return args
+
+ @staticmethod
+ def backward(ctx, *grad_outs):
+ nonlocal parents
+ assert (parents[-1] == name)
+ parents.pop()
+ return grad_outs
+
+ return PopState.apply
+
+ def enter_module(name):
+
+ def f(module, inputs):
+ nonlocal parents
+ parents.append(name)
+ inputs = normalize_tuple(inputs)
+ out = create_backwards_pop(name)(*inputs)
+ return out
+
+ return f
+
+ def exit_module(name):
+
+ def f(module, inputs, outputs):
+ nonlocal parents
+ assert (parents[-1] == name)
+ parents.pop()
+ outputs = normalize_tuple(outputs)
+ return create_backwards_push(name)(*outputs)
+
+ return f
+
+ @contextmanager
+ def instrument_module(mod):
+ registered = []
+ for name, module in dict(mod.named_children()).items():
+ registered.append(module.register_forward_pre_hook(enter_module(name)))
+ registered.append(module.register_forward_hook(exit_module(name)))
+ yield
+ for handle in registered:
+ handle.remove()
+
+ def display_flops():
+ for mod in flop_counts.keys():
+ print(f"Module: ", mod)
+ for k, v in flop_counts[mod].items():
+ print('\t', k, _format_flops(v))
+ print()
+
+ def detach_variables(r):
+ if isinstance(r, torch.Tensor):
+ requires_grad = r.requires_grad
+ r = r.detach()
+ r.requires_grad = requires_grad
+ return r
+
+ def wrap(r):
+ if isinstance(r, torch.Tensor):
+ data_ptr_fn = getattr(r, '_tensor', r).data_ptr
+ r = FlopTensor(detach_variables(r))
+ if maybe_inplace:
+ r = r + 0
+ r._tensor.data_ptr = data_ptr_fn
+ return r
+
+ with instrument_module(module):
+ cur_phase = Phase.FWD
+ rst = module(*tree_map(wrap, args), **tree_map(wrap, kwargs))
+ rst = tuple(r for r in normalize_tuple(rst) if is_autogradable(r) and r.requires_grad)
+ cur_phase = Phase.BWD
+
+ if rst:
+ grad = [torch.zeros_like(t) for t in rst]
+ torch.autograd.backward(
+ rst,
+ grad,
+ )
+
+ if verbose:
+ display_flops()
+
+ return total_flop_count[Phase.FWD], total_flop_count[Phase.BWD]
+
+
+def matmul_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for matmul.
+ """
+ # Inputs should be a list of length 2.
+ # Inputs contains the shapes of two matrices.
+ input_shapes = [v.shape for v in inputs]
+ assert len(input_shapes) == 2, input_shapes
+
+ # There are three cases: 1) gemm, 2) gemv, 3) dot
+ if all(len(shape) == 2 for shape in input_shapes):
+ # gemm
+ assert input_shapes[0][-1] == input_shapes[1][-2], input_shapes
+ elif all(len(shape) == 1 for shape in input_shapes):
+ # dot
+ assert input_shapes[0][0] == input_shapes[1][0], input_shapes
+
+ # expand shape
+ input_shapes[0] = torch.Size([1, input_shapes[0][0]])
+ input_shapes[1] = torch.Size([input_shapes[1][0], 1])
+ else:
+ # gemv
+ if len(input_shapes[0]) == 1:
+ assert input_shapes[0][0] == input_shapes[1][-2], input_shapes
+ input_shapes.reverse()
+ else:
+ assert input_shapes[1][0] == input_shapes[0][-1], input_shapes
+
+ # expand the shape of the vector to [batch size, 1]
+ input_shapes[-1] = torch.Size([input_shapes[-1][-1], 1])
+ flops = reduce(operator.mul, input_shapes[0]) * input_shapes[-1][-1]
+ return flops
+
+
+def addmm_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for fully connected layers.
+ """
+ # Count flop for nn.Linear
+ # inputs is a list of length 3.
+ input_shapes = [v.shape for v in inputs[1:3]]
+ # input_shapes[0]: [batch size, input feature dimension]
+ # input_shapes[1]: [input feature dimension, output feature dimension]
+ assert len(input_shapes[0]) == 2, input_shapes[0]
+ assert len(input_shapes[1]) == 2, input_shapes[1]
+ batch_size, input_dim = input_shapes[0]
+ output_dim = input_shapes[1][1]
+ flops = batch_size * input_dim * output_dim
+ return flops
+
+
+def linear_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for the aten::linear operator.
+ """
+ # Inputs is a list of length 3; unlike aten::addmm, it is the first
+ # two elements that are relevant.
+ input_shapes = [v.shape for v in inputs[0:2]]
+ # input_shapes[0]: [dim0, dim1, ..., input_feature_dim]
+ # input_shapes[1]: [output_feature_dim, input_feature_dim]
+ assert input_shapes[0][-1] == input_shapes[1][-1]
+ flops = reduce(operator.mul, input_shapes[0]) * input_shapes[1][0]
+ return flops
+
+
+def bmm_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for the bmm operation.
+ """
+ # Inputs should be a list of length 2.
+ # Inputs contains the shapes of two tensor.
+ assert len(inputs) == 2, len(inputs)
+ input_shapes = [v.shape for v in inputs]
+ n, c, t = input_shapes[0]
+ d = input_shapes[-1][-1]
+ flops = n * c * t * d
+ return flops
+
+
+def conv_flop_count(
+ x_shape: List[int],
+ w_shape: List[int],
+ out_shape: List[int],
+ transposed: bool = False,
+) -> Number:
+ """
+ Count flops for convolution. Note only multiplication is
+ counted. Computation for addition and bias is ignored.
+ Flops for a transposed convolution are calculated as
+ flops = (x_shape[2:] * prod(w_shape) * batch_size).
+ Args:
+ x_shape (list(int)): The input shape before convolution.
+ w_shape (list(int)): The filter shape.
+ out_shape (list(int)): The output shape after convolution.
+ transposed (bool): is the convolution transposed
+ Returns:
+ int: the number of flops
+ """
+ batch_size = x_shape[0]
+ conv_shape = (x_shape if transposed else out_shape)[2:]
+ flops = batch_size * reduce(operator.mul, w_shape) * reduce(operator.mul, conv_shape)
+ return flops
+
+
+def conv_flop_jit(inputs: List[Any], outputs: List[Any]):
+ """
+ Count flops for convolution.
+ """
+ x, w = inputs[:2]
+ x_shape, w_shape, out_shape = (x.shape, w.shape, outputs[0].shape)
+ transposed = inputs[6]
+
+ return conv_flop_count(x_shape, w_shape, out_shape, transposed=transposed)
+
+
+def transpose_shape(shape):
+ return [shape[1], shape[0]] + list(shape[2:])
+
+
+def conv_backward_flop_jit(inputs: List[Any], outputs: List[Any]):
+ grad_out_shape, x_shape, w_shape = [i.shape for i in inputs[:3]]
+ output_mask = inputs[-1]
+ fwd_transposed = inputs[7]
+ flop_count = 0
+
+ if output_mask[0]:
+ grad_input_shape = outputs[0].shape
+ flop_count += conv_flop_count(grad_out_shape, w_shape, grad_input_shape, not fwd_transposed)
+ if output_mask[1]:
+ grad_weight_shape = outputs[1].shape
+ flop_count += conv_flop_count(transpose_shape(x_shape), grad_out_shape, grad_weight_shape, fwd_transposed)
+
+ return flop_count
+
+
+def norm_flop_counter(affine_arg_index: int, input_arg_index: int) -> Callable:
+ """
+ Args:
+ affine_arg_index: index of the affine argument in inputs
+ """
+
+ def norm_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for norm layers.
+ """
+ # Inputs[0] contains the shape of the input.
+ input_shape = inputs[input_arg_index].shape
+
+ has_affine = inputs[affine_arg_index].shape is not None if hasattr(inputs[affine_arg_index],
+ 'shape') else inputs[affine_arg_index]
+ assert 2 <= len(input_shape) <= 5, input_shape
+ # 5 is just a rough estimate
+ flop = reduce(operator.mul, input_shape) * (5 if has_affine else 4)
+ return flop
+
+ return norm_flop_jit
+
+
+def batchnorm_flop_jit(inputs: List[Any], outputs: List[Any], training: bool = None) -> Number:
+ if training is None:
+ training = inputs[-3]
+ assert isinstance(training, bool), "Signature of aten::batch_norm has changed!"
+ if training:
+ return norm_flop_counter(1, 0)(inputs, outputs) # pyre-ignore
+ has_affine = inputs[1].shape is not None
+ input_shape = reduce(operator.mul, inputs[0].shape)
+ return input_shape * (2 if has_affine else 1)
+
+
+def ewise_flop_counter(input_scale: float = 1, output_scale: float = 0) -> Callable:
+ """
+ Count flops by
+ input_tensor.numel() * input_scale + output_tensor.numel() * output_scale
+ Args:
+ input_scale: scale of the input tensor (first argument)
+ output_scale: scale of the output tensor (first element in outputs)
+ """
+
+ def ewise_flop(inputs: List[Any], outputs: List[Any]) -> Number:
+ ret = 0
+ if input_scale != 0:
+ shape = inputs[0].shape
+ ret += input_scale * reduce(operator.mul, shape) if shape else 0
+ if output_scale != 0:
+ shape = outputs[0].shape
+ ret += output_scale * reduce(operator.mul, shape) if shape else 0
+ return ret
+
+ return ewise_flop
+
+
+def zero_flop_jit(*args):
+ """
+ Count flops for zero flop layers.
+ """
+ return 0
+
+
+if version.parse(torch.__version__) >= version.parse('1.12.0'):
+ flop_mapping = {
+ # gemm
+ aten.mm.default: matmul_flop_jit,
+ aten.matmul.default: matmul_flop_jit,
+ aten.addmm.default: addmm_flop_jit,
+ aten.bmm.default: bmm_flop_jit,
+
+ # convolution
+ aten.convolution.default: conv_flop_jit,
+ aten._convolution.default: conv_flop_jit,
+ aten.convolution_backward.default: conv_backward_flop_jit,
+
+ # normalization
+ aten.native_batch_norm.default: batchnorm_flop_jit,
+ aten.native_batch_norm_backward.default: batchnorm_flop_jit,
+ aten.cudnn_batch_norm.default: batchnorm_flop_jit,
+ aten.cudnn_batch_norm_backward.default: partial(batchnorm_flop_jit, training=True),
+ aten.native_layer_norm.default: norm_flop_counter(2, 0),
+ aten.native_layer_norm_backward.default: norm_flop_counter(2, 0),
+
+ # pooling
+ aten.avg_pool1d.default: ewise_flop_counter(1, 0),
+ aten.avg_pool2d.default: ewise_flop_counter(1, 0),
+ aten.avg_pool2d_backward.default: ewise_flop_counter(0, 1),
+ aten.avg_pool3d.default: ewise_flop_counter(1, 0),
+ aten.avg_pool3d_backward.default: ewise_flop_counter(0, 1),
+ aten.max_pool1d.default: ewise_flop_counter(1, 0),
+ aten.max_pool2d.default: ewise_flop_counter(1, 0),
+ aten.max_pool3d.default: ewise_flop_counter(1, 0),
+ aten.max_pool1d_with_indices.default: ewise_flop_counter(1, 0),
+ aten.max_pool2d_with_indices.default: ewise_flop_counter(1, 0),
+ aten.max_pool2d_with_indices_backward.default: ewise_flop_counter(0, 1),
+ aten.max_pool3d_with_indices.default: ewise_flop_counter(1, 0),
+ aten.max_pool3d_with_indices_backward.default: ewise_flop_counter(0, 1),
+ aten._adaptive_avg_pool2d.default: ewise_flop_counter(1, 0),
+ aten._adaptive_avg_pool2d_backward.default: ewise_flop_counter(0, 1),
+ aten._adaptive_avg_pool3d.default: ewise_flop_counter(1, 0),
+ aten._adaptive_avg_pool3d_backward.default: ewise_flop_counter(0, 1),
+ aten.embedding_dense_backward.default: ewise_flop_counter(0, 1),
+ aten.embedding.default: ewise_flop_counter(1, 0),
+ }
+
+ ewise_flop_aten = [
+ # basic op
+ aten.add.Tensor,
+ aten.add_.Tensor,
+ aten.div.Tensor,
+ aten.div_.Tensor,
+ aten.div.Scalar,
+ aten.div_.Scalar,
+ aten.mul.Tensor,
+ aten.mul.Scalar,
+ aten.mul_.Tensor,
+ aten.neg.default,
+ aten.pow.Tensor_Scalar,
+ aten.rsub.Scalar,
+ aten.sum.default,
+ aten.sum.dim_IntList,
+ aten.mean.dim,
+
+ # activation op
+ aten.hardswish.default,
+ aten.hardswish_.default,
+ aten.hardswish_backward.default,
+ aten.hardtanh.default,
+ aten.hardtanh_.default,
+ aten.hardtanh_backward.default,
+ aten.hardsigmoid_backward.default,
+ aten.hardsigmoid.default,
+ aten.gelu.default,
+ aten.gelu_backward.default,
+ aten.silu.default,
+ aten.silu_.default,
+ aten.silu_backward.default,
+ aten.sigmoid.default,
+ aten.sigmoid_backward.default,
+ aten._softmax.default,
+ aten._softmax_backward_data.default,
+ aten.relu_.default,
+ aten.relu.default,
+ aten.tanh.default,
+ aten.tanh_backward.default,
+ aten.threshold_backward.default,
+
+ # dropout
+ aten.native_dropout.default,
+ aten.native_dropout_backward.default,
+
+ # distribution
+ aten.bernoulli_.float,
+
+ # where
+ aten.where.self,
+ ]
+ for op in ewise_flop_aten:
+ flop_mapping[op] = ewise_flop_counter(1, 0)
+
+ # fix-me: this will be removed in future
+ zero_flop_aten = [
+ aten.as_strided.default,
+ aten.as_strided_.default,
+ aten.cat.default,
+ aten.clone.default,
+ aten.copy_.default,
+ aten.detach.default,
+ aten.expand.default,
+ aten.empty_like.default,
+ aten.new_empty.default,
+ aten.new_empty_strided.default,
+ aten.ones_like.default,
+ aten._reshape_alias.default,
+ aten.select.int,
+ aten.select_backward.default,
+ aten.squeeze.dim,
+ aten.slice.Tensor,
+ aten.slice_backward.default,
+ aten.split.Tensor,
+ aten.permute.default,
+ aten.t.default,
+ aten.transpose.int,
+ aten._to_copy.default,
+ aten.unsqueeze.default,
+ aten.unbind.int,
+ aten._unsafe_view.default,
+ aten.view.default,
+ aten.zero_.default,
+ aten.zeros_like.default,
+ ]
+
+ for op in zero_flop_aten:
+ flop_mapping[op] = zero_flop_jit
+else:
+ flop_mapping = {}
+ elementwise_flop_aten = {}
+ zero_flop_aten = {}
diff --git a/colossalai/_analyzer/_subclasses/meta_tensor.py b/colossalai/_analyzer/_subclasses/meta_tensor.py
new file mode 100644
index 0000000000000000000000000000000000000000..2bc212938ee08f1143b5dda354d9ec600dd64662
--- /dev/null
+++ b/colossalai/_analyzer/_subclasses/meta_tensor.py
@@ -0,0 +1,207 @@
+import uuid
+from functools import partial
+
+import torch
+import torch.distributed as dist
+from torch.types import _bool, _device, _dtype
+from torch.utils._pytree import tree_flatten, tree_map
+
+from ._monkey_patch import _AliasATen, _DistCommMethod, _InplaceATen, _MaybeInplaceATen, _TorchOverrideableFactoryMethod
+
+__all__ = ['MetaTensor', 'MetaTensorMode']
+
+
+def register_storage(r, data_ptr_fn=None):
+ if isinstance(r, torch.Tensor):
+ if data_ptr_fn is not None:
+ r.data_ptr = data_ptr_fn
+ elif not r.data_ptr():
+ data_ptr = uuid.uuid1()
+ r.data_ptr = lambda: data_ptr
+
+
+def _normalize_tuple(x):
+ if not isinstance(x, tuple):
+ return (x,)
+ return x
+
+
+# a hack of inplace execution in PyTorch
+def _assert_alias(func):
+ return func in (_AliasATen + _InplaceATen + _MaybeInplaceATen # TODO: check if should be this aggressive
+ )
+
+
+class MetaTensor(torch.Tensor):
+ """
+ A wrapping tensor that hacks ``torch.autograd`` without patching more ``torch.ops.aten`` ops.
+ `device` is the device that ``MetaTensor`` is supposed to run on. Meta tensors give you the
+ ability to run PyTorch code without having to actually do computation through tensors
+ allocated on a `meta` device. Because the device is `meta`, meta tensors do not model
+ device propagation. ``MetaTensor`` extends its usage by carrying an additional `device`
+ which tracks devices that would have been used.
+
+ Reference:
+ https://github.com/pytorch/pytorch/blob/master/torch/_subclasses/fake_tensor.py
+ """
+
+ _tensor: torch.Tensor
+
+ @staticmethod
+ def __new__(cls, elem, device=None, data_ptr_fn=None):
+ requires_grad = elem.requires_grad
+ # Avoid multiple wrapping
+ while isinstance(elem, MetaTensor):
+ device = elem.device if device is None else device
+ elem = elem._tensor
+
+ # The wrapping tensor (MetaTensor) shouldn't hold any
+ # memory for the class in question, but it should still
+ # advertise the same device as before
+ r = torch.Tensor._make_wrapper_subclass(
+ cls,
+ elem.size(),
+ strides=elem.stride(),
+ storage_offset=elem.storage_offset(),
+ dtype=elem.dtype,
+ layout=elem.layout,
+ device=device or (elem.device if elem.device.type != 'meta' else torch.device('cpu')),
+ requires_grad=requires_grad) # deceive the frontend for aten selections
+ r._tensor = elem
+ # ...the real tensor is held as an element on the tensor.
+ if not r._tensor.is_meta:
+ val = elem.data_ptr()
+ data_ptr_fn = lambda: val
+ r._tensor = r._tensor.to(torch.device('meta'))
+
+ # only tensor not on `meta` should be copied to `meta`
+ register_storage(r._tensor, data_ptr_fn)
+ if isinstance(elem, torch.nn.Parameter):
+ r = torch.nn.Parameter(r)
+ return r
+
+ def __repr__(self):
+ name = 'MetaParameter' if getattr(self, '_is_param', False) else 'MetaTensor'
+ if self.grad_fn:
+ return f"{name}(..., size={tuple(self.shape)}, device='{self.device}', dtype={self.dtype}, grad_fn={self.grad_fn})"
+ return f"{name}(..., size={tuple(self.shape)}, device='{self.device}', dtype={self.dtype})"
+
+ @classmethod
+ def __torch_dispatch__(cls, func, types, args=(), kwargs=None):
+ device = None
+
+ def unwrap(x):
+ nonlocal device
+ if isinstance(x, MetaTensor):
+ device = x.device
+ x = x._tensor
+ elif isinstance(x, torch.Tensor):
+ device = x.device
+ x = x.to(torch.device('meta'))
+ return x
+
+ args = tree_map(unwrap, args)
+ kwargs = tree_map(unwrap, kwargs)
+
+ if 'device' in kwargs:
+ device = kwargs['device']
+ kwargs['device'] = torch.device('meta')
+
+ # run aten for backend=CPU but actually on backend=Meta
+ # here we detect whether or not the execution generates a physical copy
+ # of the input tensor
+ ret = func(*args, **kwargs)
+
+ if _assert_alias(func):
+ val = args[0].data_ptr()
+ tree_map(partial(register_storage, data_ptr_fn=lambda: val), _normalize_tuple(ret))
+
+ # Now, we want to continue propagating this tensor, so we rewrap Tensors in
+ # our custom tensor subclass
+ def wrap(x):
+ return MetaTensor(x, device=device) if isinstance(x, torch.Tensor) else x
+
+ return tree_map(wrap, ret)
+
+ def to(self, *args, **kwargs) -> torch.Tensor:
+ """An extension of `torch.Tensor.to()` to MetaTensor
+ Returns:
+ result (MetaTensor): MetaTensor
+ Usage:
+ >>> tensor = MetaTensor(torch.rand(10), device='cuda:100')
+ >>> tensor.to(torch.uint8)
+ MetaTensor(tensor(..., device='meta', size=(10,), dtype=torch.uint8), device='cuda:100')
+ >>> tensor.to(torch.device('cuda:42'))
+ MetaTensor(tensor(..., device='meta', size=(10,)), device='cuda:42')
+ >>> tensor.to('vulkan')
+ MetaTensor(tensor(..., device='meta', size=(10,)), device='vulkan')
+ """
+ # this imitates c++ function in the way of @overload
+ device = None
+
+ def replace(x):
+ nonlocal device
+ if isinstance(x, str) or isinstance(x, _device):
+ device = x
+ return torch.device('meta')
+ return x
+
+ elem = self._tensor.to(*tree_map(replace, args), **tree_map(replace, kwargs))
+ return MetaTensor(elem, device=device)
+
+ def cpu(self, *args, **kwargs):
+ if self.device.type == 'cpu':
+ return self.to(*args, **kwargs)
+ return self.to(*args, device='cpu', **kwargs)
+
+ def cuda(self, device=None, non_blocking=False):
+ if device is not None:
+ return self.to(device=device, non_blocking=non_blocking)
+ return self.to(device='cuda:0', non_blocking=non_blocking)
+
+ def data_ptr(self):
+ return self._tensor.data_ptr()
+
+
+class MetaTensorMode(object):
+ """
+ A context manager that enables MetaTensor mode.
+
+ Usage:
+ >>> with MetaTensorMode():
+ >>> # all torch.xxx and torch.distributed.xxx will be replaced by patched functions
+ >>> # and the actual execution will be on torch.device('meta')
+ >>> a = torch.rand(100000, 100000)
+ >>> b = torch.rand(100000, 100000)
+ >>> c = torch.mm(a, b)
+ """
+
+ def __init__(self):
+ self.torch_overrides = {} # override torch.xxx
+ self.dist_overrides = {} # override torch.distributed.xxx
+
+ def __enter__(self):
+
+ def _dummy(*args, **kwargs):
+ pass
+
+ def _new(*args, orig_new=torch.empty, **kwargs):
+ return MetaTensor(orig_new(*args, **{
+ **kwargs, 'device': 'meta'
+ }),
+ device=kwargs.get('device', torch.device('cpu')))
+
+ for func in _TorchOverrideableFactoryMethod:
+ self.torch_overrides[func] = getattr(torch, func)
+ setattr(torch, func, partial(_new, orig_new=getattr(torch, func)))
+
+ for func in _DistCommMethod:
+ self.dist_overrides[func] = getattr(dist, func)
+ setattr(dist, func, _dummy)
+
+ def __exit__(self, exc_type, exc_value, traceback):
+ for func, func_impl in self.torch_overrides.items():
+ setattr(torch, func, func_impl)
+
+ for func, func_impl in self.dist_overrides.items():
+ setattr(dist, func, func_impl)
diff --git a/colossalai/_analyzer/envs.py b/colossalai/_analyzer/envs.py
new file mode 100644
index 0000000000000000000000000000000000000000..b537747c57a89824854b1b32f729fdb76b53dbd5
--- /dev/null
+++ b/colossalai/_analyzer/envs.py
@@ -0,0 +1,7 @@
+from dataclasses import dataclass
+
+
+@dataclass
+class MeshConfig:
+ TFLOPS: float = 1.9e12
+ BANDWIDTH = 1.2e9
diff --git a/colossalai/_analyzer/fx/__init__.py b/colossalai/_analyzer/fx/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa01de0bbe6c8e990e6b8054f525985343afa050
--- /dev/null
+++ b/colossalai/_analyzer/fx/__init__.py
@@ -0,0 +1,3 @@
+from .node_util import MetaInfo
+from .symbolic_profile import symbolic_profile
+from .tracer.symbolic_trace import symbolic_trace
diff --git a/colossalai/_analyzer/fx/codegen.py b/colossalai/_analyzer/fx/codegen.py
new file mode 100644
index 0000000000000000000000000000000000000000..41d74f2e3719a0e56adc61a6c35684584a2d80c7
--- /dev/null
+++ b/colossalai/_analyzer/fx/codegen.py
@@ -0,0 +1,459 @@
+from typing import Any, Callable, Dict, Iterable, List, Tuple
+
+import torch
+
+try:
+ from torch.fx.graph import CodeGen
+except:
+ pass
+from torch.fx.graph import (
+ PythonCode,
+ _custom_builtins,
+ _format_target,
+ _is_from_torch,
+ _Namespace,
+ _origin_type_map,
+ _register_custom_builtin,
+ inplace_methods,
+ magic_methods,
+)
+from torch.fx.node import Argument, Node, _get_qualified_name, _type_repr, map_arg
+
+import colossalai
+from colossalai.fx._compatibility import compatibility
+
+_register_custom_builtin('colossalai', 'import colossalai', colossalai)
+
+
+def _gen_ckpt_fn_def(label, free_vars: List[str]) -> str:
+ """
+ Generate the checkpoint function definition
+ """
+ return f"def checkpoint_{label}({', '.join(['self'] + free_vars)}):"
+
+
+def _gen_ckpt_output(output_vars: List[str]) -> str:
+ """
+ Generate the return statement for checkpoint region
+ """
+ return f"return {', '.join(output_vars)}"
+
+
+def _gen_ckpt_usage(label, input_vars, output_vars, use_reentrant=True):
+ """
+ Generate the checkpoint function call code text
+ """
+ outputs = ', '.join(output_vars)
+ inputs = ', '.join(input_vars)
+ return f'{outputs} = torch.utils.checkpoint.checkpoint(self.checkpoint_{label}, {inputs}, use_reentrant={use_reentrant})'
+
+
+def _end_of_ckpt(node: Node, ckpt_level: int) -> bool:
+ """
+ Check if the node could end the ckpt region at `ckpt_level`
+ """
+ if len(node.meta['info'].activation_checkpoint) > ckpt_level:
+ return node.meta['info'].activation_checkpoint[ckpt_level] is not None
+ return True
+
+
+def _find_input_and_output_nodes(nodes: List[Node]):
+ """
+ Find the input and output node names which are not found in the given list of nodes.
+ """
+ input_nodes = []
+ output_nodes = []
+
+ # if a node has an input node which is not in the node list
+ # we treat that input node as the input of the checkpoint function
+ for node in nodes:
+ for input_node in node._input_nodes.keys():
+ node_repr = repr(input_node)
+ if input_node not in nodes and node_repr not in input_nodes:
+ input_nodes.append(node_repr)
+
+ # if a node has a user node which is not in the node list
+ # we treat that user node as the node receiving the current node output
+ for node in nodes:
+ for output_node in node.users.keys():
+ node_repr = repr(node)
+ if output_node not in nodes and node_repr not in output_nodes:
+ output_nodes.append(node_repr)
+
+ return input_nodes, output_nodes
+
+
+def _find_nested_ckpt_regions(node_list: List[Node], ckpt_level: int = 0):
+ """
+ Find the nested checkpoint regions given a list of consecutive nodes. The outputs
+ will be list of tuples, each tuple is in the form of (start_index, end_index).
+ """
+ ckpt_regions = []
+ start = -1
+ end = -1
+ current_region = None
+
+ for idx, node in enumerate(node_list):
+ if len(node.meta['info'].activation_checkpoint) > ckpt_level:
+ act_ckpt_label = node.meta['info'].activation_checkpoint[ckpt_level]
+
+ # this activation checkpoint label is not set yet
+ # meaning this is the first node of the activation ckpt region
+ if current_region is None:
+ current_region = act_ckpt_label
+ start = idx
+
+ # if activation checkpoint has changed
+ # we restart the tracking
+ # e.g. node ckpt states = [ckpt1, ckpt2, ckpt2, ckpt2]
+ if act_ckpt_label != current_region:
+ assert start != -1
+ ckpt_regions.append((start, idx - 1))
+ current_region = act_ckpt_label
+ start = idx
+ end = -1
+
+ elif current_region is not None and _end_of_ckpt(node, ckpt_level):
+ # used to check the case below
+ # node ckpt states = [ckpt, ckpt, non-ckpt]
+ end = idx - 1
+ assert start != -1 and end != -1
+ ckpt_regions.append((start, end))
+ start = end = -1
+ current_region = None
+
+ else:
+ pass
+
+ if current_region is not None:
+ end = len(node_list) - 1
+ ckpt_regions.append((start, end))
+ return ckpt_regions
+
+
+def emit_ckpt_func(body,
+ ckpt_func,
+ node_list: List[Node],
+ emit_node_func,
+ delete_unused_value_func,
+ ckpt_level=0,
+ in_ckpt=False):
+ """Emit ckpt function in nested way
+
+ Args:
+ body: forward code - in recursive calls, this part will be checkpoint
+ functions code
+ ckpt_func: checkpoint functions code - in recursive calls, this part
+ will be a buffer
+ node_list (List[Node]): list of torch.fx.Node
+ emit_node_func: function to emit a node
+ delete_unused_value_func: function to delete unused value
+ level (int, optional): checkpoint level. Defaults to 0.
+ in_ckpt (bool, optional): indicates wether the func is in recursive
+ call. Defaults to False.
+ """
+ inputs, outputs = _find_input_and_output_nodes(node_list)
+
+ # label given by each layer, e.g. if you are currently at level (0, 1, 1)
+ # the label will be '0_1_1'
+ label = "_".join([str(idx) for idx in node_list[0].meta['info'].activation_checkpoint[:ckpt_level + 1]])
+ ckpt_fn_def = _gen_ckpt_fn_def(label, inputs)
+ ckpt_func.append(f'{ckpt_fn_def}\n')
+
+ # if there is more level to fetch
+ if ckpt_level + 1 < max(map(lambda node: len(node.meta['info'].activation_checkpoint), node_list)):
+ ckpt_regions = _find_nested_ckpt_regions(node_list, ckpt_level + 1)
+ start_idx = [item[0] for item in ckpt_regions]
+ end_idx = [item[1] for item in ckpt_regions]
+
+ # use ckpt_func_buffer to store nested checkpoint functions
+ ckpt_func_buffer = []
+ node_idx = 0
+ while 1:
+ if node_idx >= len(node_list):
+ break
+
+ if node_idx in start_idx:
+ ckpt_node_list = node_list[node_idx:end_idx[start_idx.index(node_idx)] + 1]
+ emit_ckpt_func(ckpt_func, ckpt_func_buffer, ckpt_node_list, emit_node_func, delete_unused_value_func,
+ ckpt_level + 1, True)
+ node_idx += len(ckpt_node_list)
+
+ else:
+ node = node_list[node_idx]
+ emit_node_func(node, ckpt_func)
+ ckpt_func[-1] = ' ' + ckpt_func[-1]
+ delete_unused_value_func(node, ckpt_func)
+ node_idx += 1
+
+ ckpt_func.append(' ' + _gen_ckpt_output(outputs) + '\n\n')
+ ckpt_func += ckpt_func_buffer
+
+ # last level
+ else:
+ for node in node_list:
+ emit_node_func(node, ckpt_func)
+ ckpt_func[-1] = ' ' + ckpt_func[-1]
+ delete_unused_value_func(node, ckpt_func)
+
+ ckpt_func.append(' ' + _gen_ckpt_output(outputs) + '\n\n')
+
+ usage = _gen_ckpt_usage(label, inputs, outputs, False) + '\n'
+ if in_ckpt:
+ usage = ' ' + usage
+ body.append(usage)
+
+
+def emit_code_with_activation_checkpoint(body, ckpt_func, nodes, emit_node_func, delete_unused_value_func):
+ """Emit code with nested activation checkpoint
+ When we detect some of the annotation is a , we will use
+ this function to emit the activation checkpoint codes.
+
+ Args:
+ body: forward code
+ ckpt_func: checkpoint functions code
+ nodes: graph.nodes
+ emit_node_func: function to emit node
+ delete_unused_value_func: function to remove the unused value
+ """
+ ckpt_regions = _find_nested_ckpt_regions(nodes, 0)
+ start_idx = [item[0] for item in ckpt_regions]
+ end_idx = [item[1] for item in ckpt_regions]
+ node_list = list(nodes)
+
+ node_idx = 0
+ while 1:
+ # break if we finish the processing all the nodes
+ if node_idx >= len(node_list):
+ break
+
+ # process ckpt_regions
+ if node_idx in start_idx:
+ ckpt_node_list = node_list[node_idx:end_idx[start_idx.index(node_idx)] + 1]
+ emit_ckpt_func(body, ckpt_func, ckpt_node_list, emit_node_func, delete_unused_value_func)
+ node_idx += len(ckpt_node_list)
+
+ # process node in forward function
+ else:
+ node = node_list[node_idx]
+ emit_node_func(node, body)
+ delete_unused_value_func(node, body)
+ node_idx += 1
+
+
+@compatibility(is_backward_compatible=True)
+class ActivationCheckpointCodeGen(CodeGen):
+
+ def _gen_python_code(self, nodes, root_module: str, namespace: _Namespace) -> PythonCode:
+ free_vars: List[str] = []
+ body: List[str] = []
+ globals_: Dict[str, Any] = {}
+ wrapped_fns: Dict[str, None] = {}
+
+ # Wrap string in list to pass by reference
+ maybe_return_annotation: List[str] = ['']
+
+ def add_global(name_hint: str, obj: Any):
+ """Add an obj to be tracked as a global.
+ We call this for names that reference objects external to the
+ Graph, like functions or types.
+ Returns: the global name that should be used to reference 'obj' in generated source.
+ """
+ if _is_from_torch(obj) and obj != torch.device: # to support registering torch.device
+ # HACK: workaround for how torch custom ops are registered. We
+ # can't import them like normal modules so they must retain their
+ # fully qualified name.
+ return _get_qualified_name(obj)
+
+ # normalize the name hint to get a proper identifier
+ global_name = namespace.create_name(name_hint, obj)
+
+ if global_name in globals_:
+ assert globals_[global_name] is obj
+ return global_name
+ globals_[global_name] = obj
+ return global_name
+
+ # Pre-fill the globals table with registered builtins.
+ for name, (_, obj) in _custom_builtins.items():
+ add_global(name, obj)
+
+ def type_repr(o: Any):
+ if o == ():
+ # Empty tuple is used for empty tuple type annotation Tuple[()]
+ return '()'
+
+ typename = _type_repr(o)
+
+ if hasattr(o, '__origin__'):
+ # This is a generic type, e.g. typing.List[torch.Tensor]
+ origin_type = _origin_type_map.get(o.__origin__, o.__origin__)
+ origin_typename = add_global(_type_repr(origin_type), origin_type)
+
+ if hasattr(o, '__args__'):
+ # Assign global names for each of the inner type variables.
+ args = [type_repr(arg) for arg in o.__args__]
+
+ if len(args) == 0:
+ # Bare type, such as `typing.Tuple` with no subscript
+ # This code-path used in Python < 3.9
+ return origin_typename
+
+ return f'{origin_typename}[{",".join(args)}]'
+ else:
+ # Bare type, such as `typing.Tuple` with no subscript
+ # This code-path used in Python 3.9+
+ return origin_typename
+
+ # Common case: this is a regular module name like 'foo.bar.baz'
+ return add_global(typename, o)
+
+ def _format_args(args: Tuple[Argument, ...], kwargs: Dict[str, Argument]) -> str:
+
+ def _get_repr(arg):
+ # Handle NamedTuples (if it has `_fields`) via add_global.
+ if isinstance(arg, tuple) and hasattr(arg, '_fields'):
+ qualified_name = _get_qualified_name(type(arg))
+ global_name = add_global(qualified_name, type(arg))
+ return f"{global_name}{repr(tuple(arg))}"
+ return repr(arg)
+
+ args_s = ', '.join(_get_repr(a) for a in args)
+ kwargs_s = ', '.join(f'{k} = {_get_repr(v)}' for k, v in kwargs.items())
+ if args_s and kwargs_s:
+ return f'{args_s}, {kwargs_s}'
+ return args_s or kwargs_s
+
+ # Run through reverse nodes and record the first instance of a use
+ # of a given node. This represents the *last* use of the node in the
+ # execution order of the program, which we will use to free unused
+ # values
+ node_to_last_use: Dict[Node, Node] = {}
+ user_to_last_uses: Dict[Node, List[Node]] = {}
+
+ def register_last_uses(n: Node, user: Node):
+ if n not in node_to_last_use:
+ node_to_last_use[n] = user
+ user_to_last_uses.setdefault(user, []).append(n)
+
+ for node in reversed(nodes):
+ map_arg(node.args, lambda n: register_last_uses(n, node))
+ map_arg(node.kwargs, lambda n: register_last_uses(n, node))
+
+ # NOTE: we add a variable to distinguish body and ckpt_func
+ def delete_unused_values(user: Node, body):
+ """
+ Delete values after their last use. This ensures that values that are
+ not used in the remainder of the code are freed and the memory usage
+ of the code is optimal.
+ """
+ if user.op == 'placeholder':
+ return
+ if user.op == 'output':
+ body.append('\n')
+ return
+ nodes_to_delete = user_to_last_uses.get(user, [])
+ if len(nodes_to_delete):
+ to_delete_str = ' = '.join([repr(n) for n in nodes_to_delete] + ['None'])
+ body.append(f'; {to_delete_str}\n')
+ else:
+ body.append('\n')
+
+ # NOTE: we add a variable to distinguish body and ckpt_func
+ def emit_node(node: Node, body):
+ maybe_type_annotation = '' if node.type is None else f' : {type_repr(node.type)}'
+ if node.op == 'placeholder':
+ assert isinstance(node.target, str)
+ maybe_default_arg = '' if not node.args else f' = {repr(node.args[0])}'
+ free_vars.append(f'{node.target}{maybe_type_annotation}{maybe_default_arg}')
+ raw_name = node.target.replace('*', '')
+ if raw_name != repr(node):
+ body.append(f'{repr(node)} = {raw_name}\n')
+ return
+ elif node.op == 'call_method':
+ assert isinstance(node.target, str)
+ body.append(f'{repr(node)}{maybe_type_annotation} = {_format_target(repr(node.args[0]), node.target)}'
+ f'({_format_args(node.args[1:], node.kwargs)})')
+ return
+ elif node.op == 'call_function':
+ assert callable(node.target)
+ # pretty print operators
+ if node.target.__module__ == '_operator' and node.target.__name__ in magic_methods:
+ assert isinstance(node.args, tuple)
+ body.append(f'{repr(node)}{maybe_type_annotation} = '
+ f'{magic_methods[node.target.__name__].format(*(repr(a) for a in node.args))}')
+ return
+
+ # pretty print inplace operators; required for jit.script to work properly
+ # not currently supported in normal FX graphs, but generated by torchdynamo
+ if node.target.__module__ == '_operator' and node.target.__name__ in inplace_methods:
+ body.append(f'{inplace_methods[node.target.__name__].format(*(repr(a) for a in node.args))}; '
+ f'{repr(node)}{maybe_type_annotation} = {repr(node.args[0])}')
+ return
+
+ qualified_name = _get_qualified_name(node.target)
+ global_name = add_global(qualified_name, node.target)
+ # special case for getattr: node.args could be 2-argument or 3-argument
+ # 2-argument: attribute access; 3-argument: fall through to attrib function call with default value
+ if global_name == 'getattr' and \
+ isinstance(node.args, tuple) and \
+ isinstance(node.args[1], str) and \
+ node.args[1].isidentifier() and \
+ len(node.args) == 2:
+ body.append(
+ f'{repr(node)}{maybe_type_annotation} = {_format_target(repr(node.args[0]), node.args[1])}')
+ return
+ body.append(
+ f'{repr(node)}{maybe_type_annotation} = {global_name}({_format_args(node.args, node.kwargs)})')
+ if node.meta.get('is_wrapped', False):
+ wrapped_fns.setdefault(global_name)
+ return
+ elif node.op == 'call_module':
+ assert isinstance(node.target, str)
+ body.append(f'{repr(node)}{maybe_type_annotation} = '
+ f'{_format_target(root_module, node.target)}({_format_args(node.args, node.kwargs)})')
+ return
+ elif node.op == 'get_attr':
+ assert isinstance(node.target, str)
+ body.append(f'{repr(node)}{maybe_type_annotation} = {_format_target(root_module, node.target)}')
+ return
+ elif node.op == 'output':
+ if node.type is not None:
+ maybe_return_annotation[0] = f" -> {type_repr(node.type)}"
+ body.append(self.generate_output(node.args[0]))
+ return
+ raise NotImplementedError(f'node: {node.op} {node.target}')
+
+ # Modified for activation checkpointing
+ ckpt_func = []
+ emit_code_with_activation_checkpoint(body, ckpt_func, nodes, emit_node, delete_unused_values)
+
+ if len(body) == 0:
+ # If the Graph has no non-placeholder nodes, no lines for the body
+ # have been emitted. To continue to have valid Python code, emit a
+ # single pass statement
+ body.append('pass\n')
+
+ if len(wrapped_fns) > 0:
+ wrap_name = add_global('wrap', torch.fx.wrap)
+ wrap_stmts = '\n'.join([f'{wrap_name}("{name}")' for name in wrapped_fns])
+ else:
+ wrap_stmts = ''
+
+ if self._body_transformer:
+ body = self._body_transformer(body)
+
+ for name, value in self.additional_globals():
+ add_global(name, value)
+
+ prologue = self.gen_fn_def(free_vars, maybe_return_annotation[0])
+ prologue = ''.join(ckpt_func) + prologue
+ prologue = prologue
+
+ code = ''.join(body)
+ code = '\n'.join(' ' + line for line in code.split('\n'))
+ fn_code = f"""
+{wrap_stmts}
+{prologue}
+{code}"""
+ return PythonCode(fn_code, globals_)
diff --git a/colossalai/_analyzer/fx/graph_module.py b/colossalai/_analyzer/fx/graph_module.py
new file mode 100644
index 0000000000000000000000000000000000000000..1fdedd758c01f8fef9c0ba2e529b528527d8d527
--- /dev/null
+++ b/colossalai/_analyzer/fx/graph_module.py
@@ -0,0 +1,239 @@
+import linecache
+import os
+import sys
+import traceback
+import warnings
+from pathlib import Path
+from typing import Any, Dict, Optional, Union
+
+import torch
+import torch.fx
+import torch.nn as nn
+from torch.fx.graph import PythonCode
+
+try:
+ from torch.fx.graph import _PyTreeCodeGen
+ SUPPORT_PT_CODEGEN = True
+except ImportError:
+ SUPPORT_PT_CODEGEN = False
+
+from torch.fx.graph_module import _exec_with_source, _forward_from_src
+from torch.nn.modules.module import _addindent
+
+
+# This is a copy of torch.fx.graph_module._WrappedCall.
+# It should be removed when we stop supporting torch < 1.12.0.
+class _WrappedCall:
+
+ def __init__(self, cls, cls_call):
+ self.cls = cls
+ self.cls_call = cls_call
+
+ # Previously, if an error occurred when valid
+ # symbolically-traced code was run with an invalid input, the
+ # user would see the source of the error as coming from
+ # `File "`, where N is some number. We use
+ # this function to generate a more informative error message. We
+ # return the traceback itself, a message explaining that the
+ # error occurred in a traced Module's generated forward
+ # function, and five lines of context surrounding the faulty
+ # line
+ @staticmethod
+ def _generate_error_message(frame_summary: traceback.FrameSummary) -> str:
+ # auxiliary variables (for readability)
+ err_lineno = frame_summary.lineno
+ assert err_lineno is not None
+ line = frame_summary.line
+ assert line is not None
+ err_line_len = len(line)
+ all_src_lines = linecache.getlines(frame_summary.filename)
+
+ # constituent substrings of the error message
+ tb_repr = traceback.format_exc()
+ custom_msg = ("Call using an FX-traced Module, "
+ f"line {err_lineno} of the traced Module's "
+ "generated forward function:")
+ before_err = "".join(all_src_lines[err_lineno - 2:err_lineno])
+ marker = "~" * err_line_len + "~~~ <--- HERE"
+ err_and_after_err = "\n".join(all_src_lines[err_lineno:err_lineno + 2])
+
+ # joined message
+ return "\n".join([tb_repr, custom_msg, before_err, marker, err_and_after_err])
+
+ def __call__(self, obj, *args, **kwargs):
+ try:
+ if self.cls_call is not None:
+ return self.cls_call(obj, *args, **kwargs)
+ else:
+ return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
+ except Exception as e:
+ assert e.__traceback__
+ topmost_framesummary: traceback.FrameSummary = \
+ traceback.StackSummary.extract(traceback.walk_tb(e.__traceback__))[-1] # type: ignore[arg-type]
+ if "eval_with_key" in topmost_framesummary.filename:
+ print(_WrappedCall._generate_error_message(topmost_framesummary), file=sys.stderr)
+ raise e.with_traceback(None)
+ else:
+ raise e
+
+
+class ColoGraphModule(torch.fx.GraphModule):
+ """
+ ColoGraphGraphModule is an nn.Module generated from an fx.Graph.
+ ColoGraphmodule has a ``graph`` attribute, as well as ``code`` and ``forward``
+ attributes generated from that ``graph``.
+
+ The difference between ``ColoGraphModule`` and ``torch.fx.GraphModule`` is that
+ ``ColoGraphModule`` has a ``bind()`` function to bind customized functions
+ (i.e. activation checkpoint) to ``code`` of ``nn.Module``. If you want to use
+ specific features in Colossal-AI that are not supported by ``torch.fx.GraphModule``,
+ you can use ``ColoGraphModule`` instead.
+
+ ``colossalai.fx.symbolic_trace()`` will return a ``ColoGraphModule`` as default.
+
+ .. warning::
+
+ When ``graph`` is reassigned, ``code`` and ``forward`` will be automatically
+ regenerated. However, if you edit the contents of the ``graph`` without reassigning
+ the ``graph`` attribute itself, you must call ``recompile()`` to update the generated
+ code.
+ """
+
+ def __init__(self,
+ root: Union[torch.nn.Module, Dict[str, Any]],
+ graph: torch.fx.Graph,
+ class_name: str = 'GraphModule'):
+ super().__init__(root, graph, class_name)
+
+ def bind(self, ckpt_def, globals):
+ """Bind function needed for correctly execute ``GraphModule.forward()``
+
+ We need to bind checkpoint functions to ``ColoGraphModule`` so that we could
+ correctly execute ``GraphModule.forward()``
+
+ Args:
+ ckpt_def (List[str]): definition before the forward function
+ globals (Dict[str, Any]): global variables
+ """
+
+ ckpt_code = "\n".join(ckpt_def)
+ globals_copy = globals.copy()
+ _exec_with_source(ckpt_code, globals_copy)
+ func_list = [func for func in globals_copy.keys() if "checkpoint" in func or "pack" in func]
+ for func in func_list:
+ tmp_func = globals_copy[func]
+ setattr(self, func, tmp_func.__get__(self, self.__class__))
+ del globals_copy[func]
+
+ def recompile(self) -> PythonCode:
+ """
+ Recompile this GraphModule from its ``graph`` attribute. This should be
+ called after editing the contained ``graph``, otherwise the generated
+ code of this ``GraphModule`` will be out of date.
+ """
+ if SUPPORT_PT_CODEGEN and isinstance(self._graph._codegen, _PyTreeCodeGen):
+ self._in_spec = self._graph._codegen.pytree_info.in_spec
+ self._out_spec = self._graph._codegen.pytree_info.out_spec
+ python_code = self._graph.python_code(root_module='self')
+ self._code = python_code.src
+
+ # To split ckpt functions code and forward code
+ _code_list = self._code.split("\n")
+ _fwd_def = [item for item in _code_list if "def forward" in item][0]
+ _fwd_idx = _code_list.index(_fwd_def)
+ ckpt_def = _code_list[:_fwd_idx]
+ self._code = "\n".join(_code_list[_fwd_idx:])
+
+ self.bind(ckpt_def, python_code.globals)
+
+ cls = type(self)
+ cls.forward = _forward_from_src(self._code, python_code.globals)
+
+ # Determine whether this class explicitly defines a __call__ implementation
+ # to wrap. If it does, save it in order to have wrapped_call invoke it.
+ # If it does not, wrapped_call can use a dynamic call to super() instead.
+ # In most cases, super().__call__ should be torch.nn.Module.__call__.
+ # We do not want to hold a reference to Module.__call__ here; doing so will
+ # bypass patching of torch.nn.Module.__call__ done while symbolic tracing.
+ cls_call = cls.__call__ if "__call__" in vars(cls) else None
+
+ if '_wrapped_call' not in vars(cls):
+ cls._wrapped_call = _WrappedCall(cls, cls_call) # type: ignore[attr-defined]
+
+ def call_wrapped(self, *args, **kwargs):
+ return self._wrapped_call(self, *args, **kwargs)
+
+ cls.__call__ = call_wrapped
+
+ # reset self._code to original src, otherwise to_folder will be wrong
+ self._code = python_code.src
+ return python_code
+
+ def to_folder(self, folder: Union[str, os.PathLike], module_name: str = "FxModule"):
+ """Dumps out module to ``folder`` with ``module_name`` so that it can be
+ imported with ``from import ``
+
+ Args:
+
+ folder (Union[str, os.PathLike]): The folder to write the code out to
+
+ module_name (str): Top-level name to use for the ``Module`` while
+ writing out the code
+ """
+ folder = Path(folder)
+ Path(folder).mkdir(exist_ok=True)
+ torch.save(self.state_dict(), folder / 'state_dict.pt')
+ tab = " " * 4
+
+ # we add import colossalai here
+ model_str = f"""
+import torch
+from torch.nn import *
+import colossalai
+
+
+class {module_name}(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+"""
+
+ def _gen_model_repr(module_name: str, module: torch.nn.Module) -> Optional[str]:
+ safe_reprs = [nn.Linear, nn.Conv1d, nn.Conv2d, nn.Conv3d, nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d]
+ if type(module) in safe_reprs:
+ return f"{module.__repr__()}"
+ else:
+ return None
+
+ blobified_modules = []
+ for module_name, module in self.named_children():
+ module_str = _gen_model_repr(module_name, module)
+ if module_str is None:
+ module_file = folder / f'{module_name}.pt'
+ torch.save(module, module_file)
+ blobified_modules.append(module_name)
+ module_repr = module.__repr__().replace('\r', ' ').replace('\n', ' ')
+ module_str = f"torch.load(r'{module_file}') # {module_repr}"
+ model_str += f"{tab*2}self.{module_name} = {module_str}\n"
+
+ for buffer_name, buffer in self._buffers.items():
+ if buffer is None:
+ continue
+ model_str += f"{tab*2}self.register_buffer('{buffer_name}', torch.empty({list(buffer.shape)}, dtype={buffer.dtype}))\n"
+
+ for param_name, param in self._parameters.items():
+ if param is None:
+ continue
+ model_str += f"{tab*2}self.{param_name} = torch.nn.Parameter(torch.empty({list(param.shape)}, dtype={param.dtype}))\n"
+
+ model_str += f"{tab*2}self.load_state_dict(torch.load(r'{folder}/state_dict.pt'))\n"
+ model_str += f"{_addindent(self.code, 4)}\n"
+
+ module_file = folder / 'module.py'
+ module_file.write_text(model_str)
+
+ init_file = folder / '__init__.py'
+ init_file.write_text('from .module import *')
+
+ if len(blobified_modules) > 0:
+ warnings.warn("Was not able to save the following children modules as reprs -"
+ f"saved as pickled files instead: {blobified_modules}")
diff --git a/colossalai/_analyzer/fx/node_util.py b/colossalai/_analyzer/fx/node_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..fbe8400a437eef944b6e8ac0a1126774797da031
--- /dev/null
+++ b/colossalai/_analyzer/fx/node_util.py
@@ -0,0 +1,211 @@
+from dataclasses import dataclass, field
+from typing import Callable, ClassVar, Dict, List, Optional, Tuple, Union
+
+import torch
+from torch.autograd.profiler_util import _format_memory, _format_time
+from torch.fx import Graph, GraphModule, Node
+
+from colossalai._analyzer.envs import MeshConfig
+
+
+def intersect(a, b):
+ return {k: a[k] for k in a if k in b}
+
+
+def subtract(a, b):
+ return {k: a[k] for k in a if k not in b}
+
+
+def union(a, b):
+ return {**a, **b}
+
+
+def compute_size_in_bytes(elem: Union[torch.Tensor, Dict, List, Tuple, int]) -> int:
+ """Compute the size of a tensor or a collection of tensors in bytes.
+
+ Args:
+ elem (torch.Tensor | Dict | List | Tuple | int): Arbitrary nested ``torch.Tensor`` data structure.
+
+ Returns:
+ int: The size of the tensor or the collection of tensors in bytes.
+ """
+ nbytes = 0
+ if isinstance(elem, torch.Tensor):
+ if elem.is_quantized:
+ nbytes += elem.numel() * torch._empty_affine_quantized([], dtype=elem.dtype).element_size()
+ else:
+ nbytes += elem.numel() * torch.tensor([], dtype=elem.dtype).element_size()
+ elif isinstance(elem, dict):
+ value_list = [v for _, v in elem.items()]
+ nbytes += compute_size_in_bytes(value_list)
+ elif isinstance(elem, tuple) or isinstance(elem, list) or isinstance(elem, set):
+ for e in elem:
+ nbytes += compute_size_in_bytes(e)
+ return nbytes
+
+
+@dataclass
+class MetaInfo:
+ r"""
+ The base class to store all profiling and static graph analysis information
+ needed for auto-parallel system in Colossal-AI.
+ ============================================================================
+ -------------------------------
+ | FX.Node | <-----
+ [input/param] are ---> |[input/param] [grad_inp]| [grad_inp] contributes to the
+ placeholders (might be | | \__________ | | profiled peak memory in backward
+ saved for backward. | | \ | | pass. [grad_param] is calculated
+ | | \ | | separately.
+ | [interm] -------> [grad_int]| <-----
+ | | \_________ | | [grad_interm] marks the peak
+ | / \ \ | | memory in backward pass.
+ [x] is not counted ---> | [x] [interm] --> [grad_int]| <-----
+ in [interm] because | | \_____ | |
+ it is not saved for | | \ | |
+ backward. | [output] \ | | <----- [output] is potentially
+ ------------------------------- [input] for the next node.
+ ============================================================================
+
+ Accumulate Size = ALL_PREVIOUS_CTX U {Interm Size + Output Size}
+ Output Size = ([output] in global_ctx and not is_alias)
+ Temp Size = ([output] not in global_ctx and not is_alias)
+ Backward Size = ([grad_inp])
+
+ Usage:
+ >>> for node in graph.nodes:
+ >>> n_info = MetaInfo(node) # will create a new MetaInfo instance and store in node.meta['info']
+ >>> # if not exist, otherwise return the existing one
+ >>> n_info.to_recompute = ... # set the to_recompute attribute
+
+ Remarks:
+ This feature is experimental and all the entries are subject to change.
+ """
+
+ # reference
+ node: Node
+
+ # directory
+ mod_dir: str = ''
+
+ # ctx[data_ptr] = Tensor
+ # mark the storage for ctx.save_for_backward
+ global_ctx: Dict[str, torch.Tensor] = field(default_factory=lambda: {}) # globally shared
+ curr_ctx: Dict[str, torch.Tensor] = field(default_factory=lambda: {}) # global_ctx till this node
+
+ # should be updated after each graph manipulation
+ # ============================== Update ====================================
+ # parameter and buffer within ``Node``
+ parameters: Dict[str, torch.nn.Parameter] = field(default_factory=lambda: {})
+ buffers: Dict[str, torch.Tensor] = field(default_factory=lambda: {})
+
+ inputs: Tuple[torch.Tensor] = ()
+ outputs: Tuple[torch.Tensor] = ()
+ is_alias: Tuple[bool] = () # whether the output is an alias of input
+
+ # compute cost
+ fwd_flop: Optional[int] = 0
+ bwd_flop: Optional[int] = 0
+
+ # communication cost (should be the size in bytes of communication)
+ fwd_comm: Optional[int] = 0
+ bwd_comm: Optional[int] = 0
+
+ # should keep the same whenever manipulated
+ # ============================= Invariant ==================================
+ activation_checkpoint: Tuple[torch.Tensor] = () # (region_0, region_1, ...) support nested codegen
+ to_offload: Optional[bool] = False
+ sharding_spec: str = 'RR'
+
+ def __new__(cls, node: Node, **kwargs):
+ orig_init = cls.__init__
+
+ # if initialized, return the existing one
+ # should disable the __init__ function
+ if node.meta.get('info', None) is not None:
+
+ def _dummy(self, *args, **kwargs):
+ if getattr(self, '_is_init', False):
+ self._is_init = True
+ orig_init(self, *args, **kwargs)
+ cls.__init__ = orig_init
+
+ cls.__init__ = _dummy
+ return node.meta['info']
+ return super().__new__(cls)
+
+ def __post_init__(self):
+ self.node.meta['info'] = self
+
+ @property
+ def fwd_time(self, tflops: float = MeshConfig.TFLOPS, bandwidth: float = MeshConfig.BANDWIDTH):
+ return self.fwd_flop / tflops + self.fwd_comm / bandwidth
+
+ @property
+ def bwd_time(self, tflops: float = MeshConfig.TFLOPS, bandwidth: float = MeshConfig.BANDWIDTH):
+ return self.bwd_flop / tflops + self.bwd_comm / bandwidth
+
+ @property
+ def param_size(self):
+ return compute_size_in_bytes(self.parameters)
+
+ @property
+ def buffer_size(self):
+ return compute_size_in_bytes(self.buffers)
+
+ @property
+ def output_size(self):
+ """Used in CheckpointSolver"""
+ output_ctx = {
+ o.data_ptr(): o
+ for o, is_alias in zip(self.outputs, self.is_alias)
+ if not is_alias and isinstance(o, torch.Tensor) and not isinstance(o, torch.nn.Parameter)
+ }
+ return compute_size_in_bytes(intersect(self.global_ctx, output_ctx))
+
+ @property
+ def accumulate_size(self):
+ """Used in CheckpointSolver"""
+ output_ctx = {
+ o.data_ptr(): o
+ for o, is_alias in zip(self.outputs, self.is_alias)
+ if not is_alias and isinstance(o, torch.Tensor) and not isinstance(o, torch.nn.Parameter)
+ }
+ return compute_size_in_bytes(union(self.curr_ctx, intersect(self.global_ctx, output_ctx)))
+
+ @property
+ def temp_size(self):
+ """Used in CheckpointSolver"""
+ output_ctx = {
+ o.data_ptr(): o
+ for o, is_alias in zip(self.outputs, self.is_alias)
+ if not is_alias and isinstance(o, torch.Tensor) and not isinstance(o, torch.nn.Parameter)
+ }
+ return compute_size_in_bytes(subtract(output_ctx, self.global_ctx))
+
+ @property
+ def backward_size(self):
+ """Used in CheckpointSolver"""
+ return compute_size_in_bytes(self.inputs)
+
+ def __repr__(self):
+ s = f'Node {self.node.name}'
+ if self.parameters:
+ s += f'\n\thas parameter of size {_format_memory(self.param_size)}'
+ if self.buffers:
+ s += f'\n\thas buffer of size {_format_memory(self.buffer_size)}'
+ if self.output_size:
+ s += f'\n\thas output activation of size {_format_memory(self.output_size)}'
+ # if self.total_size:
+ # s += f'\n\thas total activation of size {_format_memory(self.total_size)}'
+ if self.temp_size:
+ s += f'\n\thas temp activation of size {_format_memory(self.temp_size)}'
+ if self.backward_size:
+ s += f'\n\thas backward activation of size {_format_memory(self.backward_size)}'
+ s += f'\n\tfwd_flop = {self.fwd_flop}'\
+ f'\n\tbwd_flop = {self.bwd_flop}'\
+ f'\n\tfwd_comm = {self.fwd_comm}'\
+ f'\n\tbwd_comm = {self.bwd_comm}'\
+ f'\n\tto_recompute = {self.to_recompute}'\
+ f'\n\tto_offload = {self.to_offload}'\
+ f'\n\tsharding_spec = {self.sharding_spec}'
+ return s
diff --git a/colossalai/_analyzer/fx/passes/__init__.py b/colossalai/_analyzer/fx/passes/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ae02d90a236c08be74e70165d4c34c13e2884ab2
--- /dev/null
+++ b/colossalai/_analyzer/fx/passes/__init__.py
@@ -0,0 +1,2 @@
+from .graph_profile import graph_profile_pass
+from .shape_prop import ShapeProp, shape_prop_pass, sim_env
diff --git a/colossalai/_analyzer/fx/passes/graph_profile.py b/colossalai/_analyzer/fx/passes/graph_profile.py
new file mode 100644
index 0000000000000000000000000000000000000000..c3e760b31e96df2cd4f2de52c6309fefa9183417
--- /dev/null
+++ b/colossalai/_analyzer/fx/passes/graph_profile.py
@@ -0,0 +1,347 @@
+from typing import Any, Dict, Iterator, List, Optional, Tuple, Union
+
+import torch
+import torch.fx
+from torch.autograd.profiler_util import _format_memory, _format_time
+from torch.fx import GraphModule
+from torch.fx.node import Argument, Node, Target
+
+from colossalai._analyzer._subclasses import flop_count
+from colossalai._analyzer.fx.node_util import MetaInfo
+
+
+def _format_flops(flops: float) -> str:
+ """Returns a formatted FLOP size string"""
+ if flops > 1e12:
+ return f'{flops / 1e12:.2f} TFLOPs'
+ elif flops > 1e9:
+ return f'{flops / 1e9:.2f} GFLOPs'
+ elif flops > 1e6:
+ return f'{flops / 1e6:.2f} MFLOPs'
+ elif flops > 1e3:
+ return f'{flops / 1e3:.2f} kFLOPs'
+ return f'{flops} FLOPs'
+
+
+def _denormalize_tuple(t: Tuple[int, ...]) -> Tuple[int, ...]:
+ return t[0] if len(t) == 1 else t
+
+
+def _normalize_tuple(x):
+ if not isinstance(x, tuple):
+ return (x,)
+ return x
+
+
+def _current_device(module):
+ return next(module.parameters()).device
+
+
+class GraphProfiler(torch.fx.Interpreter):
+ """
+ Fetch shape argument from ``ShapeProp`` without re-executing
+ the ``GraphModule`` from scratch.
+ """
+ _profileable = [
+ 'call_function',
+ 'call_module',
+ 'call_method',
+ ]
+
+ def __init__(self, module: GraphModule, garbage_collect_values: bool = True):
+ super().__init__(module, garbage_collect_values)
+
+ def run(self, *args, initial_env: Optional[Dict[Node, Any]] = None, enable_io_processing: bool = True) -> Any:
+ """
+ Run `module` via interpretation and return the result.
+
+ Args:
+ *args: The arguments to the Module to run, in positional order
+ initial_env (Optional[Dict[Node, Any]]): An optional starting environment for execution.
+ This is a dict mapping `Node` to any value. This can be used, for example, to
+ pre-populate results for certain `Nodes` so as to do only partial evaluation within
+ the interpreter.
+ enable_io_processing (bool): If true, we process the inputs and outputs with graph's process_inputs and
+ process_outputs function first before using them.
+
+ Returns:
+ Any: The value returned from executing the Module
+ """
+ self.env = initial_env if initial_env else {}
+
+ # Positional function args are consumed left-to-right by
+ # `placeholder` nodes. Use an iterator to keep track of
+ # position and extract those values.
+ if enable_io_processing:
+ args = self.module.graph.process_inputs(*args)
+ self.args_iter: Iterator[Any] = iter(args)
+
+ for node in self.module.graph.nodes:
+
+ self.run_node(node) # No need to store.
+
+ if self.garbage_collect_values:
+ for to_delete in self.user_to_last_uses.get(node, []):
+ del self.env[to_delete]
+
+ if node.op == 'output':
+ output_val = self.env[node]
+ return self.module.graph.process_outputs(output_val) if enable_io_processing else output_val
+
+ def fetch_initial_env(self, device=None) -> Dict[Node, Any]:
+ """
+ Fetch ``initial_env`` for execution. This is because ``ShapeProp``
+ has already attached outputs of each ``Node`` to its ``MetaInfo``.
+
+ Args:
+ device (torch.device): The device to place the execution, default to ``None``
+
+ Returns:
+ Dict[Node, Any]: The initial environment for execution
+ """
+ initial_env = {}
+ for n in self.module.graph.nodes:
+ initial_env[n] = _denormalize_tuple(MetaInfo(n).outputs)
+ return initial_env
+
+ def propagate(self, *args, device=None):
+ """
+ Run `module` via interpretation and profile the execution
+ of each ``Node``.
+
+ Args:
+ *args (Tensor): The sample input, not used
+ device (torch.device): The device to place the execution, default to ``None``
+
+ Returns:
+ Any: The value returned from executing the Module
+ """
+ initial_env = self.fetch_initial_env(device)
+
+ return self.run(initial_env=initial_env)
+
+ def summary(self) -> str:
+ """
+ Summarizes the profiled statistics of the `GraphModule` in
+ tabular format. Note that this API requires the ``tabulate`` module
+ to be installed.
+
+ Returns:
+ str: The summary of the profiled statistics
+ """
+ # https://github.com/pytorch/pytorch/blob/master/torch/fx/graph.py
+ try:
+ from tabulate import tabulate
+ except ImportError:
+ print("`summary` relies on the library `tabulate`, "
+ "which could not be found on this machine. Run `pip "
+ "install tabulate` to install the library.")
+
+ # Build up a list of summary information for each node
+ node_summaries: List[List[Any]] = []
+ last_n_info = None
+
+ for node in self.module.graph.nodes:
+ node: Node
+ n_info = MetaInfo(node)
+ last_n_info = last_n_info or n_info
+ node_summaries.append([
+ node.op,
+ str(node),
+ _format_memory(n_info.accumulate_size),
+ _format_memory(n_info.accumulate_size - last_n_info.accumulate_size),
+ _format_memory(n_info.output_size),
+ _format_memory(n_info.temp_size),
+ _format_memory(n_info.param_size),
+ _format_memory(n_info.backward_size),
+ _format_flops(n_info.fwd_flop),
+ _format_flops(n_info.bwd_flop),
+ ])
+ last_n_info = n_info
+
+ # Use the ``tabulate`` library to create a well-formatted table
+ # presenting our summary information
+ headers: List[str] = [
+ 'Op type',
+ 'Op',
+ 'Accumulate size',
+ 'Incremental size',
+ 'Output size',
+ 'Temp size',
+ 'Param size',
+ 'Backward size',
+ 'Fwd FLOPs',
+ 'Bwd FLOPs',
+ ]
+
+ return tabulate(node_summaries, headers=headers, stralign='right')
+
+
+class CommunicationProfiler(GraphProfiler):
+ """
+ TODO(lyl): Add this for all comm nodes
+ """
+
+ def __init__(self, module: GraphModule, garbage_collect_values: bool = True):
+ raise NotImplementedError()
+
+
+class FlopProfiler(GraphProfiler):
+ """
+ Execute an FX graph Node-by-Node and record the meta data of the result
+ into the corresponding node.
+
+ Usage:
+ >>> model = MyModule()
+ >>> x = torch.rand(10, 10)
+ >>> gm = colossalai.fx.symbolic_trace(model, meta_args = {'x': x}})
+ >>> shape_interp = ShapeProp(gm) # must do this first
+ >>> shape_interp.propagate(x)
+ >>> profiler = FlopProfiler(gm)
+ >>> profiler.propagate(x)
+
+ Args:
+ module (GraphModule): The module to be executed
+
+ Hints:
+ If you want to add a new flop count rule, you can first
+ check the existing files in ``../_subclasses/flop_tensor.py``.
+ If your flop count rules are incompatible with the existing
+ ones, you can do so by adding a new method to this class
+ with the ``@register_flop_count_impl`` decorator. The method
+ should take (*args, **kwargs) instance as its input and
+ generate flop count for both forward and backward as its
+ output.
+
+ For example, if you want to add a flop count rule for
+ ``my_fn``, which is a hand-written operand not detected by
+ PyTorch, you can do so by adding a new method to this
+ class with the ``@register_flop_count_impl`` decorator:
+
+ >>> @register_flop_count_impl(my_fn)
+ >>> def my_fn_flop_count_impl(*args, **kwargs):
+ >>> return 0, 0
+ """
+ _custom_flop_count_impl = {}
+
+ def run_node(self, n: torch.fx.Node) -> Any:
+ """
+ Run a specific node ``n`` and profile its execution time and memory usage.
+ Calls into call_function, call_method, and call_module only.
+
+ Args:
+ n (Node): The Node to profile
+
+ Returns:
+ Any: The output of the node
+
+ Raises:
+ RuntimeError: If the node is not profileable.
+ """
+ args, kwargs = self.fetch_args_kwargs_from_env(n)
+ n_info = MetaInfo(n)
+
+ if n.op in self._profileable:
+ try:
+ (
+ n_info.fwd_flop,
+ n_info.bwd_flop,
+ ) = getattr(self, n.op)(n.target, args, kwargs)
+ except Exception as e:
+ raise RuntimeError(
+ f'Error {str(e)} occurred when profiling node {n}, node.target = {n.target}. '
+ f'Please refer to function\'s docstring to register the relevant profile_impl for this node!'
+ ) from e
+
+ # retain the autograd graph
+ for param in self.module.parameters():
+ param.grad = None
+
+ return _denormalize_tuple(n_info.outputs)
+
+ def call_function(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_function`` node and return the profiling result.
+ Dispatch to ``_custom_flop_count_impl`` if ``call_function`` should be
+ profiled in a user-defined behavior.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ flop_count (Tuple[int]): (fwd_flop, bwd_flop)
+ """
+ assert not isinstance(target, str)
+
+ # Dispatch the impl for profiling, default will be ``flop_count``
+ if target in self._custom_flop_count_impl:
+ return self._custom_flop_count_impl[target](*args, **kwargs)
+ else:
+ return flop_count(target, *args, **kwargs)
+
+ def call_method(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_method`` node and return the profiling result.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ flop_count (Tuple[int]): (fwd_flop, bwd_flop)
+ """
+ # Execute the method and return the result
+ assert isinstance(target, str)
+ return flop_count(getattr(torch.Tensor, target), *args, **kwargs)
+
+ def call_module(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_module`` node and return the profiling result.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ flop_count (Tuple[int]): (fwd_flop, bwd_flop)
+ """
+ # Retrieve executed args and kwargs values from the environment
+
+ # Execute the method and return the result
+ assert isinstance(target, str)
+ submod = self.fetch_attr(target)
+ return flop_count(submod, *args, **kwargs)
+
+
+def graph_profile_pass(module: GraphModule, *args, verbose=False) -> GraphModule:
+ """
+ Run ``module`` via interpretation and profile the execution
+ of each ``Node``.
+
+ Args:
+ module (GraphModule): The GraphModule to profile
+ *args (Any): The sample input, not used
+ verbose (bool): Whether to print the profiling summary
+
+ Returns:
+ GraphModule: The same GraphModule with profiling information
+ """
+ for profiler_cls in (FlopProfiler,
+ # CommunicationProfiler, # TODO: add communication profiling
+ ):
+ profiler = profiler_cls(module)
+ profiler.propagate(*args, device=_current_device(module))
+
+ if verbose:
+ print(profiler.summary())
+ return module
diff --git a/colossalai/_analyzer/fx/passes/shape_prop.py b/colossalai/_analyzer/fx/passes/shape_prop.py
new file mode 100644
index 0000000000000000000000000000000000000000..23e83013e02fd6a60d016f9b5c86a17d85cdaf81
--- /dev/null
+++ b/colossalai/_analyzer/fx/passes/shape_prop.py
@@ -0,0 +1,266 @@
+"""``torch.fx.ShapeProp``, but with ``MetaTensor``"""
+
+from typing import Any, Callable, Dict, Optional, Tuple, Union
+
+import torch
+import torch.fx
+from torch.autograd.graph import saved_tensors_hooks
+from torch.utils._pytree import tree_map
+
+from colossalai._analyzer._subclasses import MetaTensor, MetaTensorMode
+from colossalai._analyzer.fx.node_util import MetaInfo
+from colossalai.fx._compatibility import compatibility
+
+Target = Union[Callable[..., Any], str]
+
+
+class sim_env(saved_tensors_hooks):
+ """
+ A simulation of memory allocation and deallocation in the forward pass
+ using ``saved_tensor_hooks``.
+
+ Attributes:
+ ctx (Dict[int, torch.Tensor]): A dictionary that maps the
+ data pointer of a tensor to the tensor itself. This is used
+ to track the memory allocation and deallocation.
+
+ param_ctx (Dict[int, torch.Tensor]): A dictionary that maps the
+ data pointer of all model parameters to the parameter itself.
+ This avoids overestimating the memory usage of the intermediate activations.
+ """
+
+ def __init__(self, module: Optional[torch.nn.Module] = None):
+ super().__init__(self.pack_hook, self.unpack_hook)
+ self.ctx = {}
+ self.param_ctx = {param.data_ptr(): param for param in module.parameters()}
+ self.buffer_ctx = {buffer.data_ptr(): buffer for buffer in module.buffers()} if module else {}
+
+ def pack_hook(self, tensor: torch.Tensor):
+ if tensor.data_ptr() not in self.param_ctx and tensor.data_ptr() not in self.buffer_ctx:
+ self.ctx[tensor.data_ptr()] = tensor
+ return tensor
+
+ def unpack_hook(self, tensor):
+ return tensor
+
+
+def _normalize_tuple(x):
+ if not isinstance(x, tuple):
+ return (x,)
+ return x
+
+
+def _current_device(module):
+ try:
+ return next(module.parameters()).device
+ except StopIteration:
+ return torch.device('cpu')
+
+
+@compatibility(is_backward_compatible=False)
+class ShapeProp(torch.fx.Interpreter):
+ """
+ Execute an FX graph Node-by-Node and record the meta data of the result
+ into the corresponding node.
+
+ Usage:
+ >>> model = MyModule()
+ >>> x = torch.rand(10, 10)
+ >>> gm = colossalai.fx.symbolic_trace(model, meta_args = {'x': x})
+ >>> interp = ShapeProp(gm)
+ >>> interp.propagate(x)
+
+ Args:
+ module (GraphModule): The module to be executed
+
+ Hints:
+ If you want to add a new shape propagation rule, you can do so by
+ adding a new method to this class with the ``@register_shape_impl``
+ decorator. The method should take (*args, **kwargs) instance as its
+ input and generate output.
+
+ For example, if you want to add a shape propagation rule for
+ ``torch.nn.functional.linear``, you can do so by adding a new method
+ to this class with the ``@register_shape_impl`` decorator (Since the
+ ``MetaTensorMode`` is compatible with ``torch.nn.functional.linear``,
+ in practice you don't have to do as follows):
+
+ >>> @register_shape_impl(torch.nn.functional.linear)
+ >>> def linear_shape_impl(*args, **kwargs):
+ >>> # do something here
+ >>> return torch.empty(output_shape, device=output_device)
+ """
+ _custom_dispatch_func = {}
+ _mode = MetaTensorMode()
+
+ def __init__(self, module: torch.fx.GraphModule, garbage_collect_values: bool = True):
+ super().__init__(module, garbage_collect_values)
+ self.global_hook = sim_env(module=self.module)
+
+ def run_node(self, n: torch.fx.Node) -> Any:
+ """
+ Run a specific node ``n`` and return the result. Attach
+ (
+ ``inputs``, ``outputs``, ``parameters``, ``buffers``
+ ) to ``n``.
+
+ Args:
+ n (Node): The ``Node`` to execute
+
+ Returns:
+ Any: The result of executing ``n``
+ """
+ args, kwargs = self.fetch_args_kwargs_from_env(n)
+ with self.global_hook:
+ r = getattr(self, n.op)(n.target, args, kwargs)
+
+ def unwrap_fn(elem):
+
+ def _convert_meta(t: torch.Tensor):
+ if t.device == 'meta':
+ return t
+ else:
+ return t.to('meta')
+
+ if isinstance(elem, MetaTensor):
+ if getattr(self, '_is_param', False):
+ return torch.nn.Parameter(_convert_meta(elem._tensor))
+ return _convert_meta(elem._tensor)
+
+ elif isinstance(elem, torch.Tensor):
+ if isinstance(elem, torch.nn.Parameter):
+ return torch.nn.Parameter(_convert_meta(elem))
+ return _convert_meta(elem)
+
+ else:
+ return elem
+
+ is_pure_tensor = lambda elem: isinstance(elem, MetaTensor) and not isinstance(elem, torch.nn.Parameter)
+ n_info = MetaInfo(n)
+ n_info.outputs = _normalize_tuple(r)
+
+ if n.op == 'call_module':
+ submod = self.fetch_attr(n.target)
+ n_info.parameters.update({k: MetaTensor(v) for k, v in submod.named_parameters()})
+ n_info.buffers.update({k: MetaTensor(v) for k, v in submod.named_buffers()})
+
+ else:
+ n_info.parameters.update({
+ k.name: MetaTensor(v)
+ for k, v in zip(n.args, args)
+ if isinstance(k, torch.fx.Node) and isinstance(v, torch.nn.Parameter)
+ })
+ n_info.parameters.update({k: MetaTensor(v) for k, v in kwargs.items() if isinstance(v, torch.nn.Parameter)})
+
+ n_info.inputs = tuple(v for v in args if is_pure_tensor(v)) + \
+ tuple(v for v in kwargs.values() if is_pure_tensor(v))
+
+ # align with SPMD
+ if isinstance(r, (tuple, list)):
+ n._meta_data = tree_map(unwrap_fn, _normalize_tuple(r))
+ else:
+ n._meta_data = unwrap_fn(r)
+
+ n_info.global_ctx = self.global_hook.ctx
+ n_info.curr_ctx = self.global_hook.ctx.copy()
+
+ crit = lambda x: x.data_ptr() in self.global_hook.ctx if isinstance(x, torch.Tensor) else False
+ n_info.is_alias = _normalize_tuple(tree_map(crit, n_info.outputs))
+ return r
+
+ def call_function(self, target: 'Target', args: Tuple[Any, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_function`` node and return the result.
+ If the target of ``Node`` is registered with ``@register_shape_impl``,
+ the registered function will be used to execute the node. This is common
+ if we insert some customized kernels.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ Any: The value returned by the function invocation
+ """
+ convert_to_param = False
+ if target in (torch.transpose, torch.reshape) and isinstance(args[0], torch.nn.parameter.Parameter):
+ convert_to_param = True
+ if target in self._custom_dispatch_func:
+ res = self._custom_dispatch_func[target](*args, **kwargs)
+ else:
+ res = super().call_function(target, args, kwargs)
+ if convert_to_param:
+ return torch.nn.Parameter(res)
+ else:
+ return res
+
+ def call_method(self, target: 'Target', args: Tuple[Any, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_method`` node and return the result.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ Any: The value returned by the method invocation
+ """
+ # args[0] is the `self` object for this method call
+ self_obj, *args_tail = args
+
+ target_method = getattr(self_obj.__class__, target)
+
+ convert_to_parameter = False
+ if target_method in (torch.Tensor.view, torch.Tensor.transpose) and isinstance(
+ args[0], torch.nn.parameter.Parameter):
+ convert_to_parameter = True
+ # Execute the method and return the result
+ assert isinstance(target, str)
+ res = getattr(self_obj, target)(*args_tail, **kwargs)
+ if convert_to_parameter:
+ return torch.nn.Parameter(res)
+ else:
+ return res
+
+ def propagate(self, *args, device=None):
+ """
+ Run `module` via interpretation and return the result and record the
+ shape of each node.
+ Args:
+ *args (Tensor): The sample input.
+ Returns:
+ Any: The value returned from executing the Module
+ """
+
+ # wrap_fn = lambda elem: MetaTensor(elem, device=device)
+ def wrap_fn(elem, device=device):
+ if isinstance(elem, torch.Tensor):
+ return MetaTensor(elem, device=device)
+ else:
+ return elem
+
+ with self._mode:
+ return super().run(*tree_map(wrap_fn, args))
+
+
+def shape_prop_pass(module: torch.fx.GraphModule, *args) -> torch.fx.GraphModule:
+ """
+ Run ``module`` via interpretation and return the result and record the
+ shape of each ``Node``.
+
+ Args:
+ module (GraphModule): The GraphModule to profile
+ *args (Any): The sample input
+
+ Returns:
+ GraphModule: The same GraphModule with shape information
+ """
+
+ ShapeProp(module).propagate(*args, device=_current_device(module))
+ return module
diff --git a/colossalai/_analyzer/fx/symbolic_profile.py b/colossalai/_analyzer/fx/symbolic_profile.py
new file mode 100644
index 0000000000000000000000000000000000000000..dd7f22c6c98a0d47c946935a991a1f31d1052734
--- /dev/null
+++ b/colossalai/_analyzer/fx/symbolic_profile.py
@@ -0,0 +1,40 @@
+import torch
+import torch.fx
+from torch.fx import GraphModule
+
+from .passes import ShapeProp, graph_profile_pass, shape_prop_pass
+from .passes.graph_profile import FlopProfiler
+
+
+def register_flop_count_impl(func):
+
+ def wrapper(impl):
+ FlopProfiler._custom_flop_count_impl[func] = impl
+ return impl
+
+ return wrapper
+
+
+def register_shape_impl(func):
+
+ def wrapper(impl):
+ ShapeProp._custom_dispatch_func[func] = impl
+ return impl
+
+ return wrapper
+
+
+def symbolic_profile(module: GraphModule, *args, verbose=False) -> GraphModule:
+ """Symbolically profile a model with sample inputs.
+
+ Args:
+ module (GraphModule): The module to be profiled
+ args (Tuple): The sample inputs
+ verbose (bool): Whether to print the profiling result
+
+ Returns:
+ GraphModule: The profiled module
+ """
+ module = shape_prop_pass(module, *args)
+ module = graph_profile_pass(module, *args, verbose=verbose)
+ return module
diff --git a/colossalai/_analyzer/fx/tracer/__init__.py b/colossalai/_analyzer/fx/tracer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b1b2256aa44155883c71c10d1b2bebf511ff8d6
--- /dev/null
+++ b/colossalai/_analyzer/fx/tracer/__init__.py
@@ -0,0 +1,2 @@
+from .bias_addition import *
+from .custom_leaf_module import *
diff --git a/colossalai/_analyzer/fx/tracer/bias_addition.py b/colossalai/_analyzer/fx/tracer/bias_addition.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e75b47ca5b038aadb9c9bf0779bc3565d91bead
--- /dev/null
+++ b/colossalai/_analyzer/fx/tracer/bias_addition.py
@@ -0,0 +1,154 @@
+"""
+If FX.Graph is traced for auto-parallel module, some extra node will be added during
+graph construction to deal with the compatibility between bias-addition and all-reduce.
+"""
+
+import torch
+import torch.nn.functional as F
+from torch.nn.modules.utils import _pair, _single, _triple
+
+from .tracer import register_tracer_impl
+
+__all__ = []
+
+
+@register_tracer_impl(F.linear, name='_bias_addition_impl')
+def linear_impl(input, weight, bias=None):
+ if bias is None:
+ return F.linear(input, weight)
+ else:
+ return F.linear(input, weight) + bias
+
+
+@register_tracer_impl(F.conv1d, name='_bias_addition_impl')
+def conv1d_impl(input, weight, bias=None, stride=_single(1), padding=_single(0), dilation=_single(1), groups=1):
+ if bias is None:
+ return F.conv1d(input, weight, stride=stride, padding=padding, dilation=dilation, groups=groups)
+ else:
+ return F.conv1d(input, weight, stride=stride, padding=padding, dilation=dilation, groups=groups) + bias.reshape(
+ (-1, 1))
+
+
+@register_tracer_impl(F.conv2d, name='_bias_addition_impl')
+def conv2d_impl(input, weight, bias=None, stride=_pair(1), padding=_pair(0), dilation=_pair(1), groups=1):
+ if bias is None:
+ return F.conv2d(input, weight, stride=stride, padding=padding, dilation=dilation, groups=groups)
+ else:
+ return F.conv2d(input, weight, stride=stride, padding=padding, dilation=dilation, groups=groups) + bias.reshape(
+ (-1, 1, 1))
+
+
+@register_tracer_impl(F.conv3d, name='_bias_addition_impl')
+def conv3d_impl(input, weight, bias=None, stride=_triple(1), padding=_triple(0), dilation=_triple(1), groups=1):
+ if bias is None:
+ return F.conv3d(input, weight, stride=stride, padding=padding, dilation=dilation, groups=groups)
+ else:
+ return F.conv3d(input, weight, stride=stride, padding=padding, dilation=dilation, groups=groups) + bias.reshape(
+ (-1, 1, 1, 1))
+
+
+@register_tracer_impl(F.conv_transpose1d, name='_bias_addition_impl')
+def conv_transpose1d_impl(input,
+ weight,
+ bias=None,
+ stride=_single(1),
+ padding=_single(0),
+ output_padding=_single(0),
+ groups=1,
+ dilation=_single(1)):
+ if bias is None:
+ return F.conv_transpose1d(input,
+ weight,
+ stride=stride,
+ padding=padding,
+ output_padding=output_padding,
+ groups=groups,
+ dilation=dilation)
+ else:
+ return F.conv_transpose1d(input,
+ weight,
+ stride=stride,
+ padding=padding,
+ output_padding=output_padding,
+ groups=groups,
+ dilation=dilation) + bias.reshape((-1, 1))
+
+
+@register_tracer_impl(F.conv_transpose2d, name='_bias_addition_impl')
+def conv_transpose2d_impl(input,
+ weight,
+ bias=None,
+ stride=_pair(1),
+ padding=_pair(0),
+ output_padding=_pair(0),
+ groups=1,
+ dilation=_pair(1)):
+ if bias is None:
+ return F.conv_transpose2d(input,
+ weight,
+ stride=stride,
+ padding=padding,
+ output_padding=output_padding,
+ groups=groups,
+ dilation=dilation)
+ else:
+ return F.conv_transpose2d(input,
+ weight,
+ stride=stride,
+ padding=padding,
+ output_padding=output_padding,
+ groups=groups,
+ dilation=dilation) + bias.reshape((-1, 1, 1))
+
+
+@register_tracer_impl(F.conv_transpose3d, name='_bias_addition_impl')
+def conv_transpose3d_impl(input,
+ weight,
+ bias=None,
+ stride=_triple(1),
+ padding=_triple(0),
+ output_padding=_triple(0),
+ groups=1,
+ dilation=_triple(1)):
+ if bias is None:
+ return F.conv_transpose3d(input,
+ weight,
+ stride=stride,
+ padding=padding,
+ output_padding=output_padding,
+ groups=groups,
+ dilation=dilation)
+ else:
+ return F.conv_transpose3d(input,
+ weight,
+ stride=stride,
+ padding=padding,
+ output_padding=output_padding,
+ groups=groups,
+ dilation=dilation) + bias.reshape((-1, 1, 1, 1))
+
+
+@register_tracer_impl(torch.addmm, name='_bias_addition_impl')
+@register_tracer_impl(torch.Tensor.addmm, name='_bias_addition_impl')
+def addmm_impl(input, mat1, mat2, beta=1, alpha=1):
+ if alpha != 1 and beta != 1:
+ return F.linear(mat1, mat2.transpose(0, 1)) * alpha + input * beta
+ elif alpha != 1:
+ return F.linear(mat1, mat2.transpose(0, 1)) * alpha + input
+ elif beta != 1:
+ return F.linear(mat1, mat2.transpose(0, 1)) + input * beta
+ else:
+ return F.linear(mat1, mat2.transpose(0, 1)) + input
+
+
+@register_tracer_impl(torch.addbmm, name='_bias_addition_impl')
+@register_tracer_impl(torch.Tensor.addbmm, name='_bias_addition_impl')
+def addbmm_impl(input, batch1, batch2, beta=1, alpha=1):
+ if alpha != 1 and beta != 1:
+ return torch.bmm(batch1, batch2.transpose(1, 2)) * alpha + input * beta
+ elif alpha != 1:
+ return torch.bmm(batch1, batch2.transpose(1, 2)) * alpha + input
+ elif beta != 1:
+ return torch.bmm(batch1, batch2.transpose(1, 2)) + input * beta
+ else:
+ return torch.bmm(batch1, batch2.transpose(1, 2)) + input
diff --git a/colossalai/_analyzer/fx/tracer/custom_leaf_module.py b/colossalai/_analyzer/fx/tracer/custom_leaf_module.py
new file mode 100644
index 0000000000000000000000000000000000000000..112c7c9637d20e395dbccaace063e3fa7657041f
--- /dev/null
+++ b/colossalai/_analyzer/fx/tracer/custom_leaf_module.py
@@ -0,0 +1,29 @@
+import torch
+
+from .tracer import register_leaf_module, register_leaf_module_impl
+
+try:
+ import apex
+ register_leaf_module(apex.normalization.FusedLayerNorm)
+ register_leaf_module(apex.normalization.FusedRMSNorm)
+ register_leaf_module(apex.normalization.MixedFusedLayerNorm)
+ register_leaf_module(apex.normalization.MixedFusedRMSNorm)
+
+ @register_leaf_module_impl(apex.normalization.FusedLayerNorm)
+ @register_leaf_module_impl(apex.normalization.FusedRMSNorm)
+ @register_leaf_module_impl(apex.normalization.MixedFusedLayerNorm)
+ @register_leaf_module_impl(apex.normalization.MixedFusedRMSNorm)
+ def torch_nn_normalize(self, input: torch.Tensor):
+ # check shape
+ if isinstance(self, torch.nn.BatchNorm1d):
+ assert input.dim() in [2, 3]
+ elif isinstance(self, torch.nn.BatchNorm2d):
+ assert input.dim() == 4
+ elif isinstance(self, torch.nn.BatchNorm3d):
+ assert input.dim() == 5
+
+ # normalization maintain the same shape as the input
+ return input.clone()
+
+except (ImportError, AttributeError):
+ pass
diff --git a/colossalai/_analyzer/fx/tracer/proxy.py b/colossalai/_analyzer/fx/tracer/proxy.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce379efdcf0d7c01d5541cb9ebffac1325fa97ef
--- /dev/null
+++ b/colossalai/_analyzer/fx/tracer/proxy.py
@@ -0,0 +1,112 @@
+import operator
+from typing import Any, Callable, Dict, Optional, Set, Union
+
+import torch
+import torch.nn as nn
+from torch.fx import Graph, Node, Proxy, Tracer
+from torch.fx.graph import _Namespace
+from torch.utils._pytree import tree_map
+
+from colossalai._analyzer._subclasses import MetaTensor
+
+Target = Union[Callable[..., Any], str]
+
+
+class ColoProxy(Proxy):
+ _func_dispatch: Dict[Target, Callable[..., Any]] = {}
+
+ def __init__(self, *args, data=None, **kwargs):
+ super().__init__(*args, **kwargs)
+ self._meta_data = data
+
+ @property
+ def meta_data(self):
+ return self._meta_data
+
+ @meta_data.setter
+ def meta_data(self, args):
+ wrap_fn = lambda x: MetaTensor(x) if isinstance(x, torch.Tensor) else x
+ self._meta_data = tree_map(wrap_fn, args)
+
+ @classmethod
+ def __torch_function__(cls, orig_method, types, args=(), kwargs=None):
+ kwargs = {} if kwargs is None else kwargs
+ if orig_method in cls._func_dispatch:
+ impl = cls._func_dispatch.pop(orig_method) # avoid recursion
+ proxy = impl(*args, **kwargs)
+ cls._func_dispatch[orig_method] = impl
+ return proxy
+ else:
+ proxy = cls.from_torch_proxy(super().__torch_function__(orig_method, types, args, kwargs))
+ unwrap_fn = lambda p: p.meta_data if isinstance(p, ColoProxy) else p
+ if proxy.meta_data is None:
+ proxy.meta_data = orig_method(*tree_map(unwrap_fn, args), **tree_map(unwrap_fn, kwargs))
+ return proxy
+
+ @classmethod
+ def from_torch_proxy(cls, proxy: Proxy):
+ return cls(proxy.node, proxy.tracer)
+
+ def __repr__(self):
+ return f"ColoProxy({self.node.name}, meta_data={self.meta_data})"
+
+ def __len__(self):
+ return len(self.meta_data)
+
+ def __int__(self):
+ return int(self.meta_data)
+
+ def __index__(self):
+ try:
+ return int(self.meta_data)
+ except:
+ return torch.zeros(self.meta_data.shape, dtype=torch.bool).numpy().__index__()
+
+ def __float__(self):
+ return float(self.meta_data)
+
+ def __bool__(self):
+ return self.meta_data
+
+ def __getattr__(self, k):
+ return ColoAttribute(self, k, getattr(self._meta_data, k, None))
+
+ def __setitem__(self, key, value):
+ proxy = self.tracer.create_proxy('call_function', operator.setitem, (self, key, value), {})
+ proxy.meta_data = self._meta_data
+ return proxy
+
+ def __contains__(self, key):
+ if self.node.op == "placeholder":
+ # this is used to handle like
+ # if x in kwargs
+ # we don't handle this case for now
+ return False
+ return super().__contains__(key)
+
+ def __isinstancecheck__(self, type):
+ return isinstance(self.meta_data, type)
+
+
+class ColoAttribute(ColoProxy):
+
+ def __init__(self, root, attr: str, data=None):
+ self.root = root
+ self.attr = attr
+ self.tracer = root.tracer
+ self._meta_data = data
+ self._node: Optional[Node] = None
+
+ @property
+ def node(self):
+ # the node for attributes is added lazily, since most will just be method calls
+ # which do not rely on the getitem call
+ if self._node is None:
+ self._node = self.tracer.create_proxy('call_function', getattr, (self.root, self.attr), {}).node
+ return self._node
+
+ def __call__(self, *args, **kwargs):
+ return self.tracer.create_proxy('call_method', self.attr, (self.root,) + args, kwargs)
+
+ def __repr__(self):
+ return f"ColoAttribute({self.node.name}, attr={self.attr})"
diff --git a/colossalai/_analyzer/fx/tracer/symbolic_trace.py b/colossalai/_analyzer/fx/tracer/symbolic_trace.py
new file mode 100644
index 0000000000000000000000000000000000000000..2018863f6f5f50de7cc61eafb907a55034711993
--- /dev/null
+++ b/colossalai/_analyzer/fx/tracer/symbolic_trace.py
@@ -0,0 +1,157 @@
+from typing import Any, Callable, Dict, Iterable, List, Optional, Set, Tuple, Type, Union
+
+import torch
+from torch.fx import Tracer
+from torch.utils._pytree import tree_map
+
+from colossalai._analyzer._subclasses import MetaTensor
+
+try:
+ from ..codegen import ActivationCheckpointCodeGen
+ SUPPORT_ACTIVATION = True
+except:
+ SUPPORT_ACTIVATION = False
+from ..graph_module import ColoGraphModule
+from .tracer import ColoTracer
+
+
+def _default_device():
+ return torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
+
+
+def _current_device(module: torch.nn.Module):
+ try:
+ return next(module.parameters()).device
+ except:
+ return _default_device()
+
+
+def symbolic_trace(
+ root: Union[torch.nn.Module, Callable[..., Any]],
+ concrete_args: Optional[Dict[str, Any]] = None,
+ meta_args: Optional[Dict[str, Any]] = None,
+ trace_act_ckpt: bool = False,
+ bias_addition_split: bool = False,
+) -> ColoGraphModule:
+ """
+ Traces a ``torch.nn.Module`` or a function and returns a ``GraphModule`` with ``Node``s and ``MetaInfo``
+ attached to the ``Node``s.
+
+ Can be used to trace the usage of ``torch.utils.checkpoint`` and the path of module
+ (https://github.com/pytorch/examples/blob/main/fx/module_tracer.py).
+
+ This tracer is able to trace basic control flow and for loops.
+
+ It will split the bias addition into two parts if ``bias_addition_split`` is set to be ``True``.
+ (See ./bias_addition.py for more details).
+
+ Examples:
+ 1. Tracing a ``torch.nn.Module`` with control flow.
+
+ .. code-block:: python
+
+ class MyModule(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.linear = torch.nn.Linear(2, 2)
+
+ def forward(self, x):
+ if x.size(0) > 1:
+ x = x.sum(dim=0)
+ return self.linear(x)
+
+ traced = symbolic_trace(MyModule(), meta_args={'x': torch.randn(1, 2, 2)})
+
+ # traced code like:
+ # def forward(self, x):
+ # linear_1 = self.linear(x)
+ # return linear_1
+
+ traced = symbolic_trace(MyModule(), meta_args={'x': torch.randn(2, 2, 2)})
+
+ # traced code like:
+ # def forward(self, x):
+ # sum = x.sum(dim=0); x = None
+ # linear = self.linear(sum); sum = None
+ # return linear
+
+ 2. Tracing a ``torch.nn.Module`` with ``torch.utils.checkpoint``.
+
+ .. code-block:: python
+
+ class MyModule(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.linear = torch.nn.Linear(2, 2)
+
+ def forward(self, x):
+ def custom_forward(x):
+ return self.linear(x)
+ return torch.utils.checkpoint.checkpoint(custom_forward, x)
+
+ traced = symbolic_trace(MyModule(), meta_args={'x': torch.randn(1, 2, 2)}, trace_act_ckpt=True)
+
+ # traced code like:
+ # def checkpoint_0(self, x):
+ # linear = self.linear(x); x = None
+ # return linear
+ #
+ # def forward(self, x):
+ # linear = torch.utils.checkpoint.checkpoint(checkpoint_0, x); x = None
+ # return linear
+
+ 3. Tracing a ``torch.nn.Module`` with ``bias_addition_split``.
+
+ .. code-block:: python
+
+ class MyModule(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.linear = torch.nn.Linear(2, 2, bias=True)
+
+ def forward(self, x):
+ return self.linear(x)
+
+ traced = symbolic_trace(MyModule(), meta_args={'x': torch.randn(1, 2, 2)}, bias_addition_split=True)
+
+ # traced code like:
+ # def forward(self, x):
+ # linear_bias = self.linear.bias
+ # linear_weight = self.linear.weight
+ # linear = torch._C._nn.linear(x, linear_weight); x = linear_weight = None
+ # add = linear + linear_bias; linear = linear_bias = None
+ # return add
+
+ Args:
+ root (Union[torch.nn.Module, Callable[..., Any]]): The ``torch.nn.Module`` or function to be traced.
+ concrete_args (Optional[Dict[str, Any]], optional): Concrete arguments to be passed to the ``root``.
+ Defaults to {}.
+ meta_args (Optional[Dict[str, Any]], optional): Meta arguments to be passed to the ``root``. Mostly used
+ for tracing control flow. Defaults to {}.
+ trace_act_ckpt (bool, optional): Whether to trace the usage of ``torch.utils.checkpoint``.
+ Defaults to False.
+ bias_addition_split (bool, optional): Whether to split the bias addition into two parts. Defaults to False.
+
+ Returns:
+ ColoGraphModule: A traced ``GraphModule`` that is ready for activation checkpoint ``CodeGen``.
+
+ Remarks:
+ This part of ``symbolic_trace()`` is maintained by Colossal-AI team. If you encountered
+ any unexpected error during tracing, feel free to raise an issue on Colossal-AI GitHub
+ repo. We welcome any feedback and contributions to enhance the extensibility of
+ Colossal-AI.
+ """
+ if meta_args:
+ device, orig_device = _default_device(), _current_device(root)
+ wrap_fn = lambda elem: MetaTensor(elem, device=device) if isinstance(elem, torch.Tensor) else elem
+ graph = ColoTracer(trace_act_ckpt=trace_act_ckpt,
+ bias_addition_split=bias_addition_split).trace(root.to(device),
+ concrete_args=concrete_args,
+ meta_args=tree_map(wrap_fn, meta_args))
+ if trace_act_ckpt and SUPPORT_ACTIVATION:
+ graph.set_codegen(ActivationCheckpointCodeGen())
+ root.to(orig_device)
+ else:
+ graph = Tracer().trace(root, concrete_args=concrete_args)
+ name = root.__class__.__name__ if isinstance(root, torch.nn.Module) else root.__name__
+ return ColoGraphModule(root, graph, name)
diff --git a/colossalai/_analyzer/fx/tracer/tracer.py b/colossalai/_analyzer/fx/tracer/tracer.py
new file mode 100644
index 0000000000000000000000000000000000000000..6958a00a6a72af16bf6a9736a7c18411ff127b76
--- /dev/null
+++ b/colossalai/_analyzer/fx/tracer/tracer.py
@@ -0,0 +1,363 @@
+import functools
+import inspect
+from contextlib import contextmanager
+from typing import Any, Callable, Dict, Iterable, Optional, Set, Tuple, Type, Union
+
+import torch
+import torch.nn as nn
+from torch.fx import Graph, Node, Proxy, Tracer
+from torch.utils._pytree import tree_map
+
+from colossalai._analyzer._subclasses import _TensorPropertyMethod, _TorchFactoryMethod
+
+from ..node_util import MetaInfo
+from .proxy import ColoProxy
+
+Target = Union[Callable[..., Any], str]
+
+
+def _truncate_suffix(s: str):
+ import re
+
+ # FIXME: don't know why but torch.fx always gets a suffix like '_1' in the name
+ return re.sub(r'_\d+$', '', s)
+
+
+def register_tracer_impl(func: Callable[..., Any], name: Optional[str] = '_custom_impl'):
+
+ def wrapper(impl):
+ assert hasattr(ColoTracer, name), f"Cannot register {func.__name__} in ColoTracer.{name}"
+ getattr(ColoTracer, name)[func] = impl
+ return impl
+
+ return wrapper
+
+
+def register_leaf_module_impl(module: nn.Module):
+
+ def wrapper(impl):
+ ColoTracer._custom_leaf_module_impl[module] = impl
+ return impl
+
+ return wrapper
+
+
+def register_leaf_module(module: nn.Module):
+ ColoTracer._custom_leaf_module.add(module)
+
+
+def register_non_leaf_module(module: nn.Module):
+ ColoTracer._custom_non_leaf_module.add(module)
+
+
+class ColoTracer(Tracer):
+ _custom_leaf_module: Set[Type[nn.Module]] = set()
+ _custom_leaf_module_impl: Dict[Type[nn.Module], Callable[..., Any]] = {}
+ _custom_non_leaf_module: Set[Type[nn.Module]] = set()
+ _custom_impl: Dict[Callable[..., Any], Callable[..., Any]] = {}
+ _bias_addition_impl: Dict[Callable[..., Any], Callable[..., Any]] = {}
+ _bias_addition_module = [
+ torch.nn.Linear,
+ torch.nn.Conv1d,
+ torch.nn.Conv2d,
+ torch.nn.Conv3d,
+ torch.nn.ConvTranspose1d,
+ torch.nn.ConvTranspose2d,
+ torch.nn.ConvTranspose3d,
+ ]
+
+ def __init__(self, trace_act_ckpt: bool = False, bias_addition_split: bool = False, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.disable_module_getattr = False
+ self.proxy_buffer_attributes = True
+
+ # whether the tracer will record the usage of torch.utils.checkpoint
+ self.trace_act_ckpt = trace_act_ckpt
+ self.ckpt_regions = []
+ self.ckpt_idx = 0
+
+ self.mod_dir = ''
+
+ # whether the tracer should split the bias_add ops into two ops
+ self.bias_addition_split = bias_addition_split
+
+ def is_leaf_module(self, m: nn.Module, module_qualified_name: str) -> bool:
+ # if bias-addiction split is enabled, and module has bias, then it is not a leaf module
+ # we will enter the module and split the bias-addition ops
+ if self.bias_addition_split and type(m) in self._bias_addition_module and m.bias is not None:
+ return False
+ # user can specify which modules are leaf modules and which are not
+ return (type(m) not in self._custom_non_leaf_module
+ and (type(m) in self._custom_leaf_module or super().is_leaf_module(m, module_qualified_name)))
+
+ def call_module(self, m: torch.nn.Module, forward: Callable[..., Any], args: Tuple[Any, ...],
+ kwargs: Dict[str, Any]) -> Any:
+ curr_dir = self.mod_dir
+ self.mod_dir = 'self.' + self.path_of_module(m)
+ rst = super().call_module(m, forward, args, kwargs)
+ self.mod_dir = curr_dir
+ return rst
+
+ def proxy(self, node: Node) -> 'ColoProxy':
+ return ColoProxy(node, self)
+
+ def create_proxy(self,
+ kind: str,
+ target: Target,
+ args: Tuple[Any, ...],
+ kwargs: Dict[str, Any],
+ name: Optional[str] = None,
+ type_expr: Optional[Any] = None,
+ proxy_factory_fn: Callable[[Node], 'Proxy'] = None):
+
+ proxy: ColoProxy = super().create_proxy(kind, target, args, kwargs, name, type_expr, proxy_factory_fn)
+ unwrap_fn = lambda p: p.meta_data if isinstance(p, ColoProxy) else p
+ if kind == 'placeholder':
+ proxy.meta_data = self.meta_args[target] if target in self.meta_args else self.concrete_args.get(
+ _truncate_suffix(target), None)
+ elif kind == 'get_attr':
+ self.disable_module_getattr = True
+ try:
+ attr_itr = self.root
+ atoms = target.split(".")
+ for atom in atoms:
+ attr_itr = getattr(attr_itr, atom)
+ proxy.meta_data = attr_itr
+ finally:
+ self.disable_module_getattr = False
+ elif kind == 'call_function':
+ proxy.meta_data = target(*tree_map(unwrap_fn, args), **tree_map(unwrap_fn, kwargs))
+ elif kind == 'call_method':
+ self.disable_module_getattr = True
+ try:
+ if target == '__call__':
+ proxy.meta_data = unwrap_fn(args[0])(*tree_map(unwrap_fn, args[1:]), **tree_map(unwrap_fn, kwargs))
+ else:
+ if target not in _TensorPropertyMethod:
+ proxy._meta_data = getattr(unwrap_fn(args[0]), target)(*tree_map(unwrap_fn, args[1:]),
+ **tree_map(unwrap_fn, kwargs))
+ finally:
+ self.disable_module_getattr = False
+ elif kind == 'call_module':
+ mod = self.root.get_submodule(target)
+ self.disable_module_getattr = True
+ try:
+ args = tree_map(unwrap_fn, args)
+ kwargs = tree_map(unwrap_fn, kwargs)
+ if type(mod) in self._custom_leaf_module:
+ target = self._custom_leaf_module_impl[type(mod)]
+ proxy.meta_data = target(mod, *args, **kwargs)
+ else:
+ proxy.meta_data = mod.forward(*args, **kwargs)
+ finally:
+ self.disable_module_getattr = False
+ return proxy
+
+ def create_node(self, *args, **kwargs) -> Node:
+ node = super().create_node(*args, **kwargs)
+ n_info = MetaInfo(node, mod_dir=self.mod_dir, activation_checkpoint=tuple(self.ckpt_regions))
+ return node
+
+ def trace(self,
+ root: torch.nn.Module,
+ concrete_args: Optional[Dict[str, torch.Tensor]] = None,
+ meta_args: Optional[Dict[str, torch.Tensor]] = None) -> Graph:
+
+ if meta_args is None:
+ meta_args = {}
+
+ if concrete_args is None:
+ concrete_args = {}
+
+ # check concrete and meta args have valid names
+ sig = inspect.signature(root.forward)
+ sig_names = set(sig.parameters.keys())
+ meta_arg_names = set(meta_args.keys())
+ concrete_arg_names = set(concrete_args.keys())
+ non_concrete_arg_names = sig_names - concrete_arg_names
+ # update concrete args with default values
+ for k, v in sig.parameters.items():
+ if k in sig_names - meta_arg_names and \
+ k not in concrete_args and \
+ v.default is not inspect.Parameter.empty:
+ concrete_args[k] = v.default
+
+ def _check_arg_name_valid(names: Iterable[str]):
+ for name in names:
+ if name not in sig_names:
+ raise ValueError(f"Argument {name} is not in the signature of {root.__class__.__name__}.forward")
+
+ _check_arg_name_valid(meta_arg_names)
+ _check_arg_name_valid(concrete_arg_names)
+
+ self.concrete_args = concrete_args
+ self.meta_args = meta_args
+
+ with self._torch_factory_override(), self._tracer_override(), torch.no_grad():
+ self.mod_dir = 'self'
+ self.graph = super().trace(root, concrete_args=concrete_args)
+ self.mod_dir = ''
+ self.graph.lint()
+
+ for node in self.graph.nodes:
+ if node.op == "placeholder":
+ # Removing default values for inputs as the forward pass will fail with them.
+ if node.target in non_concrete_arg_names:
+ node.args = ()
+ # Without this, torch.jit.script fails because the inputs type is Optional[torch.Tensor].
+ # It cannot infer on the attributes and methods the input should have, and fails.
+ node.type = torch.Tensor
+ # It is a concrete arg so it is not used and should be removed.
+ else:
+ if hasattr(torch.fx._symbolic_trace, "_assert_is_none"):
+ # Newer versions of torch.fx emit an assert statement
+ # for concrete arguments; delete those before we delete
+ # the concrete arg.
+ to_delete = []
+ for user in node.users:
+ if user.target == torch.fx._symbolic_trace._assert_is_none:
+ to_delete.append(user)
+ for user in to_delete:
+ self.graph.erase_node(user)
+
+ self.graph.erase_node(node)
+
+ # TODO: solves GraphModule creation.
+ # Without this, return type annotation "Tuple" is causing code execution failure.
+ if node.op == "output":
+ node.type = None
+ return self.graph
+
+ @contextmanager
+ def _tracer_override(self):
+ # override the tracer to support custom modules and checkpointing
+ if self.trace_act_ckpt:
+ orig_ckpt_func_apply = torch.utils.checkpoint.CheckpointFunction.apply
+ orig_ckpt_func_without_reentrant = torch.utils.checkpoint._checkpoint_without_reentrant
+
+ def checkpoint(run_function, preserve_rng_state=False, *args):
+ self.ckpt_regions.append(self.ckpt_idx)
+ out = run_function(*args)
+ self.ckpt_idx = self.ckpt_regions.pop(-1) + 1
+ return out
+
+ # override the checkpoint function
+ torch.utils.checkpoint.CheckpointFunction.apply = checkpoint
+ torch.utils.checkpoint._checkpoint_without_reentrant = checkpoint
+
+ # override the custom functions
+ ColoProxy._func_dispatch.update({k: v for k, v in self._custom_impl.items()})
+
+ # override the bias addition functions
+ if self.bias_addition_split:
+ ColoProxy._func_dispatch.update({k: v for k, v in self._bias_addition_impl.items()})
+
+ yield
+
+ if self.trace_act_ckpt:
+ # recover the checkpoint function upon exit
+ torch.utils.checkpoint.CheckpointFunction.apply = orig_ckpt_func_apply
+ torch.utils.checkpoint._checkpoint_reentrant = orig_ckpt_func_without_reentrant
+
+ ColoProxy._func_dispatch = {}
+
+ @contextmanager
+ def _torch_factory_override(self):
+ # override the torch factory functions to create a proxy when the method
+ # is called during ``symbolic_trace()``.
+ def wrap_factory_method(target):
+
+ @functools.wraps(target)
+ def wrapper(*args, **kwargs):
+ is_proxy = any(isinstance(p, ColoProxy) for p in args) | any(
+ isinstance(p, ColoProxy) for p in kwargs.values())
+ if is_proxy:
+ # if the arg is a proxy, then need to record this function called on this proxy
+ # e.g. torch.ones(size) where size is an input proxy
+ self.disable_module_getattr = True
+ try:
+ proxy = self.create_proxy('call_function', target, args, kwargs)
+ finally:
+ self.disable_module_getattr = False
+ return proxy
+ else:
+ return target(*args, **kwargs)
+
+ return wrapper, target
+
+ overrides = {
+ target: wrap_factory_method(getattr(torch, target))
+ for target in _TorchFactoryMethod
+ if callable(getattr(torch, target))
+ }
+ for name, (wrapper, orig) in overrides.items():
+ setattr(torch, name, wrapper)
+
+ yield
+
+ # recover the torch factory functions upon exit
+ for name, (wrapper, orig) in overrides.items():
+ setattr(torch, name, orig)
+
+ def _post_check(self, non_concrete_arg_names: Set[str]):
+ # This is necessary because concrete args are added as input to the traced module since
+ # https://github.com/pytorch/pytorch/pull/55888.
+ for node in self.graph.nodes:
+ if node.op == "placeholder":
+ # Removing default values for inputs as the forward pass will fail with them.
+ if node.target in non_concrete_arg_names:
+ node.args = ()
+ # Without this, torch.jit.script fails because the inputs type is Optional[torch.Tensor].
+ # It cannot infer on the attributes and methods the input should have, and fails.
+ node.type = torch.Tensor
+ # It is a concrete arg so it is not used and should be removed.
+ else:
+ if hasattr(torch.fx._symbolic_trace, "_assert_is_none"):
+ # Newer versions of torch.fx emit an assert statement
+ # for concrete arguments; delete those before we delete
+ # the concrete arg.
+ to_delete = []
+ for user in node.users:
+ if user.target == torch.fx._symbolic_trace._assert_is_none:
+ to_delete.append(user)
+ for user in to_delete:
+ self.graph.erase_node(user)
+
+ self.graph.erase_node(node)
+
+ if node.op == "output":
+ node.type = None
+ self.graph.lint()
+
+ def getattr(self, attr, attr_val, parameter_proxy_cache):
+ return self._module_getattr(attr, attr_val, parameter_proxy_cache)
+
+ def _module_getattr(self, attr, attr_val, parameter_proxy_cache):
+ if getattr(self, "disable_module_getattr", False):
+ return attr_val
+
+ def maybe_get_proxy_for_attr(attr_val, collection_to_search, parameter_proxy_cache):
+ for n, p in collection_to_search:
+ if attr_val is p:
+ if n not in parameter_proxy_cache:
+ kwargs = {}
+ if 'proxy_factory_fn' in inspect.signature(self.create_proxy).parameters:
+ kwargs['proxy_factory_fn'] = (None if not self.param_shapes_constant else
+ lambda node: ColoProxy(self, node, n, attr_val))
+ val_proxy = self.create_proxy('get_attr', n, (), {}, **kwargs) # type: ignore[arg-type]
+ parameter_proxy_cache[n] = val_proxy
+ return parameter_proxy_cache[n]
+ return None
+
+ if self.proxy_buffer_attributes and isinstance(attr_val, torch.Tensor):
+ maybe_buffer_proxy = maybe_get_proxy_for_attr(attr_val, self.root.named_buffers(), parameter_proxy_cache)
+ if maybe_buffer_proxy is not None:
+ return maybe_buffer_proxy
+
+ if isinstance(attr_val, torch.nn.Parameter):
+ maybe_parameter_proxy = maybe_get_proxy_for_attr(attr_val, self.root.named_parameters(),
+ parameter_proxy_cache)
+ if maybe_parameter_proxy is not None:
+ return maybe_parameter_proxy
+
+ return attr_val
diff --git a/colossalai/amp/__init__.py b/colossalai/amp/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..963215476b6b038b2aa33c124461387e47579d3c
--- /dev/null
+++ b/colossalai/amp/__init__.py
@@ -0,0 +1,54 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import torch.nn as nn
+from torch.nn.modules.loss import _Loss
+from torch.optim import Optimizer
+
+from colossalai.context import Config
+
+from .amp_type import AMP_TYPE
+from .apex_amp import convert_to_apex_amp
+from .naive_amp import convert_to_naive_amp
+from .torch_amp import convert_to_torch_amp
+
+__all__ = ['convert_to_amp', 'convert_to_naive_amp', 'convert_to_apex_amp', 'convert_to_torch_amp', 'AMP_TYPE']
+
+
+def convert_to_amp(model: nn.Module, optimizer: Optimizer, criterion: _Loss, mode: AMP_TYPE, amp_config: Config = None):
+ """A helper function to wrap training components with Torch AMP modules.
+
+ Args:
+ param model (:class:`torch.nn.Module`): your model object.
+ optimizer (:class:`torch.optim.Optimizer`): your optimizer object.
+ criterion (:class:`torch.nn.modules.loss._Loss`): your loss function object.
+ mode (:class:`colossalai.amp.AMP_TYPE`): amp mode.
+ amp_config (Union[:class:`colossalai.context.Config`, dict]): configuration for different amp modes.
+
+ Returns:
+ A tuple (model, optimizer, criterion).
+
+ Note:
+ ``amp_config`` may vary from different mode you choose. You should check the corresponding amp mode
+ for more details about ``amp_config``.
+ For ``apex_amp``, please check
+ `apex_amp config `_.
+ For ``naive_amp``, please check
+ `naive_amp config `_.
+ For ``torch_amp``, please check
+ `torch_amp config `_.
+ """
+ assert isinstance(mode, AMP_TYPE), \
+ f'expected the argument mode be AMP_TYPE, but got {type(mode)}'
+
+ if amp_config is None:
+ amp_config = Config()
+
+ if mode == AMP_TYPE.TORCH:
+ model, optimizer, criterion = convert_to_torch_amp(model, optimizer, criterion, amp_config)
+ elif mode == AMP_TYPE.APEX:
+ model, optimizer = convert_to_apex_amp(model, optimizer, amp_config)
+ elif mode == AMP_TYPE.NAIVE:
+ model, optimizer = convert_to_naive_amp(model, optimizer, amp_config)
+
+ return model, optimizer, criterion
diff --git a/colossalai/amp/amp_type.py b/colossalai/amp/amp_type.py
new file mode 100644
index 0000000000000000000000000000000000000000..6f322f866cfc813e66e54b0c1006d62ef949e96e
--- /dev/null
+++ b/colossalai/amp/amp_type.py
@@ -0,0 +1,10 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from enum import Enum
+
+
+class AMP_TYPE(Enum):
+ APEX = 'apex'
+ TORCH = 'torch'
+ NAIVE = 'naive'
diff --git a/colossalai/amp/apex_amp/__init__.py b/colossalai/amp/apex_amp/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..51b9b97dccce877783251fb3f61f08a87a6a7659
--- /dev/null
+++ b/colossalai/amp/apex_amp/__init__.py
@@ -0,0 +1,42 @@
+import torch.nn as nn
+from torch.optim import Optimizer
+
+from .apex_amp import ApexAMPOptimizer
+
+
+def convert_to_apex_amp(model: nn.Module, optimizer: Optimizer, amp_config):
+ r"""A helper function to wrap training components with Apex AMP modules
+
+ Args:
+ model (:class:`torch.nn.Module`): your model object.
+ optimizer (:class:`torch.optim.Optimizer`): your optimizer object.
+ amp_config (Union[:class:`colossalai.context.Config`, dict]): configuration for initializing apex_amp.
+
+ Returns:
+ Tuple: A tuple (model, optimizer).
+
+ The ``amp_config`` should include parameters below:
+ ::
+
+ enabled (bool, optional, default=True)
+ opt_level (str, optional, default="O1")
+ cast_model_type (``torch.dtype``, optional, default=None)
+ patch_torch_functions (bool, optional, default=None)
+ keep_batchnorm_fp32 (bool or str, optional, default=None
+ master_weights (bool, optional, default=None)
+ loss_scale (float or str, optional, default=None)
+ cast_model_outputs (torch.dtype, optional, default=None)
+ num_losses (int, optional, default=1)
+ verbosity (int, default=1)
+ min_loss_scale (float, default=None)
+ max_loss_scale (float, default=2.**24)
+
+ More details about ``amp_config`` refer to `amp_config `_.
+ """
+ import apex.amp as apex_amp
+ model, optimizer = apex_amp.initialize(model, optimizer, **amp_config)
+ optimizer = ApexAMPOptimizer(optimizer)
+ return model, optimizer
+
+
+__all__ = ['convert_to_apex_amp', 'ApexAMPOptimizer']
diff --git a/colossalai/amp/apex_amp/apex_amp.py b/colossalai/amp/apex_amp/apex_amp.py
new file mode 100644
index 0000000000000000000000000000000000000000..e6bdbe4520f92450e80e930c0a7c746881e10bba
--- /dev/null
+++ b/colossalai/amp/apex_amp/apex_amp.py
@@ -0,0 +1,39 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import torch.nn as nn
+
+try:
+ import apex.amp as apex_amp
+except ImportError:
+ pass
+
+from torch import Tensor
+
+from colossalai.nn.optimizer import ColossalaiOptimizer
+from colossalai.utils import clip_grad_norm_fp32
+
+
+class ApexAMPOptimizer(ColossalaiOptimizer):
+ """ A wrapper class for APEX optimizer and it implements apex-specific backward and clip_grad_norm
+ methods
+ """
+
+ def backward(self, loss: Tensor):
+ """Backward pass to get all gradients
+
+ Args:
+ loss (torch.Tensor): Loss computed by a loss function
+ """
+ with apex_amp.scale_loss(loss, self.optim) as scaled_loss:
+ scaled_loss.backward()
+
+ def clip_grad_norm(self, model: nn.Module, max_norm: float):
+ """Clip gradients by norm
+
+ Args:
+ model (torch.nn.Module): Your model object
+ max_norm (float): The max norm value for gradient clipping
+ """
+ if max_norm > 0:
+ clip_grad_norm_fp32(apex_amp.master_params(self.optim), max_norm)
diff --git a/colossalai/amp/naive_amp/__init__.py b/colossalai/amp/naive_amp/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b2f71d3ced771c43d541843153c6b64613f69e1
--- /dev/null
+++ b/colossalai/amp/naive_amp/__init__.py
@@ -0,0 +1,60 @@
+import inspect
+
+import torch.nn as nn
+from torch.optim import Optimizer
+
+from colossalai.utils import is_no_pp_or_last_stage
+
+from ._fp16_optimizer import FP16Optimizer
+from .grad_scaler import ConstantGradScaler, DynamicGradScaler
+from .naive_amp import NaiveAMPModel, NaiveAMPOptimizer
+
+
+def convert_to_naive_amp(model: nn.Module, optimizer: Optimizer, amp_config):
+ """A helper function to wrap training components with naive AMP modules. In this mode,
+ we forcibly cast the model weights and inputs to FP16, and cast the model outputs to FP32 to calculate loss,
+ which is equivalent to Apex O3.
+
+ Args:
+ model (:class:`torch.nn.Module`): your model object
+ optimizer (:class:`torch.optim.Optimizer`): your optimizer object
+ amp_config (:class:`colossalai.context.Config` or dict): configuration for naive mode amp.
+
+ Returns:
+ Tuple: A tuple (model, optimizer)
+
+ The ``amp_config`` should contain parameters below::
+
+ verbose (bool, optional): if set to `True`, will print debug info (Default: False).
+ clip_grad_norm (float, optional): clip gradients with this global L2 norm (Default 0).
+ Note that clipping is ignored if clip_grad == 0.
+ dynamic_grad_scale (bool): whether to use dynamic grad scaler.
+ """
+ if isinstance(model, nn.ModuleList):
+ # interleaved pipeline
+ module_list = []
+ for chunk, m in enumerate(model):
+ output_to_fp32 = is_no_pp_or_last_stage() and chunk == len(model) - 1
+ module_list.append(NaiveAMPModel(m, output_to_fp32=output_to_fp32))
+ model = nn.ModuleList(module_list)
+ else:
+ output_to_fp32 = is_no_pp_or_last_stage()
+ model = NaiveAMPModel(model, output_to_fp32=output_to_fp32)
+
+ use_dynamic_grad_scaler = amp_config.pop('dynamic_grad_scale', True)
+ if use_dynamic_grad_scaler:
+ scaler_class = DynamicGradScaler
+ else:
+ scaler_class = ConstantGradScaler
+
+ sig = inspect.signature(scaler_class.__init__)
+ kwargs = dict()
+ for param in sig.parameters.values():
+ if param.name in amp_config:
+ kwargs[param.name] = amp_config.pop(param.name)
+ grad_scaler = scaler_class(**kwargs)
+ optimizer = NaiveAMPOptimizer(optimizer, grad_scaler, **amp_config)
+ return model, optimizer
+
+
+__all__ = ['convert_to_naive_amp', 'NaiveAMPOptimizer', 'FP16Optimizer']
diff --git a/colossalai/amp/naive_amp/_fp16_optimizer.py b/colossalai/amp/naive_amp/_fp16_optimizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4699f92b9444005086a2a625ed243f0fa49ec44
--- /dev/null
+++ b/colossalai/amp/naive_amp/_fp16_optimizer.py
@@ -0,0 +1,371 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import torch
+import torch.distributed as dist
+from torch.distributed import ProcessGroup
+from torch.optim import Optimizer
+
+from colossalai.context import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.kernel.op_builder import FusedOptimBuilder
+from colossalai.logging import get_dist_logger
+from colossalai.utils import clip_grad_norm_fp32, copy_tensor_parallel_attributes, multi_tensor_applier
+
+from ._utils import has_inf_or_nan, zero_gard_by_list
+from .grad_scaler import BaseGradScaler
+
+try:
+ from colossalai._C import fused_optim
+except:
+ fused_optim = None
+
+__all__ = ['FP16Optimizer']
+
+
+def load_fused_optim():
+ global fused_optim
+
+ if fused_optim is None:
+ fused_optim = FusedOptimBuilder().load()
+
+
+def _multi_tensor_copy_this_to_that(this, that, overflow_buf=None):
+ """
+ adapted from Megatron-LM (https://github.com/NVIDIA/Megatron-LM)
+
+ Use multi-tensor-applier to copy values from one list to another.
+ We don't have a blfoat16 implementation so for now if the overflow_buf
+ is not provided, we default back to simple loop copy to be compatible
+ with bfloat16.
+ """
+ if overflow_buf:
+ overflow_buf.fill_(0)
+ # Scaling with factor `1.0` is equivalent to copy.
+ global fused_optim
+ load_fused_optim()
+ multi_tensor_applier(fused_optim.multi_tensor_scale, overflow_buf, [this, that], 1.0)
+ else:
+ for this_, that_ in zip(this, that):
+ that_.copy_(this_)
+
+
+class FP16Optimizer(Optimizer):
+ """Float16 optimizer for fp16 and bf16 data types.
+
+ Args:
+ optimizer (torch.optim.Optimizer): base optimizer such as Adam or SGD
+ grad_scaler (BaseGradScaler): grad scaler for gradient chose in
+ ``constant_grad_scaler`` or ``dynamic_grad_scaler``.
+ clip_grad_norm (float, optional): clip gradients with this global L2 norm. Default 0.
+ Note that clipping is ignored if clip_grad == 0
+ verbose (bool, optional): if set to `True`, will print debug info. Default False.
+ """
+
+ def __init__(self,
+ optimizer: Optimizer,
+ grad_scaler: BaseGradScaler,
+ verbose: bool = False,
+ clip_grad_norm=0,
+ dp_process_group: ProcessGroup = None,
+ mp_process_group: ProcessGroup = None):
+ # have a defaults for compatibility with pytorch optim
+ self._optimizer = optimizer
+ self._defaults = optimizer.defaults
+
+ # fp16-related params
+ assert isinstance(grad_scaler, BaseGradScaler)
+ self._grad_scaler = grad_scaler
+ self._found_overflow = torch.cuda.FloatTensor([0.0])
+ self._dummy_overflow_buf = torch.cuda.IntTensor([0])
+
+ # misc params
+ self._clip_grad_max_norm = clip_grad_norm
+
+ # get process group
+ def _get_process_group(parallel_mode):
+ if gpc.is_initialized(parallel_mode) and gpc.get_world_size(parallel_mode):
+ return gpc.get_group(parallel_mode)
+ else:
+ return None
+
+ if dp_process_group is None:
+ dp_process_group = _get_process_group(ParallelMode.DATA)
+ if mp_process_group is None:
+ mp_process_group = _get_process_group(ParallelMode.MODEL)
+
+ self._dp_process_group = dp_process_group
+ self._mp_process_group = mp_process_group
+
+ # we maintain three groups of parameters
+ # so that the model can have a mixture
+ # of fp16 and fp32 params
+ # fp16_param_groups: the fp16 params of the model
+ # fp32_master_param_groups: the fp32 params cast from the fp16 param of the model
+ # fp32_param_groups: the fp32 params of the model
+ # NOTE:
+ # 1. fp16_param_groups and fp32_master_param_groups have one-to-one correspondence
+ # 2. fp32_param_groups and fp16_param_groups are exclusive of each other
+ self._fp16_param_groups = []
+ self._fp32_master_param_groups = []
+ self._fp32_param_groups = []
+
+ # For all the groups in the original optimizer:
+ for param_group in self._optimizer.param_groups:
+ fp16_params = []
+ fp32_master_params = []
+ fp32_params = []
+ # For all the parameters in this group:
+ for i, param in enumerate(param_group['params']):
+ if param.requires_grad:
+ # float16 params:
+ if param.type() in ['torch.cuda.HalfTensor']:
+ fp16_params.append(param)
+
+ # Create a fp32 copy
+ fp32_param = param.detach().clone().float()
+ # Copy tensor model parallel attributes.
+ copy_tensor_parallel_attributes(param, fp32_param)
+
+ # Replace the optimizer params with the new fp32 copy.
+ param_group['params'][i] = fp32_param
+ fp32_master_params.append(fp32_param)
+
+ # Reset existing state dict key to the new main param.
+ if param in self._optimizer.state:
+ self._optimizer.state[fp32_param] = self._optimizer.state.pop(param)
+
+ # fp32 params.
+ elif param.type() == 'torch.cuda.FloatTensor':
+ fp32_params.append(param)
+ else:
+ raise TypeError('Expected parameter of type torch.cuda.FloatTensor '
+ f'or torch.cuda.HalfTensor, but got {param.type()}')
+
+ self._fp16_param_groups.append(fp16_params)
+ self._fp32_master_param_groups.append(fp32_master_params)
+ self._fp32_param_groups.append(fp32_params)
+
+ # Leverage state_dict() and load_state_dict() to
+ # recast preexisting per-param state tensors
+ self._optimizer.load_state_dict(self._optimizer.state_dict())
+
+ # log config
+ self._logger = get_dist_logger()
+ if verbose:
+ self._logger.info(
+ f"\n========= FP16 Optimizer Config =========\n"
+ f"Optimizer: {optimizer.__class__.__name__}\n"
+ f"clip_grad_norm = {clip_grad_norm}\n"
+ f"grad_scaler = {self._grad_scaler.__class__.__name__}"
+ f"==========================================",
+ ranks=[0])
+
+ @property
+ def max_norm(self):
+ """Returns the maximum norm of gradient clipping.
+ """
+ return self._clip_grad_max_norm
+
+ @property
+ def grad_scaler(self):
+ """Returns the gradient scaler.
+
+ Returns:
+ :class:`BaseGradScaler`: gradient scaler.
+ """
+
+ return self._grad_scaler
+
+ @property
+ def loss_scale(self):
+ """Returns the loss scale.
+
+ Returns:
+ int: loss scale.
+ """
+ return self._grad_scaler.scale
+
+ @property
+ def optimizer(self):
+ """Returns the optimizer.
+
+ Returns:
+ :class:`torch.optim.Optimizer`: the optimizer object wrapped.
+ """
+ return self._optimizer
+
+ @property
+ def defaults(self):
+ """Returns the default arguments of optimizer.
+
+ Returns:
+ dict: optimizer arguments saved in defaults of the optimizer wrapped.
+ """
+ return self._defaults
+
+ def _check_overflow(self):
+ # clear previous overflow record
+ self._found_overflow.fill_(0.0)
+
+ # check for overflow
+ for group in self._optimizer.param_groups:
+ for p in group['params']:
+ if p.grad is not None and has_inf_or_nan(p.grad):
+ self._found_overflow.fill_(1.0)
+ break
+
+ # all-reduce across dp group
+ if self._dp_process_group:
+ dist.all_reduce(self._found_overflow, op=dist.ReduceOp.MAX, group=self._dp_process_group)
+
+ # all-reduce over model parallel group
+ if self._mp_process_group:
+ dist.all_reduce(self._found_overflow, op=dist.ReduceOp.MAX, group=self._mp_process_group)
+
+ return self._found_overflow.item() > 0
+
+ def zero_grad(self, set_to_none=True):
+ """Set gradient to zero.
+
+ Args:
+ set_to_none (bool): Whether set the gradient to None.
+ """
+
+ # set_to_none = True can save some memory space
+ for param_group in self._optimizer.param_groups:
+ zero_gard_by_list(param_group['params'], set_to_none=set_to_none)
+
+ def _get_fp32_param_groups_to_update(self):
+ return self._fp32_master_param_groups + self._fp32_param_groups
+
+ def _unscale_grads(self):
+ for group in self._get_fp32_param_groups_to_update():
+ for p in group:
+ if p.grad is not None:
+ p.grad.data.div_(self.loss_scale)
+
+ def _assign_grad_to_fp32_master_param(self):
+ # This only needs to be done for the float16 group.
+ for fp16_param_group, fp32_master_param_group in zip(self._fp16_param_groups, self._fp32_master_param_groups):
+ for fp16_param, fp32_param in zip(fp16_param_group, fp32_master_param_group):
+ if fp16_param.grad is not None:
+ fp32_param.grad = fp16_param.grad.float()
+ # clear unneeded grad on fp16 param
+ fp16_param.grad = None
+
+ def _update_fp16_param_from_fp32_param(self):
+ fp16_param_data = []
+ fp32_master_param_data = []
+ for fp16_group, fp32_group in zip(self._fp16_param_groups, self._fp32_master_param_groups):
+ for fp16_param, fp32_param in zip(fp16_group, fp32_group):
+ fp16_param_data.append(fp16_param.data)
+ fp32_master_param_data.append(fp32_param.data)
+ _multi_tensor_copy_this_to_that(this=fp32_master_param_data,
+ that=fp16_param_data,
+ overflow_buf=self._dummy_overflow_buf)
+
+ def step(self):
+ """Update the model parameters.
+ """
+
+ # Copy gradients from model params to main params.
+ self._assign_grad_to_fp32_master_param()
+ self._unscale_grads()
+
+ overflow = self._check_overflow()
+ self._grad_scaler.update(overflow)
+ if overflow:
+ self.zero_grad()
+
+ # Clip the main gradients.
+ grad_norm = None
+ if self._clip_grad_max_norm > 0.0:
+ grad_norm = self.clip_grad_norm(self._clip_grad_max_norm)
+
+ if not overflow:
+ # Step the optimizer.
+ self._optimizer.step()
+
+ # Update params from main params.
+ self._update_fp16_param_from_fp32_param()
+
+ # Successful update.
+ return True, grad_norm
+ else:
+ return False, None
+
+ def backward(self, loss):
+ """Execute backward pass.
+
+ Args:
+ loss (:class:`torch.Tensor`): the loss value.
+ """
+
+ scaled_loss = loss * self.grad_scaler.scale
+ scaled_loss.backward()
+
+ def state_dict(self):
+ """Returns the states of the fp16 optimizer as a dict object.
+ """
+
+ state_dict = {}
+ state_dict['optimizer'] = self._optimizer.state_dict()
+ if self.grad_scaler:
+ state_dict['grad_scaler'] = self.grad_scaler.state_dict()
+ state_dict['fp32_master_param_groups'] = self._fp32_master_param_groups
+ return state_dict
+
+ def load_state_dict(self, state_dict):
+ """Load the states of the fp16 optimizer from a dict object.
+
+ Args:
+ state_dict (dict): the states of the fp16 optimizer
+ """
+
+ # Optimizer.
+ self._optimizer.load_state_dict(state_dict['optimizer'])
+
+ # Grad scaler.
+ if 'grad_scaler' in state_dict:
+ self.grad_scaler.load_state_dict(state_dict['grad_scaler'])
+
+ # Copy data for the main params.
+ if 'fp32_master_param_groups' in state_dict:
+ for current_group, ckpt_group in zip(self._fp32_master_param_groups,
+ state_dict['fp32_master_param_groups']):
+ for current_param, ckpt_param in zip(current_group, ckpt_group):
+ current_param.data.copy_(ckpt_param.data)
+
+ def clip_grad_norm(self, clip_grad):
+ """Clip gradients by norm.
+
+ Args:
+ clip_grad (float): the max norm for clipping
+ """
+ params = []
+ for param_group in self._optimizer.param_groups:
+ for param in param_group['params']:
+ params.append(param)
+ return clip_grad_norm_fp32(params, clip_grad)
+
+ # Promote state so it can be retrieved or set via
+ # "optimizer_instance.state"
+ def _get_state(self):
+ return self._optimizer.state
+
+ def _set_state(self, value):
+ self._optimizer.state = value
+
+ state = property(_get_state, _set_state)
+
+ # Promote param_groups so it can be retrieved or set via
+ # "optimizer_instance.param_groups"
+ # (for example, to adjust the learning rate)
+ def _get_param_groups(self):
+ return self._optimizer.param_groups
+
+ def _set_param_groups(self, value):
+ self._optimizer.param_groups = value
+
+ param_groups = property(_get_param_groups, _set_param_groups)
diff --git a/colossalai/amp/naive_amp/_utils.py b/colossalai/amp/naive_amp/_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..7633705e19fbce24faec87f9691c834279f0d8ad
--- /dev/null
+++ b/colossalai/amp/naive_amp/_utils.py
@@ -0,0 +1,49 @@
+from typing import List
+
+from torch import Tensor
+
+
+def has_inf_or_nan(tensor):
+ """Check if tensor has inf or nan values.
+
+ Args:
+ tensor (:class:`torch.Tensor`): a torch tensor object
+
+ Returns:
+ bool: Whether the tensor has inf or nan. True for yes and False for no.
+ """
+ try:
+ # if tensor is half, the .float() incurs an additional deep copy, but it's necessary if
+ # Pytorch's .sum() creates a one-element tensor of the same type as tensor
+ # (which is true for some recent version of pytorch).
+ tensor_sum = float(tensor.float().sum())
+ # More efficient version that can be used if .sum() returns a Python scalar
+ # tensor_sum = float(tensor.sum())
+ except RuntimeError as instance:
+ # We want to check if inst is actually an overflow exception.
+ # RuntimeError could come from a different error.
+ # If so, we still want the exception to propagate.
+ if "value cannot be converted" not in instance.args[0]:
+ raise
+ return True
+ else:
+ if tensor_sum == float('inf') or tensor_sum == -float('inf') or tensor_sum != tensor_sum:
+ return True
+ return False
+
+
+def zero_gard_by_list(tensor_list: List[Tensor], set_to_none: bool = True) -> None:
+ """Clear the gradient of a list of tensors,
+
+ Note: copied from torch.optim.optimizer.
+ """
+ for param in tensor_list:
+ if param.grad is not None:
+ if set_to_none:
+ param.grad = None
+ else:
+ if param.grad.grad_fn is not None:
+ param.grad.detach_()
+ else:
+ param.grad.requires_grad_(False)
+ param.grad.zero_()
diff --git a/colossalai/amp/naive_amp/grad_scaler/__init__.py b/colossalai/amp/naive_amp/grad_scaler/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc8499d877e13f8e0eb14317d2cf4a8d54dfcb2a
--- /dev/null
+++ b/colossalai/amp/naive_amp/grad_scaler/__init__.py
@@ -0,0 +1,5 @@
+from .base_grad_scaler import BaseGradScaler
+from .constant_grad_scaler import ConstantGradScaler
+from .dynamic_grad_scaler import DynamicGradScaler
+
+__all__ = ['BaseGradScaler', 'ConstantGradScaler', 'DynamicGradScaler']
diff --git a/colossalai/amp/naive_amp/grad_scaler/base_grad_scaler.py b/colossalai/amp/naive_amp/grad_scaler/base_grad_scaler.py
new file mode 100644
index 0000000000000000000000000000000000000000..0d84384a7f67c6a4521a86d34f71ff03b821c7be
--- /dev/null
+++ b/colossalai/amp/naive_amp/grad_scaler/base_grad_scaler.py
@@ -0,0 +1,82 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from abc import ABC, abstractmethod
+from typing import Dict
+
+import torch
+from torch import Tensor
+
+from colossalai.logging import get_dist_logger
+
+__all__ = ['BaseGradScaler']
+
+
+class BaseGradScaler(ABC):
+ """A base class for the gradient scaler.
+
+ Args:
+ initial_scale (float): the initial loss scale
+ verbose (bool): whether to log messages
+ """
+
+ def __init__(self, initial_scale: float, verbose: bool):
+ assert initial_scale > 0
+ self._scale = torch.cuda.FloatTensor([initial_scale])
+ self._verbose = verbose
+
+ if self._verbose:
+ self._logger = get_dist_logger()
+
+ @property
+ def scale(self) -> Tensor:
+ """Returns the loss scale.
+ """
+
+ return self._scale
+
+ @property
+ def inv_scale(self) -> Tensor:
+ """Returns the inverse of the loss scale.
+ """
+
+ return self._scale.double().reciprocal().float()
+
+ def state_dict(self) -> Dict:
+ """Returns the states of the gradient scaler as a dict object.
+ """
+
+ state_dict = dict()
+ state_dict['scale'] = self.scale
+ return state_dict
+
+ def load_state_dict(self, state_dict: Dict) -> None:
+ """Load the states of the gradient scaler from a dict object.
+
+ Args:
+ state_dict (dict): the states of the gradient scaler
+ """
+
+ self._scale = state_dict['scale']
+
+ @abstractmethod
+ def update(self, overflow: bool) -> None:
+ """Update the loss scale.
+
+ Args:
+ overflow (bool): whether overflow occurs
+ """
+
+ pass
+
+ def log(self, message, *args, **kwargs):
+ """Log messages.
+
+ Args:
+ message (str): the message to log
+ *args: positional arguments for :class:`colossalai.logging.DistributedLogger`
+ **kwargs: key-word arguments for :class:`colossalai.logging.DistributedLogger`
+ """
+
+ if self._verbose:
+ self._logger.info(message, *args, **kwargs)
diff --git a/colossalai/amp/naive_amp/grad_scaler/constant_grad_scaler.py b/colossalai/amp/naive_amp/grad_scaler/constant_grad_scaler.py
new file mode 100644
index 0000000000000000000000000000000000000000..a2f518c5dd28261f98faadf9134721ef1fd67dc7
--- /dev/null
+++ b/colossalai/amp/naive_amp/grad_scaler/constant_grad_scaler.py
@@ -0,0 +1,26 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+from .base_grad_scaler import BaseGradScaler
+
+__all__ = ['ConstantGradScaler']
+
+
+class ConstantGradScaler(BaseGradScaler):
+ """A gradient scaler which uses constant loss scale
+
+ Args:
+ initial_scale (float): the initial loss scale
+ verbose (bool): whether to log messages
+ """
+
+ def __init__(self, initial_scale: int, verbose: bool):
+ super().__init__(initial_scale, verbose)
+ self.log(f"Constant Gradient Scaler is initialized with scale {self.scale}", ranks=[0])
+
+ def update(self, overflow: bool) -> None:
+ """Do nothing to keep the loss scale constant.
+
+ Args:
+ overflow (bool): whether overflow occurs
+ """
+ pass
diff --git a/colossalai/amp/naive_amp/grad_scaler/dynamic_grad_scaler.py b/colossalai/amp/naive_amp/grad_scaler/dynamic_grad_scaler.py
new file mode 100644
index 0000000000000000000000000000000000000000..e899b9ca4c89fba16352ce736cb0abc4959e163b
--- /dev/null
+++ b/colossalai/amp/naive_amp/grad_scaler/dynamic_grad_scaler.py
@@ -0,0 +1,121 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from typing import Optional
+
+import torch
+
+from .base_grad_scaler import BaseGradScaler
+
+__all__ = ['DynamicGradScaler']
+
+
+class DynamicGradScaler(BaseGradScaler):
+ """A gradient scaler which uses dynamic loss scale
+
+ Args:
+ initial_scale (float): the initial loss scale, defaults to 2**16
+ growth_factor (float): the multiplication factor for increasing loss scale, defaults to 2
+ backoff_factor (float): the multiplication factor for decreasing loss scale, defaults to 0.5
+ growth_interval (int): the number of steps to increase loss scale when no overflow occurs, defaults to 1000
+ min_scale (float): the minimum loss scale, defaults to None
+ max_scale (float): the maximum loss scale, defaults to None
+ hysteresis (int): the number of overflows before decreasing loss scale, defaults to 2
+ verbose (bool): whether to log messages, defaults to False
+ """
+
+ def __init__(self,
+ initial_scale: float = 2**16,
+ growth_factor: float = 2,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 1000,
+ min_scale: Optional[float] = None,
+ max_scale: Optional[float] = None,
+ hysteresis: int = 2,
+ verbose: bool = False):
+ super().__init__(initial_scale, verbose)
+ if min_scale:
+ self._min_scale = torch.cuda.FloatTensor([min_scale])
+ else:
+ self._min_scale = None
+
+ if max_scale:
+ self._max_scale = torch.cuda.FloatTensor([max_scale])
+ else:
+ self._max_scale = None
+
+ self._growth_factor = growth_factor
+ self._backoff_factor = backoff_factor
+ self._growth_interval = growth_interval
+ self._growth_step = 0
+ self._hysteresis = hysteresis
+ self._hysteresis_step = 0
+ self._sanity_checks()
+
+ def _sanity_checks(self) -> None:
+ """Check if the arguments are correct.
+ """
+
+ if self._min_scale:
+ assert self._min_scale > 0, 'The minimum gradient scale cannot be zero or negative'
+ assert self._min_scale <= self._scale, 'The minimum gradient scale cannot be greater than the current scale'
+ if self._max_scale:
+ assert self._max_scale > 0, 'The maximum gradient scale cannot be zero or negative'
+ assert self._max_scale >= self._scale, 'The maximum gradient scale cannot be smaller than the current scale'
+ assert self._growth_factor > 1, 'The growth factor cannot be equal or smaller than 1'
+ assert 0 < self._backoff_factor < 1, 'The backoff factor must be between 0 and 1'
+ assert self._hysteresis >= 0, 'The hysteresis cannot be negative'
+
+ def update(self, overflow: bool) -> None:
+ """Update the loss scale.
+
+ Args:
+ overflow (bool): whether overflow occurs
+ """
+ if overflow:
+ self._hysteresis_step += 1
+ self._growth_step = 0
+
+ if self._hysteresis_step >= self._hysteresis:
+ self._backoff_scale()
+ self.log(f"Overflow occurs, the loss scale is adjusted to {self.scale.item()}", ranks=[0])
+ else:
+ self._growth_step += 1
+ if self._growth_step == self._growth_interval:
+ self._growth_step = 0
+ self._hysteresis_step = 0
+ self._grow_scale()
+ self.log(
+ f"No overflow for consecutive {self._growth_interval} steps, "
+ f"the loss scale is adjusted to {self.scale.item()}",
+ ranks=[0])
+
+ def _backoff_scale(self) -> None:
+ """Decrease the loss scale
+ """
+
+ self._scale = self._scale * self._backoff_factor
+ if self._min_scale:
+ self._scale = torch.max(self._scale, self._min_scale)
+
+ def _grow_scale(self) -> None:
+ """Increase the loss scale
+ """
+
+ self._scale = self._scale * self._growth_factor
+ if self._max_scale:
+ self._scale = torch.min(self._scale, self._max_scale)
+
+ def state_dict(self):
+ state_dict = dict()
+ state_dict['scale'] = self._scale
+ state_dict['growth_factor'] = self._growth_factor
+ state_dict['backoff_factor'] = self._backoff_factor
+ state_dict['hysteresis'] = self._hysteresis
+ return state_dict
+
+ def load_state_dict(self, state_dict):
+ self._scale = state_dict['scale'].cuda(torch.cuda.current_device())
+ self._growth_factor = state_dict['growth_factor']
+ self._backoff_factor = state_dict['backoff_factor']
+ self._hysteresis = state_dict['hysteresis']
diff --git a/colossalai/amp/naive_amp/naive_amp.py b/colossalai/amp/naive_amp/naive_amp.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a39d518d3f42716b800b7673fd128a4d6afe91b
--- /dev/null
+++ b/colossalai/amp/naive_amp/naive_amp.py
@@ -0,0 +1,161 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from typing import Any
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch import Tensor
+from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors
+from torch.distributed import ReduceOp
+from torch.optim import Optimizer
+
+from colossalai.context import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.nn.optimizer import ColossalaiOptimizer
+
+from ._fp16_optimizer import FP16Optimizer
+
+
+class NaiveAMPOptimizer(ColossalaiOptimizer):
+ """A wrapper class for optimizer to cast all parameters to fp16
+
+ Args:
+ optim (torch.optim.Optimizer): A normal optimizer like Adam or SGD.
+ grad_scaler (BaseGradScaler): grad scaler for gradient chose in
+ ``constant_grad_scaler`` or ``dynamic_grad_scaler``.
+ clip_grad_norm (float, optional): clip gradients with this global L2 norm. Default 0.
+ verbose (bool, optional): if set to `True`, will print debug info. Default False.
+
+ Note:
+ clipping is ignored if ``clip_grad_norm`` equals 0.
+ """
+
+ def __init__(self, optim: Optimizer, *args, **kwargs):
+ optim = FP16Optimizer(optim, *args, **kwargs)
+ super().__init__(optim)
+
+ def backward(self, loss: Tensor):
+ self.optim.backward(loss)
+
+ def step(self):
+ return self.optim.step()
+
+ def clip_grad_norm(self, model: nn.Module, max_norm: float):
+ if self.optim.max_norm == max_norm:
+ return
+ raise RuntimeError("NaiveAMP optimizer has clipped gradients during optimizer.step(). "
+ "If you have supplied clip_grad_norm in the amp_config, "
+ "executing the method clip_grad_norm is not allowed.")
+
+
+class NaiveAMPModel(nn.Module):
+ r"""A wrapper class for model to cast the model into fp16 and
+ automatically cast the input and output
+
+ Args:
+ model (torch.nn.Module): torch.nn.Module to be wrapped.
+ output_to_fp32 (bool, optional): Whether cast output of this module into fp32. (Default: True)
+ parallel_mode (:class:`colossalai.context.ParallelMode`): Parallel group mode used in this module.
+ (Default: ``ParallelMode.DATA``)
+ sync_buffer (bool, optional): whether to synchronize buffer. (Default: True)
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+ """
+
+ def __init__(self,
+ model: nn.Module,
+ output_to_fp32: bool = True,
+ parallel_mode: ParallelMode = ParallelMode.DATA,
+ sync_buffer: bool = True):
+ super().__init__()
+ self.model = model.half()
+ self._output_to_fp32 = output_to_fp32
+ self._sync_buf = sync_buffer
+
+ if gpc.is_initialized(parallel_mode) and gpc.get_world_size(parallel_mode) > 1:
+ self._process_group = gpc.get_group(parallel_mode)
+ self._world_size = gpc.get_world_size(parallel_mode)
+ else:
+ self._process_group = None
+ self._world_size = 1
+ self._sync_buf = False
+ self._first_eval_run = False
+
+ @property
+ def sync_buffer(self):
+ return self._sync_buf
+
+ @sync_buffer.setter
+ def sync_buffer(self, state: bool):
+ self._sync_buf = state
+
+ def _convert_to_fp16(self, input_: Any):
+ if isinstance(input_, Tensor) and input_.dtype == torch.float32:
+ input_ = input_.half()
+ return input_
+
+ def _convert_to_fp32(self, input_: Any):
+ if isinstance(input_, Tensor) and input_.dtype == torch.float16:
+ input_ = input_.float()
+ return input_
+
+ def _reduce_module_buffer(self):
+ """
+ All-reduce the buffers (e.g. running stats of batch normalization) across
+ data parallel ranks so that all the ranks will produce consistent results
+ when given the same input
+ """
+ buf_list = []
+
+ # find valid buffers
+ for buf in self.model.buffers():
+ if buf is not None:
+ buf_list.append(buf)
+
+ # reduce buffers across data parallel ranks
+ if buf_list:
+ coalesced_buf = _flatten_dense_tensors(buf_list)
+ coalesced_buf.div_(self._world_size)
+ dist.all_reduce(coalesced_buf, op=ReduceOp.SUM, group=self._process_group)
+ unflattened_buf_list = _unflatten_dense_tensors(coalesced_buf, buf_list)
+ for old, new in zip(buf_list, unflattened_buf_list):
+ old.copy_(new)
+
+ def eval(self):
+ self.model.eval()
+
+ # we only sync buffer in the first eval iteration
+ # so that future eval iterations can be done without communication
+ self._first_eval_run = True
+
+ def forward(self, *args, **kwargs):
+ # reduce buffers after forward will lead to error
+ # as we cannot change the variables needed for gradient computation after forward
+ # so we sync buffer before forward
+ if (self.training or self._first_eval_run) and self._sync_buf:
+ with torch.no_grad():
+ self._reduce_module_buffer()
+
+ if self._first_eval_run:
+ self._first_eval_run = False
+
+ if args:
+ args = [self._convert_to_fp16(arg) for arg in args]
+ if kwargs:
+ for k, v in kwargs.items():
+ kwargs[k] = self._convert_to_fp16(v)
+
+ out = self.model(*args, **kwargs)
+
+ if self._output_to_fp32:
+ if isinstance(out, Tensor):
+ out = self._convert_to_fp32(out)
+ elif isinstance(out, (tuple, list)):
+ out = [self._convert_to_fp32(val) for val in out]
+ elif isinstance(out, dict):
+ out = {key: self._convert_to_fp32(val) for key, val in out.items()}
+ return out
diff --git a/colossalai/amp/torch_amp/__init__.py b/colossalai/amp/torch_amp/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..893cc890d68e423c643e6dc4bbf6343ff174a8d7
--- /dev/null
+++ b/colossalai/amp/torch_amp/__init__.py
@@ -0,0 +1,45 @@
+from typing import Optional
+
+import torch.nn as nn
+from torch.nn.modules.loss import _Loss
+from torch.optim import Optimizer
+
+from colossalai.context import Config
+
+from .torch_amp import TorchAMPLoss, TorchAMPModel, TorchAMPOptimizer
+
+
+def convert_to_torch_amp(model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Optional[_Loss] = None,
+ amp_config: Optional[Config] = None):
+ """A helper function to wrap training components with Pytorch AMP modules
+
+ Args:
+ model (:class:`torch.nn.Module`): your model object.
+ optimizer (:class:`torch.optim.Optimizer`): your optimizer object
+ criterion (:class:`torch.nn.modules.loss._Loss`, optional): your loss function object
+ amp_config (:class:`colossalai.context.Config` or dict, optional): configuration for Pytorch AMP.
+
+ The ``amp_config`` should include parameters below:
+ ::
+
+ init_scale (float, optional, default=2.**16)
+ growth_factor (float, optional, default=2.0)
+ backoff_factor (float, optional, default=0.5)
+ growth_interval (int, optional, default=2000)
+ enabled (bool, optional, default=True)
+
+ Returns:
+ A tuple (model, optimizer, criterion)
+ """
+ model = TorchAMPModel(model)
+ if amp_config is None:
+ amp_config = dict()
+ optimizer = TorchAMPOptimizer(optimizer, **amp_config)
+ if criterion:
+ criterion = TorchAMPLoss(criterion)
+ return model, optimizer, criterion
+
+
+__all__ = ['convert_to_torch_amp', 'TorchAMPModel', 'TorchAMPLoss', 'TorchAMPOptimizer']
diff --git a/colossalai/amp/torch_amp/_grad_scaler.py b/colossalai/amp/torch_amp/_grad_scaler.py
new file mode 100644
index 0000000000000000000000000000000000000000..7b78998fb8c233f13f34fdf64df95bdfd1601ee6
--- /dev/null
+++ b/colossalai/amp/torch_amp/_grad_scaler.py
@@ -0,0 +1,571 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+# modified from https://github.com/pytorch/pytorch/blob/master/torch/cuda/amp/grad_scaler.py
+# to support tensor parallel
+
+import warnings
+from collections import abc, defaultdict
+from enum import Enum
+from typing import Any, Dict, List, Optional, Tuple
+
+import torch
+import torch.distributed as dist
+from packaging import version
+from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors
+
+from colossalai.context import ParallelMode
+from colossalai.core import global_context as gpc
+
+
+class _MultiDeviceReplicator(object):
+ """
+ Lazily serves copies of a tensor to requested devices. Copies are cached per-device.
+ """
+
+ def __init__(self, master_tensor: torch.Tensor) -> None:
+ assert master_tensor.is_cuda or master_tensor.device.type == 'xla'
+ self.master = master_tensor
+ self._per_device_tensors: Dict[torch.device, torch.Tensor] = {}
+
+ def get(self, device) -> torch.Tensor:
+ retval = self._per_device_tensors.get(device, None)
+ if retval is None:
+ retval = self.master.to(device=device, non_blocking=True, copy=True)
+ self._per_device_tensors[device] = retval
+ return retval
+
+
+# Defines default_factory for GradScaler's _per_optimizer_states defaultdict,
+# as well as associated "enum" values. Prefers defining these at top level because
+# - Lambdas can't be pickled, so we don't want to supply a lambda as the factory.
+# - Defining READY, UNSCALED, STEPPED and _refresh_per_optimizer_state within GradScaler
+# causes a circular reference, which we'd rather avoid.
+class OptState(Enum):
+ READY = 0
+ UNSCALED = 1
+ STEPPED = 2
+
+
+def _refresh_per_optimizer_state():
+ return {"stage": OptState.READY, "found_inf_per_device": {}}
+
+
+class GradScaler(object):
+ _scale: Optional[torch.Tensor]
+ _grows_tracker: Optional[torch.Tensor]
+ _per_optimizer_states: Dict[int, Dict[str, Any]]
+ """
+ An instance ``scaler`` of :class:`GradScaler` helps perform the steps of gradient scaling
+ conveniently.
+
+ * ``scaler.scale(loss)`` multiplies a given loss by ``scaler``'s current scale factor.
+ * ``scaler.step(optimizer)`` safely unscales gradients and calls ``optimizer.step()``.
+ * ``scaler.update()`` updates ``scaler``'s scale factor.
+
+ Example:
+
+ # Creates a GradScaler once at the beginning of training.
+ scaler = GradScaler()
+
+ for epoch in epochs:
+ for input, target in data:
+ optimizer.zero_grad()
+ output = model(input)
+ loss = loss_fn(output, target)
+
+ # Scales loss. Calls backward() on scaled loss to create scaled gradients.
+ scaler.scale(loss).backward()
+
+ # scaler.step() first unscales gradients of the optimizer's params.
+ # If gradients don't contain infs/NaNs, optimizer.step() is then called,
+ # otherwise, optimizer.step() is skipped.
+ scaler.step(optimizer)
+
+ # Updates the scale for next iteration.
+ scaler.update()
+
+ See the :ref:`Automatic Mixed Precision examples` for usage
+ (along with autocasting) in more complex cases like gradient clipping, gradient accumulation, gradient penalty,
+ and multiple losses/optimizers.
+
+ ``scaler`` dynamically estimates the scale factor each iteration. To minimize gradient underflow,
+ a large scale factor should be used. However, ``float16`` values can "overflow" (become inf or NaN) if
+ the scale factor is too large. Therefore, the optimal scale factor is the largest factor that can be used
+ without incurring inf or NaN gradient values.
+ ``scaler`` approximates the optimal scale factor over time by checking the gradients for infs and NaNs during every
+ ``scaler.step(optimizer)`` (or optional separate ``scaler.unscale_(optimizer)``, see :meth:`unscale_`).
+
+ * If infs/NaNs are found, ``scaler.step(optimizer)`` skips the underlying ``optimizer.step()`` (so the params
+ themselves remain uncorrupted) and ``update()`` multiplies the scale by ``backoff_factor``.
+
+ * If no infs/NaNs are found, ``scaler.step(optimizer)`` runs the underlying ``optimizer.step()`` as usual.
+ If ``growth_interval`` unskipped iterations occur consecutively, ``update()`` multiplies the scale by
+ ``growth_factor``.
+
+ The scale factor often causes infs/NaNs to appear in gradients for the first few iterations as its
+ value calibrates. ``scaler.step`` will skip the underlying ``optimizer.step()`` for these
+ iterations. After that, step skipping should occur rarely (once every few hundred or thousand iterations).
+
+ Args:
+ init_scale (float, optional, default=2.**16): Initial scale factor.
+ growth_factor (float, optional, default=2.0): Factor by which the scale is multiplied during
+ :meth:`update` if no inf/NaN gradients occur for ``growth_interval`` consecutive iterations.
+ backoff_factor (float, optional, default=0.5): Factor by which the scale is multiplied during
+ :meth:`update` if inf/NaN gradients occur in an iteration.
+ growth_interval (int, optional, default=2000): Number of consecutive iterations without inf/NaN gradients
+ that must occur for the scale to be multiplied by ``growth_factor``.
+ enabled (bool, optional, default=True): If ``False``, disables gradient scaling. :meth:`step` simply
+ invokes the underlying ``optimizer.step()``, and other methods become no-ops.
+ """
+
+ def __init__(self, init_scale=2.**16, growth_factor=2.0, backoff_factor=0.5, growth_interval=2000, enabled=True):
+ if enabled and not torch.cuda.is_available():
+ warnings.warn("torch.cuda.amp.GradScaler is enabled, but CUDA is not available. Disabling.")
+ self._enabled = False
+ else:
+ self._enabled = enabled
+
+ # check version
+ torch_version = version.parse(torch.__version__)
+ assert torch_version.major == 1
+ if torch_version.minor > 8:
+ self._higher_than_torch18 = True
+ else:
+ self._higher_than_torch18 = False
+
+ if self._enabled:
+ assert growth_factor > 1.0, "The growth factor must be > 1.0."
+ assert backoff_factor < 1.0, "The backoff factor must be < 1.0."
+
+ self._init_scale = init_scale
+ # self._scale will be lazily initialized during the first call to scale()
+ self._scale = None
+ self._growth_factor = growth_factor
+ self._backoff_factor = backoff_factor
+ self._growth_interval = growth_interval
+ self._init_growth_tracker = 0
+ # self._growth_tracker will be lazily initialized during the first call to scale()
+ self._growth_tracker = None
+ self._per_optimizer_states = defaultdict(_refresh_per_optimizer_state)
+
+ def _check_scale_growth_tracker(self, funcname) -> Tuple[torch.Tensor, torch.Tensor]:
+ fix = "This may indicate your script did not use scaler.scale(loss or outputs) earlier in the iteration."
+ assert self._scale is not None, "Attempted {} but _scale is None. ".format(funcname) + fix
+ assert self._growth_tracker is not None, "Attempted {} but _growth_tracker is None. ".format(funcname) + fix
+ return (self._scale, self._growth_tracker)
+
+ def _lazy_init_scale_growth_tracker(self, dev):
+ assert self._growth_tracker is None, "_growth_tracker initialized before _scale"
+ self._scale = torch.full((1,), self._init_scale, dtype=torch.float32, device=dev)
+ self._growth_tracker = torch.full((1,), self._init_growth_tracker, dtype=torch.int32, device=dev)
+
+ def scale(self, outputs):
+ """
+ Multiplies ('scales') a tensor or list of tensors by the scale factor.
+
+ Returns scaled outputs. If this instance of :class:`GradScaler` is not enabled, outputs are returned
+ unmodified.
+
+ Args:
+ outputs (Tensor or iterable of Tensors): Outputs to scale.
+ """
+ if not self._enabled:
+ return outputs
+
+ # Short-circuit for the common case.
+ if isinstance(outputs, torch.Tensor):
+ assert outputs.is_cuda or outputs.device.type == 'xla'
+ if self._scale is None:
+ self._lazy_init_scale_growth_tracker(outputs.device)
+ assert self._scale is not None
+ return outputs * self._scale.to(device=outputs.device, non_blocking=True)
+
+ # Invoke the more complex machinery only if we're treating multiple outputs.
+ # holds a reference that can be overwritten by apply_scale
+ stash: List[_MultiDeviceReplicator] = []
+
+ def apply_scale(val):
+ if isinstance(val, torch.Tensor):
+ assert val.is_cuda or val.device.type == 'xla'
+ if len(stash) == 0:
+ if self._scale is None:
+ self._lazy_init_scale_growth_tracker(val.device)
+ assert self._scale is not None
+ stash.append(_MultiDeviceReplicator(self._scale))
+ return val * stash[0].get(val.device)
+ elif isinstance(val, abc.Iterable):
+ iterable = map(apply_scale, val)
+ if isinstance(val, list) or isinstance(val, tuple):
+ return type(val)(iterable)
+ else:
+ return iterable
+ else:
+ raise ValueError("outputs must be a Tensor or an iterable of Tensors")
+
+ return apply_scale(outputs)
+
+ def _unscale_grads_(self, optimizer, inv_scale, found_inf, allow_fp16):
+ per_device_inv_scale = _MultiDeviceReplicator(inv_scale)
+ per_device_found_inf = _MultiDeviceReplicator(found_inf)
+
+ # To set up _amp_foreach_non_finite_check_and_unscale_, split grads by device and dtype.
+ # There could be hundreds of grads, so we'd like to iterate through them just once.
+ # However, we don't know their devices or dtypes in advance.
+
+ # https://stackoverflow.com/questions/5029934/defaultdict-of-defaultdict
+ # Google says mypy struggles with defaultdicts type annotations.
+ per_device_and_dtype_grads = defaultdict(lambda: defaultdict(list)) # type: ignore[var-annotated]
+ with torch.no_grad():
+ for group in optimizer.param_groups:
+ for param in group["params"]:
+ if param.grad is None:
+ continue
+ if (not allow_fp16) and param.grad.dtype == torch.float16:
+ raise ValueError("Attempting to unscale FP16 gradients.")
+ if param.grad.is_sparse:
+ # is_coalesced() == False means the sparse grad has values with duplicate indices.
+ # coalesce() deduplicates indices and adds all values that have the same index.
+ # For scaled fp16 values, there's a good chance coalescing will cause overflow,
+ # so we should check the coalesced _values().
+ if param.grad.dtype is torch.float16:
+ param.grad = param.grad.coalesce()
+ to_unscale = param.grad._values()
+ else:
+ to_unscale = param.grad
+
+ # TODO: is there a way to split by device and dtype without appending in the inner loop?
+ per_device_and_dtype_grads[to_unscale.device][to_unscale.dtype].append(to_unscale)
+
+ for device, per_dtype_grads in per_device_and_dtype_grads.items():
+ for grads in per_dtype_grads.values():
+ torch._amp_foreach_non_finite_check_and_unscale_(grads, per_device_found_inf.get(device),
+ per_device_inv_scale.get(device))
+ # For tensor parallel paramters it should be all-reduced over tensor parallel process group
+ if gpc.is_initialized(ParallelMode.MODEL) and gpc.get_world_size(ParallelMode.MODEL) > 1:
+ vals = [val for val in per_device_found_inf._per_device_tensors.values()]
+ coalesced = _flatten_dense_tensors(vals)
+ dist.all_reduce(coalesced, op=dist.ReduceOp.MAX, group=gpc.get_group(ParallelMode.MODEL))
+ for buf, synced in zip(vals, _unflatten_dense_tensors(coalesced, vals)):
+ buf.copy_(synced)
+ return per_device_found_inf._per_device_tensors
+
+ def unscale_(self, optimizer):
+ """
+ Divides ("unscales") the optimizer's gradient tensors by the scale factor.
+
+ :meth:`unscale_` is optional, serving cases where you need to
+ :ref:`modify or inspect gradients`
+ between the backward pass(es) and :meth:`step`.
+ If :meth:`unscale_` is not called explicitly, gradients will be unscaled automatically during :meth:`step`.
+
+ Simple example, using :meth:`unscale_` to enable clipping of unscaled gradients::
+
+ ...
+ scaler.scale(loss).backward()
+ scaler.unscale_(optimizer)
+ torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
+ scaler.step(optimizer)
+ scaler.update()
+
+ Args:
+ optimizer (torch.optim.Optimizer): Optimizer that owns the gradients to be unscaled.
+
+ .. note::
+ :meth:`unscale_` does not incur a CPU-GPU sync.
+
+ .. warning::
+ :meth:`unscale_` should only be called once per optimizer per :meth:`step` call,
+ and only after all gradients for that optimizer's assigned parameters have been accumulated.
+ Calling :meth:`unscale_` twice for a given optimizer between each :meth:`step` triggers a RuntimeError.
+
+ .. warning::
+ :meth:`unscale_` may unscale sparse gradients out of place, replacing the ``.grad`` attribute.
+ """
+ if not self._enabled:
+ return
+
+ self._check_scale_growth_tracker("unscale_")
+
+ optimizer_state = self._per_optimizer_states[id(optimizer)]
+
+ if optimizer_state["stage"] is OptState.UNSCALED:
+ raise RuntimeError("unscale_() has already been called on this optimizer since the last update().")
+ elif optimizer_state["stage"] is OptState.STEPPED:
+ raise RuntimeError("unscale_() is being called after step().")
+
+ # FP32 division can be imprecise for certain compile options, so we carry out the reciprocal in FP64.
+ assert self._scale is not None
+ inv_scale = self._scale.double().reciprocal().float()
+ found_inf = torch.full((1,), 0.0, dtype=torch.float32, device=self._scale.device)
+
+ optimizer_state["found_inf_per_device"] = self._unscale_grads_(optimizer, inv_scale, found_inf, False)
+ optimizer_state["stage"] = OptState.UNSCALED
+
+ def _maybe_opt_step(self, optimizer, optimizer_state, *args, **kwargs):
+ retval = None
+ if not sum(v.item() for v in optimizer_state["found_inf_per_device"].values()):
+ retval = optimizer.step(*args, **kwargs)
+ return retval
+
+ def step(self, optimizer, *args, **kwargs):
+ """
+ :meth:`step` carries out the following two operations:
+
+ 1. Internally invokes ``unscale_(optimizer)`` (unless :meth:`unscale_` was explicitly called for ``optimizer``
+ earlier in the iteration). As part of the :meth:`unscale_`, gradients are checked for infs/NaNs.
+ 2. If no inf/NaN gradients are found, invokes ``optimizer.step()`` using the unscaled
+ gradients. Otherwise, ``optimizer.step()`` is skipped to avoid corrupting the params.
+
+ ``*args`` and ``**kwargs`` are forwarded to ``optimizer.step()``.
+
+ Returns the return value of ``optimizer.step(*args, **kwargs)``.
+
+ Args:
+ optimizer (torch.optim.Optimizer): Optimizer that applies the gradients.
+ args: Any arguments.
+ kwargs: Any keyword arguments.
+
+ .. warning::
+ Closure use is not currently supported.
+ """
+ if (not self._enabled):
+ return optimizer.step(*args, **kwargs)
+
+ if "closure" in kwargs:
+ raise RuntimeError("Closure use is not currently supported if GradScaler is enabled.")
+
+ self._check_scale_growth_tracker("step")
+
+ optimizer_state = self._per_optimizer_states[id(optimizer)]
+
+ if optimizer_state["stage"] is OptState.STEPPED:
+ raise RuntimeError("step() has already been called since the last update().")
+
+ retval = None
+
+ if (hasattr(optimizer, "_step_supports_amp_scaling") and optimizer._step_supports_amp_scaling):
+ # This optimizer has customized scale-handling logic, so we can call optimizer.step() directly.
+ # The contract with custom optimizers is that their step() should accept an additional,
+ # optional grad_scaler kwarg. We append self to the kwargs so the custom optimizer has full information:
+ # it can query its own state, invoke unscale_ on itself, etc
+ retval = optimizer.step(*args, **dict(kwargs, grad_scaler=self))
+ optimizer_state["stage"] = OptState.STEPPED
+ return retval
+
+ if optimizer_state["stage"] is OptState.READY:
+ self.unscale_(optimizer)
+
+ assert len(optimizer_state["found_inf_per_device"]) > 0, "No inf checks were recorded for this optimizer."
+
+ retval = self._maybe_opt_step(optimizer, optimizer_state, *args, **kwargs)
+
+ optimizer_state["stage"] = OptState.STEPPED
+
+ return retval
+
+ def update(self, new_scale=None):
+ """
+ Updates the scale factor.
+
+ If any optimizer steps were skipped the scale is multiplied by ``backoff_factor``
+ to reduce it. If ``growth_interval`` unskipped iterations occurred consecutively,
+ the scale is multiplied by ``growth_factor`` to increase it.
+
+ Passing ``new_scale`` sets the new scale value manually. (``new_scale`` is not
+ used directly, it's used to fill GradScaler's internal scale tensor. So if
+ ``new_scale`` was a tensor, later in-place changes to that tensor will not further
+ affect the scale GradScaler uses internally.)
+
+ Args:
+ new_scale (float or :class:`torch.cuda.FloatTensor`, optional, default=None): New scale factor.
+
+ .. warning::
+ :meth:`update` should only be called at the end of the iteration, after ``scaler.step(optimizer)`` has
+ been invoked for all optimizers used this iteration.
+ """
+ if not self._enabled:
+ return
+
+ _scale, _growth_tracker = self._check_scale_growth_tracker("update")
+
+ if new_scale is not None:
+ # Accept a new user-defined scale.
+ if isinstance(new_scale, float):
+ self._scale.fill_(new_scale) # type: ignore[union-attr]
+ else:
+ reason = "new_scale should be a float or a 1-element torch.cuda.FloatTensor with requires_grad=False."
+ # type: ignore[attr-defined]
+ assert isinstance(new_scale, torch.cuda.FloatTensor), reason
+ assert new_scale.numel() == 1, reason
+ assert new_scale.requires_grad is False, reason
+ self._scale.copy_(new_scale) # type: ignore[union-attr]
+ else:
+ # Consume shared inf/nan data collected from optimizers to update the scale.
+ # If all found_inf tensors are on the same device as self._scale, this operation is asynchronous.
+ found_infs = [
+ found_inf.to(device=_scale.device, non_blocking=True)
+ for state in self._per_optimizer_states.values()
+ for found_inf in state["found_inf_per_device"].values()
+ ]
+
+ assert len(found_infs) > 0, "No inf checks were recorded prior to update."
+
+ found_inf_combined = found_infs[0]
+ if len(found_infs) > 1:
+ for i in range(1, len(found_infs)):
+ found_inf_combined += found_infs[i]
+
+ if self._higher_than_torch18:
+ torch._amp_update_scale_(_scale, _growth_tracker, found_inf_combined, self._growth_factor,
+ self._backoff_factor, self._growth_interval)
+ else:
+ self._scale = torch._amp_update_scale(_growth_tracker, _scale, found_inf_combined, self._growth_factor,
+ self._backoff_factor, self._growth_interval)
+
+ # To prepare for next iteration, clear the data collected from optimizers this iteration.
+ self._per_optimizer_states = defaultdict(_refresh_per_optimizer_state)
+
+ def _get_scale_async(self):
+ return self._scale
+
+ def get_scale(self):
+ """
+ Returns a Python float containing the current scale, or 1.0 if scaling is disabled.
+
+ .. warning::
+ :meth:`get_scale` incurs a CPU-GPU sync.
+ """
+ if self._enabled:
+ return self._init_scale if self._scale is None else self._get_scale_async().item()
+ else:
+ return 1.0
+
+ def get_growth_factor(self):
+ r"""
+ Returns a Python float containing the scale growth factor.
+ """
+ return self._growth_factor
+
+ def set_growth_factor(self, new_factor):
+ r"""
+ Args:
+ new_scale (float): Value to use as the new scale growth factor.
+ """
+ self._growth_factor = new_factor
+
+ def get_backoff_factor(self):
+ r"""
+ Returns a Python float containing the scale backoff factor.
+ """
+ return self._backoff_factor
+
+ def set_backoff_factor(self, new_factor):
+ r"""
+ Args:
+ new_scale (float): Value to use as the new scale backoff factor.
+ """
+ self._backoff_factor = new_factor
+
+ def get_growth_interval(self):
+ r"""
+ Returns a Python int containing the growth interval.
+ """
+ return self._growth_interval
+
+ def set_growth_interval(self, new_interval):
+ r"""
+ Args:
+ new_interval (int): Value to use as the new growth interval.
+ """
+ self._growth_interval = new_interval
+
+ def _get_growth_tracker(self):
+ if self._enabled:
+ return self._init_growth_tracker if self._growth_tracker is None else self._growth_tracker.item()
+ else:
+ return 0
+
+ def is_enabled(self):
+ r"""
+ Returns a bool indicating whether this instance is enabled.
+ """
+ return self._enabled
+
+ def state_dict(self):
+ r"""
+ Returns the state of the scaler as a :class:`dict`. It contains five entries:
+
+ * ``"scale"`` - a Python float containing the current scale
+ * ``"growth_factor"`` - a Python float containing the current growth factor
+ * ``"backoff_factor"`` - a Python float containing the current backoff factor
+ * ``"growth_interval"`` - a Python int containing the current growth interval
+ * ``"_growth_tracker"`` - a Python int containing the number of recent consecutive unskipped steps.
+
+ If this instance is not enabled, returns an empty dict.
+
+ .. note::
+ If you wish to checkpoint the scaler's state after a particular iteration, :meth:`state_dict`
+ should be called after :meth:`update`.
+ """
+ return {
+ "scale": self.get_scale(),
+ "growth_factor": self._growth_factor,
+ "backoff_factor": self._backoff_factor,
+ "growth_interval": self._growth_interval,
+ "_growth_tracker": self._get_growth_tracker()
+ } if self._enabled else {}
+
+ def load_state_dict(self, state_dict):
+ r"""
+ Loads the scaler state. If this instance is disabled, :meth:`load_state_dict` is a no-op.
+
+ Args:
+ state_dict(dict): scaler state. Should be an object returned from a call to :meth:`state_dict`.
+ """
+ if not self._enabled:
+ return
+
+ if len(state_dict) == 0:
+ raise RuntimeError("The source state dict is empty, possibly because it was saved "
+ "from a disabled instance of GradScaler.")
+
+ self._init_scale = state_dict["scale"]
+ if self._scale is not None:
+ self._scale.fill_(state_dict["scale"])
+ self._growth_factor = state_dict["growth_factor"]
+ self._backoff_factor = state_dict["backoff_factor"]
+ self._growth_interval = state_dict["growth_interval"]
+ self._init_growth_tracker = state_dict["_growth_tracker"]
+ if self._growth_tracker is not None:
+ self._growth_tracker.fill_(state_dict["_growth_tracker"])
+
+ def __getstate__(self):
+ state = self.__dict__.copy()
+ if self._enabled:
+ assert len(self._per_optimizer_states) == 0, "A GradScaler instance may only be pickled at the beginning "\
+ "of an iteration, or at the end after scaler.update()."
+ # Pickling _scale and _growth_tracker Tensors directly triggers
+ # "warnings.warn("pickle support for Storage will be removed in 1.5..."
+ # so instead, we set the unpickled instance up to reinitialize them lazily.
+ state['_init_scale'] = self.get_scale()
+ state['_init_growth_tracker'] = self._get_growth_tracker()
+ state['_scale'] = None
+ state['_growth_tracker'] = None
+ return state
+
+ def __setstate__(self, state):
+ self.__dict__.update(state)
+
+ def _check_inf_per_device(self, optimizer):
+ _scale, _ = self._check_scale_growth_tracker("_check_inf_per_device")
+
+ dummy_inv_scale = torch.full((1,), 1.0, dtype=torch.float32, device=_scale.device)
+ found_inf = torch.full((1,), 0.0, dtype=torch.float32, device=_scale.device)
+
+ self._per_optimizer_states[id(optimizer)]["found_inf_per_device"] = \
+ self._unscale_grads_(optimizer, dummy_inv_scale, found_inf, True)
+
+ return self._per_optimizer_states[id(optimizer)]["found_inf_per_device"]
+
+ def _found_inf_per_device(self, optimizer):
+ return self._per_optimizer_states[id(optimizer)]["found_inf_per_device"]
diff --git a/colossalai/amp/torch_amp/torch_amp.py b/colossalai/amp/torch_amp/torch_amp.py
new file mode 100644
index 0000000000000000000000000000000000000000..65718d77c2e00cdaf83ca8c27e9c26caed0d9362
--- /dev/null
+++ b/colossalai/amp/torch_amp/torch_amp.py
@@ -0,0 +1,98 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import torch.cuda.amp as torch_amp
+import torch.nn as nn
+from torch import Tensor
+from torch.nn.modules.loss import _Loss
+from torch.optim import Optimizer
+
+from colossalai.nn.optimizer import ColossalaiOptimizer
+from colossalai.utils import clip_grad_norm_fp32
+
+from ._grad_scaler import GradScaler
+
+
+class TorchAMPOptimizer(ColossalaiOptimizer):
+ """A wrapper class which integrate Pytorch AMP with an optimizer
+
+ Args:
+ optim (torch.optim.Optimizer): A normal optimizer like Adam or SGD.
+ init_scale (float, optional, default=2.**16): Initial scale factor.
+ growth_factor (float, optional, default=2.0): Factor by which the scale is multiplied during
+ :meth:`update` if no inf/NaN gradients occur for ``growth_interval`` consecutive iterations.
+ backoff_factor (float, optional, default=0.5): Factor by which the scale is multiplied during
+ :meth:`update` if inf/NaN gradients occur in an iteration.
+ growth_interval (int, optional, default=2000): Number of consecutive iterations without inf/NaN gradients
+ that must occur for the scale to be multiplied by ``growth_factor``.
+ enabled (bool, optional, default=True): If ``False``, disables gradient scaling. :meth:`step` simply
+ invokes the underlying ``optimizer.step()``, and other methods become no-ops.
+ """
+
+ def __init__(self, optim: Optimizer, *args, **kwargs):
+ super().__init__(optim)
+ self.scaler = GradScaler(*args, **kwargs)
+
+ def backward(self, loss: Tensor):
+ """Backward with torch amp gradient scaler
+
+ Args:
+ loss (torch.Tensor): Loss computed by a loss function
+ """
+ self.scaler.scale(loss).backward()
+
+ def step(self):
+ """Update the parameters of the model
+ """
+ self.scaler.step(self.optim)
+ self.scaler.update()
+
+ def clip_grad_norm(self, model: nn.Module, max_norm: float):
+ """Apply gradient clipping to the model parameters
+
+ Args:
+ model (torch.nn.Module): Your model object
+ max_norm (float): Max norm value for gradient clipping
+ """
+ if max_norm > 0.0:
+ self.scaler.unscale_(self.optim)
+ clip_grad_norm_fp32(model.parameters(), max_norm)
+
+
+class TorchAMPModel(nn.Module):
+ """A wrapper class for a model object which executes forward with values automatically
+ cast to fp16
+
+ Args:
+ model (:class:`torch.nn.Module`): a torch model instance
+ """
+
+ def __init__(self, model: nn.Module) -> None:
+ super().__init__()
+ self.model = model
+
+ @torch_amp.autocast()
+ def forward(self, *args, **kwargs):
+ """
+ Execute forward under the torch amp context
+ """
+ return self.model(*args, **kwargs)
+
+
+class TorchAMPLoss(nn.Module):
+ """A wrapper class for a criterion object which computes the loss in mixed-precision context
+
+ Args:
+ loss (torch.nn.modules.loss._Loss): A loss function object
+ """
+
+ def __init__(self, loss: _Loss):
+ super().__init__()
+ self.loss = loss
+
+ @torch_amp.autocast()
+ def forward(self, *args, **kwargs):
+ """
+ Execute forward under the torch amp context
+ """
+ return self.loss(*args, **kwargs)
diff --git a/colossalai/auto_parallel/README.md b/colossalai/auto_parallel/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8e47e1bb0b4a6e8e86c1e76d600d3dae3c8be251
--- /dev/null
+++ b/colossalai/auto_parallel/README.md
@@ -0,0 +1,23 @@
+# Colossal-AUTO
+
+## Challenges
+Recently, large models have achieved the state of the art performances in various fields. In order to support large model training, we have to use distributed training techniques. However, finding an efficient distributed execution plan not only requires fine-grained model statistics, such as memory and computing overhead of each operator but also is a labor-intensive task even for an expert in the field of distributed training.
+
+## Our solution
+To simplify the process of distributed training for foundational models, recent advancements in machine learning systems have led to the emergence of automatic parallel systems. We investigate and research a number of current automatic parallel systems( Tofu , Flexflow , Alpa ) and some auto activation checkpoint algorithms( Rotor , Sublinear ). Inspired from these advanced systems, we build an automatic parallel system upon PyTorch framework. The input of the system is the serial PyTorch code, and the output is a PyTorch program with an optimized distributed execution plan. It is worth emphasizing that the output is a regular PyTorch program, so it is compatible with runtime optimization methods, such as ZeRO-Offload and PatrickStar.
+
+## Key modules
+
+### Analyzer
+
+**Analyzer** is a static analysis system consisting of three parts:
+A *symbolic profiler* for collecting computing and memory overhead related to static computation graph, a *cluster detector* for collecting hardware characteristics and detecting cluster topology and a *tensor layout manager* to find efficient tensor layout conversion path from different sharding spec and record conversion cost.
+
+### Solver
+
+**Solver** is designed to find the optimal execution plan for a given computation graph and cluster in two stages:
+1) *Intra-op parallelism stage* is to find the plan with the minimum total execution time of all nodes with respect to the constraint of the memory budget. The optimaztion goal of intra-op parallelism solver is modified from Alpa 's intra-op parallelsim ILP solver.
+2) *Activation checkpoint stage* is to search for the fastest execution plan that meets the memory budget on the computation graph after inserting the communication nodes by the intra-op parallelism stage. The algorithm to find optimial activation checkpoint is modified from Rotor . The reason we use two-stage optimization is that if the two tasks are formulated together, the solving time will be significantly increased, which will greatly affect the user experience of the system. On the contrary, solving in two hierarchical levels has many advantages. Firstly, compared with the computation graph with activation checkpointing, the original graph has fewer nodes, which can reduce the solving cost of intra-op parallelism solver. In addition, a more optimal solution can be found by adding the communication overhead into the activation checkpoint modeling.
+
+### Generator
+**Generator** applies the searched execution plan to the computation graph and recompiles the computation graph to optimized PyTorch code. It has *a series compile pass* to insert a communication node or do the kernel substitution as the intra-op parallelism solver required. Additionally, we implement a *code generation* feature to recognize the annotation from the activation checkpoint solver and inject the activation checkpoint block following annotation instructions.
diff --git a/colossalai/auto_parallel/__init__.py b/colossalai/auto_parallel/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/colossalai/auto_parallel/checkpoint/__init__.py b/colossalai/auto_parallel/checkpoint/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..10ade417a238753af49c3780cd6693b362b7bbb4
--- /dev/null
+++ b/colossalai/auto_parallel/checkpoint/__init__.py
@@ -0,0 +1,3 @@
+from .ckpt_solver_base import CheckpointSolverBase
+from .ckpt_solver_chen import CheckpointSolverChen
+from .ckpt_solver_rotor import CheckpointSolverRotor
diff --git a/colossalai/auto_parallel/checkpoint/build_c_ext.py b/colossalai/auto_parallel/checkpoint/build_c_ext.py
new file mode 100644
index 0000000000000000000000000000000000000000..af4349865a7b8dd748e34458eb3d5aeeb359b599
--- /dev/null
+++ b/colossalai/auto_parallel/checkpoint/build_c_ext.py
@@ -0,0 +1,16 @@
+import os
+
+from setuptools import Extension, setup
+
+this_dir = os.path.dirname(os.path.abspath(__file__))
+ext_modules = [Extension(
+ 'rotorc',
+ sources=[os.path.join(this_dir, 'ckpt_solver_rotor.c')],
+)]
+
+setup(
+ name='rotor c extension',
+ version='0.1',
+ description='rotor c extension for faster dp computing',
+ ext_modules=ext_modules,
+)
diff --git a/colossalai/auto_parallel/checkpoint/ckpt_solver_base.py b/colossalai/auto_parallel/checkpoint/ckpt_solver_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..b388d00ac553726f577575d5d770b98dfb873f12
--- /dev/null
+++ b/colossalai/auto_parallel/checkpoint/ckpt_solver_base.py
@@ -0,0 +1,195 @@
+from abc import ABC, abstractmethod
+from copy import deepcopy
+from typing import Any, List
+
+import torch
+from torch.fx import Graph, Node
+
+from colossalai.auto_parallel.passes.runtime_apply_pass import (
+ runtime_apply,
+ runtime_apply_for_iterable_object,
+ runtime_comm_spec_apply,
+)
+from colossalai.fx.codegen.activation_checkpoint_codegen import ActivationCheckpointCodeGen
+
+__all___ = ['CheckpointSolverBase']
+
+
+def _copy_output(src: Graph, dst: Graph):
+ """Copy the output node from src to dst"""
+ for n_src, n_dst in zip(src.nodes, dst.nodes):
+ if n_src.op == 'output':
+ n_dst.meta = n_src.meta
+
+
+def _get_param_size(module: torch.nn.Module):
+ """Get the size of the parameters in the module"""
+ return sum([p.numel() * torch.tensor([], dtype=p.dtype).element_size() for p in module.parameters()])
+
+
+class CheckpointSolverBase(ABC):
+
+ def __init__(
+ self,
+ graph: Graph,
+ free_memory: float = -1.0,
+ requires_linearize: bool = False,
+ cnode: List[str] = None,
+ optim_multiplier: float = 1.0,
+ ):
+ """``CheckpointSolverBase`` class will integrate information provided by the components
+ and use an existing solver to find a possible optimal strategies combination for target
+ computing graph.
+
+ Existing Solvers:
+ Chen's Greedy solver: https://arxiv.org/abs/1604.06174 (CheckpointSolverChen)
+ Rotor solver: https://hal.inria.fr/hal-02352969 (CheckpointSolverRotor)
+
+ Args:
+ graph (Graph): The computing graph to be optimized.
+ free_memory (float): Memory constraint for the solution.
+ requires_linearize (bool): Whether the graph needs to be linearized.
+ cnode (List[str], optional): Common node List, should be the subset of input. Default to None.
+ optim_multiplier (float, optional): The multiplier of extra weight storage for the
+ ``torch.optim.Optimizer``. Default to 1.0.
+
+ Warnings:
+ Meta information of the graph is required for any ``CheckpointSolver``.
+ """
+ # super-dainiu: this graph is a temporary graph which can refer to
+ # the owning module, but we will return another deepcopy of it after
+ # the solver is executed.
+ self.graph = deepcopy(graph)
+ self.graph.owning_module = graph.owning_module
+ _copy_output(graph, self.graph)
+ self.graph.set_codegen(ActivationCheckpointCodeGen())
+
+ # check if has meta information
+ if any(len(node.meta) == 0 for node in self.graph.nodes):
+ raise RuntimeError(
+ "Nodes meta information hasn't been prepared! Please extract from graph before constructing the solver!"
+ )
+
+ # parameter memory = parameter size + optimizer extra weight storage
+ self.free_memory = free_memory - _get_param_size(self.graph.owning_module) * (optim_multiplier + 1)
+ self.cnode = cnode
+ self.requires_linearize = requires_linearize
+ if self.requires_linearize:
+ self.node_list = self._linearize_graph()
+ else:
+ self.node_list = self.get_node_list()
+
+ @abstractmethod
+ def solve(self):
+ """Solve the checkpointing problem and return the solution.
+ """
+ pass
+
+ def get_node_list(self):
+ """Get the node list.
+ """
+ return [[node] for node in self.graph.nodes]
+
+ def _linearize_graph(self) -> List[List[Node]]:
+ """Linearizing the graph
+
+ Args:
+ graph (Graph): The computing graph to be optimized.
+
+ Returns:
+ List[List[Node]]: List of list, each inside list of Node presents
+ the actual 'node' in linearized manner.
+
+ Remarks:
+ Do merge the inplace ops and shape-consistency ops into the previous node.
+ """
+
+ # Common nodes are type of nodes that could be seen as attributes and remain
+ # unchanged throughout the whole model, it will be used several times by
+ # different blocks of model, so that it is hard for us to linearize the graph
+ # when we encounter those kinds of nodes. We let users to annotate some of the
+ # input as common node, such as attention mask, and the followings are some of
+ # the ops that could actually be seen as common nodes. With our common node prop,
+ # we could find some of the "real" common nodes (e.g. the real attention mask
+ # used in BERT and GPT), the rule is simple, for node who's parents are all common
+ # nodes or it's op belongs to the following operations, we view this node as a
+ # newly born common node.
+ # List of target name that could be seen as common node
+ common_ops = ["getattr", "getitem", "size"]
+
+ def _is_cop(target: Any) -> bool:
+ """Check if an op could be seen as common node
+
+ Args:
+ target (Any): node target
+
+ Returns:
+ bool
+ """
+
+ if isinstance(target, str):
+ return target in common_ops
+ else:
+ return target.__name__ in common_ops
+
+ def _is_sink() -> bool:
+ """Check if we can free all dependencies
+
+ Returns:
+ bool
+ """
+
+ def _is_inplace(n: Node):
+ """Get the inplace argument from ``torch.fx.Node``
+ """
+ inplace = False
+ if n.op == "call_function":
+ inplace = n.kwargs.get("inplace", False)
+ elif n.op == "call_module":
+ inplace = getattr(n.graph.owning_module.get_submodule(n.target), "inplace", False)
+ return inplace
+
+ def _is_shape_consistency(n: Node):
+ """Check if this node is shape-consistency node (i.e. ``runtime_apply`` or ``runtime_apply_for_iterable_object``)
+ """
+ return n.target in [runtime_apply, runtime_apply_for_iterable_object, runtime_comm_spec_apply]
+
+ return not sum([v for _, v in deps.items()]) and not any(map(_is_inplace, n.users)) and not any(
+ map(_is_shape_consistency, n.users))
+
+ # make sure that item in cnode is valid
+ if self.cnode:
+ for name in self.cnode:
+ try:
+ assert next(node for node in self.graph.nodes if node.name == name).op == "placeholder", \
+ f"Common node {name} is not an input of the model."
+ except StopIteration:
+ raise ValueError(f"Common node name {name} not in graph.")
+
+ else:
+ self.cnode = []
+
+ deps = {}
+ node_list = []
+ region = []
+
+ for n in self.graph.nodes:
+ if n.op != "placeholder" and n.op != "output":
+ for n_par in n.all_input_nodes:
+ if n_par.op != "placeholder" and n_par.name not in self.cnode:
+ deps[n_par] -= 1
+ region.append(n)
+
+ # if the node could free all dependencies in graph
+ # we could begin a new node
+ if _is_sink():
+ node_list.append(region)
+ region = []
+
+ # propagate common node attr if possible
+ if len(n.all_input_nodes) == len([node for node in n.all_input_nodes if node.name in self.cnode
+ ]) or _is_cop(n.target):
+ self.cnode.append(n.name)
+ else:
+ deps[n] = len([user for user in n.users if user.op != "output"])
+ return node_list
diff --git a/colossalai/auto_parallel/checkpoint/ckpt_solver_chen.py b/colossalai/auto_parallel/checkpoint/ckpt_solver_chen.py
new file mode 100644
index 0000000000000000000000000000000000000000..19b2ef5987c9ebc160078339b764741a71b34dbf
--- /dev/null
+++ b/colossalai/auto_parallel/checkpoint/ckpt_solver_chen.py
@@ -0,0 +1,87 @@
+import math
+from copy import deepcopy
+from typing import List, Set, Tuple
+
+from torch.fx import Graph, Node
+
+from colossalai.fx.profiler import calculate_fwd_in, calculate_fwd_tmp
+
+from .ckpt_solver_base import CheckpointSolverBase
+
+__all__ = ['CheckpointSolverChen']
+
+
+class CheckpointSolverChen(CheckpointSolverBase):
+
+ def __init__(self, graph: Graph, cnode: List[str] = None, num_grids: int = 6):
+ """
+ This is the simple implementation of Algorithm 3 in https://arxiv.org/abs/1604.06174.
+ Note that this algorithm targets at memory optimization only, using techniques in appendix A.
+
+ Usage:
+ Assume that we have a ``GraphModule``, and we have already done the extractions
+ to the graph to retrieve all information needed, then we could use the following
+ code to find a solution using ``CheckpointSolverChen``:
+ >>> solver = CheckpointSolverChen(gm.graph)
+ >>> chen_graph = solver.solve()
+ >>> gm.graph = chen_graph # set the graph to a new graph
+
+ Args:
+ graph (Graph): The computing graph to be optimized.
+ cnode (List[str], optional): Common node List, should be the subset of input. Defaults to None.
+ num_grids (int, optional): Number of grids to search for b. Defaults to 6.
+ """
+ super().__init__(graph, 0, 0, True, cnode)
+ self.num_grids = num_grids
+
+ def solve(self) -> Graph:
+ """Solve the checkpointing problem using Algorithm 3.
+
+ Returns:
+ graph (Graph): The optimized graph, should be a copy of the original graph.
+ """
+ checkpointable_op = ['call_module', 'call_method', 'call_function', 'get_attr']
+ ckpt = self.grid_search()
+ for i, seg in enumerate(ckpt):
+ for idx in range(*seg):
+ nodes = self.node_list[idx]
+ for n in nodes:
+ if n.op in checkpointable_op:
+ n.meta['activation_checkpoint'] = i
+ return deepcopy(self.graph)
+
+ def run_chen_greedy(self, b: int = 0) -> Tuple[Set, int]:
+ """
+ This is the simple implementation of Algorithm 3 in https://arxiv.org/abs/1604.06174.
+ """
+ ckpt_intv = []
+ temp = 0
+ x = 0
+ y = 0
+ prev_idx = 2
+ for idx, nodes in enumerate(self.node_list):
+ for n in nodes:
+ n: Node
+ temp += calculate_fwd_in(n) + calculate_fwd_tmp(n)
+ y = max(y, temp)
+ if temp > b and idx > prev_idx:
+ x += calculate_fwd_in(nodes[0])
+ temp = 0
+ ckpt_intv.append((prev_idx, idx + 1))
+ prev_idx = idx + 1
+ return ckpt_intv, math.floor(math.sqrt(x * y))
+
+ def grid_search(self) -> Set:
+ """
+ Search ckpt strategy with b = 0, then run the allocation algorithm again with b = √xy.
+ Grid search over [√2/2 b, √2 b] for ``ckpt_opt`` over ``num_grids`` as in appendix A.
+ """
+ _, b_approx = self.run_chen_greedy(0)
+ b_min, b_max = math.floor(b_approx / math.sqrt(2)), math.ceil(b_approx * math.sqrt(2))
+ b_opt = math.inf
+ for b in range(b_min, b_max, (b_max - b_min) // self.num_grids):
+ ckpt_intv, b_approx = self.run_chen_greedy(b)
+ if b_approx < b_opt:
+ b_opt = b_approx
+ ckpt_opt = ckpt_intv
+ return ckpt_opt
diff --git a/colossalai/auto_parallel/checkpoint/ckpt_solver_rotor.c b/colossalai/auto_parallel/checkpoint/ckpt_solver_rotor.c
new file mode 100644
index 0000000000000000000000000000000000000000..8dad074bc894d31f4c6c20fabddcff06c57f23cd
--- /dev/null
+++ b/colossalai/auto_parallel/checkpoint/ckpt_solver_rotor.c
@@ -0,0 +1,209 @@
+#define PY_SSIZE_T_CLEAN
+#include
+
+/*
+Rotor solver for checkpointing problem in C. We follow the modeling mentioned in
+paper `Optimal checkpointing for heterogeneous chains: how to train deep neural
+networks with limited memory` https://hal.inria.fr/hal-02352969. Some lines of
+the code are adapted from https://gitlab.inria.fr/hiepacs/rotor.
+*/
+long* PySequenceToLongArray(PyObject* pylist) {
+ if (!(pylist && PySequence_Check(pylist))) return NULL;
+ Py_ssize_t len = PySequence_Size(pylist);
+ long* result = (long*)calloc(len + 1, sizeof(long));
+ for (Py_ssize_t i = 0; i < len; ++i) {
+ PyObject* item = PySequence_GetItem(pylist, i);
+ result[i] = PyLong_AsLong(item);
+ Py_DECREF(item);
+ }
+ result[len] = 0;
+ return result;
+}
+
+double* PySequenceToDoubleArray(PyObject* pylist) {
+ if (!(pylist && PySequence_Check(pylist))) return NULL;
+ Py_ssize_t len = PySequence_Size(pylist);
+ double* result = (double*)calloc(len + 1, sizeof(double));
+ for (Py_ssize_t i = 0; i < len; ++i) {
+ PyObject* item = PySequence_GetItem(pylist, i);
+ result[i] = PyFloat_AsDouble(item);
+ Py_DECREF(item);
+ }
+ result[len] = 0;
+ return result;
+}
+
+long* getLongArray(PyObject* container, const char* attributeName) {
+ PyObject* sequence = PyObject_GetAttrString(container, attributeName);
+ long* result = PySequenceToLongArray(sequence);
+ Py_DECREF(sequence);
+ return result;
+}
+
+double* getDoubleArray(PyObject* container, const char* attributeName) {
+ PyObject* sequence = PyObject_GetAttrString(container, attributeName);
+ double* result = PySequenceToDoubleArray(sequence);
+ Py_DECREF(sequence);
+ return result;
+}
+
+static PyObject* computeTable(PyObject* self, PyObject* args) {
+ PyObject* chainParam;
+ int mmax;
+
+ if (!PyArg_ParseTuple(args, "Oi", &chainParam, &mmax)) return NULL;
+
+ double* ftime = getDoubleArray(chainParam, "ftime");
+ if (!ftime) return NULL;
+
+ double* btime = getDoubleArray(chainParam, "btime");
+ if (!btime) return NULL;
+
+ long* x = getLongArray(chainParam, "x");
+ if (!x) return NULL;
+
+ long* xbar = getLongArray(chainParam, "xbar");
+ if (!xbar) return NULL;
+
+ long* ftmp = getLongArray(chainParam, "btmp");
+ if (!ftmp) return NULL;
+
+ long* btmp = getLongArray(chainParam, "btmp");
+ if (!btmp) return NULL;
+
+ long chainLength = PyObject_Length(chainParam);
+ if (!chainLength) return NULL;
+
+#define COST_TABLE(m, i, l) \
+ costTable[(m) * (chainLength + 1) * (chainLength + 1) + \
+ (i) * (chainLength + 1) + (l)]
+ double* costTable = (double*)calloc(
+ (mmax + 1) * (chainLength + 1) * (chainLength + 1), sizeof(double));
+
+#define BACK_PTR(m, i, l) \
+ backPtr[(m) * (chainLength + 1) * (chainLength + 1) + \
+ (i) * (chainLength + 1) + (l)]
+ long* backPtr = (long*)calloc(
+ (mmax + 1) * (chainLength + 1) * (chainLength + 1), sizeof(long));
+
+ for (long m = 0; m <= mmax; ++m)
+ for (long i = 0; i <= chainLength; ++i) {
+ if ((m >= x[i + 1] + xbar[i + 1] + btmp[i]) &&
+ (m >= x[i + 1] + xbar[i + 1] + ftmp[i])) {
+ COST_TABLE(m, i, i) = ftime[i] + btime[i];
+ } else {
+ COST_TABLE(m, i, i) = INFINITY;
+ }
+ }
+
+ for (long m = 0; m <= mmax; ++m) {
+ for (long d = 1; d <= chainLength; ++d) {
+ for (long i = 0; i <= chainLength - d; ++i) {
+ long idx = i + d;
+ long mmin = x[idx + 1] + x[i + 1] + ftmp[i];
+ if (idx > i + 1) {
+ long maxCostFWD = 0;
+ for (long j = i + 1; j < idx; j++) {
+ maxCostFWD = fmaxl(maxCostFWD, x[j] + x[j + 1] + ftmp[j]);
+ }
+ mmin = fmaxl(mmin, x[idx + 1] + maxCostFWD);
+ }
+ if ((m >= mmin)) {
+ long bestLeaf = -1;
+ double sumFw = 0;
+ double bestLeafCost = INFINITY;
+ for (long j = i + 1; j <= idx; ++j) {
+ sumFw += ftime[j - 1];
+ if (m >= x[j]) {
+ double cost = sumFw + COST_TABLE(m - x[j], j, idx) +
+ COST_TABLE(m, i, j - 1);
+ if (cost < bestLeafCost) {
+ bestLeafCost = cost;
+ bestLeaf = j;
+ }
+ }
+ }
+ double chainCost = INFINITY;
+ if (m >= xbar[i + 1]) {
+ chainCost =
+ COST_TABLE(m, i, i) + COST_TABLE(m - xbar[i + 1], i + 1, idx);
+ }
+ if (bestLeafCost <= chainCost) {
+ COST_TABLE(m, i, idx) = bestLeafCost;
+ BACK_PTR(m, i, idx) = bestLeaf;
+ } else {
+ COST_TABLE(m, i, idx) = chainCost;
+ BACK_PTR(m, i, idx) = -1;
+ }
+ } else {
+ COST_TABLE(m, i, idx) = INFINITY;
+ }
+ }
+ }
+ }
+
+ free(ftime);
+ free(btime);
+ free(x);
+ free(xbar);
+ free(ftmp);
+ free(btmp);
+
+ PyObject* pyCostTable = PyList_New(mmax + 1);
+ PyObject* pyBackPtr = PyList_New(mmax + 1);
+
+ // Convert the result into Python world
+ for (long m = 0; m <= mmax; ++m) {
+ PyObject* pyCostTable_m = PyList_New(chainLength + 1);
+ PyList_SET_ITEM(pyCostTable, m, pyCostTable_m);
+ PyObject* pyBackPtr_m = PyList_New(chainLength + 1);
+ PyList_SET_ITEM(pyBackPtr, m, pyBackPtr_m);
+ for (long i = 0; i <= chainLength; ++i) {
+ PyObject* pyCostTable_m_i = PyDict_New();
+ PyList_SET_ITEM(pyCostTable_m, i, pyCostTable_m_i);
+ PyObject* pyBackPtr_m_i = PyDict_New();
+ PyList_SET_ITEM(pyBackPtr_m, i, pyBackPtr_m_i);
+ for (long l = i; l <= chainLength; ++l) {
+ PyObject* pyVar_l = PyLong_FromLong(l);
+ PyObject* pyCostTable_m_i_l = PyFloat_FromDouble(COST_TABLE(m, i, l));
+ PyDict_SetItem(pyCostTable_m_i, pyVar_l, pyCostTable_m_i_l);
+ Py_DECREF(pyCostTable_m_i_l);
+ PyObject* pyBackPtr_m_i_l;
+ if (BACK_PTR(m, i, l) < 0) {
+ pyBackPtr_m_i_l = Py_BuildValue("(O)", Py_True);
+ } else {
+ pyBackPtr_m_i_l = Py_BuildValue("(Ol)", Py_False, BACK_PTR(m, i, l));
+ }
+ PyDict_SetItem(pyBackPtr_m_i, pyVar_l, pyBackPtr_m_i_l);
+ Py_DECREF(pyBackPtr_m_i_l);
+ Py_DECREF(pyVar_l);
+ }
+ }
+ }
+
+ free(costTable);
+ free(backPtr);
+
+ PyObject* result = PyTuple_Pack(2, pyCostTable, pyBackPtr);
+ Py_DECREF(pyCostTable);
+ Py_DECREF(pyBackPtr);
+ return result;
+}
+
+static PyMethodDef rotorMethods[] = {
+ {"compute_table", computeTable, METH_VARARGS,
+ "Compute the optimal table with the rotor algorithm."},
+ {NULL, NULL, 0, NULL} /* Sentinel */
+};
+
+static struct PyModuleDef rotorModule = {
+ PyModuleDef_HEAD_INIT, "rotorc", /* name of module */
+ "A simple implementation of dynamic programming algorithm rotor with C in "
+ "https://hal.inria.fr/hal-02352969. Some code are adapted from "
+ "https://gitlab.inria.fr/hiepacs/rotor.", /* module documentation, may be
+ NULL */
+ -1, /* size of per-interpreter state of the module,
+ or -1 if the module keeps state in global variables. */
+ rotorMethods};
+
+PyMODINIT_FUNC PyInit_rotorc(void) { return PyModule_Create(&rotorModule); }
diff --git a/colossalai/auto_parallel/checkpoint/ckpt_solver_rotor.py b/colossalai/auto_parallel/checkpoint/ckpt_solver_rotor.py
new file mode 100644
index 0000000000000000000000000000000000000000..21c3bf0da758bd061eaa9bcf08534e9a2df8d6cf
--- /dev/null
+++ b/colossalai/auto_parallel/checkpoint/ckpt_solver_rotor.py
@@ -0,0 +1,439 @@
+from copy import deepcopy
+from typing import Any, Dict, List, Tuple
+
+from torch import Tensor
+from torch.fx import Graph, Node
+
+from colossalai.auto_parallel.passes.runtime_apply_pass import runtime_apply, runtime_comm_spec_apply
+from colossalai.fx.codegen.activation_checkpoint_codegen import _find_nested_ckpt_regions
+from colossalai.fx.profiler import (
+ activation_size,
+ calculate_bwd_time,
+ calculate_fwd_out,
+ calculate_fwd_time,
+ calculate_fwd_tmp,
+)
+from colossalai.logging import get_dist_logger
+
+from .ckpt_solver_base import CheckpointSolverBase
+from .operation import Backward, Chain, ForwardCheck, ForwardEnable, ForwardNograd, Loss, Sequence
+
+__all__ = ['CheckpointSolverRotor']
+
+
+class CheckpointSolverRotor(CheckpointSolverBase):
+
+ def __init__(self,
+ graph: Graph,
+ free_memory: float = -1,
+ cnode: List[str] = None,
+ memory_slots: int = 500,
+ optim_multiplier: float = 1.0):
+ """This is the simple implementation of dynamic programming algorithm rotor
+ in https://hal.inria.fr/hal-02352969. Some code are adapted from
+ https://gitlab.inria.fr/hiepacs/rotor.
+
+ Usage:
+ Assume that we have a ``GraphModule``, and we have already done the extractions
+ to the graph to retrieve all information needed, then we could use the following
+ code to find a solution using ``CheckpointSolverRotor``:
+ >>> solver = CheckpointSolverRotor(gm.graph, free_memory=torch.cuda.mem_get_info(device=0)[0])
+ >>> rotor_graph = solver.solve(force_python=True) # otherwise use C solver
+ >>> gm.graph = rotor_graph # set the graph to a new graph
+
+ Args:
+ graph (Graph): The computing graph to be optimized.
+ free_memory (float, optional): Memory constraint for the solution, unit is byte.
+ Use ``torch.cuda.mem_get_info(device=0)[0]`` to estimate the free_memory. Defaults to -1.
+ cnode (List[str], optional): Common node List, should be the subset of input. Defaults to None.
+ memory_slots (int, optional): Number of slots for discretizing memory budget. Defaults to 500.
+ optim_multiplier (float, optional): The multiplier of extra weight storage for the
+ ``torch.optim.Optimizer``. Default to 1.0.
+ """
+ super().__init__(graph, free_memory, True, cnode, optim_multiplier)
+ self.memory_slots = memory_slots
+
+ # construct chain
+ unit = self.free_memory // self.memory_slots
+ self.chain = self._construct_chain(self.graph, self.node_list)
+ self.chain.discretize_all(unit)
+
+ self.cost_table = None
+ self.back_ptr = None
+ self.sequence = None
+
+ def solve(self, force_python: bool = False, verbose: bool = False) -> Graph:
+ """Solve the checkpointing problem using rotor algorithm.
+
+ Args:
+ force_python (bool, optional): Use Python version of solver, else use C version. Defaults to False.
+ verbose (bool, optional): Print verbose information. Defaults to False.
+
+ Returns:
+ graph (Graph): The optimized graph, should be a copy of the original graph.
+ """
+ chain = self.chain
+
+ # compute cost table
+ if force_python:
+ self.cost_table, self.back_ptr = self._compute_table(chain, self.memory_slots)
+ else:
+ self.cost_table, self.back_ptr = self._compute_table_c(chain, self.memory_slots)
+
+ if verbose:
+ self.print_chain()
+
+ # backtrack
+ try:
+ self.sequence = self._backtrack(chain, 0, len(chain), self.memory_slots - chain.x[0], self.cost_table,
+ self.back_ptr)
+ self._annotate_from_sequence(self.sequence, self.node_list)
+ except ValueError as e:
+ # using logger to annonce that the solver is failed
+ logger = get_dist_logger()
+ logger.warning(f'Checkpoint solver failed: {e}')
+ raise ValueError
+
+ if verbose:
+ self.print_sequence()
+
+ return deepcopy(self.graph)
+
+ def print_chain(self):
+ print('[input]', self.chain.x[0], self.chain.xbar[0], self.chain.ftmp[0], self.chain.btmp[0])
+ for idx in range(len(self.node_list) - 1):
+ print(self.node_list[idx], self.chain.x[idx + 1], self.chain.xbar[idx + 1], self.chain.ftmp[idx],
+ self.chain.btmp[idx])
+ print(f'Chain = {self.chain}')
+
+ def print_sequence(self):
+ print(f'Sequence = {self.sequence}')
+
+ @classmethod
+ def _construct_chain(cls, graph: Graph, node_list: List[List[Node]]) -> Chain:
+ input_tensors = cls._extract_input(graph)
+ ftime, btime, ftmp, btmp = list(), list(), list(), list()
+ xbar, x = [activation_size(input_tensors)], [activation_size(input_tensors)]
+
+ for node in node_list:
+ node_info = cls._extract_node_info(node)
+ ftime.append(node_info[0])
+ btime.append(node_info[1])
+ x.append(node_info[2])
+ xbar.append(node_info[3])
+ ftmp.append(node_info[4])
+ btmp.append(node_info[5])
+
+ # currently we view loss backward temp as zero
+ btime.append(0)
+ btmp.append(0)
+
+ return Chain(ftime, btime, x, xbar, ftmp, btmp)
+
+ @classmethod
+ def _extract_node_info(cls, node: List[Node]) -> Tuple[int, ...]:
+ """Extract node info from a list of nodes"""
+ xbar = 0
+ ftime = 0
+ btime = 0
+ fwd_mem_peak = 0
+ for n in node:
+ assert isinstance(n, Node), f'{n} is not a Node'
+ if n.target == runtime_apply or n.target == runtime_comm_spec_apply:
+ # in this case we need to calculate memory usage directly based on the statics that hooked in node.meta
+ xbar += n.meta['fwd_mem_out']
+ fwd_mem_peak = max(fwd_mem_peak, xbar + n.meta['fwd_mem_tmp'])
+ else:
+ xbar += calculate_fwd_tmp(n) + calculate_fwd_out(n)
+ fwd_mem_peak = max(fwd_mem_peak, xbar + n.meta['fwd_mem_tmp'] + cls._extract_unused_output(n))
+
+ # minimum flop count is required
+ ftime += max(calculate_fwd_time(n), 1.0)
+ btime += max(calculate_bwd_time(n), 1.0)
+
+ x = calculate_fwd_out(node[-1])
+ xbar = max(x, xbar)
+ ftmp = fwd_mem_peak - xbar
+ btmp = cls._extract_btmp(node)
+ return ftime, btime, x, xbar, ftmp, btmp
+
+ @staticmethod
+ def _extract_input(graph: Graph) -> Tuple[Tensor, ...]:
+ """Extract input tensors from a Graph"""
+ input_tensors = []
+ for node in graph.nodes:
+ if node.op == 'placeholder':
+ input_tensors.append(node.meta['fwd_out'])
+ return input_tensors
+
+ @staticmethod
+ def _extract_unused_output(node: Node) -> int:
+ """Extract unused output from `torch.fx.Node`"""
+ return activation_size(node.meta['fwd_out']) - calculate_fwd_out(node)
+
+ @staticmethod
+ def _extract_btmp(node: List[Node]) -> int:
+ """Extract btmp from a list of nodes"""
+
+ def _extract_deps_size():
+ deps_size = 0
+ for k, v in deps.items():
+ k: Node
+ if v > 0:
+ deps_size += k.meta['bwd_mem_out']
+ if v == float('-inf'):
+ deps_size -= calculate_fwd_tmp(k) + calculate_fwd_out(k)
+
+ return deps_size
+
+ btmp = 0
+ deps = {}
+ for n in reversed(node):
+ deps[n] = len(n.all_input_nodes)
+ btmp = max(btmp, _extract_deps_size() + n.meta['bwd_mem_tmp'])
+ for child in n.users:
+ if child in deps:
+ deps[child] -= 1
+ if deps[child] <= 0:
+ deps[child] = float('-inf') # free
+ return btmp
+
+ @staticmethod
+ def _compute_table(chain: Chain, mmax: int) -> Tuple:
+ """Compute the table using dynamic programming. Returns the cost table and the backtracking pointer.
+
+ Args:
+ chain (Chain): A basic linearized structure for solving the dynamic programming problem.
+ mmax (int): Maximum number of memory slots.
+
+ Returns:
+ cost_table (List): cost_table[m][lhs][rhs] indicates the optimal cost of the subproblem from lhs to rhs
+ with m memory slots.
+ back_ptr (List): back_ptr[m][lhs][rhs] indicates the best operation at this point. It is (True,) if the optimal choice
+ is a chain checkpoint, it is (False, j) if the optimal choice is a leaf checkpoint of length j
+ """
+
+ ftime = chain.ftime + [0.0]
+ btime = chain.btime
+ x = chain.x + [0]
+ xbar = chain.xbar + [0]
+ ftmp = chain.ftmp + [0]
+ btmp = chain.btmp + [0]
+
+ # Build table
+ cost_table = [[{} for _ in range(len(chain) + 1)] for _ in range(mmax + 1)]
+ back_ptr = [[{} for _ in range(len(chain) + 1)] for _ in range(mmax + 1)]
+
+ # Initialize corner cases where length of sequence equals to 1, i.e. lhs == rhs
+ for m in range(mmax + 1):
+ for i in range(len(chain) + 1):
+ limit = max(x[i + 1] + xbar[i + 1] + ftmp[i], x[i + 1] + xbar[i + 1] + btmp[i])
+ if m >= limit:
+ cost_table[m][i][i] = ftime[i] + btime[i]
+ else:
+ cost_table[m][i][i] = float("inf")
+
+ # Compute tables
+ for m in range(mmax + 1):
+ for d in range(1, len(chain) + 1):
+ for i in range(len(chain) + 1 - d):
+ idx = i + d
+ mmin = x[idx + 1] + x[i + 1] + ftmp[i]
+ if idx > i + 1:
+ mmin = max(mmin, x[idx + 1] + max(x[j] + x[j + 1] + ftmp[j] for j in range(i + 1, idx)))
+ if m < mmin:
+ cost_table[m][i][idx] = float("inf")
+ else:
+ leaf_checkpoints = [(j,
+ sum(ftime[i:j]) + cost_table[m - x[j]][j][idx] + cost_table[m][i][j - 1])
+ for j in range(i + 1, idx + 1)
+ if m >= x[j]]
+ if leaf_checkpoints:
+ best_leaf = min(leaf_checkpoints, key=lambda t: t[1])
+ else:
+ best_leaf = None
+ if m >= xbar[i + 1]:
+ chain_checkpoint = cost_table[m][i][i] + cost_table[m - xbar[i + 1]][i + 1][idx]
+ else:
+ chain_checkpoint = float("inf")
+ if best_leaf and best_leaf[1] <= chain_checkpoint:
+ cost_table[m][i][idx] = best_leaf[1]
+ back_ptr[m][i][idx] = (False, best_leaf[0])
+ else:
+ cost_table[m][i][idx] = chain_checkpoint
+ back_ptr[m][i][idx] = (True,)
+ return cost_table, back_ptr
+
+ @staticmethod
+ def _compute_table_c(chain: Chain, mmax: int) -> Tuple:
+ try:
+ from .rotorc import compute_table
+
+ # build module if module not found
+ except ModuleNotFoundError:
+ import os
+ import subprocess
+ import sys
+ logger = get_dist_logger()
+ logger.info("rotorc hasn't been built! Building library...", ranks=[0])
+ this_dir = os.path.dirname(os.path.abspath(__file__))
+ result = subprocess.Popen(
+ [
+ f"{sys.executable}", f"{os.path.join(this_dir, 'build_c_ext.py')}", "build_ext",
+ f"--build-lib={this_dir}"
+ ],
+ stdout=subprocess.PIPE,
+ stderr=subprocess.PIPE,
+ )
+ if result.wait() == 0:
+ logger.info("rotorc has been built!", ranks=[0])
+ from .rotorc import compute_table
+ else:
+ logger.warning("rotorc built failed! Using python version!", ranks=[0])
+ return CheckpointSolverRotor._compute_table(chain, mmax)
+ return compute_table(chain, mmax)
+
+ @staticmethod
+ def _backtrack(chain: Chain, lhs: int, rhs: int, budget: int, cost_table: List[Any],
+ back_ptr: List[Any]) -> "Sequence":
+ """Backtrack the cost table and retrieve the optimal checkpointing strategy.
+
+ Args:
+ chain (Chain): A basic linearized structure for solving the dynamic programming problem.
+ lhs (int): The left index of the interval to backtrack.
+ rhs (int): The right index of the interval to backtrack.
+ budget (int): The memory budget for processing this interval.
+ cost_table (List[Any]): See ``._compute_table()`` for definitions
+ back_ptr (List[Any]): See ``._compute_table()`` for definitions
+
+ Raises:
+ ValueError: Can not process the chain.
+
+ Returns:
+ sequence (Sequence): The sequence of executing nodes with checkpoints.
+ """
+ if budget <= 0:
+ raise ValueError(f"Can not process a chain with negative memory {budget}")
+ elif cost_table[budget][lhs][rhs] == float("inf"):
+ raise ValueError(f"Can not process this chain from index {lhs} to {rhs} with memory {budget}")
+
+ sequence = Sequence()
+ if rhs == lhs:
+ if lhs == len(chain):
+ sequence += [Loss()]
+ else:
+ sequence += [ForwardEnable(lhs), Backward(lhs)]
+ return sequence
+
+ if back_ptr[budget][lhs][rhs][0]:
+ sequence += [
+ ForwardEnable(lhs),
+ CheckpointSolverRotor._backtrack(chain, lhs + 1, rhs, budget - chain.xbar[lhs + 1], cost_table,
+ back_ptr),
+ Backward(lhs),
+ ]
+ else:
+ best_leaf = back_ptr[budget][lhs][rhs][1]
+ sequence += [ForwardCheck(lhs)]
+ sequence += [ForwardNograd(k) for k in range(lhs + 1, best_leaf)]
+ sequence += [
+ CheckpointSolverRotor._backtrack(chain, best_leaf, rhs, budget - chain.x[best_leaf], cost_table,
+ back_ptr),
+ CheckpointSolverRotor._backtrack(chain, lhs, best_leaf - 1, budget, cost_table, back_ptr),
+ ]
+ return sequence
+
+ @staticmethod
+ def _annotate_from_sequence(sequence: Sequence, node_list: List[List[Node]]):
+ """Annotate the nodes in the ``node_list`` with activation checkpoint from the sequence.
+
+ Args:
+ sequence (Sequence): The sequence of executing nodes with activation checkpoint annotations.
+ node_list (List[List[Node]]): The list of nodes to annotate.
+ """
+ op_list = sequence.list_operations()
+ loss_op = next(op for op in op_list if isinstance(op, Loss))
+ fwd_list = op_list[:op_list.index(loss_op)]
+ bwd_list = op_list[op_list.index(loss_op) + 1:]
+ ckpt_idx = 0
+ in_ckpt = False
+ ckpt_region = []
+
+ # forward annotation
+ for idx, op in enumerate(fwd_list, 0):
+ if in_ckpt:
+ if isinstance(op, ForwardNograd):
+ ckpt_region.append(idx)
+
+ elif isinstance(op, ForwardEnable):
+ in_ckpt = False
+ for node_idx in ckpt_region:
+ for n in node_list[node_idx]:
+ n.meta['activation_checkpoint'] = [ckpt_idx]
+
+ ckpt_idx += 1
+ ckpt_region = []
+
+ elif isinstance(op, ForwardCheck):
+ for node_idx in ckpt_region:
+ for n in node_list[node_idx]:
+ n.meta['activation_checkpoint'] = [ckpt_idx]
+
+ ckpt_idx += 1
+ ckpt_region = [idx]
+
+ else:
+ if isinstance(op, ForwardCheck):
+ in_ckpt = True
+ ckpt_region.append(idx)
+
+ # annotate the backward if there is any nested activation checkpoint
+ in_recompute = False
+ for op in bwd_list:
+ if in_recompute:
+ if isinstance(op, ForwardNograd):
+ ckpt_region.append(op.index)
+
+ elif isinstance(op, ForwardEnable):
+ for node_idx in ckpt_region:
+ for n in node_list[node_idx]:
+ n.meta['activation_checkpoint'].append(ckpt_idx)
+
+ ckpt_idx += 1
+ ckpt_region = []
+
+ elif isinstance(op, ForwardCheck):
+ for node_idx in ckpt_region:
+ for n in node_list[node_idx]:
+ n.meta['activation_checkpoint'].append(ckpt_idx)
+
+ ckpt_idx += 1
+ ckpt_region = [op.index]
+
+ elif isinstance(op, Backward):
+ for node_idx in ckpt_region:
+ for n in node_list[node_idx]:
+ n.meta['activation_checkpoint'].append(ckpt_idx)
+
+ in_recompute = False
+
+ else:
+ if not isinstance(op, Backward):
+ in_recompute = True
+ ckpt_idx = 0
+ ckpt_region = []
+ if isinstance(op, ForwardCheck):
+ ckpt_region.append(op.index)
+
+ # postprocess, make sure every activation checkpoint label in the
+ # same activation checkpoint region (level = 0) has the same length
+ op_list = []
+ for node in node_list:
+ op_list += node
+ ckpt_regions = _find_nested_ckpt_regions(op_list)
+ for (start_idx, end_idx) in ckpt_regions:
+ nested_length = max(
+ len(op_list[idx].meta['activation_checkpoint']) for idx in range(start_idx, end_idx + 1))
+ for idx in range(start_idx, end_idx + 1):
+ op_list[idx].meta['activation_checkpoint'] += [None] * (nested_length -
+ len(op_list[idx].meta['activation_checkpoint']))
diff --git a/colossalai/auto_parallel/checkpoint/operation.py b/colossalai/auto_parallel/checkpoint/operation.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab0c6c5ad38d171d470931aa9b2bdedf6cd17668
--- /dev/null
+++ b/colossalai/auto_parallel/checkpoint/operation.py
@@ -0,0 +1,184 @@
+import math
+from abc import ABC
+from typing import Any, Iterable, List
+
+from torch.utils._pytree import tree_map
+
+
+class Chain:
+
+ def __init__(self,
+ ftime: List[float],
+ btime: List[float],
+ x: List[int],
+ xbar: List[int],
+ ftmp: List[int],
+ btmp: List[int],
+ check_consistency: bool = True):
+ """The chain is a basic linearized structure for solving the dynamic programming problem for activation checkpoint.
+ See paper https://hal.inria.fr/hal-02352969 for details.
+
+ Args:
+ ftime (List[float]): The forward time of each node.
+ btime (List[float]): The backward time of each node.
+ x (List[int]): The forward memory of each node (if save_output). Same as `a` in the paper.
+ xbar (List[int]): The forward memory of each node (if save_all). Same as `a_bar` in the paper.
+ ftmp (List[int]): The temporary forward memory of each node.
+ btmp (List[int]): The temporary backward memory of each node, can be used to control memory budget.
+ check_consistency (bool, optional): Check the lengths consistency for the `Chain`. Defaults to True.
+ """
+ self.ftime = ftime
+ self.btime = btime
+ self.x = x
+ self.xbar = xbar
+ self.ftmp = ftmp
+ self.btmp = btmp
+ if check_consistency and not self.check_lengths():
+ raise AttributeError("In Chain, input lists do not have consistent lengths")
+
+ def check_lengths(self):
+ return ((len(self.ftime) == len(self)) and (len(self.btime) == len(self) + 1) and (len(self.x) == len(self) + 1)
+ and (len(self.ftmp) == len(self)) and (len(self.btmp) == len(self) + 1)
+ and (len(self.xbar) == len(self) + 1))
+
+ def __repr__(self):
+ chain_list = []
+ for i in range(len(self)):
+ chain_list.append((self.ftime[i], self.btime[i], self.x[i], self.xbar[i], self.ftmp[i], self.btmp[i]))
+ i = len(self)
+ chain_list.append((None, self.btime[i], self.x[i], self.xbar[i], None, self.btmp[i]))
+ return chain_list.__repr__()
+
+ def __len__(self):
+ return len(self.ftime)
+
+ def discretize_all(self, unit: int):
+ """Discretize the chain into a list of chains according to unit size."""
+ discretizer = lambda val: math.ceil(val / unit)
+ self.x = tree_map(discretizer, self.x)
+ self.xbar = tree_map(discretizer, self.xbar)
+ self.ftmp = tree_map(discretizer, self.ftmp)
+ self.btmp = tree_map(discretizer, self.btmp)
+
+
+class Operation(ABC):
+ name = "Op"
+
+ def __repr__(self) -> str:
+ return f"{self.name}_{self.index}"
+
+ def shift(self, value):
+ if type(self.index) is tuple:
+ self.index = tuple(x + value for x in self.index)
+ else:
+ self.index += value
+
+
+class Forward(Operation):
+ name = "F"
+
+ def __init__(self, index):
+ self.index = index
+
+ def cost(self, chain: Chain):
+ if chain is not None:
+ return chain.ftime[self.index]
+ else:
+ return 1
+
+
+class ForwardEnable(Forward):
+ name = "Fe"
+
+
+class ForwardNograd(Forward):
+ name = "Fn"
+
+
+class ForwardCheck(Forward):
+ name = "CF"
+
+
+class Forwards(Operation):
+
+ def __init__(self, start, end):
+ self.index = (start, end)
+
+ def __repr__(self):
+ return "F_{i}->{j}".format(i=self.index[0], j=self.index[1])
+
+ def cost(self, chain: Chain):
+ if chain is not None:
+ return sum(chain.ftime[self.index[0]:self.index[1] + 1])
+ else:
+ return (self.index[1] - self.index[0] + 1)
+
+
+def isForward(op):
+ return type(op) is Forward or type(op) is Forwards
+
+
+class Backward(Operation):
+ name = "B"
+
+ def __init__(self, index):
+ self.index = index
+
+ def cost(self, chain: Chain):
+ if chain is not None:
+ return chain.btime[self.index]
+ else:
+ return 1
+
+
+class Loss(Operation):
+
+ def __init__(self):
+ pass
+
+ def __repr__(self):
+ return "L"
+
+ def cost(self, chain):
+ return 0
+
+
+class MemoryAccess(Operation):
+ name = "MA"
+
+ def __init__(self, index):
+ self.index = index
+
+ def cost(self, chain: Chain):
+ return 0
+
+
+class WriteMemory(MemoryAccess):
+ name = "WM"
+
+
+class ReadMemory(MemoryAccess):
+ name = "RM"
+
+
+class DiscardMemory(MemoryAccess):
+ name = "DM"
+
+
+class Sequence(list):
+
+ def __init__(self):
+ super().__init__()
+
+ def __repr__(self):
+ return repr(self.list_operations())
+
+ def list_operations(self):
+ op_list = []
+ for x in self:
+ if isinstance(x, Operation):
+ op_list.append(x)
+ else:
+ assert isinstance(x, Sequence)
+ op_list += x.list_operations()
+ return op_list
diff --git a/colossalai/auto_parallel/meta_profiler/__init__.py b/colossalai/auto_parallel/meta_profiler/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3741d8e5a8adcf20cb963dda760731911b719c98
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/__init__.py
@@ -0,0 +1,3 @@
+from .meta_registry import *
+from .registry import meta_register
+from .shard_metainfo import *
diff --git a/colossalai/auto_parallel/meta_profiler/constants.py b/colossalai/auto_parallel/meta_profiler/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..35b8c13ee8fff717df39a96c60fa101eb0b2a781
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/constants.py
@@ -0,0 +1,15 @@
+import operator
+
+import torch
+import torch.nn as nn
+
+from ..tensor_shard.constants import *
+
+# list of inplace module
+INPLACE_MODULE = [nn.ReLU]
+
+# list of inplace operations
+INPLACE_OPS = [torch.flatten]
+
+# list of operations that do not save forward activations
+NO_SAVE_ACTIVATION = [torch.add, torch.sub, operator.add, operator.sub]
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/__init__.py b/colossalai/auto_parallel/meta_profiler/meta_registry/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4d8b656e17e176670cc98755fb4ae93a9832573d
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/__init__.py
@@ -0,0 +1,10 @@
+from .activation import *
+from .binary_elementwise_ops import *
+from .conv import *
+from .embedding import *
+from .linear import *
+from .non_spmd import *
+from .norm import *
+from .pooling import *
+from .tensor import *
+from .where import *
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/activation.py b/colossalai/auto_parallel/meta_profiler/meta_registry/activation.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f2e9e44f91cedfdb888171dd373d4d6163f579f
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/activation.py
@@ -0,0 +1,85 @@
+from typing import Callable, List, Tuple
+
+import torch
+
+from colossalai._analyzer._subclasses.flop_tensor import ewise_flop_counter as elementwise_flop_counter
+from colossalai._analyzer.fx.node_util import compute_size_in_bytes as activation_size
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, OperationDataType, TrainCycleItem
+
+from ..registry import meta_register
+
+__all__ = ["elementwise_meta_info"]
+
+
+def elementwise_meta_info(temp_mem_scale: float = 0, buffer_mem_scale: float = 0) -> Callable:
+ """This is a function to create the meta information generator for elementwise operations
+
+ Args:
+ temp_mem_scale (float, optional): temp memory scaling factor for backward. Defaults to 0.
+ buffer_mem_scale (float, optional): buffer memory scaling factor for forward. Defaults to 0.
+
+ Returns:
+ Callable: meta information generator
+ """
+
+ def meta_func(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ input_tensor = next(
+ filter(
+ lambda x:
+ (x.type == OperationDataType.ARG or x.type == OperationDataType.PARAM) and x.name != 'softmax_dim',
+ args)).data
+ output_tensor = next(filter(lambda x: x.type == OperationDataType.OUTPUT, args)).data
+ is_inplace = 1 if kwargs.get('inplace', False) else 0
+
+ flop_counter = elementwise_flop_counter(1, 0)
+ # calculate compute cost
+ fwd_compute_cost = flop_counter([input_tensor], [output_tensor])
+ bwd_compute_cost = flop_counter([output_tensor], [input_tensor])
+
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost,
+ bwd=bwd_compute_cost,
+ total=fwd_compute_cost + bwd_compute_cost)
+
+ # calculate memory cost
+ # NOTE: currently in SPMD solver we always believe that there will be a new tensor created in forward
+ # NOTE: if in_place is True, we will not create a new tensor in forward
+ fwd_memory_cost = MemoryCost(activation=activation_size(input_tensor) * (2 - is_inplace),
+ parameter=0,
+ temp=0,
+ buffer=activation_size(input_tensor) * buffer_mem_scale)
+
+ # temp_mem_scale is for situation like softmax backward
+ # the buffer will be removed during backward phase
+ bwd_memory_cost = MemoryCost(
+ activation=activation_size(input_tensor) - activation_size(input_tensor) * buffer_mem_scale,
+ parameter=0,
+ temp=activation_size(input_tensor) * temp_mem_scale + activation_size(input_tensor) * buffer_mem_scale,
+ buffer=0)
+
+ # total cost is the sum of forward and backward cost
+ total_cost = MemoryCost(activation=fwd_memory_cost.activation + bwd_memory_cost.activation,
+ parameter=fwd_memory_cost.parameter + bwd_memory_cost.parameter,
+ temp=fwd_memory_cost.temp + bwd_memory_cost.temp,
+ buffer=fwd_memory_cost.buffer + bwd_memory_cost.buffer)
+
+ memory_cost = TrainCycleItem(fwd=fwd_memory_cost, bwd=bwd_memory_cost, total=total_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = []
+ fwd_buffer = [torch.zeros_like(output_tensor, device='meta')]
+ fwd_out = [torch.zeros_like(output_tensor, device='meta')]
+
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
+
+ return meta_func
+
+
+# register meta information
+# (0, 0)
+meta_register.register([torch.nn.ReLU, torch.nn.functional.relu, torch.tanh])(elementwise_meta_info(0, 0))
+
+# (1, 0)
+meta_register.register([torch.nn.Softmax, torch.nn.functional.softmax])(elementwise_meta_info(1, 0))
+
+# (0, 0.25) for dropout, the buffer is in bool type so that the buffer memory cost is 0.25 times of input tensor
+meta_register.register([torch.nn.Dropout, torch.nn.functional.dropout])(elementwise_meta_info(0, 0.25))
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/binary_elementwise_ops.py b/colossalai/auto_parallel/meta_profiler/meta_registry/binary_elementwise_ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..e451748512b9abebcc4f63ad854be3f129ee52bd
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/binary_elementwise_ops.py
@@ -0,0 +1,66 @@
+from typing import List, Tuple
+
+import torch
+
+from colossalai._analyzer._subclasses.flop_tensor import flop_mapping
+from colossalai._analyzer.fx.node_util import compute_size_in_bytes as activation_size
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, OperationDataType, TrainCycleItem
+
+from ..constants import BCAST_FUNC_OP, NO_SAVE_ACTIVATION
+from ..registry import meta_register
+
+__all__ = ['binary_elementwise_meta_info']
+
+
+@meta_register.register(BCAST_FUNC_OP)
+def binary_elementwise_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """Meta information generator for binary elementwise operations
+ NOTE: Some of the binary elementwise operations will discard the input activation after computation, as they
+ don't need those tensors for back propagation, for example, if there are two tensors being sent for `torch.add`,
+ they will be discarded right after add operation is done. We create a simple API in `ShardMetaInfo` class to identify
+ this behavior, it is critical for better memory estimation.
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]: compute cost, memory cost and forward inputs
+ """
+
+ input_op_data = [arg for arg in args if arg.type != OperationDataType.OUTPUT]
+ output_op_data = next(filter(lambda arg: arg.type == OperationDataType.OUTPUT, args))
+
+ # construct forward args for flop mapping
+ fwd_in_args = [opdata.data for opdata in input_op_data]
+ fwd_out_args = [output_op_data.data]
+
+ # calculate cost
+
+ # calculate compute cost
+ # NOTE: we set bwd_compute_cost two times of fwd_compute_cost in this case
+ fwd_compute_cost = flop_mapping[torch.ops.aten.add.Tensor](fwd_in_args, fwd_out_args)
+ bwd_compute_cost = fwd_compute_cost * 2
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost, bwd=bwd_compute_cost, total=fwd_compute_cost + bwd_compute_cost)
+
+ # calculate memory cost
+ param_mem_cost = activation_size([arg.data for arg in input_op_data if arg.type == OperationDataType.PARAM])
+ fwd_mem_cost = MemoryCost(
+ activation=activation_size(output_op_data.data),
+ parameter=param_mem_cost,
+ )
+ bwd_mem_cost = MemoryCost(
+ activation=activation_size(fwd_in_args),
+ parameter=param_mem_cost,
+ )
+
+ # total cost
+ total_mem_cost = MemoryCost(
+ activation=fwd_mem_cost.activation + bwd_mem_cost.activation,
+ parameter=fwd_mem_cost.parameter + bwd_mem_cost.parameter,
+ )
+
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = []
+ fwd_buffer = []
+ fwd_out = [torch.zeros_like(output_op_data.data, device='meta')]
+
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/conv.py b/colossalai/auto_parallel/meta_profiler/meta_registry/conv.py
new file mode 100644
index 0000000000000000000000000000000000000000..4336bf68363c8a708b877c8d8116c44986a85592
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/conv.py
@@ -0,0 +1,137 @@
+from typing import Callable, Dict, List, Tuple, Union
+
+import torch
+
+from colossalai._analyzer._subclasses.flop_tensor import flop_mapping
+from colossalai._analyzer.fx.node_util import compute_size_in_bytes
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ MemoryCost,
+ OperationData,
+ OperationDataType,
+ ShardingStrategy,
+ StrategiesVector,
+ TrainCycleItem,
+)
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+from ..registry import meta_register
+
+__all__ = ['convnd_meta_info']
+
+
+@meta_register.register(torch.nn.Conv1d)
+@meta_register.register(torch.nn.Conv2d)
+@meta_register.register(torch.nn.Conv3d)
+@meta_register.register(torch.nn.functional.conv1d)
+@meta_register.register(torch.nn.functional.conv2d)
+@meta_register.register(torch.nn.functional.conv3d)
+def convnd_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """torch.nn.Conv1d, torch.nn.Conv2d, torch.nn.Conv3d meta info generator
+ The atens graph of torch.nn.Convnd with bias is
+ graph():
+ %input_2 : [#users=2] = placeholder[target=placeholder](default=)
+ %convolution_default : [#users=1] = call_function[target=torch.ops.aten.convolution.default](args = (%input_2, None, None, [None, None, None], [None, None, None], [None, None, None], None, [None, None, None], None), kwargs = {})
+ %zeros_like_default : [#users=1] = call_function[target=torch.ops.aten.zeros_like.default](args = (%convolution_default,), kwargs = {dtype: None, layout: None, device: None, pin_memory: None})
+ %detach_default : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%input_2,), kwargs = {})
+ %convolution_backward_default : [#users=3] = call_function[target=torch.ops.aten.convolution_backward.default](args = (%zeros_like_default, %detach_default, None, [None], [None, None, None], [None, None, None], [None, None, None], None, [None, None, None], None, [None, None, None]), kwargs = {})
+ %detach_default_1 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%convolution_backward_default,), kwargs = {})
+ %detach_default_2 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_1,), kwargs = {})
+ %detach_default_3 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%convolution_backward_default,), kwargs = {})
+ %detach_default_4 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_3,), kwargs = {})
+ %detach_default_5 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%convolution_backward_default,), kwargs = {})
+ %detach_default_6 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_5,), kwargs = {})
+
+ The atens graph of torch.nn.Convnd without bias is
+ graph():
+ %input_2 : [#users=2] = placeholder[target=placeholder](default=)
+ %convolution_default : [#users=1] = call_function[target=torch.ops.aten.convolution.default](args = (%input_2, None, None, [None, None], [None, None], [None, None], None, [None, None], None), kwargs = {})
+ %zeros_like_default : [#users=1] = call_function[target=torch.ops.aten.zeros_like.default](args = (%convolution_default,), kwargs = {dtype: None, layout: None, device: None, pin_memory: None})
+ %detach_default : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%input_2,), kwargs = {})
+ %convolution_backward_default : [#users=2] = call_function[target=torch.ops.aten.convolution_backward.default](args = (%zeros_like_default, %detach_default, None, [None], [None, None], [None, None], [None, None], None, [None, None], None, [None, None, None]), kwargs = {})
+ %detach_default_1 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%convolution_backward_default,), kwargs = {})
+ %detach_default_2 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_1,), kwargs = {})
+ %detach_default_3 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%convolution_backward_default,), kwargs = {})
+ %detach_default_4 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_3,), kwargs = {})
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]: compute cost, memory cost and forward inputs
+ """
+
+ has_bias: bool = False
+ input_tensor = args[0].data
+ output_tensor = next(filter(lambda x: x.type == OperationDataType.OUTPUT, args)).data
+ if len(args) == 4:
+ weight_tensors = [args[1].data, args[3].data]
+ else:
+ weight_tensors = [args[1].data]
+
+ # check if conv has bias
+ if len(weight_tensors) > 1:
+ has_bias = True
+ # bias tensor's shape only has one dimension
+ if len(weight_tensors[0].shape) == 1:
+ bias_tensor, weight_tensor = weight_tensors
+ else:
+ weight_tensor, bias_tensor = weight_tensors
+
+ else:
+ weight_tensor = weight_tensors[0]
+
+ # construct input args for forward
+ fwd_args = [None] * 9
+
+ # weight and input
+ fwd_args[0] = input_tensor
+ fwd_args[1] = weight_tensor
+ fwd_args[2] = bias_tensor if has_bias else None
+
+ # transpose indicator should be set to False
+ fwd_args[6] = False
+
+ # construct input args for backward
+ bwd_args = [None] * 11
+
+ # weight and input
+ bwd_args[0] = output_tensor
+ bwd_args[1] = input_tensor
+ bwd_args[2] = weight_tensor
+ bwd_args[-1] = [True, True, True] if has_bias else [True, True, False]
+
+ # calculate cost
+ # the fwd op with compute cost is convolution.default
+ # the bwd op with compute cost is convolution_backward.default
+
+ # calculate compute cost
+ fwd_compute_cost = flop_mapping[torch.ops.aten.convolution.default](fwd_args, (output_tensor,))
+ bwd_compute_cost = flop_mapping[torch.ops.aten.convolution_backward.default](bwd_args, (input_tensor, weight_tensor, bias_tensor)) if has_bias else \
+ flop_mapping[torch.ops.aten.convolution_backward.default](bwd_args, (input_tensor, weight_tensor))
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost, bwd=bwd_compute_cost, total=fwd_compute_cost + bwd_compute_cost)
+
+ # calculate memory cost
+ # TODO: use profiler to check conv temp memory
+ # NOTE: currently in SPMD solver we always believe that there will be a new tensor created in forward
+ fwd_memory_cost = MemoryCost(activation=compute_size_in_bytes([input_tensor, output_tensor]),
+ parameter=compute_size_in_bytes([weight_tensor, bias_tensor])
+ if has_bias else compute_size_in_bytes(weight_tensor),
+ temp=0,
+ buffer=0)
+
+ bwd_memory_cost = MemoryCost(activation=compute_size_in_bytes([input_tensor, weight_tensor, bias_tensor])
+ if has_bias else compute_size_in_bytes([input_tensor, weight_tensor]),
+ parameter=compute_size_in_bytes([weight_tensor, bias_tensor])
+ if has_bias else compute_size_in_bytes(weight_tensor),
+ temp=0,
+ buffer=0)
+
+ # total cost is the sum of forward and backward cost
+ total_cost = MemoryCost(activation=fwd_memory_cost.activation + bwd_memory_cost.activation,
+ parameter=fwd_memory_cost.parameter + bwd_memory_cost.parameter)
+
+ memory_cost = TrainCycleItem(fwd=fwd_memory_cost, bwd=bwd_memory_cost, total=total_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = [torch.zeros_like(input_tensor, device='meta')]
+ fwd_buffer = []
+ fwd_out = [torch.zeros_like(output_tensor, device='meta')]
+
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/embedding.py b/colossalai/auto_parallel/meta_profiler/meta_registry/embedding.py
new file mode 100644
index 0000000000000000000000000000000000000000..d5d80f5b3700b6b644c0b630496bd907c0b5aac2
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/embedding.py
@@ -0,0 +1,52 @@
+from typing import List, Tuple
+
+import torch
+
+from colossalai._analyzer._subclasses.flop_tensor import flop_mapping
+from colossalai._analyzer.fx.node_util import compute_size_in_bytes
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, OperationDataType, TrainCycleItem
+
+from ..registry import meta_register
+
+__all__ = ["embedding_meta_info"]
+
+
+@meta_register.register(torch.nn.Embedding)
+def embedding_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """torch.nn.Embedding metainfo generator
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]: compute cost, memory cost and forward inputs
+ """
+ input_tensor = next(filter(lambda x: x.type == OperationDataType.ARG, args)).data
+ weight_tensor = next(filter(lambda x: x.type == OperationDataType.PARAM, args)).data
+ output_tensor = next(filter(lambda x: x.type == OperationDataType.OUTPUT, args)).data
+
+ # compute cost
+ fwd_compute_cost = flop_mapping[torch.ops.aten.embedding.default]([weight_tensor, input_tensor], [output_tensor])
+ bwd_compute_cost = flop_mapping[torch.ops.aten.embedding_dense_backward.default]([output_tensor, weight_tensor],
+ [weight_tensor])
+
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost, bwd=bwd_compute_cost, total=fwd_compute_cost + bwd_compute_cost)
+
+ # memory cost
+ # NOTE: currently in SPMD solver we always believe that there will be a new tensor created in forward
+ # NOTE: during the backward phase of torch.nn.Embedding, it seems when the input is large enough, it will
+ # have a temp memory which is kind of weird and we don't know the reason yet, so currently we just assume
+ # that there will be no temp memory, as the temp memory is significantly smaller than the gradient memory
+ fwd_memory_cost = MemoryCost(activation=compute_size_in_bytes([input_tensor, output_tensor]),
+ parameter=0,
+ temp=0,
+ buffer=0)
+ bwd_memory_cost = MemoryCost(activation=compute_size_in_bytes([weight_tensor]), parameter=0, temp=0, buffer=0)
+
+ total_memory_cost = MemoryCost(activation=fwd_memory_cost.activation + bwd_memory_cost.activation)
+
+ memory_cost = TrainCycleItem(fwd=fwd_memory_cost, bwd=bwd_memory_cost, total=total_memory_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = [torch.zeros_like(input_tensor)]
+ fwd_buffer = []
+ fwd_out = [torch.zeros_like(output_tensor)]
+
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py b/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py
new file mode 100644
index 0000000000000000000000000000000000000000..7697fc6c383d8154acfe76dba7d8baec225930ac
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/linear.py
@@ -0,0 +1,406 @@
+from functools import reduce
+from typing import Callable, Dict, List, Tuple, Union
+
+import torch
+
+from colossalai._analyzer._subclasses.flop_tensor import flop_mapping
+from colossalai._analyzer.fx.node_util import compute_size_in_bytes
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ MemoryCost,
+ OperationData,
+ OperationDataType,
+ ShardingStrategy,
+ StrategiesVector,
+ TrainCycleItem,
+)
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+from ..registry import meta_register
+
+__all__ = ['linear_meta_info', 'matmul_meta_info']
+
+
+@meta_register.register(torch.nn.functional.linear)
+@meta_register.register(torch.nn.Linear)
+def linear_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """torch.nn.Linear & torch.nn.functional.linear meta info generator
+ NOTE: currently we separate the bias part from the biased linear ops, we will consider the memory consumption in add metainfo generator,
+ but we will hold the bias mechanism in the linear metainfo generator for future use.
+
+ graph():
+ %input_2 : [#users=2] = placeholder[target=placeholder](default=)
+ %addmm_default : [#users=1] = call_function[target=torch.ops.aten.addmm.default](args = (None, %input_2, None), kwargs = {})
+ %zeros_like_default : [#users=3] = call_function[target=torch.ops.aten.zeros_like.default](args = (%addmm_default,), kwargs = {dtype: None, layout: None, device: None, pin_memory: None})
+ %detach_default : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%input_2,), kwargs = {})
+ %mm_default : [#users=1] = call_function[target=torch.ops.aten.mm.default](args = (%zeros_like_default, None), kwargs = {})
+ %t_default : [#users=1] = call_function[target=torch.ops.aten.t.default](args = (%zeros_like_default,), kwargs = {})
+ %mm_default_1 : [#users=1] = call_function[target=torch.ops.aten.mm.default](args = (%t_default, %detach_default), kwargs = {})
+ %t_default_1 : [#users=1] = call_function[target=torch.ops.aten.t.default](args = (%mm_default_1,), kwargs = {})
+ %sum_dim_int_list : [#users=1] = call_function[target=torch.ops.aten.sum.dim_IntList](args = (%zeros_like_default, [None], None), kwargs = {})
+ %view_default : [#users=1] = call_function[target=torch.ops.aten.view.default](args = (%sum_dim_int_list, [None]), kwargs = {})
+ %detach_default_1 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%view_default,), kwargs = {})
+ %detach_default_2 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_1,), kwargs = {})
+ %detach_default_3 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%mm_default,), kwargs = {})
+ %detach_default_4 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_3,), kwargs = {})
+ %t_default_2 : [#users=1] = call_function[target=torch.ops.aten.t.default](args = (%t_default_1,), kwargs = {})
+ %detach_default_5 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%t_default_2,), kwargs = {})
+ %detach_default_6 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_5,), kwargs = {})
+
+ The one without bias is
+ graph():
+ %input_2 : [#users=2] = placeholder[target=placeholder](default=)
+ %mm_default : [#users=1] = call_function[target=torch.ops.aten.mm.default](args = (%input_2, None), kwargs = {})
+ %zeros_like_default : [#users=2] = call_function[target=torch.ops.aten.zeros_like.default](args = (%mm_default,), kwargs = {dtype: None, layout: None, device: None, pin_memory: None})
+ %detach_default : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%input_2,), kwargs = {})
+ %t_default : [#users=1] = call_function[target=torch.ops.aten.t.default](args = (%zeros_like_default,), kwargs = {})
+ %mm_default_1 : [#users=1] = call_function[target=torch.ops.aten.mm.default](args = (%t_default, %detach_default), kwargs = {})
+ %t_default_1 : [#users=1] = call_function[target=torch.ops.aten.t.default](args = (%mm_default_1,), kwargs = {})
+ %mm_default_2 : [#users=1] = call_function[target=torch.ops.aten.mm.default](args = (%zeros_like_default, None), kwargs = {})
+ %detach_default_1 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%mm_default_2,), kwargs = {})
+ %detach_default_2 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_1,), kwargs = {})
+ %t_default_2 : [#users=1] = call_function[target=torch.ops.aten.t.default](args = (%t_default_1,), kwargs = {})
+ %detach_default_3 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%t_default_2,), kwargs = {})
+ %detach_default_4 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_3,), kwargs = {})
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, bool]: compute cost, memory cost and forward inputs
+ """
+
+ has_bias: bool = False
+
+ input_tensor = args[0].data
+ output_tensor = args[2].data
+ if len(args) == 4:
+ weight_tensors = [args[1].data, args[3].data]
+ else:
+ weight_tensors = [args[1].data]
+
+ # process the dimension of input and output
+ if len(input_tensor.shape) > 2:
+ input_tensor: torch.Tensor
+ input_tensor = input_tensor.view(-1, input_tensor.shape[-1])
+
+ if len(output_tensor.shape) > 2:
+ output_tensor: torch.Tensor
+ output_tensor = output_tensor.view(-1, output_tensor.shape[-1])
+
+ if len(weight_tensors) > 1:
+ has_bias = True
+ if len(weight_tensors[0].shape) == 2:
+ weight_tensor, bias_tensor = weight_tensors
+ else:
+ bias_tensor, weight_tensor = weight_tensors
+ else:
+ weight_tensor = weight_tensors[0]
+
+ if has_bias:
+ # calculate cost with bias
+ # the fwd op with compute cost is addmm
+ # the bwd op with compute cost is mm * 2 and sum.dim_IntList
+
+ # calculate compute cost
+ fwd_compute_cost = flop_mapping[torch.ops.aten.addmm.default](
+ [bias_tensor, input_tensor, torch.transpose(weight_tensor, 0, 1)], (output_tensor,))
+ bwd_compute_cost = flop_mapping[torch.ops.aten.mm.default]([output_tensor, weight_tensor], (input_tensor,)) + \
+ flop_mapping[torch.ops.aten.mm.default]([torch.transpose(output_tensor, 0, 1), input_tensor], (weight_tensor,)) + \
+ flop_mapping[torch.ops.aten.sum.dim_IntList]([output_tensor], (bias_tensor,))
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost,
+ bwd=bwd_compute_cost,
+ total=fwd_compute_cost + bwd_compute_cost)
+
+ # calculate memory cost
+ # NOTE: Linear don't have buffer and temp in forward and backward phase
+ # the forward activation cost is the size of output_tensor, parameter cost is the size of weight_tensor and bias_tensor
+ # NOTE: currently in SPMD solver we always believe that there will be a new tensor created in forward
+ fwd_memory_cost = MemoryCost(activation=compute_size_in_bytes([input_tensor, output_tensor]),
+ parameter=compute_size_in_bytes([weight_tensor, bias_tensor]),
+ temp=0,
+ buffer=0)
+
+ # the backward activation cost is the size of input_tensor, weight_tensor and bias_tensor, parameter cost is 0
+ bwd_memory_cost = MemoryCost(activation=compute_size_in_bytes([input_tensor, weight_tensor, bias_tensor]),
+ parameter=compute_size_in_bytes([weight_tensor, bias_tensor]),
+ temp=0,
+ buffer=0)
+
+ # total cost is to sum the forward and backward cost
+ total_cost = MemoryCost(activation=fwd_memory_cost.activation + bwd_memory_cost.activation,
+ parameter=fwd_memory_cost.parameter + bwd_memory_cost.parameter)
+
+ memory_cost = TrainCycleItem(fwd=fwd_memory_cost, bwd=bwd_memory_cost, total=total_cost)
+
+ else:
+ # calculate cost without bias
+ # the fwd op with compute cost is mm
+ # the bwd op with compute cost is mm * 2
+
+ # calculate compute cost
+ fwd_compute_cost = flop_mapping[torch.ops.aten.mm.default](
+ [input_tensor, torch.transpose(weight_tensor, 0, 1)], (output_tensor,))
+ bwd_compute_cost = flop_mapping[torch.ops.aten.mm.default]([output_tensor, weight_tensor], (input_tensor,)) + \
+ flop_mapping[torch.ops.aten.mm.default]([torch.transpose(output_tensor, 0, 1), input_tensor], (weight_tensor,))
+
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost,
+ bwd=bwd_compute_cost,
+ total=fwd_compute_cost + bwd_compute_cost)
+
+ # calculate memory cost
+ # NOTE: Linear don't have buffer and temp in forward and backward phase
+ # the forward activation cost is the size of output_tensor, parameter cost is the size of weight_tensor
+ # NOTE: currently in SPMD solver we always believe that there will be a new tensor created in forward
+ fwd_memory_cost = MemoryCost(activation=compute_size_in_bytes([input_tensor, output_tensor]),
+ parameter=compute_size_in_bytes(weight_tensor),
+ temp=0,
+ buffer=0)
+
+ # the backward activation cost is the size of input_tensor and weight_tensor, parameter cost is 0
+ bwd_memory_cost = MemoryCost(activation=compute_size_in_bytes([input_tensor, weight_tensor]),
+ parameter=compute_size_in_bytes(weight_tensor),
+ temp=0,
+ buffer=0)
+
+ # total cost is to sum the forward and backward cost
+ total_cost = MemoryCost(activation=fwd_memory_cost.activation + bwd_memory_cost.activation,
+ parameter=fwd_memory_cost.parameter + bwd_memory_cost.parameter)
+
+ memory_cost = TrainCycleItem(fwd=fwd_memory_cost, bwd=bwd_memory_cost, total=total_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = [torch.zeros_like(input_tensor, device='meta')]
+ fwd_buffer = []
+ fwd_out = [torch.zeros_like(output_tensor, device='meta')]
+
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
+
+
+@meta_register.register(torch.matmul)
+def matmul_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """torch.matmul meta info generator
+ There are several cases for torch.matmul:
+ 1. Vector-vector multiplication => no temp memory, forward memory cost is 1 element (could be neglected), backward memory cost is the same
+ as two input vectors.
+ 2. Matrix-vector multiplication => if the first input is matrix, no temp memory is needed, otherwise, there is a temp memory in the backward
+ phase for the transpose of the matrix. The forward memory cost is the size of output tensor, backward memory cost is the size of the two inputs; if
+ the first input is vector, the forward memory cost is the size of the output tensor, and during the backward phase, it will allocate a temp memory
+ the same size as the input matrix, and allocate memory for the gradient of two inputs.
+ 3. Batched Matrix-vector multiplication => if the first input is the batched matrix, no temp memory, the forward memory cost is the size of
+ output tensor, backward memory cost is the size of the two inputs; if the second input is the batched matrix, the matmul will allocate memory for
+ the gradient of the batched matrix in the forward phase (as they create a new tensor without the former batches), so the forward memory cost is
+ the output tensor and the newly created matrix (take the same amount of memory of the input batched matrix). During the backward phase, it will
+ allocate a temp memory the same size as input batched matrix, and allocate a tensor for the gradient of the input vector. The gradient of the batched
+ matrix will be stored in the memory allocated during the forward phase.
+ 3. Matrix-matrix multiplication => no temp memory, forward memory is the size of output tensor, backward memory is the size of the two inputs
+ 4. Batched matrix-matrix multiplication => if the first input is the batched matrix, no temp memory, the forward memory cost is the size of two
+ inputs and backward memory cost is the size of the output tensor; if the second input is the batched matrix, during the forward phase it will allocate
+ memory for the output and gradient of the second input, and has a temp memory the same size as the output, during the backward phase, it
+ will allocate memory for the gradient of the first input and has a temp memory which is as big as output and the second input.
+ 5. Batched matrix-batched matrix multiplication => if the two inputs have the same batch dimensions, no temp memory, the forward memory cost is the size
+ of output, backward memory cost is the size of the two inputs; it the two inputs have different batch dimensions, during the forward phase it will allocate
+ memory of the expanded inputs (so that the batch dimensions could match) and the output, and during the backward phase, it has a temp memory of the size of
+ two expanded inputs, and it will allocate memory for the gradient of the two inputs and discard the expanded inputs allocated during the forward phase.
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, bool]: compute cost, memory cost and forward inputs
+
+ """
+ # Get input and output tensors
+ input_tensors = [args[0].data, args[1].data]
+ output_tensors = [args[-1].data]
+
+ # Check dimension
+ if all(len(tensor.shape) == 1 for tensor in input_tensors):
+ # Dot
+ fwd_compute_cost = flop_mapping[torch.ops.aten.matmul.default](input_tensors, output_tensors)
+ bwd_compute_cost = flop_mapping[torch.ops.aten.mul.Tensor](input_tensors[0], output_tensors) * 2
+
+ fwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(output_tensors), parameter=0, temp=0, buffer=0)
+ bwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(input_tensors), parameter=0, temp=0, buffer=0)
+
+ elif len(input_tensors[0].shape) >= 2 and len(input_tensors[1].shape) == 1:
+ # gemv case 1: matrix-vector multiplication
+ # &
+ # batched gemv case 1: batched matrix-vector multiplication
+
+ fwd_compute_cost = flop_mapping[torch.ops.aten.matmul.default](
+ [input_tensors[0].reshape(-1, input_tensors[0].shape[-1]), input_tensors[1]], output_tensors)
+
+ # combine the dimensions of output
+ bwd_compute_cost = flop_mapping[torch.ops.aten.mul.Tensor](
+ [output_tensors[0].reshape(-1), input_tensors[1]],
+ output_tensors) + \
+ flop_mapping[torch.ops.aten.matmul.default](
+ [input_tensors[0].reshape(-1, input_tensors[0].shape[-1]).transpose(0, 1), output_tensors[0].reshape(-1)],
+ output_tensors)
+
+ fwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(output_tensors), parameter=0, temp=0, buffer=0)
+ bwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(input_tensors), parameter=0, temp=0, buffer=0)
+
+ elif len(input_tensors[0].shape) == 1 and len(input_tensors[1].shape) == 2:
+ # gemv case 2: vector-matrix multiplication
+ fwd_compute_cost = flop_mapping[torch.ops.aten.matmul.default](input_tensors, output_tensors)
+
+ bwd_compute_cost = flop_mapping[torch.ops.aten.mul.Tensor]([output_tensors[0], input_tensors[0]], output_tensors) + \
+ flop_mapping[torch.ops.aten.matmul.default]([input_tensors[1], output_tensors[0]], output_tensors)
+
+ fwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(output_tensors), parameter=0, temp=0, buffer=0)
+ bwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(input_tensors),
+ parameter=0,
+ temp=compute_size_in_bytes(input_tensors[1]),
+ buffer=0)
+
+ elif len(input_tensors[0].shape) == 1 and len(input_tensors[1].shape) >= 3:
+ # batched gemv case 2: vector-batched matrix multiplication
+
+ fwd_compute_cost = flop_mapping[torch.ops.aten.matmul.default](
+ [input_tensors[1].transpose(-2, -1).reshape(-1, input_tensors[1].shape[-2]), input_tensors[0]],
+ [output_tensors[0].reshape(-1)])
+
+ # combine the dimensions of output
+ bwd_compute_cost = flop_mapping[torch.ops.aten.mul.Tensor](
+ [output_tensors[0].reshape(-1), input_tensors[0]],
+ output_tensors
+ ) + \
+ flop_mapping[torch.ops.aten.matmul.default](
+ [input_tensors[1].transpose(-2, -1).reshape(-1, input_tensors[1].shape[-2]).transpose(0, 1), output_tensors[0].reshape(-1)],
+ output_tensors
+ )
+
+ fwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(output_tensors + [input_tensors[1]]))
+ bwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(input_tensors[0]),
+ parameter=0,
+ temp=compute_size_in_bytes(input_tensors[1]),
+ buffer=0)
+
+ elif len(input_tensors[0].shape) >= 2 and len(input_tensors[1].shape) == 2:
+ # gemm & batched gemm case 1: batched matrix-matrix multiplication
+
+ fwd_compute_cost = flop_mapping[torch.ops.aten.mm.default](
+ [input_tensors[0].reshape(-1, input_tensors[0].shape[-1]), input_tensors[1]],
+ [output_tensors[0].reshape(-1, output_tensors[0].shape[-1])])
+
+ bwd_compute_cost = flop_mapping[torch.ops.aten.mm.default](
+ [input_tensors[0].reshape(-1, input_tensors[0].shape[-1]).transpose(0, 1), output_tensors[0].reshape(-1, output_tensors[0].shape[-1])],
+ [input_tensors[1]]
+ ) + \
+ flop_mapping[torch.ops.aten.mm.default](
+ [output_tensors[0].reshape(-1, output_tensors[0].shape[-1]), input_tensors[1].transpose(0, 1)],
+ [input_tensors[0].reshape(-1, input_tensors[0].shape[-1])]
+ )
+
+ fwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(output_tensors), parameter=0, temp=0, buffer=0)
+ bwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(input_tensors), parameter=0, temp=0, buffer=0)
+
+ elif len(input_tensors[0].shape) == 2 and len(input_tensors[1].shape) >= 3:
+ # batched gemm case 2: matrix-batched matrix multiplication
+ fwd_compute_cost = flop_mapping[torch.ops.aten.mm.default]([
+ input_tensors[1].transpose(-2, -1).reshape(-1, input_tensors[1].shape[-2]), input_tensors[0].transpose(
+ 0, 1)
+ ], [output_tensors[0].transpose(-2, -1)])
+
+ bwd_compute_cost = flop_mapping[torch.ops.aten.mm.default](
+ [output_tensors[0].transpose(-2, -1).reshape(-1, output_tensors[0].shape[-2]).transpose(0, 1), input_tensors[1].transpose(-2, -1).reshape(-1, input_tensors[1].shape[-2])],
+ [input_tensors[0]]
+ ) + \
+ flop_mapping[torch.ops.aten.mm.default](
+ [output_tensors[0].transpose(-2, -1).reshape(-1, output_tensors[0].shape[-2]), input_tensors[0]],
+ [input_tensors[1].transpose(-2, -1).reshape(-1, input_tensors[1].shape[-2])]
+ )
+
+ fwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(output_tensors) +
+ compute_size_in_bytes(input_tensors[1]),
+ temp=compute_size_in_bytes(output_tensors))
+ bwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(input_tensors[0]),
+ parameter=0,
+ temp=compute_size_in_bytes(input_tensors[1]) + compute_size_in_bytes(output_tensors))
+
+ elif all(len(tensor.shape) >= 3 for tensor in input_tensors):
+ # Batched matrix-batched matrix multiplication
+ # Fetch shape of the two inputs and see if the batch dimensions are the same
+ _is_batch_dims_same = True
+ if len(input_tensors[0].shape) == len(input_tensors[1].shape):
+ for (shape_0, shape_1) in zip(input_tensors[0].shape[:-2], input_tensors[1].shape[:-2]):
+ if shape_0 != shape_1:
+ _is_batch_dims_same = False
+ break
+ else:
+ _is_batch_dims_same = False
+
+ # retireve dimensions
+ input_dim_00 = input_tensors[0].shape[-2]
+ input_dim_01 = input_tensors[0].shape[-1]
+ input_dim_10 = input_tensors[1].shape[-2]
+ input_dim_11 = input_tensors[1].shape[-1]
+ output_dim_0 = output_tensors[0].shape[-2]
+ output_dim_1 = output_tensors[0].shape[-1]
+
+ if _is_batch_dims_same:
+ # Case 1: batch dimensions are the same
+
+ # Forward compute cost: C = A * B
+ fwd_compute_cost = flop_mapping[torch.ops.aten.bmm.default]([
+ input_tensors[0].reshape(-1, input_dim_00, input_dim_01), input_tensors[1].reshape(
+ -1, input_dim_10, input_dim_11)
+ ], [output_tensors[0].reshape(-1, output_dim_0, output_dim_1)])
+
+ # Backward compute cost: dB = A^T * dC, dA = dC * B^T
+ bwd_compute_cost = flop_mapping[torch.ops.aten.bmm.default](
+ [input_tensors[0].transpose(-2, -1).reshape(-1, input_dim_01, input_dim_00), output_tensors[0].reshape(-1, output_dim_0, output_dim_1)],
+ [input_tensors[1].reshape(-1, input_dim_11, input_dim_10)]
+ ) + \
+ flop_mapping[torch.ops.aten.bmm.default](
+ [output_tensors[0].reshape(-1, output_dim_0, output_dim_1), input_tensors[1].transpose(-2, -1).reshape(-1, input_dim_11, input_dim_10)],
+ [input_tensors[0].reshape(-1, input_dim_00, input_dim_01)]
+ )
+
+ fwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(output_tensors))
+ bwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(input_tensors))
+
+ else:
+ # Case 2: batch dimensions are different
+ batch_dims = output_tensors[0].shape[:-2]
+ extended_input_0 = torch.rand(reduce(lambda x, y: x * y, batch_dims),
+ input_dim_00,
+ input_dim_01,
+ device="meta")
+ extended_input_1 = torch.rand(reduce(lambda x, y: x * y, batch_dims),
+ input_dim_10,
+ input_dim_11,
+ device="meta")
+
+ # Forward compute cost: C = A * B
+ fwd_compute_cost = flop_mapping[torch.ops.aten.bmm.default](
+ [extended_input_0, extended_input_1], [output_tensors[0].reshape(-1, output_dim_0, output_dim_1)])
+
+ # Backward compute cost: dB = A^T * dC, dA = dC * B^T
+ bwd_compute_cost = flop_mapping[torch.ops.aten.bmm.default](
+ [extended_input_0.transpose(-2, -1), output_tensors[0].reshape(-1, output_dim_0, output_dim_1)],
+ [extended_input_1]
+ ) + \
+ flop_mapping[torch.ops.aten.bmm.default](
+ [output_tensors[0].reshape(-1, output_dim_0, output_dim_1), extended_input_1.transpose(-2, -1)],
+ [extended_input_0]
+ )
+
+ fwd_mem_cost = MemoryCost(
+ activation=compute_size_in_bytes([output_tensors[0], extended_input_0, extended_input_1]))
+ bwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(input_tensors) -
+ compute_size_in_bytes([extended_input_0, extended_input_1]),
+ temp=compute_size_in_bytes([extended_input_0, extended_input_1]))
+
+ # compute cost
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost, bwd=bwd_compute_cost, total=fwd_compute_cost + bwd_compute_cost)
+
+ # memory cost
+ total_cost = MemoryCost(activation=fwd_mem_cost.activation + bwd_mem_cost.activation,
+ parameter=fwd_mem_cost.parameter + bwd_mem_cost.parameter,
+ temp=fwd_mem_cost.temp + bwd_mem_cost.temp,
+ buffer=fwd_mem_cost.buffer + bwd_mem_cost.buffer)
+
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = input_tensors
+ fwd_buffer = []
+ fwd_out = output_tensors
+
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/non_spmd.py b/colossalai/auto_parallel/meta_profiler/meta_registry/non_spmd.py
new file mode 100644
index 0000000000000000000000000000000000000000..12874810b13e252c0597e2adf124ab7875e992a3
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/non_spmd.py
@@ -0,0 +1,27 @@
+import operator
+from typing import List, Tuple
+
+import torch
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, OperationDataType, TrainCycleItem
+
+from ..registry import meta_register
+
+__all__ = ["non_spmd_meta_info"]
+
+
+@meta_register.register(torch.Size)
+@meta_register.register(torch.Tensor.size)
+@meta_register.register(torch.finfo)
+@meta_register.register(operator.le)
+def non_spmd_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """Non-SPMD node meta information generator
+ Those nodes will not be handled by SPMD solver, so we just return all zero meta information for it
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]: compute cost, memory cost and forward inputs
+ """
+ compute_cost = TrainCycleItem(fwd=0, bwd=0, total=0)
+ memory_cost = TrainCycleItem(fwd=MemoryCost(), bwd=MemoryCost(), total=MemoryCost())
+ fwd_in, fwd_buffer, fwd_out = [], [], []
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/norm.py b/colossalai/auto_parallel/meta_profiler/meta_registry/norm.py
new file mode 100644
index 0000000000000000000000000000000000000000..b872fdc8bdcd19717e7b81d436fffd860ec88519
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/norm.py
@@ -0,0 +1,158 @@
+from typing import Callable, Dict, List, Tuple, Union
+
+import torch
+
+from colossalai._analyzer._subclasses.flop_tensor import flop_mapping
+from colossalai._analyzer.fx.node_util import compute_size_in_bytes
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ MemoryCost,
+ OperationData,
+ OperationDataType,
+ ShardingStrategy,
+ StrategiesVector,
+ TrainCycleItem,
+)
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+from ..registry import meta_register
+
+__all__ = ['batchnormnd_meta_info', 'layernorm_meta_info']
+
+
+@meta_register.register(torch.nn.BatchNorm1d)
+@meta_register.register(torch.nn.BatchNorm2d)
+@meta_register.register(torch.nn.BatchNorm3d)
+def batchnormnd_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """BatchNorm1d, BatchNorm2d, BatchNorm3d, meta info generator
+ The aten graph of BatchNorm2d is like
+
+ graph():
+ %input_2 : [#users=2] = placeholder[target=placeholder](default=)
+ %cudnn_batch_norm_default : [#users=4] = call_function[target=torch.ops.aten.cudnn_batch_norm.default](args = (%input_2, None, None, None, None, None, None, None), kwargs = {})
+ %zeros_like_default : [#users=1] = call_function[target=torch.ops.aten.zeros_like.default](args = (%cudnn_batch_norm_default,), kwargs = {dtype: None, layout: None, device: None, pin_memory: None})
+ %detach_default : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%input_2,), kwargs = {})
+ %detach_default_1 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%cudnn_batch_norm_default,), kwargs = {})
+ %detach_default_2 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%cudnn_batch_norm_default,), kwargs = {})
+ %detach_default_3 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%cudnn_batch_norm_default,), kwargs = {})
+ %cudnn_batch_norm_backward_default : [#users=3] = call_function[target=torch.ops.aten.cudnn_batch_norm_backward.default](args = (%detach_default, %zeros_like_default, None, None, None, %detach_default_1, %detach_default_2, None, %detach_default_3), kwargs = {})
+ %detach_default_4 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%cudnn_batch_norm_backward_default,), kwargs = {})
+ %detach_default_5 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_4,), kwargs = {})
+ %detach_default_6 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%cudnn_batch_norm_backward_default,), kwargs = {})
+ %detach_default_7 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_6,), kwargs = {})
+ %detach_default_8 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%cudnn_batch_norm_backward_default,), kwargs = {})
+ %detach_default_9 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_8,), kwargs = {})
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]: compute cost, memory cost and forward inputs
+ """
+
+ input_tensor = args[0].data
+ output_tensor = next(filter(lambda x: x.type == OperationDataType.OUTPUT, args)).data
+ weight_tensor = next(filter(lambda x: x.name == "weight", args)).data
+ bias_tensor = next(filter(lambda x: x.name == "bias", args)).data
+ mean_tensor = next(filter(lambda x: x.name == "running_mean", args)).data
+ var_tensor = next(filter(lambda x: x.name == "running_var", args)).data
+ num_batch = next(filter(lambda x: x.name == "num_batches_tracked", args)).data
+
+ # construct fwd args
+ # the fwd inputs are input, weight, bias, running_mean, running_var and some other args
+ # indicating the status of the module
+ # the fwd outputs are output, saved mean, saved inv std and num batches tracked
+ fwd_in_args = [input_tensor, weight_tensor, bias_tensor, mean_tensor, var_tensor, True, 0.1, 1e-5]
+ fwd_out_args = [output_tensor, mean_tensor, var_tensor, num_batch]
+
+ # construct bwd args
+ # the bwd inputs are upstream grad, input, weight, running_mean, running_var, saved mean,
+ # saved inv std and some other args indicating the status of the module
+ # the bwd outputs are input grad, weight grad and bias grad
+ bwd_in_args = [
+ output_tensor, output_tensor, weight_tensor, mean_tensor, var_tensor, mean_tensor, var_tensor, 1e-5, num_batch
+ ]
+ bwd_out_args = [input_tensor, weight_tensor, bias_tensor]
+
+ # calculate cost
+ fwd_compute_cost = flop_mapping[torch.ops.aten.cudnn_batch_norm.default](fwd_in_args, fwd_out_args)
+ bwd_compute_cost = flop_mapping[torch.ops.aten.cudnn_batch_norm_backward.default](bwd_in_args, bwd_out_args)
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost, bwd=bwd_compute_cost, total=fwd_compute_cost + bwd_compute_cost)
+
+ # calculate memory cost
+ # the fwd activation cost is output plus saved mean and saved inv std
+ # NOTE: currently in SPMD solver we always believe that there will be a new tensor created in forward
+ fwd_memory_cost = MemoryCost(activation=compute_size_in_bytes(
+ [input_tensor, output_tensor, mean_tensor, var_tensor]),
+ parameter=compute_size_in_bytes([weight_tensor, bias_tensor]),
+ temp=0,
+ buffer=compute_size_in_bytes([mean_tensor, var_tensor]))
+
+ # the bwd memory cost is quite tricky here, BatchNorm will remove saved mean
+ # and saved inv std during backward phase
+ bwd_memory_cost = MemoryCost(activation=compute_size_in_bytes([input_tensor]),
+ parameter=compute_size_in_bytes([weight_tensor, bias_tensor]),
+ temp=compute_size_in_bytes([mean_tensor, var_tensor]),
+ buffer=compute_size_in_bytes([mean_tensor, var_tensor]))
+
+ # total cost is the sum of forward and backward cost
+ total_cost = MemoryCost(activation=fwd_memory_cost.activation + bwd_memory_cost.activation,
+ parameter=fwd_memory_cost.parameter + bwd_memory_cost.parameter)
+
+ memory_cost = TrainCycleItem(fwd=fwd_memory_cost, bwd=bwd_memory_cost, total=total_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = [torch.zeros_like(input_tensor, device='meta')]
+ fwd_buffer = [torch.zeros_like(mean_tensor, device='meta'), torch.zeros_like(var_tensor, device='meta')]
+ fwd_out = [torch.zeros_like(output_tensor, device='meta')]
+
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
+
+
+@meta_register.register(torch.nn.LayerNorm)
+def layernorm_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """LayerNorm meta information
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]: compute cost, memory cost and forward inputs
+ """
+ # construct needed tensors
+ input_tensor = next(filter(lambda x: x.type == OperationDataType.ARG, args)).data
+ output_tensor = next(filter(lambda x: x.type == OperationDataType.OUTPUT, args)).data
+ weight_tensor = next(filter(lambda x: x.name == "weight", args)).data
+ bias_tensor = next(filter(lambda x: x.name == "bias", args)).data
+ running_mean = torch.rand(input_tensor.shape[0], 1, device='meta')
+ running_var = torch.rand(input_tensor.shape[0], 1, device='meta')
+
+ # construct args
+ fwd_in_args = [input_tensor, [input_tensor.shape[0]], weight_tensor]
+ fwd_out_args = [output_tensor]
+ bwd_in_args = [input_tensor, output_tensor, [input_tensor.shape[0]]]
+ bwd_out_args = [weight_tensor, bias_tensor]
+
+ # compute cost
+ fwd_compute_cost = flop_mapping[torch.ops.aten.native_layer_norm.default](fwd_in_args, fwd_out_args)
+ bwd_compute_cost = flop_mapping[torch.ops.aten.native_layer_norm_backward.default](bwd_in_args, bwd_out_args)
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost, bwd=bwd_compute_cost, total=fwd_compute_cost + bwd_compute_cost)
+
+ # memory cost
+ # NOTE: currently in SPMD solver we always believe that there will be a new tensor created in forward
+ fwd_memory_cost = MemoryCost(activation=compute_size_in_bytes(
+ [input_tensor, output_tensor, weight_tensor, bias_tensor]),
+ parameter=compute_size_in_bytes([weight_tensor, bias_tensor]),
+ temp=0,
+ buffer=compute_size_in_bytes([running_mean, running_var]))
+
+ bwd_memory_cost = MemoryCost(activation=compute_size_in_bytes([input_tensor, weight_tensor, bias_tensor]),
+ parameter=compute_size_in_bytes([weight_tensor, bias_tensor]),
+ temp=compute_size_in_bytes([running_mean, running_var]),
+ buffer=compute_size_in_bytes([running_mean, running_var]))
+
+ total_cost = MemoryCost(activation=fwd_memory_cost.activation + bwd_memory_cost.activation,
+ parameter=fwd_memory_cost.parameter + bwd_memory_cost.parameter,
+ temp=fwd_memory_cost.temp + bwd_memory_cost.temp,
+ buffer=fwd_memory_cost.buffer + bwd_memory_cost.buffer)
+
+ memory_cost = TrainCycleItem(fwd=fwd_memory_cost, bwd=bwd_memory_cost, total=total_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = [torch.zeros_like(input_tensor, device='meta')]
+ fwd_buffer = [torch.zeros_like(running_mean, device='meta'), torch.zeros_like(running_var, device='meta')]
+ fwd_out = [torch.zeros_like(output_tensor, device='meta')]
+
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/pooling.py b/colossalai/auto_parallel/meta_profiler/meta_registry/pooling.py
new file mode 100644
index 0000000000000000000000000000000000000000..d785dfcca9bacb46e129adda5f83486090975859
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/pooling.py
@@ -0,0 +1,133 @@
+from typing import List, Tuple
+
+import torch
+
+from colossalai._analyzer._subclasses.flop_tensor import flop_mapping
+from colossalai._analyzer.fx.node_util import compute_size_in_bytes
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, OperationDataType, TrainCycleItem
+
+from ..registry import meta_register
+
+__all__ = ["avgpool_meta_info", "maxpool_meta_info"]
+
+
+@meta_register.register(torch.nn.AdaptiveAvgPool1d)
+@meta_register.register(torch.nn.AdaptiveAvgPool2d)
+@meta_register.register(torch.nn.AdaptiveAvgPool3d)
+def avgpool_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """Meta info for AdaptiveAvgPool
+ The aten graph of AdaptiveAvgPool is
+ graph():
+ %input_2 : [#users=2] = placeholder[target=placeholder](default=)
+ %_adaptive_avg_pool2d_default : [#users=1] = call_function[target=torch.ops.aten._adaptive_avg_pool2d.default](args = (%input_2, [None, None]), kwargs = {})
+ %zeros_like_default : [#users=1] = call_function[target=torch.ops.aten.zeros_like.default](args = (%_adaptive_avg_pool2d_default,), kwargs = {dtype: None, layout: None, device: None, pin_memory: None})
+ %detach_default : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%input_2,), kwargs = {})
+ %_adaptive_avg_pool2d_backward_default : [#users=1] = call_function[target=torch.ops.aten._adaptive_avg_pool2d_backward.default](args = (%zeros_like_default, %detach_default), kwargs = {})
+ %detach_default_1 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%_adaptive_avg_pool2d_backward_default,), kwargs = {})
+ %detach_default_2 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_1,), kwargs = {})
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]: compute cost, memory cost and forward inputs
+ """
+
+ input_tensor = args[0].data
+ output_tensor = next(filter(lambda x: x.type == OperationDataType.OUTPUT, args)).data
+ is_inplace = kwargs.get("inplace", False)
+
+ # construct forward args for flop mapping
+ fwd_in_args = [input_tensor]
+ fwd_out_args = [output_tensor]
+
+ # construct backward args for flop mapping
+ bwd_in_args = [output_tensor]
+ bwd_out_args = [input_tensor]
+
+ # calculate cost
+ # the fwd op with compute cost is _adaptive_avg_pool2d.default
+ # the bwd op with compute cost is _adaptive_avg_pool2d_backward.default
+
+ # calculate compute cost
+ fwd_compute_cost = flop_mapping[torch.ops.aten._adaptive_avg_pool2d.default](fwd_in_args, fwd_out_args)
+ bwd_compute_cost = flop_mapping[torch.ops.aten._adaptive_avg_pool2d_backward.default](bwd_in_args, bwd_out_args)
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost, bwd=bwd_compute_cost, total=fwd_compute_cost + bwd_compute_cost)
+
+ # calculate memory cost
+ fwd_mem_cost = MemoryCost() if is_inplace else MemoryCost(activation=compute_size_in_bytes(output_tensor))
+ bwd_mem_cost = MemoryCost() if is_inplace else MemoryCost(activation=compute_size_in_bytes(input_tensor))
+
+ # total cost
+ total_mem_cost = MemoryCost(activation=fwd_mem_cost.activation + bwd_mem_cost.activation)
+
+ mem_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = []
+ fwd_buffer = []
+ fwd_out = [torch.zeros_like(output_tensor, device='meta')]
+
+ return compute_cost, mem_cost, fwd_in, fwd_buffer, fwd_out
+
+
+@meta_register.register(torch.nn.MaxPool1d)
+@meta_register.register(torch.nn.MaxPool2d)
+@meta_register.register(torch.nn.MaxPool3d)
+def maxpool_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """Meta info for MaxPool
+ The aten graph of MaxPool is
+ graph():
+ %input_2 : [#users=2] = placeholder[target=placeholder](default=)
+ %max_pool2d_with_indices_default : [#users=2] = call_function[target=torch.ops.aten.max_pool2d_with_indices.default](args = (%input_2, [None, None], [None, None]), kwargs = {})
+ %zeros_like_default : [#users=1] = call_function[target=torch.ops.aten.zeros_like.default](args = (%max_pool2d_with_indices_default,), kwargs = {dtype: None, layout: None, device: None, pin_memory: None})
+ %detach_default : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%input_2,), kwargs = {})
+ %detach_default_1 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%max_pool2d_with_indices_default,), kwargs = {})
+ %max_pool2d_with_indices_backward_default : [#users=1] = call_function[target=torch.ops.aten.max_pool2d_with_indices_backward.default](args = (%zeros_like_default, %detach_default, [None, None], [None, None], [None, None], [None, None], None, %detach_default_1), kwargs = {})
+ %detach_default_2 : [#users=1] = call_function[target=torch.ops.aten.detach.default](args = (%max_pool2d_with_indices_backward_default,), kwargs = {})
+ %detach_default_3 : [#users=0] = call_function[target=torch.ops.aten.detach.default](args = (%detach_default_2,), kwargs = {})
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]: compute cost, memory cost and forward inputs
+ """
+
+ input_tensor = next(filter(lambda x: x.type == OperationDataType.ARG, args)).data
+ output_tensor = next(filter(lambda x: x.type == OperationDataType.OUTPUT, args)).data
+
+ # construct forward args for flop mapping
+ fwd_in_args = [input_tensor]
+ fwd_out_args = [output_tensor]
+
+ # construct backward args for flop mapping
+ bwd_in_args = [output_tensor]
+ bwd_out_args = [input_tensor]
+
+ # construct index matrix
+ index_matrix = torch.zeros_like(output_tensor, device="meta", dtype=torch.int64)
+
+ # calculate cost
+ # the fwd op with compute cost is max_pool2d_with_indices.default
+ # the bwd op with compute cost is max_pool2d_with_indices_backward.default
+
+ # calculate compute cost
+ fwd_compute_cost = flop_mapping[torch.ops.aten.max_pool2d_with_indices.default](fwd_in_args, fwd_out_args)
+ bwd_compute_cost = flop_mapping[torch.ops.aten.max_pool2d_with_indices_backward.default](bwd_in_args, bwd_out_args)
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost, bwd=bwd_compute_cost, total=fwd_compute_cost + bwd_compute_cost)
+
+ # calculate memory cost
+ # NOTE: the index matrix will be discarded in backward phase
+ # NOTE: currently in SPMD solver we always believe that there will be a new tensor created in forward
+ fwd_mem_cost = MemoryCost(activation=compute_size_in_bytes([input_tensor, output_tensor, index_matrix]))
+
+ # temp memory for backward is the index matrix to be discarded
+ bwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(input_tensor) - compute_size_in_bytes(index_matrix),
+ temp=compute_size_in_bytes(index_matrix))
+
+ # total cost
+ total_mem_cost = MemoryCost(activation=fwd_mem_cost.activation + bwd_mem_cost.activation, temp=bwd_mem_cost.temp)
+
+ mem_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = [torch.zeros_like(input_tensor, device='meta')]
+ fwd_buffer = [torch.zeros_like(index_matrix, device='meta')]
+ fwd_out = [torch.zeros_like(output_tensor, device='meta')]
+
+ return compute_cost, mem_cost, fwd_in, fwd_buffer, fwd_out
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/tensor.py b/colossalai/auto_parallel/meta_profiler/meta_registry/tensor.py
new file mode 100644
index 0000000000000000000000000000000000000000..97fe3c6196f591af7bbfcbdcf59ff3afd114175f
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/tensor.py
@@ -0,0 +1,79 @@
+from typing import Callable, List, Tuple
+
+import torch
+
+from colossalai._analyzer._subclasses.flop_tensor import flop_mapping
+from colossalai._analyzer.fx.node_util import compute_size_in_bytes
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, OperationDataType, TrainCycleItem
+
+from ..registry import meta_register
+
+__all__ = ["tensor_related_metainfo"]
+
+
+def tensor_related_metainfo(bwd_mem_out_factor: float = 1, bwd_mem_tmp_factor: float = 0) -> Callable:
+ """torch.Tensor related metainfo generator template
+
+ Args:
+ bwd_mem_out_factor (float, optional): backward activation memory cost factor. Defaults to 1.
+ bwd_mem_tmp_factor (float, optional): backward temp memory cost factor. Defaults to 0.
+
+ Returns:
+ Callable: torch.Tensor related metainfo generator
+ """
+
+ def meta_func(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """torch.Tensor related metainfo generator
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]: compute cost, memory cost and forward inputs
+ """
+ outputs = next(filter(lambda x: x.type == OperationDataType.OUTPUT, args)).data
+
+ # compute costs are all zero
+ compute_cost = TrainCycleItem(fwd=0, bwd=0, total=0)
+
+ # memory costs
+ # NOTE: currently in SPMD solver we always believe that there will be a new tensor created in forward
+ fwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(outputs) * 2, parameter=0, temp=0, buffer=0)
+
+ bwd_mem_cost = MemoryCost(activation=compute_size_in_bytes(outputs) * bwd_mem_out_factor,
+ parameter=0,
+ temp=compute_size_in_bytes(outputs) * bwd_mem_tmp_factor,
+ buffer=0)
+
+ total_mem_cost = MemoryCost(activation=fwd_mem_cost.activation + bwd_mem_cost.activation,
+ parameter=fwd_mem_cost.parameter + bwd_mem_cost.parameter,
+ temp=fwd_mem_cost.temp + bwd_mem_cost.temp,
+ buffer=fwd_mem_cost.buffer + bwd_mem_cost.buffer)
+
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = []
+ fwd_buffer = []
+ if isinstance(outputs, tuple) or isinstance(outputs, list) or isinstance(outputs, dict):
+ # tuple of tensors
+ fwd_out = [torch.zeros_like(tensor) for tensor in outputs]
+ else:
+ # enaged_tensors is a single tensor
+ fwd_out = [torch.zeros_like(outputs)]
+
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
+
+ return meta_func
+
+
+# register torch.Tensor related metainfo
+# (0, 0)
+meta_register.register([torch.tensor, torch.Tensor.to, torch.Tensor.unsqueeze, torch.unsqueeze,
+ torch.arange])(tensor_related_metainfo(0, 0))
+
+# (1, 0)
+meta_register.register([
+ torch.Tensor.flatten, torch.flatten, torch.Tensor.transpose, torch.transpose, torch.Tensor.permute, torch.permute,
+ torch.Tensor.split, torch.split, torch.Tensor.view
+])(tensor_related_metainfo(1, 0))
+
+# (1, 1)
+meta_register.register([torch.Tensor.type, torch.Tensor.contiguous])(tensor_related_metainfo(1, 1))
diff --git a/colossalai/auto_parallel/meta_profiler/meta_registry/where.py b/colossalai/auto_parallel/meta_profiler/meta_registry/where.py
new file mode 100644
index 0000000000000000000000000000000000000000..5cba1b5b6e2b16521ed2a0df2fbab98b19492c53
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/meta_registry/where.py
@@ -0,0 +1,60 @@
+from typing import List, Tuple
+
+import torch
+
+from colossalai._analyzer._subclasses.flop_tensor import flop_mapping
+from colossalai._analyzer.fx.node_util import compute_size_in_bytes as activation_size
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, OperationDataType, TrainCycleItem
+
+from ..registry import meta_register
+
+__all__ = ["where_meta_info"]
+
+
+@meta_register.register(torch.where)
+def where_meta_info(*args, **kwargs) -> Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]:
+ """torch.where meta information generator
+
+ Returns:
+ Tuple[TrainCycleItem, TrainCycleItem, List[torch.Tensor]]: compute cost, memory cost and forward inputs
+ """
+
+ condition_tensor, x_tensor, y_tensor, output_tensor = [arg.data for arg in args]
+
+ # compute cost
+ fwd_compute_cost = 0
+
+ # if we need to broadcast the condition tensor, during backward we need to do a reduce_sum
+ bwd_compute_cost = 0
+ if x_tensor.shape != output_tensor.shape:
+ bwd_compute_cost += flop_mapping[torch.ops.aten.sum.dim_IntList]([output_tensor], [x_tensor])
+ if y_tensor.shape != output_tensor.shape:
+ bwd_compute_cost += flop_mapping[torch.ops.aten.sum.dim_IntList]([output_tensor], [y_tensor])
+
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost, bwd=bwd_compute_cost, total=fwd_compute_cost + bwd_compute_cost)
+
+ # memory cost
+ # during the forward phase, torch.where will allocate memory for output tensor and condition tensor
+ # during the backward phase, torch.where will allocate temp memory which is 3 times as output tensor, then generate
+ # gradient matrix for input x and input y, remove the temp memory and condition tensor generated in forward phase
+ # NOTE: currently in SPMD solver we always believe that there will be a new input tensor created in forward
+ fwd_mem_cost = MemoryCost(activation=activation_size([condition_tensor, x_tensor, y_tensor, output_tensor]))
+ bwd_mem_cost = MemoryCost(activation=activation_size([x_tensor, y_tensor]) - activation_size([condition_tensor]),
+ parameter=0,
+ temp=activation_size([output_tensor]) * 3 + activation_size([condition_tensor]) -
+ activation_size([x_tensor, y_tensor]),
+ buffer=0)
+
+ total_mem_cost = MemoryCost(activation=fwd_mem_cost.activation + bwd_mem_cost.activation,
+ parameter=fwd_mem_cost.parameter + bwd_mem_cost.parameter,
+ temp=fwd_mem_cost.temp + bwd_mem_cost.temp,
+ buffer=fwd_mem_cost.buffer + bwd_mem_cost.buffer)
+
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+
+ # store fwd_in, fwd_buffer, fwd_out
+ fwd_in = [condition_tensor]
+ fwd_buffer = []
+ fwd_out = [output_tensor]
+
+ return compute_cost, memory_cost, fwd_in, fwd_buffer, fwd_out
diff --git a/colossalai/auto_parallel/meta_profiler/registry.py b/colossalai/auto_parallel/meta_profiler/registry.py
new file mode 100644
index 0000000000000000000000000000000000000000..46350c4dd406691c344eb92a933636d6b029b8bd
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/registry.py
@@ -0,0 +1,32 @@
+__all__ = ['Registry']
+
+
+class Registry:
+
+ def __init__(self, name):
+ self.name = name
+ self.store = {}
+
+ def register(self, source):
+
+ def wrapper(func):
+ if isinstance(source, (list, tuple)):
+ # support register a list of items for this func
+ for element in source:
+ self.store[element] = func
+ else:
+ self.store[source] = func
+ return func
+
+ return wrapper
+
+ def get(self, source):
+ assert source in self.store, f'{source} not found in the {self.name} registry'
+ target = self.store[source]
+ return target
+
+ def has(self, source):
+ return source in self.store
+
+
+meta_register = Registry('meta')
diff --git a/colossalai/auto_parallel/meta_profiler/shard_metainfo.py b/colossalai/auto_parallel/meta_profiler/shard_metainfo.py
new file mode 100644
index 0000000000000000000000000000000000000000..0eee908b48b73d9d1cd5e0e35fbf50b8d844e3a6
--- /dev/null
+++ b/colossalai/auto_parallel/meta_profiler/shard_metainfo.py
@@ -0,0 +1,131 @@
+from typing import Callable, List
+
+import torch
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ MemoryCost,
+ OperationData,
+ OperationDataType,
+ ShardingStrategy,
+ StrategiesVector,
+ TrainCycleItem,
+)
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+from .constants import INPLACE_MODULE, INPLACE_OPS, NO_SAVE_ACTIVATION
+from .registry import meta_register
+
+__all__ = ['ShardMetaInfo']
+
+
+class ShardMetaInfo:
+ """ShardMetaInfo class
+ This class is used to store meta info based on sharding strategy and the given
+ target function.
+ """
+
+ def __init__(self, strategy: ShardingStrategy = None, target: Callable = None) -> None:
+ # compute cost of forward and backward computation
+ self.compute_cost: TrainCycleItem
+
+ # compute memory cost of forward and backward phase
+ self.memory_cost: TrainCycleItem
+
+ # list of input tensors
+ self.fwd_in: List[torch.Tensor]
+
+ # list of buffer tensors
+ self.fwd_buffer: List[torch.Tensor]
+
+ # list of output tensors
+ self.fwd_out: List[torch.Tensor]
+
+ # sharding strategy
+ self._strategy = strategy
+
+ # target function
+ self._target = target
+
+ # compute shard_metainfo if possible
+ if self._strategy is not None and self._target is not None:
+ self.compute_shard_metainfo()
+
+ @property
+ def strategy(self) -> ShardingStrategy:
+ return self._strategy
+
+ @property
+ def target(self) -> Callable:
+ return self._target
+
+ @strategy.setter
+ def strategy(self, strategy: ShardingStrategy) -> None:
+ self._strategy = strategy
+ if self._strategy is not None and self._target is not None:
+ self.compute_shard_metainfo()
+
+ @target.setter
+ def target(self, target: Callable) -> None:
+ self._target = target
+ if self._strategy is not None and self._target is not None:
+ self.compute_shard_metainfo()
+
+ def compute_sharded_opdata(self, operation_data: OperationData, sharding_spec: ShardingSpec):
+ """
+ Compute sharded opdata based on the given data and sharding spec.
+ """
+
+ if isinstance(sharding_spec, ShardingSpec):
+ op_data = OperationData(name=operation_data.name,
+ data=torch.zeros(sharding_spec.get_sharded_shape_per_device(), device="meta"),
+ type=operation_data.type,
+ logical_shape=operation_data.logical_shape)
+ elif isinstance(sharding_spec, (list, tuple)):
+ data = operation_data.data
+ assert isinstance(data, (list, tuple)), f"Data Should be list or tuple, but got {type(data)}."
+ assert len(data) == len(sharding_spec), f"Length of data and sharding spec should be the same."
+ sharded_data = []
+ for d, s in zip(data, sharding_spec):
+ sharded_data.append(torch.zeros(s.get_sharded_shape_per_device(), device="meta"))
+ op_data = OperationData(name=operation_data.name, data=sharded_data, type=operation_data.type)
+ else:
+ raise ValueError(f"Sharding spec should be ShardingSpec or list, but got {type(sharding_spec)}.")
+
+ return op_data
+
+ def compute_shard_metainfo(self):
+ """
+ Compute meta info based on sharding strategy and the given target function.
+ """
+ assert meta_register.has(self._target.__class__) or meta_register.has(self._target), \
+ f"Meta info for {self._target} is not registered."
+ if meta_register.has(self._target.__class__):
+ # module
+ meta_func = meta_register.get(self._target.__class__)
+
+ # check whether the target in the list that we don't need to save activation
+ save_fwd_in = self._target.__class__ not in NO_SAVE_ACTIVATION
+ else:
+ # function
+ meta_func = meta_register.get(self._target)
+
+ # check whether the target in the list that we don't need to save activation
+ save_fwd_in = self._target.__class__ not in NO_SAVE_ACTIVATION
+
+ # construct args for meta_func
+ args = [self.compute_sharded_opdata(k, v) for k, v in self._strategy.sharding_specs.items()]
+
+ # construct kwargs
+ if self.target in INPLACE_MODULE:
+ kwargs = {'inplace': self.target.inplace}
+ elif self.target in INPLACE_OPS:
+ kwargs = {'inplace': True}
+ else:
+ kwargs = {'inplace': False}
+
+ # compute metainfo with meta_func
+ self.compute_cost, self.memory_cost, self.fwd_in, self.fwd_buffer, self.fwd_out = meta_func(*args, **kwargs)
+
+ # process corner case for NO_SAVE_ACTIVATION
+ if not save_fwd_in:
+ self.fwd_in = []
diff --git a/colossalai/auto_parallel/offload/__init__.py b/colossalai/auto_parallel/offload/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/colossalai/auto_parallel/offload/amp_optimizer.py b/colossalai/auto_parallel/offload/amp_optimizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..a79e5006e7d2ac264f00b5a597e7b869f6f580eb
--- /dev/null
+++ b/colossalai/auto_parallel/offload/amp_optimizer.py
@@ -0,0 +1,177 @@
+from typing import Dict, Tuple
+from enum import Enum
+import torch
+from torch.optim import Optimizer
+
+from colossalai.logging import get_dist_logger
+from colossalai.nn.optimizer import ColossalaiOptimizer
+from colossalai.amp.naive_amp.grad_scaler import DynamicGradScaler
+from colossalai.utils import get_current_device
+
+from .base_offload_module import BaseOffloadModule
+from .region_manager import RegionManager
+from .region import Region
+
+
+class OptimState(Enum):
+ SCALED = 0
+ UNSCALED = 1
+
+class AMPOptimizer(ColossalaiOptimizer):
+
+ """
+ A wrapper for Optimizer.
+ Code reference: https://github.com/hpcaitech/ColossalAI/blob/main/colossalai/nn/optimizer/zero_optimizer.py
+
+ Args:
+ optimizer (Optimizer): An Optimizer instance.
+ module (BaseOffloadModule): A ``BaseOffloadModule`` instance.
+ initial_scale (float, optional): Initial scale used by DynamicGradScaler. Defaults to 2**16.
+ growth_factor (float, optional): growth_factor used by DynamicGradScaler. Defaults to 2.
+ backoff_factor (float, optional): backoff_factor used by DynamicGradScaler. Defaults to 0.5.
+ growth_interval (float, optional): growth_interval used by DynamicGradScaler. Defaults to 1000.
+ hysteresis (float, optional): hysteresis used by DynamicGradScaler. Defaults to 2.
+ min_scale (float, optional): Min scale used by DynamicGradScaler. Defaults to 1.
+ max_scale (int, optional): max_scale used by DynamicGradScaler. Defaults to 2**32.
+ norm_type (float, optional): norm_type used for `clip_grad_norm`.
+ """
+
+ def __init__(self,
+ optimizer: Optimizer,
+ module: BaseOffloadModule,
+ initial_scale: float = 2**16,
+ growth_factor: float = 2,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 1000,
+ hysteresis: int = 2,
+ min_scale: float = 1,
+ max_scale: float = 2**32,
+ clipping_norm: float = 0.0,
+ norm_type: float = 2.0):
+
+ super().__init__(optimizer)
+
+ self.module = module
+ self.optim_state = OptimState.UNSCALED
+ self.clipping_flag = clipping_norm > 0.0
+ self.max_norm = clipping_norm
+
+ self.region_manager: RegionManager = self.module.region_manager
+ self.param_to_range: Dict[torch.nn.Parameter, Tuple[int, int]] = dict()
+ self.param_to_region: Dict[torch.nn.Parameter, Region] = dict()
+
+ self.fp32_to_fp16_params: Dict[torch.Tensor, torch.nn.Parameter] = dict()
+
+ if self.clipping_flag:
+ assert norm_type == 2.0, "AMPOptimizer only supports L2 norm now"
+
+ self.__init__optimizer()
+
+ # Grad scaler
+ self.grad_scaler = DynamicGradScaler(initial_scale=initial_scale,
+ min_scale=min_scale,
+ growth_factor=growth_factor,
+ backoff_factor=backoff_factor,
+ growth_interval=growth_interval,
+ hysteresis=hysteresis,
+ max_scale=max_scale)
+ self._found_overflow: torch.Tensor = torch.zeros(1, dtype=torch.int64, device=get_current_device())
+ self._logger = get_dist_logger()
+
+ def _set_grad_ptr(self):
+ for group in self.param_groups:
+ for fake_param in group['params']:
+ region = self.param_to_region[fake_param]
+ begin, end = self.param_to_range[fake_param]
+
+ fake_param.data = region.cpu_grad[begin:end]
+ fake_param.grad = fake_param.data
+ fake_param.data = region.fp32_data[begin:end]
+
+ def _update_fp16_params(self):
+ none_tensor = torch.empty([0])
+ for group in self.param_groups:
+ for fake_param in group['params']:
+ assert fake_param.grad is None
+ fake_param.data = none_tensor
+ self.param_to_region[fake_param].cpu_grad = None
+
+ def _check_overflow(self):
+ # clear previous overflow record
+ self._found_overflow.fill_(self.module.overflow_counter.item())
+ return self._found_overflow.item() > 0
+
+ def _get_combined_scale(self):
+ loss_scale = 1
+
+ if self.optim_state == OptimState.SCALED:
+ loss_scale = self.loss_scale
+ self.optim_state = OptimState.UNSCALED
+
+ combined_scale = loss_scale
+
+ if combined_scale == 1:
+ return -1
+ else:
+ return combined_scale
+
+ @property
+ def loss_scale(self):
+ return self.grad_scaler.scale.item()
+
+ def zero_grad(self, *args, **kwargs):
+ self.module.overflow_counter = torch.cuda.IntTensor([0])
+ return self.optim.zero_grad(set_to_none=True)
+
+ def step(self, *args, **kwargs):
+ # Copy gradients from model params to main params.
+ self._set_grad_ptr()
+
+ found_inf = self._check_overflow()
+ if found_inf:
+ self.optim_state = OptimState.UNSCALED # no need to unscale grad
+ self.grad_scaler.update(found_inf) # update gradient scaler
+ self._logger.info(f'Found overflow. Skip step')
+ self.zero_grad() # reset all gradients
+ self._update_fp16_params()
+ return
+
+ # get combined scale. combined scale = loss scale * clipping norm
+ # so that gradient = gradient / combined scale
+ combined_scale = self._get_combined_scale()
+ self.grad_scaler.update(found_inf)
+
+ ret = self.optim.step(div_scale=combined_scale, *args, **kwargs)
+ self.zero_grad()
+ self._update_fp16_params()
+ return ret
+
+ def clip_grad_norm(self, model: torch.nn.Module, max_norm: float, norm_type: float = 2.0):
+ raise NotImplementedError
+
+ def backward(self, loss: torch.Tensor):
+ loss = self.loss_scale * loss
+ self.optim_state = OptimState.SCALED
+ self.module.backward(loss)
+
+ def __init__optimizer(self):
+
+ for group in self.optim.param_groups:
+ fake_params_list = list()
+
+ for param in group['params']:
+ region = self.region_manager.get_region(param)
+ fake_param = torch.nn.Parameter(torch.empty([0]))
+ self.param_to_range[fake_param] = region.param_to_range[param]
+ self.param_to_region[fake_param] = region
+ fake_params_list.append(fake_param)
+
+ # Reset existing state dict key to the new main param.
+ if param in self.optim.state:
+ self.optim.state[fake_param] = self.optim.state.pop(param)
+
+ group['params'] = fake_params_list
+
+ # Leverage state_dict() and load_state_dict() to
+ # recast preexisting per-param state tensors
+ self.optim.load_state_dict(self.optim.state_dict())
\ No newline at end of file
diff --git a/colossalai/auto_parallel/offload/base_offload_module.py b/colossalai/auto_parallel/offload/base_offload_module.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0c328e134ff5696ea2f8c17d5fc3468e4c891a2
--- /dev/null
+++ b/colossalai/auto_parallel/offload/base_offload_module.py
@@ -0,0 +1,107 @@
+from functools import partial
+from typing import Optional, Set
+
+import torch
+import torch.nn as nn
+
+from colossalai.nn.parallel.data_parallel import _cast_float
+from colossalai.zero.legacy.gemini.tensor_utils import free_storage
+
+from .region_manager import RegionManager
+from .util import GlobalRuntimeInfo
+
+
+class BaseOffloadModule:
+ """
+ BaseOffloadModule: A model wrapper for parameter offloading.
+
+ Args:
+ model (nn.Module): model to apply offloading.
+ region_manager (RegionManager): a ``RegionManager`` instance.
+ is_sync (bool): synchronous mode or not.
+ """
+
+ def __init__(self, model: nn.Module, region_manager: RegionManager, is_sync=True):
+
+ self.model = model
+ self.region_manager = region_manager
+ self.grad_hook_list = []
+ self.overflow_counter = torch.cuda.IntTensor([0])
+
+ self.grad_offload_stream = torch.cuda.current_stream() if is_sync else GlobalRuntimeInfo.d2h_stream
+
+ self._cast_buffers()
+
+ def register_grad_hook(self):
+ for p in self.model.parameters():
+ if p.requires_grad:
+ self.grad_hook_list.append(p.register_hook(partial(self.grad_handle, p)))
+
+ def remove_grad_hook(self):
+ for hook in self.grad_hook_list:
+ hook.remove()
+
+ def __call__(self, *args, **kwargs):
+ return self.forward(*args, **kwargs)
+
+ def _pre_forward(self):
+ self.register_grad_hook()
+ for region in self.region_manager.region_list:
+ region.cpu_grad = None
+
+ def forward(self, *args, **kwargs):
+ args, kwargs = _cast_float(args, torch.half), _cast_float(kwargs, torch.half)
+ self.model.zero_grad(set_to_none=True)
+ self._pre_forward()
+ outputs = self.model(*args, **kwargs)
+ return outputs
+
+ def backward(self, loss):
+ loss.backward()
+ self._post_backward()
+
+ def _post_backward(self):
+ torch.cuda.synchronize()
+ self.remove_grad_hook()
+
+ for p in self.model.parameters():
+ p.grad = None
+
+ GlobalRuntimeInfo().fwd_prefetch_event_map.clear()
+ GlobalRuntimeInfo().bwd_prefetch_event_map.clear()
+
+ def grad_handle(self, p, grad):
+ empty_grad = torch.empty_like(grad)
+ free_storage(empty_grad)
+ with torch._C.DisableTorchFunction():
+ region = self.region_manager.get_region(p)
+ region.copy_grad_to_region_slice(p, grad)
+ if region.can_release:
+ self.overflow_counter += region.has_inf_or_nan
+ master_stream = torch.cuda.current_stream()
+ with torch.cuda.stream(self.grad_offload_stream):
+ GlobalRuntimeInfo().d2h_stream.wait_stream(master_stream)
+ region.move_grad_to_cpu()
+ return empty_grad
+
+ def _cast_buffers(self):
+ for buffer in self.model.buffers():
+ buffer.data = buffer.cuda()
+
+ def parameters(self, recurse: bool = True):
+ return self.model.parameters(recurse)
+
+ def named_parameters(self, prefix: str = '', recurse: bool = True):
+ return self.model.named_parameters(prefix, recurse)
+
+ def named_buffers(self, prefix: str = '', recurse: bool = True):
+ return self.model.named_buffers(prefix, recurse)
+
+ def named_children(self):
+ return self.model.named_children()
+
+ def named_modules(self,
+ memo: Optional[Set[torch.nn.Module]] = None,
+ prefix: str = '',
+ remove_duplicate: bool = True):
+ return self.model.named_modules(memo, prefix, remove_duplicate)
diff --git a/colossalai/auto_parallel/offload/mem_optimize.py b/colossalai/auto_parallel/offload/mem_optimize.py
new file mode 100644
index 0000000000000000000000000000000000000000..d56166dea982288bdea160e1347c8ca3f67ed297
--- /dev/null
+++ b/colossalai/auto_parallel/offload/mem_optimize.py
@@ -0,0 +1,52 @@
+from typing import Dict
+
+import torch
+import torch.fx
+from torch.fx import GraphModule
+from torch.utils._pytree import tree_map
+
+from colossalai.fx import ColoTracer, is_compatible_with_meta
+from colossalai.fx.passes.meta_info_prop import MetaInfoProp
+
+from .base_offload_module import BaseOffloadModule
+from .region_manager import RegionManager
+from .runtime import runtime_asyn_offload_apply_pass, runtime_syn_offload_apply_pass
+from .util import GlobalRuntimeInfo, compute_act_peak_mem, compute_max_param_mem, compute_total_param_mem
+
+
+def memory_optimize(model: torch.nn.Module,
+ inps: Dict[str, torch.Tensor],
+ memory_budget: float = -1.0,
+ solver_name: str = 'asyn'):
+
+ model = model.cpu().half()
+ tracer = ColoTracer()
+ assert is_compatible_with_meta()
+ wrap_fn = lambda x: x.to("meta") if isinstance(x, torch.Tensor) else x
+ meta_args = tree_map(wrap_fn, inps)
+ graph = tracer.trace(model, meta_args=meta_args)
+ gm = GraphModule(model, graph, model.__class__.__name__)
+ interp = MetaInfoProp(gm)
+ interp.propagate(*meta_args.values())
+
+ region_manager = RegionManager(graph, solver_name=solver_name, memory_budget=memory_budget)
+ region_manager._build_regions()
+ GlobalRuntimeInfo().region_list = region_manager.region_list
+
+ act_peak_mem = compute_act_peak_mem(region_manager.region_list) / 1024**2
+ max_param_mem = compute_max_param_mem(region_manager.region_list) / 1024**2
+ total_param_mem = compute_total_param_mem(region_manager.region_list) / 1024**2
+ print(
+ f"act_peak_mem={act_peak_mem:.3f} MB | max_param_mem={max_param_mem:.3f} MB | total_param_mem={total_param_mem:.3f}"
+ )
+
+ if solver_name == 'syn':
+ gm = runtime_syn_offload_apply_pass(gm, region_manager.region_list)
+ elif solver_name == 'asyn':
+ gm = runtime_asyn_offload_apply_pass(gm, region_manager.region_list)
+ else:
+ raise TypeError(f"Unknown solver name {solver_name}!")
+
+ gm.recompile()
+ optimized_model = BaseOffloadModule(gm, region_manager, solver_name == 'syn')
+ return optimized_model
diff --git a/colossalai/auto_parallel/offload/region.py b/colossalai/auto_parallel/offload/region.py
new file mode 100644
index 0000000000000000000000000000000000000000..819ffbd96eb19098f168519ca6e3e0036fa3a638
--- /dev/null
+++ b/colossalai/auto_parallel/offload/region.py
@@ -0,0 +1,145 @@
+from typing import Dict, List, Tuple
+
+import torch
+from torch.fx import Node
+
+from colossalai.zero.legacy.gemini.tensor_utils import alloc_storage, free_storage
+
+
+class Region:
+ """
+ Region: A container owning a piece of contiguous nodes in the DNN computing graph.
+
+ Args:
+ r_id (int): the index of the region in the computing graph.
+ """
+
+ def __init__(self, r_id: int = 0) -> None:
+ self.r_id: int = r_id
+ self.fp16_params: List[torch.nn.Parameter] = []
+ self.param_size: int = 0
+ self.shared_rid: int = self.r_id
+
+ self.param_num: int = 0
+ self.grad_num: int = 0
+ self.fp16_data = None
+ self.fp32_data = None
+ self.cpu_grad = None
+ self.temp_fp32_data = None
+ self.param_to_range: Dict[torch.nn.Parameter, Tuple[int, int]] = dict()
+
+ self.need_offload: bool = False
+ self.is_syn: bool = False
+ self.nodes: List[Node] = []
+ self.fwd_prefetch_region = None
+ self.bwd_prefetch_region = None
+
+ self.in_mem_pool_flag: bool = False
+
+ @property
+ def can_release(self) -> bool:
+ """
+ Check if the region can be released.
+ """
+ return self.grad_num == self.param_num
+
+ @property
+ def has_inf_or_nan(self) -> bool:
+ """
+ Check if the grad of the region has inf or nan values on CUDA.
+ """
+ return torch.isinf(self.fp16_data).any() | torch.isnan(self.fp16_data).any()
+
+ def init_param_data(self, pre_alloc_tensor: torch.Tensor = None):
+ """
+ Map the parameters in the region to a contiguous memory space.
+ """
+
+ self.fp16_data = torch.zeros(self.param_num, dtype=torch.half, device='cuda')
+ offset = 0
+ for param in self.fp16_params:
+ param.data = param.data.cuda()
+ p_num = param.data.numel()
+ self.fp16_data[offset:offset + p_num].copy_(param.data.flatten())
+ param.data = self.fp16_data[offset:offset + p_num].view(param.data.shape)
+ self.param_to_range[param] = (offset, offset + p_num)
+ offset += p_num
+
+ self.fp32_data = self.fp16_data.float().cpu().pin_memory()
+ free_storage(self.fp16_data)
+ if self.in_mem_pool_flag and pre_alloc_tensor is not None:
+ self.fp16_data = pre_alloc_tensor
+
+ def move_param_to_cuda(self):
+ """
+ Move parameters from CPU to GPU.
+ It first moves float32 parameters to GPU and
+ then transforms float32 parameters to half-precision on the GPU.
+ The reason is that the performance of precision conversion on the CPU
+ is much slower than the data transfer overhead.
+ """
+
+ self.temp_fp32_data.copy_(self.fp32_data, non_blocking=True)
+ self.temp_fp32_data.record_stream(torch.cuda.current_stream())
+ if not self.in_mem_pool_flag:
+ alloc_storage(self.fp16_data)
+ self.fp16_data[:self.param_num].copy_(self.temp_fp32_data)
+ self.fp16_data.record_stream(torch.cuda.current_stream())
+
+ self.__update_params_ptr()
+
+ def move_grad_to_cpu(self):
+ """
+ Move gradients from GPU to CPU.
+ """
+
+ self.cpu_grad = torch.empty(self.param_num, dtype=torch.half, pin_memory=True)
+ self.cpu_grad.copy_(self.fp16_data[:self.param_num], non_blocking=True)
+ self.fp16_data.record_stream(torch.cuda.current_stream())
+ if not self.in_mem_pool_flag:
+ self.free_cuda_data()
+
+ self.grad_num = 0
+
+ def free_cuda_data(self):
+ free_storage(self.fp16_data)
+
+ # torch.cuda.empty_cache()
+
+ def copy_grad_to_region_slice(self, param: torch.nn.Parameter, data_slice: torch.Tensor) -> None:
+ """
+ Copy data slice to the memory space indexed by the input tensor in the region.
+
+ Args:
+ param (torch.nn.Parameter): the param used to retrieve meta information
+ data_slice (torch.Tensor): the tensor to be copied to the region
+ """
+
+ begin, end = self.param_to_range[param]
+ self.fp16_data[begin:end].copy_(data_slice.data.flatten())
+ param.data = self.fp16_data[begin:end].view(param.data.shape)
+
+ self.grad_num += data_slice.numel()
+
+ def split(self, cut_node_idx: int, cut_param_idx: int):
+ """
+ Split the region into two and return the latter.
+ """
+ new_reg = Region(r_id=self.r_id + 1)
+ new_reg.nodes = self.nodes[cut_node_idx:]
+ new_reg.fp16_params = self.fp16_params[cut_param_idx:]
+ for p in new_reg.fp16_params:
+ new_reg.param_size += p.data.numel() * p.data.element_size()
+ new_reg.param_num += p.data.numel()
+
+ self.nodes = self.nodes[:cut_node_idx]
+ self.fp16_params = self.fp16_params[:cut_param_idx]
+ self.param_size -= new_reg.param_size
+ self.param_num -= new_reg.param_num
+
+ return new_reg
+
+ def __update_params_ptr(self) -> None:
+ for param in self.fp16_params:
+ begin, end = self.param_to_range[param]
+ param.data = self.fp16_data[begin:end].view(param.data.shape)
diff --git a/colossalai/auto_parallel/offload/region_manager.py b/colossalai/auto_parallel/offload/region_manager.py
new file mode 100644
index 0000000000000000000000000000000000000000..30bfaf00d4939afadc3c2aaaec3f27ce70db4a20
--- /dev/null
+++ b/colossalai/auto_parallel/offload/region_manager.py
@@ -0,0 +1,526 @@
+from typing import List, Any, Dict, Tuple
+import torch
+from torch.fx import Graph, Node
+
+from .solver import SolverFactory
+from .training_simulator import TrainingSimulator
+from .region import Region
+from .util import NodeInfo
+
+
+class RegionManager:
+ """
+ RegionManager is used to construct and manage the offload plan for the model execution.
+
+ Args:
+ graph (Graph): a Graph object used for analysis and strategy generation.
+ solver_name (str): a solver name which specifies the preferences for plan searching.
+ memory_budget (float): the given memory budget.
+ cnode (List[str], optional): Common node List, should be the subset of input.
+ """
+
+ def __init__(self,
+ graph: Graph,
+ solver_name: str = 'asyn',
+ memory_budget: float = -1.0,
+ cnode: List[str] = None):
+
+ self.graph = graph
+ assert graph.owning_module is not None, 'The given graph is not associated with a owning_module'
+ self.root_module = self.graph.owning_module
+ self.nodes = list(graph.nodes)
+ self.cnode = cnode
+ self.only_param_ops = []
+ self.param_region_map: Dict[torch.nn.Parameter, Region] = dict()
+ self.shared_region_pairs: List[Tuple[Region, Region]] = list()
+ self.region_list: List[Region] = list()
+ self.rid_in_pool: List[int] = list()
+ self.mem_block_size: int = 0
+ self.memory_budget = memory_budget
+
+ self.solver_name = solver_name
+ self.require_pool: bool = solver_name == 'asyn'
+
+ self.reg_to_block: Dict[int, int] = dict()
+
+ def _build_regions(self):
+ """
+ 1. Pre-processing, mainly contains linearized computing graph and
+ merge smaller regions into larger ones.
+ 2. Construct a solver to search for an efficient offload strategy.
+ 3. Post-processing, mainly contains early region placement if using asynchronous mode,
+ and initialize region data.
+ """
+
+ self._pre_process()
+
+ solver_cls = SolverFactory.create(self.solver_name)
+ solver = solver_cls(self.region_list, self.memory_budget)
+ solver._call_solver()
+
+ self._post_process(solver.best_ts)
+
+ def _pre_process(self):
+
+ init_region_list = self._linearize_graph()
+
+ if len(self.shared_region_pairs) > 1:
+ raise NotImplementedError(
+ 'The current version only considers at most one pair of parameter sharing.')
+
+ elif len(self.shared_region_pairs) == 1:
+ shared_regs = self.shared_region_pairs[0]
+ assert shared_regs[0].shared_rid == shared_regs[1].r_id \
+ and shared_regs[1].shared_rid == shared_regs[0].r_id
+ fst_id = shared_regs[0].r_id
+ lst_id = shared_regs[1].r_id
+ regs_left_out = init_region_list[:fst_id + 1]
+ regs_right_out = init_region_list[lst_id:]
+ hold_regs = init_region_list[fst_id + 1:lst_id]
+ else:
+ regs_left_out = []
+ regs_right_out = []
+ hold_regs = init_region_list
+
+ self.mem_block_size = self._search_block_size(hold_regs)
+ hold_regs = self._merge_small_regions(hold_regs)
+
+ if self.require_pool:
+ for reg in hold_regs:
+ reg.in_mem_pool_flag = True
+ self.rid_in_pool.append(reg.r_id)
+
+ self.region_list.extend(regs_left_out)
+ self.region_list.extend(hold_regs)
+
+ for reg in regs_right_out:
+ reg.r_id = self.region_list[-1].r_id + 1
+ self.region_list[reg.shared_rid].shared_rid = reg.r_id
+ self.region_list.append(reg)
+
+ self._process_shared_region()
+
+ self.max_param_num = max([reg.param_num for reg in self.region_list])
+ self.memory_budget -= self.max_param_num * torch.tensor([], dtype=torch.float32).element_size()
+
+ def _post_process(self, ts: TrainingSimulator = None):
+ if self.require_pool:
+ self._early_region_placement(ts)
+ self._init_region_data()
+
+ def _early_region_placement(self, ts: TrainingSimulator):
+ """
+ Implemented the early region placement strategy to avoid GPU memory fragmentation.
+ It maps all region data into a contiguous memory space and
+ reuses the same memory space for regions that do not coexist.
+
+ Args:
+ ts (TrainingSimulator): the best training simulator, which records region execution flow.
+
+ Raises:
+ NotImplementedError: due to the naive implementation,
+ it may not find a suitable region placement strategy for the given execution flow.
+ """
+
+ reg_flow = torch.cat(
+ [ts.fwd_reg_flow, ts.bwd_reg_flow], dim=0)
+ mem_block_num = torch.max(
+ torch.sum(reg_flow[:, self.rid_in_pool], dim=1))
+ coexist_matrix = torch.logical_or(
+ ts.fwd_reg_flow, ts.bwd_reg_flow)
+
+ block_to_regs = {}
+ for block_idx in range(mem_block_num):
+ block_to_regs[block_idx] = []
+ for reg in self.region_list:
+ if reg.r_id in self.rid_in_pool:
+ cur_reg_appears = coexist_matrix[:, reg.r_id]
+ cur_reg_coexists = torch.sum(
+ coexist_matrix[cur_reg_appears], dim=0).bool()
+ for block_idx in range(mem_block_num):
+ if not any(cur_reg_coexists[block_to_regs[block_idx]]):
+ block_to_regs[block_idx].append(reg.r_id)
+ self.reg_to_block[reg.r_id] = block_idx
+ break
+
+ if reg.r_id not in self.reg_to_block:
+ raise NotImplementedError(
+ f'can not find a block from the memory pool to store parameters of the region')
+ self.memory_pool = torch.chunk(torch.zeros(int(
+ mem_block_num * self.mem_block_size / 2), dtype=torch.half, device='cuda'), chunks=int(mem_block_num))
+
+ def _merge_small_regions(self, orig_reg_list: List[Region]) -> List[Region]:
+ """
+ Merge smaller regions into larger ones for better bandwidth utilization and easier management.
+ It is inspired by Gemini.
+
+ Args:
+ orig_reg_list (List[Region]): original region list.
+
+ Returns:
+ List[Region]: region list after merging.
+ """
+
+ r_id = orig_reg_list[0].r_id
+ region = Region(r_id=r_id)
+ region_list = [region]
+
+ for orig_reg in orig_reg_list:
+ if region_list[-1].param_size + orig_reg.param_size > self.mem_block_size:
+ r_id += 1
+ region = Region(r_id=r_id)
+ region_list.append(region)
+ region.param_size += orig_reg.param_size
+ region.param_num += orig_reg.param_num
+ region.nodes.extend(orig_reg.nodes)
+ region.fp16_params.extend(orig_reg.fp16_params)
+ self.__update_param_region_map(orig_reg.fp16_params, region)
+
+ return region_list
+
+ def _search_block_size(self,
+ region_list: List[Region],
+ search_interval_byte: int = 1024,
+ search_range_byte: int = 128 * 1024 ** 2) -> int:
+ """
+ Search for a suitable memory block size.
+
+ Args:
+ region_list (List[Region]): region list.
+ search_interval_byte (int): searching interval in byte.
+ search_range_byte (int): searching range in byte.
+
+ Returns:
+ int: the best memory block size.
+ """
+
+ def _get_wasted_mem(size_list: List[int], blk_size: int):
+ """
+ Get wasted byte for a certain block size.
+ """
+ acc_wasted = 0
+ left = 0
+ for s in size_list:
+ if left + s > blk_size:
+ acc_wasted += blk_size - left
+ left = s
+ left += s
+ acc_wasted += blk_size - left
+ return acc_wasted
+
+ param_size_list = [
+ region.param_size for region in region_list if region.r_id == region.shared_rid]
+
+ start_size = max(param_size_list)
+ min_mem_waste = float('+inf')
+ best_block_size = start_size
+
+ for block_size in range(start_size, start_size + search_range_byte + 1, search_interval_byte):
+ temp_waste = 0
+ temp_waste += _get_wasted_mem(param_size_list, block_size)
+ if temp_waste < min_mem_waste:
+ min_mem_waste = temp_waste
+ best_block_size = block_size
+
+ return best_block_size
+
+ def _init_region_data(self):
+ """
+ Initialize region data, which maps the parameters in the region to a contiguous memory space.
+ """
+
+ self.temp_fp32_data = torch.zeros(self.max_param_num, device='cuda', dtype=torch.float32)
+
+ for region in self.region_list:
+ pre_alloc_tensor = None
+ if self.require_pool and region.r_id in self.rid_in_pool:
+ block_idx = self.reg_to_block[region.r_id]
+ pre_alloc_tensor = self.memory_pool[block_idx]
+
+ if region.r_id <= region.shared_rid:
+ region.init_param_data(pre_alloc_tensor)
+ else:
+ shared_region = self.region_list[region.shared_rid]
+ region.fp16_data = shared_region.fp16_data
+ region.fp32_data = shared_region.fp32_data
+ region.param_to_range = shared_region.param_to_range
+ region.temp_fp32_data = self.temp_fp32_data[:region.param_num].detach(
+ )
+
+ torch.cuda.empty_cache()
+
+ def _process_shared_region(self):
+ """
+ Special processing for the shared region, which uses GPT2 and Bert case as a priori knowledge.
+ """
+
+ if len(self.shared_region_pairs):
+ assert len(self.shared_region_pairs) <= 1
+ former_reg, latter_reg = self.shared_region_pairs[0]
+ assert latter_reg.param_num >= former_reg.param_num
+ embedding_node = former_reg.nodes[-1]
+ assert embedding_node.op == 'call_module' and isinstance(
+ self.root_module.get_submodule(embedding_node.target), torch.nn.Embedding)
+ if latter_reg.param_num > former_reg.param_num:
+ for idx, n in enumerate(latter_reg.nodes):
+ if (n.op == 'call_module' and isinstance(self.root_module.get_submodule(n.target),
+ torch.nn.Linear)) or \
+ (n.op == 'call_function' and n.target is torch.nn.functional.linear):
+ cut_node_idx = idx + 1
+ break
+ assert len(latter_reg.fp16_params) == 2
+ new_reg = latter_reg.split(cut_node_idx, 1)
+ for p in new_reg.fp16_params:
+ self.param_region_map[p] = new_reg
+ self.region_list.insert(new_reg.r_id, new_reg)
+ for reg in self.region_list[new_reg.r_id + 1:]:
+ reg.r_id += 1
+ latter_reg.shared_rid = former_reg.r_id
+ former_reg.shared_rid = latter_reg.r_id
+
+ def _linearize_graph(self) -> List[Region]:
+ """Linearizing the graph
+
+ Args:
+ graph (Graph): The computing graph to be optimized.
+
+ Returns:
+ List[Region]: each region contains the actual 'node' in linearized manner.
+
+ Remarks:
+ Do merge the inplace ops and shape-consistency ops into the previous node.
+ """
+
+ # List of target name that could be seen as common node
+ common_ops = ["getattr", "getitem", "size"]
+
+ def _is_cop(target: Any) -> bool:
+ """Check if an op could be seen as common node
+
+ Args:
+ target (Any): node target
+
+ Returns:
+ bool
+ """
+
+ if isinstance(target, str):
+ return target in common_ops
+ else:
+ return target.__name__ in common_ops
+
+ def _is_act(data: Any) -> bool:
+ """Check if an op could be seen as parameter computation start
+
+ Args:
+ data (Any): meta_data
+
+ Returns:
+ bool
+ """
+
+ label = False
+ if isinstance(data, torch.Tensor):
+ return True
+ elif isinstance(data, (tuple, list)):
+ for d in data:
+ label = label or _is_act(d)
+ return label
+
+ def _maybe_param_comp_start() -> bool:
+ """Check if an op could be seen as parameter computation start
+
+ Args:
+ n (Node): node
+
+ Returns:
+ bool
+ """
+
+ label = False
+ if n.op == "get_attr":
+ label = True
+ elif n.op == "call_module":
+ target = n.target
+ submod = self.root_module.get_submodule(target)
+ if (
+ len(list(submod.named_parameters(recurse=False))) != 0
+ or len(list(submod.named_buffers(recurse=False))) != 0
+ ):
+ label = True
+
+ return label and not sum([v for _, v in param_op_deps.items()])
+
+ def _is_param_comp_end() -> bool:
+ """Check if an op could be seen as parameter computation end
+
+ Args:
+ n (Node): node
+
+ Returns:
+ bool
+ """
+
+ def _is_inplace(n: Node):
+ """Get the inplace argument from ``torch.fx.Node``
+ """
+ inplace = False
+ if n.op == "call_function":
+ inplace = n.kwargs.get("inplace", False)
+ elif n.op == "call_module":
+ inplace = getattr(n.graph.owning_module.get_submodule(
+ n.target), "inplace", False)
+ return inplace
+
+ label = False
+
+ if n.op == "call_module":
+ target = n.target
+ submod = self.root_module.get_submodule(target)
+ if (
+ len(list(submod.named_parameters(recurse=False))) != 0
+ or len(list(submod.named_buffers(recurse=False))) != 0
+ ):
+ label = True
+
+ elif n.op == "call_function":
+ label = any(map(lambda x: x.name in self.only_param_ops, n.all_input_nodes)) and any(
+ map(lambda x: x.name not in self.only_param_ops and not _is_cop(n.target), n.all_input_nodes))
+
+ return label and not sum([v for _, v in param_op_deps.items()]) and not any(map(_is_inplace, n.users))
+
+ def _exception_node_handling():
+ # TODO meta info prop bug
+ if n.name.__contains__("transpose") and n.meta['fwd_out'][0].dim() <= 2:
+ n.meta['fwd_out'] = []
+
+ # make sure that item in cnode is valid
+ if self.cnode:
+ for name in self.cnode:
+ try:
+ assert next(node for node in self.graph.nodes if node.name == name).op == "placeholder", \
+ f"Common node {name} is not an input of the model."
+ except StopIteration:
+ raise ValueError(f"Common node name {name} not in graph.")
+ else:
+ self.cnode = []
+
+ node_id = 0
+ region_id = 0
+
+ param_op_deps = {}
+
+ deps = {}
+ region_list = []
+ region = Region(r_id=region_id)
+
+ act_n = None
+
+ for n in self.graph.nodes:
+ if n.op != "placeholder" and n.op != "output":
+ for n_par in n.all_input_nodes:
+ if n_par.op != "placeholder" and n_par.name not in self.cnode:
+ deps[n_par] -= 1
+ if n_par.op != "placeholder" and n_par.name in self.only_param_ops:
+ param_op_deps[n_par] -= 1
+
+ if act_n in region.nodes and _maybe_param_comp_start():
+ ns = []
+ border_n_idx = region.nodes.index(act_n)
+ if border_n_idx < len(region.nodes):
+ ns = region.nodes[border_n_idx + 1:]
+ region.nodes = region.nodes[:border_n_idx + 1]
+ region_list.append(region)
+ region_id += 1
+ region = Region(r_id=region_id)
+ region.nodes = ns
+
+ _exception_node_handling()
+ region.nodes.append(n)
+ self._set_node_and_region_info(node_id, n, region)
+ node_id += 1
+
+ # if the node could free all dependencies in graph
+ # we could begin a new region
+ if _is_param_comp_end():
+ region_list.append(region)
+ region_id += 1
+ region = Region(r_id=region_id)
+
+ # propagate common node attr if possible
+ if len(n.all_input_nodes) == len([node for node in n.all_input_nodes if node.name in self.cnode
+ ]) or _is_cop(n.target):
+ self.cnode.append(n.name)
+ else:
+ deps[n] = len(
+ [user for user in n.users if user.op != "output"])
+
+ # propagate param node attr if possible
+ if len(n.all_input_nodes) == len([node for node in n.all_input_nodes if node.name in self.only_param_ops
+ ]) or n.op == "get_attr":
+ self.only_param_ops.append(n.name)
+ param_op_deps[n] = len(
+ [user for user in n.users if user.op != "output"])
+
+ # record last activation node
+ if _is_act(n._meta_data):
+ act_n = n
+
+ if len(region.nodes):
+ region_list.append(region)
+
+ return region_list
+
+ def _set_node_and_region_info(self, node_id: int, cur_n: Node, cur_reg: Region):
+
+ cur_n.node_info = NodeInfo(node_id)
+
+ if cur_n.op == 'call_module':
+ target = cur_n.target
+ submod = self.root_module.get_submodule(target)
+ for p in list(submod.parameters(recurse=False)):
+
+ if p in self.param_region_map:
+ cur_reg.shared_rid = self.param_region_map[p].r_id
+ self.param_region_map[p].shared_rid = cur_reg.r_id
+ self.shared_region_pairs.append(
+ (self.param_region_map[p], cur_reg))
+ else:
+ self.param_region_map[p] = cur_reg
+
+ cur_reg.fp16_params.append(p)
+ cur_reg.param_num += p.data.numel()
+ cur_reg.param_size += p.data.numel() * p.data.element_size()
+
+ elif cur_n.op == "get_attr":
+ attr_itr = self.root_module
+ atoms = cur_n.target.split(".")
+ for atom in atoms:
+ attr_itr = getattr(attr_itr, atom)
+
+ if isinstance(attr_itr, torch.nn.Parameter):
+
+ if attr_itr in self.param_region_map:
+ cur_reg.shared_rid = self.param_region_map[attr_itr].r_id
+ self.param_region_map[attr_itr].shared_rid = cur_reg.r_id
+ self.shared_region_pairs.append(
+ (self.param_region_map[attr_itr], cur_reg))
+ else:
+ self.param_region_map[attr_itr] = cur_reg
+
+ cur_reg.fp16_params.append(attr_itr)
+ cur_reg.param_num += attr_itr.data.numel()
+ cur_reg.param_size += attr_itr.data.numel() * attr_itr.data.element_size()
+
+ def get_region(self, param: torch.nn.Parameter) -> Region:
+ """
+ Return the region owning the parameter.
+
+ Args:
+ param (torch.nn.Parameter): a torch parameter object
+ """
+ return self.param_region_map[param]
+
+ def __update_param_region_map(self, params: List[torch.nn.Parameter], region: Region):
+ for p in params:
+ self.param_region_map[p] = region
diff --git a/colossalai/auto_parallel/offload/runtime.py b/colossalai/auto_parallel/offload/runtime.py
new file mode 100644
index 0000000000000000000000000000000000000000..764ac608826b2860f3294ec9a5883745dfa10f57
--- /dev/null
+++ b/colossalai/auto_parallel/offload/runtime.py
@@ -0,0 +1,256 @@
+from typing import List
+
+import torch
+from torch.fx.node import Node
+
+from .region import Region
+from .util import GlobalRuntimeInfo, requires_upload_p_in_fwd
+
+
+class SynPreFwdPostBwdOP(torch.autograd.Function):
+ """
+ A customized prefetch and offload operation.
+
+ Args:
+ input_: input tensor.
+ fwd_info: information dict, which contains region indices
+ that need to be uploaded or freed during forward pass.
+ bwd_info: information dict, which contains region indices
+ that need to be uploaded during backward pass.
+ """
+
+ @staticmethod
+ def forward(ctx, input_, fwd_info, bwd_info):
+ ctx.bwd_info = bwd_info
+ d2h_rid = fwd_info.get('d2h_rid', None)
+ if d2h_rid is not None:
+ free_region = GlobalRuntimeInfo().region_list[d2h_rid]
+ assert isinstance(free_region, Region)
+ free_region.free_cuda_data()
+
+ h2d_rid = fwd_info.get('h2d_rid', None)
+ if h2d_rid is not None:
+ h2d_region = GlobalRuntimeInfo().region_list[h2d_rid]
+ assert isinstance(h2d_region, Region)
+ h2d_region.move_param_to_cuda()
+
+ return input_
+
+ @staticmethod
+ def backward(ctx, grad_output):
+
+ h2d_rid = ctx.bwd_info.get('h2d_rid', None)
+ if h2d_rid is not None:
+ pref_region = GlobalRuntimeInfo().region_list[h2d_rid]
+ assert isinstance(pref_region, Region)
+ pref_region.move_param_to_cuda()
+
+ return grad_output, None, None
+
+
+class AsynPreFwdPostBwdOP(torch.autograd.Function):
+ """
+ A customized prefetch and offload operation.
+
+ Args:
+ input_: input tensor.
+ fwd_info: information dict, which contains region indices
+ that need to be prefetched, waited, or freed during forward pass.
+ bwd_info: information dict, which contains region indices
+ that need to be prefetched or waited during backward pass.
+ """
+
+ @staticmethod
+ def forward(ctx, input_, fwd_info, bwd_info):
+ ctx.bwd_info = bwd_info
+
+ sync_rid = fwd_info.get('sync_rid', None)
+ if sync_rid is not None:
+ prefetch_event = GlobalRuntimeInfo().fwd_prefetch_event_map.get(sync_rid, None)
+ if prefetch_event:
+ prefetch_event.wait()
+
+ h2d_rid = fwd_info.get('h2d_rid', None)
+ if h2d_rid is not None:
+ pref_region = GlobalRuntimeInfo().region_list[h2d_rid]
+ assert isinstance(pref_region, Region)
+ master_stream = torch.cuda.current_stream()
+ with torch.cuda.stream(GlobalRuntimeInfo().h2d_stream):
+ GlobalRuntimeInfo().h2d_stream.wait_stream(master_stream)
+ pref_region.move_param_to_cuda()
+
+ prefetch_event = torch.cuda.Event()
+ prefetch_event.record(GlobalRuntimeInfo().h2d_stream)
+ GlobalRuntimeInfo().fwd_prefetch_event_map[h2d_rid] = prefetch_event
+
+ return input_
+
+ @staticmethod
+ def backward(ctx, grad_output):
+
+ sync_rid = ctx.bwd_info.get('sync_rid', None)
+ if sync_rid is not None:
+ wait_region = GlobalRuntimeInfo().region_list[sync_rid]
+ assert isinstance(wait_region, Region)
+ prefetch_event = GlobalRuntimeInfo().bwd_prefetch_event_map.get(sync_rid, None)
+ if prefetch_event:
+ prefetch_event.wait()
+ else:
+ wait_region.move_param_to_cuda()
+
+ h2d_rid = ctx.bwd_info.get('h2d_rid', None)
+ if h2d_rid is not None:
+ pref_region = GlobalRuntimeInfo().region_list[h2d_rid]
+ assert isinstance(pref_region, Region)
+ master_stream = torch.cuda.current_stream()
+ with torch.cuda.stream(GlobalRuntimeInfo().h2d_stream):
+ GlobalRuntimeInfo().h2d_stream.wait_stream(master_stream)
+ pref_region.move_param_to_cuda()
+
+ prefetch_event = torch.cuda.Event()
+ prefetch_event.record(GlobalRuntimeInfo().h2d_stream)
+ GlobalRuntimeInfo().bwd_prefetch_event_map[h2d_rid] = prefetch_event
+ return grad_output, None, None
+
+
+def convert_fwd_upload_bwd_offload_to_action(tensor, fwd_info, bwd_info):
+ '''
+ Convert Upload and Offload operation into runtime action.
+
+ Argument:
+ tensor(torch.Tensor): input tensor.
+ fwd_info(dict): information dict, which contains region indices
+ that need to be uploaded, or freed during forward pass.
+ bwd_info(dict): information dict, which contains region indices
+ that need to be uploaded during backward pass.
+ '''
+ with torch._C.DisableTorchFunction():
+ ret = SynPreFwdPostBwdOP.apply(tensor, fwd_info, bwd_info)
+ return ret
+
+
+def convert_fwd_prefetch_bwd_offload_to_action(tensor, fwd_info, bwd_info):
+ '''
+ Convert Prefetch and Offload operation into runtime action.
+
+ Argument:
+ tensor(torch.Tensor): input tensor.
+ fwd_info(dict): information dict, which contains region indices
+ that need to be prefetched, waited, or freed during forward pass.
+ bwd_info(dict): information dict, which contains region indices
+ that need to be prefetched or waited during backward pass.
+ '''
+ with torch._C.DisableTorchFunction():
+ ret = AsynPreFwdPostBwdOP.apply(tensor, fwd_info, bwd_info)
+ return ret
+
+
+def replace_node_users(orig_node: Node, inserted_node: Node, rep_user_nodes: List[Node] = None):
+ user_list = list(orig_node.users.keys())
+ if rep_user_nodes is not None:
+ user_list = rep_user_nodes
+ for user in user_list:
+ if user == inserted_node:
+ continue
+ new_args = list(user.args)
+ new_kwargs = dict(user.kwargs)
+ # the origin node may be a positional argument or key word argument of user node
+ if orig_node in new_args:
+ # substitute the origin node with offload_apply_node
+ new_args[new_args.index(orig_node)] = inserted_node
+ user.args = tuple(new_args)
+ elif str(orig_node) in new_kwargs:
+ # substitute the origin node with offload_apply_node
+ new_kwargs[str(orig_node)] = inserted_node
+ user.kwargs = new_kwargs
+
+
+def runtime_syn_offload_apply_pass(gm: torch.fx.GraphModule, region_list: List[Region]):
+ """
+ This pass is used to add the synchronous upload and offload spec apply node to the origin graph.
+ """
+ mod_graph = gm.graph
+ last_inp_node = tuple(mod_graph.nodes)[0]
+
+ for r_idx, region in enumerate(region_list):
+ # forward upload
+ fwd_info = {}
+ if requires_upload_p_in_fwd(region_list[region.shared_rid]):
+ fwd_info['h2d_rid'] = region.r_id
+
+ # forward offload
+ if r_idx > 0 and region_list[r_idx - 1].need_offload:
+ fwd_info['d2h_rid'] = r_idx - 1
+
+ bwd_info = {}
+ # backward upload
+ if r_idx > 0 and region_list[r_idx - 1].need_offload:
+ bwd_info['h2d_rid'] = region_list[r_idx - 1].r_id
+
+ if fwd_info or bwd_info:
+ with mod_graph.inserting_after(last_inp_node):
+ new_node = mod_graph.create_node('call_function',
+ convert_fwd_upload_bwd_offload_to_action,
+ args=(last_inp_node, fwd_info, bwd_info))
+ replace_node_users(last_inp_node, new_node)
+
+ last_inp_node = region.nodes[-1]
+
+ return gm
+
+
+def runtime_asyn_offload_apply_pass(gm: torch.fx.GraphModule, region_list: List[Region]):
+ """
+ This pass is used to add the asynchronous prefetch and offload spec apply node to the origin graph.
+ """
+ mod_graph = gm.graph
+
+ # upload parameters of the first region
+ last_inp_node = tuple(mod_graph.nodes)[0]
+ first_region_with_p = [region for region in region_list if region.param_size][0]
+ fwd_info = {"h2d_rid": first_region_with_p.r_id}
+ with mod_graph.inserting_after(last_inp_node):
+ upload_apply_node = mod_graph.create_node('call_function',
+ convert_fwd_upload_bwd_offload_to_action,
+ args=(last_inp_node, fwd_info, {}))
+ replace_node_users(last_inp_node, upload_apply_node)
+ last_inp_node = upload_apply_node
+
+ for r_idx, region in enumerate(region_list):
+ # forward prefetch
+ fwd_info = {}
+ if region.param_size:
+ fwd_info['sync_rid'] = region.r_id
+ fwd_prefetch_region = region.fwd_prefetch_region
+ if fwd_prefetch_region and requires_upload_p_in_fwd(region_list[fwd_prefetch_region.shared_rid]):
+ fwd_info['h2d_rid'] = fwd_prefetch_region.r_id
+
+ # forward offload
+ if r_idx > 0 and region_list[r_idx - 1].need_offload:
+ fwd_info['d2h_rid'] = r_idx - 1
+
+ bwd_info = {}
+ # backward prefetch
+ if r_idx > 0 and region_list[r_idx - 1].need_offload:
+ bwd_info['sync_rid'] = r_idx - 1
+ if r_idx > 0 and region_list[r_idx - 1].bwd_prefetch_region:
+ bwd_info['h2d_rid'] = region_list[r_idx - 1].bwd_prefetch_region.r_id
+
+ if fwd_info or bwd_info:
+ with mod_graph.inserting_after(last_inp_node):
+ new_node = mod_graph.create_node('call_function',
+ convert_fwd_prefetch_bwd_offload_to_action,
+ args=(last_inp_node, fwd_info, bwd_info))
+ replace_node_users(last_inp_node, new_node)
+
+ last_inp_node = region.nodes[-1]
+
+ if region.bwd_prefetch_region:
+ bwd_info = {'h2d_rid': region.bwd_prefetch_region.r_id}
+ with mod_graph.inserting_after(last_inp_node):
+ new_node = mod_graph.create_node('call_function',
+ convert_fwd_prefetch_bwd_offload_to_action,
+ args=(last_inp_node, {}, bwd_info))
+ replace_node_users(last_inp_node, new_node)
+ # gm.graph.print_tabular()
+ return gm
diff --git a/colossalai/auto_parallel/offload/solver.py b/colossalai/auto_parallel/offload/solver.py
new file mode 100644
index 0000000000000000000000000000000000000000..161f7ff868981d913047d7073bb144694ab68591
--- /dev/null
+++ b/colossalai/auto_parallel/offload/solver.py
@@ -0,0 +1,523 @@
+import time
+from typing import List, Dict, Type
+from abc import ABC, abstractmethod
+
+NOT_NVML = False
+try:
+ from pynvml import *
+except:
+ NOT_NVML = True
+
+import torch
+from torch.fx.node import Node
+from colossalai.utils.cuda import get_current_device
+
+from .training_simulator import TrainingSimulator, SynTrainingSimulator, AsynTrainingSimulator
+from .region import Region
+from .util import NodeInfo, NvDevicePower
+
+
+def benchmark_func(func, number=1, repeat=1, warmup=3):
+ """
+ benchmark data transfer cost.
+ """
+
+ for i in range(warmup):
+ func()
+
+ costs = []
+
+ for i in range(repeat):
+ torch.cuda.synchronize()
+ begin = time.time()
+ for i in range(number):
+ func()
+ torch.cuda.synchronize()
+ costs.append((time.time() - begin) / number)
+
+ return sum(costs) / len(costs)
+
+
+class Solver(ABC):
+ """
+ The parameter offload solver.
+
+ Args:
+ region_list (List[Region]): represents the linearized DNN computing graph.
+ memory_budget (float): the given memory budget.
+ error_factor (float): the error factor.
+ It is used to reduce the memory budget. Due to some errors in the estimation of peak memory and execution time.
+ """
+
+ def __init__(self,
+ region_list: List[Region],
+ memory_budget: float = -1.0,
+ error_factor: float = 0.95) -> None:
+
+ self.region_list = region_list
+
+ self.error_factor: float = error_factor
+ if memory_budget > 0:
+ self.memory_budget = memory_budget * self.error_factor
+ else:
+ self.memory_budget = torch.cuda.get_device_properties(
+ get_current_device()).total_memory * self.error_factor
+
+ self.link_to_bandwidth: Dict[str, Dict[float, float]] = self._profile_bandwidth()
+ self.comp_power: float = self._extract_computing_power()
+
+ @abstractmethod
+ def _call_solver(self):
+ raise NotImplementedError
+
+ @abstractmethod
+ def _try_to_offload(self, *args):
+ raise NotImplementedError
+
+ @abstractmethod
+ def _eval_one_choice(self, *args):
+ raise NotImplementedError
+
+ def _compute_offload_profit(self, total_mem_saving: float, peak_mem_saving: float, extra_cost: float):
+ """
+ Compute the profits of the offload strategies,
+ which packages the memory savings information for subsequent comparisons.
+
+ Args:
+ total_mem_saving (float): the total memory saving of the offload strategy.
+ peak_mem_saving (float): the peak memory saving of the offload strategy.
+ extra_cost (float): extra data transfer cost.
+
+ Returns:
+ tuple: profit information, the first term represents memory savings per unit of time.
+ """
+
+ if extra_cost == 0:
+ # means data transfer overhead can be completely overlapped
+ return (float('inf'), total_mem_saving, peak_mem_saving)
+ return (total_mem_saving / extra_cost, total_mem_saving, peak_mem_saving)
+
+ def _compare_profit(self, profit_a: tuple, profit_b: tuple) -> bool:
+ """
+ Compare the profits of the two offload strategies using the dictionary order algorithm.
+
+ Args:
+ profit_a (tuple): the profit of a offload strategy.
+ profit_b (tuple): the profit of another offload strategy.
+
+ Returns:
+ bool: whether profit_a is greater than profit_b.
+ """
+
+ for val1, val2 in zip(profit_a, profit_b):
+ if val1 != val2:
+ return val1 > val2
+ return False
+
+ def _update_state(self, best_ts: TrainingSimulator):
+ """
+ Update the solver state.
+ """
+
+ self.best_ts = best_ts
+ self._update_node_mem_info(best_ts.fwd_node_mem, best_ts.bwd_node_mem)
+
+ def _update_node_mem_info(self,
+ fwd_mem_info: Dict[Node, float],
+ bwd_mem_info: Dict[Node, float]):
+ """
+ Update the runtime memory information of the node.
+
+ Args:
+ fwd_mem_info (Dict[Node, float]): the runtime memory of each node in forward pass.
+ bwd_mem_info (Dict[Node, float]): the runtime memory of each node in backward pass.
+ """
+
+ for node, mem in fwd_mem_info.items():
+ assert hasattr(node, 'node_info') and isinstance(
+ node.node_info, NodeInfo)
+ node.node_info.runtime_fwd_mem = mem
+ for node, mem in bwd_mem_info.items():
+ assert hasattr(node, 'node_info') and isinstance(
+ node.node_info, NodeInfo)
+ node.node_info.runtime_bwd_mem = mem
+
+ def _extract_computing_power(self):
+ """
+ return the FP16 computing performance of the current NVIDIA GPU.
+
+ Raises:
+ TypeError: Unknown NVIDIA GPU device.
+ """
+
+ nvmlInit()
+ handle = nvmlDeviceGetHandleByIndex(0)
+ device_name = nvmlDeviceGetName(handle)
+ units = 1e12
+
+ if device_name.__contains__("RTX 3080"):
+ return NvDevicePower.RTX3080_FP16 * units
+ elif device_name.__contains__("RTX 3090"):
+ return NvDevicePower.RTX3090_FP16 * units
+ elif device_name.__contains__('V100'):
+ return NvDevicePower.V100_FP16 * units
+ elif device_name.__contains__("A100"):
+ return NvDevicePower.A100_FP16 * units
+ else:
+ raise TypeError(f'Unknown NVIDIA GPU device name {device_name}')
+
+ def _profile_bandwidth(self):
+ """
+ Profile the bidirectional communication bandwidth between CPU and GPU
+ using data volumes ranging from 1KB to 1GB.
+ """
+
+ print('profiling bandwidth ......')
+ link_to_bandwidth = {}
+ links = ['h2d', 'd2h']
+
+ for link in links:
+ t_size = 1024
+ size_to_bandwidth = {}
+
+ # from 1KB to 1GB
+ for i in range(21):
+ if link == 'h2d':
+ src_tensor = torch.ones(
+ int(t_size), dtype=torch.int8, pin_memory=True)
+ dst_tensor = torch.ones(
+ (int(t_size)), dtype=torch.int8, device='cuda')
+ elif link == 'd2h':
+ src_tensor = torch.ones(
+ int(t_size), dtype=torch.int8, device='cuda')
+ dst_tensor = torch.ones(
+ (int(t_size)), dtype=torch.int8, pin_memory=True)
+
+ def func():
+ dst_tensor.copy_(src_tensor)
+
+ size_to_bandwidth[t_size] = t_size / benchmark_func(func, number=5, repeat=3)
+ print(f'size: {t_size / 1024 ** 2:.3f} MB, '
+ f'{src_tensor.device.type}-to-{dst_tensor.device.type} '
+ f'bandwidth: {size_to_bandwidth[t_size] / 1024 ** 3:.3f} GB/s')
+
+ t_size *= 2
+
+ link_to_bandwidth[link] = size_to_bandwidth
+ return link_to_bandwidth
+
+
+class SynGreedySolver(Solver):
+
+ def __init__(self,
+ region_list: List[Region],
+ memory_budget: float = -1.0) -> None:
+ super().__init__(region_list, memory_budget)
+
+ self.best_ts: SynTrainingSimulator = None
+ self._init_state()
+
+ def _init_state(self):
+ """
+ Initialize the solver state when without offloading.
+ """
+
+ ts = SynTrainingSimulator(self.region_list, self.comp_power, self.link_to_bandwidth)
+ ts.execute()
+ self._update_state(ts)
+
+ def _call_solver(self):
+ """
+ Call the solver to search an efficient parameter offloading strategy for the linearized graph.
+ The solver adopts greedy algorithm.
+
+ Raises:
+ NotImplementedError: Unable to find a solution for the given memory budget.
+ """
+
+ print("search offloading strategy ......")
+ while self.best_ts.peak_mem > self.memory_budget:
+ offload_region = None
+ best_ts = None
+ max_profit = (0,)
+
+ # search which region should be offloaded,
+ # the last region does not need to be offloaded.
+ for region in self.region_list[:-1]:
+ if region.param_size and not region.need_offload:
+ temp_ts, profit = self._try_to_offload(region)
+ if self._compare_profit(profit, max_profit):
+ offload_region = region
+ max_profit = profit
+ best_ts = temp_ts
+
+ if offload_region is not None and best_ts is not None:
+ offload_region.need_offload = True
+ offload_region.is_syn = True
+ self._update_state(best_ts)
+ else:
+ raise NotImplementedError(
+ f"can't find the offload strategy met the memory budget {self.memory_budget / 1024 ** 2} MB, "
+ f"it needs {self.best_ts.peak_mem / 1024 ** 2:.3f} MB at least!")
+
+ def _call_solver_l2l(self):
+ """
+ The layer-wise offload strategy.
+ """
+
+ for region in self.region_list[:-1]:
+ region.need_offload = True
+ region.is_syn = True
+
+ def _try_to_offload(self, offload_region: Region):
+
+ # record previous information
+ orig_need_offload = offload_region.need_offload
+ assert not orig_need_offload
+ offload_region.need_offload = True
+
+ ts, profit = self._eval_one_choice(offload_region)
+
+ # restore previous information
+ offload_region.need_offload = orig_need_offload
+ return ts, profit
+
+ def _eval_one_choice(self, offload_region: Region):
+ """
+ Evaluate the profit of a strategy choice.
+
+ Args:
+ offload_region (Region): the offload region of current choice.
+
+ Returns:
+ SynTrainingSimulator: the training simulator corresponding to the current strategy.
+ tuple: contains memory saving and cost information of the current strategy.
+ """
+
+ ts = SynTrainingSimulator(self.region_list, self.comp_power, self.link_to_bandwidth)
+ ts.execute()
+
+ extra_comm_cost = 2.0 * \
+ ts._get_communication_overhead('h2d', offload_region.param_size)
+ # the shared region needs to be moved twice
+ if offload_region.r_id < offload_region.shared_rid:
+ extra_comm_cost *= 2.0
+ profit = self._compute_offload_profit(
+ ts.total_mem_saving, self.best_ts.peak_mem - ts.peak_mem, extra_comm_cost)
+
+ return ts, profit
+
+
+class AsynGreedySolver(Solver):
+
+ def __init__(self,
+ region_list: List[Region],
+ memory_budget: float = -1.0,
+ search_window_size: int = 3):
+ super().__init__(region_list, memory_budget)
+
+ self.search_window_size = search_window_size
+ # Records the prefetch execution location of the offloaded region
+ self.region_to_region_map = {}
+ self.best_ts: AsynTrainingSimulator = None
+
+ self._init_state()
+
+ def _init_state(self):
+ """
+ Initialize the solver state when without offloading.
+ """
+
+ ts = AsynTrainingSimulator(self.region_list, self.comp_power, self.link_to_bandwidth)
+ ts.execute()
+ self._update_state(ts)
+ print("init peak memory", self.best_ts.peak_mem / 1024 ** 2, "MB")
+
+ def _call_solver(self):
+ """
+ Call the solver to search an efficient parameter offloading strategy for the linearized graph.
+ The solver adopts greedy algorithm.
+
+ Raises:
+ NotImplementedError: Unable to find a solution for the given memory budget.
+ """
+
+ print("search for offloading strategy ......")
+ # Records the prefetch execution location of the offloaded region
+ region_to_region_map = {}
+ while self.best_ts.peak_mem > self.memory_budget:
+ region_to_offload = None
+ max_offload_profit = (0,)
+ best_offl_ts = None
+
+ # search which region should be offloaded,
+ # the last region does not need to be offloaded
+ for region in self.region_list[:-1]:
+ if region.param_size and not region.need_offload:
+ max_prefetch_profit = (0,)
+ best_pref_ts = None
+
+ # search when to prefetch the region offloaded
+ for host_region in self.region_list[region.r_id + 1:region.r_id + 1 + self.search_window_size]:
+ if host_region.bwd_prefetch_region is not None:
+ continue
+
+ temp_ts, profit = self._try_to_offload(
+ host_region, region)
+
+ if self._compare_profit(profit, max_prefetch_profit):
+ region_to_region_map[region.r_id] = host_region
+ max_prefetch_profit = profit
+ best_pref_ts = temp_ts
+ if profit[0] == float('inf'):
+ break
+
+ if self._compare_profit(max_prefetch_profit, max_offload_profit):
+ region_to_offload = region
+ max_offload_profit = max_prefetch_profit
+ best_offl_ts = best_pref_ts
+
+ if (region_to_offload is not None) and (best_offl_ts is not None):
+ region_to_offload.need_offload = True
+ if region_to_region_map[region_to_offload.r_id] == region_to_offload:
+ region_to_offload.is_syn = True
+ else:
+ region_to_region_map[region_to_offload.r_id].bwd_prefetch_region = region_to_offload
+ self.region_to_region_map[region_to_offload.r_id] = region_to_region_map[region_to_offload.r_id]
+
+ self._update_state(best_offl_ts)
+
+ elif self.region_to_region_map.__len__() > 0:
+ self._repair_strategy()
+ else:
+ raise NotImplementedError(
+ f"can't find the offload strategy met the memory budget {self.memory_budget / 1024 ** 2} MB, "
+ f"it needs {self.best_ts.peak_mem / 1024 ** 2:.3f} MB at least!")
+
+ region_to_region_map.clear()
+
+ def _try_to_offload(self, host_region: Region, offload_region: Region):
+ """
+ Attempts to offload the region and prefetch it in backward pass.
+ """
+
+ # record previous information
+ orig_prefetch = host_region.bwd_prefetch_region
+ orig_is_syn = offload_region.is_syn
+ orig_need_offload = offload_region.need_offload
+
+ if host_region == offload_region:
+ offload_region.is_syn = True
+ else:
+ host_region.bwd_prefetch_region = offload_region
+ offload_region.need_offload = True
+
+ ts, profit = self._eval_one_choice()
+
+ # restore previous information
+ host_region.bwd_prefetch_region = orig_prefetch
+ offload_region.is_syn = orig_is_syn
+ offload_region.need_offload = orig_need_offload
+
+ return ts, profit
+
+ def _try_convert_to_syn_upload(self, host_region: Region, offload_region: Region):
+ """
+ Attempts to convert asynchronous prefetch into synchronous upload operations.
+ """
+
+ # record previous information
+ orig_prefetch = host_region.bwd_prefetch_region
+ orig_is_syn = offload_region.is_syn
+ assert orig_prefetch is not None and not orig_is_syn
+
+ host_region.bwd_prefetch_region = None
+ offload_region.is_syn = True
+
+ ts, profit = self._eval_one_choice()
+
+ # restore previous information
+ host_region.bwd_prefetch_region = orig_prefetch
+ offload_region.is_syn = orig_is_syn
+
+ return ts, profit
+
+ def _repair_strategy(self):
+ """
+ Repair offload strategy.
+ It attempts to convert asynchronous prefetch into synchronous upload operations and selects the best one.
+ The repair process does not end until peak memory is reduced or there is no asynchronous prefetch operation.
+ """
+ print("repair strategy ......")
+
+ peak_mem_saving = 0
+ while len(self.region_to_region_map) and peak_mem_saving <= 0:
+
+ max_profit = (0,)
+ best_ts = None
+ undo_host_region = None
+ undo_offload_region = None
+
+ for offload_region_id, host_region in self.region_to_region_map.items():
+ offload_region = self.region_list[offload_region_id]
+ assert host_region.bwd_prefetch_region == offload_region
+ assert offload_region.need_offload
+ assert not offload_region.is_syn
+
+ ts, profit = self._try_convert_to_syn_upload(host_region,
+ offload_region)
+
+ if self._compare_profit(profit, max_profit):
+ undo_host_region = host_region
+ undo_offload_region = offload_region
+ max_profit = profit
+ best_ts = ts
+
+ if best_ts is None:
+ raise NotImplementedError('repair error!')
+
+ assert not undo_offload_region.is_syn
+ undo_offload_region.is_syn = True
+ undo_host_region.bwd_prefetch_region = None
+
+ peak_mem_saving = self.best_ts.peak_mem - best_ts.peak_mem
+
+ self._update_state(best_ts)
+ self.region_to_region_map.pop(undo_offload_region.r_id)
+
+ return best_ts
+
+ def _eval_one_choice(self):
+ """
+ Evaluate the profit of a strategy choice.
+
+ Returns:
+ AsynTrainingSimulator: the training simulator corresponding to the current strategy.
+ tuple: contains memory saving and cost information of the current strategy.
+ """
+
+ ts = AsynTrainingSimulator(self.region_list, self.comp_power, self.link_to_bandwidth)
+ ts.execute()
+
+ extra_comm_cost = max(ts.iter_end_time - self.best_ts.iter_end_time, 0)
+ profit = self._compute_offload_profit(
+ ts.total_mem_saving, self.best_ts.peak_mem - ts.peak_mem, extra_comm_cost)
+
+ return ts, profit
+
+
+class SolverFactory:
+ solvers: Dict[str, Type[Solver]] = {
+ 'syn': SynGreedySolver,
+ 'asyn': AsynGreedySolver
+ }
+
+ @staticmethod
+ def create(solver_name: str) -> Type[Solver]:
+ if solver_name not in SolverFactory.solvers:
+ raise TypeError(f"Unknown parameter offload policy {solver_name}")
+ return SolverFactory.solvers[solver_name]
+
+ @staticmethod
+ def get_solver_names():
+ return tuple(SolverFactory.solvers.keys())
diff --git a/colossalai/auto_parallel/offload/training_simulator.py b/colossalai/auto_parallel/offload/training_simulator.py
new file mode 100644
index 0000000000000000000000000000000000000000..de58023ec2d6a4b4247ad838f4e9c2e9a56da692
--- /dev/null
+++ b/colossalai/auto_parallel/offload/training_simulator.py
@@ -0,0 +1,458 @@
+import bisect
+from typing import List, Dict
+from collections import OrderedDict
+from abc import ABC, abstractmethod
+
+from torch.fx.node import Node
+
+from .region import Region
+from .util import *
+
+
+@dataclass
+class ExecutionPeriod:
+ start_time: float = 0
+ end_time: float = 0
+
+
+class TrainingSimulator(ABC):
+ """
+ The Training Simulator is used to simulate the training process.
+ It records computation, communication, and runtime memory during forward and backward passes.
+
+ Args:
+ region_list (List[Region]): represents the linearized DNN computing graph.
+ comp_power (float): the NVIDIA GPU FP16 computing power.
+ link_to_bw (Dict[str, Dict[float, float]]): communication links and the corresponding bandwidth.
+ """
+
+ def __init__(self,
+ region_list: List[Region],
+ comp_power: float,
+ link_to_bw: Dict[str, Dict[float, float]]) -> None:
+ self.region_list = region_list
+ self.region_num = len(region_list)
+
+ self.runtime_mem: int = 0
+ self.peak_mem: int = 0
+ self.total_mem_saving: int = 0
+
+ self.fwd_node_mem: Dict[Node, float] = {}
+ self.bwd_node_mem: Dict[Node, float] = {}
+
+ # Node dependencies in backward pass
+ self.bwd_node_deps: Dict[Node, int] = {}
+
+ self.comp_power: float = comp_power
+ self.link_to_bandwidth: Dict[str, Dict[float, float]] = link_to_bw
+
+ @abstractmethod
+ def execute(self):
+ raise NotImplementedError
+
+ @abstractmethod
+ def _eval_fwd_mem_per_region(self, region: Region):
+ raise NotImplementedError
+
+ @abstractmethod
+ def _eval_bwd_mem_per_region(self, region: Region):
+ raise NotImplementedError
+
+ def _get_bandwidth(self, link: str, comm_volumn: float) -> float:
+ """
+ Get the data transfer bandwidth.
+
+ Args:
+ link (str): the data transfer link.
+ comm_volumn (float): the amount of data transferred.
+
+ Returns:
+ float: the data transfer bandwidth.
+ """
+
+ assert len(self.link_to_bandwidth)
+ if link not in self.link_to_bandwidth:
+ raise TypeError(f"Unknown data transfer link {link}")
+
+ # size_list = sorted(list(map(float, self.link_to_bandwidth[link].keys())))
+ size_list = sorted(self.link_to_bandwidth[link].keys())
+ d_idx = bisect.bisect_left(size_list, comm_volumn)
+ return self.link_to_bandwidth[link][size_list[d_idx]]
+
+ def _get_communication_overhead(self, link: str, comm_volumn: float) -> float:
+ return comm_volumn / self._get_bandwidth(link, comm_volumn)
+
+ def _get_computing_overhead(self, flop: float) -> float:
+ return flop / self.comp_power
+
+
+class SynTrainingSimulator(TrainingSimulator):
+
+ def __init__(self,
+ region_list: List[Region],
+ comp_power: float,
+ link_to_bw: Dict[str, Dict[float, float]]) -> None:
+ super().__init__(region_list, comp_power, link_to_bw)
+
+ def execute(self):
+ """
+ Simulate synchronous training process.
+ """
+
+ for reg in self.region_list:
+ self._eval_fwd_mem_per_region(reg)
+
+ for reg in self.region_list.__reversed__():
+ self._eval_bwd_mem_per_region(reg)
+
+ def _eval_fwd_mem_per_region(self, region: Region):
+ """
+ Evaluate the runtime and peak memory when the forward execution reaches the current region.
+ """
+
+ # upload parameters of the current region
+ if requires_upload_p_in_fwd(self.region_list[region.shared_rid]):
+ self.runtime_mem += region.param_size
+
+ for node in region.nodes:
+ self.runtime_mem += calculate_fwd_tmp(node) + \
+ calculate_fwd_out(node)
+ self.fwd_node_mem[node] = self.runtime_mem
+ self.peak_mem = max(self.runtime_mem, self.peak_mem)
+ self.total_mem_saving += node.node_info.runtime_fwd_mem - self.runtime_mem
+
+ if region.need_offload:
+ self.runtime_mem -= region.param_size
+
+ def _eval_bwd_mem_per_region(self, region: Region):
+ """
+ Evaluate the runtime and peak memory when the backward execution reaches the current region.
+ """
+
+ # upload parameters of the current region
+ if region.need_offload:
+ self.runtime_mem += region.param_size
+
+ # add the gradient of the parameter
+ if region.r_id < region.shared_rid:
+ # gradient accumulation is required for shared parameters
+ self.runtime_mem += 2.0 * region.param_size
+ else:
+ self.runtime_mem += region.param_size
+
+ for node in region.nodes.__reversed__():
+
+ self.runtime_mem -= calculate_fwd_out(node)
+ self.runtime_mem += node.meta['bwd_mem_tmp'] + \
+ node.meta['bwd_mem_out']
+ self.peak_mem = max(self.runtime_mem, self.peak_mem)
+
+ # The memory savings of a node may be negative due to parameter prefetch.
+ self.total_mem_saving += node.node_info.runtime_bwd_mem - self.runtime_mem
+ self.bwd_node_mem[node] = self.runtime_mem
+
+ self.runtime_mem -= (node.meta['bwd_mem_tmp'] +
+ calculate_fwd_tmp(node))
+
+ # free bwd_mem_out
+ self.bwd_node_deps[node] = len(node.all_input_nodes)
+ for user_node in node.users:
+ if user_node in self.bwd_node_deps:
+ self.bwd_node_deps[user_node] -= 1
+ if self.bwd_node_deps[user_node] <= 0:
+ self.runtime_mem -= user_node.meta['bwd_mem_out']
+
+ if self.runtime_mem < 0:
+ raise ValueError(f"region id: {region.r_id}, node name: {node.name}, "
+ f"runtime_mem: {self.runtime_mem / 1024 ** 2:.3f}MB ---"
+ f"runtime memory computed less than 0, which is miscalculated!")
+
+ # release parameter and offload gradient in region
+ if region.r_id == region.shared_rid:
+ self.runtime_mem -= 2.0 * region.param_size
+ elif region.r_id < region.shared_rid:
+ self.runtime_mem -= 3.0 * region.param_size
+ elif self.region_list[region.shared_rid].need_offload:
+ self.runtime_mem -= region.param_size
+
+
+class AsynTrainingSimulator(TrainingSimulator):
+
+ def __init__(self,
+ region_list: List[Region],
+ comp_power: float,
+ link_to_bw: Dict[str, Dict[float, float]]) -> None:
+ super().__init__(region_list, comp_power, link_to_bw)
+
+ self.iter_end_time: int = 0
+ # the last computation execution period
+ self.last_comp: ExecutionPeriod = ExecutionPeriod(
+ start_time=0, end_time=0)
+ # the last parameter prefetch execution period
+ self.last_h2d: ExecutionPeriod = ExecutionPeriod(
+ start_time=0, end_time=0)
+ # the last gradient offload execution period
+ self.last_d2h: ExecutionPeriod = ExecutionPeriod(
+ start_time=0, end_time=0)
+ # the forward computation execution period of the region
+ self.fwd_reg_to_comp: OrderedDict[int, ExecutionPeriod] = OrderedDict()
+ # the forward parameter prefetch execution period of the region
+ self.fwd_reg_to_pref: OrderedDict[int, ExecutionPeriod] = OrderedDict()
+ # the backward computation execution period of the region
+ self.bwd_reg_to_comp: OrderedDict[int, ExecutionPeriod] = OrderedDict()
+ # the backward parameter prefetch execution period of the region
+ self.bwd_reg_to_pref: OrderedDict[int, ExecutionPeriod] = OrderedDict()
+ # the gradient offload execution period of the region
+ # which is divided into those that are waiting and those that have been released
+ self.bwd_reg_to_offl_waiting: OrderedDict[int,
+ ExecutionPeriod] = OrderedDict()
+ self.bwd_reg_to_offl_freed: OrderedDict[int,
+ ExecutionPeriod] = OrderedDict()
+ # the region buffer, which records regions that are offloaded but not released
+ self.reg_buffer_to_free: List[int] = []
+
+ # node dependencies in backward pass
+ self.bwd_node_deps: Dict[Node, int] = {}
+
+ # the region execution flow,
+ # where fwd_reg_flow[i,j] denotes whether the parameters of j-th region are in the GPU
+ # when the execution reaches the i-th region.
+ self.fwd_reg_flow = torch.zeros(
+ (self.region_num, self.region_num)).bool()
+ self.bwd_reg_flow = torch.zeros(
+ (self.region_num, self.region_num)).bool()
+
+ def execute(self):
+ """
+ Simulate asynchronous training process.
+ In forward pass, parameter prefetching is advanced by one region.
+ In backward pass, parameter prefetching is executed at the specified location,
+ and gradient offloading is urgent.
+ """
+
+ for reg in self.region_list:
+ if reg.param_size and reg.r_id < self.region_num - 1:
+ for nr in self.region_list[reg.r_id + 1:]:
+ if nr.param_size and requires_upload_p_in_fwd(self.region_list[nr.shared_rid]):
+ reg.fwd_prefetch_region = nr
+ break
+ self._eval_fwd_cost_per_region(reg)
+ self._eval_fwd_mem_per_region(reg)
+
+ for reg in self.region_list.__reversed__():
+ self._eval_bwd_cost_per_region(reg)
+ self._eval_bwd_mem_per_region(reg)
+
+ # release remaining grads
+ for reg_id, offl_exec in self.bwd_reg_to_offl_waiting.items():
+ self.bwd_reg_to_offl_freed[reg_id] = offl_exec
+ self.runtime_mem -= self.region_list[reg_id].param_size
+ self.bwd_reg_to_offl_waiting.clear()
+
+ self.iter_end_time = max(
+ self.last_comp.end_time, self.last_d2h.end_time)
+
+ def _insert_h2d_exec(self, region: Region, is_fwd: bool = True):
+ """
+ Insert parameter prefetch execution period of the current region to the end of the h2d stream
+ """
+
+ pref_start_time = max(self.last_h2d.end_time, self.last_comp.end_time)
+ pref_end_time = pref_start_time + \
+ 2.0 * self._get_communication_overhead('h2d', region.param_size)
+ pref_ep = ExecutionPeriod(
+ start_time=pref_start_time, end_time=pref_end_time)
+ if is_fwd:
+ self.fwd_reg_to_pref[region.r_id] = pref_ep
+ else:
+ self.bwd_reg_to_pref[region.r_id] = pref_ep
+ self.last_h2d = pref_ep
+
+ def _insert_comp_exec(self, region: Region, is_fwd: bool = True):
+ """
+ Insert computation execution period of the current region to the end of the computing stream
+ """
+
+ if is_fwd:
+ reg_to_comp = self.fwd_reg_to_comp
+ reg_to_pref = self.fwd_reg_to_pref
+ flop_key = 'fwd_flop'
+ else:
+ reg_to_comp = self.bwd_reg_to_comp
+ reg_to_pref = self.bwd_reg_to_pref
+ flop_key = 'bwd_flop'
+ comp_start_time = max(self.last_comp.end_time, reg_to_pref.get(
+ region.r_id, ExecutionPeriod(0, 0)).end_time)
+ comp_end_time = comp_start_time + \
+ sum([self._get_computing_overhead(node.meta.get(flop_key, 0))
+ for node in region.nodes])
+ comp_ep = ExecutionPeriod(
+ start_time=comp_start_time, end_time=comp_end_time)
+ reg_to_comp[region.r_id] = comp_ep
+ self.last_comp = comp_ep
+
+ def _insert_d2h_exec(self, region: Region):
+ """
+ Insert gradient offload execution period of the current region to the end of the d2h stream
+ """
+
+ offl_start_time = max(self.last_d2h.end_time, self.last_comp.end_time)
+ offl_end_time = offl_start_time + \
+ self._get_communication_overhead('d2h', region.param_size)
+ offl_ep = ExecutionPeriod(
+ start_time=offl_start_time, end_time=offl_end_time)
+ self.bwd_reg_to_offl_waiting[region.r_id] = offl_ep
+ self.last_d2h = offl_ep
+
+ def _eval_fwd_cost_per_region(self, region: Region):
+ """
+ Evaluate computation and communication execution period of the region in forward pass.
+ """
+
+ # upload parameters of the first region
+ if region.r_id == 0:
+ self._insert_h2d_exec(region)
+
+ # prefetch parameters of the next region
+ fwd_prefetch_region = region.fwd_prefetch_region
+ if fwd_prefetch_region and requires_upload_p_in_fwd(self.region_list[fwd_prefetch_region.shared_rid]):
+ self._insert_h2d_exec(fwd_prefetch_region)
+
+ # execute computation
+ self._insert_comp_exec(region)
+
+ def _eval_fwd_mem_per_region(self, region: Region):
+ """
+ Evaluate the runtime and peak memory when the forward execution reaches the current region.
+ """
+
+ # upload parameters of the current region
+ if region.r_id <= 0:
+ self.runtime_mem += region.param_size
+ self.fwd_reg_flow[region.r_id, region.r_id] = True
+ else:
+ self.fwd_reg_flow[region.r_id] = self.fwd_reg_flow[region.r_id - 1]
+ self.fwd_reg_flow[region.r_id,
+ self.reg_buffer_to_free] = False
+ self.reg_buffer_to_free.clear()
+
+ # prefetch parameters of the next region
+ fwd_prefetch_region = region.fwd_prefetch_region
+ if fwd_prefetch_region and requires_upload_p_in_fwd(self.region_list[fwd_prefetch_region.shared_rid]):
+ self.runtime_mem += fwd_prefetch_region.param_size
+ self.fwd_reg_flow[region.r_id,
+ fwd_prefetch_region.r_id] = True
+
+ for node in region.nodes:
+ self.runtime_mem += calculate_fwd_tmp(node) + \
+ calculate_fwd_out(node)
+ self.peak_mem = max(self.runtime_mem, self.peak_mem)
+
+ self.total_mem_saving += node.node_info.runtime_fwd_mem - self.runtime_mem
+ self.fwd_node_mem[node] = self.runtime_mem
+
+ if region.need_offload:
+ self.runtime_mem -= region.param_size
+
+ assert len(
+ self.reg_buffer_to_free) <= 1, f'{len(self.reg_buffer_to_free)}'
+ self.reg_buffer_to_free.append(region.r_id)
+
+ def _eval_bwd_cost_per_region(self, region: Region):
+ """
+ Evaluate computation and communication execution period of the region in backward pass.
+ """
+
+ # upload parameters of the current region
+ if region.is_syn:
+ assert region.need_offload
+ self._insert_h2d_exec(region, is_fwd=False)
+
+ # prefetch parameters of the region choiced, which is parallel to computation
+ if region.bwd_prefetch_region is not None:
+ self._insert_h2d_exec(region.bwd_prefetch_region, is_fwd=False)
+
+ # execute computation
+ self._insert_comp_exec(region, is_fwd=False)
+
+ # offload gradient
+ if requires_offload_g_in_bwd(region):
+ self._insert_d2h_exec(region)
+
+ assert len(self.reg_buffer_to_free) == 0
+ for reg_id, offl_exec in self.bwd_reg_to_offl_waiting.items():
+ if offl_exec.end_time >= self.last_comp.start_time:
+ break
+ self.reg_buffer_to_free.append(reg_id)
+ self.bwd_reg_to_offl_freed[reg_id] = offl_exec
+
+ for reg_id in self.reg_buffer_to_free:
+ self.bwd_reg_to_offl_waiting.pop(reg_id)
+
+ def _eval_bwd_mem_per_region(self, region: Region):
+ """
+ Evaluate the runtime and peak memory when the backward execution reaches the current region.
+ """
+
+ if region.r_id + 1 < self.region_num:
+ self.bwd_reg_flow[region.r_id] = self.bwd_reg_flow[region.r_id + 1]
+ else:
+ self.bwd_reg_flow[region.r_id] = self.fwd_reg_flow[-1]
+ self.bwd_reg_flow[region.r_id,
+ self.reg_buffer_to_free] = False
+
+ # free gradients in the buffer
+ while len(self.reg_buffer_to_free):
+ reg_id = self.reg_buffer_to_free.pop(0)
+ self.runtime_mem -= self.region_list[reg_id].param_size
+
+ # upload parameters of the current region
+ if region.is_syn:
+ self.runtime_mem += region.param_size
+ self.bwd_reg_flow[region.r_id, region.r_id] = True
+
+ # prefetch parameters of the region choiced
+ bwd_prefetch_region = region.bwd_prefetch_region
+ if bwd_prefetch_region:
+ self.runtime_mem += bwd_prefetch_region.param_size
+ self.bwd_reg_flow[region.r_id,
+ bwd_prefetch_region.r_id] = True
+
+ # add the gradient of the parameter
+ if region.r_id < region.shared_rid:
+ # gradient accumulation is required for shared parameters
+ self.runtime_mem += 2.0 * region.param_size
+ else:
+ self.runtime_mem += region.param_size
+
+ for node in region.nodes.__reversed__():
+
+ self.runtime_mem -= calculate_fwd_out(node)
+ self.runtime_mem += node.meta['bwd_mem_tmp'] + \
+ node.meta['bwd_mem_out']
+ self.peak_mem = max(self.runtime_mem, self.peak_mem)
+
+ # The memory savings of a node may be negative due to parameter prefetch.
+ self.total_mem_saving += node.node_info.runtime_bwd_mem - self.runtime_mem
+
+ self.bwd_node_mem[node] = self.runtime_mem
+
+ self.runtime_mem -= (node.meta['bwd_mem_tmp'] +
+ calculate_fwd_tmp(node))
+
+ # free bwd_mem_out
+ self.bwd_node_deps[node] = len(node.all_input_nodes)
+ for user_node in node.users:
+ if user_node in self.bwd_node_deps:
+ self.bwd_node_deps[user_node] -= 1
+ if self.bwd_node_deps[user_node] <= 0:
+ self.runtime_mem -= user_node.meta['bwd_mem_out']
+
+ if self.runtime_mem < 0:
+ raise ValueError(f"region id: {region.r_id}, node name: {node.name}, "
+ f"runtime_mem: {self.runtime_mem / 1024 ** 2:.3f}MB ---"
+ f"runtime memory computed less than 0, which is miscalculated!")
+
+ # release parameters of the region
+ if requires_release_p_in_bwd(self.region_list[region.shared_rid]):
+ self.runtime_mem -= region.param_size
diff --git a/colossalai/auto_parallel/offload/util.py b/colossalai/auto_parallel/offload/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b010512cc9c99b6dff4acf2e7bd97d12d8146c0
--- /dev/null
+++ b/colossalai/auto_parallel/offload/util.py
@@ -0,0 +1,99 @@
+from dataclasses import dataclass
+from typing import List
+
+import torch
+
+from colossalai.context.singleton_meta import SingletonMeta
+from colossalai.fx.profiler import calculate_fwd_out, calculate_fwd_tmp
+
+from .region import Region
+
+
+@dataclass
+class NodeInfo:
+ node_id: int = 0
+ runtime_fwd_mem: float = 0
+ runtime_bwd_mem: float = 0
+
+
+class NvDevicePower:
+ """
+ NVIDIA GPU computing performance (TFLOPs).
+ """
+
+ RTX3080_FP16 = 70
+ RTX3080_FP32 = 34.1
+
+ RTX3090_FP16 = 71
+ RTX3090_FP32 = 35.7
+
+ V100_FP16 = 31.4
+ V100_FP32 = 15.7
+
+ A100_FP16 = 78
+ A100_FP32 = 19.5
+
+
+class GlobalRuntimeInfo(metaclass=SingletonMeta):
+
+ def __init__(self):
+ self.h2d_stream = torch.cuda.Stream()
+ self.d2h_stream = torch.cuda.Stream()
+ self.fwd_prefetch_event_map = {}
+ self.bwd_prefetch_event_map = {}
+ self.region_list = []
+
+
+def compute_act_peak_mem(region_list: List[Region]) -> float:
+ act_peak_mem = 0
+ runtime_mem = 0
+ # forward
+ for region in region_list:
+ for node in region.nodes:
+ runtime_mem = runtime_mem + \
+ calculate_fwd_tmp(node) + calculate_fwd_out(node)
+ act_peak_mem = max(runtime_mem, act_peak_mem)
+ # backward
+ bwd_deps = {}
+ for region in region_list.__reversed__():
+ for node in region.nodes.__reversed__():
+ runtime_mem -= calculate_fwd_out(node)
+ runtime_mem = runtime_mem + \
+ node.meta['bwd_mem_tmp'] + node.meta['bwd_mem_out']
+
+ act_peak_mem = max(runtime_mem, act_peak_mem)
+
+ runtime_mem = runtime_mem - \
+ node.meta['bwd_mem_tmp'] - calculate_fwd_tmp(node)
+
+ # free bwd_mem_out
+ bwd_deps[node] = len(node.all_input_nodes)
+ for user_node in node.users:
+ if user_node in bwd_deps:
+ bwd_deps[user_node] -= 1
+ if bwd_deps[user_node] <= 0:
+ runtime_mem -= user_node.meta['bwd_mem_out']
+
+ return act_peak_mem
+
+
+def compute_max_param_mem(region_list: List[Region]) -> float:
+ return max(region.param_size for region in region_list)
+
+
+def compute_total_param_mem(region_list: List[Region]) -> float:
+ return sum(region.param_size for region in region_list if region.r_id <= region.shared_rid)
+
+
+def requires_upload_p_in_fwd(shared_reg: Region):
+ return (shared_reg.r_id >= shared_reg.shared_rid) or (shared_reg.r_id < shared_reg.shared_rid
+ and shared_reg.need_offload)
+
+
+def requires_release_p_in_bwd(shared_reg: Region):
+ return (shared_reg.r_id >= shared_reg.shared_rid) or (shared_reg.r_id < shared_reg.shared_rid
+ and shared_reg.need_offload)
+
+
+def requires_offload_g_in_bwd(region: Region):
+ return region.param_size and (region.r_id <= region.shared_rid)
diff --git a/colossalai/auto_parallel/passes/__init__.py b/colossalai/auto_parallel/passes/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/colossalai/auto_parallel/passes/comm_metainfo_pass.py b/colossalai/auto_parallel/passes/comm_metainfo_pass.py
new file mode 100644
index 0000000000000000000000000000000000000000..ffda58e0689f1b0e7fa962dd328eee7453e559ec
--- /dev/null
+++ b/colossalai/auto_parallel/passes/comm_metainfo_pass.py
@@ -0,0 +1,113 @@
+from typing import Dict
+
+import torch
+from torch.fx import GraphModule
+from torch.fx.node import Node
+
+from colossalai.auto_parallel.meta_profiler import ShardMetaInfo
+from colossalai.auto_parallel.passes.runtime_apply_pass import runtime_apply, runtime_comm_spec_apply
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, TrainCycleItem
+from colossalai.tensor.comm_spec import CommSpec
+from colossalai.tensor.shape_consistency import ShapeConsistencyManager
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+shape_consistency_manager = ShapeConsistencyManager()
+
+
+def _construct_shard_meta_info(node: Node, origin_sharding_spec: ShardingSpec,
+ target_sharding_spec: ShardingSpec) -> ShardMetaInfo:
+ # get comm_action_sequence and total_cost from shape_consistency_manager
+ _, comm_action_sequence, total_cost = shape_consistency_manager.shape_consistency(
+ origin_sharding_spec, target_sharding_spec)
+
+ meta_info = ShardMetaInfo()
+ # NOTE: the cost in shape_consistency_manager.mem_cost is the count in number of numel
+ # get mem cost for ShardMetaInfo
+ mem_cost = shape_consistency_manager.mem_cost(comm_action_sequence)
+ # extract user that has _meta_data and extract element length
+ input_node = next(n for n in node._input_nodes if hasattr(n, '_meta_data'))
+ element_length = input_node._meta_data.element_size()
+
+ mem_cost.fwd.activation *= element_length
+ mem_cost.fwd.temp *= element_length
+ mem_cost.bwd.activation *= element_length
+ mem_cost.bwd.temp *= element_length
+ mem_cost.total.activation *= element_length
+
+ meta_info.memory_cost = mem_cost
+
+ # get computation cost for ShardMetaInfo
+ meta_info.compute_cost = TrainCycleItem(total_cost['forward'] * element_length,
+ total_cost['backward'] * element_length,
+ total_cost['total'] * element_length)
+
+ # get tensor shape for ShardMetaInfo
+ origin_sharding_spec: ShardingSpec
+ target_sharding_spec: ShardingSpec
+ input_shape = origin_sharding_spec.get_sharded_shape_per_device()
+ output_shape = target_sharding_spec.get_sharded_shape_per_device()
+
+ meta_info.fwd_in = [torch.rand(input_shape, device='meta')]
+ meta_info.fwd_buffer = []
+ meta_info.fwd_out = [torch.rand(output_shape, device='meta')]
+
+ return meta_info
+
+
+def _runtime_apply_meta_info(node: Node, origin_spec_dict, sharding_spec_dict) -> ShardMetaInfo:
+ """
+ This method is used to construct `MetaInto` for shape consistency node
+ """
+
+ # extract node index and user node index
+ args = node.args
+ node_index, user_node_index = args[3], args[4]
+ origin_sharding_spec, target_sharding_spec = origin_spec_dict[node_index], sharding_spec_dict[node_index][
+ user_node_index]
+
+ return _construct_shard_meta_info(node, origin_sharding_spec, target_sharding_spec)
+
+
+def _runtime_comm_spec_apply_meta_info(node: Node, comm_actions_dict: Dict) -> ShardMetaInfo:
+ # extract node_index and op_data_name
+ node_index, op_data_name = node.args[2], node.args[3]
+
+ comm_action = comm_actions_dict[node_index][op_data_name]
+ if isinstance(comm_action.comm_spec, CommSpec):
+ # this case is for all_reduce, there will be no memory cost
+ meta_info = ShardMetaInfo()
+ meta_info.memory_cost = TrainCycleItem(MemoryCost(), MemoryCost(), MemoryCost)
+ output_node = next(n for n in node.users if hasattr(n, '_meta_data'))
+ element_length = output_node._meta_data.element_size()
+
+ total_cost = comm_action.comm_spec.get_comm_cost()
+ meta_info.compute_cost = TrainCycleItem(total_cost['forward'] * element_length,
+ total_cost['backward'] * element_length,
+ total_cost['total'] * element_length)
+
+ input_shape = output_shape = comm_action.comm_spec.sharding_spec.get_sharded_shape_per_device()
+ meta_info.fwd_in = [torch.rand(input_shape, device='meta')]
+ meta_info.fwd_buffer = []
+ meta_info.fwd_out = [torch.rand(output_shape, device='meta')]
+ else:
+ # this case will be handled by shape consistency manager
+ origin_sharding_spec, target_sharding_spec = comm_action.comm_spec['src_spec'], comm_action.comm_spec[
+ 'tgt_spec']
+ meta_info = _construct_shard_meta_info(node, origin_sharding_spec, target_sharding_spec)
+
+ return meta_info
+
+
+def comm_metainfo_pass(gm: GraphModule, sharding_spec_dict: Dict, origin_spec_dict: Dict,
+ comm_actions_dict: Dict) -> GraphModule:
+ """
+ The method manages all the metainfo of the communication node (run_time_apply, runtime_comm_spec_apply) in the graph.
+ """
+ for node in gm.graph.nodes:
+ if node.target == runtime_apply:
+ setattr(node, 'best_strategy_info', _runtime_apply_meta_info(node, origin_spec_dict, sharding_spec_dict))
+ elif node.target == runtime_comm_spec_apply:
+ setattr(node, 'best_strategy_info', _runtime_comm_spec_apply_meta_info(node, comm_actions_dict))
+ else:
+ pass
+ return gm
diff --git a/colossalai/auto_parallel/passes/constants.py b/colossalai/auto_parallel/passes/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..485a87492f4ce5fca3f2401108e285449f931788
--- /dev/null
+++ b/colossalai/auto_parallel/passes/constants.py
@@ -0,0 +1,13 @@
+import torch
+
+OUTPUT_SAVED_OPS = [torch.nn.functional.relu, torch.nn.functional.softmax, torch.flatten]
+
+OUTPUT_SAVED_MOD = [
+ torch.nn.ReLU,
+ torch.nn.Softmax,
+]
+
+# SHAPE_ARGUMENT_OPS contains node with (input, *shape) style args.
+# This list could be extended if any other method has the same
+# argument style as view and reshape.
+SHAPE_ARGUMENT_OPS = [torch.Tensor.view, torch.Tensor.reshape, torch.reshape]
diff --git a/colossalai/auto_parallel/passes/meta_info_prop.py b/colossalai/auto_parallel/passes/meta_info_prop.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc0960483980b9242af531d4b309a9c74f735c16
--- /dev/null
+++ b/colossalai/auto_parallel/passes/meta_info_prop.py
@@ -0,0 +1,165 @@
+import uuid
+from dataclasses import asdict
+from typing import List
+
+import torch
+import torch.fx
+from torch.fx import GraphModule
+from torch.fx.node import Node
+
+from colossalai.auto_parallel.meta_profiler import ShardMetaInfo
+from colossalai.auto_parallel.passes.constants import OUTPUT_SAVED_MOD, OUTPUT_SAVED_OPS
+from colossalai.fx._compatibility import compatibility
+from colossalai.fx.profiler import GraphInfo
+
+
+def _normalize_tuple(x):
+ if not isinstance(x, tuple):
+ return (x,)
+ return x
+
+
+@compatibility(is_backward_compatible=False)
+class MetaInfoProp:
+
+ def __init__(self, module: GraphModule) -> None:
+ self.module = module
+ self.func_dict = {
+ 'placeholder': self.placeholder_handler,
+ 'get_attr': self.get_attr_handler,
+ 'output': self.output_handler,
+ 'call_function': self.node_handler,
+ 'call_module': self.node_handler,
+ 'call_method': self.node_handler,
+ }
+
+ def _set_data_ptr(self, x):
+ """
+ Set uuid to tensor
+ """
+ if isinstance(x, torch.Tensor):
+ if not x.data_ptr():
+ data_ptr = uuid.uuid4()
+ x.data_ptr = lambda: data_ptr
+
+ def _is_inplace(self, node: Node):
+ """
+ Check if the node is inplace operation.
+ """
+ if node.op == 'call_module':
+ return node.graph.owning_module.get_submodule(node.target).__class__ in OUTPUT_SAVED_MOD
+ elif node.op == "call_function":
+ return node.target in OUTPUT_SAVED_OPS
+ return False
+
+ def run(self) -> GraphModule:
+ """
+ Run the meta information propagation pass on the module.
+ """
+ for node in self.module.graph.nodes:
+ node: Node
+ self.func_dict[node.op](node)
+
+ @compatibility(is_backward_compatible=False)
+ def placeholder_handler(self, node: Node) -> None:
+ """
+ Handle the placeholder node.
+ """
+ graph_info = GraphInfo()
+ out = _normalize_tuple(getattr(node, '_meta_data', None))
+ graph_info.fwd_out = list(out) if out[0] is not None else []
+ node.meta = {**asdict(graph_info)}
+
+ @compatibility(is_backward_compatible=False)
+ def get_attr_handler(self, node: Node) -> None:
+ """
+ Handle the get_attr node.
+ """
+ graph_info = GraphInfo()
+ node.meta = {**asdict(graph_info)}
+
+ @compatibility(is_backward_compatible=False)
+ def output_handler(self, node: Node) -> None:
+ """
+ Handle the output node.
+ """
+ graph_info = GraphInfo()
+ output_tensors = []
+ for par in node._input_nodes:
+ if par.meta:
+ output_tensors += par.meta["fwd_out"]
+ graph_info.fwd_in = output_tensors
+ node.meta = {**asdict(graph_info)}
+
+ @compatibility(is_backward_compatible=False)
+ def node_handler(self, node: Node) -> None:
+ """
+ Handle other kind of nodes
+ """
+ assert hasattr(node, 'best_strategy_info'), f"Cannot find best_strategy_info in node {node}, {node.op}"
+ graph_info = GraphInfo()
+ meta_info = node.best_strategy_info
+ meta_info: ShardMetaInfo
+
+ # set data_ptr for input_tensor in ShardMetaInfo class
+ input_tensors: List[torch.Tensor] = meta_info.fwd_in
+ buffer_tensors: List[torch.Tensor] = meta_info.fwd_buffer
+ output_tensors: List[torch.Tensor] = meta_info.fwd_out
+
+ if self._is_inplace(node):
+ # inplace operation will not create new tensor, and it only has one parent node
+ # TODO: Verify this observation
+ # set data_ptr for input_tensor, buffer_tensor and output_tensor of current node
+ parent_node = list(node._input_nodes.keys())[0]
+ parent_tensor = parent_node.meta.get("fwd_out")[0]
+ parent_tensor: torch.Tensor
+ for tensor in input_tensors:
+ tensor.data_ptr = parent_tensor.data_ptr
+ for tensor in buffer_tensors:
+ tensor.data_ptr = parent_tensor.data_ptr
+ for tensor in output_tensors:
+ tensor.data_ptr = parent_tensor.data_ptr
+
+ else:
+ for par in node._input_nodes:
+ # set data_ptr for the input_tensor of current node from the output_tensor of its parent node
+ for tensor in par.meta.get("fwd_out", []):
+ tensor: torch.Tensor
+ target_input_tensor = next(
+ (x for x in input_tensors if not x.data_ptr() and x.shape == tensor.shape), None)
+ if target_input_tensor is not None:
+ target_input_tensor.data_ptr = tensor.data_ptr
+
+ # set data_ptr for tensor in input_tensor that is not set
+ for tensor in input_tensors:
+ if not tensor.data_ptr():
+ self._set_data_ptr(tensor)
+
+ # set data_ptr for buffer_tensor
+ for tensor in buffer_tensors:
+ self._set_data_ptr(tensor)
+
+ # set data_ptr for output_tensor
+ for tensor in output_tensors:
+ self._set_data_ptr(tensor)
+
+ # attach them to graph_info
+ graph_info.fwd_in = input_tensors
+ graph_info.fwd_tmp = buffer_tensors
+ graph_info.fwd_out = output_tensors
+
+ # fetch other memory informations
+ memory_cost = meta_info.memory_cost
+ graph_info.fwd_mem_tmp = memory_cost.fwd.temp
+ graph_info.fwd_mem_out = memory_cost.fwd.activation
+ graph_info.bwd_mem_tmp = memory_cost.bwd.temp
+ graph_info.bwd_mem_out = memory_cost.bwd.activation
+
+ # fetch flop information
+ # here we use fwd_time and bwd_time to deal with the case that
+ # communication cost is a float
+ compute_cost = meta_info.compute_cost
+ graph_info.fwd_time = compute_cost.fwd
+ graph_info.bwd_time = compute_cost.bwd
+
+ node.meta = {**asdict(graph_info)}
diff --git a/colossalai/auto_parallel/passes/runtime_apply_pass.py b/colossalai/auto_parallel/passes/runtime_apply_pass.py
new file mode 100644
index 0000000000000000000000000000000000000000..a473bb6e973de453f47c7bc16c2e83b8e7fe86df
--- /dev/null
+++ b/colossalai/auto_parallel/passes/runtime_apply_pass.py
@@ -0,0 +1,256 @@
+from copy import deepcopy
+from typing import Dict, List
+
+import torch
+from torch.fx.node import Node
+
+from colossalai._analyzer.fx.node_util import MetaInfo
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommAction,
+ CommType,
+ OperationData,
+ OperationDataType,
+ TrainCycleItem,
+)
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.tensor.comm_spec import CommSpec
+from colossalai.tensor.shape_consistency import ShapeConsistencyManager
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+shape_consistency_manager = ShapeConsistencyManager()
+
+
+def runtime_apply(node: Node, origin_dict: Dict, input_dict: Dict, node_index: int, user_node_index: int):
+ """
+ This method will be invoked during runtime to do the shape consistency, which make sure the activations is converted into
+ the user node expected form.
+ """
+ origin_sharding_spec = origin_dict[node_index]
+ target_sharding_spec = input_dict[node_index][user_node_index]
+ return shape_consistency_manager.apply_for_autoparallel_runtime(node, origin_sharding_spec, target_sharding_spec)
+
+
+def runtime_apply_for_iterable_object(node: Node, origin_dict: Dict, input_dict: Dict, node_index: int,
+ user_node_index: int):
+ """
+ This method will be invoked during runtime to do the shape consistency, which makes sure the activations in type of tuple or list
+ is converted into the user node expected form.
+ """
+ rst = []
+ for index, (origin_sharding_spec,
+ target_sharding_spec) in enumerate(zip(origin_dict[node_index],
+ input_dict[node_index][user_node_index])):
+ rst.append(
+ shape_consistency_manager.apply_for_autoparallel_runtime(node[index], origin_sharding_spec,
+ target_sharding_spec))
+ rst = type(node)(rst)
+ return rst
+
+
+def runtime_comm_spec_apply(tensor: torch.Tensor, comm_actions_dict: Dict, node_index: int, op_data_name: str):
+ """
+ This method will be invoked during runtime to apply the comm action following the instruction of comm spec.
+ """
+ comm_action = comm_actions_dict[node_index][op_data_name]
+ if isinstance(comm_action.comm_spec, CommSpec):
+ rst = comm_action.comm_spec.covert_spec_to_action(tensor)
+ else:
+ origin_sharding_spec = comm_action.comm_spec['src_spec']
+ tgt_sharding_spec = comm_action.comm_spec['tgt_spec']
+ rst = shape_consistency_manager.apply_for_autoparallel_runtime(tensor, origin_sharding_spec, tgt_sharding_spec)
+ return rst
+
+
+def _preprocess_graph(nodes: List[Node]):
+ """
+ This method is used to extract all the placeholders with sharding information,
+ and mapping the nodes into the index of the origin graph.
+ """
+ # mapping the node into the origin graph index
+ node_to_index_dict = {}
+ index = 0
+ for node in nodes:
+ if node.target == 'sharding_spec_convert_dict':
+ input_dict_node = node
+ continue
+ if node.target == 'origin_node_sharding_spec_dict':
+ origin_dict_node = node
+ continue
+ if node.target == 'comm_actions_dict':
+ comm_actions_dict_node = node
+ continue
+ if not hasattr(node, 'best_strategy'):
+ continue
+ node_to_index_dict[node] = index
+ index += 1
+
+ return input_dict_node, origin_dict_node, comm_actions_dict_node, node_to_index_dict
+
+
+def _shape_consistency_apply(gm: torch.fx.GraphModule):
+ """
+ This pass is used to add the shape consistency node to the origin graph.
+ """
+ mod_graph = gm.graph
+ nodes = tuple(mod_graph.nodes)
+
+ input_dict_node, origin_dict_node, _, node_to_index_dict = _preprocess_graph(nodes)
+
+ for node in nodes:
+ if not hasattr(node, 'best_strategy') or node.op == 'output':
+ continue
+
+ for user_node_index, user_node in enumerate(node.strategies_vector.successor_nodes):
+ if isinstance(node.sharding_spec, (list, tuple)):
+ assert isinstance(
+ node.target_sharding_specs,
+ (list,
+ tuple)), 'target sharding specs should be tuple or list when node.sharding_spec is tuple or list'
+ total_difference = 0
+ for sharding_spec, target_sharding_spec in zip(node.sharding_spec,
+ node.target_sharding_specs[user_node_index]):
+ total_difference += sharding_spec.sharding_sequence_difference(target_sharding_spec)
+ if total_difference == 0:
+ continue
+ with mod_graph.inserting_before(user_node):
+ shape_consistency_node = mod_graph.create_node('call_function',
+ runtime_apply_for_iterable_object,
+ args=(node, origin_dict_node, input_dict_node,
+ node_to_index_dict[node], user_node_index))
+
+ else:
+ assert isinstance(node.sharding_spec,
+ ShardingSpec), 'node.sharding_spec should be type of ShardingSpec, tuple or list.'
+ if node.sharding_spec.sharding_sequence_difference(node.target_sharding_specs[user_node_index]) == 0:
+ continue
+ with mod_graph.inserting_before(user_node):
+ shape_consistency_node = mod_graph.create_node('call_function',
+ runtime_apply,
+ args=(node, origin_dict_node, input_dict_node,
+ node_to_index_dict[node], user_node_index))
+ if hasattr(user_node.meta['info'], 'activation_checkpoint'):
+ MetaInfo(shape_consistency_node,
+ mod_dir=user_node.meta['info'].mod_dir,
+ activation_checkpoint=tuple(user_node.meta['info'].activation_checkpoint))
+ new_args = list(user_node.args)
+ new_kwargs = dict(user_node.kwargs)
+ # the origin node may be a positional argument or key word argument of user node
+ if node in new_args:
+ # substitute the origin node with shape_consistency_node
+ origin_index_args = new_args.index(node)
+ new_args[origin_index_args] = shape_consistency_node
+ user_node.args = tuple(new_args)
+ elif str(node) in new_kwargs:
+ # substitute the origin node with shape_consistency_node
+ new_kwargs[str(node)] = shape_consistency_node
+ user_node.kwargs = new_kwargs
+
+ return gm
+
+
+def _comm_spec_apply(gm: torch.fx.GraphModule):
+ """
+ This pass is used to add the comm spec apply node to the origin graph.
+ """
+ mod_graph = gm.graph
+ nodes = tuple(mod_graph.nodes)
+
+ _, _, comm_actions_dict_node, node_to_index_dict = _preprocess_graph(nodes)
+
+ for node in nodes:
+ if not hasattr(node, 'best_strategy') or node.op == 'output':
+ continue
+
+ comm_actions = node.best_strategy.communication_actions
+ for op_data, comm_action in comm_actions.items():
+
+ if comm_action.comm_type == CommType.HOOK:
+ continue
+ if comm_action.comm_type == CommType.BEFORE:
+ if op_data.type == OperationDataType.OUTPUT:
+ comm_object = node
+ elif comm_action.key_for_kwarg is not None:
+ comm_object = node.kwargs[comm_action.key_for_kwarg]
+ else:
+ comm_object = node.args[comm_action.arg_index]
+ with mod_graph.inserting_before(node):
+ comm_spec_apply_node = mod_graph.create_node('call_function',
+ runtime_comm_spec_apply,
+ args=(comm_object, comm_actions_dict_node,
+ node_to_index_dict[node], op_data.name))
+ # the origin node may be a positional argument or key word argument of user node
+ if comm_action.key_for_kwarg is not None:
+ # substitute the origin node with comm_spec_apply_node
+ new_kwargs = dict(node.kwargs)
+ new_kwargs[comm_action.key_for_kwarg] = comm_spec_apply_node
+ node.kwargs = new_kwargs
+ else:
+ # substitute the origin node with comm_spec_apply_node
+ new_args = list(node.args)
+ new_args[comm_action.arg_index] = comm_spec_apply_node
+ node.args = tuple(new_args)
+
+ elif comm_action.comm_type == CommType.AFTER:
+ with mod_graph.inserting_after(node):
+ comm_spec_apply_node = mod_graph.create_node('call_function',
+ runtime_comm_spec_apply,
+ args=(node, comm_actions_dict_node,
+ node_to_index_dict[node], op_data.name))
+ user_list = list(node.users.keys())
+ for user in user_list:
+ if user == comm_spec_apply_node:
+ continue
+ new_args = list(user.args)
+ new_kwargs = dict(user.kwargs)
+ # the origin node may be a positional argument or key word argument of user node
+ if node in new_args:
+ # substitute the origin node with comm_spec_apply_node
+ new_args[new_args.index(node)] = comm_spec_apply_node
+ user.args = tuple(new_args)
+ elif str(node) in new_kwargs:
+ # substitute the origin node with comm_spec_apply_node
+ new_kwargs[str(node)] = comm_spec_apply_node
+ user.kwargs = new_kwargs
+ if hasattr(node.meta['info'], 'activation_checkpoint'):
+ MetaInfo(comm_spec_apply_node,
+ mod_dir=node.meta['info'].mod_dir,
+ activation_checkpoint=tuple(node.meta['info'].activation_checkpoint))
+
+ return gm
+
+
+def _act_annotataion_pass(gm: torch.fx.GraphModule):
+ """
+ This pass is used to add the act annotation to the new inserted nodes.
+ """
+ mod_graph = gm.graph
+ nodes = tuple(mod_graph.nodes)
+
+ for node in nodes:
+ if not hasattr(node.meta, 'activation_checkpoint'):
+ from .runtime_preparation_pass import size_processing
+
+ user_act_annotation = -1
+ input_act_annotation = -1
+ for user_node in node.users.keys():
+ if 'activation_checkpoint' in user_node.meta:
+ user_act_annotation = user_node.meta['activation_checkpoint']
+ break
+ for input_node in node._input_nodes.keys():
+ if 'activation_checkpoint' in input_node.meta:
+ input_act_annotation = input_node.meta['activation_checkpoint']
+ break
+ if user_act_annotation == input_act_annotation and user_act_annotation != -1:
+ node.meta['activation_checkpoint'] = user_act_annotation
+
+ return gm
+
+
+def runtime_apply_pass(gm: torch.fx.GraphModule):
+ """
+ The method manages all the passes acting on the distributed training runtime.
+ """
+ gm = _shape_consistency_apply(gm)
+ gm = _comm_spec_apply(gm)
+
+ return gm
diff --git a/colossalai/auto_parallel/passes/runtime_preparation_pass.py b/colossalai/auto_parallel/passes/runtime_preparation_pass.py
new file mode 100644
index 0000000000000000000000000000000000000000..08af846b221db60b3950a0cf285238f616b17711
--- /dev/null
+++ b/colossalai/auto_parallel/passes/runtime_preparation_pass.py
@@ -0,0 +1,507 @@
+import operator
+from copy import deepcopy
+from typing import Dict, List, Union
+
+import torch
+from torch.fx import symbolic_trace
+from torch.fx.node import Node
+
+from colossalai._analyzer.fx.node_util import MetaInfo
+from colossalai.auto_parallel.tensor_shard.constants import RESHAPE_FUNC_OP
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommAction,
+ CommType,
+ OperationDataType,
+ ShardingStrategy,
+)
+from colossalai.auto_parallel.tensor_shard.solver.strategies_constructor import StrategiesConstructor
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.tensor.comm_spec import _all_reduce
+from colossalai.tensor.shape_consistency import ShapeConsistencyManager
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+from .constants import SHAPE_ARGUMENT_OPS
+
+shape_consistency_manager = ShapeConsistencyManager()
+
+
+def size_processing(size: Union[int, torch.Size],
+ dim_partition_dict: Dict[int, List[int]],
+ device_mesh_info: Dict[int, int],
+ target_dim: int = None,
+ node_name: str = None):
+ """
+ This method will be invoked during runtime to convert size node value depending on distributed information.
+ """
+ if target_dim is not None:
+ assert isinstance(size, int)
+ if target_dim in dim_partition_dict:
+ total_shard_size = 1
+ for shard_dim in dim_partition_dict[target_dim]:
+ total_shard_size *= device_mesh_info[shard_dim]
+ size = size * total_shard_size
+
+ else:
+ size = list(size)
+ for dim, dim_size in enumerate(size):
+ if dim in dim_partition_dict:
+ total_shard_size = 1
+ for shard_dim in dim_partition_dict[dim]:
+ total_shard_size *= device_mesh_info[shard_dim]
+ size[dim] = dim_size * total_shard_size
+ size = torch.Size(size)
+
+ return size
+
+
+def solution_annotatation_pass(gm: torch.fx.GraphModule, solution: List[int],
+ strategies_constructor: StrategiesConstructor):
+ """
+ This method is used to stick the solution strategy to the nodes and add the information
+ required in runtime into graph as placeholder nodes.
+ """
+ mod_graph = gm.graph
+
+ nodes = [strategies_vector.node for strategies_vector in strategies_constructor.leaf_strategies]
+ no_strategy_nodes = strategies_constructor.no_strategy_nodes
+
+ # the dict to get origin sharding spec of node
+ origin_node_sharding_spec_dict = {}
+ for node_index, (node, strategy_index) in enumerate(zip(nodes, solution)):
+ strategies_vector = node.strategies_vector
+ # stick the solution strategy to the corresponding node
+ setattr(node, 'best_strategy', strategies_vector[strategy_index])
+ setattr(node, 'sharding_spec', strategies_vector[strategy_index].get_sharding_spec_by_name(str(node)))
+ origin_node_sharding_spec_dict[node_index] = strategies_vector[strategy_index].get_sharding_spec_by_name(
+ str(node))
+
+ # attach the corresponding metainfo if node has the attribute `strategies_info`
+ if hasattr(node, 'strategies_info'):
+ setattr(node, 'best_strategy_info', node.strategies_info[strategy_index])
+
+ # the dict to get input sharding specs of user node
+ sharding_spec_convert_dict = {}
+ # the dict to record comm actions of nodes
+ comm_actions_dict = {}
+ for index, node in enumerate(nodes):
+ target_sharding_specs = []
+ for user_node in node.strategies_vector.successor_nodes:
+ if user_node in no_strategy_nodes:
+ target_sharding_spec = node.best_strategy.get_sharding_spec_by_name(str(node.name))
+ else:
+ target_sharding_spec = user_node.best_strategy.get_sharding_spec_by_name(str(node.name))
+ target_sharding_specs.append(target_sharding_spec)
+ sharding_spec_convert_dict[index] = target_sharding_specs
+ setattr(node, 'target_sharding_specs', target_sharding_specs)
+
+ # the get_attr node strategy is kind of pending strategy, which means we will change it
+ # to the same strategy of the user node.
+ if node.op == 'get_attr':
+ assert len(target_sharding_specs) == 1, f'sharing weight is not supported in current version.'
+ target_node = node.strategies_vector.successor_nodes[0]
+ node_name = str(node)
+ if target_node.op == 'call_function' and target_node.target in RESHAPE_FUNC_OP:
+ node_name = str(target_node)
+ target_node = target_node.strategies_vector.successor_nodes[0]
+ user_strategy = target_node.best_strategy
+ op_data_in_user = user_strategy.get_op_data_by_name(node_name)
+ origin_pending_strategy = node.best_strategy
+ origin_op_data = origin_pending_strategy.get_op_data_by_name(str(node))
+
+ new_communication_actions = {}
+ if op_data_in_user in user_strategy.communication_actions:
+ new_communication_action = user_strategy.communication_actions.pop(op_data_in_user)
+ new_communication_action.arg_index = 0
+ new_communication_actions[origin_op_data] = new_communication_action
+ node.best_strategy.communication_actions = new_communication_actions
+
+ comm_action_dict = {}
+ for op_data, comm_action in node.best_strategy.communication_actions.items():
+ comm_action_dict[op_data.name] = comm_action
+ comm_actions_dict[index] = comm_action_dict
+
+ # add above dicts into graph
+ for node in nodes:
+ if node.op != 'placeholder':
+ with mod_graph.inserting_before(node):
+ input_specs_node = mod_graph.create_node('placeholder', target='sharding_spec_convert_dict')
+ origin_specs_node = mod_graph.create_node('placeholder', target='origin_node_sharding_spec_dict')
+ comm_actions_dict_node = mod_graph.create_node('placeholder', target='comm_actions_dict')
+ break
+ return gm, sharding_spec_convert_dict, origin_node_sharding_spec_dict, comm_actions_dict
+
+
+def size_value_converting_pass(gm: torch.fx.GraphModule, device_mesh: DeviceMesh):
+ """
+ In the auto parallel system, tensors may get shard on different devices, so the size of tensors
+ need to be converted to the size of original tensor and managed by the users, such as torch.view,
+ torch.reshape, etc. These nodes have enough information like input sharding_spec and
+ output sharding_spec to decide how to convert the size value.
+ """
+ mod_graph = gm.graph
+ nodes = tuple(mod_graph.nodes)
+ node_pairs = {}
+
+ # DeviceMesh information instructs the scaling of the size value
+ device_mesh_info = {}
+ for dim, dim_size in enumerate(device_mesh.mesh_shape):
+ device_mesh_info[dim] = dim_size
+
+ def _extract_target_dim(node):
+ '''
+ A helper function to extract the target dimension from size node.
+ There are two usages of torch.Tensor.size:
+ 1. tensor.size()
+ 2. tensor.size(dim)
+
+ If a target_dim is assigned, then the output will be in type of int, instead of torch.Size.
+ Otherwise, the output will be in type of torch.Size and this function will return None.
+ '''
+ target_dim = None
+ if len(node.args) > 1:
+ target_dim = node.args[1]
+ if target_dim < 0:
+ target_dim += node.args[0]._meta_data.dim()
+ return target_dim
+
+ def _post_processing(node, size_processing_node):
+ '''
+ This function is used to process the dependency between the size node and its users after
+ inserting the size_process_node.
+ '''
+ # store original node and processing node pair in node_pairs dictioanry
+ # It will be used to replace the original node with processing node in slice object
+ node_pairs[node] = size_processing_node
+ size_processing_node._meta_data = node._meta_data
+
+ if hasattr(node.meta['info'], 'activation_checkpoint'):
+ MetaInfo(size_processing_node,
+ mod_dir=node.meta['info'].mod_dir,
+ activation_checkpoint=tuple(node.meta['info'].activation_checkpoint))
+
+ user_list = list(node.users.keys())
+ for user in user_list:
+ if user == size_processing_node:
+ continue
+ new_args = list(user.args)
+ new_kwargs = dict(user.kwargs)
+ # the origin node may be a positional argument or key word argument of user node
+ if node in new_args:
+ # substitute the origin node with size_processing_node
+ new_args[new_args.index(node)] = size_processing_node
+ user.args = tuple(new_args)
+ elif str(node) in new_kwargs:
+ # substitute the origin node with size_processing_node
+ new_kwargs[str(node)] = size_processing_node
+ user.kwargs = new_kwargs
+
+ def _update_slice_object_args(slice_object):
+ '''
+ This function is used to update the slice object argument list.
+ If the slice object contains the Node argument, then the size node will be replaced with
+ '''
+ if isinstance(slice_object, slice):
+ start = slice_object.start
+ stop = slice_object.stop
+ step = slice_object.step
+ if start in node_pairs:
+ start = node_pairs[start]
+ if stop in node_pairs:
+ stop = node_pairs[stop]
+ if step in node_pairs:
+ step = node_pairs[step]
+ return slice(start, stop, step)
+ elif isinstance(slice_object, int):
+ if slice_object in node_pairs:
+ return node_pairs[slice_object]
+ else:
+ return slice_object
+ else:
+ raise RuntimeError(f"Unsupported slice object type: {type(slice_object)}")
+
+ for node in nodes:
+
+ if node.op == 'call_method' and node.target == 'size':
+ # extract useful information from size node
+ # dim_partition_dict will instruct the size value on which
+ # dimension should be enlarged.
+ sharding_spec = node.args[0].sharding_spec
+ dim_partition_dict = sharding_spec.dim_partition_dict
+
+ target_dim = _extract_target_dim(node)
+
+ # insert size_processing node
+ with mod_graph.inserting_after(node):
+ size_processing_node = mod_graph.create_node('call_function',
+ size_processing,
+ args=(node, dim_partition_dict, device_mesh_info,
+ target_dim, node.name))
+ _post_processing(node, size_processing_node)
+
+ if node.op == 'call_function' and node.target == operator.getitem:
+
+ getitem_index = node.args[1]
+ # slice object is quite special in torch.fx graph,
+ # On one side, we treat slice object same as type of int,
+ # so we do not create a node for slice object. On the other side,
+ # slice object could take fx.Node as its argument. And the user
+ # relationship cannot be tracked in fx graph.
+ # Therefore, I record the node_pairs in this pass, and use the it
+ # to replace the original node argument inside the slice object if
+ # it has been processed in above pass.
+
+ # There are three main usages of operator.getitem:
+ # getitem(input, int)
+ # getitem(input, slice)
+ # getitem(input, Tuple[slice])
+ # In this pass, we need process the last two cases because
+ # node arguments may potentially appear in these cases.
+ if isinstance(getitem_index, slice):
+ new_slice_item = _update_slice_object_args(getitem_index)
+ new_args = (node.args[0], new_slice_item)
+ node.args = new_args
+
+ elif isinstance(getitem_index, (tuple, list)):
+ if not isinstance(getitem_index[0], slice):
+ continue
+ new_slice_items = []
+
+ for slice_item in getitem_index:
+ if slice_item is None:
+ new_slice_items.append(None)
+ continue
+ new_slice_item = _update_slice_object_args(slice_item)
+ new_slice_items.append(new_slice_item)
+
+ new_args = (node.args[0], tuple(new_slice_items))
+ node.args = new_args
+
+ return gm
+
+
+def node_args_converting_pass(gm: torch.fx.GraphModule, device_mesh: DeviceMesh):
+ """
+ This pass will process node args to adapt the distributed tensor layout.
+ """
+ mod_graph = gm.graph
+ nodes = tuple(mod_graph.nodes)
+
+ def _extract_info_from_sharding_spec(sharding_spec):
+ '''
+ This function is used to extract the dim_partition_dict and device_mesh from
+ sharding spec instance or a list of sharding spec.
+ '''
+ if isinstance(sharding_spec, ShardingSpec):
+ dim_partition_dict = sharding_spec.dim_partition_dict
+ device_mesh = sharding_spec.device_mesh
+ return dim_partition_dict, device_mesh
+ if sharding_spec is None:
+ return None, None
+ assert isinstance(sharding_spec,
+ (tuple, list)), 'sharding_spec should be type of ShardingSpec, tuple, list or None'
+
+ device_mesh = sharding_spec[0].device_mesh
+ dim_partition_dict = []
+ for element in sharding_spec:
+ dim_partition_dict.append(_extract_info_from_sharding_spec(element))
+ return dim_partition_dict, sharding_spec
+
+ def _process_node_arguments(node):
+ new_args = []
+ for arg in node.args:
+ # There are two args style:
+ # 1. (input, *shape)
+ # 2. (input, shape)
+ # We will extract the elements from shape and add them into the new_args
+ # Finally, the args style of new_args will be unified to (input, *shape)
+ if isinstance(arg, Node):
+ if isinstance(arg._meta_data, (tuple, list)):
+ new_args.extend(arg._meta_data)
+ elif isinstance(arg._meta_data, int):
+ new_args.append(arg._meta_data)
+ else:
+ new_args.append(arg)
+ else:
+ assert isinstance(arg,
+ (int, tuple, list)), 'The argument in view node should be either type of Node or int.'
+ if isinstance(arg, (tuple, list)):
+ new_args.extend(arg)
+ else:
+ new_args.append(arg)
+ return new_args
+
+ def _scale_args_adapt_sharding_spec(dim_partition_dict, device_mesh, node):
+ new_args = _process_node_arguments(node)
+ if node.op == 'call_method':
+ args_to_process = list(new_args[1:])
+ else:
+ args_to_process = list(new_args)
+ for dim, shard_dims in dim_partition_dict.items():
+ total_shard_size = 1
+ for shard_dim in shard_dims:
+ total_shard_size *= device_mesh.shape[shard_dim]
+
+ # we will skip the dim with -1 value
+ if args_to_process[dim] == -1:
+ continue
+ else:
+ # TODO: add assertion here to make sure the dim size is divisible by total_shard_size
+ args_to_process[dim] //= total_shard_size
+
+ args_to_process = tuple(args_to_process)
+
+ if node.op == 'call_method':
+ new_args = (new_args[0],) + args_to_process
+ else:
+ new_args = args_to_process
+
+ node.args = new_args
+
+ def _filter_node_with_shape_args(node):
+ if node.op == 'call_method':
+ target = getattr(node.args[0]._meta_data.__class__, node.target)
+ elif node.op == 'call_function':
+ target = node.target
+ else:
+ target = None
+
+ if target in SHAPE_ARGUMENT_OPS:
+ return True
+ return False
+
+ for node in nodes:
+ # skip the placeholder node added in _solution_annotation pass
+ if not hasattr(node, 'sharding_spec'):
+ continue
+
+ output_dim_partition_dict, device_mesh = _extract_info_from_sharding_spec(node.sharding_spec)
+ if _filter_node_with_shape_args(node):
+ _scale_args_adapt_sharding_spec(output_dim_partition_dict, device_mesh, node)
+
+ return gm
+
+
+def module_params_sharding_pass(gm: torch.fx.GraphModule, device_mesh: DeviceMesh, overlap=False):
+ """
+ Apply the sharding action to the module parameters and buffers following the
+ instructions of solver solution.
+ """
+ mod_graph = gm.graph
+ nodes = tuple(mod_graph.nodes)
+ # This stream is created for overlaping the communication and computation.
+ reduction_stream = torch.cuda.Stream()
+
+ def _add_hook_for_grad_communication(node, param, name=None):
+
+ comm_actions = node.best_strategy.communication_actions
+
+ def _filter_param_to_hook(node, op_data, comm_action, name):
+
+ if node.op == 'call_module' and op_data.type == OperationDataType.PARAM and op_data.name == name and comm_action.comm_type == CommType.HOOK:
+ return True
+ if node.op == 'get_attr' and isinstance(
+ node._meta_data, torch.nn.parameter.Parameter) and comm_action.comm_type == CommType.HOOK:
+ return True
+ return False
+
+ for operation_data, comm_action in comm_actions.items():
+ comm_spec_to_use = comm_action.comm_spec
+ # register hook to the parameters
+ if _filter_param_to_hook(node, operation_data, comm_action, name=name):
+
+ def wrapper(param, comm_spec, stream, overlap):
+
+ def hook_fn(grad):
+ if overlap:
+ with torch.cuda.stream(stream):
+ _all_reduce(grad, comm_spec, async_op=True)
+ else:
+ _all_reduce(grad, comm_spec, async_op=False)
+
+ param.register_hook(hook_fn)
+
+ wrapper(param, comm_spec_to_use, reduction_stream, overlap=overlap)
+
+ def _shard_param(param, target_sharding_spec):
+ # apply the sharding spec of parameters
+ if target_sharding_spec.dim_partition_dict != {}:
+ origin_sharding_spec = ShardingSpec(device_mesh, param.shape, {})
+ setattr(param, 'sharding_spec', origin_sharding_spec)
+ # TODO: build a ColoParameter class to manager the distributed parameters
+ # we could use .data here, because all the operations just happen before the real training
+ # loop, so we don't need to track these operations in the autograd graph.
+ param = torch.nn.Parameter(
+ shape_consistency_manager.apply_for_autoparallel_runtime(param.data, param.sharding_spec,
+ target_sharding_spec).detach().clone())
+ return param
+
+ for node in nodes:
+ if node.op == 'call_module':
+ target_module = node.graph.owning_module.get_submodule(node.target)
+ # TODO: we need to do more actions to take care of the shared parameters.
+ if hasattr(target_module, 'processed') and target_module.processed:
+ continue
+ setattr(target_module, 'processed', True)
+ for name, param in target_module.named_parameters():
+ target_sharding_spec = node.best_strategy.get_sharding_spec_by_name(name)
+ param = _shard_param(param, target_sharding_spec)
+
+ setattr(target_module, name, param)
+ _add_hook_for_grad_communication(node, param, name)
+
+ sharded_buffer_dict = {}
+ # apply the sharding spec of buffers
+ for name, buffer in target_module.named_buffers():
+ origin_sharding_spec = ShardingSpec(device_mesh, buffer.shape, {})
+ setattr(buffer, 'sharding_spec', origin_sharding_spec)
+ target_sharding_spec = node.best_strategy.get_sharding_spec_by_name(name)
+ buffer_sharded = shape_consistency_manager.apply(buffer, target_sharding_spec)
+ sharded_buffer_dict[name] = buffer_sharded
+
+ for name, buffer_sharded in sharded_buffer_dict.items():
+ setattr(target_module, name, buffer_sharded.detach().clone())
+
+ if node.op == 'get_attr':
+ root = node.graph.owning_module
+ atoms = node.target.split(".")
+ attr_len = len(atoms)
+ if attr_len == 1:
+ target_module = root
+ target = getattr(root, atoms[0])
+ else:
+ target_module = root
+ for atom in atoms[:-1]:
+ target_module = getattr(target_module, atom)
+ target = getattr(target_module, atoms[-1])
+
+ target_sharding_spec = node.sharding_spec
+ target = _shard_param(target, target_sharding_spec)
+
+ assert hasattr(target_module, atoms[-1])
+ setattr(target_module, atoms[-1], target)
+ _add_hook_for_grad_communication(node, target)
+
+ return gm
+
+
+def implicit_comm_action_apply(gm: torch.fx.GraphModule):
+ """
+ replace the origin kernel into kernel with implicit communication inside.
+ """
+ pass
+
+
+def runtime_preparation_pass(gm: torch.fx.GraphModule,
+ solution: List[int],
+ device_mesh: DeviceMesh,
+ strategies_constructor: StrategiesConstructor,
+ overlap=False):
+ gm, sharding_spec_convert_dict, origin_node_sharding_spec_dict, comm_actions_dict = solution_annotatation_pass(
+ gm, solution, strategies_constructor)
+ gm = size_value_converting_pass(gm, device_mesh)
+ gm = node_args_converting_pass(gm, device_mesh)
+ # TODO: the pass below should be uncommented after the implementation of implicit_comm_action_apply_pass completed.
+ # gm = implicit_comm_action_apply(gm)
+ gm = module_params_sharding_pass(gm, device_mesh, overlap=overlap)
+
+ return gm, sharding_spec_convert_dict, origin_node_sharding_spec_dict, comm_actions_dict
diff --git a/colossalai/auto_parallel/pipeline_shard/__init__.py b/colossalai/auto_parallel/pipeline_shard/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/colossalai/auto_parallel/tensor_shard/__init__.py b/colossalai/auto_parallel/tensor_shard/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/colossalai/auto_parallel/tensor_shard/constants.py b/colossalai/auto_parallel/tensor_shard/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..99c1249340602daee1a1314f102bc600eae6667d
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/constants.py
@@ -0,0 +1,91 @@
+import operator
+
+import torch
+
+__all__ = [
+ 'ELEMENTWISE_MODULE_OP', 'ELEMENTWISE_FUNC_OP', 'RESHAPE_FUNC_OP', 'CONV_MODULE_OP', 'CONV_FUNC_OP',
+ 'LINEAR_MODULE_OP', 'LINEAR_FUNC_OP', 'BATCHNORM_MODULE_OP', 'POOL_MODULE_OP', 'NON_PARAM_FUNC_OP', 'BCAST_FUNC_OP',
+ 'EMBEDDING_MODULE_OP', 'LAYERNORM_MODULE_OP', 'ELEMENTWISE_METHOD_OP', 'RESHAPE_METHOD_OP', 'INFINITY_COST'
+]
+
+ELEMENTWISE_MODULE_OP = [torch.nn.Dropout, torch.nn.ReLU]
+ELEMENTWISE_FUNC_OP = [
+ torch.abs,
+ torch.cos,
+ torch.exp,
+ operator.neg,
+ torch.multiply,
+ torch.nn.functional.relu,
+ torch.nn.functional.dropout,
+ # softmax should not be here
+ torch.nn.functional.softmax
+]
+ELEMENTWISE_METHOD_OP = [
+ torch.Tensor.to,
+ torch.Tensor.type,
+ # TODO: contiguous maybe need some extra processes.
+ torch.Tensor.contiguous
+]
+RESHAPE_FUNC_OP = [
+ torch.flatten,
+ torch.reshape,
+ torch.transpose,
+ torch.split,
+ torch.permute,
+ operator.getitem,
+]
+RESHAPE_METHOD_OP = [
+ torch.Tensor.view,
+ torch.Tensor.unsqueeze,
+ torch.Tensor.split,
+ torch.Tensor.permute,
+ torch.Tensor.transpose,
+]
+BCAST_FUNC_OP = [
+ torch.add, torch.sub, torch.mul, torch.div, torch.floor_divide, torch.true_divide, operator.add, operator.sub,
+ operator.mul, operator.floordiv, operator.truediv, torch.matmul, operator.pow, torch.pow
+]
+CONV_MODULE_OP = [
+ torch.nn.Conv1d, torch.nn.Conv2d, torch.nn.Conv3d, torch.nn.ConvTranspose1d, torch.nn.ConvTranspose2d,
+ torch.nn.ConvTranspose3d
+]
+CONV_FUNC_OP = [
+ torch.conv1d, torch.conv2d, torch.conv3d, torch.conv_transpose1d, torch.conv_transpose2d, torch.conv_transpose3d
+]
+EMBEDDING_MODULE_OP = [torch.nn.modules.sparse.Embedding]
+LINEAR_MODULE_OP = [torch.nn.Linear]
+LINEAR_FUNC_OP = [torch.nn.functional.linear, torch.matmul, torch.bmm]
+BATCHNORM_MODULE_OP = [torch.nn.BatchNorm1d, torch.nn.BatchNorm2d, torch.nn.BatchNorm3d, torch.nn.SyncBatchNorm]
+LAYERNORM_MODULE_OP = [torch.nn.LayerNorm]
+POOL_MODULE_OP = [torch.nn.MaxPool1d, torch.nn.MaxPool2d, torch.nn.MaxPool3d, torch.nn.AdaptiveAvgPool2d]
+NON_PARAM_FUNC_OP = [
+ torch.flatten,
+ torch.reshape,
+ torch.abs,
+ torch.cos,
+ torch.exp,
+ operator.neg,
+ torch.multiply,
+ torch.nn.functional.relu,
+ torch.nn.functional.dropout,
+ torch.flatten,
+ torch.where,
+ operator.pow,
+ torch.pow,
+ torch.tanh,
+ torch.add,
+ torch.sub,
+ torch.mul,
+ torch.div,
+ torch.floor_divide,
+ torch.true_divide,
+ operator.add,
+ operator.sub,
+ operator.mul,
+ operator.floordiv,
+ operator.truediv,
+ # softmax should not be here
+ torch.nn.functional.softmax
+]
+
+INFINITY_COST = 1e13
diff --git a/colossalai/auto_parallel/tensor_shard/initialize.py b/colossalai/auto_parallel/tensor_shard/initialize.py
new file mode 100644
index 0000000000000000000000000000000000000000..b406ca6fb7e0fd28a9a6d3e98365b093f73f7171
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/initialize.py
@@ -0,0 +1,356 @@
+from typing import Dict, List, Tuple
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch.fx import GraphModule
+from torch.fx.graph import Graph
+
+from colossalai._analyzer.fx.codegen import ActivationCheckpointCodeGen
+from colossalai._analyzer.fx.graph_module import ColoGraphModule
+from colossalai._analyzer.fx.passes import shape_prop_pass
+from colossalai._analyzer.fx.tracer.tracer import ColoTracer
+from colossalai.auto_parallel.passes.runtime_apply_pass import runtime_apply_pass
+from colossalai.auto_parallel.passes.runtime_preparation_pass import runtime_preparation_pass
+from colossalai.auto_parallel.tensor_shard.options import DataloaderOption, ShardOption, SolverOptions, SolverPerference
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import CommAction
+from colossalai.auto_parallel.tensor_shard.solver import CostGraph, GraphAnalyser, Solver, StrategiesConstructor
+from colossalai.device.alpha_beta_profiler import AlphaBetaProfiler
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+
+class ModuleWrapper(nn.Module):
+ '''
+ This class is used to wrap the original module, and add the sharding_spec_dict, origin_spec_dict, comm_actions_dict
+ into the forward function.
+ '''
+
+ def __init__(self, module: ColoGraphModule, sharding_spec_dict: Dict[int, List[ShardingSpec]],
+ origin_spec_dict: Dict[int, ShardingSpec], comm_actions_dict: Dict[int, Dict[str, CommAction]]):
+ '''
+ Args:
+ module: the original module
+ sharding_spec_dict: The sharding_spec_dict is used to record the target sharding specs of each tensor required in user node.
+ origin_spec_dict: The origin_spec_dict is used to record the original sharding spec of each tensor.
+ comm_actions_dict: The comm_actions_dict is used to record the communication actions of each tensor.
+ '''
+ super(ModuleWrapper, self).__init__()
+ self.module = module
+ self.sharding_spec_dict = sharding_spec_dict
+ self.origin_spec_dict = origin_spec_dict
+ self.comm_actions_dict = comm_actions_dict
+
+ def forward(self, *args, **kwargs):
+ return self.module(*args,
+ sharding_spec_convert_dict=self.sharding_spec_dict,
+ origin_node_sharding_spec_dict=self.origin_spec_dict,
+ comm_actions_dict=self.comm_actions_dict,
+ **kwargs)
+
+
+def extract_meta_args_from_dataloader(data_loader: torch.utils.data.DataLoader, data_process_func: callable):
+ '''
+ This method is used to extract the meta_args from the dataloader under the instruction of the data_process_func.
+ '''
+ # TODO: implement this function
+ pass
+
+
+def extract_alpha_beta_for_device_mesh(alpha_beta_dict: Dict[Tuple[int], Tuple[float]], logical_mesh_shape: Tuple[int]):
+ '''
+ This method is used to extract the mesh_alpha and mesh_beta for the given logical_mesh_shape
+ from the alpha_beta_dict. These two values will be used to estimate the communication cost.
+ '''
+ # TODO: implement this function
+ pass
+
+
+def build_strategy_constructor(graph: Graph, device_mesh: DeviceMesh, solver_preference: str, dataloader_option: str,
+ shard_option: str):
+ '''
+ This method is used to build the strategy_constructor for the given graph.
+ After this method, each node in the graph will have a strategies_vector which
+ is constructed by the related node handler.
+ '''
+ if solver_preference == 'standard':
+ solver_preference = SolverPerference.STANDARD
+ elif solver_preference == 'tp':
+ solver_preference = SolverPerference.TP
+ elif solver_preference == 'dp':
+ solver_preference = SolverPerference.DP
+ else:
+ raise ValueError(f'Invalid solver_preference: {solver_preference}')
+
+ if dataloader_option == 'replicated':
+ dataloader_option = DataloaderOption.REPLICATED
+ elif dataloader_option == 'distributed':
+ dataloader_option = DataloaderOption.DISTRIBUTED
+ else:
+ raise ValueError(f'Invalid dataloader_option: {dataloader_option}')
+
+ if shard_option == 'standard':
+ shard_option = ShardOption.STANDARD
+ elif shard_option == 'shard':
+ shard_option = ShardOption.SHARD
+ elif shard_option == 'shard_last_axis':
+ shard_option = ShardOption.SHARD_LAST_AXIS
+ elif shard_option == 'full_shard':
+ shard_option = ShardOption.FULL_SHARD
+ else:
+ raise ValueError(f'Invalid shard_option: {shard_option}')
+
+ solver_options = SolverOptions(solver_perference=solver_preference,
+ dataloader_option=dataloader_option,
+ shard_option=shard_option)
+ strategies_constructor = StrategiesConstructor(graph, device_mesh, solver_options)
+ strategies_constructor.build_strategies_and_cost()
+
+ return strategies_constructor
+
+
+def solve_solution(gm: ColoGraphModule, strategy_constructor: StrategiesConstructor, memory_budget: float = -1.0):
+ '''
+ This method is used to solve the best solution for the given graph.
+ The solution is a list of integers, each integer represents the best strategy index of the corresponding node.
+ '''
+ # temporarily we use all nodes as liveness list, we count the backward memory cost together with
+ # forward memory cost into the node memory cost, and no activation checkpoint is used in this phase.
+ # graph_analyser = GraphAnalyser(gm)
+ # liveness_list = graph_analyser.liveness_analysis()
+ cost_graph = CostGraph(strategy_constructor.leaf_strategies)
+ cost_graph.simplify_graph()
+ solver = Solver(gm.graph, strategy_constructor, cost_graph, memory_budget=memory_budget)
+ ret = solver.call_solver_serialized_args()
+ solution = list(ret[0])
+
+ return solution
+
+
+def transform_to_sharded_model(gm: ColoGraphModule,
+ meta_args: Dict,
+ solution: List[int],
+ device_mesh: DeviceMesh,
+ strategies_constructor: StrategiesConstructor,
+ overlap: bool = False):
+ '''
+ This method is used to transform the original graph to the sharded graph.
+ The model parameters will be sharded according to the solution and the grad hooks
+ will be added to the sharded graph using the runtime_preparation_pass.
+ The communication node will be added into the graph using the runtime_apply_pass.
+ '''
+ gm, sharding_spec_dict, origin_spec_dict, comm_actions_dict = runtime_preparation_pass(gm,
+ solution,
+ device_mesh,
+ strategies_constructor,
+ overlap=overlap)
+ gm = runtime_apply_pass(gm)
+ shape_prop_pass(gm, *meta_args.values(), sharding_spec_dict, origin_spec_dict, comm_actions_dict)
+ gm.recompile()
+ sharding_spec_dicts = (sharding_spec_dict, origin_spec_dict, comm_actions_dict)
+
+ return gm, sharding_spec_dicts
+
+
+def initialize_device_mesh(world_size: int = -1,
+ physical_devices: List[int] = None,
+ alpha_beta_dict: Dict[Tuple[int], Tuple[float]] = None,
+ logical_mesh_shape: Tuple[int] = None,
+ logical_mesh_id: torch.Tensor = None):
+ '''
+ This method is used to initialize the device mesh.
+
+ Args:
+ world_size: the size of device mesh. If the world_size is -1,
+ the world size will be set to the number of GPUs in the current machine.
+ physical_devices: the physical devices used to initialize the device mesh.
+ alpha_beta_dict(optional): the alpha_beta_dict contains the alpha and beta values
+ for each devices. if the alpha_beta_dict is None, the alpha_beta_dict will be
+ generated by profile_alpha_beta function.
+ logical_mesh_shape(optional): the logical_mesh_shape is used to specify the logical
+ mesh shape.
+ logical_mesh_id(optional): the logical_mesh_id is used to specify the logical mesh id.
+ '''
+ # if world_size is not set, use the world size from torch.distributed
+ if world_size == -1:
+ world_size = dist.get_world_size()
+
+ if physical_devices is None:
+ physical_devices = [i for i in range(world_size)]
+ physical_mesh = torch.tensor(physical_devices)
+
+ if alpha_beta_dict is None:
+ # if alpha_beta_dict is not given, use a series of executions to profile alpha and beta values for each device
+ ab_profiler = AlphaBetaProfiler(physical_devices)
+ alpha_beta_dict = ab_profiler.alpha_beta_dict
+ else:
+ ab_profiler = AlphaBetaProfiler(physical_devices, alpha_beta_dict=alpha_beta_dict)
+
+ if logical_mesh_shape is None and logical_mesh_id is None:
+ # search for the best logical mesh shape
+ logical_mesh_id = ab_profiler.search_best_logical_mesh()
+ logical_mesh_id = torch.Tensor(logical_mesh_id).to(torch.int)
+ logical_mesh_shape = logical_mesh_id.shape
+
+ # extract alpha and beta values for the chosen logical mesh shape
+ mesh_alpha, mesh_beta = ab_profiler.extract_alpha_beta_for_device_mesh()
+
+ elif logical_mesh_shape is not None and logical_mesh_id is None:
+ logical_mesh_id = physical_mesh.reshape(logical_mesh_shape)
+
+ # extract alpha and beta values for the chosen logical mesh shape
+ mesh_alpha, mesh_beta = extract_alpha_beta_for_device_mesh(alpha_beta_dict, logical_mesh_id)
+
+ device_mesh = DeviceMesh(physical_mesh_id=physical_mesh,
+ logical_mesh_id=logical_mesh_id,
+ mesh_alpha=mesh_alpha,
+ mesh_beta=mesh_beta,
+ init_process_group=True)
+ return device_mesh
+
+
+def initialize_model(model: nn.Module,
+ meta_args: Dict[str, torch.Tensor],
+ device_mesh: DeviceMesh,
+ memory_budget: float = -1.0,
+ overlap: bool = False,
+ solver_preference: str = 'standard',
+ dataloader_option: str = 'replicated',
+ shard_option: str = 'standard',
+ save_solver_solution: bool = False,
+ load_solver_solution: bool = False,
+ solution_path: str = None,
+ return_solution: bool = False):
+ '''
+ This method is used to initialize the sharded model which could be used as normal pytorch model.
+
+ Args:
+ model: the model to be sharded.
+ meta_args: the meta_args is used to specify the input shapes of the model.
+ device_mesh: the device mesh to execute the model.
+ memory_budget(optional): the max cuda memory could be used. If the memory budget is -1.0,
+ the memory budget will be infinity.
+ overlap(optional): the overlap is used to specify whether to overlap gradient communication and
+ backward computing.
+ solver_preference(optional): the solver_preference is used to specify which parallelism algorithm
+ has higher priority. The valid solver_preference could be 'standard', 'tp', or 'dp'.
+ dataloader_option(optional): the dataloader_option is used to specify which kind of data_loader will
+ be used. The valid dataloader_option could be 'replicated' or 'distributed'.
+ shard_option(optional): the shard_option is used to specify how many axes will be used to shard the
+ model. The valid shard_option could be 'standard', 'shard', 'shard_last_axis', or 'full_shard'.
+ save_solver_solution(optional): if the save_solver_solution is True, the solution will be saved
+ to the solution_path.
+ load_solver_solution(optional): if the load_solver_solution is True, the solution will be loaded
+ from the solution_path.
+ solution_path(optional): the path to save or load the solution.
+ return_solution(optional): if the return_solution is True, the solution will be returned. The returned
+ solution will be used to debug or help to analyze the sharding result. Therefore, we will not just
+ return a series of integers, but return the best strategies.
+ '''
+ tracer = ColoTracer(trace_act_ckpt=True, bias_addition_split=True)
+
+ graph = tracer.trace(root=model, meta_args=meta_args)
+ graph.set_codegen(ActivationCheckpointCodeGen())
+ gm = ColoGraphModule(model, graph, model.__class__.__name__)
+
+ shape_prop_pass(gm, *meta_args.values())
+ gm.recompile()
+
+ strategies_constructor = build_strategy_constructor(graph,
+ device_mesh,
+ solver_preference=solver_preference,
+ dataloader_option=dataloader_option,
+ shard_option=shard_option)
+ if load_solver_solution:
+ solution = torch.load(solution_path)
+ else:
+ solution = solve_solution(gm, strategies_constructor, memory_budget)
+ if save_solver_solution:
+ torch.save(solution, solution_path)
+
+ gm, sharding_spec_dicts = transform_to_sharded_model(gm, meta_args, solution, device_mesh, strategies_constructor,
+ overlap)
+
+ model_to_return = ModuleWrapper(gm, *sharding_spec_dicts)
+
+ if return_solution:
+ solution_to_return = []
+ nodes = [strategies_vector.node for strategies_vector in strategies_constructor.leaf_strategies]
+ for index, node in enumerate(nodes):
+ solution_to_return.append(f'{node.name} {node.strategies_vector[solution[index]].name}')
+ return model_to_return, solution_to_return
+ else:
+ return model_to_return
+
+
+def autoparallelize(model: nn.Module,
+ meta_args: Dict[str, torch.Tensor] = None,
+ data_loader: torch.utils.data.DataLoader = None,
+ data_process_func: callable = None,
+ alpha_beta_dict: Dict[Tuple[int], Tuple[float]] = None,
+ logical_mesh_shape: Tuple[int] = None,
+ logical_mesh_id: torch.Tensor = None,
+ solver_preference: str = 'standard',
+ dataloader_option: str = 'replicated',
+ shard_option: str = 'standard',
+ save_solver_solution: bool = False,
+ load_solver_solution: bool = False,
+ solver_solution_path: str = None,
+ return_solution: bool = False,
+ memory_budget: float = -1.0):
+ '''
+ This method is used to initialize the device mesh, extract the meta_args, and
+ use them to create a sharded model.
+
+ Args:
+ model: the model to be sharded.
+ meta_args(optional): the meta_args is used to specify the input shapes of the model.
+ If the meta_args is None, the meta_args will be extracted from the data_loader.
+ data_loader(optional): the data_loader to be used in normal training loop.
+ data_process_func(optional): the data_process_func is used to process the data from the data_loader.
+ alpha_beta_dict(optional): the alpha_beta_dict contains the alpha and beta values
+ for each devices. if the alpha_beta_dict is None, the alpha_beta_dict will be
+ generated by profile_alpha_beta function.
+ logical_mesh_shape(optional): the logical_mesh_shape is used to specify the logical
+ mesh shape. If the logical_mesh_shape is None, the logical_mesh_shape will be
+ generated by search_best_logical_mesh_shape function.
+ logical_mesh_id(optional): the logical_mesh_id is used to specify the logical mesh id.
+ solver_preference(optional): the solver_preference is used to specify which parallelism algorithm
+ has higher priority. The valid solver_preference could be 'standard', 'tp', or 'dp'.
+ dataloader_option(optional): the dataloader_option is used to specify which kind of data_loader will
+ be used. The valid dataloader_option could be 'replicated' or 'distributed'.
+ shard_option(optional): the shard_option is used to specify how many axes will be used to shard the
+ model. The valid shard_option could be 'standard', 'shard', 'shard_last_axis', or 'full_shard'.
+ save_solver_solution(optional): if the save_solver_solution is True, the solution will be saved
+ to the solution_path.
+ load_solver_solution(optional): if the load_solver_solution is True, the solution will be loaded
+ from the solution_path.
+ solver_solution_path(optional): the path to save or load the solution.
+ return_solution(optional): if the return_solution is True, the solution will be returned.
+ memory_budget(optional): the max cuda memory could be used. If the memory budget is -1.0,
+ the memory budget will be infinity.
+ '''
+ device_mesh = initialize_device_mesh(alpha_beta_dict=alpha_beta_dict,
+ logical_mesh_shape=logical_mesh_shape,
+ logical_mesh_id=logical_mesh_id)
+ if meta_args is None:
+ meta_args = extract_meta_args_from_dataloader(data_loader, data_process_func)
+
+ rst_to_unpack = initialize_model(model,
+ meta_args,
+ device_mesh,
+ solver_preference=solver_preference,
+ dataloader_option=dataloader_option,
+ shard_option=shard_option,
+ save_solver_solution=save_solver_solution,
+ load_solver_solution=load_solver_solution,
+ solution_path=solver_solution_path,
+ return_solution=return_solution,
+ memory_budget=memory_budget)
+
+ if return_solution:
+ model, solution = rst_to_unpack
+ return model, solution
+ else:
+ model = rst_to_unpack
+ return model
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/__init__.py b/colossalai/auto_parallel/tensor_shard/node_handler/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..9903ca54e52cb70559cce2c68169c84ca08bef9c
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/__init__.py
@@ -0,0 +1,35 @@
+from .addmm_handler import ADDMMFunctionHandler
+from .batch_norm_handler import BatchNormModuleHandler
+from .binary_elementwise_handler import BinaryElementwiseHandler
+from .bmm_handler import AddBMMFunctionHandler, BMMFunctionHandler
+from .conv_handler import ConvFunctionHandler, ConvModuleHandler
+from .default_reshape_handler import DefaultReshapeHandler
+from .embedding_handler import EmbeddingFunctionHandler, EmbeddingModuleHandler
+from .getattr_handler import GetattrHandler
+from .getitem_handler import GetItemHandler
+from .layer_norm_handler import LayerNormModuleHandler
+from .linear_handler import LinearFunctionHandler, LinearModuleHandler
+from .matmul_handler import MatMulHandler
+from .normal_pooling_handler import NormPoolingHandler
+from .output_handler import OutputHandler
+from .permute_handler import PermuteHandler
+from .placeholder_handler import PlaceholderHandler
+from .registry import operator_registry
+from .softmax_handler import SoftmaxHandler
+from .split_handler import SplitHandler
+from .sum_handler import SumHandler
+from .tensor_constructor_handler import TensorConstructorHandler
+from .transpose_handler import TransposeHandler
+from .unary_elementwise_handler import UnaryElementwiseHandler
+from .view_handler import ViewHandler
+from .where_handler import WhereHandler
+
+__all__ = [
+ 'LinearFunctionHandler', 'LinearModuleHandler', 'BMMFunctionHandler', 'AddBMMFunctionHandler',
+ 'LayerNormModuleHandler', 'BatchNormModuleHandler', 'ConvModuleHandler', 'ConvFunctionHandler',
+ 'UnaryElementwiseHandler', 'DefaultReshapeHandler', 'PlaceholderHandler', 'OutputHandler', 'WhereHandler',
+ 'NormPoolingHandler', 'BinaryElementwiseHandler', 'MatMulHandler', 'operator_registry', 'ADDMMFunctionHandler',
+ 'GetItemHandler', 'GetattrHandler', 'ViewHandler', 'PermuteHandler', 'TensorConstructorHandler',
+ 'EmbeddingModuleHandler', 'EmbeddingFunctionHandler', 'SumHandler', 'SoftmaxHandler', 'TransposeHandler',
+ 'SplitHandler'
+]
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/addmm_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/addmm_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..da0d199c5e05b37340cb4ddcfee0b52a9102fadf
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/addmm_handler.py
@@ -0,0 +1,91 @@
+from typing import Dict, List, Union
+
+import torch
+
+from colossalai.tensor.shape_consistency import CollectiveCommPattern, CommSpec, ShapeConsistencyManager
+
+from ..sharding_strategy import CommAction, CommType, OperationData, OperationDataType, ShardingStrategy
+from ..utils import comm_actions_for_oprands, recover_sharding_spec_for_broadcast_shape
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import LinearProjectionStrategyGenerator, StrategyGenerator
+
+__all__ = ['ADDMMFunctionHandler']
+
+
+@operator_registry.register(torch.addmm)
+@operator_registry.register(torch.Tensor.addmm)
+class ADDMMFunctionHandler(NodeHandler):
+ """
+ This is a NodeHandler class which deals with the batched matrix multiplication operation in PyTorch.
+ Such operations including `torch.bmm` and `torch.Tensor.bmm` require the tensor to be 3D, thus, there is
+ no logical-physical shape conversion in this handler.
+ """
+
+ def _infer_op_data_type(self, tensor: torch.Tensor) -> OperationDataType:
+ if isinstance(tensor, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+ return data_type
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+
+ # input operand
+ input_data = self.node.args[1]._meta_data
+ physical_input_operand = OperationData(name=str(self.node.args[1]),
+ type=self._infer_op_data_type(input_data),
+ data=input_data)
+
+ # other operand
+ other_data = self.node.args[2]._meta_data
+ physical_other_operand = OperationData(name=str(self.node.args[2]),
+ type=self._infer_op_data_type(other_data),
+ data=other_data)
+ # bias physical shape
+ bias_logical_shape = self.node._meta_data.shape
+ bias_data = self.node.args[0]._meta_data
+ physical_bias_operand = OperationData(name=str(self.node.args[0]),
+ type=self._infer_op_data_type(bias_data),
+ data=bias_data,
+ logical_shape=bias_logical_shape)
+
+ # output
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ mapping = {
+ "input": physical_input_operand,
+ "other": physical_other_operand,
+ "output": physical_output,
+ 'bias': physical_bias_operand
+ }
+
+ return mapping
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(
+ LinearProjectionStrategyGenerator(op_data_mapping, self.device_mesh, linear_projection_type='addmm'))
+ return generators
+
+ def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, List[ShardingStrategy]]:
+ # convert bias from its logical sharding spec to its physical sharding spec
+ op_data_mapping = self.get_operation_data_mapping()
+
+ bias_op_data = op_data_mapping['bias']
+ bias_physical_shape = bias_op_data.data.shape
+ bias_logical_shape = bias_op_data.logical_shape
+ bias_sharding_spec = strategy.get_sharding_spec_by_name(bias_op_data.name)
+ bias_sharding_spec, removed_dims = recover_sharding_spec_for_broadcast_shape(
+ bias_sharding_spec, bias_logical_shape, bias_physical_shape)
+ strategy.sharding_specs[bias_op_data] = bias_sharding_spec
+
+ if len(removed_dims) > 0:
+ comm_action = comm_actions_for_oprands(node=self.node,
+ removed_dims=removed_dims,
+ op_data=bias_op_data,
+ sharding_spec=bias_sharding_spec)
+ strategy.communication_actions[bias_op_data] = comm_action
+
+ return strategy
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/batch_norm_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/batch_norm_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb1bb36b78796db3d5656213518376f8f365dce0
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/batch_norm_handler.py
@@ -0,0 +1,69 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType, StrategiesVector
+from .node_handler import MetaInfoModuleHandler, ModuleHandler
+from .registry import operator_registry
+from .strategy import BatchNormStrategyGenerator, StrategyGenerator
+
+__all__ = ['BatchNormModuleHandler']
+
+
+@operator_registry.register(torch.nn.BatchNorm1d)
+@operator_registry.register(torch.nn.BatchNorm2d)
+@operator_registry.register(torch.nn.BatchNorm3d)
+class BatchNormModuleHandler(MetaInfoModuleHandler):
+ """
+ A BatchNormModuleHandler which deals with the sharding strategies for nn.BatchNormXd module.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(BatchNormStrategyGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.node.args[0]._meta_data)
+ physical_other_operand = OperationData(name="weight",
+ type=OperationDataType.PARAM,
+ data=self.named_parameters['weight'],
+ logical_shape=self.named_parameters['weight'].shape)
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ physical_running_mean_operand = OperationData(name="running_mean",
+ type=OperationDataType.BUFFER,
+ data=self.named_buffers['running_mean'],
+ logical_shape=self.named_buffers['running_mean'].shape)
+
+ physical_running_var_operand = OperationData(name="running_var",
+ type=OperationDataType.BUFFER,
+ data=self.named_buffers['running_var'],
+ logical_shape=self.named_buffers['running_var'].shape)
+
+ physical_num_batches_tracked_operand = OperationData(
+ name="num_batches_tracked",
+ type=OperationDataType.BUFFER,
+ data=self.named_buffers['num_batches_tracked'],
+ logical_shape=self.named_buffers['num_batches_tracked'].shape)
+
+ mapping = {
+ "input": physical_input_operand,
+ "other": physical_other_operand,
+ "output": physical_output,
+ "running_mean": physical_running_mean_operand,
+ "running_var": physical_running_var_operand,
+ "num_batches_tracked": physical_num_batches_tracked_operand
+ }
+
+ if self.named_parameters['bias'] is not None:
+ physical_bias_operand = OperationData(name="bias",
+ type=OperationDataType.PARAM,
+ data=self.named_parameters['bias'])
+ mapping['bias'] = physical_bias_operand
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/binary_elementwise_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/binary_elementwise_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..db8f0b54ddeeb1c5250951f0c9e8bfef364eb16d
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/binary_elementwise_handler.py
@@ -0,0 +1,113 @@
+from typing import Dict, List, Union
+
+import torch
+from torch.fx.node import Node
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import OperationData, OperationDataType, ShardingStrategy
+from colossalai.tensor.shape_consistency import CollectiveCommPattern, CommSpec, ShapeConsistencyManager
+
+from ..constants import BCAST_FUNC_OP
+from ..utils import comm_actions_for_oprands, recover_sharding_spec_for_broadcast_shape
+from .node_handler import MetaInfoNodeHandler, NodeHandler
+from .registry import operator_registry
+from .strategy import BinaryElementwiseStrategyGenerator, StrategyGenerator
+
+__all__ = ['BinaryElementwiseHandler']
+
+
+@operator_registry.register(BCAST_FUNC_OP)
+class BinaryElementwiseHandler(MetaInfoNodeHandler):
+ """
+ An BinaryBcastOpHandler is a node handler which deals with operations which have two
+ operands and broadcasting occurs such as torch.add.
+ """
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ bcast_shape = self.node._meta_data.shape
+
+ def _get_op_data_type(tensor):
+ if isinstance(tensor, torch.nn.parameter.Parameter):
+ return OperationDataType.PARAM
+ else:
+ return OperationDataType.ARG
+
+ def _get_arg_value(idx):
+ non_tensor = False
+ if isinstance(self.node.args[idx], Node):
+ meta_data = self.node.args[idx]._meta_data
+ # The meta_data of node type argument could also possibly be a non-tensor object.
+ if not isinstance(meta_data, torch.Tensor):
+ assert isinstance(meta_data, (int, float))
+ meta_data = torch.Tensor([meta_data]).to('meta')
+ non_tensor = True
+
+ else:
+ # this is in fact a real data like int 1
+ # but we can deem it as meta data
+ # as it won't affect the strategy generation
+ assert isinstance(self.node.args[idx], (int, float))
+ meta_data = torch.Tensor([self.node.args[idx]]).to('meta')
+ non_tensor = True
+
+ return meta_data, non_tensor
+
+ input_meta_data, non_tensor_input = _get_arg_value(0)
+ other_meta_data, non_tensor_other = _get_arg_value(1)
+ output_meta_data = self.node._meta_data
+ # we need record op_data with non-tensor data in this list,
+ # and filter the non-tensor op_data in post_process.
+ self.non_tensor_list = []
+ # assert False
+ input_op_data = OperationData(name=str(self.node.args[0]),
+ type=_get_op_data_type(input_meta_data),
+ data=input_meta_data,
+ logical_shape=bcast_shape)
+ other_op_data = OperationData(name=str(self.node.args[1]),
+ type=_get_op_data_type(other_meta_data),
+ data=other_meta_data,
+ logical_shape=bcast_shape)
+ output_op_data = OperationData(name=str(self.node),
+ type=OperationDataType.OUTPUT,
+ data=output_meta_data,
+ logical_shape=bcast_shape)
+ if non_tensor_input:
+ self.non_tensor_list.append(input_op_data)
+ if non_tensor_other:
+ self.non_tensor_list.append(other_op_data)
+
+ mapping = {'input': input_op_data, 'other': other_op_data, 'output': output_op_data}
+ return mapping
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(BinaryElementwiseStrategyGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+ def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, List[ShardingStrategy]]:
+ # convert bias from its logical sharding spec to its physical sharding spec
+ op_data_mapping = self.get_operation_data_mapping()
+
+ for op_name, op_data in op_data_mapping.items():
+ if op_data in self.non_tensor_list:
+ # remove the sharding spec if the op_data is not a tensor, e.g. torch.pow(tensor, 2)
+ strategy.sharding_specs.pop(op_data)
+
+ else:
+ # convert the logical sharding spec to physical sharding spec if broadcast
+ # e.g. torch.rand(4, 4) + torch.rand(4)
+ physical_shape = op_data.data.shape
+ logical_shape = op_data.logical_shape
+ sharding_spec = strategy.get_sharding_spec_by_name(op_data.name)
+ sharding_spec, removed_dims = recover_sharding_spec_for_broadcast_shape(
+ sharding_spec, logical_shape, physical_shape)
+
+ strategy.sharding_specs[op_data] = sharding_spec
+ if len(removed_dims) > 0:
+ comm_action = comm_actions_for_oprands(node=self.node,
+ removed_dims=removed_dims,
+ op_data=op_data,
+ sharding_spec=sharding_spec)
+ strategy.communication_actions[op_data] = comm_action
+
+ return strategy
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/bmm_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/bmm_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..da2b733c9f7afda075c10dc3dd17a0d4f42fbc01
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/bmm_handler.py
@@ -0,0 +1,110 @@
+from typing import Dict, List, Union
+
+import torch
+
+from colossalai.tensor.shape_consistency import CollectiveCommPattern, CommSpec, ShapeConsistencyManager
+
+from ..sharding_strategy import CommAction, CommType, OperationData, OperationDataType, ShardingStrategy
+from ..utils import comm_actions_for_oprands, recover_sharding_spec_for_broadcast_shape
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import BatchedMatMulStrategyGenerator, StrategyGenerator
+
+__all__ = ['BMMFunctionHandler', 'AddBMMFunctionHandler']
+
+
+def _get_data_mapping_for_bmm_op(node, input_idx, other_idx, bias_idx=None):
+ """
+ This function is a helper function which extracts the common logic for both `bmm` and `addbmm`
+ node handler to reduce code redundancy.
+ """
+ # input operand
+ physical_input_operand = OperationData(name=str(node.args[input_idx]),
+ type=OperationDataType.ARG,
+ data=node.args[input_idx]._meta_data)
+
+ # other operand
+ physical_other_operand = OperationData(name=str(node.args[other_idx]),
+ type=OperationDataType.ARG,
+ data=node.args[other_idx]._meta_data)
+
+ # output
+ physical_output = OperationData(name=str(node), type=OperationDataType.OUTPUT, data=node._meta_data)
+ mapping = {"input": physical_input_operand, "other": physical_other_operand, "output": physical_output}
+
+ if bias_idx is not None:
+ # bias physical shape
+ bias_logical_shape = node._meta_data.shape
+ physical_bias_operand = OperationData(name=str(node.args[bias_idx]),
+ type=OperationDataType.ARG,
+ data=node.args[bias_idx]._meta_data,
+ logical_shape=bias_logical_shape)
+ mapping['bias'] = physical_bias_operand
+ return mapping
+
+
+@operator_registry.register(torch.bmm)
+@operator_registry.register(torch.Tensor.bmm)
+class BMMFunctionHandler(NodeHandler):
+ """
+ This is a NodeHandler class which deals with the batched matrix multiplication operation in PyTorch.
+ Such operations including `torch.bmm` and `torch.Tensor.bmm` require the tensor to be 3D, thus, there is
+ no logical-physical shape conversion in this handler.
+ """
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ mapping = _get_data_mapping_for_bmm_op(node=self.node, input_idx=0, other_idx=1)
+ return mapping
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(BatchedMatMulStrategyGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+
+@operator_registry.register(torch.addbmm)
+@operator_registry.register(torch.Tensor.addbmm)
+class AddBMMFunctionHandler(NodeHandler):
+ """
+ This is a NodeHandler class which deals with the addition + batched matrix multiplication operation in PyTorch.
+ Such operations including `torch.addbmm` and `torch.Tensor.addbmm` require the two matmul tensor to be 3D. However, due to the
+ addition, logical-physical shape conversion is required for the bias term.
+
+ As the addbmm operation will reduce the batch dimension, the bias is maximum 2D.
+ """
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ mapping = _get_data_mapping_for_bmm_op(node=self.node, input_idx=1, other_idx=2, bias_idx=0)
+ return mapping
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generator = BatchedMatMulStrategyGenerator(op_data_mapping, self.device_mesh)
+ # addbmm will shrink the first batch dim
+ generator.squeeze_batch_dim = True
+ generators.append(generator)
+ return generators
+
+ def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, List[ShardingStrategy]]:
+ # convert bias from its logical sharding spec to its physical sharding spec
+ op_data_mapping = self.get_operation_data_mapping()
+
+ if 'bias' in op_data_mapping:
+ bias_op_data = op_data_mapping['bias']
+ bias_physical_shape = bias_op_data.data.shape
+ bias_logical_shape = bias_op_data.logical_shape
+ bias_sharding_spec = strategy.get_sharding_spec_by_name(bias_op_data.name)
+ bias_sharding_spec, removed_dims = recover_sharding_spec_for_broadcast_shape(
+ bias_sharding_spec, bias_logical_shape, bias_physical_shape)
+ strategy.sharding_specs[bias_op_data] = bias_sharding_spec
+
+ if len(removed_dims) > 0:
+ comm_action = comm_actions_for_oprands(node=self.node,
+ removed_dims=removed_dims,
+ op_data=bias_op_data,
+ sharding_spec=bias_sharding_spec)
+ strategy.communication_actions[bias_op_data] = comm_action
+
+ return strategy
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/conv_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/conv_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..272b1c85630a8ab15145e701740a44e20d5103b8
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/conv_handler.py
@@ -0,0 +1,120 @@
+from typing import Dict, List
+
+import torch
+import torch.nn.functional as F
+
+from ..sharding_strategy import OperationData, OperationDataType, ShardingStrategy, StrategiesVector
+from ..utils import transpose_partition_dim
+from .node_handler import MetaInfoModuleHandler, MetaInfoNodeHandler, ModuleHandler, NodeHandler
+from .registry import operator_registry
+from .strategy import ConvStrategyGenerator, StrategyGenerator
+
+__all__ = ['ConvModuleHandler', 'ConvFunctionHandler']
+
+
+@operator_registry.register(torch.nn.Conv1d)
+@operator_registry.register(torch.nn.Conv2d)
+@operator_registry.register(torch.nn.Conv3d)
+class ConvModuleHandler(MetaInfoModuleHandler):
+ """
+ A ConvModuleHandler which deals with the sharding strategies for nn.Convxd module.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(ConvStrategyGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.node.args[0]._meta_data)
+ logical_shape_for_weight = list(self.named_parameters["weight"].shape)
+ logical_shape_for_weight[0], logical_shape_for_weight[1] = logical_shape_for_weight[
+ 1], logical_shape_for_weight[0]
+ physical_other_operand = OperationData(name="weight",
+ type=OperationDataType.PARAM,
+ data=self.named_parameters['weight'],
+ logical_shape=torch.Size(logical_shape_for_weight))
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ mapping = {"input": physical_input_operand, "other": physical_other_operand, "output": physical_output}
+
+ if "bias" in self.named_parameters:
+ physical_bias_operand = OperationData(name="bias",
+ type=OperationDataType.PARAM,
+ data=self.named_parameters['bias'])
+ mapping['bias'] = physical_bias_operand
+ return mapping
+
+ def post_process(self, strategy: ShardingStrategy):
+ """
+ Convert the sharding spec of the weight parameter back to its original shape.
+ """
+ for op_data, sharding_spec in strategy.input_sharding_specs.items():
+ if op_data.name == "weight":
+ transpose_partition_dim(sharding_spec, 0, 1)
+ return strategy
+
+
+@operator_registry.register(F.conv1d)
+@operator_registry.register(F.conv2d)
+@operator_registry.register(F.conv3d)
+class ConvFunctionHandler(MetaInfoNodeHandler):
+ """
+ A ConvFunctionHandler which deals with the sharding strategies for nn.functional.ConvXd functions.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(ConvStrategyGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.node.args[0]._meta_data)
+
+ # check if the other operand is a parameter
+ if isinstance(self.node.args[1]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+
+ logical_shape_for_weight = list(self.node.args[1]._meta_data.shape)
+ logical_shape_for_weight[0], logical_shape_for_weight[1] = logical_shape_for_weight[
+ 1], logical_shape_for_weight[0]
+ physical_other_operand = OperationData(name=str(self.node.args[1]),
+ type=data_type,
+ data=self.node.args[1]._meta_data,
+ logical_shape=torch.Size(logical_shape_for_weight))
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ mapping = {"input": physical_input_operand, "other": physical_other_operand, "output": physical_output}
+
+ if "bias" in self.node.kwargs and self.node.kwargs['bias'] is not None:
+ # check if the other operand is a parameter
+ if isinstance(self.node.kwargs["bias"]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+ physical_bias_operand = OperationData(name=str(self.node.kwargs["bias"]),
+ type=data_type,
+ data=self.node.kwargs["bias"]._meta_data)
+ mapping['bias'] = physical_bias_operand
+ return mapping
+
+ def post_process(self, strategy: ShardingStrategy):
+ """
+ Convert the sharding spec of the weight parameter back to its original shape.
+ """
+ for op_data, sharding_spec in strategy.input_sharding_specs.items():
+ if op_data.name == str(self.node.args[1]):
+ transpose_partition_dim(sharding_spec, 0, 1)
+ return strategy
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/default_reshape_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/default_reshape_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c5b9f39e1fba75b44308d57569c3b8c0b5087c0
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/default_reshape_handler.py
@@ -0,0 +1,71 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import MetaInfoNodeHandler, NodeHandler
+from .registry import operator_registry
+from .strategy import DefaultReshapeGenerator, StrategyGenerator
+
+__all__ = ['DefaultReshapeHandler']
+
+
+@operator_registry.register(torch.flatten)
+@operator_registry.register(torch.Tensor.unsqueeze)
+@operator_registry.register(torch.nn.AdaptiveAvgPool2d)
+class DefaultReshapeHandler(MetaInfoNodeHandler):
+ """
+ A DefaultReshapeHandler which deals with the sharding strategies for Reshape Op, such as torch.reshape.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(DefaultReshapeGenerator(op_data_mapping, self.device_mesh, self.node.args[0]))
+ return generators
+
+ def infer_logical_shape(self, data):
+ """
+ This function is used to infer logical shape for operands.
+
+ Notes: This function is only used for the operands whose data are not only in type of tensor,
+ such as tuple of tensor.
+ """
+ if isinstance(data, torch.Tensor):
+ return data.shape
+ else:
+ assert isinstance(data, tuple), "input_data should be a tuple of tensor or a tensor."
+ logical_shape = []
+ for tensor in data:
+ assert isinstance(tensor, torch.Tensor), "input_data should be a tuple of tensor or a tensor."
+ logical_shape.append(tensor.shape)
+ logical_shape = tuple(logical_shape)
+ return logical_shape
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+
+ # check if the input operand is a parameter
+ if isinstance(self.node.args[0]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+
+ input_data = self.node.args[0]._meta_data
+ input_logical_shape = self.infer_logical_shape(input_data)
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=data_type,
+ data=input_data,
+ logical_shape=input_logical_shape)
+
+ output_data = self.node._meta_data
+ output_logical_shape = self.infer_logical_shape(output_data)
+ physical_output = OperationData(name=str(self.node),
+ type=OperationDataType.OUTPUT,
+ data=output_data,
+ logical_shape=output_logical_shape)
+
+ mapping = {"input": physical_input_operand, "output": physical_output}
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/embedding_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/embedding_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..e154105b672de30b5675ca56147fb6b68205a469
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/embedding_handler.py
@@ -0,0 +1,230 @@
+from typing import Dict, List, Union
+
+import torch
+import torch.nn.functional as F
+
+from colossalai.auto_parallel.tensor_shard.utils import update_partition_dim
+from colossalai.logging import get_dist_logger
+from colossalai.tensor.sharding_spec import ShardingNotDivisibleError
+
+from ..sharding_strategy import OperationData, OperationDataType, ShardingStrategy
+from .node_handler import ModuleHandler, NodeHandler
+from .registry import operator_registry
+from .strategy import EmbeddingStrategyGenerator, StrategyGenerator
+
+__all__ = ['EmbeddingModuleHandler', 'EmbeddingFunctionHandler']
+
+
+def _convert_logical_sharding_to_physical_sharding_spec_for_embedding(strategy: ShardingStrategy, input_name: str,
+ output_name: str) -> List[ShardingStrategy]:
+ """
+ This function converts the logical sharding spec to the physical sharding spec for both the input and output
+ of the embedding operation.
+
+ Args:
+ strategy (ShardingStrategy): the logical strategy generated by the strategy generator.
+ input_name (str): the name of the OperationData object for the input.
+ output_name (str): the name of the OperationData object for the output.
+ """
+ # the result will be a list of strategies
+ sharding_strategies = []
+
+ # get operation data
+ input_op_data = strategy.get_op_data_by_name(input_name)
+ output_op_data = strategy.get_op_data_by_name(output_name)
+ input_sharding_spec = strategy.get_sharding_spec_by_name(input_op_data.name)
+ output_sharding_spec = strategy.get_sharding_spec_by_name(output_op_data.name)
+
+ # recover the last logical dimension to physical dimension
+ last_logical_output_dims = len(output_op_data.logical_shape) - 1
+ last_physical_output_dims = output_op_data.data.dim() - 1
+
+ # get logger for debug message
+ logger = get_dist_logger()
+
+ # For the input of the embedding operation, it can be multi-dimensional. The sharding spec is only generated for
+ # logical 1D non-matrix dimension, the logical non-matrix dimension can belong to the 0th to Nth dimension of the
+ # physical input shape. Thus, we enumerate to get all possible cases.
+ if input_sharding_spec.dim_partition_dict:
+ # if bool(input_sharding_spec.dim_partition_dict), it means that the
+ # the generated sharding strategy does shard the non-matrix dimension,
+ # in this case, we need to do enumeration
+ num_input_dims = input_op_data.data.dim()
+ for i in range(num_input_dims):
+ strategy_copy = strategy.clone()
+ input_sharding_spec = strategy_copy.get_sharding_spec_by_name(input_op_data.name)
+ output_sharding_spec = strategy_copy.get_sharding_spec_by_name(output_op_data.name)
+ try:
+ # replace the 0th dimension in the logical sharding with ith dimension in the physical sharding
+ update_partition_dim(sharding_spec=input_sharding_spec,
+ dim_mapping={0: i},
+ physical_shape=input_op_data.data.shape,
+ inplace=True)
+
+ if last_logical_output_dims in output_sharding_spec.dim_partition_dict:
+ dim_mapping = {0: i, last_logical_output_dims: last_physical_output_dims}
+ else:
+ dim_mapping = {0: i}
+
+ update_partition_dim(sharding_spec=output_sharding_spec,
+ dim_mapping=dim_mapping,
+ physical_shape=output_op_data.data.shape,
+ inplace=True)
+
+ strategy_copy.name = f'{strategy.name}_{i}'
+ sharding_strategies.append(strategy_copy)
+
+ except ShardingNotDivisibleError as e:
+ logger.debug(
+ f'Errored occurred when converting the logical sharding spec to the physical one. Error details: {e}'
+ )
+ else:
+ # the generated sharding strategy does not shard the non-matrix dimension,
+ # in this case, we don't need to do enumeration
+ # but instead, we still need to convert the logical shape to physical shape
+ strategy_copy = strategy.clone()
+ input_sharding_spec = strategy_copy.get_sharding_spec_by_name(input_op_data.name)
+ output_sharding_spec = strategy_copy.get_sharding_spec_by_name(output_op_data.name)
+
+ # after updating, the logical shape will be replaced by the physical shape
+ update_partition_dim(sharding_spec=input_sharding_spec,
+ dim_mapping={},
+ physical_shape=input_op_data.data.shape,
+ inplace=True)
+
+ if last_logical_output_dims in output_sharding_spec.dim_partition_dict:
+ dim_mapping = {last_logical_output_dims: last_physical_output_dims}
+ else:
+ dim_mapping = {}
+
+ update_partition_dim(sharding_spec=output_sharding_spec,
+ dim_mapping=dim_mapping,
+ physical_shape=output_op_data.data.shape,
+ inplace=True)
+ sharding_strategies.append(strategy_copy)
+
+ return sharding_strategies
+
+
+@operator_registry.register(torch.nn.Embedding)
+class EmbeddingModuleHandler(ModuleHandler):
+ """
+ A EmbeddingModuleHandler which deals with the sharding strategies for nn.Embedding module.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(EmbeddingStrategyGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # In nn.Embedding operation, all the dimensions of input will be treated as the batch dimension,
+ # and then the sharding spec will be generated based on the logical 1D tensor.
+ # After that, the logical sharding info will be enumerated among all the physical dimensions.
+ # Finally, the input will be transformed back to its original shape in self.post_process
+ input_meta_data = self.node.args[0]._meta_data
+ input_logical_shape = input_meta_data.view(-1).shape
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=input_meta_data,
+ logical_shape=input_logical_shape)
+
+ physical_other_operand = OperationData(name="weight",
+ type=OperationDataType.PARAM,
+ data=self.named_parameters['weight'])
+
+ # Same as input, in nn.Embedding operation, all the dimensions of output will be treated as
+ # (batch dimension, embedding dimension), and then the sharding spec will be generated based
+ # on the logical 2D tensor.
+ # After that, the logical sharding info of batch dimension will be enumerated among all the physical dimensions.
+ # Finally, the output will be transformed back to its original shape in self.post_process
+ output_meta_data = self.node._meta_data
+ output_logical_shape = output_meta_data.view(-1, output_meta_data.shape[-1]).shape
+ physical_output = OperationData(name=str(self.node),
+ type=OperationDataType.OUTPUT,
+ data=output_meta_data,
+ logical_shape=output_logical_shape)
+
+ mapping = {"input": physical_input_operand, "other": physical_other_operand, "output": physical_output}
+
+ return mapping
+
+ def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, List[ShardingStrategy]]:
+ """
+ Convert the sharding spec from the logical shape to the physical shape.
+ """
+ # create multiple sharding strategies for the inputs
+ # as input can be multi-dimensinal and the partition dim is only 2D,
+ # we need to map the partition at logical dim 0 to one of the first few dimensions of the input and output
+ strategies = _convert_logical_sharding_to_physical_sharding_spec_for_embedding(strategy=strategy,
+ input_name=str(
+ self.node.args[0]),
+ output_name=str(self.node))
+ return strategies
+
+
+@operator_registry.register(F.embedding)
+class EmbeddingFunctionHandler(NodeHandler):
+ """
+ A EmbeddingFunctionHandler which deals with the sharding strategies for F.embedding.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(EmbeddingStrategyGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # In F.embedding operation, all the dimensions of input will be treated as the batch dimension,
+ # and then the sharding spec will be generated based on the logical 1D tensor.
+ # After that, the logical sharding info will be enumerated among all the physical dimensions.
+ # Finally, the input will be transformed back to its original shape in self.post_process
+ input_meta_data = self.node.args[0]._meta_data
+ input_logical_shape = input_meta_data.view(-1).shape
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.node.args[0]._meta_data,
+ logical_shape=input_logical_shape)
+
+ # check if the other operand is a parameter
+ if isinstance(self.node.args[1]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+
+ physical_other_operand = OperationData(name=str(self.node.args[1]),
+ type=data_type,
+ data=self.node.args[1]._meta_data)
+
+ # Same as input, in F.embedding operation, all the dimensions of output will be treated as
+ # (batch dimension, embedding dimension), and then the sharding spec will be generated based
+ # on the logical 2D tensor.
+ # After that, the logical sharding info of batch dimension will be enumerated among all the physical dimensions.
+ # Finally, the output will be transformed back to its original shape in self.post_process
+ output_meta_data = self.node._meta_data
+ output_logical_shape = output_meta_data.view(-1, output_meta_data.shape[-1]).shape
+ physical_output = OperationData(
+ name=str(self.node),
+ type=OperationDataType.OUTPUT,
+ data=self.node._meta_data,
+ logical_shape=output_logical_shape,
+ )
+
+ mapping = {"input": physical_input_operand, "other": physical_other_operand, "output": physical_output}
+
+ return mapping
+
+ def post_process(self, strategy: ShardingStrategy):
+ """
+ Convert the sharding spec from the logical shape to the physical shape.
+ """
+ # create multiple sharding strategies for the inputs
+ # as input can be multi-dimensinal and the partition dim is only 2D,
+ # we need to map the partition at logical dim 0 to one of the first few dimensions of the input and output
+ strategies = _convert_logical_sharding_to_physical_sharding_spec_for_embedding(strategy=strategy,
+ input_name=str(
+ self.node.args[0]),
+ output_name=str(self.node))
+ return strategies
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/getattr_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/getattr_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..53addb873d1d1a014352058f8ec127f6bf7c4d91
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/getattr_handler.py
@@ -0,0 +1,34 @@
+from typing import Dict, List
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import NodeHandler
+from .strategy import GetattrGenerator, StrategyGenerator
+
+__all__ = ['GetattrHandler']
+
+
+class GetattrHandler(NodeHandler):
+ """
+ A GetattrHandler which deals with the sharding strategies for Getattr Node.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(GetattrGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+
+ # There are only two possible types for get_attr node:
+ # 1. torch.Tensor(torch.nn.Parameters or torch.nn.Buffers)
+ # 2. torch.nn.Module
+ # temporarily, we just support first case in Tracer, so we don't have to worry about
+ # issue related to the node._meta_data type.
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ mapping = {"output": physical_output}
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/getitem_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/getitem_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..3466e9dd9940e748da4bc8abb3488aacf98cd8ff
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/getitem_handler.py
@@ -0,0 +1,41 @@
+import operator
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import StrategyGenerator, TensorStrategyGenerator, TensorTupleStrategyGenerator
+
+__all__ = ['GetItemHandler']
+
+
+@operator_registry.register(operator.getitem)
+class GetItemHandler(NodeHandler):
+ """
+ A GetItemHandler which deals with the sharding strategies for operator.getitem.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ if isinstance(op_data_mapping["input"].data, torch.Tensor):
+ generators.append(TensorStrategyGenerator(op_data_mapping, self.device_mesh, self.node.args[0]))
+ else:
+ generators.append(TensorTupleStrategyGenerator(op_data_mapping, self.device_mesh, self.node.args[0]))
+
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.node.args[0]._meta_data)
+ physical_other_operand = OperationData(name="index", type=OperationDataType.ARG, data=self.node.args[1])
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ mapping = {"input": physical_input_operand, "index": physical_other_operand, "output": physical_output}
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/layer_norm_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/layer_norm_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..452381169b74d093188e0f8d7775037f8bf5019c
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/layer_norm_handler.py
@@ -0,0 +1,44 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import MetaInfoModuleHandler, ModuleHandler
+from .registry import operator_registry
+from .strategy import LayerNormGenerator, StrategyGenerator
+
+__all__ = ['LayerNormModuleHandler']
+
+
+@operator_registry.register(torch.nn.LayerNorm)
+class LayerNormModuleHandler(MetaInfoModuleHandler):
+ """
+ A LayerNormModuleHandler which deals with the sharding strategies for nn.LayerNorm module.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(LayerNormGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.node.args[0]._meta_data)
+ physical_other_operand = OperationData(name="weight",
+ type=OperationDataType.PARAM,
+ data=self.named_parameters['weight'],
+ logical_shape=self.named_parameters['weight'].shape)
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ mapping = {"input": physical_input_operand, "other": physical_other_operand, "output": physical_output}
+
+ if self.named_parameters['bias'] is not None:
+ physical_bias_operand = OperationData(name="bias",
+ type=OperationDataType.PARAM,
+ data=self.named_parameters['bias'])
+ mapping['bias'] = physical_bias_operand
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/linear_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/linear_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..59091dab519f4e4458461b84e444b9a034f4df98
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/linear_handler.py
@@ -0,0 +1,275 @@
+from typing import Dict, List, Union
+
+import torch
+import torch.nn.functional as F
+
+from colossalai.auto_parallel.tensor_shard.utils import (
+ check_sharding_spec_validity,
+ transpose_partition_dim,
+ update_partition_dim,
+)
+from colossalai.logging import get_dist_logger
+from colossalai.tensor.sharding_spec import ShardingNotDivisibleError
+
+from ..sharding_strategy import OperationData, OperationDataType, ShardingStrategy, StrategiesVector
+from .node_handler import MetaInfoModuleHandler, MetaInfoNodeHandler, ModuleHandler, NodeHandler
+from .registry import operator_registry
+from .strategy import LinearProjectionStrategyGenerator, StrategyGenerator
+
+__all__ = ['LinearModuleHandler', 'LinearFunctionHandler']
+
+
+def _update_sharding_spec_for_transposed_weight_for_linear(strategy: ShardingStrategy,
+ weight_name: str) -> ShardingStrategy:
+ """
+ This function is a helper function used by both module node handler and function node handler. This function will
+ convert the sharding spec for the transposed weight to the correct partititon spec.
+
+ Args:
+ strategy (ShardingStrategy): the strategy generated by the strategy generator.
+ weight_name (str): the name of the OperationData object for the weight.
+ """
+ # switch the dimensions of the transposed weight
+ sharding_spec = strategy.get_sharding_spec_by_name(weight_name)
+ op_data = strategy.get_op_data_by_name(weight_name)
+ assert op_data.logical_shape[0] == op_data.data.shape[1] and \
+ op_data.logical_shape[1] == op_data.data.shape[0], \
+ "Expected the logical shape of the linear operator's weight is equal to transposed physical shape"
+ dim_size = len(op_data.logical_shape)
+ transpose_partition_dim(sharding_spec, 0, dim_size - 1)
+ return strategy
+
+
+def _convert_logical_sharding_to_physical_sharding_spec_for_linear(strategy: ShardingStrategy, input_name: str,
+ output_name: str) -> List[ShardingStrategy]:
+ """
+ This function converts the logical sharding spec to the physical sharding spec for both the input and output of the linear operation. The input and output
+ should have the same sharding spec.
+
+ Args:
+ strategy (ShardingStrategy): the logical strategy generated by the strategy generator.
+ input_name (str): the name of the OperationData object for the input.
+ output_name (str): the name of the OperationData object for the output.
+
+
+ """
+ # the result will be a list of strategies
+ sharding_strategies = []
+
+ # get operation data
+ input_op_data = strategy.get_op_data_by_name(input_name)
+ output_op_data = strategy.get_op_data_by_name(output_name)
+ input_sharding_spec = strategy.get_sharding_spec_by_name(input_op_data.name)
+ output_sharding_spec = strategy.get_sharding_spec_by_name(output_op_data.name)
+
+ # recover the last logical dimension to physical dimension
+ last_logical_input_dims = len(input_op_data.logical_shape) - 1
+ last_logical_output_dims = len(output_op_data.logical_shape) - 1
+ last_physical_input_dims = input_op_data.data.dim() - 1
+ last_physical_output_dims = output_op_data.data.dim() - 1
+
+ if last_logical_input_dims in input_sharding_spec.dim_partition_dict:
+ input_last_dim_mapping = {last_logical_input_dims: last_physical_input_dims}
+ else:
+ input_last_dim_mapping = {}
+
+ if last_logical_output_dims in output_sharding_spec.dim_partition_dict:
+ output_last_dim_mapping = {last_logical_output_dims: last_physical_output_dims}
+ else:
+ output_last_dim_mapping = {}
+
+ # get logger for debug message
+ logger = get_dist_logger()
+
+ # for the input of the linear operation, it can be multi-dimensional. The sharding spec generated is only
+ # 2D, where the first dimension is non-matrix dimension and the last dimension is the matrix dimension.
+ # the logical non-matrix dimension can belong to the 0th to (N-1)th dimension of the physical input shape.
+ # Thus, we enumerate to get all possible cases.
+ if 0 in input_sharding_spec.dim_partition_dict:
+ # if 0 is in the dim_partition_dict, it means that the
+ # the generated sharding strategy does shard the non-matrix dimension,
+ # in this case, we need to do enumeration
+ num_input_dims = input_op_data.data.dim()
+ for i in range(num_input_dims - 1):
+ strategy_copy = strategy.clone()
+ input_sharding_spec = strategy_copy.get_sharding_spec_by_name(input_op_data.name)
+ output_sharding_spec = strategy_copy.get_sharding_spec_by_name(output_op_data.name)
+ try:
+ # replace the 0th dimension in the logical sharding with ith dimension in the physical sharding
+ input_dim_mapping = {0: i}
+ input_dim_mapping.update(input_last_dim_mapping)
+
+ update_partition_dim(sharding_spec=input_sharding_spec,
+ dim_mapping=input_dim_mapping,
+ physical_shape=input_op_data.data.shape,
+ inplace=True)
+ output_dim_mapping = {0: i}
+ output_dim_mapping.update(output_last_dim_mapping)
+
+ update_partition_dim(sharding_spec=output_sharding_spec,
+ dim_mapping=output_dim_mapping,
+ physical_shape=output_op_data.data.shape,
+ inplace=True)
+ strategy_copy.name = f'{strategy.name}_{i}'
+ sharding_strategies.append(strategy_copy)
+ except ShardingNotDivisibleError as e:
+ logger.debug(
+ f'Errored occurred when converting the logical sharding spec to the physical one. Error details: {e}'
+ )
+ else:
+ # the generated sharding strategy does not shard the non-matrix dimension,
+ # in this case, we don't need to do enumeration
+ # but instead, we still need to convert the logical shape to physical shape
+ strategy_copy = strategy.clone()
+ input_sharding_spec = strategy_copy.get_sharding_spec_by_name(input_op_data.name)
+ output_sharding_spec = strategy_copy.get_sharding_spec_by_name(output_op_data.name)
+
+ # after updating, the logical shape will be replaced by the physical shape
+ input_dim_mapping = {}
+ input_dim_mapping.update(input_last_dim_mapping)
+ update_partition_dim(sharding_spec=input_sharding_spec,
+ dim_mapping=input_dim_mapping,
+ physical_shape=input_op_data.data.shape,
+ inplace=True)
+
+ output_dim_mapping = {}
+ output_dim_mapping.update(output_last_dim_mapping)
+ update_partition_dim(sharding_spec=output_sharding_spec,
+ dim_mapping=output_dim_mapping,
+ physical_shape=output_op_data.data.shape,
+ inplace=True)
+ sharding_strategies.append(strategy_copy)
+ return sharding_strategies
+
+
+@operator_registry.register(torch.nn.Linear)
+class LinearModuleHandler(MetaInfoModuleHandler):
+ """
+ A LinearModuleHandler which deals with the sharding strategies for nn.Linear module.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(
+ LinearProjectionStrategyGenerator(op_data_mapping,
+ self.device_mesh,
+ linear_projection_type='linear',
+ solver_perference=self.solver_perference))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ input_meta_data = self.node.args[0]._meta_data
+ input_logical_shape = input_meta_data.view(-1, input_meta_data.shape[-1]).shape
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=input_meta_data,
+ logical_shape=input_logical_shape)
+ physical_other_operand = OperationData(name="weight",
+ type=OperationDataType.PARAM,
+ data=self.named_parameters['weight'],
+ logical_shape=self.named_parameters['weight'].shape[::-1])
+ output_meta_data = self.node._meta_data
+ output_logical_shape = output_meta_data.view(-1, output_meta_data.shape[-1]).shape
+ physical_output = OperationData(name=str(self.node),
+ type=OperationDataType.OUTPUT,
+ data=output_meta_data,
+ logical_shape=output_logical_shape)
+
+ mapping = {"input": physical_input_operand, "other": physical_other_operand, "output": physical_output}
+
+ if 'bias' in self.named_parameters is not None:
+ physical_bias_operand = OperationData(name="bias",
+ type=OperationDataType.PARAM,
+ data=self.named_parameters['bias'])
+ mapping['bias'] = physical_bias_operand
+ return mapping
+
+ def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, List[ShardingStrategy]]:
+ """
+ Convert the sharding spec from the logical shape to the physical shape. In this function, two tasks are completed:
+ 1. the sharding spec is updated for the transposed weight
+ 2. the input and output sharding specs are updated to physical shape.
+ """
+ # switch the dimensions of the transposed weight
+ strategy = _update_sharding_spec_for_transposed_weight_for_linear(strategy=strategy, weight_name='weight')
+
+ # create multiple sharding strategies for the inputs
+ # as input can be multi-dimensinal and the partition dim is only 2D,
+ # we need to map the partition at dim 0 to one of the first few dimensions of the input
+ strategies = _convert_logical_sharding_to_physical_sharding_spec_for_linear(strategy=strategy,
+ input_name=str(self.node.args[0]),
+ output_name=str(self.node))
+ return strategies
+
+
+@operator_registry.register(F.linear)
+class LinearFunctionHandler(MetaInfoNodeHandler):
+ """
+ A LinearFunctionHandler which deals with the sharding strategies for F.Linear.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(
+ LinearProjectionStrategyGenerator(op_data_mapping, self.device_mesh, linear_projection_type='linear'))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ input_meta_data = self.node.args[0]._meta_data
+ input_logical_shape = input_meta_data.view(-1, input_meta_data.shape[-1]).shape
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.node.args[0]._meta_data,
+ logical_shape=input_logical_shape)
+
+ # check if the other operand is a parameter
+ if isinstance(self.node.args[1]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+
+ physical_other_operand = OperationData(name=str(self.node.args[1]),
+ type=data_type,
+ data=self.node.args[1]._meta_data,
+ logical_shape=self.node.args[1]._meta_data.shape[::-1])
+ output_meta_data = self.node._meta_data
+ output_logical_shape = output_meta_data.view(-1, output_meta_data.shape[-1]).shape
+ physical_output = OperationData(
+ name=str(self.node),
+ type=OperationDataType.OUTPUT,
+ data=self.node._meta_data,
+ logical_shape=output_logical_shape,
+ )
+
+ mapping = {"input": physical_input_operand, "other": physical_other_operand, "output": physical_output}
+
+ if 'bias' in self.node.kwargs and self.node.kwargs['bias'] is not None:
+ # check if the other operand is a parameter
+ if isinstance(self.node.kwargs["bias"]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+ physical_bias_operand = OperationData(name=str(self.node.kwargs["bias"]),
+ type=data_type,
+ data=self.node.kwargs["bias"]._meta_data)
+ mapping['bias'] = physical_bias_operand
+
+ return mapping
+
+ def post_process(self, strategy: ShardingStrategy):
+ # switch the dimensions of the transposed weight
+ strategy = _update_sharding_spec_for_transposed_weight_for_linear(strategy=strategy,
+ weight_name=str(self.node.args[1]))
+ # create multiple sharding strategies for the inputs
+ # as input can be multi-dimensinal and the partition dim is only 2D,
+ # we need to map the partition at dim 0 to one of the first few dimensions of the input
+ strategies = _convert_logical_sharding_to_physical_sharding_spec_for_linear(strategy=strategy,
+ input_name=str(self.node.args[0]),
+ output_name=str(self.node))
+ return strategies
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/matmul_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/matmul_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3c9d0cbf8267e2321415ae29887e308a9af35b2
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/matmul_handler.py
@@ -0,0 +1,488 @@
+import operator
+from abc import ABC, abstractmethod
+from copy import deepcopy
+from enum import Enum
+from functools import reduce
+from typing import Dict, List, Union
+
+import torch
+
+from colossalai.auto_parallel.tensor_shard.utils.broadcast import (
+ BroadcastType,
+ get_broadcast_dim_info,
+ get_broadcast_shape,
+)
+from colossalai.tensor.sharding_spec import ShardingSpecException
+
+from ..sharding_strategy import OperationData, OperationDataType, ShardingStrategy
+from ..utils import recover_sharding_spec_for_broadcast_shape
+from .node_handler import MetaInfoNodeHandler, NodeHandler
+from .registry import operator_registry
+from .strategy import (
+ BatchedMatMulStrategyGenerator,
+ DotProductStrategyGenerator,
+ LinearProjectionStrategyGenerator,
+ MatVecStrategyGenerator,
+ StrategyGenerator,
+)
+
+
+class MatMulType(Enum):
+ """
+ The MatMulType is categorized into 4 types based on the reference of torch.matmul
+ in https://pytorch.org/docs/stable/generated/torch.matmul.html.
+
+ DOT: dot product, both tensors are 1D, these two tensors need to have the same number of elements
+ MM: matrix-matrix product, both tensors are 2D or the 1st tensor is 1D and the 2nd tensor is 2D
+ MV: matrix-vector product: the 1st tensor is 2D and the 2nd tensor is 1D
+ BMM: batched matrix-matrix multiplication, one tensor is at least 1D and the other is at least 3D
+ """
+ DOT = 0
+ MM = 1
+ MV = 2
+ BMM = 3
+
+
+def get_matmul_type(input_dim: int, other_dim: int):
+ """
+ Determine which type of matmul operation should be executed for the given tensor dimensions.
+
+ Args:
+ input_dim (int): the number of dimensions for the input tenosr
+ other_dim (int): the number of dimensions for the other tenosr
+ """
+ if input_dim == 1 and other_dim == 1:
+ matmul_type = MatMulType.DOT
+ elif input_dim in [1, 2] and other_dim == 2:
+ matmul_type = MatMulType.MM
+ elif input_dim == 2 and other_dim == 1:
+ matmul_type = MatMulType.MV
+ elif input_dim >= 1 and other_dim >= 1 and (input_dim > 2 or other_dim > 2):
+ matmul_type = MatMulType.BMM
+ else:
+ raise ValueError(
+ f"The input and other tensors are of {input_dim} and {other_dim} which cannot used to execute matmul operation"
+ )
+ return matmul_type
+
+
+class BmmTransform(ABC):
+ """
+ BmmTransform is an abstraction of the shape conversion between logical and physical operation data
+ during the strategy generation.
+ """
+
+ @abstractmethod
+ def apply(self, shape_mapping: Dict[str, List[int]]):
+ pass
+
+ @abstractmethod
+ def recover(self, op_data_mapping: Dict[str, OperationData], strategy: ShardingStrategy):
+ pass
+
+
+class Padder(BmmTransform):
+ """
+ Add padding to the matrix dimensions for batched matrix multiplication.
+ """
+
+ def __init__(self) -> None:
+ # keep the padding dim, op_name -> padded_dim
+ self.padded_dim_mapping = {}
+
+ def apply(self, shape_mapping: Dict[str, List[int]]):
+ mapping_copy = deepcopy(shape_mapping)
+ input_shape = mapping_copy['input']
+ other_shape = mapping_copy['other']
+
+ if len(input_shape) == 1:
+ # if the input is a 1D tensor, 1 is prepended to its shape
+ # and it will be removed afterwards
+ input_shape.insert(0, 1)
+ self.padded_dim_mapping['input'] = -2
+ self.padded_dim_mapping['output'] = -2
+ elif len(other_shape) == 1:
+ # if the other is a 1D tensor, 1 is appended to its shape
+ # and it will be removed afterwards
+ other_shape = other_shape.append(1)
+ self.padded_dim_mapping['other'] = -1
+ self.padded_dim_mapping['output'] = -1
+ return mapping_copy
+
+ def recover(self, op_data_mapping: Dict[str, OperationData], strategy: ShardingStrategy):
+ input_op_data = op_data_mapping['input']
+ other_op_data = op_data_mapping['other']
+
+ def _remove_padded_dim(key, strategy):
+ op_data = op_data_mapping[key]
+ sharding_spec = strategy.get_sharding_spec_by_name(op_data.name)
+ tensor_shape = list(sharding_spec.entire_shape)
+ dim_partition_list = [None] * len(tensor_shape)
+
+ # padded dim is a negative number as the padded dim must be a matrix dim
+ padded_dim = self.padded_dim_mapping[key]
+
+ # compute the new dim partition
+ for tensor_dim, mesh_dims in sharding_spec.dim_partition_dict.items():
+ dim_partition_list[tensor_dim] = mesh_dims
+ dim_partition_list.pop(padded_dim)
+ unpadded_dim_partition_list = {k: v for k, v in enumerate(dim_partition_list) if v is not None}
+
+ # compute unpadded tensor shape
+ tensor_shape.pop(padded_dim)
+
+ assert tensor_shape == list(op_data.data.shape), f'{tensor_shape} vs {list(op_data.data.shape)}'
+
+ # update sharding spec
+ sharding_spec.__init__(sharding_spec.device_mesh, tensor_shape, unpadded_dim_partition_list)
+
+ # enumerate all sharding strategies
+ strategies = []
+ try:
+ strategy_copy = strategy.clone()
+
+ # only one of input and other will be padded
+ if 'input' in self.padded_dim_mapping:
+ _remove_padded_dim('input', strategy_copy)
+ _remove_padded_dim('output', strategy_copy)
+ elif 'other' in self.padded_dim_mapping:
+ _remove_padded_dim('other', strategy_copy)
+ _remove_padded_dim('output', strategy_copy)
+
+ strategies.append(strategy_copy)
+ except ShardingSpecException as e:
+ pass
+ return strategies
+
+
+class Broadcaster(BmmTransform):
+ """
+ Broadcast the non-matrix dimensions for batched matrix multiplication.
+ """
+
+ def __init__(self) -> None:
+ self.broadcast_dim_info = {}
+
+ def apply(self, shape_mapping: Dict[str, List[int]]):
+ mapping_copy = shape_mapping.copy()
+
+ # get shapes
+ input_shape = mapping_copy['input']
+ other_shape = mapping_copy['other']
+
+ # sanity check
+ assert len(input_shape) > 1 and len(other_shape) > 1
+
+ # broadcast the batch dim and record
+ bcast_non_matrix_dims = get_broadcast_shape(input_shape[:-2], other_shape[:-2])
+
+ # store the broadcast dim info
+ input_broadcast_dim_info = get_broadcast_dim_info(bcast_non_matrix_dims, input_shape[:-2])
+ other_broadcast_dim_info = get_broadcast_dim_info(bcast_non_matrix_dims, other_shape[:-2])
+ self.broadcast_dim_info['input'] = input_broadcast_dim_info
+ self.broadcast_dim_info['other'] = other_broadcast_dim_info
+
+ # create the full logical shape
+ input_shape = bcast_non_matrix_dims + input_shape[-2:]
+ other_shape = bcast_non_matrix_dims + other_shape[-2:]
+ assert len(input_shape) == len(other_shape)
+
+ mapping_copy['input'] = input_shape
+ mapping_copy['other'] = other_shape
+
+ return mapping_copy
+
+ def recover(self, op_data_mapping: Dict[str, OperationData], strategy: ShardingStrategy):
+ # remove sharding on the broadcast dim
+ def _remove_sharding_on_broadcast_dim(key, strategy):
+ op_data = op_data_mapping[key]
+ sharding_spec = strategy.get_sharding_spec_by_name(op_data.name)
+ tensor_shape = list(sharding_spec.entire_shape)
+
+ for dim_idx, broadcast_type in self.broadcast_dim_info[key].items():
+ if broadcast_type == BroadcastType.MULTIPLE:
+ # if the dim is originally 1 and multiplied during broadcast
+ # we set its sharding to R
+ # e.g. [1, 2, 4] x [4, 4, 8] -> [4, 2, 8]
+ # the dim 0 of [1, 2, 4] is multiplied to 4
+ tensor_shape[dim_idx] = 1
+ elif broadcast_type == BroadcastType.PADDDING:
+ # if the dim is padded
+ # we remove its sharding
+ tensor_shape[dim_idx] = None
+
+ tensor_shape_before_broadcast = [dim for dim in tensor_shape if dim is not None]
+
+ physical_sharding_spec, removed_dims = recover_sharding_spec_for_broadcast_shape(
+ logical_sharding_spec=sharding_spec,
+ logical_shape=sharding_spec.entire_shape,
+ physical_shape=tensor_shape_before_broadcast)
+ strategy.sharding_specs[op_data] = physical_sharding_spec
+
+ # enumerate all sharding strategies
+ strategies = []
+ try:
+ strategy_copy = strategy.clone()
+ _remove_sharding_on_broadcast_dim('input', strategy_copy)
+ _remove_sharding_on_broadcast_dim('other', strategy_copy)
+ strategies.append(strategy_copy)
+ except ShardingSpecException as e:
+ pass
+ return strategies
+
+
+class Viewer(BmmTransform):
+ """
+ Change the shape of the tensor from N-D to 3D
+ """
+
+ def __init__(self) -> None:
+ self.batch_dims_before_view = None
+
+ def apply(self, shape_mapping: Dict[str, List[int]]):
+ mapping_copy = shape_mapping.copy()
+ self.batch_dims_before_view = list(mapping_copy['input'][:-2])
+
+ # get shapes
+ input_shape = shape_mapping['input']
+ other_shape = shape_mapping['other']
+
+ # view to 3d tensor
+ assert len(input_shape) >= 3 and len(other_shape) >= 3
+ input_shape = [reduce(operator.mul, input_shape[:-2])] + input_shape[-2:]
+ other_shape = [reduce(operator.mul, other_shape[:-2])] + other_shape[-2:]
+ output_shape = input_shape[:2] + other_shape[2:]
+ mapping_copy['input'] = input_shape
+ mapping_copy['other'] = other_shape
+ mapping_copy['output'] = output_shape
+ return mapping_copy
+
+ def recover(self, op_data_mapping: Dict[str, OperationData], strategy: ShardingStrategy):
+ # get operation data
+ def _update_sharding_spec(key, strategy, physical_batch_dim):
+ """
+ Map the logical batch dim to the physical batch dim
+ """
+ op_data = op_data_mapping[key]
+ sharding_spec = strategy.get_sharding_spec_by_name(op_data.name)
+ dim_partition_dict = sharding_spec.dim_partition_dict
+ entire_shape = sharding_spec.entire_shape
+
+ # upddate the dimension index for the matrix dimensions
+ if 2 in dim_partition_dict:
+ dim_partition_dict[len(self.batch_dims_before_view) + 1] = dim_partition_dict.pop(2)
+ if 1 in dim_partition_dict:
+ dim_partition_dict[len(self.batch_dims_before_view)] = dim_partition_dict.pop(1)
+
+ # map the logical batch dim to phyiscal batch dim
+ if 0 in dim_partition_dict:
+ batch_dim_shard = dim_partition_dict.pop(0)
+ dim_partition_dict[physical_batch_dim] = batch_dim_shard
+
+ # the new shape will be the batch dims + the last 2 matrix dims
+ shape_before_view = self.batch_dims_before_view + list(entire_shape[-2:])
+ sharding_spec.__init__(sharding_spec.device_mesh, shape_before_view, dim_partition_dict)
+
+ num_batch_dim_before_view = len(self.batch_dims_before_view)
+
+ # enumerate all sharding strategies
+ strategies = []
+ for i in range(num_batch_dim_before_view):
+ # create a new strategy
+ strategy_copy = strategy.clone()
+ try:
+ _update_sharding_spec('input', strategy_copy, i)
+ _update_sharding_spec('other', strategy_copy, i)
+ _update_sharding_spec('output', strategy_copy, i)
+ strategies.append(strategy_copy)
+ except ShardingSpecException as e:
+ continue
+ return strategies
+
+
+def _get_bmm_logical_shape(input_shape, other_shape, transforms):
+ """
+ Compute the logical shapes for BMM operation. BMM has a general representation
+ [b, i, k] = [b, i, j] x [b, j, k]
+
+ The dimension b is called non-matrix (batch) dimension and the remaining dimensions are called matrix dimensions
+ The logical shape for the bmm operands will undergo three stages
+ 1. append/prepend the 1 to the 1D tensor if there is any
+ 2. broadcast the non-matrix dimensions
+ 3. reshape to 3 dimensions
+
+ """
+ shape_mapping = {'input': input_shape, 'other': other_shape}
+
+ for transform in transforms:
+ shape_mapping = transform.apply(shape_mapping)
+
+ input_shape = shape_mapping.get('input', None)
+ other_shape = shape_mapping.get('other', None)
+ output_shape = shape_mapping.get('output', None)
+
+ return input_shape, other_shape, output_shape
+
+
+@operator_registry.register(torch.matmul)
+@operator_registry.register(torch.Tensor.matmul)
+class MatMulHandler(MetaInfoNodeHandler):
+ """
+ The MatMulHandler is a node handler which handles the sharding strategy generation for the matmul operation.
+ According to https://pytorch.org/docs/stable/generated/torch.matmul.html, the operations will vary depending on
+ the operands.
+ """
+
+ def __init__(self, *args, **kwargs) -> None:
+ super().__init__(*args, **kwargs)
+
+ # check which type of operation this matmul will call
+ self.input_meta_data = self.node.args[0]._meta_data
+ self.other_meta_data = self.node.args[1]._meta_data
+ self.output_meta_data = self.node._meta_data
+
+ input_dim = self.input_meta_data.dim()
+ other_dim = self.other_meta_data.dim()
+ self.matmul_type = get_matmul_type(input_dim, other_dim)
+
+ if self.matmul_type == MatMulType.BMM:
+ # bmm operation can possibly involve padding, broadcasting and view
+ # these transforms will be used to create logical shape and
+ # recover physical sharding spec
+ self.transforms = [Padder(), Broadcaster(), Viewer()]
+ else:
+ self.transforms = None
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ generators = []
+ op_data_mapping = self.get_operation_data_mapping()
+ if self.matmul_type == MatMulType.BMM:
+ generators.append(BatchedMatMulStrategyGenerator(op_data_mapping, self.device_mesh))
+ elif self.matmul_type == MatMulType.DOT:
+ generators.append(DotProductStrategyGenerator(op_data_mapping, self.device_mesh))
+ elif self.matmul_type == MatMulType.MV:
+ generators.append(MatVecStrategyGenerator(op_data_mapping, self.device_mesh))
+ elif self.matmul_type == MatMulType.MM:
+ generators.append(
+ LinearProjectionStrategyGenerator(op_data_mapping, self.device_mesh, linear_projection_type='linear'))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ logical_shape_func = {
+ MatMulType.DOT: self._get_logical_shape_for_dot,
+ MatMulType.MM: self._get_logical_shape_for_mm,
+ MatMulType.MV: self._get_logical_shape_for_mv,
+ MatMulType.BMM: self._get_logical_shape_for_bmm
+ }
+ logical_shapes = logical_shape_func[self.matmul_type]()
+ op_data_mapping = self._get_op_data_mapping(*logical_shapes)
+ return op_data_mapping
+
+ def _get_op_data_mapping(self, input_logical_shape, other_logical_shape, output_logical_shape):
+ # convert list to torch.Size
+ if input_logical_shape:
+ input_logical_shape = torch.Size(input_logical_shape)
+
+ if other_logical_shape:
+ other_logical_shape = torch.Size(other_logical_shape)
+
+ if output_logical_shape:
+ output_logical_shape = torch.Size(output_logical_shape)
+
+ # create op data
+ input_op_data = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.input_meta_data,
+ logical_shape=input_logical_shape)
+ other_op_data = OperationData(name=str(self.node.args[1]),
+ type=OperationDataType.ARG,
+ data=self.other_meta_data,
+ logical_shape=other_logical_shape)
+ output_op_data = OperationData(name=str(self.node),
+ type=OperationDataType.OUTPUT,
+ data=self.output_meta_data,
+ logical_shape=output_logical_shape)
+
+ mapping = {'input': input_op_data, 'other': other_op_data, 'output': output_op_data}
+ return mapping
+
+ def _get_logical_shape_for_dot(self):
+ """
+ The operands for the dot operation have the same logical shape as the physical shape
+ """
+ return None, None, None
+
+ def _get_logical_shape_for_mm(self):
+ """
+ We need to handle the input tensor for a matrix-matrix multiplcation as the input
+ tensor can be a 1D or 2D tensor. If it is a 1D tensor, 1 will be prepended to its shape
+ (e.g. [4] -> [1, 4]).
+ """
+ if self.input_meta_data.dim() == 1:
+ input_logical_shape = [1] + list(self.input_meta_data.shape)
+ input_logical_shape = torch.Size(input_logical_shape)
+ else:
+ input_logical_shape = None
+ return input_logical_shape, None, None
+
+ def _get_logical_shape_for_mv(self):
+ """
+ No broadcasting or dim insertion occurs for matrix-vector operation.
+ """
+ return None, None, None
+
+ def _get_logical_shape_for_bmm(self):
+ input_physical_shape = list(self.input_meta_data.shape)
+ other_physical_shape = list(self.other_meta_data.shape)
+ return _get_bmm_logical_shape(input_physical_shape, other_physical_shape, self.transforms)
+
+ def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, List[ShardingStrategy]]:
+ if self.matmul_type in [MatMulType.DOT, MatMulType.MV]:
+ return strategy
+ elif self.matmul_type == MatMulType.MM:
+ if self.input_meta_data.dim() == 1:
+ # if a 1 is prepended to the input shape (this occurs when input is a 1D tensor)
+ # we need to remove that dim
+ input_sharding_spec = strategy.get_sharding_spec_by_name(str(self.node.args[0]))
+ input_physical_shape = self.node.args[0]._meta_data.shape
+ dim_partition_dict = input_sharding_spec.dim_partition_dict
+
+ # remove the partitioning in the dim 0
+ if 0 in dim_partition_dict:
+ dim_partition_dict.pop(0, None)
+
+ # move the partitioning in dim 1 to dim 0
+ if -1 in dim_partition_dict:
+ shard = dim_partition_dict.pop(-1)
+ dim_partition_dict[0] = shard
+ if 1 in dim_partition_dict:
+ shard = dim_partition_dict.pop(1)
+ dim_partition_dict[0] = shard
+
+ # re-init the sharding spec
+ input_sharding_spec.__init__(input_sharding_spec.device_mesh,
+ entire_shape=input_physical_shape,
+ dim_partition_dict=dim_partition_dict)
+ return strategy
+ else:
+ return strategy
+ elif self.matmul_type == MatMulType.BMM:
+ op_data_mapping = self.get_operation_data_mapping()
+
+ strategies = [strategy]
+ # recover the physical sharding spec
+ for transform in self.transforms[::-1]:
+ recovered_stragies = []
+ for strategy_ in strategies:
+ output = transform.recover(op_data_mapping, strategy_)
+ if isinstance(output, ShardingStrategy):
+ recovered_stragies.append(output)
+ elif isinstance(output, (list, tuple)):
+ recovered_stragies.extend(output)
+ else:
+ raise TypeError(
+ f"Found unexpected output type {type(output)} from the recover method of BmmTransform")
+ strategies = recovered_stragies
+ for index, strategies in enumerate(strategies):
+ strategies.name = f"{strategies.name}_{index}"
+ return strategies
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab391ebfaf80960ef49a4e9c4761c76f82567d25
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
@@ -0,0 +1,338 @@
+from abc import ABC, abstractmethod
+from typing import Dict, List, Tuple, Union
+
+import torch
+from torch.fx.node import Node
+
+from colossalai.auto_parallel.meta_profiler.shard_metainfo import ShardMetaInfo, meta_register
+from colossalai.auto_parallel.tensor_shard.options import ShardOption, SolverPerference
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ OperationData,
+ OperationDataType,
+ ShardingSpec,
+ ShardingStrategy,
+ StrategiesVector,
+ TrainCycleItem,
+)
+from colossalai.auto_parallel.tensor_shard.utils import check_sharding_spec_validity
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.logging import get_dist_logger
+from colossalai.tensor.shape_consistency import ShapeConsistencyManager
+
+from .strategy import StrategyGenerator
+
+
+class NodeHandler(ABC):
+ '''
+ The NodeHandler is an abstract class used to generate every possible strategies for an operator node.
+
+ Args:
+ node (Node): the input node in node argument list.
+ device_mesh (DeviceMesh): A logical view of a physical mesh.
+ strategies_vector (StrategiesVector): all the strategies generated in this handler will be recorded into the strategies_vector.
+ '''
+
+ def __init__(self,
+ node: Node,
+ device_mesh: DeviceMesh,
+ strategies_vector: StrategiesVector,
+ shard_option: ShardOption = ShardOption.STANDARD,
+ solver_perference: SolverPerference = SolverPerference.STANDARD) -> None:
+ self.node = node
+ self.predecessor_node = list(node._input_nodes.keys())
+ self.successor_node = list(node.users.keys())
+ self.device_mesh = device_mesh
+ self.strategies_vector = strategies_vector
+ self.shard_option = shard_option
+ self.solver_perference = solver_perference
+
+ def update_resharding_cost(self, strategy: ShardingStrategy) -> None:
+ """
+ Compute the resharding costs and save the costs in the ShardingStrategy object.
+ """
+ # TODO: test this function when other handlers are ready
+ resharding_costs = {}
+ shape_consistency_manager = ShapeConsistencyManager()
+
+ for node in self.predecessor_node:
+ node_name = str(node)
+ # get the current sharding spec generated by this node handler
+
+ # we will not compute the resharding costs for the node not counted in the strategy.
+ # And the node with tuple or list output need to be handled below.
+ node_in_strategy = [op_data.name for op_data in strategy.sharding_specs.keys()]
+ if str(node) not in node_in_strategy:
+ continue
+
+ op_data = strategy.get_op_data_by_name(node_name)
+ current_sharding_spec = strategy.sharding_specs[op_data]
+ # get the sharding specs for this node generated
+ # in its own node handler
+ assert hasattr(node, 'strategies_vector'), \
+ f'The predecessor node {node_name} has no strategy vector to compute the resharding cost.'
+ prev_strategy_vector = node.strategies_vector
+ prev_sharding_specs = [
+ prev_strategy.get_sharding_spec_by_name(node_name) for prev_strategy in prev_strategy_vector
+ ]
+
+ # create data structrure to store costs
+ if node not in resharding_costs:
+ resharding_costs[node] = []
+
+ def _compute_resharding_cost(
+ prev_sharding_spec: Union[ShardingSpec,
+ List[ShardingSpec]], current_sharding_spec: Union[ShardingSpec,
+ List[ShardingSpec]],
+ data: Union[torch.Tensor, List[torch.Tensor], Tuple[torch.Tensor]]) -> TrainCycleItem:
+ """
+ This is a helper function to compute the resharding cost for a specific strategy of a node.
+ """
+ if prev_sharding_spec is None:
+ return TrainCycleItem(fwd=0, bwd=0, total=0)
+ elif isinstance(prev_sharding_spec, ShardingSpec):
+ if isinstance(data, torch.Tensor):
+ dtype = data.dtype
+ size_per_elem_bytes = torch.tensor([], dtype=dtype).element_size()
+ _, _, consistency_cost = shape_consistency_manager.shape_consistency(
+ prev_sharding_spec, current_sharding_spec)
+
+ resharding_cost = TrainCycleItem(fwd=consistency_cost["forward"] * size_per_elem_bytes,
+ bwd=consistency_cost["backward"] * size_per_elem_bytes,
+ total=consistency_cost["total"] * size_per_elem_bytes)
+ return resharding_cost
+ else:
+ # This raise is used to check if we have missed any type of data.
+ # It could be merged into Parameter branch, which means we won't handle
+ # non-tensor arguments.
+ raise ValueError(f'Unsupported data type {type(data)}')
+ else:
+ assert isinstance(prev_sharding_spec, (tuple, list)), \
+ f'prev_sharding_spec should be in type of ShardingSpec, List[ShardingSpec], \
+ or Tuple[ShardingSpec], but got {type(prev_sharding_spec)}'
+
+ fwd_cost = 0
+ bwd_cost = 0
+ total_cost = 0
+ for index, (prev_sharding_spec_item,
+ current_sharding_spec_item) in enumerate(zip(prev_sharding_spec,
+ current_sharding_spec)):
+ item_cost = _compute_resharding_cost(prev_sharding_spec_item, current_sharding_spec_item,
+ data[index])
+ fwd_cost += item_cost.fwd
+ bwd_cost += item_cost.bwd
+ total_cost += item_cost.total
+ resharding_cost = TrainCycleItem(fwd=fwd_cost, bwd=bwd_cost, total=total_cost)
+ return resharding_cost
+
+ # for each sharding spec generated by the predecessor's node handler
+ # compute the resharding cost to switch to the sharding spec generated
+ # by the current node handler
+ for prev_sharding_spec in prev_sharding_specs:
+ resharding_cost = _compute_resharding_cost(prev_sharding_spec, current_sharding_spec, op_data.data)
+ resharding_costs[node].append(resharding_cost)
+ strategy.resharding_costs = resharding_costs
+ return strategy
+
+ def get_target_function(self) -> callable:
+ """
+ This function is used to get the target function for the node handler.
+ The target function is used to analyze the costs of strategies.
+ """
+ if self.node.op in ('placeholder', 'get_attr', 'output'):
+ return None
+
+ if self.node.op == 'call_module':
+ target = self.node.graph.owning_module.get_submodule(self.node.target)
+ elif self.node.op == 'call_function':
+ target = self.node.target
+ elif self.node.op == 'call_method':
+ target = getattr(self.node.args[0]._meta_data.__class__, self.node.target)
+ else:
+ raise ValueError(f'Unsupported node type: {self.node.op}')
+
+ return target
+
+ def register_strategy(self, compute_resharding_cost: bool = True) -> StrategiesVector:
+ """
+ Register different sharding strategies for the current node.
+ """
+ strategy_generators = self.get_strategy_generator()
+ for generator in strategy_generators:
+ strategies = generator.generate()
+
+ # postprocess a strategy
+ # postprocess can produce one strategy or multiple strategies
+ post_processed_strategies_map = map(self.post_process, strategies)
+ post_processed_strategies = []
+
+ for strategy in post_processed_strategies_map:
+ if isinstance(strategy, (list, tuple)):
+ post_processed_strategies.extend(strategy)
+ else:
+ post_processed_strategies.append(strategy)
+
+ # compute the resharding costs based on the previous node
+ # strategies if specified
+ if compute_resharding_cost:
+ updated_strategies = map(self.update_resharding_cost, post_processed_strategies)
+ post_processed_strategies = list(updated_strategies)
+
+ self.strategies_vector.extend(post_processed_strategies)
+
+ # validating the correctness of the sharding strategy
+ for strategy in self.strategies_vector:
+ for op_data, sharding_spec in strategy.sharding_specs.items():
+ if op_data.data is not None and isinstance(op_data.data, torch.Tensor):
+ check_sharding_spec_validity(sharding_spec, op_data.data)
+
+ remove_strategy_list = []
+ for strategy in self.strategies_vector:
+ shard_axis_list = []
+ last_axis = len(self.device_mesh.mesh_shape) - 1
+ for op_data, sharding_spec in strategy.sharding_specs.items():
+ if op_data.data is not None and isinstance(op_data.data, torch.Tensor):
+ for dim, shard_axes in sharding_spec.dim_partition_dict.items():
+ for shard_axis in shard_axes:
+ if shard_axis not in shard_axis_list:
+ shard_axis_list.append(shard_axis)
+
+ shard_level = len(shard_axis_list)
+ using_last_axis = last_axis in shard_axis_list or -1 in shard_axis_list
+ if self.shard_option == ShardOption.SHARD and shard_level == 0:
+ remove_strategy_list.append(strategy)
+ if self.shard_option == ShardOption.FULL_SHARD and shard_level <= 1:
+ remove_strategy_list.append(strategy)
+ if self.shard_option == ShardOption.SHARD_LAST_AXIS:
+ if shard_level != 1 or using_last_axis == False:
+ remove_strategy_list.append(strategy)
+
+ for strategy in remove_strategy_list:
+ self.strategies_vector.remove(strategy)
+
+ return self.strategies_vector
+
+ def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, List[ShardingStrategy]]:
+ # tranform the strategy generated
+ # e.g. to process the sharding strategy for the transposed weights
+ return strategy
+
+ @abstractmethod
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ """
+ Define which generators should be used by this NodeHandler object.
+ """
+ pass
+
+ @abstractmethod
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ """
+ Returns the mapping between the logical operation data to its physical data.
+ A logical operation data is a data associated with an operation, which can be input and output. It is
+ defined by the strategy generator, for example, a matrix multiplication operation has two operands "input"
+ and "other" and one result "output". For a nn.Linear module, the physical operand for "input" is
+ the module input, the physical operand for "other" is the module weight, and the physical result for "output"
+ is the module output.
+ Note that the operand name is specified by the StrategyGenerator object.
+
+ For example:
+
+ # for a linear layer
+ mapping = {
+ "input": Operand(name=str(self.node.args[0]), type=OperationDataType.ARG, data=self.node.args[0]._meta_data),
+ "other": Operand(name="weight", type=OperationDataType.PARAM, data=self.named_parameters['weight']),
+ "bias": Operand(name="bias", type=OperationDataType.PARAM, data=self.named_parameters['bias']),
+ "output": Operand(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data),
+ }
+ """
+ pass
+
+
+class MetaInfoNodeHandler(NodeHandler):
+ """
+ This is a base class to handle the nodes patched in the meta profiler.
+
+ Note: this class will be integrated into the NodeHandler class in the future, after
+ all the functions are patched.
+ """
+
+ def register_strategy(self, compute_resharding_cost: bool = True) -> StrategiesVector:
+ """
+ This method is inherited from NodeHandler. It will register the strategies first,
+ and rewrite the memory_cost and compute_cost of the strategy using the ShardMetaInfo class.
+ """
+ super().register_strategy(compute_resharding_cost=compute_resharding_cost)
+ target = self.get_target_function()
+ # Currently we haven't patched all the torch functions and modules, so if the target
+ # is not patched, we will use the default cost model to compute the cost.
+ # TODO: patch all torch functions and modules to make it clean
+ if meta_register.has(target.__class__) or meta_register.has(target):
+ strategies_info = []
+ for strategy in self.strategies_vector:
+ metainfo = ShardMetaInfo(strategy, target)
+ strategy.compute_cost = metainfo.compute_cost
+ strategy.memory_cost = metainfo.memory_cost
+ strategies_info.append(metainfo)
+
+ # attach metainfos to the handler
+ setattr(self, "strategies_info", strategies_info)
+
+ else:
+ logger = get_dist_logger()
+ logger.warning(f'The target function {target} is not patched yet, ')
+
+ return self.strategies_vector
+
+
+class ModuleHandler(NodeHandler):
+
+ def __init__(self, *args, **kwargs) -> None:
+ super().__init__(*args, **kwargs)
+
+ # set attributes to access module parameters for convenience
+ assert self.node.graph.owning_module is not None, \
+ f'The graph is not associated with a module, please make sure it can be used to instantiate a GraphModule object.'
+ module = self.node.graph.owning_module.get_submodule(self.node.target)
+ named_parameters = list(module.named_parameters(recurse=False))
+ named_buffers = list(module.named_buffers(recurse=False))
+ # convert named parameters from list to dict
+ named_parameters = {k: v for k, v in named_parameters}
+ named_buffers = {k: v for k, v in named_buffers}
+ self.module = module
+ self.named_parameters = named_parameters
+ self.named_buffers = named_buffers
+
+
+class MetaInfoModuleHandler(ModuleHandler):
+ """
+ This is a base class to handle the module patched in the meta profiler.
+
+ Note: this class will be integrated into the ModuleHandler class in the future, after
+ all the modules are patched.
+ """
+
+ def register_strategy(self, compute_resharding_cost: bool = True) -> StrategiesVector:
+ """
+ This method is inherited from NodeHandler. It will register the strategies first,
+ and rewrite the memory_cost and compute_cost of the strategy using the ShardMetaInfo class.
+ """
+ super().register_strategy(compute_resharding_cost=compute_resharding_cost)
+ target = self.get_target_function()
+ # Currently we haven't patched all the torch functions and modules, so if the target
+ # is not patched, we will use the default cost model to compute the cost.
+ # TODO: patch all torch functions and modules to make it clean
+ if meta_register.has(target.__class__) or meta_register.has(target):
+ strategies_info = []
+ for strategy in self.strategies_vector:
+ metainfo = ShardMetaInfo(strategy, target)
+ strategy.compute_cost = metainfo.compute_cost
+ strategy.memory_cost = metainfo.memory_cost
+ strategies_info.append(metainfo)
+
+ # attach metainfos to the handler
+ setattr(self, "strategies_info", strategies_info)
+
+ else:
+ logger = get_dist_logger()
+ logger.warning(f'The target function {target} is not patched yet')
+
+ return self.strategies_vector
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/normal_pooling_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/normal_pooling_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..4e71ccba95a7e6457309a455986400dc49893d18
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/normal_pooling_handler.py
@@ -0,0 +1,41 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import MetaInfoModuleHandler, ModuleHandler
+from .registry import operator_registry
+from .strategy import NormalPoolStrategyGenerator, StrategyGenerator
+
+__all__ = ['NormPoolingHandler']
+
+
+@operator_registry.register(torch.nn.MaxPool1d)
+@operator_registry.register(torch.nn.MaxPool2d)
+@operator_registry.register(torch.nn.MaxPool1d)
+@operator_registry.register(torch.nn.AvgPool1d)
+@operator_registry.register(torch.nn.AvgPool2d)
+@operator_registry.register(torch.nn.AvgPool3d)
+class NormPoolingHandler(MetaInfoModuleHandler):
+ """
+ A NormPoolingHandler which deals with the sharding strategies for nn.MaxPoolxd module.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(NormalPoolStrategyGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.node.args[0]._meta_data)
+ physical_weight_operand = OperationData(name="kernel", type=OperationDataType.ARG, data=self.module.kernel_size)
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ mapping = {"input": physical_input_operand, "other": physical_weight_operand, "output": physical_output}
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/output_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/output_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed120a8c3d6df9b5d10f44f2b86be1c3cf283c10
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/output_handler.py
@@ -0,0 +1,52 @@
+from typing import Dict, List
+
+import torch
+
+from colossalai.device.device_mesh import DeviceMesh
+
+from ..sharding_strategy import OperationData, OperationDataType, StrategiesVector
+from .node_handler import NodeHandler
+from .strategy import OutputGenerator, StrategyGenerator
+
+__all__ = ['OutputHandler']
+
+
+class OutputHandler(NodeHandler):
+ """
+ A OutputHandler which deals with the sharding strategies for Output Node.
+ """
+
+ def __init__(self, node: torch.fx.node.Node, device_mesh: DeviceMesh, strategies_vector: StrategiesVector,
+ output_option: str) -> None:
+ super().__init__(node, device_mesh, strategies_vector)
+ self.output_option = output_option
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(OutputGenerator(op_data_mapping, self.device_mesh, self.predecessor_node, self.output_option))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ mapping = {}
+ output_meta_data = []
+ for index, input_node in enumerate(self.predecessor_node):
+ input_meta_data = input_node._meta_data
+ physical_inputs = OperationData(name=str(input_node), type=OperationDataType.ARG, data=input_meta_data)
+ name_key = f'input_{index}'
+ mapping[name_key] = physical_inputs
+ output_meta_data.append(input_meta_data)
+
+ assert len(output_meta_data) > 0, f'Output node {self.node} has no input node.'
+ if len(output_meta_data) == 1:
+ output_meta_data = output_meta_data[0]
+ else:
+ output_meta_data = tuple(output_meta_data)
+
+ self.node._meta_data = output_meta_data
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ mapping["output"] = physical_output
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/permute_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/permute_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..91e4a5105a08ff7d28cebba41f4962daa951259c
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/permute_handler.py
@@ -0,0 +1,75 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import PermuteGenerator, StrategyGenerator
+
+__all__ = ['PermuteHandler']
+
+
+@operator_registry.register(torch.Tensor.permute)
+@operator_registry.register(torch.permute)
+class PermuteHandler(NodeHandler):
+ """
+ A PermuteHandler which deals with the sharding strategies for torch.permute or torch.transpose.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(PermuteGenerator(op_data_mapping, self.device_mesh, self.node.args[0]))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # check if the input operand is a parameter
+ if isinstance(self.node.args[0]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+
+ input_data = self.node.args[0]._meta_data
+ physical_input_operand = OperationData(name=str(self.node.args[0]), type=data_type, data=input_data)
+
+ permute_dims = []
+ if self.node.op == 'call_method':
+ # torch.Tensor.permute (input, *dims)
+ for arg in self.node.args:
+ if isinstance(arg, torch.fx.Node):
+ if isinstance(arg._meta_data, int):
+ permute_dims.append(arg._meta_data)
+ else:
+ assert isinstance(arg, int), 'The argument in permute node should be either type of Node or int.'
+ permute_dims.append(arg)
+ else:
+ # torch.permute (input, dims)
+ for arg in self.node.args:
+ if isinstance(arg, torch.fx.Node):
+ if isinstance(arg._meta_data, (tuple, list)):
+ permute_dims.extend(arg._meta_data)
+ else:
+ assert isinstance(
+ arg,
+ (tuple, list)), 'The argument in permute node should be type of Node, Tuple[int] or List[int].'
+ permute_dims.extend(arg)
+
+ num_dims = self.node._meta_data.dim()
+ for i in range(num_dims):
+ # recover negative value to positive
+ if permute_dims[i] < 0:
+ permute_dims[i] += num_dims
+
+ physical_shape_operand = OperationData(name='permute_dims', type=OperationDataType.ARG, data=list(permute_dims))
+
+ output_data = self.node._meta_data
+ physical_output_operand = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=output_data)
+
+ mapping = {
+ "input": physical_input_operand,
+ "permute_dims": physical_shape_operand,
+ "output": physical_output_operand
+ }
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/placeholder_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/placeholder_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4f40fc935a404dd8625c82fbb4dc7511c9fc839
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/placeholder_handler.py
@@ -0,0 +1,38 @@
+from typing import Dict, List
+
+from torch.fx.node import Node
+
+from colossalai.device.device_mesh import DeviceMesh
+
+from ..sharding_strategy import OperationData, OperationDataType, StrategiesVector
+from .node_handler import NodeHandler
+from .strategy import PlaceholderGenerator, StrategyGenerator
+
+__all__ = ['PlaceholderHandler']
+
+
+class PlaceholderHandler(NodeHandler):
+ """
+ A PlaceholderHandler which deals with the sharding strategies for Placeholder Node.
+ """
+
+ def __init__(self, node: Node, device_mesh: DeviceMesh, strategies_vector: StrategiesVector,
+ placeholder_option: str) -> None:
+ super().__init__(node, device_mesh, strategies_vector)
+ self.placeholder_option = placeholder_option
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(
+ PlaceholderGenerator(op_data_mapping, self.device_mesh, placeholder_option=self.placeholder_option))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ mapping = {"output": physical_output}
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/registry.py b/colossalai/auto_parallel/tensor_shard/node_handler/registry.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e06cec4f463a8600b2abe1a7f6713ec2ffb2931
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/registry.py
@@ -0,0 +1,30 @@
+class Registry:
+ # TODO: refactor the registry classes used in colossalai.registry, colossalai.fx and here
+
+ def __init__(self, name):
+ self.name = name
+ self.store = {}
+
+ def register(self, source):
+
+ def wrapper(func):
+ if isinstance(source, (list, tuple)):
+ # support register a list of items for this func
+ for element in source:
+ self.store[element] = func
+ else:
+ self.store[source] = func
+ return func
+
+ return wrapper
+
+ def get(self, source):
+ assert source in self.store, f'{source} not found in the {self.name} registry'
+ target = self.store[source]
+ return target
+
+ def has(self, source):
+ return source in self.store
+
+
+operator_registry = Registry('operator')
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/softmax_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/softmax_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..743a1f90eaafa869b3a62882648cbde53f9e3166
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/softmax_handler.py
@@ -0,0 +1,55 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import SoftmaxGenerator, StrategyGenerator
+
+__all__ = ['SoftmaxHandler']
+
+
+@operator_registry.register(torch.nn.Softmax)
+@operator_registry.register(torch.nn.functional.softmax)
+class SoftmaxHandler(NodeHandler):
+ """
+ A SoftmaxHandler which deals with the sharding strategies for
+ torch.nn.Softmax or torch.nn.functional.softmax.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(SoftmaxGenerator(op_data_mapping, self.device_mesh, self.node.args[0]))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # check if the input operand is a parameter
+ if isinstance(self.node.args[0]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+
+ input_data = self.node.args[0]._meta_data
+ physical_input_operand = OperationData(name=str(self.node.args[0]), type=data_type, data=input_data)
+
+ softmax_dim = self.node.kwargs['dim']
+
+ num_dims = self.node.args[0]._meta_data.dim()
+ # recover negative value to positive
+ if softmax_dim < 0:
+ softmax_dim += num_dims
+
+ physical_dim_operand = OperationData(name='softmax_dim', type=OperationDataType.ARG, data=softmax_dim)
+
+ output_data = self.node._meta_data
+ physical_output_operand = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=output_data)
+
+ mapping = {
+ "input": physical_input_operand,
+ "softmax_dim": physical_dim_operand,
+ "output": physical_output_operand
+ }
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/split_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/split_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..653d158b7c36ee1ff27791add2edad4093ce8675
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/split_handler.py
@@ -0,0 +1,62 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import SplitGenerator, StrategyGenerator
+
+__all__ = ['SplitHandler']
+
+
+@operator_registry.register(torch.Tensor.split)
+@operator_registry.register(torch.split)
+class SplitHandler(NodeHandler):
+ """
+ A SplitHandler which deals with the sharding strategies for torch.permute or torch.split.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(SplitGenerator(op_data_mapping, self.device_mesh, self.node.args[0]))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # check if the input operand is a parameter
+ if isinstance(self.node.args[0]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+
+ input_data = self.node.args[0]._meta_data
+ physical_input_operand = OperationData(name=str(self.node.args[0]), type=data_type, data=input_data)
+ split_size = self.node.args[1]
+ if len(self.node.args) == 3:
+ # (input, split_size, split_dim)
+ split_dim = self.node.args[2]
+ else:
+ if self.node.kwargs:
+ split_dim = self.node.kwargs['dim']
+ else:
+ split_dim = 0
+
+ num_dims = self.node.args[0]._meta_data.dim()
+ # recover negative value to positive
+ if split_dim < 0:
+ split_dim += num_dims
+
+ split_info = (split_size, split_dim)
+ physical_shape_operand = OperationData(name='split_info', type=OperationDataType.ARG, data=split_info)
+
+ output_data = self.node._meta_data
+ physical_output_operand = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=output_data)
+
+ mapping = {
+ "input": physical_input_operand,
+ "split_info": physical_shape_operand,
+ "output": physical_output_operand
+ }
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/__init__.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..db1f31521c86ef1842e93d9bbdbc58953e11934d
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/__init__.py
@@ -0,0 +1,39 @@
+from .batch_norm_generator import BatchNormStrategyGenerator
+from .binary_elementwise_generator import BinaryElementwiseStrategyGenerator
+from .conv_strategy_generator import ConvStrategyGenerator
+from .embedding_generator import EmbeddingStrategyGenerator
+from .getattr_generator import GetattrGenerator
+from .getitem_generator import GetItemStrategyGenerator, TensorStrategyGenerator, TensorTupleStrategyGenerator
+from .layer_norm_generator import LayerNormGenerator
+from .matmul_strategy_generator import (
+ BatchedMatMulStrategyGenerator,
+ DotProductStrategyGenerator,
+ LinearProjectionStrategyGenerator,
+ MatVecStrategyGenerator,
+)
+from .normal_pooling_generator import NormalPoolStrategyGenerator
+from .output_generator import OutputGenerator
+from .placeholder_generator import PlaceholderGenerator
+from .reshape_generator import (
+ DefaultReshapeGenerator,
+ PermuteGenerator,
+ SplitGenerator,
+ TransposeGenerator,
+ ViewGenerator,
+)
+from .softmax_generator import SoftmaxGenerator
+from .strategy_generator import StrategyGenerator
+from .sum_generator import SumGenerator
+from .tensor_constructor_generator import TensorConstructorGenerator
+from .unary_elementwise_generator import UnaryElementwiseGenerator
+from .where_generator import WhereGenerator
+
+__all__ = [
+ 'StrategyGenerator', 'DotProductStrategyGenerator', 'MatVecStrategyGenerator', 'LinearProjectionStrategyGenerator',
+ 'BatchedMatMulStrategyGenerator', 'ConvStrategyGenerator', 'UnaryElementwiseGenerator',
+ 'BatchNormStrategyGenerator', 'GetItemStrategyGenerator', 'TensorStrategyGenerator', 'TensorTupleStrategyGenerator',
+ 'LayerNormGenerator', 'PlaceholderGenerator', 'OutputGenerator', 'WhereGenerator', 'NormalPoolStrategyGenerator',
+ 'BinaryElementwiseStrategyGenerator', 'GetattrGenerator', 'TensorConstructorGenerator',
+ 'EmbeddingStrategyGenerator', 'SumGenerator', 'SoftmaxGenerator', 'ViewGenerator', 'PermuteGenerator',
+ 'TransposeGenerator', 'SplitGenerator', 'DefaultReshapeGenerator'
+]
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..1f3812429fc274064163f5859d0fedb04f8115fb
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/batch_norm_generator.py
@@ -0,0 +1,350 @@
+import copy
+import operator
+from functools import reduce
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommType,
+ MemoryCost,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.auto_parallel.tensor_shard.utils import ignore_sharding_exception
+from colossalai.tensor.shape_consistency import CollectiveCommPattern
+
+from .strategy_generator import StrategyGenerator
+
+__all__ = ['BatchNormStrategyGenerator']
+
+
+class BatchNormStrategyGenerator(StrategyGenerator):
+ """
+ A StrategyGenerator which deals with the sharding strategies of batch normalization.
+
+ To keep the math consistency, there are two way to do BatchNorm if the input
+ shards on batch dimension:
+ 1. We gather the input partitions through batch dimension, then do the normal BatchNorm.
+ 2. We do the SyncBatchNorm on the each input partition seperately, the SyncBN op will help
+ us to keep the computing correctness.
+ In this generator, both methods will be considered.
+ """
+
+ def validate(self) -> bool:
+ '''
+ In sanity check, we need make sure the input data having correct dimension size.
+ For BatchNorm1d, the dim of input data should be 3([N, C, L]).
+ For BatchNorm2d, the dim of input data should be 4([N, C, H, W]).
+ For BatchNorm3d, the dim of input data should be 5([N, C, H, W, D]).
+ '''
+ input_op_data = self.op_data['input']
+ assert input_op_data.data.dim() in (
+ 3, 4, 5), f'We suppose the dim of input fed into conv op should in range of [3, 5].'
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the computation cost per device with this specific strategy.
+
+ Note: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ '''
+ # TODO: a constant coefficient need to be added.
+ # 1D: (L) * N * Cin
+ # 2D: (H * W) * N * Cin
+ # 3D: (H * W * D) * N * Cin
+ sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+ sharded_output_shape = strategy.sharding_specs[self.op_data['output']].get_sharded_shape_per_device()
+ if self.has_bias:
+ # bias add is an element wise operation, so the cost is equal to product of output shape.
+ bias_compute_cost = reduce(operator.mul, sharded_output_shape)
+ input_product = reduce(operator.mul, sharded_input_shape, 1)
+ forward_compute_cost = input_product
+ backward_activation_compute_cost = input_product
+ backward_weight_compute_cost = input_product
+ backward_compute_cost = backward_weight_compute_cost + backward_activation_compute_cost
+ if self.has_bias:
+ forward_compute_cost += bias_compute_cost
+ backward_compute_cost += bias_compute_cost
+ total_compute_cost = forward_compute_cost + backward_compute_cost
+ compute_cost = TrainCycleItem(fwd=forward_compute_cost, bwd=backward_compute_cost, total=total_compute_cost)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ forward_size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'other': self._compute_size_in_bytes(strategy, "other"),
+ 'output': self._compute_size_in_bytes(strategy, "output"),
+ 'running_mean': self._compute_size_in_bytes(strategy, "running_mean"),
+ 'running_var': self._compute_size_in_bytes(strategy, "running_var"),
+ }
+
+ if self.has_bias:
+ bias_size = self._compute_size_in_bytes(strategy, "bias")
+ forward_size_mapping['bias'] = bias_size
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = input + other + bias + output
+ fwd_activation_cost = sum(
+ [v for k, v in forward_size_mapping.items() if not self.is_param(k) and not self.is_buffer(k)])
+ fwd_parameter_cost = sum([v for k, v in forward_size_mapping.items() if self.is_param(k)])
+ fwd_buffer_cost = sum([v for k, v in forward_size_mapping.items() if self.is_buffer(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost, buffer=fwd_buffer_cost)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad + other_grad + bias_grad
+ bwd_activation_cost = sum(
+ [v for k, v in backward_size_mapping.items() if not self.is_param(k) and not self.is_buffer(k)])
+ bwd_parameter_cost = sum([v for k, v in backward_size_mapping.items() if self.is_param(k)])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=bwd_parameter_cost)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost,
+ parameter=fwd_parameter_cost + bwd_parameter_cost,
+ buffer=fwd_buffer_cost)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ @ignore_sharding_exception
+ def split_input_channel(self, mesh_dim_0):
+ name = f'RS{mesh_dim_0} = RS{mesh_dim_0} x S{mesh_dim_0}'
+ dim_partition_dict_mapping = {
+ "input": {
+ 1: [mesh_dim_0]
+ },
+ "other": {
+ 0: [mesh_dim_0]
+ },
+ "output": {
+ 1: [mesh_dim_0]
+ },
+ "running_mean": {
+ 0: [mesh_dim_0]
+ },
+ "running_var": {
+ 0: [mesh_dim_0]
+ },
+ "num_batches_tracked": {},
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {0: [mesh_dim_0]}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ communication_action_mapping = {}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_input_channel_1d(self, mesh_dim_0, mesh_dim_1):
+ name = f'RS{mesh_dim_0}{mesh_dim_1} = RS{mesh_dim_0}{mesh_dim_1} x S{mesh_dim_0}{mesh_dim_1}'
+ dim_partition_dict_mapping = {
+ "input": {
+ 1: [mesh_dim_0, mesh_dim_1]
+ },
+ "other": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ "output": {
+ 1: [mesh_dim_0, mesh_dim_1]
+ },
+ "running_mean": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ "running_var": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ "num_batches_tracked": {},
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {0: [mesh_dim_0, mesh_dim_1]}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ communication_action_mapping = {}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def non_split(self):
+ name = f'RR = RR x R'
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {},
+ "output": {},
+ "running_mean": {},
+ "running_var": {},
+ "num_batches_tracked": {},
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ communication_action_mapping = {}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_input_batch(self, mesh_dim_0):
+ name = f'S{mesh_dim_0}R = S{mesh_dim_0}R x R WITH SYNC_BN'
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0]
+ },
+ "other": {},
+ "output": {
+ 0: [mesh_dim_0]
+ },
+ "running_mean": {},
+ "running_var": {},
+ "num_batches_tracked": {},
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ # For SyncBN case, we don't need to do communication for weight and bias.
+ # TODO: the communication happens interally at SyncBN operation. We need to replace the BN operation
+ # to SyncBN operation instead of inserting a communication node.
+ output_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["output"],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.IMPLICIT)
+
+ # TODO: Temporary solution has no communication cost,
+ # above action should be added after the SyncBN replace pass completed.
+ communication_action_mapping = {}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_input_batch_1d(self, mesh_dim_0, mesh_dim_1):
+ name = f'S{mesh_dim_0}{mesh_dim_1}R = S{mesh_dim_0}{mesh_dim_1}R x R WITH SYNC_BN'
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ "other": {},
+ "output": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ "running_mean": {},
+ "running_var": {},
+ "num_batches_tracked": {},
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ # For SyncBN case, we don't need to do communication for gradients of weight and bias.
+ # TODO: the communication happens interally at SyncBN operation. We need to replace the BN operation
+ # to SyncBN operation instead of inserting a communication node.
+ output_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["output"],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.IMPLICIT)
+
+ # TODO: Temporary solution has no communication cost,
+ # above action should be added after the SyncBN replace pass completed.
+ communication_action_mapping = {}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_input_both_dim(self, mesh_dim_0, mesh_dim_1):
+ name = f'S{mesh_dim_0}S{mesh_dim_1} = S{mesh_dim_0}S{mesh_dim_1} x S{mesh_dim_1} WITH SYNC_BN'
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0],
+ 1: [mesh_dim_1],
+ },
+ "other": {
+ 0: [mesh_dim_1],
+ },
+ "output": {
+ 0: [mesh_dim_0],
+ 1: [mesh_dim_1],
+ },
+ "running_mean": {
+ 0: [mesh_dim_1],
+ },
+ "running_var": {
+ 0: [mesh_dim_1],
+ },
+ "num_batches_tracked": {},
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {
+ 0: [mesh_dim_1],
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ # For SyncBN case, we don't need to do communication for gradients of weight and bias.
+ # TODO: the communication happens interally at SyncBN operation. We need to replace the BN operation
+ # to SyncBN operation instead of inserting a communication node.
+ output_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["output"],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=[mesh_dim_0],
+ comm_type=CommType.IMPLICIT)
+
+ # TODO: Temporary solution has no communication cost,
+ # above action should be added after the SyncBN replace pass completed.
+ communication_action_mapping = {}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ '''
+ Generate every possible strategies for a BatchNorm node, and record all strategies into the strategies_vector.
+ '''
+
+ strategy_list = []
+ # RS = RS x S
+ strategy_list.append(self.split_input_channel(0))
+ strategy_list.append(self.split_input_channel(1))
+
+ # RR = RR x R
+ strategy_list.append(self.non_split())
+
+ # RS01 = RS01 x S01
+ strategy_list.append(self.split_input_channel_1d(0, 1))
+
+ # The strategies with SYNC_BN are temporarily commented,
+ # because it requires some additional passes to keep runtime
+ # computation correctness.
+
+ # TODO: The strategies below should be uncommented after runtime
+ # passes ready.
+ # SR = SR x R WITH SYNC_BN
+ strategy_list.append(self.split_input_batch(0))
+ strategy_list.append(self.split_input_batch(1))
+
+ # SS = SS x S WITH SYNC_BN
+ strategy_list.append(self.split_input_both_dim(0, 1))
+ strategy_list.append(self.split_input_both_dim(1, 0))
+
+ # S01R = S01R x R WITH SYNC_BN
+ strategy_list.append(self.split_input_batch_1d(0, 1))
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd7f811c8972412eaec88bb1dcfc639cdf1fe630
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/binary_elementwise_generator.py
@@ -0,0 +1,111 @@
+import operator
+from functools import reduce
+from typing import List
+
+import torch
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, ShardingStrategy, TrainCycleItem
+from colossalai.auto_parallel.tensor_shard.utils import (
+ enumerate_all_possible_1d_sharding,
+ enumerate_all_possible_2d_sharding,
+ ignore_sharding_exception,
+)
+from colossalai.tensor.sharding_spec import ShardingSpecException
+
+from .strategy_generator import StrategyGenerator
+
+__all__ = ['BinaryElementwiseStrategyGenerator']
+
+
+class BinaryElementwiseStrategyGenerator(StrategyGenerator):
+ """
+ An BinaryElementwiseStrategyGenerator is a node handler which deals with elementwise operations
+ which have two operands and broadcasting occurs such as torch.add.
+
+ The logical shape for this operation will be `input other`.
+ """
+
+ def validate(self) -> bool:
+ assert len(self.op_data) == 3, \
+ f'BinaryElementwiseStrategyGenerator only accepts three operation data (input, other and output), but got {len(self.op_data)}'
+ for name, op_data in self.op_data.items():
+ if not isinstance(op_data.data, (torch.Tensor, int, float)):
+ raise TypeError(f'The operation data {name} is not a torch.Tensor/int/float.')
+
+ def update_compute_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+
+ # since elementwise ops are not compute-intensive,
+ # we approximate the backward compute cost
+ # to be twice the fwd compute cost
+ fwd_compute_cost = reduce(operator.mul, shape)
+ bwd_compute_cost = fwd_compute_cost * 2
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost,
+ bwd=bwd_compute_cost,
+ total=fwd_compute_cost + bwd_compute_cost)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ # all input, output and outputs have the same shape
+ shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+
+ # compute fwd memory cost in bytes
+ # as the elementwise ops are not memory-intensive
+ # we approximate the fwd memroy cost to be the output
+ # and the backward memory cost to be grad of input and other
+ input_bytes = self._compute_size_in_bytes(strategy, 'input')
+ other_bytes = self._compute_size_in_bytes(strategy, 'other')
+ output_bytes = self._compute_size_in_bytes(strategy, 'output')
+ fwd_memory_cost = MemoryCost(activation=output_bytes)
+ bwd_memory_cost = MemoryCost(activation=input_bytes + other_bytes)
+ total_memory_cost = MemoryCost(activation=input_bytes + other_bytes + output_bytes)
+ memory_cost = TrainCycleItem(fwd=fwd_memory_cost, bwd=bwd_memory_cost, total=total_memory_cost)
+ strategy.memory_cost = memory_cost
+
+ @ignore_sharding_exception
+ def enumerate_all_possible_output(self, mesh_dim_0, mesh_dim_1):
+ # we check for the output logical shape to get the number of dimensions
+ dim_partition_list = []
+ dim_size = len(self.op_data['output'].logical_shape)
+
+ # enumerate all the 2D sharding cases
+ sharding_list_2d = enumerate_all_possible_2d_sharding(mesh_dim_0, mesh_dim_1, dim_size)
+ dim_partition_list.extend(sharding_list_2d)
+
+ # enumerate all the 1D sharding cases
+ sharding_list_1d_on_dim_0 = enumerate_all_possible_1d_sharding(mesh_dim_0, dim_size)
+ dim_partition_list.extend(sharding_list_1d_on_dim_0)
+ sharding_list_1d_on_dim_1 = enumerate_all_possible_1d_sharding(mesh_dim_1, dim_size)
+ dim_partition_list.extend(sharding_list_1d_on_dim_1)
+
+ # add empty dict for fully replicated case
+ dim_partition_list.append({})
+
+ # sharding strategy bookkeeping
+ strategy_list = []
+
+ # convert these dim partition dict to sharding strategy
+ for dim_partition_dict in dim_partition_list:
+ dim_partition_dict_mapping = dict(input=dim_partition_dict,
+ other=dim_partition_dict,
+ output=dim_partition_dict)
+
+ try:
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+ communication_action_mapping = {}
+
+ # get name
+ sharding_seq = sharding_spec_mapping['input'].sharding_sequence
+ name = f'{sharding_seq} = {sharding_seq} {sharding_seq}'
+ sharding_strategy = self.get_sharding_strategy(
+ name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(sharding_strategy)
+ except ShardingSpecException:
+ continue
+ return strategy_list
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = self.enumerate_all_possible_output(0, 1)
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/conv_strategy_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/conv_strategy_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..c2154b3104d3d52e994a2add25ddc796792e1c66
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/conv_strategy_generator.py
@@ -0,0 +1,584 @@
+import copy
+import operator
+import warnings
+from functools import reduce
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommAction,
+ CommType,
+ MemoryCost,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.auto_parallel.tensor_shard.utils import ignore_sharding_exception
+from colossalai.tensor.shape_consistency import CollectiveCommPattern
+
+from .strategy_generator import StrategyGenerator
+
+
+class ConvStrategyGenerator(StrategyGenerator):
+ """
+ ConvStrategyGenerator is a generic class to generate strategies.
+ The operation data is defined as `output = input x other + bias`.
+ """
+
+ def validate(self) -> bool:
+ '''
+ In sanity check, we need make sure the input data having correct dimension size.
+ For Conv1d, the dim of input data should be 3([N, C, L]).
+ For Conv2d, the dim of input data should be 4([N, C, H, W]).
+ For Conv3d, the dim of input data should be 5([N, C, H, W, D]).
+ '''
+ input_op_data = self.op_data['input']
+ assert input_op_data.data.dim() in (
+ 3, 4, 5), f'We suppose the dim of input fed into conv op should in range of [3, 5].'
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the computation cost per device with this specific strategy.
+
+ Note: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ '''
+ # TODO: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ # 1D: (L) * N * Cout * Cin * kernel
+ # 2D: (H * W) * N * Cout * Cin * kernel
+ # 3D: (H * W * D) * N * Cout * Cin * kernel
+ sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+ sharded_other_shape = strategy.sharding_specs[self.op_data['other']].get_sharded_shape_per_device()
+ sharded_output_shape = strategy.sharding_specs[self.op_data['output']].get_sharded_shape_per_device()
+ if self.has_bias:
+ # bias add is an element wise operation, so the cost is equal to product of output shape.
+ bias_compute_cost = reduce(operator.mul, sharded_output_shape)
+
+ output_size = sharded_output_shape[2:]
+ output_size_product = reduce(operator.mul, output_size)
+ input_size = sharded_input_shape[2:]
+ input_size_product = reduce(operator.mul, input_size, 1)
+ kernel_size = sharded_other_shape[2:]
+ kernel_size_product = reduce(operator.mul, kernel_size, 1)
+ batch_size = sharded_input_shape[0]
+ channel_in = sharded_input_shape[1]
+ channel_out = sharded_other_shape[1]
+
+ forward_compute_cost = output_size_product * batch_size * channel_in * channel_out * kernel_size_product
+
+ backward_activation_cost = input_size_product * batch_size * channel_in * channel_out * kernel_size_product
+ backward_weight_cost = output_size_product * batch_size * channel_in * channel_out * kernel_size_product
+ backward_compute_cost = backward_weight_cost + backward_activation_cost
+ if self.has_bias:
+ forward_compute_cost += bias_compute_cost
+ backward_compute_cost += bias_compute_cost
+ total_compute_cost = forward_compute_cost + backward_compute_cost
+
+ compute_cost = TrainCycleItem(fwd=forward_compute_cost, bwd=backward_compute_cost, total=total_compute_cost)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ forward_size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'other': self._compute_size_in_bytes(strategy, "other"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ if self.has_bias:
+ bias_size = self._compute_size_in_bytes(strategy, "bias")
+ forward_size_mapping['bias'] = bias_size
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = input + other + bias + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items() if not self.is_param(k)])
+ fwd_parameter_cost = sum([v for k, v in forward_size_mapping.items() if self.is_param(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad + other_grad + bias_grad
+ bwd_activation_cost = sum([v for k, v in backward_size_mapping.items() if not self.is_param(k)])
+ bwd_parameter_cost = sum([v for k, v in backward_size_mapping.items() if self.is_param(k)])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=bwd_parameter_cost)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost,
+ parameter=fwd_parameter_cost + bwd_parameter_cost)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ @ignore_sharding_exception
+ def split_input_batch_weight_out_channel(self, mesh_dim_0, mesh_dim_1):
+ name = f'S{mesh_dim_0}S{mesh_dim_1} = S{mesh_dim_0}R x RS{mesh_dim_1}'
+
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0]
+ },
+ "other": {
+ 1: [mesh_dim_1]
+ },
+ "output": {
+ 0: [mesh_dim_0],
+ 1: [mesh_dim_1]
+ },
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {0: [mesh_dim_1]}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ input_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_1,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ communication_action_mapping = {"input": input_comm_action}
+
+ if self.is_param("other"):
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+
+ communication_action_mapping["other"] = other_comm_action
+
+ if self.has_bias:
+ if self.is_param('bias'):
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+ else:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ key_for_kwarg='bias')
+ communication_action_mapping["bias"] = bias_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_input_batch(self, mesh_dim_0):
+ name = f'S{mesh_dim_0}R = S{mesh_dim_0}R x RR'
+
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0]
+ },
+ "other": {},
+ "output": {
+ 0: [mesh_dim_0],
+ },
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ communication_action_mapping = {}
+ if self.is_param("other"):
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+
+ communication_action_mapping["other"] = other_comm_action
+
+ if self.has_bias:
+ if self.is_param('bias'):
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+ else:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ key_for_kwarg='bias')
+ communication_action_mapping["bias"] = bias_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_input_both_dim_weight_in_channel(self, mesh_dim_0, mesh_dim_1):
+ name = f'S{mesh_dim_0}R = S{mesh_dim_0}S{mesh_dim_1} x S{mesh_dim_1}R'
+
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0],
+ 1: [mesh_dim_1],
+ },
+ "other": {
+ 0: [mesh_dim_1]
+ },
+ "output": {
+ 0: [mesh_dim_0],
+ },
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ output_comm_action = self.get_communication_action(
+ sharding_spec_mapping["output"],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=mesh_dim_1,
+ comm_type=CommType.AFTER)
+
+ communication_action_mapping = {"output": output_comm_action}
+
+ if self.is_param("other"):
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+ communication_action_mapping["other"] = other_comm_action
+ if self.has_bias:
+ if self.is_param("bias"):
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+ else:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ key_for_kwarg='bias')
+ communication_action_mapping["bias"] = bias_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_input_in_channel_weight_both_channel(self, mesh_dim_0, mesh_dim_1):
+ name = f'RS{mesh_dim_1} = RS{mesh_dim_0} x S{mesh_dim_0}S{mesh_dim_1}'
+
+ dim_partition_dict_mapping = {
+ "input": {
+ 1: [mesh_dim_0],
+ },
+ "other": {
+ 0: [mesh_dim_0],
+ 1: [mesh_dim_1],
+ },
+ "output": {
+ 1: [mesh_dim_1],
+ },
+ }
+
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {
+ 0: [mesh_dim_1],
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ output_comm_action = self.get_communication_action(
+ sharding_spec_mapping["output"],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.AFTER)
+ input_comm_action = self.get_communication_action(
+ sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_1,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+
+ communication_action_mapping = {"output": output_comm_action, "input": input_comm_action}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_input_in_channel_weight_in_channel(self, mesh_dim_0):
+ name = f'RR = RS{mesh_dim_0} x S{mesh_dim_0}R'
+
+ dim_partition_dict_mapping = {
+ "input": {
+ 1: [mesh_dim_0],
+ },
+ "other": {
+ 0: [mesh_dim_0],
+ },
+ "output": {},
+ }
+
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ output_comm_action = self.get_communication_action(
+ sharding_spec_mapping["output"],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.AFTER)
+
+ communication_action_mapping = {"output": output_comm_action}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_weight_out_channel(self, mesh_dim_0):
+ name = f'RS{mesh_dim_0} = RR x RS{mesh_dim_0}'
+
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {
+ 1: [mesh_dim_0],
+ },
+ "output": {
+ 1: [mesh_dim_0],
+ },
+ }
+
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {
+ 0: [mesh_dim_0],
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ input_comm_action = self.get_communication_action(
+ sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+
+ communication_action_mapping = {"input": input_comm_action}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def non_split(self):
+ name = f'RR = RR x RR'
+
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {},
+ "output": {},
+ }
+
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping={})
+
+ @ignore_sharding_exception
+ def split_1d_parallel_on_input_batch(self, mesh_dim_0, mesh_dim_1):
+ name = f'S{mesh_dim_0}{mesh_dim_1}R = S{mesh_dim_0}{mesh_dim_1}R x RR'
+
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0, mesh_dim_1],
+ },
+ "other": {},
+ "output": {
+ 0: [mesh_dim_0, mesh_dim_1],
+ },
+ }
+
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ communication_action_mapping = {}
+ if self.is_param("other"):
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.HOOK)
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+
+ communication_action_mapping["other"] = other_comm_action
+
+ if self.has_bias:
+ if self.is_param("bias"):
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.HOOK)
+ else:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.BEFORE,
+ key_for_kwarg='bias')
+ communication_action_mapping["bias"] = bias_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_1d_parallel_on_in_channel(self, mesh_dim_0, mesh_dim_1):
+ name = f'RR = RS{mesh_dim_0}{mesh_dim_1} x S{mesh_dim_0}{mesh_dim_1}R'
+ dim_partition_dict_mapping = {
+ "input": {
+ 1: [mesh_dim_0, mesh_dim_1],
+ },
+ "other": {
+ 0: [mesh_dim_0, mesh_dim_1],
+ },
+ "output": {},
+ }
+
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ output_comm_action = self.get_communication_action(
+ sharding_spec_mapping["output"],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.AFTER)
+
+ communication_action_mapping = {"output": output_comm_action}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_1d_parallel_on_out_channel(self, mesh_dim_0, mesh_dim_1):
+ name = f'RS{mesh_dim_0}{mesh_dim_1} = RR x RS{mesh_dim_0}{mesh_dim_1}'
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {
+ 1: [mesh_dim_0, mesh_dim_1],
+ },
+ "output": {
+ 1: [mesh_dim_0, mesh_dim_1],
+ },
+ }
+
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {
+ 0: [mesh_dim_0, mesh_dim_1],
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ input_comm_action = self.get_communication_action(
+ sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+
+ communication_action_mapping = {"input": input_comm_action}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategies = []
+ # SS = SR x RS
+ strategies.append(self.split_input_batch_weight_out_channel(0, 1))
+ strategies.append(self.split_input_batch_weight_out_channel(1, 0))
+
+ # SR = SR x RR
+ strategies.append(self.split_input_batch(0))
+ strategies.append(self.split_input_batch(1))
+
+ # SR = SS x SR
+ strategies.append(self.split_input_both_dim_weight_in_channel(0, 1))
+ strategies.append(self.split_input_both_dim_weight_in_channel(1, 0))
+
+ # RS = RS x SS
+ strategies.append(self.split_input_in_channel_weight_both_channel(0, 1))
+ strategies.append(self.split_input_in_channel_weight_both_channel(1, 0))
+
+ # RR = RS x SR
+ strategies.append(self.split_input_in_channel_weight_in_channel(0))
+ strategies.append(self.split_input_in_channel_weight_in_channel(1))
+
+ # RS = RR x RS
+ strategies.append(self.split_weight_out_channel(0))
+ strategies.append(self.split_weight_out_channel(1))
+
+ # RR= RR x RR
+ strategies.append(self.non_split())
+
+ # S01R = S01R x RR
+ strategies.append(self.split_1d_parallel_on_input_batch(0, 1))
+
+ # RR = RS01 x S01R
+ strategies.append(self.split_1d_parallel_on_in_channel(0, 1))
+
+ # RS01 = RR x RS01
+ strategies.append(self.split_1d_parallel_on_out_channel(0, 1))
+
+ return strategies
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/embedding_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/embedding_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..82a04ab52e739ae3db29efde2a66f30ff24cb8d0
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/embedding_generator.py
@@ -0,0 +1,310 @@
+import copy
+import operator
+import warnings
+from functools import reduce
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommAction,
+ CommType,
+ MemoryCost,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.auto_parallel.tensor_shard.utils import ignore_sharding_exception
+from colossalai.tensor.shape_consistency import CollectiveCommPattern
+
+from .strategy_generator import StrategyGenerator
+
+
+class EmbeddingStrategyGenerator(StrategyGenerator):
+ """
+ EmbeddingStrategyGenerator is a generic class to generate strategies for nn.Embedding or F.embedding.
+ The operation data is defined as `output = input x other`.
+ """
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the computation cost per device with this specific strategy.
+
+ Note: The computation cost for the embedding handler is estimated as dense computing now.
+ It may not be accurate.
+ '''
+ # TODO: estimate the embedding computation cost as sparse operation
+ sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+ sharded_other_shape = strategy.sharding_specs[self.op_data['other']].get_sharded_shape_per_device()
+ sharded_output_shape = strategy.sharding_specs[self.op_data['output']].get_sharded_shape_per_device()
+
+ input_size_product = reduce(operator.mul, sharded_input_shape)
+ other_size_product = reduce(operator.mul, sharded_other_shape)
+ output_size_product = reduce(operator.mul, sharded_output_shape)
+
+ forward_compute_cost = input_size_product * other_size_product
+
+ backward_activation_cost = other_size_product * output_size_product / sharded_output_shape[-1]
+ backward_weight_cost = input_size_product * other_size_product
+ backward_compute_cost = backward_weight_cost + backward_activation_cost
+
+ total_compute_cost = forward_compute_cost + backward_compute_cost
+
+ compute_cost = TrainCycleItem(fwd=forward_compute_cost, bwd=backward_compute_cost, total=total_compute_cost)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ forward_size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'other': self._compute_size_in_bytes(strategy, "other"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = input + other + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items() if not self.is_param(k)])
+ fwd_parameter_cost = sum([v for k, v in forward_size_mapping.items() if self.is_param(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad + other_grad
+ bwd_activation_cost = sum([v for k, v in backward_size_mapping.items() if not self.is_param(k)])
+ bwd_parameter_cost = sum([v for k, v in backward_size_mapping.items() if self.is_param(k)])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=bwd_parameter_cost)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost,
+ parameter=fwd_parameter_cost + bwd_parameter_cost)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ @ignore_sharding_exception
+ def non_split(self):
+ name = f'RR = R x RR'
+
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {},
+ "output": {},
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping={})
+
+ @ignore_sharding_exception
+ def split_input(self, mesh_dim_0):
+ name = f'S{mesh_dim_0}R = S{mesh_dim_0} x RR'
+
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0]
+ },
+ "other": {},
+ "output": {
+ 0: [mesh_dim_0],
+ },
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ communication_action_mapping = {}
+ if self.is_param("other"):
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+
+ communication_action_mapping["other"] = other_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_input_and_embedding_dim(self, mesh_dim_0, mesh_dim_1):
+ name = f'S{mesh_dim_0}S{mesh_dim_1} = S{mesh_dim_0} x RS{mesh_dim_1}'
+
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0],
+ },
+ "other": {
+ 1: [mesh_dim_1],
+ },
+ "output": {
+ 0: [mesh_dim_0],
+ 1: [mesh_dim_1],
+ },
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ input_comm_action = self.get_communication_action(
+ sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_1,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ communication_action_mapping = {"input": input_comm_action}
+
+ if self.is_param("other"):
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+
+ communication_action_mapping["other"] = other_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_1d_parallel_on_input(self, mesh_dim_0, mesh_dim_1):
+ name = f'S{mesh_dim_0}{mesh_dim_1}R = S{mesh_dim_0}{mesh_dim_1} x RR'
+
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ "other": {},
+ "output": {
+ 0: [mesh_dim_0, mesh_dim_1],
+ },
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ communication_action_mapping = {}
+
+ if self.is_param("other"):
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.HOOK)
+
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+
+ communication_action_mapping["other"] = other_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_embedding_dim(self, mesh_dim_0):
+ name = f'RS{mesh_dim_0} = R x RS{mesh_dim_0}'
+
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {
+ 1: [mesh_dim_0],
+ },
+ "output": {
+ 1: [mesh_dim_0],
+ },
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ input_comm_action = self.get_communication_action(
+ sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+
+ communication_action_mapping = {"input": input_comm_action}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_1d_parallel_on_embedding_dim(self, mesh_dim_0, mesh_dim_1):
+ name = f'RS{mesh_dim_0}{mesh_dim_1} = R x RS{mesh_dim_0}{mesh_dim_1}'
+
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {
+ 1: [mesh_dim_0, mesh_dim_1],
+ },
+ "output": {
+ 1: [mesh_dim_0, mesh_dim_1],
+ },
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ input_comm_action = self.get_communication_action(
+ sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+
+ communication_action_mapping = {"input": input_comm_action}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategies = []
+
+ # RR= R x RR
+ strategies.append(self.non_split())
+
+ # SR = S x RR
+ strategies.append(self.split_input(0))
+ strategies.append(self.split_input(1))
+
+ # SS = S x RS
+ strategies.append(self.split_input_and_embedding_dim(0, 1))
+ strategies.append(self.split_input_and_embedding_dim(1, 0))
+
+ # S01R = S01 x RR
+ strategies.append(self.split_1d_parallel_on_input(0, 1))
+
+ # RS = R x RS
+ strategies.append(self.split_embedding_dim(0))
+ strategies.append(self.split_embedding_dim(1))
+
+ # RS01 = R x RS01
+ strategies.append(self.split_1d_parallel_on_embedding_dim(0, 1))
+
+ return strategies
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/getattr_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/getattr_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbeb9a639c835869634417e5ceff1a2cad082339
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/getattr_generator.py
@@ -0,0 +1,89 @@
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, ShardingStrategy, TrainCycleItem
+from colossalai.auto_parallel.tensor_shard.utils import (
+ enumerate_all_possible_1d_sharding,
+ enumerate_all_possible_2d_sharding,
+ ignore_sharding_exception,
+)
+from colossalai.tensor.sharding_spec import ShardingSpecException
+
+from .strategy_generator import StrategyGenerator
+
+__all__ = ['GetattrGenerator']
+
+
+class GetattrGenerator(StrategyGenerator):
+ """
+ PlaceholderGenerator is a generic class to generate strategies for placeholder node.
+ """
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ compute_cost = TrainCycleItem(fwd=10, bwd=10, total=20)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ forward_size_mapping = {'output': self._compute_size_in_bytes(strategy, "output")}
+
+ # compute fwd cost incurred
+ # fwd_cost = output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items()])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=0)
+
+ bwd_mem_cost = MemoryCost(activation=0, parameter=0)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=0)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ @ignore_sharding_exception
+ def enumerate_all_possible_output(self, mesh_dim_0, mesh_dim_1):
+ # we check for the output logical shape to get the number of dimensions
+ dim_partition_list = []
+ dim_size = len(self.op_data['output'].logical_shape)
+
+ # enumerate all the 2D sharding cases
+ sharding_list_2d = enumerate_all_possible_2d_sharding(mesh_dim_0, mesh_dim_1, dim_size)
+ dim_partition_list.extend(sharding_list_2d)
+
+ # enumerate all the 1D sharding cases
+ sharding_list_1d_on_dim_0 = enumerate_all_possible_1d_sharding(mesh_dim_0, dim_size)
+ dim_partition_list.extend(sharding_list_1d_on_dim_0)
+ sharding_list_1d_on_dim_1 = enumerate_all_possible_1d_sharding(mesh_dim_1, dim_size)
+ dim_partition_list.extend(sharding_list_1d_on_dim_1)
+
+ # add empty dict for fully replicated case
+ dim_partition_list.append({})
+
+ # sharding strategy bookkeeping
+ strategy_list = []
+
+ # convert these dim partition dict to sharding strategy
+ for dim_partition_dict in dim_partition_list:
+ dim_partition_dict_mapping = dict(output=dim_partition_dict)
+
+ try:
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+ communication_action_mapping = {}
+
+ # get name
+ name = f"get_attr {sharding_spec_mapping['output'].sharding_sequence}"
+ sharding_strategy = self.get_sharding_strategy(
+ name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(sharding_strategy)
+ except ShardingSpecException:
+ continue
+
+ return strategy_list
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ return self.enumerate_all_possible_output(0, 1)
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/getitem_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/getitem_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..0aeb2e0d4079ea1b302d580554ed7ca24ab7096d
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/getitem_generator.py
@@ -0,0 +1,171 @@
+import copy
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommType,
+ MemoryCost,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.logging import get_dist_logger
+from colossalai.tensor.shape_consistency import CollectiveCommPattern
+from colossalai.tensor.sharding_spec import ShardingSpecException
+
+from .strategy_generator import FollowingStrategyGenerator
+
+__all__ = ['GetItemStrategyGenerator', 'TensorStrategyGenerator', 'TensorTupleStrategyGenerator']
+
+
+class GetItemStrategyGenerator(FollowingStrategyGenerator):
+ """
+ GetItemStrategyGenerator is a generic class to generate strategies for operator.getitem.
+ The operation data is defined as `output = input[other]`.
+
+ There are mainly three use cases:
+ 1. args_0._meta_data: torch.Tensor, args_1._meta_data: int
+ 2. args_0._meta_data: torch.Tensor, args_1._meta_data: slice
+ 3. args_0._meta_data: Tuple[torch.Tensor], args_1._meta_data: int
+ """
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ compute_cost = TrainCycleItem(fwd=10, bwd=10, total=20)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ forward_size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = input + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items() if not self.is_param(k)])
+ fwd_parameter_cost = sum([v for k, v in forward_size_mapping.items() if self.is_param(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad
+ bwd_activation_cost = sum([v for k, v in backward_size_mapping.items() if not self.is_param(k)])
+ bwd_parameter_cost = sum([v for k, v in backward_size_mapping.items() if self.is_param(k)])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=bwd_parameter_cost)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost,
+ parameter=fwd_parameter_cost + bwd_parameter_cost)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+
+class TensorStrategyGenerator(GetItemStrategyGenerator):
+ '''
+ Deal with case 1 and 2.
+ '''
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ getitem_index = self.op_data['index'].data
+ for index, strategy in enumerate(self.predecessor_node.strategies_vector):
+ try:
+ logger = get_dist_logger()
+ dim_partition_dict_mapping = {}
+ communication_action_mapping = {}
+ dim_partition_dict_for_input = copy.deepcopy(
+ strategy.output_sharding_specs[self.op_data["input"]].dim_partition_dict)
+
+ int_index = False
+ if isinstance(getitem_index, int):
+ int_index = True
+ getitem_dims = [
+ 0,
+ ]
+ shift_length = 1
+ elif isinstance(getitem_index, slice):
+ getitem_dims = [
+ 0,
+ ]
+ else:
+ getitem_dims = [i for i in range(len(getitem_index))]
+ if isinstance(getitem_index[0], int):
+ int_index = True
+ shift_length = len(getitem_index)
+
+ gather_dims = []
+ for dim in getitem_dims:
+ if dim in dim_partition_dict_for_input:
+ gather_dims.append(dim)
+
+ for dim in gather_dims:
+ dim_partition_dict_for_input.pop(dim)
+ dim_partition_dict_for_output = copy.deepcopy(dim_partition_dict_for_input)
+
+ if int_index:
+ shift_dim_partition_dict_for_output = {}
+ for dim, mesh_dim_list in dim_partition_dict_for_output.items():
+ shift_dim_partition_dict_for_output[dim - shift_length] = mesh_dim_list
+ dim_partition_dict_for_output = shift_dim_partition_dict_for_output
+
+ dim_partition_dict_mapping = {
+ "input": dim_partition_dict_for_input,
+ "output": dim_partition_dict_for_output,
+ }
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ name = f'{sharding_spec_mapping["output"].sharding_sequence} = {sharding_spec_mapping["input"].sharding_sequence}_{index}'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ except ShardingSpecException as e:
+ logger.debug(e)
+ continue
+ strategy_list.append(strategy)
+
+ for strategy in strategy_list:
+ self.update_communication_cost(strategy)
+ self.update_compute_cost(strategy)
+ self.update_memory_cost(strategy)
+
+ return strategy_list
+
+
+class TensorTupleStrategyGenerator(GetItemStrategyGenerator):
+ '''
+ Deal with case 3.
+ '''
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ index = self.op_data["index"].data
+
+ for strategy_index, strategy in enumerate(self.predecessor_node.strategies_vector):
+ # the sharding spec for input in this case is a tuple of ShardingSpec.
+ sharding_spec_for_input = strategy.output_sharding_specs[self.op_data["input"]]
+ dim_partition_dict_for_output = sharding_spec_for_input[index].dim_partition_dict
+ dim_partition_dict_mapping = {}
+ communication_action_mapping = {}
+ dim_partition_dict_mapping = {
+ "output": dim_partition_dict_for_output,
+ }
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+ sharding_spec_mapping["input"] = sharding_spec_for_input
+ input_sharding_info = f"get the {index} element from ("
+ for sharding_spec in sharding_spec_for_input:
+ input_sharding_info += f'{sharding_spec.sharding_sequence}, '
+ input_sharding_info += ")"
+ name = f'{sharding_spec_mapping["output"].sharding_sequence} = {input_sharding_info}_{strategy_index}'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ strategy_list.append(strategy)
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/layer_norm_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/layer_norm_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..fbb6070f7e82c9a41848c626c6271d1a7b9d73ee
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/layer_norm_generator.py
@@ -0,0 +1,195 @@
+import copy
+import operator
+from functools import reduce
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommType,
+ MemoryCost,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.auto_parallel.tensor_shard.utils import (
+ enumerate_all_possible_1d_sharding,
+ enumerate_all_possible_2d_sharding,
+ ignore_sharding_exception,
+)
+from colossalai.tensor.shape_consistency import CollectiveCommPattern
+
+from .strategy_generator import StrategyGenerator
+
+__all__ = ['LayerNormGenerator']
+
+
+class LayerNormGenerator(StrategyGenerator):
+ """
+ LayerNormGenerator is a generic class to generate strategies for LayerNorm operation.
+ The operation data is defined as `output = input x other + bias`.
+ """
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the computation cost per device with this specific strategy.
+
+ Note: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ '''
+ # TODO: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ # TODO: a constant coefficient need to be added.
+
+ sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+ sharded_weight_shape = strategy.sharding_specs[self.op_data['other']].get_sharded_shape_per_device()
+ if self.has_bias:
+ # bias add is an element wise operation, so the cost is equal to product of output shape.
+ bias_compute_cost = reduce(operator.mul, sharded_weight_shape)
+ # in LayerNorm context, batch dimensions mean all the dimensions do not join the normalization.
+ input_batch_shape = sharded_input_shape[:-len(sharded_weight_shape)]
+ input_batch_product = reduce(operator.mul, input_batch_shape, 1)
+ norm_kernel_product = reduce(operator.mul, sharded_weight_shape, 1)
+ forward_compute_cost = input_batch_product * norm_kernel_product
+ backward_activation_compute_cost = input_batch_product * norm_kernel_product
+ # To compute gradient of on norm kernel element requires input_batch_product times computation, so
+ # the total cost is input_batch_product * norm_kernel_product
+ backward_weight_compute_cost = input_batch_product * norm_kernel_product
+ backward_compute_cost = backward_activation_compute_cost + backward_weight_compute_cost
+ if self.has_bias:
+ forward_compute_cost += bias_compute_cost
+ backward_compute_cost += bias_compute_cost
+ total_compute_cost = forward_compute_cost + backward_compute_cost
+ compute_cost = TrainCycleItem(fwd=forward_compute_cost, bwd=backward_compute_cost, total=total_compute_cost)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ forward_size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'other': self._compute_size_in_bytes(strategy, "other"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ if self.has_bias:
+ bias_size = self._compute_size_in_bytes(strategy, "bias")
+ forward_size_mapping['bias'] = bias_size
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = input + other + bias + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items() if not self.is_param(k)])
+ fwd_parameter_cost = sum([v for k, v in forward_size_mapping.items() if self.is_param(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad + other_grad + bias_grad
+ bwd_activation_cost = sum([v for k, v in backward_size_mapping.items() if not self.is_param(k)])
+ bwd_parameter_cost = sum([v for k, v in backward_size_mapping.items() if self.is_param(k)])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=bwd_parameter_cost)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost,
+ parameter=fwd_parameter_cost + bwd_parameter_cost)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ @ignore_sharding_exception
+ def _generate_strategy_with_dim_partition(self, dim_partition):
+ dim_partition_dict_mapping = {
+ "input": dim_partition,
+ "other": {},
+ "output": dim_partition,
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ name = f'{sharding_spec_mapping["output"].sharding_sequence} = {sharding_spec_mapping["input"].sharding_sequence} x {sharding_spec_mapping["other"].sharding_sequence}'
+ total_mesh_dim_list = []
+ for mesh_dim_list in dim_partition.values():
+ total_mesh_dim_list.extend(mesh_dim_list)
+ # if there is only one sharding dimension, we should use the value instead of list as logical_process_axis.
+ if len(total_mesh_dim_list) == 1:
+ total_mesh_dim_list = total_mesh_dim_list[0]
+ communication_action_mapping = {}
+
+ other_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=total_mesh_dim_list,
+ comm_type=CommType.HOOK)
+ communication_action_mapping["other"] = other_comm_action
+
+ if self.has_bias:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=total_mesh_dim_list,
+ comm_type=CommType.HOOK)
+ communication_action_mapping["bias"] = bias_comm_action
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ return strategy
+
+ def split_input_batch_single_mesh_dim(self, mesh_dim_0, batch_dimension_length):
+ strategy_list = []
+ dim_partition_list = enumerate_all_possible_1d_sharding(mesh_dim_0, batch_dimension_length)
+ for dim_partition in dim_partition_list:
+ strategy = self._generate_strategy_with_dim_partition(dim_partition)
+ strategy_list.append(strategy)
+ return strategy_list
+
+ def split_input_batch_both_mesh_dim(self, mesh_dim_0, mesh_dim_1, batch_dimension_length):
+ strategy_list = []
+ dim_partition_list = enumerate_all_possible_2d_sharding(mesh_dim_0, mesh_dim_1, batch_dimension_length)
+ for dim_partition in dim_partition_list:
+ strategy = self._generate_strategy_with_dim_partition(dim_partition)
+ strategy_list.append(strategy)
+ return strategy_list
+
+ @ignore_sharding_exception
+ def non_split(self):
+ name = f'RR = RR x R'
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {},
+ "output": {},
+ }
+ if self.has_bias:
+ dim_partition_dict_mapping["bias"] = {}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ communication_action_mapping = {}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ '''
+ Generate every possible strategies for a LayerNorm node, and record all strategies into the strategies_vector.
+ '''
+ strategy_list = []
+ input_data_dim = len(self.op_data["input"].logical_shape)
+ weight_data_dim = len(self.op_data["other"].logical_shape)
+ # in LayerNorm context, batch dimensions mean all the dimensions do not join the normalization.
+ batch_dimension_length = input_data_dim - weight_data_dim
+
+ # SR = SR x R with single mesh dim on batch dimensions
+ strategy_list.extend(self.split_input_batch_single_mesh_dim(0, batch_dimension_length))
+ strategy_list.extend(self.split_input_batch_single_mesh_dim(1, batch_dimension_length))
+
+ # SR = SR x R with both mesh dims on batch dimensions
+ strategy_list.extend(self.split_input_batch_both_mesh_dim(0, 1, batch_dimension_length))
+
+ # RR = RR x R
+ strategy_list.append(self.non_split())
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/matmul_strategy_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/matmul_strategy_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ce5a08f2d6b70d20f10476309034ab1a26b75d1
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/matmul_strategy_generator.py
@@ -0,0 +1,1020 @@
+import operator
+from ast import arg
+from functools import reduce
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.options import SolverPerference
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommType,
+ MemoryCost,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.auto_parallel.tensor_shard.utils import ignore_sharding_exception
+from colossalai.tensor.shape_consistency import CollectiveCommPattern
+
+from .strategy_generator import StrategyGenerator
+
+
+class MatMulStrategyGenerator(StrategyGenerator):
+ """
+ MatMulStrategyGenerator is a generic class to cover all matrix multiplication cases.
+ The operation data is defined as `output = input x other + bias`.
+ """
+
+ def update_memory_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'other': self._compute_size_in_bytes(strategy, "other"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ if self.has_bias:
+ bias_size = self._compute_size_in_bytes(strategy, "bias")
+ size_mapping['bias'] = bias_size
+
+ # compute fwd cost incurred
+ # fwd_cost = input + other + bias + output
+ fwd_activation_cost = sum([v for k, v in size_mapping.items() if not self.is_param(k)])
+ fwd_parameter_cost = sum([v for k, v in size_mapping.items() if self.is_param(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad + bias_grad
+ bwd_activation_cost = sum([v for k, v in size_mapping.items() if k in ['input', 'other', 'bias']])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=0)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost,
+ parameter=fwd_parameter_cost + 0)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+
+class DotProductStrategyGenerator(MatMulStrategyGenerator):
+
+ def validate(self) -> bool:
+ input_op_data = self.op_data['input']
+ other_op_data = self.op_data['other']
+ assert input_op_data.data.dim() == 1 and other_op_data.data.dim() == 1
+
+ def update_compute_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+ fwd_compute_cost = sharded_input_shape[0]
+ bwd_compute_cost = fwd_compute_cost * 2
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost,
+ bwd=bwd_compute_cost,
+ total=fwd_compute_cost + bwd_compute_cost)
+ return compute_cost
+
+ @ignore_sharding_exception
+ def no_split(self):
+ name = f'R = R dot R'
+ dim_partition_dict = {"input": {}, "other": {}, "output": {}, 'bias': {}}
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict)
+ communication_action_mapping = {}
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_one_dim(self, mesh_dim):
+ name = f'R = S{mesh_dim} dot S{mesh_dim}'
+
+ # get sharding spec
+ dim_partition_dict = {"input": {0: [mesh_dim]}, "other": {0: [mesh_dim]}, "output": {}, "bias": {0: [mesh_dim]}}
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict)
+
+ # get communication action
+ output_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['output'],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=mesh_dim,
+ comm_type=CommType.AFTER)
+ communication_action_mapping = {"output": output_comm_action}
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+
+ # do not split dimensions for dot product
+ # R = R dot R
+ strategy_list.append(self.no_split())
+
+ # split two tensors in the same dimensions
+ # S = S dot S
+ strategy_list.append(self.split_one_dim(0))
+ strategy_list.append(self.split_one_dim(1))
+
+ return strategy_list
+
+
+class MatVecStrategyGenerator(MatMulStrategyGenerator):
+
+ def validate(self) -> bool:
+ input_op_data = self.op_data['input']
+ other_op_data = self.op_data['other']
+ assert input_op_data.data.dim() == 2 and other_op_data.data.dim() == 1
+
+ def update_compute_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+ fwd_compute_cost = sharded_input_shape[0]
+ bwd_compute_cost = fwd_compute_cost * 2
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost,
+ bwd=bwd_compute_cost,
+ total=fwd_compute_cost + bwd_compute_cost)
+ return compute_cost
+
+ @ignore_sharding_exception
+ def no_split(self):
+ name = "R = R x R"
+ dim_partition_dict = {"input": {}, "other": {}, "output": {}}
+
+ if self.has_bias:
+ dim_partition_dict['bias'] = {}
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict)
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping={})
+
+ @ignore_sharding_exception
+ def split_input_batch(self, mesh_dim):
+ name = f'S{mesh_dim}R = S{mesh_dim}R x R'
+
+ # get sharding spec
+ dim_partition_dict = {
+ "input": {
+ 0: [mesh_dim]
+ },
+ "other": {},
+ "output": {
+ 0: [mesh_dim]
+ },
+ }
+
+ if self.has_bias:
+ dim_partition_dict['bias'] = {}
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict)
+
+ # get communication action
+ communication_action_mapping = {}
+ if self.is_param('other'):
+ other_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['other'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim,
+ comm_type=CommType.HOOK)
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['other'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim,
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+ communication_action_mapping['other'] = other_comm_action
+
+ if self.has_bias:
+ if self.is_param('bias'):
+ bias_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['bias'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim,
+ comm_type=CommType.HOOK)
+ else:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['bias'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim,
+ comm_type=CommType.BEFORE,
+ arg_index=2)
+ communication_action_mapping['bias'] = bias_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+
+ # no split
+ strategy_list.append(self.no_split())
+
+ # split the batch dim for the first tensor only
+ strategy_list.append(self.split_input_batch(0))
+ strategy_list.append(self.split_input_batch(1))
+
+ return strategy_list
+
+
+class LinearProjectionStrategyGenerator(MatMulStrategyGenerator):
+
+ def __init__(self,
+ operation_data_mapping,
+ device_mesh,
+ linear_projection_type='linear',
+ solver_perference=SolverPerference.STANDARD):
+ super().__init__(operation_data_mapping, device_mesh)
+ self.linear_projection_type = linear_projection_type
+ self.solver_perference = solver_perference
+
+ def update_compute_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ # C = AB
+ # C: [M, N], A: [M, P], B: [P, N]
+ # fwd cost = MNP (only count mul)
+ # bwd: 2 x fwd_cost
+ sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+ sharded_other_shape = strategy.sharding_specs[self.op_data['other']].get_sharded_shape_per_device()
+ dim_m_val = reduce(operator.mul, sharded_input_shape[:-1])
+ dim_n_val = sharded_other_shape[-1]
+ dim_p_val = sharded_other_shape[0]
+
+ fwd_compute_cost = dim_m_val * dim_n_val * dim_p_val
+ bwd_compute_cost = fwd_compute_cost * 2
+ compute_cost = TrainCycleItem(fwd=bwd_compute_cost,
+ bwd=bwd_compute_cost,
+ total=fwd_compute_cost + bwd_compute_cost)
+ strategy.compute_cost = compute_cost
+
+ def dp_strategies(self) -> List[ShardingStrategy]:
+ strategies = []
+
+ # S01R = S01R x RR
+ strategies.append(self.split_lhs_1st_dim_1d(0, 1))
+
+ return strategies
+
+ def tp_strategies(self) -> List[ShardingStrategy]:
+ strategies = []
+
+ # RR = RS01 x S01R
+ strategies.append(self.split_lhs_2nd_dim_1d(0, 1))
+
+ # RS01 = RR x RS01
+ strategies.append(self.split_rhs_2nd_dim_1d(0, 1))
+
+ # RS = RS x SS
+ strategies.append(self.split_rhs_space_both_contract(0, 1))
+ strategies.append(self.split_rhs_space_both_contract(1, 0))
+
+ # RR= RS x SR
+ strategies.append(self.recompute_split_both_contract(0))
+ strategies.append(self.recompute_split_both_contract(1))
+
+ # RS = RR x RS
+ strategies.append(self.split_rhs_space_only(0))
+ strategies.append(self.split_rhs_space_only(1))
+
+ return strategies
+
+ def mix_strategies(self) -> List[ShardingStrategy]:
+ strategies = []
+
+ # SS = SR x RS
+ strategies.append(self.split_lhs_space_rhs_space(0, 1))
+ strategies.append(self.split_lhs_space_rhs_space(1, 0))
+
+ # SR = SS x SR
+ strategies.append(self.split_lhs_space_both_contract(0, 1))
+ strategies.append(self.split_lhs_space_both_contract(1, 0))
+
+ # RR = RR x RR
+ strategies.append(self.non_split())
+
+ return strategies
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategies = []
+
+ if self.solver_perference == SolverPerference.STANDARD:
+ strategies.extend(self.dp_strategies())
+ strategies.extend(self.tp_strategies())
+ strategies.extend(self.mix_strategies())
+ elif self.solver_perference == SolverPerference.DP:
+ strategies.extend(self.dp_strategies())
+ elif self.solver_perference == SolverPerference.TP:
+ strategies.extend(self.tp_strategies())
+
+ return strategies
+
+ @ignore_sharding_exception
+ def split_lhs_space_rhs_space(self, mesh_dim_0, mesh_dim_1):
+ # handle case SS = SR x RS
+ name = f'S{mesh_dim_0}S{mesh_dim_1} = S{mesh_dim_0}R x RS{mesh_dim_1}'
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0]
+ },
+ "other": {
+ -1: [mesh_dim_1]
+ },
+ "output": {
+ 0: [mesh_dim_0],
+ -1: [mesh_dim_1]
+ },
+ }
+
+ # linear bias only has one dimension, but addmm bias has same dimensions
+ # as the output logically.
+ if self.linear_projection_type == 'linear':
+ dim_partition_dict_mapping['bias'] = {-1: [mesh_dim_1]}
+ elif self.linear_projection_type == 'addmm':
+ dim_partition_dict_mapping['bias'] = {0: [mesh_dim_0], -1: [mesh_dim_1]}
+ else:
+ raise ('Unsupported linear projection type')
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # set communication action
+ communication_action_mapping = {}
+ input_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_1,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+
+ if self.is_param('other'):
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+
+ communication_action_mapping['input'] = input_comm_action
+ communication_action_mapping['other'] = other_comm_action
+
+ # we only add allreduce comm action for linear bias, because
+ # allreduce comm action for addmm bias will be considered in post processing
+ if self.has_bias and self.linear_projection_type == 'linear':
+ if self.is_param('bias'):
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+ else:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ key_for_kwarg='bias')
+ communication_action_mapping['bias'] = bias_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_lhs_space_both_contract(self, mesh_dim_0, mesh_dim_1):
+ # handle the case SR = SS x SR
+ name = f'S{mesh_dim_0}R = S{mesh_dim_0}S{mesh_dim_1} x S{mesh_dim_1}R'
+
+ # get sharding spec mapping
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0],
+ -1: [mesh_dim_1]
+ },
+ "other": {
+ 0: [mesh_dim_1]
+ },
+ "bias": {},
+ "output": {
+ 0: [mesh_dim_0]
+ },
+ }
+
+ # linear bias only has one dimension, but addmm bias has same dimensions
+ # as the output logically.
+ if self.linear_projection_type == 'linear':
+ dim_partition_dict_mapping['bias'] = {}
+ elif self.linear_projection_type == 'addmm':
+ dim_partition_dict_mapping['bias'] = {0: [mesh_dim_0]}
+ else:
+ raise ('Unsupported linear projection type')
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # get communication action mapping
+ communication_action_mapping = {}
+
+ output_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["output"],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=mesh_dim_1,
+ comm_type=CommType.AFTER)
+
+ if self.is_param('other'):
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec_mapping["other"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+
+ communication_action_mapping['other'] = other_comm_action
+ communication_action_mapping['output'] = output_comm_action
+
+ # we only add allreduce comm action for linear bias, because
+ # allreduce comm action for addmm bias will be considered in post processing
+ if self.has_bias and self.linear_projection_type == 'linear':
+ if self.is_param('bias'):
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.HOOK)
+ else:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec_mapping["bias"],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ key_for_kwarg='bias')
+ communication_action_mapping['bias'] = bias_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_rhs_space_both_contract(self, mesh_dim_0, mesh_dim_1):
+ name = f'RS{mesh_dim_1} = RS{mesh_dim_0} x S{mesh_dim_0}S{mesh_dim_1}'
+
+ # get sharding specs
+ dim_partition_dict_mapping = {
+ "input": {
+ -1: [mesh_dim_0]
+ },
+ "other": {
+ 0: [mesh_dim_0],
+ -1: [mesh_dim_1]
+ },
+ "bias": {
+ -1: [mesh_dim_1]
+ },
+ "output": {
+ -1: [mesh_dim_1]
+ },
+ }
+
+ # We don't have to do anything special for bias here, because
+ # the bias is already the same sharding spec as the output.
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # get communication actions
+ communication_action_mapping = {}
+ output_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['output'],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.AFTER)
+ input_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['input'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_1,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ communication_action_mapping["input"] = input_comm_action
+ communication_action_mapping['output'] = output_comm_action
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def recompute_split_both_contract(self, mesh_dim):
+ name = f'RR = RS{mesh_dim} x S{mesh_dim}R'
+
+ # get sharding spec
+ dim_partition_dict_mapping = {
+ "input": {
+ -1: [mesh_dim]
+ },
+ "other": {
+ 0: [mesh_dim]
+ },
+ "bias": {},
+ "output": {},
+ }
+ # We don't have to do anything special for bias here, because
+ # the bias is already the same sharding spec as the output.
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # get communication action
+ communication_action_mapping = {}
+ output_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['output'],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=mesh_dim,
+ comm_type=CommType.AFTER)
+
+ communication_action_mapping['output'] = output_comm_action
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_rhs_space_only(self, mesh_dim):
+ name = f'RS{mesh_dim} = RR x RS{mesh_dim}'
+
+ # get sharding spec
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {
+ -1: [mesh_dim]
+ },
+ "bias": {
+ -1: [mesh_dim]
+ },
+ "output": {
+ -1: [mesh_dim]
+ },
+ }
+ # We don't have to do anything special for bias here, because
+ # the bias is already the same sharding spec as the output.
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # get communication actions
+ communication_action_mapping = {}
+ input_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['input'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+
+ communication_action_mapping['input'] = input_comm_action
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_lhs_1st_dim_1d(self, mesh_dim_0, mesh_dim_1):
+ name = f'S{mesh_dim_0}{mesh_dim_1}R = S{mesh_dim_0}{mesh_dim_1}R x RR'
+ # get sharding spec
+ dim_partition_dict_mapping = {
+ "input": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ "other": {},
+ "bias": {},
+ "output": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ }
+
+ # linear bias only has one dimension, but addmm bias has same dimensions
+ # as the output logically.
+ if self.linear_projection_type == 'linear':
+ dim_partition_dict_mapping['bias'] = {}
+ elif self.linear_projection_type == 'addmm':
+ dim_partition_dict_mapping['bias'] = {0: [mesh_dim_0, mesh_dim_1]}
+ else:
+ raise ('Unsupported linear projection type')
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # get communication action
+ communication_action_mapping = {}
+ if self.is_param('other'):
+ other_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['other'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.HOOK)
+ else:
+ other_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['other'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+ communication_action_mapping['other'] = other_comm_action
+
+ # we only add allreduce comm action for linear bias, because
+ # allreduce comm action for addmm bias will be considered in post processing
+ if self.has_bias and self.linear_projection_type == 'linear':
+ if self.is_param('bias'):
+ bias_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['bias'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.HOOK)
+ else:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['bias'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.BEFORE,
+ key_for_kwarg='bias')
+ communication_action_mapping['bias'] = bias_comm_action
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_lhs_2nd_dim_1d(self, mesh_dim_0, mesh_dim_1):
+ name = f'RR = RS{mesh_dim_0}{mesh_dim_1} x S{mesh_dim_0}{mesh_dim_1}R'
+
+ # get sharding spec
+ dim_partition_dict_mapping = {
+ "input": {
+ -1: [mesh_dim_0, mesh_dim_1]
+ },
+ "other": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ "bias": {},
+ "output": {},
+ }
+
+ # We don't have to do anything special for bias here, because
+ # the bias is already the same sharding spec as the output.
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # get communication action
+ communication_action_mapping = {}
+ output_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['output'],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.AFTER)
+ communication_action_mapping['output'] = output_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_rhs_2nd_dim_1d(self, mesh_dim_0, mesh_dim_1):
+ name = f'RS{mesh_dim_0}{mesh_dim_1} = RR x RS{mesh_dim_0}{mesh_dim_1}'
+
+ # get sharding spec
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {
+ -1: [mesh_dim_0, mesh_dim_1]
+ },
+ "bias": {
+ -1: [mesh_dim_0, mesh_dim_1]
+ },
+ "output": {
+ -1: [mesh_dim_0, mesh_dim_1]
+ },
+ }
+
+ # We don't have to do anything special for bias here, because
+ # the bias is already the same sharding spec as the output.
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # get communication action
+ communication_action_mapping = {}
+ input_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['input'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ communication_action_mapping['input'] = input_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def non_split(self):
+ name = f'RR = RR x RR'
+
+ # get sharding spec
+ dim_partition_dict_mapping = {
+ "input": {},
+ "other": {},
+ "bias": {},
+ "output": {},
+ }
+
+ # We don't have to do anything special for bias here, because
+ # the bias is already the same sharding spec as the output.
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # get communication action
+ communication_action_mapping = {}
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ def validate(self) -> bool:
+ assert "input" in self.op_data
+ assert "other" in self.op_data
+
+ # make sure the other has 2 dim
+ input_data = self.op_data['input']
+ other_data = self.op_data['other']
+ assert input_data.data.dim() > 0 and other_data.data.dim() == 2
+ assert other_data.logical_shape[0] == input_data.logical_shape[-1]
+
+ if self.has_bias:
+ bias_data = self.op_data['bias']
+ assert bias_data.logical_shape[-1] == other_data.logical_shape[-1]
+
+
+class BatchedMatMulStrategyGenerator(MatMulStrategyGenerator):
+ """
+ Generate sharding strategies for the batched matrix multiplication.
+
+ A batched matrix multiplication can be viewed as
+ [b, i, k] x [b, k, j] -> [b, i, j]
+
+ The bias term is considered to have a 2D logical shape.
+
+ Note: This class will be used to generate strategies for torch.bmm
+ and torch.addbmm. However, the result of torch.addbmm is not correct,
+ some extra runtime apply actions are required to keep numerical correctness.
+ """
+
+ # TODO: torch.addbmm correctness issue need to be fixed.
+ def __init__(self, *args, **kwargs):
+ self.squeeze_batch_dim = False
+ super().__init__(*args, **kwargs)
+
+ def _pop_batch_dim_sharding_for_output(self, dim_partition_dict):
+ # remove partition dict for dim 0
+ dim_partition_dict['output'].pop(0, None)
+
+ # decrease the remaining dim index by 1
+ temp_dim_partition = {}
+ keys = list(dim_partition_dict['output'].keys())
+ for key in keys:
+ val = dim_partition_dict['output'].pop(key)
+ temp_dim_partition[key - 1] = val
+ dim_partition_dict['output'].update(temp_dim_partition)
+
+ def validate(self) -> bool:
+ input_op_data = self.op_data['input']
+ other_op_data = self.op_data['other']
+ assert len(input_op_data.logical_shape) == 3 or len(other_op_data.logical_shape) == 3
+
+ if 'bias' in self.op_data:
+ bias_op_data = self.op_data['bias']
+ assert bias_op_data.data.dim() < 3 and len(bias_op_data.logical_shape) == 2
+
+ def update_compute_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ fwd_compute_cost = self.op_data['input'].data.shape[-1] * reduce(operator.mul,
+ self.op_data['output'].data.shape)
+ bwd_compute_cost = fwd_compute_cost * 2
+ compute_cost = TrainCycleItem(fwd=fwd_compute_cost,
+ bwd=bwd_compute_cost,
+ total=fwd_compute_cost + bwd_compute_cost)
+ strategy.compute_cost = compute_cost
+
+ @ignore_sharding_exception
+ def split_one_batch_dim(self, mesh_dim):
+ name = f'Sb{mesh_dim} = Sb{mesh_dim} x Sb{mesh_dim}'
+
+ # get sharding_spec
+ dim_partition_dict = {"input": {0: [mesh_dim]}, "other": {0: [mesh_dim]}, "bias": {}, "output": {0: [mesh_dim]}}
+ if self.squeeze_batch_dim:
+ self._pop_batch_dim_sharding_for_output(dim_partition_dict)
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict)
+
+ # get communication actions
+ communication_action_mapping = {}
+ if self.has_bias:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['bias'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ communication_action_mapping['bias'] = bias_comm_action
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_two_batch_dim(self, mesh_dim_0, mesh_dim_1):
+ name = f'Sb{mesh_dim_0}{mesh_dim_1} = Sb{mesh_dim_0}{mesh_dim_1} x Sb{mesh_dim_0}{mesh_dim_1}'
+ dim_partition_dict = {
+ "input": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ "other": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ },
+ "bias": {},
+ "output": {
+ 0: [mesh_dim_0, mesh_dim_1]
+ }
+ }
+ if self.squeeze_batch_dim:
+ self._pop_batch_dim_sharding_for_output(dim_partition_dict)
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict)
+
+ # get communication actions
+ communication_action_mapping = {}
+ if self.has_bias:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['bias'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ communication_action_mapping['bias'] = bias_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_batch_dim_lhs_space(self, mesh_dim_0, mesh_dim_1):
+ name = f'Sb{mesh_dim_0}Si{mesh_dim_1} = Sb{mesh_dim_0}Si{mesh_dim_1} x Sb{mesh_dim_0}'
+ dim_partition_dict = {
+ "input": {
+ 0: [mesh_dim_0],
+ 1: [mesh_dim_1]
+ },
+ "other": {
+ 0: [mesh_dim_0]
+ },
+ "bias": {
+ 0: [mesh_dim_1]
+ },
+ "output": {
+ 0: [mesh_dim_0],
+ 1: [mesh_dim_1]
+ }
+ }
+ if self.squeeze_batch_dim:
+ self._pop_batch_dim_sharding_for_output(dim_partition_dict)
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict)
+
+ # get communication actions
+ communication_action_mapping = {}
+ other_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['other'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_1,
+ comm_type=CommType.BEFORE,
+ arg_index=1)
+ communication_action_mapping['other'] = other_comm_action
+
+ if self.has_bias:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['bias'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=[mesh_dim_0, mesh_dim_1],
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ communication_action_mapping['bias'] = bias_comm_action
+ # for addbmm case, other is the third argument instead of second.
+ communication_action_mapping['other'].arg_index += 1
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_batch_dim_rhs_space(self, mesh_dim_0, mesh_dim_1):
+ name = f'Sb{mesh_dim_0}Sj{mesh_dim_1} = Sb{mesh_dim_0}R x Sb{mesh_dim_0}Sj{mesh_dim_1}'
+ dim_partition_dict = {
+ "input": {
+ 0: [mesh_dim_0]
+ },
+ "other": {
+ 0: [mesh_dim_0],
+ 2: [mesh_dim_1]
+ },
+ "bias": {
+ 1: [mesh_dim_1]
+ },
+ "output": {
+ 0: [mesh_dim_0],
+ 2: [mesh_dim_1]
+ }
+ }
+ if self.squeeze_batch_dim:
+ self._pop_batch_dim_sharding_for_output(dim_partition_dict)
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict)
+
+ # get communication actions
+ communication_action_mapping = {}
+ input_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['input'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_1,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ communication_action_mapping['input'] = input_comm_action
+
+ if self.has_bias:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['bias'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE)
+ communication_action_mapping['bias'] = bias_comm_action
+ # for addbmm case, other is the second argument instead of first.
+ communication_action_mapping['input'].arg_index += 1
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ @ignore_sharding_exception
+ def split_batch_dim_both_contract(self, mesh_dim_0, mesh_dim_1):
+ name = f'Sb{mesh_dim_0}R = Sb{mesh_dim_0}Sk{mesh_dim_1} x Sb{mesh_dim_0}Sk{mesh_dim_1}'
+ dim_partition_dict = {
+ "input": {
+ 0: [mesh_dim_0],
+ 2: [mesh_dim_1]
+ },
+ "other": {
+ 0: [mesh_dim_0],
+ 1: [mesh_dim_1]
+ },
+ "bias": {},
+ "output": {
+ 0: [mesh_dim_0],
+ }
+ }
+ if self.squeeze_batch_dim:
+ self._pop_batch_dim_sharding_for_output(dim_partition_dict)
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict)
+
+ # get communication actions
+ communication_action_mapping = {}
+ output_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['output'],
+ communication_pattern=CollectiveCommPattern.ALLREDUCE_FWD_IDENTITY_BWD,
+ logical_process_axis=mesh_dim_1,
+ comm_type=CommType.AFTER)
+ communication_action_mapping['output'] = output_comm_action
+
+ if self.has_bias:
+ bias_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping['bias'],
+ communication_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ logical_process_axis=mesh_dim_0,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ communication_action_mapping['bias'] = bias_comm_action
+
+ return self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ device_mesh_is_1d = True
+ if len(self.device_mesh.mesh_shape) == 2 and 1 not in self.device_mesh.mesh_shape:
+ device_mesh_is_1d = False
+
+ if device_mesh_is_1d:
+ # split only the batch dimension
+ # Sb = Sb x Sb
+ # can be None as it is only for 1D device mesh
+ # only for 1D device mesh
+ if len(self.device_mesh.mesh_shape) == 1:
+ mesh_dim = 0
+ else:
+ mesh_dim = self.device_mesh.mesh_shape.index(1)
+ strategy_list.append(self.split_one_batch_dim(mesh_dim))
+ else:
+ # for 2D device mesh
+ # split batch dim of two inputs and the i dim of the first tensor
+ # SbSi = SbSi x Sb
+ strategy_list.append(self.split_batch_dim_lhs_space(0, 1))
+ strategy_list.append(self.split_batch_dim_lhs_space(1, 0))
+
+ # split batch dim of two inputs and the j of the second tensor
+ # SbSj = Sb x SbSj
+ strategy_list.append(self.split_batch_dim_rhs_space(0, 1))
+ strategy_list.append(self.split_batch_dim_rhs_space(1, 0))
+
+ # split batch dim of two inputs and the k dim of two inputs
+ # Sb = SbSk x SbSk, need to all-reduce by k dim
+ strategy_list.append(self.split_batch_dim_both_contract(0, 1))
+ strategy_list.append(self.split_batch_dim_both_contract(1, 0))
+
+ # split two batch dim
+ strategy_list.append(self.split_two_batch_dim(0, 1))
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/normal_pooling_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/normal_pooling_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..9df6d2fbfa127b71eba66256fb27f204fb1da5fe
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/normal_pooling_generator.py
@@ -0,0 +1,118 @@
+import copy
+import operator
+from functools import reduce
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, ShardingStrategy, TrainCycleItem
+from colossalai.auto_parallel.tensor_shard.utils import (
+ enumerate_all_possible_1d_sharding,
+ enumerate_all_possible_2d_sharding,
+ ignore_sharding_exception,
+)
+
+from .strategy_generator import StrategyGenerator
+
+
+class NormalPoolStrategyGenerator(StrategyGenerator):
+ """
+ NormalPoolStrategyGenerator is a generic class to generate strategies for pool operation like MaxPoolxd.
+ The reason we call this normal pool is AvgPoolxd and MaxPoolxd are taking the kernel size element from image,
+ and reduce them depening on the operation type.
+ """
+
+ def validate(self) -> bool:
+ '''
+ In sanity check, we need make sure the input data having correct dimension size.
+ For Pool1d, the dim of input data should be 3([N, C, L]).
+ For Pool2d, the dim of input data should be 4([N, C, H, W]).
+ For Pool3d, the dim of input data should be 5([N, C, H, W, D]).
+ '''
+ input_op_data = self.op_data['input']
+ assert input_op_data.data.dim() in (
+ 3, 4, 5), f'We suppose the dim of input fed into Pool op should in range of [3, 5].'
+
+ def update_compute_cost(self, strategy: ShardingStrategy) -> TrainCycleItem:
+ '''
+ Compute the computation cost per device with this specific strategy.
+
+ Note: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ '''
+ # TODO: compute_cost need to be devided by TFLOPS, now it just shows the computation size.
+ # 1D: (Lout) * N * C * kernel
+ # 2D: (H * W) * N * Cout * Cin * kernel
+ # 3D: (H * W * D) * N * Cout * Cin * kernel
+ sharded_output_shape = strategy.sharding_specs[self.op_data['output']].get_sharded_shape_per_device()
+ sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+
+ kernel_size = self.op_data["other"].data
+ if isinstance(kernel_size, int):
+ kernel_size = [kernel_size] * (len(sharded_output_shape) - 2)
+ kernel_size_product = reduce(operator.mul, kernel_size)
+ output_size_product = reduce(operator.mul, sharded_output_shape)
+ input_size_product = reduce(operator.mul, sharded_input_shape)
+
+ forward_compute_cost = output_size_product * kernel_size_product
+ backward_compute_cost = input_size_product * kernel_size_product
+
+ total_compute_cost = forward_compute_cost + backward_compute_cost
+
+ compute_cost = TrainCycleItem(fwd=forward_compute_cost, bwd=backward_compute_cost, total=total_compute_cost)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ forward_size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = input + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items()])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=0)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad
+ bwd_activation_cost = sum([v for k, v in backward_size_mapping.items()])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=0)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost, parameter=0)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ @ignore_sharding_exception
+ def _generate_strategy_with_dim_partition(self, dim_partition):
+ dim_partition_dict_mapping = {"input": dim_partition, "output": dim_partition}
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ name = f'{sharding_spec_mapping["output"].sharding_sequence} = {sharding_spec_mapping["input"].sharding_sequence}'
+ communication_action_mapping = {}
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ return strategy
+
+ def enumerate_all_possible_batch_dimensions_dim_partition(self, mesh_dim_0, mesh_dim_1):
+ dim_partition_list = []
+ dim_partition_list.extend(enumerate_all_possible_1d_sharding(mesh_dim_0, 2))
+ dim_partition_list.extend(enumerate_all_possible_1d_sharding(mesh_dim_1, 2))
+ dim_partition_list.extend(enumerate_all_possible_2d_sharding(mesh_dim_0, mesh_dim_1, 2))
+ # append {} for non_split case
+ dim_partition_list.append({})
+
+ return dim_partition_list
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+
+ dim_partition_list = self.enumerate_all_possible_batch_dimensions_dim_partition(0, 1)
+ for dim_partition in dim_partition_list:
+ strategy = self._generate_strategy_with_dim_partition(dim_partition)
+ strategy_list.append(strategy)
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/output_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/output_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..69d1642d4f808038d0eeb58547a7b1c0604c85eb
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/output_generator.py
@@ -0,0 +1,121 @@
+from typing import Dict, List
+
+from torch.fx import Node
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ MemoryCost,
+ OperationData,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.device.device_mesh import DeviceMesh
+
+from .strategy_generator import OutputStrategyGenerator
+
+__all__ = ['OutputGenerator']
+
+
+class OutputGenerator(OutputStrategyGenerator):
+ """
+ OutputGenerator is a generic class to generate strategies for Output Node.
+ """
+
+ def __init__(self, operation_data_mapping: Dict[str, OperationData], device_mesh: DeviceMesh,
+ predecessor_nodes: List[Node], output_option: str):
+ super().__init__(operation_data_mapping, device_mesh, predecessor_nodes)
+ self.output_option = output_option
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ compute_cost = TrainCycleItem(fwd=10, bwd=10, total=20)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ fwd_mem_cost = MemoryCost(activation=0, parameter=0)
+
+ bwd_mem_cost = MemoryCost(activation=0, parameter=0)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=0, parameter=0)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ def replica_strategy(self) -> List[ShardingStrategy]:
+ """
+ Generate replica strategy for output node.
+ """
+ dim_partition_dict_mapping = {}
+ dim_partition_dict_for_output = []
+ for index, _ in enumerate(self.predecessor_nodes):
+ mapping_name = f"input_{index}"
+ if isinstance(self.op_data[mapping_name].data, (tuple, list)):
+ dim_partition_dict_for_input = [{} for _ in range(len(self.op_data[mapping_name].data))]
+ else:
+ dim_partition_dict_for_input = {}
+ dim_partition_dict_mapping[mapping_name] = dim_partition_dict_for_input
+ dim_partition_dict_for_output.append(dim_partition_dict_for_input)
+
+ if len(dim_partition_dict_for_output) == 1:
+ dim_partition_dict_for_output = dim_partition_dict_for_output[0]
+ else:
+ dim_partition_dict_for_output = tuple(dim_partition_dict_for_output)
+
+ dim_partition_dict_mapping['output'] = dim_partition_dict_for_output
+
+ communication_action_mapping = {}
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ name = 'Replica Output'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ return strategy
+
+ def distributed_strategy(self, mesh_list: List[List[int]] = None) -> List[ShardingStrategy]:
+ """
+ Generate distributed strategy for output node.
+ """
+ # TODO: need to take care of the case when the first element of output only need to be sharded.
+ output_op_data = self.op_data['output']
+ if isinstance(output_op_data.data, tuple):
+ length = len(output_op_data.data)
+ dim_partition_dict_mapping = {
+ "output": [{
+ 0: mesh_list
+ }] * length,
+ }
+ else:
+ dim_partition_dict_mapping = {
+ "output": {
+ 0: mesh_list
+ },
+ }
+ for index, _ in enumerate(self.predecessor_nodes):
+ mapping_name = f"input_{index}"
+ dim_partition_dict_mapping[mapping_name] = {0: mesh_list}
+
+ communication_action_mapping = {}
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ name = 'Distributed Output'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ return strategy
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ mesh_list = [0, 1]
+ if self.output_option == 'replicated':
+ strategy_list.append(self.replica_strategy())
+ elif self.output_option == 'distributed':
+ strategy_list.append(self.distributed_strategy(mesh_list))
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/placeholder_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/placeholder_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..779a7ced93bb503c390bd89382d087230e48d2f0
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/placeholder_generator.py
@@ -0,0 +1,100 @@
+from typing import Dict, List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ MemoryCost,
+ OperationData,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.device.device_mesh import DeviceMesh
+
+from .strategy_generator import StrategyGenerator
+
+__all__ = ['PlaceholderGenerator']
+
+
+class PlaceholderGenerator(StrategyGenerator):
+ """
+ PlaceholderGenerator is a generic class to generate strategies for placeholder node.
+ """
+
+ def __init__(self, operation_data_mapping: Dict[str, OperationData], device_mesh: DeviceMesh,
+ placeholder_option: str):
+ super().__init__(operation_data_mapping, device_mesh)
+ self.placeholder_option = placeholder_option
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ compute_cost = TrainCycleItem(fwd=10, bwd=10, total=20)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ forward_size_mapping = {'output': self._compute_size_in_bytes(strategy, "output")}
+
+ # compute fwd cost incurred
+ # fwd_cost = output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items()])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=0)
+
+ bwd_mem_cost = MemoryCost(activation=0, parameter=0)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=0)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ def replica_placeholder(self) -> ShardingStrategy:
+ """
+ Generate replica strategy for placeholder node.
+ """
+ dim_partition_dict_mapping = {
+ "output": {},
+ }
+ communication_action_mapping = {}
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ name = 'Replica Placeholder'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ return strategy
+
+ def distributed_placeholder(self, mesh_list) -> ShardingStrategy:
+ """
+ Generate distributed strategy for placeholder node.
+ """
+ dim_partition_dict_mapping = {
+ "output": {
+ 0: mesh_list
+ },
+ }
+ communication_action_mapping = {}
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ name = 'Distributed Placeholder'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ return strategy
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ if self.placeholder_option == 'distributed':
+ mesh_list = [0, 1]
+ distributed_strategy = self.distributed_placeholder(mesh_list)
+ strategy_list.append(distributed_strategy)
+ else:
+ assert self.placeholder_option == 'replicated', f'placeholder_option {self.placeholder_option} is not supported'
+ replicated_strategy = self.replica_placeholder()
+ strategy_list.append(replicated_strategy)
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/reshape_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/reshape_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..24f75e352935f149e02c399b2c8e90c0f3ddc2f7
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/reshape_generator.py
@@ -0,0 +1,366 @@
+import copy
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.node_handler.strategy.strategy_generator import FollowingStrategyGenerator
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommAction,
+ CommType,
+ MemoryCost,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.auto_parallel.tensor_shard.utils import (
+ check_keep_sharding_status,
+ detect_reshape_mapping,
+ infer_output_dim_partition_dict,
+)
+from colossalai.tensor.shape_consistency import CollectiveCommPattern
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+__all__ = ['ReshapeGenerator', 'ViewGenerator', 'PermuteGenerator', 'TransposeGenerator', 'SplitGenerator']
+
+
+class ReshapeGenerator(FollowingStrategyGenerator):
+ """
+ ReshapeGenerator is the base class for all the reshape operation.
+ """
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ compute_cost = TrainCycleItem(fwd=10, bwd=10, total=20)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ forward_size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = input + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items() if not self.is_param(k)])
+ fwd_parameter_cost = sum([v for k, v in forward_size_mapping.items() if self.is_param(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad
+ bwd_activation_cost = sum([v for k, v in backward_size_mapping.items() if not self.is_param(k)])
+ bwd_parameter_cost = sum([v for k, v in backward_size_mapping.items() if self.is_param(k)])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=bwd_parameter_cost)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost,
+ parameter=fwd_parameter_cost + bwd_parameter_cost)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ return super().collate_strategies()
+
+
+class ViewGenerator(ReshapeGenerator):
+ """
+ ViewGenerator deals with the sharding strategies of view op.
+ """
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ for index, strategy in enumerate(self.predecessor_node.strategies_vector):
+ dim_partition_dict_mapping = {}
+ communication_action_mapping = {}
+ input_sharding_spec = strategy.output_sharding_specs[self.op_data["input"]]
+
+ origin_shape = self.op_data['input'].data.shape
+ tgt_shape = self.op_data['tgt_shape'].data
+
+ reshape_mapping_dict = detect_reshape_mapping(origin_shape, tgt_shape)
+
+ dim_partition_dict_for_input = input_sharding_spec.dim_partition_dict
+ keep_sharding_status = check_keep_sharding_status(dim_partition_dict_for_input, reshape_mapping_dict)
+
+ if keep_sharding_status:
+ dim_partition_dict_for_output = infer_output_dim_partition_dict(dim_partition_dict_for_input,
+ reshape_mapping_dict)
+ else:
+ dim_partition_dict_for_output = {}
+
+ dim_partition_dict_mapping = {
+ "input": dim_partition_dict_for_input,
+ "output": dim_partition_dict_for_output,
+ }
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # add index into name to pass the duplicated check
+ # we keep same strategies with different name for node merging, and it will not increase the searching space,
+ # because in solver, this node will be merged into other nodes, and solver will not create a new variable for this node.
+ if keep_sharding_status:
+ name = f'{sharding_spec_mapping["input"].sharding_sequence} -> {sharding_spec_mapping["output"].sharding_sequence}_{index}'
+ else:
+ name = f'{sharding_spec_mapping["input"].sharding_sequence} -> FULLY REPLICATED_{index}'
+
+ # add comm action for converting input to fully replicated
+ total_mesh_dim_list = []
+ for mesh_dim_list in dim_partition_dict_for_input.values():
+ total_mesh_dim_list.extend(mesh_dim_list)
+ # if there is only one sharding dimension, we should use the value instead of list as logical_process_axis.
+ if len(total_mesh_dim_list) == 1:
+ total_mesh_dim_list = total_mesh_dim_list[0]
+ # the total mesh dim list only has one element, so the shard dim has only one element as well.
+ shard_dim = list(dim_partition_dict_for_input.keys())[0]
+ input_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.GATHER_FWD_SPLIT_BWD,
+ logical_process_axis=total_mesh_dim_list,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ # it will gather the input through gather_dim during forward phase.
+ input_comm_action.comm_spec.gather_dim = shard_dim
+ # it will split the input activation grad through shard_dim during backward phase.
+ input_comm_action.comm_spec.shard_dim = shard_dim
+
+ elif len(total_mesh_dim_list) >= 2:
+ source_spec = sharding_spec_mapping["input"]
+ target_spec = ShardingSpec(device_mesh=self.device_mesh,
+ entire_shape=source_spec.entire_shape,
+ dim_partition_dict={})
+ comm_spec = {'src_spec': source_spec, 'tgt_spec': target_spec}
+ input_comm_action = CommAction(comm_spec=comm_spec, comm_type=CommType.BEFORE, arg_index=0)
+
+ else:
+ input_comm_action = None
+
+ if input_comm_action is not None:
+ communication_action_mapping["input"] = input_comm_action
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(strategy)
+
+ return strategy_list
+
+
+class PermuteGenerator(ReshapeGenerator):
+ """
+ PermuteGenerator deals with the sharding strategies of permute op.
+ """
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ for index, strategy in enumerate(self.predecessor_node.strategies_vector):
+ dim_partition_dict_mapping = {}
+ communication_action_mapping = {}
+ input_sharding_spec = strategy.output_sharding_specs[self.op_data["input"]]
+
+ permute_dims = self.op_data['permute_dims'].data
+ dim_partition_dict_for_input = input_sharding_spec.dim_partition_dict
+ dim_partition_dict_for_output = {}
+ for dim_index, permute_dim in enumerate(permute_dims):
+ if permute_dim in dim_partition_dict_for_input:
+ dim_partition_dict_for_output[dim_index] = dim_partition_dict_for_input[permute_dim]
+
+ dim_partition_dict_mapping = {
+ "input": dim_partition_dict_for_input,
+ "output": dim_partition_dict_for_output,
+ }
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # add index into name to pass the duplicated check
+ # we keep same strategies with different name for node merging, and it will not increase the searching space,
+ # because in solver, this node will be merged into other nodes, and solver will not create a new variable for this node.
+ name = f'{sharding_spec_mapping["input"].sharding_sequence} -> {sharding_spec_mapping["output"].sharding_sequence}_{index}'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(strategy)
+
+ return strategy_list
+
+
+class TransposeGenerator(ReshapeGenerator):
+ """
+ TransposeGenerator deals with the sharding strategies of permute op.
+ """
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ for index, strategy in enumerate(self.predecessor_node.strategies_vector):
+ dim_partition_dict_mapping = {}
+ communication_action_mapping = {}
+ input_sharding_spec = strategy.output_sharding_specs[self.op_data["input"]]
+ dim_partition_dict_for_input = input_sharding_spec.dim_partition_dict
+ dim_partition_dict_for_output = {}
+
+ transpose_dims = self.op_data['transpose_dims'].data
+ dim_0 = transpose_dims[0]
+ dim_1 = transpose_dims[1]
+ for dim, sharded_dims in dim_partition_dict_for_input.items():
+ if dim == dim_0:
+ dim_partition_dict_for_output[dim_1] = dim_partition_dict_for_input[dim_0]
+ elif dim == dim_1:
+ dim_partition_dict_for_output[dim_0] = dim_partition_dict_for_input[dim_1]
+ else:
+ dim_partition_dict_for_output[dim] = sharded_dims
+
+ dim_partition_dict_mapping = {
+ "input": dim_partition_dict_for_input,
+ "output": dim_partition_dict_for_output,
+ }
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ # add index into name to pass the duplicated check
+ # we keep same strategies with different name for node merging, and it will not increase the searching space,
+ # because in solver, this node will be merged into other nodes, and solver will not create a new variable for this node.
+ name = f'{sharding_spec_mapping["input"].sharding_sequence} -> {sharding_spec_mapping["output"].sharding_sequence}_{index}'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(strategy)
+
+ return strategy_list
+
+
+class SplitGenerator(ReshapeGenerator):
+ """
+ SplitGenerator deals with the sharding strategies of split op.
+ """
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ for index, strategy in enumerate(self.predecessor_node.strategies_vector):
+ recover_dims = None
+ dim_partition_dict_mapping = {}
+ communication_action_mapping = {}
+ input_sharding_spec = strategy.output_sharding_specs[self.op_data["input"]]
+ dim_partition_dict_for_input = copy.deepcopy(input_sharding_spec.dim_partition_dict)
+ split_size, split_dim = self.op_data['split_info'].data
+
+ if split_dim in dim_partition_dict_for_input:
+ recover_dims = dim_partition_dict_for_input.pop(split_dim)
+
+ dim_partition_dict_for_output = [
+ copy.deepcopy(dim_partition_dict_for_input) for _ in range(len(self.op_data["output"].data))
+ ]
+ assert len(dim_partition_dict_for_output) >= 2
+ dim_partition_dict_mapping = {
+ "input": dim_partition_dict_for_input,
+ "output": dim_partition_dict_for_output,
+ }
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+ # add index into name to pass the duplicated check
+ # we keep same strategies with different name for node merging, and it will not increase the searching space,
+ # because in solver, this node will be merged into other nodes, and solver will not create a new variable for this node.
+ name = f'{sharding_spec_mapping["input"].sharding_sequence}_{index}'
+
+ # add comm action if the input need to be recovered to replica in the split dimension.
+ if recover_dims:
+ # if there is only one sharding dimension, we should use the value instead of list as logical_process_axis.
+ if len(recover_dims) == 1:
+ recover_dims = recover_dims[0]
+ input_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.GATHER_FWD_SPLIT_BWD,
+ logical_process_axis=recover_dims,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ # it will gather the input through gather_dim during forward phase.
+ input_comm_action.comm_spec.gather_dim = split_dim
+ # it will split the input activation grad through split_dim during backward phase.
+ input_comm_action.comm_spec.shard_dim = split_dim
+
+ elif len(recover_dims) >= 2:
+ # original sharding spec
+ source_spec = input_sharding_spec
+ # target sharding spec
+ target_spec = sharding_spec_mapping["input"]
+ comm_spec = {'src_spec': source_spec, 'tgt_spec': target_spec}
+ input_comm_action = CommAction(comm_spec=comm_spec, comm_type=CommType.BEFORE, arg_index=0)
+
+ else:
+ input_comm_action = None
+
+ if input_comm_action is not None:
+ communication_action_mapping["input"] = input_comm_action
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(strategy)
+
+ return strategy_list
+
+
+class DefaultReshapeGenerator(ReshapeGenerator):
+ """
+ DefaultReshapeGenerator which deals with the sharding strategies of Reshape Op which have to recover the tensor
+ to Replica status.
+ """
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ # For default reshape strategy, to keep the computing correctness we keep the
+ # sharding spec of input is fully replicated. In addition, we will keep the output
+ # in replica status and let the successor node choose the way to resharding the
+ # output node. Therefore, the different strategies of input node with same
+ # output sharding spec will generate same strategy for reshape function.
+ for index, strategy in enumerate(self.predecessor_node.strategies_vector):
+ dim_partition_dict_mapping = {}
+ communication_action_mapping = {}
+ input_sharding_spec = strategy.output_sharding_specs[self.op_data["input"]]
+ dim_partition_dict_for_input = input_sharding_spec.dim_partition_dict
+ dim_partition_dict_for_output = {}
+ if isinstance(self.op_data["output"].data, tuple):
+ dim_partition_dict_for_output = [{} for _ in range(len(self.op_data["output"].data))]
+ dim_partition_dict_mapping = {
+ "input": dim_partition_dict_for_input,
+ "output": dim_partition_dict_for_output,
+ }
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+ # add index into name to pass the duplicated check
+ # we keep same strategies with different name for node merging, and it will not increase the searching space,
+ # because in solver, this node will be merged into other nodes, and solver will not create a new variable for this node.
+ name = f'{sharding_spec_mapping["input"].sharding_sequence} -> FULLY REPLICATED_{index}'
+
+ total_mesh_dim_list = []
+ for mesh_dim_list in dim_partition_dict_for_input.values():
+ total_mesh_dim_list.extend(mesh_dim_list)
+ # if there is only one sharding dimension, we should use the value instead of list as logical_process_axis.
+ if len(total_mesh_dim_list) == 1:
+ total_mesh_dim_list = total_mesh_dim_list[0]
+ input_comm_action = self.get_communication_action(
+ sharding_spec=sharding_spec_mapping["input"],
+ communication_pattern=CollectiveCommPattern.GATHER_FWD_SPLIT_BWD,
+ logical_process_axis=total_mesh_dim_list,
+ comm_type=CommType.BEFORE,
+ arg_index=0)
+ input_comm_action.comm_spec.gather_dim = total_mesh_dim_list
+ input_comm_action.comm_spec.shard_dim = total_mesh_dim_list
+
+ elif len(total_mesh_dim_list) >= 2:
+ source_spec = sharding_spec_mapping["input"]
+ target_spec = ShardingSpec(device_mesh=self.device_mesh,
+ entire_shape=source_spec.entire_shape,
+ dim_partition_dict={})
+ comm_spec = {'src_spec': source_spec, 'tgt_spec': target_spec}
+ input_comm_action = CommAction(comm_spec=comm_spec, comm_type=CommType.BEFORE, arg_index=0)
+
+ else:
+ input_comm_action = None
+
+ if input_comm_action is not None:
+ communication_action_mapping["input"] = input_comm_action
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(strategy)
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/softmax_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/softmax_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1ebadd043e2c2e563fcdc611567bca3ededfa51
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/softmax_generator.py
@@ -0,0 +1,104 @@
+import copy
+import operator
+from functools import reduce
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.node_handler.strategy.strategy_generator import FollowingStrategyGenerator
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommAction,
+ CommType,
+ MemoryCost,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.auto_parallel.tensor_shard.utils import (
+ check_keep_sharding_status,
+ detect_reshape_mapping,
+ infer_output_dim_partition_dict,
+)
+from colossalai.tensor.shape_consistency import CollectiveCommPattern
+
+__all__ = ['SoftmaxGenerator']
+
+
+class SoftmaxGenerator(FollowingStrategyGenerator):
+ """
+ SoftmaxGenerator is used to generate strategies for torch.nn.Softmax or F.softmax.
+ """
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the computation cost per device with this specific strategy.
+ '''
+ sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+ sharded_output_shape = strategy.sharding_specs[self.op_data['output']].get_sharded_shape_per_device()
+ input_size_product = reduce(operator.mul, sharded_input_shape)
+ output_size_product = reduce(operator.mul, sharded_output_shape)
+
+ forward_compute_cost = output_size_product * 2
+ backward_compute_cost = input_size_product
+ total_compute_cost = forward_compute_cost + backward_compute_cost
+ compute_cost = TrainCycleItem(fwd=forward_compute_cost, bwd=backward_compute_cost, total=total_compute_cost)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ forward_size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = input + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items() if not self.is_param(k)])
+ fwd_parameter_cost = sum([v for k, v in forward_size_mapping.items() if self.is_param(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad
+ bwd_activation_cost = sum([v for k, v in backward_size_mapping.items() if not self.is_param(k)])
+ bwd_parameter_cost = sum([v for k, v in backward_size_mapping.items() if self.is_param(k)])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=bwd_parameter_cost)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost,
+ parameter=fwd_parameter_cost + bwd_parameter_cost)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ for index, strategy in enumerate(self.predecessor_node.strategies_vector):
+ dim_partition_dict_mapping = {}
+ communication_action_mapping = {}
+ input_sharding_spec = strategy.output_sharding_specs[self.op_data["input"]]
+ dim_partition_dict_for_input = copy.deepcopy(input_sharding_spec.dim_partition_dict)
+ softmax_dim = self.op_data['softmax_dim'].data
+
+ if softmax_dim in dim_partition_dict_for_input:
+ recover_dims = dim_partition_dict_for_input.pop(softmax_dim)
+
+ dim_partition_dict_for_output = copy.deepcopy(dim_partition_dict_for_input)
+ dim_partition_dict_mapping = {
+ "input": dim_partition_dict_for_input,
+ "output": dim_partition_dict_for_output,
+ }
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+ # add index into name to pass the duplicated check
+ # we keep same strategies with different name for node merging, and it will not increase the searching space,
+ # because in solver, this node will be merged into other nodes, and solver will not create a new variable for this node.
+ name = f'{sharding_spec_mapping["input"].sharding_sequence} -> {sharding_spec_mapping["output"].sharding_sequence}_{index}'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(strategy)
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d68521aaea7989c085c24f32a8dc92f4b1b71fc
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/strategy_generator.py
@@ -0,0 +1,298 @@
+import operator
+from abc import ABC, abstractmethod
+from functools import reduce
+from typing import Any, Dict, List, Union
+
+import torch
+from torch.fx import Node
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommAction,
+ CommType,
+ OperationData,
+ OperationDataType,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.tensor.shape_consistency import CollectiveCommPattern, CommSpec, ShapeConsistencyManager
+from colossalai.tensor.sharding_spec import ShardingSpec
+from colossalai.tensor.utils import convert_dim_partition_dict
+
+
+class StrategyGenerator(ABC):
+ """
+ StrategyGenerator is used to generate the same group of sharding strategies.
+
+ TODO: remove the original strategy_generator.py after refactoring
+ """
+
+ def __init__(self, operation_data_mapping: Dict[str, OperationData], device_mesh: DeviceMesh):
+ self.op_data = operation_data_mapping
+ self.device_mesh = device_mesh
+
+ # validate the whether operation data is of desired value
+ self.validate()
+
+ @property
+ def has_bias(self):
+ """
+ A utility method to check for the existence of bias operand for convenience.
+ """
+ return 'bias' in self.op_data
+
+ def is_param(self, op_data_name):
+ other_data = self.op_data[op_data_name]
+ return other_data.type == OperationDataType.PARAM
+
+ def is_buffer(self, op_data_name):
+ other_data = self.op_data[op_data_name]
+ return other_data.type == OperationDataType.BUFFER
+
+ def get_sharding_strategy(self, name: str, sharding_spec_mapping: Dict[str, ShardingSpec],
+ communication_action_mapping: Dict[str, CommSpec]):
+ """
+ A factory method to produce a ShardingStrategy object.
+
+ Args:
+ sharding_spec_mapping (Dict[str, ShardingSpec]): the mapping between the operation data name and the ShardingSpec object.
+ communication_action_mapping (Dict[str, CommSpec]): the mapping between the operation data name and the CommSpec object.
+ """
+ sharding_specs = self.replace_op_name_with_op_data(sharding_spec_mapping)
+ communication_actions = self.replace_op_name_with_op_data(communication_action_mapping)
+ return ShardingStrategy(name=name, sharding_specs=sharding_specs, communication_actions=communication_actions)
+
+ def to_sharding_spec_mapping(self, mapping: Dict[str, Dict[int, List[int]]]):
+ """
+ A utility method to convert the the dim partition dict to a ShardingSpec object.
+
+ Args:
+ mapping (Dict[str, Dict[int, List[int]]]): the key of the mapping is the operation data name and the value is a dim partition dictionary.
+
+ Notes:
+ The op_data.data is commonly type of torch.Tensor, torch.nn.Parameter, so the sharding spec is easy to create from the shape of the data.
+ However, if the op_data.data is of other non-iterative types, such as float or int, we should return None. If the op_data.data is of some iterative types, such as
+ list or tuple, we should return a list of ShardingSpec objects follow the same rule as above mentioned.
+ """
+ results = {}
+ for op_data_name, dim_partition_dict in mapping.items():
+ if op_data_name in self.op_data:
+ op_data = self.op_data[op_data_name]
+
+ def _to_sharding_spec(
+ data: any, logical_shape: any,
+ dim_partition_dict: Dict[int, List[int]]) -> Union[ShardingSpec, List[ShardingSpec], None]:
+ """
+ This is a recursive function to convert the dim partition dict to a ShardingSpec object.
+ """
+ if isinstance(data, torch.Tensor):
+ dim_size = len(logical_shape)
+ dim_partition_dict = convert_dim_partition_dict(dim_size, dim_partition_dict)
+ sharding_spec = ShardingSpec(device_mesh=self.device_mesh,
+ entire_shape=logical_shape,
+ dim_partition_dict=dim_partition_dict)
+ return sharding_spec
+ elif isinstance(data, (list, tuple)):
+ sharding_spec = []
+ for data_element, logical_shape_element, dim_partition_dict_element in zip(
+ data, logical_shape, dim_partition_dict):
+ sharding_spec.append(
+ _to_sharding_spec(data_element, logical_shape_element, dim_partition_dict_element))
+ return sharding_spec
+ else:
+ return None
+
+ sharding_spec = _to_sharding_spec(op_data.data, op_data.logical_shape, dim_partition_dict)
+ results[op_data_name] = sharding_spec
+ return results
+
+ def replace_op_name_with_op_data(self, mapping: Dict[str, Any]):
+ """
+ Convert the key of the dictionary from the operation data name to an OperationData object.
+ """
+ results = {}
+ for k, v in mapping.items():
+ op_data = self.op_data[k]
+ results[op_data] = v
+ return results
+
+ def get_communication_spec(self, sharding_spec: ShardingSpec, communication_pattern: CollectiveCommPattern,
+ logical_process_axis: Union[int, List[int]]):
+ """
+ A factory method to produce a CommSpec object.
+ """
+ return CommSpec(comm_pattern=communication_pattern,
+ sharding_spec=sharding_spec,
+ logical_process_axis=logical_process_axis)
+
+ def get_communication_action(self,
+ sharding_spec: ShardingSpec,
+ communication_pattern: CollectiveCommPattern,
+ logical_process_axis: Union[int, List[int]],
+ comm_type: CommType,
+ arg_index: int = -1,
+ key_for_kwarg: any = None) -> CommAction:
+ """
+ A factory method to produce a CommAction object.
+ """
+ return CommAction(comm_spec=self.get_communication_spec(sharding_spec=sharding_spec,
+ communication_pattern=communication_pattern,
+ logical_process_axis=logical_process_axis),
+ comm_type=comm_type,
+ arg_index=arg_index,
+ key_for_kwarg=key_for_kwarg)
+
+ def update_communication_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ """
+ Compute the communication cost involved in the forward and backward iteration.
+ """
+
+ comm_cost = TrainCycleItem(fwd=0, bwd=0, total=0)
+
+ def _compute_and_add(op_data: OperationData, comm_spec: CommSpec):
+ num_ele_in_comm = comm_spec.get_comm_cost()
+ dtype = op_data.data.dtype
+ size_per_elem_bytes = torch.tensor([], dtype=dtype).element_size()
+ for phase, cost in num_ele_in_comm.items():
+ num_ele_in_comm[phase] = num_ele_in_comm[phase] * size_per_elem_bytes
+ comm_cost.fwd += num_ele_in_comm['forward']
+ comm_cost.bwd += num_ele_in_comm['backward']
+ comm_cost.total += num_ele_in_comm['total']
+
+ # check if communication action exists
+ # if so, loop over each action and compute the cost of each action
+ if strategy.communication_actions is not None:
+ for operand, comm_action in strategy.communication_actions.items():
+ if isinstance(comm_action, CommAction):
+ comm_spec = comm_action.comm_spec
+ else:
+ # this condition branch will be removed after all the handler updated.
+ comm_spec = comm_action
+ if isinstance(comm_spec, dict):
+ src_spec = comm_spec['src_spec']
+ tgt_spec = comm_spec['tgt_spec']
+ shape_consistency_manager = ShapeConsistencyManager()
+ _, comm_action_sequence, _ = shape_consistency_manager.shape_consistency(src_spec, tgt_spec)
+ for comm_spec_ in comm_action_sequence:
+ _compute_and_add(operand, comm_spec_)
+ else:
+ _compute_and_add(operand, comm_spec)
+
+ # update the communication cost attribute in-place
+ strategy.communication_cost = comm_cost
+ return strategy
+
+ @abstractmethod
+ def update_compute_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ """
+ Customize this method to compute the computation flops.
+ """
+ pass
+
+ @abstractmethod
+ def update_memory_cost(self, strategy: ShardingStrategy) -> ShardingStrategy:
+ """
+ Customize this method to compute the memory cost in bytes.
+ """
+ pass
+
+ def _compute_size_in_bytes(self, strategy: ShardingStrategy, key: str):
+ """
+ Compute the size of a tensor in bytes.
+
+ Args:
+ strategy (ShardingStrategy): the ShardingStrategy generated.
+ key (str): the name of the operation data defined by the generator.
+ """
+ op_data = self.op_data[key]
+
+ def _compute_size_in_bytes_helper(sharding_spec, meta_data):
+ sharded_shape = sharding_spec.get_sharded_shape_per_device()
+ if len(sharded_shape) == 0:
+ num_elements = 1
+ else:
+ num_elements = reduce(operator.mul, sharded_shape)
+ dtype = getattr(meta_data, 'dtype')
+ size_per_elem_bytes = torch.tensor([], dtype=dtype).element_size()
+ return num_elements * size_per_elem_bytes
+
+ if isinstance(op_data.data, tuple):
+ assert isinstance(strategy.sharding_specs[op_data], list), \
+ 'sharding_spec of op_data should be a list of sharding specs if op_data.data is a tuple.'
+ total_bytes = 0
+ for index, sharding_spec in enumerate(strategy.sharding_specs[op_data]):
+ meta_data = op_data.data[index]
+ if isinstance(meta_data, torch.Tensor):
+ element_bytes = _compute_size_in_bytes_helper(sharding_spec, meta_data)
+ else:
+ # if meta_data is not a tensor, we count the memroy as 0
+ element_bytes = 0
+ total_bytes += element_bytes
+
+ else:
+ if isinstance(op_data.data, torch.Tensor):
+ total_bytes = _compute_size_in_bytes_helper(strategy.sharding_specs[op_data], op_data.data)
+ else:
+ # if op_data.data is not a tensor, we count the memroy as 0
+ total_bytes = 0
+
+ return total_bytes
+
+ def generate(self) -> List[ShardingStrategy]:
+ """
+ Generate all possible sharding strategies for this operation.
+ """
+ strategies = self.collate_strategies()
+
+ # some strategies may be None as ignore_sharding_exception may return None
+ # when ShardingSpecException occurs.
+ # thus, remove those None values
+ strategies = [strategy for strategy in strategies if strategy]
+
+ # update the costs
+ # update mete info on cost
+ # these update methods are all in-place, the default method will do nothing
+ # the cost info will only be added if the child class overrides these methods
+ for strategy in strategies:
+ self.update_communication_cost(strategy)
+ self.update_compute_cost(strategy)
+ self.update_memory_cost(strategy)
+
+ return strategies
+
+ @abstractmethod
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ pass
+
+ @abstractmethod
+ def validate(self) -> bool:
+ """
+ Validate if the operands are of desired shape.
+ If True, means this generator can be used for the current operation.
+ """
+ pass
+
+
+class FollowingStrategyGenerator(StrategyGenerator):
+ """
+ FollowingStrategyGenerator is used to generate the sharding strategies which depends on its predecessor node.
+
+ TODO: remove the original strategy_generator.py after refactoring
+ """
+
+ def __init__(self, operation_data_mapping: Dict[str, OperationData], device_mesh: DeviceMesh,
+ predecessor_node: Node):
+ self.op_data = operation_data_mapping
+ self.device_mesh = device_mesh
+ self.predecessor_node = predecessor_node
+
+
+class OutputStrategyGenerator(StrategyGenerator):
+ """
+ OutputStrategyGenerator is used to generate the sharding strategies for Output Node.
+ """
+
+ def __init__(self, operation_data_mapping: Dict[str, OperationData], device_mesh: DeviceMesh,
+ predecessor_nodes: List[Node]):
+ super().__init__(operation_data_mapping, device_mesh)
+ self.predecessor_nodes = predecessor_nodes
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/sum_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/sum_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0fbc58d70c0feba2c78305fb14d9bcb38a82e41
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/sum_generator.py
@@ -0,0 +1,113 @@
+import copy
+import operator
+from functools import reduce
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.node_handler.strategy.strategy_generator import FollowingStrategyGenerator
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommAction,
+ CommType,
+ MemoryCost,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.auto_parallel.tensor_shard.utils import (
+ check_keep_sharding_status,
+ detect_reshape_mapping,
+ infer_output_dim_partition_dict,
+)
+from colossalai.tensor.shape_consistency import CollectiveCommPattern
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+__all__ = ['SumGenerator']
+
+
+class SumGenerator(FollowingStrategyGenerator):
+ """
+ SumGenerator deals with the sharding strategies of torch.sum op.
+ """
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ sharded_input_shape = strategy.sharding_specs[self.op_data['input']].get_sharded_shape_per_device()
+ sharded_output_shape = strategy.sharding_specs[self.op_data['output']].get_sharded_shape_per_device()
+ input_size_product = reduce(operator.mul, sharded_input_shape)
+ output_size_product = reduce(operator.mul, sharded_output_shape)
+
+ compute_cost = TrainCycleItem(fwd=input_size_product,
+ bwd=output_size_product,
+ total=input_size_product + output_size_product)
+
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ forward_size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = input + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items() if not self.is_param(k)])
+ fwd_parameter_cost = sum([v for k, v in forward_size_mapping.items() if self.is_param(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad
+ bwd_activation_cost = sum([v for k, v in backward_size_mapping.items() if not self.is_param(k)])
+ bwd_parameter_cost = sum([v for k, v in backward_size_mapping.items() if self.is_param(k)])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=bwd_parameter_cost)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost,
+ parameter=fwd_parameter_cost + bwd_parameter_cost)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ for index, strategy in enumerate(self.predecessor_node.strategies_vector):
+ dim_partition_dict_mapping = {}
+ communication_action_mapping = {}
+ input_sharding_spec = strategy.output_sharding_specs[self.op_data["input"]]
+ dim_partition_dict_for_input = copy.deepcopy(input_sharding_spec.dim_partition_dict)
+ sum_dims, sum_mapping_dict = self.op_data['sum_info'].data
+
+ # TODO: a better way to handle the distributed sum is sum all the data on chip and then do all reduce
+ # among all the shard groups
+ recover_dims = []
+ dim_partition_dict_for_output = {}
+ for dim in dim_partition_dict_for_input:
+ if dim in sum_dims:
+ recover_dims.append(dim)
+ elif dim in sum_mapping_dict:
+ dim_partition_dict_for_output[sum_mapping_dict[dim]] = dim_partition_dict_for_input[dim]
+ else:
+ raise RuntimeError(f'dim {dim} is not in sum_mapping_dict or sum_dims')
+
+ for dim in recover_dims:
+ dim_partition_dict_for_input.pop(dim)
+
+ dim_partition_dict_mapping = {
+ "input": dim_partition_dict_for_input,
+ "output": dim_partition_dict_for_output,
+ }
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+ # add index into name to pass the duplicated check
+ # we keep same strategies with different name for node merging, and it will not increase the searching space,
+ # because in solver, this node will be merged into other nodes, and solver will not create a new variable for this node.
+ name = f'{sharding_spec_mapping["input"].sharding_sequence} -> {sharding_spec_mapping["output"].sharding_sequence}_{index}'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(strategy)
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/tensor_constructor_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/tensor_constructor_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..93cfc9eeea532ac4383f0821008deeccb13951d0
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/tensor_constructor_generator.py
@@ -0,0 +1,67 @@
+import copy
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommAction,
+ CommType,
+ MemoryCost,
+ ShardingStrategy,
+ TrainCycleItem,
+)
+from colossalai.tensor.shape_consistency import CollectiveCommPattern
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+from .strategy_generator import StrategyGenerator
+
+__all__ = ['TensorConstructorGenerator']
+
+
+class TensorConstructorGenerator(StrategyGenerator):
+ """
+ TensorConstructorGenerator which deals with
+ the sharding strategies for tensor constructor operation, such as torch.arange.
+ """
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ compute_cost = TrainCycleItem(fwd=10, bwd=10, total=20)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ forward_size_mapping = {'output': self._compute_size_in_bytes(strategy, "output")}
+
+ # compute fwd cost incurred
+ # fwd_cost = input + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items() if not self.is_param(k)])
+ fwd_parameter_cost = sum([v for k, v in forward_size_mapping.items() if self.is_param(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+
+ # compute bwd cost incurred
+ bwd_mem_cost = MemoryCost(activation=0, parameter=0)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ dim_partition_dict_mapping = {
+ "output": {},
+ }
+ communication_action_mapping = {}
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ name = 'Replica Tensor Constructor'
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(strategy)
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/unary_elementwise_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/unary_elementwise_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..b867a30686eb97a55096895d344dcc28b51f347a
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/unary_elementwise_generator.py
@@ -0,0 +1,77 @@
+import copy
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (MemoryCost, ShardingStrategy, TrainCycleItem)
+
+from .strategy_generator import FollowingStrategyGenerator
+
+__all__ = ['UnaryElementwiseGenerator']
+
+
+class UnaryElementwiseGenerator(FollowingStrategyGenerator):
+ """
+ UnaryElementwiseGenerator which deals with the sharding strategies of UnaryElementwiseOp.
+ """
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ compute_cost = TrainCycleItem(fwd=10, bwd=10, total=20)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ forward_size_mapping = {
+ 'input': self._compute_size_in_bytes(strategy, "input"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = input + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items() if not self.is_param(k)])
+ fwd_parameter_cost = sum([v for k, v in forward_size_mapping.items() if self.is_param(k)])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=fwd_parameter_cost)
+
+ # compute bwd cost incurred
+ # bwd_cost = input_grad
+ bwd_activation_cost = sum([v for k, v in backward_size_mapping.items() if not self.is_param(k)])
+ bwd_parameter_cost = sum([v for k, v in backward_size_mapping.items() if self.is_param(k)])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=bwd_parameter_cost)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost,
+ parameter=fwd_parameter_cost + bwd_parameter_cost)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ strategy_list = []
+ # For element-wise function, we keep the sharding spec of output node same as
+ # the input. Therefore, the different strategies of input node with same
+ # output sharding spec will generate same strategy for element-wise function.
+ for index, strategy in enumerate(self.predecessor_node.strategies_vector):
+ dim_partition_dict_mapping = {}
+ communication_action_mapping = {}
+ input_sharding_spec = strategy.output_sharding_specs[self.op_data["input"]]
+ dim_partition_dict_for_input = input_sharding_spec.dim_partition_dict
+ dim_partition_dict_for_output = copy.deepcopy(dim_partition_dict_for_input)
+ dim_partition_dict_mapping = {
+ "input": dim_partition_dict_for_input,
+ "output": dim_partition_dict_for_output,
+ }
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+ # add index into name to pass the duplicated check
+ # we keep same strategies with different name for node merging, and it will not increase the searching space,
+ # because in solver, this node will be merged into other nodes, and solver will not create a new variable for this node.
+ name = f'{sharding_spec_mapping["input"].sharding_sequence} -> {sharding_spec_mapping["output"].sharding_sequence}_{index}'
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+ strategy_list.append(strategy)
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/strategy/where_generator.py b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/where_generator.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa941f2cc51dc4d817bfc8f49c54bbaf7a8a5407
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/strategy/where_generator.py
@@ -0,0 +1,98 @@
+import copy
+from typing import List
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import MemoryCost, ShardingStrategy, TrainCycleItem
+from colossalai.auto_parallel.tensor_shard.utils import (
+ enumerate_all_possible_1d_sharding,
+ enumerate_all_possible_2d_sharding,
+ ignore_sharding_exception,
+)
+
+from .strategy_generator import StrategyGenerator
+
+__all__ = ['WhereGenerator']
+
+
+class WhereGenerator(StrategyGenerator):
+ """
+ WhereGenerator is a generic class to generate strategies for Where operation.
+ """
+
+ def validate(self) -> bool:
+ return super().validate()
+
+ def update_compute_cost(self, strategy: ShardingStrategy):
+ compute_cost = TrainCycleItem(fwd=10, bwd=10, total=20)
+ strategy.compute_cost = compute_cost
+
+ def update_memory_cost(self, strategy: ShardingStrategy):
+ '''
+ Compute the memory cost per device with this specific strategy.
+ '''
+ forward_size_mapping = {
+ 'condition': self._compute_size_in_bytes(strategy, "condition"),
+ 'x': self._compute_size_in_bytes(strategy, "x"),
+ 'y': self._compute_size_in_bytes(strategy, "y"),
+ 'output': self._compute_size_in_bytes(strategy, "output")
+ }
+
+ backward_size_mapping = copy.deepcopy(forward_size_mapping)
+ backward_size_mapping.pop("output")
+ # compute fwd cost incurred
+ # fwd_cost = condition + x + y + output
+ fwd_activation_cost = sum([v for k, v in forward_size_mapping.items()])
+ fwd_mem_cost = MemoryCost(activation=fwd_activation_cost, parameter=0)
+
+ # compute bwd cost incurred
+ # bwd_cost = condition_grad + x_grad + y_grad
+ bwd_activation_cost = sum([v for k, v in backward_size_mapping.items()])
+ bwd_mem_cost = MemoryCost(activation=bwd_activation_cost, parameter=0)
+
+ # compute total cost
+ total_mem_cost = MemoryCost(activation=fwd_activation_cost + bwd_activation_cost, parameter=0)
+ memory_cost = TrainCycleItem(fwd=fwd_mem_cost, bwd=bwd_mem_cost, total=total_mem_cost)
+ strategy.memory_cost = memory_cost
+
+ @ignore_sharding_exception
+ def _generate_strategy_with_dim_partition(self, dim_partition):
+ dim_partition_dict_mapping = {
+ "condition": dim_partition,
+ "x": dim_partition,
+ "y": dim_partition,
+ "output": dim_partition
+ }
+
+ sharding_spec_mapping = self.to_sharding_spec_mapping(dim_partition_dict_mapping)
+
+ name = f'{sharding_spec_mapping["output"].sharding_sequence} = {sharding_spec_mapping["condition"].sharding_sequence} x {sharding_spec_mapping["x"].sharding_sequence} x {sharding_spec_mapping["y"].sharding_sequence}'
+ communication_action_mapping = {}
+
+ strategy = self.get_sharding_strategy(name=name,
+ sharding_spec_mapping=sharding_spec_mapping,
+ communication_action_mapping=communication_action_mapping)
+
+ return strategy
+
+ def enumerate_all_possible_output_spec(self, mesh_dim_0, mesh_dim_1, dimension_length):
+ dim_partition_list = []
+ dim_partition_list.extend(enumerate_all_possible_1d_sharding(mesh_dim_0, dimension_length))
+ dim_partition_list.extend(enumerate_all_possible_1d_sharding(mesh_dim_1, dimension_length))
+ dim_partition_list.extend(enumerate_all_possible_2d_sharding(mesh_dim_0, mesh_dim_1, dimension_length))
+ # append {} for non_split case
+ dim_partition_list.append({})
+
+ return dim_partition_list
+
+ def collate_strategies(self) -> List[ShardingStrategy]:
+ '''
+ Generate every possible strategies for a where node, and record all strategies into the strategies_vector.
+ '''
+ strategy_list = []
+
+ dimension_length = len(self.op_data["output"].logical_shape)
+ dim_partition_list = self.enumerate_all_possible_output_spec(0, 1, dimension_length)
+ for dim_partition in dim_partition_list:
+ strategy = self._generate_strategy_with_dim_partition(dim_partition)
+ strategy_list.append(strategy)
+
+ return strategy_list
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/sum_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/sum_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..86f90694e0604f72e9564020ccab455cfdee29a0
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/sum_handler.py
@@ -0,0 +1,81 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import StrategyGenerator, SumGenerator
+
+__all__ = ['SumHandler']
+
+
+@operator_registry.register(torch.Tensor.sum)
+@operator_registry.register(torch.sum)
+class SumHandler(NodeHandler):
+ """
+ A SumHandler which deals with the sharding strategies for torch.sum or torch.Tensor.sum.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(SumGenerator(op_data_mapping, self.device_mesh, self.node.args[0]))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # check if the input operand is a parameter
+ if isinstance(self.node.args[0]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+
+ input_data = self.node.args[0]._meta_data
+ physical_input_operand = OperationData(name=str(self.node.args[0]), type=data_type, data=input_data)
+
+ if len(self.node.args) > 1:
+ sum_dims = self.node.args[1]
+ else:
+ sum_dims = tuple(range(self.node.args[0]._meta_data.dim()))
+
+ if isinstance(sum_dims, int):
+ sum_dims = (sum_dims,)
+
+ # recover negative value to positive
+ num_dims = self.node.args[0]._meta_data.dim()
+ for i in range(len(sum_dims)):
+ if sum_dims[i] < 0:
+ sum_dims[i] += num_dims
+
+ # mapping the input dims to output dims
+ # For examples:
+ # input: torch.rand(2, 3, 4, 5)
+ # output: torch.sum(input, (0, 2))
+ # sum_mapping_dict = {1: 0, 3: 1}
+ # sum_mapping_dict[1] = 0 means the 0th dim of output is the 1st dim of input
+ # sum_mapping_dict[3] = 1 means the 1st dim of output is the 3rd dim of input
+ sum_mapping_dict = {}
+ if 'keepdim' in self.node.kwargs and self.node.kwargs['keepdim']:
+ for i in range(num_dims):
+ sum_mapping_dict.update({i: i})
+ else:
+ output_index = 0
+ for i in range(num_dims):
+ if i not in sum_dims:
+ sum_mapping_dict.update({i: output_index})
+ output_index += 1
+ assert output_index == self.node._meta_data.dim()
+
+ sum_info = (sum_dims, sum_mapping_dict)
+ physical_shape_operand = OperationData(name='sum_info', type=OperationDataType.ARG, data=sum_info)
+
+ output_data = self.node._meta_data
+ physical_output_operand = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=output_data)
+
+ mapping = {
+ "input": physical_input_operand,
+ "sum_info": physical_shape_operand,
+ "output": physical_output_operand
+ }
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/tensor_constructor_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/tensor_constructor_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..855a2e7612af0cb59cae9bc8574197fad098f983
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/tensor_constructor_handler.py
@@ -0,0 +1,32 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import StrategyGenerator
+from .strategy.tensor_constructor_generator import TensorConstructorGenerator
+
+__all__ = ['TensorConstructorHandler']
+
+
+@operator_registry.register(torch.arange)
+class TensorConstructorHandler(NodeHandler):
+ """
+ A TensorConstructorHandler which deals with the sharding strategies for tensor constructor operations, such as torch.arange.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(TensorConstructorGenerator(op_data_mapping, self.device_mesh))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ output_data = self.node._meta_data
+ physical_output_operand = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=output_data)
+
+ mapping = {"output": physical_output_operand}
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/transpose_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/transpose_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a9d377264905a650fd991cb10e98f8c3f16f871
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/transpose_handler.py
@@ -0,0 +1,64 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import StrategyGenerator, TransposeGenerator
+
+__all__ = ['TransposeHandler']
+
+
+@operator_registry.register(torch.Tensor.transpose)
+@operator_registry.register(torch.transpose)
+class TransposeHandler(NodeHandler):
+ """
+ A TransposeHandler which deals with the sharding strategies for torch.permute or torch.transpose.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(TransposeGenerator(op_data_mapping, self.device_mesh, self.node.args[0]))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # check if the input operand is a parameter
+ if isinstance(self.node.args[0]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+
+ input_data = self.node.args[0]._meta_data
+ physical_input_operand = OperationData(name=str(self.node.args[0]), type=data_type, data=input_data)
+
+ transpose_dims = []
+ # torch.transpose (input, dim0, dim1)
+ for arg in self.node.args:
+ if isinstance(arg, torch.fx.Node):
+ if isinstance(arg._meta_data, int):
+ transpose_dims.append(arg._meta_data)
+ else:
+ transpose_dims.append(arg)
+
+ num_dims = self.node._meta_data.dim()
+ for i in range(2):
+ # recover negative value to positive
+ if transpose_dims[i] < 0:
+ transpose_dims[i] += num_dims
+
+ physical_shape_operand = OperationData(name='transpose_dims',
+ type=OperationDataType.ARG,
+ data=list(transpose_dims))
+
+ output_data = self.node._meta_data
+ physical_output_operand = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=output_data)
+
+ mapping = {
+ "input": physical_input_operand,
+ "transpose_dims": physical_shape_operand,
+ "output": physical_output_operand
+ }
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/unary_elementwise_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/unary_elementwise_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..0362de780d7af0fa9569a575a122f84ffb42b0db
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/unary_elementwise_handler.py
@@ -0,0 +1,43 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import MetaInfoNodeHandler, NodeHandler
+from .registry import operator_registry
+from .strategy import StrategyGenerator, UnaryElementwiseGenerator
+
+__all__ = ['UnaryElementwiseHandler']
+
+
+@operator_registry.register(torch.Tensor.to)
+@operator_registry.register(torch.Tensor.type)
+@operator_registry.register(torch.abs)
+@operator_registry.register(torch.nn.ReLU)
+@operator_registry.register(torch.nn.Tanh)
+@operator_registry.register(torch.tanh)
+@operator_registry.register(torch.nn.modules.dropout.Dropout)
+@operator_registry.register(torch.Tensor.contiguous)
+@operator_registry.register(torch.nn.functional.dropout)
+class UnaryElementwiseHandler(MetaInfoNodeHandler):
+ """
+ A UnaryElementwiseHandler which deals with the sharding strategies for UnaryElementwise Op.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(UnaryElementwiseGenerator(op_data_mapping, self.device_mesh, self.node.args[0]))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ physical_input_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.node.args[0]._meta_data)
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+
+ mapping = {"input": physical_input_operand, "output": physical_output}
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/view_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/view_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..7dff89d1d7a39a6e4fe73514bfb16abe2e3e7bea
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/view_handler.py
@@ -0,0 +1,52 @@
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import StrategyGenerator, ViewGenerator
+
+__all__ = ['ViewHandler']
+
+
+@operator_registry.register(torch.Tensor.reshape)
+@operator_registry.register(torch.reshape)
+@operator_registry.register(torch.Tensor.view)
+class ViewHandler(NodeHandler):
+ """
+ A ViewHandler which deals with the sharding strategies for Reshape Op, such as torch.reshape.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ op_data_mapping = self.get_operation_data_mapping()
+ generators = []
+ generators.append(ViewGenerator(op_data_mapping, self.device_mesh, self.node.args[0]))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+
+ # check if the input operand is a parameter
+ if isinstance(self.node.args[0]._meta_data, torch.nn.parameter.Parameter):
+ data_type = OperationDataType.PARAM
+ else:
+ data_type = OperationDataType.ARG
+
+ input_data = self.node.args[0]._meta_data
+ physical_input_operand = OperationData(name=str(self.node.args[0]), type=data_type, data=input_data)
+
+ target_shape = self.node._meta_data.shape
+ physical_shape_operand = OperationData(name='tgt_shape', type=OperationDataType.ARG, data=target_shape)
+
+ output_data = self.node._meta_data
+ physical_output_operand = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=output_data)
+
+ mapping = {
+ "input": physical_input_operand,
+ "tgt_shape": physical_shape_operand,
+ "output": physical_output_operand
+ }
+
+ return mapping
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/where_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/where_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..6de2aaafdd018f08195563ef882f07eb39d8d20a
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/where_handler.py
@@ -0,0 +1,71 @@
+import copy
+import operator
+from typing import Dict, List
+
+import torch
+
+from ..sharding_strategy import OperationData, OperationDataType, ShardingStrategy, StrategiesVector
+from ..utils import recover_sharding_spec_for_broadcast_shape
+from .node_handler import NodeHandler
+from .registry import operator_registry
+from .strategy import StrategyGenerator, WhereGenerator
+
+__all__ = ['WhereHandler']
+
+
+@operator_registry.register(torch.where)
+class WhereHandler(NodeHandler):
+ """
+ A WhereHandler which deals with the sharding strategies for torch.where.
+ """
+
+ def get_strategy_generator(self) -> List[StrategyGenerator]:
+ logical_op_data_mapping, _ = self.get_operation_data_mapping()
+ generators = []
+ generators.append(WhereGenerator(logical_op_data_mapping, self.device_mesh))
+ return generators
+
+ def get_operation_data_mapping(self) -> Dict[str, OperationData]:
+ # use transposed shape for strategies
+ # the strategies will be transformed back to its original shape in self.post_process
+ physical_condition_operand = OperationData(name=str(self.node.args[0]),
+ type=OperationDataType.ARG,
+ data=self.node.args[0]._meta_data)
+ physical_x_operand = OperationData(name=str(self.node.args[1]),
+ type=OperationDataType.ARG,
+ data=self.node.args[1]._meta_data)
+ physical_y_operand = OperationData(name=str(self.node.args[2]),
+ type=OperationDataType.ARG,
+ data=self.node.args[2]._meta_data)
+ physical_output = OperationData(name=str(self.node), type=OperationDataType.OUTPUT, data=self.node._meta_data)
+ physical_mapping = {
+ "condition": physical_condition_operand,
+ "x": physical_x_operand,
+ "y": physical_y_operand,
+ "output": physical_output
+ }
+ logical_shape_for_all = self.node._meta_data.shape
+ logical_mapping = {}
+ for key, physical_operand in physical_mapping.items():
+ logical_mapping[key] = self.convert_physical_operand_to_logical_operand(physical_operand,
+ logical_shape_for_all)
+
+ return logical_mapping, physical_mapping
+
+ def convert_physical_operand_to_logical_operand(self, physical_operand, target_shape):
+ logical_operand = copy.deepcopy(physical_operand)
+ logical_operand.logical_shape = target_shape
+ return logical_operand
+
+ def post_process(self, strategy: ShardingStrategy):
+ logical_op_data_mapping, physical_op_data_mapping = self.get_operation_data_mapping()
+ for key in logical_op_data_mapping.keys():
+ logical_sharding_spec = strategy.sharding_specs[logical_op_data_mapping[key]]
+ logical_shape = logical_op_data_mapping[key].logical_shape
+ physical_shape = physical_op_data_mapping[key].logical_shape
+ physical_sharding_spec, removed_dims = recover_sharding_spec_for_broadcast_shape(
+ logical_sharding_spec, logical_shape, physical_shape)
+ strategy.sharding_specs.pop(logical_op_data_mapping[key])
+ strategy.sharding_specs[physical_op_data_mapping[key]] = physical_sharding_spec
+ strategy.name = f"{strategy.sharding_specs[physical_op_data_mapping['output']].sharding_sequence} = {strategy.sharding_specs[physical_op_data_mapping['condition']].sharding_sequence} x {strategy.sharding_specs[physical_op_data_mapping['x']].sharding_sequence} x {strategy.sharding_specs[physical_op_data_mapping['y']].sharding_sequence}"
+ return strategy
diff --git a/colossalai/auto_parallel/tensor_shard/options.py b/colossalai/auto_parallel/tensor_shard/options.py
new file mode 100644
index 0000000000000000000000000000000000000000..f0ea502a6f0e2c4412ac333f9465aec6873e9791
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/options.py
@@ -0,0 +1,49 @@
+from dataclasses import dataclass
+from enum import Enum
+
+__all__ = ['SolverOptions', 'SolverPerference', 'DataloaderOption', 'ShardOption']
+
+
+class SolverPerference(Enum):
+ """
+ This enum class is to define the solver preference.
+ """
+ STANDARD = 0
+ DP = 1
+ TP = 2
+
+
+class ShardOption(Enum):
+ """
+ This enum class is to define the shard level required in node strategies.
+
+ Notes:
+ STANDARD: We do not add any extra shard requirements.
+ SHARD: We require the node to be shard using at least one device mesh axis.
+ SHARD_ONE_AXIS: We require the node to be shard using the last device mesh axis.
+ FULL_SHARD: We require the node to be shard using all device mesh axes.
+ TP_SHARD: We require the node to be shard using tensor parallel strategies on last device mesh axis.
+ TP_FULL_SHARD: We require the node to be shard using tensor parallel strategies on all device mesh axes.
+ """
+ STANDARD = 0
+ SHARD = 1
+ SHARD_LAST_AXIS = 2
+ FULL_SHARD = 3
+
+
+class DataloaderOption(Enum):
+ """
+ This enum class is to define the dataloader option.
+ """
+ REPLICATED = 0
+ DISTRIBUTED = 1
+
+
+@dataclass
+class SolverOptions:
+ """
+ SolverOptions is a dataclass used to configure the preferences for the parallel execution plan search.
+ """
+ solver_perference: SolverPerference = SolverPerference.STANDARD
+ dataloader_option: DataloaderOption = DataloaderOption.REPLICATED
+ shard_option: ShardOption = ShardOption.STANDARD
diff --git a/colossalai/auto_parallel/tensor_shard/sharding_strategy.py b/colossalai/auto_parallel/tensor_shard/sharding_strategy.py
new file mode 100644
index 0000000000000000000000000000000000000000..6af92727243759bf2d0e0e1b8f472e1e59308ca3
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/sharding_strategy.py
@@ -0,0 +1,277 @@
+from copy import deepcopy
+from dataclasses import dataclass
+from enum import Enum
+from typing import Any, Dict, List, Tuple, Union
+
+import torch
+from torch.fx.node import Node
+
+from colossalai.tensor.comm_spec import CommSpec
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+from .constants import (
+ BCAST_FUNC_OP,
+ ELEMENTWISE_FUNC_OP,
+ ELEMENTWISE_METHOD_OP,
+ ELEMENTWISE_MODULE_OP,
+ RESHAPE_FUNC_OP,
+ RESHAPE_METHOD_OP,
+)
+
+__all__ = ['OperationDataType', 'OperationData', 'TrainCycleItem', 'MemoryCost', 'ShardingStrategy', 'StrategiesVector']
+
+
+class OperationDataType(Enum):
+ """
+ An operation can come from the argument list of an operator or the parameter list of a module.
+ """
+ INPUT = 0
+ ARG = 1
+ PARAM = 2
+ BUFFER = 3
+ OUTPUT = 4
+
+
+@dataclass
+class OperationData:
+ """
+ OperationData is the data related to an operator, the data can be the operand or the output.
+
+ Args:
+ name (str): the name of the operation-related data
+ type (OperationDataType): the type of the operation data
+ data (Any): the value for this data, usually it is a meta tensor.
+ logical_shape (Tuple[int]): the logical shape of the data, it can be different from the its actual shape in memory.
+ """
+ name: str
+ type: OperationDataType
+ data: Any
+ logical_shape: Tuple[int] = None
+
+ def __post_init__(self):
+ # if no logical shape is specified, use the data shape as the logical shape
+ if self.logical_shape is None:
+
+ def _infer_logical_shape(data: any):
+ """
+ This function is used to infer the logical shape of the data.
+ """
+ if isinstance(data, torch.Tensor):
+ return data.shape
+ elif isinstance(data, torch.Size):
+ return None
+ elif isinstance(data, (tuple, list)):
+ data_type = type(data)
+ return data_type([_infer_logical_shape(d) for d in data])
+ else:
+ return None
+
+ self.logical_shape = _infer_logical_shape(self.data)
+
+ def __repr__(self) -> str:
+ return f'OperationData(name={self.name}, type={self.type})'
+
+ def __eq__(self, other) -> bool:
+ return other.name == self.name
+
+ def __hash__(self) -> int:
+ return hash(f'{self.name}')
+
+
+@dataclass
+class TrainCycleItem:
+ """
+ TrainCycleItem is a dataclass to store the items which have different values for the forward and backward pass
+ in a training iteration.
+
+ Args:
+ fwd (float): the item for the forward pass
+ bwd (float): the item for the backward pass
+ """
+ fwd: Any
+ bwd: Any
+ total: Any
+
+
+@dataclass
+class MemoryCost:
+ """
+ MemoryCost is a dataclass which stores the memory usage in the program.
+
+ Args:
+ activation (int): the memory cost incurred by the activations in bytes.
+ parameter (int): the memory cost incurred by the module parameter in bytes.
+ temp (int): the memory cost incurred by the temporary tensors in bytes.
+ buffer (int): the memory cost incurred by the module buffer in bytes.
+ """
+ activation: int = 0
+ parameter: int = 0
+ temp: int = 0
+ buffer: int = 0
+
+
+class CommType(Enum):
+ """
+ CommType describes the sequential order of a communication action and a computation action.
+
+ Meaning:
+ BEFORE: the communication action happens just before the computation operation.
+ AFTER: the communication action happens after the computation operation.
+ HOOK: the communication action is used to do the grad all reduce.
+ IMPLICIT: the communication action happens during the kernel execution, such as SyncBatchNorm
+ """
+ BEFORE = 0
+ AFTER = 1
+ HOOK = 2
+ IMPLICIT = 3
+
+
+@dataclass
+class CommAction:
+ """
+ CommAction is used to record the communication action.
+
+ Args:
+ comm_spec: express the communication pattern and the process groups to execute the communication action.
+ comm_type: describes the sequential order of a communication action and a computation action.
+ arg_index: record the location of tensor which join the communication, we cannot use name of node or op_data at runtime,
+ because the args of node may be changed by graph transform passes.
+ """
+ comm_spec: CommSpec = None
+ comm_type: CommType = None
+ arg_index: int = -1
+ key_for_kwarg: any = None
+
+
+@dataclass
+class ShardingStrategy:
+ """
+ ShardingStrategy is a dataclass to store the meta information on tensor sharding for a node.
+
+ Args:
+ name (str): express the sharding strategies in string, such as 'S0S1 = S0R x RS1'.
+ output_sharding_spec (ShardingSpec): ShardingSpec of the output node.
+ compute_cost (TrainCycleItem): Computation cost to complete this strategy. (default to None)
+ communication_cost (TrainCycleItem): Communication cost to complete this strategy. (default to None)
+ memory_cost (TrainCycleItem): Memory cost of the output node using this strategy. (default to None)
+ input_sharding_specs (List(ShardingSpec)): The ShardingSpecs of the input nodes.
+ """
+ name: str
+ sharding_specs: Dict[OperationData, Union[ShardingSpec, Tuple[ShardingSpec]]] = None
+ compute_cost: TrainCycleItem = None
+ communication_cost: TrainCycleItem = None
+ memory_cost: TrainCycleItem = None
+ communication_actions: Dict[OperationData, CommAction] = None
+ resharding_costs: Dict[Node, List[TrainCycleItem]] = None
+
+ @property
+ def input_sharding_specs(self) -> Dict[OperationData, ShardingSpec]:
+ specs = {}
+ specs.update(self._get_sharding_spec(OperationDataType.ARG))
+ specs.update(self._get_sharding_spec(OperationDataType.PARAM))
+ return specs
+
+ @property
+ def argument_sharding_specs(self) -> Dict[OperationData, ShardingSpec]:
+ return self._get_sharding_spec(OperationDataType.ARG)
+
+ @property
+ def param_sharding_specs(self) -> Dict[OperationData, ShardingSpec]:
+ return self._get_sharding_spec(OperationDataType.PARAM)
+
+ @property
+ def output_sharding_specs(self) -> Dict[OperationData, ShardingSpec]:
+ return self._get_sharding_spec(OperationDataType.OUTPUT)
+
+ def _get_sharding_spec(self, operation_data_type: OperationDataType):
+ specs = {k: v for k, v in self.sharding_specs.items() if k.type == operation_data_type}
+ return specs
+
+ def get_op_data_by_name(self, name: str):
+ for op_data in self.sharding_specs.keys():
+ if op_data.name == name:
+ return op_data
+ raise KeyError(f"Could not find the OperationData with name {name}")
+
+ def get_sharding_spec_by_name(self, name: str):
+ for op_data, sharding_spec in self.sharding_specs.items():
+ if op_data.name == name:
+ return sharding_spec
+ raise KeyError(f"Could not find the ShardingSpec for OperationData with name {name}")
+
+ def clone(self):
+
+ def _deepcopy_dict_vals(data: Dict):
+ return {k: deepcopy(v) for k, v in data.items()}
+
+ sharding_specs = _deepcopy_dict_vals(self.sharding_specs) if self.sharding_specs is not None else None
+ # We need to deepcopy it when self.communication_actions is not None, instead of checking its __bool__ value.
+ # Consider the examples below:
+ # If self.communication_actions is an empty dictionary {}, then self.communication_actions is not None, but its __bool__ value is False.
+ # In this case, if we set None to the new object, program will crash when we try to access the communication_actions.items.
+ communication_actions = _deepcopy_dict_vals(
+ self.communication_actions) if self.communication_actions is not None else None
+ # same reason as communication_actions
+ resharding_costs = _deepcopy_dict_vals(self.resharding_costs) if self.resharding_costs is not None else None
+ compute_cost = deepcopy(self.compute_cost)
+ communication_cost = deepcopy(self.communication_cost)
+ memory_cost = deepcopy(self.memory_cost)
+
+ return ShardingStrategy(name=self.name,
+ sharding_specs=sharding_specs,
+ compute_cost=compute_cost,
+ communication_cost=communication_cost,
+ memory_cost=memory_cost,
+ communication_actions=communication_actions,
+ resharding_costs=resharding_costs)
+
+
+class StrategiesVector(list):
+ '''
+ Each node in fx graph will have a corresponding StrategiesVector, to store all the possible
+ strategies of the node.
+
+ Argument:
+ node (Node): node for which the list of sharding strategies are generated.
+ '''
+
+ def __init__(self, node: Node):
+ super().__init__()
+ self.node = node
+ # fetch its input and output nodes
+ # TODO: placeholder input nodes
+ self.predecessor_nodes = list(node._input_nodes.keys())
+ self.successor_nodes = list(node.users.keys())
+
+ def check_merge(self):
+ merge_label = False
+ if self.node.op == 'call_module':
+ target = self.node.target
+ root_module = self.node.graph.owning_module
+ submod = root_module.get_submodule(target)
+ submod_type = type(submod)
+ # merge elementwise module node into source nodes
+ # we could merge element-wise op, because the output sharding spec is always same as the input sharding spec.
+ if submod_type in ELEMENTWISE_MODULE_OP:
+ merge_label = True
+
+ if self.node.op == 'call_function':
+ # we could merge element-wise op, because the output sharding spec is always same as the input sharding spec.
+ if self.node.target in ELEMENTWISE_FUNC_OP:
+ merge_label = True
+ # we could merge bcast op if the rhs is a scalar, because it will fall back to the element-wise case.
+ # TODO: remove this after we support the fall back logic.
+ # if self.node.target in BCAST_FUNC_OP and len(self.predecessor_nodes) == 1:
+ # merge_label = True
+ # we could merge reshape op, because their computation costs are negligible.
+ if self.node.target in RESHAPE_FUNC_OP:
+ merge_label = True
+
+ if self.node.op == 'call_method':
+ # we could merge reshape op, because their computation costs are negligible.
+ method = getattr(self.node.args[0]._meta_data.__class__, self.node.target)
+ if method in RESHAPE_METHOD_OP:
+ merge_label = True
+ if method in ELEMENTWISE_METHOD_OP:
+ merge_label = True
+ return merge_label
diff --git a/colossalai/auto_parallel/tensor_shard/solver/__init__.py b/colossalai/auto_parallel/tensor_shard/solver/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f9e6bd9239214c4def03b1b419a2845581fa083a
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/solver/__init__.py
@@ -0,0 +1,6 @@
+from .cost_graph import CostGraph
+from .graph_analysis import GraphAnalyser
+from .solver import Solver
+from .strategies_constructor import StrategiesConstructor
+
+__all__ = ['GraphAnalyser', 'Solver', 'StrategiesConstructor', 'CostGraph']
diff --git a/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py b/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..74290453ca0c2dd40008ec51584a134c8f278410
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/solver/cost_graph.py
@@ -0,0 +1,205 @@
+import torch
+
+from colossalai.auto_parallel.tensor_shard.constants import INFINITY_COST
+
+
+class CostGraph:
+ '''
+ A graph data structure to simplify the edge cost graph. It has two main functions:
+ 1. To feed the quadratic resharding costs into solver, we need to linearize it. We build edge_cost in
+ CostGraph, and it stored every combinations of strategies for a src-dst node pair in an 1D list.
+ 2. To reduce the searching space, we merge computationally-trivial operators, such as
+ element-wise operators, transpose, and reduction, into their following nodes. The merging infomation will
+ be given by the StrategiesVector depending on the type of target node and following nodes.
+
+ Argument:
+ leaf_strategies(List[StrategiesVector]): It stores StrategiesVector of every nodes on the graph.
+ simplify(bool, optional): The generated cost graph will be simplified if it is true. (default to True)
+ '''
+
+ def __init__(self, leaf_strategies, simplify=True, forward_only=False):
+ self.leaf_strategies = leaf_strategies
+ self.nodes = [strategies_vector.node for strategies_vector in self.leaf_strategies]
+ # stores number of strategies in each node
+ self.node_lens = {strategies_vector.node: len(strategies_vector) for strategies_vector in self.leaf_strategies}
+ # extra_node_costs will store the extra costs introduced by merging nodes
+ self.extra_node_costs = {}
+ self.following_dict = {}
+ self.simplify = simplify
+ self.forward_only = forward_only
+ self._build_cost_graph()
+
+ def _remove_invalid_node(self, node, attr_name):
+ remove_list = []
+ target_node_list = getattr(node, attr_name, [])
+ for target_node in target_node_list:
+ if target_node not in self.nodes:
+ remove_list.append(target_node)
+ for element in remove_list:
+ target_node_list.remove(element)
+
+ def _build_cost_graph(self):
+ '''
+ This method will generate edge_cost for adjacent node pair. Additionally, 'parents' and 'children' attribute will be
+ set to node.
+ '''
+ self.edge_costs = {}
+ if self.simplify:
+ self.merge_pair = []
+ for strategies_vector in self.leaf_strategies:
+ # build edge_cost
+ dst_node = strategies_vector.node
+ for src_node in strategies_vector.predecessor_nodes:
+ if src_node not in self.nodes:
+ continue
+ node_pair = (src_node, dst_node)
+ edge_cost = {}
+ for i in range(len(strategies_vector)):
+ for j in range(len(src_node.strategies_vector)):
+ resharding_cost_item = strategies_vector[i].resharding_costs[src_node][j]
+ if self.forward_only:
+ edge_cost[(j, i)] = resharding_cost_item.fwd
+ else:
+ edge_cost[(j, i)] = resharding_cost_item.total
+ self.edge_costs[node_pair] = edge_cost
+ parent_nodes = []
+ children_nodes = []
+
+ def _check_tensor_in_node(data):
+ """
+ This method is used to check whether the data has a tensor inside or not.
+ """
+ has_tensor_flag = False
+ if isinstance(data, torch.Tensor):
+ return True
+ elif isinstance(data, (tuple, list)):
+ for d in data:
+ has_tensor_flag = has_tensor_flag or _check_tensor_in_node(d)
+ return has_tensor_flag
+
+ for node in strategies_vector.predecessor_nodes:
+ if _check_tensor_in_node(node._meta_data):
+ parent_nodes.append(node)
+ for node in strategies_vector.successor_nodes:
+ if _check_tensor_in_node(node._meta_data):
+ children_nodes.append(node)
+
+ setattr(dst_node, 'parents', parent_nodes)
+ setattr(dst_node, 'children', children_nodes)
+
+ if self.simplify and strategies_vector.check_merge():
+ for followed_node in strategies_vector.predecessor_nodes:
+ # we only merge node pairs which src node has a tensor element inside.
+ # This is necessay because the node without a tensor element inside will not
+ # be assigned any strategy.
+ if _check_tensor_in_node(followed_node._meta_data):
+ self.merge_pair.append((followed_node, dst_node))
+
+ def get_edge_cost(self, src_node, dst_node):
+ return self.edge_costs[(src_node, dst_node)]
+
+ def merge_node(self, src_node, dst_node):
+ '''
+ To merge dst_node into src_node, we need to do it in following steps:
+
+ 1. For each strategy in dst_node, we need to pick an appropriate strategy
+ of src_node to merge, it is important because the logical resharding costs
+ between the parents node of src_node and merged node depend on the src_node
+ strategies dispatching. For example, for the graph 0->1->2, after merging node 1
+ into node 2, edge_costs[(node 0, node 2)][(0, 0)] = edge_costs[(node 0, node 1)][(0, x)]
+ x represents the picking strategy of node 1 merged into node 2 strategy 0.
+
+ 2. We need to accumulate the extra costs introduced by merging nodes, the extra costs
+ contains two parts, one is resharding costs between src_node strategy and dst_node strategy,
+ another is the origin extra costs in src_node strategy.
+
+ 3. Build connections between new node pairs, and remove the src_node after all consumer nodes
+ detached from it.
+
+ Argument:
+ src_node(Node): The node will be merged into dst_node.
+ dst_node(Node): The node to integrate src_node.
+ '''
+ # build merge_map
+ merge_map = {}
+ for src_index, _ in enumerate(src_node.strategies_vector):
+ min_cost = INFINITY_COST
+ lowest_cost_index = -1
+ for dst_index, dst_strategy in enumerate(dst_node.strategies_vector):
+ resharding_cost_item = dst_strategy.resharding_costs[src_node][src_index]
+ if self.forward_only:
+ resharding_cost = resharding_cost_item.fwd
+ else:
+ resharding_cost = resharding_cost_item.total
+ if resharding_cost <= min_cost:
+ min_cost = resharding_cost
+ lowest_cost_index = dst_index
+ merge_map[src_index] = lowest_cost_index
+
+ # extra_node_cost for src node
+ self.extra_node_costs[src_node] = [0.0] * self.node_lens[src_node]
+ for src_index, strategy in enumerate(src_node.strategies_vector):
+ target_strate_index = merge_map[src_index]
+ target_strategy = dst_node.strategies_vector[target_strate_index]
+ resharding_cost_item = target_strategy.resharding_costs[src_node][src_index]
+ if self.forward_only:
+ resharding_cost_to_add = resharding_cost_item.fwd
+ else:
+ resharding_cost_to_add = resharding_cost_item.total
+ self.extra_node_costs[src_node][src_index] += resharding_cost_to_add
+ if dst_node in self.extra_node_costs:
+ self.extra_node_costs[src_node][src_index] += self.extra_node_costs[dst_node][target_strate_index]
+
+ # add new node pair to cost graph
+ for child_node in dst_node.children:
+ new_node_pair = (src_node, child_node)
+ old_node_pair = (dst_node, child_node)
+ if new_node_pair in self.edge_costs:
+ continue
+ edge_cost = {}
+ for i in range(self.node_lens[src_node]):
+ for j in range(self.node_lens[child_node]):
+ dst_strate_index = merge_map[i]
+ edge_cost[(i, j)] = self.edge_costs[old_node_pair][(dst_strate_index, j)]
+ if new_node_pair not in self.edge_costs:
+ self.edge_costs[new_node_pair] = edge_cost
+ else:
+ # we should accumulate the resharding costs if args of child node contain
+ # both src node and dst node.
+ for index_pair, resharding_cost in self.edge_costs[new_node_pair]:
+ self.edge_costs[new_node_pair][index_pair] += edge_cost[index_pair]
+
+ # connect src node and children of dst node
+ dst_node.parents.remove(src_node)
+ src_node.children.remove(dst_node)
+ self.edge_costs.pop((src_node, dst_node))
+ for child_node in dst_node.children:
+ if child_node not in src_node.children:
+ src_node.children.append(child_node)
+ if src_node not in child_node.parents:
+ child_node.parents.append(src_node)
+ # remove dst node from cost graph when dst node has no producer.
+ if len(dst_node.parents) == 0:
+ child_node.parents.remove(dst_node)
+ node_pair = (dst_node, child_node)
+ self.edge_costs.pop(node_pair)
+ if len(dst_node.parents) == 0:
+ self.following_dict[dst_node] = src_node
+ dst_node.children = []
+
+ def _reindexing_src(self, src):
+ if src not in self.following_dict:
+ return src
+ return self._reindexing_src(self.following_dict[src])
+
+ def simplify_graph(self):
+ if not self.simplify:
+ return
+ self.merge_pair.reverse()
+ for (src_node, dst_node) in self.merge_pair:
+ self.merge_node(src_node, dst_node)
+ self.merge_pair.reverse()
+ reindexing_following_dict = {}
+ for dst, src in self.following_dict.items():
+ reindexing_following_dict[dst] = self._reindexing_src(src)
+ self.following_dict = reindexing_following_dict
diff --git a/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py b/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py
new file mode 100644
index 0000000000000000000000000000000000000000..be39a74cb23755f9ff2b83cf1123a7a7f9708ffa
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/solver/graph_analysis.py
@@ -0,0 +1,164 @@
+from dataclasses import dataclass
+from typing import List
+
+from torch.fx.graph import Graph
+from torch.fx.graph_module import GraphModule
+from torch.fx.node import Node
+
+from colossalai.fx.passes.utils import get_node_module
+
+__all__ = ['LiveVariable', 'LiveVariableVector', 'LiveStage', 'GraphAnalyser']
+
+
+@dataclass
+class LiveVariable:
+ """
+ LiveVariable is a data structure to store the meta information of a variable for liveness analysis.
+ """
+ name: str
+ node: Node
+ is_inplace: bool
+
+
+class LiveVariableVector(list):
+ """
+ LiveVariableVector is a data structure to store the list of LiveVariable objects.
+ """
+
+ def exists(self, name) -> bool:
+ """
+ Check if a variable has already existed in the current list by name.
+ """
+ for var in self:
+ if name == var.name:
+ return True
+ return False
+
+ def get(self, name) -> LiveVariable:
+ for var in self:
+ if name == var.name:
+ return var
+ raise KeyError(f"Variable {name} is not found")
+
+ def copy(self) -> "LiveVariableVector":
+ """
+ Create a copy of this vector
+ """
+ vector = LiveVariableVector()
+ for var in self:
+ vector.append(var)
+ return vector
+
+
+@dataclass
+class LiveStage:
+ """
+ LiveStage is a data structure to record the living variables at this current node.
+ """
+ name: str
+ node: Node
+ all_live_vars: LiveVariableVector
+ unique_live_vars: LiveVariableVector
+
+
+class GraphAnalyser:
+
+ def __init__(self, gm: GraphModule):
+ self._gm = gm
+ self._graph = gm.graph
+
+ @property
+ def gm(self) -> GraphModule:
+ """
+ Return the GraphModule object associated with this analyser.
+ """
+ return self._gm
+
+ @property
+ def graph(self) -> Graph:
+ """
+ Return the Graph object associated with this analyser.
+ """
+ return self._graph
+
+ def liveness_analysis(self) -> List[LiveStage]:
+ """
+ Analyse the graph to obtain the variable liveness information. This function returns
+ an ordered dictionary where the key is the compute stage ID and the value is a LivenessStage object.
+ """
+ compute_nodes = self.graph.nodes
+ liveness_list = []
+
+ # checked: record all variables created since the first stage
+ # all: record the live variables only exist until the current stage.
+ # this can be different from the `checked list`` as some varialbes may be destroyed prior to this stage.
+ # unique: record the unique live variables only exist until the current stage.
+ # this is different from `all list` as some variables are duplicated.
+ checked_variables = LiveVariableVector()
+ all_live_variables = LiveVariableVector()
+ unique_live_vars = LiveVariableVector()
+
+ for idx, node in enumerate(compute_nodes):
+ #############################
+ # find new living variables #
+ #############################
+ # detect whether the current op is an in-place op
+ # if it is an in-place op, we would deem it as a duplciate var
+ is_inplace = False
+ if node.op == 'call_function':
+ # check if this is an inplace op such as torch.nn.functional.relu(x, inplace=True)
+ if node.kwargs.get('inplace', False):
+ is_inplace = True
+ elif node.op == 'call_module':
+ # to check if this is an inplace op such as torch.nn.Relu(inplace=True)
+ module = get_node_module(node)
+ if getattr(module, 'inplace', False):
+ is_inplace = True
+
+ # add the output var
+ meta = getattr(node, '_meta_data', None)
+ live_var = LiveVariable(name=node.name, node=node, is_inplace=is_inplace)
+ if not is_inplace:
+ unique_live_vars.append(live_var)
+ checked_variables.append(live_var)
+ all_live_variables.append(live_var)
+
+ # check if any input is not checked yet
+ for arg in node.args:
+ if not isinstance(arg, Node):
+ continue
+ arg_name = arg.name
+ if not checked_variables.exists(arg_name):
+ live_var_from_arg = LiveVariable(name=arg_name, node=node, is_inplace=False)
+ all_live_variables.append(live_var_from_arg)
+ checked_variables.append(live_var_from_arg)
+ unique_live_vars.append(live_var_from_arg)
+
+ # TODO: add the logic to remove live variables
+ # this should be completed if we are able to trace the backward compute graph
+
+ # add this stage to liveness dict
+ stage = LiveStage(name=node.name,
+ node=node,
+ all_live_vars=all_live_variables.copy(),
+ unique_live_vars=unique_live_vars.copy())
+ # if a LiveStage is covered by another LiveStage, we just keep the larger one.
+ replace = False
+ for index, prev_stage in enumerate(liveness_list):
+ all_covered = True
+ for ele in prev_stage.unique_live_vars:
+ if ele not in stage.unique_live_vars:
+ all_covered = False
+ break
+ if all_covered:
+ replace = True
+ break
+ if replace:
+ liveness_list[index] = stage
+ else:
+ liveness_list.append(stage)
+
+ return liveness_list
+
+ def get_alias_set(self):
+ pass
diff --git a/colossalai/auto_parallel/tensor_shard/solver/solver.py b/colossalai/auto_parallel/tensor_shard/solver/solver.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5c6663dce80671199dcaf235380178622813310
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/solver/solver.py
@@ -0,0 +1,501 @@
+"""This code is adapted from Alpa
+ https://github.com/alpa-projects/alpa/
+ with some changes. """
+
+import multiprocessing
+import time
+import warnings
+from typing import Dict
+
+import numpy as np
+from torch.fx.graph import Graph
+from torch.fx.node import Node
+
+from colossalai.auto_parallel.tensor_shard.constants import INFINITY_COST
+
+from .cost_graph import CostGraph
+from .graph_analysis import GraphAnalyser
+from .strategies_constructor import StrategiesConstructor
+
+try:
+ import pulp
+ from pulp import LpMinimize, LpProblem, LpStatus, LpVariable, lpDot, lpSum
+except:
+ warnings.warn(f'please install the pulp')
+
+__all___ = ['Solver']
+
+
+class Solver:
+
+ def __init__(self,
+ graph: Graph,
+ strategies_constructor: StrategiesConstructor,
+ cost_graph: CostGraph,
+ graph_analyser: GraphAnalyser = None,
+ memory_budget: float = -1.0,
+ solution_numbers: int = 1,
+ forward_only: bool = False,
+ memory_increasing_coefficient: float = 1.3,
+ verbose=False):
+ '''
+ Solver class will integrate information provided by the components and use ILP solver to find a possible optimal strategies combination for target computing graph.
+ Argument:
+ graph: The computing graph to be optimized.
+ strategies_constructor: It will provide all the possible strategies for each node in the computing graph.
+ cost_graph: A graph data structure to simplify the edge cost graph.
+ graph_analyser: graph_analyser will analyse the graph to obtain the variable liveness information, which will be used to generate memory constraints.
+ memory_budget: Memory constraint for the solution.
+ solution_numbers: If solution_numbers is larger than one, solver will us a serious of solutions based on different memory budget.
+ memory_increasing_coefficient: If solution_numbers is larger than one, we will use this coefficient to generate new memory budget.
+ '''
+ self.graph = graph
+ self.strategies_constructor = strategies_constructor
+ self.cost_graph = cost_graph
+ self.graph_analyser = graph_analyser
+ self.leaf_strategies = self.strategies_constructor.leaf_strategies
+ self.nodes = [strategies_vector.node for strategies_vector in self.leaf_strategies]
+ self.strategy_map = self.strategies_constructor.strategy_map
+ self.memory_budget = memory_budget
+ self.solution_numbers = solution_numbers
+ self.forward_only = forward_only
+ if self.solution_numbers > 1:
+ self.memory_increasing_coefficient = memory_increasing_coefficient
+ else:
+ self.memory_increasing_coefficient = 1
+ # temporarily we use all nodes as liveness list, we count the backward memory cost together with
+ # forward memory cost into the node memory cost, and no activation checkpoint is used in this phase.
+ # self.liveness_list = self.graph_analyser.liveness_analysis()
+ self.liveness_list = self.nodes
+ self.node_index_dict = self._generate_node_index_dict()
+ # The last solution vector of auto sharding.
+ self.last_s_val = None
+ # The last objective value of the best ILP solution.
+ self.last_objective = None
+ self.verbose = verbose
+
+ def _recover_merged_node_strategy(self):
+ '''
+ During cost graph constructing, some nodes, such as unary element-wise node or ReshapeOp, were merged into the previous node.
+ Therefore, the index of those strategies are copied from the previous node. This method is used to recover the strategy index of those merged
+ node.
+ '''
+ for node_index, node in enumerate(self.nodes):
+ if node.strategies_vector.check_merge():
+ # the merged node has only one input, and its strategies follow the input sharding strategy
+ input_strategies_vector = node.args[0].strategies_vector
+ input_best_strategy_index = self.last_s_val[node_index - 1]
+ input_sharding_spec = input_strategies_vector[input_best_strategy_index].output_sharding_spec
+ for strategy_index, strategy in enumerate(node.strategies_vector):
+ if strategy.input_shardings[0].sharding_sequence == input_sharding_spec.sharding_sequence:
+ self.last_s_val[node_index] = strategy_index
+ break
+
+ def _generate_node_index_dict(self) -> Dict[Node, int]:
+ node_index_dict = {}
+ for index, strategies_vector in enumerate(self.leaf_strategies):
+ node_index_dict[strategies_vector.node] = index
+ return node_index_dict
+
+ def _prepare_data_for_solver(self):
+ '''
+ Extract information from components for solver.
+ '''
+ node_nums = len(self.leaf_strategies)
+ memory_budget = self.memory_budget
+
+ # prepare strategies_len
+ strategies_len = []
+ for node in self.nodes:
+ strategies_len.append(self.cost_graph.node_lens[node])
+ strategies_len = np.array(strategies_len)
+
+ # prepare following_nodes
+ following_nodes = self.cost_graph.following_dict
+ index_following_nodes = {}
+ for src, target in following_nodes.items():
+ src_index = self.node_index_dict[src]
+ target_index = self.node_index_dict[target]
+ index_following_nodes[src_index] = target_index
+ following_nodes = index_following_nodes
+ for index in range(node_nums):
+ if index not in following_nodes:
+ following_nodes[index] = -1
+
+ # prepare edge_pairs and resharding costs
+ edge_pairs = []
+ resharding_costs = []
+ for pairs, edge_cost in self.cost_graph.edge_costs.items():
+ src_node = pairs[0]
+ dst_node = pairs[1]
+ src_node_index = self.node_index_dict[src_node]
+ dst_node_index = self.node_index_dict[dst_node]
+ edge_pairs.append(src_node_index)
+ edge_pairs.append(dst_node_index)
+
+ for i in range(strategies_len[src_node_index]):
+ for j in range(strategies_len[dst_node_index]):
+ resharding_costs.append(edge_cost[(i, j)])
+ edge_pairs = np.array(edge_pairs)
+ resharding_costs = np.array(resharding_costs)
+
+ # prepare liveness_set
+ liveness_set = self.liveness_list
+
+ # omit alias_set now
+ alias_set = self.strategies_constructor.alias_set
+ alias_convert_costs = None
+
+ # prepare compute_costs, communication_costs and memory_costs
+ compute_costs = []
+ communication_costs = []
+ memory_costs = []
+ extra_node_costs = self.cost_graph.extra_node_costs
+ for strategies_vector in self.leaf_strategies:
+ node = strategies_vector.node
+ for index, strategy in enumerate(strategies_vector):
+ compute_cost_item = strategy.compute_cost
+ communication_cost_item = strategy.communication_cost
+ memory_cost_item = strategy.memory_cost
+
+ if self.forward_only:
+ origin_communication_cost = communication_cost_item.fwd
+ compute_cost = compute_cost_item.fwd
+ # extract MemoryCost item from the memory TrainCycleItem
+ memory_cost = memory_cost_item.fwd
+ else:
+ origin_communication_cost = communication_cost_item.total
+ compute_cost = compute_cost_item.total
+ # extract MemoryCost item from the memory TrainCycleItem
+ memory_cost = memory_cost_item.total
+
+ # extract the memory cost in float from MemoryCost item and sum them up
+ memory_cost = memory_cost.parameter + memory_cost.activation + memory_cost.buffer
+ compute_costs.append(compute_cost)
+ # node in extra_node_costs means it has some extra communication
+ # cost from node merging, so we need to add those extra communication
+ # cost into
+ if node in extra_node_costs:
+ extra_node_cost = extra_node_costs[node][index]
+ communication_cost = origin_communication_cost + extra_node_cost
+ communication_costs.append(communication_cost)
+ else:
+ communication_costs.append(origin_communication_cost)
+ memory_costs.append(memory_cost)
+
+ compute_costs = np.array(compute_costs)
+ communication_costs = np.array(communication_costs)
+ memory_costs = np.array(memory_costs)
+
+ # omit initial value for nodes
+ s_init_np = None
+
+ return node_nums, memory_budget, strategies_len, following_nodes, edge_pairs, alias_set, liveness_set, compute_costs, communication_costs, memory_costs, resharding_costs, alias_convert_costs, s_init_np, self.verbose
+
+ def _call_solver_serialized_args(self,
+ node_nums,
+ memory_budget,
+ strategies_len,
+ following_nodes,
+ edge_pairs,
+ alias_set,
+ liveness_set,
+ compute_costs,
+ communication_costs,
+ memory_costs,
+ resharding_costs,
+ alias_convert_costs,
+ s_init_np=None,
+ verbose=True):
+ """
+ Call the solver with serialized arguments.
+ """
+
+ tic = time.time()
+
+ for x in [strategies_len, edge_pairs, compute_costs, communication_costs, memory_costs, resharding_costs]:
+ assert isinstance(x, np.ndarray)
+ assert len(strategies_len) == node_nums, "strategies_len"
+
+ def get_non_zero_index(binary_vector):
+ """
+ Get the index of non-zero item in a vector.
+ """
+ ct = 0
+ ret = None
+ for i, elem in enumerate(binary_vector):
+ if pulp.value(elem):
+ ret = i
+ ct += 1
+
+ assert ct == 1
+ return ret
+
+ # 0. Unpack flatten numpy arrays
+ s_follow = following_nodes
+ s_alias = alias_set
+
+ E = edge_pairs.reshape((-1, 2)) # noqa
+ r = []
+ pt = 0
+ edge_set = set()
+ for (i, j) in E:
+ prod_length = strategies_len[i] * strategies_len[j]
+
+ if (i, j) in edge_set:
+ raise ValueError(f"Duplicated edges: {(i, j)}")
+
+ edge_set.add((i, j))
+ r.append(resharding_costs[pt:pt + prod_length])
+ pt += prod_length
+ assert pt == len(resharding_costs)
+
+ ######################
+ # omit alias set now #
+ ######################
+
+ # A = alias_set.reshape((-1, 2)) # noqa
+ # for (i, j) in A:
+ # prod_length = strategies_len[i] * strategies_len[j]
+ # v.append(alias_convert_costs[pt:pt + prod_length])
+ # pt += prod_length
+ # assert pt == len(alias_convert_costs)
+
+ # L = [] # noqa
+ # pt = node_nums
+ # for i in range(node_nums):
+ # length = liveness_set[i]
+ # L.append(liveness_set[pt:pt + length])
+ # pt += length
+ # assert pt == len(liveness_set)
+ v = []
+ pt = 0
+
+ c = []
+ d = []
+ m = []
+ pt = 0
+ for i in range(node_nums):
+ length = strategies_len[i]
+ c.append(compute_costs[pt:pt + length])
+ d.append(communication_costs[pt:pt + length])
+ m.append(memory_costs[pt:pt + length])
+ pt += length
+ assert pt == len(compute_costs), f"{pt} == {len(compute_costs)}"
+ assert pt == len(communication_costs), f"{pt} == {len(communication_costs)}"
+ assert pt == len(memory_costs), f"{pt} == {len(memory_costs)}"
+
+ # 1. Create variables
+
+ #############################
+ # create variables for node #
+ #############################
+ s = []
+ num_nodes = 0
+ reverse_follow_backpatch = []
+ for i in range(node_nums):
+ if s_follow[i] < 0:
+ if strategies_len[i] == 1:
+ s.append([1])
+ else:
+ if i not in s_alias:
+ num_nodes += 1
+ s.append(LpVariable.matrix(f"s[{i}]", (range(strategies_len[i]),), cat="Binary"))
+ else:
+ s.append(s[s_alias[i]])
+ else:
+ if s_follow[i] < len(s):
+ s.append(s[s_follow[i]])
+ else:
+ s.append(None)
+ reverse_follow_backpatch.append(i)
+
+ for i in reverse_follow_backpatch:
+ s[i] = s[s_follow[i]]
+
+ #############################
+ # create variables for edge #
+ #############################
+ e = []
+ num_edges = 0
+ map_edge_to_idx = {}
+ for (idx, (i, j)) in enumerate(E):
+ if len(s[i]) == 1:
+ e.append(s[j])
+ elif len(s[j]) == 1:
+ e.append(s[i])
+ else:
+ if i in s_alias and j in s_alias and (s_alias[i], s_alias[j]) in map_edge_to_idx:
+ e.append(e[map_edge_to_idx[(s_alias[i], s_alias[j])]])
+ else:
+ num_edges += 1
+ e.append(LpVariable.matrix(f"e[{i},{j}]", (range(len(s[i]) * len(s[j])),), cat="Binary"))
+ assert len(e[idx]) == len(r[idx])
+ map_edge_to_idx[(i, j)] = idx
+ for element in s:
+ assert len(element) > 0
+ # 2. Set initial value
+ ######################################
+ # set a initial value for warm start #
+ ######################################
+ if s_init_np is not None:
+ s_init = s_init_np.reshape((-1, 3))
+ for (idx, value, fix) in s_init:
+ for i in range(len(s[idx])):
+ s[idx][i].setInitialValue(i == value)
+ if fix:
+ s[idx][i].fixValue()
+
+ # 3. Objective
+ prob = LpProblem("myProblem", LpMinimize)
+ ###################################################################
+ # computing the node cost(computing cost and communication cost) #
+ ###################################################################
+ obj = 0
+ for i in range(node_nums):
+ assert len(s[i]) == len(c[i])
+ assert len(s[i]) == len(d[i])
+
+ obj += lpDot(s[i], c[i]) + lpDot(s[i], d[i])
+
+ #############################################
+ # computing the edge cost(resharding cost) #
+ #############################################
+ for i in range(len(E)):
+ assert len(e[i]) == len(r[i])
+ obj += lpDot(e[i], r[i])
+
+ prob += obj
+
+ # 4. Constraints
+ # (a). specified by `cat="Binary"`
+
+ # (b)
+ #################################################
+ # make sure each node only choose one strategy #
+ #################################################
+ for i in range(node_nums):
+ if s_follow[i] < 0:
+ prob += lpSum(s[i]) == 1
+
+ # (c)
+ #################################################
+ # compute memory consumption with liveness set #
+ #################################################
+ if memory_budget > 0:
+ mem = 0
+ for node in liveness_set:
+ if node not in self.node_index_dict:
+ continue
+ node_index = self.node_index_dict[node]
+ mem += lpSum(s[node_index][j] * m[node_index][j] for j in range(len(s[node_index])))
+ prob += mem <= memory_budget
+
+ # (d). specified by `cat="Binary"`
+
+ for (idx, (i, j)) in enumerate(E):
+ if strategies_len[i] == 1 or strategies_len[j] == 1:
+ continue
+
+ # (e)
+ prob += lpSum(e[idx]) == 1
+
+ # (f)
+ for row in range(len(s[i])):
+ C = len(s[j]) # noqa
+ prob += lpSum(e[idx][row * C + col] for col in range(0, C)) <= s[i][row]
+
+ # (g)
+ for col in range(len(s[j])):
+ R = len(s[i]) # noqa
+ C = len(s[j]) # noqa
+ prob += lpSum(e[idx][row * C + col] for row in range(0, R)) <= s[j][col]
+
+ # (h)
+ ######################
+ # omit alias set now #
+ ######################
+
+ # alias_set = set()
+ # for (idx, (i, j)) in enumerate(A):
+ # R = len(s[i]) # noqa
+ # C = len(s[j]) # noqa
+ # if (i, j) in alias_set:
+ # raise ValueError(f"Duplicated edges: {(i, j)}")
+
+ # alias_set.add((i, j))
+ # alias_set.add((j, i))
+
+ # for row in range(len(s[i])):
+ # for col in range(len(s[j])):
+ # if v[idx][row * C + col] > 0.5:
+ # prob += s[i][row] + s[j][col] <= 1
+
+ msg = verbose
+ time_limit = 600
+ assert "COIN_CMD" in pulp.listSolvers(
+ onlyAvailable=True), ("Please install ILP solvers by 'sudo apt install coinor-cbc'")
+
+ solver = pulp.COIN_CMD(mip=True, msg=msg, timeLimit=time_limit, threads=multiprocessing.cpu_count())
+ # solver = pulp.GLPK_CMD(mip=True, msg=msg, timeLimit=time_limit)
+ prob.solve(solver)
+
+ status = prob.status
+ objective = pulp.value(prob.objective)
+ objective = float(objective) if objective is not None else -1.0
+ if verbose:
+ print(f"ILP Status: {LpStatus[status]}\tObjective: {objective}\t"
+ f"Time: {time.time() - tic}")
+ print(f"#nodes: {num_nodes}, #edges: {num_edges}")
+
+ if prob.status in [pulp.LpStatusInfeasible]:
+ raise RuntimeError("Cannot run the function under the given memory budget. "
+ "Please increase the memory budget.")
+
+ # Get and check results
+ s_val = np.full((node_nums,), -1, dtype=np.int32)
+ for i in range(node_nums):
+ s_val[i] = get_non_zero_index(s[i])
+
+ e_val = np.full((len(E),), -1, dtype=np.int32)
+ for (idx, (i, j)) in enumerate(E):
+ e_val[idx] = get_non_zero_index(e[idx])
+ i_spec_index = e_val[idx] // len(s[j])
+ j_spec_index = e_val[idx] % len(s[j])
+ assert i_spec_index == s_val[i], f"e_val[{i}][{j}]"
+ assert j_spec_index == s_val[j], f"e_val[{i}][{j}]"
+ if verbose and r[idx][e_val[idx]] > 0:
+ print(f"Edge cost {(i, j)} : {r[idx][e_val[idx]]}")
+
+ self.last_s_val = list(s_val)
+ # self._recover_merged_node_strategy()
+ self.last_objective = objective
+
+ if objective > INFINITY_COST:
+ warnings.warn("Detect unexpected behaviors in the auto-sharding pass.")
+
+ return self.last_s_val, e_val, self.last_objective, status
+
+ def call_solver_serialized_args(self):
+ """
+ Call the solver with serialized arguments and handle python errors. Additionally,
+ we could give a serious of solutions with different memory budget.
+ """
+ if self.solution_numbers == 1:
+ args = self._prepare_data_for_solver()
+ ret = self._call_solver_serialized_args(*args)
+
+ return ret
+
+ origin_memory_budget = self.memory_budget
+ memory_budget_list = [
+ origin_memory_budget * self.memory_increasing_coefficient**i for i in range(self.solution_numbers)
+ ]
+ ret_list = []
+ for memory_budget in memory_budget_list:
+ self.memory_budget = memory_budget
+ args = self._prepare_data_for_solver()
+ ret = self._call_solver_serialized_args(*args)
+ ret_list.append(ret)
+
+ return ret_list
diff --git a/colossalai/auto_parallel/tensor_shard/solver/strategies_constructor.py b/colossalai/auto_parallel/tensor_shard/solver/strategies_constructor.py
new file mode 100644
index 0000000000000000000000000000000000000000..044a8ac847ead4b6b7d9f05c3d19a43a8fc2346c
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/solver/strategies_constructor.py
@@ -0,0 +1,198 @@
+import builtins
+import math
+import operator
+from copy import deepcopy
+from typing import Dict, List
+
+import torch
+from torch.fx import Graph, Node
+
+from colossalai.auto_parallel.tensor_shard.node_handler import (
+ GetattrHandler,
+ OutputHandler,
+ PlaceholderHandler,
+ operator_registry,
+)
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import StrategiesVector
+from colossalai.auto_parallel.tensor_shard.utils import generate_resharding_costs, generate_sharding_spec
+from colossalai.auto_parallel.tensor_shard.utils.factory import find_repeat_blocks
+from colossalai.device.device_mesh import DeviceMesh
+
+from ..options import DataloaderOption, SolverOptions
+
+__all__ = ['StrategiesConstructor']
+
+
+class StrategiesConstructor:
+ """
+ StrategiesConstructor is used to construct the parallelization plan for the model execution.
+
+ Args:
+ graph (Graph): a Graph object used for analysis and strategy generation.
+ device_mesh (DeviceMesh): a DeviceMesh object which contains the meta information about the cluster.
+ solver_options (SolverOptions): a SolverOptions object which specifies the preferences for plan searching.
+ """
+
+ def __init__(self, graph: Graph, device_mesh: DeviceMesh, solver_options: SolverOptions):
+ self.graph = graph
+ assert graph.owning_module is not None, 'The given graph is not associated with a owning_module'
+ self.root_module = self.graph.owning_module
+ self.nodes = list(graph.nodes)
+ self.device_mesh = device_mesh
+ self.leaf_strategies = []
+ self.strategy_map = {}
+ self.solver_options = solver_options
+ self.no_strategy_nodes = []
+ self.alias_set = None
+
+ def remove_duplicated_strategy(self, strategies_vector):
+ '''
+ In build_strategies_and_cost method, we may produce some duplicated strategies.
+ In this method, we will remove the duplicated strategies depending on the strategies name.
+ Note that this operation is in-place.
+ '''
+ name_checklist = []
+ remove_list = []
+ for strategy in strategies_vector:
+ if strategy.name not in name_checklist:
+ name_checklist.append(strategy.name)
+ else:
+ remove_list.append(strategy)
+ for strategy in remove_list:
+ strategies_vector.remove(strategy)
+
+ def generate_alias_set(self):
+
+ node_list = [strategy_vector.node for strategy_vector in self.leaf_strategies]
+ common_blocks = find_repeat_blocks(node_list, self.root_module, common_length_threshold=10)
+
+ repeat_block_nums = len(common_blocks)
+ alias_set = {}
+
+ if repeat_block_nums == 0:
+ return alias_set
+
+ for index, common_node in enumerate(common_blocks[0]):
+ for i in range(1, repeat_block_nums):
+ alias_set[node_list.index(common_blocks[i][index])] = node_list.index(common_node)
+ return alias_set
+
+ def build_strategies_and_cost(self):
+ """
+ This method is to build the strategy vector for each node in the computation graph.
+ """
+
+ def _check_no_strategy_for_node(node):
+ if node.op in ('placeholder', 'get_attr', 'output'):
+ return False
+
+ def _check_no_strategy_for_data(data):
+ label = True
+ if isinstance(data, torch.Tensor):
+ return False
+ elif isinstance(data, (tuple, list)):
+ for d in data:
+ label = label and _check_no_strategy_for_data(d)
+ return label
+
+ return _check_no_strategy_for_data(node._meta_data)
+
+ for node in self.nodes:
+ strategies_vector = StrategiesVector(node)
+
+ if _check_no_strategy_for_node(node):
+ self.no_strategy_nodes.append(node)
+ pass
+
+ # placeholder node
+ elif node.op == 'placeholder':
+ if self.solver_options.dataloader_option == DataloaderOption.DISTRIBUTED:
+ placeholder_option = 'distributed'
+ else:
+ assert self.solver_options.dataloader_option == DataloaderOption.REPLICATED, f'placeholder_option {self.solver_options.dataloader_option} is not supported'
+ placeholder_option = 'replicated'
+ placeholder_handler = PlaceholderHandler(node,
+ self.device_mesh,
+ strategies_vector,
+ placeholder_option=placeholder_option)
+ placeholder_handler.register_strategy()
+
+ # get_attr node
+ elif node.op == 'get_attr':
+ getattr_handler = GetattrHandler(node,
+ self.device_mesh,
+ strategies_vector,
+ shard_option=self.solver_options.shard_option,
+ solver_perference=self.solver_options.solver_perference)
+ getattr_handler.register_strategy()
+
+ # call_module node
+ elif node.op == 'call_module':
+ target = node.target
+ submod = self.root_module.get_submodule(target)
+ submod_type = type(submod)
+ handler = operator_registry.get(submod_type)(node,
+ self.device_mesh,
+ strategies_vector,
+ shard_option=self.solver_options.shard_option,
+ solver_perference=self.solver_options.solver_perference)
+ handler.register_strategy()
+ # attach strategies_info to node
+ if hasattr(handler, 'strategies_info'):
+ setattr(node, 'strategies_info', handler.strategies_info)
+
+ # call_function node
+ elif node.op == 'call_function':
+ target = node.target
+ handler = operator_registry.get(target)(node,
+ self.device_mesh,
+ strategies_vector,
+ shard_option=self.solver_options.shard_option,
+ solver_perference=self.solver_options.solver_perference)
+ handler.register_strategy()
+ # attach strategies_info to node
+ if hasattr(handler, 'strategies_info'):
+ setattr(node, 'strategies_info', handler.strategies_info)
+
+ # call_method node
+ elif node.op == 'call_method':
+ method = getattr(node.args[0]._meta_data.__class__, node.target)
+ handler = operator_registry.get(method)(node,
+ self.device_mesh,
+ strategies_vector,
+ shard_option=self.solver_options.shard_option,
+ solver_perference=self.solver_options.solver_perference)
+ handler.register_strategy()
+ # attach strategies_info to node
+ if hasattr(handler, 'strategies_info'):
+ setattr(node, 'strategies_info', handler.strategies_info)
+
+ # output node
+ elif node.op == 'output':
+ if self.solver_options.dataloader_option == DataloaderOption.DISTRIBUTED:
+ output_option = 'distributed'
+ else:
+ assert self.solver_options.dataloader_option == DataloaderOption.REPLICATED, f'placeholder_option {self.solver_options.dataloader_option} is not supported'
+ output_option = 'replicated'
+ output_handler = OutputHandler(node, self.device_mesh, strategies_vector, output_option=output_option)
+ output_handler.register_strategy()
+
+ self.remove_duplicated_strategy(strategies_vector)
+ setattr(node, 'strategies_vector', strategies_vector)
+ self.leaf_strategies.append(strategies_vector)
+ self.strategy_map[node] = strategies_vector
+
+ # remove no strategy nodes
+ remove_list = []
+ for strategies_vector in self.leaf_strategies:
+ if len(strategies_vector) == 0:
+ remove_list.append(strategies_vector.node)
+
+ for node in remove_list:
+ if node.strategies_vector in self.leaf_strategies:
+ self.leaf_strategies.remove(node.strategies_vector)
+ if node in self.strategy_map:
+ self.strategy_map.pop(node)
+
+ alias_set = self.generate_alias_set()
+ self.alias_set = alias_set
diff --git a/colossalai/auto_parallel/tensor_shard/utils/__init__.py b/colossalai/auto_parallel/tensor_shard/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7fe5430bf136b08d93706b33cf4dbf82e342013
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/utils/__init__.py
@@ -0,0 +1,25 @@
+from .broadcast import (
+ BroadcastType,
+ comm_actions_for_oprands,
+ get_broadcast_shape,
+ is_broadcastable,
+ recover_sharding_spec_for_broadcast_shape,
+)
+from .factory import generate_resharding_costs, generate_sharding_spec
+from .misc import check_sharding_spec_validity, ignore_sharding_exception, pytree_map
+from .reshape import check_keep_sharding_status, detect_reshape_mapping, infer_output_dim_partition_dict
+from .sharding import (
+ enumerate_all_possible_1d_sharding,
+ enumerate_all_possible_2d_sharding,
+ generate_sharding_size,
+ transpose_partition_dim,
+ update_partition_dim,
+)
+
+__all__ = [
+ 'BroadcastType', 'get_broadcast_shape', 'is_broadcastable', 'recover_sharding_spec_for_broadcast_shape',
+ 'generate_resharding_costs', 'generate_sharding_spec', 'ignore_sharding_exception', 'check_sharding_spec_validity'
+ 'transpose_partition_dim', 'update_partition_dim', 'enumerate_all_possible_1d_sharding',
+ 'enumerate_all_possible_2d_sharding', 'generate_sharding_size', 'comm_actions_for_oprands', 'pytree_map',
+ 'detect_reshape_mapping', 'check_keep_sharding_status', 'infer_output_dim_partition_dict'
+]
diff --git a/colossalai/auto_parallel/tensor_shard/utils/broadcast.py b/colossalai/auto_parallel/tensor_shard/utils/broadcast.py
new file mode 100644
index 0000000000000000000000000000000000000000..28aa551328d7a6d5f283338fe55c90eb102d253c
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/utils/broadcast.py
@@ -0,0 +1,160 @@
+from enum import Enum, auto
+from typing import List
+
+import torch
+from torch.fx.node import Node
+
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
+ CommAction,
+ CommType,
+ OperationData,
+ OperationDataType,
+)
+from colossalai.tensor.comm_spec import CollectiveCommPattern, CommSpec
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+__all__ = [
+ 'BroadcastType', 'is_broadcastable', 'get_broadcast_shape', 'recover_sharding_spec_for_broadcast_shape',
+ 'comm_actions_for_oprands'
+]
+
+
+class BroadcastType(Enum):
+ EQUAL = auto()
+ PADDDING = auto()
+ MULTIPLE = auto()
+
+
+def is_broadcastable(shape1: torch.Size, shape2: torch.Size) -> bool:
+ """
+ Check if two shapes are broadcastable to each other.
+ """
+ for s1, s2 in zip(shape1[::-1], shape2[::-1]):
+ if s1 == 1 or s2 == 1 or s1 == s2:
+ pass
+ else:
+ return False
+ return True
+
+
+def get_broadcast_shape(shape1: torch.Size, shape2: torch.Size) -> List[int]:
+ """
+ Compute the broadcast shape given two shapes.
+ """
+ assert is_broadcastable(shape1, shape2), f'{shape1} and {shape2} are not broadcastable'
+ shape1_reverse = shape1[::-1]
+ shape2_reverse = shape2[::-1]
+ min_common_dim = min(len(shape1), len(shape2))
+ dims = []
+ for s1, s2 in zip(shape1_reverse, shape2_reverse):
+ dims.append(max(s1, s2))
+
+ # append the remaining dims
+ dims.extend(shape1_reverse[min_common_dim:])
+ dims.extend(shape2_reverse[min_common_dim:])
+ return dims[::-1]
+
+
+def get_broadcast_dim_info(logical_shape, physical_shape):
+ # get the number of dimensions
+ logical_num_dims = len(logical_shape)
+ physical_num_dims = len(physical_shape)
+
+ assert logical_num_dims >= physical_num_dims, \
+ 'The number of dimensions in the logical shape is smaller than that of the physical shape, this tensor is not broadcast!'
+
+ # track the dim and its broadcasting type
+ logical_dim_broadcast_info = {}
+
+ for i in range(logical_num_dims):
+ # get the trailing dim size
+ logical_dim_idx = logical_num_dims - i - 1
+ phyiscal_dim_idx = physical_num_dims - i - 1
+ logical_dim_size = logical_shape[logical_dim_idx]
+
+ if phyiscal_dim_idx >= 0:
+ physical_dim_size = physical_shape[phyiscal_dim_idx]
+
+ if physical_dim_size == logical_dim_size:
+ logical_dim_broadcast_info[logical_dim_idx] = BroadcastType.EQUAL
+ elif physical_dim_size == 1 and physical_dim_size != logical_dim_size:
+ logical_dim_broadcast_info[logical_dim_idx] = BroadcastType.MULTIPLE
+ else:
+ logical_dim_broadcast_info[logical_dim_idx] = BroadcastType.PADDDING
+
+ return logical_dim_broadcast_info
+
+
+def recover_sharding_spec_for_broadcast_shape(logical_sharding_spec: ShardingSpec, logical_shape: torch.Size,
+ physical_shape: torch.Size) -> ShardingSpec:
+ """
+ This function computes the sharding spec for the physical shape of a broadcast tensor.
+
+ Args:
+ logical_sharding_spec (ShardingSpec): the sharding spec for the broadcast tensor
+ logical_shape (torch.Size): logical shape is the broadcast shape of a tensor
+ physical_shape (torch.Size): the shape of the tensor before broadcasting
+ """
+ # if the two shapes are the same, no broadcast occurs
+ # we directly return the current sharding spec
+
+ # recording the sharding dimensions removed during logical shape converting to physical one
+ removed_dims = []
+ if list(logical_shape) == list(physical_shape):
+ return logical_sharding_spec, removed_dims
+
+ # get the number of dimensions
+ logical_num_dims = len(logical_shape)
+ physical_num_dims = len(physical_shape)
+
+ # get the broadcast info
+ logical_dim_broadcast_info = get_broadcast_dim_info(logical_shape, physical_shape)
+
+ # generate the sharding spec for the physical shape
+ physical_dim_partition = {}
+ logical_dim_partition = logical_sharding_spec.dim_partition_dict
+
+ for shape_dim, mesh_dim in logical_dim_partition.items():
+ logical_broadcast_type = logical_dim_broadcast_info[shape_dim]
+
+ if logical_broadcast_type == BroadcastType.PADDDING or logical_broadcast_type == BroadcastType.MULTIPLE:
+ removed_dims.extend(mesh_dim)
+ else:
+ # get the corresponding physical dim
+ physical_dim = physical_num_dims - (logical_num_dims - shape_dim)
+ physical_dim_partition[physical_dim] = mesh_dim
+
+ physical_sharding_spec = ShardingSpec(device_mesh=logical_sharding_spec.device_mesh,
+ entire_shape=physical_shape,
+ dim_partition_dict=physical_dim_partition)
+
+ return physical_sharding_spec, removed_dims
+
+
+def comm_actions_for_oprands(node: Node, removed_dims: List[int], op_data: OperationData,
+ sharding_spec: ShardingSpec) -> CommAction:
+ """
+ This method is used to generate communication actions for oprands which lose information
+ during convert logical shape to physical shape.
+ """
+ if len(removed_dims) == 1:
+ # if list length is 1, extract element from list to avoid using flatten device mesh
+ removed_dims = removed_dims[0]
+ comm_spec = CommSpec(comm_pattern=CollectiveCommPattern.IDENTITY_FWD_ALLREDUCE_BWD,
+ sharding_spec=sharding_spec,
+ logical_process_axis=removed_dims)
+ if op_data.type == OperationDataType.PARAM:
+ comm_type = CommType.HOOK
+ else:
+ comm_type = CommType.BEFORE
+ arg_index = -1
+ for index, arg in enumerate(node.args):
+ if op_data.name == str(arg):
+ arg_index = index
+ assert arg_index >= 0, f'op_data should be an argument of node.'
+ comm_action = CommAction(
+ comm_spec=comm_spec,
+ comm_type=comm_type,
+ arg_index=arg_index,
+ )
+ return comm_action
diff --git a/colossalai/auto_parallel/tensor_shard/utils/factory.py b/colossalai/auto_parallel/tensor_shard/utils/factory.py
new file mode 100644
index 0000000000000000000000000000000000000000..05331e56000110a982cc776a24eb81d45fceb825
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/utils/factory.py
@@ -0,0 +1,206 @@
+import copy
+import operator
+import warnings
+from functools import reduce
+from typing import Dict, List, Optional, Union
+
+import torch
+from torch.fx.node import Node
+from torch.utils._pytree import tree_map
+
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.tensor.shape_consistency import ShapeConsistencyManager
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+from ..constants import INFINITY_COST
+
+__all__ = ['generate_sharding_spec', 'generate_resharding_costs']
+
+
+def generate_sharding_spec(input_: Union[Node, torch.Tensor], device_mesh: DeviceMesh,
+ dim_partition_dict: Dict[int, List[int]]) -> ShardingSpec:
+ """
+ Generate the sharding spec of the tensor based on the given dim_partition_dict.
+
+
+ Args:
+ input_ (Union[Node, torch.Tensor]): the input can be a Node object or a PyTorch tensor. If a node is used, it will look for its meta data associated with this node.
+ device_mesh (DeviceMesh): a DeviceMesh object which contains the meta information about the cluster.
+ dim_partition_dict (Dict[int, List[int]]): a dictionary to specify the sharding specs, the key is the tensor dimension and the value is the mesh dimension for sharding.
+ """
+
+ if isinstance(input_, Node):
+ assert hasattr(input_, '_meta_data'), f'The given node has no attribte _meta_data'
+ meta_tensor = input_._meta_data
+ assert meta_tensor is not None, "The given node's _meta_data attribute is None"
+ shape = meta_tensor.shape
+ elif isinstance(input_, torch.Tensor):
+ shape = input_.shape
+ else:
+ raise TypeError(
+ f'We cannot generate sharding spec for {type(input_)} type, only torch.fx.Node or torch.Tensor is expected.'
+ )
+ for dim_index, sharding_index_list in dim_partition_dict.items():
+ sharding_list = [device_mesh.mesh_shape[sharding_index] for sharding_index in sharding_index_list]
+ sharding_size = reduce(operator.mul, sharding_list, 1)
+ assert shape[
+ dim_index] % sharding_size == 0, f'we cannot shard the {dim_index} dimension of tensor into {sharding_size} partitions.'
+
+ sharding_spec = ShardingSpec(device_mesh=device_mesh, entire_shape=shape, dim_partition_dict=dim_partition_dict)
+ return sharding_spec
+
+
+def generate_resharding_costs(nodes: List[Node],
+ sharding_specs: List[ShardingSpec],
+ count_backward: Optional[bool] = True,
+ dtype: Optional[torch.dtype] = None,
+ index=None):
+ '''
+ Compute the resharding costs with this specific strategy.
+
+ Argument:
+ nodes (List[Node]): a list of nodes
+ sharding_spec_for_input(ShardingSpec): a list of ShardingSpec for the nodes.
+ count_backward (Optional[bool]): whether to include the cost of resharding in the backward pass, default is True. False can be used for inference.
+ dtype (Optional[torch.dtype]): the data type for cost calculation, default is None.
+ '''
+ # The resharding_cost of weight is counted due to sharing weight cases.
+ resharding_costs = {}
+ size_per_elem_bytes = torch.tensor([], dtype=dtype).element_size()
+
+ # shape consistency manager is a singleton class
+ shape_consistency_manager = ShapeConsistencyManager()
+
+ for input_node, input_spec in zip(nodes, sharding_specs):
+ resharding_costs[input_node] = []
+ for strategy in input_node.strategies_vector:
+ input_sharding_spec = strategy.output_sharding_spec
+ if not isinstance(input_sharding_spec, ShardingSpec):
+ assert isinstance(input_sharding_spec, list), 'only ShardingSpec or List[ShardingSpec] is expected.'
+ input_sharding_spec = input_sharding_spec[index]
+ assert isinstance(input_sharding_spec, ShardingSpec), f'The input node should NOT be a tuple of tensor.'
+ try:
+ # compute the resharding cost
+ _, _, total_resharding_cost = shape_consistency_manager.shape_consistency(
+ input_sharding_spec, input_spec)
+
+ # we need multiply the size of elem dtype to get correct communication cost
+ resharding_cost = total_resharding_cost["total"] * size_per_elem_bytes
+ except AssertionError as e:
+ warnings.warn(f'{e}')
+ resharding_cost = INFINITY_COST
+ resharding_costs[input_node].append(resharding_cost)
+ return resharding_costs
+
+
+def find_repeat_blocks(node_list: List[torch.fx.Node], root_module, common_length_threshold: int = 20):
+ '''
+ Find the largest repeat blocks in the graph, whose length is larger than the threshold.
+
+ Args:
+ gm (GraphModule): the graph module to be analyzed.
+ common_length_threshold (int): the threshold of the repeat block length.
+ '''
+
+ # graph = gm.graph
+
+ def _process_args(args):
+ new_args = []
+ for arg in args:
+ if hasattr(arg, '_meta_data'):
+ meta_data = arg._meta_data
+ else:
+ meta_data = arg
+
+ def _process_arg(data):
+ if isinstance(data, torch.Tensor):
+ data = data.size()
+ elif isinstance(data, slice):
+ data = (data.start, data.step, data.stop)
+ return data
+
+ new_meta_data = tree_map(_process_arg, meta_data)
+ new_args.append(new_meta_data)
+
+ return new_args
+
+ def _all_equal(check_list, check_fn):
+ base_value = check_list[-1]
+ for e in check_list:
+ if not check_fn(e, base_value):
+ return False
+ return True
+
+ def _check_node_list_equal(l1, l2):
+ if len(l1) != len(l2):
+ return False
+ for node1, node2 in zip(l1, l2):
+ if hash(node1.hash_key) != hash(node2.hash_key):
+ return False
+ return True
+
+ def _check_node_equal(node1, node2):
+ if hash(node1.hash_key) == hash(node2.hash_key):
+ return True
+ return False
+
+ for index, node in enumerate(node_list):
+ if node.op == 'call_module':
+ target = node.target
+ submod = root_module.get_submodule(target)
+ submod_type = type(submod)
+ target = submod_type
+ else:
+ target = node.target
+
+ new_args = _process_args(node.args)
+
+ if node.op != 'get_attr':
+ hash_key = (node.op, target, *new_args)
+ else:
+ hash_key = (node.op,)
+
+ setattr(node, 'hash_key', hash_key)
+
+ hash_value_to_node_dict = {}
+
+ for index, node in enumerate(node_list):
+ hash_value = hash(node.hash_key)
+ if hash_value not in hash_value_to_node_dict:
+ hash_value_to_node_dict[hash_value] = []
+ hash_value_to_node_dict[hash_value].append(index)
+
+ # node_list = list(graph.nodes)
+
+ node_list_start = 0
+ max_common_length = common_length_threshold
+ common_blocks_index = []
+ for index, node in enumerate(node_list):
+ # the comparison will be triggered if a common node appears
+ if len(hash_value_to_node_dict[hash(node.hash_key)]) >= 2:
+ start_index_list = hash_value_to_node_dict[hash(node.hash_key)]
+ check_block_list = [node_list[start:start + max_common_length] for start in start_index_list]
+
+ common_label = True
+ if not _all_equal(check_block_list, _check_node_list_equal):
+ common_label = False
+
+ if common_label:
+ common_blocks_index = copy.deepcopy(start_index_list)
+ max_step = len(node_list) - common_blocks_index[-1] - max_common_length - 1
+
+ for i in range(max_step):
+ # add assertion to avoid out of index
+ next_node_list = [node_list[index + max_common_length + i] for index in start_index_list]
+ if not _all_equal(next_node_list, _check_node_equal):
+ max_step = i
+ break
+ max_common_length += max_step
+ node_list_start += max_common_length
+
+ # recover common subgraph from the index
+ common_blocks = []
+ for start in common_blocks_index:
+ common_blocks.append(node_list[start:start + max_common_length])
+
+ return common_blocks
diff --git a/colossalai/auto_parallel/tensor_shard/utils/misc.py b/colossalai/auto_parallel/tensor_shard/utils/misc.py
new file mode 100644
index 0000000000000000000000000000000000000000..9e402dab757820c5d76ee6d1166de473c040784b
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/utils/misc.py
@@ -0,0 +1,97 @@
+import functools
+from typing import Any, Callable, Dict, List, Tuple, Type, Union
+
+import torch
+
+from colossalai.logging import get_dist_logger
+from colossalai.tensor.sharding_spec import ShardingSpec, ShardingSpecException
+
+__all__ = ['ignore_sharding_exception', 'pytree_map']
+
+
+def ignore_sharding_exception(func):
+ """
+ A function wrapper to handle the ShardingSpecException in the function.
+ If ShardingSpecException occurs, this function will return None.
+
+ Usage:
+ # mute the assertion error in the function
+ @ignore_sharding_exception
+ def do_something():
+ ...
+ """
+
+ @functools.wraps(func)
+ def wrapper(*args, **kwargs):
+ try:
+ logger = get_dist_logger()
+ rst = func(*args, **kwargs)
+ return rst
+ except ShardingSpecException as e:
+ logger.debug(e)
+ return None
+
+ return wrapper
+
+
+def check_sharding_spec_validity(sharding_spec: ShardingSpec, tensor: torch.Tensor):
+ """
+ This function checks whether the ShardingSpec is valid for the physical tensor.
+ This check includes 3 items:
+ 1. the sharding spec covers all dimensions of the physical tensor
+ 2. the sharding spec for each dimension is divisible by the number of devices.
+ 3. the sharding spec's entire shape must match the tensor shape
+ #
+ """
+ # make sure all dims are covered in sharding spec
+ sharding_len = len(sharding_spec.sharding_sequence)
+ tensor_num_dim = tensor.dim()
+ num_devices_in_col = sharding_spec.device_mesh.mesh_shape[0]
+ num_devices_in_row = sharding_spec.device_mesh.mesh_shape[1]
+ assert sharding_len == tensor_num_dim, \
+ f'The ShardingSpec ({sharding_spec.sharding_sequence}) is created for {sharding_len}-dimension tensor, but the given tensor is {tensor_num_dim}-dimension ({tensor.shape}).'
+
+ # make sure the sharding is valid for each dim
+ for i in range(tensor_num_dim):
+ dim_size = tensor.shape[i]
+ dim_spec = sharding_spec.sharding_sequence[i]
+
+ if str(dim_spec).startswith('S'):
+ devices_str = str(dim_spec).lstrip('S')
+ num_devices = 1
+
+ if '0' in devices_str:
+ num_devices *= num_devices_in_col
+ if '1' in devices_str:
+ num_devices *= num_devices_in_row
+
+ assert dim_size >= num_devices and dim_size % num_devices == 0, \
+ f'The dimension at index {i} has value {dim_size}, but it is sharded over {num_devices} devices.'
+
+ # make sure the entire shape matches the physical tensor shape
+ assert sharding_spec.entire_shape == tensor.shape, \
+ f'The entire_shape of the sharding spec {sharding_spec.entire_shape} does not match the tensor shape {tensor.shape}'
+
+
+def pytree_map(obj: Any, fn: Callable, process_types: Union[Type, Tuple[Type]] = (), map_all: bool = False) -> Any:
+ """process object recursively, like pytree
+
+ Args:
+ obj (:class:`Any`): object to process
+ fn (:class:`Callable`): a function to process subobject in obj
+ process_types (:class: `type | tuple[type]`): types to determine the type to process
+ map_all (:class: `bool`): if map_all is True, then any type of element will use fn
+
+ Returns:
+ :class:`Any`: returns have the same structure of `obj` and type in process_types after map of `fn`
+ """
+ if isinstance(obj, dict):
+ return {k: pytree_map(obj[k], fn, process_types, map_all) for k in obj}
+ elif isinstance(obj, tuple):
+ return tuple(pytree_map(o, fn, process_types, map_all) for o in obj)
+ elif isinstance(obj, list):
+ return list(pytree_map(o, fn, process_types, map_all) for o in obj)
+ elif isinstance(obj, process_types):
+ return fn(obj)
+ else:
+ return fn(obj) if map_all else obj
diff --git a/colossalai/auto_parallel/tensor_shard/utils/reshape.py b/colossalai/auto_parallel/tensor_shard/utils/reshape.py
new file mode 100644
index 0000000000000000000000000000000000000000..a32a14bf7d577713ae2cb986ffbb42d87b0cabc1
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/utils/reshape.py
@@ -0,0 +1,192 @@
+from enum import Enum
+from typing import Dict, List, Tuple
+
+import torch
+
+
+class PreviousStatus(Enum):
+ """
+ This class shows the status of previous comparision.
+ """
+ RESET = 0
+ # ORIGIN means the dimension size of original tensor is larger in the previous comparision.
+ ORIGIN = 1
+ # TGT means the dimension size of target tensor is larger in the previous comparision.
+ TGT = 2
+
+
+def detect_reshape_mapping(origin_shape: torch.Size, tgt_shape: torch.Size) -> Dict[Tuple[int], Tuple[int]]:
+ """
+ This method is used to detect the reshape mapping between original tensor and target tensor.
+
+ Returns:
+ reshape_mapping_dict: The dictionary shows how a tuple of origin dims(keys) mapping to the related
+ target dims(values) during reshaping operation.
+ Examples:
+ import torch
+ origin_shape = torch.Size([4, 4, 4])
+ tgt_shape = torch.Size([2, 8, 2, 2])
+ reshape_mapping_dict = detect_reshape_mapping(origin_shape, tgt_shape)
+ print(reshape_mapping_dict)
+ Output:
+ {(2,): (3, 2), (1, 0): (1,), (0,): (0, 1)}
+ """
+
+ # reverse the shape object
+ origin_shape = list(origin_shape)
+ tgt_shape = list(tgt_shape)
+ origin_shape.reverse()
+ tgt_shape.reverse()
+
+ # initialize arguments
+ reshape_mapping_dict = {}
+ origin_len = len(origin_shape)
+ tgt_len = len(tgt_shape)
+ origin_index = 0
+ tgt_index = 0
+ original_dimension_size = origin_shape[origin_index]
+ tgt_dimension_size = tgt_shape[tgt_index]
+ tgt_dims = [tgt_len - tgt_index - 1]
+ origin_dims = [origin_len - origin_index - 1]
+ previous_label = PreviousStatus.RESET
+
+ while origin_index != len(origin_shape) or tgt_index != len(tgt_shape):
+ if original_dimension_size == tgt_dimension_size:
+ reshape_mapping_dict[tuple(origin_dims)] = tuple(tgt_dims)
+ # if the origin_dims has no element, it means the original tensor has been fully matched.
+ # Therefore, we do not have to increase the origin_index for that case.
+ if len(origin_dims) > 0:
+ origin_index += 1
+ # if the tgt_dims has no element, it means the original tensor has been fully matched.
+ # Therefore, we do not have to increase the tgt_index for that case.
+ if len(tgt_dims) > 0:
+ tgt_index += 1
+ # the last step of loop should always end with condition
+ # so we need to manually skip the preparation for next step
+ # in the last step.
+ if origin_index == len(origin_shape) and tgt_index == len(tgt_shape):
+ continue
+
+ # If origin_index equals to origin_len, we just need to set the original_dimension_size
+ # to 1 to match the remaining '1's in the target tensor shape.
+ if origin_index == len(origin_shape):
+ original_dimension_size = 1
+ origin_dims = []
+ else:
+ original_dimension_size = origin_shape[origin_index]
+ origin_dims = [origin_len - origin_index - 1]
+
+ # If tgt_index equals to tgt_len, we just need to set the tgt_dimension_size
+ # to 1 to match the remaining '1's in the original tensor shape.
+ if tgt_index == len(tgt_shape):
+ tgt_dimension_size = 1
+ tgt_dims = []
+ else:
+ tgt_dimension_size = tgt_shape[tgt_index]
+ tgt_dims = [tgt_len - tgt_index - 1]
+
+ previous_label = PreviousStatus.RESET
+
+ elif original_dimension_size > tgt_dimension_size:
+ tgt_index += 1
+
+ if previous_label == PreviousStatus.TGT:
+ # if the target dimension size is larger in the previous comparision, which means
+ # the origin dimension size has already accumulated larger than target dimension size, so
+ # we need to offload the origin dims and tgt dims into the reshape_mapping_dict.
+ reshape_mapping_dict[tuple(origin_dims)] = tuple(tgt_dims)
+ original_dimension_size = original_dimension_size // tgt_dimension_size
+ origin_dims = [origin_len - origin_index - 1]
+ tgt_dimension_size = tgt_shape[tgt_index]
+ tgt_dims = [tgt_len - tgt_index - 1, tgt_len - tgt_index]
+ # reset the previous_label after offloading the origin dims and tgt dims
+ previous_label = PreviousStatus.RESET
+ else:
+ # accumulate the tgt_dimension_size until tgt_dimension_size larger than original_dimension_size
+ tgt_dimension_size *= tgt_shape[tgt_index]
+ tgt_dims.append(tgt_len - tgt_index - 1)
+ previous_label = PreviousStatus.ORIGIN
+
+ else:
+ origin_index += 1
+
+ if previous_label == PreviousStatus.ORIGIN:
+ # if the origin element is larger in the previous comparision, which means
+ # the target element has already accumulated larger than origin element, so
+ # we need to offload the origin dims and tgt dims into the reshape_mapping_dict.
+ reshape_mapping_dict[tuple(origin_dims)] = tuple(tgt_dims)
+ tgt_dimension_size = tgt_dimension_size // original_dimension_size
+ tgt_dims = [tgt_len - tgt_index - 1]
+ original_dimension_size = origin_shape[origin_index]
+ origin_dims = [origin_len - origin_index - 1, origin_len - origin_index]
+ # reset the previous_label after offloading the origin dims and tgt dims
+ previous_label = PreviousStatus.RESET
+ else:
+ # accumulate the original_dimension_size until original_dimension_size larger than tgt_dimension_size
+ original_dimension_size *= origin_shape[origin_index]
+ origin_dims.append(origin_len - origin_index - 1)
+ previous_label = PreviousStatus.TGT
+
+ return reshape_mapping_dict
+
+
+def check_keep_sharding_status(input_dim_partition_dict: Dict[int, List[int]],
+ reshape_mapping_dict: Dict[Tuple[int], Tuple[int]]) -> bool:
+ """
+ This method is used to check whether the reshape operation could implement without converting
+ the input to fully replicated status.
+
+ Rule:
+ For a sharded dimension of input tensor, if it is not the minimum element of the input tuple,
+ the function will return false.
+ To illustrate this issue, there are two cases to analyse:
+ 1. no sharded dims in the input tuple: we could do the reshape operation safely just as the normal
+ operation without distributed tensor.
+ 2. sharded dims in the input tuple: the sharded dim must be the minimum element, then during shape
+ consistency process, torch.cat will be implemented on the sharded dim, and everything after the sharded
+ dim get recovered.
+
+ Examples:
+ # the second dimension of the input has been sharded.
+ input_dim_partition_dict = {1: [1]}
+ origin_shape = torch.Size([8, 4, 2])
+ tgt_shape = torch.Size([2, 4, 8])
+ reshape_mapping_dict = detect_reshape_mapping(origin_shape, tgt_shape)
+ # {(2, 1): (2,), (0,): (1, 0)}
+ # the sharded dim of input is 1, which is the minimum element of the tuple (2, 1),
+ # so we do not have to convert the input to fully replicated status.
+ print(check_keep_sharding_status(input_dim_partition_dict, reshape_mapping_dict))
+
+ Output:
+ True
+ """
+ sharded_dims = list(input_dim_partition_dict.keys())
+ for input_dims in reshape_mapping_dict.keys():
+ # if input_dims has no element, we could just skip this iteration.
+ if len(input_dims) == 0:
+ continue
+ min_element = min(input_dims)
+ for dim in input_dims:
+ if dim in sharded_dims and dim is not min_element:
+ return False
+ return True
+
+
+def infer_output_dim_partition_dict(input_dim_partition_dict: Dict[int, List[int]],
+ reshape_mapping_dict: Dict[Tuple[int], Tuple[int]]) -> Dict[Tuple[int], Tuple[int]]:
+ """
+ This method is used to infer the output dim partition dict for a reshape operation,
+ given the input dim partition dict and reshape mapping dict.
+ """
+ assert check_keep_sharding_status(input_dim_partition_dict, reshape_mapping_dict), \
+ 'we only infer output dim partition dict for the reshape operation could keep sharding spec.'
+ sharded_dims = list(input_dim_partition_dict.keys())
+ output_dim_partition_dict = {}
+ for input_dims, output_dims in reshape_mapping_dict.items():
+ for dim in input_dims:
+ if dim in sharded_dims:
+ output_dim_partition_dict[min(output_dims)] = input_dim_partition_dict[dim]
+ # we could break because input dims cannot contain two sharded dims, otherwise
+ # the keep sharding status check will fail.
+ break
+ return output_dim_partition_dict
diff --git a/colossalai/auto_parallel/tensor_shard/utils/sharding.py b/colossalai/auto_parallel/tensor_shard/utils/sharding.py
new file mode 100644
index 0000000000000000000000000000000000000000..e2ce59e0b5772679be11e960322e3110c500d6aa
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/utils/sharding.py
@@ -0,0 +1,120 @@
+import operator
+from copy import deepcopy
+from functools import reduce
+from typing import Dict
+
+import torch
+
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+__all__ = [
+ 'transpose_partition_dim', 'update_partition_dim', 'enumerate_all_possible_1d_sharding',
+ 'enumerate_all_possible_2d_sharding', 'generate_sharding_size'
+]
+
+
+def transpose_partition_dim(sharding_spec: ShardingSpec, dim1: int, dim2: int) -> ShardingSpec:
+ """
+ Switch the sharding mesh dimensions for two tensor dimensions. This operation is in-place.
+
+ Args:
+ sharding_spec (ShardingSpec): the sharding spec for which partition dim are switched
+ dim1 (int): the tensor dimension to switch
+ dim2 (int): the tensor dimension to switch
+ """
+ assert len(sharding_spec.entire_shape) >= 2, \
+ 'The entire_shape of the sharding spec must have at least 2 dimensions'
+ dim_partition_dict = sharding_spec.dim_partition_dict
+
+ # transpose the dim partition
+ dim1_partition = dim_partition_dict.pop(dim1, None)
+ dim2_partition = dim_partition_dict.pop(dim2, None)
+
+ if dim1_partition:
+ dim_partition_dict[dim2] = dim1_partition
+ if dim2_partition:
+ dim_partition_dict[dim1] = dim2_partition
+
+ # get the transposed shape
+ new_shape = list(sharding_spec.entire_shape[:])
+ new_shape[dim2], new_shape[dim1] = new_shape[dim1], new_shape[dim2]
+ new_shape = torch.Size(new_shape)
+
+ # re-init the sharding spec
+ sharding_spec.__init__(sharding_spec.device_mesh, new_shape, dim_partition_dict)
+ return sharding_spec
+
+
+def update_partition_dim(sharding_spec: ShardingSpec,
+ dim_mapping: Dict[int, int],
+ physical_shape: torch.Size,
+ inplace: bool = False):
+ """
+ This method is used to update the partition dim dict from the logical one to the physical one.
+
+ Args:
+ sharding_spec (ShardingSpec): the sharding spec for which partition dims are updated
+ dim_mapping (Dict[int, int]): the mapping from the logical tensor dimension to the physical tensor dimension
+ physical_shape (torch.Size): the physical shape for the tensor
+ """
+
+ if inplace:
+ current_sharding_spec = sharding_spec
+ else:
+ current_sharding_spec = deepcopy(sharding_spec)
+
+ old_dim_partition_dict = current_sharding_spec.dim_partition_dict
+ new_dim_partition_dict = {}
+
+ # assign new dim
+ for old_dim, new_dim in dim_mapping.items():
+ mesh_dims = old_dim_partition_dict.pop(old_dim)
+ new_dim_partition_dict[new_dim] = mesh_dims
+
+ for tensor_dim, mesh_dims in old_dim_partition_dict.items():
+ if tensor_dim in new_dim_partition_dict:
+ raise KeyError(f"There are duplicated entries for the tensor sharding dimension {tensor_dim}")
+ else:
+ new_dim_partition_dict[tensor_dim] = mesh_dims
+
+ # update sharding spec
+ current_sharding_spec.__init__(device_mesh=sharding_spec.device_mesh,
+ entire_shape=physical_shape,
+ dim_partition_dict=new_dim_partition_dict)
+ return current_sharding_spec
+
+
+def enumerate_all_possible_2d_sharding(mesh_dim_0, mesh_dim_1, dim_size):
+ dim_partition_list = []
+ # enumerate all the 2D sharding cases
+ for i in range(dim_size):
+ for j in range(i + 1, dim_size):
+ dim_partition_dict_0 = {i: [mesh_dim_0], j: [mesh_dim_1]}
+ dim_partition_dict_1 = {i: [mesh_dim_1], j: [mesh_dim_0]}
+ dim_partition_list.append(dim_partition_dict_0)
+ dim_partition_list.append(dim_partition_dict_1)
+ for i in range(dim_size):
+ dim_partition_dict_flatten = {i: [mesh_dim_0, mesh_dim_1]}
+ dim_partition_list.append(dim_partition_dict_flatten)
+
+ return dim_partition_list
+
+
+def enumerate_all_possible_1d_sharding(mesh_dim_0, dim_size):
+ dim_partition_list = []
+ # enumerate all the 1D sharding cases
+ for i in range(dim_size):
+ dim_partition_dict_0 = {i: [mesh_dim_0]}
+ dim_partition_list.append(dim_partition_dict_0)
+
+ return dim_partition_list
+
+
+def generate_sharding_size(dim_partition_dict, device_mesh):
+ total_sharding_size = 1
+ for mesh_dim_list in dim_partition_dict.values():
+ mesh_dim_sharding_size = [device_mesh.shape[mesh_dim] for mesh_dim in mesh_dim_list]
+ sharding_size = reduce(operator.mul, mesh_dim_sharding_size)
+ total_sharding_size *= sharding_size
+
+ return total_sharding_size
diff --git a/colossalai/autochunk/autochunk_codegen.py b/colossalai/autochunk/autochunk_codegen.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0a467254d7279c37031a755fa62a53fc4e0d9b9
--- /dev/null
+++ b/colossalai/autochunk/autochunk_codegen.py
@@ -0,0 +1,561 @@
+from typing import Any, Callable, Dict, Iterable, List, Tuple
+
+import torch
+
+import colossalai
+from colossalai.fx._compatibility import is_compatible_with_meta
+from colossalai.fx.codegen.activation_checkpoint_codegen import CODEGEN_AVAILABLE
+
+AUTOCHUNK_AVAILABLE = CODEGEN_AVAILABLE and is_compatible_with_meta()
+
+if AUTOCHUNK_AVAILABLE:
+ from torch.fx.graph import CodeGen, PythonCode, _custom_builtins, _CustomBuiltin, _format_target, _is_from_torch, _Namespace, _origin_type_map, inplace_methods, magic_methods
+
+from torch.fx.node import Argument, Node, _get_qualified_name, _type_repr, map_arg
+
+from .search_chunk import SearchChunk
+from .utils import delete_free_var_from_last_use, get_logger, get_node_name, get_node_shape
+
+
+def _gen_chunk_slice_dim(chunk_dim: int, chunk_indice_name: str, shape: List) -> str:
+ """
+ Generate chunk slice string, eg. [:, :, chunk_idx_name:chunk_idx_name + chunk_size, :]
+
+ Args:
+ chunk_dim (int)
+ chunk_indice_name (str): chunk indice name
+ shape (List): node shape
+
+ Returns:
+ new_shape (str): return slice
+ """
+ new_shape = "["
+ for idx, _ in enumerate(shape):
+ if idx == chunk_dim:
+ new_shape += "%s:%s + chunk_size" % (chunk_indice_name, chunk_indice_name)
+ else:
+ new_shape += ":"
+ new_shape += ", "
+ new_shape = new_shape[:-2] + "]"
+ return new_shape
+
+
+def _gen_loop_start(chunk_input: List[Node], chunk_output: List[Node], chunk_ouput_dim: int, chunk_size=2) -> str:
+ """
+ Generate chunk loop start
+
+ eg. chunk_result = torch.empty([100, 100], dtype=input_node.dtype, device=input_node.device)
+ chunk_size = 32
+ for chunk_idx in range(0, 100, 32):
+ ......
+
+ Args:
+ chunk_input (List[Node]): chunk input node
+ chunk_output (Node): chunk output node
+ chunk_ouput_dim (int): chunk output node chunk dim
+ chunk_size (int): chunk size. Defaults to 2.
+
+ Returns:
+ context (str): generated str
+ """
+ input_node = chunk_input[0]
+
+ context = ""
+ for i in range(len(chunk_output)):
+ shape_str = str(list(get_node_shape(chunk_output[i])))
+ if get_node_name(chunk_output[i]) in ["split", "unbind"]:
+ tensor_str = "torch.empty(%s, dtype=%s.dtype, device=%s.device), " % (shape_str, input_node.name,
+ input_node.name)
+ tensor_str = tensor_str * len(chunk_output[i].meta['tensor_meta'])
+ tensor_str = "[" + tensor_str[:-2] + "]"
+ context += "%s = %s; " % (chunk_output[i].name, tensor_str)
+ else:
+ context += "%s = torch.empty(%s, dtype=%s.dtype, device=%s.device); " % (chunk_output[i].name, shape_str,
+ input_node.name, input_node.name)
+
+ out_shape = get_node_shape(chunk_output[0])
+ chunk_shape = out_shape[chunk_ouput_dim[0]]
+ context += "chunk_size = %d\nfor chunk_idx in range(0, %d, chunk_size):\n" % (chunk_size, chunk_shape)
+ return context
+
+
+def _gen_loop_end(chunk_inputs: List[Node], chunk_non_compute_inputs: List[Node], node_list: List[Node],
+ chunk_outputs_idx: int, chunk_outputs_non_tensor: List[Node], search_chunk: SearchChunk) -> str:
+ """
+ Generate chunk loop end
+
+ eg. chunk_result[chunk_idx:chunk_idx + chunk_size] = output_node
+ output_node = chunk_result; xx = None; xx = None
+
+ Args:
+ chunk_inputs (List[Node]): chunk input node
+ chunk_non_compute_inputs (List[Node]): input node without chunk
+ chunk_outputs (Node): chunk output node
+ chunk_outputs_dim (int): chunk output node chunk dim
+ node_list (List)
+
+ Returns:
+ context (str): generated str
+ """
+ context = "chunk_size = None"
+ # determine if its the last use for chunk input
+ for chunk_input in chunk_inputs + chunk_non_compute_inputs:
+ if all([search_chunk.node_mgr.find_node_idx(user) <= chunk_outputs_idx for user in chunk_input.users.keys()]):
+ context += "; %s = None" % chunk_input.name
+ for chunk_output_non_tensor, chunk_output_non_tensor_val in chunk_outputs_non_tensor.items():
+ context += "; %s = %s" % (chunk_output_non_tensor.name, chunk_output_non_tensor_val)
+ context += "\n"
+ return context
+
+
+def _replace_name(context: str, name_from: str, name_to: str) -> str:
+ """
+ replace node name
+ """
+ patterns = [(" ", " "), (" ", "."), (" ", ","), ("(", ")"), ("(", ","), (" ", ")"), (" ", ""), ("", " ")]
+ for p in patterns:
+ source = p[0] + name_from + p[1]
+ target = p[0] + name_to + p[1]
+ if source in context:
+ context = context.replace(source, target)
+ break
+ return context
+
+
+def _replace_reshape_size(context: str, node_name: str, reshape_size_dict: Dict) -> str:
+ """
+ replace reshape size, some may have changed due to chunk
+ """
+ if node_name not in reshape_size_dict:
+ return context
+ context = context.replace(reshape_size_dict[node_name][0], reshape_size_dict[node_name][1])
+ return context
+
+
+def _replace_new_tensor_like_shape(
+ search_chunk: SearchChunk,
+ chunk_infos: List[Dict],
+ region_idx: int,
+ node_idx: int,
+ node: Node,
+ body: List[str],
+) -> List[str]:
+ """
+ add chunk slice for new tensor op such as ones like
+ """
+ if get_node_name(node) in ["ones_like", "zeros_like", "empty_like"]:
+ meta_node = search_chunk.node_mgr.get_node_by_idx(node_idx)
+ chunk_dim = chunk_infos[region_idx]["node_chunk_dim"][meta_node]["chunk_dim"]
+ if get_node_shape(meta_node)[chunk_dim] != 1:
+ source_node = meta_node.args[0].args[0]
+ if (source_node not in chunk_infos[region_idx]["node_chunk_dim"]
+ or chunk_infos[region_idx]["node_chunk_dim"][source_node]["chunk_dim"] is None):
+ chunk_slice = _gen_chunk_slice_dim(chunk_dim, "chunk_idx", get_node_shape(node))
+ body[-1] = _replace_name(body[-1], node.args[0].name, node.args[0].name + chunk_slice)
+ return body
+
+
+def _replace_new_tensor_shape(
+ search_chunk: SearchChunk,
+ chunk_infos: List[Dict],
+ region_idx: int,
+ node_idx: int,
+ node: Node,
+ body: List[str],
+) -> List[str]:
+ """
+ add chunk slice for new tensor op such as ones
+ """
+ if get_node_name(node) in ["ones", "zeros", "empty"]:
+ meta_node = search_chunk.node_mgr.get_node_by_idx(node_idx)
+ chunk_dim = chunk_infos[region_idx]["node_chunk_dim"][meta_node]["chunk_dim"]
+ if chunk_dim is None:
+ return
+ if get_node_shape(meta_node)[chunk_dim] == 1:
+ return
+ origin_shape = str(node.args)
+ new_shape = list(node.args)
+ new_shape[chunk_dim] = "min(chunk_size, %d - chunk_idx)" % get_node_shape(meta_node)[chunk_dim]
+ new_shape = str(new_shape)
+ new_shape = new_shape.replace("'", "")
+ body[-1] = _replace_name(body[-1], origin_shape[1:-1], new_shape[1:-1])
+ return body
+
+
+def _add_node_slice(
+ chunk_nodes: List[Node],
+ region_idx: int,
+ chunk_nodes_dim: Dict,
+ node_idx: int,
+ body: List[str],
+ node: Node,
+) -> List[str]:
+ """
+ add chunk slice for input nodes
+ """
+ for chunk_node_idx, chunk_node in enumerate(chunk_nodes[region_idx]):
+ # inputs node
+ if isinstance(chunk_nodes_dim[region_idx][chunk_node_idx], dict):
+ for idx, dim in chunk_nodes_dim[region_idx][chunk_node_idx].items():
+ if idx == node_idx:
+ chunk_slice = _gen_chunk_slice_dim(dim[0], "chunk_idx", get_node_shape(chunk_node))
+ body[-1] = _replace_name(body[-1], chunk_node.name, chunk_node.name + chunk_slice)
+ # outputs node
+ else:
+ if chunk_node.name == node.name or (chunk_node.name in [i.name for i in node.all_input_nodes]):
+ chunk_slice = _gen_chunk_slice_dim(chunk_nodes_dim[region_idx][chunk_node_idx], "chunk_idx",
+ get_node_shape(chunk_node))
+ if get_node_name(chunk_node) in ["split", "unbind"]:
+ split_chunk_slice = ""
+ for i in range(len(chunk_node.meta['tensor_meta'])):
+ split_chunk_slice += "%s[%d]%s, " % (chunk_node.name, i, chunk_slice)
+ split_chunk_slice = split_chunk_slice[:-2]
+ body[-1] = _replace_name(body[-1], chunk_node.name, split_chunk_slice)
+ else:
+ body[-1] = _replace_name(body[-1], chunk_node.name, chunk_node.name + chunk_slice)
+ return body
+
+
+def emit_code_with_chunk(body: List[str],
+ nodes: Iterable[Node],
+ emit_node_func: Callable,
+ delete_unused_value_func: Callable,
+ search_chunk: SearchChunk,
+ chunk_infos: List,
+ eval_mem: bool = False):
+ """
+ Emit code with chunk according to chunk_infos.
+
+ It will generate a for loop in chunk regions, and
+ replace inputs and outputs of regions with chunked variables.
+
+ Args:
+ body: forward code
+ nodes: graph.nodes
+ emit_node_func: function to emit node
+ delete_unused_value_func: function to remove the unused value
+ search_chunk: the class to search all chunks
+ chunk_infos: store all information about all chunks.
+ """
+ node_list = list(nodes)
+
+ # chunk region
+ chunk_starts = [i["region"][0] for i in chunk_infos]
+ chunk_ends = [i["region"][1] for i in chunk_infos]
+
+ # chunk inputs
+ chunk_inputs = [i["inputs"] for i in chunk_infos] # input with chunk
+ chunk_inputs_non_chunk = [i["inputs_non_chunk"] for i in chunk_infos] # input without chunk
+ chunk_inputs_dim = [i["inputs_dim"] for i in chunk_infos] # input chunk dim
+ chunk_inputs_names = [j.name for i in chunk_inputs for j in i] + [j.name for i in chunk_inputs_non_chunk for j in i]
+
+ # chunk outputs
+ chunk_outputs = [i["outputs"] for i in chunk_infos]
+ chunk_outputs_non_tensor = [i["outputs_non_tensor"] for i in chunk_infos]
+ chunk_outputs_dim = [i["outputs_dim"] for i in chunk_infos]
+
+ node_list = search_chunk.reorder_graph.reorder_node_list(node_list)
+ node_idx = 0
+ region_idx = 0
+ within_chunk_region = False
+
+ if eval_mem:
+ body.append("init_memory = torch.cuda.memory_allocated() / 1024**2\n")
+
+ while node_idx < len(node_list):
+ node = node_list[node_idx]
+
+ # if is chunk start, generate for loop start
+ if node_idx in chunk_starts:
+ within_chunk_region = True
+ region_idx = chunk_starts.index(node_idx)
+ body.append(
+ _gen_loop_start(
+ chunk_inputs[region_idx],
+ chunk_outputs[region_idx],
+ chunk_outputs_dim[region_idx],
+ chunk_infos[region_idx]["chunk_size"],
+ ))
+
+ if within_chunk_region:
+ emit_node_func(node, body)
+ # replace input var with chunk var
+ body = _add_node_slice(chunk_inputs, region_idx, chunk_inputs_dim, node_idx, body, node)
+ # replace output var with chunk var
+ body = _add_node_slice(chunk_outputs, region_idx, chunk_outputs_dim, node_idx, body, node)
+ # new tensor like
+ body = _replace_new_tensor_like_shape(search_chunk, chunk_infos, region_idx, node_idx, node, body)
+ # new tensor
+ body = _replace_new_tensor_shape(search_chunk, chunk_infos, region_idx, node_idx, node, body)
+ # reassign reshape size
+ body[-1] = _replace_reshape_size(body[-1], node.name, chunk_infos[region_idx]["reshape_size"])
+ body[-1] = " " + body[-1]
+ delete_unused_value_func(node, body, chunk_inputs_names)
+ if eval_mem:
+ body.append(
+ " if chunk_idx == 0:\n print('%s', torch.cuda.max_memory_allocated() / 1024**2 - init_memory); torch.cuda.reset_peak_memory_stats()\n"
+ % (node.name))
+ else:
+ emit_node_func(node, body)
+ if node_idx not in chunk_inputs:
+ delete_unused_value_func(node, body, chunk_inputs_names)
+ if eval_mem:
+ body.append(
+ "print('%s', torch.cuda.max_memory_allocated() / 1024**2 - init_memory); torch.cuda.reset_peak_memory_stats()\n"
+ % (node.name))
+
+ # generate chunk region end
+ if node_idx in chunk_ends:
+ body.append(
+ _gen_loop_end(chunk_inputs[region_idx], chunk_inputs_non_chunk[region_idx], node_list,
+ chunk_ends[region_idx], chunk_outputs_non_tensor[region_idx], search_chunk))
+ within_chunk_region = False
+
+ node_idx += 1
+
+
+if AUTOCHUNK_AVAILABLE:
+
+ class AutoChunkCodeGen(CodeGen):
+
+ def __init__(self,
+ meta_graph,
+ max_memory: int = None,
+ print_mem: bool = False,
+ print_progress: bool = False,
+ eval_mem: bool = False) -> None:
+ super().__init__()
+ self.eval_mem = eval_mem
+ # find the chunk regions
+ self.search_chunk = SearchChunk(meta_graph, max_memory, print_mem, print_progress)
+ self.chunk_infos = self.search_chunk.search_region()
+ if print_progress:
+ get_logger().info("AutoChunk start codegen")
+
+ def _gen_python_code(self, nodes, root_module: str, namespace: _Namespace) -> PythonCode:
+ free_vars: List[str] = []
+ body: List[str] = []
+ globals_: Dict[str, Any] = {}
+ wrapped_fns: Dict[str, None] = {}
+
+ # Wrap string in list to pass by reference
+ maybe_return_annotation: List[str] = [""]
+
+ def add_global(name_hint: str, obj: Any):
+ """Add an obj to be tracked as a global.
+
+ We call this for names that reference objects external to the
+ Graph, like functions or types.
+
+ Returns: the global name that should be used to reference 'obj' in generated source.
+ """
+ if (_is_from_torch(obj) and obj != torch.device): # to support registering torch.device
+ # HACK: workaround for how torch custom ops are registered. We
+ # can't import them like normal modules so they must retain their
+ # fully qualified name.
+ return _get_qualified_name(obj)
+
+ # normalize the name hint to get a proper identifier
+ global_name = namespace.create_name(name_hint, obj)
+
+ if global_name in globals_:
+ assert globals_[global_name] is obj
+ return global_name
+ globals_[global_name] = obj
+ return global_name
+
+ # set _custom_builtins here so that we needn't import colossalai in forward
+ _custom_builtins["colossalai"] = _CustomBuiltin("import colossalai", colossalai)
+
+ # Pre-fill the globals table with registered builtins.
+ for name, (_, obj) in _custom_builtins.items():
+ add_global(name, obj)
+
+ def type_repr(o: Any):
+ if o == ():
+ # Empty tuple is used for empty tuple type annotation Tuple[()]
+ return "()"
+
+ typename = _type_repr(o)
+
+ if hasattr(o, "__origin__"):
+ # This is a generic type, e.g. typing.List[torch.Tensor]
+ origin_type = _origin_type_map.get(o.__origin__, o.__origin__)
+ origin_typename = add_global(_type_repr(origin_type), origin_type)
+
+ if hasattr(o, "__args__"):
+ # Assign global names for each of the inner type variables.
+ args = [type_repr(arg) for arg in o.__args__]
+
+ if len(args) == 0:
+ # Bare type, such as `typing.Tuple` with no subscript
+ # This code-path used in Python < 3.9
+ return origin_typename
+
+ return f'{origin_typename}[{",".join(args)}]'
+ else:
+ # Bare type, such as `typing.Tuple` with no subscript
+ # This code-path used in Python 3.9+
+ return origin_typename
+
+ # Common case: this is a regular module name like 'foo.bar.baz'
+ return add_global(typename, o)
+
+ def _format_args(args: Tuple[Argument, ...], kwargs: Dict[str, Argument]) -> str:
+
+ def _get_repr(arg):
+ # Handle NamedTuples (if it has `_fields`) via add_global.
+ if isinstance(arg, tuple) and hasattr(arg, "_fields"):
+ qualified_name = _get_qualified_name(type(arg))
+ global_name = add_global(qualified_name, type(arg))
+ return f"{global_name}{repr(tuple(arg))}"
+ return repr(arg)
+
+ args_s = ", ".join(_get_repr(a) for a in args)
+ kwargs_s = ", ".join(f"{k} = {_get_repr(v)}" for k, v in kwargs.items())
+ if args_s and kwargs_s:
+ return f"{args_s}, {kwargs_s}"
+ return args_s or kwargs_s
+
+ # Run through reverse nodes and record the first instance of a use
+ # of a given node. This represents the *last* use of the node in the
+ # execution order of the program, which we will use to free unused
+ # values
+ node_to_last_use: Dict[Node, Node] = {}
+ user_to_last_uses: Dict[Node, List[Node]] = {}
+
+ def register_last_uses(n: Node, user: Node):
+ if n not in node_to_last_use:
+ node_to_last_use[n] = user
+ user_to_last_uses.setdefault(user, []).append(n)
+
+ for node in reversed(nodes):
+ map_arg(node.args, lambda n: register_last_uses(n, node))
+ map_arg(node.kwargs, lambda n: register_last_uses(n, node))
+
+ delete_free_var_from_last_use(user_to_last_uses)
+
+ # NOTE: we add a variable to distinguish body and ckpt_func
+ def delete_unused_values(user: Node, body, to_keep=[]):
+ """
+ Delete values after their last use. This ensures that values that are
+ not used in the remainder of the code are freed and the memory usage
+ of the code is optimal.
+ """
+ if user.op == "placeholder":
+ return
+ if user.op == "output":
+ body.append("\n")
+ return
+ nodes_to_delete = user_to_last_uses.get(user, [])
+ nodes_to_delete = [i for i in nodes_to_delete if i.name not in to_keep]
+ if len(nodes_to_delete):
+ to_delete_str = " = ".join([repr(n) for n in nodes_to_delete] + ["None"])
+ body.append(f"; {to_delete_str}\n")
+ else:
+ body.append("\n")
+
+ # NOTE: we add a variable to distinguish body and ckpt_func
+ def emit_node(node: Node, body):
+ maybe_type_annotation = ("" if node.type is None else f" : {type_repr(node.type)}")
+ if node.op == "placeholder":
+ assert isinstance(node.target, str)
+ maybe_default_arg = ("" if not node.args else f" = {repr(node.args[0])}")
+ free_vars.append(f"{node.target}{maybe_type_annotation}{maybe_default_arg}")
+ raw_name = node.target.replace("*", "")
+ if raw_name != repr(node):
+ body.append(f"{repr(node)} = {raw_name}\n")
+ return
+ elif node.op == "call_method":
+ assert isinstance(node.target, str)
+ body.append(
+ f"{repr(node)}{maybe_type_annotation} = {_format_target(repr(node.args[0]), node.target)}"
+ f"({_format_args(node.args[1:], node.kwargs)})")
+ return
+ elif node.op == "call_function":
+ assert callable(node.target)
+ # pretty print operators
+ if (node.target.__module__ == "_operator" and node.target.__name__ in magic_methods):
+ assert isinstance(node.args, tuple)
+ body.append(f"{repr(node)}{maybe_type_annotation} = "
+ f"{magic_methods[node.target.__name__].format(*(repr(a) for a in node.args))}")
+ return
+
+ # pretty print inplace operators; required for jit.script to work properly
+ # not currently supported in normal FX graphs, but generated by torchdynamo
+ if (node.target.__module__ == "_operator" and node.target.__name__ in inplace_methods):
+ body.append(f"{inplace_methods[node.target.__name__].format(*(repr(a) for a in node.args))}; "
+ f"{repr(node)}{maybe_type_annotation} = {repr(node.args[0])}")
+ return
+
+ qualified_name = _get_qualified_name(node.target)
+ global_name = add_global(qualified_name, node.target)
+ # special case for getattr: node.args could be 2-argument or 3-argument
+ # 2-argument: attribute access; 3-argument: fall through to attrib function call with default value
+ if (global_name == "getattr" and isinstance(node.args, tuple) and isinstance(node.args[1], str)
+ and node.args[1].isidentifier() and len(node.args) == 2):
+ body.append(
+ f"{repr(node)}{maybe_type_annotation} = {_format_target(repr(node.args[0]), node.args[1])}")
+ return
+ body.append(
+ f"{repr(node)}{maybe_type_annotation} = {global_name}({_format_args(node.args, node.kwargs)})")
+ if node.meta.get("is_wrapped", False):
+ wrapped_fns.setdefault(global_name)
+ return
+ elif node.op == "call_module":
+ assert isinstance(node.target, str)
+ body.append(f"{repr(node)}{maybe_type_annotation} = "
+ f"{_format_target(root_module, node.target)}({_format_args(node.args, node.kwargs)})")
+ return
+ elif node.op == "get_attr":
+ assert isinstance(node.target, str)
+ body.append(f"{repr(node)}{maybe_type_annotation} = {_format_target(root_module, node.target)}")
+ return
+ elif node.op == "output":
+ if node.type is not None:
+ maybe_return_annotation[0] = f" -> {type_repr(node.type)}"
+ body.append(self.generate_output(node.args[0]))
+ return
+ raise NotImplementedError(f"node: {node.op} {node.target}")
+
+ # Modified for activation checkpointing
+ ckpt_func = []
+
+ # if any node has a list of labels for activation_checkpoint, we
+ # will use nested type of activation checkpoint codegen
+ emit_code_with_chunk(body, nodes, emit_node, delete_unused_values, self.search_chunk, self.chunk_infos,
+ self.eval_mem)
+
+ if len(body) == 0:
+ # If the Graph has no non-placeholder nodes, no lines for the body
+ # have been emitted. To continue to have valid Python code, emit a
+ # single pass statement
+ body.append("pass\n")
+
+ if len(wrapped_fns) > 0:
+ wrap_name = add_global("wrap", torch.fx.wrap)
+ wrap_stmts = "\n".join([f'{wrap_name}("{name}")' for name in wrapped_fns])
+ else:
+ wrap_stmts = ""
+
+ if self._body_transformer:
+ body = self._body_transformer(body)
+
+ for name, value in self.additional_globals():
+ add_global(name, value)
+
+ # as we need colossalai.utils.checkpoint, we need to import colossalai
+ # in forward function
+ prologue = self.gen_fn_def(free_vars, maybe_return_annotation[0])
+ prologue = "".join(ckpt_func) + prologue
+ prologue = prologue
+
+ code = "".join(body)
+ code = "\n".join(" " + line for line in code.split("\n"))
+ fn_code = f"""
+{wrap_stmts}
+
+{prologue}
+{code}"""
+ # print(fn_code)
+ return PythonCode(fn_code, globals_)
diff --git a/colossalai/autochunk/estimate_memory.py b/colossalai/autochunk/estimate_memory.py
new file mode 100644
index 0000000000000000000000000000000000000000..77bc2ef17bc3bc5faca5903ddd4dfc5a7653275a
--- /dev/null
+++ b/colossalai/autochunk/estimate_memory.py
@@ -0,0 +1,240 @@
+import copy
+from typing import Any, Callable, Dict, Iterable, List, Tuple
+
+import torch
+from torch.fx.node import Node
+
+from colossalai.fx.profiler import activation_size, parameter_size
+
+from .utils import NodeMgr, get_node_shape, is_non_memory_node
+
+
+class EstimateMemory(object):
+ """
+ Estimate memory with chunk
+ """
+
+ def __init__(self) -> None:
+ pass
+
+ def _get_node_size(self, x: Node) -> float:
+ """
+ return node size in MB
+ """
+ x = x.meta["tensor_meta"]
+ if not hasattr(x, "numel"):
+ out = sum([i.numel * torch.tensor([], dtype=i.dtype).element_size() for i in x])
+ else:
+ out = x.numel * torch.tensor([], dtype=x.dtype).element_size()
+ out = float(out) / 1024**2
+ return out
+
+ def _add_active_node(self, n: Node, active_nodes: Dict, chunk_ratio: float) -> None:
+ """
+ add an active node and its shape to active node dict
+ """
+ if get_node_shape(n) is None:
+ return
+ if n.op == "placeholder":
+ return
+ if n not in active_nodes:
+ node_size = self._get_node_size(n) * chunk_ratio
+ active_nodes[n] = node_size
+
+ def _build_delete_node_dict(self, node_mgr: NodeMgr) -> Dict:
+ """
+ build delete node dict, means node should be deleted at what time
+ """
+ delete_node_dict = {}
+ for idx, node in enumerate(node_mgr.get_node_list()):
+ # skip non shape node
+ if get_node_shape(node) is None:
+ continue
+ # dont remove free nodes
+ elif node.op == "placeholder":
+ delete_node_dict[node] = len(node_mgr.get_node_list())
+ # node no user
+ elif len(node.users) == 0:
+ delete_node_dict[node] = idx
+ # log max use
+ else:
+ node_user_idx = [node_mgr.find_node_idx(i) for i in node.users.keys()]
+ delete_node_dict[node] = max(node_user_idx)
+ return delete_node_dict
+
+ def _remove_deactive_node(self,
+ user_idx: int,
+ user: Node,
+ active_nodes: List,
+ delete_node_dict: List,
+ kept_nodes: List = None) -> None:
+ """
+ remove deactivate nodes from active nodes
+ """
+ if kept_nodes is None:
+ kept_nodes = []
+ if user.op in ("output",):
+ return
+
+ for node in list(active_nodes.keys()):
+ # dont delete kept nodes
+ if node in kept_nodes:
+ continue
+ # should be deleted
+ if delete_node_dict[node] <= user_idx:
+ active_nodes.pop(node)
+
+ def _get_tmp_memory(self, node, not_contiguous_list, delete=False):
+ mem = 0
+ not_contiguous_ops = ["permute"]
+
+ if node.op == "call_function" and any(n in node.name for n in ["matmul", "reshape"]):
+ for n in node.args:
+ if n in not_contiguous_list:
+ # matmul won't change origin tensor, but create a tmp copy
+ mem += self._get_node_size(n)
+ elif node.op == "call_module":
+ for n in node.args:
+ if n in not_contiguous_list:
+ # module will just make origin tensor to contiguous
+ if delete:
+ not_contiguous_list.remove(n)
+ elif node.op == "call_method" and any(i in node.name for i in not_contiguous_ops):
+ if node not in not_contiguous_list:
+ not_contiguous_list.append(node)
+ return mem
+
+ def _get_chunk_ratio(self, node, chunk_node_dim, chunk_size):
+ if node not in chunk_node_dim:
+ return 1.0
+ node_shape = get_node_shape(node)
+ chunk_dim = chunk_node_dim[node]["chunk_dim"]
+ if chunk_dim is None:
+ return 1.0
+ else:
+ return chunk_size / float(node_shape[chunk_dim])
+
+ def _print_compute_op_mem_log(self, log, nodes, title=None):
+ if title:
+ print(title)
+ for idx, (l, n) in enumerate(zip(log, nodes)):
+ if n.op in ["placeholder", "get_attr", "output"]:
+ continue
+ if any(i in n.name for i in ["getitem", "getattr"]):
+ continue
+ print("%s:%.2f \t" % (n.name, l), end="")
+ if (idx + 1) % 3 == 0:
+ print("")
+ print("\n")
+
+ def _add_active_nodes_from_list(self, active_nodes: List, nodes: List) -> List:
+ """
+ add active nodes from nodes
+ """
+ for n in nodes:
+ self._add_active_node(n, active_nodes, 1)
+
+ def _get_memory_from_active_nodes(self, active_nodes: Dict) -> float:
+ """
+ sum all memory of active nodes
+ """
+ out = [i for i in active_nodes.values()]
+ out = sum(out)
+ return out
+
+ def estimate_chunk_inference_mem(self, node_list: List, chunk_infos: Dict = None, print_mem: bool = False):
+ """
+ Estimate inference memory with chunk
+
+ Args:
+ node_list (List): _description_
+ chunk_infos (Dict): Chunk information. Defaults to None.
+ print_mem (bool): Wether to print peak memory of every node. Defaults to False.
+
+ Returns:
+ act_memory_peak_log (List): peak memory of every node
+ act_memory_after_node_log (List): memory after executing every node
+ active_node_list_log (List): active nodes of every node. active nodes refer to
+ nodes generated but not deleted.
+ """
+ act_memory = 0.0
+ act_memory_peak_log = []
+ act_memory_after_node_log = []
+ active_nodes = {}
+ active_nodes_log = []
+ not_contiguous_list = []
+ node_mgr = NodeMgr(node_list)
+ delete_node_dict = self._build_delete_node_dict(node_mgr)
+
+ use_chunk = True if chunk_infos is not None else False
+ chunk_within = False
+ chunk_region_idx = None
+ chunk_ratio = 1 # use it to estimate chunk mem
+ chunk_inputs_all = []
+
+ if use_chunk:
+ chunk_regions = [i["region"] for i in chunk_infos]
+ chunk_starts = [i[0] for i in chunk_regions]
+ chunk_ends = [i[1] for i in chunk_regions]
+ chunk_inputs = [i["inputs"] for i in chunk_infos]
+ chunk_inputs_non_chunk = [i["inputs_non_chunk"] for i in chunk_infos]
+ chunk_inputs_all = [j for i in chunk_inputs for j in i] + [j for i in chunk_inputs_non_chunk for j in i]
+ chunk_outputs = [i["outputs"] for i in chunk_infos]
+ chunk_node_dim = [i["node_chunk_dim"] for i in chunk_infos]
+ chunk_sizes = [i["chunk_size"] if "chunk_size" in i else 1 for i in chunk_infos]
+
+ for idx, node in enumerate(node_mgr.get_node_list()):
+
+ # if node in chunk start nodes, change chunk ratio and add chunk_tensor
+ if use_chunk and idx in chunk_starts:
+ chunk_within = True
+ chunk_region_idx = chunk_starts.index(idx)
+ self._add_active_nodes_from_list(active_nodes, chunk_outputs[chunk_region_idx])
+
+ # determine chunk ratio for current node
+ if chunk_within:
+ chunk_ratio = self._get_chunk_ratio(node, chunk_node_dim[chunk_region_idx],
+ chunk_sizes[chunk_region_idx])
+
+ # add current node as active node
+ self._add_active_node(node, active_nodes, chunk_ratio)
+ act_memory = self._get_memory_from_active_nodes(active_nodes)
+
+ # if node is placeholder, just add the size of the node
+ if node.op == "placeholder":
+ act_memory_peak_log.append(act_memory)
+ # skip output
+ elif node.op == "output":
+ continue
+ # no change for non compute node
+ elif is_non_memory_node(node):
+ act_memory_peak_log.append(act_memory)
+ # node is a compute op, calculate tmp
+ else:
+ # forward memory
+ # TODO: contiguous_memory still not accurate for matmul, view, reshape and transpose
+ tmp_memory = self._get_tmp_memory(node, not_contiguous_list, delete=True) * chunk_ratio
+ # record max act memory
+ act_memory_peak_log.append(act_memory + tmp_memory)
+
+ # remove_deactive_node
+ self._remove_deactive_node(idx, node, active_nodes, delete_node_dict, kept_nodes=chunk_inputs_all)
+
+ # if node in chunk end nodes, restore chunk settings
+ if use_chunk and idx in chunk_ends:
+ self._remove_deactive_node(idx, node, active_nodes, delete_node_dict) # dont provide kept nodes now
+ chunk_within = False
+ chunk_ratio = 1
+ chunk_region_idx = None
+
+ act_memory = self._get_memory_from_active_nodes(active_nodes)
+ act_memory_after_node_log.append(act_memory)
+ active_nodes_log.append(active_nodes.copy())
+
+ if print_mem:
+ print("with chunk" if use_chunk else "without chunk")
+ self._print_compute_op_mem_log(act_memory_peak_log, node_mgr.get_node_list(), "peak")
+
+ # param_memory = parameter_size(gm)
+ # all_memory = act_memory + param_memory
+ return act_memory_peak_log, act_memory_after_node_log, active_nodes_log
diff --git a/colossalai/autochunk/reorder_graph.py b/colossalai/autochunk/reorder_graph.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b00d47fb9555f0187d8bd290ecb74f78fd94f50
--- /dev/null
+++ b/colossalai/autochunk/reorder_graph.py
@@ -0,0 +1,111 @@
+from .trace_indice import TraceIndice
+from .utils import NodeMgr
+
+
+class ReorderGraph(object):
+ """
+ Reorder node list and indice trace list
+ """
+
+ def __init__(self, trace_indice: TraceIndice, node_mgr: NodeMgr) -> None:
+ self.trace_indice = trace_indice
+ self.node_mgr = node_mgr
+ self.all_reorder_map = {i: i for i in range(len(self.node_mgr.get_node_list()))}
+
+ def _get_reorder_map(self, chunk_info):
+ reorder_map = {i: i for i in range(len(self.node_mgr.get_node_list()))}
+
+ chunk_region_start = chunk_info["region"][0]
+ chunk_region_end = chunk_info["region"][1]
+ chunk_prepose_nodes = chunk_info["args"]["prepose_nodes"]
+ chunk_prepose_nodes_idx = [self.node_mgr.find_node_idx(i) for i in chunk_prepose_nodes]
+ # put prepose nodes ahead
+ for idx, n in enumerate(chunk_prepose_nodes):
+ n_idx = chunk_prepose_nodes_idx[idx]
+ reorder_map[n_idx] = chunk_region_start + idx
+ # put other nodes after prepose nodes
+ for n in self.node_mgr.get_node_slice_by_idx(chunk_region_start, chunk_region_end + 1):
+ if n in chunk_prepose_nodes:
+ continue
+ n_idx = self.node_mgr.find_node_idx(n)
+ pos = sum([n_idx < i for i in chunk_prepose_nodes_idx])
+ reorder_map[n_idx] = n_idx + pos
+
+ return reorder_map
+
+ def _reorder_chunk_info(self, chunk_info, reorder_map):
+ # update chunk info
+ chunk_info["region"] = (
+ chunk_info["region"][0] + len(chunk_info["args"]["prepose_nodes"]),
+ chunk_info["region"][1],
+ )
+ new_inputs_dim = []
+ for _, input_dim in enumerate(chunk_info["inputs_dim"]):
+ new_input_dim = {}
+ for k, v in input_dim.items():
+ new_input_dim[reorder_map[k]] = v
+ new_inputs_dim.append(new_input_dim)
+ chunk_info["inputs_dim"] = new_inputs_dim
+ return chunk_info
+
+ def _update_all_reorder_map(self, reorder_map):
+ for origin_idx, map_idx in self.all_reorder_map.items():
+ self.all_reorder_map[origin_idx] = reorder_map[map_idx]
+
+ def _reorder_self_node_list(self, reorder_map):
+ new_node_list = [None for _ in range(len(self.node_mgr.get_node_list()))]
+ for old_idx, new_idx in reorder_map.items():
+ new_node_list[new_idx] = self.node_mgr.get_node_by_idx(old_idx)
+ self.node_mgr.update_node_list(new_node_list)
+
+ def _reorder_idx_trace(self, reorder_map):
+ # reorder list
+ new_idx_trace_list = [None for _ in range(len(self.trace_indice.indice_trace_list))]
+ for old_idx, new_idx in reorder_map.items():
+ new_idx_trace_list[new_idx] = self.trace_indice.indice_trace_list[old_idx]
+ self.trace_indice.indice_trace_list = new_idx_trace_list
+ # update compute
+ for idx_trace in self.trace_indice.indice_trace_list:
+ compute = idx_trace["compute"]
+ for dim_compute in compute:
+ for idx, i in enumerate(dim_compute):
+ dim_compute[idx] = reorder_map[i]
+ # update source
+ for idx_trace in self.trace_indice.indice_trace_list:
+ source = idx_trace["source"]
+ for dim_idx, dim_source in enumerate(source):
+ new_dim_source = {}
+ for k, v in dim_source.items():
+ new_dim_source[reorder_map[k]] = v
+ source[dim_idx] = new_dim_source
+
+ def reorder_all(self, chunk_info):
+ if chunk_info is None:
+ return chunk_info
+ if len(chunk_info["args"]["prepose_nodes"]) == 0:
+ return chunk_info
+ reorder_map = self._get_reorder_map(chunk_info)
+ self._update_all_reorder_map(reorder_map)
+ self._reorder_idx_trace(reorder_map)
+ self._reorder_self_node_list(reorder_map)
+ chunk_info = self._reorder_chunk_info(chunk_info, reorder_map)
+ return chunk_info
+
+ def reorder_node_list(self, node_list):
+ new_node_list = [None for _ in range(len(node_list))]
+ for old_idx, new_idx in self.all_reorder_map.items():
+ new_node_list[new_idx] = node_list[old_idx]
+ return new_node_list
+
+ def tmp_reorder(self, node_list, chunk_info):
+ if len(chunk_info["args"]["prepose_nodes"]) == 0:
+ return node_list, chunk_info
+ reorder_map = self._get_reorder_map(chunk_info)
+
+ # new tmp node list
+ new_node_list = [None for _ in range(len(node_list))]
+ for old_idx, new_idx in reorder_map.items():
+ new_node_list[new_idx] = node_list[old_idx]
+
+ chunk_info = self._reorder_chunk_info(chunk_info, reorder_map)
+ return new_node_list, chunk_info
diff --git a/colossalai/autochunk/search_chunk.py b/colossalai/autochunk/search_chunk.py
new file mode 100644
index 0000000000000000000000000000000000000000..59645c80e8089d63a53abd8a27c7784f2f90cd8d
--- /dev/null
+++ b/colossalai/autochunk/search_chunk.py
@@ -0,0 +1,293 @@
+import copy
+from typing import Dict, List, Tuple
+
+from torch.fx.node import Node
+
+from .estimate_memory import EstimateMemory
+from .reorder_graph import ReorderGraph
+from .select_chunk import SelectChunk
+from .trace_flow import TraceFlow
+from .trace_indice import TraceIndice
+from .utils import NodeMgr, get_logger, get_node_shape, is_non_compute_node, is_non_compute_node_except_placeholder
+
+
+class SearchChunk(object):
+ """
+ This is the core class for AutoChunk.
+
+ It defines the framework of the strategy of AutoChunk.
+ Chunks will be selected one by one until search stops.
+
+ The chunk search is as follows:
+ 1. find the peak memory node
+ 2. find the max chunk region according to the peak memory node
+ 3. find all possible chunk regions in the max chunk region
+ 4. find the best chunk region for current status
+ 5. goto 1
+
+ Attributes:
+ gm: graph model
+ print_mem (bool): print estimated memory
+ trace_index: trace the flow of every dim of every node to find all free dims
+ trace_flow: determine the region chunk strategy
+ reorder_graph: reorder nodes to improve chunk efficiency
+ estimate_memory: estimate memory with chunk
+ select_chunk: select the best chunk region
+
+ Args:
+ gm: graph model
+ max_memory (int): max memory in MB
+ print_mem (bool): print estimated memory
+ """
+
+ def __init__(self, gm, max_memory=None, print_mem=False, print_progress=False) -> None:
+ self.print_mem = print_mem
+ self.max_memory = max_memory
+ self.print_progress = print_progress
+ self.node_mgr = NodeMgr(list(gm.graph.nodes))
+ self.trace_indice = TraceIndice(self.node_mgr)
+ self.estimate_memory = EstimateMemory()
+ self._init_trace()
+ self.trace_flow = TraceFlow(self.trace_indice, self.node_mgr)
+ self.reorder_graph = ReorderGraph(self.trace_indice, self.node_mgr)
+ self.select_chunk = SelectChunk(
+ self.trace_indice,
+ self.estimate_memory,
+ self.reorder_graph,
+ self.node_mgr,
+ max_memory=max_memory,
+ )
+
+ def _init_trace(self) -> None:
+ """
+ find the max trace range for every node
+ reduce the computation complexity of trace_indice
+ """
+ # find all max ranges
+ active_nodes = self.estimate_memory.estimate_chunk_inference_mem(self.node_mgr.get_node_list())[2]
+ # set trace range and do the trace
+ if self.print_progress:
+ get_logger().info("AutoChunk start tracing indice")
+ self.trace_indice.set_active_nodes(active_nodes)
+ self.trace_indice.trace_indice()
+
+ def _find_peak_region(self, mem_peak: List) -> int:
+ """
+ find peak node, along with its neighbor nodes exceeds max mem
+ """
+ max_value = max(mem_peak)
+ max_idx = mem_peak.index(max_value)
+ peak_region = [max_idx, max_idx]
+ if self.max_memory is None:
+ return peak_region
+
+ # to left
+ count = 0
+ for i in range(max_idx - 1, -1, -1):
+ if mem_peak[i] > self.max_memory:
+ peak_region[0] = i
+ else:
+ count += 1
+ if count >= 3:
+ break
+ # to right
+ count = 0
+ for i in range(max_idx + 1, len(mem_peak) - 1):
+ if mem_peak[i] > self.max_memory:
+ peak_region[1] = i
+ count = 0
+ else:
+ count += 1
+ if count >= 3:
+ break
+
+ return peak_region
+
+ def _search_max_chunk_region(self, active_node: List, peak_region: int, chunk_regions: List = None) -> Tuple:
+ """
+ Search max chunk region according to peak memory node
+
+ Chunk region starts extending from the peak node, stops where free var num is min
+
+ Args:
+ active_node (List): active node status for every node
+ peak_node_idx (int): peak memory node idx
+ chunk_regions (List): chunk region infos
+
+ Returns:
+ chunk_region_start (int)
+ chunk_region_end (int)
+ """
+ # check if peak node already in chunk info
+ if chunk_regions is not None:
+ for i in chunk_regions:
+ if i["region"][0] < peak_region[0] <= i["region"][1] or \
+ i["region"][0] < peak_region[1] <= i["region"][1]:
+ return None
+
+ active_node_num = [len(i) for i in active_node]
+ window_size = 100
+ # search min for start
+ min_num = 1e4
+ for i in range(peak_region[0], max(peak_region[0] - window_size, -1), -1):
+ if active_node_num[i] < min_num:
+ min_num = active_node_num[i]
+ chunk_region_start = i
+ # search min for end
+ min_num = 1e4
+ for i in range(peak_region[1], min(peak_region[1] + window_size, len(active_node_num))):
+ if active_node_num[i] < min_num:
+ min_num = active_node_num[i]
+ chunk_region_end = i
+
+ # avoid chunk regions overlap
+ if chunk_regions is not None:
+ for i in chunk_regions:
+ region = i["region"]
+ if chunk_region_start >= region[0] and chunk_region_end <= region[1]:
+ return None
+ elif (region[0] <= chunk_region_start <= region[1] and chunk_region_end > region[1]):
+ chunk_region_start = region[1] + 1
+ elif (region[0] <= chunk_region_end <= region[1] and chunk_region_start < region[0]):
+ chunk_region_end = region[0] - 1
+ return chunk_region_start, chunk_region_end
+
+ def _find_chunk_info(self, input_trace, output_trace, start_idx, end_idx) -> List:
+ """
+ Find chunk info for a region.
+
+ We are given the region start and region end, and need to find out all chunk info for it.
+ We first loop every dim of start node and end node, to see if we can find dim pair,
+ which is linked in a flow and not computed.
+ If found, we then search flow in the whole region to find out all chunk infos.
+
+ Args:
+ input_trace (List): node's input trace in region
+ output_trace (List): node's output trace in region
+ start_idx (int): region start node index
+ end_idx (int): region end node index
+
+ Returns:
+ chunk_infos: possible regions found
+ """
+ start_traces = input_trace[start_idx]
+ if len(start_traces) > 1: # TODO need to be removed
+ return []
+ end_trace = output_trace[end_idx]
+ end_node = self.node_mgr.get_node_by_idx(end_idx)
+
+ chunk_infos = []
+ for end_dim, _ in enumerate(end_trace["indice"]):
+ for start_node, start_trace in start_traces.items():
+ for start_dim, _ in enumerate(start_trace["indice"]):
+ if not self.trace_flow.check_region_start_end(start_node, start_dim, start_idx, end_node, end_dim,
+ end_idx):
+ continue
+ # flow search
+ chunk_info = self.trace_flow.flow_search(start_idx, start_dim, end_idx, end_dim)
+ if chunk_info is None:
+ continue
+ chunk_infos.append(chunk_info)
+ return chunk_infos
+
+ def _search_possible_chunk_regions(self, max_chunk_region: Tuple, peak_region: Node) -> List:
+ """
+ Search every possible region within the max chunk region.
+
+ Args:
+ max_chunk_region (Tuple)
+ peak_node (Node): peak memory node
+
+ Returns:
+ possible_chunk_region (List)
+ """
+ possible_chunk_region = []
+ output_trace = copy.deepcopy(self.trace_indice.indice_trace_list)
+ input_trace = [] # trace of a node's input nodes
+ for _, n in enumerate(self.node_mgr.get_node_list()):
+ cur_trace = {}
+ for arg in n.args:
+ if type(arg) == type(n) and not is_non_compute_node_except_placeholder(arg):
+ cur_trace[arg] = self.trace_indice._find_trace_from_node(arg)
+ input_trace.append(cur_trace)
+
+ for start_idx in range(max_chunk_region[0], peak_region[0] + 1):
+ for end_idx in range(peak_region[1], max_chunk_region[1] + 1):
+ # skip non compute nodes
+ if is_non_compute_node(self.node_mgr.get_node_by_idx(start_idx)) or is_non_compute_node(
+ self.node_mgr.get_node_by_idx(end_idx)):
+ continue
+ # select free dim
+ chunk_info = self._find_chunk_info(input_trace, output_trace, start_idx, end_idx)
+ if len(chunk_info) > 0:
+ possible_chunk_region.extend(chunk_info)
+ return possible_chunk_region
+
+ def _step_search(
+ self,
+ mem_peak: List[float],
+ active_node: List[List[Node]],
+ chunk_infos: List[Dict],
+ ) -> Dict:
+ """
+ Find one chunk region
+
+ The chunk search is as follows:
+ 1. find the peak memory node
+ 2. find the max chunk region according to the peak memory node
+ 3. find all possible chunk regions in the max chunk region
+ 4. find the best chunk region for current status
+
+ Args:
+ mem_peak (List): peak memory for every node
+ active_node (List[List[Node]]): active node for every node
+ chunk_infos (List[Dict]): all chunk info
+
+ Returns:
+ best_chunk_region (Dict)
+ """
+ peak_region = self._find_peak_region(mem_peak)
+ max_chunk_region = self._search_max_chunk_region(active_node, peak_region, chunk_infos)
+ if max_chunk_region == None:
+ return None
+ possible_chunk_regions = self._search_possible_chunk_regions(max_chunk_region, peak_region)
+ best_chunk_region = self.select_chunk._select_best_chunk_region(possible_chunk_regions, chunk_infos, mem_peak)
+ best_chunk_region = self.reorder_graph.reorder_all(best_chunk_region)
+ return best_chunk_region
+
+ def search_region(self) -> Dict:
+ """
+ Search all chunk regions:
+ 1. Estimate current memory
+ 2. Find best chunk for current memory
+ 3. goto 1
+
+ Returns:
+ chunk_infos (Dict)
+ """
+ if self.print_progress:
+ get_logger().info("AutoChunk start searching chunk regions")
+
+ chunk_infos = []
+ init_mem_peak, _, active_node = self.estimate_memory.estimate_chunk_inference_mem(self.node_mgr.get_node_list())
+ mem_peak = init_mem_peak
+
+ while True:
+ chunk_info = self._step_search(mem_peak, active_node, chunk_infos)
+ if chunk_info is None:
+ break
+ chunk_infos.append(chunk_info)
+
+ mem_peak, _, active_node = self.estimate_memory.estimate_chunk_inference_mem(
+ self.node_mgr.get_node_list(), chunk_infos)
+
+ if self.print_progress:
+ get_logger().info("AutoChunk find chunk region %d = (%d, %d)" %
+ (len(chunk_infos), chunk_info["region"][0], chunk_info["region"][1]))
+
+ if self.print_mem:
+ self.print_mem = False
+ self.estimate_memory.estimate_chunk_inference_mem(self.node_mgr.get_node_list(),
+ chunk_infos,
+ print_mem=True)
+ return chunk_infos
diff --git a/colossalai/autochunk/select_chunk.py b/colossalai/autochunk/select_chunk.py
new file mode 100644
index 0000000000000000000000000000000000000000..94a29bfd56911eb9df749f284ae64fbd1b5d7a18
--- /dev/null
+++ b/colossalai/autochunk/select_chunk.py
@@ -0,0 +1,181 @@
+from .estimate_memory import EstimateMemory
+from .reorder_graph import ReorderGraph
+from .trace_indice import TraceIndice
+from .utils import NodeMgr, is_non_compute_node
+
+
+class SelectChunk(object):
+
+ def __init__(
+ self,
+ trace_indice: TraceIndice,
+ estimate_memory: EstimateMemory,
+ reorder_graph: ReorderGraph,
+ node_mgr: NodeMgr,
+ max_memory=None,
+ ):
+ self.trace_indice = trace_indice
+ self.estimate_memory = estimate_memory
+ self.reorder_graph = reorder_graph
+ self.node_mgr = node_mgr
+ if max_memory is not None:
+ self.stratge = "fit_memory"
+ self.max_memory = max_memory # MB
+ else:
+ self.stratge = "min_memory"
+
+ def _select_best_chunk_region(self, possible_chunk_regions, chunk_infos, mem_peak):
+ if self.stratge == "min_memory":
+ best_region = self._select_min_memory_chunk_region(possible_chunk_regions, chunk_infos)
+ elif self.stratge == "fit_memory":
+ best_region = self._select_fit_memory_chunk_region(possible_chunk_regions, chunk_infos, mem_peak)
+ else:
+ raise RuntimeError()
+ return best_region
+
+ def _select_fit_memory_chunk_region(self, possible_chunk_regions, chunk_infos, mem_peak):
+ # stop chunk if max memory satisfy memory limit
+ if max(mem_peak) < self.max_memory:
+ return None
+
+ # remove illegal regions
+ illegal_regions = []
+ for i in possible_chunk_regions:
+ if not self._is_legal_region(i, chunk_infos):
+ illegal_regions.append(i)
+ for i in illegal_regions:
+ if i in possible_chunk_regions:
+ possible_chunk_regions.remove(i)
+
+ if len(possible_chunk_regions) == 0:
+ return None
+
+ # get mem for chunk region
+ regions_dict = []
+ for region in possible_chunk_regions:
+ cur_region = region.copy()
+ cur_node_list, cur_region = self.reorder_graph.tmp_reorder(self.node_mgr.get_node_list(), cur_region)
+ cur_chunk_infos = chunk_infos + [cur_region]
+ cur_mem = self.estimate_memory.estimate_chunk_inference_mem(cur_node_list, cur_chunk_infos)[0]
+ cur_chunk_region_peak = cur_mem[cur_region["region"][0]:cur_region["region"][1] + 1]
+ cur_chunk_region_max_peak = max(cur_chunk_region_peak)
+ if cur_chunk_region_max_peak < self.max_memory:
+ regions_dict.append({
+ "chunk_info": region,
+ "chunk_max_mem": cur_chunk_region_max_peak,
+ "chunk_len": self._get_compute_node_num(region["region"][0], region["region"][1]),
+ "reorder_chunk_info": cur_region,
+ "reorder_node_list": cur_node_list,
+ })
+ # no region found
+ if len(regions_dict) == 0:
+ raise RuntimeError("Search failed. Try a larger memory threshold.")
+
+ # select the min chunk len
+ chunk_len = [i["chunk_len"] for i in regions_dict]
+ best_region_idx = chunk_len.index(min(chunk_len))
+ best_region = regions_dict[best_region_idx]
+
+ # get max chunk size
+ best_region = self._get_fit_chunk_size(best_region, chunk_infos)
+ return best_region
+
+ def _get_fit_chunk_size(self, chunk_region_dict, chunk_infos):
+ chunk_size = 1
+ reorder_chunk_info = chunk_region_dict["reorder_chunk_info"]
+ reorder_chunk_info["chunk_size"] = chunk_size
+ cur_chunk_max_mem = 0
+ # search a region
+ while cur_chunk_max_mem < self.max_memory:
+ chunk_size *= 2
+ reorder_chunk_info["chunk_size"] = chunk_size
+ cur_chunk_infos = chunk_infos + [reorder_chunk_info]
+ cur_mem_peak = self.estimate_memory.estimate_chunk_inference_mem(chunk_region_dict["reorder_node_list"],
+ cur_chunk_infos)[0]
+ cur_chunk_max_mem = max(cur_mem_peak[reorder_chunk_info["region"][0]:reorder_chunk_info["region"][1] + 1])
+ # search exact size
+ chunk_info = chunk_region_dict["chunk_info"]
+ chunk_info["chunk_size"] = self._chunk_size_binary_search(chunk_size // 2, chunk_size, chunk_region_dict,
+ chunk_infos)
+ return chunk_info
+
+ def _chunk_size_binary_search(self, left, right, chunk_region_dict, chunk_infos):
+ if left >= 16:
+ gap = 4
+ else:
+ gap = 1
+ chunk_info = chunk_region_dict["reorder_chunk_info"]
+ while right >= left + gap:
+ mid = int((left + right) / 2 + 0.5)
+ chunk_info["chunk_size"] = mid
+ cur_chunk_infos = chunk_infos + [chunk_info]
+ cur_mem_peak = self.estimate_memory.estimate_chunk_inference_mem(chunk_region_dict["reorder_node_list"],
+ cur_chunk_infos)[0]
+ cur_chunk_max_mem = max(cur_mem_peak[chunk_info["region"][0]:chunk_info["region"][1] + 1])
+ if cur_chunk_max_mem >= self.max_memory:
+ right = mid - gap
+ else:
+ left = mid + gap
+ return left
+
+ def _get_compute_node_num(self, start, end):
+ count = 0
+ for i in self.node_mgr.get_node_slice_by_idx(start, end + 1):
+ if not is_non_compute_node(i):
+ count += 1
+ return count
+
+ def _select_min_memory_chunk_region(self, possible_chunk_regions, chunk_infos):
+ # remove illegal regions
+ illegal_regions = []
+ for i in possible_chunk_regions:
+ if not self._is_legal_region(i, chunk_infos):
+ illegal_regions.append(i)
+ for i in illegal_regions:
+ if i in possible_chunk_regions:
+ possible_chunk_regions.remove(i)
+
+ if len(possible_chunk_regions) == 0:
+ return None
+
+ # get max possible chunk region
+ max_possible_chunk_region = (min([i["region"][0] for i in possible_chunk_regions]),
+ max([i["region"][1] for i in possible_chunk_regions]))
+
+ # get mem for chunk region
+ regions_dict_list = []
+ for region in possible_chunk_regions:
+ cur_region = region.copy()
+ cur_node_list, cur_region = self.reorder_graph.tmp_reorder(self.node_mgr.get_node_list(), cur_region)
+ cur_chunk_infos = chunk_infos + [cur_region]
+ cur_mem_peak = self.estimate_memory.estimate_chunk_inference_mem(cur_node_list, cur_chunk_infos)[0]
+ cur_chunk_region_peak = cur_mem_peak[max_possible_chunk_region[0]:max_possible_chunk_region[1] + 1]
+ cur_chunk_region_max_peak = max(cur_chunk_region_peak)
+ regions_dict_list.append({
+ "chunk_info": region,
+ "chunk_max_mem": cur_chunk_region_max_peak,
+ "chunk_len": self._get_compute_node_num(region["region"][0], region["region"][1]),
+ "reorder_chunk_info": cur_region,
+ "reorder_node_list": cur_node_list,
+ })
+
+ # select the min mem
+ chunk_max_mem = [i["chunk_max_mem"] for i in regions_dict_list]
+ best_region_idx = chunk_max_mem.index(min(chunk_max_mem))
+ best_region = regions_dict_list[best_region_idx]["chunk_info"]
+ if best_region is not None:
+ best_region["chunk_size"] = 1
+ return best_region
+
+ def _is_legal_region(self, cur_chunk_info, chunk_infos):
+ (chunk_region_start, chunk_region_end) = cur_chunk_info["region"]
+ if cur_chunk_info in chunk_infos:
+ return False
+ if chunk_region_end < chunk_region_start:
+ return False
+ for i in chunk_infos:
+ region = i["region"]
+ if not ((chunk_region_start > region[1] and chunk_region_end > region[1]) or
+ (chunk_region_start < region[0] and chunk_region_end < region[0])):
+ return False
+ return True
diff --git a/colossalai/autochunk/trace_flow.py b/colossalai/autochunk/trace_flow.py
new file mode 100644
index 0000000000000000000000000000000000000000..db25267e9b4200414c3cb89afaacd529a1534e06
--- /dev/null
+++ b/colossalai/autochunk/trace_flow.py
@@ -0,0 +1,485 @@
+from typing import Dict, List, Tuple
+
+from torch.fx.node import Node
+
+from .trace_indice import TraceIndice
+from .utils import (
+ NodeMgr,
+ find_chunk_all_input_nodes,
+ find_chunk_compute_input_and_output_nodes,
+ find_tensor_shape_node,
+ flat_list,
+ get_node_name,
+ get_node_shape,
+ is_non_compute_node,
+)
+
+
+class TraceFlow(object):
+
+ def __init__(self, trace_indice: TraceIndice, node_mgr: NodeMgr) -> None:
+ self.trace_indice = trace_indice
+ self.node_mgr = node_mgr
+
+ def check_index_source(self, start_dim, start_node, start_idx, end_dim, end_node):
+ """
+ Check 2 given index: one index should be source of the other
+ Args:
+ start_idx(int): start node chunk dim
+ start_node(node): start node
+ end_idx(int): end node chunk dim
+ end_node(node): end node
+
+ Returns:
+ bool: True if check pass
+ """
+ # we use start_node_idx instead of real chunk index
+ start_node_idx = self.node_mgr.find_node_idx(start_node)
+ end_node_trace = self.trace_indice._find_trace_from_node(end_node)
+ end_node_trace_source = end_node_trace["source"][end_dim]
+ sorted_source = sorted(end_node_trace_source.items(), key=lambda d: d[0], reverse=True)
+ for node_idx, node_dim in sorted_source:
+ if node_idx == start_node_idx and start_dim in node_dim:
+ return True
+ # it means we meet a node outside the loop, and the node is not input node
+ if node_idx < start_node_idx:
+ return False
+ return False
+
+ def check_index_compute(self, start_idx, end_dim, end_node, end_idx):
+ """
+ Check 2 given index: check they haven't been computed in the source trace.
+ Args:
+ start_idx(int): start node chunk dim
+ start_node(node): start node
+ end_idx(int): end node chunk dim
+ end_node(node): end node
+
+ Returns:
+ bool: True if check pass
+ """
+ end_node_trace = self.trace_indice._find_trace_from_node(end_node)
+ end_node_compute = end_node_trace["compute"][end_dim]
+ if any(start_idx <= i <= end_idx for i in end_node_compute):
+ return False
+ return True
+
+ def _assgin_single_node_flow(
+ self,
+ arg_node: Node,
+ start_idx: int,
+ end_idx: int,
+ cur_node: Node,
+ cur_node_dim: int,
+ cur_node_compute: Dict,
+ cur_node_source: Dict,
+ cur_node_fix_dim: List,
+ all_node_info: Dict,
+ next_node_list: List,
+ ) -> bool:
+ """
+ Given the current node and one of its arg node,
+ this function finds out arg node's chunk dim and fix dim
+
+ Args:
+ arg_node (Node): input node
+ start_idx (int): chunk region start
+ end_idx (int): chunk region end
+ cur_node_dim (int): current node chunk dim
+ cur_node_compute (Dict): current node compute dict
+ cur_node_source (Dict): current node source dict
+ cur_node_fix_dim (List): current node fix dim
+ all_node_info (Dict): all node chunk info in the chunk region
+ next_node_list (List)
+
+ Returns:
+ bool: True if this node can be added to the flow, vice versa.
+ """
+ arg_idx = self.node_mgr.find_node_idx(arg_node)
+ # arg in chunk range or be inputs
+ if not (start_idx <= arg_idx < end_idx):
+ return True
+
+ # get fix dim
+ arg_fix_dim = []
+ if cur_node_dim is not None:
+ for i in cur_node_fix_dim:
+ fix_dim_source = cur_node_source[i]
+ if arg_idx in fix_dim_source:
+ arg_fix_dim.append(fix_dim_source[arg_idx][0])
+ if arg_node in all_node_info:
+ arg_fix_dim = list(set(all_node_info[arg_node]["fix_dim"] + arg_fix_dim))
+
+ # find arg dim
+ if cur_node_dim is not None:
+ # dim is computed
+ if arg_idx in cur_node_compute[cur_node_dim]:
+ return False
+ if arg_idx not in cur_node_source[cur_node_dim]:
+ arg_dim = None
+ else:
+ arg_dim = cur_node_source[cur_node_dim][arg_idx][0]
+ # chunk dim cannot be in fix dims
+ if arg_dim in arg_fix_dim:
+ return False
+ # chunk dim should be None if shape size is 1
+ if get_node_shape(arg_node)[arg_dim] == 1:
+ arg_dim = None
+ # chunk shape should equal cur node
+ elif get_node_shape(arg_node)[arg_dim] != 1:
+ if cur_node_dim is not None and get_node_shape(cur_node)[cur_node_dim] != 1:
+ if get_node_shape(arg_node)[arg_dim] != get_node_shape(cur_node)[cur_node_dim]:
+ return False
+ else:
+ arg_dim = None
+
+ # add arg rest dim as fix dim
+ arg_fix_dim = list(range(len(get_node_shape(arg_node))))
+ if arg_dim is not None:
+ arg_fix_dim.remove(arg_dim)
+
+ # if already in node_info, arg dim must be same
+ if arg_node in all_node_info:
+ if all_node_info[arg_node]["chunk_dim"] != arg_dim:
+ return False
+ all_node_info[arg_node]["fix_dim"] = arg_fix_dim
+ # else add it to list
+ else:
+ all_node_info[arg_node] = {"chunk_dim": arg_dim, "fix_dim": arg_fix_dim}
+
+ next_node_list.append(arg_node)
+ return True
+
+ def _get_all_node_info(self, end_dim, start_idx, end_idx):
+ cur_node_list = [self.node_mgr.get_node_by_idx(end_idx)] # start from the last node
+ all_node_info = {cur_node_list[0]: {"chunk_dim": end_dim, "fix_dim": []}}
+
+ while len(cur_node_list) > 0:
+ next_node_list = []
+
+ for cur_node in cur_node_list:
+ # get cur node info
+ cur_node_chunk_dim = all_node_info[cur_node]["chunk_dim"]
+ cur_node_fix_dim = all_node_info[cur_node]["fix_dim"]
+ if cur_node_chunk_dim is not None:
+ cur_node_compute = self.trace_indice._find_compute_trace_from_node(cur_node)
+ cur_node_source = self.trace_indice._find_source_trace_from_node(cur_node)
+ else:
+ cur_node_compute = cur_node_source = None
+
+ # get all valid args
+ arg_list = []
+ for arg in cur_node.all_input_nodes:
+ if type(arg) != type(cur_node):
+ continue
+ if is_non_compute_node(arg):
+ continue
+ if get_node_shape(arg) is None:
+ continue
+ arg_list.append(arg)
+ flow_flag = self._assgin_single_node_flow(
+ arg,
+ start_idx,
+ end_idx,
+ cur_node,
+ cur_node_chunk_dim,
+ cur_node_compute,
+ cur_node_source,
+ cur_node_fix_dim,
+ all_node_info,
+ next_node_list,
+ )
+ if flow_flag == False:
+ return None
+
+ cur_node_list = next_node_list
+ return all_node_info
+
+ def _get_input_nodes_dim(self, inputs: List[Node], start_idx: int, end_idx: int, all_node_info: Dict) -> Tuple:
+ """
+ Get chunk dim for every input node for their every entry, remove unchunked nodes
+
+ Args:
+ inputs (List[Node]): input nodes
+ all_node_info (Dict): describe all node's chunk dim and fix dim
+ start_idx (int): chunk start idx
+ end_idx (int): chunk end idx
+
+ Returns:
+ inputs (List(Node)): new inputs
+ inputs_dim (List): chunk dim for inputs
+ """
+ inputs_dim = []
+ remove_inputs = []
+ for input_node in inputs:
+ input_dict = {}
+ input_node_idx = self.node_mgr.find_node_idx(input_node)
+ for user in input_node.users.keys():
+ # skip non compute
+ if is_non_compute_node(user):
+ continue
+ # untraced node, mostly non compute
+ if user not in all_node_info:
+ continue
+ user_idx = self.node_mgr.find_node_idx(user)
+ if start_idx <= user_idx <= end_idx:
+ chunk_dim = all_node_info[user]["chunk_dim"]
+ if chunk_dim is not None:
+ user_source = self.trace_indice._find_source_trace_from_node(user)[chunk_dim]
+ if input_node_idx in user_source:
+ if get_node_shape(input_node)[user_source[input_node_idx][0]] == 1:
+ input_dict[user_idx] = [None]
+ else:
+ input_dict[user_idx] = user_source[input_node_idx]
+ else:
+ return None, None
+ if len(input_dict) == 0:
+ remove_inputs.append(input_node)
+ else:
+ inputs_dim.append(input_dict)
+ # remove unchunked inputs
+ for i in remove_inputs:
+ if i in inputs:
+ inputs.remove(i)
+ return inputs, inputs_dim
+
+ def _get_prepose_nodes(self, all_node_info: Dict, start_idx: int, end_idx: int, chunk_info) -> List[Node]:
+ """
+ get all useless nodes in chunk region and prepose them
+
+ Args:
+ all_node_info (Dict): describe all node's chunk dim and fix dim
+ start_idx (int): chunk start idx
+ end_idx (int): chunk end idx
+
+ Returns:
+ List[Node]: all nodes to be preposed
+ """
+ # get all possible prepose nodes
+ maybe_prepose_nodes = []
+ for node, node_info in all_node_info.items():
+ if node_info["chunk_dim"] is None:
+ maybe_prepose_nodes.append(node)
+ for node in self.node_mgr.get_node_slice_by_idx(start_idx, end_idx):
+ if node not in all_node_info and node not in chunk_info["outputs"]:
+ maybe_prepose_nodes.append(node)
+ maybe_prepose_nodes.sort(
+ key=lambda x: self.node_mgr.find_node_idx(x),
+ reverse=True,
+ ) # from last node to first node
+ prepose_nodes = []
+ # set every node as root, search its args, if all legal, turn root and args as prepose nodes
+ while len(maybe_prepose_nodes) > 0:
+ tmp_cur_prepose_nodes = [maybe_prepose_nodes[0]]
+ tmp_cur_related_prepose_nodes = []
+ prepose_flag = True
+
+ # loop cur node's all arg until out of chunk
+ while len(tmp_cur_prepose_nodes) > 0:
+ if prepose_flag == False:
+ break
+ tmp_next_prepose_nodes = []
+ tmp_cur_related_prepose_nodes.extend(tmp_cur_prepose_nodes)
+ for cur_prepose_node in tmp_cur_prepose_nodes:
+ if prepose_flag == False:
+ break
+ for cur_prepose_node_arg in cur_prepose_node.all_input_nodes:
+ if type(cur_prepose_node_arg) != type(cur_prepose_node):
+ continue
+ # out of loop
+ if not (start_idx <= self.node_mgr.find_node_idx(cur_prepose_node_arg) < end_idx):
+ continue
+ # compute op in loop
+ elif cur_prepose_node_arg in all_node_info:
+ if all_node_info[cur_prepose_node_arg]["chunk_dim"] is None:
+ tmp_next_prepose_nodes.append(cur_prepose_node_arg)
+ else:
+ prepose_flag = False
+ break
+ # non compute op
+ else:
+ tmp_next_prepose_nodes.append(cur_prepose_node_arg)
+ tmp_cur_prepose_nodes = tmp_next_prepose_nodes
+
+ if prepose_flag == False:
+ maybe_prepose_nodes.remove(maybe_prepose_nodes[0])
+ continue
+ else:
+ for n in tmp_cur_related_prepose_nodes:
+ if n not in prepose_nodes:
+ prepose_nodes.append(n)
+ if n in maybe_prepose_nodes:
+ maybe_prepose_nodes.remove(n)
+ # sort by index
+ prepose_nodes.sort(key=lambda x: self.node_mgr.find_node_idx(x))
+ chunk_info["args"]["prepose_nodes"] = prepose_nodes
+
+ def _get_non_chunk_inputs(self, chunk_info, start_idx, end_idx):
+ # we need to log input nodes to avoid deleteing them in the loop
+ chunk_node_list = self.node_mgr.get_node_slice_by_idx(start_idx, end_idx + 1)
+ # also need to get some prepose node's arg out of non_chunk_inputs
+ for n in chunk_info["args"]["prepose_nodes"]:
+ chunk_node_list.remove(n)
+ non_chunk_inputs = find_chunk_all_input_nodes(chunk_node_list)
+ for i in non_chunk_inputs:
+ if i not in chunk_info["inputs"]:
+ chunk_info["inputs_non_chunk"].append(i)
+ return chunk_info
+
+ def flow_search(self, start_idx, start_dim, end_idx, end_dim):
+ inputs, outputs = find_chunk_compute_input_and_output_nodes(
+ self.node_mgr.get_node_slice_by_idx(start_idx, end_idx + 1))
+
+ # get every node's chunk dim and fix dim
+ all_node_info = self._get_all_node_info(end_dim, start_idx, end_idx)
+ if all_node_info is None:
+ return None
+
+ chunk_info = {
+ "region": (start_idx, end_idx),
+ "inputs": [],
+ "inputs_non_chunk": [],
+ "inputs_dim": [],
+ "outputs": [self.node_mgr.get_node_by_idx(end_idx)],
+ "outputs_non_tensor": {},
+ "outputs_dim": [end_dim],
+ "node_chunk_dim": all_node_info,
+ "args": {},
+ }
+
+ # find chunk info for other outputs
+ if len(find_tensor_shape_node(outputs)) > 1:
+ chunk_info = self._get_other_output_info(outputs, start_idx, start_dim, end_idx, end_dim, chunk_info)
+ if chunk_info is None:
+ return None
+
+ # get input nodes' chunk dim
+ inputs, inputs_dim = self._get_input_nodes_dim(inputs, start_idx, end_idx, all_node_info)
+ if inputs is None:
+ return None
+ chunk_info["inputs"] = inputs
+ chunk_info["inputs_dim"] = inputs_dim
+
+ # move useless nodes ahead of loop
+ self._get_prepose_nodes(all_node_info, start_idx, end_idx, chunk_info)
+
+ # find non chunk inputs
+ chunk_info = self._get_non_chunk_inputs(chunk_info, start_idx, end_idx)
+
+ # reassgin reshape size, some size may have changed due to chunk
+ chunk_info = self._reassgin_reshape_size(chunk_info)
+
+ return chunk_info
+
+ def _get_other_output_info(self, outputs: List[Node], start_idx: int, start_dim: int, end_idx: int, end_dim: int,
+ chunk_info: Dict):
+ start_node = self.node_mgr.get_node_by_idx(start_idx)
+ # loop all outputs
+ for output in outputs:
+ output_legal = False
+ output_idx = self.node_mgr.find_node_idx(output)
+ # skip the origin output
+ if output_idx == end_idx:
+ continue
+ # skip non tensor
+ if get_node_shape(output) is None:
+ # log shape tensor
+ if len(output.meta['fwd_out']) > 0 and isinstance(output.meta['fwd_out'][0], int):
+ chunk_info["outputs_non_tensor"][output] = str(output.meta['fwd_out'])
+ continue
+ # loop every dim of outputs, try to find a legal one
+ for output_dim in range(len(get_node_shape(output))):
+ if not self.check_region_start_end(start_node, start_dim, start_idx, output, output_dim, output_idx):
+ continue
+ new_all_node_info = self._get_all_node_info(output_dim, start_idx, output_idx)
+ if new_all_node_info is None:
+ continue
+ # check node info legal
+ if self._update_chunk_info(chunk_info, new_all_node_info, output, output_dim) == True:
+ output_legal = True
+ break
+ # not legal
+ if output_legal == False:
+ return None
+ return chunk_info
+
+ def _update_chunk_info(self, chunk_info: Dict, new_all_node_info: Dict, output: Node, output_dim: int) -> bool:
+ """
+ check if there is conflict between new node info and old chunk info. If not, update old chunk info
+ """
+ # check if conflict
+ overlap_flag = False
+ for k, v in new_all_node_info.items():
+ if k in chunk_info["node_chunk_dim"]:
+ overlap_flag = True
+ if chunk_info["node_chunk_dim"][k]["chunk_dim"] != v["chunk_dim"]:
+ return False
+ # if no overlap, we just consider them as prepose nodes, instead of new output
+ if overlap_flag == False:
+ return True
+ # update chunk info
+ for k, v in new_all_node_info.items():
+ if k in chunk_info["node_chunk_dim"]:
+ chunk_info["node_chunk_dim"][k]["fix_dim"] = list(
+ set(chunk_info["node_chunk_dim"][k]["fix_dim"] + v["fix_dim"]))
+ else:
+ chunk_info["node_chunk_dim"][k] = v
+ chunk_info["outputs"].append(output)
+ chunk_info["outputs_dim"].append(output_dim)
+ return True
+
+ def _reassgin_reshape_size(self, chunk_info):
+ """
+ Some shape args in reshape may have changed due to chunk
+ reassgin those changed shape
+ """
+ chunk_region = chunk_info["region"]
+ reshape_size = {}
+ chunk_shape = get_node_shape(chunk_info["outputs"][0])[chunk_info["outputs_dim"][0]]
+ for node in self.node_mgr.get_node_slice_by_idx(chunk_region[0], chunk_region[1] + 1):
+ if any(i == get_node_name(node) for i in ["reshape", "view"]):
+ if node in chunk_info["args"]["prepose_nodes"]:
+ continue
+ if node.args[0] in chunk_info["inputs_non_chunk"]:
+ continue
+ reshape_args = flat_list(node.args[1:])
+ if len(reshape_args) == 1 and get_node_shape(reshape_args[0]) is None and len(
+ reshape_args[0].meta['fwd_out']) > 1:
+ continue
+ chunk_dim = chunk_info["node_chunk_dim"][node]["chunk_dim"]
+ new_shape = ""
+ for reshape_arg_dim, reshape_arg in enumerate(reshape_args):
+ if reshape_arg_dim == chunk_dim:
+ new_shape += "min(chunk_size, %d - chunk_idx), " % chunk_shape
+ else:
+ if isinstance(reshape_arg, int):
+ new_shape += "%s, " % str(reshape_arg)
+ else:
+ new_shape += "%s, " % reshape_arg.name
+ new_shape = new_shape[:-2]
+ origin_shape = str(reshape_args)[1:-1]
+ reshape_size[node.name] = [origin_shape, new_shape]
+ chunk_info["reshape_size"] = reshape_size
+ return chunk_info
+
+ def check_region_start_end(self, start_node: Node, start_dim: int, start_idx: int, end_node: Node, end_dim: int,
+ end_idx: int) -> bool:
+ """
+ check if region start and end is legal
+ """
+ # dim cannot be None
+ if (get_node_shape(end_node) is None or get_node_shape(start_node) is None):
+ return False
+ # dim size cannot be 1
+ if (get_node_shape(end_node)[end_dim] == 1 or get_node_shape(start_node)[start_dim] == 1):
+ return False
+ # must have users
+ if len(end_node.users) == 0:
+ return False
+ # check index source align
+ if not self.check_index_source(start_dim, start_node, start_idx, end_dim, end_node):
+ return False
+ # check index compute
+ if not self.check_index_compute(start_idx, end_dim, end_node, end_idx):
+ return False
+ return True
diff --git a/colossalai/autochunk/trace_indice.py b/colossalai/autochunk/trace_indice.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7fce4c8bee1f2886d63c9ca6bb35c332cb293d8
--- /dev/null
+++ b/colossalai/autochunk/trace_indice.py
@@ -0,0 +1,930 @@
+import copy
+from typing import Dict, List, Tuple
+
+from torch.fx.node import Node
+
+from .utils import NodeMgr, find_first_tensor_arg, flat_list, get_module_node_name, get_node_name, get_node_shape
+
+
+class TraceIndice(object):
+ """
+ Trace all indice information for every node.
+
+ Indice is a logical concept. Equal dims can been treated as one indice.
+ eg. dim(x1) = [a, b, c]
+ dim(x2) = [d, e, f]
+ and we have x3 = x1 * x2.
+ then a=d, b=e, c=f, due to the broadcast property,
+ dim(x1)=dim(x2)=dim(x3)=[a, b, c]
+ This class will record every node's dims' indice, compute and source.
+
+ Attibutes:
+ node_list (List)
+ indice_trace_list (List): [{"indice": [...], "compute": [...], "source": [...]}, {...}]
+ indice_view_list (Dict): not used for now
+ indice_count (int): record indice number
+
+ Args:
+ node_list (List)
+ """
+
+ def __init__(self, node_mgr: NodeMgr) -> None:
+ self.node_mgr = node_mgr
+ self.indice_trace_list = self._init_indice_trace_list()
+ self.indice_view_list = {}
+ self.indice_count = -1
+ self.active_node_list = []
+
+ def _init_indice_trace_list(self) -> List:
+ indice_trace_list = []
+ for n in self.node_mgr.get_node_list():
+ if get_node_shape(n) != None:
+ cur_trace = {
+ "indice": [None for _ in range(len(get_node_shape(n)))],
+ "compute": [[] for _ in range(len(get_node_shape(n)))],
+ "source": [{} for _ in range(len(get_node_shape(n)))],
+ }
+ else:
+ cur_trace = {"indice": [], "compute": [], "source": []}
+ indice_trace_list.append(cur_trace)
+ return indice_trace_list
+
+ def set_active_nodes(self, active_node_list: List) -> None:
+ self.active_node_list = active_node_list
+
+ def _add_indice(self) -> int:
+ """
+ Update the count and return it. To record the idx number.
+
+ Returns:
+ indice_count: int
+ """
+ self.indice_count += 1
+ return self.indice_count
+
+ def _del_dim(self, idx: int, dim_idx: int) -> None:
+ """
+ delete a dim for indice, compute and source
+ """
+ self.indice_trace_list[idx]["indice"].pop(dim_idx)
+ self.indice_trace_list[idx]["compute"].pop(dim_idx)
+ self.indice_trace_list[idx]["source"].pop(dim_idx)
+
+ def _add_dim(self, node_idx: int, dim_idx: int) -> None:
+ """
+ add a dim for indice, compute and source
+ """
+ # need to remap if dim_idx < 0, e.g. -1
+ if dim_idx < 0:
+ dim_idx = list(range(len(self.indice_trace_list[node_idx]["indice"]) + 1))[dim_idx]
+ self.indice_trace_list[node_idx]["indice"].insert(dim_idx, self._add_indice())
+ self.indice_trace_list[node_idx]["compute"].insert(dim_idx, [])
+ self.indice_trace_list[node_idx]["source"].insert(dim_idx, {})
+
+ def _add_source(
+ self,
+ node_from: Node,
+ node_from_dim: int,
+ node_to: Node,
+ node_to_dim: int,
+ init=False,
+ ) -> None:
+ node_from_dim = self._transform_indice(node_from, node_from_dim)
+ node_from_trace_source = self._find_source_trace_from_node(node_from)
+ node_to_dim = self._transform_indice(node_to, node_to_dim)
+ node_to_trace_source = self._find_source_trace_from_node(node_to)
+ node_from_idx = self.node_mgr.find_node_idx(node_from)
+ if init:
+ node_to_trace_source[node_to_dim] = {}
+ # add dim to cur new source
+ if node_from_idx not in node_to_trace_source[node_to_dim]:
+ node_to_trace_source[node_to_dim][node_from_idx] = [node_from_dim]
+ else:
+ if node_from_dim not in node_to_trace_source[node_to_dim][node_from_idx]:
+ node_to_trace_source[node_to_dim][node_from_idx].append(node_from_dim)
+ # update inputs source
+ for node_idx, node_dim in node_from_trace_source[node_from_dim].items():
+ if node_idx not in node_to_trace_source[node_to_dim]:
+ node_to_trace_source[node_to_dim][node_idx] = copy.deepcopy(node_dim)
+ else:
+ for d in node_dim:
+ if d not in node_to_trace_source[node_to_dim][node_idx]:
+ node_to_trace_source[node_to_dim][node_idx].append(d)
+
+ def _transform_indice(self, node: Node, node_dim: int) -> int:
+ node_idx = self._find_indice_trace_from_node(node)
+ dims = list(range(len(node_idx)))
+ return dims[node_dim]
+
+ def _inherit_indice(
+ self,
+ node_from: Node,
+ node_from_dim: int,
+ node_to: Node,
+ node_to_dim: int,
+ init: bool = True,
+ ) -> None:
+ """
+ node_to's node_to_dim inherit node_from's node_from_dim by indice, compute and source
+ """
+ node_from_dim = self._transform_indice(node_from, node_from_dim)
+ node_to_dim = self._transform_indice(node_to, node_to_dim)
+ node_from_trace = self._find_trace_from_node(node_from)
+ node_to_trace = self._find_trace_from_node(node_to)
+ if init:
+ node_to_trace["indice"][node_to_dim] = node_from_trace["indice"][node_from_dim]
+ node_to_trace["compute"][node_to_dim] = copy.deepcopy(node_from_trace["compute"][node_from_dim])
+ else:
+ for j in node_from_trace["compute"][node_from_dim]:
+ if j not in node_to_trace["compute"][node_to_dim]:
+ node_to_trace["compute"][node_to_dim].append(j)
+ self._add_source(node_from, node_from_dim, node_to, node_to_dim, init)
+
+ def _inherit_all_indice(self, node_from: Node, node_to: Node) -> None:
+ """
+ inherit all dims with init
+ """
+ # find indice just for assert length
+ node_from_indice = self._find_indice_trace_from_node(node_from)
+ node_to_indice = self._find_indice_trace_from_node(node_to)
+ assert len(node_from_indice) == len(node_to_indice)
+ for i in range(len(node_from_indice)):
+ self._inherit_indice(node_from, i, node_to, i, init=True)
+
+ def _inherit_more_indice_from_node_with_exclude(self, node_from: Node, node_to: Node, exclude: List = None) -> None:
+ """
+ inherit indice from node without init
+ """
+ if exclude == None:
+ exclude = []
+ else:
+ exclude = [self._transform_indice(node_to, i) for i in exclude]
+ node_from_compute = self._find_compute_trace_from_node(node_from)
+ node_to_compute = self._find_compute_trace_from_node(node_to)
+ # assert len(node_from_compute) == len(node_to_compute)
+ for i in range(-1, -min(len(node_from_compute), len(node_to_compute)) - 1, -1):
+ if self._transform_indice(node_to, i) in exclude:
+ continue
+ self._inherit_indice(node_from, i, node_to, i, init=False)
+
+ def _mark_computation(self, node: Node, idx: int, dim: int) -> None:
+ """
+ Mark some dims of node as computed.
+
+ Args:
+ node (node)
+ idx (int): node index
+ dim (list or int): dims to be marked as computed
+ """
+ if isinstance(dim, int):
+ dim = [dim]
+ dims = list(range(len(get_node_shape(node))))
+ for d in dim:
+ cur_dim = dims[d]
+ if idx not in self.indice_trace_list[idx]["compute"][cur_dim]:
+ self.indice_trace_list[idx]["compute"][cur_dim].append(idx)
+
+ def _find_trace_from_node(self, node: Node) -> Dict:
+ """
+ Find node idx and compute trace by the node.
+
+ Args:
+ node (node)
+ Returns:
+ idx (list): idx of the node
+ compute (list): computed idx of the node.
+ """
+ node_idx = self.node_mgr.find_node_idx(node)
+ node_dict = self.indice_trace_list[node_idx]
+ return node_dict
+
+ def _find_source_trace_from_node(self, node: Node) -> List:
+ """
+ Find node source trace by the node.
+
+ Args:
+ node (node)
+ Returns:
+ idx (list): idx of the node
+ compute (list): computed idx of the node.
+ """
+ node_idx = self.node_mgr.find_node_idx(node)
+ node_dict = self.indice_trace_list[node_idx]
+ return node_dict["source"]
+
+ def _find_indice_trace_from_node(self, node) -> List:
+ """
+ Find node idx trace by the node.
+
+ Args:
+ node (node)
+ Returns:
+ idx (list): idx of the node
+ """
+ node_idx = self.node_mgr.find_node_idx(node)
+ return self.indice_trace_list[node_idx]["indice"]
+
+ def _find_compute_trace_from_node(self, node: Node) -> List:
+ """
+ Find node compute trace by the node.
+
+ Args:
+ node (node)
+ Returns:
+ compute (list): computed idx of the node.
+ """
+ node_idx = self.node_mgr.find_node_idx(node)
+ return self.indice_trace_list[node_idx]["compute"]
+
+ def _assign_indice_as_input(self, node: Node, node_idx: int, input_node=None) -> None:
+ """
+ Assign node's trace as its input node.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ if input_node == None:
+ input_node = find_first_tensor_arg(node)
+ self._inherit_all_indice(input_node, node)
+
+ def _assign_all_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Add new indice for all node's dims.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ shape = node.meta["tensor_meta"].shape
+ if shape is None:
+ return
+ new_trace = []
+ for _ in shape:
+ new_trace.append(self._add_indice())
+ self.indice_trace_list[node_idx]["indice"] = new_trace
+
+ def _assign_transpose_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for transpose op.
+ 1. swap input's dim according to transpose args
+ 2. inherit input's computation
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ input_node = node.args[0]
+ tranpose_dim = node.args[1:]
+
+ self._assign_indice_as_input(node, node_idx, input_node)
+ self._inherit_indice(input_node, tranpose_dim[1], node, tranpose_dim[0])
+ self._inherit_indice(input_node, tranpose_dim[0], node, tranpose_dim[1])
+
+ def _assign_permute_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for permute op.
+ 1. swap input's dim according to permute args
+ 2. inherit input's computation
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ permute_dim = flat_list(node.args[1:])
+ input_node = node.args[0]
+
+ self._assign_indice_as_input(node, node_idx, input_node)
+ for idx, d in enumerate(permute_dim):
+ self._inherit_indice(input_node, d, node, idx)
+
+ def _assign_linear_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for linear op.
+ 1. copy trace from input node and change last indice according to weight
+ 2. mark equal for input node last indice, weight first dim and bias dim.
+ 3. inherit input's computation, mark computation for last dim.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._assign_indice_as_input(node, node_idx)
+
+ if len(node.args) >= 2:
+ weight = node.args[1]
+ self._inherit_indice(weight, 1, node, -1)
+ else:
+ self._del_dim(node_idx, -1)
+ self._add_dim(node_idx, -1)
+ self._mark_computation(node, node_idx, [-1])
+
+ def _assign_addmm_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for addmm op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ bias, input_node, weight = node.args
+ assert len(get_node_shape(bias)) == 1 and len(get_node_shape(weight)) == 2
+ self._assign_indice_as_input(node, node_idx, input_node)
+ self._inherit_indice(weight, 1, node, -1)
+ self._inherit_more_indice_from_node_with_exclude(bias, node)
+
+ self._mark_computation(node, node_idx, [-1])
+
+ def _assign_baddbmm_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for baddbmm(batch add and batch matmul) op.
+ add, matmul_left, matmul_right = args
+ out = add + (matmul_left x matmul_right)
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ add, matmul_left, matmul_right = node.args
+
+ assert get_node_shape(add) == get_node_shape(node)
+ assert len(get_node_shape(matmul_left)) == len(get_node_shape(matmul_right))
+ self._assign_indice_as_input(node, node_idx, matmul_left)
+ # matmul
+ self._inherit_indice(matmul_right, -1, node, -1)
+ self._inherit_more_indice_from_node_with_exclude(matmul_right, node, [-2, -1])
+ self._mark_computation(node, node_idx, [-1])
+ # add
+ self._inherit_more_indice_from_node_with_exclude(add, node)
+
+ def _assign_matmul_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for matmul op.
+ 1. copy trace from matmul_left and change last indice according to matmul_right. (assert they have same length)
+ 2. mark equal for input matmul_left -1 indice and matmul_right -2 dim.
+ 3. inherit matmul_left and matmul_right computation, mark computation for last dim.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ matmul_left, matmul_right = node.args
+
+ assert len(get_node_shape(matmul_left)) == len(get_node_shape(matmul_right))
+ self._assign_indice_as_input(node, node_idx, matmul_left)
+
+ self._inherit_indice(matmul_right, -1, node, -1)
+ self._inherit_more_indice_from_node_with_exclude(matmul_right, node, [-1, -2])
+ self._mark_computation(node, node_idx, [-1])
+
+ def _assign_conv2d_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for conv2d op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ # get conv module
+ node_targets = node.target.split(".")
+ conv_module = node.graph.owning_module
+ for i in node_targets:
+ conv_module = getattr(conv_module, i)
+ assert conv_module.dilation == (1, 1), "dilation for conv2d not implemented"
+
+ # get conv input
+ assert len(node.args) == 1
+ input_node = node.args[0]
+ assert len(get_node_shape(input_node)) == 4
+
+ # assgin index
+ self._assign_indice_as_input(node, node_idx, input_node)
+ self._del_dim(node_idx, 1)
+ self._add_dim(node_idx, 1)
+ self._mark_computation(node, node_idx, [1, 2, 3])
+
+ def _assign_interpolate_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for interpolate op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ # get conv input
+ assert node.kwargs['size'] is None
+ assert len(get_node_shape(node)) == 4
+
+ # assgin index
+ self._assign_indice_as_input(node, node_idx)
+ self._mark_computation(node, node_idx, [-1, -2])
+
+ def _assign_layernorm_indice(self, node, idx):
+ """
+ Assign indice for layernorm op.
+ 1. assign indice as input node
+ 2. inherit computation and mark last 2 dims as computed.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._assign_indice_as_input(node, idx)
+ self._mark_computation(node, idx, [-1])
+
+ def _assign_groupnorm_indice(self, node, idx):
+ """
+ Assign indice for groupnorm op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ assert len(get_node_shape(node)) == 4
+ self._assign_indice_as_input(node, idx)
+ self._mark_computation(node, idx, [-1, -2, -3])
+
+ def _assign_elementwise_indice(self, node, idx):
+ """
+ Assign indice for element-wise op (eg. relu sigmoid add mul).
+ 1. assign indice as input node
+ 2. inherit computation from all input nodes.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._assign_indice_as_input(node, idx)
+ nodes_in = []
+ for node_in in node.args:
+ if type(node_in) == type(node):
+ nodes_in.append(node_in)
+ self._inherit_more_indice_from_node_with_exclude(node_in, node)
+
+ def _assgin_no_change_indice(self, node, idx):
+ self._assign_indice_as_input(node, idx)
+ for node_in in node.args:
+ if type(node_in) == type(node):
+ self._inherit_more_indice_from_node_with_exclude(node_in, node)
+
+ def _assign_einsum_indice(self, node, idx):
+ """
+ Assign indice for einsum op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ patterns = node.args[0]
+ input_nodes = node.args[1:]
+
+ patterns = patterns.replace(" ", "")
+ left, right = patterns.split("->")
+ left = left.split(",")
+
+ if "..." in right:
+ replace_list = "!@#$%^&*"
+ target_len = len(get_node_shape(node))
+ add_len = target_len - len(right) + 3
+ replace_str = replace_list[:add_len]
+ right = right.replace("...", replace_str)
+ for ll in range(len(left)):
+ left[ll] = left[ll].replace("...", replace_str)
+
+ all_index = []
+ for i in left:
+ for c in i:
+ all_index.append(c)
+ all_index = set(all_index)
+
+ for right_idx, right_indice in enumerate(right):
+ for left_idx, left_str in enumerate(left):
+ if right_indice in left_str:
+ source_idx = left_str.index(right_indice)
+ self._inherit_indice(input_nodes[left_idx], source_idx, node, right_idx)
+
+ def _assign_softmax_indice(self, node, idx):
+ """
+ Assign indice for softmax op.
+ 1. assign indice as input node
+ 2. inherit computation and mark softmax dim as computed.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._assign_indice_as_input(node, idx)
+ self._mark_computation(node, idx, [node.kwargs["dim"]])
+
+ def _assign_split_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for split op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._assign_indice_as_input(node, node_idx)
+ dim_idx = node.kwargs["dim"]
+ self._del_dim(node_idx, dim_idx)
+ self._add_dim(node_idx, dim_idx)
+
+ def _assign_unsqueeze_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for unsqueeze op.
+ 1. assign new indice for unsqueeze dim
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._del_dim(node_idx, -1)
+ self._assign_indice_as_input(node, node_idx)
+ dim_idx = node.args[1]
+ # unsqueeze(-1) = unsqueeze(shape_num + 1)
+ if dim_idx < 0:
+ dim_idx = list(range(len(get_node_shape(node))))[dim_idx]
+ self._add_dim(node_idx, dim_idx)
+
+ def _assign_cat_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for cat op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ nodes_in = flat_list(node.args[0])
+ self._assign_indice_as_input(node, node_idx, input_node=nodes_in[0])
+ for n in nodes_in[1:]:
+ self._inherit_more_indice_from_node_with_exclude(n, node)
+ cat_dim = node.kwargs["dim"]
+ self._del_dim(node_idx, cat_dim)
+ self._add_dim(node_idx, cat_dim)
+
+ def _assign_sum_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for sum op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ nodes_in = flat_list(node.args[0])
+ self._add_dim(node_idx, 0)
+ self._assign_indice_as_input(node, node_idx, input_node=nodes_in[0])
+ for n in nodes_in[1:]:
+ self._inherit_more_indice_from_node_with_exclude(n, node)
+ cat_dim = node.kwargs["dim"]
+ self._del_dim(node_idx, cat_dim)
+
+ def _assign_flatten_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for flatten op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ nodes_in = node.args[0]
+ nodes_in_shape = get_node_shape(nodes_in)
+ flatten_start_dim = node.args[1]
+ flatten_dim_num = len(nodes_in_shape) - flatten_start_dim - 1
+ assert flatten_dim_num > 0
+ for _ in range(flatten_dim_num):
+ self._add_dim(node_idx, 0)
+ self._assign_indice_as_input(node, node_idx, nodes_in)
+ for _ in range(flatten_dim_num + 1):
+ self._del_dim(node_idx, -1)
+ self._add_dim(node_idx, -1)
+
+ def _assign_expand_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for expand op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ expand_shape = node.args[1:]
+ node_in_shape = get_node_shape(node.args[0])
+ assert len(expand_shape) == len(node_in_shape)
+ self._assign_indice_as_input(node, node_idx)
+ for i in range(len(node_in_shape)):
+ if expand_shape[i] == node_in_shape[i] or expand_shape[i] == -1:
+ continue
+ elif expand_shape[i] > node_in_shape[i]:
+ self._del_dim(node_idx, i)
+ self._add_dim(node_idx, i)
+ else:
+ raise RuntimeError()
+
+ def _assign_unbind_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for unbind op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ unbind_dim = node.args[1]
+ self._add_dim(node_idx, unbind_dim)
+ self._assign_indice_as_input(node, node_idx)
+ self._del_dim(node_idx, unbind_dim)
+
+ def _assign_embedding_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for embedding op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._del_dim(node_idx, -1)
+ self._assign_indice_as_input(node, node_idx)
+ self._add_dim(node_idx, -1)
+
+ def _assign_getitem_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for getitem.
+ getitem can act like slice sometimes
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ node_args = flat_list(node.args[1:])
+
+ # deal with split
+ if get_node_name(node.args[0]) == "split":
+ self._assign_indice_as_input(node, node_idx)
+ self._del_dim(node_idx, node.args[0].kwargs["dim"])
+ self._add_dim(node_idx, node.args[0].kwargs["dim"])
+ return
+
+ # skip non tensor
+ if get_node_shape(node) is None:
+ return
+
+ # find if slice
+ flag = False
+ for node_arg in node_args:
+ node_arg_str = str(node_arg)
+ if any(i == node_arg_str for i in ["None", "Ellipsis"]):
+ flag = True
+ break
+ if "slice" in node_arg_str:
+ flag = True
+ break
+ if flag == False:
+ return
+
+ # node args should be like [Ellipsis, slice(start, step, end), None]
+ node_shape = get_node_shape(node)
+ origin_idx_count = 0
+ new_idx_count = 0
+ new_dim_num = sum([1 if str(i) == "None" else 0 for i in node_args])
+ for _ in range(new_dim_num):
+ self._del_dim(node_idx, 0)
+ delete_dim_num = sum([1 if str(i) == "0" else 0 for i in node_args])
+ for _ in range(delete_dim_num):
+ self._add_dim(node_idx, 0)
+ self._assign_indice_as_input(node, node_idx)
+
+ for _, node_arg in enumerate(node_args):
+ node_arg_str = str(node_arg)
+ # Ellipsis means [..., ]
+ if "Ellipsis" == node_arg_str:
+ shape_gap = len(node_shape) - len(node_args) + 1
+ origin_idx_count += shape_gap
+ new_idx_count += shape_gap
+ # slice(None, None, None) means all indexes
+ elif "slice" in node_arg_str:
+ if "slice(None, None, None)" != node_arg_str:
+ self._del_dim(node_idx, new_idx_count)
+ self._add_dim(node_idx, new_idx_count)
+ origin_idx_count += 1
+ new_idx_count += 1
+ # None means a new dim
+ elif "None" == node_arg_str:
+ self._add_dim(node_idx, new_idx_count)
+ new_idx_count += 1
+ elif "0" == node_arg_str:
+ self._del_dim(node_idx, new_idx_count)
+ origin_idx_count += 1
+ else:
+ raise NotImplementedError()
+
+ def _assign_view_reshape_indice(self, node: Node, node_idx: int) -> None:
+ """
+ Assign indice for view and reshape op.
+ 1. get origin shape and target shape by meta info.
+ 2. compute the real value of -1 in target shape.
+ 3. determine changed dim, and assign indice for generated dim.
+ 4. log changed dim and generated dim for restore
+ 5. inherit computation.
+ 6. look into view list to see whether the view is associated with other,
+ if so assign equal dim according to previous view.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ # get data, turn into number
+ origin_node = node.args[0]
+ origin_shape = origin_node.meta["tensor_meta"].shape
+ target_shape = []
+ unflated_args = flat_list(node.args)
+ for i in range(1, len(unflated_args)):
+ if isinstance(unflated_args[i], int):
+ target_shape.append(unflated_args[i])
+ else:
+ target_shape.extend(unflated_args[i].meta["fwd_out"])
+
+ # compute the value of -1
+ if -1 in target_shape:
+ origin_product = 1
+ for i in origin_shape:
+ origin_product *= i
+ target_product = -1
+ for i in target_shape:
+ target_product *= i
+ shape_idx = target_shape.index(-1)
+ target_shape[shape_idx] = origin_product // target_product
+
+ # find same dim
+ dim_to_same_dim = []
+ dim_from_same_dim = []
+ for i in range(len(origin_shape)):
+ if origin_shape[i] == target_shape[i]:
+ dim_to_same_dim.append(i)
+ dim_from_same_dim.append(i)
+ else:
+ break
+ for i in range(-1, -len(origin_shape), -1):
+ if origin_shape[i] == target_shape[i]:
+ dim_to_same_dim.append(len(target_shape) + i)
+ dim_from_same_dim.append(len(origin_shape) + i)
+ else:
+ break
+
+ dim_from = list(set(range(len(origin_shape))) - set(dim_from_same_dim))
+ dim_to = list(set(range(len(target_shape))) - set(dim_to_same_dim))
+ assert len(dim_from) == 1 or len(dim_to) == 1 or len(dim_from) == len(dim_to)
+
+ dim_diff = len(dim_from) - len(dim_to)
+ if dim_diff > 0:
+ # dim merge
+ for i in range(dim_diff):
+ self._add_dim(node_idx, -1)
+ elif dim_diff < 0:
+ # dim expand
+ for i in range(-dim_diff):
+ self._del_dim(node_idx, -1)
+
+ # get new indice
+ origin_trace = self._find_indice_trace_from_node(origin_node)
+ self._assign_indice_as_input(node, node_idx, origin_node)
+ dim_from.reverse()
+ for i in dim_from:
+ self._del_dim(node_idx, i)
+ for i in dim_to:
+ self._add_dim(node_idx, i)
+ dim_from.reverse()
+
+ # inheirt indice from current node
+ if len(dim_from) != 0 and len(dim_to) != 0:
+ if dim_diff == 1:
+ if origin_shape[dim_from[0]] == 1:
+ self._inherit_indice(origin_node, dim_from[1], node, dim_to[0], init=False)
+ elif origin_shape[dim_from[1]] == 1:
+ self._inherit_indice(origin_node, dim_from[0], node, dim_to[0], init=False)
+ elif dim_diff == -1:
+ if target_shape[dim_to[0]] == 1:
+ self._inherit_indice(origin_node, dim_from[0], node, dim_to[1], init=False)
+ elif target_shape[dim_to[1]] == 1:
+ self._inherit_indice(origin_node, dim_from[0], node, dim_to[0], init=False)
+
+ # log view, not used now
+ view_dict = {
+ "idx_from": [origin_trace[i] for i in dim_from],
+ "dim_from": dim_from,
+ "idx_to": [self.indice_trace_list[node_idx]["indice"][i] for i in dim_to],
+ "dim_to": dim_to,
+ }
+ self.indice_view_list[node] = view_dict
+
+ def _clear_trace(self, node_idx: int) -> None:
+ """
+ clear too far trace to speed up computation
+ """
+ trace_barrier = max(node_idx - 100, 0)
+ active_nodes = self.active_node_list[trace_barrier]
+ active_nodes = [self.node_mgr.find_node_idx(i) for i in active_nodes.keys()]
+
+ trace = self.indice_trace_list[node_idx]
+ # clear compute
+ for dim_compute in trace["compute"]:
+ for i in range(len(dim_compute) - 1, -1, -1):
+ if (dim_compute[i] < trace_barrier and dim_compute[i] not in active_nodes):
+ dim_compute.pop(i)
+ continue
+ # clear source
+ for dim_source in trace["source"]:
+ for k in list(dim_source.keys()):
+ if k < trace_barrier and k not in active_nodes:
+ dim_source.pop(k)
+
+ def trace_indice(self) -> None:
+ for idx, node in enumerate(self.node_mgr.get_node_list()):
+ node_name = get_node_name(node)
+ if node.op == "placeholder":
+ self._assign_all_indice(node, idx)
+ elif node.op == "call_method":
+ if "transpose" == node_name:
+ self._assign_transpose_indice(node, idx)
+ elif "permute" == node_name:
+ self._assign_permute_indice(node, idx)
+ elif "view" == node_name or "reshape" == node_name:
+ self._assign_view_reshape_indice(node, idx)
+ elif "unsqueeze" == node_name:
+ self._assign_unsqueeze_indice(node, idx)
+ elif "split" == node_name:
+ self._assign_split_indice(node, idx)
+ elif any(i == node_name for i in ["to", "contiguous", "clone", "type", "float"]):
+ self._assgin_no_change_indice(node, idx)
+ elif "new_ones" == node_name:
+ self._assign_all_indice(node, idx)
+ elif "flatten" == node_name:
+ self._assign_flatten_indice(node, idx)
+ elif "expand" == node_name:
+ self._assign_expand_indice(node, idx)
+ elif "unbind" == node_name:
+ self._assign_unbind_indice(node, idx)
+ elif "softmax" == node_name:
+ self._assign_softmax_indice(node, idx)
+ elif any(i == node_name for i in ["size"]):
+ continue
+ else:
+ raise NotImplementedError(node_name, "method not implemented yet!")
+ elif node.op == "call_function":
+ if "linear" == node_name:
+ self._assign_linear_indice(node, idx)
+ elif "cat" == node_name:
+ self._assign_cat_indice(node, idx)
+ elif any(n == node_name for n in ["matmul", "bmm"]):
+ self._assign_matmul_indice(node, idx)
+ elif "softmax" == node_name:
+ self._assign_softmax_indice(node, idx)
+ elif any(n == node_name for n in [
+ "mul", "add", "sigmoid", "relu", "sub", "truediv", "pow", "dropout", "where", "tanh", "exp",
+ "sin", "cos"
+ ]):
+ self._assign_elementwise_indice(node, idx)
+ elif "einsum" == node_name:
+ self._assign_einsum_indice(node, idx)
+ elif "sum" == node_name:
+ self._assign_sum_indice(node, idx)
+ elif "layer_norm" == node_name:
+ self._assign_layernorm_indice(node, idx)
+ elif "getitem" == node_name:
+ self._assign_getitem_indice(node, idx)
+ elif "addmm" == node_name:
+ self._assign_addmm_indice(node, idx)
+ elif "baddbmm" == node_name:
+ self._assign_baddbmm_indice(node, idx)
+ elif "interpolate" == node_name:
+ self._assign_interpolate_indice(node, idx)
+ elif any(i == node_name for i in ["arange", "ones", "ones_like", "tensor", "empty"]):
+ self._assign_all_indice(node, idx)
+ elif any(i == node_name for i in ["getattr", "eq", "_assert_is_none", "_assert", "finfo"]):
+ continue
+ else:
+ raise NotImplementedError(node_name, "function not implemented yet!")
+ elif node.op == "call_module":
+ node_name = get_module_node_name(node)
+ if "layernorm" == node_name:
+ self._assign_layernorm_indice(node, idx)
+ elif "groupnorm" == node_name:
+ self._assign_groupnorm_indice(node, idx)
+ elif "embedding" == node_name:
+ self._assign_embedding_indice(node, idx)
+ elif "linear" == node_name:
+ self._assign_linear_indice(node, idx)
+ elif "conv2d" == node_name:
+ self._assign_conv2d_indice(node, idx)
+ elif "identity" == node_name:
+ self._assgin_no_change_indice(node, idx)
+ elif any(n == node_name for n in ["sigmoid", "dropout", "relu", "silu", "gelu"]):
+ self._assign_elementwise_indice(node, idx)
+ else:
+ raise NotImplementedError(node_name, "module not implemented yet!")
+ elif node.op == "get_attr":
+ self._assign_all_indice(node, idx) # get param
+ elif node.op == "output":
+ continue
+ else:
+ raise NotImplementedError(node.op, "op not implemented yet!")
+
+ # limit trace range
+ self._clear_trace(idx)
diff --git a/colossalai/autochunk/utils.py b/colossalai/autochunk/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..064baa047155ac399b14ae0fcdb044db1125d70b
--- /dev/null
+++ b/colossalai/autochunk/utils.py
@@ -0,0 +1,244 @@
+from typing import Any, Callable, Dict, Iterable, List, Tuple, Union
+
+from torch.fx.node import Node
+
+from colossalai.logging import get_dist_logger
+
+NON_COMPUTE_OP = ["placeholder", "get_attr", "output"]
+NON_COMPUTE_NAME = ["getattr", "eq", "_assert_is_none", "_assert", "finfo", "size"]
+logger = get_dist_logger()
+
+
+class NodeMgr(object):
+
+ def __init__(self, nodes_list: List[Node]) -> None:
+ self._node_list = nodes_list
+ self._node_dict = {}
+ self._set_node_dict()
+
+ def _set_node_dict(self) -> None:
+ """
+ create a dict {node_name: node_idx}
+ """
+ self._node_dict.clear()
+ for idx, node in enumerate(self._node_list):
+ self._node_dict[node.name] = idx
+
+ def find_node_idx(self, node: Node) -> int:
+ """
+ find node's index
+ """
+ return self._node_dict[node.name]
+
+ def find_node_idx_by_name(self, node_name: str) -> int:
+ """
+ find node's index
+ """
+ return self._node_dict[node_name]
+
+ def get_node_by_idx(self, idx: int) -> Node:
+ """
+ get a node by index
+ """
+ return self._node_list[idx]
+
+ def get_node_slice_by_idx(self, start: int, end: int) -> List[Node]:
+ """
+ get a slice of node by index
+ """
+ return self._node_list[start:end]
+
+ def get_node_list(self) -> List:
+ """
+ get full node list
+ """
+ return self._node_list
+
+ def update_node_list(self, node_list: List) -> None:
+ """
+ update node list, reset node dict
+ """
+ self._node_list = node_list
+ self._set_node_dict()
+
+
+def get_logger() -> Any:
+ return logger
+
+
+def flat_list(inputs: Any) -> List:
+ """
+ flat a list by recursion
+ """
+ if not (isinstance(inputs, list) or isinstance(inputs, set) or isinstance(inputs, tuple)):
+ return [inputs]
+ res = []
+ for i in inputs:
+ if isinstance(i, list) or isinstance(i, set) or isinstance(i, tuple):
+ res.extend(flat_list(i))
+ elif isinstance(i, dict):
+ res.extend(flat_list(list(i.keys())))
+ else:
+ res.append(i)
+ return res
+
+
+def find_first_tensor_arg(node: Node) -> Node:
+ """
+ Find the first input tensor arg for a node
+ """
+ for arg in node.args:
+ if type(arg) == type(node):
+ return arg
+ raise RuntimeError()
+
+
+def is_non_compute_node(node: Node) -> bool:
+ if any(i == node.op for i in NON_COMPUTE_OP) or any(i == get_node_name(node) for i in NON_COMPUTE_NAME):
+ return True
+ if "getitem" in node.name:
+ if get_node_shape(node) is not None:
+ return False
+ node_args = flat_list(node.args[1:])
+ for node_arg in node_args:
+ if any(i == str(node_arg) for i in ["None", "Ellipsis"]):
+ return False
+ if "slice" in str(node_arg):
+ return False
+ return True
+ return False
+
+
+def get_node_shape(node: Node) -> Any:
+ """
+ return node data shape
+ """
+ if get_node_name(node) in ["split", "unbind"]:
+ return node.meta["tensor_meta"][0].shape
+ if hasattr(node.meta["tensor_meta"], "shape"):
+ return node.meta["tensor_meta"].shape
+ return None
+
+
+def is_non_memory_node(node: Node) -> bool:
+ if "getitem" in node.name:
+ return True
+ if "output" in node.op:
+ return True
+ return is_non_compute_node(node)
+
+
+def is_non_compute_node_except_placeholder(node: Node) -> bool:
+ if "placeholder" in node.op:
+ return False
+ return is_non_compute_node(node)
+
+
+def is_non_compute_node_except_placeholder_output(node: Node) -> bool:
+ if "output" in node.op:
+ return False
+ return is_non_compute_node_except_placeholder(node)
+
+
+def delete_free_var_from_last_use(user_to_last_uses: Dict) -> None:
+ for key, value in user_to_last_uses.items():
+ for n in value:
+ if n.op == "placeholder":
+ user_to_last_uses[key].remove(n)
+
+
+def find_chunk_all_input_nodes(nodes: List[Node]) -> List:
+ """
+ Find non-compute input and output node names.
+ input nodes are nodes used in the list
+ output nodes are nodes will use nodes in the list
+ """
+ input_nodes = []
+ for node in nodes:
+ for input_node in node._input_nodes.keys():
+ if input_node not in nodes and input_node not in input_nodes:
+ input_nodes.append(input_node)
+ return input_nodes
+
+
+def find_chunk_compute_input_and_output_nodes(nodes: List[Node]) -> Union[List, List]:
+ """
+ Find non-compute input and output node names.
+ input nodes are nodes used in the list
+ output nodes are nodes will use nodes in the list
+ """
+ input_nodes = []
+ output_nodes = []
+
+ # if a node has an input node which is not in the node list
+ # we treat that input node as the input of the checkpoint function
+ for node in nodes:
+ for input_node in node._input_nodes.keys():
+ if (input_node not in nodes and input_node not in input_nodes
+ and not is_non_compute_node_except_placeholder(input_node)):
+ input_nodes.append(input_node)
+
+ # if a node has a user node which is not in the node list
+ # we treat that user node as the node receiving the current node output
+ for node in nodes:
+ for output_node in node.users.keys():
+ if (output_node not in nodes and node not in output_nodes
+ and not is_non_compute_node_except_placeholder_output(output_node)):
+ output_nodes.append(node)
+
+ return input_nodes, output_nodes
+
+
+def get_module_node_name(node: Node) -> str:
+ """
+ get module class name
+ """
+ node_targets = node.target.split(".")
+ module = node.graph.owning_module
+ for i in node_targets:
+ module = getattr(module, i)
+ module_name = str(module.__class__).split(".")[-1][:-2]
+ module_name = module_name.lower()
+ return module_name
+
+
+def get_node_name(node: Node) -> str:
+ """
+ get node name
+ """
+ node_name = node.name
+ if "_" in node_name:
+ for i in range(len(node_name) - 1, -1, -1):
+ if node_name[i] == "_":
+ node_name = node_name[:i]
+ break
+ elif node_name[i] in ["1", "2", "3", "4", "5", "6", "7", "8", "9", "0"]:
+ continue
+ else:
+ break
+ return node_name
+
+
+def find_tensor_node(node_list: List[Node]) -> List[Node]:
+ """
+ find tensor nodes from a node list
+ """
+ out = []
+ for node in node_list:
+ if get_node_shape(node) is not None:
+ out.append(node)
+ return out
+
+
+def find_tensor_shape_node(node_list: List[Node]) -> List[Node]:
+ """
+ find tensor and shape nodes from a node list
+ """
+ out = []
+ for node in node_list:
+ if get_node_shape(node) is not None:
+ out.append(node)
+ elif len(node.meta['fwd_out']) > 0 and isinstance(node.meta['fwd_out'], list) and isinstance(
+ node.meta['fwd_out'][0], int):
+ out.append(node)
+ return out
diff --git a/colossalai/booster/__init__.py b/colossalai/booster/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..841054a9c67273fb9cb155070b81edf51f8316d2
--- /dev/null
+++ b/colossalai/booster/__init__.py
@@ -0,0 +1,3 @@
+from .accelerator import Accelerator
+from .booster import Booster
+from .plugin import Plugin
diff --git a/colossalai/booster/accelerator.py b/colossalai/booster/accelerator.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc2c4a40068b50cb49db8a3f9c33f22b8f307966
--- /dev/null
+++ b/colossalai/booster/accelerator.py
@@ -0,0 +1,54 @@
+import torch
+import torch.nn as nn
+
+__all__ = ['Accelerator']
+
+_supported_devices = [
+ 'cpu',
+ 'cuda',
+
+ # To be supported
+ # 'xpu',
+ # 'npu',
+ # 'tpu',
+]
+
+
+class Accelerator:
+ """
+ Accelerator is an abstraction for the hardware device that is used to run the model.
+
+ Args:
+ device (str): The device to be used. Currently only support 'cpu' and 'gpu'.
+ """
+
+ def __init__(self, device: str):
+ self.device = device
+
+ assert self.device in _supported_devices, f"Device {self.device} is not supported yet, supported devices include {_supported_devices}"
+
+ def bind(self):
+ """
+ Set the default device for the current process.
+ """
+ if self.device == 'cpu':
+ pass
+ elif self.device == 'cuda':
+ # TODO(FrankLeeeee): use global environment to check if it is a dist job
+ # if is_distributed:
+ # local_rank = EnvTable().get_local_rank()
+ # torch.cuda.set_device(torch.device(f'cuda:{local_rank}'))
+ torch.cuda.set_device(torch.device('cuda'))
+ pass
+ else:
+ raise ValueError(f"Device {self.device} is not supported yet")
+
+ def configure_model(self, model: nn.Module) -> nn.Module:
+ """
+ Move the model to the device.
+
+ Args:
+ model (nn.Module): The model to be moved.
+ """
+ model = model.to(torch.device(self.device))
+ return model
diff --git a/colossalai/booster/booster.py b/colossalai/booster/booster.py
new file mode 100644
index 0000000000000000000000000000000000000000..c14e602deaf5ce60808a87bbbd238c9419b9d502
--- /dev/null
+++ b/colossalai/booster/booster.py
@@ -0,0 +1,174 @@
+import warnings
+from contextlib import contextmanager
+from typing import Callable, Iterator, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
+from torch.utils.data import DataLoader
+
+from colossalai.checkpoint_io import GeneralCheckpointIO
+
+from .accelerator import Accelerator
+from .mixed_precision import MixedPrecision, mixed_precision_factory
+from .plugin import Plugin
+
+__all__ = ['Booster']
+
+
+class Booster:
+ """
+ Booster is a high-level API for training neural networks. It provides a unified interface for
+ training with different precision, accelerator, and plugin.
+
+ Examples:
+ >>> colossalai.launch(...)
+ >>> plugin = GeminiPlugin(stage=3, ...)
+ >>> booster = Booster(precision='fp16', plugin=plugin)
+ >>>
+ >>> model = GPT2()
+ >>> optimizer = Adam(model.parameters())
+ >>> dataloader = Dataloader(Dataset)
+ >>> lr_scheduler = LinearWarmupScheduler()
+ >>> criterion = GPTLMLoss()
+ >>>
+ >>> model, optimizer, lr_scheduler, dataloader = booster.boost(model, optimizer, lr_scheduler, dataloader)
+ >>>
+ >>> for epoch in range(max_epochs):
+ >>> for input_ids, attention_mask in dataloader:
+ >>> outputs = model(input_ids, attention_mask)
+ >>> loss = criterion(outputs.logits, input_ids)
+ >>> booster.backward(loss, optimizer)
+ >>> optimizer.step()
+ >>> lr_scheduler.step()
+ >>> optimizer.zero_grad()
+
+
+ Args:
+ device (str or torch.device): The device to run the training. Default: 'cuda'.
+ mixed_precision (str or MixedPrecision): The mixed precision to run the training. Default: None.
+ If the argument is a string, it can be 'fp16', 'fp16_apex', 'bf16', or 'fp8'.
+ 'fp16' would use PyTorch AMP while `fp16_apex` would use Nvidia Apex.
+ plugin (Plugin): The plugin to run the training. Default: None.
+ """
+
+ def __init__(self,
+ device: str = 'cuda',
+ mixed_precision: Union[MixedPrecision, str] = None,
+ plugin: Optional[Plugin] = None) -> None:
+ if plugin is not None:
+ assert isinstance(
+ plugin, Plugin), f'Expected the argument plugin to be an instance of Plugin, but got {type(plugin)}.'
+ self.plugin = plugin
+
+ # set accelerator
+ if self.plugin and self.plugin.control_device():
+ self.accelerator = None
+ warnings.warn('The plugin will control the accelerator, so the device argument will be ignored.')
+ else:
+ self.accelerator = Accelerator(device)
+
+ # set precision
+ if self.plugin and self.plugin.control_precision():
+ warnings.warn('The plugin will control the precision, so the mixed_precision argument will be ignored.')
+ self.mixed_precision = None
+ elif mixed_precision is None:
+ self.mixed_precision = None
+ else:
+ # validate and set precision
+ if isinstance(mixed_precision, str):
+ # the user will take the default arguments for amp training
+ self.mixed_precision = mixed_precision_factory(mixed_precision)
+ elif isinstance(mixed_precision, MixedPrecision):
+ # the user can customize the arguments by passing the precision object
+ self.mixed_precision = mixed_precision
+ else:
+ raise ValueError(
+ f'Expected the argument mixed_precision to be a string or an instance of Precision, but got {type(mixed_precision)}.'
+ )
+
+ if self.plugin is not None and self.plugin.control_checkpoint_io():
+ self.checkpoint_io = self.plugin.get_checkpoint_io()
+ else:
+ self.checkpoint_io = GeneralCheckpointIO()
+
+ def boost(
+ self,
+ model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Callable = None,
+ dataloader: DataLoader = None,
+ lr_scheduler: LRScheduler = None,
+ ) -> List[Union[nn.Module, Optimizer, LRScheduler, DataLoader]]:
+ """
+ Boost the model, optimizer, criterion, lr_scheduler, and dataloader.
+
+ Args:
+ model (nn.Module): The model to be boosted.
+ optimizer (Optimizer): The optimizer to be boosted.
+ criterion (Callable): The criterion to be boosted.
+ dataloader (DataLoader): The dataloader to be boosted.
+ lr_scheduler (LRScheduler): The lr_scheduler to be boosted.
+ """
+ # TODO(FrankLeeeee): consider multi-model and multi-optimizer case
+ # TODO(FrankLeeeee): consider multi-dataloader case
+ # transform model for mixed precision
+ if self.plugin:
+ model, optimizer, criterion, dataloader, lr_scheduler = self.plugin.configure(
+ model, optimizer, criterion, dataloader, lr_scheduler)
+
+ if self.plugin and not self.plugin.control_device():
+ # transform model for accelerator
+ model = self.accelerator.configure(model)
+
+ if self.mixed_precision and (self.plugin is None or self.plugin and not self.plugin.control_precision()):
+ # transform model for mixed precision
+ # when mixed_precision is specified and the plugin is not given or does not control the precision
+ model, optimizer, criterion = self.mixed_precision.configure(model, optimizer, criterion)
+
+ return model, optimizer, criterion, dataloader, lr_scheduler
+
+ def backward(self, loss: torch.Tensor, optimizer: Optimizer) -> None:
+ # TODO: implement this method with plugin
+ optimizer.backward(loss)
+
+ def execute_pipeline(self,
+ data_iter: Iterator,
+ model: nn.Module,
+ criterion: Callable[[torch.Tensor], torch.Tensor],
+ optimizer: Optimizer,
+ return_loss: bool = True,
+ return_outputs: bool = False) -> Tuple[Optional[torch.Tensor], ...]:
+ # TODO: implement this method
+ # run pipeline forward backward pass
+ # return loss or outputs if needed
+ pass
+
+ def no_sync(self, model: nn.Module) -> contextmanager:
+ assert self.plugin is not None, f'no_sync is only enabled when a plugin is provided and the plugin supports no_sync.'
+ assert self.plugin.support_no_sync, f'The plugin {self.plugin.__class__.__name__} does not support no_sync.'
+ return self.plugin.no_sync(model)
+
+ def load_model(self, model: nn.Module, checkpoint: str, strict: bool = True):
+ self.checkpoint_io.load_model(model, checkpoint, strict)
+
+ def save_model(self,
+ model: nn.Module,
+ checkpoint: str,
+ prefix: str = None,
+ shard: bool = False,
+ size_per_shard: int = 1024):
+ self.checkpoint_io.save_model(model, checkpoint, prefix, shard, size_per_shard)
+
+ def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
+ self.checkpoint_io.load_optimizer(optimizer, checkpoint)
+
+ def save_optimizer(self, optimizer: Optimizer, checkpoint: str, shard: bool = False, size_per_shard: int = 1024):
+ self.checkpoint_io.save_optimizer(optimizer, checkpoint, shard, size_per_shard)
+
+ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ self.checkpoint_io.save_lr_scheduler(lr_scheduler, checkpoint)
+
+ def load_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ self.checkpoint_io.load_lr_scheduler(lr_scheduler, checkpoint)
diff --git a/colossalai/booster/mixed_precision/__init__.py b/colossalai/booster/mixed_precision/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3cf0ad28cdbe78b24e1c8fd18fd6bd473e095bd6
--- /dev/null
+++ b/colossalai/booster/mixed_precision/__init__.py
@@ -0,0 +1,33 @@
+from .bf16 import BF16MixedPrecision
+from .fp8 import FP8MixedPrecision
+from .fp16_apex import FP16ApexMixedPrecision
+from .fp16_torch import FP16TorchMixedPrecision
+from .mixed_precision_base import MixedPrecision
+
+__all__ = [
+ 'MixedPrecision', 'mixed_precision_factory', 'FP16_Apex_MixedPrecision', 'FP16_Torch_MixedPrecision',
+ 'FP32_MixedPrecision', 'BF16_MixedPrecision', 'FP8_MixedPrecision'
+]
+
+_mixed_precision_mapping = {
+ 'fp16': FP16TorchMixedPrecision,
+ 'fp16_apex': FP16ApexMixedPrecision,
+ 'bf16': BF16MixedPrecision,
+ 'fp8': FP8MixedPrecision
+}
+
+
+def mixed_precision_factory(mixed_precision_type: str) -> MixedPrecision:
+ """
+ Factory method to create mixed precision object
+
+ Args:
+ mixed_precision_type (str): mixed precision type, including None, 'fp16', 'fp16_apex', 'bf16', and 'fp8'.
+ """
+
+ if mixed_precision_type in _mixed_precision_mapping:
+ return _mixed_precision_mapping[mixed_precision_type]()
+ else:
+ raise ValueError(
+ f'Mixed precision type {mixed_precision_type} is not supported, support types include {list(_mixed_precision_mapping.keys())}'
+ )
diff --git a/colossalai/booster/mixed_precision/bf16.py b/colossalai/booster/mixed_precision/bf16.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a840fea69ea280b43c451e033b131993fffd857
--- /dev/null
+++ b/colossalai/booster/mixed_precision/bf16.py
@@ -0,0 +1,5 @@
+from .mixed_precision_base import MixedPrecision
+
+
+class BF16MixedPrecision(MixedPrecision):
+ pass
diff --git a/colossalai/booster/mixed_precision/fp16_apex.py b/colossalai/booster/mixed_precision/fp16_apex.py
new file mode 100644
index 0000000000000000000000000000000000000000..266a750734b14ade3c5f53fc71ef276d09e1ec83
--- /dev/null
+++ b/colossalai/booster/mixed_precision/fp16_apex.py
@@ -0,0 +1,5 @@
+from .mixed_precision_base import MixedPrecision
+
+
+class FP16ApexMixedPrecision(MixedPrecision):
+ pass
diff --git a/colossalai/booster/mixed_precision/fp16_torch.py b/colossalai/booster/mixed_precision/fp16_torch.py
new file mode 100644
index 0000000000000000000000000000000000000000..9999aa5e0eb475b8303b76382d9287b3ac876696
--- /dev/null
+++ b/colossalai/booster/mixed_precision/fp16_torch.py
@@ -0,0 +1,124 @@
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+from torch import Tensor
+from torch.optim import Optimizer
+
+from colossalai.interface import ModelWrapper, OptimizerWrapper
+
+from .mixed_precision_base import MixedPrecision
+
+__all__ = ['FP16_Torch_MixedPrecision', 'TorchAMPOptimizer', 'TorchAMPModule']
+
+
+class TorchAMPOptimizer(OptimizerWrapper):
+ """
+ Optimizer wrapper for mixed precision training in FP16 using PyTorch AMP.
+
+ Args:
+ optim (Optimizer): Optimizer to wrap.
+ init_scale (float): Initial scale factor. Default: 2**16.
+ growth_factor (float): Factor by which the scale is multiplied during
+ :meth:`torch.cuda.amp.GradScaler.step` if gradients were found to be finite
+ this iteration. Default: 2.0.
+ backoff_factor (float): Factor by which the scale is multiplied during
+ :meth:`torch.cuda.amp.GradScaler.step` if gradients were found to be infinite
+ this iteration. Default: 0.5.
+ growth_interval (int): Number of iterations between :meth:`torch.cuda.amp.GradScaler.step`
+ calls that may cause the scale to increase. Default: 2000.
+ """
+
+ def __init__(self,
+ optim: Optimizer,
+ init_scale: float = 2.**16,
+ growth_factor: float = 2.0,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 2000) -> None:
+ super().__init__(optim)
+ self.scaler = torch.cuda.amp.GradScaler(init_scale=init_scale,
+ growth_factor=growth_factor,
+ backoff_factor=backoff_factor,
+ growth_interval=growth_interval)
+
+ def backward(self, loss: Tensor, *args, **kwargs) -> None:
+ scaled_loss = self.scale_loss(loss)
+ scaled_loss.backward(*args, **kwargs)
+
+ def step(self, *args, **kwargs) -> Optional[float]:
+ out = self.scaler.step(self.optim, *args, **kwargs)
+ self.scaler.update()
+ return out
+
+ def scale_loss(self, loss: Tensor) -> Tensor:
+ return self.scaler.scale(loss)
+
+ def unscale_grad(self) -> None:
+ self.scaler.unscale_(self.optim)
+
+ def clip_grad_by_value(self, clip_value: float, *args, **kwargs) -> None:
+ self.unscale_grad()
+ super().clip_grad_by_value(clip_value, *args, **kwargs)
+
+ def clip_grad_by_norm(self,
+ max_norm: Union[float, int],
+ norm_type: Union[float, int] = 2.0,
+ error_if_nonfinite: bool = False,
+ *args,
+ **kwargs) -> None:
+ self.unscale_grad()
+ super().clip_grad_by_norm(max_norm, norm_type, error_if_nonfinite, *args, **kwargs)
+
+
+class TorchAMPModule(ModelWrapper):
+ """
+ Module wrapper for mixed precision training in FP16 using PyTorch AMP.
+
+ Args:
+ module (nn.Module): Module to wrap.
+ """
+
+ def __init__(self, module: nn.Module):
+ super().__init__(module)
+
+ def forward(self, *args, **kwargs):
+ with torch.cuda.amp.autocast():
+ return self.module(*args, **kwargs)
+
+
+class FP16TorchMixedPrecision(MixedPrecision):
+ """
+ Precision for mixed precision training in FP16 using PyTorch AMP.
+
+ Args:
+ init_scale (float): Initial scale factor. Default: 2**16.
+ growth_factor (float): Factor by which the scale is multiplied during
+ :meth:`torch.cuda.amp.GradScaler.step` if gradients were found to be finite
+ this iteration. Default: 2.0.
+ backoff_factor (float): Factor by which the scale is multiplied during
+ :meth:`torch.cuda.amp.GradScaler.step` if gradients were found to be infinite
+ this iteration. Default: 0.5.
+ growth_interval (int): Number of iterations between :meth:`torch.cuda.amp.GradScaler.step`
+ calls that may cause the scale to increase. Default: 2000.
+ """
+
+ def __init__(self,
+ init_scale: float = 2.**16,
+ growth_factor: float = 2.0,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 2000) -> None:
+ super().__init__()
+ self.torch_amp_kwargs = dict(init_scale=init_scale,
+ growth_factor=growth_factor,
+ backoff_factor=backoff_factor,
+ growth_interval=growth_interval)
+
+ def configure(self,
+ model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Callable = None) -> Tuple[nn.Module, OptimizerWrapper, Callable]:
+ model = TorchAMPModule(model)
+ optimizer = TorchAMPOptimizer(optimizer, **self.torch_amp_kwargs)
+ if criterion is not None:
+ criterion = TorchAMPModule(criterion)
+ return model, optimizer, criterion
diff --git a/colossalai/booster/mixed_precision/fp8.py b/colossalai/booster/mixed_precision/fp8.py
new file mode 100644
index 0000000000000000000000000000000000000000..28847345d91d1a6ab176b6d4675f2728c8e67641
--- /dev/null
+++ b/colossalai/booster/mixed_precision/fp8.py
@@ -0,0 +1,5 @@
+from .mixed_precision_base import MixedPrecision
+
+
+class FP8MixedPrecision(MixedPrecision):
+ pass
diff --git a/colossalai/booster/mixed_precision/mixed_precision_base.py b/colossalai/booster/mixed_precision/mixed_precision_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..2490e9811ccf3ef71a1dcb90d30ddb794fc82d04
--- /dev/null
+++ b/colossalai/booster/mixed_precision/mixed_precision_base.py
@@ -0,0 +1,21 @@
+from abc import ABC, abstractmethod
+from typing import Callable, Tuple
+
+import torch.nn as nn
+from torch.optim import Optimizer
+
+from colossalai.interface import OptimizerWrapper
+
+
+class MixedPrecision(ABC):
+ """
+ An abstract class for mixed precision training.
+ """
+
+ @abstractmethod
+ def configure(self,
+ model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Callable = None) -> Tuple[nn.Module, OptimizerWrapper, Callable]:
+ # TODO: implement this method
+ pass
diff --git a/colossalai/booster/plugin/__init__.py b/colossalai/booster/plugin/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa45bcb59ad7b9b25a06bea5fa1c0f776e6870ae
--- /dev/null
+++ b/colossalai/booster/plugin/__init__.py
@@ -0,0 +1,6 @@
+from .gemini_plugin import GeminiPlugin
+from .low_level_zero_plugin import LowLevelZeroPlugin
+from .plugin_base import Plugin
+from .torch_ddp_plugin import TorchDDPPlugin
+
+__all__ = ['Plugin', 'TorchDDPPlugin', 'GeminiPlugin', 'LowLevelZeroPlugin']
diff --git a/colossalai/booster/plugin/gemini_plugin.py b/colossalai/booster/plugin/gemini_plugin.py
new file mode 100644
index 0000000000000000000000000000000000000000..deda00d8a7b3b6849a1cf5b1db0b796a1a1c7d89
--- /dev/null
+++ b/colossalai/booster/plugin/gemini_plugin.py
@@ -0,0 +1,302 @@
+import random
+import warnings
+from typing import Callable, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch import Tensor
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
+from torch.utils.data import DataLoader
+from torch.utils.data.distributed import DistributedSampler
+
+from colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO
+from colossalai.checkpoint_io.utils import save_state_dict
+from colossalai.cluster import DistCoordinator
+from colossalai.interface import ModelWrapper, OptimizerWrapper
+from colossalai.utils import get_current_device
+from colossalai.zero import GeminiDDP, zero_model_wrapper, zero_optim_wrapper
+from colossalai.zero.gemini.memory_tracer import MemStats
+
+from .plugin_base import Plugin
+
+__all__ = ['GeminiPlugin']
+
+
+class GeminiCheckpointIO(GeneralCheckpointIO):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.coordinator = DistCoordinator()
+
+ def load_unsharded_model(self, model: GeminiDDP, checkpoint: str, strict: bool = True):
+ """
+ Load model from checkpoint with automatic unwrapping.
+ """
+ # the model should be unwrapped in self.load_model via ModelWrapper.unwrap
+ return super().load_unsharded_model(model, checkpoint, strict=strict)
+
+ def save_unsharded_model(self, model: GeminiDDP, checkpoint: str, gather_dtensor: bool, use_safetensors: bool):
+ """
+ Save model to checkpoint but only on master process.
+ """
+ # the model should be unwrapped in self.load_model via ModelWrapper.unwrap
+ # as there is communication when get state dict, this must be called on all processes
+ state_dict = model.state_dict(only_rank_0=True)
+ if self.coordinator.is_master():
+ save_state_dict(state_dict, checkpoint, use_safetensors)
+
+ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):
+ """
+ Save optimizer to checkpoint but only on master process.
+ """
+ # TODO(ver217): optimizer state dict is sharded
+ super().save_unsharded_optimizer(optimizer, checkpoint, gather_dtensor)
+
+ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """
+ Save model to checkpoint but only on master process.
+ """
+ if self.coordinator.is_master():
+ super().save_lr_scheduler(lr_scheduler, checkpoint)
+
+
+class GeminiModel(ModelWrapper):
+
+ def __init__(self, module: nn.Module, gemini_config: dict, verbose: bool = False) -> None:
+ super().__init__(module)
+ self.module = zero_model_wrapper(module, zero_stage=3, gemini_config=gemini_config, verbose=verbose)
+
+ def unwrap(self):
+ # as save/load state dict is coupled with the GeminiDDP, we only return GeminiDDP model
+ return self.module
+
+
+class GeminiOptimizer(OptimizerWrapper):
+
+ def __init__(self,
+ module: GeminiDDP,
+ optimizer: Optimizer,
+ zero_optim_config: dict,
+ optim_kwargs: dict,
+ verbose: bool = False) -> None:
+ optimizer = zero_optim_wrapper(module,
+ optimizer,
+ optim_config=zero_optim_config,
+ **optim_kwargs,
+ verbose=verbose)
+ super().__init__(optimizer)
+
+ def backward(self, loss: Tensor, *args, **kwargs):
+ self.optim.backward(loss)
+
+ def clip_grad_by_norm(self,
+ max_norm: Union[float, int],
+ norm_type: Union[float, int] = 2,
+ error_if_nonfinite: bool = False,
+ *args,
+ **kwargs) -> Tensor:
+ warnings.warn(f'Gemini controls grad clipping by itself, so you should not use clip_grad_by_norm')
+
+ def clip_grad_by_value(self, clip_value: float, *args, **kwargs) -> None:
+ raise NotImplementedError('Gemini does not support clip_grad_by_value')
+
+
+class GeminiPlugin(Plugin):
+ """
+ Plugin for Gemini.
+
+ Example:
+ >>> from colossalai.booster import Booster
+ >>> from colossalai.booster.plugin import GeminiPlugin
+ >>>
+ >>> model, train_dataset, optimizer, criterion = ...
+ >>> plugin = GeminiPlugin()
+
+ >>> train_dataloader = plugin.prepare_train_dataloader(train_dataset, batch_size=8)
+ >>> booster = Booster(plugin=plugin)
+ >>> model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
+
+ Args:
+ device (torch.device): device to place the model.
+ placement_policy (str, optional): "cpu", "cuda", "auto". Defaults to "cpu".
+ pin_memory (bool, optional): use pin memory on CPU. Defaults to False.
+ force_outputs_fp32 (bool, optional): force outputs are fp32. Defaults to False.
+ strict_ddp_mode (bool, optional): use strict ddp mode (only use dp without other parallelism). Defaults to False.
+ search_range_mb (int, optional): chunk size searching range in MegaByte. Defaults to 32.
+ hidden_dim (int, optional): the hidden dimension of DNN.
+ Users can provide this argument to speed up searching.
+ If users do not know this argument before training, it is ok. We will use a default value 1024.
+ min_chunk_size_mb (float, optional): the minimum chunk size in MegaByte.
+ If the aggregate size of parameters is still samller than the minimum chunk size,
+ all parameters will be compacted into one small chunk.
+ memstats (MemStats, optional) the memory statistics collector by a runtime memory tracer.
+ gpu_margin_mem_ratio (float, optional): The ratio of GPU remaining memory (after the first forward-backward)
+ which will be used when using hybrid CPU optimizer.
+ This argument is meaningless when `placement_policy` of `GeminiManager` is not "auto".
+ Defaults to 0.0.
+ initial_scale (float, optional): Initial scale used by DynamicGradScaler. Defaults to 2**32.
+ min_scale (float, optional): Min scale used by DynamicGradScaler. Defaults to 1.
+ growth_factor (float, optional): growth_factor used by DynamicGradScaler. Defaults to 2.
+ backoff_factor (float, optional): backoff_factor used by DynamicGradScaler. Defaults to 0.5.
+ growth_interval (float, optional): growth_interval used by DynamicGradScaler. Defaults to 1000.
+ hysteresis (float, optional): hysteresis used by DynamicGradScaler. Defaults to 2.
+ max_scale (int, optional): max_scale used by DynamicGradScaler. Defaults to 2**32.
+ max_norm (float, optional): max_norm used for `clip_grad_norm`. You should notice that you shall not do
+ clip_grad_norm by yourself when using ZeRO DDP. The ZeRO optimizer will take care of clip_grad_norm.
+ norm_type (float, optional): norm_type used for `clip_grad_norm`.
+ verbose (bool, optional): verbose mode. Debug info including chunk search result will be printed. Defaults to False.
+ """
+
+ def __init__(
+ self,
+ device: Optional[torch.device] = None,
+ placement_policy: str = "cpu",
+ pin_memory: bool = False,
+ force_outputs_fp32: bool = False,
+ strict_ddp_mode: bool = False,
+ search_range_mb: int = 32,
+ hidden_dim: Optional[int] = None,
+ min_chunk_size_mb: float = 32,
+ memstats: Optional[MemStats] = None,
+ gpu_margin_mem_ratio: float = 0.0,
+ initial_scale: float = 2**32,
+ min_scale: float = 1,
+ growth_factor: float = 2,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 1000,
+ hysteresis: int = 2,
+ max_scale: float = 2**32,
+ max_norm: float = 0.0,
+ norm_type: float = 2.0,
+ verbose: bool = False,
+ ) -> None:
+
+ assert dist.is_initialized(
+ ), 'torch.distributed is not initialized, please use colossalai.launch to create the distributed environment'
+ self.rank = dist.get_rank()
+ self.world_size = dist.get_world_size()
+ self.gemini_config = dict(
+ device=(device or get_current_device()),
+ placement_policy=placement_policy,
+ pin_memory=pin_memory,
+ force_outputs_fp32=force_outputs_fp32,
+ strict_ddp_mode=strict_ddp_mode,
+ search_range_mb=search_range_mb,
+ hidden_dim=hidden_dim,
+ min_chunk_size_mb=min_chunk_size_mb,
+ memstats=memstats,
+ )
+ self.zero_optim_config = dict(gpu_margin_mem_ratio=gpu_margin_mem_ratio,)
+ self.optim_kwargs = dict(initial_scale=initial_scale,
+ growth_factor=growth_factor,
+ backoff_factor=backoff_factor,
+ growth_interval=growth_interval,
+ hysteresis=hysteresis,
+ min_scale=min_scale,
+ max_scale=max_scale,
+ max_norm=max_norm,
+ norm_type=norm_type)
+ self.verbose = verbose
+
+ def support_no_sync(self) -> bool:
+ return False
+
+ def control_precision(self) -> bool:
+ return True
+
+ def supported_precisions(self) -> List[str]:
+ return ['fp16']
+
+ def control_device(self) -> bool:
+ return True
+
+ def supported_devices(self) -> List[str]:
+ return ['cuda']
+
+ def prepare_train_dataloader(self,
+ dataset,
+ batch_size,
+ shuffle=False,
+ seed=1024,
+ drop_last=False,
+ pin_memory=False,
+ num_workers=0,
+ **kwargs):
+ r"""
+ Prepare a dataloader for distributed training. The dataloader will be wrapped by
+ `torch.utils.data.DataLoader` and `torch.utils.data.DistributedSampler`.
+
+ Note:
+ 1. Evaluation datasets should not be passed to this function.
+
+ Args:
+ dataset (`torch.utils.data.Dataset`): The dataset to be loaded.
+ shuffle (bool, optional): Whether to shuffle the dataset. Defaults to False.
+ seed (int, optional): Random worker seed for sampling, defaults to 1024.
+ add_sampler: Whether to add ``DistributedDataParallelSampler`` to the dataset. Defaults to True.
+ drop_last (bool, optional): Set to True to drop the last incomplete batch, if the dataset size
+ is not divisible by the batch size. If False and the size of dataset is not divisible by
+ the batch size, then the last batch will be smaller, defaults to False.
+ pin_memory (bool, optional): Whether to pin memory address in CPU memory. Defaults to False.
+ num_workers (int, optional): Number of worker threads for this dataloader. Defaults to 0.
+ kwargs (dict): optional parameters for ``torch.utils.data.DataLoader``, more details could be found in
+ `DataLoader `_.
+
+ Returns:
+ :class:`torch.utils.data.DataLoader`: A DataLoader used for training or testing.
+ """
+ _kwargs = kwargs.copy()
+ sampler = DistributedSampler(dataset, num_replicas=self.world_size, rank=self.rank, shuffle=shuffle)
+
+ # Deterministic dataloader
+ def seed_worker(worker_id):
+ worker_seed = seed
+ np.random.seed(worker_seed)
+ torch.manual_seed(worker_seed)
+ random.seed(worker_seed)
+
+ return DataLoader(dataset,
+ batch_size=batch_size,
+ sampler=sampler,
+ worker_init_fn=seed_worker,
+ drop_last=drop_last,
+ pin_memory=pin_memory,
+ num_workers=num_workers,
+ **_kwargs)
+
+ def configure(
+ self,
+ model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Callable = None,
+ dataloader: DataLoader = None,
+ lr_scheduler: LRScheduler = None,
+ ) -> Tuple[Union[nn.Module, OptimizerWrapper, LRScheduler, DataLoader]]:
+
+ if not isinstance(model, ModelWrapper):
+ # convert model to sync bn
+ # FIXME(ver217): gemini does not support sync bn
+ # In torch/nn/modules/_functions.py, line 22, ``mean, invstd = torch.batch_norm_stats(input, eps)`` will get fp32 mean and invstd even though the input is fp16.
+ # This inconsistency of dtype will cause the error.
+ # We have two possible solutions:
+ # 1. keep batch norm always in fp32. This is hard for gemini, as it use chunks.
+ # 2. patch sync bn or write a new on. This is relatively easy, but we need to test it.
+ # model = nn.SyncBatchNorm.convert_sync_batchnorm(model, None)
+
+ # wrap the model with Gemini
+ model = GeminiModel(model, self.gemini_config, self.verbose)
+
+ if not isinstance(optimizer, OptimizerWrapper):
+ optimizer = GeminiOptimizer(model.unwrap(), optimizer, self.zero_optim_config, self.optim_kwargs,
+ self.verbose)
+
+ return model, optimizer, criterion, dataloader, lr_scheduler
+
+ def control_checkpoint_io(self) -> bool:
+ return True
+
+ def get_checkpoint_io(self) -> CheckpointIO:
+ return GeminiCheckpointIO()
diff --git a/colossalai/booster/plugin/low_level_zero_plugin.py b/colossalai/booster/plugin/low_level_zero_plugin.py
new file mode 100644
index 0000000000000000000000000000000000000000..969c430bd317600091e69a68276a5f14006d5420
--- /dev/null
+++ b/colossalai/booster/plugin/low_level_zero_plugin.py
@@ -0,0 +1,259 @@
+import random
+import warnings
+from typing import Callable, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch import Tensor
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
+from torch.utils._pytree import tree_map
+from torch.utils.data import DataLoader
+from torch.utils.data.distributed import DistributedSampler
+
+from colossalai.checkpoint_io import CheckpointIO
+from colossalai.interface import ModelWrapper, OptimizerWrapper
+from colossalai.utils import get_current_device
+from colossalai.zero import zero_model_wrapper, zero_optim_wrapper
+
+from .plugin_base import Plugin
+from .torch_ddp_plugin import TorchDDPCheckpointIO
+
+__all__ = ['LowLevelZeroPlugin']
+
+
+def _convert_to_fp16(x):
+ if isinstance(x, torch.Tensor) and torch.is_floating_point(x):
+ return x.half()
+ return x
+
+
+class LowLevelZeroCheckpointIO(TorchDDPCheckpointIO):
+
+ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):
+ """
+ Save optimizer to checkpoint but only on master process.
+ """
+ # TODO(ver217): optimizer state dict is sharded
+ super().save_unsharded_optimizer(optimizer, checkpoint, gather_dtensor)
+
+
+class LowLevelZeroModel(ModelWrapper):
+
+ def __init__(self, module: nn.Module, stage: int, precision: str) -> None:
+ super().__init__(module)
+ self.convert_inputs = (precision == 'fp16')
+ module = zero_model_wrapper(module, zero_stage=stage)
+ if precision == 'fp16':
+ module = module.half()
+ module = module.to(get_current_device())
+ self.module = module
+
+ def forward(self, *args, **kwargs):
+ if self.convert_inputs:
+ args = tree_map(_convert_to_fp16, args)
+ kwargs = tree_map(_convert_to_fp16, kwargs)
+ return super().forward(*args, **kwargs)
+
+
+class LowLevelZeroOptimizer(OptimizerWrapper):
+
+ def __init__(self,
+ module: nn.Module,
+ optimizer: Optimizer,
+ zero_optim_config: dict,
+ optim_kwargs: dict,
+ verbose: bool = False) -> None:
+ optimizer = zero_optim_wrapper(module,
+ optimizer,
+ optim_config=zero_optim_config,
+ **optim_kwargs,
+ verbose=verbose)
+ super().__init__(optimizer)
+
+ def backward(self, loss: Tensor, *args, **kwargs):
+ self.optim.backward(loss)
+
+ def clip_grad_by_norm(self,
+ max_norm: Union[float, int],
+ norm_type: Union[float, int] = 2,
+ error_if_nonfinite: bool = False,
+ *args,
+ **kwargs) -> Tensor:
+ warnings.warn(f'LowLevelZero controls grad clipping by itself, so you should not use clip_grad_by_norm')
+
+ def clip_grad_by_value(self, clip_value: float, *args, **kwargs) -> None:
+ raise NotImplementedError('LowLevelZero does not support clip_grad_by_value')
+
+
+class LowLevelZeroPlugin(Plugin):
+ """
+ Plugin for low level zero.
+
+ Example:
+ >>> from colossalai.booster import Booster
+ >>> from colossalai.booster.plugin import LowLevelZeroPlugin
+ >>>
+ >>> model, train_dataset, optimizer, criterion = ...
+ >>> plugin = LowLevelZeroPlugin()
+
+ >>> train_dataloader = plugin.prepare_train_dataloader(train_dataset, batch_size=8)
+ >>> booster = Booster(plugin=plugin)
+ >>> model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
+
+ Args:
+ strage (int, optional): ZeRO stage. Defaults to 1.
+ precision (str, optional): precision. Support 'fp16' and 'fp32'. Defaults to 'fp16'.
+ initial_scale (float, optional): Initial scale used by DynamicGradScaler. Defaults to 2**32.
+ min_scale (float, optional): Min scale used by DynamicGradScaler. Defaults to 1.
+ growth_factor (float, optional): growth_factor used by DynamicGradScaler. Defaults to 2.
+ backoff_factor (float, optional): backoff_factor used by DynamicGradScaler. Defaults to 0.5.
+ growth_interval (float, optional): growth_interval used by DynamicGradScaler. Defaults to 1000.
+ hysteresis (float, optional): hysteresis used by DynamicGradScaler. Defaults to 2.
+ max_scale (int, optional): max_scale used by DynamicGradScaler. Defaults to 2**32.
+ max_norm (float, optional): max_norm used for `clip_grad_norm`. You should notice that you shall not do
+ clip_grad_norm by yourself when using ZeRO DDP. The ZeRO optimizer will take care of clip_grad_norm.
+ norm_type (float, optional): norm_type used for `clip_grad_norm`.
+ reduce_bucket_size_in_m (int, optional): grad reduce bucket size in M. Defaults to 12.
+ communication_dtype (torch.dtype, optional): communication dtype. If not specified, the dtype of param will be used. Defaults to None.
+ overlap_communication (bool, optional): whether to overlap communication and computation. Defaults to True.
+ cpu_offload (bool, optional): whether to offload grad, master weight and optimizer state to cpu. Defaults to False.
+ verbose (bool, optional): verbose mode. Debug info including grad overflow will be printed. Defaults to False.
+ """
+
+ def __init__(
+ self,
+ stage: int = 1,
+ precision: str = 'fp16',
+ initial_scale: float = 2**32,
+ min_scale: float = 1,
+ growth_factor: float = 2,
+ backoff_factor: float = 0.5,
+ growth_interval: int = 1000,
+ hysteresis: int = 2,
+ max_scale: float = 2**32,
+ max_norm: float = 0.0,
+ norm_type: float = 2.0,
+ reduce_bucket_size_in_m: int = 12,
+ communication_dtype: Optional[torch.dtype] = None,
+ overlap_communication: bool = True,
+ cpu_offload: bool = False,
+ verbose: bool = False,
+ ) -> None:
+
+ assert dist.is_initialized(
+ ), 'torch.distributed is not initialized, please use colossalai.launch to create the distributed environment'
+ assert stage in (1, 2), f'LowLevelZeroPlugin only supports stage 1/2 training'
+ assert precision in ('fp16', 'fp32'), f'LowLevelZeroPlugin only supports fp16/fp32 training'
+
+ self.rank = dist.get_rank()
+ self.world_size = dist.get_world_size()
+
+ self.stage = stage
+ self.precision = precision
+ self.zero_optim_config = dict(reduce_bucket_size=reduce_bucket_size_in_m * 1024 * 1024,
+ communication_dtype=communication_dtype,
+ overlap_communication=overlap_communication,
+ cpu_offload=cpu_offload)
+ self.optim_kwargs = dict(initial_scale=initial_scale,
+ growth_factor=growth_factor,
+ backoff_factor=backoff_factor,
+ growth_interval=growth_interval,
+ hysteresis=hysteresis,
+ min_scale=min_scale,
+ max_scale=max_scale,
+ max_norm=max_norm,
+ norm_type=norm_type)
+ self.verbose = verbose
+
+ def support_no_sync(self) -> bool:
+ return False
+
+ def control_precision(self) -> bool:
+ return True
+
+ def supported_precisions(self) -> List[str]:
+ return ['fp16', 'fp32']
+
+ def control_device(self) -> bool:
+ return True
+
+ def supported_devices(self) -> List[str]:
+ return ['cuda']
+
+ def prepare_train_dataloader(self,
+ dataset,
+ batch_size,
+ shuffle=False,
+ seed=1024,
+ drop_last=False,
+ pin_memory=False,
+ num_workers=0,
+ **kwargs):
+ r"""
+ Prepare a dataloader for distributed training. The dataloader will be wrapped by
+ `torch.utils.data.DataLoader` and `torch.utils.data.DistributedSampler`.
+
+ Note:
+ 1. Evaluation datasets should not be passed to this function.
+
+ Args:
+ dataset (`torch.utils.data.Dataset`): The dataset to be loaded.
+ shuffle (bool, optional): Whether to shuffle the dataset. Defaults to False.
+ seed (int, optional): Random worker seed for sampling, defaults to 1024.
+ add_sampler: Whether to add ``DistributedDataParallelSampler`` to the dataset. Defaults to True.
+ drop_last (bool, optional): Set to True to drop the last incomplete batch, if the dataset size
+ is not divisible by the batch size. If False and the size of dataset is not divisible by
+ the batch size, then the last batch will be smaller, defaults to False.
+ pin_memory (bool, optional): Whether to pin memory address in CPU memory. Defaults to False.
+ num_workers (int, optional): Number of worker threads for this dataloader. Defaults to 0.
+ kwargs (dict): optional parameters for ``torch.utils.data.DataLoader``, more details could be found in
+ `DataLoader `_.
+
+ Returns:
+ :class:`torch.utils.data.DataLoader`: A DataLoader used for training or testing.
+ """
+ _kwargs = kwargs.copy()
+ sampler = DistributedSampler(dataset, num_replicas=self.world_size, rank=self.rank, shuffle=shuffle)
+
+ # Deterministic dataloader
+ def seed_worker(worker_id):
+ worker_seed = seed
+ np.random.seed(worker_seed)
+ torch.manual_seed(worker_seed)
+ random.seed(worker_seed)
+
+ return DataLoader(dataset,
+ batch_size=batch_size,
+ sampler=sampler,
+ worker_init_fn=seed_worker,
+ drop_last=drop_last,
+ pin_memory=pin_memory,
+ num_workers=num_workers,
+ **_kwargs)
+
+ def configure(
+ self,
+ model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Callable = None,
+ dataloader: DataLoader = None,
+ lr_scheduler: LRScheduler = None,
+ ) -> Tuple[Union[nn.Module, OptimizerWrapper, LRScheduler, DataLoader]]:
+
+ if not isinstance(model, ModelWrapper):
+ model = LowLevelZeroModel(model, self.stage, self.precision)
+
+ if not isinstance(optimizer, OptimizerWrapper):
+ optimizer = LowLevelZeroOptimizer(model.unwrap(), optimizer, self.zero_optim_config, self.optim_kwargs,
+ self.verbose)
+
+ return model, optimizer, criterion, dataloader, lr_scheduler
+
+ def control_checkpoint_io(self) -> bool:
+ return True
+
+ def get_checkpoint_io(self) -> CheckpointIO:
+ return LowLevelZeroCheckpointIO()
diff --git a/colossalai/booster/plugin/plugin_base.py b/colossalai/booster/plugin/plugin_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a222022c1b264585b03ea4c402e580a909c4af7
--- /dev/null
+++ b/colossalai/booster/plugin/plugin_base.py
@@ -0,0 +1,61 @@
+from abc import ABC, abstractmethod
+from typing import Callable, List, Tuple, Union
+
+import torch.nn as nn
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
+from torch.utils.data import DataLoader
+
+from colossalai.checkpoint_io import CheckpointIO
+from colossalai.interface import OptimizerWrapper
+
+__all__ = ['Plugin']
+
+
+class Plugin(ABC):
+
+ @abstractmethod
+ def supported_devices(self) -> List[str]:
+ pass
+
+ @abstractmethod
+ def supported_precisions(self) -> List[str]:
+ pass
+
+ @abstractmethod
+ def control_precision(self) -> bool:
+ pass
+
+ @abstractmethod
+ def control_device(self) -> bool:
+ pass
+
+ @abstractmethod
+ def support_no_sync(self) -> bool:
+ pass
+
+ @abstractmethod
+ def configure(
+ self,
+ model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Callable = None,
+ dataloader: DataLoader = None,
+ lr_scheduler: LRScheduler = None,
+ ) -> Tuple[Union[nn.Module, OptimizerWrapper, LRScheduler, DataLoader]]:
+ # implement this method
+ pass
+
+ @abstractmethod
+ def control_checkpoint_io(self) -> bool:
+ """
+ Whether the plugin controls the checkpoint io
+ """
+ pass
+
+ @abstractmethod
+ def get_checkpoint_io(self) -> CheckpointIO:
+ """
+ Get checkpoint io object for this plugin, only invoked when control_checkpoint_io is True.
+ """
+ pass
diff --git a/colossalai/booster/plugin/torch_ddp_plugin.py b/colossalai/booster/plugin/torch_ddp_plugin.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5e310c7e7695893266784e9b90018b0d373f6f2
--- /dev/null
+++ b/colossalai/booster/plugin/torch_ddp_plugin.py
@@ -0,0 +1,204 @@
+import random
+from typing import Callable, List, Tuple, Union
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
+from torch.utils.data import DataLoader
+from torch.utils.data.distributed import DistributedSampler
+
+from colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO
+from colossalai.cluster import DistCoordinator
+from colossalai.interface import ModelWrapper, OptimizerWrapper
+
+from .plugin_base import Plugin
+
+__all__ = ['TorchDDPPlugin']
+
+
+class TorchDDPCheckpointIO(GeneralCheckpointIO):
+
+ def __init__(self) -> None:
+ super().__init__()
+ self.coordinator = DistCoordinator()
+
+ def load_unsharded_model(self, model: nn.Module, checkpoint: str, strict: bool = True):
+ """
+ Load model from checkpoint with automatic unwrapping.
+ """
+ # the model should be unwrapped in self.load_model via ModelWrapper.unwrap
+ return super().load_unsharded_model(model, checkpoint, strict=strict)
+
+ def save_unsharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, use_safetensors: bool):
+ """
+ Save model to checkpoint but only on master process.
+ """
+ # the model should be unwrapped in self.load_model via ModelWrapper.unwrap
+ if self.coordinator.is_master():
+ super().save_unsharded_model(model, checkpoint, gather_dtensor, use_safetensors)
+
+ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: str, gather_dtensor: bool):
+ """
+ Save optimizer to checkpoint but only on master process.
+ """
+ if self.coordinator.is_master():
+ super().save_unsharded_optimizer(optimizer, checkpoint, gather_dtensor)
+
+ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """
+ Save model to checkpoint but only on master process.
+ """
+ if self.coordinator.is_master():
+ super().save_lr_scheduler(lr_scheduler, checkpoint)
+
+
+class TorchDDPModel(ModelWrapper):
+
+ def __init__(self, module: nn.Module, *args, **kwargs) -> None:
+ super().__init__(module)
+ self.module = DDP(module, *args, **kwargs)
+
+ def unwrap(self):
+ return self.module.module
+
+
+class TorchDDPPlugin(Plugin):
+ """
+ Plugin for PyTorch DDP.
+
+ Example:
+ >>> from colossalai.booster import Booster
+ >>> from colossalai.booster.plugin import TorchDDPPlugin
+ >>>
+ >>> model, train_dataset, optimizer, criterion = ...
+ >>> plugin = TorchDDPPlugin()
+
+ >>> train_dataloader = plugin.prepare_train_dataloader(train_dataset, batch_size=8)
+ >>> booster = Booster(plugin=plugin)
+ >>> model, optimizer, train_dataloader, criterion = booster.boost(model, optimizer, train_dataloader, criterion)
+
+ Args:
+ broadcast_buffers (bool, optional): Whether to broadcast buffers in the beginning of training. Defaults to True.
+ bucket_cap_mb (int, optional): The bucket size in MB. Defaults to 25.
+ find_unused_parameters (bool, optional): Whether to find unused parameters. Defaults to False.
+ check_reduction (bool, optional): Whether to check reduction. Defaults to False.
+ gradient_as_bucket_view (bool, optional): Whether to use gradient as bucket view. Defaults to False.
+ static_graph (bool, optional): Whether to use static graph. Defaults to False.
+ """
+
+ def __init__(self,
+ broadcast_buffers: bool = True,
+ bucket_cap_mb: int = 25,
+ find_unused_parameters: bool = False,
+ check_reduction: bool = False,
+ gradient_as_bucket_view: bool = False,
+ static_graph: bool = False) -> None:
+
+ assert dist.is_initialized(
+ ), 'torch.distributed is not initialized, please use colossalai.launch to create the distributed environment'
+ self.rank = dist.get_rank()
+ self.world_size = dist.get_world_size()
+ self.ddp_kwargs = dict(broadcast_buffers=broadcast_buffers,
+ bucket_cap_mb=bucket_cap_mb,
+ find_unused_parameters=find_unused_parameters,
+ check_reduction=check_reduction,
+ gradient_as_bucket_view=gradient_as_bucket_view,
+ static_graph=static_graph)
+
+ def support_no_sync(self) -> bool:
+ return True
+
+ def control_precision(self) -> bool:
+ return False
+
+ def supported_precisions(self) -> List[str]:
+ return ['fp16', 'fp16_apex', 'bf16', 'fp8']
+
+ def control_device(self) -> bool:
+ return True
+
+ def supported_devices(self) -> List[str]:
+ return ['cuda']
+
+ def prepare_train_dataloader(self,
+ dataset,
+ batch_size,
+ shuffle=False,
+ seed=1024,
+ drop_last=False,
+ pin_memory=False,
+ num_workers=0,
+ **kwargs):
+ r"""
+ Prepare a dataloader for distributed training. The dataloader will be wrapped by
+ `torch.utils.data.DataLoader` and `torch.utils.data.DistributedSampler`.
+
+ Note:
+ 1. Evaluation datasets should not be passed to this function.
+
+ Args:
+ dataset (`torch.utils.data.Dataset`): The dataset to be loaded.
+ shuffle (bool, optional): Whether to shuffle the dataset. Defaults to False.
+ seed (int, optional): Random worker seed for sampling, defaults to 1024.
+ add_sampler: Whether to add ``DistributedDataParallelSampler`` to the dataset. Defaults to True.
+ drop_last (bool, optional): Set to True to drop the last incomplete batch, if the dataset size
+ is not divisible by the batch size. If False and the size of dataset is not divisible by
+ the batch size, then the last batch will be smaller, defaults to False.
+ pin_memory (bool, optional): Whether to pin memory address in CPU memory. Defaults to False.
+ num_workers (int, optional): Number of worker threads for this dataloader. Defaults to 0.
+ kwargs (dict): optional parameters for ``torch.utils.data.DataLoader``, more details could be found in
+ `DataLoader `_.
+
+ Returns:
+ :class:`torch.utils.data.DataLoader`: A DataLoader used for training or testing.
+ """
+ _kwargs = kwargs.copy()
+ sampler = DistributedSampler(dataset, num_replicas=self.world_size, rank=self.rank, shuffle=shuffle)
+
+ # Deterministic dataloader
+ def seed_worker(worker_id):
+ worker_seed = seed
+ np.random.seed(worker_seed)
+ torch.manual_seed(worker_seed)
+ random.seed(worker_seed)
+
+ return DataLoader(dataset,
+ batch_size=batch_size,
+ sampler=sampler,
+ worker_init_fn=seed_worker,
+ drop_last=drop_last,
+ pin_memory=pin_memory,
+ num_workers=num_workers,
+ **_kwargs)
+
+ def configure(
+ self,
+ model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Callable = None,
+ dataloader: DataLoader = None,
+ lr_scheduler: LRScheduler = None,
+ ) -> Tuple[Union[nn.Module, OptimizerWrapper, LRScheduler, DataLoader]]:
+ # cast model to cuda
+ model = model.cuda()
+
+ # convert model to sync bn
+ model = nn.SyncBatchNorm.convert_sync_batchnorm(model, None)
+
+ # wrap the model with PyTorch DDP
+ model = TorchDDPModel(model, **self.ddp_kwargs)
+
+ if not isinstance(optimizer, OptimizerWrapper):
+ optimizer = OptimizerWrapper(optimizer)
+
+ return model, optimizer, criterion, dataloader, lr_scheduler
+
+ def control_checkpoint_io(self) -> bool:
+ return True
+
+ def get_checkpoint_io(self) -> CheckpointIO:
+ return TorchDDPCheckpointIO()
diff --git a/colossalai/builder/__init__.py b/colossalai/builder/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf09e1e7a31a15e979c5358c5da27683a0ccb2f9
--- /dev/null
+++ b/colossalai/builder/__init__.py
@@ -0,0 +1,3 @@
+from .builder import build_from_config, build_from_registry, build_gradient_handler
+
+__all__ = ['build_gradient_handler', 'build_from_config', 'build_from_registry']
diff --git a/colossalai/builder/builder.py b/colossalai/builder/builder.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a907601327c9c938243bfee121165937c02537c
--- /dev/null
+++ b/colossalai/builder/builder.py
@@ -0,0 +1,79 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import inspect
+
+from colossalai.registry import *
+
+
+def build_from_config(module, config: dict):
+ """Returns an object of :class:`module` constructed from `config`.
+
+ Args:
+ module: A python or user-defined class
+ config: A python dict containing information used in the construction of the return object
+
+ Returns: An ``object`` of interest
+
+ Raises:
+ AssertionError: Raises an AssertionError if `module` is not a class
+
+ """
+ assert inspect.isclass(module), 'module must be a class'
+ return module(**config)
+
+
+def build_from_registry(config, registry: Registry):
+ r"""Returns an object constructed from `config`, the type of the object
+ is specified by `registry`.
+
+ Note:
+ the `config` is used to construct the return object such as `LAYERS`, `OPTIMIZERS`
+ and other support types in `registry`. The `config` should contain
+ all required parameters of corresponding object. The details of support
+ types in `registry` and the `mod_type` in `config` could be found in
+ `registry `_.
+
+ Args:
+ config (dict or :class:`colossalai.context.colossalai.context.Config`): information
+ used in the construction of the return object.
+ registry (:class:`Registry`): A registry specifying the type of the return object
+
+ Returns:
+ A Python object specified by `registry`.
+
+ Raises:
+ Exception: Raises an Exception if an error occurred when building from registry.
+ """
+ config_ = config.copy() # keep the original config untouched
+ assert isinstance(registry, Registry), f'Expected type Registry but got {type(registry)}'
+
+ mod_type = config_.pop('type')
+ assert registry.has(mod_type), f'{mod_type} is not found in registry {registry.name}'
+ try:
+ obj = registry.get_module(mod_type)(**config_)
+ except Exception as e:
+ print(f'An error occurred when building {mod_type} from registry {registry.name}', flush=True)
+ raise e
+
+ return obj
+
+
+def build_gradient_handler(config, model, optimizer):
+ """Returns a gradient handler object of :class:`BaseGradientHandler` constructed from `config`,
+ `model` and `optimizer`.
+
+ Args:
+ config (dict or :class:`colossalai.context.Config`): A python dict or
+ a :class:`colossalai.context.Config` object containing information
+ used in the construction of the ``GRADIENT_HANDLER``.
+ model (:class:`nn.Module`): A model containing parameters for the gradient handler
+ optimizer (:class:`torch.optim.Optimizer`): An optimizer object containing parameters for the gradient handler
+
+ Returns:
+ An object of :class:`colossalai.engine.BaseGradientHandler`
+ """
+ config_ = config.copy()
+ config_['model'] = model
+ config_['optimizer'] = optimizer
+ return build_from_registry(config_, GRADIENT_HANDLER)
diff --git a/colossalai/checkpoint_io/__init__.py b/colossalai/checkpoint_io/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c25048e25754eb6fc55db1b1de4ac7b21d05bda3
--- /dev/null
+++ b/colossalai/checkpoint_io/__init__.py
@@ -0,0 +1,5 @@
+from .checkpoint_io_base import CheckpointIO
+from .general_checkpoint_io import GeneralCheckpointIO
+from .index_file import CheckpointIndexFile
+
+__all__ = ['CheckpointIO', 'CheckpointIndexFile', 'GeneralCheckpointIO']
diff --git a/colossalai/checkpoint_io/checkpoint_io_base.py b/colossalai/checkpoint_io/checkpoint_io_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb853559c48c1a6ceb41231e312a2480fd68bd97
--- /dev/null
+++ b/colossalai/checkpoint_io/checkpoint_io_base.py
@@ -0,0 +1,330 @@
+from abc import ABC, abstractmethod
+from pathlib import Path
+from typing import Union
+from typing import Optional
+
+import torch
+import torch.nn as nn
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler as LRScheduler
+
+from colossalai.interface import ModelWrapper
+
+from .utils import has_index_file
+
+__all__ = ['CheckpointIO']
+
+
+class CheckpointIO(ABC):
+ """
+ CheckpointIO is the base class for all checkpoint IO classes. It defines the interface for checkpoint IO.
+
+
+ Examples:
+ >>> from colossalai.checkpoint_io import GeneralCheckpointIO
+ >>> checkpoint_io = CheckpointIO()
+ >>>
+ >>> # load model from checkpoint
+ >>> model = checkpoint_io.load_model(model, 'model.pt')
+ >>>
+ >>> # save model to checkpoint, any distributed tensor is gathered by default
+ >>> checkpoint_io.save_model(model, 'model.pt')
+ >>>
+ >>> # if the model contains distributed tensor, and you don't want to gather it
+ >>> # each rank will save its own shard of the distributed tensor
+ >>> checkpoint_io.save_model(model, 'model.pt', gather_dtensor=False)
+ >>>
+ >>> # save model to sharded checkpoints
+ >>> checkpoint_io.save_model(model, './checkpoints/', shard=True)
+ >>>
+ >>> # save model to sharded and assume we don't want to gather distributed tensors
+ >>> checkpoint_io.save_model(model, './checkpoints/', shard=True, gather_dtensor=False)
+ >>>
+ >>> # Note:
+ >>> # 1. we don't support loading from distributed tensors, conversion from distributed tensors
+ >>> # checkpoints to full tensor checkpoint should be done offline via our CLI
+ >>> # 2. you don't have to specify whether the model is sharded or not when loading the model
+ >>> # as it will be automatically detected
+ >>>
+ >>> # load model from sharded checkpoints
+ >>> model = checkpoint_io.load_model(model, './checkpoints/')
+ >>>
+ >>> # load model from unsharded checkpoints
+ >>> model = checkpoint_io.load_model(model, './checkpoints/')
+ >>>
+ >>> # load optimizer from checkpoint
+ >>> optimizer = checkpoint_io.load_optimizer(optimizer, 'optimizer.pt')
+ >>>
+ >>> # save optimizer to checkpoint
+ >>> checkpoint_io.save_optimizer(optimizer, 'optimizer.pt')
+ """
+
+ # ======================================
+ # Public methods
+ # ======================================
+ def load_model(self,
+ model: Union[nn.Module, ModelWrapper],
+ checkpoint: str,
+ strict: bool = True) -> Union[nn.Module, ModelWrapper]:
+ """
+ Load model from checkpoint.
+
+ Args:
+ model (nn.Module): model to be loaded.
+ checkpoint (str): checkpoint path. This value is made compatibility with the model checkpoints in the
+ mainstream model zoos such as Hugging Face and TIMM. The checkpoint path can be:
+ 1. a file path, e.g. 'model.pt'
+ 2. a path to a json file which defines the index to the sharded checkpoint
+ 3. a path to a folder containing a unique .index.json file for sharded checkpoint
+ Distributed tensors cannot be loaded directly unless gathered offline via our CLI.
+ strict (bool): whether to strictly enforce that the param name in
+ the checkpoint match the keys returned by this module's.
+ """
+ # since we only support loaded sharded and unsharded weight format
+ # containing no distributed tensors, dtensor -> full tensor conversion
+ # should be done offline via our CLI
+ # the existence of index file means it is a sharded checkpoint
+ ckpt_path = Path(checkpoint)
+ index_file_exists, index_file_path = has_index_file(checkpoint)
+
+ # return the origin model instead of the unwrapped model
+ origin_model = model
+
+ if isinstance(model, ModelWrapper):
+ model = model.unwrap()
+
+ if index_file_exists:
+ self.load_sharded_model(model, index_file_path, strict)
+ else:
+ self.load_unsharded_model(model, checkpoint, strict)
+
+ return origin_model
+
+ def save_model(self,
+ model: Union[nn.Module, ModelWrapper],
+ checkpoint: str,
+ shard: bool = False,
+ gather_dtensor: bool = True,
+ variant: str = None,
+ size_per_shard: int = 1024,
+ use_safetensors: bool = False):
+ """
+ Save model to checkpoint.
+
+ Examples:
+ >>> from colossalai.checkpoint_io import GeneralCheckpointIO
+ >>> checkpoint_io = CheckpointIO()
+ >>>
+ >>> # save model to a single file
+ >>> save_model(model, 'model.pt')
+ >>>
+ >>> # save model to a sharded checkpoint
+ >>> save_model(model, './checkpoints/', shard=True)
+
+ Args:
+ model (nn.Module): model to be saved.
+ checkpoint (str): checkpoint path. The checkpoint path can be :
+ 1. a file path, e.g. 'model.pt'
+ 2. a directory path to save the sharded checkpoint, e.g. './checkpoints/' when shard = True.
+ shard (bool): whether to shard the checkpoint. Default: False. If set to True, the checkpoint will be sharded into
+ multiple files. The model shards will be specified by a `model.index.json` file. When shard = True, please ensure
+ that the checkpoint path is a directory path instead of a file path.
+ gather_dtensor (bool): whether to gather the distributed tensor to the first device. Default: True.
+ variant (str): If specified, weights are saved in the format pytorch_model..bin. Default: None.
+ size_per_shard (int): size per shard in MB. Default: 1024. This value is only used when shard = True.
+ use_safetensors (bool): whether to use safe tensors. Default: False. If set to True, the checkpoint will be saved
+ """
+
+ if isinstance(model, ModelWrapper):
+ model = model.unwrap()
+
+ if shard:
+ self.save_sharded_model(model, checkpoint, gather_dtensor, variant, size_per_shard, use_safetensors)
+ else:
+ self.save_unsharded_model(model, checkpoint, gather_dtensor, use_safetensors)
+
+ def load_optimizer(self, optimizer: Optimizer, checkpoint: str):
+ """
+ Load optimizer from checkpoint.
+
+ Args:
+ optimizer (Optimizer): optimizer to be loaded.
+ checkpoint (str): checkpoint path. This value is made compatibility with the model checkpoints in the
+ """
+ index_file_exists, index_file_path = has_index_file(checkpoint)
+
+ if Path(checkpoint).is_dir() and not index_file_exists:
+ # if the checkpoint is a directory and there is no index file, raise error
+ raise ValueError(f'Cannot find index file in {checkpoint}')
+
+ if index_file_exists:
+ # the existence of index file means it is a sharded checkpoint
+ self.load_sharded_optimizer(optimizer, index_file_path)
+ else:
+ self.load_unsharded_optimizer(optimizer, checkpoint)
+
+ def save_optimizer(self,
+ optimizer: Optimizer,
+ checkpoint: str,
+ shard: bool = False,
+ gather_dtensor=True,
+ prefix: str = None,
+ size_per_shard: int = 1024):
+ """
+ Save optimizer to checkpoint. Optimizer states saving is not compatible with safetensors.
+
+ Args:
+ optimizer (Optimizer): optimizer to be saved.
+ checkpoint (str): checkpoint path. The checkpoint path can be :
+ 1. a file path, e.g. 'model.pt'
+ 2. a path to a json file which defines the index to the sharded checkpoint for the optimizer
+ 3. a path to a folder containing a unique .index.json file for sharded checkpoint
+ shard (bool): whether to shard the checkpoint. Default: False. If set to True, the checkpoint will be sharded into
+ multiple files. The optimizer shards will be specified by a `optimizer.index.json` file.
+ gather_dtensor (bool): whether to gather the distributed tensor to the first device. Default: True.
+ prefix (str): prefix for the optimizer checkpoint when shard = True. Default: None.
+ size_per_shard (int): size per shard in MB. Default: 1024. This value is only used when shard is set to True.
+ """
+ if shard:
+ self.save_sharded_optimizer(optimizer, checkpoint, gather_dtensor, prefix, size_per_shard)
+ else:
+ self.save_unsharded_optimizer(optimizer, checkpoint, gather_dtensor)
+
+ # ========================================================
+ # Abstract methods for model loading/saving implementation
+ # ========================================================
+ @abstractmethod
+ def load_sharded_model(self, model: nn.Module, index_file_path: str, strict: bool):
+ """
+ Load model from sharded checkpoint.
+
+ Args:
+ model (nn.Module): model to be loaded.
+ index_file_path (str): checkpoint path. It should be path to the .index.json file or a path to a directory which contains a .index.json file.
+ strict (bool): whether to strictly enforce that the param name in
+ the checkpoint match the keys returned by this module's.
+ """
+ pass
+
+ @abstractmethod
+ def load_unsharded_model(self, model: nn.Module, checkpoint: str, strict: bool):
+ """
+ Load model from unsharded checkpoint.
+
+ Args:
+ model (nn.Module): model to be loaded.
+ checkpoint (str): checkpoint path. It should be a single file path pointing to a model weight binary.
+ strict (bool): whether to strictly enforce that the param name in
+ the checkpoint match the keys returned by this module's.
+ """
+ pass
+
+ @abstractmethod
+ def save_sharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, variant: Optional[str],
+ size_per_shard: int, use_safetensors: bool):
+ """
+ Save model to sharded checkpoint.
+
+ Args:
+ model (nn.Module): model to be saved.
+ checkpoint (str): checkpoint path. It should be a directory path.
+ gather_dtensor (bool): whether to gather the distributed tensor to the first device.
+ prefix (str): prefix for the model checkpoint.
+ size_per_shard (int): size per shard in MB.
+ use_safetensors (bool): whether to use safe tensors.
+ """
+ pass
+
+ @abstractmethod
+ def save_unsharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, use_safetensors: bool):
+ """
+ Save model to unsharded checkpoint.
+
+ Args:
+ model (nn.Module): model to be saved.
+ checkpoint (str): checkpoint path. It should be a single file path pointing to a model weight binary.
+ gather_dtensor (bool): whether to gather the distributed tensor to the first device.
+ use_safetensors (bool): whether to use safe tensors.
+ """
+ pass
+
+ # ========================================================
+ # Abstract methods for optimizer loading/saving implementation
+ # ========================================================
+
+ @abstractmethod
+ def load_sharded_optimizer(self, optimizer: Optimizer, index_file_path: str, prefix: str, size_per_shard: int):
+ """
+ Load optimizer from sharded checkpoint.
+
+ Args:
+ optimizer (Optimizer): optimizer to be loaded.
+ index_file_path (str): checkpoint path. It should be path to the .index.json file or a path to a directory which contains a .index.json file.
+ prefix (str): prefix for the optimizer checkpoint.
+ size_per_shard (int): size per shard in MB.
+ """
+ pass
+
+ @abstractmethod
+ def load_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path):
+ """
+ Load optimizer from unsharded checkpoint.
+
+ Args:
+ optimizer (Optimizer): optimizer to be loaded.
+ checkpoint (str): checkpoint path. It should be a single file path pointing to a model weight binary.
+ """
+ pass
+
+ @abstractmethod
+ def save_sharded_optimizer(self, optimizer: Optimizer, checkpoint: Path, gather_dtensor: bool, prefix: str,
+ size_per_shard: int):
+ """
+ Save optimizer to sharded checkpoint.
+
+ Args:
+ optimizer (Optimizer): optimizer to be saved.
+ checkpoint (Path): checkpoint path. It should be a directory path.
+ gather_dtensor (bool): whether to gather the distributed tensor to the first device.
+ prefix (str): prefix for the optimizer checkpoint.
+ size_per_shard (int): size per shard in MB.
+ """
+ pass
+
+ @abstractmethod
+ def save_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path, gather_dtensor: bool):
+ """
+ Save optimizer to unsharded checkpoint.
+
+ Args:
+ optimizer (Optimizer): optimizer to be saved.
+ checkpoint (str): checkpoint path. It should be a single file path pointing to a model weight binary.
+ gather_dtensor (bool): whether to gather the distributed tensor to the first device.
+ """
+ pass
+
+ # ============================================
+ # methods for loading and saving lr scheduler
+ # as this is quite standard, there is no need
+ # to make them abstract
+ # ============================================
+ def save_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """
+ Save lr scheduler to checkpoint.
+
+ Args:
+ lr_scheduler (LRScheduler): lr scheduler to be saved.
+ checkpoint: checkpoint path. The checkpoint path can only be a file path.
+ """
+ torch.save(lr_scheduler.state_dict(), checkpoint)
+
+ def load_lr_scheduler(self, lr_scheduler: LRScheduler, checkpoint: str):
+ """
+ Load lr scheduler from checkpoint.
+
+ Args:
+ lr_scheduler (LRScheduler): lr scheduler to be loaded.
+ checkpoint (str): the path for a single checkpoint file.
+ """
+ state_dict = torch.load(checkpoint)
+ lr_scheduler.load_state_dict(state_dict)
diff --git a/colossalai/checkpoint_io/general_checkpoint_io.py b/colossalai/checkpoint_io/general_checkpoint_io.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf584f45d045228c5d6d1e02b470c7696f5194db
--- /dev/null
+++ b/colossalai/checkpoint_io/general_checkpoint_io.py
@@ -0,0 +1,138 @@
+from pathlib import Path
+
+import torch.nn as nn
+from torch.optim import Optimizer
+import logging
+import os
+import json
+import gc
+from typing import Optional
+
+from .checkpoint_io_base import CheckpointIO
+from .index_file import CheckpointIndexFile
+from .utils import (
+ has_index_file,
+ load_state_dict,
+ save_state_dict,
+ is_safetensors_available,
+ shard_checkpoint,
+ load_shard_state_dict,
+ load_state_dict_into_model,
+ add_variant
+ )
+from .utils import SAFE_WEIGHTS_NAME, WEIGHTS_NAME, SAFE_WEIGHTS_INDEX_NAME, WEIGHTS_INDEX_NAME
+
+
+__all__ = ['GeneralCheckpointIO']
+
+
+class GeneralCheckpointIO(CheckpointIO):
+ """
+ Checkpoint IO
+ """
+ def load_unsharded_model(self, model: nn.Module, checkpoint: str, strict: bool):
+ checkpoint = load_state_dict(checkpoint)
+ model.load_state_dict(checkpoint, strict=strict)
+
+ def save_unsharded_model(self, model: nn.Module, checkpoint: str, gather_dtensor: bool, use_safetensors: bool):
+ state_dict = model.state_dict()
+
+ # TODO(FrankLeeeee): add support for gather_dtensor
+ if gather_dtensor:
+ pass
+
+ # save the checkpoint
+ save_state_dict(state_dict, checkpoint, use_safetensors)
+
+ def load_sharded_optimizer(self, optimizer: Optimizer, checkpoint: Path, prefix: str, size_per_shard: int):
+ raise NotImplementedError("Sharded optimizer checkpoint is not supported yet.")
+
+ def load_unsharded_optimizer(self, optimizer: Optimizer, checkpoint: Path):
+ checkpoint = load_state_dict(checkpoint)
+ optimizer.load_state_dict(checkpoint)
+
+ def save_sharded_optimizer(
+ self,
+ optimizer: Optimizer,
+ checkpoint: Path,
+ gather_dtensor: bool,
+ prefix: str,
+ size_per_shard: int,
+ ):
+ raise NotImplementedError("Sharded optimizer checkpoint is not supported yet.")
+
+ def save_unsharded_optimizer(
+ self,
+ optimizer: Optimizer,
+ checkpoint: Path,
+ gather_dtensor: bool,
+ ):
+ # TODO(FrankLeeeee): handle distributed tensors
+ save_state_dict(optimizer.state_dict(), checkpoint, use_safetensors=False)
+
+
+ def save_sharded_model(self, model: nn.Module, checkpoint_path: str, gather_dtensor:bool = False,
+ variant: Optional[str] = None, max_shard_size: int = 1024, use_safetensors: bool = False):
+ """
+ implement this method as it can be supported by Huggingface model,
+ save shard model, save model to multiple files
+ """
+ if os.path.isfile(checkpoint_path):
+ logging.error(f"Provided path ({checkpoint_path}) should be a directory, not a file")
+ return
+
+ Path(checkpoint_path).mkdir(parents=True, exist_ok=True)
+
+ # shard checkpoint
+ state_dict = model.state_dict()
+ weights_name = SAFE_WEIGHTS_NAME if use_safetensors else WEIGHTS_NAME
+ weights_name = add_variant(weights_name, variant)
+ shards, index = shard_checkpoint(state_dict, max_shard_size=max_shard_size, weights_name=weights_name)
+
+ # Save the model
+ for shard_file, shard in shards.items():
+ checkpoint_file_path = os.path.join(checkpoint_path, shard_file)
+ save_state_dict(shard, checkpoint_file_path, use_safetensors)
+
+ # save index file
+ save_index_file = SAFE_WEIGHTS_INDEX_NAME if use_safetensors else WEIGHTS_INDEX_NAME
+
+ save_index_file = os.path.join(checkpoint_path, add_variant(save_index_file, variant))
+ with open(save_index_file, "w", encoding="utf-8") as f:
+ content = json.dumps(index, indent=2, sort_keys=True) + "\n"
+ f.write(content)
+ logging.info(
+ f"The model is bigger than the maximum size per checkpoint ({max_shard_size}) and is going to be "
+ f"split in {len(shards)} checkpoint shards. You can find where each parameters has been saved in the "
+ f"index located at {save_index_file}."
+ )
+
+
+ def load_sharded_model(self, model: nn.Module, checkpoint_index_file: Path, strict: bool = False, use_safetensors: bool = False):
+ """
+ load shard model, load model from multiple files
+ """
+ use_safetensors = False
+ if "safetensors" in checkpoint_index_file.name:
+ use_safetensors = True
+
+ if use_safetensors and not is_safetensors_available():
+ raise ImportError("`safe_serialization` requires the `safetensors` library: `pip install safetensors`.")
+
+ # read checkpoint index file
+ ckpt_index_file = CheckpointIndexFile.from_file(checkpoint_index_file)
+ checkpoint_files, _ = ckpt_index_file.get_checkpoint_fileanames()
+ missing_keys = ckpt_index_file.get_all_param_names()
+
+ for shard_file in checkpoint_files:
+ state_dict = load_shard_state_dict(Path(shard_file), use_safetensors)
+ load_state_dict_into_model(model, state_dict, missing_keys, strict)
+ del state_dict
+ gc.collect()
+
+ if strict and len(missing_keys) > 0:
+ error_msgs = 'Missing key(s) in state_dict: {}. '.format(
+ ', '.join('"{}"'.format(k) for k in missing_keys))
+ raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
+ self.__class__.__name__, "\n\t".join(error_msgs)))
+
diff --git a/colossalai/checkpoint_io/index_file.py b/colossalai/checkpoint_io/index_file.py
new file mode 100644
index 0000000000000000000000000000000000000000..89224787a91b9824f2261aece909f6a1cb094a17
--- /dev/null
+++ b/colossalai/checkpoint_io/index_file.py
@@ -0,0 +1,156 @@
+import json
+from pathlib import Path
+from typing import Any, List, Union
+
+from .utils import is_dtensor_checkpoint
+
+__all__ = ['CheckpointIndexFile']
+
+
+class CheckpointIndexFile:
+ """
+ This class is a data structure to keep the content in the index.json file for sharded checkpoint.
+
+ Example:
+ >>> index = CheckpointIndexFile.from_file('model.index.json')
+ >>> index.append_metadata('model_type', 'bert')
+ >>> index.append_weight_map('bert.embeddings.word_embeddings.weight', 'model_0001-of-0002.bin')
+ >>> index.export('new_index.json')
+ """
+
+ def __init__(self) -> None:
+ self.root_path = None
+ self.metadata: dict = dict()
+ self.weight_map: dict = dict()
+
+ @staticmethod
+ def from_file(index_path: Union[str, Path]):
+ """
+ Create a CheckpointIndexFile object from a json file.
+
+ Args:
+ index_path (str): path to the json file.
+
+ Returns:
+ CheckpointIndexFile: CheckpointIndexFile object.
+ """
+ index = CheckpointIndexFile()
+ index.load(index_path)
+ return index
+
+ def load(self, json_path: str):
+ """
+ Load the index file from a json file.
+
+ Args:
+ json_path (str): path to the json file.
+ """
+ # load the json file
+ with open(json_path, 'r') as f:
+ index = json.load(f)
+
+ # assign attributes if exists
+ if "metadata" in index:
+ self.metadata = index["metadata"]
+ if "weight_map" in index:
+ self.weight_map = index["weight_map"]
+
+ # assign the root directory for the index file
+ self.root_path = Path(json_path).absolute().parent
+
+ def export(self, json_path: str):
+ """
+ Export the index file to a json file.
+
+ Args:
+ json_path (str): path to the json file.
+ """
+ # create the index file
+ index = dict()
+ index["metadata"] = self.metadata
+ index["weight_map"] = self.weight_map
+
+ # export the index file
+ with open(json_path, 'w') as f:
+ json.dump(index, f, indent=4)
+
+ def append_weight_map(self, param_name: str, shard_file: str):
+ """
+ Append a weight map entry to the index file.
+
+ Args:
+ param_name (str): name of the parameter.
+ shard_file (str): name of the shard file.
+ """
+ self.weight_map[param_name] = shard_file
+
+ def append_meta_data(self, name: str, val: Any):
+ """
+ Append a metadata entry to the index file.
+
+ Args:
+ name (str): name of the metadata.
+ val (Any): value of the metadata.
+ """
+ self.metadata[name] = val
+
+ def contains_dtensor(self):
+ """
+ Check if the index file contains any distributed tensor. The distributed tensors will be stored in
+ `dtensor/module.linear.weight.*.bin` or `dtensor/module.linear.weight.*.safetensors` in the weight map.
+
+ Returns:
+ bool: True if the index file contains any distributed tensor, False otherwise.
+ """
+ for value in self.weight_map.values():
+ if value.endswith(".*.bin") or value.endswith(".*.safetensors"):
+ return True
+ return False
+
+ def get_checkpoint_fileanames(self) -> List[str]:
+ """
+ Get the set of checkpoint filenames in the weight map.
+
+ Returns:
+ list: checkpoint shard filenames.
+ """
+ # read the checkpoint file list from the json file and get a list of unique file names
+ checkpoint_files = sorted(list(set(self.weight_map.values())))
+
+ # get the absolute paths for all checkpoint files
+ checkpoint_files = [str(self.root_path.joinpath(f)) for f in checkpoint_files]
+
+ dtensor_list = []
+ checkpoint_list = []
+
+ for ckpt_file in checkpoint_files:
+ if is_dtensor_checkpoint(ckpt_file):
+ dtensor_list.append(ckpt_file)
+ else:
+ checkpoint_list.append(ckpt_file)
+
+ return checkpoint_list, dtensor_list
+
+ def assert_no_dtensor_checkpoint(self):
+ for val in self.weight_map.values():
+ if is_dtensor_checkpoint(val):
+ raise ValueError(f"Checkpoint file {val} contains distributed tensor")
+
+ def get_checkpoint_file(self, param_name: str) -> str:
+ """
+ Get the checkpoint file name for a parameter.
+
+ Args:
+ param_name (str): name of the parameter.
+
+ Returns:
+ str: checkpoint file name.
+ """
+ ckpt_path = self.weight_map[param_name]
+ return ckpt_path
+
+ def get_all_param_names(self):
+ """
+ Get all the weight keys.
+ """
+ return list(self.weight_map.keys())
diff --git a/colossalai/checkpoint_io/utils.py b/colossalai/checkpoint_io/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..37d22d08df40eaaa209ad32b097ce735a14378dc
--- /dev/null
+++ b/colossalai/checkpoint_io/utils.py
@@ -0,0 +1,419 @@
+# coding=utf-8
+from pathlib import Path
+import torch
+import torch.nn as nn
+from typing import List, Dict, Mapping, OrderedDict, Optional, Tuple
+from colossalai.tensor.d_tensor.d_tensor import DTensor
+import re
+
+SAFE_WEIGHTS_NAME = "model.safetensors"
+WEIGHTS_NAME = "pytorch_model.bin"
+SAFE_WEIGHTS_INDEX_NAME = "model.safetensors.index.json"
+WEIGHTS_INDEX_NAME = "pytorch_model.bin.index.json"
+
+# ======================================
+# General helper functions
+# ======================================
+
+def calculate_tensor_size(tensor: torch.Tensor) -> float:
+ """
+ Calculate the size of a parameter in MB. Used to compute whether a group of params exceed the shard size.
+ If so, a new shard should be created.
+
+ Args:
+ tenosr (torch.Tensor): the tensor to calculate size for.
+
+ Returns:
+ float: size of the tensor in MB.
+ """
+ return tensor.numel() * tensor.element_size() / 1024 / 1024
+
+def is_safetensors_available() -> bool:
+ """
+ Check whether safetensors is available.
+
+ Returns:
+ bool: whether safetensors is available.
+ """
+ try:
+ import safetensors
+ return True
+ except ImportError:
+ return False
+
+
+def is_dtensor_checkpoint(checkpoint_file_path: str) -> bool:
+ """
+ Check whether the checkpoint file is a dtensor checkpoint.
+
+ Args:
+ checkpoint_file_path (str): path to the checkpoint file.
+
+ Returns:
+ bool: whether the checkpoint file is a dtensor checkpoint.
+ """
+ if checkpoint_file_path.endswith('.*.safetensors') or checkpoint_file_path.endswith('.*.bin'):
+ return True
+ else:
+ return False
+
+
+def is_safetensor_checkpoint(checkpoint_file_path: str) -> bool:
+ """
+ Check whether the checkpoint file is a safetensor checkpoint.
+
+ Args:
+ checkpoint_file_path (str): path to the checkpoint file.
+
+ Returns:
+ bool: whether the checkpoint file is a safetensor checkpoint.
+ """
+ if checkpoint_file_path.endswith('.safetensors'):
+ return True
+ else:
+ return False
+
+
+# ======================================
+# Helper functions for saving shard file
+# ======================================
+def shard_checkpoint(state_dict: torch.Tensor, max_shard_size: int = 1024, weights_name: str = WEIGHTS_NAME):
+
+ """
+ Splits a model state dictionary in sub-checkpoints so that the final size of each sub-checkpoint does not exceed a
+ given size.
+ """
+ sharded_state_dicts = []
+ current_block = {}
+ current_block_size = 0
+ total_size = 0
+
+ for key, weight in state_dict.items():
+ if type(weight) != DTensor:
+ weight_size = calculate_tensor_size(weight)
+
+ # If this weight is going to tip up over the maximal size, we split.
+ if current_block_size + weight_size > max_shard_size:
+ sharded_state_dicts.append(current_block)
+ current_block = {}
+ current_block_size = 0
+
+ current_block[key] = weight
+ current_block_size += weight_size
+ total_size += weight_size
+
+ # Add the last block
+ sharded_state_dicts.append(current_block)
+
+ # If we only have one shard, we return it
+ if len(sharded_state_dicts) == 1:
+ return {weights_name: sharded_state_dicts[0]}, None
+
+ # Otherwise, let's build the index
+ weight_map = {}
+ shards = {}
+
+ for idx, shard in enumerate(sharded_state_dicts):
+ shard_file = weights_name.replace(".bin", f"-{idx+1:05d}-of-{len(sharded_state_dicts):05d}.bin")
+ shard_file = shard_file.replace(
+ ".safetensors", f"-{idx + 1:05d}-of-{len(sharded_state_dicts):05d}.safetensors"
+ )
+ shards[shard_file] = shard
+ for key in shard.keys():
+ weight_map[key] = shard_file
+
+ # Add the metadata
+ metadata = {"total_size": total_size}
+ index = {"metadata": metadata, "weight_map": weight_map}
+ return shards, index
+
+def load_shard_state_dict(checkpoint_file: Path, use_safetensors: bool =False):
+ """
+ load shard state dict into model
+ """
+ if use_safetensors and not checkpoint_file.suffix == ".safetensors":
+ raise Exception("load the model using `safetensors`, but no file endwith .safetensors")
+ if use_safetensors:
+ from safetensors.torch import safe_open
+ from safetensors.torch import load_file as safe_load_file
+ with safe_open(checkpoint_file, framework="pt") as f:
+ metadata = f.metadata()
+ if metadata["format"] != "pt":
+ raise NotImplementedError(
+ f"Conversion from a {metadata['format']} safetensors archive to PyTorch is not implemented yet."
+ )
+ return safe_load_file(checkpoint_file)
+ else:
+ return torch.load(checkpoint_file)
+
+def load_state_dict_into_model(model: nn.Module, state_dict: torch.Tensor, missing_keys: List, strict: bool = False):
+ r"""Copies parameters and buffers from :attr:`state_dict` into
+ this module and its descendants.
+
+ Args:
+ state_dict (dict): a dict containing parameters and
+ persistent buffers.
+ """
+ if not isinstance(state_dict, Mapping):
+ raise TypeError("Expected state_dict to be dict-like, got {}.".format(type(state_dict)))
+
+ unexpected_keys: List[str] = []
+ sub_missing_keys: List[str] = []
+ error_msgs: List[str] = []
+
+ # copy state_dict so _load_from_state_dict can modify it
+ metadata = getattr(state_dict, '_metadata', None)
+ state_dict = OrderedDict(state_dict)
+ if metadata is not None:
+ state_dict._metadata = metadata
+
+ def load(module: nn.Module, state_dict, prefix=""):
+ local_metadata = {} if metadata is None else metadata.get(prefix[:-1], {})
+ args = (state_dict, prefix, local_metadata, True, [], [], error_msgs)
+ # Parameters of module and children will start with prefix. We can exit early if there are none in this
+ # state_dict
+ if len([key for key in state_dict if key.startswith(prefix)]) > 0:
+ module._load_from_state_dict(*args)
+
+ for name, child in module._modules.items():
+ if child is not None:
+ load(child, state_dict, prefix + name + ".")
+
+ load(model, state_dict, "")
+ del load
+
+ # deal with missing key
+ if len(missing_keys) > 0:
+ deleted_keys = []
+ for key in missing_keys:
+ if key not in sub_missing_keys:
+ deleted_keys.append(key)
+ for key in deleted_keys:
+ missing_keys.remove(key)
+
+ if strict:
+ if len(unexpected_keys) > 0:
+ error_msgs = 'Unexpected key(s) in state_dict: {}. '.format(
+ ', '.join('"{}"'.format(k) for k in unexpected_keys))
+ raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
+ model.__class__.__name__, "\n\t".join(error_msgs)))
+
+# ======================================
+# Helper functions for saving state dict
+# ======================================
+
+
+def save_state_dict(state_dict: dict, checkpoint_file_path: str, use_safetensors: bool) -> None:
+ """
+ Save state dict to checkpoint.
+
+ Args:
+ state_dict (dict): state dict.
+ checkpoint_file_path (str): path to the checkpoint file.
+ use_safetensors (bool): whether to use safetensors to save the checkpoint.
+ """
+ if use_safetensors:
+ assert is_safetensors_available(), "safetensors is not available."
+ assert checkpoint_file_path.endswith('.safetensors'), \
+ "safetensors only supports .safetensors suffix for checkpoint file."
+ from safetensors.torch import save_file as safe_save_file
+ safe_save_file(state_dict, checkpoint_file_path, metadata={"format": "pt"})
+ else:
+ torch.save(state_dict, checkpoint_file_path)
+
+
+def save_dtensor(name: str, tensor: torch.Tensor, index_file: "CheckpointIndexFile", use_safetensors: bool) -> None:
+ """
+ Save distributed tensor to checkpoint. This checkpoint will be a dictionary which contains
+ only one tensor.
+
+ Args:
+ tensor (Tensor): tensor to be saved.
+ index_file (CheckpointIndexFile): path to the checkpoint file.
+ size_per_shard (int): size per shard in MB.
+ """
+ root_path = index_file.root_path
+ output_root_path = root_path.joinpath('dtensor')
+
+ # create directory
+ output_root_path.mkdir(exist_ok=True)
+
+ # save tensor to this directory
+ # TODO(YuliangLiu): get index of the tensor shard
+ # e.g. index =
+ index = 0
+
+ # save tensor to file
+ ckpt_file_name = generate_dtensor_file_name(name, index, use_safetensors)
+ ckpt_file_path = output_root_path.joinpath(ckpt_file_name)
+
+ # dtensor ckpt file always contains only one tensor
+ state_dict = {name: tensor}
+ save_state_dict(state_dict, str(ckpt_file_path), use_safetensors)
+
+ # update the weight map
+ # * means all shards
+ ckpt_file_name_in_weight_map = 'dtensor/' + generate_dtensor_file_name(name, '*', use_safetensors)
+ index_file.append_weight_map(name, ckpt_file_name_in_weight_map)
+
+
+def get_checkpoint_file_suffix(use_safetensors: bool) -> str:
+ """
+ Get checkpoint file suffix.
+
+ Args:
+ use_safetensors (bool): whether to use safetensors to save the checkpoint.
+
+ Returns:
+ str: checkpoint file suffix.
+ """
+ if use_safetensors:
+ return '.safetensors'
+ else:
+ return '.bin'
+
+
+def generate_checkpoint_shard_file_name(index: int,
+ total_number: int,
+ use_safetensors: bool,
+ prefix: str = None) -> str:
+ """
+ Generate checkpoint shard file name.
+
+ Args:
+ index (int): index of the shard.
+ total_number (int): total number of shards.
+ use_safetensors (bool): whether to use safetensors to save the checkpoint.
+ prefix (str): prefix of the shard file name. Default: None.
+
+ Returns:
+ str: checkpoint shard file name.
+ """
+ suffix = get_checkpoint_file_suffix(use_safetensors)
+
+ if prefix is None:
+ return f"{index:05d}-of-{total_number:05d}.{suffix}"
+ else:
+ return f"{prefix}-{index:05d}-of-{total_number:05d}.{suffix}"
+
+
+def generate_dtensor_file_name(param_name: str, index: int, use_safetensors: bool) -> str:
+ """
+ Generate dtensor file name.
+
+ Args:
+ param_name (str): name of the distributed parameter.
+ index (int): index of the shard.
+ use_safetensors (bool): whether to use safetensors to save the checkpoint.
+
+ Returns:
+ str: dtensor file name.
+ """
+ suffix = get_checkpoint_file_suffix(use_safetensors)
+ return f'{param_name}.{index}.{suffix}'
+
+
+def save_state_dict_as_shard(
+ state_dict: dict,
+ checkpoint_path: str,
+ index: int,
+ total_number: int,
+ use_safetensors: bool,
+ prefix: str = None,
+) -> None:
+ """
+ Save state dict as shard.
+
+ Args:
+ state_dict (dict): state dict.
+ checkpoint_path (str): path to the checkpoint file.
+ index (int): index of the shard.
+ total_number (int): total number of shards.
+ prefix (str): prefix of the shard file name.
+ use_safetensors (bool): whether to use safetensors to save the checkpoint.
+ """
+ # generate the shard name
+ shard_file_name = generate_checkpoint_shard_file_name(index, total_number, use_safetensors, prefix)
+ shard_file_path = Path(checkpoint_path).joinpath(shard_file_name).absolute()
+
+ # save the shard
+ save_state_dict(state_dict, str(shard_file_path), use_safetensors)
+
+
+# ========================================
+# Helper functions for loading state dict
+# ========================================
+
+
+def has_index_file(checkpoint_path: str) -> Tuple[bool, Optional[Path]]:
+ """
+ Check whether the checkpoint has an index file.
+
+ Args:
+ checkpoint_path (str): path to the checkpoint.
+
+ Returns:
+ Tuple[bool, Optional[Path]]: a tuple of (has_index_file, index_file_path)
+ """
+ checkpoint_path = Path(checkpoint_path)
+ if checkpoint_path.is_file():
+ # check if it is .index.json
+ reg = re.compile("(.*?).index((\..*)?).json")
+ if reg.fullmatch(checkpoint_path.name) is not None:
+ return True, checkpoint_path
+ else:
+ return False, None
+ elif checkpoint_path.is_dir():
+ # check if there is only one a file ending with .index.json in this directory
+ index_files = list(checkpoint_path.glob('*.index.*json'))
+
+ # if we found a .index.json file, make sure there is only one
+ if len(index_files) > 0:
+ assert len(
+ index_files
+ ) == 1, f'Expected to find one .index.json file in {checkpoint_path}, but found {len(index_files)}'
+
+ if len(index_files) == 1:
+ return True, index_files[0]
+ else:
+ return False, None
+
+
+def load_state_dict(checkpoint_file_path: Path):
+ """
+ Load state dict from checkpoint.
+
+ Args:
+ checkpoint_file_path (Path): path to the checkpoint file.
+
+ Returns:
+ dict: state dict.
+ """
+
+ assert not is_dtensor_checkpoint(checkpoint_file_path), \
+ f'Cannot load state dict from dtensor checkpoint {checkpoint_file_path}, you should convert the distributed tensors to gathered tensors with our CLI offline.'
+
+ if is_safetensor_checkpoint(checkpoint_file_path):
+ assert is_safetensors_available(), \
+ f'Cannot load state dict from safetensor checkpoint {checkpoint_file_path}, because safetensors is not available. Please install safetensors first with pip install safetensors.'
+ # load with safetensors
+ from safetensors import safe_open
+ state_dict = {}
+ with safe_open(checkpoint_file_path, framework="pt", device="cpu") as f:
+ for k in f.keys():
+ state_dict[k] = f.get_tensor(k)
+ return state_dict
+
+ else:
+ # load with torch
+ return torch.load(checkpoint_file_path)
+
+
+
+def add_variant(weights_name: str, variant: Optional[str] = None) -> str:
+ if variant is not None and len(variant) > 0:
+ splits = weights_name.split(".")
+ splits = splits[:-1] + [variant] + splits[-1:]
+ weights_name = ".".join(splits)
+
+ return weights_name
diff --git a/colossalai/cli/__init__.py b/colossalai/cli/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..658e35e4c72e77f7b3161bf86b0c9600a80562e5
--- /dev/null
+++ b/colossalai/cli/__init__.py
@@ -0,0 +1,3 @@
+from .cli import cli
+
+__all__ = ['cli']
diff --git a/colossalai/cli/benchmark/__init__.py b/colossalai/cli/benchmark/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..618ff8c61dd41ec83d567e7cd9103f2aa9921846
--- /dev/null
+++ b/colossalai/cli/benchmark/__init__.py
@@ -0,0 +1,28 @@
+import click
+
+from colossalai.context import Config
+
+from .benchmark import run_benchmark
+from .utils import *
+
+__all__ = ['benchmark']
+
+
+@click.command()
+@click.option("-g", "--gpus", type=int, default=None, help="Total number of devices to use.")
+@click.option("-b", "--batch_size", type=int, default=8, help="Batch size of the input tensor.")
+@click.option("-s", "--seq_len", type=int, default=512, help="Sequence length of the input tensor.")
+@click.option("-d", "--dimension", type=int, default=1024, help="Hidden dimension of the input tensor.")
+@click.option("-w", "--warmup_steps", type=int, default=10, help="The number of warmup steps.")
+@click.option("-p", "--profile_steps", type=int, default=50, help="The number of profiling steps.")
+@click.option("-l", "--layers", type=int, default=2)
+@click.option("-m",
+ "--model",
+ type=click.Choice(['mlp'], case_sensitive=False),
+ default='mlp',
+ help="Select the model to benchmark, currently only supports MLP")
+def benchmark(gpus: int, batch_size: int, seq_len: int, dimension: int, warmup_steps: int, profile_steps: int,
+ layers: int, model: str):
+ args_dict = locals()
+ args = Config(args_dict)
+ run_benchmark(args)
diff --git a/colossalai/cli/benchmark/benchmark.py b/colossalai/cli/benchmark/benchmark.py
new file mode 100644
index 0000000000000000000000000000000000000000..97a9f45722dd6a4c1e316d1e91f27439797ae17a
--- /dev/null
+++ b/colossalai/cli/benchmark/benchmark.py
@@ -0,0 +1,105 @@
+from functools import partial
+from typing import Dict, List
+
+import click
+import torch.multiprocessing as mp
+
+import colossalai
+from colossalai.cli.benchmark.utils import find_all_configs, get_batch_data, profile_model
+from colossalai.context import Config
+from colossalai.context.random import reset_seeds
+from colossalai.core import global_context as gpc
+from colossalai.logging import disable_existing_loggers, get_dist_logger
+from colossalai.testing import free_port
+from colossalai.utils import MultiTimer
+
+from .models import MLP
+
+
+def run_benchmark(args: Config) -> None:
+ """
+ Run benchmarking with torch.multiprocessing.
+ """
+
+ # sanity checks
+ if args.gpus is None:
+ click.echo("Error: --num_gpus is not given")
+ exit()
+ if args.gpus <= 1:
+ click.echo("Warning: tensor parallel will be activated with at least 2 devices.")
+
+ click.echo("=== Benchmarking Parameters ===")
+ for k, v in args.items():
+ click.echo(f'{k}: {v}')
+ click.echo('')
+
+ config_list = find_all_configs(args.gpus)
+
+ avail_ports = [free_port() for _ in range(len(config_list))]
+ run_func = partial(run_dist_profiling,
+ world_size=args.gpus,
+ port_list=avail_ports,
+ config_list=config_list,
+ hyperparams=args)
+ mp.spawn(run_func, nprocs=args.gpus)
+
+
+def run_dist_profiling(rank: int, world_size: int, port_list: List[int], config_list: List[Dict],
+ hyperparams: Config) -> None:
+ """
+ A function executed for profiling, this function should be spawn by torch.multiprocessing.
+
+ Args:
+ rank (int): rank of the process
+ world_size (int): the number of processes
+ port_list (List[int]): a list of free ports for initializing distributed networks
+ config_list (List[Dict]): a list of configuration
+ hyperparams (Config): the hyperparameters given by the user
+
+ """
+
+ # disable logging for clean output
+ disable_existing_loggers()
+ logger = get_dist_logger()
+ logger.set_level('WARNING')
+
+ for config, port in zip(config_list, port_list):
+ colossalai.launch(config=config, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ timer = MultiTimer()
+
+ # 1D parallel should be skipped if in_features or out_features is not able to be divided exactly by 1D parallel size.
+ if config.parallel.tensor.mode == '1d' and hyperparams.dimension % config.parallel.tensor.size != 0:
+ click.echo(
+ "1D parallel will be skipped because in_features or out_features is not able to be divided exactly by 1D parallel size."
+ )
+ continue
+
+ if hyperparams.model == 'mlp':
+ model = MLP(dim=hyperparams.dimension, layers=hyperparams.layers)
+ else:
+ if gpc.get_global_rank() == 0:
+ click.echo("Error: Invalid argument for --model")
+ exit()
+
+ data_func = partial(get_batch_data,
+ dim=hyperparams.dimension,
+ batch_size=hyperparams.batch_size,
+ seq_length=hyperparams.seq_len,
+ mode=config.parallel.tensor.mode)
+
+ fwd_time, bwd_time, max_allocated, max_cached = profile_model(model=model,
+ warmup_steps=hyperparams.warmup_steps,
+ profile_steps=hyperparams.profile_steps,
+ data_func=data_func,
+ timer=timer)
+
+ gpc.destroy()
+ reset_seeds()
+
+ if gpc.get_global_rank() == 0:
+ config_str = ', '.join([f'{k}: {v}' for k, v in config.parallel.tensor.items()])
+ click.echo(f"=== {config_str} ===")
+ click.echo(f"Average forward time: {fwd_time}")
+ click.echo(f"Average backward time: {bwd_time}")
+ click.echo(f"Max allocated GPU memory: {max_allocated}")
+ click.echo(f"Max cached GPU memory: {max_cached}\n")
diff --git a/colossalai/cli/benchmark/models.py b/colossalai/cli/benchmark/models.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8fd1c41a059806891713340f2ea4931ec9726f2
--- /dev/null
+++ b/colossalai/cli/benchmark/models.py
@@ -0,0 +1,18 @@
+import torch
+
+import colossalai.nn as col_nn
+
+
+class MLP(torch.nn.Module):
+
+ def __init__(self, dim: int, layers: int):
+ super().__init__()
+ self.layers = torch.nn.ModuleList()
+
+ for _ in range(layers):
+ self.layers.append(col_nn.Linear(dim, dim))
+
+ def forward(self, x):
+ for layer in self.layers:
+ x = layer(x)
+ return x
diff --git a/colossalai/cli/benchmark/utils.py b/colossalai/cli/benchmark/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..825b795f21f680bcb2e2ea5eee4b328c2e1777db
--- /dev/null
+++ b/colossalai/cli/benchmark/utils.py
@@ -0,0 +1,158 @@
+import math
+import time
+import torch
+
+from colossalai.utils import MultiTimer
+from colossalai.context import ParallelMode, Config
+from typing import List, Dict, Tuple, Callable
+
+
+def get_time_stamp() -> int:
+ """
+ Return the time stamp for profiling.
+
+ Returns:
+ time_stamp (int): the time given by time.time()
+ """
+
+ torch.cuda.synchronize()
+ time_stamp = time.time()
+ return time_stamp
+
+
+def get_memory_states() -> Tuple[float]:
+ """
+ Return the memory statistics.
+
+ Returns:
+ max_allocated (float): the allocated CUDA memory
+ max_cached (float): the cached CUDA memory
+ """
+
+ max_allocated = torch.cuda.max_memory_allocated() / (1024**3)
+ max_cached = torch.cuda.max_memory_reserved() / (1024**3)
+ torch.cuda.reset_peak_memory_stats()
+ torch.cuda.empty_cache()
+ return max_allocated, max_cached
+
+
+def find_all_configs(device_cnt: int) -> List[Dict]:
+ """
+ Find all possible configurations for tensor parallelism
+
+ Args:
+ device_cnt (int): the number of devices
+
+ Returns:
+ config_list (List[Dict]): a list of configurations
+ """
+
+ def _is_square(num):
+ # 2D parallel should be implemented with at least 2 devices.
+ if num <= 1:
+ return False
+ return math.floor(math.sqrt(num))**2 == num
+
+ def _is_cube(num):
+ # 3D parallel should be implemented with at least 2 devices.
+ if num <= 1:
+ return False
+ return math.floor(num**(1. / 3.))**3 == num
+
+ config_list = []
+
+ # add non-parallel config
+ config = dict(parallel=dict(tensor=dict(size=device_cnt, mode=None)))
+ config_list.append(config)
+
+ # add 1D config
+ config = dict(parallel=dict(tensor=dict(size=device_cnt, mode='1d')))
+ config_list.append(config)
+
+ # add 2D config only if device_cnt is a square
+ if _is_square(device_cnt):
+ config = dict(parallel=dict(tensor=dict(size=device_cnt, mode='2d')))
+ config_list.append(config)
+
+ # check for 2.5D
+ # iterate over depth
+ for depth in range(1, device_cnt):
+ if device_cnt % depth == 0 and _is_square(device_cnt // depth):
+ config = dict(parallel=dict(tensor=dict(size=device_cnt, mode='2.5d', depth=depth)))
+ config_list.append(config)
+
+ # check for 3D if device_cnt is a cube
+ if _is_cube(device_cnt):
+ config = dict(parallel=dict(tensor=dict(size=device_cnt, mode='3d')))
+ config_list.append(config)
+
+ config_list = [Config(cfg) for cfg in config_list]
+ return config_list
+
+
+def profile_model(model: torch.nn.Module, warmup_steps: int, profile_steps: int, data_func: Callable,
+ timer: MultiTimer) -> Tuple[float]:
+ """
+ Profile the forward and backward of a model
+
+ Args:
+ model (torch.nn.Module): a PyTorch model
+ warmup_steps (int): the number of steps for warmup
+ profile_steps (int): the number of steps for profiling
+ data_func (Callable): a function to generate random data
+ timer (colossalai.utils.Multitimer): a timer instance for time recording
+
+ Returns:
+ fwd_time (float): the average forward time taken by forward pass in second
+ bwd_time (float): the average backward time taken by forward pass in second
+ max_allocated (float): the maximum GPU memory allocated in GB
+ max_cached (float): the maximum GPU memory cached in GB
+ """
+
+ def _run_step(data):
+ timer.start('forward')
+ out = model(data)
+ timer.stop('forward', keep_in_history=True)
+ timer.start('backward')
+ out.mean().backward()
+ timer.stop('backward', keep_in_history=True)
+
+ data_list = [data_func() for _ in range(warmup_steps)]
+ for data in data_list:
+ _run_step(data)
+ timer.reset('forward')
+ timer.reset('backward')
+
+ for _ in range(profile_steps):
+ data = data_func()
+ _run_step(data)
+
+ max_allocated, max_cached = get_memory_states()
+ fwd_time = timer.get_timer('forward').get_history_mean()
+ bwd_time = timer.get_timer('backward').get_history_mean()
+ return fwd_time, bwd_time, max_allocated, max_cached
+
+
+def get_batch_data(dim: int, batch_size: int, seq_length: int, mode: ParallelMode) -> torch.Tensor:
+ """
+ Return a random data of shape (batch_size, seq_length, dim) for profiling.
+
+ Args:
+ dim (int): hidden size
+ batch_size (int): the number of data samples
+ seq_length (int): the number of tokens
+ mode (ParallelMode): Colossal-AI ParallelMode enum
+
+ Returns:
+ data (torch.Tensor): random data
+ """
+
+ if mode in ['2d', '2.5d']:
+ batch_size = batch_size // 2
+ dim = dim // 2
+ elif mode == '3d':
+ batch_size = batch_size // 4
+ dim = dim // 2
+
+ data = torch.rand(batch_size, seq_length, dim).cuda()
+ return data
diff --git a/colossalai/cli/check/__init__.py b/colossalai/cli/check/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a86b32bb6a181a7c75bfa6682c2f7514169d9a7f
--- /dev/null
+++ b/colossalai/cli/check/__init__.py
@@ -0,0 +1,13 @@
+import click
+from .check_installation import check_installation
+
+__all__ = ['check']
+
+
+@click.command(help="Check if Colossal-AI is correct based on the given option")
+@click.option('-i', '--installation', is_flag=True, help="Check if Colossal-AI is built correctly")
+def check(installation):
+ if installation:
+ check_installation()
+ return
+ click.echo("No option is given")
diff --git a/colossalai/cli/check/check_installation.py b/colossalai/cli/check/check_installation.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb3dbbc09301012aa662264f241e1fce89470d39
--- /dev/null
+++ b/colossalai/cli/check/check_installation.py
@@ -0,0 +1,214 @@
+import subprocess
+
+import click
+import torch
+from torch.utils.cpp_extension import CUDA_HOME
+
+import colossalai
+
+
+def to_click_output(val):
+ # installation check output to understandable symbols for readability
+ VAL_TO_SYMBOL = {True: u'\u2713', False: 'x', None: 'N/A'}
+
+ if val in VAL_TO_SYMBOL:
+ return VAL_TO_SYMBOL[val]
+ else:
+ return val
+
+
+def check_installation():
+ """
+ This function will check the installation of colossalai, specifically, the version compatibility of
+ colossalai, pytorch and cuda.
+
+ Example:
+ ```text
+ ```
+
+ Returns: A table of installation information.
+ """
+ found_aot_cuda_ext = _check_aot_built_cuda_extension_installed()
+ cuda_version = _check_cuda_version()
+ torch_version, torch_cuda_version = _check_torch_version()
+ colossalai_verison, prebuilt_torch_version_required, prebuilt_cuda_version_required = _parse_colossalai_version()
+
+ # if cuda_version is None, that means either
+ # CUDA_HOME is not found, thus cannot compare the version compatibility
+ if not cuda_version:
+ sys_torch_cuda_compatibility = None
+ else:
+ sys_torch_cuda_compatibility = _is_compatible([cuda_version, torch_cuda_version])
+
+ # if cuda_version or cuda_version_required is None, that means either
+ # CUDA_HOME is not found or AOT compilation is not enabled
+ # thus, there is no need to compare the version compatibility at all
+ if not cuda_version or not prebuilt_cuda_version_required:
+ sys_colossalai_cuda_compatibility = None
+ else:
+ sys_colossalai_cuda_compatibility = _is_compatible([cuda_version, prebuilt_cuda_version_required])
+
+ # if torch_version_required is None, that means AOT compilation is not enabled
+ # thus there is no need to compare the versions
+ if prebuilt_torch_version_required is None:
+ torch_compatibility = None
+ else:
+ torch_compatibility = _is_compatible([torch_version, prebuilt_torch_version_required])
+
+ click.echo(f'#### Installation Report ####')
+ click.echo(f'\n------------ Environment ------------')
+ click.echo(f"Colossal-AI version: {to_click_output(colossalai_verison)}")
+ click.echo(f"PyTorch version: {to_click_output(torch_version)}")
+ click.echo(f"System CUDA version: {to_click_output(cuda_version)}")
+ click.echo(f"CUDA version required by PyTorch: {to_click_output(torch_cuda_version)}")
+ click.echo("")
+ click.echo(f"Note:")
+ click.echo(f"1. The table above checks the versions of the libraries/tools in the current environment")
+ click.echo(f"2. If the System CUDA version is N/A, you can set the CUDA_HOME environment variable to locate it")
+ click.echo(
+ f"3. If the CUDA version required by PyTorch is N/A, you probably did not install a CUDA-compatible PyTorch. This value is give by torch.version.cuda and you can go to https://pytorch.org/get-started/locally/ to download the correct version."
+ )
+
+ click.echo(f'\n------------ CUDA Extensions AOT Compilation ------------')
+ click.echo(f"Found AOT CUDA Extension: {to_click_output(found_aot_cuda_ext)}")
+ click.echo(f"PyTorch version used for AOT compilation: {to_click_output(prebuilt_torch_version_required)}")
+ click.echo(f"CUDA version used for AOT compilation: {to_click_output(prebuilt_cuda_version_required)}")
+ click.echo("")
+ click.echo(f"Note:")
+ click.echo(
+ f"1. AOT (ahead-of-time) compilation of the CUDA kernels occurs during installation when the environment variable CUDA_EXT=1 is set"
+ )
+ click.echo(f"2. If AOT compilation is not enabled, stay calm as the CUDA kernels can still be built during runtime")
+
+ click.echo(f"\n------------ Compatibility ------------")
+ click.echo(f'PyTorch version match: {to_click_output(torch_compatibility)}')
+ click.echo(f"System and PyTorch CUDA version match: {to_click_output(sys_torch_cuda_compatibility)}")
+ click.echo(f"System and Colossal-AI CUDA version match: {to_click_output(sys_colossalai_cuda_compatibility)}")
+ click.echo(f"")
+ click.echo(f"Note:")
+ click.echo(f"1. The table above checks the version compatibility of the libraries/tools in the current environment")
+ click.echo(
+ f" - PyTorch version mismatch: whether the PyTorch version in the current environment is compatible with the PyTorch version used for AOT compilation"
+ )
+ click.echo(
+ f" - System and PyTorch CUDA version match: whether the CUDA version in the current environment is compatible with the CUDA version required by PyTorch"
+ )
+ click.echo(
+ f" - System and Colossal-AI CUDA version match: whether the CUDA version in the current environment is compatible with the CUDA version used for AOT compilation"
+ )
+
+
+def _is_compatible(versions):
+ """
+ Compare the list of versions and return whether they are compatible.
+ """
+ if None in versions:
+ return False
+
+ # split version into [major, minor, patch]
+ versions = [version.split('.') for version in versions]
+
+ for version in versions:
+ if len(version) == 2:
+ # x means unknown
+ version.append('x')
+
+ for idx, version_values in enumerate(zip(*versions)):
+ equal = len(set(version_values)) == 1
+
+ if idx in [0, 1] and not equal:
+ return False
+ elif idx == 1:
+ return True
+ else:
+ continue
+
+
+def _parse_colossalai_version():
+ """
+ Get the Colossal-AI version information.
+
+ Returns:
+ colossalai_version: Colossal-AI version.
+ torch_version_for_aot_build: PyTorch version used for AOT compilation of CUDA kernels.
+ cuda_version_for_aot_build: CUDA version used for AOT compilation of CUDA kernels.
+ """
+ # colossalai version can be in two formats
+ # 1. X.X.X+torchX.XXcuXX.X (when colossalai is installed with CUDA extensions)
+ # 2. X.X.X (when colossalai is not installed with CUDA extensions)
+ # where X represents an integer.
+ colossalai_verison = colossalai.__version__.split('+')[0]
+
+ try:
+ torch_version_for_aot_build = colossalai.__version__.split('torch')[1].split('cu')[0]
+ cuda_version_for_aot_build = colossalai.__version__.split('cu')[1]
+ except:
+ torch_version_for_aot_build = None
+ cuda_version_for_aot_build = None
+ return colossalai_verison, torch_version_for_aot_build, cuda_version_for_aot_build
+
+
+def _check_aot_built_cuda_extension_installed():
+ """
+ According to `op_builder/README.md`, the CUDA extension can be built with either
+ AOT (ahead-of-time) or JIT (just-in-time) compilation.
+ AOT compilation will build CUDA extensions to `colossalai._C` during installation.
+ JIT (just-in-time) compilation will build CUDA extensions to `~/.cache/colossalai/torch_extensions` during runtime.
+ """
+ try:
+ import colossalai._C.fused_optim
+ found_aot_cuda_ext = True
+ except ImportError:
+ found_aot_cuda_ext = False
+ return found_aot_cuda_ext
+
+
+def _check_torch_version():
+ """
+ Get the PyTorch version information.
+
+ Returns:
+ torch_version: PyTorch version.
+ torch_cuda_version: CUDA version required by PyTorch.
+ """
+ # get torch version
+ # torch version can be of two formats
+ # - 1.13.1+cu113
+ # - 1.13.1.devxxx
+ torch_version = torch.__version__.split('+')[0]
+ torch_version = '.'.join(torch_version.split('.')[:3])
+
+ # get cuda version in pytorch build
+ try:
+ torch_cuda_major = torch.version.cuda.split(".")[0]
+ torch_cuda_minor = torch.version.cuda.split(".")[1]
+ torch_cuda_version = f'{torch_cuda_major}.{torch_cuda_minor}'
+ except:
+ torch_cuda_version = None
+
+ return torch_version, torch_cuda_version
+
+
+def _check_cuda_version():
+ """
+ Get the CUDA version information.
+
+ Returns:
+ cuda_version: CUDA version found on the system.
+ """
+
+ # get cuda version
+ if CUDA_HOME is None:
+ cuda_version = CUDA_HOME
+ else:
+ try:
+ raw_output = subprocess.check_output([CUDA_HOME + "/bin/nvcc", "-V"], universal_newlines=True)
+ output = raw_output.split()
+ release_idx = output.index("release") + 1
+ release = output[release_idx].split(".")
+ bare_metal_major = release[0]
+ bare_metal_minor = release[1][0]
+ cuda_version = f'{bare_metal_major}.{bare_metal_minor}'
+ except:
+ cuda_version = None
+ return cuda_version
diff --git a/colossalai/cli/cli.py b/colossalai/cli/cli.py
new file mode 100644
index 0000000000000000000000000000000000000000..a94e1150e49fc00a210c20b32a9bfc85eda66aa6
--- /dev/null
+++ b/colossalai/cli/cli.py
@@ -0,0 +1,25 @@
+import click
+
+from .benchmark import benchmark
+from .check import check
+from .launcher import run
+
+
+class Arguments():
+
+ def __init__(self, arg_dict):
+ for k, v in arg_dict.items():
+ self.__dict__[k] = v
+
+
+@click.group()
+def cli():
+ pass
+
+
+cli.add_command(run)
+cli.add_command(check)
+cli.add_command(benchmark)
+
+if __name__ == '__main__':
+ cli()
diff --git a/colossalai/cli/launcher/__init__.py b/colossalai/cli/launcher/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d9ec147d401a2e5d055852e661e189985b6db6e
--- /dev/null
+++ b/colossalai/cli/launcher/__init__.py
@@ -0,0 +1,87 @@
+import click
+
+from colossalai.context import Config
+
+from .run import launch_multi_processes
+
+
+@click.command(help="Launch distributed training on a single node or multiple nodes",
+ context_settings=dict(ignore_unknown_options=True))
+@click.option("-H",
+ "-host",
+ "--host",
+ type=str,
+ default=None,
+ help="the list of hostnames to launch in the format ,")
+@click.option(
+ "--hostfile",
+ type=str,
+ default=None,
+ help="Hostfile path that defines the device pool available to the job, each line in the file is a hostname")
+@click.option("--include",
+ type=str,
+ default=None,
+ help="Specify computing devices to use during execution. String format is ,,"
+ " only effective when used with --hostfile.")
+@click.option(
+ "--exclude",
+ type=str,
+ default=None,
+ help=
+ "Specify computing devices to NOT use during execution. Mutually exclusive with --include. Formatting is the same as --includ,"
+ " only effective when used with --hostfile.")
+@click.option("--num_nodes",
+ type=int,
+ default=-1,
+ help="Total number of worker nodes to use, only effective when used with --hostfile.")
+@click.option("--nproc_per_node", type=int, default=None, help="Number of GPUs to use on each node.")
+@click.option("--master_port",
+ type=int,
+ default=29500,
+ help="(optional) Port used by PyTorch distributed for communication during distributed training.")
+@click.option("--master_addr",
+ type=str,
+ default="127.0.0.1",
+ help="(optional) IP address of node 0, will be inferred via 'hostname -I' if not specified.")
+@click.option(
+ "--extra_launch_args",
+ type=str,
+ default=None,
+ help=
+ "Set additional torch distributed launcher arguments such as --standalone. The format is --extra_launch_args arg1=1,arg2=2. "
+ "This will be converted to --arg1=1 --arg2=2 during execution")
+@click.option("--ssh-port", type=int, default=None, help="(optional) the port used for ssh connection")
+@click.argument("user_script", type=str)
+@click.argument('user_args', nargs=-1)
+def run(host: str, hostfile: str, num_nodes: int, nproc_per_node: int, include: str, exclude: str, master_addr: str,
+ master_port: int, extra_launch_args: str, ssh_port: int, user_script: str, user_args: str) -> None:
+ """
+ To launch multiple processes on a single node or multiple nodes via command line.
+
+ Usage::
+ # run with 4 GPUs on the current node use default port 29500
+ colossalai run --nprocs_per_node 4 train.py
+
+ # run with 2 GPUs on the current node at port 29550
+ colossalai run --nprocs_per_node 4 --master_port 29550 train.py
+
+ # run on two nodes
+ colossalai run --host , --master_addr host1 --nprocs_per_node 4 train.py
+
+ # run with hostfile
+ colossalai run --hostfile --master_addr --nprocs_per_node 4 train.py
+
+ # run with hostfile with only included hosts
+ colossalai run --hostfile --master_addr host1 --include host1,host2 --nprocs_per_node 4 train.py
+
+ # run with hostfile excluding the hosts selected
+ colossalai run --hostfile --master_addr host1 --exclude host2 --nprocs_per_node 4 train.py
+ """
+ if not user_script.endswith('.py'):
+ click.echo(f'Error: invalid Python file {user_script}. Did you use a wrong option? Try colossalai run --help')
+ exit()
+
+ args_dict = locals()
+ args = Config(args_dict)
+ args.user_args = list(args.user_args)
+ launch_multi_processes(args)
diff --git a/colossalai/cli/launcher/hostinfo.py b/colossalai/cli/launcher/hostinfo.py
new file mode 100644
index 0000000000000000000000000000000000000000..065cbc37101f9705319d96120779edcbbbf6dde9
--- /dev/null
+++ b/colossalai/cli/launcher/hostinfo.py
@@ -0,0 +1,127 @@
+import socket
+from typing import List
+
+
+class HostInfo:
+ """
+ A data class to store host connection-related data.
+
+ Args:
+ hostname (str): name or IP address of the host
+ port (str): the port for ssh connection
+ """
+
+ def __init__(
+ self,
+ hostname: str,
+ port: str = None,
+ ):
+ self.hostname = hostname
+ self.port = port
+ self.is_local_host = HostInfo.is_host_localhost(hostname, port)
+
+ @staticmethod
+ def is_host_localhost(hostname: str, port: str = None) -> None:
+ """
+ Check if the host refers to the local machine.
+
+ Args:
+ hostname (str): name or IP address of the host
+ port (str): the port for ssh connection
+
+ Returns:
+ bool: True if it is local, False otherwise
+ """
+
+ if port is None:
+ port = 22 # no port specified, lets just use the ssh port
+
+ # socket.getfqdn("127.0.0.1") does not return localhost
+ # on some users' machines
+ # thus, we directly return True if hostname is locahost, 127.0.0.1 or 0.0.0.0
+ if hostname in ("localhost", "127.0.0.1", "0.0.0.0"):
+ return True
+
+ hostname = socket.getfqdn(hostname)
+ localhost = socket.gethostname()
+ localaddrs = socket.getaddrinfo(localhost, port)
+ targetaddrs = socket.getaddrinfo(hostname, port)
+ for (family, socktype, proto, canonname, sockaddr) in localaddrs:
+ for (rfamily, rsocktype, rproto, rcanonname, rsockaddr) in targetaddrs:
+ if rsockaddr[0] == sockaddr[0]:
+ return True
+ return False
+
+ def __str__(self):
+ return f'hostname: {self.hostname}, port: {self.port}'
+
+ def __repr__(self):
+ return self.__str__()
+
+
+class HostInfoList:
+ """
+ A data class to store a list of HostInfo objects.
+ """
+
+ def __init__(self):
+ self.hostinfo_list = []
+
+ def append(self, hostinfo: HostInfo) -> None:
+ """
+ Add an HostInfo object to the list.
+
+ Args:
+ hostinfo (HostInfo): host information
+ """
+
+ self.hostinfo_list.append(hostinfo)
+
+ def remove(self, hostname: str) -> None:
+ """
+ Add an HostInfo object to the list.
+
+ Args:
+ hostname (str): the name of the host
+ """
+
+ hostinfo = self.get_hostinfo(hostname)
+ self.hostinfo_list.remove(hostinfo)
+
+ def get_hostinfo(self, hostname: str) -> HostInfo:
+ """
+ Return the HostInfo object which matches with the hostname.
+
+ Args:
+ hostname (str): the name of the host
+
+ Returns:
+ hostinfo (HostInfo): the HostInfo object which matches with the hostname
+ """
+
+ for hostinfo in self.hostinfo_list:
+ if hostinfo.hostname == hostname:
+ return hostinfo
+
+ raise Exception(f"Hostname {hostname} is not found")
+
+ def has(self, hostname: str) -> bool:
+ """
+ Check if the hostname has been added.
+
+ Args:
+ hostname (str): the name of the host
+
+ Returns:
+ bool: True if added, False otherwise
+ """
+ for hostinfo in self.hostinfo_list:
+ if hostinfo.hostname == hostname:
+ return True
+ return False
+
+ def __iter__(self):
+ return iter(self.hostinfo_list)
+
+ def __len__(self):
+ return len(self.hostinfo_list)
diff --git a/colossalai/cli/launcher/multinode_runner.py b/colossalai/cli/launcher/multinode_runner.py
new file mode 100644
index 0000000000000000000000000000000000000000..a51e1e371f13df492c16ac5b554d02ba6491d65b
--- /dev/null
+++ b/colossalai/cli/launcher/multinode_runner.py
@@ -0,0 +1,123 @@
+from multiprocessing import Pipe, Process
+from multiprocessing import connection as mp_connection
+
+import click
+import fabric
+
+from .hostinfo import HostInfo, HostInfoList
+
+
+def run_on_host(hostinfo: HostInfo, workdir: str, recv_conn: mp_connection.Connection,
+ send_conn: mp_connection.Connection, env: dict) -> None:
+ """
+ Use fabric connection to execute command on local or remote hosts.
+
+ Args:
+ hostinfo (HostInfo): host information
+ workdir (str): the directory to execute the command
+ recv_conn (multiprocessing.connection.Connection): receive messages from the master sender
+ send_conn (multiprocessing.connection.Connection): send messages to the master receiver
+ env (dict): a dictionary for environment variables
+ """
+
+ fab_conn = fabric.Connection(hostinfo.hostname, port=hostinfo.port)
+ finish = False
+ env_msg = ' '.join([f'{k}=\"{v}\"' for k, v in env.items()])
+
+ # keep listening until exit
+ while not finish:
+ # receive cmd
+ cmds = recv_conn.recv()
+
+ if cmds == 'exit':
+ # exit from the loop
+ finish = True
+ break
+ else:
+ # execute the commands
+ try:
+ # cd to execute directory
+ with fab_conn.cd(workdir):
+ # propagate the runtime environment
+ with fab_conn.prefix(f"export {env_msg}"):
+ if hostinfo.is_local_host:
+ # execute on the local machine
+ fab_conn.local(cmds, hide=False)
+ else:
+ # execute on the remote machine
+ fab_conn.run(cmds, hide=False)
+ send_conn.send('success')
+ except Exception as e:
+ click.echo(
+ f"Error: failed to run {cmds} on {hostinfo.hostname}, is localhost: {hostinfo.is_local_host}, exception: {e}"
+ )
+ send_conn.send('failure')
+
+ # shutdown
+ send_conn.send("finish")
+ fab_conn.close()
+
+
+class MultiNodeRunner:
+ """
+ A runner to execute commands on an array of machines. This runner
+ is inspired by Nezha (https://github.com/zhuzilin/NeZha).
+ """
+
+ def __init__(self):
+ self.processes = {}
+ self.master_send_conns = {}
+ self.master_recv_conns = {}
+
+ def connect(self, host_info_list: HostInfoList, workdir: str, env: dict) -> None:
+ """
+ Establish connections to a list of hosts
+
+ Args:
+ host_info_list (HostInfoList): a list of HostInfo objects
+ workdir (str): the directory where command is executed
+ env (dict): environment variables to propagate to hosts
+ """
+ for hostinfo in host_info_list:
+ master_send_conn, worker_recv_conn = Pipe()
+ master_recv_conn, worker_send_conn = Pipe()
+ p = Process(target=run_on_host, args=(hostinfo, workdir, worker_recv_conn, worker_send_conn, env))
+ p.start()
+ self.processes[hostinfo.hostname] = p
+ self.master_recv_conns[hostinfo.hostname] = master_recv_conn
+ self.master_send_conns[hostinfo.hostname] = master_send_conn
+
+ def send(self, hostinfo: HostInfo, cmd: str) -> None:
+ """
+ Send a command to a local/remote host.
+
+ Args:
+ hostinfo (HostInfo): host information
+ cmd (str): the command to execute
+ """
+
+ assert hostinfo.hostname in self.master_send_conns, \
+ f'{hostinfo} is not found in the current connections'
+ conn = self.master_send_conns[hostinfo.hostname]
+ conn.send(cmd)
+
+ def stop_all(self) -> None:
+ """
+ Stop connections to all hosts.
+ """
+
+ for hostname, conn in self.master_send_conns.items():
+ conn.send('exit')
+
+ def recv_from_all(self) -> dict:
+ """
+ Receive messages from all hosts
+
+ Returns:
+ msg_from_node (dict): a dictionry which contains messages from each node
+ """
+
+ msg_from_node = dict()
+ for hostname, conn in self.master_recv_conns.items():
+ msg_from_node[hostname] = conn.recv()
+ return msg_from_node
diff --git a/colossalai/cli/launcher/run.py b/colossalai/cli/launcher/run.py
new file mode 100644
index 0000000000000000000000000000000000000000..6411b4302e95d25efc5a55da1b523b76ee6ee1e3
--- /dev/null
+++ b/colossalai/cli/launcher/run.py
@@ -0,0 +1,311 @@
+import os
+import sys
+from typing import List
+
+import click
+import torch
+from packaging import version
+
+from colossalai.context import Config
+
+from .hostinfo import HostInfo, HostInfoList
+from .multinode_runner import MultiNodeRunner
+
+# Constants that define our syntax
+NODE_SEP = ','
+
+
+def fetch_hostfile(hostfile_path: str, ssh_port: int) -> HostInfoList:
+ """
+ Parse the hostfile to obtain a list of hosts.
+
+ A hostfile should look like:
+ worker-0
+ worker-1
+ worker-2
+ ...
+
+ Args:
+ hostfile_path (str): the path to the hostfile
+ ssh_port (int): the port to connect to the host
+ """
+
+ if not os.path.isfile(hostfile_path):
+ click.echo(f"Error: Unable to find the hostfile, no such file: {hostfile_path}")
+ exit()
+
+ with open(hostfile_path, 'r') as fd:
+ device_pool = HostInfoList()
+
+ for line in fd.readlines():
+ line = line.strip()
+ if line == '':
+ # skip empty lines
+ continue
+
+ # build the HostInfo object
+ hostname = line.strip()
+ hostinfo = HostInfo(hostname=hostname, port=ssh_port)
+
+ if device_pool.has(hostname):
+ click.echo(f"Error: found duplicate host {hostname} in the hostfile")
+ exit()
+
+ device_pool.append(hostinfo)
+ return device_pool
+
+
+def parse_device_filter(device_pool: HostInfoList, include_str=None, exclude_str=None) -> HostInfoList:
+ '''Parse an inclusion or exclusion string and filter a hostfile dictionary.
+
+ Examples:
+ include_str="worker-0,worker-1" will execute jobs only on worker-0 and worker-1.
+ exclude_str="worker-1" will use all available devices except worker-1.
+
+ Args:
+ device_pool (HostInfoList): a list of HostInfo objects
+ include_str (str): --include option passed by user, default None
+ exclude_str (str): --exclude option passed by user, default None
+
+ Returns:
+ filtered_hosts (HostInfoList): filtered hosts after inclusion/exclusion
+ '''
+
+ # Ensure include/exclude are mutually exclusive
+ if include_str and exclude_str:
+ click.echo("--include and --exclude are mutually exclusive, only one can be used")
+ exit()
+
+ # no-op
+ if include_str is None and exclude_str is None:
+ return device_pool
+
+ # Either build from scratch or remove items
+ if include_str:
+ parse_str = include_str
+ filtered_hosts = HostInfoList()
+ elif exclude_str:
+ parse_str = exclude_str
+ filtered_hosts = device_pool
+
+ # foreach node in the list
+ for node_config in parse_str.split(NODE_SEP):
+ hostname = node_config
+ hostinfo = device_pool.get_hostinfo(hostname)
+ # sanity check hostname
+ if not device_pool.has(hostname):
+ click.echo(f"Error: Hostname '{hostname}' not found in hostfile")
+ exit()
+
+ if include_str:
+ filtered_hosts.append(hostinfo)
+ elif exclude_str:
+ filtered_hosts.remove(hostname)
+
+ return filtered_hosts
+
+
+def get_launch_command(
+ master_addr: str,
+ master_port: int,
+ nproc_per_node: int,
+ user_script: str,
+ user_args: List[str],
+ node_rank: int,
+ num_nodes: int,
+ extra_launch_args: str = None,
+) -> str:
+ """
+ Generate a command for distributed training.
+
+ Args:
+ master_addr (str): the host of the master node
+ master_port (str): the port of the master node
+ nproc_per_node (str): the number of processes to launch on each node
+ user_script (str): the user Python file
+ user_args (str): the arguments for the user script
+ node_rank (int): the unique ID for the node
+ num_nodes (int): the number of nodes to execute jobs
+
+ Returns:
+ cmd (str): the command the start distributed training
+ """
+
+ def _arg_dict_to_list(arg_dict):
+ ret = []
+
+ for k, v in arg_dict.items():
+ if v:
+ ret.append(f'--{k}={v}')
+ else:
+ ret.append(f'--{k}')
+ return ret
+
+ if extra_launch_args:
+ extra_launch_args_dict = dict()
+ for arg in extra_launch_args.split(','):
+ if '=' in arg:
+ k, v = arg.split('=')
+ extra_launch_args_dict[k] = v
+ else:
+ extra_launch_args_dict[arg] = None
+ extra_launch_args = extra_launch_args_dict
+ else:
+ extra_launch_args = dict()
+
+ torch_version = version.parse(torch.__version__)
+ assert torch_version.major == 1
+
+ if torch_version.minor < 9:
+ cmd = [
+ sys.executable, "-m", "torch.distributed.launch", f"--nproc_per_node={nproc_per_node}",
+ f"--master_addr={master_addr}", f"--master_port={master_port}", f"--nnodes={num_nodes}",
+ f"--node_rank={node_rank}"
+ ]
+ else:
+ # extra launch args for torch distributed launcher with torch >= 1.9
+ default_torchrun_rdzv_args = dict(rdzv_backend="c10d",
+ rdzv_endpoint=f"{master_addr}:{master_port}",
+ rdzv_id="colossalai-default-job")
+
+ # update rdzv arguments
+ for key in default_torchrun_rdzv_args.keys():
+ if key in extra_launch_args:
+ value = extra_launch_args.pop(key)
+ default_torchrun_rdzv_args[key] = value
+
+ if torch_version.minor < 10:
+ cmd = [
+ sys.executable, "-m", "torch.distributed.run", f"--nproc_per_node={nproc_per_node}",
+ f"--nnodes={num_nodes}", f"--node_rank={node_rank}"
+ ]
+ else:
+ cmd = [
+ "torchrun", f"--nproc_per_node={nproc_per_node}", f"--nnodes={num_nodes}", f"--node_rank={node_rank}"
+ ]
+ cmd += _arg_dict_to_list(default_torchrun_rdzv_args)
+
+ cmd += _arg_dict_to_list(extra_launch_args) + [user_script] + user_args
+ cmd = ' '.join(cmd)
+ return cmd
+
+
+def launch_multi_processes(args: Config) -> None:
+ """
+ Launch multiple processes on a single node or multiple nodes.
+
+ The overall logic can be summarized as the pseudo code below:
+
+ if hostfile given:
+ hostinfo = parse_hostfile(hostfile)
+ hostinfo = include_or_exclude_hosts(hostinfo)
+ launch_on_multi_nodes(hostinfo)
+ elif hosts given:
+ hostinfo = parse_hosts(hosts)
+ launch_on_multi_nodes(hostinfo)
+ else:
+ launch_on_current_node()
+
+ Args:
+ args (Config): the arguments taken from command line
+
+ """
+ assert isinstance(args, Config)
+
+ if args.nproc_per_node is None:
+ click.echo("--nproc_per_node did not receive any value")
+ exit()
+
+ # cannot accept hosts and hostfile at the same time
+ if args.host and args.hostfile:
+ click.echo("Error: hostfile and hosts are mutually exclusive, only one is required")
+
+ # check if hostfile is given
+ if args.hostfile:
+ device_pool = fetch_hostfile(args.hostfile, ssh_port=args.ssh_port)
+ active_device_pool = parse_device_filter(device_pool, args.include, args.exclude)
+
+ if args.num_nodes > 0:
+ # only keep the first num_nodes to execute jobs
+ updated_active_device_pool = HostInfoList()
+ for count, hostinfo in enumerate(active_device_pool):
+ if args.num_nodes == count:
+ break
+ updated_active_device_pool.append(hostinfo)
+ active_device_pool = updated_active_device_pool
+ else:
+ active_device_pool = None
+
+ env = os.environ.copy()
+
+ # use hosts if hostfile is not given
+ if args.host and active_device_pool is None:
+ active_device_pool = HostInfoList()
+ host_list = args.host.strip().split(NODE_SEP)
+ for hostname in host_list:
+ hostinfo = HostInfo(hostname=hostname, port=args.ssh_port)
+ active_device_pool.append(hostinfo)
+
+ if not active_device_pool:
+ # run on local node if not hosts or hostfile is given
+ # add local node to host info list
+ active_device_pool = HostInfoList()
+ localhost_info = HostInfo(hostname='127.0.0.1', port=args.ssh_port)
+ active_device_pool.append(localhost_info)
+
+ # launch distributed processes
+ runner = MultiNodeRunner()
+ curr_path = os.path.abspath('.')
+
+ # collect current path env
+ env = dict()
+ for k, v in os.environ.items():
+ # do not support multi-line env var
+ if v and '\n' not in v:
+ env[k] = v
+
+ # establish remote connection
+ runner.connect(host_info_list=active_device_pool, workdir=curr_path, env=env)
+
+ # execute distributed launching command
+ for node_id, hostinfo in enumerate(active_device_pool):
+ cmd = get_launch_command(master_addr=args.master_addr,
+ master_port=args.master_port,
+ nproc_per_node=args.nproc_per_node,
+ user_script=args.user_script,
+ user_args=args.user_args,
+ node_rank=node_id,
+ num_nodes=len(active_device_pool),
+ extra_launch_args=args.extra_launch_args)
+ runner.send(hostinfo=hostinfo, cmd=cmd)
+
+ # start training
+ msg_from_node = runner.recv_from_all()
+ has_error = False
+
+ # print node status
+ click.echo("\n====== Training on All Nodes =====")
+ for hostname, msg in msg_from_node.items():
+ click.echo(f"{hostname}: {msg}")
+
+ # check if a process failed
+ if msg == "failure":
+ has_error = True
+
+ # stop all nodes
+ runner.stop_all()
+
+ # receive the stop status
+ msg_from_node = runner.recv_from_all()
+
+ # printe node status
+ click.echo("\n====== Stopping All Nodes =====")
+ for hostname, msg in msg_from_node.items():
+ click.echo(f"{hostname}: {msg}")
+
+ # give the process an exit code
+ # so that it behaves like a normal process
+ if has_error:
+ sys.exit(1)
+ else:
+ sys.exit(0)
diff --git a/colossalai/cluster/__init__.py b/colossalai/cluster/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2fbdfd3cc9996b1044720ef0c1669f5f67fbe8b3
--- /dev/null
+++ b/colossalai/cluster/__init__.py
@@ -0,0 +1,5 @@
+from .device_mesh_manager import DeviceMeshManager
+from .dist_coordinator import DistCoordinator
+from .process_group_manager import ProcessGroupManager
+
+__all__ = ['DistCoordinator', 'ProcessGroupManager', 'DeviceMeshManager']
diff --git a/colossalai/cluster/device_mesh_manager.py b/colossalai/cluster/device_mesh_manager.py
new file mode 100644
index 0000000000000000000000000000000000000000..8754baa19792adf6c5ec79c115d36fac9a3f3c5d
--- /dev/null
+++ b/colossalai/cluster/device_mesh_manager.py
@@ -0,0 +1,117 @@
+from dataclasses import dataclass
+from typing import Dict, List, Tuple, Union
+
+import torch
+import torch.distributed as dist
+
+from colossalai.device.alpha_beta_profiler import AlphaBetaProfiler
+from colossalai.device.device_mesh import DeviceMesh
+
+
+@dataclass
+class DeviceMeshInfo:
+ '''
+ This class is used to store the information used to initialize the device mesh.
+
+ Args:
+ physical_ids (List[int]): The physical ids of the current booster. For example, if we have the last 4 GPUs on a 8-devices cluster, then the physical ids should be [4, 5, 6, 7].
+ mesh_shapes (List[Union[torch.Size, List[int], Tuple[int]]]): The shape of the mesh. For example, if we have 4 GPUs and we want to use 2D mesh with mesh shape [2, 2], then the mesh shape should be [2, 2].
+ '''
+ physical_ids: List[int]
+ mesh_shape: Union[torch.Size, List[int], Tuple[int]] = None
+
+ def __post_init__(self):
+ if self.mesh_shape is not None:
+ world_size = len(self.physical_ids)
+ mesh_shape_numel = torch.Size(self.mesh_shape).numel()
+ assert world_size == mesh_shape_numel, f'the numel of mesh_shape should be equal to world size, but got {world_size} != {mesh_shape_numel}'
+
+
+def initialize_device_mesh(device_mesh_info: DeviceMeshInfo):
+ '''
+ This method is used to initialize the device mesh.
+
+ Args:
+ device_mesh_info (DeviceMeshInfo): The information used to initialize device mesh.
+ '''
+ # parse the device mesh info
+ physical_devices = device_mesh_info.physical_ids
+ physical_mesh = torch.tensor(physical_devices)
+ logical_mesh_shape = device_mesh_info.mesh_shape
+
+ if logical_mesh_shape is None:
+ ab_profiler = AlphaBetaProfiler(physical_devices)
+ # search for the best logical mesh shape
+ logical_mesh_id = ab_profiler.search_best_logical_mesh()
+ logical_mesh_id = torch.Tensor(logical_mesh_id).to(torch.int)
+
+ else:
+ logical_mesh_id = physical_mesh.reshape(logical_mesh_shape)
+
+ device_mesh = DeviceMesh(physical_mesh_id=physical_mesh, logical_mesh_id=logical_mesh_id, init_process_group=True)
+ return device_mesh
+
+
+class DeviceMeshManager:
+ """
+ Device mesh manager is responsible for creating and managing device meshes.
+ """
+
+ def __init__(self):
+ self.device_mesh_store: Dict[str, DeviceMesh] = dict()
+
+ def create_device_mesh(self, name, device_mesh_info: DeviceMeshInfo) -> DeviceMesh:
+ """
+ Create a device mesh and store it in the manager.
+
+ Args:
+ name (str): name of the device mesh
+ device_mesh_info (DeviceMeshInfo): the information used to initialize the device mesh
+ """
+ if name not in self.device_mesh_store:
+ device_mesh = initialize_device_mesh(device_mesh_info)
+ self.device_mesh_store[name] = device_mesh
+ return device_mesh
+ else:
+ raise ValueError(f'Device mesh {name} already exists.')
+
+ def get(self, name: str) -> DeviceMesh:
+ """
+ Get a device mesh by name.
+
+ Args:
+ name (str): name of the device mesh
+
+ Returns:
+ DeviceMesh: the device mesh
+ """
+ if name in self.device_mesh_store:
+ return self.device_mesh_store[name]
+ else:
+ raise ValueError(f'Device mesh {name} does not exist.')
+
+ def destroy(self, name: str) -> None:
+ """
+ Destroy a device mesh by name.
+
+ Args:
+ name (str): name of the device mesh
+ """
+ if name in self.device_mesh_store:
+ for pgs in self.device_mesh_store[name].process_groups_dict.values():
+ for pg in pgs:
+ dist.destroy_process_group(pg)
+ del self.device_mesh_store[name]
+ else:
+ raise ValueError(f'Device mesh {name} does not exist.')
+
+ def destroy_all(self):
+ """
+ Destroy all device meshes.
+ """
+ for name in self.device_mesh_store:
+ for pgs in self.device_mesh_store[name].process_groups_dict.values():
+ for pg in pgs:
+ dist.destroy_process_group(pg)
+
+ self.device_mesh_store.clear()
diff --git a/colossalai/cluster/dist_coordinator.py b/colossalai/cluster/dist_coordinator.py
new file mode 100644
index 0000000000000000000000000000000000000000..99dde810e11251e16235573f6dd88e68b74a64b3
--- /dev/null
+++ b/colossalai/cluster/dist_coordinator.py
@@ -0,0 +1,194 @@
+import functools
+import os
+from contextlib import contextmanager
+
+import torch.distributed as dist
+from torch.distributed import ProcessGroup
+
+from colossalai.context.singleton_meta import SingletonMeta
+
+
+class DistCoordinator(metaclass=SingletonMeta):
+ """
+ This class is used to coordinate distributed training. It is a singleton class, which means that there is only one instance of this
+ class in the whole program.
+
+ There are some terms that are used in this class:
+ - rank: the rank of the current process
+ - world size: the total number of processes
+ - local rank: the rank of the current process on the current node
+ - master: the process with rank 0
+ - node master: the process with local rank 0 on the current node
+
+ Example:
+ >>> from colossalai.cluster.dist_coordinator import DistCoordinator
+ >>> coordinator = DistCoordinator()
+ >>>
+ >>> if coordinator.is_master():
+ >>> do_something()
+ >>>
+ >>> coordinator.print_on_master('hello world')
+
+ Attributes:
+ rank (int): the rank of the current process
+ world_size (int): the total number of processes
+ local_rank (int): the rank of the current process on the current node
+ """
+
+ def __init__(self):
+ assert dist.is_initialized(
+ ), 'Distributed is not initialized. Please call `torch.distributed.init_process_group` or `colossalai.launch` first.'
+ self._rank = dist.get_rank()
+ self._world_size = dist.get_world_size()
+ # this is often passed by launchers such as torchrun
+ self._local_rank = os.environ.get('LOCAL_RANK', -1)
+
+ @property
+ def rank(self) -> int:
+ return self._rank
+
+ @property
+ def world_size(self) -> int:
+ return self._world_size
+
+ @property
+ def local_rank(self) -> int:
+ return self._local_rank
+
+ def _assert_local_rank_set(self):
+ """
+ Assert that the local rank is set. This is often passed by launchers such as torchrun.
+ """
+ assert self.local_rank >= 0, 'The environment variable LOCAL_RANK is not set, thus the coordinator is not aware of the local rank of the current process.'
+
+ def is_master(self, process_group: ProcessGroup = None) -> bool:
+ """
+ Check if the current process is the master process (rank is 0). It can accept a sub process group to check the rank 0 with respect to the process.
+
+ Args:
+ process_group (ProcessGroup, optional): process group to use for the rank 0 check. Defaults to None, which refers to the default process group.
+
+ Returns:
+ bool: True if the current process is the master process, False otherwise
+ """
+ rank = dist.get_rank(group=process_group)
+ return rank == 0
+
+ def is_node_master(self) -> bool:
+ """
+ Check if the current process is the master process on the current node (local rank is 0).
+
+ Returns:
+ bool: True if the current process is the master process on the current node, False otherwise
+ """
+ self._assert_local_rank_set()
+ return self.local_rank == 0
+
+ def is_last_process(self, process_group: ProcessGroup = None) -> bool:
+ """
+ Check if the current process is the last process (rank is world size - 1). It can accept a sub process group to check the last rank with respect to the process.
+
+ Args:
+ process_group (ProcessGroup, optional): process group to use for the last rank check. Defaults to None, which refers to the default process group.
+
+ Returns:
+ bool: True if the current process is the last process, False otherwise
+ """
+ rank = dist.get_rank(group=process_group)
+ world_size = dist.get_world_size(group=process_group)
+ return rank == world_size - 1
+
+ def print_on_master(self, msg: str, process_group: ProcessGroup = None):
+ """
+ Print message only from rank 0.
+
+ Args:
+ msg (str): message to print
+ process_group (ProcessGroup, optional): process group to use for the rank 0 check. Defaults to None, which refers to the default process group.
+ """
+ rank = dist.get_rank(group=process_group)
+ if rank == 0:
+ print(msg)
+
+ def print_on_node_master(self, msg: str):
+ """
+ Print message only from local rank 0. Local rank 0 refers to the 0th process running the current node.
+
+ Args:
+ msg (str): message to print
+ """
+ self._assert_local_rank_set()
+ if self.local_rank == 0:
+ print(msg)
+
+ @contextmanager
+ def priority_execution(self, executor_rank: int = 0, process_group: ProcessGroup = None):
+ """
+ This context manager is used to allow one process to execute while blocking all
+ other processes in the same process group. This is often useful when downloading is required
+ as we only want to download in one process to prevent file corruption.
+
+ Example:
+ >>> from colossalai.cluster import DistCoordinator
+ >>> dist_coordinator = DistCoordinator()
+ >>> with dist_coordinator.priority_execution():
+ >>> dataset = CIFAR10(root='./data', download=True)
+
+ Args:
+ executor_rank (int): the process rank to execute without blocking, all other processes will be blocked
+ process_group (ProcessGroup, optional): process group to use for the executor rank check. Defaults to None, which refers to the default process group.
+ """
+ rank = dist.get_rank(group=process_group)
+ should_block = rank != executor_rank
+
+ if should_block:
+ self.block_all(process_group)
+
+ yield
+
+ if not should_block:
+ self.block_all(process_group)
+
+ def destroy(self, process_group: ProcessGroup = None):
+ """
+ Destroy the distributed process group.
+
+ Args:
+ process_group (ProcessGroup, optional): process group to destroy. Defaults to None, which refers to the default process group.
+ """
+ dist.destroy_process_group(process_group)
+
+ def block_all(self, process_group: ProcessGroup = None):
+ """
+ Block all processes in the process group.
+
+ Args:
+ process_group (ProcessGroup, optional): process group to block. Defaults to None, which refers to the default process group.
+ """
+ dist.barrier(group=process_group)
+
+ def on_master_only(self, process_group: ProcessGroup = None):
+ """
+ A function wrapper that only executes the wrapped function on the master process (rank 0).
+
+ Example:
+ >>> from colossalai.cluster import DistCoordinator
+ >>> dist_coordinator = DistCoordinator()
+ >>>
+ >>> @dist_coordinator.on_master_only()
+ >>> def print_on_master(msg):
+ >>> print(msg)
+ """
+ is_master = self.is_master(process_group)
+
+ # define an inner functiuon
+ def decorator(func):
+
+ @functools.wraps(func)
+ def wrapper(*args, **kwargs):
+ if is_master:
+ return func(*args, **kwargs)
+
+ return wrapper
+
+ return decorator
diff --git a/colossalai/cluster/process_group_manager.py b/colossalai/cluster/process_group_manager.py
new file mode 100644
index 0000000000000000000000000000000000000000..e52661846f3ed6d25602252886401837613a75e3
--- /dev/null
+++ b/colossalai/cluster/process_group_manager.py
@@ -0,0 +1,75 @@
+from typing import List
+
+import torch.distributed as dist
+from torch.distributed import ProcessGroup
+
+
+class ProcessGroupManager:
+ """
+ ProcessGroupManager is used to manage the process groups in the cluster.
+
+ There are some terms used in this class:
+ - pg: the short name for process group
+ - pg_name: the name of the process group
+ - pg_size: the world size of the process group
+ - rank: the rank of the current process in the process group
+ - world_size: the total number of processes in the process group
+ """
+
+ def __init__(self):
+ self.pg_store = dict()
+
+ def create_process_group(self, name: str, ranks: List[int], backend: str = 'nccl') -> ProcessGroup:
+ """
+ Get a process group by name. If the process group does not exist, it will be created.
+
+ Args:
+ name (str): name of the process group
+ ranks (List[int]): ranks of the process group
+ backend (str, optional): backend of the process group. Defaults to 'nccl'.
+
+ Returns:
+ ProcessGroup: the process group
+ """
+ if name not in self.pg_store:
+ pg = dist.new_group(ranks=ranks, backend=backend)
+ self.pg_store[name] = pg
+ return pg
+ else:
+ raise ValueError(f'Process group {name} already exists.')
+
+ def get(self, name: str) -> ProcessGroup:
+ """
+ Get a process group by name.
+
+ Args:
+ name (str): name of the process group
+
+ Returns:
+ ProcessGroup: the process group
+ """
+ if name in self.pg_store:
+ return self.pg_store[name]
+ else:
+ raise ValueError(f'Process group {name} does not exist.')
+
+ def destroy(self, name: str) -> None:
+ """
+ Destroy a process group by name.
+
+ Args:
+ name (str): name of the process group
+ """
+ if name in self.pg_store:
+ dist.destroy_process_group(self.pg_store[name])
+ del self.pg_store[name]
+ else:
+ raise ValueError(f'Process group {name} does not exist.')
+
+ def destroy_all(self) -> None:
+ """
+ Destroy all process groups.
+ """
+ for name in self.pg_store:
+ dist.destroy_process_group(self.pg_store[name])
+ self.pg_store.clear()
diff --git a/colossalai/communication/__init__.py b/colossalai/communication/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..220481b7af15bcada443ed7c9f8c91350a5f76b1
--- /dev/null
+++ b/colossalai/communication/__init__.py
@@ -0,0 +1,26 @@
+from .collective import all_gather, reduce_scatter, all_reduce, broadcast, reduce
+from .p2p import (send_forward, send_forward_recv_forward, send_backward_recv_forward, send_backward,
+ send_backward_recv_backward, send_forward_recv_backward, send_forward_backward_recv_forward_backward,
+ recv_forward, recv_backward)
+from .ring import ring_forward
+from .utils import send_obj_meta, recv_obj_meta
+
+__all__ = [
+ 'all_gather',
+ 'reduce_scatter',
+ 'all_reduce',
+ 'broadcast',
+ 'reduce',
+ 'send_forward',
+ 'send_forward_recv_forward',
+ 'send_forward_backward_recv_forward_backward',
+ 'send_backward',
+ 'send_backward_recv_backward',
+ 'send_backward_recv_forward',
+ 'send_forward_recv_backward',
+ 'recv_backward',
+ 'recv_forward',
+ 'ring_forward',
+ 'send_obj_meta',
+ 'recv_obj_meta',
+]
diff --git a/colossalai/communication/collective.py b/colossalai/communication/collective.py
new file mode 100644
index 0000000000000000000000000000000000000000..64fb5b8b5296fa8afe7b20c9c96609f7b999e8c0
--- /dev/null
+++ b/colossalai/communication/collective.py
@@ -0,0 +1,248 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import torch
+import torch.distributed as dist
+from torch import Tensor
+from torch.distributed import ReduceOp
+
+from colossalai.context import ParallelMode
+from colossalai.core import global_context as gpc
+
+_all_gather_func = dist._all_gather_base \
+ if "all_gather_into_tensor" not in dir(dist) else dist.all_gather_into_tensor
+_reduce_scatter_func = dist._reduce_scatter_base \
+ if "reduce_scatter_tensor" not in dir(dist) else dist.reduce_scatter_tensor
+
+
+def all_gather(tensor: Tensor, dim: int, parallel_mode: ParallelMode, async_op: bool = False) -> Tensor:
+ r"""Gathers all tensors from the parallel group and concatenates them in a
+ specific dimension.
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+
+ Args:
+ tensor (:class:`torch.Tensor`): Tensor to be gathered.
+ dim (int): The dimension concatenating in.
+ parallel_mode (:class:`colossalai.context.ParallelMode`): Parallel group mode used in this communication.
+ async_op (bool, optional): Whether operations are asynchronous.
+
+ Returns:
+ Union[tuple(:class:`torch.Tensor`, work handle), :class:`torch.Tensor`]: The result of all-together only,
+ if async_op is set to False. A tuple of output of all-gather and Async work handle, if async_op is set to True.
+ """
+ depth = gpc.get_world_size(parallel_mode)
+ if depth == 1:
+ out = tensor
+ work = None
+ else:
+ tensor_in = tensor.contiguous() if dim == 0 else tensor.transpose(0, dim).contiguous()
+ out_shape = (tensor_in.shape[0] * depth,) + tensor_in.shape[1:]
+ tensor_out = torch.empty(out_shape, dtype=tensor.dtype, device=tensor.device)
+ group = gpc.get_cpu_group(parallel_mode) if tensor.device.type == "cpu" else gpc.get_group(parallel_mode)
+ work = _all_gather_func(tensor_out, tensor_in, group=group, async_op=async_op)
+ out = tensor_out if dim == 0 else tensor_out.transpose(0, dim)
+ if async_op:
+ return out, work
+ else:
+ return out
+
+
+def reduce_scatter(tensor: Tensor,
+ dim: int,
+ parallel_mode: ParallelMode,
+ op: ReduceOp = ReduceOp.SUM,
+ async_op: bool = False) -> Tensor:
+ r"""Reduces all tensors then scatters it in a specific dimension to all
+ members in the parallel group.
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+
+ Args:
+ tensor (:class:`torch.Tensor`): Tensor to be reduce_scattered.
+ dim (int): The dimension concatenating in.
+ parallel_mode (:class:`colossalai.context.ParallelMode`): Parallel group mode used in this communication.
+ op (torch.distributed.ReduceOp, optional): The type of reduce operation,
+ should be included in [SUM, AVG, PRODUCT, MIN, MAX, BAND, BOR, BXOR].
+ More details about ReduceOp please refer to
+ `ReduceOp `_.
+ async_op (bool, optional): Whether operations are asynchronous.
+
+ Returns:
+ Union[tuple(:class:`torch.Tensor`, work handle), :class:`torch.Tensor`]: The result of reduce_scatter only,
+ if async_op is set to False. A tuple of output of all-gather and Async work handle, if async_op is set to True.
+ """
+ depth = gpc.get_world_size(parallel_mode)
+ if depth == 1:
+ out = tensor
+ work = None
+ else:
+ tensor_in = tensor.contiguous() if dim == 0 else tensor.transpose(0, dim).contiguous()
+ out_shape = (tensor_in.shape[0] // depth,) + tensor_in.shape[1:]
+ tensor_out = torch.empty(out_shape, dtype=tensor.dtype, device=tensor.device)
+ group = gpc.get_cpu_group(parallel_mode) if tensor.device.type == "cpu" else gpc.get_group(parallel_mode)
+ work = _reduce_scatter_func(tensor_out, tensor_in, op=op, group=group, async_op=async_op)
+ out = tensor_out if dim == 0 else tensor_out.transpose(0, dim)
+ if async_op:
+ return out, work
+ else:
+ return out
+
+
+def all_reduce(tensor: Tensor,
+ parallel_mode: ParallelMode,
+ op: ReduceOp = ReduceOp.SUM,
+ async_op: bool = False) -> Tensor:
+ r"""Reduces the tensor data across whole parallel group in such a way that all get the final result.
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+
+ Args:
+ tensor (:class:`torch.Tensor`): Tensor to be all-reduced.
+ parallel_mode (:class:`colossalai.context.ParallelMode`): Parallel group mode used in this communication.
+ op (torch.distributed.ReduceOp, optional): The type of reduce operation,
+ should be included in [SUM, AVG, PRODUCT, MIN, MAX, BAND, BOR, BXOR].
+ More details about ReduceOp please refer to
+ `ReduceOp `_.
+ async_op (bool, optional): Whether operations are asynchronous.
+
+ Returns:
+ Union[tuple(:class:`torch.Tensor`, work handle), :class:`torch.Tensor`]: The result of all-gather only,
+ if async_op is set to False. A tuple of output of all-gather and Async work handle, if async_op is set to True.
+ """
+ depth = gpc.get_world_size(parallel_mode)
+ if depth == 1:
+ out = tensor
+ work = None
+ else:
+ out = tensor.contiguous()
+ group = gpc.get_cpu_group(parallel_mode) if tensor.device.type == "cpu" else gpc.get_group(parallel_mode)
+ work = dist.all_reduce(out, op=op, group=group, async_op=async_op)
+ if async_op:
+ return out, work
+ else:
+ return out
+
+
+def broadcast(tensor: Tensor, src: int, parallel_mode: ParallelMode, async_op: bool = False):
+ r"""Broadcast tensors to whole parallel group. Tensor must have the same
+ number of elements in all processes participating in the collective.
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+
+ Args:
+ tensor (:class:`torch.Tensor`): Tensor to be broadcast.
+ src (int): Source rank.
+ parallel_mode (:class:`colossalai.context.ParallelMode`): Parallel group mode used in this communication.
+ async_op (bool, optional): Whether operations are asynchronous.
+
+ Returns:
+ Union[tuple(:class:`torch.Tensor`, work handle), :class:`torch.Tensor`]: The tensor need to be broadcast only,
+ if async_op is set to False. A tuple of output of all-gather and Async work handle, if async_op is set to True.
+ """
+ depth = gpc.get_world_size(parallel_mode)
+ if depth == 1:
+ out = tensor
+ work = None
+ else:
+ out = tensor.contiguous()
+ group = gpc.get_cpu_group(parallel_mode) if tensor.device.type == "cpu" else gpc.get_group(parallel_mode)
+ work = dist.broadcast(out, src=src, group=group, async_op=async_op)
+ if async_op:
+ return out, work
+ else:
+ return out
+
+
+def reduce(tensor: Tensor, dst: int, parallel_mode: ParallelMode, op: ReduceOp = ReduceOp.SUM, async_op: bool = False):
+ r"""Reduce tensors across whole parallel group. Only the process with
+ rank ``dst`` is going to receive the final result.
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+
+ Args:
+ tensor (:class:`torch.Tensor`): Tensor to be reduced.
+ dst (int): Destination rank.
+ parallel_mode (:class:`colossalai.context.ParallelMode`): Parallel group mode used in this communication.
+ async_op (bool, optional): Whether operations are asynchronous.
+
+ Returns:
+ Union[tuple(:class:`torch.Tensor`, work handle), :class:`torch.Tensor`]: The result of reduce only,
+ if async_op is set to False. A tuple of output of all-gather and Async work handle, if async_op is set to True.
+ """
+ depth = gpc.get_world_size(parallel_mode)
+ if depth == 1:
+ out = tensor
+ work = None
+ else:
+ out = tensor.contiguous()
+ group = gpc.get_cpu_group(parallel_mode) if tensor.device.type == "cpu" else gpc.get_group(parallel_mode)
+ work = dist.reduce(out, dst=dst, op=op, group=group, async_op=async_op)
+ if async_op:
+ return out, work
+ else:
+ return out
+
+
+def scatter_object_list(scatter_object_output_list, scatter_object_input_list, src=0, group=None) -> None:
+ r"""Modified from `torch.distributed.scatter_object_list
+ ` to fix issues
+ """
+ if dist.distributed_c10d._rank_not_in_group(group):
+ return
+
+ if (not isinstance(scatter_object_output_list, list) or len(scatter_object_output_list) < 1):
+ raise RuntimeError("Expected argument scatter_object_output_list to be a list of size at least 1.")
+
+ # set tensor device to cuda if backend is nccl
+ device = torch.cuda.current_device() if dist.get_backend(group) == 'nccl' else torch.device("cpu")
+
+ my_rank = dist.get_rank() # use global rank
+ if my_rank == src:
+ tensor_list, tensor_sizes = zip(
+ *[dist.distributed_c10d._object_to_tensor(obj) for obj in scatter_object_input_list])
+ tensor_list = list(map(lambda x: x.to(device), tensor_list))
+ tensor_sizes = list(map(lambda x: x.to(device), tensor_sizes))
+
+ # Src rank broadcasts the maximum tensor size. This is because all ranks are
+ # expected to call into scatter() with equal-sized tensors.
+ if my_rank == src:
+ max_tensor_size = max(tensor_sizes)
+ for tensor in tensor_list:
+ tensor.resize_(max_tensor_size)
+ else:
+ max_tensor_size = torch.tensor([0], dtype=torch.long).to(device)
+
+ dist.broadcast(max_tensor_size, src=src, group=group)
+
+ # Scatter actual serialized objects
+ output_tensor = torch.empty(max_tensor_size.item(), dtype=torch.uint8).to(device)
+ dist.scatter(
+ output_tensor,
+ scatter_list=None if my_rank != src else tensor_list,
+ src=src,
+ group=group,
+ )
+
+ # Scatter per-object sizes to trim tensors when deserializing back to object
+ obj_tensor_size = torch.tensor([0], dtype=torch.long).to(device)
+ dist.scatter(
+ obj_tensor_size,
+ scatter_list=None if my_rank != src else tensor_sizes,
+ src=src,
+ group=group,
+ )
+
+ output_tensor, obj_tensor_size = output_tensor.cpu(), obj_tensor_size.cpu()
+ # Deserialize back to object
+ scatter_object_output_list[0] = dist.distributed_c10d._tensor_to_object(output_tensor, obj_tensor_size)
diff --git a/colossalai/communication/p2p.py b/colossalai/communication/p2p.py
new file mode 100644
index 0000000000000000000000000000000000000000..0200cd3c6553dc8e2b3bbaa60ffb1d416c699370
--- /dev/null
+++ b/colossalai/communication/p2p.py
@@ -0,0 +1,405 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from typing import List, Tuple, Union
+import torch
+import torch.distributed as dist
+
+from colossalai.context.parallel_mode import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.utils import get_current_device
+from functools import reduce
+import operator
+from .utils import split_tensor_into_1d_equal_chunks, gather_split_1d_tensor
+
+TensorShape = Union[torch.Size, List[int], Tuple[int]]
+
+
+def _get_tensor_shape(tensor_shape: TensorShape, chunk_tensor: bool = False) -> Tuple[TensorShape, bool]:
+ """get the exact tensor shape when communicating and return whether the tensor is a chunk
+
+ Args:
+ tensor_shape (:class:`torch.Size`): shape of tensor
+ chunk_tensor (bool, optional): whether to chunk tensor, defaults to False
+
+ Returns:
+ Tuple[Union[:class:`torch.Size`, List[int], Tuple[int]], bool]: exact tensor shape, whether to chunk tensor
+ """
+ if chunk_tensor:
+ tensor_chunk_shape = reduce(operator.mul, tensor_shape, 1)
+ tensor_parallel_world_size = gpc.get_world_size(ParallelMode.TENSOR)
+ if tensor_chunk_shape % tensor_parallel_world_size == 0:
+ tensor_chunk_shape = tensor_chunk_shape // tensor_parallel_world_size
+ else:
+ tensor_chunk_shape = tensor_shape
+ chunk_tensor = False
+ else:
+ tensor_chunk_shape = tensor_shape
+ return tensor_chunk_shape, chunk_tensor
+
+
+def create_recv_buffer_with_shapes(recv_shapes, dtype, scatter_gather_tensors):
+ if isinstance(recv_shapes, torch.Size):
+ recv_chunk_shape, recv_split = _get_tensor_shape(recv_shapes, scatter_gather_tensors)
+ buffer_recv = torch.empty(recv_chunk_shape, requires_grad=True, device=get_current_device(), dtype=dtype)
+ return buffer_recv, recv_split
+ buffer_recv = []
+ for recv_shape in recv_shapes:
+ recv_chunk_shape, recv_split = _get_tensor_shape(recv_shape, scatter_gather_tensors)
+ tensor_recv = torch.empty(recv_chunk_shape, requires_grad=True, device=get_current_device(), dtype=dtype)
+ buffer_recv.append(tensor_recv)
+ return buffer_recv, recv_split
+
+
+def process_object_to_send(object_send, scatter_gather_tensors):
+ if isinstance(object_send, torch.Tensor):
+ send_split = _get_tensor_shape(object_send.shape, scatter_gather_tensors)[1]
+ if send_split:
+ object_send = split_tensor_into_1d_equal_chunks(object_send)
+ return object_send
+
+ object_send_list = []
+ for tensor_send in object_send:
+ send_split = _get_tensor_shape(tensor_send.shape, scatter_gather_tensors)[1]
+ if send_split:
+ object_send_list.append(split_tensor_into_1d_equal_chunks(tensor_send))
+ else:
+ object_send_list.append(tensor_send)
+ object_send = tuple(object_send_list)
+
+ return object_send
+
+
+def filling_ops_queue(obj, comm_op, comm_rank, ops_queue):
+ if isinstance(obj, torch.Tensor):
+ op_to_add = dist.P2POp(comm_op, obj, comm_rank)
+ ops_queue.append(op_to_add)
+ else:
+ for tensor_to_comm in obj:
+ op_to_add = dist.P2POp(comm_op, tensor_to_comm, comm_rank)
+ ops_queue.append(op_to_add)
+
+
+def _communicate(object_send_next: Union[torch.Tensor, List[torch.Tensor]] = None,
+ object_send_prev: Union[torch.Tensor, List[torch.Tensor]] = None,
+ recv_prev: bool = False,
+ recv_next: bool = False,
+ recv_prev_shape: Union[torch.Size, List[torch.Size]] = None,
+ recv_next_shape: Union[torch.Size, List[torch.Size]] = None,
+ prev_rank: int = None,
+ next_rank: int = None,
+ dtype: torch.dtype = None,
+ scatter_gather_tensors: bool = False) -> Tuple[Union[torch.Tensor, List[torch.Tensor]]]:
+ """
+ Adapted from megatron.p2p_communication.
+ Communicate tensors between stages. Used as helper method in other
+ communication methods that are used in pipeline schedule.
+ Takes the following arguments:
+ object_send_next (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): tensor to send to next rank (no tensor sent if
+ set to None).
+ object_send_prev (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): tensor to send to prev rank (no tensor sent if
+ set to None).
+ recv_prev (bool): boolean for whether tensor should be received from
+ previous rank.
+ recv_next (bool): boolean for whether tensor should be received from
+ next rank.
+ recv_prev_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): shape of the tensor to be received from the previous stage, defaults to None.
+ recv_next_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): shape of the tensor to be received from the next stage, defaults to None.
+ prev_rank (int): the rank of the previous pipeline stage, defaults to None,
+ next_rank (int): the rank of the next pipeline stage, defaults to None,
+ dtype (torch.dtype): data type of intermediate buffers, defaults to None
+ scatter_gather_tensors (bool): whether to scatter and gather tensor between pipeline stages, defaults to False
+
+ Returns:
+ Tuple[Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]]: returns tensor_recv_prev, tensor_recv_next
+ """
+
+ # Create placeholder tensors for receive in forward and backward directions
+ # if needed.
+ tensor_recv_prev = None
+ tensor_recv_next = None
+
+ if recv_prev:
+ assert recv_prev_shape is not None
+ tensor_recv_prev, recv_prev_split = create_recv_buffer_with_shapes(recv_prev_shape, dtype,
+ scatter_gather_tensors)
+
+ if recv_next:
+ assert recv_next_shape is not None
+ tensor_recv_next, recv_next_split = create_recv_buffer_with_shapes(recv_next_shape, dtype,
+ scatter_gather_tensors)
+
+ if object_send_prev is not None or recv_prev:
+ if prev_rank is None:
+ prev_rank = gpc.get_prev_global_rank(ParallelMode.PIPELINE)
+
+ if object_send_next is not None or recv_next:
+ if next_rank is None:
+ next_rank = gpc.get_next_global_rank(ParallelMode.PIPELINE)
+
+ if object_send_prev is not None:
+ object_send_prev = process_object_to_send(object_send_prev, scatter_gather_tensors)
+
+ if object_send_next is not None:
+ object_send_next = process_object_to_send(object_send_next, scatter_gather_tensors)
+
+ ops = []
+ if object_send_prev is not None:
+ filling_ops_queue(object_send_prev, dist.isend, prev_rank, ops)
+
+ if tensor_recv_prev is not None:
+ filling_ops_queue(tensor_recv_prev, dist.irecv, prev_rank, ops)
+
+ if tensor_recv_next is not None:
+ filling_ops_queue(tensor_recv_next, dist.irecv, next_rank, ops)
+
+ if object_send_next is not None:
+ filling_ops_queue(object_send_next, dist.isend, next_rank, ops)
+
+ if len(ops) > 0:
+ reqs = dist.batch_isend_irecv(ops)
+ for req in reqs:
+ req.wait()
+ # To protect against race condition when using batch_isend_irecv().
+ torch.cuda.synchronize()
+
+ if recv_prev and recv_prev_split:
+ if isinstance(tensor_recv_prev, torch.Tensor):
+ tensor_recv_prev = gather_split_1d_tensor(tensor_recv_prev).view(recv_prev_shape).requires_grad_()
+ else:
+ for index in range(len(tensor_recv_prev)):
+ tensor_recv_prev[index] = gather_split_1d_tensor(tensor_recv_prev[index]).view(
+ recv_prev_shape[index]).requires_grad_()
+
+ if recv_next and recv_next_split:
+ if isinstance(tensor_recv_next, torch.Tensor):
+ tensor_recv_next = gather_split_1d_tensor(tensor_recv_next).view(recv_next_shape).requires_grad_()
+ else:
+ for index in range(len(tensor_recv_next)):
+ tensor_recv_next[index] = gather_split_1d_tensor(tensor_recv_next[index]).view(
+ recv_next_shape[index]).requires_grad_()
+
+ return tensor_recv_prev, tensor_recv_next
+
+
+def recv_forward(input_tensor_shape,
+ prev_rank=None,
+ dtype=torch.float,
+ scatter_gather_tensors=False) -> Union[torch.Tensor, List[torch.Tensor]]:
+ """Copy the forward output from the previous stage in pipeline as the input tensor of this stage.
+
+ Args:
+ input_tensor_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the tensor to be received.
+ prev_rank (int, optional): The rank of the source of the tensor.
+
+ Returns:
+ Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]: The input tensor or input tensor list.
+ """
+ if gpc.is_pipeline_first_stage():
+ input_tensor = None
+ else:
+ input_tensor, _ = _communicate(recv_prev=True,
+ recv_prev_shape=input_tensor_shape,
+ prev_rank=prev_rank,
+ dtype=dtype,
+ scatter_gather_tensors=scatter_gather_tensors)
+ return input_tensor
+
+
+def recv_backward(output_grad_shape,
+ next_rank=None,
+ dtype=torch.float,
+ scatter_gather_tensors=False) -> Union[torch.Tensor, List[torch.Tensor]]:
+ """Copy the gradient tensor from the next stage in pipeline as the input gradient of this stage.
+
+ Args:
+ output_grad_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the tensor to be received.
+ next_rank (int, optional): The rank of the source of the tensor.
+
+ Returns:
+ Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]: The input gradient tensor or gradident tensor list.
+ """
+ if gpc.is_pipeline_last_stage():
+ output_tensor_grad = None
+ else:
+ _, output_tensor_grad = _communicate(recv_next=True,
+ recv_next_shape=output_grad_shape,
+ next_rank=next_rank,
+ dtype=dtype,
+ scatter_gather_tensors=scatter_gather_tensors)
+ return output_tensor_grad
+
+
+def send_forward(output_tensor, next_rank=None, scatter_gather_tensors=False) -> None:
+ """Sends the input tensor to the next stage in pipeline.
+
+ Args:
+ output_tensor (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Tensor to be sent.
+ next_rank (int, optional): The rank of the recipient of the tensor.
+ """
+ if not gpc.is_pipeline_last_stage():
+ _communicate(object_send_next=output_tensor, next_rank=next_rank, scatter_gather_tensors=scatter_gather_tensors)
+
+
+def send_backward(input_tensor_grad, prev_rank=None, scatter_gather_tensors=False) -> None:
+ """Sends the gradient tensor to the previous stage in pipeline.
+
+ Args:
+ input_tensor_grad (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Tensor to be sent
+ prev_rank (int, optional): The rank of the recipient of the tensor
+ """
+ if not gpc.is_pipeline_first_stage():
+ _communicate(object_send_prev=input_tensor_grad,
+ prev_rank=prev_rank,
+ scatter_gather_tensors=scatter_gather_tensors)
+
+
+def send_forward_recv_backward(output_tensor,
+ output_grad_shape,
+ recv_next=True,
+ next_rank=None,
+ dtype=torch.float,
+ scatter_gather_tensors=False) -> Union[torch.Tensor, List[torch.Tensor]]:
+ """Batched communication operation. Sends the input tensor to the
+ next stage in pipeline, while receives the gradient tensor from the
+ next stage in pipeline as the input gradient tensor of this stage.
+
+ Args:
+ output_tensor (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Tensor to be sent.
+ output_grad_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the tensor to be received.
+
+ Returns:
+ Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]: The input gradient tensor.
+ """
+ if gpc.is_pipeline_last_stage():
+ output_tensor_grad = None
+ else:
+ _, output_tensor_grad = _communicate(object_send_next=output_tensor,
+ recv_next=recv_next,
+ recv_next_shape=output_grad_shape,
+ next_rank=next_rank,
+ dtype=dtype,
+ scatter_gather_tensors=scatter_gather_tensors)
+ return output_tensor_grad
+
+
+def send_backward_recv_forward(input_tensor_grad,
+ input_tensor_shape,
+ recv_prev=True,
+ prev_rank=None,
+ dtype=torch.float,
+ scatter_gather_tensors=False) -> Union[torch.Tensor, List[torch.Tensor]]:
+ """Batched communication operation. Sends the gradient tensor to the
+ previous stage in pipeline, while receives the output tensor from the
+ previous stage in pipeline as the input of this stage.
+
+ Args:
+ input_tensor_grad (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Tensor to be sent.
+ input_tensor_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the tensor to be received.
+
+ Returns:
+ Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]: The input tensor.
+ """
+ if gpc.is_pipeline_first_stage():
+ input_tensor = None
+ else:
+ input_tensor, _ = _communicate(object_send_prev=input_tensor_grad,
+ recv_prev=recv_prev,
+ recv_prev_shape=input_tensor_shape,
+ prev_rank=prev_rank,
+ dtype=dtype,
+ scatter_gather_tensors=scatter_gather_tensors)
+ return input_tensor
+
+
+def send_forward_recv_forward(output_tensor,
+ input_tensor_shape,
+ recv_prev=True,
+ prev_rank=None,
+ next_rank=None,
+ dtype=torch.float,
+ scatter_gather_tensors=False) -> Union[torch.Tensor, List[torch.Tensor]]:
+ """Batched communication operation. Sends the input tensor to the
+ next stage in pipeline, while receives the output tensor from the
+ previous stage in pipeline as the input of this stage.
+
+ Args:
+ output_tensor (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Tensor to be sent.
+ input_tensor_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the tensor to be received.
+
+ Returns:
+ Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]: The input tensor.
+ """
+ input_tensor, _ = _communicate(object_send_next=output_tensor,
+ recv_prev=recv_prev,
+ recv_prev_shape=input_tensor_shape,
+ prev_rank=prev_rank,
+ next_rank=next_rank,
+ dtype=dtype,
+ scatter_gather_tensors=scatter_gather_tensors)
+ return input_tensor
+
+
+def send_backward_recv_backward(input_tensor_grad,
+ output_grad_shape,
+ recv_next=True,
+ prev_rank=None,
+ next_rank=None,
+ dtype=torch.float,
+ scatter_gather_tensors=False) -> Union[torch.Tensor, List[torch.Tensor]]:
+ """Batched communication operation. Sends the gradient tensor to the
+ previous stage in pipeline, while receives the gradient tensor from the
+ next member in pipeline as the input of this stage.
+
+ Args:
+ input_tensor_grad (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Tensor to be sent.
+ output_grad_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the tensor to be received.
+
+ Returns:
+ Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]: The input gradient tensor.
+ """
+ _, output_tensor_grad = _communicate(object_send_prev=input_tensor_grad,
+ recv_next=recv_next,
+ recv_next_shape=output_grad_shape,
+ prev_rank=prev_rank,
+ next_rank=next_rank,
+ dtype=dtype,
+ scatter_gather_tensors=scatter_gather_tensors)
+ return output_tensor_grad
+
+
+def send_forward_backward_recv_forward_backward(
+ output_tensor,
+ input_tensor_grad,
+ input_tensor_shape,
+ output_grad_shape,
+ recv_prev=True,
+ recv_next=True,
+ prev_rank=None,
+ next_rank=None,
+ dtype=torch.float,
+ scatter_gather_tensors=False) -> Tuple[Union[torch.Tensor, List[torch.Tensor]]]:
+ """Batched communication operation. Sends the input tensor to the next stage in pipeline and
+ the gradient tensor to the previous stage, while receives the input gradient tensor from the
+ next stage and the input tensor from the previous stage.
+
+ Args:
+ output_tensor (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Tensor sent to the next.
+ input_tensor_grad (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Tensor sent to the previous.
+ input_tensor_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the tensor received from the previous.
+ output_grad_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the tensor received from the next.
+
+ Returns:
+ Tuple(Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]], Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): (the input tensor, the input gradient tensor)
+ """
+ input_tensor, output_tensor_grad = _communicate(object_send_next=output_tensor,
+ object_send_prev=input_tensor_grad,
+ recv_prev=recv_prev,
+ recv_next=recv_next,
+ recv_prev_shape=input_tensor_shape,
+ recv_next_shape=output_grad_shape,
+ prev_rank=prev_rank,
+ next_rank=next_rank,
+ dtype=dtype,
+ scatter_gather_tensors=scatter_gather_tensors)
+ return input_tensor, output_tensor_grad
diff --git a/colossalai/communication/p2p_v2.py b/colossalai/communication/p2p_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..0dacd8c3c9b5bacf65aee3168bcbd170c5a5b6dc
--- /dev/null
+++ b/colossalai/communication/p2p_v2.py
@@ -0,0 +1,268 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import io
+import pickle
+from typing import Any, List, Tuple, Union
+
+import torch
+import torch.distributed as dist
+from torch.distributed import ProcessGroupNCCL
+from torch.distributed import distributed_c10d as c10d
+
+from colossalai.context.parallel_mode import ParallelMode
+from colossalai.core import global_context as gpc
+
+TensorShape = Union[torch.Size, List[int], Tuple[int]]
+_pg_manager = {}
+_unpickler = pickle.Unpickler
+
+
+def init_process_group():
+ """intialise process group by dist.new_group in the adjacent stages
+
+ Args:
+ None
+
+ Returns:
+ None
+ """
+ world_size = gpc.get_world_size(ParallelMode.PIPELINE)
+ for i in range(world_size - 1):
+ _pg_manager[(i, i + 1)] = dist.new_group([i, i + 1])
+
+
+def _acquire_pair_group_handle(first_rank: int, second_rank: int) -> ProcessGroupNCCL:
+ """get the group handle of two given ranks
+
+ Args:
+ first_rank (int): first rank in the pair
+ second_rank (int): second rank in the pair
+
+ Returns:
+ :class:`ProcessGroupNCCL`: the handle of the group consisting of the given two ranks
+ """
+ if len(_pg_manager) == 0:
+ init_process_group()
+ if first_rank > second_rank:
+ first_rank, second_rank = second_rank, first_rank
+ pair_key = (first_rank, second_rank)
+ return _pg_manager[pair_key]
+
+
+def _cuda_safe_tensor_to_object(tensor: torch.Tensor, tensor_size: torch.Size) -> object:
+ """transform tensor to object with unpickle.
+ Info of the device in bytes stream will be modified into current device before unpickling
+
+ Args:
+ tensor (:class:`torch.tensor`): tensor to be unpickled
+ tensor_size (:class:`torch.Size`): Size of the real info in bytes
+
+ Returns:
+ Any: object after unpickled
+ """
+ buf = tensor.numpy().tobytes()[:tensor_size]
+ if b'cuda' in buf:
+ buf_array = bytearray(buf)
+ device_index = torch.cuda.current_device()
+ buf_array[buf_array.find(b'cuda') + 5] = 48 + device_index
+ buf = bytes(buf_array)
+
+ io_bytes = io.BytesIO(buf)
+ byte_pickler = _unpickler(io_bytes)
+ unpickle = byte_pickler.load()
+
+ return unpickle
+
+
+def _broadcast_object_list(object_list: List[Any], src: int, dst: int, device=None):
+ """This is a modified version of the broadcast_object_list in torch.distribution
+ The only difference is that object will be move to correct device after unpickled.
+ If local_rank = src, then object list will be sent to rank src. Otherwise, object list will
+ be updated with data sent from rank src.
+
+ Args:
+ object_list (List[Any]): list of object to broadcast
+ src (int): source rank to broadcast
+ dst (int): dst rank to broadcast
+ device (:class:`torch.device`): device to do broadcast. current device in default
+
+ """
+ group = _acquire_pair_group_handle(src, dst)
+
+ if c10d._rank_not_in_group(group):
+ c10d._warn_not_in_group("broadcast_object_list")
+ return
+
+ local_rank = gpc.get_local_rank(ParallelMode.PIPELINE)
+ # Serialize object_list elements to tensors on src rank.
+ if local_rank == src:
+ tensor_list, size_list = zip(*[c10d._object_to_tensor(obj) for obj in object_list])
+ object_sizes_tensor = torch.cat(size_list)
+ else:
+ object_sizes_tensor = torch.empty(len(object_list), dtype=torch.long)
+
+ is_nccl_backend = c10d._check_for_nccl_backend(group)
+ current_device = None
+
+ if device is not None:
+ if is_nccl_backend and device.type != "cuda":
+ raise ValueError("device type must be cuda for nccl backend")
+ current_device = device
+ else:
+ current_device = torch.device("cpu")
+ if is_nccl_backend:
+ current_device = torch.device("cuda", torch.cuda.current_device())
+ if is_nccl_backend:
+ object_sizes_tensor = object_sizes_tensor.to(current_device)
+
+ # Broadcast object sizes
+ c10d.broadcast(object_sizes_tensor, src=src, group=group, async_op=False)
+
+ # Concatenate and broadcast serialized object tensors
+ if local_rank == src:
+ object_tensor = torch.cat(tensor_list)
+ else:
+ object_tensor = torch.empty( # type: ignore[call-overload]
+ torch.sum(object_sizes_tensor).item(), # type: ignore[arg-type]
+ dtype=torch.uint8,
+ )
+
+ if is_nccl_backend:
+ object_tensor = object_tensor.to(current_device)
+
+ c10d.broadcast(object_tensor, src=src, group=group, async_op=False)
+
+ # Deserialize objects using their stored sizes.
+ offset = 0
+
+ if local_rank != src:
+ for i, obj_size in enumerate(object_sizes_tensor):
+ obj_view = object_tensor[offset:offset + obj_size]
+ obj_view = obj_view.type(torch.uint8)
+ if obj_view.device != torch.device("cpu"):
+ obj_view = obj_view.cpu()
+ offset += obj_size
+ # unpickle
+ unpickle_object = _cuda_safe_tensor_to_object(obj_view, obj_size)
+
+ # unconsistence in device
+ if isinstance(unpickle_object,
+ torch.Tensor) and unpickle_object.device.index != torch.cuda.current_device():
+ unpickle_object = unpickle_object.cuda()
+
+ object_list[i] = unpickle_object
+
+
+def _send_object(object: Any, dst: int) -> None:
+ """send anything to dst rank
+ Args:
+ object (Any): object needed to be sent
+ dst (int): rank of the destination
+
+ Returns:
+ None
+ """
+ local_rank = gpc.get_local_rank(ParallelMode.PIPELINE)
+ # handler = _acquire_pair_group_handle(local_rank, dst)
+
+ # transform to list if not
+ if isinstance(object, torch.Tensor):
+ object = [object]
+
+ # broadcast length first
+ # TODO : more elegant ? P.S. reduce a _broadcast_object_list
+ _broadcast_object_list([len(object)], local_rank, dst)
+ # then broadcast safely
+ _broadcast_object_list(object, local_rank, dst)
+
+
+def _recv_object(src: int) -> Any:
+ """recv anything from src
+
+ Args:
+ src (int): source rank of data. local rank will receive data from src rank.
+
+ Returns:
+ Any: Object received from src.
+ """
+ local_rank = gpc.get_local_rank(ParallelMode.PIPELINE)
+ # handler = _acquire_pair_group_handle(local_rank, src)
+ # recv length first
+ length = [0]
+ _broadcast_object_list(length, src, local_rank)
+
+ # then create recv buff from length[0] and broadcast
+ object = [None] * length[0]
+ _broadcast_object_list(object, src, local_rank)
+
+ if length[0] == 1:
+ object = object[0]
+
+ return object
+
+
+def recv_forward(prev_rank: int = None) -> Any:
+ """Copy the forward output from the previous stage in pipeline as the input tensor of this stage.
+
+ Args:
+ input_tensor_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the tensor to be received.
+ prev_rank (int, optional): The rank of the source of the tensor.
+
+ Returns:
+ Any: The input tensor or input tensor list.
+ """
+ if gpc.is_pipeline_first_stage():
+ input_tensor = None
+ else:
+ if prev_rank is None:
+ prev_rank = gpc.get_prev_global_rank(ParallelMode.PIPELINE)
+ input_tensor = _recv_object(prev_rank)
+
+ return input_tensor
+
+
+def recv_backward(next_rank: int = None) -> Any:
+ """Copy the gradient tensor from the next stage in pipeline as the input gradient of this stage.
+
+ Args:
+ output_grad_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the tensor to be received.
+ next_rank (int, optional): The rank of the source of the tensor.
+
+ Returns:
+ Any: The input gradient tensor or gradient tensor list.
+ """
+ if gpc.is_pipeline_last_stage():
+ output_tensor_grad = None
+ else:
+ if next_rank is None:
+ next_rank = gpc.get_next_global_rank(ParallelMode.PIPELINE)
+ output_tensor_grad = _recv_object(next_rank)
+
+ return output_tensor_grad
+
+
+def send_forward(output_object: Any, next_rank: int = None) -> None:
+ """Sends the input tensor to the next stage in pipeline.
+
+ Args:
+ output_object Any: Object to be sent.
+ next_rank (int, optional): The rank of the recipient of the tensor.
+ """
+ if not gpc.is_pipeline_last_stage():
+ if next_rank is None:
+ next_rank = gpc.get_next_global_rank(ParallelMode.PIPELINE)
+ _send_object(output_object, next_rank)
+
+
+def send_backward(input_object: Any, prev_rank: int = None) -> None:
+ """Sends the gradient tensor to the previous stage in pipeline.
+
+ Args:
+ input_tensor_grad (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Tensor to be sent
+ prev_rank (int, optional): The rank of the recipient of the tensor
+ """
+ if not gpc.is_pipeline_first_stage():
+ if prev_rank is None:
+ prev_rank = gpc.get_prev_global_rank(ParallelMode.PIPELINE)
+ _send_object(input_object, prev_rank)
diff --git a/colossalai/communication/ring.py b/colossalai/communication/ring.py
new file mode 100644
index 0000000000000000000000000000000000000000..aece7574b7c41cac3b16cd5891b1e26d0ede9c36
--- /dev/null
+++ b/colossalai/communication/ring.py
@@ -0,0 +1,56 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import torch
+
+from colossalai.context.parallel_mode import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.utils import get_current_device, synchronize
+
+
+def ring_forward(tensor_send_next: torch.Tensor, parallel_mode: ParallelMode) -> torch.Tensor:
+ """Sends a tensor to the next member and receives a tensor from the previous member.
+ This function returns the received tensor from the previous member.
+
+ Args:
+ tensor_send_next (:class:`torch.Tensor`): Tensor sent to next member
+ parallel_mode (ParallelMode): Parallel group mode used in this communication
+
+ Returns:
+ :class:`torch.Tensor`: The tensor received from the previous.
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+ """
+ buffer_shape = tensor_send_next.size()
+
+ ops = []
+ current_rank = gpc.get_global_rank()
+
+ tensor_recv_prev = torch.empty(buffer_shape,
+ requires_grad=True,
+ device=get_current_device(),
+ dtype=tensor_send_next.dtype)
+
+ # send to next rank
+ send_next_op = torch.distributed.P2POp(torch.distributed.isend, tensor_send_next,
+ gpc.get_next_global_rank(parallel_mode))
+ ops.append(send_next_op)
+
+ # receive from prev rank
+ recv_prev_op = torch.distributed.P2POp(torch.distributed.irecv, tensor_recv_prev,
+ gpc.get_prev_global_rank(parallel_mode))
+ ops.append(recv_prev_op)
+
+ if current_rank % 2 == 0:
+ ops = ops[::-1]
+
+ reqs = torch.distributed.batch_isend_irecv(ops)
+ for req in reqs:
+ req.wait()
+
+ # To protect against race condition when using batch_isend_irecv().
+ synchronize()
+
+ return tensor_recv_prev
diff --git a/colossalai/communication/utils.py b/colossalai/communication/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef9eceea847dd3d6cb036e87e369529dcbe0db41
--- /dev/null
+++ b/colossalai/communication/utils.py
@@ -0,0 +1,126 @@
+import torch
+import torch.distributed as dist
+
+from colossalai.context.parallel_mode import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.utils import get_current_device
+from typing import Union, List, Tuple
+
+TensorShape = Union[torch.Size, List[int], Tuple[int]]
+
+
+def send_meta_helper(obj, next_rank, tensor_kwargs):
+ send_shape = torch.tensor(obj.size(), **tensor_kwargs)
+ send_ndims = torch.tensor(len(obj.size()), **tensor_kwargs)
+ dist.send(send_ndims, next_rank)
+ dist.send(send_shape, next_rank)
+
+
+def send_obj_meta(obj, need_meta=True, next_rank=None) -> bool:
+ """Sends obj meta information before sending a specific obj.
+ Since the recipient must know the shape of the obj in p2p communications,
+ meta information of the obj should be sent before communications. This function
+ synchronizes with :func:`recv_obj_meta`.
+
+ Args:
+ obj (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): obj to be sent.
+ need_meta (bool, optional): If False, meta information won't be sent.
+ next_rank (int): The rank of the next member in pipeline parallel group.
+
+ Returns:
+ bool: False
+ """
+ if need_meta:
+ if next_rank is None:
+ next_rank = gpc.get_next_global_rank(ParallelMode.PIPELINE)
+
+ tensor_kwargs = {'dtype': torch.long, 'device': get_current_device()}
+ if isinstance(obj, torch.Tensor):
+ send_obj_nums = torch.tensor(1, **tensor_kwargs)
+ dist.send(send_obj_nums, next_rank)
+ send_meta_helper(obj, next_rank, tensor_kwargs)
+ else:
+ send_obj_nums = torch.tensor(len(obj), **tensor_kwargs)
+ dist.send(send_obj_nums, next_rank)
+ for tensor_to_send in obj:
+ send_meta_helper(tensor_to_send, next_rank, tensor_kwargs)
+
+ return False
+
+
+def recv_meta_helper(prev_rank, tensor_kwargs):
+ recv_ndims = torch.empty((), **tensor_kwargs)
+ dist.recv(recv_ndims, prev_rank)
+ recv_shape = torch.empty(recv_ndims, **tensor_kwargs)
+ dist.recv(recv_shape, prev_rank)
+ return recv_shape
+
+
+def recv_obj_meta(obj_shape, prev_rank=None) -> torch.Size:
+ """Receives obj meta information before receiving a specific obj.
+ Since the recipient must know the shape of the obj in p2p communications,
+ meta information of the obj should be received before communications. This function
+ synchronizes with :func:`send_obj_meta`.
+
+ Args:
+ obj_shape (Union[:class:`torch.Size`, List[:class:`torch.Size`]]): The shape of the obj to be received.
+ prev_rank (int): The rank of the source of the obj.
+
+ Returns:
+ Union[:class:`torch.Size`, List[:class:`torch.Size`]]: The shape of the obj to be received.
+ """
+ if obj_shape is None:
+ if prev_rank is None:
+ prev_rank = gpc.get_prev_global_rank(ParallelMode.PIPELINE)
+
+ tensor_kwargs = {'dtype': torch.long, 'device': get_current_device()}
+ recv_obj_nums = torch.empty((), **tensor_kwargs)
+ dist.recv(recv_obj_nums, prev_rank)
+ if recv_obj_nums.item() == 1:
+ recv_shape = recv_meta_helper(prev_rank, tensor_kwargs)
+ obj_shape = torch.Size(recv_shape)
+ else:
+ obj_shape = []
+ for i in range(recv_obj_nums.item()):
+ recv_shape = recv_meta_helper(prev_rank, tensor_kwargs)
+ obj_shape.append(torch.Size(recv_shape))
+
+ return obj_shape
+
+
+def split_tensor_into_1d_equal_chunks(tensor: torch.Tensor, new_buffer=False) -> torch.Tensor:
+ """Break a tensor into equal 1D chunks.
+
+ Args:
+ tensor (:class:`torch.Tensor`): Tensor to be split before communication.
+ new_buffer (bool, optional): Whether to use a new buffer to store sliced tensor.
+
+ Returns:
+ :class:`torch.Tensor`: The split tensor
+ """
+ partition_size = torch.numel(tensor) // gpc.get_world_size(ParallelMode.PARALLEL_1D)
+ start_index = partition_size * gpc.get_local_rank(ParallelMode.PARALLEL_1D)
+ end_index = start_index + partition_size
+ if new_buffer:
+ data = torch.empty(partition_size, dtype=tensor.dtype, device=torch.cuda.current_device(), requires_grad=False)
+ data.copy_(tensor.view(-1)[start_index:end_index])
+ else:
+ data = tensor.view(-1)[start_index:end_index]
+ return data
+
+
+def gather_split_1d_tensor(tensor: torch.Tensor) -> torch.Tensor:
+ """Opposite of above function, gather values from model parallel ranks.
+
+ Args:
+ tensor (:class:`torch.Tensor`): Tensor to be gathered after communication.
+ Returns:
+ :class:`torch.Tensor`: The gathered tensor.
+ """
+ world_size = gpc.get_world_size(ParallelMode.PARALLEL_1D)
+ numel = torch.numel(tensor)
+ numel_gathered = world_size * numel
+ gathered = torch.empty(numel_gathered, dtype=tensor.dtype, device=torch.cuda.current_device(), requires_grad=False)
+ chunks = [gathered[i * numel:(i + 1) * numel] for i in range(world_size)]
+ dist.all_gather(chunks, tensor, group=gpc.get_group(ParallelMode.PARALLEL_1D))
+ return gathered
diff --git a/colossalai/constants.py b/colossalai/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..6cf9085f9fbb63ea18d2712f99c08f24b539245d
--- /dev/null
+++ b/colossalai/constants.py
@@ -0,0 +1,32 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+ALLOWED_MODES = [None, '1d', '2d', '2.5d', '3d', 'sequence']
+TENSOR_PARALLEL_MODE = 'tensor_parallel_mode'
+
+# initializer
+INITIALIZER_MAPPING = {
+ 'data': 'Initializer_Data',
+ 'tensor': 'Initializer_Tensor',
+ 'pipeline': 'Initializer_Pipeline',
+ 'embedding': 'Initializer_Embedding',
+ '1d': 'Initializer_1D',
+ '2d': 'Initializer_2D',
+ '2.5d': 'Initializer_2p5D',
+ '3d': 'Initializer_3D',
+ 'sequence': 'Initializer_Sequence',
+ 'model': 'Initializer_Model',
+ 'moe': 'Initializer_Moe'
+}
+
+# 3D parallelism groups
+INPUT_GROUP_3D = 'input_group_3d'
+WEIGHT_GROUP_3D = 'weight_group_3d'
+OUTPUT_GROUP_3D = 'output_group_3d'
+INPUT_X_WEIGHT_3D = 'input_x_weight_group_3d'
+OUTPUT_X_WEIGHT_3D = 'output_x_weight_group_3d'
+
+# Attributes of tensor parallel parameters
+IS_TENSOR_PARALLEL = 'is_tensor_parallel'
+NUM_PARTITIONS = 'num_partitions'
+TENSOR_PARALLEL_ATTRIBUTES = [IS_TENSOR_PARALLEL, NUM_PARTITIONS]
diff --git a/colossalai/context/__init__.py b/colossalai/context/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..50178b5fa850777f8455798cc6ab9d7254c5a9fe
--- /dev/null
+++ b/colossalai/context/__init__.py
@@ -0,0 +1,6 @@
+from .config import Config, ConfigException
+from .parallel_context import ParallelContext
+from .parallel_mode import ParallelMode
+from .moe_context import MOE_CONTEXT
+from .process_group_initializer import *
+from .random import *
diff --git a/colossalai/context/config.py b/colossalai/context/config.py
new file mode 100644
index 0000000000000000000000000000000000000000..8903707708df96eac7a0a70343e37e984e6fabed
--- /dev/null
+++ b/colossalai/context/config.py
@@ -0,0 +1,106 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import inspect
+import sys
+from importlib.machinery import SourceFileLoader
+from pathlib import Path
+from colossalai.logging import get_dist_logger
+
+
+class Config(dict):
+ """This is a wrapper class for dict objects so that values of which can be
+ accessed as attributes.
+
+ Args:
+ config (dict): The dict object to be wrapped.
+ """
+
+ def __init__(self, config: dict = None):
+ if config is not None:
+ for k, v in config.items():
+ self._add_item(k, v)
+
+ def __missing__(self, key):
+ raise KeyError(key)
+
+ def __getattr__(self, key):
+ try:
+ value = super(Config, self).__getitem__(key)
+ return value
+ except KeyError:
+ raise AttributeError(key)
+
+ def __setattr__(self, key, value):
+ super(Config, self).__setitem__(key, value)
+
+ def _add_item(self, key, value):
+ if isinstance(value, dict):
+ self.__setattr__(key, Config(value))
+ else:
+ self.__setattr__(key, value)
+
+ def update(self, config):
+ assert isinstance(config, (Config, dict)), 'can only update dictionary or Config objects.'
+ for k, v in config.items():
+ self._add_item(k, v)
+ return self
+
+ @staticmethod
+ def from_file(filename: str):
+ """Reads a python file and constructs a corresponding :class:`Config` object.
+
+ Args:
+ filename (str): Name of the file to construct the return object.
+
+ Returns:
+ :class:`Config`: A :class:`Config` object constructed with information in the file.
+
+ Raises:
+ AssertionError: Raises an AssertionError if the file does not exist, or the file is not .py file
+ """
+
+ # check config path
+ if isinstance(filename, str):
+ filepath = Path(filename).absolute()
+ elif isinstance(filename, Path):
+ filepath = filename.absolute()
+
+ assert filepath.exists(), f'{filename} is not found, please check your configuration path'
+
+ # check extension
+ extension = filepath.suffix
+ assert extension == '.py', 'only .py files are supported'
+
+ # import the config as module
+ remove_path = False
+ if filepath.parent not in sys.path:
+ sys.path.insert(0, (filepath))
+ remove_path = True
+
+ module_name = filepath.stem
+ source_file = SourceFileLoader(fullname=str(module_name), path=str(filepath))
+ module = source_file.load_module()
+
+ # load into config
+ config = Config()
+
+ for k, v in module.__dict__.items():
+ if k.startswith('__') or inspect.ismodule(v) or inspect.isclass(v):
+ continue
+ else:
+ config._add_item(k, v)
+
+ logger = get_dist_logger()
+ logger.debug('variables which starts with __, is a module or class declaration are omitted in config file')
+
+ # remove module
+ del sys.modules[module_name]
+ if remove_path:
+ sys.path.pop(0)
+
+ return config
+
+
+class ConfigException(Exception):
+ pass
diff --git a/colossalai/context/moe_context.py b/colossalai/context/moe_context.py
new file mode 100644
index 0000000000000000000000000000000000000000..b41f4072a4052113b3e3a79a20c0278b9fed8295
--- /dev/null
+++ b/colossalai/context/moe_context.py
@@ -0,0 +1,129 @@
+from typing import Tuple
+
+import torch
+import torch.distributed as dist
+
+from colossalai.context.parallel_mode import ParallelMode
+from colossalai.context.singleton_meta import SingletonMeta
+from colossalai.tensor import ProcessGroup
+
+
+def _check_sanity():
+ from colossalai.core import global_context as gpc
+ if gpc.tensor_parallel_size > 1 or gpc.pipeline_parallel_size > 1:
+ raise NotImplementedError("Moe is not compatible with tensor or "
+ "pipeline parallel at present.")
+
+
+class MoeParallelInfo:
+ """Moe parallelism information, storing parallel sizes and groups.
+ """
+
+ def __init__(self, ep_size: int, dp_size: int):
+ _check_sanity()
+ self.ep_size = ep_size
+ self.dp_size = dp_size
+ self.pg = ProcessGroup(tp_degree=ep_size, dp_degree=dp_size)
+ self.ep_group = self.pg.tp_process_group()
+ self.dp_group = self.pg.dp_process_group()
+
+
+class MoeContext(metaclass=SingletonMeta):
+ """MoE parallel context manager. This class manages different
+ parallel groups in MoE context and MoE loss in training.
+ """
+
+ def __init__(self):
+ self.world_size = 1
+ # Users may want to set maximum expert parallel size smaller than the world size
+ # since very low bandwidth across nodes may constrain the performance of MoE
+ # When we have a maximum expert parallel size, we have a minimum data parallel size naturally
+ self.max_ep_size = 1
+ self.min_dp_size = 1
+ self.aux_loss = None
+ self.use_kernel_optim = True
+
+ self.has_setup = False
+ self._parallel_info_dict = dict()
+
+ @property
+ def parallel_info_dict(self):
+ return self._parallel_info_dict
+
+ @property
+ def is_initialized(self):
+ return self.has_setup
+
+ def setup(self, seed: int, use_kernel_optim: bool = True):
+ assert not self.is_initialized, "MoE distributed context shouldn't be set up again"
+ _check_sanity()
+ assert torch.cuda.is_available(), "MoE requires to enable CUDA first"
+
+ self.world_size = dist.get_world_size()
+
+ from colossalai.core import global_context as gpc
+ self.max_ep_size = gpc.config.get('max_ep_size', self.world_size)
+ assert self.world_size % self.max_ep_size == 0, \
+ "Maximum expert parallel size must be a factor of the number of GPUs"
+ self.min_dp_size = self.world_size // self.max_ep_size
+
+ # Enabling kernel optimization may raise error in some cases
+ # Users can close kernel optimization manually
+ self.use_kernel_optim = use_kernel_optim
+
+ from .random import moe_set_seed
+ moe_set_seed(seed)
+ self.has_setup = True
+
+ def get_info(self, num_experts: int) -> Tuple[int, MoeParallelInfo]:
+ """Calculate the Data Parallel Group and Expert Parallel Group.
+
+ Parameters
+ ----------
+ num_experts : int
+ The number experts
+
+ Returns
+ -------
+ int, MoeParallelInfo
+ number of local experts, the MoeParallelInfo of the current ep_size
+ """
+
+ gt_flag = num_experts % self.max_ep_size == 0 # check whether num_experts is greater
+ lt_flag = self.max_ep_size % num_experts == 0 # check whether num_experts is less
+
+ assert gt_flag or lt_flag, "Automatic experts placement dose not not support expert number" \
+ " is not a multiple of ep size or vice versa."
+
+ # If the number of experts is greater than maximum expert parallel size. a.k.a ep_size,
+ # there are multiple experts in each GPU and each GPU has different experts
+ # So it's data parallel size is 1
+ # Otherwise, there is only one expert in each GPU
+ # The data parallel size should be calculated
+ dp_size = 1 if gt_flag else self.max_ep_size // num_experts
+ ep_size = self.max_ep_size // dp_size
+
+ # Calculate the number of experts for each GPU
+ num_local_experts = 1 if lt_flag else num_experts // self.max_ep_size
+
+ # Don't forget to multiply minimum data parallel size
+ dp_size *= self.min_dp_size
+ if not (ep_size in self.parallel_info_dict):
+ self.parallel_info_dict[ep_size] = MoeParallelInfo(ep_size, dp_size)
+
+ return num_local_experts, self.parallel_info_dict[ep_size]
+
+ def set_kernel_not_use(self):
+ self.use_kernel_optim = False
+
+ def reset_loss(self):
+ self.aux_loss = 0
+
+ def add_loss(self, loss):
+ self.aux_loss += loss
+
+ def get_loss(self):
+ return self.aux_loss
+
+
+MOE_CONTEXT = MoeContext()
diff --git a/colossalai/context/parallel_context.py b/colossalai/context/parallel_context.py
new file mode 100644
index 0000000000000000000000000000000000000000..003f0cdd91b6630fe1a88271eed3afdd4021c3b8
--- /dev/null
+++ b/colossalai/context/parallel_context.py
@@ -0,0 +1,578 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import random
+import socket
+from collections import Counter
+from threading import local
+from typing import Union
+
+import numpy as np
+import torch
+import torch.distributed as dist
+
+from colossalai.constants import ALLOWED_MODES, INITIALIZER_MAPPING
+from colossalai.context.config import Config
+from colossalai.context.singleton_meta import SingletonMeta
+from colossalai.global_variables import tensor_parallel_env as env
+from colossalai.logging import get_dist_logger
+from colossalai.registry import DIST_GROUP_INITIALIZER
+
+from .parallel_mode import ParallelMode
+from .random import add_seed, get_seeds, set_mode
+
+
+class ParallelContext(metaclass=SingletonMeta):
+ """This class provides interface functions for users to get the parallel context,
+ such as the global rank, the local rank, the world size, etc. of each device.
+
+ Note:
+ The parallel_mode used in this class should be concluded in ``ParallelMode``.
+ More details about ``ParallelMode`` could be found in
+ `parallel_mode `_.
+ """
+
+ def __init__(self):
+ # distributed settings
+ self._global_ranks = dict()
+ self._local_ranks = dict()
+ self._world_sizes = dict()
+ self._groups = dict()
+ self._cpu_groups = dict()
+ self._ranks_in_group = dict()
+
+ # load config from file
+ self._config = None
+
+ # default 3D parallel args, will be overwritten during process group initialization
+ self.world_size = 1
+ self.data_parallel_size = 1
+ self.pipeline_parallel_size = 1
+ self.tensor_parallel_size = 1
+ self.num_processes_on_current_node = -1
+ self.virtual_pipeline_parallel_size = None
+ self.virtual_pipeline_parallel_rank = None
+
+ # logging
+ self._verbose = False
+ self._logger = get_dist_logger()
+
+ @property
+ def config(self):
+ return self._config
+
+ @property
+ def verbose(self):
+ return self._verbose
+
+ @verbose.setter
+ def verbose(self, verbose_: bool):
+ self._verbose = verbose_
+
+ def load_config(self, config: Union[dict, str]):
+ """Loads the configuration from either a dict or a file.
+
+ Args:
+ config (dict or str): Either a dict containing the configuration information or the filename
+ of a file containing the configuration information.
+
+ Raises:
+ TypeError: Raises a TypeError if `config` is neither a dict nor a str.
+ """
+ if isinstance(config, str):
+ self._config = Config.from_file(config)
+ elif isinstance(config, dict):
+ self._config = Config(config)
+ else:
+ raise TypeError("Invalid type for config, only dictionary or string is supported")
+
+ def detect_num_processes_on_current_node(self):
+ hostname = socket.gethostname()
+ hostname_list = [None for _ in range(self.get_world_size(ParallelMode.GLOBAL))]
+ dist.all_gather_object(hostname_list, hostname, group=self.get_group(ParallelMode.GLOBAL))
+ counter = Counter(hostname_list)
+ self.num_processes_on_current_node = counter[hostname]
+
+ @staticmethod
+ def _check_parallel_mode(parallel_mode: ParallelMode):
+ assert isinstance(parallel_mode, ParallelMode), \
+ f'expected the argument parallel_mode to be of enum ParallelMode, but got {type(parallel_mode)}'
+
+ def get_global_rank(self):
+ """Returns the global rank of the current device.
+
+ Returns:
+ int: The global rank of the current device
+ """
+ return self._global_ranks[ParallelMode.GLOBAL]
+
+ def add_global_rank(self, parallel_mode: ParallelMode, rank: int):
+ """Adds the global rank of the current device for `parallel_mode` to the context.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The parallel mode for the rank.
+ rank (int): The rank to be added
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+ """
+ self._check_parallel_mode(parallel_mode)
+ self._global_ranks[parallel_mode] = rank
+
+ def get_local_rank(self, parallel_mode: ParallelMode):
+ """Returns the local rank of the current device.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+
+ Returns:
+ int: The local rank of the current device for `parallel_mode`.
+ """
+ self._check_parallel_mode(parallel_mode)
+ return self._local_ranks[parallel_mode]
+
+ def _add_local_rank(self, parallel_mode: ParallelMode, rank: int):
+ """Adds the local rank of the current device for `parallel_mode` to the context.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The parallel mode for the rank.
+ rank (int): The rank to be added.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+ """
+ self._check_parallel_mode(parallel_mode)
+ self._local_ranks[parallel_mode] = rank
+
+ def get_next_global_rank(self, parallel_mode: ParallelMode):
+ """Returns the global rank of the next device.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+
+ Returns:
+ int: The global rank of the next device for `parallel_mode`.
+ """
+ self._check_parallel_mode(parallel_mode)
+
+ # get rank and world size
+ local_rank = self.get_local_rank(parallel_mode)
+ world_size = self.get_world_size(parallel_mode)
+ ranks_in_group = self.get_ranks_in_group(parallel_mode)
+
+ return ranks_in_group[(local_rank + 1) % world_size]
+
+ def get_prev_global_rank(self, parallel_mode: ParallelMode):
+ """Returns the global rank of the previous device.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+
+ Returns:
+ int: The global rank of the previous device for `parallel_mode`.
+ """
+ self._check_parallel_mode(parallel_mode)
+
+ # get rank and world size
+ local_rank = self.get_local_rank(parallel_mode)
+ world_size = self.get_world_size(parallel_mode)
+ ranks_in_group = self.get_ranks_in_group(parallel_mode)
+
+ return ranks_in_group[(local_rank - 1) % world_size]
+
+ def is_first_rank(self, parallel_mode: ParallelMode):
+ """Returns a boolean value indicating whether the current device is the first one
+ among its group for `parallel_mode`.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+
+ Returns:
+ bool: a boolean value indicating whether the current device is the first one
+ among its group for `parallel_mode`.
+ """
+ rank = self.get_local_rank(parallel_mode)
+ return rank == 0
+
+ def is_last_rank(self, parallel_mode: ParallelMode):
+ """Returns a boolean value indicating whether the current device is the last one
+ among its group for `parallel_mode`.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+
+ Returns:
+ bool: a boolean value indicating whether the current device is the first one
+ among its group for `parallel_mode`.
+ """
+ rank = self.get_local_rank(parallel_mode)
+ world_size = self.get_world_size(parallel_mode)
+ return rank == world_size - 1
+
+ def is_pipeline_first_stage(self, ignore_virtual=False):
+ if not ignore_virtual:
+ if self.virtual_pipeline_parallel_size is not None and self.virtual_pipeline_parallel_rank != 0:
+ return False
+ return self.is_first_rank(ParallelMode.PIPELINE)
+
+ def is_pipeline_last_stage(self, ignore_virtual=False):
+ if not ignore_virtual:
+ if self.virtual_pipeline_parallel_size \
+ is not None and self.virtual_pipeline_parallel_rank != self.virtual_pipeline_parallel_size - 1:
+ return False
+ return self.is_last_rank(ParallelMode.PIPELINE)
+
+ def get_world_size(self, parallel_mode: ParallelMode):
+ """Returns the world size for `parallel_mode`.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+
+ Returns:
+ int: The world size for `parallel_mode`.
+ """
+ self._check_parallel_mode(parallel_mode)
+ return self._world_sizes[parallel_mode]
+
+ def _add_world_size(self, parallel_mode: ParallelMode, world_size: int):
+ """Adds world size for `parallel_mode`.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The parallel mode corresponding to the process group
+ world_size (int): The world size to be added
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+ """
+ self._check_parallel_mode(parallel_mode)
+ self._world_sizes[parallel_mode] = world_size
+
+ def get_group(self, parallel_mode: ParallelMode):
+ """Returns the group of the current device for `parallel_mode`.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+
+ Returns:
+ torch.distributed.ProcessGroup: The group of the current device for `parallel_mode`.
+ """
+ self._check_parallel_mode(parallel_mode)
+ return self._groups[parallel_mode]
+
+ def _add_group(self, parallel_mode: ParallelMode, group: dist.ProcessGroup):
+ """Adds the group of the current device for `parallel_mode`.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+ group (torch.distributed.ProcessGroup): The group to be added
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+ """
+ self._check_parallel_mode(parallel_mode)
+ self._groups[parallel_mode] = group
+
+ def get_cpu_group(self, parallel_mode: ParallelMode):
+ """Returns the Gloo group of the current device for `parallel_mode`.
+
+ :param parallel_mode: The chosen parallel mode
+ :type parallel_mode: :class:`colossalai.context.ParallelMode`
+ :raises AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`
+ :return: The group of the current device for `parallel_mode`
+ :rtype: torch.distributed.ProcessGroup
+ """
+ self._check_parallel_mode(parallel_mode)
+ return self._cpu_groups[parallel_mode]
+
+ def _add_cpu_group(self, parallel_mode: ParallelMode, group: dist.ProcessGroup):
+ """Adds the Gloo group of the current device for `parallel_mode`.
+
+ :param parallel_mode: The chosen parallel mode
+ :type parallel_mode: :class:`colossalai.context.ParallelMode`
+ :param group: The group to be added
+ :type group: torch.distributed.ProcessGroup
+ :raises AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`
+ """
+ self._check_parallel_mode(parallel_mode)
+ self._cpu_groups[parallel_mode] = group
+
+ def get_ranks_in_group(self, parallel_mode: ParallelMode):
+ """Returns the rank of the current device for `parallel_mode` in the group.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+
+ Returns:
+ int: The rank of the current device for `parallel_mode` in the group.
+ """
+ self._check_parallel_mode(parallel_mode)
+ return self._ranks_in_group[parallel_mode]
+
+ def _add_ranks_in_group(self, parallel_mode: ParallelMode, ranks: list):
+ """Adds the ranks of the current device for `parallel_mode` in the group.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+ ranks (list): List of ranks to be added
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance
+ of :class:`colossalai.context.ParallelMode`.
+ """
+ self._check_parallel_mode(parallel_mode)
+ self._ranks_in_group[parallel_mode] = ranks
+
+ def init_global_dist(self, rank: int, world_size: int, backend: str, host: str, port: int):
+ """Initializes the global distributed environment
+
+ Args:
+ rank (int): rank for the default process group.
+ world_size (int): world size of the default process group.
+ backend (str): backend for ``torch.distributed``
+ host (str): the master address for distributed training.
+ port (str): the master port for distributed training
+ """
+ # initialize the default process group
+ init_method = f'tcp://[{host}]:{port}'
+ dist.init_process_group(rank=rank, world_size=world_size, backend=backend, init_method=init_method)
+
+ # None will give the default global process group for pytorch dist operations
+ ranks = list(range(world_size))
+ cpu_group = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else None
+ self._register_dist(rank, world_size, dist.GroupMember.WORLD, cpu_group, ranks, ParallelMode.GLOBAL)
+ self.add_global_rank(ParallelMode.GLOBAL, rank)
+
+ def _register_dist(self, local_rank, world_size, process_group, cpu_group, ranks_in_group, mode):
+ self._add_local_rank(mode, local_rank)
+ self._add_world_size(mode, world_size)
+ self._add_group(mode, process_group)
+ self._add_cpu_group(mode, cpu_group)
+ self._add_ranks_in_group(mode, ranks_in_group)
+
+ def check_sanity(self):
+ """Checks sanity of the parallel context.
+
+ Raises:
+ AssertionError: Raises an AssertionError if the world size does not equal to the product
+ of data parallel size, pipeline parallel size and tensor parallel size.
+ """
+ dps = self.data_parallel_size
+ pps = self.pipeline_parallel_size
+ tps = self.tensor_parallel_size
+ ws = self.world_size
+ assert ws == dps * pps * \
+ tps, f"Expected the world size {ws} to be equal to data" \
+ f" parallel size ({dps}) * pipeline parallel size " \
+ f"({pps}) * tensor parallel size ({tps})"
+
+ def _set_parallel_size_from_config(self, config: dict, key: str, attr_name: str):
+ if key in config:
+ ele = config[key]
+ if isinstance(ele, int):
+ setattr(self, attr_name, ele)
+ elif isinstance(ele, dict):
+ setattr(self, attr_name, ele['size'])
+ else:
+ raise NotImplementedError(
+ f'{"Parallel configuration does not support this kind of argument, please use int or dict"}')
+
+ def init_parallel_groups(self):
+ """Initializes the parallel groups.
+
+ Raises:
+ AssertionError: Raises an AssertionError if the field parallel is not present in the config file.
+ """
+
+ # get rank and world size
+ rank = self.get_global_rank()
+ world_size = self.get_world_size(ParallelMode.GLOBAL)
+ self.world_size = world_size
+
+ # set parallel size as attributes for global context
+ parallel_config = self.config.get('parallel', None)
+ if parallel_config is not None:
+ self._set_parallel_size_from_config(parallel_config, 'pipeline', 'pipeline_parallel_size')
+ self._set_parallel_size_from_config(parallel_config, 'tensor', 'tensor_parallel_size')
+
+ # the user should not set the data parallel size manually
+ # instead, it should be calculated based on other parallel config
+ self.data_parallel_size = self.world_size // (self.pipeline_parallel_size * self.tensor_parallel_size)
+
+ # get the tensor parallel mode and check
+ tensor_parallel_mode = None
+ if parallel_config is not None and 'tensor' in \
+ parallel_config and 'mode' in parallel_config['tensor']:
+ tensor_parallel_mode = parallel_config['tensor']['mode']
+ assert tensor_parallel_mode in ALLOWED_MODES, \
+ f"mode in the parallel config must be set to one of {ALLOWED_MODES}"
+ env.mode = tensor_parallel_mode
+
+ self.check_sanity()
+
+ pg_init = []
+ # LSG: init data parallel process group for compatibility with other parallel module such as zero
+ pg_init.append(dict(type=INITIALIZER_MAPPING['data']))
+
+ # LSG: init model parallel process group for compatibility with amp and clip grad
+ pg_init.append(dict(type=INITIALIZER_MAPPING['model']))
+
+ if self.pipeline_parallel_size > 1:
+ pg_init.append(dict(type=INITIALIZER_MAPPING['pipeline']))
+ pg_init.append(dict(type=INITIALIZER_MAPPING['tensor']))
+
+ # init specific tensor parallel group
+ if tensor_parallel_mode is not None:
+ tensor_parallel_cfg = parallel_config['tensor'].copy()
+
+ # remove duplicate parameters
+ tensor_parallel_cfg.pop('mode')
+ tensor_parallel_cfg.pop('size')
+
+ # add this config to initialize later
+ pg_init.append(dict(type=INITIALIZER_MAPPING[tensor_parallel_mode.lower()], **tensor_parallel_cfg))
+
+ # run initialization of different process groups
+ for initializer_cfg in pg_init:
+ cfg = initializer_cfg.copy()
+ initializer_type = cfg.pop('type')
+ initializer = DIST_GROUP_INITIALIZER.get_module(initializer_type)(rank, world_size, self.config,
+ self.data_parallel_size,
+ self.pipeline_parallel_size,
+ self.tensor_parallel_size, **cfg)
+ parallel_setting = initializer.init_dist_group()
+ if isinstance(parallel_setting, list):
+ for args in parallel_setting:
+ self._register_dist(*args)
+ else:
+ self._register_dist(*parallel_setting)
+
+ def is_initialized(self, parallel_mode: ParallelMode):
+ """Returns a boolean value indicating whether `parallel_mode` is initialized
+ in the current system.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+
+ Returns:
+ bool: a boolean value indicating whether `parallel_mode` is initialized in the current system.
+ """
+ return parallel_mode in self._groups
+
+ def destroy(self):
+ """Destroys the current distributed parallel environment.
+ """
+ for mode, group in self._groups.items():
+ if mode is not ParallelMode.GLOBAL:
+ dist.destroy_process_group(group)
+ # destroy global process group
+ dist.destroy_process_group()
+ self._groups.clear()
+
+ def set_device(self, device_ordinal: int = None):
+ """Sets distributed processes to be bound to devices.
+
+ Args:
+ device_ordinal (int, optional): the device id to be bound to
+ """
+ global_rank = self.get_global_rank()
+ if device_ordinal is None:
+ devices_per_node = torch.cuda.device_count()
+ device_ordinal = global_rank % devices_per_node
+
+ torch.cuda.set_device(device_ordinal)
+ if self._verbose:
+ self._logger.info(f'process rank {global_rank} is bound to device {device_ordinal}')
+
+ def set_seed(self, seed: int):
+ """Sets seeds for all random libraries.
+
+ Args:
+ seed (int): seed for random states
+ """
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+
+ global_rank = self.get_global_rank()
+
+ if torch.cuda.is_available():
+ # create random seed for different parallel modes
+ # data parallel seed are kept the same
+ parallel_seed = seed
+ add_seed(ParallelMode.DATA, parallel_seed)
+
+ # model parallel seeds are different across ranks
+ pipeline_offset = self._local_ranks.get(ParallelMode.PIPELINE, 0)
+
+ # add seed for data parallel and tensor parallel only
+ if self.is_initialized(ParallelMode.TENSOR):
+ tp_rank = self.get_local_rank(ParallelMode.TENSOR)
+ # 100 is only to increase the diff in seeds between pipeline stages
+ tp_rank_with_offset = tp_rank + pipeline_offset * 1024
+ tp_seed = seed + tp_rank_with_offset
+ add_seed(ParallelMode.TENSOR, tp_seed)
+
+ set_mode(ParallelMode.DATA)
+ seeds = get_seeds()
+ seed_str = ', '.join([f'{k}: {v}' for k, v in seeds.items()])
+
+ if self._verbose:
+ self._logger.info(f"initialized seed on rank {global_rank}, "
+ f"numpy: {seed}, python random: {seed}, {seed_str},"
+ f"the default parallel seed is {ParallelMode.DATA}.")
+ else:
+ if self._verbose:
+ self._logger.info(
+ f"initialized seed on rank {global_rank}, "
+ f"numpy: {seed}, python random: {seed}, pytorch: {seed}",
+ ranks=[0])
+ self._logger.info(
+ 'WARNING: CUDA is not available, thus CUDA RNG cannot be used to track CUDA random number states',
+ ranks=[0])
+
+ def set_virtual_pipeline_parallel_size(self, size):
+ self.virtual_pipeline_parallel_size = size
+
+ def set_virtual_pipeline_parallel_rank(self, rank):
+ self.virtual_pipeline_parallel_rank = rank
+
+
+global_context = ParallelContext()
diff --git a/colossalai/context/parallel_mode.py b/colossalai/context/parallel_mode.py
new file mode 100644
index 0000000000000000000000000000000000000000..1cf6fa53dc1e5c31fbaf1c9140e0915419af704c
--- /dev/null
+++ b/colossalai/context/parallel_mode.py
@@ -0,0 +1,49 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from enum import Enum
+
+
+# parallel modes
+class ParallelMode(Enum):
+ """This is an enumeration class containing all possible parallel modes.
+ """
+
+ GLOBAL = 'global'
+
+ # common parallel
+ DATA = 'data'
+
+ # model parallel - containing tensor and pipeline parallel groups
+ # this is added to facilitate amp and grad clipping in hybrid parallel
+ MODEL = 'model'
+
+ # pipeline parallel
+ PIPELINE = 'pipe'
+
+ # containing all ranks in tensor parallel
+ TENSOR = 'tensor'
+
+ # sequence parallel
+ SEQUENCE = 'sequence'
+ SEQUENCE_DP = 'sequence_dp'
+
+ # 1D Parallel
+ PARALLEL_1D = '1d'
+
+ # 2D parallel
+ PARALLEL_2D_ROW = '2d_row'
+ PARALLEL_2D_COL = '2d_col'
+
+ # 3D parallel
+ PARALLEL_3D_INPUT = '3d_input'
+ PARALLEL_3D_WEIGHT = '3d_weight'
+ PARALLEL_3D_OUTPUT = '3d_output'
+ PARALLEL_3D_INPUT_X_WEIGHT = "3d_input_x_weight"
+ PARALLEL_3D_OUTPUT_X_WEIGHT = "3d_output_x_weight"
+
+ # 2.5D parallel
+ PARALLEL_2P5D_ROW = '2p5d_row'
+ PARALLEL_2P5D_COL = '2p5d_col'
+ PARALLEL_2P5D_DEP = '2p5d_dep'
+ PARALLEL_2P5D_XZ = '2p5d_xz'
diff --git a/colossalai/context/process_group_initializer/__init__.py b/colossalai/context/process_group_initializer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3937a9474376f0ecb7af612121bb4c3e5f5a497
--- /dev/null
+++ b/colossalai/context/process_group_initializer/__init__.py
@@ -0,0 +1,15 @@
+from .initializer_1d import Initializer_1D
+from .initializer_2d import Initializer_2D
+from .initializer_2p5d import Initializer_2p5D
+from .initializer_3d import Initializer_3D
+from .initializer_data import Initializer_Data
+from .initializer_pipeline import Initializer_Pipeline
+from .initializer_sequence import Initializer_Sequence
+from .initializer_tensor import Initializer_Tensor
+from .initializer_model import Initializer_Model
+from .process_group_initializer import ProcessGroupInitializer
+
+__all__ = [
+ 'Initializer_Tensor', 'Initializer_Sequence', 'Initializer_Pipeline', 'Initializer_Data', 'Initializer_2p5D',
+ 'Initializer_2D', 'Initializer_3D', 'Initializer_1D', 'ProcessGroupInitializer', 'Initializer_Model'
+]
diff --git a/colossalai/context/process_group_initializer/initializer_1d.py b/colossalai/context/process_group_initializer/initializer_1d.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c05028041cef2a9ad453b05d17d35b09ec2617d
--- /dev/null
+++ b/colossalai/context/process_group_initializer/initializer_1d.py
@@ -0,0 +1,56 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import torch.distributed as dist
+from colossalai.global_variables import tensor_parallel_env as env
+from colossalai.registry import DIST_GROUP_INITIALIZER
+
+from ..parallel_mode import ParallelMode
+from .process_group_initializer import ProcessGroupInitializer
+
+
+@DIST_GROUP_INITIALIZER.register_module
+class Initializer_1D(ProcessGroupInitializer):
+ """A ProcessGroupInitializer for 1d tensor parallelism.
+
+ Args:
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.num_group = self.world_size // self.tensor_parallel_size
+
+ def init_dist_group(self):
+ """Initialize 1D tensor parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 1D tensor parallelism's information in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_1D
+ env.parallel_input_1d = False
+
+ for i in range(self.num_group):
+ ranks = [i * self.tensor_parallel_size + j for j in range(self.tensor_parallel_size)]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
diff --git a/colossalai/context/process_group_initializer/initializer_2d.py b/colossalai/context/process_group_initializer/initializer_2d.py
new file mode 100644
index 0000000000000000000000000000000000000000..7fbe3be5901f73b8c670c71582771ab861e9fccd
--- /dev/null
+++ b/colossalai/context/process_group_initializer/initializer_2d.py
@@ -0,0 +1,155 @@
+import math
+
+import torch.distributed as dist
+
+from colossalai.global_variables import tensor_parallel_env as env
+from colossalai.registry import DIST_GROUP_INITIALIZER
+
+from ..parallel_mode import ParallelMode
+from .process_group_initializer import ProcessGroupInitializer
+
+
+def _check_summa_env_var(summa_dim):
+ # check environment variable for SUMMA
+ env_summa_dim = env.summa_dim
+
+ if env_summa_dim:
+ assert int(env_summa_dim) == summa_dim, \
+ 'SUMMA_DIM has been set in the current environment and ' \
+ 'does not match with the value passed to this initialized'
+ else:
+ env.summa_dim = summa_dim
+
+
+class Initializer_2D_Row(ProcessGroupInitializer):
+ """2d tensor parallel initialization among rows.
+
+ Args:
+ num_group (int): The number of all tensor groups.
+ summa_dim (int): The dimension of SUMMA.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, num_group, summa_dim, *args, **kwargs):
+ super(Initializer_2D_Row, self).__init__(*args, **kwargs)
+ self.num_group = num_group
+ self.summa_dim = summa_dim
+
+ def init_dist_group(self):
+ """Initialize 2D tensor row parallel groups, and assign local_ranks and groups to each gpu.
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 2D tensor row parallelism's information in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_2D_ROW
+
+ for i in range(self.num_group):
+ for j in range(self.summa_dim):
+ ranks = [i * self.tensor_parallel_size + j * self.summa_dim + k for k in range(self.summa_dim)]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+class Initializer_2D_Col(ProcessGroupInitializer):
+ """2d tensor parallel initialization among cols.
+
+ Args:
+ num_group (int): The number of all tensor groups.
+ summa_dim (int): The dimension of SUMMA.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, num_group, summa_dim, *args, **kwargs):
+ super(Initializer_2D_Col, self).__init__(*args, **kwargs)
+ self.num_group = num_group
+ self.summa_dim = summa_dim
+
+ def init_dist_group(self):
+ """Initialize 2D tensor row parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 2D tensor col parallelism's information in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_2D_COL
+
+ for i in range(self.num_group):
+ for j in range(self.summa_dim):
+ ranks = [i * self.tensor_parallel_size + j + k * self.summa_dim for k in range(self.summa_dim)]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+@DIST_GROUP_INITIALIZER.register_module
+class Initializer_2D(ProcessGroupInitializer):
+ """
+ Serve as the single entry point to 2D parallel initialization.
+
+ Args:
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.num_group = self.world_size // self.tensor_parallel_size
+ self.summa_dim = int(math.sqrt(self.tensor_parallel_size))
+
+ assert self.tensor_parallel_size == self.summa_dim ** 2, \
+ "2D summa dim should equal to tensor parallel size ^ 0.5"
+ _check_summa_env_var(self.summa_dim)
+
+ self.col_initializer = Initializer_2D_Col(self.num_group, self.summa_dim, *args, **kwargs)
+ self.row_initializer = Initializer_2D_Row(self.num_group, self.summa_dim, *args, **kwargs)
+
+ def init_dist_group(self):
+ """Initialize 2D tensor row and col parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ List[Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode)]:
+ 2D tensor parallelism's information in a list of tuples.
+ """
+ parallel_setting = [self.row_initializer.init_dist_group(), self.col_initializer.init_dist_group()]
+ return parallel_setting
diff --git a/colossalai/context/process_group_initializer/initializer_2p5d.py b/colossalai/context/process_group_initializer/initializer_2p5d.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b6fdc5d715c30169f04cef54abd946c4c46b904
--- /dev/null
+++ b/colossalai/context/process_group_initializer/initializer_2p5d.py
@@ -0,0 +1,297 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import math
+
+import torch.distributed as dist
+from colossalai.context import Config
+from colossalai.global_variables import tensor_parallel_env as env
+from colossalai.registry import DIST_GROUP_INITIALIZER
+
+from ..parallel_mode import ParallelMode
+from .process_group_initializer import ProcessGroupInitializer
+
+
+def _check_tesseract_env_var(tesseract_dim: int, tesseract_dep: int):
+ # check global variable for TESSERACT
+ env_tesseract_dim = env.tesseract_dim
+ env_tesseract_dep = env.tesseract_dep
+
+ if env_tesseract_dim and env_tesseract_dep:
+ assert int(env_tesseract_dim) == tesseract_dim, \
+ 'TESSERACT_DIM has been set in the current environment and ' \
+ 'does not match with the value passed to this initialized'
+ assert int(env_tesseract_dep) == tesseract_dep, \
+ 'TESSERACT_DEP has been set in the current environment and ' \
+ 'does not match with the value passed to this initialized'
+ else:
+ env.tesseract_dim = tesseract_dim
+ env.tesseract_dep = tesseract_dep
+
+
+# i row j col k dep
+class Initializer_2p5D_ROW(ProcessGroupInitializer):
+ """2.5d tensor parallel initialization among rows.
+
+ Args:
+ tesseract_dim (int): The dimension of tesseract.
+ tesseract_dep (int): The dimension of depth.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, tesseract_dim: int, tesseract_dep: int, *args):
+ super(Initializer_2p5D_ROW, self).__init__(*args)
+ self.num_group = self.world_size // self.tensor_parallel_size
+ self.tesseract_dep = tesseract_dep
+ self.tesseract_dim = tesseract_dim
+ assert self.tensor_parallel_size == self.tesseract_dim ** 2 * self.tesseract_dep, \
+ "Tensor parallel size should be depth * dim ** 2 in 2.5D parallel"
+
+ def init_dist_group(self):
+ """Initialize 2.5D tensor row parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 2.5D tensor row parallelism's information in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_2P5D_ROW
+
+ for h in range(self.num_group):
+ for j in range(self.tesseract_dim):
+ for k in range(self.tesseract_dep):
+ ranks = [
+ h * self.tensor_parallel_size + i + self.tesseract_dim * (j + self.tesseract_dim * k)
+ for i in range(self.tesseract_dim)
+ ]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+class Initializer_2p5D_Col(ProcessGroupInitializer):
+ """2.5d tensor parallel initialization among cols.
+
+ Args:
+ tesseract_dim (int): The dimension of tesseract.
+ tesseract_dep (int): The dimension of depth.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, tesseract_dim: int, tesseract_dep: int, *args):
+ super(Initializer_2p5D_Col, self).__init__(*args)
+ self.num_group = self.world_size // self.tensor_parallel_size
+ self.tesseract_dep = tesseract_dep
+ self.tesseract_dim = tesseract_dim
+
+ def init_dist_group(self):
+ """Initialize 2.5D tensor col parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 2.5D tensor col parallelism's information in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_2P5D_COL
+
+ for h in range(self.num_group):
+ for i in range(self.tesseract_dim):
+ for k in range(self.tesseract_dep):
+ ranks = [
+ h * self.tensor_parallel_size + i + self.tesseract_dim * (j + self.tesseract_dim * k)
+ for j in range(self.tesseract_dim)
+ ]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+class Initializer_2p5D_Dep(ProcessGroupInitializer):
+ """2.5D tensor parallel initialization among depths.
+
+ Args:
+ tesseract_dim (int): The dimension of tesseract.
+ tesseract_dep (int): The dimension of depth.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, tesseract_dim: int, tesseract_dep: int, *args):
+ super(Initializer_2p5D_Dep, self).__init__(*args)
+ self.num_group = self.world_size // self.tensor_parallel_size
+ self.tesseract_dep = tesseract_dep
+ self.tesseract_dim = tesseract_dim
+
+ def init_dist_group(self):
+ """Initialize 2.5D tensor depth parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 2.5D tensor depth parallelism's information in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_2P5D_DEP
+
+ for h in range(self.num_group):
+ for i in range(self.tesseract_dim):
+ for j in range(self.tesseract_dim):
+ ranks = [
+ h * self.tensor_parallel_size + i + self.tesseract_dim * (j + self.tesseract_dim * k)
+ for k in range(self.tesseract_dep)
+ ]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+# i row j col k dep
+class Initializer_2p5D_XZ(ProcessGroupInitializer):
+ """2.5d tensor parallel initialization among cols times dep.
+
+ Args:
+ tesseract_dim (int): The dimension of tesseract.
+ tesseract_dep (int): The dimension of depth.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, tesseract_dim: int, tesseract_dep: int, *args):
+ super(Initializer_2p5D_XZ, self).__init__(*args)
+ self.num_group = self.world_size // self.tensor_parallel_size
+ self.tesseract_dep = tesseract_dep
+ self.tesseract_dim = tesseract_dim
+
+ def init_dist_group(self):
+ """Initialize 2.5D tensor colXdepth parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 2.5D tensor colXdepth parallelism's information in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_2P5D_XZ
+
+ for h in range(self.num_group):
+ for i in range(self.tesseract_dim):
+ ranks = [
+ h * self.tensor_parallel_size + i + self.tesseract_dim * (j + self.tesseract_dim * k)
+ for k in range(self.tesseract_dep)
+ for j in range(self.tesseract_dim)
+ ]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+@DIST_GROUP_INITIALIZER.register_module
+class Initializer_2p5D(ProcessGroupInitializer):
+ """
+ Serve as the single entry point to Tesseract parallel initialization.
+
+ Args:
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ depth (int): The depth of 2.5d parallel.
+ """
+
+ def __init__(self, rank: int, world_size: int, config: Config, data_parallel_size: int, pipeline_parallel_size: int,
+ tensor_parallel_size: int, depth: int):
+ args = (rank, world_size, config, data_parallel_size, pipeline_parallel_size, tensor_parallel_size)
+ super().__init__(*args)
+ self.num_group = self.world_size // self.tensor_parallel_size
+ self.tesseract_dim = int(math.sqrt(self.tensor_parallel_size / depth))
+ self.tesseract_dep = depth
+
+ assert self.tensor_parallel_size == self.tesseract_dim ** 2 * self.tesseract_dep, \
+ "2.5D tesseract dim should equal to (tensor parallel size / tesseract dep) ^ 0.5"
+ _check_tesseract_env_var(self.tesseract_dim, self.tesseract_dep)
+
+ self.col_initializer = Initializer_2p5D_Col(self.tesseract_dim, self.tesseract_dep, *args)
+ self.row_initializer = Initializer_2p5D_ROW(self.tesseract_dim, self.tesseract_dep, *args)
+ self.dep_initializer = Initializer_2p5D_Dep(self.tesseract_dim, self.tesseract_dep, *args)
+ self.xz_initializer = Initializer_2p5D_XZ(self.tesseract_dim, self.tesseract_dep, *args)
+
+ def init_dist_group(self):
+ """Initialize 2.5D tensor row, col, depth, and colXdepth parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ List[Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode)]:
+ Whole 2.5D tensor parallelism's information in a list of tuples.
+ """
+ parallel_setting = [
+ self.col_initializer.init_dist_group(),
+ self.row_initializer.init_dist_group(),
+ self.dep_initializer.init_dist_group(),
+ self.xz_initializer.init_dist_group()
+ ]
+ return parallel_setting
diff --git a/colossalai/context/process_group_initializer/initializer_3d.py b/colossalai/context/process_group_initializer/initializer_3d.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ed8eec86efc83315ee8b549a9a035bc36dca6da
--- /dev/null
+++ b/colossalai/context/process_group_initializer/initializer_3d.py
@@ -0,0 +1,329 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import math
+
+import torch.distributed as dist
+
+from colossalai.global_variables import tensor_parallel_env as env
+from colossalai.registry import DIST_GROUP_INITIALIZER
+
+from ..parallel_mode import ParallelMode
+from .process_group_initializer import ProcessGroupInitializer
+
+
+def _check_depth_env_var(depth):
+ # check global variable
+ env_depth = env.depth_3d
+
+ if env_depth:
+ assert int(env_depth) == depth, \
+ 'DEPTH_3D has been set in the current environment and ' \
+ 'does not match with the value passed to this initialized'
+ else:
+ env.depth_3d = depth
+
+
+class Initializer_3D_Input(ProcessGroupInitializer):
+ """3D tensor parallel initialization among input.
+
+ Args:
+ num_group (int): The number of all tensor groups.
+ depth (int): Depth of 3D parallelism.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, num_group: int, depth: int, *args):
+ super().__init__(*args)
+ self.num_group = num_group
+ self.depth = depth
+
+ def init_dist_group(self):
+ """Initialize 3D tensor parallel groups among input, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 3D tensor parallelism's information among input in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_3D_INPUT
+ env.input_group_3d = mode
+
+ for h in range(self.num_group):
+ for i in range(self.depth):
+ for k in range(self.depth):
+ ranks = [h * self.depth**3 + i + self.depth * (j + self.depth * k) for j in range(self.depth)]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+class Initializer_3D_Weight(ProcessGroupInitializer):
+ """3D tensor parallel initialization among weight.
+
+ Args:
+ num_group (int): The number of all tensor groups.
+ depth (int): Depth of 3D parallelism.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, num_group: int, depth: int, *args):
+ super().__init__(*args)
+ self.num_group = num_group
+ self.depth = depth
+
+ def init_dist_group(self):
+ """Initialize 3D tensor parallel groups among weight, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 3D tensor parallelism's information among weight in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_3D_WEIGHT
+ env.weight_group_3d = mode
+
+ for h in range(self.num_group):
+ for k in range(self.depth):
+ for j in range(self.depth):
+ ranks = [h * self.depth**3 + i + self.depth * (j + self.depth * k) for i in range(self.depth)]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+class Initializer_3D_Output(ProcessGroupInitializer):
+ """3D tensor parallel initialization among output.
+
+ Args:
+ num_group (int): The number of all tensor groups.
+ depth (int): Depth of 3D parallelism.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, num_group: int, depth: int, *args):
+ super().__init__(*args)
+ self.num_group = num_group
+ self.depth = depth
+
+ def init_dist_group(self):
+ """Initialize 3D tensor parallel groups among output, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 3D tensor parallelism's information among output in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_3D_OUTPUT
+ env.output_group_3d = mode
+
+ for h in range(self.num_group):
+ for i in range(self.depth):
+ for j in range(self.depth):
+ ranks = [h * self.depth**3 + i + self.depth * (j + self.depth * k) for k in range(self.depth)]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+class Initializer_3D_InputxWeight(ProcessGroupInitializer):
+ """3D tensor parallel initialization among input.
+
+ Args:
+ num_group (int): The number of all tensor groups.
+ depth (int): Depth of 3D parallelism.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, num_group: int, depth: int, *args):
+ super().__init__(*args)
+ self.num_group = num_group
+ self.depth = depth
+
+ def init_dist_group(self):
+ """Initialize 3D tensor parallel groups among input, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 3D tensor parallelism's information among input in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_3D_INPUT_X_WEIGHT
+ env.input_x_weight_group_3d = mode
+
+ for h in range(self.num_group):
+ for k in range(self.depth):
+ ranks = [
+ h * self.depth**3 + i + self.depth * (j + self.depth * k)
+ for j in range(self.depth)
+ for i in range(self.depth)
+ ]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+class Initializer_3D_OutputxWeight(ProcessGroupInitializer):
+ """3D tensor parallel initialization among input.
+
+ Args:
+ num_group (int): The number of all tensor groups.
+ depth (int): Depth of 3D parallelism.
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, num_group: int, depth: int, *args):
+ super().__init__(*args)
+ self.num_group = num_group
+ self.depth = depth
+
+ def init_dist_group(self):
+ """Initialize 3D tensor parallel groups among input, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ 3D tensor parallelism's information among input in a tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.PARALLEL_3D_OUTPUT_X_WEIGHT
+ env.output_x_weight_group_3d = mode
+
+ for h in range(self.num_group):
+ for j in range(self.depth):
+ ranks = [
+ h * self.depth**3 + i + self.depth * (j + self.depth * k)
+ for k in range(self.depth)
+ for i in range(self.depth)
+ ]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+@DIST_GROUP_INITIALIZER.register_module
+class Initializer_3D(ProcessGroupInitializer):
+ """Serve as the single entry point to 3D parallel initialization.
+
+ Args:
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, *args):
+ super().__init__(*args)
+ self.num_group = self.world_size // self.tensor_parallel_size
+ self.depth = round(math.pow(self.tensor_parallel_size, 1 / 3))
+ assert self.tensor_parallel_size == self.depth ** 3, \
+ f'3D depth ({self.depth}) if not cube root of tensor parallel size ({self.tensor_parallel_size})'
+ _check_depth_env_var(self.depth)
+
+ self.input_initializer = Initializer_3D_Input(self.num_group, self.depth, *args)
+ self.weight_initializer = Initializer_3D_Weight(self.num_group, self.depth, *args)
+ self.output_initializer = Initializer_3D_Output(self.num_group, self.depth, *args)
+ self.input_x_weight_initializer = Initializer_3D_InputxWeight(self.num_group, self.depth, *args)
+ self.output_x_weight_initializer = Initializer_3D_OutputxWeight(self.num_group, self.depth, *args)
+
+ def init_dist_group(self):
+ """Initialize 3D tensor parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ List[Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode)]:
+ Whole 3D tensor parallelism's information in a list of tuples.
+ """
+ parallel_setting = [
+ self.input_initializer.init_dist_group(),
+ self.weight_initializer.init_dist_group(),
+ self.output_initializer.init_dist_group(),
+ self.input_x_weight_initializer.init_dist_group(),
+ self.output_x_weight_initializer.init_dist_group()
+ ]
+ return parallel_setting
diff --git a/colossalai/context/process_group_initializer/initializer_data.py b/colossalai/context/process_group_initializer/initializer_data.py
new file mode 100644
index 0000000000000000000000000000000000000000..9715ebff7f00f0fc8a3f13a5dfca436c9b0e144b
--- /dev/null
+++ b/colossalai/context/process_group_initializer/initializer_data.py
@@ -0,0 +1,55 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from torch import distributed as dist
+
+from colossalai.registry import DIST_GROUP_INITIALIZER
+
+from ..parallel_mode import ParallelMode
+from .process_group_initializer import ProcessGroupInitializer
+
+
+@DIST_GROUP_INITIALIZER.register_module
+class Initializer_Data(ProcessGroupInitializer):
+ """A ProcessGroupInitializer for data parallelism.
+
+ Args:
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.num_data_parallel_group = self.world_size // self.data_parallel_size
+
+ def init_dist_group(self):
+ """Initialize data parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ A Data parallelism's information tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.DATA
+
+ for i in range(self.num_data_parallel_group):
+ ranks = [i + j * self.num_data_parallel_group for j in range(self.data_parallel_size)]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
diff --git a/colossalai/context/process_group_initializer/initializer_model.py b/colossalai/context/process_group_initializer/initializer_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..99b9cc0d4edce35915c52c01fa5875545256ba97
--- /dev/null
+++ b/colossalai/context/process_group_initializer/initializer_model.py
@@ -0,0 +1,55 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import torch.distributed as dist
+from colossalai.registry import DIST_GROUP_INITIALIZER
+from .process_group_initializer import ProcessGroupInitializer
+from ..parallel_mode import ParallelMode
+
+
+@DIST_GROUP_INITIALIZER.register_module
+class Initializer_Model(ProcessGroupInitializer):
+ """A ProcessGroupInitializer for model parallelism (model parallel group contains pipeline and tensor parallel
+ groups).
+
+ Args:
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.model_parallel_size = self.tensor_parallel_size * self.pipeline_parallel_size
+ self.num_group = self.world_size // self.model_parallel_size
+
+ def init_dist_group(self):
+ """Initialize model parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ A Model parallelism's information tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.MODEL
+
+ for i in range(self.num_group):
+ ranks = [i * self.model_parallel_size + j for j in range(self.model_parallel_size)]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
diff --git a/colossalai/context/process_group_initializer/initializer_pipeline.py b/colossalai/context/process_group_initializer/initializer_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..0ddb52f63e22f29aff9920d5cdd2aba1748e1eb6
--- /dev/null
+++ b/colossalai/context/process_group_initializer/initializer_pipeline.py
@@ -0,0 +1,56 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from torch import distributed as dist
+
+from colossalai.registry import DIST_GROUP_INITIALIZER
+
+from ..parallel_mode import ParallelMode
+from .process_group_initializer import ProcessGroupInitializer
+
+
+@DIST_GROUP_INITIALIZER.register_module
+class Initializer_Pipeline(ProcessGroupInitializer):
+ """A ProcessGroupInitializer for pipeline parallelism.
+
+ Args:
+ rank (int): The rank of current process
+ world_size (int): Size of whole communication world
+ config (Config): Running configuration
+ data_parallel_size (int): Size of data parallel
+ pipeline_parallel_size (int): Size of pipeline parallel
+ tensor_parallel_size (int): Size of tensor parallel
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.data_group_size = self.world_size // self.data_parallel_size
+ self.pipeline_stage_size = self.data_group_size // self.pipeline_parallel_size
+
+ def init_dist_group(self):
+ """Initialize pipeline parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ List[Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode)]:
+ A Pipeline parallelism's information in list of tuples.
+ """
+ dist_settings = list()
+ for i in range(self.data_parallel_size):
+ for j in range(self.pipeline_stage_size):
+ pipe_ranks = list(
+ range(i * self.data_group_size + j, (i + 1) * self.data_group_size, self.pipeline_stage_size))
+ pipe_group_size = len(pipe_ranks)
+ pipe_group = dist.new_group(pipe_ranks)
+ group_cpu = dist.new_group(pipe_ranks, backend='gloo') if dist.get_backend() != 'gloo' else pipe_group
+
+ if self.rank in pipe_ranks:
+ local_rank = pipe_ranks.index(self.rank)
+ group_world_size = pipe_group_size
+ process_group = pipe_group
+ cpu_group = group_cpu
+ ranks_in_group = pipe_ranks
+ dist_settings.append(
+ tuple((local_rank, group_world_size, process_group, cpu_group, ranks_in_group,
+ ParallelMode.PIPELINE)))
+
+ return dist_settings
diff --git a/colossalai/context/process_group_initializer/initializer_sequence.py b/colossalai/context/process_group_initializer/initializer_sequence.py
new file mode 100644
index 0000000000000000000000000000000000000000..eaacb14d22825db7913e1c87cfe08063ab5865ee
--- /dev/null
+++ b/colossalai/context/process_group_initializer/initializer_sequence.py
@@ -0,0 +1,101 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+import torch.distributed as dist
+
+from colossalai.registry import DIST_GROUP_INITIALIZER
+
+from ..parallel_mode import ParallelMode
+from .initializer_tensor import Initializer_Tensor
+from .process_group_initializer import ProcessGroupInitializer
+
+
+@DIST_GROUP_INITIALIZER.register_module
+class Initializer_Sequence_DP(ProcessGroupInitializer):
+ """A ProcessGroupInitializer for sequence parallelism all-reduce.
+
+ In Sequence Parallelism, each GPU holds the full copy of model weights,
+ thus, gradient all-reduce occurs across all processes in the same pipeline stage
+
+ Args:
+ rank (int): The rank of current process
+ world_size (int): Size of whole communication world
+ config (Config): Running configuration
+ data_parallel_size (int): Size of data parallel
+ pipeline_parallel_size (int): Size of pipeline parallel
+ tensor_parallel_size (int): Size of tensor parallel
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.dp_size = self.world_size // self.pipeline_parallel_size
+ self.num_group = self.pipeline_parallel_size
+
+ def init_dist_group(self):
+ """Initialize Sequence Parallel process groups used for gradient all-reduce.
+
+ Returns:
+ Tuple: A tuple (local_rank, group_world_size, process_group, ranks_in_group, mode).
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.SEQUENCE_DP
+
+ for i in range(self.num_group):
+ ranks = [i * self.dp_size + j for j in range(self.dp_size)]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
+
+
+@DIST_GROUP_INITIALIZER.register_module
+class Initializer_Sequence(ProcessGroupInitializer):
+ """A ProcessGroupInitializer for sequence parallelism.
+
+ Args:
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ # reuse tensor parallel initializer code
+ self._sequence_initializer = Initializer_Tensor(*args, **kwargs)
+ self._sequence_dp_initializer = Initializer_Sequence_DP(*args, **kwargs)
+
+ def init_dist_group(self):
+ """Initialize Sequence parallel process groups and assign local_ranks and groups to each gpu.
+
+ Sequence parallelism requires 2 process groups. The first is for model forward where several processes
+ exchange partial query, key and value embedding to compute self attention values. The second is for
+ all-reduce to synchronize the model parameters.
+
+ Returns:
+ List[Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode)]:
+ A Sequence parallelism's information in list of tuples.
+ """
+
+ parallel_setting = []
+
+ local_rank, group_world_size, process_group, cpu_grop, ranks_in_group, mode = \
+ self._sequence_initializer.init_dist_group()
+ # change mode to sequence
+ mode = ParallelMode.SEQUENCE
+
+ parallel_setting.append((local_rank, group_world_size, process_group, cpu_grop, ranks_in_group, mode))
+ parallel_setting.append(self._sequence_dp_initializer.init_dist_group())
+ return parallel_setting
diff --git a/colossalai/context/process_group_initializer/initializer_tensor.py b/colossalai/context/process_group_initializer/initializer_tensor.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2b5be9cfffbe9eb7234411c6526d4055c078f12
--- /dev/null
+++ b/colossalai/context/process_group_initializer/initializer_tensor.py
@@ -0,0 +1,54 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import torch.distributed as dist
+
+from colossalai.registry import DIST_GROUP_INITIALIZER
+from .process_group_initializer import ProcessGroupInitializer
+from ..parallel_mode import ParallelMode
+
+
+@DIST_GROUP_INITIALIZER.register_module
+class Initializer_Tensor(ProcessGroupInitializer):
+ """A ProcessGroupInitializer for tensor parallelism.
+
+ Args:
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.num_tensor_parallel_group = self.world_size // self.tensor_parallel_size
+
+ def init_dist_group(self):
+ """Initialize tensor parallel groups, and assign local_ranks and groups to each gpu.
+
+ Returns:
+ Tuple (local_rank, group_world_size, process_group, ranks_in_group, mode):
+ A Tensor parallelism's information tuple.
+ """
+ local_rank = None
+ ranks_in_group = None
+ process_group = None
+ cpu_group = None
+ group_world_size = None
+ mode = ParallelMode.TENSOR
+
+ for i in range(self.num_tensor_parallel_group):
+ ranks = [i * self.tensor_parallel_size + j for j in range(self.tensor_parallel_size)]
+ group = dist.new_group(ranks)
+ group_cpu = dist.new_group(ranks, backend='gloo') if dist.get_backend() != 'gloo' else group
+
+ if self.rank in ranks:
+ local_rank = ranks.index(self.rank)
+ group_world_size = len(ranks)
+ process_group = group
+ cpu_group = group_cpu
+ ranks_in_group = ranks
+
+ return local_rank, group_world_size, process_group, cpu_group, ranks_in_group, mode
diff --git a/colossalai/context/process_group_initializer/process_group_initializer.py b/colossalai/context/process_group_initializer/process_group_initializer.py
new file mode 100644
index 0000000000000000000000000000000000000000..98150ce8e428a3b9bf81185719685b38efc2bdfd
--- /dev/null
+++ b/colossalai/context/process_group_initializer/process_group_initializer.py
@@ -0,0 +1,33 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from abc import ABC, abstractmethod
+
+from colossalai.context import Config
+
+
+class ProcessGroupInitializer(ABC):
+ """An object, knowing the parallelism configuration, that initializes parallel groups.
+
+ Args:
+ rank (int): The rank of current process.
+ world_size (int): Size of whole communication world.
+ config (Config): Running configuration.
+ data_parallel_size (int): Size of data parallel.
+ pipeline_parallel_size (int): Size of pipeline parallel.
+ tensor_parallel_size (int): Size of tensor parallel.
+ """
+
+ def __init__(self, rank: int, world_size: int, config: Config, data_parallel_size: int, pipeline_parallel_size: int,
+ tensor_parallel_size: int):
+ self.rank = rank
+ self.world_size = world_size
+ self.data_parallel_size = data_parallel_size
+ self.config = config
+ self.pipeline_parallel_size = pipeline_parallel_size
+ self.tensor_parallel_size = tensor_parallel_size
+ super().__init__()
+
+ @abstractmethod
+ def init_dist_group(self):
+ pass
diff --git a/colossalai/context/random/__init__.py b/colossalai/context/random/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d64b993257c1574706ee5028224692b4e666fc19
--- /dev/null
+++ b/colossalai/context/random/__init__.py
@@ -0,0 +1,18 @@
+from ._helper import (
+ add_seed,
+ get_current_mode,
+ get_seeds,
+ get_states,
+ moe_set_seed,
+ reset_seeds,
+ seed,
+ set_mode,
+ set_seed_states,
+ sync_states,
+ with_seed,
+)
+
+__all__ = [
+ 'seed', 'set_mode', 'with_seed', 'add_seed', 'get_seeds', 'get_states', 'get_current_mode', 'set_seed_states',
+ 'sync_states', 'moe_set_seed', 'reset_seeds'
+]
diff --git a/colossalai/context/random/_helper.py b/colossalai/context/random/_helper.py
new file mode 100644
index 0000000000000000000000000000000000000000..973c4d9faa325820aa1dedc5e133551430778057
--- /dev/null
+++ b/colossalai/context/random/_helper.py
@@ -0,0 +1,172 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import functools
+from contextlib import contextmanager
+
+import torch.cuda
+from torch import Tensor
+
+from .seed_manager import SeedManager
+from ..parallel_mode import ParallelMode
+
+_SEED_MANAGER = SeedManager()
+
+
+def get_seeds():
+ """Returns the seeds of the seed manager.
+
+ Returns:
+ dict: The seeds of the seed manager.
+ """
+ return _SEED_MANAGER.seeds
+
+
+def get_states(copy=False):
+ """Returns the seed states of the seed manager.
+
+ Returns:
+ dict: The seed states of the seed manager.
+ """
+ states = _SEED_MANAGER.seed_states
+
+ if copy:
+ new_states = dict()
+
+ for parallel_mode, state in states.items():
+ new_states[parallel_mode] = state.clone()
+ return new_states
+ else:
+ return _SEED_MANAGER.seed_states
+
+
+def get_current_mode():
+ """Returns the current mode of the seed manager.
+
+ Returns:
+ :class:`torch.ByteTensor`: The current mode of the seed manager.
+ """
+ return _SEED_MANAGER.current_mode
+
+
+def add_seed(parallel_mode: ParallelMode, seed: int, overwrite: bool = False):
+ """Adds a seed to the seed manager for `parallel_mode`.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+ seed (int): The seed to be added
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance of
+ :class:`colossalai.context.ParallelMode` or the seed for `parallel_mode` has been added.
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+ """
+ _SEED_MANAGER.add_seed(parallel_mode, seed, overwrite)
+
+
+def set_mode(parallel_mode: ParallelMode):
+ """Sets the current mode of the seed manager.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+ """
+ _SEED_MANAGER.set_mode(parallel_mode)
+
+
+def set_seed_states(parallel_mode: ParallelMode, state: Tensor):
+ """Sets the state of the seed manager for `parallel_mode`.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+ state (:class:`torch.Tensor`): the state to be set.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not found in the seed manager.
+ """
+ _SEED_MANAGER.set_state(parallel_mode, state)
+
+
+def sync_states():
+ current_mode = get_current_mode()
+ current_states = torch.cuda.get_rng_state()
+ set_seed_states(current_mode, current_states)
+
+
+@contextmanager
+def seed(parallel_mode: ParallelMode):
+ """ A context for seed switch
+
+ Examples:
+
+ >>> with seed(ParallelMode.DATA):
+ >>> output = F.dropout(input)
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+ """
+ try:
+ # set to new mode
+ current_mode = _SEED_MANAGER.current_mode
+ yield _SEED_MANAGER.set_mode(parallel_mode)
+ finally:
+ # recover
+ _SEED_MANAGER.set_mode(current_mode)
+
+
+def with_seed(func, parallel_mode: ParallelMode):
+ """
+ A function wrapper which executes the function with a specified seed.
+
+ Examples:
+
+ >>> # use with decorator
+ >>> @with_seed(ParallelMode.DATA)
+ >>> def forward(input):
+ >>> return F.dropout(input)
+ >>> out = forward(input)
+ >>> # OR use it inline
+ >>> def forward(input):
+ >>> return F.dropout(input)
+ >>> wrapper_forward = with_seed(forward, ParallelMode.DATA)
+ >>> out = wrapped_forward(input)
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+ """
+
+ @functools.wraps(func)
+ def wrapper(*args, **kwargs):
+ # switch mode
+ current_mode = _SEED_MANAGER.current_mode
+ _SEED_MANAGER.set_mode(parallel_mode)
+
+ # exec func
+ out = func(*args, **kwargs)
+
+ # recover state
+ _SEED_MANAGER.set_mode(current_mode)
+
+ return out
+
+ return wrapper
+
+
+def moe_set_seed(seed):
+ if torch.cuda.is_available():
+ from colossalai.core import global_context as gpc
+ global_rank = gpc.get_global_rank()
+ diff_seed = seed + global_rank
+ add_seed(ParallelMode.TENSOR, diff_seed, True)
+ print(f"moe seed condition: {global_rank} with tensor seed {diff_seed}", flush=True)
+
+
+def reset_seeds():
+ _SEED_MANAGER.reset()
diff --git a/colossalai/context/random/seed_manager.py b/colossalai/context/random/seed_manager.py
new file mode 100644
index 0000000000000000000000000000000000000000..956f9001200d8706bbd45e1c9b09a175ff10b82d
--- /dev/null
+++ b/colossalai/context/random/seed_manager.py
@@ -0,0 +1,89 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import torch
+from torch import Tensor
+
+from colossalai.context.parallel_mode import ParallelMode
+
+
+class SeedManager:
+ """This class is a manager of all random seeds involved in the system.
+
+ Note:
+ The parallel_mode should be concluded in ``ParallelMode``. More details about ``ParallelMode`` could be found
+ in `parallel_mode `_.
+ """
+
+ def __init__(self):
+ self._current_mode = None
+ self._seeds = dict()
+ self._seed_states = dict()
+
+ @property
+ def current_mode(self):
+ return self._current_mode
+
+ @property
+ def seeds(self):
+ return self._seeds
+
+ @property
+ def seed_states(self):
+ return self._seed_states
+
+ def set_state(self, parallel_mode: ParallelMode, state: Tensor):
+ """Sets the state of the seed manager for `parallel_mode`.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+ state (:class:`torch.Tensor`): the state to be set.
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not found in the seed manager.
+ """
+ assert parallel_mode in self._seed_states, f'Parallel mode {parallel_mode} is not found in the seed manager'
+ self._seed_states[parallel_mode] = state
+
+ def set_mode(self, parallel_mode: ParallelMode):
+ """Sets the current mode of the seed manager.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+ """
+ if self.current_mode:
+ # save the current state for current mode
+ self._seed_states[self._current_mode] = torch.cuda.get_rng_state()
+
+ # set the new state for new mode
+ self._current_mode = parallel_mode
+ torch.cuda.set_rng_state(self._seed_states[parallel_mode])
+
+ def add_seed(self, parallel_mode: ParallelMode, seed: int, overwrite: bool = False):
+ """Adds a seed to the seed manager for `parallel_mode`.
+
+ Args:
+ parallel_mode (:class:`colossalai.context.ParallelMode`): The chosen parallel mode.
+ seed (int): The seed to be added.
+ overwrite (bool, optional): Whether allows to overwrite the seed that has been set already
+
+ Raises:
+ AssertionError: Raises an AssertionError if `parallel_mode` is not an instance of :class:`colossalai.context.ParallelMode`
+ or the seed for `parallel_mode` has been added.
+ """
+ assert isinstance(parallel_mode, ParallelMode), 'A valid ParallelMode must be provided'
+ if overwrite is False:
+ assert parallel_mode not in self._seed_states, f'The seed for {parallel_mode} has been added'
+ elif parallel_mode in self._seed_states:
+ print(f"Warning: {parallel_mode} seed has been overwritten.", flush=True)
+
+ current_state = torch.cuda.get_rng_state()
+ torch.cuda.manual_seed(seed)
+ self._seed_states[parallel_mode] = torch.cuda.get_rng_state()
+ self._seeds[parallel_mode] = seed
+ torch.cuda.set_rng_state(current_state)
+
+ def reset(self):
+ self._current_mode = None
+ self._seeds = dict()
+ self._seed_states = dict()
diff --git a/colossalai/context/singleton_meta.py b/colossalai/context/singleton_meta.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ca335119d52ad2a212b1e0c578202b2fc6bb60f
--- /dev/null
+++ b/colossalai/context/singleton_meta.py
@@ -0,0 +1,21 @@
+class SingletonMeta(type):
+ """
+ The Singleton class can be implemented in different ways in Python. Some
+ possible methods include: base class, decorator, metaclass. We will use the
+ metaclass because it is best suited for this purpose.
+ """
+
+ _instances = {}
+
+ def __call__(cls, *args, **kwargs):
+ """
+ Possible changes to the value of the `__init__` argument do not affect
+ the returned instance.
+ """
+ if cls not in cls._instances:
+ instance = super().__call__(*args, **kwargs)
+ cls._instances[cls] = instance
+ else:
+ assert len(args) == 0 and len(
+ kwargs) == 0, f'{cls.__name__} is a singleton class and a instance has been created.'
+ return cls._instances[cls]
diff --git a/colossalai/core.py b/colossalai/core.py
new file mode 100644
index 0000000000000000000000000000000000000000..153247bbed9c65db0b2255247137fa9a64a693fa
--- /dev/null
+++ b/colossalai/core.py
@@ -0,0 +1,6 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from colossalai.context.parallel_context import global_context
+
+__all__ = ['global_context']
\ No newline at end of file
diff --git a/colossalai/device/__init__.py b/colossalai/device/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..689189998c3f6490145ba2648c522570c6f40b4c
--- /dev/null
+++ b/colossalai/device/__init__.py
@@ -0,0 +1,4 @@
+from .alpha_beta_profiler import AlphaBetaProfiler
+from .calc_pipeline_strategy import alpa_dp
+
+__all__ = ['AlphaBetaProfiler', 'alpa_dp']
diff --git a/colossalai/device/alpha_beta_profiler.py b/colossalai/device/alpha_beta_profiler.py
new file mode 100644
index 0000000000000000000000000000000000000000..af2b10928c6f2f99a429aaa413d527d77d52faf0
--- /dev/null
+++ b/colossalai/device/alpha_beta_profiler.py
@@ -0,0 +1,388 @@
+import math
+import time
+from typing import Dict, List, Tuple
+
+import torch
+import torch.distributed as dist
+
+from colossalai.logging import get_dist_logger
+
+GB = int((1 << 30))
+BYTE = 4
+FRAMEWORK_LATENCY = 0
+
+
+class AlphaBetaProfiler:
+ '''
+ Profile alpha and beta value for a given device list.
+
+ Usage:
+ # Note: the environment of execution is supposed to be
+ # multi-process with multi-gpu in mpi style.
+ >>> physical_devices = [0, 1, 4, 5]
+ >>> ab_profiler = AlphaBetaProfiler(physical_devices)
+ >>> ab_dict = profiler.alpha_beta_dict
+ >>> print(ab_dict)
+ {(0, 1): (1.9641406834125518e-05, 4.74049549614719e-12), (0, 4): (1.9506998360157013e-05, 6.97421973297474e-11), (0, 5): (2.293858677148819e-05, 7.129930361393644e-11),
+ (1, 4): (1.9010603427886962e-05, 7.077968863788975e-11), (1, 5): (1.9807778298854827e-05, 6.928845708992215e-11), (4, 5): (1.8681809306144713e-05, 4.7522367291330524e-12),
+ (1, 0): (1.9641406834125518e-05, 4.74049549614719e-12), (4, 0): (1.9506998360157013e-05, 6.97421973297474e-11), (5, 0): (2.293858677148819e-05, 7.129930361393644e-11),
+ (4, 1): (1.9010603427886962e-05, 7.077968863788975e-11), (5, 1): (1.9807778298854827e-05, 6.928845708992215e-11), (5, 4): (1.8681809306144713e-05, 4.7522367291330524e-12)}
+ '''
+
+ def __init__(self,
+ physical_devices: List[int],
+ alpha_beta_dict: Dict[Tuple[int, int], Tuple[float, float]] = None,
+ ctype: str = 'a',
+ warmup: int = 5,
+ repeat: int = 25,
+ latency_iters: int = 5,
+ homogeneous_tolerance: float = 0.1):
+ '''
+ Args:
+ physical_devices: A list of device id, each element inside it is the global rank of that device.
+ alpha_beta_dict: A dict which maps a process group to alpha-beta value pairs.
+ ctype: 'a' for all-reduce, 'b' for broadcast.
+ warmup: Number of warmup iterations.
+ repeat: Number of iterations to measure.
+ latency_iters: Number of iterations to measure latency.
+ '''
+ self.physical_devices = physical_devices
+ self.ctype = ctype
+ self.world_size = len(physical_devices)
+ self.warmup = warmup
+ self.repeat = repeat
+ self.latency_iters = latency_iters
+ self.homogeneous_tolerance = homogeneous_tolerance
+ self.process_group_dict = None
+ self._init_profiling()
+ if alpha_beta_dict is None:
+ self.alpha_beta_dict = self.profile_ab()
+ else:
+ self.alpha_beta_dict = alpha_beta_dict
+
+ def _init_profiling(self):
+ # Create process group list based on its global rank
+ process_group_list = []
+ for f_index in range(self.world_size - 1):
+ for b_index in range(f_index + 1, self.world_size):
+ process_group_list.append((self.physical_devices[f_index], self.physical_devices[b_index]))
+
+ # Create process group dict which maps process group to its handler
+ process_group_dict = {}
+ for process_group in process_group_list:
+ pg_handler = dist.new_group(process_group)
+ process_group_dict[process_group] = pg_handler
+
+ self.process_group_dict = process_group_dict
+
+ def _profile(self, process_group, pg_handler, nbytes):
+ logger = get_dist_logger()
+ rank = dist.get_rank()
+ src_device_num = process_group[0]
+ world_size = len(process_group)
+
+ device = torch.cuda.current_device()
+ buf = torch.randn(nbytes // 4).to(device)
+
+ torch.cuda.synchronize()
+ # warmup
+ for _ in range(self.warmup):
+ if self.ctype == "a":
+ dist.all_reduce(buf, op=dist.ReduceOp.SUM, group=pg_handler)
+ elif self.ctype == "b":
+ dist.broadcast(buf, src=src_device_num, group=pg_handler)
+ torch.cuda.synchronize()
+
+ dist.barrier(group=pg_handler)
+ begin = time.perf_counter()
+ for _ in range(self.repeat):
+ if self.ctype == "a":
+ dist.all_reduce(buf, op=dist.ReduceOp.SUM, group=pg_handler)
+ elif self.ctype == "b":
+ dist.broadcast(buf, src=src_device_num, group=pg_handler)
+ torch.cuda.synchronize()
+ end = time.perf_counter()
+ dist.barrier(group=pg_handler)
+
+ if rank == src_device_num:
+ avg_time_s = (end - begin) / self.repeat - FRAMEWORK_LATENCY
+ alg_band = nbytes / avg_time_s
+ if self.ctype == "a":
+ # convert the bandwidth of all-reduce algorithm to the bandwidth of the hardware.
+ bus_band = 2 * (world_size - 1) / world_size * alg_band
+ bus_band = alg_band
+ elif self.ctype == "b":
+ bus_band = alg_band
+
+ logger.info(
+ f"GPU:{rank}, Bytes: {nbytes} B,Time: {round(avg_time_s * 1e6,2)} us, Bus bandwidth: {round(bus_band / GB,2)} GB/s"
+ )
+ return (avg_time_s, alg_band)
+ else:
+ # Just a placeholder
+ return (None, None)
+
+ def profile_latency(self, process_group, pg_handler):
+ '''
+ This function is used to profile the latency of the given process group with a series of bytes.
+
+ Args:
+ process_group: A tuple of global rank of the process group.
+ pg_handler: The handler of the process group.
+
+ Returns:
+ latency: None if the latency is not measured, otherwise the median of the latency_list.
+ '''
+ latency_list = []
+ for i in range(self.latency_iters):
+ nbytes = int(BYTE << i)
+ (t, _) = self._profile(process_group, pg_handler, nbytes)
+ latency_list.append(t)
+
+ if latency_list[0] is None:
+ latency = None
+ else:
+ median_index = math.floor(self.latency_iters / 2)
+ latency = latency_list[median_index]
+
+ return latency
+
+ def profile_bandwidth(self, process_group, pg_handler, maxbytes=(1 * GB)):
+ '''
+ This function is used to profile the bandwidth of the given process group.
+
+ Args:
+ process_group: A tuple of global rank of the process group.
+ pg_handler: The handler of the process group.
+ '''
+ (_, bandwidth) = self._profile(process_group, pg_handler, maxbytes)
+ return bandwidth
+
+ def profile_ab(self):
+ '''
+ This method is used to profiling the alpha and beta value for a given device list.
+
+ Returns:
+ alpha_beta_dict: A dict which maps process group to its alpha and beta value.
+ '''
+ alpha_beta_dict: Dict[Tuple[int], Tuple[float]] = {}
+ rank = dist.get_rank()
+ global_pg_handler = dist.new_group(self.physical_devices)
+
+ def get_max_nbytes(process_group: Tuple[int], pg_handler: dist.ProcessGroup):
+ assert rank in process_group
+ device = torch.cuda.current_device()
+ rank_max_nbytes = torch.cuda.mem_get_info(device)[0]
+ rank_max_nbytes = torch.tensor(rank_max_nbytes, device=device)
+ dist.all_reduce(rank_max_nbytes, op=dist.ReduceOp.MIN, group=pg_handler)
+ max_nbytes = min(int(1 * GB), int(GB << int(math.log2(rank_max_nbytes.item() / GB))))
+ return max_nbytes
+
+ for process_group, pg_handler in self.process_group_dict.items():
+ if rank not in process_group:
+ max_nbytes = None
+ alpha = None
+ bandwidth = None
+ else:
+ max_nbytes = get_max_nbytes(process_group, pg_handler)
+ alpha = self.profile_latency(process_group, pg_handler)
+ bandwidth = self.profile_bandwidth(process_group, pg_handler, maxbytes=max_nbytes)
+
+ if bandwidth is None:
+ beta = None
+ else:
+ beta = 1 / bandwidth
+
+ broadcast_list = [alpha, beta]
+ dist.broadcast_object_list(broadcast_list, src=process_group[0])
+ alpha_beta_dict[process_group] = tuple(broadcast_list)
+
+ # add symmetry pair to the apha_beta_dict
+ symmetry_ab_dict = {}
+ for process_group, alpha_beta_pair in alpha_beta_dict.items():
+ symmetry_process_group = (process_group[1], process_group[0])
+ symmetry_ab_dict[symmetry_process_group] = alpha_beta_pair
+
+ alpha_beta_dict.update(symmetry_ab_dict)
+
+ return alpha_beta_dict
+
+ def search_best_logical_mesh(self):
+ '''
+ This method is used to search the best logical mesh for the given device list.
+
+ The best logical mesh is searched in following steps:
+ 1. detect homogeneous device groups, we assume that the devices in the alpha_beta_dict
+ are homogeneous if the beta value is close enough.
+ 2. Find the best homogeneous device group contains all the physical devices. The best homogeneous
+ device group means the lowest beta value in the groups which contains all the physical devices.
+ And the reason we require the group contains all the physical devices is that the devices not in
+ the group will decrease the bandwidth of the group.
+ 3. If the best homogeneous device group is found, we will construct the largest ring for each device
+ based on the best homogeneous device group, and the best logical mesh will be the union of all the
+ rings. Otherwise, the best logical mesh will be the balanced logical mesh, such as shape (2, 2) for
+ 4 devices.
+
+ Returns:
+ best_logical_mesh: The best logical mesh for the given device list.
+
+ Usage:
+ >>> physical_devices = [0, 1, 2, 3]
+ >>> ab_profiler = AlphaBetaProfiler(physical_devices)
+ >>> best_logical_mesh = profiler.search_best_logical_mesh()
+ >>> print(best_logical_mesh)
+ [[0, 1], [2, 3]]
+ '''
+
+ def _power_of_two(integer):
+ return integer & (integer - 1) == 0
+
+ def _detect_homogeneous_device(alpha_beta_dict):
+ '''
+ This function is used to detect whether the devices in the alpha_beta_dict are homogeneous.
+
+ Note: we assume that the devices in the alpha_beta_dict are homogeneous if the beta value
+ of the devices are in range of [(1 - self.homogeneous_tolerance), (1 + self.homogeneous_tolerance)]
+ * base_beta.
+ '''
+ homogeneous_device_dict: Dict[float, List[Tuple[int]]] = {}
+ for process_group, (_, beta) in alpha_beta_dict.items():
+ if homogeneous_device_dict is None:
+ homogeneous_device_dict[beta] = []
+ homogeneous_device_dict[beta].append(process_group)
+
+ match_beta = None
+ for beta_value in homogeneous_device_dict.keys():
+ if beta <= beta_value * (1 + self.homogeneous_tolerance) and beta >= beta_value * (
+ 1 - self.homogeneous_tolerance):
+ match_beta = beta_value
+ break
+
+ if match_beta is not None:
+ homogeneous_device_dict[match_beta].append(process_group)
+ else:
+ homogeneous_device_dict[beta] = []
+ homogeneous_device_dict[beta].append(process_group)
+
+ return homogeneous_device_dict
+
+ def _check_contain_all_devices(homogeneous_group: List[Tuple[int]]):
+ '''
+ This function is used to check whether the homogeneous_group contains all physical devices.
+ '''
+ flatten_mesh = []
+ for process_group in homogeneous_group:
+ flatten_mesh.extend(process_group)
+ non_duplicated_flatten_mesh = set(flatten_mesh)
+ return len(non_duplicated_flatten_mesh) == len(self.physical_devices)
+
+ def _construct_largest_ring(homogeneous_group: List[Tuple[int]]):
+ '''
+ This function is used to construct the largest ring in the homogeneous_group for each rank.
+ '''
+ # Construct the ring
+ ring = []
+ ranks_in_ring = []
+ for rank in self.physical_devices:
+ if rank in ranks_in_ring:
+ continue
+ stable_status = False
+ ring_for_rank = []
+ ring_for_rank.append(rank)
+ check_rank_list = [rank]
+ rank_to_check_list = []
+
+ while not stable_status:
+ stable_status = True
+ check_rank_list.extend(rank_to_check_list)
+ rank_to_check_list = []
+ for i in range(len(check_rank_list)):
+ check_rank = check_rank_list.pop()
+ for process_group in homogeneous_group:
+ if check_rank in process_group:
+ rank_to_append = process_group[0] if process_group[1] == check_rank else process_group[1]
+ if rank_to_append not in ring_for_rank:
+ stable_status = False
+ rank_to_check_list.append(rank_to_append)
+ ring_for_rank.append(rank_to_append)
+
+ ring.append(ring_for_rank)
+ ranks_in_ring.extend(ring_for_rank)
+
+ return ring
+
+ assert _power_of_two(self.world_size)
+ power_of_two = int(math.log2(self.world_size))
+ median = power_of_two // 2
+ balanced_logical_mesh_shape = (2**median, 2**(power_of_two - median))
+ row_size, column_size = balanced_logical_mesh_shape[0], balanced_logical_mesh_shape[1]
+ balanced_logical_mesh = []
+ for row_index in range(row_size):
+ balanced_logical_mesh.append([])
+ for column_index in range(column_size):
+ balanced_logical_mesh[row_index].append(self.physical_devices[row_index * column_size + column_index])
+
+ homogeneous_device_dict = _detect_homogeneous_device(self.alpha_beta_dict)
+ beta_list = [b for b in homogeneous_device_dict.keys()]
+ beta_list.sort()
+ beta_list.reverse()
+ homogeneous_types = len(beta_list)
+ best_logical_mesh = None
+ if homogeneous_types >= 2:
+ for _ in range(homogeneous_types - 1):
+ lowest_beta = beta_list.pop()
+ best_homogeneous_group = homogeneous_device_dict[lowest_beta]
+ # if the best homogeneous group contains all physical devices,
+ # we will build the logical device mesh based on it. Otherwise,
+ # we will check next level homogeneous group.
+ if _check_contain_all_devices(best_homogeneous_group):
+ # We choose the largest ring for each rank to maximum the best bus utilization.
+ best_logical_mesh = _construct_largest_ring(best_homogeneous_group)
+ break
+
+ if homogeneous_types == 1 or best_logical_mesh is None:
+ # in this case, we use balanced logical mesh as the best
+ # logical mesh.
+ best_logical_mesh = balanced_logical_mesh
+
+ return best_logical_mesh
+
+ def extract_alpha_beta_for_device_mesh(self):
+ '''
+ Extract the mesh_alpha list and mesh_beta list based on the
+ best logical mesh, which will be used to initialize the device mesh.
+
+ Usage:
+ >>> physical_devices = [0, 1, 2, 3]
+ >>> ab_profiler = AlphaBetaProfiler(physical_devices)
+ >>> mesh_alpha, mesh_beta = profiler.extract_alpha_beta_for_device_mesh()
+ >>> print(mesh_alpha)
+ [2.5917552411556242e-05, 0.00010312341153621673]
+ >>> print(mesh_beta)
+ [5.875573704655635e-11, 4.7361584445959614e-12]
+ '''
+ best_logical_mesh = self.search_best_logical_mesh()
+
+ first_axis = [row[0] for row in best_logical_mesh]
+ second_axis = best_logical_mesh[0]
+
+ # init process group for both axes
+ first_axis_process_group = dist.new_group(first_axis)
+ second_axis_process_group = dist.new_group(second_axis)
+
+ # extract alpha and beta for both axes
+ def _extract_alpha_beta(pg, pg_handler):
+ latency = self.profile_latency(pg, pg_handler)
+ bandwidth = self.profile_bandwidth(pg, pg_handler)
+ broadcast_object = [latency, bandwidth]
+ dist.broadcast_object_list(broadcast_object, src=pg[0])
+ return broadcast_object
+
+ first_latency, first_bandwidth = _extract_alpha_beta(first_axis, first_axis_process_group)
+ second_latency, second_bandwidth = _extract_alpha_beta(second_axis, second_axis_process_group)
+ mesh_alpha = [first_latency, second_latency]
+ # The beta values have been enlarged by 1e10 times temporarilly because the computation cost
+ # is still estimated in the unit of TFLOPs instead of time. We will remove this factor in future.
+ mesh_beta = [1e10 / first_bandwidth, 1e10 / second_bandwidth]
+
+ return mesh_alpha, mesh_beta
diff --git a/colossalai/device/calc_pipeline_strategy.py b/colossalai/device/calc_pipeline_strategy.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ab72dfe60f0c73f0e4f5186ed54205b68513bc0
--- /dev/null
+++ b/colossalai/device/calc_pipeline_strategy.py
@@ -0,0 +1,127 @@
+from math import pow
+
+import numpy as np
+
+
+def get_submesh_choices(num_hosts, num_devices_per_host, mode="new"):
+ submesh_choices = []
+ i = 1
+ p = -1
+ while i <= num_devices_per_host:
+ i *= 2
+ p += 1
+ assert pow(2, p) == num_devices_per_host, ("Only supports the cases where num_devices_per_host is power of two, "
+ f"while now num_devices_per_host = {num_devices_per_host}")
+ if mode == "alpa":
+ for i in range(p + 1):
+ submesh_choices.append((1, pow(2, i)))
+ for i in range(2, num_hosts + 1):
+ submesh_choices.append((i, num_devices_per_host))
+ elif mode == "new":
+ for i in range(p // 2 + 1):
+ for j in range(i, p - i + 1):
+ submesh_choices.append((pow(2, i), pow(2, j)))
+ return submesh_choices
+
+
+def alpa_dp_impl(num_layers, num_devices, num_microbatches, submesh_choices, compute_cost, max_stage_cost,
+ best_configs):
+ """Implementation of Alpa DP for pipeline strategy
+ Paper reference: https://www.usenix.org/system/files/osdi22-zheng-lianmin.pdf
+
+ Arguments:
+ num_layers: K
+ num_devices: N*M
+ num_microbatches: B
+ submesh_choices: List[(n_i,m_i)]
+ compute_cost: t_intra
+ """
+ # For f, layer ID start from 0
+ # f[#pipeline stages, layer id that is currently being considered, number of devices used]
+ f = np.full((num_layers + 1, num_layers + 1, num_devices + 1), np.inf, dtype=np.float32)
+ f_stage_max = np.full((num_layers + 1, num_layers + 1, num_devices + 1), 0.0, dtype=np.float32)
+ f_argmin = np.full((num_layers + 1, num_layers + 1, num_devices + 1, 3), -1, dtype=np.int32)
+ f[0, num_layers, 0] = 0
+ for s in range(1, num_layers + 1):
+ for k in range(num_layers - 1, -1, -1):
+ for d in range(1, num_devices + 1):
+ for m, submesh in enumerate(submesh_choices):
+ n_submesh_devices = np.prod(np.array(submesh))
+ if n_submesh_devices <= d:
+ # TODO: [luzgh]: Why alpa needs max_n_succ_stages? Delete.
+ # if s - 1 <= max_n_succ_stages[i, k - 1, m, n_config]:
+ # ...
+ for i in range(num_layers, k, -1):
+ stage_cost = compute_cost[k, i, m]
+ new_cost = f[s - 1, k, d - n_submesh_devices] + stage_cost
+ if (stage_cost <= max_stage_cost and new_cost < f[s, k, d]):
+ f[s, k, d] = new_cost
+ f_stage_max[s, k, d] = max(stage_cost, f_stage_max[s - 1, i, d - n_submesh_devices])
+ f_argmin[s, k, d] = (i, m, best_configs[k, i, m])
+ best_s = -1
+ best_total_cost = np.inf
+ for s in range(1, num_layers + 1):
+ if f[s, 0, num_devices] < best_total_cost:
+ best_s = s
+ best_total_cost = f[s, 0, num_devices]
+
+ if np.isinf(best_total_cost):
+ return np.inf, None
+
+ total_cost = f[best_s, 0, num_devices] + (num_microbatches - 1) * f_stage_max[best_s, 0, num_devices]
+ current_s = best_s
+ current_layer = 0
+ current_devices = num_devices
+
+ res = []
+ while current_s > 0 and current_layer < num_layers and current_devices > 0:
+ next_start_layer, submesh_choice, autosharding_choice = (f_argmin[current_s, current_layer, current_devices])
+ assert next_start_layer != -1 and current_devices != -1
+ res.append(((current_layer, next_start_layer), submesh_choice, autosharding_choice))
+ current_s -= 1
+ current_layer = next_start_layer
+ current_devices -= np.prod(np.array(submesh_choices[submesh_choice]))
+ assert (current_s == 0 and current_layer == num_layers and current_devices == 0)
+
+ return total_cost, res
+
+
+def alpa_dp(num_layers,
+ num_devices,
+ num_microbatches,
+ submesh_choices,
+ num_autosharding_configs,
+ compute_cost,
+ gap=1e-6):
+ """Alpa auto stage dynamic programming.
+ Code reference: https://github.com/alpa-projects/alpa/blob/main/alpa/pipeline_parallel/stage_construction.py
+
+ Arguments:
+ submesh_choices: List[(int,int)]
+ num_autosharding_configs: Max number of t_intra(start_layer, end_layer, LogicalMesh)
+ compute_cost: np.array(num_layers,num_layers,num_submesh_choices,num_autosharding_configs)
+ """
+ assert np.shape(compute_cost) == (num_layers, num_layers, len(submesh_choices),
+ num_autosharding_configs), "Cost shape wrong."
+ all_possible_stage_costs = np.sort(np.unique(compute_cost))
+ best_cost = np.inf
+ best_solution = None
+ last_max_stage_cost = 0.0
+ # TODO: [luzgh]: Why alpa needs the num_autosharding_configs dimension in compute_cost?
+ # In dp_impl it seems the argmin n_config will be chosen. Just amin here.
+ best_configs = np.argmin(compute_cost, axis=3)
+ best_compute_cost = np.amin(compute_cost, axis=3)
+ assert len(all_possible_stage_costs), "no solution in auto stage construction."
+ for max_stage_cost in all_possible_stage_costs:
+ if max_stage_cost * num_microbatches >= best_cost:
+ break
+ if max_stage_cost - last_max_stage_cost < gap:
+ continue
+ cost, solution = alpa_dp_impl(num_layers, num_devices, num_microbatches, submesh_choices, best_compute_cost,
+ max_stage_cost, best_configs)
+ if cost < best_cost:
+ best_cost = cost
+ best_solution = solution
+ last_max_stage_cost = max_stage_cost
+
+ return best_cost, best_solution
diff --git a/colossalai/device/device_mesh.py b/colossalai/device/device_mesh.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a5f747fbc238c7799b3076e695030020f491d5b
--- /dev/null
+++ b/colossalai/device/device_mesh.py
@@ -0,0 +1,249 @@
+"""This code is adapted from Alpa
+ https://github.com/alpa-projects/alpa/
+ with some changes. """
+
+import operator
+from functools import reduce
+from typing import List, Tuple
+
+import torch
+import torch.distributed as dist
+
+
+# modified from alpa LogicalDeviceMesh(https://github.com/alpa-projects/alpa/blob/main/alpa/shard_parallel/auto_sharding.py)
+class DeviceMesh:
+ """A logical view of a physical cluster. For example, we could view a physical cluster
+ with 16 devices as a device mesh with shape (2, 2, 4) or (4, 4).
+
+ Arguments:
+ physical_mesh_id (torch.Tensor): physical view of the devices in global rank.
+ logical_mesh_id (torch.Tensor): logical view of the devices in global rank.
+ mesh_shape (torch.Size, optional): shape of logical view.
+ mesh_alpha (List[float], optional): coefficients used for computing
+ communication cost (default: None)
+ mesh_beta (List[float], optional): coefficients used for computing
+ communication cost (default: None)
+ init_process_group (bool, optional): initialize logical process group
+ during initializing the DeviceMesh instance if the init_process_group set to True.
+ Otherwise, users need to call create_process_groups_for_logical_mesh manually to init logical process group.
+ (default: False)
+ need_flatten(bool, optional): initialize flatten_device_mesh during initializing the DeviceMesh instance if the need_flatten set to True.
+ """
+
+ def __init__(self,
+ physical_mesh_id: torch.Tensor,
+ mesh_shape: torch.Size = None,
+ logical_mesh_id: torch.Tensor = None,
+ mesh_alpha: List[float] = None,
+ mesh_beta: List[float] = None,
+ init_process_group: bool = False,
+ need_flatten: bool = True):
+ self.physical_mesh_id = physical_mesh_id
+ if logical_mesh_id is None:
+ self.mesh_shape = mesh_shape
+ self._logical_mesh_id = self.physical_mesh_id.reshape(self.mesh_shape)
+ else:
+ self._logical_mesh_id = logical_mesh_id
+ self.mesh_shape = self._logical_mesh_id.shape
+
+ # map global rank into logical rank
+ self.convert_map = {}
+ self._global_rank_to_logical_rank_map(self._logical_mesh_id, [])
+ # coefficient for alpha-beta communication model
+ if mesh_alpha is None:
+ mesh_alpha = [1] * len(self.mesh_shape)
+ if mesh_beta is None:
+ mesh_beta = [1] * len(self.mesh_shape)
+ self.mesh_alpha = tuple(mesh_alpha)
+ self.mesh_beta = tuple(mesh_beta)
+ self.init_process_group = init_process_group
+ self.need_flatten = need_flatten
+ if self.init_process_group:
+ self.process_groups_dict = self.create_process_groups_for_logical_mesh()
+ if self.need_flatten and self._logical_mesh_id.dim() > 1:
+ self.flatten_device_mesh = self.flatten()
+ # Create a new member `flatten_device_meshes` to distinguish from original flatten methods (Because I'm not sure if there are functions that rely on the self.flatten())
+ # self.flatten_device_meshes = FlattenDeviceMesh(self.physical_mesh_id, self.mesh_shape, self.mesh_alpha,
+ # self.mesh_beta)
+
+ @property
+ def shape(self):
+ return self.mesh_shape
+
+ @property
+ def num_devices(self):
+ return reduce(operator.mul, self.physical_mesh_id.shape, 1)
+
+ @property
+ def logical_mesh_id(self):
+ return self._logical_mesh_id
+
+ def __deepcopy__(self, memo):
+ cls = self.__class__
+ result = cls.__new__(cls)
+ memo[id(self)] = result
+ for k, v in self.__dict__.items():
+ if k != 'process_groups_dict':
+ setattr(result, k, __import__("copy").deepcopy(v, memo))
+ else:
+ setattr(result, k, v)
+
+ return result
+
+ def flatten(self):
+ """
+ Flatten the logical mesh into an effective 1d logical mesh,
+ """
+ flatten_mesh_shape_size = len(self.mesh_shape)
+ flatten_mesh_shape = [self.num_devices]
+ return DeviceMesh(self.physical_mesh_id,
+ tuple(flatten_mesh_shape),
+ mesh_alpha=[max(self.mesh_alpha)] * (flatten_mesh_shape_size - 1),
+ mesh_beta=[max(self.mesh_beta)] * (flatten_mesh_shape_size - 1),
+ init_process_group=self.init_process_group,
+ need_flatten=False)
+
+ def _global_rank_to_logical_rank_map(self, tensor, index_list):
+ '''
+ This method is a helper function to build convert_map recursively.
+ '''
+ for index, inner_tensor in enumerate(tensor):
+ if inner_tensor.numel() == 1:
+ self.convert_map[int(inner_tensor)] = index_list + [index]
+ else:
+ self._global_rank_to_logical_rank_map(inner_tensor, index_list + [index])
+
+ def create_process_groups_for_logical_mesh(self):
+ '''
+ This method is used to initialize the logical process groups which will be used in communications
+ among logical device mesh.
+ Note: if init_process_group set to False, you have to call this method manually. Otherwise,
+ the communication related function, such as ShapeConsistencyManager.apply will raise errors.
+ '''
+ process_groups_dict = {}
+ check_duplicate_list = []
+ global_rank_flatten_list = self.physical_mesh_id.view(-1).tolist()
+ for global_rank in global_rank_flatten_list:
+ process_groups = self.global_rank_to_process_groups_with_global_rank(global_rank)
+ for axis, process_group in process_groups.items():
+ if axis not in process_groups_dict:
+ process_groups_dict[axis] = []
+ if process_group not in check_duplicate_list:
+ check_duplicate_list.append(process_group)
+ process_group_handler = dist.new_group(process_group)
+ process_groups_dict[axis].append((process_group, process_group_handler))
+
+ return process_groups_dict
+
+ def global_rank_to_logical_rank(self, rank):
+ return self.convert_map[rank]
+
+ def global_rank_to_process_groups_with_logical_rank(self, rank):
+ '''
+ Give a global rank and return all logical process groups of this rank.
+ for example:
+ physical_mesh_id = torch.arange(0, 16).reshape(2, 8)
+ mesh_shape = (4, 4)
+ # [[0, 1, 2, 3],
+ # [4, 5, 6, 7],
+ # [8, 9, 10,11],
+ # [12,13,14,15]]
+ device_mesh = DeviceMesh(physical_mesh_id, mesh_shape)
+ print(device_mesh.global_rank_to_process_groups_with_logical_rank(0))
+ output:
+ # key is axis name
+ # value is a list of logical ranks in same axis with rank 0
+ {0: [[0, 0], [1, 0], [2, 0], [3, 0]], 1: [[0, 0], [0, 1], [0, 2], [0, 3]]}
+ '''
+ process_groups = {}
+ for d in range(self.logical_mesh_id.dim()):
+ for replacer in range(self.logical_mesh_id.shape[d]):
+ if d not in process_groups:
+ process_groups[d] = []
+ process_group_member = self.convert_map[rank].copy()
+ process_group_member[d] = replacer
+ process_groups[d].append(process_group_member)
+ return process_groups
+
+ def global_rank_to_process_groups_with_global_rank(self, rank):
+ '''
+ Give a global rank and return all process groups of this rank.
+ for example:
+ physical_mesh_id = torch.arange(0, 16).reshape(2, 8)
+ mesh_shape = (4, 4)
+ # [[0, 1, 2, 3],
+ # [4, 5, 6, 7],
+ # [8, 9, 10,11],
+ # [12,13,14,15]]
+ device_mesh = DeviceMesh(physical_mesh_id, mesh_shape)
+ print(device_mesh.global_rank_to_process_groups_with_global_rank(0))
+ output:
+ # key is axis name
+ # value is a list of global ranks in same axis with rank 0
+ {0: [0, 4, 8, 12], 1: [0, 1, 2, 3]}
+ '''
+ logical_process_groups = self.global_rank_to_process_groups_with_logical_rank(rank)
+ process_groups = {}
+ for dim, logical_ranks in logical_process_groups.items():
+ process_groups[dim] = []
+ for logical_rank in logical_ranks:
+ for g_rank, l_rank in self.convert_map.items():
+ if l_rank == logical_rank:
+ process_groups[dim].append(g_rank)
+ return process_groups
+
+ def all_gather_cost(self, num_bytes, mesh_dim):
+ num_devices = self.logical_mesh_id.shape[mesh_dim]
+ return (self.mesh_alpha[mesh_dim] + self.mesh_beta[mesh_dim] * (num_devices - 1) / num_devices * num_bytes +
+ 0.1)
+
+ def all_reduce_cost(self, num_bytes, mesh_dim):
+ num_devices = self.logical_mesh_id.shape[mesh_dim]
+ return (self.mesh_alpha[mesh_dim] + self.mesh_beta[mesh_dim] * 2 * (num_devices - 1) / num_devices * num_bytes +
+ 0.01)
+
+ def reduce_scatter_cost(self, num_bytes, mesh_dim):
+ num_devices = self.logical_mesh_id.shape[mesh_dim]
+ return (self.mesh_alpha[mesh_dim] + self.mesh_beta[mesh_dim] * (num_devices - 1) / num_devices * num_bytes +
+ 0.001)
+
+ def all_to_all_cost(self, num_bytes, mesh_dim):
+ num_devices = self.logical_mesh_id.shape[mesh_dim]
+ penalty_factor = num_devices / 2.0
+ return (self.mesh_alpha[mesh_dim] + self.mesh_beta[mesh_dim] *
+ (num_devices - 1) / num_devices / num_devices * num_bytes * penalty_factor + 0.001)
+
+
+class FlattenDeviceMesh(DeviceMesh):
+
+ def __init__(self, physical_mesh_id, mesh_shape, mesh_alpha=None, mesh_beta=None):
+ super().__init__(physical_mesh_id,
+ mesh_shape,
+ mesh_alpha,
+ mesh_beta,
+ init_process_group=False,
+ need_flatten=False)
+ # Different from flatten(), mesh_shape leaves unchanged, mesh_alpha and mesh_beta are scalars
+ self.mesh_alpha = max(self.mesh_alpha)
+ self.mesh_beta = min(self.mesh_beta)
+ # Different from original process_groups_dict, rank_list is not stored
+ self.process_number_dict = self.create_process_numbers_for_logical_mesh()
+
+ def create_process_numbers_for_logical_mesh(self):
+ '''
+ Build 1d DeviceMesh in column-major(0) and row-major(1)
+ for example:
+ mesh_shape = (2,4)
+ # [[0, 1, 2, 3],
+ # [4, 5, 6, 7]]
+ # return {0: [0, 4, 1, 5, 2, 6, 3, 7], 1: [0, 1, 2, 3, 4, 5, 6, 7]}
+ '''
+ num_devices = reduce(operator.mul, self.mesh_shape, 1)
+ process_numbers_dict = {}
+ process_numbers_dict[0] = torch.arange(num_devices).reshape(self.mesh_shape).transpose(1, 0).flatten().tolist()
+ process_numbers_dict[1] = torch.arange(num_devices).reshape(self.mesh_shape).flatten().tolist()
+ return process_numbers_dict
+
+ def mix_gather_cost(self, num_bytes):
+ num_devices = reduce(operator.mul, self.mesh_shape, 1)
+ return (self.mesh_alpha + self.mesh_beta * (num_devices - 1) / num_devices * num_bytes + 0.1)
diff --git a/colossalai/engine/__init__.py b/colossalai/engine/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..158796befb312755ed92f77f7828557f55800e4c
--- /dev/null
+++ b/colossalai/engine/__init__.py
@@ -0,0 +1,4 @@
+from ._base_engine import Engine
+from .gradient_handler import *
+
+__all__ = ['Engine']
diff --git a/colossalai/engine/_base_engine.py b/colossalai/engine/_base_engine.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff8979d82401931b04649ffadff615932a1e1b37
--- /dev/null
+++ b/colossalai/engine/_base_engine.py
@@ -0,0 +1,214 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+# this code is inspired by the DeepSpeed library and implemented with our own design from scratch
+
+from typing import Iterable, List, Optional, Type
+
+from torch import Tensor
+from torch.nn import Module
+from torch.nn.modules.loss import _Loss
+
+from colossalai.engine.gradient_handler import BaseGradientHandler
+from colossalai.engine.schedule import BaseSchedule, InterleavedPipelineSchedule, NonPipelineSchedule, PipelineSchedule
+from colossalai.logging import get_dist_logger
+from colossalai.zero.legacy.gemini import BaseOpHook, register_ophooks_recursively
+
+
+class Engine:
+ """Basic engine class for training and evaluation. It runs a specific process method
+ :meth:`step` which is based on the given :attr:`schedule` over each batch of a dataset.
+ It controls a iteration in training.
+
+ Args:
+ model (``torch.nn.Module``): The neural network model.
+ optimizer (``colossalai.nn.optimizer.ColossalaiOptimizer``): Optimizer for updating the parameters.
+ criterion (``torch.nn.modules.loss._Loss``, optional): Loss function for calculating loss.
+ gradient_handlers (List[``BaseGradientHandler``], optional): A list of gradient handler used in backward.
+ clip_grad_norm (float, optional): The norm of gradient clipping.
+ ophook_list (list): List of ophook.
+ verbose (bool): whether to display log info.
+ schedule (''BaseSchedule''): Runtime schedule.
+
+ Examples:
+ >>> # define model, criterion, optimizer, lr_scheduler, train_dataloader for your training
+ >>> model = ...
+ >>> criterion = ...
+ >>> optimizer = ...
+ >>> train_dataloader = ...
+ >>> engine, _, _, _ = colossalai.initialize(model, optimizer, criterion)
+ >>> engine.train()
+ >>> for inputs, labels in train_dataloader
+ >>> # set gradients to zero
+ >>> engine.zero_grad()
+ >>> # run forward pass
+ >>> outputs = engine(inputs)
+ >>> # compute loss value and run backward pass
+ >>> loss = engine.criterion(outputs, labels)
+ >>> engine.backward(loss)
+ >>> # update parameters
+ >>> engine.step()
+
+ The example of using Engine in training could be find in
+ `Training with engine and trainer `_. and
+ `Run resnet cifar10 with engine `_.
+ """
+
+ def __init__(self,
+ model: Module,
+ optimizer: "ColossalaiOptimizer",
+ criterion: Optional[_Loss] = None,
+ gradient_handlers: Optional[List[BaseGradientHandler]] = None,
+ clip_grad_norm: float = 0.0,
+ ophook_list: Optional[List[BaseOpHook]] = None,
+ verbose: bool = True,
+ schedule: Optional[BaseSchedule] = None):
+ self._model = model
+ self._optimizer = optimizer
+ self._criterion = criterion
+ self._clip_grad_norm = clip_grad_norm
+ self._verbose = verbose
+ self._logger = get_dist_logger()
+
+ # state
+ self.training = True # default
+
+ # build gradient handler
+ if gradient_handlers:
+ self._gradient_handlers = gradient_handlers
+ else:
+ self._gradient_handlers = []
+
+ if ophook_list is None:
+ self._ophook_list = []
+ else:
+ self._ophook_list = ophook_list
+
+ # build schedule
+ if schedule:
+ assert isinstance(schedule, BaseSchedule), \
+ f'expected schedule to be of type BaseSchedule, but got {type(schedule)}'
+ self._schedule = schedule
+ else:
+ self._schedule = NonPipelineSchedule()
+ if self.uses_pipeline:
+ self._schedule.pre_processing(self)
+
+ # register hook if any
+ if len(self._ophook_list) > 0:
+ register_ophooks_recursively(self._model, self._ophook_list)
+
+ @property
+ def ophooks(self):
+ """show current activated ophooks"""
+ return self._ophook_list
+
+ @property
+ def model(self):
+ """Model attached to the engine"""
+ return self._model
+
+ @property
+ def optimizer(self):
+ """Optimizer attached to the engine"""
+ return self._optimizer
+
+ @property
+ def criterion(self):
+ """Criterion attached to the engine"""
+ return self._criterion
+
+ @property
+ def schedule(self):
+ """Schedule attached to the engine"""
+ return self._schedule
+
+ @property
+ def uses_pipeline(self):
+ """show the pipeline parallel used or not"""
+ return isinstance(self._schedule, (PipelineSchedule, InterleavedPipelineSchedule))
+
+ def add_hook(self, ophook: Type[BaseOpHook]) -> None:
+ """add necessary hook"""
+ # whether this hook exist
+ for h in self._ophook_list:
+ if type(h) == type(ophook):
+ logger = get_dist_logger()
+ logger.warning(f"duplicate hooks, at least two instance of {type(ophook)}")
+ self._ophook_list.append(ophook)
+ register_ophooks_recursively(self._model, self._ophook_list)
+
+ def remove_hook(self, ophook: Type[BaseOpHook]) -> None:
+ """remove hook"""
+ logger = get_dist_logger()
+ logger.warning(f"removing hooks is currently not supported")
+
+ def zero_grad(self):
+ """Set the gradient of parameters to zero
+ """
+ self.optimizer.zero_grad()
+
+ def step(self):
+ """Execute parameter update
+ """
+ self._all_reduce_gradients()
+ self.optimizer.clip_grad_norm(self.model, self._clip_grad_norm)
+ return self.optimizer.step()
+
+ def backward(self, loss: Tensor):
+ """Start backward propagation given the loss value computed by a loss function.
+
+ Args:
+ loss (:class:`torch.Tensor`): Loss value computed by a loss function.
+ """
+ ret = self.optimizer.backward(loss)
+ for ophook in self._ophook_list:
+ ophook.post_iter()
+ return ret
+
+ def backward_by_grad(self, tensor, grad):
+ """Start backward propagation given the gradient of the output tensor.
+
+ Args:
+ tensor (:class:`torch.Tensor`): Output tensor.
+ grad (:class:`torch.Tensor`): Gradient passed back to the output.
+ """
+ ret = self.optimizer.backward_by_grad(tensor, grad)
+ for ophook in self._ophook_list:
+ ophook.post_iter()
+ return ret
+
+ def __call__(self, *args, **kwargs):
+ """Run the forward step for the model.
+
+ Returns:
+ Tuple[:class:`torch.Tensor`] or :class:`torch.Tensor`: Output of the model.
+ """
+ return self.model(*args, **kwargs)
+
+ def _all_reduce_gradients(self):
+ """Handles all-reduce operations of gradients across different parallel groups.
+ """
+ for handler in self._gradient_handlers:
+ handler.handle_gradient()
+
+ def execute_schedule(self, data_iter: Iterable, **kwargs):
+ """Run the forward, loss computation, and backward for the model.
+ Returns a tuple of (output, label, loss).
+
+ Returns:
+ Tuple[:class:`torch.Tensor`]: A tuple of (output, label, loss).
+ """
+ output, label, loss = self._schedule.forward_backward_step(self, data_iter, **kwargs)
+ return output, label, loss
+
+ def train(self):
+ """Sets the model to training mode.
+ """
+ self.training = True
+ self._model.train()
+
+ def eval(self):
+ """Sets the model to evaluation mode.
+ """
+ self.training = False
+ self._model.eval()
diff --git a/colossalai/engine/gradient_accumulation/__init__.py b/colossalai/engine/gradient_accumulation/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cb6f4ad7384dda6136d98a0a73521e37d4027ba
--- /dev/null
+++ b/colossalai/engine/gradient_accumulation/__init__.py
@@ -0,0 +1,57 @@
+from typing import Iterable, List
+
+import torch.nn as nn
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler
+
+from colossalai.engine import BaseGradientHandler
+
+from ._gradient_accumulation import (
+ GradAccumDataloader,
+ GradAccumGradientHandler,
+ GradAccumLrSchedulerByStep,
+ GradAccumOptimizer,
+)
+
+__all__ = [
+ 'accumulate_gradient', 'GradAccumDataloader', 'GradAccumOptimizer', 'GradAccumLrSchedulerByStep',
+ 'GradAccumGradientHandler'
+]
+
+
+def accumulate_gradient(model: nn.Module,
+ optimizer: Optimizer,
+ dataloader: Iterable,
+ accumulate_size: int,
+ gradient_handlers: List[BaseGradientHandler] = None,
+ lr_scheduler: _LRScheduler = None):
+ r"""Turning model, optimizer, dataloader into corresponding object for gradient accumulation.
+
+ Args:
+ model (:class:`torch.nn.Module`): your model object for gradient accumulation.
+ optimizer (:class:`torch.optim.Optimizer`): your optimizer object for gradient accumulation.
+ dataloader (:class:`torch.utils.data.DataLoader` or iterable objects):
+ your dataloader object, would be called like iter(dataloader)
+ accumulate_size (int): the number of steps to accumulate gradients
+ gradient_handlers (List[:class:`colossalai.engine.BaseGradientHandler`]):
+ list of gradient handler objects. Default is None.
+ lr_scheduler (`torch.optim.lr_scheduler` or `colossalai.nn.lr_scheduler`):
+ your ``lr_scheduler`` object for gradient accumulation. Defaults to None.
+
+ More details about `gradient_handlers` could be found in
+ `Gradient_handler `_.
+
+ More details about `lr_scheduler` could be found
+ `lr_scheduler `_. and
+ `how to adjust learning rate `_.
+ """
+ optimizer = GradAccumOptimizer(optimizer, accumulate_size=accumulate_size, model=model)
+ dataloader = GradAccumDataloader(dataloader, accumulate_size=accumulate_size)
+
+ if gradient_handlers is not None:
+ gradient_handlers = [GradAccumGradientHandler(handler, accumulate_size) for handler in gradient_handlers]
+
+ if lr_scheduler is not None:
+ lr_scheduler = GradAccumLrSchedulerByStep(lr_scheduler, accumulate_size=accumulate_size)
+
+ return optimizer, dataloader, gradient_handlers, lr_scheduler
diff --git a/colossalai/engine/gradient_accumulation/_gradient_accumulation.py b/colossalai/engine/gradient_accumulation/_gradient_accumulation.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf66be1cd8218e8dc35177f9d69115ec1553c687
--- /dev/null
+++ b/colossalai/engine/gradient_accumulation/_gradient_accumulation.py
@@ -0,0 +1,291 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from typing import Any, Iterable, Tuple, Union
+
+import torch.nn as nn
+from torch import Tensor
+from torch.nn.parallel.distributed import DistributedDataParallel
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler
+from torch.utils.data import DataLoader
+
+from colossalai.engine import BaseGradientHandler
+from colossalai.nn.optimizer import ColossalaiOptimizer
+from colossalai.utils import conditional_context
+
+
+class GradAccumOptimizer(ColossalaiOptimizer):
+ """A wrapper for the optimizer to enable gradient accumulation by skipping the steps
+ before accumulation size is reached.
+
+ Args:
+ optim (:class:`torch.optim.Optimizer`): Your optimizer object for gradient accumulation.
+ accumulate_size (int): The number of steps to accumulate gradients.
+ model (:class:`torch.nn.Module`):
+ Your model object to check if it is DistributedDataParallel for special handling of no_sync() context.
+ """
+
+ def __init__(self, optim: Optimizer, accumulate_size: int, model: nn.Module = None):
+ super().__init__(optim)
+ self.accumulate_size = accumulate_size
+ self.accumulate_step = 0
+
+ # handle pytorch ddp auto all reduce
+ self.model = model
+ self.is_torch_ddp = isinstance(self.model, DistributedDataParallel)
+
+ def zero_grad(self, *args, **kwargs) -> None:
+ """
+ Set all gradients to zero.
+
+ Args:
+ *args: positional arguments for the optimizer wrapped
+ **kwargs: keyword arguments for the optimizer wrapped
+ """
+
+ if self.accumulate_step == 0:
+ self.optim.zero_grad(*args, **kwargs)
+
+ def step(self, *args, **kwargs) -> None:
+ """
+ Update the model parameters.
+
+ Args:
+ *args: positional arguments for the optimizer wrapped
+ **kwargs: keyword arguments for the optimizer wrapped
+ """
+
+ if self.accumulate_step < self.accumulate_size:
+ return None
+ else:
+ self.accumulate_step = 0
+ return self.optim.step(*args, **kwargs)
+
+ def clip_grad_norm(self, model: nn.Module, max_norm: float) -> None:
+ """
+ Clip gradients by norm.
+
+ Args:
+ model (:class:`torch.nn.Module`): a torch module instance
+ max_norm (float): the max norm for gradient clipping
+ """
+
+ if self.accumulate_step < self.accumulate_size:
+ pass
+ else:
+ self.optim.clip_grad_norm(model, max_norm)
+
+ def backward(self, loss: Tensor) -> None:
+ """Execute backward pass.
+
+ Args:
+ loss (:class:`torch.Tensor`): the loss value.
+ """
+
+ self.accumulate_step += 1
+
+ if self.is_torch_ddp:
+ no_sync = self.accumulate_step < self.accumulate_size
+ with conditional_context(self.model.no_sync(), enable=no_sync):
+ scaled_loss = loss / self.accumulate_size
+ self.optim.backward(scaled_loss)
+ else:
+ scaled_loss = loss / self.accumulate_size
+ self.optim.backward(scaled_loss)
+
+ def backward_by_grad(self, tensor: Tensor, grad: Tensor) -> None:
+ """Execute backward pass given the gradients of the output.
+
+ Args:
+ loss (:class:`torch.Tensor`): the loss value.
+ grad (:class:`torch.Tensor`): the output gradient.
+ """
+
+ self.accumulate_step += 1
+ no_sync = self.is_torch_ddp and self.accumulate_step < self.accumulate_size
+
+ if no_sync:
+ with self.model.no_sync():
+ self.optim.backward_by_grad(tensor, grad)
+ else:
+ self.optim.backward_by_grad(tensor, grad)
+
+
+class GradAccumDataloader:
+ """A wrapper for dataloader to enable gradient accumulation by dropping the last incomplete steps.
+
+ Note:
+ The dataloader would drop the last incomplete steps for gradient accumulation.
+ For example, if a dataloader has 10 batches of data and accumulate size is 4. The model parameters will
+ be updated only twice at step 4 and step 8. The last two batches of data do not form a complete 4-step cycle.
+ Thus, they will be automatically skipped by this class. If the dataloader is not standard PyTorch dataloader,
+ (e.g. Dali dataloader), this class will automatically consume (load data for nothing) the remaining 2 batches.
+
+ Args:
+ dataloader (``Iterable``): Your dataloader object for gradient accumulation.
+ accumulate_size (int): The number of steps to accumulate gradients.
+ """
+
+ def __init__(self, dataloader: Iterable, accumulate_size: int) -> None:
+ self.dataloader = dataloader
+ self.consume_remain_data = not isinstance(dataloader, DataLoader)
+ self.steps_per_epoch = len(dataloader) - len(dataloader) % accumulate_size
+
+ def __getattr__(self, __name: str) -> Any:
+ return getattr(self.dataloader, __name)
+
+ def __len__(self) -> int:
+ return self.steps_per_epoch
+
+ def __iter__(self) -> Iterable:
+ self._cur_step = 0
+ self._dataiter = iter(self.dataloader)
+ return self
+
+ def __next__(self) -> Union[Tensor, Tuple[Tensor]]:
+ if self._cur_step < self.steps_per_epoch:
+ self._cur_step += 1
+ data = next(self._dataiter)
+
+ if self._cur_step == self.steps_per_epoch and self.consume_remain_data:
+ # this is to handle non standard pytorch dataloader
+ # such as dali dataloader
+ while True:
+ try:
+ _ = next(self._dataiter)
+ except StopIteration:
+ break
+ return data
+ else:
+ raise StopIteration
+
+
+class GradAccumLrSchedulerByStep(_LRScheduler):
+ """A wrapper for the LR scheduler to enable gradient accumulation by skipping the steps
+ before accumulation size is reached.
+
+ Args:
+ lr_scheduler (:class:`torch.optim.lr_scheduler._LRScheduler`):
+ Your ``lr_scheduler`` object for gradient accumulation.
+ accumulate_size (int): The number of steps to accumulate gradients.
+ """
+
+ def __init__(self, lr_scheduler: _LRScheduler, accumulate_size: int) -> None:
+ self.lr_scheduler = lr_scheduler
+ self.accumulate_size = accumulate_size
+ self.accumulate_step = 0
+
+ @staticmethod
+ def compute_effective_steps_per_epoch(dataloader: Iterable, accumulate_size: int) -> int:
+ """
+ Computes the number of effective training iterations. An effective iteration is defined
+ as the the aggregation of iterations. For examples, if accumulate_size = 4,
+ then 4 iterations are considered as one effective iteration.
+
+ Args:
+ dataloader (``Iterable``): Your dataloader object for gradient accumulation.
+ accumulate_size (int): The number of steps to accumulate gradients.
+
+ """
+ return len(dataloader) // accumulate_size
+
+ def __getattr__(self, __name: str) -> Any:
+ return getattr(self.lr_scheduler, __name)
+
+ def step(self, *args, **kwargs) -> None:
+ """
+ Update the learning rate.
+
+ Args:
+ *args: positional arguments for the lr scheduler wrapped.
+ **kwargs: keyword arguments for the lr scheduler wrapped.
+ """
+ self.accumulate_step += 1
+ if self.accumulate_step < self.accumulate_size:
+ pass
+ else:
+ self.accumulate_step = 0
+ self.lr_scheduler.step(*args, **kwargs)
+
+ def get_lr(self) -> Tensor:
+ """
+ Compute the next learning rate.
+
+ Returns:
+ Tensor: the upcoming learning rate.
+ """
+
+ return self.lr_scheduler.get_lr()
+
+ def get_last_lr(self) -> Tensor:
+ """
+ Returns the current learning rate.
+
+ Returns:
+ Tensor: the current learning rate.
+ """
+
+ return self.lr_scheduler.get_last_lr()
+
+ def print_lr(self, *args, **kwargs) -> None:
+ """
+ Print he learning rate.
+
+ Args:
+ *args: positional arguments for the lr scheduler wrapped.
+ **kwargs: keyword arguments for the lr scheduler wrapped.
+ """
+ self.lr_scheduler.print_lr(*args, **kwargs)
+
+ def state_dict(self) -> dict:
+ """
+ Returns the states of the lr scheduler as dictionary.
+
+ Returns:
+ dict: the states of the lr scheduler.
+ """
+ return self.lr_scheduler.state_dict()
+
+ def load_state_dict(self, state_dict: dict) -> None:
+ """
+ Load the states of the lr scheduler from a dictionary object.
+
+ Returns:
+ dict: the states of the lr scheduler.
+ """
+ self.lr_scheduler.load_state_dict(state_dict)
+
+
+class GradAccumGradientHandler:
+ r"""A wrapper for the gradient handler to enable gradient accumulation by skipping the steps
+ before accumulation size is reached.
+
+ Args:
+ grad_handler (:class:`colossalai.engine.BaseGradientHandler`):
+ Your ``gradient_handler`` object for gradient accumulation, would be called when achieving `accumulate_size`.
+ accumulate_size (int): The number of steps to accumulate gradients.
+
+ More details about ``gradient_handlers`` could be found in
+ `Gradient_handler `_.
+
+ """
+
+ def __init__(self, grad_handler: BaseGradientHandler, accumulate_size: int) -> None:
+ assert isinstance(grad_handler, BaseGradientHandler), \
+ f'expected grad_handler to be type BaseGradientHandler, but got {type(grad_handler)}'
+ self.grad_handler = grad_handler
+ self.accumulate_size = accumulate_size
+ self.accumulate_step = 0
+
+ def handle_gradient(self) -> None:
+ """
+ Handle gradients reduction only in the last gradient accumulation step.
+ """
+
+ self.accumulate_step += 1
+ if self.accumulate_step < self.accumulate_size:
+ pass
+ else:
+ self.accumulate_step = 0
+ self.grad_handler.handle_gradient()
diff --git a/colossalai/engine/gradient_handler/__init__.py b/colossalai/engine/gradient_handler/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..2dea768bad7ecf1feed8bae69f733cda943509b5
--- /dev/null
+++ b/colossalai/engine/gradient_handler/__init__.py
@@ -0,0 +1,11 @@
+from ._base_gradient_handler import BaseGradientHandler
+from ._data_parallel_gradient_handler import DataParallelGradientHandler
+from ._moe_gradient_handler import MoeGradientHandler
+from ._pipeline_parallel_gradient_handler import PipelineSharedModuleGradientHandler
+from ._sequence_parallel_gradient_handler import SequenceParallelGradientHandler
+from ._zero_gradient_handler import ZeROGradientHandler
+
+__all__ = [
+ 'BaseGradientHandler', 'DataParallelGradientHandler', 'ZeROGradientHandler', 'PipelineSharedModuleGradientHandler',
+ 'MoeGradientHandler', 'SequenceParallelGradientHandler'
+]
diff --git a/colossalai/engine/gradient_handler/_base_gradient_handler.py b/colossalai/engine/gradient_handler/_base_gradient_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d96dd8a88a63d9f0c40ceefb99bf2809a37662d
--- /dev/null
+++ b/colossalai/engine/gradient_handler/_base_gradient_handler.py
@@ -0,0 +1,25 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from abc import ABC, abstractmethod
+
+
+class BaseGradientHandler(ABC):
+ """A basic helper class to handle all-reduce operations of gradients across different parallel groups
+ before optimization.
+
+ Args:
+ model (Module): Model where the gradients accumulate.
+ optimizer (Optimizer): Optimizer for updating the parameters.
+ """
+
+ def __init__(self, model, optimizer):
+ self._model = model
+ self._optimizer = optimizer
+
+ @abstractmethod
+ def handle_gradient(self):
+ """A method to accumulate gradients across different parallel groups. Users should
+ write their own functions or just use the functions in pre-defined subclasses.
+ """
+ pass
diff --git a/colossalai/engine/gradient_handler/_data_parallel_gradient_handler.py b/colossalai/engine/gradient_handler/_data_parallel_gradient_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..5cc7169c5a9f630dcb9e1b981f33c3fb35548cc0
--- /dev/null
+++ b/colossalai/engine/gradient_handler/_data_parallel_gradient_handler.py
@@ -0,0 +1,27 @@
+from colossalai.core import global_context as gpc
+from colossalai.registry import GRADIENT_HANDLER
+
+from ...context.parallel_mode import ParallelMode
+from ._base_gradient_handler import BaseGradientHandler
+from .utils import bucket_allreduce
+
+
+@GRADIENT_HANDLER.register_module
+class DataParallelGradientHandler(BaseGradientHandler):
+ """A helper class to handle all-reduce operations in a data parallel group.
+ A all-reduce collective communication will be operated in
+ :func:`handle_gradient` among a data parallel group.
+ For better performance, it bucketizes the gradients of all parameters that are
+ the same type to improve the efficiency of communication.
+
+ Args:
+ model (Module): Model where the gradients accumulate.
+ optimizer (Optimizer): Optimizer for updating the parameters.
+ """
+
+ def handle_gradient(self):
+ """A method running a all-reduce operation in a data parallel group.
+ """
+ # TODO: add memory buffer
+ if gpc.data_parallel_size > 1:
+ bucket_allreduce(param_list=self._model.parameters(), group=gpc.get_group(ParallelMode.DATA))
diff --git a/colossalai/engine/gradient_handler/_moe_gradient_handler.py b/colossalai/engine/gradient_handler/_moe_gradient_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..b499345d4e184662b3a242aa71d24859ad843c7c
--- /dev/null
+++ b/colossalai/engine/gradient_handler/_moe_gradient_handler.py
@@ -0,0 +1,46 @@
+from colossalai.context.moe_context import MOE_CONTEXT
+from colossalai.core import global_context as gpc
+from colossalai.registry import GRADIENT_HANDLER
+from colossalai.utils.moe import get_moe_epsize_param_dict
+
+from ...context.parallel_mode import ParallelMode
+from ._base_gradient_handler import BaseGradientHandler
+from .utils import bucket_allreduce
+
+
+@GRADIENT_HANDLER.register_module
+class MoeGradientHandler(BaseGradientHandler):
+ """A helper class to handle all-reduce operations in a data parallel group and
+ moe model parallel. A all-reduce collective communication will be operated in
+ :func:`handle_gradient` among a data parallel group.
+ For better performance, it bucketizes the gradients of all parameters that are
+ the same type to improve the efficiency of communication.
+
+ Args:
+ model (Module): Model where the gradients accumulate.
+ optimizer (Optimizer): Optimizer for updating the parameters.
+ """
+
+ def __init__(self, model, optimizer=None):
+ super().__init__(model, optimizer)
+
+ def handle_gradient(self):
+ """A method running an all-reduce operation in a data parallel group.
+ Then running an all-reduce operation for all parameters in experts
+ across moe model parallel group
+ """
+ global_data = gpc.data_parallel_size
+
+ if global_data > 1:
+ epsize_param_dict = get_moe_epsize_param_dict(self._model)
+
+ # epsize is 1, indicating the params are replicated among processes in data parallelism
+ # use the ParallelMode.DATA to get data parallel group
+ # reduce gradients for all parameters in data parallelism
+ if 1 in epsize_param_dict:
+ bucket_allreduce(param_list=epsize_param_dict[1], group=gpc.get_group(ParallelMode.DATA))
+
+ for ep_size in epsize_param_dict:
+ if ep_size != 1 and ep_size != MOE_CONTEXT.world_size:
+ bucket_allreduce(param_list=epsize_param_dict[ep_size],
+ group=MOE_CONTEXT.parallel_info_dict[ep_size].dp_group)
diff --git a/colossalai/engine/gradient_handler/_pipeline_parallel_gradient_handler.py b/colossalai/engine/gradient_handler/_pipeline_parallel_gradient_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b49a9c0360dca600b8f1226ce0334f959e2265b
--- /dev/null
+++ b/colossalai/engine/gradient_handler/_pipeline_parallel_gradient_handler.py
@@ -0,0 +1,53 @@
+#!/usr/bin/env python
+
+from collections import defaultdict
+
+import torch
+import torch.distributed as dist
+from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors
+
+from colossalai.core import global_context as gpc
+from colossalai.registry import GRADIENT_HANDLER
+
+from ._base_gradient_handler import BaseGradientHandler
+
+
+@GRADIENT_HANDLER.register_module
+class PipelineSharedModuleGradientHandler(BaseGradientHandler):
+ """A helper class to handle all-reduce operations in sub parallel groups.
+ A all-reduce collective communication will be operated in
+ :func:`handle_gradient` among all sub pipeline parallel groups.
+ For better performance, it bucketizes the gradients of all parameters that are
+ the same type to improve the efficiency of communication.
+
+ Args:
+ model (Module): Model where the gradients accumulate.
+ optimizer (Optimizer): Optimizer for updating the parameters.
+ """
+
+ def handle_gradient(self):
+ """A method running a all-reduce operation in sub pipeline parallel groups.
+ """
+ if gpc.pipeline_parallel_size > 1:
+ # bucketize and all-reduce
+ buckets = defaultdict(lambda: defaultdict(list))
+ # Pack the buckets.
+ for param in self._model.parameters():
+ group = getattr(param, 'pipeline_shared_module_pg', None)
+ if param.requires_grad and group is not None and (
+ (hasattr(param, 'colo_attr') and not param.colo_attr.saved_grad.is_null())
+ or param.grad is not None):
+ tp = param.data.type()
+ buckets[group][tp].append(param)
+
+ # For each bucket, all-reduce and copy all-reduced grads.
+ for group, group_buckets in buckets.items():
+ for tp, bucket in group_buckets.items():
+ grads = [
+ param.colo_attr.grad_payload if hasattr(param, 'colo_attr') else param.grad.data
+ for param in bucket
+ ]
+ coalesced = _flatten_dense_tensors(grads).to(torch.cuda.current_device())
+ dist.all_reduce(coalesced, op=dist.ReduceOp.SUM, group=group)
+ for buf, synced in zip(grads, _unflatten_dense_tensors(coalesced, grads)):
+ buf.copy_(synced)
diff --git a/colossalai/engine/gradient_handler/_sequence_parallel_gradient_handler.py b/colossalai/engine/gradient_handler/_sequence_parallel_gradient_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea4f0fbb1c718965deae37fc0a148aafca3d104a
--- /dev/null
+++ b/colossalai/engine/gradient_handler/_sequence_parallel_gradient_handler.py
@@ -0,0 +1,26 @@
+from colossalai.core import global_context as gpc
+from colossalai.registry import GRADIENT_HANDLER
+
+from ...context.parallel_mode import ParallelMode
+from ._base_gradient_handler import BaseGradientHandler
+from .utils import bucket_allreduce
+
+
+@GRADIENT_HANDLER.register_module
+class SequenceParallelGradientHandler(BaseGradientHandler):
+ """A helper class to handle all-reduce operations in a data parallel group.
+ A all-reduce collective communication will be operated in
+ :func:`handle_gradient` among a data parallel group.
+ For better performance, it bucketizes the gradients of all parameters that are
+ the same type to improve the efficiency of communication.
+
+ Args:
+ model (Module): Model where the gradients accumulate.
+ optimizer (Optimizer): Optimizer for updating the parameters.
+ """
+
+ def handle_gradient(self):
+ """A method running a all-reduce operation in a data parallel group.
+ """
+ if gpc.get_world_size(ParallelMode.SEQUENCE_DP) > 1:
+ bucket_allreduce(param_list=self._model.parameters(), group=gpc.get_group(ParallelMode.SEQUENCE_DP))
diff --git a/colossalai/engine/gradient_handler/_zero_gradient_handler.py b/colossalai/engine/gradient_handler/_zero_gradient_handler.py
new file mode 100644
index 0000000000000000000000000000000000000000..19fd1e97f86f035826666f766fa1983eb9aae2cc
--- /dev/null
+++ b/colossalai/engine/gradient_handler/_zero_gradient_handler.py
@@ -0,0 +1,21 @@
+from colossalai.registry import GRADIENT_HANDLER
+
+from ._base_gradient_handler import BaseGradientHandler
+
+
+@GRADIENT_HANDLER.register_module
+class ZeROGradientHandler(BaseGradientHandler):
+ """A helper class to handle all-reduce operations in a data parallel group.
+ A all-reduce collective communication will be operated in
+ :func:`handle_gradient` among a data parallel group.
+ This class is specialized with ZeRO optimization.
+
+ Args:
+ model (Module): Model where the gradients accumulate.
+ optimizer (Optimizer): Optimizer for updating the parameters.
+ """
+
+ def handle_gradient(self):
+ """A method running a all-reduce operation in a data parallel group.
+ """
+ self._optimizer.sync_grad()
diff --git a/colossalai/engine/gradient_handler/utils.py b/colossalai/engine/gradient_handler/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..fca5f2ec9da9e73aa76e2e41ca5b99f6db8ef773
--- /dev/null
+++ b/colossalai/engine/gradient_handler/utils.py
@@ -0,0 +1,30 @@
+from typing import Iterable
+
+import torch.distributed as dist
+import torch.nn as nn
+from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors
+
+
+def bucket_allreduce(param_list: Iterable[nn.Parameter], group=None):
+ # get communication world size
+ comm_size = dist.get_world_size(group)
+ # bucketize and all-reduce
+ buckets = {}
+ # Pack the buckets.
+ for param in param_list:
+ if param.requires_grad and param.grad is not None:
+ tp = param.data.type()
+ if tp not in buckets:
+ buckets[tp] = []
+ buckets[tp].append(param)
+
+ # For each bucket, all-reduce and copy all-reduced grads.
+ for tp in buckets:
+ bucket = buckets[tp]
+ grads = [param.grad.data for param in bucket]
+ coalesced = _flatten_dense_tensors(grads)
+ coalesced /= comm_size
+
+ dist.all_reduce(coalesced, group=group)
+ for buf, synced in zip(grads, _unflatten_dense_tensors(coalesced, grads)):
+ buf.copy_(synced)
diff --git a/colossalai/engine/schedule/__init__.py b/colossalai/engine/schedule/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f2c039d7057324676d30938c6ec112279077b61
--- /dev/null
+++ b/colossalai/engine/schedule/__init__.py
@@ -0,0 +1,5 @@
+from ._base_schedule import BaseSchedule
+from ._non_pipeline_schedule import NonPipelineSchedule
+from ._pipeline_schedule import InterleavedPipelineSchedule, PipelineSchedule, get_tensor_shape
+
+__all__ = ['BaseSchedule', 'NonPipelineSchedule', 'PipelineSchedule', 'InterleavedPipelineSchedule', 'get_tensor_shape']
diff --git a/colossalai/engine/schedule/_base_schedule.py b/colossalai/engine/schedule/_base_schedule.py
new file mode 100644
index 0000000000000000000000000000000000000000..a2d50041127ace67726f1390fbb58331925e8af5
--- /dev/null
+++ b/colossalai/engine/schedule/_base_schedule.py
@@ -0,0 +1,139 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from abc import ABC, abstractmethod
+from typing import Callable, Iterable
+
+import torch
+
+from colossalai.logging import get_dist_logger
+from colossalai.utils import get_current_device
+
+
+class BaseSchedule(ABC):
+ """A basic helper class to control the process of training or evaluation.
+ It mainly composes of forward_backward_step for gradient backward and
+ optimizer_step for parameters update.
+ For the convenience to enable FP16, we aggregate all codes that contain the
+ control of FP16 in class schedule.
+
+ Args:
+ data_process_func (Callable, optional): The preprocessing function which receives a batch of data and arranges them into data and label.
+ """
+
+ def __init__(self, data_process_func: Callable = None):
+ self.logger = get_dist_logger()
+ self.data_process_func = data_process_func
+
+ @staticmethod
+ def _move_tensor(element):
+ if torch.is_tensor(element):
+ if not element.is_cuda:
+ return element.to(get_current_device()).detach()
+ return element
+
+ def _move_to_device(self, data):
+ if isinstance(data, torch.Tensor):
+ data = data.to(get_current_device())
+ elif isinstance(data, (list, tuple)):
+ data_to_return = []
+ for element in data:
+ if isinstance(element, dict):
+ data_to_return.append({k: self._move_tensor(v) for k, v in element.items()})
+ else:
+ data_to_return.append(self._move_tensor(element))
+ data = data_to_return
+ elif isinstance(data, dict):
+ data = {k: self._move_tensor(v) for k, v in data.items()}
+ else:
+ raise TypeError(
+ f"Expected batch data to be of type torch.Tensor, list, tuple, or dict, but got {type(data)}")
+ return data
+
+ def _get_batch_size(self, data):
+ if isinstance(data, torch.Tensor):
+ return data.size(0)
+ elif isinstance(data, (list, tuple)):
+ if isinstance(data[0], dict):
+ return data[0][list(data[0].keys())[0]].size(0)
+ return data[0].size(0)
+ elif isinstance(data, dict):
+ return data[list(data.keys())[0]].size(0)
+
+ def load_batch(self, data_iter, to_gpu=True):
+ """Loads a batch from data iterator. It returns the data and labels which are
+ already in the same GPU as where the model's.
+
+ Args:
+ data_iter (Iterable): Data iterator from which get a batch of data, obtained by calling iter(dataloader).
+ to_gpu (bool, optional): Whether the data should be moved to GPU
+
+ Returns:
+ Tuple (:class:`Tensor`, :class:`torch.Tensor`): A tuple of (data, label).
+ """
+ if data_iter is None:
+ raise RuntimeError('Dataloader is not defined.')
+ batch_data = next(data_iter)
+
+ if to_gpu:
+ batch_data = self._move_to_device(batch_data)
+ self.batch_size = self._get_batch_size(batch_data)
+ return batch_data
+
+ def pre_processing(self, engine):
+ """To perform actions before running the schedule.
+ """
+ pass
+
+ @abstractmethod
+ def forward_backward_step(self,
+ engine,
+ data_iter: Iterable,
+ forward_only: bool,
+ return_loss: bool = True,
+ return_output_label: bool = True):
+ """The process function over a batch of dataset for training or evaluation.
+
+ Args:
+ engine (colossalai.engine.Engine): Colossalai engine for training and inference.
+ data_iter (Iterable): Data iterator from which get a batch of data, obtained by calling iter(dataloader).
+ forward_only (bool): If True, the process won't include backward.
+ return_loss (bool, optional): If False, the loss won't be returned.
+ return_output_label (bool, optional): If False, the output and label won't be returned.
+ """
+ pass
+
+ @staticmethod
+ def _call_engine(engine, inputs):
+ if isinstance(inputs, torch.Tensor):
+ return engine(inputs)
+ elif isinstance(inputs, (list, tuple)):
+ return engine(*inputs)
+ elif isinstance(inputs, dict):
+ return engine(**inputs)
+ else:
+ TypeError(
+ f"Expected engine inputs to be of type torch.Tensor, list, tuple, or dict, but got {type(inputs)}")
+
+ @staticmethod
+ def _call_engine_criterion(engine, outputs, labels):
+ assert isinstance(outputs,
+ (torch.Tensor, list, tuple,
+ dict)), f'Expect output of model is (torch.Tensor, list, tuple), got {type(outputs)}'
+ if isinstance(outputs, torch.Tensor):
+ outputs = (outputs,)
+ if isinstance(labels, torch.Tensor):
+ labels = (labels,)
+
+ if isinstance(outputs, (tuple, list)) and isinstance(labels, (tuple, list)):
+ return engine.criterion(*outputs, *labels)
+ elif isinstance(outputs, (tuple, list)) and isinstance(labels, dict):
+ return engine.criterion(*outputs, **labels)
+ elif isinstance(outputs, dict) and isinstance(labels, dict):
+ return engine.criterion(**outputs, **labels)
+ elif isinstance(outputs, dict) and isinstance(labels, (list, tuple)):
+ raise ValueError(f"Expected labels to be a dict when the model outputs are dict, but got {type(labels)}")
+ else:
+ raise TypeError(f"Expected model outputs and labels to be of type torch.Tensor ' \
+ '(which is auto-converted to tuple), list, tuple, or dict, ' \
+ 'but got {type(outputs)} (model outputs) and {type(labels)} (labels)")
diff --git a/colossalai/engine/schedule/_non_pipeline_schedule.py b/colossalai/engine/schedule/_non_pipeline_schedule.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9239d928a7ba4e9471071f1c4e08c8443f5edb1
--- /dev/null
+++ b/colossalai/engine/schedule/_non_pipeline_schedule.py
@@ -0,0 +1,95 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import inspect
+from typing import Callable, Iterable
+
+import torch
+
+from colossalai.utils import conditional_context
+
+from ._base_schedule import BaseSchedule
+
+
+class NonPipelineSchedule(BaseSchedule):
+ """A helper schedule class for no pipeline parallelism running environment.
+ During one process, it loads a batch of dataset and feeds it to the model.
+ After getting the output and calculating the loss, it will use :meth:`step`
+ to update the parameters if it is in training mode.
+
+ Args:
+ data_process_func (Callable, optional): The preprocessing function which receives a batch of data
+ and returns a tuple in the form of (data, label).
+ and it will be executed in load_batch.
+
+ Example:
+ # this shows an example of customized data_process_func
+ def data_process_func(dataloader_output):
+ item1, item2, item3 = dataloader_output
+ data = (item1, item2)
+ label = item3
+ return data, label
+ """
+
+ def __init__(self, data_process_func: Callable = None):
+ # check that non-pipeline schedule data process func only takes in one parameter
+ # which is the batch data
+
+ if data_process_func:
+ sig = inspect.signature(data_process_func)
+ assert len(sig.parameters) == 1, \
+ 'The data_process_func only takes in one parameter for NonPipelineSchedule, ' \
+ 'which is a tuple of tensors for the current batch, ' \
+ 'i.e. data_process_func(dataloader_output).'
+
+ super().__init__(data_process_func)
+
+ def forward_backward_step(self,
+ engine,
+ data_iter: Iterable,
+ forward_only: bool = False,
+ return_loss: bool = True,
+ return_output_label: bool = True):
+ """The process function that loads a batch of dataset and feeds it to the model.
+ The returned labels and loss will None if :attr:`return_loss` is False.
+
+ Args:
+ engine (colossalai.engine.Engine): Colossalai engine for training and inference.
+ data_iter (Iterable): Dataloader as the form of an iterator, obtained by calling iter(dataloader).
+ forward_only (bool, optional):
+ If True, the model is run for the forward pass, else back propagation will be executed.
+ return_loss (bool, optional): Loss will be returned if True.
+ return_output_label (bool, optional): Output and label will be returned if True.
+
+ Returns:
+ Tuple[:class:`torch.Tensor`]: A tuple of (output, label, loss), loss and label could be None.
+ """
+ assert forward_only or return_loss, \
+ "The argument 'return_loss' has to be True when 'forward_only' is False, but got False."
+ batch_data = self.load_batch(data_iter)
+ if self.data_process_func:
+ data, label = self.data_process_func(batch_data)
+ else:
+ # if not batch data process func is given,
+ # then we regard the batch data as a simple tuple of (data, label)
+ data, label = batch_data
+
+ # forward
+ with conditional_context(torch.no_grad(), enable=forward_only):
+ output = self._call_engine(engine, data)
+ if return_loss:
+ loss = self._call_engine_criterion(engine, output, label)
+
+ if not forward_only:
+ engine.backward(loss)
+
+ if return_output_label:
+ if return_loss:
+ return output, label, loss
+ else:
+ return output, label, None
+ else:
+ if return_loss:
+ return None, None, loss
+ else:
+ return None, None, None
diff --git a/colossalai/engine/schedule/_pipeline_schedule.py b/colossalai/engine/schedule/_pipeline_schedule.py
new file mode 100644
index 0000000000000000000000000000000000000000..38175fe0941c1c053bf91fe1df558ee9e763c360
--- /dev/null
+++ b/colossalai/engine/schedule/_pipeline_schedule.py
@@ -0,0 +1,833 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import inspect
+from typing import Callable, List, Tuple, Union
+
+import torch.cuda
+
+import colossalai.communication as comm
+from colossalai.amp.naive_amp import NaiveAMPModel
+from colossalai.context.parallel_mode import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.logging import get_dist_logger
+from colossalai.utils import switch_virtual_pipeline_parallel_rank
+from colossalai.utils.cuda import get_current_device
+
+from ._base_schedule import BaseSchedule
+
+
+def get_tensor_shape():
+ if hasattr(gpc.config, 'TENSOR_SHAPE'):
+ return gpc.config.TENSOR_SHAPE
+
+ if not gpc.is_initialized(ParallelMode.PIPELINE):
+ return None
+
+ if hasattr(gpc.config, 'SEQ_LENGTH') and hasattr(gpc.config, 'GLOBAL_BATCH_SIZE') and hasattr(
+ gpc.config, 'GLOBAL_BATCH_SIZE') and hasattr(gpc.config, 'HIDDEN_SIZE'):
+ if gpc.is_initialized(ParallelMode.DATA):
+ dp_size = gpc.get_world_size(ParallelMode.DATA)
+ else:
+ dp_size = 1
+ if gpc.is_initialized(ParallelMode.SEQUENCE):
+ seq_size = gpc.get_world_size(ParallelMode.SEQUENCE)
+ else:
+ seq_size = 1
+
+ tensor_shape = (gpc.config.SEQ_LENGTH // seq_size,
+ gpc.config.GLOBAL_BATCH_SIZE // dp_size // gpc.config.NUM_MICRO_BATCHES, gpc.config.HIDDEN_SIZE)
+ return tensor_shape
+ else:
+ return None
+
+
+def pack_return_tensors(return_tensors):
+ output, label = tuple(zip(*return_tensors))
+ if isinstance(output[0], torch.Tensor):
+ output = torch.cat(output, dim=0)
+ elif isinstance(output[0], (list, tuple)):
+ output = tuple(torch.cat(tensors, dim=0) for tensors in zip(*output))
+ else:
+ raise TypeError(f'Output of model must be tensor or list/tuple of tensors')
+ if isinstance(label[0], torch.Tensor):
+ label = torch.cat(label, dim=0)
+ else:
+ merged_label = {k: [] for k in label[0].keys()}
+ for d in label:
+ for k, v in d.items():
+ merged_label[k].append(v)
+ label = {k: torch.cat(v, dim=0) for k, v in merged_label.items()}
+ return output, label
+
+
+class PipelineSchedule(BaseSchedule):
+ """A helper schedule class for pipeline parallelism running environment.
+ It uses non-interleaved 1F1B strategy. Other properties are similar as
+ :class:`NonPipelineSchedule`.
+
+ Args:
+ num_microbatches (int): The number of microbatches.
+ data_process_func (Callable, optional):
+ The preprocessing function which receives a batch of data, and it will be executed in `load_batch`.
+ tensor_shape (torch.Size, optional): Specified shape in pipeline communication.
+ scatter_gather_tensors (bool, optional):
+ If set to `True`, communication will be reduced over pipeline when using 1D tensor parallelization.
+
+ Example:
+
+ # this shows an example of customized data_process_func
+ def data_process_func(stage_output, dataloader_output):
+ output1, output2 = stage_output
+ item1, item2, item3 = dataloader_output
+
+ # assume item2 is not needed
+ data = (output1, output2, item1)
+ label = item3
+ return data, label
+
+ """
+
+ def __init__(self,
+ num_microbatches,
+ data_process_func: Callable = None,
+ tensor_shape: Union[torch.Size, List[int], Tuple[int]] = None,
+ scatter_gather_tensors: bool = False):
+
+ # we need to make sure that the signature of the data_process_func is valid
+ if data_process_func:
+ sig = inspect.signature(data_process_func)
+ assert len(sig.parameters) == 2, \
+ 'The data_process_func only takes in two parameters for NonPipelineSchedule, ' \
+ 'which is the tensors passed by the previous pipeline stage and the dataloader output from this stage, ' \
+ 'i.e. data_process_func(stage_output, dataloader_output).'
+
+ super().__init__(data_process_func=data_process_func)
+
+ assert num_microbatches > 0, f'expected num_microbatches to be larger then 1, but got {num_microbatches}'
+
+ self.num_microbatches = num_microbatches
+ self.dtype = torch.float
+ assert not isinstance(tensor_shape,
+ int), "tensor_shape type should be one of Union[torch.Size, List[int], Tuple[int]]."
+ if tensor_shape is None:
+ self.tensor_shape = tensor_shape
+ elif isinstance(tensor_shape, torch.Size):
+ self.tensor_shape = tensor_shape
+ else:
+ self.tensor_shape = torch.Size(tensor_shape)
+ self.scatter_gather_tensors = False
+ if gpc.is_initialized(ParallelMode.PARALLEL_1D) and gpc.get_world_size(ParallelMode.PARALLEL_1D) > 1:
+ self.scatter_gather_tensors = scatter_gather_tensors
+ self._logger = get_dist_logger()
+
+ # cache for the batch data
+ self.batch_data = None
+
+ def load_batch(self, data_iter):
+ # Pipeline schedule just puts data in memory
+ batch_data = super().load_batch(data_iter, to_gpu=False)
+ self.microbatch_offset = 0
+ assert self.batch_size % self.num_microbatches == 0, \
+ "Batch size should divided by the number of microbatches"
+ self.microbatch_size = self.batch_size // self.num_microbatches
+ self.batch_data = batch_data
+
+ def _get_data_slice(self, data, offset):
+ if isinstance(data, torch.Tensor):
+ return data[offset:offset + self.microbatch_size]
+ elif isinstance(data, (list, tuple)):
+ data_dict = {}
+ for element in data:
+ if isinstance(element, dict):
+ data_dict.update({k: v[offset:offset + self.microbatch_size] for k, v in element.items()})
+ elif data_dict:
+ data_dict['label'] = element[offset:offset + self.microbatch_size]
+ if data_dict:
+ return data_dict
+ return [val[offset:offset + self.microbatch_size] for val in data]
+ elif isinstance(data, dict):
+ return {k: v[offset:offset + self.microbatch_size] for k, v in data.items()}
+ else:
+ raise TypeError(f"Expected data to be of type torch.Tensor, list, tuple, or dict, but got {type(data)}")
+
+ def load_micro_batch(self):
+ mciro_batch_data = self._get_data_slice(self.batch_data, self.microbatch_offset)
+ self.microbatch_offset += self.microbatch_size
+ return self._move_to_device(mciro_batch_data)
+
+ def pre_processing(self, engine):
+ from colossalai.zero.legacy import ShardedModelV2
+
+ # TODO: remove this after testing new zero with pipeline parallelism
+ model = engine.model
+ if isinstance(model, NaiveAMPModel):
+ self.dtype = torch.half
+ model = model.model
+ if isinstance(model, ShardedModelV2):
+ self.dtype = torch.half
+ model = model.module
+ # sig = inspect.signature(model.forward)
+ # for p in sig.parameters.values():
+ # assert p.kind != inspect.Parameter.VAR_POSITIONAL, '*args is not supported'
+
+ @staticmethod
+ def _call_engine(model, data):
+ if data is not None:
+ if isinstance(data, torch.Tensor):
+ return model(data)
+ elif isinstance(data, (list, tuple)):
+ return model(*data)
+ elif isinstance(data, dict):
+ stage_output = None
+ if 'stage_output' in data:
+ stage_output = data.pop('stage_output')
+ if stage_output is None:
+ return model(**data)
+ elif isinstance(stage_output, torch.Tensor):
+ return model(stage_output, **data)
+ elif isinstance(stage_output, (tuple, list)):
+ return model(*stage_output, **data)
+ else:
+ raise TypeError(
+ f"Expected stage_output to be of type torch.Tensor, list, or tuple, but got {type(stage_output)}"
+ )
+ else:
+ raise TypeError(f"Expected data to be of type torch.Tensor, list, tuple, or dict, but got {type(data)}")
+
+ def _get_actual_forward_func(self, module):
+ if isinstance(module, NaiveAMPModel):
+ sig = inspect.signature(module.model.forward)
+ elif hasattr(module, 'colo_attr'):
+ sig = inspect.signature(module.module.forward)
+ else:
+ sig = inspect.signature(module.forward)
+ return sig
+
+ def _get_data_label_for_current_step(self, stage_output, micro_batch_data, criterion, model):
+ if self.data_process_func:
+ # use customized function to get data and label
+ data, label = self.data_process_func(stage_output, micro_batch_data)
+ else:
+ if isinstance(micro_batch_data, (tuple, list)):
+ if gpc.is_first_rank(ParallelMode.PIPELINE):
+ # for the first stage, we use the data from the
+ # dataloader output by default
+ data, label = micro_batch_data
+ else:
+ # for non-first stage, we use the output passed
+ # by the previous as the model input
+ data = stage_output
+ _, label = micro_batch_data
+ elif isinstance(micro_batch_data, dict):
+ data = {}
+ data['stage_output'] = stage_output
+ if 'label' in micro_batch_data:
+ label = micro_batch_data.pop('label')
+ else:
+ label = None
+ load_data = micro_batch_data
+ data.update(load_data)
+ return data, label
+
+ def _forward_step(self, engine, input_obj, return_tensors, return_output_label=True, accum_loss=None):
+ """Forward step for passed-in model. If it is the first stage, the input tensor
+ is obtained from data_iterator, otherwise the passed-in input_obj is used.
+ Returns output tensor. This is a helper function and can be ignored by users.
+
+ Args:
+ engine (colossalai.engine.Engine): Colossalai engine for training and inference.
+ input_obj (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Input tensor for this pipeline stage.
+ return_tensors (List[:class:`torch.Tensor`]): A list of tensors to return.
+ return_output_label (bool, optional): Whether returns output labels.
+ accum_loss (optional): Where accumulated loss stores.
+ Returns:
+ Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]: output or the loss value of the current pipeline stage.
+ """
+ micro_batch_data = self.load_micro_batch()
+
+ data, label = self._get_data_label_for_current_step(input_obj, micro_batch_data, engine.criterion, engine.model)
+
+ output_obj = self._call_engine(engine.model, data)
+
+ if gpc.is_last_rank(ParallelMode.PIPELINE):
+ if return_output_label:
+ return_tensors.append((output_obj, label))
+ if accum_loss is not None:
+ loss_reduced = self._call_engine_criterion(engine, output_obj, label) / self.num_microbatches
+ accum_loss.add_(loss_reduced.detach())
+ return loss_reduced
+ else:
+ # forward only, it's useless since backward is not needed
+ return output_obj
+ else:
+ if isinstance(output_obj, torch.Tensor):
+ self._logger.debug(
+ f'Global rank {gpc.get_global_rank()}, pipeline rank {gpc.get_local_rank(ParallelMode.PIPELINE)} forward output tensor {output_obj.shape}, dtype {output_obj.dtype}'
+ )
+ return output_obj
+
+ def _backward_step(self, engine, input_obj, output_obj, output_obj_grad):
+ """Backward step through the passed-in output tensor. If it is the last stage, the
+ output_obj_grad is None, otherwise it is the gradients with respect to stage's output tensor.
+ Returns the gradients with respect to the input tensor (None if first stage).
+ This is a helper function and can be ignored by users.
+
+ Args:
+ engine (colossalai.engine.Engine): Colossalai engine for training and inference.
+ input_obj (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): input tensor for this pipeline stage.
+ output_obj (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): output tensor for this pipeline stage.
+ output_obj_grad (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): gradient of output tensor for this pipeline stage.
+
+ Returns:
+ Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]: gradient of input tensor.
+ """
+
+ # Retain the grad on the input_obj.
+ if input_obj is not None:
+ if isinstance(input_obj, torch.Tensor):
+ input_obj.retain_grad()
+ else:
+ for in_tensor in input_obj:
+ if in_tensor is not None:
+ in_tensor.retain_grad()
+ # Backward pass.
+ if output_obj_grad is None:
+ engine.backward(output_obj)
+ else:
+ engine.backward_by_grad(output_obj, output_obj_grad)
+
+ # Collect the grad of the input_obj.
+ input_obj_grad = None
+ if input_obj is not None:
+ if isinstance(input_obj, torch.Tensor):
+ input_obj_grad = input_obj.grad
+ else:
+ input_obj_grad = []
+ for in_tensor in input_obj:
+ input_obj_grad.append(in_tensor.grad)
+
+ return input_obj_grad
+
+ def forward_backward_step(self, engine, data_iter, forward_only=False, return_loss=True, return_output_label=True):
+ """Runs non-interleaved 1F1B schedule, with communication between pipeline stages.
+ Returns a tuple with losses if the last stage, an empty tuple otherwise.
+
+ Args:
+ engine (colossalai.engine.Engine): Colossalai engine for training and inference.
+ data_iter (Iterable): Dataloader as the form of an iterator, obtained by calling iter(dataloader).
+ forward_only (bool, optional):
+ Whether run forward step only. Default is false. If true, no backward will be run.
+ return_loss (bool, optional): Whether returns the loss value. Default is true.
+ return_output_label (bool, optional): If False, the output and label won't be returned.
+
+ Returns:
+ Tuple[:class:`torch.Tensor`]: A tuple of (output, label, loss), loss and label could be None.
+ """
+
+ assert forward_only or return_loss, \
+ 'The argument \'return_loss\' has to be True when \'forward_only\' is False, but got False.'
+ self.load_batch(data_iter)
+ num_warmup_microbatches = \
+ (gpc.get_world_size(ParallelMode.PIPELINE)
+ - gpc.get_local_rank(ParallelMode.PIPELINE) - 1)
+ num_warmup_microbatches = min(num_warmup_microbatches, self.num_microbatches)
+ num_microbatches_remaining = self.num_microbatches - num_warmup_microbatches
+
+ # Input, output tensors only need to be saved when doing backward passes
+ input_objs = None
+ output_objs = None
+ if not forward_only:
+ input_objs = []
+ output_objs = []
+ return_tensors = []
+ if return_loss and gpc.is_pipeline_last_stage(ignore_virtual=True):
+ accum_loss = torch.zeros(1, device=get_current_device())
+ else:
+ accum_loss = None
+ # Used for tensor meta information communication
+ ft_shapes = self.tensor_shape
+ bt_shapes = None
+ fs_checker = self.tensor_shape is None
+
+ # Run warmup forward passes.
+ for i in range(num_warmup_microbatches):
+ if not gpc.is_first_rank(ParallelMode.PIPELINE):
+ ft_shapes = comm.recv_obj_meta(ft_shapes)
+ input_obj = comm.recv_forward(ft_shapes,
+ dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors)
+ output_obj = self._forward_step(engine,
+ input_obj,
+ return_tensors,
+ return_output_label=return_output_label,
+ accum_loss=accum_loss)
+ if not gpc.is_last_rank(ParallelMode.PIPELINE):
+ if isinstance(output_obj, torch.Tensor):
+ bt_shapes = output_obj.shape
+ else:
+ bt_shapes = []
+ for out_tensor in output_obj:
+ bt_shapes.append(out_tensor.shape)
+ fs_checker = comm.send_obj_meta(output_obj, fs_checker)
+ comm.send_forward(output_obj, scatter_gather_tensors=self.scatter_gather_tensors)
+
+ if not forward_only:
+ input_objs.append(input_obj)
+ output_objs.append(output_obj)
+
+ # Before running 1F1B, need to receive first forward tensor.
+ # If all microbatches are run in warmup / cooldown phase, then no need to
+ # receive this tensor here.
+ if num_microbatches_remaining > 0:
+ if not gpc.is_first_rank(ParallelMode.PIPELINE):
+ ft_shapes = comm.recv_obj_meta(ft_shapes)
+ input_obj = comm.recv_forward(ft_shapes,
+ dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors)
+
+ # Run 1F1B in steady state.
+ for i in range(num_microbatches_remaining):
+ last_iteration = (i == (num_microbatches_remaining - 1))
+
+ output_obj = self._forward_step(engine,
+ input_obj,
+ return_tensors,
+ return_output_label=return_output_label,
+ accum_loss=accum_loss)
+ if forward_only:
+ comm.send_forward(output_obj, scatter_gather_tensors=self.scatter_gather_tensors)
+
+ if not last_iteration:
+ input_obj = comm.recv_forward(ft_shapes,
+ dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors)
+
+ else:
+ output_obj_grad = comm.send_forward_recv_backward(output_obj,
+ bt_shapes,
+ dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors)
+
+ # Add input_obj and output_obj to end of list.
+ input_objs.append(input_obj)
+ output_objs.append(output_obj)
+
+ # Pop output_obj and output_obj from the start of the list for
+ # the backward pass.
+ input_obj = input_objs.pop(0)
+ output_obj = output_objs.pop(0)
+
+ input_obj_grad = self._backward_step(engine, input_obj, output_obj, output_obj_grad)
+
+ if last_iteration:
+ input_obj = None
+ comm.send_backward(input_obj_grad, scatter_gather_tensors=self.scatter_gather_tensors)
+ else:
+ input_obj = comm.send_backward_recv_forward(input_obj_grad,
+ ft_shapes,
+ dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors)
+
+ # Run cooldown backward passes.
+ if not forward_only:
+ for i in range(num_warmup_microbatches):
+ input_obj = input_objs.pop(0)
+ output_obj = output_objs.pop(0)
+
+ output_obj_grad = comm.recv_backward(bt_shapes,
+ dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors)
+
+ input_obj_grad = self._backward_step(engine, input_obj, output_obj, output_obj_grad)
+
+ comm.send_backward(input_obj_grad, scatter_gather_tensors=self.scatter_gather_tensors)
+
+ if len(return_tensors) > 0:
+ output, label = pack_return_tensors(return_tensors)
+ return output, label, accum_loss
+ else:
+ return None, None, accum_loss
+
+
+class InterleavedPipelineSchedule(PipelineSchedule):
+
+ def __init__(self,
+ num_microbatches: int,
+ num_model_chunks: int,
+ data_process_func: Callable = None,
+ tensor_shape: Union[torch.Size, List[int], Tuple[int]] = None,
+ scatter_gather_tensors: bool = False):
+ """A helper schedule class for pipeline parallelism running environment.
+ It uses interleaved 1F1B strategy. Other properties are similar as
+ :class:`NonPipelineSchedule`.
+
+ Args:
+ num_microbatches (int): The number of microbatches.
+ num_model_chunks (int): The number of model chunks.
+ data_process_func (Callable, optional):
+ The preprocessing function which receives a batch of data, and it will be executed in `load_batch`.
+ tensor_shape (torch.Size, optional): Specified shape in pipeline communication.
+ scatter_gather_tensors (bool, optional):
+ If set to `True`, communication will be reduced over pipeline when using 1D tensor parallelization.
+ """
+ assert num_microbatches % gpc.get_world_size(ParallelMode.PIPELINE) == 0, \
+ 'num_microbatches must be an integer multiple of pipeline parallel world size'
+ assert isinstance(num_model_chunks, int) and num_model_chunks > 0, \
+ f'expected num_model_chunks to be an integer and larger than 0, but got {num_model_chunks}'
+ super().__init__(num_microbatches,
+ data_process_func=data_process_func,
+ tensor_shape=tensor_shape,
+ scatter_gather_tensors=scatter_gather_tensors)
+ gpc.set_virtual_pipeline_parallel_size(num_model_chunks)
+ gpc.set_virtual_pipeline_parallel_rank(0)
+ self.num_model_chunks = num_model_chunks
+
+ def pre_processing(self, engine):
+ from colossalai.zero.sharded_model.sharded_model_v2 import ShardedModelV2
+ if isinstance(engine.model, ShardedModelV2):
+ self.dtype = torch.half
+ elif isinstance(engine.model[0], NaiveAMPModel):
+ self.dtype = torch.half
+ for model in engine.model:
+ if isinstance(model, NaiveAMPModel):
+ model = model.model
+ sig = inspect.signature(model.forward)
+ for p in sig.parameters.values():
+ assert p.kind != inspect.Parameter.VAR_POSITIONAL, '*args is not supported'
+
+ def load_batch(self, data_iter):
+ super().load_batch(data_iter)
+ # overwrite microbatch_offset, since model chunks load the same microbatch, and should tract the offset
+ self.microbatch_offset = [0 for _ in range(self.num_model_chunks)]
+
+ def load_micro_batch(self, model_chunk_id):
+ data = self._get_data_slice(self.batch_data, self.microbatch_offset[model_chunk_id])
+ self.microbatch_offset[model_chunk_id] += self.microbatch_size
+ return self._move_to_device(data)
+
+ def _forward_step(self,
+ engine,
+ model_chunk_id,
+ input_obj,
+ return_tensors,
+ return_output_label=True,
+ accum_loss=None):
+ """Forward step for passed-in model. If it is the first stage, the input tensor
+ is obtained from data_iterator, otherwise the passed-in input_obj is used.
+ Returns output tensor. This is a helper function and can be ignored by users.
+
+ Args:
+ engine (colossalai.engine.Engine): Colossalai engine for training and inference.
+ model_chunk_id (int): The id of model chunks.
+ input_obj (Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]): Input tensor for this pipeline stage.
+ return_tensors (List[:class:`torch.Tensor`]): A list of tensors to return.
+ return_output_label (bool, optional): Whether returns output labels.
+ accum_loss (optional): Where accumulated loss stores.
+ Returns:
+ Union[:class:`torch.Tensor`, List[:class:`torch.Tensor`]]: output or the loss value of the current pipeline stage.
+ """
+ micro_batch_data = self.load_micro_batch(model_chunk_id)
+ data, label = self._get_data_label_for_current_step(input_obj, micro_batch_data, engine.criterion,
+ engine.model[model_chunk_id])
+
+ output_obj = self._call_engine(engine.model[model_chunk_id], data)
+
+ if gpc.is_pipeline_last_stage():
+ if return_output_label:
+ return_tensors.append((output_obj, label))
+ if accum_loss is not None:
+ loss_reduced = self._call_engine_criterion(engine, output_obj, label) / self.num_microbatches
+ accum_loss.add_(loss_reduced.detach())
+ return loss_reduced
+ else:
+ # forward only, it's useless since backward is not needed
+ return output_obj
+ else:
+ if isinstance(output_obj, torch.Tensor):
+ self._logger.debug(
+ f'Global rank {gpc.get_global_rank()}, pipeline rank {gpc.get_local_rank(ParallelMode.PIPELINE)} forward output tensor {output_obj.shape}, dtype {output_obj.dtype}'
+ )
+ return output_obj
+
+ def forward_backward_step(self, engine, data_iter, forward_only=False, return_loss=True, return_output_label=True):
+ """Run interleaved 1F1B schedule (model split into model chunks), with
+ communication between pipeline stages as needed.
+
+ Args:
+ engine (colossalai.engine.Engine): Colossalai engine for training and inference.
+ data_iter (Iterable): Dataloader as the form of an iterator, obtained by calling iter(dataloader).
+ forward_only (bool, optional):
+ Whether run forward step only. Default is false. If true, no backward will be run.
+ return_loss (bool, optional): Whether returns the loss value. Default is true.
+ return_output_label (bool, optional): If False, the output and label won't be returned.
+
+ Returns:
+ Tuple[:class:`torch.Tensor`]: A tuple of (output, label, loss), loss and label could be None.
+ The loss would be returned only in the last stage.
+ """
+ assert forward_only or return_loss, \
+ 'The argument \'return_loss\' has to be True when \'forward_only\' is False, but got False.'
+ self.load_batch(data_iter)
+ model = engine.model
+ input_objs = [[] for _ in range(len(model))]
+ output_objs = [[] for _ in range(len(model))]
+ return_tensors = []
+ if not forward_only:
+ output_obj_grads = [[] for _ in range(len(model))]
+ if return_loss and gpc.is_pipeline_last_stage(ignore_virtual=True):
+ accum_loss = torch.zeros(1, device=get_current_device())
+ else:
+ accum_loss = None
+
+ # Used for obj meta information communication
+ input_obj_shapes = [self.tensor_shape for _ in range(len(model))]
+ output_obj_shapes = [None for _ in range(len(model))]
+ send_tensor_shape_flags = [self.tensor_shape is None for _ in range(len(model))]
+
+ pipeline_parallel_size = gpc.get_world_size(ParallelMode.PIPELINE)
+ pipeline_parallel_rank = gpc.get_local_rank(ParallelMode.PIPELINE)
+
+ # Compute number of warmup and remaining microbatches.
+ num_model_chunks = len(model)
+ num_microbatches = self.num_microbatches * num_model_chunks
+ all_warmup_microbatches = False
+ if forward_only:
+ num_warmup_microbatches = num_microbatches
+ else:
+ # Run all forward passes and then all backward passes if number of
+ # microbatches is just the number of pipeline stages.
+ # Otherwise, perform (num_model_chunks-1)*pipeline_parallel_size on
+ # all workers, followed by more microbatches after depending on
+ # stage ID (more forward passes for earlier stages, later stages can
+ # immediately start with 1F1B).
+ if self.num_microbatches == pipeline_parallel_size:
+ num_warmup_microbatches = num_microbatches
+ all_warmup_microbatches = True
+ else:
+ num_warmup_microbatches = \
+ (pipeline_parallel_size - pipeline_parallel_rank - 1) * 2
+ num_warmup_microbatches += (num_model_chunks - 1) * pipeline_parallel_size
+ num_warmup_microbatches = min(num_warmup_microbatches, num_microbatches)
+ num_microbatches_remaining = \
+ num_microbatches - num_warmup_microbatches
+
+ def get_model_chunk_id(microbatch_id, forward):
+ """Helper method to get the model chunk ID given the iteration number."""
+ microbatch_id_in_group = microbatch_id % (pipeline_parallel_size * num_model_chunks)
+ model_chunk_id = microbatch_id_in_group // pipeline_parallel_size
+ if not forward:
+ model_chunk_id = (num_model_chunks - model_chunk_id - 1)
+ return model_chunk_id
+
+ def _forward_step_helper(microbatch_id):
+ """Helper method to run forward step with model split into chunks
+ (run set_virtual_pipeline_model_parallel_rank() before calling
+ forward_step())."""
+ model_chunk_id = get_model_chunk_id(microbatch_id, forward=True)
+ gpc.set_virtual_pipeline_parallel_rank(model_chunk_id)
+
+ # forward step
+ if gpc.is_pipeline_first_stage():
+ if len(input_objs[model_chunk_id]) == \
+ len(output_objs[model_chunk_id]):
+ input_objs[model_chunk_id].append(None)
+ input_obj = input_objs[model_chunk_id][-1]
+ output_obj = self._forward_step(engine,
+ model_chunk_id,
+ input_obj,
+ return_tensors,
+ return_output_label=return_output_label,
+ accum_loss=accum_loss)
+ output_objs[model_chunk_id].append(output_obj)
+
+ # if forward-only, no need to save tensors for a backward pass
+ if forward_only:
+ input_objs[model_chunk_id].pop()
+ output_objs[model_chunk_id].pop()
+
+ return output_obj
+
+ def _backward_step_helper(microbatch_id):
+ """Helper method to run backward step with model split into chunks
+ (run set_virtual_pipeline_model_parallel_rank() before calling
+ backward_step())."""
+ model_chunk_id = get_model_chunk_id(microbatch_id, forward=False)
+ gpc.set_virtual_pipeline_parallel_rank(model_chunk_id)
+
+ if gpc.is_pipeline_last_stage():
+ if len(output_obj_grads[model_chunk_id]) == 0:
+ output_obj_grads[model_chunk_id].append(None)
+ input_obj = input_objs[model_chunk_id].pop(0)
+ output_obj = output_objs[model_chunk_id].pop(0)
+ output_obj_grad = output_obj_grads[model_chunk_id].pop(0)
+ input_obj_grad = self._backward_step(engine, input_obj, output_obj, output_obj_grad)
+
+ return input_obj_grad
+
+ # Run warmup forward passes.
+ gpc.set_virtual_pipeline_parallel_rank(0)
+ if not gpc.is_pipeline_first_stage():
+ input_obj_shapes[0] = comm.recv_obj_meta(input_obj_shapes[0])
+ input_objs[0].append(
+ comm.recv_forward(input_obj_shapes[0], dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors))
+
+ for k in range(num_warmup_microbatches):
+ model_chunk_id = get_model_chunk_id(k, forward=True)
+ output_obj = _forward_step_helper(k)
+ if not gpc.is_pipeline_last_stage():
+ if isinstance(output_obj, torch.Tensor):
+ output_obj_shapes[model_chunk_id] = output_obj.shape
+ else:
+ output_obj_shapes[model_chunk_id] = []
+ for out_tensor in output_obj:
+ output_obj_shapes[model_chunk_id].append(out_tensor.shape)
+ send_tensor_shape_flags[model_chunk_id] = comm.send_obj_meta(output_obj,
+ send_tensor_shape_flags[model_chunk_id])
+ # Determine if tensor should be received from previous stage.
+ next_forward_model_chunk_id = get_model_chunk_id(k + 1, forward=True)
+ recv_prev = True
+ if gpc.is_pipeline_first_stage(ignore_virtual=True):
+ if next_forward_model_chunk_id == 0:
+ recv_prev = False
+ if k == (num_microbatches - 1):
+ recv_prev = False
+
+ # Don't send tensor downstream if on last stage.
+ if gpc.is_pipeline_last_stage():
+ output_obj = None
+
+ with switch_virtual_pipeline_parallel_rank(next_forward_model_chunk_id):
+ if not gpc.is_pipeline_first_stage():
+ input_obj_shapes[next_forward_model_chunk_id] = comm.recv_obj_meta(
+ input_obj_shapes[next_forward_model_chunk_id])
+ # Send and receive tensors as appropriate (send tensors computed
+ # in this iteration; receive tensors for next iteration).
+ input_shape = input_obj_shapes[next_forward_model_chunk_id] if recv_prev else None
+ if k == (num_warmup_microbatches - 1) and not forward_only and \
+ not all_warmup_microbatches:
+ input_obj_grad = None
+ recv_next = True
+ if gpc.is_pipeline_last_stage(ignore_virtual=True):
+ recv_next = False
+ output_shape = output_obj_shapes[num_model_chunks - 1] if recv_next else None
+ input_obj, output_obj_grad = \
+ comm.send_forward_backward_recv_forward_backward(
+ output_obj, input_obj_grad,
+ input_shape,
+ output_shape,
+ recv_prev=recv_prev, recv_next=recv_next,
+ dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors)
+ output_obj_grads[num_model_chunks - 1].append(output_obj_grad)
+ else:
+ input_obj = \
+ comm.send_forward_recv_forward(
+ output_obj,
+ input_shape,
+ recv_prev=recv_prev,
+ dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors)
+ input_objs[next_forward_model_chunk_id].append(input_obj)
+
+ # Run 1F1B in steady state.
+ for k in range(num_microbatches_remaining):
+ # Forward pass.
+ forward_k = k + num_warmup_microbatches
+ output_obj = _forward_step_helper(forward_k)
+
+ # Backward pass.
+ backward_k = k
+ input_obj_grad = _backward_step_helper(backward_k)
+
+ # Send output_obj and input_obj_grad, receive input_obj
+ # and output_obj_grad.
+
+ # Determine if current stage has anything to send in either direction,
+ # otherwise set obj to None.
+ forward_model_chunk_id = get_model_chunk_id(forward_k, forward=True)
+ gpc.set_virtual_pipeline_parallel_rank(forward_model_chunk_id)
+ if gpc.is_pipeline_last_stage():
+ output_obj = None
+
+ backward_model_chunk_id = get_model_chunk_id(backward_k, forward=False)
+ gpc.set_virtual_pipeline_parallel_rank(backward_model_chunk_id)
+ if gpc.is_pipeline_first_stage():
+ input_obj_grad = None
+
+ # Determine if peers are sending, and where in data structure to put
+ # received tensors.
+ recv_prev = True
+ if gpc.is_pipeline_first_stage(ignore_virtual=True):
+ # First stage is ahead of last stage by (pipeline_parallel_size - 1).
+ next_forward_model_chunk_id = get_model_chunk_id(forward_k - (pipeline_parallel_size - 1), forward=True)
+ if next_forward_model_chunk_id == (num_model_chunks - 1):
+ recv_prev = False
+ next_forward_model_chunk_id += 1
+ else:
+ next_forward_model_chunk_id = get_model_chunk_id(forward_k + 1, forward=True)
+
+ recv_next = True
+ if gpc.is_pipeline_last_stage(ignore_virtual=True):
+ # Last stage is ahead of first stage by (pipeline_parallel_size - 1).
+ next_backward_model_chunk_id = get_model_chunk_id(backward_k - (pipeline_parallel_size - 1),
+ forward=False)
+ if next_backward_model_chunk_id == 0:
+ recv_next = False
+ next_backward_model_chunk_id -= 1
+ else:
+ next_backward_model_chunk_id = get_model_chunk_id(backward_k + 1, forward=False)
+
+ # If last iteration, don't receive; we already received one extra
+ # before the start of the for loop.
+ if k == (num_microbatches_remaining - 1):
+ recv_prev = False
+
+ input_shape = input_obj_shapes[next_forward_model_chunk_id] if recv_prev else None
+ output_shape = output_obj_shapes[next_backward_model_chunk_id] if recv_next else None
+ # Communicate objs.
+ input_obj, output_obj_grad = \
+ comm.send_forward_backward_recv_forward_backward(
+ output_obj, input_obj_grad,
+ input_shape,
+ output_shape,
+ recv_prev=recv_prev, recv_next=recv_next,
+ dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors)
+
+ # Put input_obj and output_obj_grad in data structures in the
+ # right location.
+ if recv_prev:
+ input_objs[next_forward_model_chunk_id].append(input_obj)
+ if recv_next:
+ output_obj_grads[next_backward_model_chunk_id].append(output_obj_grad)
+
+ # Run cooldown backward passes (flush out pipeline).
+ if not forward_only:
+ if all_warmup_microbatches:
+ output_obj_grads[num_model_chunks - 1].append(
+ comm.recv_backward(output_obj_shapes[num_model_chunks - 1],
+ scatter_gather_tensors=self.scatter_gather_tensors))
+ for k in range(num_microbatches_remaining, num_microbatches):
+ input_obj_grad = _backward_step_helper(k)
+ next_backward_model_chunk_id = get_model_chunk_id(k + 1, forward=False)
+ recv_next = True
+ if gpc.is_pipeline_last_stage(ignore_virtual=True):
+ if next_backward_model_chunk_id == (num_model_chunks - 1):
+ recv_next = False
+ if k == (num_microbatches - 1):
+ recv_next = False
+ output_shape = output_obj_shapes[next_backward_model_chunk_id] if recv_next else None
+ output_obj_grads[next_backward_model_chunk_id].append(
+ comm.send_backward_recv_backward(input_obj_grad,
+ output_shape,
+ recv_next=recv_next,
+ dtype=self.dtype,
+ scatter_gather_tensors=self.scatter_gather_tensors))
+
+ if len(return_tensors) > 0:
+ output, label = pack_return_tensors(return_tensors)
+ return output, label, accum_loss
+ else:
+ return None, None, accum_loss
diff --git a/colossalai/engine/schedule/_pipeline_schedule_v2.py b/colossalai/engine/schedule/_pipeline_schedule_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..28c58bd82b5c3f6969337c0a718a5698346744d9
--- /dev/null
+++ b/colossalai/engine/schedule/_pipeline_schedule_v2.py
@@ -0,0 +1,182 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+from typing import Iterable, Tuple
+
+import torch.cuda
+
+import colossalai.communication.p2p_v2 as comm
+from colossalai import engine
+from colossalai.context.parallel_mode import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.utils.cuda import get_current_device
+
+from ._pipeline_schedule import PipelineSchedule
+
+
+def pack_return_tensors(return_tensors):
+ output, label = tuple(zip(*return_tensors))
+ if isinstance(output[0], torch.Tensor):
+ output = torch.cat(output, dim=0)
+ elif isinstance(output[0], (list, tuple)):
+ output = tuple(torch.cat(tensors, dim=0) for tensors in zip(*output))
+ else:
+ raise TypeError(f'Output of model must be tensor or list/tuple of tensors')
+ if isinstance(label[0], torch.Tensor):
+ label = torch.cat(label, dim=0)
+ else:
+ merged_label = {k: [] for k in label[0].keys()}
+ for d in label:
+ for k, v in d.items():
+ merged_label[k].append(v)
+ label = {k: torch.cat(v, dim=0) for k, v in merged_label.items()}
+ return output, label
+
+
+class PipelineScheduleV2(PipelineSchedule):
+ """Derived class of PipelineSchedule, the only difference is that
+ forward_backward_step is reconstructed with p2p_v2
+
+ Args:
+ num_microbatches (int): The number of microbatches.
+ data_process_func (Callable, optional):
+ The preprocessing function which receives a batch of data, and it will be executed in `load_batch`.
+ tensor_shape (torch.Size, optional): Specified shape in pipeline communication.
+ scatter_gather_tensors (bool, optional):
+ If set to `True`, communication will be reduced over pipeline when using 1D tensor parallelization.
+
+ Example:
+
+ # this shows an example of customized data_process_func
+ def data_process_func(stage_output, dataloader_output):
+ output1, output2 = stage_output
+ item1, item2, item3 = dataloader_output
+
+ # assume item2 is not needed
+ data = (output1, output2, item1)
+ label = item3
+ return data, label
+
+ """
+
+ def forward_backward_step(self,
+ engine: engine.Engine,
+ data_iter: Iterable,
+ forward_only=False,
+ return_loss=True,
+ return_output_label=True) -> Tuple[torch.Tensor]:
+ """Runs non-interleaved 1F1B schedule, with communication between pipeline stages.
+ Returns a tuple with losses if the last stage, an empty tuple otherwise.
+
+ Args:
+ engine (colossalai.engine.Engine): Colossalai engine for training and inference.
+ data_iter (Iterable): Dataloader as the form of an iterator, obtained by calling iter(dataloader).
+ forward_only (bool, optional):
+ Whether run forward step only. Default is false. If true, no backward will be run.
+ return_loss (bool, optional): Whether returns the loss value. Default is true.
+ return_output_label (bool, optional): If False, the output and label won't be returned.
+
+ Returns:
+ Tuple[:class:`torch.Tensor`]: A tuple of (output, label, loss), loss and label could be None.
+ """
+
+ assert forward_only or return_loss, \
+ 'The argument \'return_loss\' has to be True when \'forward_only\' is False, but got False.'
+ self.load_batch(data_iter)
+
+ # num_warmup_microbatches is the step when not all the processers are working
+ num_warmup_microbatches = \
+ (gpc.get_world_size(ParallelMode.PIPELINE)
+ - gpc.get_local_rank(ParallelMode.PIPELINE) - 1)
+ num_warmup_microbatches = min(num_warmup_microbatches, self.num_microbatches)
+ num_microbatches_remaining = self.num_microbatches - num_warmup_microbatches
+
+ # Input, output tensors only need to be saved when doing backward passes
+ input_objs = None
+ output_objs = None
+ # local_rank = gpc.get_local_rank(ParallelMode.PIPELINE)
+
+ if not forward_only:
+ input_objs = []
+ output_objs = []
+ return_tensors = []
+ if return_loss and gpc.is_pipeline_last_stage(ignore_virtual=True):
+ accum_loss = torch.zeros(1, device=get_current_device())
+ else:
+ accum_loss = None
+
+ # Run warmup forward passes.
+ for i in range(num_warmup_microbatches):
+ input_obj = comm.recv_forward()
+
+ output_obj = self._forward_step(engine,
+ input_obj,
+ return_tensors,
+ return_output_label=return_output_label,
+ accum_loss=accum_loss)
+
+ comm.send_forward(output_obj)
+
+ if not forward_only:
+ input_objs.append(input_obj)
+ output_objs.append(output_obj)
+
+ # Before running 1F1B, need to receive first forward tensor.
+ # If all microbatches are run in warmup / cooldown phase, then no need to
+ # receive this tensor here.
+ if num_microbatches_remaining > 0:
+ input_obj = comm.recv_forward()
+
+ # Run 1F1B in steady state.
+ for i in range(num_microbatches_remaining):
+ last_iteration = (i == (num_microbatches_remaining - 1))
+
+ output_obj = self._forward_step(engine,
+ input_obj,
+ return_tensors,
+ return_output_label=return_output_label,
+ accum_loss=accum_loss)
+ if forward_only:
+ comm.send_forward(output_obj)
+
+ if not last_iteration:
+ input_obj = comm.recv_forward()
+
+ else:
+ # TODO adjust here
+ comm.send_forward(output_obj)
+ output_obj_grad = comm.recv_backward()
+
+ # Add input_obj and output_obj to end of list.
+ input_objs.append(input_obj)
+ output_objs.append(output_obj)
+
+ # Pop output_obj and output_obj from the start of the list for
+ # the backward pass.
+ input_obj = input_objs.pop(0)
+ output_obj = output_objs.pop(0)
+
+ input_obj_grad = self._backward_step(engine, input_obj, output_obj, output_obj_grad)
+
+ if last_iteration:
+ input_obj = None
+ comm.send_backward(input_obj_grad)
+ else:
+ input_obj = comm.recv_forward()
+ comm.send_backward(input_obj_grad)
+
+ # Run cooldown backward passes.
+ if not forward_only:
+ for i in range(num_warmup_microbatches):
+ input_obj = input_objs.pop(0)
+ output_obj = output_objs.pop(0)
+
+ output_obj_grad = comm.recv_backward()
+ input_obj_grad = self._backward_step(engine, input_obj, output_obj, output_obj_grad)
+ comm.send_backward(input_obj_grad)
+
+ if len(return_tensors) > 0:
+ output, label = pack_return_tensors(return_tensors)
+ return output, label, accum_loss
+ else:
+ return None, None, accum_loss
diff --git a/colossalai/fx/__init__.py b/colossalai/fx/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d39fa579943d7a4f3cccd7ea7f6e2a20613373c8
--- /dev/null
+++ b/colossalai/fx/__init__.py
@@ -0,0 +1,4 @@
+from ._compatibility import compatibility, is_compatible_with_meta
+from .graph_module import ColoGraphModule
+from .passes import MetaInfoProp, metainfo_trace
+from .tracer import ColoTracer, meta_trace, symbolic_trace
diff --git a/colossalai/fx/_compatibility.py b/colossalai/fx/_compatibility.py
new file mode 100644
index 0000000000000000000000000000000000000000..0444a481627356e202912c491495364134aa65dd
--- /dev/null
+++ b/colossalai/fx/_compatibility.py
@@ -0,0 +1,54 @@
+from typing import Callable
+
+import torch
+
+TORCH_MAJOR = int(torch.__version__.split('.')[0])
+TORCH_MINOR = int(torch.__version__.split('.')[1])
+
+if TORCH_MAJOR == 1 and TORCH_MINOR < 12:
+ META_COMPATIBILITY = False
+elif TORCH_MAJOR == 1 and TORCH_MINOR == 12:
+ from . import _meta_regist_12
+ META_COMPATIBILITY = True
+elif TORCH_MAJOR == 1 and TORCH_MINOR == 13:
+ from . import _meta_regist_13
+ META_COMPATIBILITY = True
+elif TORCH_MAJOR == 2:
+ META_COMPATIBILITY = True
+
+
+def compatibility(is_backward_compatible: bool = False) -> Callable:
+ """A decorator to make a function compatible with different versions of PyTorch.
+
+ Args:
+ is_backward_compatible (bool, optional): Whether the function is backward compatible. Defaults to False.
+
+ Returns:
+ Callable: The decorated function
+ """
+
+ def decorator(func):
+ if META_COMPATIBILITY:
+ return func
+ else:
+ if is_backward_compatible:
+ return func
+ else:
+
+ def wrapper(*args, **kwargs):
+ raise RuntimeError(f'Function `{func.__name__}` is not compatible with PyTorch {torch.__version__}')
+
+ return wrapper
+
+ return decorator
+
+
+def is_compatible_with_meta() -> bool:
+ """Check the meta compatibility. Normally it should be called before importing some of the `colossalai.fx`
+ modules. If the meta compatibility is not satisfied, the `colossalai.fx` modules will be replaced by its
+ experimental counterparts.
+
+ Returns:
+ bool: The meta compatibility
+ """
+ return META_COMPATIBILITY
diff --git a/colossalai/fx/_meta_regist_12.py b/colossalai/fx/_meta_regist_12.py
new file mode 100644
index 0000000000000000000000000000000000000000..52e8d63ae54355a0d3e27dfc6a3347a2304dc0d7
--- /dev/null
+++ b/colossalai/fx/_meta_regist_12.py
@@ -0,0 +1,506 @@
+# meta patch from https://github.com/pytorch/pytorch/blob/master/torch/_meta_registrations.py
+# should be activated for PyTorch version 1.12.0 and below
+# refer to https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/native_functions.yaml
+# for more meta_registrations
+
+from typing import Callable, List, Optional, Tuple, Union
+
+import torch
+from torch.utils._pytree import tree_map
+
+aten = torch.ops.aten
+
+meta_lib = torch.library.Library("aten", "IMPL", "Meta")
+
+meta_table = {}
+
+
+def register_meta(op, register_dispatcher=True):
+
+ def wrapper(f):
+
+ def add_func(op):
+ meta_table[op] = f
+ if register_dispatcher:
+ name = (op.__name__ if op._overloadname != "default" else op.overloadpacket.__name__)
+ try:
+ meta_lib.impl(name, f)
+ except:
+ pass
+
+ tree_map(add_func, op)
+ return f
+
+ return wrapper
+
+
+# ============================== Convolutions ======================================
+# https://github.com/pytorch/pytorch/pull/79834
+@register_meta(aten.convolution.default)
+def meta_conv(
+ input_tensor: torch.Tensor,
+ weight: torch.Tensor,
+ bias: torch.Tensor,
+ stride: List[int],
+ padding: List[int],
+ dilation: List[int],
+ is_transposed: bool,
+ output_padding: List[int],
+ groups: int,
+):
+
+ def _formula(ln: int, p: int, d: int, k: int, s: int) -> int:
+ """
+ Formula to apply to calculate the length of some dimension of the output
+ See: https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
+ Args:
+ ln: length of the dimension
+ p: padding in that dim
+ d: dilation in that dim
+ k: kernel size in that dim
+ s: stride in that dim
+ Returns:
+ The output length
+ """
+ return (ln + 2 * p - d * (k - 1) - 1) // s + 1
+
+ def _formula_transposed(ln: int, p: int, d: int, k: int, s: int, op: int) -> int:
+ """
+ Formula to apply to calculate the length of some dimension of the output
+ if transposed convolution is used.
+ See: https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose2d.html
+ Args:
+ ln: length of the dimension
+ p: padding in that dim
+ d: dilation in that dim
+ k: kernel size in that dim
+ s: stride in that dim
+ op: output padding in that dim
+ Returns:
+ The output length
+ """
+ return (ln - 1) * s - 2 * p + d * (k - 1) + op + 1
+
+ def calc_conv_nd_return_shape(
+ dims: torch.Size,
+ kernel_size: torch.Size,
+ stride: Union[List[int], int],
+ padding: Union[List[int], int],
+ dilation: Union[List[int], int],
+ output_padding: Optional[Union[List[int], int]] = None,
+ ):
+ ret_shape = []
+ if isinstance(stride, int):
+ stride = [stride] * len(dims)
+ elif len(stride) == 1:
+ stride = [stride[0]] * len(dims)
+
+ if isinstance(padding, int):
+ padding = [padding] * len(dims)
+ elif len(padding) == 1:
+ padding = [padding[0]] * len(dims)
+
+ if isinstance(dilation, int):
+ dilation = [dilation] * len(dims)
+ elif len(dilation) == 1:
+ dilation = [dilation[0]] * len(dims)
+
+ output_padding_list: Optional[List[int]] = None
+ if output_padding:
+ if isinstance(output_padding, int):
+ output_padding_list = [output_padding] * len(dims)
+ elif len(output_padding) == 1:
+ output_padding_list = [output_padding[0]] * len(dims)
+ else:
+ output_padding_list = output_padding
+
+ for i in range(len(dims)):
+ # If output_padding is present, we are dealing with a transposed convolution
+ if output_padding_list:
+ ret_shape.append(
+ _formula_transposed(
+ dims[i],
+ padding[i],
+ dilation[i],
+ kernel_size[i],
+ stride[i],
+ output_padding_list[i],
+ ))
+ else:
+ ret_shape.append(_formula(dims[i], padding[i], dilation[i], kernel_size[i], stride[i]))
+ return ret_shape
+
+ def pick_memory_format():
+ if input_tensor.is_contiguous(memory_format=torch.channels_last):
+ return torch.channels_last
+ elif input_tensor.is_contiguous(memory_format=torch.contiguous_format):
+ return torch.contiguous_format
+ elif input_tensor.is_contiguous(memory_format=torch.preserve_format):
+ return torch.preserve_format
+
+ kernel_size = weight.shape[2:]
+ dims = input_tensor.shape[2:]
+ if is_transposed:
+ out_channels = groups * weight.shape[1]
+
+ shape_out = calc_conv_nd_return_shape(
+ dims,
+ kernel_size,
+ stride,
+ padding,
+ dilation,
+ output_padding,
+ )
+
+ else:
+ out_channels = weight.shape[0]
+ if weight.shape[1] != input_tensor.shape[1] / groups:
+ raise RuntimeError("Invalid channel dimensions")
+ shape_out = calc_conv_nd_return_shape(dims, kernel_size, stride, padding, dilation)
+ out = input_tensor.new_empty((input_tensor.shape[0], out_channels, *shape_out))
+ mem_fmt = pick_memory_format()
+ out = out.to(memory_format=mem_fmt) # type: ignore[call-overload]
+ return out
+
+
+@register_meta(aten._convolution.default)
+def meta_conv_1(input_tensor: torch.Tensor, weight: torch.Tensor, bias: torch.Tensor, stride: List[int],
+ padding: List[int], dilation: List[int], is_transposed: bool, output_padding: List[int], groups: int,
+ *extra_args):
+ out = meta_conv(input_tensor, weight, bias, stride, padding, dilation, is_transposed, output_padding, groups)
+ return out
+
+
+@register_meta(aten.convolution_backward.default)
+def meta_conv_backward(grad_output: torch.Tensor, input: torch.Tensor, weight: torch.Tensor, bias_sizes, stride,
+ padding, dilation, transposed, output_padding, groups, output_mask):
+ return torch.empty_like(input), torch.empty_like(weight), torch.empty((bias_sizes), device='meta')
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/AdaptiveAveragePooling.cpp
+@register_meta(aten._adaptive_avg_pool2d_backward.default)
+def meta_adaptive_avg_pool2d_backward(
+ grad_output: torch.Tensor,
+ input: torch.Tensor,
+):
+ grad_input = torch.empty_like(input)
+ return grad_input
+
+
+# ================================ RNN =============================================
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/RNN.cpp
+@register_meta(aten._cudnn_rnn.default)
+def meta_cuda_rnn(
+ input,
+ weight,
+ weight_stride0,
+ weight_buf,
+ hx,
+ cx,
+ mode,
+ hidden_size,
+ proj_size,
+ num_layers,
+ batch_first,
+ dropout,
+ train,
+ bidirectional,
+ batch_sizes,
+ dropout_state,
+):
+
+ is_input_packed = len(batch_sizes) != 0
+ if is_input_packed:
+ seq_length = len(batch_sizes)
+ mini_batch = batch_sizes[0]
+ batch_sizes_sum = input.shape[0]
+ else:
+ seq_length = input.shape[1] if batch_first else input.shape[0]
+ mini_batch = input.shape[0] if batch_first else input.shape[1]
+ batch_sizes_sum = -1
+
+ num_directions = 2 if bidirectional else 1
+ out_size = proj_size if proj_size != 0 else hidden_size
+ if is_input_packed:
+ out_shape = [batch_sizes_sum, out_size * num_directions]
+ else:
+ out_shape = ([mini_batch, seq_length, out_size *
+ num_directions] if batch_first else [seq_length, mini_batch, out_size * num_directions])
+ output = input.new_empty(out_shape)
+
+ cell_shape = [num_layers * num_directions, mini_batch, hidden_size]
+ cy = torch.empty(0) if cx is None else cx.new_empty(cell_shape)
+
+ hy = hx.new_empty([num_layers * num_directions, mini_batch, out_size])
+
+ # TODO: Query cudnnGetRNNTrainingReserveSize (expose to python)
+ reserve_shape = 0 if train else 0
+ reserve = input.new_empty(reserve_shape, dtype=torch.uint8)
+
+ return output, hy, cy, reserve, weight_buf
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/RNN.cpp
+@register_meta(aten._cudnn_rnn_backward.default)
+def meta_cudnn_rnn_backward(input: torch.Tensor,
+ weight: torch.Tensor,
+ weight_stride0: int,
+ hx: torch.Tensor,
+ cx: Optional[torch.Tensor] = None,
+ *args,
+ **kwargs):
+ print(input, weight, hx, cx)
+ grad_input = torch.empty_like(input)
+ grad_weight = torch.empty_like(weight)
+ grad_hx = torch.empty_like(hx)
+ grad_cx = torch.empty_like(cx) if cx is not None else torch.empty((), device='meta')
+ return grad_input, grad_weight, grad_hx, grad_cx
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Activation.cpp
+# ============================== Activations =======================================
+@register_meta(aten.relu.default)
+def meta_relu(input: torch.Tensor):
+ return torch.empty_like(input)
+
+
+@register_meta(aten.prelu.default)
+def meta_prelu(input: torch.Tensor, weight: torch.Tensor):
+ return torch.empty_like(input)
+
+
+@register_meta(aten.hardswish.default)
+def meta_hardswish(input: torch.Tensor):
+ return torch.empty_like(input)
+
+
+@register_meta(aten.hardtanh.default)
+def meta_hardtanh(input: torch.Tensor, min, max):
+ return torch.empty_like(input)
+
+
+@register_meta(aten.hardswish_backward.default)
+def meta_hardswish_backward(grad_out: torch.Tensor, input: torch.Tensor):
+ grad_in = torch.empty_like(input)
+ return grad_in
+
+
+@register_meta(aten.hardtanh_backward.default)
+def meta_hardtanh_backward(grad_out: torch.Tensor, input: torch.Tensor, min_val: int, max_val: int):
+ grad_in = torch.empty_like(input)
+ return grad_in
+
+
+# ============================== Normalization =====================================
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/BatchNorm.cpp
+@register_meta(aten.native_batch_norm.default)
+def meta_bn(input: torch.Tensor, weight, bias, running_mean, running_var, training, momentum, eps):
+ n_input = input.size(1)
+
+ output = torch.empty_like(input)
+ running_mean = torch.empty((n_input), device='meta')
+ running_var = torch.empty((n_input), device='meta')
+ return output, running_mean, running_var
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/BatchNorm.cpp
+@register_meta(aten.native_batch_norm_backward.default)
+def meta_bn_backward(dY: torch.Tensor, input: torch.Tensor, weight: torch.Tensor, running_mean, running_var, save_mean,
+ save_invstd, train, eps, output_mask):
+ dX = torch.empty_like(input)
+ dgamma = torch.empty_like(weight)
+ dbeta = torch.empty_like(weight)
+ return dX, dgamma, dbeta
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/BatchNorm.cpp
+@register_meta(aten.cudnn_batch_norm.default)
+def meta_cudnn_bn(input: torch.Tensor, weight, bias, running_mean, running_var, training, momentum, eps):
+ n_input = input.size(1)
+
+ output = torch.empty_like(input)
+ running_mean = torch.empty((n_input), device='meta')
+ running_var = torch.empty((n_input), device='meta')
+ reserve = torch.empty((0), dtype=torch.uint8, device='meta')
+ return output, running_mean, running_var, reserve
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cudnn/BatchNorm.cpp
+# NB: CuDNN only implements the backward algorithm for batchnorm
+# in training mode (evaluation mode batchnorm has a different algorithm),
+# which is why this doesn't accept a 'training' parameter.
+@register_meta(aten.cudnn_batch_norm_backward.default)
+def meta_cudnn_bn_backward(dY: torch.Tensor, input: torch.Tensor, weight: torch.Tensor, running_mean, running_var,
+ save_mean, save_invstd, eps, reserve):
+ dX = torch.empty_like(input)
+ dgamma = torch.empty_like(weight)
+ dbeta = torch.empty_like(weight)
+ return dX, dgamma, dbeta
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/layer_norm.cpp
+@register_meta(aten.native_layer_norm.default)
+def meta_ln(input: torch.Tensor, normalized_shape, weight, bias, eps):
+ bs = input.size(0)
+ n_input = input.size(1)
+
+ output = torch.empty_like(input)
+ running_mean = torch.empty((bs, n_input, 1), device='meta')
+ running_var = torch.empty((bs, n_input, 1), device='meta')
+ return output, running_mean, running_var
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/layer_norm.cpp
+@register_meta(aten.native_layer_norm_backward.default)
+def meta_ln_backward(dY: torch.Tensor, input: torch.Tensor, normalized_shape, mean, rstd, weight, bias,
+ grad_input_mask):
+ dX = torch.empty_like(input)
+ dgamma = torch.empty_like(weight)
+ dbeta = torch.empty_like(bias)
+ return dX, dgamma, dbeta
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/group_norm.cpp
+@register_meta(aten.native_group_norm_backward.default)
+def meta_gn_backward(dY: torch.Tensor, input: torch.Tensor, mean, rstd, gamma, N, C, HxW, group, grad_input_mask):
+ dX = torch.empty_like(input)
+ dgamma = torch.empty_like(gamma)
+ dbeta = torch.empty_like(gamma)
+ return dX, dgamma, dbeta
+
+
+# ================================== Misc ==========================================
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/native_functions.yaml
+@register_meta(aten.roll.default)
+def meta_roll(input: torch.Tensor, shifts, dims):
+ return input
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Scalar.cpp
+@register_meta(aten._local_scalar_dense.default)
+def meta_local_scalar_dense(self: torch.Tensor):
+ return 0
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/TensorCompare.cpp
+@register_meta(aten.where.self)
+def meta_where_self(condition: torch.Tensor, self: torch.Tensor, other: torch.Tensor):
+ result_type = torch.result_type(self, other)
+ return torch.empty_like(condition + self + other, dtype=result_type)
+
+
+@register_meta(aten.index.Tensor)
+def meta_index_Tensor(self, indices):
+ assert indices, "at least one index must be provided"
+ # aten::index is the internal advanced indexing implementation
+ # checkIndexTensorTypes and expandTensors
+ result: List[Optional[torch.Tensor]] = []
+ for i, index in enumerate(indices):
+ if index is not None:
+ assert index.dtype in [torch.long, torch.int8, torch.bool],\
+ "tensors used as indices must be long, byte or bool tensors"
+ if index.dtype in [torch.int8, torch.bool]:
+ nonzero = index.nonzero()
+ k = len(result)
+ assert k + index.ndim <= self.ndim, f"too many indices for tensor of dimension {self.ndim}"
+ for j in range(index.ndim):
+ assert index.shape[j] == self.shape[
+ k +
+ j], f"The shape of the mask {index.shape} at index {i} does not match the shape of the indexed tensor {self.shape} at index {k + j}"
+ result.append(nonzero.select(1, j))
+ else:
+ result.append(index)
+ else:
+ result.append(index)
+ indices = result
+ assert len(indices) <= self.ndim, f"too many indices for tensor of dimension {self.ndim} (got {len(indices)})"
+ # expand_outplace
+ import torch._refs as refs
+
+ indices = list(refs._maybe_broadcast(*indices))
+ # add missing null tensors
+ while len(indices) < self.ndim:
+ indices.append(None)
+
+ # hasContiguousSubspace
+ # true if all non-null tensors are adjacent
+ # See:
+ # https://numpy.org/doc/stable/user/basics.indexing.html#combining-advanced-and-basic-indexing
+ # https://stackoverflow.com/questions/53841497/why-does-numpy-mixed-basic-advanced-indexing-depend-on-slice-adjacency
+ state = 0
+ has_contiguous_subspace = False
+ for index in indices:
+ if state == 0:
+ if index is not None:
+ state = 1
+ elif state == 1:
+ if index is None:
+ state = 2
+ else:
+ if index is not None:
+ break
+ else:
+ has_contiguous_subspace = True
+
+ # transposeToFront
+ # This is the logic that causes the newly inserted dimensions to show up
+ # at the beginning of the tensor, if they're not contiguous
+ if not has_contiguous_subspace:
+ dims = []
+ transposed_indices = []
+ for i, index in enumerate(indices):
+ if index is not None:
+ dims.append(i)
+ transposed_indices.append(index)
+ for i, index in enumerate(indices):
+ if index is None:
+ dims.append(i)
+ transposed_indices.append(index)
+ self = self.permute(dims)
+ indices = transposed_indices
+
+ # AdvancedIndex::AdvancedIndex
+ # Now we can assume the indices have contiguous subspace
+ # This is simplified from AdvancedIndex which goes to more effort
+ # to put the input and indices in a form so that TensorIterator can
+ # take them. If we write a ref for this, probably that logic should
+ # get implemented
+ before_shape: List[int] = []
+ after_shape: List[int] = []
+ replacement_shape: List[int] = []
+ for dim, index in enumerate(indices):
+ if index is None:
+ if replacement_shape:
+ after_shape.append(self.shape[dim])
+ else:
+ before_shape.append(self.shape[dim])
+ else:
+ replacement_shape = list(index.shape)
+ return self.new_empty(before_shape + replacement_shape + after_shape)
+
+
+# ============================== Embedding =========================================
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Embedding.cpp
+@register_meta(aten.embedding_dense_backward.default)
+def meta_embedding_dense_backward(grad_output: torch.Tensor, indices: torch.Tensor, num_weights, padding_idx,
+ scale_grad_by_freq):
+ return torch.empty((num_weights, grad_output.size(-1)),
+ dtype=grad_output.dtype,
+ device=grad_output.device,
+ layout=grad_output.layout)
+
+
+# ============================== Dropout ===========================================
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Dropout.cpp
+@register_meta(aten.native_dropout.default)
+def meta_native_dropout_default(input: torch.Tensor, p: float, train: bool = False):
+ # notice that mask is bool
+ output = torch.empty_like(input)
+ mask = torch.empty_like(input, dtype=torch.bool)
+ return output, mask
+
+
+# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Dropout.cpp
+@register_meta(aten.native_dropout_backward.default)
+def meta_native_dropout_backward_default(grad: torch.Tensor, mask: torch.Tensor, scale: float):
+ return torch.empty_like(grad)
diff --git a/colossalai/fx/_meta_regist_13.py b/colossalai/fx/_meta_regist_13.py
new file mode 100644
index 0000000000000000000000000000000000000000..6caa87c449abb7cd332384f622ff484bcc97b68f
--- /dev/null
+++ b/colossalai/fx/_meta_regist_13.py
@@ -0,0 +1,57 @@
+import torch
+from torch._meta_registrations import register_meta
+from torch._prims_common import check
+
+aten = torch.ops.aten
+
+
+# since we fix the torch version to 1.13.1, we have to add unimplemented meta ops
+# all these functions are from here https://github.com/pytorch/pytorch/blob/master/torch/_meta_registrations.py
+@register_meta([aten.convolution_backward.default])
+def meta_convolution_backward(
+ grad_output_,
+ input_,
+ weight_,
+ bias_sizes_opt,
+ stride,
+ padding,
+ dilation,
+ transposed,
+ output_padding,
+ groups,
+ output_mask,
+):
+ # High level logic taken from slow_conv3d_backward_cpu which should
+ # be representative of all convolution_backward impls
+ backend_grad_input = None
+ backend_grad_weight = None
+ backend_grad_bias = None
+
+ if output_mask[0]:
+ backend_grad_input = grad_output_.new_empty(input_.size())
+ if output_mask[1]:
+ backend_grad_weight = grad_output_.new_empty(weight_.size())
+ if output_mask[2]:
+ backend_grad_bias = grad_output_.new_empty(bias_sizes_opt)
+
+ return (backend_grad_input, backend_grad_weight, backend_grad_bias)
+
+
+@register_meta(aten._adaptive_avg_pool2d_backward.default)
+def meta__adaptive_avg_pool2d_backward(grad_out, self):
+ ndim = grad_out.ndim
+ for i in range(1, ndim):
+ check(
+ grad_out.size(i) > 0,
+ lambda: f"adaptive_avg_pool2d_backward(): Expected grad_output to have non-zero \
+ size for non-batch dimensions, {grad_out.shape} with dimension {i} being empty",
+ )
+ check(
+ ndim == 3 or ndim == 4,
+ lambda: f"adaptive_avg_pool2d_backward(): Expected 3D or 4D tensor, but got {self.shape}",
+ )
+ check(
+ self.dtype == grad_out.dtype,
+ lambda: f"expected dtype {self.dtype} for `grad_output` but got dtype {grad_out.dtype}",
+ )
+ return self.new_empty(self.shape)
diff --git a/colossalai/fx/codegen/__init__.py b/colossalai/fx/codegen/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..794692f511537db5a8a54588f15ecafb41242ea2
--- /dev/null
+++ b/colossalai/fx/codegen/__init__.py
@@ -0,0 +1 @@
+from .activation_checkpoint_codegen import *
diff --git a/colossalai/fx/codegen/activation_checkpoint_codegen.py b/colossalai/fx/codegen/activation_checkpoint_codegen.py
new file mode 100644
index 0000000000000000000000000000000000000000..5a72cb9ca923bcdf5f9b3daddad9b5e7c339d5c5
--- /dev/null
+++ b/colossalai/fx/codegen/activation_checkpoint_codegen.py
@@ -0,0 +1,1058 @@
+from typing import Any, Callable, Dict, Iterable, List, Tuple
+
+import torch
+
+import colossalai
+
+try:
+ from torch.fx.graph import (
+ CodeGen,
+ PythonCode,
+ _custom_builtins,
+ _CustomBuiltin,
+ _format_target,
+ _is_from_torch,
+ _Namespace,
+ _origin_type_map,
+ inplace_methods,
+ magic_methods,
+ )
+ from torch.fx.node import Argument, Node, _get_qualified_name, _type_repr, map_arg
+ CODEGEN_AVAILABLE = True
+except:
+ from torch.fx.graph import (
+ PythonCode,
+ _custom_builtins,
+ _CustomBuiltin,
+ _format_args,
+ _format_target,
+ _is_from_torch,
+ _Namespace,
+ _origin_type_map,
+ magic_methods,
+ )
+ from torch.fx.node import Argument, Node, _get_qualified_name, _type_repr, map_arg
+ CODEGEN_AVAILABLE = False
+
+if CODEGEN_AVAILABLE:
+ __all__ = ['ActivationCheckpointCodeGen']
+else:
+ __all__ = ['python_code_with_activation_checkpoint']
+
+
+def _gen_saved_tensors_hooks():
+ """
+ Generate saved tensors hooks
+ """
+
+ pack_hook = """def pack_hook_input(self, x):
+ if getattr(x, "offload", False):
+ return (x.device, x.cpu())
+ else:
+ return x
+
+def pack_hook_no_input(self, x):
+ if getattr(x, "offload", True):
+ return (x.device, x.cpu())
+ else:
+ return x
+"""
+
+ unpack_hook = """def unpack_hook(self, packed):
+ if isinstance(packed, tuple):
+ device, tensor = packed
+ return tensor.to(device)
+ else:
+ return packed
+"""
+
+ return pack_hook, unpack_hook
+
+
+def _gen_save_tensors_hooks_context(offload_input=True) -> str:
+ """Generate customized saved_tensors_hooks
+ Args:
+ offload_input (bool, optional): whether we need offload input, if offload_input=False,
+ we will use self.pack_hook_no_input instead. Defaults to True.
+ Returns:
+ str: generated context
+ """
+
+ if offload_input:
+ context = "with torch.autograd.graph.saved_tensors_hooks(self.pack_hook_input, self.unpack_hook):\n"
+ else:
+ context = "with torch.autograd.graph.saved_tensors_hooks(self.pack_hook_no_input, self.unpack_hook):\n"
+ return context
+
+
+def _gen_save_on_cpu_context():
+ """
+ Generate save on cpu context
+ """
+
+ context = "with torch.autograd.graph.save_on_cpu(pin_memory=True):\n"
+ return context
+
+
+def _find_input_and_output_nodes(nodes: List[Node]):
+ """
+ Find the input and output node names which are not found in the given list of nodes.
+ """
+ input_nodes = []
+ output_nodes = []
+
+ # if a node has an input node which is not in the node list
+ # we treat that input node as the input of the checkpoint function
+ for node in nodes:
+ for input_node in node._input_nodes.keys():
+ node_repr = repr(input_node)
+ if input_node not in nodes and node_repr not in input_nodes:
+ input_nodes.append(node_repr)
+
+ # if a node has a user node which is not in the node list
+ # we treat that user node as the node receiving the current node output
+ for node in nodes:
+ for output_node in node.users.keys():
+ node_repr = repr(node)
+ if output_node not in nodes and node_repr not in output_nodes:
+ output_nodes.append(node_repr)
+
+ return input_nodes, output_nodes
+
+
+def _find_ckpt_regions(nodes: List[Node]):
+ """
+ Find the checkpoint regions given a list of consecutive nodes. The outputs will be list
+ of tuples, each tuple is in the form of (start_index, end_index).
+ """
+ ckpt_nodes = []
+ ckpt_regions = []
+ start = -1
+ end = -1
+ current_region = None
+
+ for idx, node in enumerate(nodes):
+ if 'activation_checkpoint' in node.meta:
+ act_ckpt_label = node.meta['activation_checkpoint']
+
+ # this activation checkpoint label is not set yet
+ # meaning this is the first node of the activation ckpt region
+ if current_region is None:
+ current_region = act_ckpt_label
+ start = idx
+
+ # if activation checkpoint has changed
+ # we restart the tracking
+ # e.g. node ckpt states = [ckpt1, ckpt2, ckpt2, ckpt2]
+ if act_ckpt_label != current_region:
+ assert start != -1
+ ckpt_regions.append((start, idx - 1))
+ current_region = act_ckpt_label
+ start = idx
+ end = -1
+ elif current_region is not None and not 'activation_checkpoint' in node.meta:
+ # used to check the case below
+ # node ckpt states = [ckpt, ckpt, non-ckpt]
+ end = idx - 1
+ assert start != -1 and end != -1
+ ckpt_regions.append((start, end))
+ start = end = -1
+ current_region = None
+ else:
+ pass
+ return ckpt_regions
+
+
+def _find_offload_regions(nodes: List[Node]):
+ """This function is to find the offload regions
+ In pofo algorithm, during annotation, we will annotate the offload region with the
+ list in the form of [idx, offload_input, offload_bar]. idx indicates the offload
+ region's index, offload_input is a bool type indicates whether we need to offload
+ the input, offload_bar is a bool type indicates whether we need to offload all the
+ intermediate x_bars of this region.
+ """
+ offload_regions = []
+ offload_labels = []
+ start = -1
+ end = -1
+ current_region = None
+
+ for idx, node in enumerate(nodes):
+ if 'activation_offload' in node.meta and isinstance(node.meta['activation_offload'], Iterable):
+ act_offload_label = node.meta['activation_offload']
+
+ if current_region == None:
+ current_region = act_offload_label
+ start = idx
+ offload_labels.append(act_offload_label)
+
+ if act_offload_label != current_region:
+ assert start != -1
+ offload_regions.append((start, idx - 1))
+ offload_labels.append(act_offload_label)
+ current_region = act_offload_label
+ start = idx
+ end = -1
+
+ else:
+ if current_region is not None:
+ end = idx - 1
+ assert start != -1 and end != -1
+ offload_regions.append((start, end))
+ start = end = -1
+ current_region = None
+
+ else:
+ pass
+
+ return offload_regions, offload_labels
+
+
+def _gen_ckpt_fn_def(label, free_vars: List[str]) -> str:
+ """
+ Generate the checkpoint function definition
+ """
+ return f"def checkpoint_{label}({', '.join(['self'] + free_vars)}):"
+
+
+def _gen_ckpt_output(output_vars: List[str]) -> str:
+ """
+ Generate the return statement for checkpoint region
+ """
+ return f"return {', '.join(output_vars)}"
+
+
+def _gen_ckpt_usage(label, activation_offload, input_vars, output_vars, use_reentrant=True):
+ """
+ Generate the checkpoint function call code text
+ """
+ outputs = ', '.join(output_vars)
+ inputs = ', '.join(input_vars)
+ return f'{outputs} = colossalai.utils.activation_checkpoint.checkpoint(self.checkpoint_{label}, {activation_offload}, {inputs}, use_reentrant={use_reentrant})'
+
+
+def _end_of_ckpt(node: Node, check_idx: int) -> bool:
+ """Check if the node could end the ckpt region
+ Args:
+ node (Node): torch.fx.Node
+ check_idx (int): the index of checkpoint level for
+ nested checkpoint
+ Returns:
+ bool
+ """
+ if 'activation_checkpoint' in node.meta:
+ if isinstance(node.meta['activation_checkpoint'], list):
+ return node.meta['activation_checkpoint'][check_idx] == None
+ else:
+ return False
+ else:
+ return True
+
+
+def _find_nested_ckpt_regions(nodes, check_idx=0):
+ """
+ Find the nested checkpoint regions given a list of consecutive nodes. The outputs
+ will be list of tuples, each tuple is in the form of (start_index, end_index).
+ """
+ ckpt_regions = []
+ start = -1
+ end = -1
+ current_region = None
+
+ for idx, node in enumerate(nodes):
+ if 'activation_checkpoint' in node.meta:
+ if isinstance(node.meta['activation_checkpoint'], int):
+ act_ckpt_label = node.meta['activation_checkpoint']
+ else:
+ act_ckpt_label = node.meta['activation_checkpoint'][check_idx]
+
+ # this activation checkpoint label is not set yet
+ # meaning this is the first node of the activation ckpt region
+ if current_region is None:
+ current_region = act_ckpt_label
+ start = idx
+
+ # if activation checkpoint has changed
+ # we restart the tracking
+ # e.g. node ckpt states = [ckpt1, ckpt2, ckpt2, ckpt2]
+ if act_ckpt_label != current_region:
+ assert start != -1
+ ckpt_regions.append((start, idx - 1))
+ current_region = act_ckpt_label
+ start = idx
+ end = -1
+ elif current_region is not None and _end_of_ckpt(node, check_idx):
+ # used to check the case below
+ # node ckpt states = [ckpt, ckpt, non-ckpt]
+ end = idx - 1
+ assert start != -1 and end != -1
+ ckpt_regions.append((start, end))
+ start = end = -1
+ current_region = None
+ else:
+ pass
+
+ if current_region is not None:
+ end = len(nodes) - 1
+ ckpt_regions.append((start, end))
+ return ckpt_regions
+
+
+def emit_ckpt_func(body,
+ ckpt_func,
+ node_list: List[Node],
+ emit_node_func,
+ delete_unused_value_func,
+ level=0,
+ in_ckpt=False):
+ """Emit ckpt function in nested way
+ Args:
+ body: forward code, in recursive calls, this part will be checkpoint
+ functions code
+ ckpt_func: checkpoint functions code, in recursive calls, this part
+ will be a buffer
+ node_list (List[Node]): list of torch.fx.Node
+ emit_node_func: function to emit a node
+ delete_unused_value_func: function to delete unused value
+ level (int, optional): checkpoint level. Defaults to 0.
+ in_ckpt (bool, optional): indicates wether the func is in recursive
+ call. Defaults to False.
+ """
+ inputs, outputs = _find_input_and_output_nodes(node_list)
+
+ # if the current checkpoint function use int as label, using old generation method
+ if isinstance(node_list[0].meta['activation_checkpoint'], int):
+ label = node_list[0].meta['activation_checkpoint']
+ ckpt_fn_def = _gen_ckpt_fn_def(label, inputs)
+ ckpt_func.append(f'{ckpt_fn_def}\n')
+ for node in node_list:
+ emit_node_func(node, ckpt_func)
+ ckpt_func[-1] = ' ' + ckpt_func[-1]
+ delete_unused_value_func(node, ckpt_func)
+
+ ckpt_func.append(' ' + _gen_ckpt_output(outputs) + '\n\n')
+ activation_offload = node_list[0].meta.get('activation_offload', False)
+ usage = _gen_ckpt_usage(label, activation_offload, inputs, outputs, False)
+ usage += "\n"
+ body.append(usage)
+
+ # use nested ckpt function codegen
+ else:
+ # label given by each layer, e.g. if you are currently at level [0, 1, 1]
+ # the label will be '0_1_1'
+ label = "_".join([str(idx) for idx in node_list[0].meta['activation_checkpoint'][:level + 1]])
+ ckpt_fn_def = _gen_ckpt_fn_def(label, inputs)
+ ckpt_func.append(f'{ckpt_fn_def}\n')
+
+ # if there is more level to fetch
+ if level + 1 < len(node_list[0].meta['activation_checkpoint']):
+ ckpt_regions = _find_nested_ckpt_regions(node_list, level + 1)
+ start_idx = [item[0] for item in ckpt_regions]
+ end_idx = [item[1] for item in ckpt_regions]
+
+ # use ckpt_func_buffer to store nested checkpoint functions
+ ckpt_func_buffer = []
+ node_idx = 0
+ while 1:
+ if node_idx >= len(node_list):
+ break
+
+ if node_idx in start_idx:
+ ckpt_node_list = node_list[node_idx:end_idx[start_idx.index(node_idx)] + 1]
+ emit_ckpt_func(ckpt_func, ckpt_func_buffer, ckpt_node_list, emit_node_func,
+ delete_unused_value_func, level + 1, True)
+ node_idx += len(ckpt_node_list)
+
+ else:
+ node = node_list[node_idx]
+ emit_node_func(node, ckpt_func)
+ ckpt_func[-1] = ' ' + ckpt_func[-1]
+ delete_unused_value_func(node, ckpt_func)
+ node_idx += 1
+
+ ckpt_func.append(' ' + _gen_ckpt_output(outputs) + '\n\n')
+ ckpt_func += ckpt_func_buffer
+ activation_offload = node_list[0].meta.get('activation_offload', False)
+ usage = _gen_ckpt_usage(label, activation_offload, inputs, outputs, False) + '\n'
+ if in_ckpt:
+ usage = ' ' + usage
+ body.append(usage)
+
+ # last level
+ else:
+ for node in node_list:
+ emit_node_func(node, ckpt_func)
+ ckpt_func[-1] = ' ' + ckpt_func[-1]
+ delete_unused_value_func(node, ckpt_func)
+
+ ckpt_func.append(' ' + _gen_ckpt_output(outputs) + '\n\n')
+ activation_offload = node_list[0].meta.get('activation_offload', False)
+ usage = _gen_ckpt_usage(label, activation_offload, inputs, outputs, False) + '\n'
+ if in_ckpt:
+ usage = ' ' + usage
+ body.append(usage)
+
+
+def emit_code_with_nested_activation_checkpoint(body, ckpt_func, nodes, emit_node_func, delete_unused_value_func):
+ """Emit code with nested activation checkpoint
+ When we detect some of the node.activation_checkpoint is a List, we will use
+ this function to emit the activation checkpoint codes.
+ Args:
+ body: forward code
+ ckpt_func: checkpoint functions code
+ nodes: graph.nodes
+ emit_node_func: function to emit node
+ delete_unused_value_func: function to remove the unused value
+ """
+ ckpt_regions = _find_nested_ckpt_regions(nodes, 0)
+ start_idx = [item[0] for item in ckpt_regions]
+ end_idx = [item[1] for item in ckpt_regions]
+
+ # find the offload regions
+ offload_regions, offload_labels = _find_offload_regions(nodes)
+ offload_starts = [item[0] for item in offload_regions]
+ offload_ends = [item[1] for item in offload_regions]
+ offload_inputs = []
+ offload_outputs = []
+ within_offload_region = False
+
+ node_list = list(nodes)
+
+ # find the input and output var names for each offload region
+ for idx, (start, end) in enumerate(offload_regions):
+ offload_node_list = node_list[start:end + 1]
+ inputs, outputs = _find_input_and_output_nodes(offload_node_list)
+ offload_inputs.append(inputs)
+ offload_outputs.append(outputs)
+
+ # this flag is to prevent repeated insert of save tensors
+ # hooks definition in ckpt_func
+ is_hook_inserted = False
+ node_idx = 0
+ while 1:
+ # break if we finish the processing all the nodes
+ if node_idx >= len(node_list):
+ break
+
+ # process ckpt_regions
+ if node_idx in start_idx:
+ ckpt_node_list = node_list[node_idx:end_idx[start_idx.index(node_idx)] + 1]
+ emit_ckpt_func(body, ckpt_func, ckpt_node_list, emit_node_func, delete_unused_value_func)
+ node_idx += len(ckpt_node_list)
+
+ # process node in forward function
+ else:
+ node = node_list[node_idx]
+
+ if node_idx in offload_starts:
+ offload_label = offload_labels[offload_starts.index(node_idx)]
+ _, offload_input, offload_bar = offload_label
+ within_offload_region = True
+
+ # insert hook functions if needed
+ if not is_hook_inserted:
+ pack_hook, unpack_hook = _gen_saved_tensors_hooks()
+ ckpt_func.insert(0, "\n".join([pack_hook, unpack_hook]) + "\n")
+ is_hook_inserted = True
+
+ if offload_input and offload_bar:
+ body.append(_gen_save_on_cpu_context())
+
+ elif offload_input:
+ for par in offload_inputs[offload_label[0]]:
+ body.append(f"setattr({par}, 'offload', True)\n")
+ body.append(_gen_save_tensors_hooks_context(offload_input=True))
+
+ else:
+ for par in offload_inputs[offload_label[0]]:
+ body.append(f"setattr({par}, 'offload', False)\n")
+ body.append(_gen_save_tensors_hooks_context(offload_input=False))
+
+ if within_offload_region:
+ emit_node_func(node, body)
+ body[-1] = ' ' + body[-1]
+ delete_unused_value_func(node, body)
+
+ else:
+ emit_node_func(node, body)
+ delete_unused_value_func(node, body)
+
+ if node_idx in offload_ends:
+ within_offload_region = False
+
+ node_idx += 1
+
+
+def emit_code_with_activation_checkpoint(body, ckpt_func, nodes, emit_node_func, delete_unused_value_func):
+ # find the activation checkpoint regions
+ ckpt_regions = _find_ckpt_regions(nodes)
+ start_idx = [item[0] for item in ckpt_regions]
+ end_idx = [item[1] for item in ckpt_regions]
+ input_vars = []
+ output_vars = []
+ within_ckpt_region = False
+
+ # find the offload regions
+ offload_regions, offload_labels = _find_offload_regions(nodes)
+ offload_starts = [item[0] for item in offload_regions]
+ offload_ends = [item[1] for item in offload_regions]
+ offload_inputs = []
+ offload_outputs = []
+ within_offload_region = False
+
+ node_list = list(nodes)
+
+ # use this variable to avoid inserting hook functions
+ # to ckpt_func repeatedly
+ is_hook_inserted = False
+
+ # find the input and output var names for each region
+ for idx, (start, end) in enumerate(ckpt_regions):
+ ckpt_node_list = node_list[start:end + 1]
+ inputs, outputs = _find_input_and_output_nodes(ckpt_node_list)
+ input_vars.append(inputs)
+ output_vars.append(outputs)
+
+ # find the input and output var names for each offload region
+ for idx, (start, end) in enumerate(offload_regions):
+ offload_node_list = node_list[start:end + 1]
+ inputs, outputs = _find_input_and_output_nodes(offload_node_list)
+ offload_inputs.append(inputs)
+ offload_outputs.append(outputs)
+
+ # append code text to body
+ for idx, node in enumerate(node_list):
+ # if this is the first node of the ckpt region
+ # append the ckpt function defition
+ if idx in start_idx:
+ label = start_idx.index(idx)
+ ckpt_fn_def = _gen_ckpt_fn_def(label, input_vars[label])
+ ckpt_func.append(f'{ckpt_fn_def}\n')
+ within_ckpt_region = True
+
+ if idx in offload_starts:
+ offload_label = offload_labels[offload_starts.index(idx)]
+ _, offload_input, offload_bar = offload_label
+ within_offload_region = True
+
+ # insert hook functions if needed
+ if not is_hook_inserted:
+ pack_hook, unpack_hook = _gen_saved_tensors_hooks()
+ ckpt_func.insert(0, "\n".join([pack_hook, unpack_hook]) + "\n")
+ is_hook_inserted = True
+
+ if offload_input and offload_bar:
+ body.append(_gen_save_on_cpu_context())
+
+ elif offload_input:
+ for par in offload_inputs[offload_label[0]]:
+ body.append(f"setattr({par}, 'offload', True)\n")
+ body.append(_gen_save_tensors_hooks_context(offload_input=True))
+
+ else:
+ for par in offload_inputs[offload_label[0]]:
+ body.append(f"setattr({par}, 'offload', False)\n")
+ body.append(_gen_save_tensors_hooks_context(offload_input=False))
+
+ # NOTE: emit_node does not emit a string with newline. It depends
+ # on delete_unused_values to append one
+ # NOTE: currently we separate body and ckpt_func definition
+ if within_ckpt_region:
+ emit_node_func(node, ckpt_func)
+ ckpt_func[-1] = ' ' + ckpt_func[-1]
+ delete_unused_value_func(node, ckpt_func)
+
+ elif within_offload_region:
+ emit_node_func(node, body)
+ body[-1] = ' ' + body[-1]
+ delete_unused_value_func(node, body)
+
+ else:
+ emit_node_func(node, body)
+ delete_unused_value_func(node, body)
+
+ if idx in end_idx:
+ # if this is the last node of the ckpt region
+ # generate return statement
+ label = end_idx.index(idx)
+ return_statement = _gen_ckpt_output(output_vars[label])
+ return_statement = f' {return_statement}\n\n'
+ ckpt_func.append(return_statement)
+
+ # we need to check if the checkpoint need to offload the input
+ start_node_idx = start_idx[label]
+ if 'activation_offload' in node_list[start_node_idx].meta:
+ activation_offload = node_list[start_node_idx].meta['activation_offload']
+ else:
+ activation_offload = False
+
+ # we need to check if the checkpoint need use_reentrant=False
+ use_reentrant = True
+ non_leaf_input = 0
+ for var in input_vars[label]:
+ input_node = next(item for item in node_list if item.name == var)
+ if input_node.op != "placeholder":
+ non_leaf_input = 1
+ for user in input_node.users:
+ if 'activation_checkpoint' in user.meta:
+ if user.meta['activation_checkpoint'] == label:
+ if user.op == "call_module":
+ if hasattr(user.graph.owning_module.get_submodule(user.target), "inplace"):
+ use_reentrant = not user.graph.owning_module.get_submodule(user.target).inplace
+
+ elif user.op == "call_function":
+ if "inplace" in user.kwargs:
+ use_reentrant = not user.kwargs["inplace"]
+
+ # if all the inputs are leaf nodes, we need to set use_reentrant = False
+ if not non_leaf_input:
+ use_reentrant = False
+
+ # generate checkpoint function call in a new line
+ usage = _gen_ckpt_usage(label, activation_offload, input_vars[label], output_vars[label], use_reentrant)
+ usage += '\n'
+ body.append(usage)
+ within_ckpt_region = False
+
+ if idx in offload_ends:
+ within_offload_region = False
+
+
+if CODEGEN_AVAILABLE:
+
+ class ActivationCheckpointCodeGen(CodeGen):
+
+ def _gen_python_code(self, nodes, root_module: str, namespace: _Namespace) -> PythonCode:
+ free_vars: List[str] = []
+ body: List[str] = []
+ globals_: Dict[str, Any] = {}
+ wrapped_fns: Dict[str, None] = {}
+
+ # Wrap string in list to pass by reference
+ maybe_return_annotation: List[str] = ['']
+
+ def add_global(name_hint: str, obj: Any):
+ """Add an obj to be tracked as a global.
+ We call this for names that reference objects external to the
+ Graph, like functions or types.
+ Returns: the global name that should be used to reference 'obj' in generated source.
+ """
+ if _is_from_torch(obj) and obj != torch.device: # to support registering torch.device
+ # HACK: workaround for how torch custom ops are registered. We
+ # can't import them like normal modules so they must retain their
+ # fully qualified name.
+ return _get_qualified_name(obj)
+
+ # normalize the name hint to get a proper identifier
+ global_name = namespace.create_name(name_hint, obj)
+
+ if global_name in globals_:
+ assert globals_[global_name] is obj
+ return global_name
+ globals_[global_name] = obj
+ return global_name
+
+ # set _custom_builtins here so that we needn't import colossalai in forward
+ _custom_builtins["colossalai"] = _CustomBuiltin("import colossalai", colossalai)
+
+ # Pre-fill the globals table with registered builtins.
+ for name, (_, obj) in _custom_builtins.items():
+ add_global(name, obj)
+
+ def type_repr(o: Any):
+ if o == ():
+ # Empty tuple is used for empty tuple type annotation Tuple[()]
+ return '()'
+
+ typename = _type_repr(o)
+
+ if hasattr(o, '__origin__'):
+ # This is a generic type, e.g. typing.List[torch.Tensor]
+ origin_type = _origin_type_map.get(o.__origin__, o.__origin__)
+ origin_typename = add_global(_type_repr(origin_type), origin_type)
+
+ if hasattr(o, '__args__'):
+ # Assign global names for each of the inner type variables.
+ args = [type_repr(arg) for arg in o.__args__]
+
+ if len(args) == 0:
+ # Bare type, such as `typing.Tuple` with no subscript
+ # This code-path used in Python < 3.9
+ return origin_typename
+
+ return f'{origin_typename}[{",".join(args)}]'
+ else:
+ # Bare type, such as `typing.Tuple` with no subscript
+ # This code-path used in Python 3.9+
+ return origin_typename
+
+ # Common case: this is a regular module name like 'foo.bar.baz'
+ return add_global(typename, o)
+
+ def _format_args(args: Tuple[Argument, ...], kwargs: Dict[str, Argument]) -> str:
+
+ def _get_repr(arg):
+ # Handle NamedTuples (if it has `_fields`) via add_global.
+ if isinstance(arg, tuple) and hasattr(arg, '_fields'):
+ qualified_name = _get_qualified_name(type(arg))
+ global_name = add_global(qualified_name, type(arg))
+ return f"{global_name}{repr(tuple(arg))}"
+ return repr(arg)
+
+ args_s = ', '.join(_get_repr(a) for a in args)
+ kwargs_s = ', '.join(f'{k} = {_get_repr(v)}' for k, v in kwargs.items())
+ if args_s and kwargs_s:
+ return f'{args_s}, {kwargs_s}'
+ return args_s or kwargs_s
+
+ # Run through reverse nodes and record the first instance of a use
+ # of a given node. This represents the *last* use of the node in the
+ # execution order of the program, which we will use to free unused
+ # values
+ node_to_last_use: Dict[Node, Node] = {}
+ user_to_last_uses: Dict[Node, List[Node]] = {}
+
+ def register_last_uses(n: Node, user: Node):
+ if n not in node_to_last_use:
+ node_to_last_use[n] = user
+ user_to_last_uses.setdefault(user, []).append(n)
+
+ for node in reversed(nodes):
+ map_arg(node.args, lambda n: register_last_uses(n, node))
+ map_arg(node.kwargs, lambda n: register_last_uses(n, node))
+
+ # NOTE: we add a variable to distinguish body and ckpt_func
+ def delete_unused_values(user: Node, body):
+ """
+ Delete values after their last use. This ensures that values that are
+ not used in the remainder of the code are freed and the memory usage
+ of the code is optimal.
+ """
+ if user.op == 'placeholder':
+ return
+ if user.op == 'output':
+ body.append('\n')
+ return
+ nodes_to_delete = user_to_last_uses.get(user, [])
+ if len(nodes_to_delete):
+ to_delete_str = ' = '.join([repr(n) for n in nodes_to_delete] + ['None'])
+ body.append(f'; {to_delete_str}\n')
+ else:
+ body.append('\n')
+
+ # NOTE: we add a variable to distinguish body and ckpt_func
+ def emit_node(node: Node, body):
+ maybe_type_annotation = '' if node.type is None else f' : {type_repr(node.type)}'
+ if node.op == 'placeholder':
+ assert isinstance(node.target, str)
+ maybe_default_arg = '' if not node.args else f' = {repr(node.args[0])}'
+ free_vars.append(f'{node.target}{maybe_type_annotation}{maybe_default_arg}')
+ raw_name = node.target.replace('*', '')
+ if raw_name != repr(node):
+ body.append(f'{repr(node)} = {raw_name}\n')
+ return
+ elif node.op == 'call_method':
+ assert isinstance(node.target, str)
+ body.append(
+ f'{repr(node)}{maybe_type_annotation} = {_format_target(repr(node.args[0]), node.target)}'
+ f'({_format_args(node.args[1:], node.kwargs)})')
+ return
+ elif node.op == 'call_function':
+ assert callable(node.target)
+ # pretty print operators
+ if node.target.__module__ == '_operator' and node.target.__name__ in magic_methods:
+ assert isinstance(node.args, tuple)
+ body.append(f'{repr(node)}{maybe_type_annotation} = '
+ f'{magic_methods[node.target.__name__].format(*(repr(a) for a in node.args))}')
+ return
+
+ # pretty print inplace operators; required for jit.script to work properly
+ # not currently supported in normal FX graphs, but generated by torchdynamo
+ if node.target.__module__ == '_operator' and node.target.__name__ in inplace_methods:
+ body.append(f'{inplace_methods[node.target.__name__].format(*(repr(a) for a in node.args))}; '
+ f'{repr(node)}{maybe_type_annotation} = {repr(node.args[0])}')
+ return
+
+ qualified_name = _get_qualified_name(node.target)
+ global_name = add_global(qualified_name, node.target)
+ # special case for getattr: node.args could be 2-argument or 3-argument
+ # 2-argument: attribute access; 3-argument: fall through to attrib function call with default value
+ if global_name == 'getattr' and \
+ isinstance(node.args, tuple) and \
+ isinstance(node.args[1], str) and \
+ node.args[1].isidentifier() and \
+ len(node.args) == 2:
+ body.append(
+ f'{repr(node)}{maybe_type_annotation} = {_format_target(repr(node.args[0]), node.args[1])}')
+ return
+ body.append(
+ f'{repr(node)}{maybe_type_annotation} = {global_name}({_format_args(node.args, node.kwargs)})')
+ if node.meta.get('is_wrapped', False):
+ wrapped_fns.setdefault(global_name)
+ return
+ elif node.op == 'call_module':
+ assert isinstance(node.target, str)
+ body.append(f'{repr(node)}{maybe_type_annotation} = '
+ f'{_format_target(root_module, node.target)}({_format_args(node.args, node.kwargs)})')
+ return
+ elif node.op == 'get_attr':
+ assert isinstance(node.target, str)
+ body.append(f'{repr(node)}{maybe_type_annotation} = {_format_target(root_module, node.target)}')
+ return
+ elif node.op == 'output':
+ if node.type is not None:
+ maybe_return_annotation[0] = f" -> {type_repr(node.type)}"
+ body.append(self.generate_output(node.args[0]))
+ return
+ raise NotImplementedError(f'node: {node.op} {node.target}')
+
+ # Modified for activation checkpointing
+ ckpt_func = []
+
+ # if any node has a list of labels for activation_checkpoint, we
+ # will use nested type of activation checkpoint codegen
+ if any(isinstance(node.meta.get('activation_checkpoint', None), Iterable) for node in nodes):
+ emit_code_with_nested_activation_checkpoint(body, ckpt_func, nodes, emit_node, delete_unused_values)
+ else:
+ emit_code_with_activation_checkpoint(body, ckpt_func, nodes, emit_node, delete_unused_values)
+
+ if len(body) == 0:
+ # If the Graph has no non-placeholder nodes, no lines for the body
+ # have been emitted. To continue to have valid Python code, emit a
+ # single pass statement
+ body.append('pass\n')
+
+ if len(wrapped_fns) > 0:
+ wrap_name = add_global('wrap', torch.fx.wrap)
+ wrap_stmts = '\n'.join([f'{wrap_name}("{name}")' for name in wrapped_fns])
+ else:
+ wrap_stmts = ''
+
+ if self._body_transformer:
+ body = self._body_transformer(body)
+
+ for name, value in self.additional_globals():
+ add_global(name, value)
+
+ # as we need colossalai.utils.checkpoint, we need to import colossalai
+ # in forward function
+ prologue = self.gen_fn_def(free_vars, maybe_return_annotation[0])
+ prologue = ''.join(ckpt_func) + prologue
+ prologue = prologue
+
+ code = ''.join(body)
+ code = '\n'.join(' ' + line for line in code.split('\n'))
+ fn_code = f"""
+{wrap_stmts}
+{prologue}
+{code}"""
+ return PythonCode(fn_code, globals_)
+
+else:
+
+ def python_code_with_activation_checkpoint(self, root_module: str, namespace: _Namespace) -> PythonCode:
+ """
+ This method is copied from the _python_code of torch.fx.graph.Graph. Modifications are made so that it can generate
+ code for activation checkpoint.
+ """
+ free_vars: List[str] = []
+ body: List[str] = []
+ globals_: Dict[str, Any] = {}
+ wrapped_fns: Dict[str, None] = {}
+
+ # Wrap string in list to pass by reference
+ maybe_return_annotation: List[str] = ['']
+
+ def add_global(name_hint: str, obj: Any):
+ """Add an obj to be tracked as a global.
+ We call this for names that reference objects external to the
+ Graph, like functions or types.
+ Returns: the global name that should be used to reference 'obj' in generated source.
+ """
+ if _is_from_torch(obj) and obj != torch.device: # to support registering torch.device
+ # HACK: workaround for how torch custom ops are registered. We
+ # can't import them like normal modules so they must retain their
+ # fully qualified name.
+ return _get_qualified_name(obj)
+
+ # normalize the name hint to get a proper identifier
+ global_name = namespace.create_name(name_hint, obj)
+
+ if global_name in globals_:
+ assert globals_[global_name] is obj
+ return global_name
+ globals_[global_name] = obj
+ return global_name
+
+ # set _custom_builtins here so that we needn't import colossalai in forward
+ _custom_builtins["colossalai"] = _CustomBuiltin("import colossalai", colossalai)
+
+ # Pre-fill the globals table with registered builtins.
+ for name, (_, obj) in _custom_builtins.items():
+ add_global(name, obj)
+
+ def type_repr(o: Any):
+ if o == ():
+ # Empty tuple is used for empty tuple type annotation Tuple[()]
+ return '()'
+
+ typename = _type_repr(o)
+
+ # This is a generic type, e.g. typing.List[torch.Tensor]
+ if hasattr(o, '__origin__'):
+ origin_type = _origin_type_map.get(o.__origin__, o.__origin__)
+ origin_typename = add_global(_type_repr(origin_type), origin_type)
+
+ # Assign global names for each of the inner type variables.
+ args = [type_repr(arg) for arg in o.__args__]
+
+ return f'{origin_typename}[{",".join(args)}]'
+
+ # Common case: this is a regular module name like 'foo.bar.baz'
+ return add_global(typename, o)
+
+ # Run through reverse nodes and record the first instance of a use
+ # of a given node. This represents the *last* use of the node in the
+ # execution order of the program, which we will use to free unused
+ # values
+ node_to_last_use: Dict[Node, Node] = {}
+ user_to_last_uses: Dict[Node, List[Node]] = {}
+
+ def register_last_uses(n: Node, user: Node):
+ if n not in node_to_last_use:
+ node_to_last_use[n] = user
+ user_to_last_uses.setdefault(user, []).append(n)
+
+ for node in reversed(self.nodes):
+ map_arg(node.args, lambda n: register_last_uses(n, node))
+ map_arg(node.kwargs, lambda n: register_last_uses(n, node))
+
+ # NOTE: we add a variable to distinguish body and ckpt_func
+ def delete_unused_values(user: Node, body):
+ """
+ Delete values after their last use. This ensures that values that are
+ not used in the remainder of the code are freed and the memory usage
+ of the code is optimal.
+ """
+ if user.op == 'placeholder':
+ return
+ if user.op == 'output':
+ body.append('\n')
+ return
+ nodes_to_delete = user_to_last_uses.get(user, [])
+ if len(nodes_to_delete):
+ to_delete_str = ' = '.join([repr(n) for n in nodes_to_delete] + ['None'])
+ body.append(f'; {to_delete_str}\n')
+ else:
+ body.append('\n')
+
+ # NOTE: we add a variable to distinguish body and ckpt_func
+ def emit_node(node: Node, body):
+ maybe_type_annotation = '' if node.type is None else f' : {type_repr(node.type)}'
+ if node.op == 'placeholder':
+ assert isinstance(node.target, str)
+ maybe_default_arg = '' if not node.args else f' = {repr(node.args[0])}'
+ free_vars.append(f'{node.target}{maybe_type_annotation}{maybe_default_arg}')
+ raw_name = node.target.replace('*', '')
+ if raw_name != repr(node):
+ body.append(f'{repr(node)} = {raw_name}\n')
+ return
+ elif node.op == 'call_method':
+ assert isinstance(node.target, str)
+ body.append(f'{repr(node)}{maybe_type_annotation} = {_format_target(repr(node.args[0]), node.target)}'
+ f'({_format_args(node.args[1:], node.kwargs)})')
+ return
+ elif node.op == 'call_function':
+ assert callable(node.target)
+ # pretty print operators
+ if node.target.__module__ == '_operator' and node.target.__name__ in magic_methods:
+ assert isinstance(node.args, tuple)
+ body.append(f'{repr(node)}{maybe_type_annotation} = '
+ f'{magic_methods[node.target.__name__].format(*(repr(a) for a in node.args))}')
+ return
+ qualified_name = _get_qualified_name(node.target)
+ global_name = add_global(qualified_name, node.target)
+ # special case for getattr: node.args could be 2-argument or 3-argument
+ # 2-argument: attribute access; 3-argument: fall through to attrib function call with default value
+ if global_name == 'getattr' and \
+ isinstance(node.args, tuple) and \
+ isinstance(node.args[1], str) and \
+ node.args[1].isidentifier() and \
+ len(node.args) == 2:
+ body.append(
+ f'{repr(node)}{maybe_type_annotation} = {_format_target(repr(node.args[0]), node.args[1])}')
+ return
+ body.append(
+ f'{repr(node)}{maybe_type_annotation} = {global_name}({_format_args(node.args, node.kwargs)})')
+ if node.meta.get('is_wrapped', False):
+ wrapped_fns.setdefault(global_name)
+ return
+ elif node.op == 'call_module':
+ assert isinstance(node.target, str)
+ body.append(f'{repr(node)}{maybe_type_annotation} = '
+ f'{_format_target(root_module, node.target)}({_format_args(node.args, node.kwargs)})')
+ return
+ elif node.op == 'get_attr':
+ assert isinstance(node.target, str)
+ body.append(f'{repr(node)}{maybe_type_annotation} = {_format_target(root_module, node.target)}')
+ return
+ elif node.op == 'output':
+ if node.type is not None:
+ maybe_return_annotation[0] = f" -> {type_repr(node.type)}"
+ if self._pytree_info is None:
+ body.append(f'return {repr(node.args[0])}')
+ else:
+ body.append(f'return pytree.tree_unflatten({repr(node.args[0])}, self._out_spec)')
+ return
+ raise NotImplementedError(f'node: {node.op} {node.target}')
+
+ # Modified for activation checkpointing
+ ckpt_func = []
+
+ # if any node has a list of labels for activation_checkpoint, we
+ # will use nested type of activation checkpoint codegen
+ if any(isinstance(node.meta.get('activation_checkpoint', None), Iterable) for node in self.nodes):
+ emit_code_with_nested_activation_checkpoint(body, ckpt_func, self.nodes, emit_node, delete_unused_values)
+ else:
+ emit_code_with_activation_checkpoint(body, ckpt_func, self.nodes, emit_node, delete_unused_values)
+
+ if len(body) == 0:
+ # If the Graph has no non-placeholder nodes, no lines for the body
+ # have been emitted. To continue to have valid Python code, emit a
+ # single pass statement
+ body.append('pass\n')
+ if self._pytree_info is not None:
+ orig_args = self._pytree_info.orig_args
+ has_orig_self = (orig_args[0] == 'self')
+ if has_orig_self:
+ free_vars.insert(0, 'self')
+ if len(free_vars) > 0: # pytree has placeholders in it
+ body.insert(
+ 0,
+ f"{', '.join(free_vars)}, = fx_pytree.tree_flatten_spec([{', '.join(orig_args)}], self._in_spec)\n")
+ else:
+ orig_args = free_vars
+
+ if len(wrapped_fns) > 0:
+ wrap_name = add_global('wrap', torch.fx.wrap)
+ wrap_stmts = '\n'.join([f'{wrap_name}("{name}")' for name in wrapped_fns])
+ else:
+ wrap_stmts = ''
+
+ ckpt_func = ''.join(ckpt_func)
+
+ # If the original function didn't have self as its first argument, we
+ # would have added it.
+ if len(orig_args) == 0 or orig_args[0] != 'self':
+ orig_args.insert(0, 'self')
+ code = ''.join(body)
+ code = '\n'.join(' ' + line for line in code.split('\n'))
+
+ # as we need colossalai.utils.checkpoint, we need to import colossalai
+ # in forward function
+ fn_code = f"""
+{wrap_stmts}
+{ckpt_func}
+def forward({', '.join(orig_args)}){maybe_return_annotation[0]}:
+{code}"""
+ return PythonCode(fn_code, globals_)
diff --git a/colossalai/fx/graph_module.py b/colossalai/fx/graph_module.py
new file mode 100644
index 0000000000000000000000000000000000000000..ebb9975f27dbf312870fdb9d7beea98faf7889b7
--- /dev/null
+++ b/colossalai/fx/graph_module.py
@@ -0,0 +1,174 @@
+import os
+import warnings
+from pathlib import Path
+from typing import Any, Dict, List, Optional, Set, Type, Union
+
+import torch
+import torch.nn as nn
+from torch.nn.modules.module import _addindent
+
+try:
+ from torch.fx.graph import Graph, PythonCode, _custom_builtins, _is_from_torch, _PyTreeCodeGen
+ from torch.fx.graph_module import GraphModule, _EvalCacheLoader, _exec_with_source, _forward_from_src, _WrappedCall
+
+ from colossalai.fx.codegen.activation_checkpoint_codegen import ActivationCheckpointCodeGen
+ COLOGM = True
+except:
+ from torch.fx.graph import Graph
+ from torch.fx.graph_module import GraphModule
+ COLOGM = False
+
+if COLOGM:
+
+ class ColoGraphModule(GraphModule):
+
+ def __init__(self,
+ root: Union[torch.nn.Module, Dict[str, Any]],
+ graph: Graph,
+ class_name: str = 'GraphModule',
+ ckpt_codegen: bool = True):
+ if ckpt_codegen:
+ graph.set_codegen(ActivationCheckpointCodeGen())
+ super().__init__(root, graph, class_name)
+
+ def bind(self, ckpt_def, globals):
+ """Bind function needed for correctly execute gm forward
+
+ We need to bind checkpoint functions and saved_tensor_hooks functions
+ to gm so that we could correctly execute gm forward
+
+ Args:
+ ckpt_def (_type_): definition before the forward function
+ globals (_type_): global variables
+ """
+
+ ckpt_code = "\n".join(ckpt_def)
+ globals_copy = globals.copy()
+ _exec_with_source(ckpt_code, globals_copy)
+ func_list = [func for func in globals_copy.keys() if "checkpoint" in func or "pack" in func]
+ for func in func_list:
+ tmp_func = globals_copy[func]
+ setattr(self, func, tmp_func.__get__(self, self.__class__))
+ del globals_copy[func]
+
+ def recompile(self) -> PythonCode:
+ """
+ Recompile this GraphModule from its ``graph`` attribute. This should be
+ called after editing the contained ``graph``, otherwise the generated
+ code of this ``GraphModule`` will be out of date.
+ """
+ if isinstance(self._graph._codegen, _PyTreeCodeGen):
+ self._in_spec = self._graph._codegen.pytree_info.in_spec
+ self._out_spec = self._graph._codegen.pytree_info.out_spec
+ python_code = self._graph.python_code(root_module='self')
+ self._code = python_code.src
+
+ # To split ckpt functions code and forward code
+ _code_list = self._code.split("\n")
+ _fwd_def = [item for item in _code_list if "def forward" in item][0]
+ _fwd_idx = _code_list.index(_fwd_def)
+ ckpt_def = _code_list[:_fwd_idx]
+ self._code = "\n".join(_code_list[_fwd_idx:])
+
+ self.bind(ckpt_def, python_code.globals)
+
+ cls = type(self)
+ cls.forward = _forward_from_src(self._code, python_code.globals)
+
+ # Determine whether this class explicitly defines a __call__ implementation
+ # to wrap. If it does, save it in order to have wrapped_call invoke it.
+ # If it does not, wrapped_call can use a dynamic call to super() instead.
+ # In most cases, super().__call__ should be torch.nn.Module.__call__.
+ # We do not want to hold a reference to Module.__call__ here; doing so will
+ # bypass patching of torch.nn.Module.__call__ done while symbolic tracing.
+ cls_call = cls.__call__ if "__call__" in vars(cls) else None
+
+ if '_wrapped_call' not in vars(cls):
+ cls._wrapped_call = _WrappedCall(cls, cls_call) # type: ignore[attr-defined]
+
+ def call_wrapped(self, *args, **kwargs):
+ return self._wrapped_call(self, *args, **kwargs)
+
+ cls.__call__ = call_wrapped
+
+ # reset self._code to original src, otherwise to_folder will be wrong
+ self._code = python_code.src
+ return python_code
+
+ def to_folder(self, folder: Union[str, os.PathLike], module_name: str = "FxModule"):
+ """Dumps out module to ``folder`` with ``module_name`` so that it can be
+ imported with ``from import ``
+
+ Args:
+
+ folder (Union[str, os.PathLike]): The folder to write the code out to
+
+ module_name (str): Top-level name to use for the ``Module`` while
+ writing out the code
+ """
+ folder = Path(folder)
+ Path(folder).mkdir(exist_ok=True)
+ torch.save(self.state_dict(), folder / 'state_dict.pt')
+ tab = " " * 4
+
+ # we add import colossalai here
+ model_str = f"""
+import torch
+from torch.nn import *
+import colossalai
+
+
+class {module_name}(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+"""
+
+ def _gen_model_repr(module_name: str, module: torch.nn.Module) -> Optional[str]:
+ safe_reprs = [
+ nn.Linear, nn.Conv1d, nn.Conv2d, nn.Conv3d, nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d
+ ]
+ if type(module) in safe_reprs:
+ return f"{module.__repr__()}"
+ else:
+ return None
+
+ blobified_modules = []
+ for module_name, module in self.named_children():
+ module_str = _gen_model_repr(module_name, module)
+ if module_str is None:
+ module_file = folder / f'{module_name}.pt'
+ torch.save(module, module_file)
+ blobified_modules.append(module_name)
+ module_repr = module.__repr__().replace('\r', ' ').replace('\n', ' ')
+ module_str = f"torch.load(r'{module_file}') # {module_repr}"
+ model_str += f"{tab*2}self.{module_name} = {module_str}\n"
+
+ for buffer_name, buffer in self._buffers.items():
+ if buffer is None:
+ continue
+ model_str += f"{tab*2}self.register_buffer('{buffer_name}', torch.empty({list(buffer.shape)}, dtype={buffer.dtype}))\n"
+
+ for param_name, param in self._parameters.items():
+ if param is None:
+ continue
+ model_str += f"{tab*2}self.{param_name} = torch.nn.Parameter(torch.empty({list(param.shape)}, dtype={param.dtype}))\n"
+
+ model_str += f"{tab*2}self.load_state_dict(torch.load(r'{folder}/state_dict.pt'))\n"
+ model_str += f"{_addindent(self.code, 4)}\n"
+
+ module_file = folder / 'module.py'
+ module_file.write_text(model_str)
+
+ init_file = folder / '__init__.py'
+ init_file.write_text('from .module import *')
+
+ if len(blobified_modules) > 0:
+ warnings.warn("Was not able to save the following children modules as reprs -"
+ f"saved as pickled files instead: {blobified_modules}")
+
+else:
+
+ class ColoGraphModule(GraphModule):
+
+ def __init__(self, root: Union[torch.nn.Module, Dict[str, Any]], graph: Graph, class_name: str = 'GraphModule'):
+ super().__init__(root, graph, class_name)
diff --git a/colossalai/fx/passes/__init__.py b/colossalai/fx/passes/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6f948cb2d3b37ce73e03044a944732a7d8370d6b
--- /dev/null
+++ b/colossalai/fx/passes/__init__.py
@@ -0,0 +1,4 @@
+from .adding_split_node_pass import balanced_split_pass, split_with_split_nodes_pass
+from .concrete_info_prop import ConcreteInfoProp
+from .meta_info_prop import MetaInfoProp, metainfo_trace
+from .shard_1d_pass import column_shard_linear_pass, row_shard_linear_pass
diff --git a/colossalai/fx/passes/adding_split_node_pass.py b/colossalai/fx/passes/adding_split_node_pass.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c7b842b530cc12fb669154456dc51e489ccc85d
--- /dev/null
+++ b/colossalai/fx/passes/adding_split_node_pass.py
@@ -0,0 +1,363 @@
+import numpy as np
+import torch
+import tqdm
+from torch.fx import symbolic_trace
+from torch.fx.node import Node
+
+from colossalai.fx.passes.split_module import split_module
+
+
+def pipe_split():
+ pass
+
+
+def block_split():
+ pass
+
+
+# Construct blocks with the condition that (block_flops / total_flops) >= limit.
+def construct_blocks(gm: torch.fx.GraphModule, limit=0.01):
+ total_fwd_flop = 0
+ total_bwd_flop = 0
+ for node in gm.graph.nodes:
+ total_fwd_flop += node.fwd_flop
+ total_bwd_flop += node.bwd_flop
+
+ total_flop = total_fwd_flop + total_bwd_flop
+ per_block_flop = total_flop * limit
+ accumulate_fwd_flop = 0
+ accumulate_bwd_flop = 0
+ block_nodes = []
+ for node in gm.graph.nodes:
+ if 'block_split' in node.name:
+ continue
+ accumulate_fwd_flop += node.fwd_flop
+ accumulate_bwd_flop += node.bwd_flop
+ if accumulate_fwd_flop + accumulate_bwd_flop >= per_block_flop:
+ with gm.graph.inserting_after(node):
+ block_node = gm.graph.create_node('call_function', block_split)
+ setattr(block_node, 'fwd_flop', accumulate_fwd_flop)
+ setattr(block_node, 'bwd_flop', accumulate_bwd_flop)
+ accumulate_fwd_flop = 0
+ accumulate_bwd_flop = 0
+ block_nodes.append(block_node)
+
+ return block_nodes
+
+
+def remove_blocks(gm: torch.fx.GraphModule):
+ for node in gm.graph.nodes:
+ if (node.op, node.target) == ('call_function', block_split):
+ gm.graph.erase_node(node)
+
+
+def get_compute_costs(node_list):
+ num_nodes = len(node_list)
+ all_compute_cost = np.full((num_nodes, num_nodes), np.inf, dtype=np.float64)
+
+ for start in tqdm.tqdm(range(num_nodes), desc='start pos', position=0):
+ for end in tqdm.tqdm(range(start, num_nodes), desc='end pos', position=1, leave=False):
+ selected_flops = [(node_list[i].fwd_flop + node_list[i].bwd_flop) for i in range(start, end + 1)]
+ all_compute_cost[start, end] = sum(selected_flops)
+
+ return all_compute_cost
+
+
+def do_dp_split_gpipe_impl(num_nodes, num_stages, num_microbatches, compute_costs, max_compute_cost):
+ """The core implementation of the DP algorithm."""
+ # Adapted from Alpa DP Formulation.
+ # For f, node ID start from 0
+ # f[number of stages,
+ # node id that is currently being considered]
+
+ # record time cost(assess by fwd+bwd flop now)
+ f = np.full((num_stages + 1, num_nodes + 1), np.inf, dtype=np.float32)
+
+ # record max stage compute cost among all stages in this partition.
+ f_stage_max = np.full((num_stages + 1, num_nodes + 1), 0.0, dtype=np.float32)
+ # record start node index for next stage in this partition
+ f_argmin = np.full((num_stages + 1, num_nodes + 1), -1, dtype=np.int32)
+ f[0, num_nodes] = 0
+ for s in tqdm.tqdm(range(1, num_stages + 1), desc='stage', position=2, leave=False): # pylint: disable=too-many-nested-blocks
+ for i in tqdm.tqdm(range(num_nodes - 1, -1, -1), desc='start node', position=3, leave=False):
+ for k in tqdm.tqdm(range(num_nodes, i, -1), desc='mid node', position=4, leave=False):
+ stage_cost = compute_costs[i, k - 1]
+ new_cost = f[s - 1, k] + stage_cost
+ if (stage_cost <= max_compute_cost and new_cost < f[s, i]):
+ f[s, i] = new_cost
+ f_stage_max[s, i] = max(f_stage_max[s - 1, k], stage_cost)
+ f_argmin[s, i] = k
+
+ best_total_cost = f[num_stages, 0]
+ if np.isinf(best_total_cost):
+ return np.inf, None
+
+ total_cost = f[num_stages, 0] + (num_microbatches - 1) * f_stage_max[num_stages, 0]
+
+ current_s = num_stages
+ current_node = 0
+
+ res = []
+ while current_s > 0 and current_node < num_nodes:
+ next_start_node = f_argmin[current_s, current_node]
+ res.append((current_node, next_start_node))
+ current_s -= 1
+ current_node = next_start_node
+
+ return total_cost, res
+
+
+def do_dp_split_gpipe(node_list, compute_costs, num_stages: int, num_microbatches: int):
+ # Ignore the memory cost profiling in Alpa's design for convenience.
+ max_compute_costs = np.sort(np.unique(compute_costs))
+ best_cost = np.inf
+ best_solution = None
+ last_max_compute_cost = 0.0
+ gap = 1e6 # temporary magic number, unit: flops
+
+ for max_compute_cost in tqdm.tqdm(max_compute_costs):
+ # Pruning to reduce search space.
+ if max_compute_cost * num_microbatches >= best_cost:
+ break
+ if max_compute_cost - last_max_compute_cost < gap:
+ continue
+
+ cost, solution = do_dp_split_gpipe_impl(len(node_list), num_stages, num_microbatches, compute_costs,
+ max_compute_cost)
+
+ if cost < best_cost:
+ best_cost = cost
+ best_solution = solution
+ last_max_compute_cost = max_compute_cost
+ return best_cost, best_solution
+
+
+# Auto DP partition based on Alpa.
+# Adapted to Gpipe Scheduler
+# split_mode:
+# 'node': fx_node
+# 'block': many fx_nodes construct a block
+def gpipe_dp_split_pass(gm: torch.fx.GraphModule, pp_size: int, num_microbatches: int, mode='block', block_limit=0.01):
+ assert mode in ['node', 'block']
+
+ # nodes or blocks will be used in partition.
+ node_list = []
+ if mode == 'node':
+ for node in gm.graph.nodes:
+ node_list.append(node)
+ elif mode == 'block':
+ node_list = construct_blocks(gm, limit=block_limit)
+ else:
+ pass
+
+ compute_costs = get_compute_costs(node_list)
+
+ best_cost, best_solution = do_dp_split_gpipe(node_list, compute_costs, pp_size, num_microbatches)
+
+ for (_, next_start_node) in best_solution:
+ if pp_size <= 1:
+ break
+ node = node_list[next_start_node]
+ with gm.graph.inserting_before(node):
+ split_node = gm.graph.create_node('call_function', pipe_split)
+ pp_size -= 1
+
+ # remove block node if possible
+ if mode == 'block':
+ remove_blocks(gm)
+
+ gm.recompile()
+ return gm
+
+
+def avgcompute_split_pass(gm: torch.fx.GraphModule, pp_size: int):
+ """
+ In avgcompute_split_pass, we split module by the fwd flops.
+ """
+ mod_graph = gm.graph
+ # To use avgcompute_split_pass, we need run meta_info_prop interpreter first.
+ # If nodes don't have meta info, this pass will fall back to normal balanced split pass.
+ check_node = list(mod_graph.nodes)[0]
+ if 'tensor_meta' not in check_node.meta:
+ return balanced_split_pass(gm, pp_size)
+
+ total_fwd_flop = 0
+ for node in mod_graph.nodes:
+ total_fwd_flop += node.fwd_flop
+
+ partition_flop = total_fwd_flop // pp_size
+ accumulate_fwd_flop = 0
+ for node in mod_graph.nodes:
+ if pp_size <= 1:
+ break
+ if 'pipe_split' in node.name:
+ continue
+ accumulate_fwd_flop += node.fwd_flop
+ if accumulate_fwd_flop >= partition_flop:
+ total_fwd_flop = total_fwd_flop - accumulate_fwd_flop
+ accumulate_fwd_flop = 0
+ pp_size -= 1
+ partition_flop = total_fwd_flop // pp_size
+ with mod_graph.inserting_after(node):
+ split_node = mod_graph.create_node('call_function', pipe_split)
+ gm.recompile()
+ return gm
+
+
+def avgnode_split_pass(gm: torch.fx.GraphModule, pp_size: int):
+ """
+ In avgnode_split_pass, simpliy split graph by node number.
+ """
+ mod_graph = gm.graph
+ avg_num_node = len(mod_graph.nodes) // pp_size
+ accumulate_num_node = 0
+ for node in mod_graph.nodes:
+ if pp_size <= 1:
+ break
+ accumulate_num_node += 1
+ if accumulate_num_node >= avg_num_node:
+ accumulate_num_node = 0
+ pp_size -= 1
+ if node.next.op == 'output':
+ with mod_graph.inserting_before(node):
+ split_node = mod_graph.create_node('call_function', pipe_split)
+ else:
+ with mod_graph.inserting_after(node):
+ split_node = mod_graph.create_node('call_function', pipe_split)
+ gm.recompile()
+ return gm
+
+
+def balanced_split_pass(gm: torch.fx.GraphModule, pp_size: int):
+ """
+ In balanced_split_pass, we split module by the size of parameters(weights+bias).
+ """
+ mod_graph = gm.graph
+ total_param_amount = 0
+ for param in mod_graph.owning_module.parameters():
+ total_param_amount += param.numel()
+ params_per_partition = total_param_amount // pp_size
+ accumulate_param_amount = 0
+ for node in mod_graph.nodes:
+ if pp_size <= 1:
+ break
+ if node.op == "call_module":
+ target_module = node.graph.owning_module.get_submodule(node.target)
+ for param in target_module.parameters():
+ accumulate_param_amount += param.numel()
+ if accumulate_param_amount >= params_per_partition:
+ accumulate_param_amount = 0
+ pp_size -= 1
+ # If the next node is output node, we will insert split annotation before
+ # node to make sure there is at least one node in last partition.
+ if node.next.op == 'output':
+ with mod_graph.inserting_before(node):
+ split_node = mod_graph.create_node('call_function', pipe_split)
+ else:
+ with mod_graph.inserting_after(node):
+ split_node = mod_graph.create_node('call_function', pipe_split)
+ if pp_size > 1:
+ node_counter = 0
+ for node in mod_graph.nodes:
+ if pp_size <= 1:
+ break
+ if node.op == 'placeholder':
+ continue
+ elif node_counter == 0:
+ node_counter += 1
+ else:
+ pp_size -= 1
+ node_counter = 0
+ with mod_graph.inserting_before(node):
+ split_node = mod_graph.create_node('call_function', pipe_split)
+
+ gm.recompile()
+ return gm
+
+
+def balanced_split_pass_v2(gm: torch.fx.GraphModule, pp_size: int):
+ """
+ In balanced_split_pass_v12, we split module by the size of nodes(weights+bias+outputs).
+ """
+ mod_graph = gm.graph
+ # To use balanced_split_pass_v2, we need run meta_info_prop interpreter first.
+ # If nodes don't have meta info, this pass will fall back to normal balanced split pass.
+ check_node = list(mod_graph.nodes)[0]
+ if 'tensor_meta' not in check_node.meta:
+ return balanced_split_pass(gm, pp_size)
+
+ total_element_size = 0
+ for node in mod_graph.nodes:
+ total_element_size += node.node_size
+
+ partition_size = total_element_size // pp_size
+ accumulate_node_size = 0
+ for node in mod_graph.nodes:
+ if pp_size <= 1:
+ break
+ if 'pipe_split' in node.name:
+ continue
+ accumulate_node_size += node.node_size
+ if accumulate_node_size >= partition_size:
+ total_element_size = total_element_size - accumulate_node_size
+ accumulate_node_size = 0
+ pp_size -= 1
+ partition_size = total_element_size // pp_size
+ with mod_graph.inserting_after(node):
+ split_node = mod_graph.create_node('call_function', pipe_split)
+ gm.recompile()
+ return gm
+
+
+def uniform_split_pass(gm: torch.fx.GraphModule, pp_size: int):
+ mod_graph = gm.graph
+ valid_children_size = 0
+ valid_children = []
+ for module in mod_graph.owning_module.children():
+ valid_children_size += 1
+ valid_children.append(module)
+
+ if valid_children_size < pp_size:
+ # If valid children is not enough to shard, we will use balanced policy instead of uniform policy.
+ return balanced_split_pass(gm, pp_size)
+ layers_per_partition = valid_children_size // pp_size
+ accumulate_layer_amount = 0
+ for node in mod_graph.nodes:
+ if pp_size <= 1:
+ break
+ if node.op == "call_module":
+ target_module = node.graph.owning_module.get_submodule(node.target)
+ if target_module in valid_children:
+ accumulate_layer_amount += 1
+ if accumulate_layer_amount == layers_per_partition:
+ accumulate_layer_amount = 0
+ pp_size -= 1
+ with mod_graph.inserting_after(node):
+ split_node = mod_graph.create_node('call_function', pipe_split)
+ gm.recompile()
+ return gm
+
+
+def split_with_split_nodes_pass(annotated_gm: torch.fx.GraphModule, merge_output=False):
+ # TODO(lyl): use partition IR to assign partition ID to each node.
+ # Currently: analyzing graph -> annotate graph by inserting split node -> use split module pass to split graph
+ # In future: graph to partitions -> analyzing partition IR -> recombining partitions to get best performance -> assign partition ID to each node
+ part_idx = 0
+
+ def split_callback(n: torch.fx.Node):
+ nonlocal part_idx
+ if (n.op, n.target) == ('call_function', pipe_split):
+ part_idx += 1
+ return part_idx
+
+ split_mod = split_module(annotated_gm, None, split_callback, merge_output)
+ split_submodules = []
+ for name, submodule in split_mod.named_modules():
+ if isinstance(submodule, torch.fx.GraphModule):
+ for node in submodule.graph.nodes:
+ if (node.op, node.target) == ('call_function', pipe_split):
+ submodule.graph.erase_node(node)
+ submodule.recompile()
+ split_submodules.append(submodule)
+
+ return split_mod, split_submodules
diff --git a/colossalai/fx/passes/concrete_info_prop.py b/colossalai/fx/passes/concrete_info_prop.py
new file mode 100644
index 0000000000000000000000000000000000000000..81ac6420552815a5cea2d3fe5aef175efb36ece0
--- /dev/null
+++ b/colossalai/fx/passes/concrete_info_prop.py
@@ -0,0 +1,290 @@
+from dataclasses import asdict
+from typing import Any, Dict, List, NamedTuple, Optional, Tuple
+
+import torch
+import torch.fx
+from torch.fx.node import Argument, Node, Target
+from torch.utils._pytree import tree_flatten
+
+from colossalai.fx._compatibility import compatibility
+from colossalai.fx.profiler import GraphInfo, profile_function, profile_method, profile_module
+
+
+@compatibility(is_backward_compatible=True)
+class ConcreteInfoProp(torch.fx.Interpreter):
+ """
+ Execute an FX graph Node-by-Node with concrete tensor and record the memory
+ usage, execution time of forward and backward, and type of the result into
+ the corresponding node.
+
+ Usage:
+ BATCH_SIZE = 2
+ DIM_IN = 4
+ DIM_HIDDEN = 16
+ DIM_OUT = 16
+ model = torch.nn.Sequential(
+ torch.nn.Linear(DIM_IN, DIM_HIDDEN),
+ torch.nn.Linear(DIM_HIDDEN, DIM_OUT),
+ ).cuda()
+ input_sample = torch.rand(BATCH_SIZE, DIM_IN, device="cuda")
+ gm = symbolic_trace(model)
+ interp = ConcreteInfoProp(gm)
+ interp.run(input_sample)
+ print(interp.summary(unit='kb'))
+
+
+ output of above code is
+ Op type Op Forward time Backward time SAVE_FWD_IN FWD_OUT FWD_TMP BWD_OUT BWD_TMP
+ ----------- ------- ----------------------- ------------------------ ------------- --------- --------- --------- ---------
+ placeholder input_1 0.0 s 0.0 s False 0.00 KB 0.00 KB 0.00 KB 0.00 KB
+ call_module _0 0.0003993511199951172 s 0.00706791877746582 s False 0.50 KB 0.00 KB 0.03 KB 0.66 KB
+ call_module _1 6.29425048828125e-05 s 0.00018286705017089844 s False 0.50 KB 0.00 KB 0.12 KB 0.81 KB
+ output output 0.0 s 0.0 s True 0.00 KB 0.00 KB 0.00 KB 0.00 KB
+ Args:
+ module (GraphModule): The module to be executed
+
+ """
+
+ _is_proped: bool = False
+
+ def run(self, *args, initial_env: Optional[Dict[Node, Any]] = None, enable_io_processing: bool = True) -> Any:
+ """Customized run for ConcreteInfoProp
+ We need to store the device in self.device
+
+ Args:
+ *args: The arguments to the Module to run, in positional order
+ initial_env (Optional[Dict[Node, Any]]): An optional starting environment for execution.
+ This is a dict mapping `Node` to any value. This can be used, for example, to
+ pre-populate results for certain `Nodes` so as to do only partial evaluation within
+ the interpreter.
+ enable_io_processing (bool): If true, we process the inputs and outputs with graph's process_inputs and
+ process_outputs function first before using them.
+
+ Returns:
+ Any: The value returned from executing the Module
+ """
+
+ flatten_args, _ = tree_flatten(args)
+ self.device = next(item for item in flatten_args if hasattr(item, "device")).device
+ return super().run(*args, initial_env, enable_io_processing)
+
+ @compatibility(is_backward_compatible=True)
+ def run_node(self, n: Node) -> Any:
+ """
+ Run a specific node ``n`` and return the result.
+ Calls into placeholder, get_attr, call_function,
+ call_method, call_module, or output depending
+ on ``node.op``
+
+ Args:
+ n (Node): The Node to execute
+
+ Returns:
+ Any: The result of executing ``n``
+ """
+ self._is_proped = True
+ result, meta_info = super().run_node(n)
+
+ n.meta = {**n.meta, **asdict(meta_info)} # extend MetaInfo to `n.meta`
+ # TODO: the attribute node_size should be removed in the future
+ setattr(n, 'node_size', n.meta.get('fwd_mem_tmp', 0) + n.meta.get('fwd_mem_out', 0))
+ n.meta['type'] = type(result)
+
+ # retain the autograd graph
+ for param in self.module.parameters():
+ param.grad = None
+
+ return result
+
+ # Main Node running APIs
+ @compatibility(is_backward_compatible=True)
+ def placeholder(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``placeholder`` node. Note that this is stateful:
+ ``Interpreter`` maintains an internal iterator over
+ arguments passed to ``run`` and this method returns
+ next() on that iterator.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Returns:
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and forward & backward time.
+ """
+ return super().placeholder(target, args, kwargs), GraphInfo()
+
+ @compatibility(is_backward_compatible=True)
+ def get_attr(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``get_attr`` node. Will retrieve an attribute
+ value from the ``Module`` hierarchy of ``self.module``.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return:
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and FLOPs estimated with `MetaTensor`.
+ """
+ return super().get_attr(target, args, kwargs), GraphInfo()
+
+ @compatibility(is_backward_compatible=True)
+ def call_function(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_function`` node with meta tensor and return the result and its meta profile.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and forward & backward time.
+ """
+ assert not isinstance(target, str)
+ return profile_function(target, self.device)(*args, **kwargs)
+
+ @compatibility(is_backward_compatible=True)
+ def call_method(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_method`` node with meta tensor and return the result and its meta profile.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and forward & backward time.
+ """
+ return profile_method(target, self.device)(*args, **kwargs)
+
+ @compatibility(is_backward_compatible=True)
+ def call_module(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_module`` node with meta tensor and return the result and its meta profile.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and forward & backward time.
+ """
+ # Retrieve executed args and kwargs values from the environment
+ # Execute the method and return the result
+ assert isinstance(target, str)
+ submod = self.fetch_attr(target)
+ return profile_module(submod, self.device)(*args, **kwargs)
+
+ @compatibility(is_backward_compatible=True)
+ def output(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute an ``output`` node. This really just retrieves
+ the value referenced by the ``output`` node and returns it.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return:
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and forward & backward time.
+ """
+ return args[0], GraphInfo(save_fwd_in=True)
+
+ def propagate(self, *args):
+ """
+ Run `module` via interpretation and return the result and
+ record the shape and type of each node.
+
+ Args:
+ *args (Tensor): the sample input.
+
+ Returns:
+ Any: The value returned from executing the Module
+ """
+ return self.run(*args)
+
+ def summary(self, unit: str = 'MB') -> str:
+ """
+ Summarizes the memory and FLOPs statistics of the `GraphModule` in
+ tabular format. Note that this API requires the ``tabulate`` module
+ to be installed.
+ """
+ # https://github.com/pytorch/pytorch/blob/master/torch/fx/graph.py
+ try:
+ from tabulate import tabulate
+ except ImportError:
+ print("`summary` relies on the library `tabulate`, "
+ "which could not be found on this machine. Run `pip "
+ "install tabulate` to install the library.")
+
+ assert self._is_proped, "Please call `interp.run(input)` before calling `interp.summary()`."
+
+ # Build up a list of summary information for each node
+ node_summaries: List[List[Any]] = []
+
+ def mem_repr(mem: int) -> str:
+ unit_divisor_map = {
+ 'kb': 1024,
+ 'mb': 1024**2,
+ 'gb': 1024**3,
+ 'tb': 1024**4,
+ }
+ return f"{mem / unit_divisor_map[unit.lower()]:.2f} {unit.upper()}"
+
+ def time_repr(time: float):
+ return f"{time:,} s"
+
+ for node in self.module.graph.nodes:
+ node: Node
+ node_summaries.append([
+ node.op,
+ str(node),
+ time_repr(node.meta['fwd_time']),
+ time_repr(node.meta['bwd_time']),
+ node.meta['save_fwd_in'],
+ mem_repr(node.meta['fwd_mem_out']),
+ mem_repr(node.meta['fwd_mem_tmp']),
+ mem_repr(node.meta['bwd_mem_out']),
+ mem_repr(node.meta['bwd_mem_tmp']),
+ ])
+
+ # Use the ``tabulate`` library to create a well-formatted table
+ # presenting our summary information
+ headers: List[str] = [
+ 'Op type',
+ 'Op',
+ 'Forward time',
+ 'Backward time',
+ 'SAVE_FWD_IN',
+ 'FWD_OUT',
+ 'FWD_TMP',
+ 'BWD_OUT',
+ 'BWD_TMP',
+ ]
+
+ return tabulate(node_summaries, headers=headers, stralign='right')
diff --git a/colossalai/fx/passes/experimental/adding_shape_consistency_pass.py b/colossalai/fx/passes/experimental/adding_shape_consistency_pass.py
new file mode 100644
index 0000000000000000000000000000000000000000..f28d65e2668ac39e7b189c7d181d018468648614
--- /dev/null
+++ b/colossalai/fx/passes/experimental/adding_shape_consistency_pass.py
@@ -0,0 +1,111 @@
+import torch
+from typing import List
+from torch.fx import symbolic_trace
+from torch.fx.node import Node
+from colossalai.fx.passes.split_module import split_module
+from colossalai.tensor.shape_consistency import ShapeConsistencyManager
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.tensor.sharding_spec import ShardingSpec, _DimSpec
+import builtins
+import operator
+from copy import deepcopy
+
+
+def apply(*args, **kwargs):
+ shape_consistency_manager = ShapeConsistencyManager()
+ return shape_consistency_manager.apply(*args, **kwargs)
+
+
+def solution_annotatation_pass(gm: torch.fx.GraphModule, solution: List[int], device_mesh):
+ mod_graph = gm.graph
+ nodes = tuple(mod_graph.nodes)
+
+ # the dict to get origin sharding spec of node
+ origin_node_sharding_spec_dict = {}
+ for node_index, (node, strategy_index) in enumerate(zip(nodes, solution)):
+ strategies_vector = node.strategies_vector
+ setattr(node, 'best_strategy', strategies_vector[strategy_index])
+ setattr(node, 'sharding_spec', strategies_vector[strategy_index].output_sharding_spec)
+ origin_node_sharding_spec_dict[node_index] = strategies_vector[strategy_index].output_sharding_spec
+
+ # apply the sharding spec of parameters
+ for node in nodes:
+ if node.op == 'call_module':
+ target_module = node.graph.owning_module.get_submodule(node.target)
+ origin_sharding_spec = ShardingSpec(device_mesh, target_module.weight.shape, {})
+ setattr(target_module.weight, 'sharding_spec', origin_sharding_spec)
+ target_weight_sharding_spec = node.best_strategy.input_shardings[1]
+ target_module.weight.data = target_module.weight.data.permute((1, 0, 2, 3))
+ apply(target_module.weight, target_weight_sharding_spec)
+ target_module.weight.data = target_module.weight.data.permute((1, 0, 2, 3))
+
+ # the dict to get input sharding specs of user node
+ sharding_spec_convert_dict = {}
+ for index, node in enumerate(nodes):
+ target_sharding_specs = []
+ for user_node in node.strategies_vector.successor_nodes:
+ node_index = user_node.strategies_vector.predecessor_nodes.index(node)
+ target_sharding_spec = user_node.best_strategy.input_shardings[node_index]
+ target_sharding_specs.append(target_sharding_spec)
+ sharding_spec_convert_dict[index] = target_sharding_specs
+
+ # add above dicts into graph
+ for node in nodes:
+ if node.op != 'placeholder':
+ with mod_graph.inserting_before(node):
+ input_specs_node = mod_graph.create_node('placeholder', target='sharding_spec_convert_dict')
+ origin_specs_node = mod_graph.create_node('placeholder', target='origin_node_sharding_spec_dict')
+ break
+
+ return sharding_spec_convert_dict, origin_node_sharding_spec_dict
+
+
+def shape_consistency_pass(gm: torch.fx.GraphModule):
+ mod_graph = gm.graph
+ nodes = tuple(mod_graph.nodes)
+ input_dict_node = None
+ origin_dict_node = None
+
+ # mapping the node into the origin graph index
+ node_to_index_dict = {}
+ index = 0
+ for node in nodes:
+ if node.target == 'sharding_spec_convert_dict':
+ input_dict_node = node
+ continue
+ if node.target == 'origin_node_sharding_spec_dict':
+ origin_dict_node = node
+ continue
+ if not hasattr(node, 'best_strategy'):
+ continue
+ node_to_index_dict[node] = index
+ index += 1
+ assert input_dict_node is not None
+
+ # add shape consistency apply function into graph
+ for node in nodes:
+ if not hasattr(node, 'best_strategy'):
+ continue
+ with mod_graph.inserting_after(node):
+ origin_spec_node = mod_graph.create_node('call_function',
+ operator.getitem,
+ args=(origin_dict_node, node_to_index_dict[node]))
+ with mod_graph.inserting_after(origin_spec_node):
+ set_sharding_spec_node = mod_graph.create_node('call_function',
+ builtins.setattr,
+ args=(node, 'sharding_spec', origin_spec_node))
+
+ for user_node in node.strategies_vector.successor_nodes:
+ node_index = user_node.strategies_vector.predecessor_nodes.index(node)
+ with mod_graph.inserting_before(user_node):
+ input_specs_node = mod_graph.create_node('call_function',
+ operator.getitem,
+ args=(input_dict_node, node_to_index_dict[node]))
+ with mod_graph.inserting_before(user_node):
+ sharding_spec_node = mod_graph.create_node('call_function',
+ operator.getitem,
+ args=(input_specs_node, node_index))
+ with mod_graph.inserting_before(user_node):
+ shape_consistency_node = mod_graph.create_node('call_function', apply, args=(node, sharding_spec_node))
+
+ return gm
diff --git a/colossalai/fx/passes/meta_info_prop.py b/colossalai/fx/passes/meta_info_prop.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b4a8749cfd776e3ac22d75fc2e47c2475c521d6
--- /dev/null
+++ b/colossalai/fx/passes/meta_info_prop.py
@@ -0,0 +1,358 @@
+from dataclasses import asdict
+from typing import Any, Dict, List, NamedTuple, Tuple
+
+import torch
+import torch.fx
+from torch.fx.node import Argument, Node, Target
+from torch.utils._pytree import tree_map
+
+from colossalai.fx._compatibility import compatibility, is_compatible_with_meta
+from colossalai.fx.profiler import (
+ GraphInfo,
+ activation_size,
+ calculate_fwd_in,
+ calculate_fwd_out,
+ calculate_fwd_tmp,
+ profile_function,
+ profile_method,
+ profile_module,
+)
+
+
+@compatibility(is_backward_compatible=True)
+class TensorMetadata(NamedTuple):
+ # TensorMetadata is a structure containing pertinent information
+ # about a tensor within a PyTorch program.
+
+ shape: torch.Size
+ dtype: torch.dtype
+ requires_grad: bool
+ stride: Tuple[int]
+ numel: int
+ is_tensor: bool
+ # TODO: we can add a list of sharding spec here, and record the sharding
+ # behaviour by appending sharding spec into list.
+
+
+def _extract_tensor_metadata(result: torch.Tensor) -> TensorMetadata:
+ """
+ Extract a TensorMetadata NamedTuple describing `result`.
+ """
+ shape = result.shape
+ dtype = result.dtype
+ requires_grad = result.requires_grad
+ stride = result.stride()
+ numel = result.numel()
+ is_tensor = True
+
+ return TensorMetadata(shape, dtype, requires_grad, stride, numel, is_tensor)
+
+
+@compatibility(is_backward_compatible=True)
+class MetaInfoProp(torch.fx.Interpreter):
+ """
+ Execute an FX graph Node-by-Node with meta tensor and
+ record the memory usage, FLOPs, and type of the result
+ into the corresponding node.
+
+ Usage:
+ BATCH_SIZE = 2
+ DIM_IN = 4
+ DIM_HIDDEN = 16
+ DIM_OUT = 16
+ model = torch.nn.Sequential(
+ torch.nn.Linear(DIM_IN, DIM_HIDDEN),
+ torch.nn.Linear(DIM_HIDDEN, DIM_OUT),
+ )
+ input_sample = torch.rand(BATCH_SIZE, DIM_IN)
+ gm = symbolic_trace(model)
+ interp = MetaInfoProp(gm)
+ interp.run(input_sample)
+ print(interp.summary(format='kb')) # don't panic if some statistics are 0.00 MB
+
+
+ # output of above code is
+ Op type Op Forward FLOPs Backward FLOPs FWD_OUT FWD_TMP BWD_OUT BWD_TMP
+ ----------- ------- --------------- ---------------- --------- --------- --------- ---------
+ placeholder input_1 0 FLOPs 0 FLOPs 0.00 KB 0.00 KB 0.00 KB 0.00 KB
+ call_module _0 128 FLOPs 288 FLOPs 0.12 KB 0.00 KB 0.34 KB 0.00 KB
+ call_module _1 512 FLOPs 1,056 FLOPs 0.12 KB 0.00 KB 1.19 KB 0.00 KB
+ output output 0 FLOPs 0 FLOPs 0.00 KB 0.00 KB 0.00 KB 0.00 KB
+ Args:
+ module (GraphModule): The module to be executed
+
+ """
+
+ _is_proped: bool = False
+
+ @compatibility(is_backward_compatible=True)
+ def run_node(self, n: Node) -> Any:
+ """
+ Run a specific node ``n`` and return the result.
+ Calls into placeholder, get_attr, call_function,
+ call_method, call_module, or output depending
+ on ``node.op``
+
+ Args:
+ n (Node): The Node to execute
+
+ Returns:
+ Any: The result of executing ``n``
+ """
+ self._is_proped = True
+ result, meta_info = super().run_node(n)
+
+ def extract_tensor_meta(obj):
+ if isinstance(obj, torch.Tensor):
+ return _extract_tensor_metadata(obj)
+ else:
+ return TensorMetadata(None, None, False, None, 0, False)
+
+ tensor_meta = tree_map(extract_tensor_meta, result)
+ n.meta['tensor_meta'] = tensor_meta
+ n.meta = {**n.meta, **asdict(meta_info)} # extend MetaInfo to `n.meta`
+ # TODO: the attribute node_size should be removed in the future
+ setattr(n, 'node_size', activation_size(n.meta.get('fwd_out', 0)) + activation_size(n.meta.get('fwd_tmp', 0)))
+ setattr(n, 'fwd_flop', n.meta.get('fwd_flop', 0))
+ setattr(n, 'bwd_flop', n.meta.get('bwd_flop', 0))
+ n.meta['type'] = type(result)
+
+ # retain the autograd graph
+ for param in self.module.parameters():
+ param.grad = None
+
+ return result
+
+ # Main Node running APIs
+ @compatibility(is_backward_compatible=True)
+ def placeholder(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``placeholder`` node. Note that this is stateful:
+ ``Interpreter`` maintains an internal iterator over
+ arguments passed to ``run`` and this method returns
+ next() on that iterator.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Returns:
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and FLOPs estimated with `MetaTensor`.
+ """
+ return super().placeholder(target, args, kwargs), GraphInfo()
+
+ @compatibility(is_backward_compatible=True)
+ def get_attr(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``get_attr`` node. Will retrieve an attribute
+ value from the ``Module`` hierarchy of ``self.module``.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return:
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and FLOPs estimated with `MetaTensor`.
+ """
+ return super().get_attr(target, args, kwargs), GraphInfo()
+
+ @compatibility(is_backward_compatible=True)
+ def call_function(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_function`` node with meta tensor and return the result and its meta profile.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and FLOPs estimated with `MetaTensor`.
+ """
+ assert not isinstance(target, str)
+ return profile_function(target)(*args, **kwargs)
+
+ @compatibility(is_backward_compatible=True)
+ def call_method(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_method`` node with meta tensor and return the result and its meta profile.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and FLOPs estimated with `MetaTensor`.
+ """
+ return profile_method(target)(*args, **kwargs)
+
+ @compatibility(is_backward_compatible=True)
+ def call_module(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute a ``call_module`` node with meta tensor and return the result and its meta profile.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and FLOPs estimated with `MetaTensor`.
+ """
+ # Retrieve executed args and kwargs values from the environment
+ # Execute the method and return the result
+ assert isinstance(target, str)
+ submod = self.fetch_attr(target)
+ return profile_module(submod)(*args, **kwargs)
+
+ @compatibility(is_backward_compatible=True)
+ def output(self, target: 'Target', args: Tuple[Argument, ...], kwargs: Dict[str, Any]) -> Any:
+ """
+ Execute an ``output`` node. This really just retrieves
+ the value referenced by the ``output`` node and returns it.
+
+ Args:
+ target (Target): The call target for this node. See
+ `Node `__ for
+ details on semantics
+ args (Tuple): Tuple of positional args for this invocation
+ kwargs (Dict): Dict of keyword arguments for this invocation
+
+ Return:
+ result (Any): The argument value that was retrieved
+ meta_info (MetaInfo): The memory cost and FLOPs estimated with `MetaTensor`.
+ """
+ if hasattr(args[0], '_tensor'):
+ return args[0], GraphInfo(fwd_in=[args[0]._tensor])
+ return args[0], GraphInfo(save_fwd_in=True)
+
+ def propagate(self, *args):
+ """
+ Run `module` via interpretation and return the result and
+ record the shape and type of each node.
+
+ Args:
+ *args (Tensor): the sample input.
+
+ Returns:
+ Any: The value returned from executing the Module
+ """
+ return super().run(*args)
+
+ def summary(self, unit: str = 'MB') -> str:
+ """
+ Summarizes the memory and FLOPs statistics of the `GraphModule` in
+ tabular format. Note that this API requires the ``tabulate`` module
+ to be installed.
+ """
+ # https://github.com/pytorch/pytorch/blob/master/torch/fx/graph.py
+ try:
+ from tabulate import tabulate
+ except ImportError:
+ print("`summary` relies on the library `tabulate`, "
+ "which could not be found on this machine. Run `pip "
+ "install tabulate` to install the library.")
+
+ assert self._is_proped, "Please call `interp.run(input)` before calling `interp.summary()`."
+
+ # Build up a list of summary information for each node
+ node_summaries: List[List[Any]] = []
+
+ def mem_repr(mem: int) -> str:
+ unit_divisor_map = {
+ 'kb': 1024,
+ 'mb': 1024**2,
+ 'gb': 1024**3,
+ 'tb': 1024**4,
+ }
+ return f"{mem / unit_divisor_map[unit.lower()]:.2f} {unit.upper()}"
+
+ def flops_repr(flop: int) -> str:
+ return f"{flop:,} FLOPs"
+
+ accumulate_size = 0
+ for node in self.module.graph.nodes:
+ node: Node
+ accumulate_size += calculate_fwd_out(node) + calculate_fwd_tmp(node)
+ node_summaries.append([
+ node.op,
+ str(node),
+ flops_repr(node.meta['fwd_flop']),
+ flops_repr(node.meta['bwd_flop']),
+ mem_repr(accumulate_size),
+ mem_repr(calculate_fwd_in(node)),
+ mem_repr(calculate_fwd_out(node)),
+ mem_repr(calculate_fwd_tmp(node)),
+ mem_repr(node.meta['bwd_mem_out']),
+ mem_repr(node.meta['bwd_mem_tmp']),
+ ])
+
+ # Use the ``tabulate`` library to create a well-formatted table
+ # presenting our summary information
+ headers: List[str] = [
+ 'Op type',
+ 'Op',
+ 'Forward FLOPs',
+ 'Backward FLOPs',
+ 'Accumulated Memory',
+ 'FWD_IN',
+ 'FWD_OUT',
+ 'FWD_TMP',
+ 'BWD_OUT',
+ 'BWD_TMP',
+ ]
+
+ return tabulate(node_summaries, headers=headers, stralign='right')
+
+
+def metainfo_trace(gm: torch.fx.GraphModule, *args, verbose: bool = False, unit: str = "MB", **kwargs) -> None:
+ """
+ MetaInfo tracing API
+
+ Given a ``GraphModule`` and a sample input, this API will trace the MetaInfo of a single training cycle,
+ and annotate them on ``gm.graph``.
+
+ Uses:
+ >>> model = ...
+ >>> gm = symbolic_trace(model)
+ >>> args = ... # sample input to the ``GraphModule``
+ >>> metainfo_trace(gm, *args)
+
+ Args:
+ gm (torch.fx.GraphModule): The ``GraphModule`` to be annotated with MetaInfo.
+ verbose (bool, optional): Whether to show ``MetaInfoProp.summary()`. Defaults to False.
+ unit (str, optional): The unit of memory. Defaults to "MB".
+
+ Returns:
+ torch.fx.GraphModule: The ``GraphModule`` annotated with MetaInfo.
+ """
+ device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
+ interp = MetaInfoProp(gm.to(device))
+ if is_compatible_with_meta():
+ from colossalai.fx.profiler import MetaTensor
+ args = tree_map(lambda x: MetaTensor(x, fake_device=device), args)
+ kwargs = tree_map(lambda x: MetaTensor(x, fake_device=device), kwargs)
+ interp.propagate(*args, **kwargs)
+ if verbose:
+ interp.summary(unit)
+ gm.to('cpu')
+ del interp
+ return gm
diff --git a/colossalai/fx/passes/passes_for_gpt2_test.py b/colossalai/fx/passes/passes_for_gpt2_test.py
new file mode 100644
index 0000000000000000000000000000000000000000..abc1a089e9a90ebaff0681879aaa68d488edb624
--- /dev/null
+++ b/colossalai/fx/passes/passes_for_gpt2_test.py
@@ -0,0 +1,371 @@
+import inspect
+from typing import Any, Callable, Dict, List, Optional
+
+import torch
+from packaging import version
+from torch.fx._compatibility import compatibility
+from torch.fx.graph_module import GraphModule
+from torch.fx.node import Node
+
+from colossalai.fx.passes.adding_split_node_pass import balanced_split_pass, pipe_split
+from colossalai.fx.passes.meta_info_prop import TensorMetadata
+from colossalai.fx.passes.split_module import Partition
+
+
+def customized_split_pass_for_gpt2(gm: torch.fx.GraphModule, pp_size: int, partition_list: List[int]):
+ '''
+ This pass is only used to do the gpt2 performance test, it may move into adding_split_node_pass.py, and will be deprecated in future.
+ '''
+ mod_graph = gm.graph
+ valid_children_size = 0
+ valid_children = []
+ for node in mod_graph.nodes:
+ if node.op == "call_module":
+ valid_children_size += 1
+ valid_children.append(node.target)
+ if valid_children_size < pp_size:
+ # If valid children is not enough to shard, we will use balanced policy instead of uniform policy.
+ return balanced_split_pass(gm, pp_size)
+ accumulate_layer_amount = 0
+ list_of_part = partition_list
+ part_index = 0
+ for node in mod_graph.nodes:
+ if pp_size <= 1:
+ break
+ if node.op == "call_module":
+ if node.target in valid_children:
+ accumulate_layer_amount += 1
+ if accumulate_layer_amount == list_of_part[part_index]:
+ part_index += 1
+ pp_size -= 1
+ with mod_graph.inserting_after(node):
+ split_node = mod_graph.create_node('call_function', pipe_split)
+
+ gm.recompile()
+ return gm
+
+
+def split_with_split_nodes_pass_for_gp2_test(annotated_gm: torch.fx.GraphModule):
+ '''
+ This pass will be used in gpt2 test, only a part of changes may be added into
+ split_with_split_nodes_pass, and it will be deprecated in future.
+ '''
+ part_idx = 0
+
+ def eliminate_unused_placeholders(gm):
+ for node in gm.graph.nodes:
+ if node.op == 'placeholder':
+ if not len(node.users):
+ gm.graph.erase_node(node)
+ gm.recompile()
+ return gm
+
+ def refill_outputs_and_placeholders(gm, next_partition_placeholders):
+ '''
+ This method is used to eliminate the outputs in previous partition which is unused in next partition.
+ In split module pass, it treats partitions as a DAG, but we need treat them as a single direction linked list in pipeline parallel.
+ The difference is if a output from partition 0 is an input argument of partition 3, the DAG will not transfer it
+ to partition 1 and partition 2. However, in single direction linked list, we need to do so.
+ '''
+ output_type = None
+ output_args = []
+ non_output_list = []
+ new_placeholder_list = []
+ for node in gm.graph.nodes:
+ if node.op == 'output':
+ if isinstance(node.args[0], (tuple, list)):
+ output_type = node.args[0].__class__
+ output_args.extend([n.name for n in node.args[0]])
+ else:
+ output_args.append(node.args[0].name)
+ rm_list = []
+ for name in output_args:
+ if next_partition_placeholders and name not in next_partition_placeholders:
+ rm_list.append(name)
+ for name in rm_list:
+ output_args.remove(name)
+ gm.graph.erase_node(node)
+ else:
+ non_output_list.append(node.name)
+
+ for name in next_partition_placeholders:
+ if name not in output_args:
+ output_args.append(name)
+
+ for name in output_args:
+ if name not in non_output_list:
+ gm.graph.placeholder(name)
+
+ # convert name to node for output_args
+ for index, name in enumerate(output_args):
+ for n in gm.graph.nodes:
+ if n.name == name:
+ output_args[index] = n
+ continue
+
+ # reorder the output args to make sure
+ # output args has same order as next partition placeholder
+ reorder_output_args = []
+ if next_partition_placeholders:
+ for name in next_partition_placeholders:
+ for node in output_args:
+ if node.name == name:
+ reorder_output_args.append(node)
+ continue
+
+ for node in gm.graph.nodes:
+ if node.op == 'placeholder':
+ new_placeholder_list.append(node.name)
+ if output_type is not None:
+ gm.graph.output(output_type(output_args))
+ else:
+ gm.graph.output(output_args)
+ gm.recompile()
+ return gm, new_placeholder_list
+
+ def split_callback(n: torch.fx.Node):
+ nonlocal part_idx
+ if (n.op, n.target) == ('call_function', pipe_split):
+ part_idx += 1
+ return part_idx
+
+ split_mod = split_module_for_gpt2_test(annotated_gm, None, split_callback)
+ split_submodules = []
+ for name, submodule in split_mod.named_modules():
+ if isinstance(submodule, torch.fx.GraphModule):
+ for node in submodule.graph.nodes:
+ if (node.op, node.target) == ('call_function', pipe_split):
+ submodule.graph.erase_node(node)
+ submodule.recompile()
+ split_submodules.append(submodule)
+
+ submodules = list(split_mod.children())
+ placeholder_dict = {}
+ for submodule in submodules:
+ submodule = eliminate_unused_placeholders(submodule)
+ placeholder_dict[submodule] = []
+ submodules.reverse()
+ for index, submodule in enumerate(submodules):
+ if index == 0:
+ placeholder_list = []
+ else:
+ placeholder_list = placeholder_dict[submodules[index - 1]]
+ submodule, placeholder_dict[submodule] = refill_outputs_and_placeholders(submodule, placeholder_list)
+ submodule.recompile()
+
+ split_mod.recompile()
+
+ return split_mod, split_submodules
+
+
+@compatibility(is_backward_compatible=True)
+def split_module_for_gpt2_test(
+ m: GraphModule,
+ root_m: torch.nn.Module,
+ split_callback: Callable[[torch.fx.node.Node], int],
+):
+ """
+ This pass will be used in gpt2 pp performance test, only a part of changes may be added into
+ split_module, and it will be deprecated in future.
+ """
+ partitions: Dict[str, Partition] = {}
+ orig_nodes: Dict[str, torch.fx.node.Node] = {}
+
+ def _node_with_all_tensor_element(node_metadata: Any) -> int:
+ """
+ return whether node contains non-tensor element.
+ """
+ all_tensor_node = True
+
+ if isinstance(node_metadata, TensorMetadata):
+ all_tensor_node = node_metadata.is_tensor and all_tensor_node
+ elif isinstance(node_metadata, dict):
+ value_list = [v for _, v in node_metadata.items()]
+ all_tensor_node += _node_with_all_tensor_element(value_list)
+ else:
+ for element in node_metadata:
+ all_tensor_node += _node_with_all_tensor_element(element)
+
+ return all_tensor_node
+
+ def _move_all_ancestors_into_partition(node, partition_name):
+ all_ancestors = set()
+
+ def _gen_all_ancestors_set(node):
+ all_ancestors.add(node)
+ for n in node.all_input_nodes:
+ if n in all_ancestors:
+ continue
+ _gen_all_ancestors_set(n)
+
+ _gen_all_ancestors_set(node)
+ for n in list(all_ancestors):
+ if n.op != 'placeholder' and n._fx_partition > partition_name:
+ n._fx_partition = partition_name
+
+ def record_cross_partition_use(def_node: torch.fx.node.Node,
+ use_node: Optional[torch.fx.node.Node]): # noqa: B950
+ def_partition_name = getattr(def_node, '_fx_partition', None)
+ use_partition_name = getattr(use_node, '_fx_partition', None)
+ if def_partition_name != use_partition_name:
+ # if 'tensor_meta' in def_node.meta:
+ # if not _node_with_all_tensor_element(def_node.meta['tensor_meta']):
+ # _move_all_ancestors_into_partition(use_node, def_partition_name)
+ # node_process_list.extend(use_node.all_input_nodes)
+ # node_process_list.extend(list(use_node.users))
+ # node_process_list.append(use_node)
+
+ # return
+
+ if def_partition_name is not None:
+ def_partition = partitions[def_partition_name]
+ def_partition.outputs.setdefault(def_node.name)
+ if use_partition_name is not None:
+ def_partition.partition_dependents.setdefault(use_partition_name)
+
+ if use_partition_name is not None:
+ use_partition = partitions[use_partition_name]
+ use_partition.inputs.setdefault(def_node.name)
+ if def_partition_name is not None:
+ use_partition.partitions_dependent_on.setdefault(def_partition_name)
+
+ node_process_list = list(m.graph.nodes)
+ # split nodes into parititons
+ while node_process_list:
+ node = node_process_list.pop(0)
+ orig_nodes[node.name] = node
+
+ if node.op in ["placeholder"]:
+ continue
+ if node.op == 'output':
+ # partition_name = str(split_callback(node))
+ # def _set_output_args_partition(n, partition_name):
+ # n._fx_partition = partition_name
+ # torch.fx.graph.map_arg(node.args[0], lambda n: _set_output_args_partition(n, partition_name))
+ torch.fx.graph.map_arg(node.args[0], lambda n: record_cross_partition_use(n, None))
+ continue
+ partition_name = str(split_callback(node))
+
+ # add node to partitions
+ partition = partitions.get(partition_name)
+ if partition is None:
+ partitions[partition_name] = partition = Partition(partition_name)
+
+ partition.node_names.append(node.name)
+ origin_partition_name = getattr(node, '_fx_partition', None)
+ if origin_partition_name is None:
+ node._fx_partition = partition_name
+
+ torch.fx.graph.map_arg(node.args, lambda def_node: record_cross_partition_use(def_node, node))
+ torch.fx.graph.map_arg(node.kwargs, lambda def_node: record_cross_partition_use(def_node, node)) # noqa: B950
+
+ # find partitions with no dependencies
+ root_partitions: List[str] = []
+ for partition_name, partition in partitions.items():
+ if not len(partition.partitions_dependent_on):
+ root_partitions.append(partition_name)
+
+ # check partitions for circular dependencies and create topological partition ordering
+ sorted_partitions: List[str] = []
+ while root_partitions:
+ root_partition = root_partitions.pop()
+ sorted_partitions.append(root_partition)
+ for dependent in partitions[root_partition].partition_dependents:
+ partitions[dependent].partitions_dependent_on.pop(root_partition)
+ if not partitions[dependent].partitions_dependent_on:
+ root_partitions.append(dependent)
+ if len(sorted_partitions) != len(partitions):
+ raise RuntimeError("cycle exists between partitions!")
+
+ # add placeholders to parititons
+ for partition_name in sorted_partitions:
+ partition = partitions[partition_name]
+ for input in partition.inputs:
+ placeholder = partition.graph.placeholder(input)
+ placeholder.meta = orig_nodes[input].meta.copy()
+ partition.environment[orig_nodes[input]] = placeholder
+
+ # Transform nodes and collect targets for partition's submodule
+ for node in m.graph.nodes:
+ if hasattr(node, '_fx_partition'):
+ partition = partitions[node._fx_partition]
+
+ # swap out old graph nodes in kw/args with references to new nodes in this submodule
+ environment = partition.environment
+ gathered_args = torch.fx.graph.map_arg(node.args, lambda n: environment[n])
+ gathered_kwargs = torch.fx.graph.map_arg(node.kwargs, lambda n: environment[n])
+
+ if node.op not in ['call_module', 'get_attr']:
+ target = node.target
+ else:
+ target_atoms = node.target.split('.')
+ target_attr = m
+ for atom in target_atoms:
+ if not hasattr(target_attr, atom):
+ raise RuntimeError(f'Operator target {node.target} not found!')
+ target_attr = getattr(target_attr, atom)
+ # target = target_atoms[-1]
+ target = '_'.join(target_atoms)
+ partition.targets[target] = target_attr
+
+ assert isinstance(gathered_args, tuple)
+ assert isinstance(gathered_kwargs, dict)
+ new_node = partition.graph.create_node(op=node.op,
+ target=target,
+ args=gathered_args,
+ kwargs=gathered_kwargs,
+ name=node.name)
+ new_node.meta = node.meta.copy()
+ partition.environment[node] = new_node
+
+ # Set up values to construct base module
+ base_mod_env: Dict[str, torch.fx.node.Node] = {}
+ base_mod_graph: torch.fx.graph.Graph = torch.fx.graph.Graph()
+ base_mod_attrs: Dict[str, torch.fx.graph_module.GraphModule] = {}
+ for node in m.graph.nodes:
+ if node.op == 'placeholder':
+ if version.parse(torch.__version__) < version.parse('1.11.0'):
+ base_mod_env[node.name] = base_mod_graph.placeholder(node.name, type_expr=node.type)
+ else:
+ default_value = node.args[0] if len(node.args) > 0 else inspect.Signature.empty
+ base_mod_env[node.name] = base_mod_graph.placeholder(node.name,
+ type_expr=node.type,
+ default_value=default_value)
+ base_mod_env[node.name].meta = node.meta.copy()
+
+ # Do some things iterating over the partitions in topological order again:
+ # 1) Finish off submodule Graphs by setting corresponding outputs
+ # 2) Construct GraphModules for each submodule
+ # 3) Construct the base graph by emitting calls to those submodules in
+ # topological order
+
+ for partition_name in sorted_partitions:
+ partition = partitions[partition_name]
+
+ # Set correct output values
+ output_vals = tuple(partition.environment[orig_nodes[name]] for name in partition.outputs)
+ output_vals = output_vals[0] if len(output_vals) == 1 else output_vals # type: ignore[assignment]
+ partition.graph.output(output_vals)
+
+ # Construct GraphModule for this partition
+ submod_name = f'submod_{partition_name}'
+ base_mod_attrs[submod_name] = torch.fx.graph_module.GraphModule(partition.targets,
+ partition.graph) # noqa: B950
+
+ # Emit call in base graph to this submodule
+ output_val = base_mod_graph.call_module(submod_name, tuple(base_mod_env[name] for name in partition.inputs))
+ if len(partition.outputs) > 1:
+ # Unpack multiple return values from submodule
+ output_val_proxy = torch.fx.proxy.Proxy(output_val)
+ for i, output_name in enumerate(partition.outputs):
+ base_mod_env[output_name] = output_val_proxy[i].node # type: ignore[index]
+ else:
+ if not partition.outputs:
+ continue
+ base_mod_env[list(partition.outputs)[0]] = output_val
+
+ for node in m.graph.nodes:
+ if node.op == 'output':
+ base_mod_graph.output(torch.fx.graph.map_arg(node.args[0], lambda n: base_mod_env[n.name])) # noqa: B950
+
+ return torch.fx.graph_module.GraphModule(base_mod_attrs, base_mod_graph)
diff --git a/colossalai/fx/passes/shard_1d_pass.py b/colossalai/fx/passes/shard_1d_pass.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2bad06bb45a1393543039ef55dea6c8d1e9f50b
--- /dev/null
+++ b/colossalai/fx/passes/shard_1d_pass.py
@@ -0,0 +1,151 @@
+import torch
+import torch.nn as nn
+import operator
+from colossalai.tensor import ProcessGroup
+from colossalai.tensor.distspec import ShardSpec
+from colossalai.tensor.compute_spec import ComputePattern, ComputeSpec
+
+ELEMENTWISE_MODULE_OP = [torch.nn.Dropout, torch.nn.ReLU]
+ELEMENTWISE_FUNC_OP = [
+ torch.add, operator.add, torch.abs, torch.cos, torch.exp, torch.mul, operator.mul, operator.floordiv,
+ operator.truediv, operator.neg, torch.multiply, torch.nn.functional.relu, torch.nn.functional.dropout
+]
+
+
+def weight_split(weight: torch.nn.parameter.Parameter, dim: int, col_normal: bool) -> torch.nn.parameter.Parameter:
+ """weight_split
+ split a nn.Parameter
+
+ Args:
+ weight (torch.nn.parameter.Parameter): a torch Parameter instance
+ dim (int): the dimension to be sharded along with
+ col_normal(bool): col shard with gather or not
+ Returns:
+ _type_: _description_
+ """
+ if col_normal:
+ setattr(weight, "fx_attr", (dim, "SHARD", "TP", "col_normal"))
+ else:
+ setattr(weight, "fx_attr", (dim, "SHARD", "TP", "col_needs_many_outputs"))
+ return weight
+
+
+def column_shard_linear_pass(gm: torch.fx.GraphModule):
+ # Split all the linear module with column shard. Currently for testing only.
+ mod_graph = gm.graph
+ for node in mod_graph.nodes:
+ if node.op == "call_module":
+ target_module = node.graph.owning_module.get_submodule(node.target)
+ if isinstance(target_module, torch.nn.Linear):
+ target_module.weight = weight_split(target_module.weight, dim=0, col_normal=False)
+ if target_module.bias is not None:
+ target_module.bias.data = weight_split(target_module.bias.data, dim=0, col_normal=False)
+
+ gm.recompile()
+ return gm
+
+
+def row_shard_linear_pass(gm: torch.fx.GraphModule):
+ # Split all the linear module with row shard. Currently for testing only.
+ mod_graph = gm.graph
+ for node in mod_graph.nodes:
+ if node.op == "call_module":
+ target_module = node.graph.owning_module.get_submodule(node.target)
+ if isinstance(target_module, torch.nn.Linear):
+ target_module.weight = weight_split(target_module.weight, dim=-1, col_normal=False)
+
+ gm.recompile()
+ return gm
+
+
+def transformer_mlp_pass(graph_module: torch.fx.GraphModule, process_group: ProcessGroup):
+ """
+ This IR pass checks for transformer MLP like structure and annotate column and row sharding to the linear layers.
+ """
+ #TODO: Needs to handle special cases, like x = linear(x) + linear(x)
+ graph = graph_module.graph
+ world_size = process_group.world_size()
+
+ def _traverse_and_annotate(node, start_tracking, annotation_record, world_size):
+ # traverse the graph to look for consecutive linear layers
+ is_linear_module = False
+
+ if node.op == 'call_module':
+ # look for the linear layer
+ module = node.graph.owning_module.get_submodule(node.target)
+ if isinstance(module, nn.Linear):
+ is_linear_module = True
+ if start_tracking:
+ # when start_tracking = True
+ # it means the first linear has been found and the current module
+ # is the second linear
+ # set the current linear module to be row-sharded
+ annotation_record['row'] = module
+
+ for shard_type, module in annotation_record.items():
+ # add row sharding spec
+ if shard_type == 'row':
+ dist_spec = ShardSpec(dims=[-1], num_partitions=[world_size])
+ comp_spec = ComputeSpec(ComputePattern.TP1D)
+ setattr(module.weight, 'pg', process_group)
+ setattr(module.weight, 'dist_spec', dist_spec)
+ setattr(module.weight, 'comp_spec', comp_spec)
+ elif shard_type == 'col':
+ weight_dist_spec = ShardSpec(dims=[0], num_partitions=[world_size])
+ weight_comp_spec = ComputeSpec(ComputePattern.TP1D)
+ weight_comp_spec.output_replicate = False
+ setattr(module.weight, 'pg', process_group)
+ setattr(module.weight, 'dist_spec', weight_dist_spec)
+ setattr(module.weight, 'comp_spec', weight_comp_spec)
+
+ if module.bias is not None:
+ bias_dist_spec = ShardSpec(dims=[0], num_partitions=[world_size])
+ bias_comp_spec = ComputeSpec(ComputePattern.TP1D)
+ bias_comp_spec.output_replicate = False
+ setattr(module.bias, 'pg', process_group)
+ setattr(module.bias, 'dist_spec', bias_dist_spec)
+ setattr(module.bias, 'comp_spec', bias_comp_spec)
+ start_tracking = False
+ annotation_record.clear()
+ else:
+ # when start tracking = False
+ # it means the current layer is the first linear
+ # set the linear layer to be col-sharded
+ start_tracking = True
+ annotation_record['col'] = module
+
+ if start_tracking and not is_linear_module:
+ # check against the white list
+ # if non-element wise op is found, we reset the tracking
+ if node.op == 'call_module':
+ module = node.graph.owning_module.get_submodule(node.target)
+ if module.__class__ not in ELEMENTWISE_MODULE_OP:
+ start_tracking = False
+ elif node.op == 'call_function' or node.op == 'call_method':
+ if node.target not in ELEMENTWISE_FUNC_OP:
+ start_tracking = False
+ elif len(node.users.keys()) > 1:
+ start_tracking = False
+
+ if not start_tracking:
+ annotation_record.clear()
+
+ # stop tracking for consecutive linear when branch is found
+ # e.g.
+ # out1 = self.linear1(x)
+ # out2 = self.linear2(x)
+ # return out1+out2
+ next_nodes = list(node.users.keys())
+ if len(next_nodes) > 1:
+ start_tracking = False
+ annotation_record.clear()
+
+ # traverse
+ for node in next_nodes:
+ _traverse_and_annotate(node, start_tracking, annotation_record, world_size)
+
+ placeholder_node = list(graph.nodes)[0]
+ annotate_record = {}
+ _traverse_and_annotate(placeholder_node, False, annotate_record, world_size)
+
+ return graph_module
diff --git a/colossalai/fx/passes/split_module.py b/colossalai/fx/passes/split_module.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ce5b969cbdefc0e347eb9f156f5268658e988fc
--- /dev/null
+++ b/colossalai/fx/passes/split_module.py
@@ -0,0 +1,296 @@
+import inspect
+from typing import Any, Callable, Dict, List, Optional
+
+import torch
+from packaging import version
+from torch.fx._compatibility import compatibility
+from torch.fx.graph_module import GraphModule
+
+
+@compatibility(is_backward_compatible=True)
+class Partition:
+ """
+ Adapted from https://github.com/pytorch/pytorch/blob/master/torch/fx/passes/split_module.py
+ """
+
+ def __init__(self, name: str):
+ self.name: str = name
+ self.node_names: List[str] = []
+ self.inputs: Dict[str, None] = {}
+ self.outputs: Dict[str, None] = {}
+ self.partitions_dependent_on: Dict[str, None] = {}
+ self.partition_dependents: Dict[str, None] = {}
+ self.graph: torch.fx.graph.Graph = torch.fx.graph.Graph()
+ self.environment: Dict[torch.fx.node.Node, torch.fx.node.Node] = {}
+ self.targets: Dict[str, Any] = {}
+
+ def __repr__(self) -> str:
+ return f"name: {self.name},\n" \
+ f" nodes: {self.node_names},\n" \
+ f" inputs: {self.inputs},\n" \
+ f" outputs: {self.outputs},\n" \
+ f" partitions depenent on: {self.partitions_dependent_on},\n" \
+ f" parition dependents: {self.partition_dependents}"
+
+
+# Creates subgraphs out of main graph
+@compatibility(is_backward_compatible=True)
+def split_module(
+ m: GraphModule,
+ root_m: torch.nn.Module,
+ split_callback: Callable[[torch.fx.node.Node], int],
+ merge_output=False,
+):
+ """
+ Adapted from https://github.com/pytorch/pytorch/blob/master/torch/fx/passes/split_module.py
+ Creates subgraphs out of main graph
+ Args:
+ m (GraphModule): Graph module to split
+ root_m (torch.nn.Module): root nn module. Not currently used. Included
+ because the root nn module is usually transformed via
+ torch.fx._symbolic_trace.symbolic_trace (see example below)
+ split_callback (Callable[[torch.fx.node.Node], int]): Callable function
+ that maps a given Node instance to a numeric partition identifier.
+ split_module will use this function as the policy for which operations
+ appear in which partitions in the output Module.
+ Returns:
+ GraphModule: the module after split.
+ Example:
+ This is a sample setup:
+ import torch
+ from torch.fx.symbolic_trace import symbolic_trace
+ from torch.fx.graph_module import GraphModule
+ from torch.fx.node import Node
+ from colossalai.fx.passes.split_module import split_module
+ class MyModule(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.param = torch.nn.Parameter(torch.rand(3, 4))
+ self.linear = torch.nn.Linear(4, 5)
+ def forward(self, x, y):
+ z = self.linear(x + self.param).clamp(min=0.0, max=1.0)
+ w = self.linear(y).clamp(min=0.0, max=1.0)
+ return z + w
+ # symbolically trace model
+ my_module = MyModule()
+ my_module_traced = symbolic_trace(my_module)
+ # random mod partitioning
+ partition_counter = 0
+ NPARTITIONS = 3
+ def mod_partition(node: Node):
+ global partition_counter
+ partition = partition_counter % NPARTITIONS
+ partition_counter = (partition_counter + 1) % NPARTITIONS
+ return partition
+ # split module in module with submodules
+ module_with_submodules = split_module(
+ my_module_traced, my_module, mod_partition
+ )
+ Output looks like this. Original graph is broken into partitions
+ > print(module_with_submodules)
+ GraphModule(
+ (submod_0): GraphModule(
+ (linear): Linear(in_features=4, out_features=5, bias=True)
+ )
+ (submod_1): GraphModule(
+ (linear): Linear(in_features=4, out_features=5, bias=True)
+ )
+ (submod_2): GraphModule()
+ )
+ def forward(self, x, y):
+ param = self.param
+ submod_0 = self.submod_0(x, param, y); x = param = y = None
+ getitem = submod_0[0]
+ getitem_1 = submod_0[1]; submod_0 = None
+ submod_1 = self.submod_1(getitem, getitem_1); getitem = getitem_1 = None
+ getitem_2 = submod_1[0]
+ getitem_3 = submod_1[1]; submod_1 = None
+ submod_2 = self.submod_2(getitem_2, getitem_3); getitem_2 = getitem_3 = None
+ return submod_2
+ Output of split module is the same as output of input traced module.
+ This is an example within a test setting:
+ > orig_out = my_module_traced(x, y)
+ > submodules_out = module_with_submodules(x, y)
+ > self.assertEqual(orig_out, submodules_out)
+ True
+ """
+ partitions: Dict[str, Partition] = {}
+ orig_nodes: Dict[str, torch.fx.node.Node] = {}
+
+ def record_cross_partition_use(def_node: torch.fx.node.Node,
+ use_node: Optional[torch.fx.node.Node]): # noqa: B950
+ def_partition_name = getattr(def_node, '_fx_partition', None)
+ use_partition_name = getattr(use_node, '_fx_partition', None)
+ if def_partition_name != use_partition_name:
+ if def_partition_name is not None:
+ def_partition = partitions[def_partition_name]
+ def_partition.outputs.setdefault(def_node.name)
+ if use_partition_name is not None:
+ def_partition.partition_dependents.setdefault(use_partition_name)
+
+ if use_partition_name is not None:
+ use_partition = partitions[use_partition_name]
+ use_partition.inputs.setdefault(def_node.name)
+ if def_partition_name is not None:
+ use_partition.partitions_dependent_on.setdefault(def_partition_name)
+
+ def record_output(def_node: torch.fx.node.Node, use_node: Optional[torch.fx.node.Node]): # noqa: B950
+ def_partition_name = getattr(def_node, "_fx_partition", None)
+ use_partition_name = getattr(use_node, "_fx_partition", None)
+ if def_partition_name != use_partition_name:
+ if def_partition_name is not None:
+ def_partition = partitions[def_partition_name]
+ def_partition.outputs.setdefault(def_node.name)
+ if use_partition_name is not None:
+ def_partition.partition_dependents.setdefault(use_partition_name)
+
+ if use_partition_name is not None:
+ use_partition = partitions[use_partition_name]
+ use_partition.inputs.setdefault(def_node.name)
+ if def_partition_name is not None:
+ use_partition.partitions_dependent_on.setdefault(def_partition_name)
+ use_partition.outputs.setdefault(def_node.name)
+ else:
+ if use_partition_name is not None:
+ use_partition = partitions[use_partition_name]
+ use_partition.outputs.setdefault(def_node.name)
+
+ # split nodes into partitions
+ for node in m.graph.nodes:
+ orig_nodes[node.name] = node
+
+ if node.op in ["placeholder"]:
+ continue
+ if node.op == 'output':
+ if merge_output:
+ torch.fx.graph.map_arg(node.args[0], lambda n: record_output(n, node.prev))
+ else:
+ torch.fx.graph.map_arg(node.args[0], lambda n: record_cross_partition_use(n, None))
+ continue
+ partition_name = str(split_callback(node))
+
+ # add node to partitions
+ partition = partitions.get(partition_name)
+ if partition is None:
+ partitions[partition_name] = partition = Partition(partition_name)
+
+ partition.node_names.append(node.name)
+ node._fx_partition = partition_name
+
+ torch.fx.graph.map_arg(node.args, lambda def_node: record_cross_partition_use(def_node, node))
+ torch.fx.graph.map_arg(node.kwargs, lambda def_node: record_cross_partition_use(def_node, node)) # noqa: B950
+
+ # find partitions with no dependencies
+ root_partitions: List[str] = []
+ for partition_name, partition in partitions.items():
+ if not len(partition.partitions_dependent_on):
+ root_partitions.append(partition_name)
+
+ # check partitions for circular dependencies and create topological partition ordering
+ sorted_partitions: List[str] = []
+ while root_partitions:
+ root_partition = root_partitions.pop()
+ sorted_partitions.append(root_partition)
+ for dependent in partitions[root_partition].partition_dependents:
+ partitions[dependent].partitions_dependent_on.pop(root_partition)
+ if not partitions[dependent].partitions_dependent_on:
+ root_partitions.append(dependent)
+ if len(sorted_partitions) != len(partitions):
+ raise RuntimeError("cycle exists between partitions!")
+
+ # add placeholders to partitions
+ for partition_name in sorted_partitions:
+ partition = partitions[partition_name]
+ for input in partition.inputs:
+ placeholder = partition.graph.placeholder(input)
+ placeholder.meta = orig_nodes[input].meta.copy()
+ partition.environment[orig_nodes[input]] = placeholder
+
+ # Transform nodes and collect targets for partition's submodule
+ for node in m.graph.nodes:
+ if hasattr(node, '_fx_partition'):
+ partition = partitions[node._fx_partition]
+
+ # swap out old graph nodes in kw/args with references to new nodes in this submodule
+ environment = partition.environment
+ gathered_args = torch.fx.graph.map_arg(node.args, lambda n: environment[n])
+ gathered_kwargs = torch.fx.graph.map_arg(node.kwargs, lambda n: environment[n])
+
+ if node.op not in ['call_module', 'get_attr']:
+ target = node.target
+ else:
+ target_atoms = node.target.split('.')
+ target_attr = m
+ for atom in target_atoms:
+ if not hasattr(target_attr, atom):
+ raise RuntimeError(f'Operator target {node.target} not found!')
+ target_attr = getattr(target_attr, atom)
+ # target = target_atoms[-1]
+ target = '_'.join(target_atoms)
+ partition.targets[target] = target_attr
+
+ assert isinstance(gathered_args, tuple)
+ assert isinstance(gathered_kwargs, dict)
+ new_node = partition.graph.create_node(op=node.op,
+ target=target,
+ args=gathered_args,
+ kwargs=gathered_kwargs)
+ new_node.meta = node.meta.copy()
+ partition.environment[node] = new_node
+
+ # Set up values to construct base module
+ base_mod_env: Dict[str, torch.fx.node.Node] = {}
+ base_mod_graph: torch.fx.graph.Graph = torch.fx.graph.Graph()
+ base_mod_attrs: Dict[str, torch.fx.graph_module.GraphModule] = {}
+ for node in m.graph.nodes:
+ if node.op == 'placeholder':
+ if version.parse(torch.__version__) < version.parse('1.11.0'):
+ base_mod_env[node.name] = base_mod_graph.placeholder(node.target, type_expr=node.type)
+ else:
+ default_value = node.args[0] if len(node.args) > 0 else inspect.Signature.empty
+ base_mod_env[node.name] = base_mod_graph.placeholder(node.target,
+ type_expr=node.type,
+ default_value=default_value)
+ base_mod_env[node.name].meta = node.meta.copy()
+
+ # Do some things iterating over the partitions in topological order again:
+ # 1) Finish off submodule Graphs by setting corresponding outputs
+ # 2) Construct GraphModules for each submodule
+ # 3) Construct the base graph by emitting calls to those submodules in
+ # topological order
+
+ for partition_name in sorted_partitions:
+ partition = partitions[partition_name]
+
+ # Set correct output values
+ output_vals = tuple(partition.environment[orig_nodes[name]] for name in partition.outputs)
+ output_vals = output_vals[0] if len(output_vals) == 1 else output_vals # type: ignore[assignment]
+ partition.graph.output(output_vals)
+
+ # Construct GraphModule for this partition
+ submod_name = f'submod_{partition_name}'
+ base_mod_attrs[submod_name] = torch.fx.graph_module.GraphModule(partition.targets,
+ partition.graph) # noqa: B950
+
+ # Emit call in base graph to this submodule
+ output_val = base_mod_graph.call_module(submod_name, tuple(base_mod_env[name] for name in partition.inputs))
+ if len(partition.outputs) > 1:
+ # Unpack multiple return values from submodule
+ output_val_proxy = torch.fx.proxy.Proxy(output_val)
+ for i, output_name in enumerate(partition.outputs):
+ base_mod_env[output_name] = output_val_proxy[i].node # type: ignore[index]
+ else:
+ if not partition.outputs:
+ continue
+ base_mod_env[list(partition.outputs)[0]] = output_val
+
+ for node in m.graph.nodes:
+ if node.op == 'output':
+ base_mod_graph.output(torch.fx.graph.map_arg(node.args[0], lambda n: base_mod_env[n.name])) # noqa: B950
+
+ for partition_name in sorted_partitions:
+ partition = partitions[partition_name]
+
+ new_gm = torch.fx.graph_module.GraphModule(base_mod_attrs, base_mod_graph)
+
+ return new_gm
diff --git a/colossalai/fx/passes/utils.py b/colossalai/fx/passes/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..bb4f3cd6a4908177ca13f9d7fb82ff42b5ad1d5e
--- /dev/null
+++ b/colossalai/fx/passes/utils.py
@@ -0,0 +1,172 @@
+import torch
+from typing import Dict
+from torch.fx.node import Node, map_arg
+from torch.fx.graph import Graph
+
+def get_comm_size(prev_partition, next_partition):
+ """
+ Given two partitions (parent and child),
+ calculate the communication size between the two.
+ """
+ # Keep tracking the communication size between parent and child
+ comm_size = 0
+ # Keep tracking all the counted node
+ visited_nodes = set()
+ # Go through all nodes in the child partition
+ # If a node has input nodes from the parent partition,
+ # the output size of those input nodes will be counted
+ # and added to comm_size
+ parent_node_names = [n.name for n in prev_partition.graph.nodes]
+ for node in next_partition.graph.nodes:
+ input_nodes: Dict[Node, None] = {}
+ map_arg(node.args, lambda n: input_nodes.setdefault(n))
+ map_arg(node.kwargs, lambda n: input_nodes.setdefault(n))
+ for n in input_nodes:
+ if n.name in parent_node_names and n not in visited_nodes:
+ comm_size += n.meta['tensor_meta'].numel
+ visited_nodes.add(n)
+ return comm_size
+
+
+def get_leaf(graph: Graph):
+ """
+ Given a graph, return leaf nodes of this graph.
+ Note: If we remove ``root`` nodes, ``placeholder`` nodes, and ``output`` nodes from fx graph,
+ we will get a normal DAG. Leaf nodes in this context means leaf nodes in that DAG.
+ """
+ input_nodes: Dict[Node, None] = {}
+ for node in graph.nodes:
+ if node.op == 'output':
+ map_arg(node.args, lambda n: input_nodes.setdefault(n))
+ map_arg(node.kwargs, lambda n: input_nodes.setdefault(n))
+ placeholder_nodes = []
+ for node in input_nodes.keys():
+ if node.op == 'placeholder':
+ placeholder_nodes.append(node)
+ for node in placeholder_nodes:
+ input_nodes.pop(node)
+ return list(input_nodes.keys())
+
+
+def is_leaf(graph: Graph, node: Node):
+ return node in get_leaf(graph)
+
+
+def get_top(graph: Graph):
+ """
+ Given a graph, return top nodes of this graph.
+ Note: If we remove ``root`` nodes, ``placeholder`` nodes, and ``output`` nodes from fx graph,
+ we will get a normal DAG. Top nodes in this context means nodes with BFS level 0 in that DAG.
+ """
+ top_node_list = set()
+ for node in graph.nodes:
+ if node.op == 'output':
+ continue
+ is_top = False
+
+ def _get_top(node):
+ nonlocal is_top
+ if node.op == 'placeholder':
+ is_top = True
+
+ map_arg(node.args, lambda n: _get_top(n))
+ map_arg(node.kwargs, lambda n: _get_top(n))
+ if is_top:
+ top_node_list.add(node)
+ return list(top_node_list)
+
+
+def is_top(graph: Graph, node: Node):
+ return node in get_top(graph)
+
+
+def get_all_consumers(graph: Graph, node: Node):
+ """
+ Given a graph and a node of this graph, return all consumers of the node.
+
+ Returns:
+ List of ``Nodes`` that node appear in these nodes ``args`` and ``kwargs``.
+ """
+ consumer_list = []
+ for n in graph.nodes:
+ if node in n.all_input_nodes:
+ consumer_list.append(n)
+ return consumer_list
+
+
+def assign_bfs_level_to_nodes(graph: Graph):
+ """
+ Give a graph, assign bfs level to each node of this graph excluding ``placeholder`` and ``output`` nodes.
+ Example:
+ class MLP(torch.nn.Module):
+ def __init__(self, dim: int):
+ super().__init__()
+ self.linear1 = torch.nn.Linear(dim, dim)
+ self.linear2 = torch.nn.Linear(dim, dim)
+ self.linear3 = torch.nn.Linear(dim, dim)
+ self.linear4 = torch.nn.Linear(dim, dim)
+ self.linear5 = torch.nn.Linear(dim, dim)
+ def forward(self, x):
+ l1 = self.linear1(x)
+ l2 = self.linear2(x)
+ l3 = self.linear3(l1)
+ l4 = self.linear4(l2)
+ l5 = self.linear5(l3)
+ return l4, l5
+ model = MLP(4)
+ gm = symbolic_trace(model)
+ print(gm.graph)
+ assign_bfs_level_to_nodes(gm.graph)
+ for node in gm.graph.nodes:
+ if hasattr(node, 'bfs_level'):
+ print(node.name, node.bfs_level)
+
+ Output:
+ graph():
+ %x : [#users=2] = placeholder[target=x]
+ %linear1 : [#users=1] = call_module[target=linear1](args = (%x,), kwargs = {})
+ %linear2 : [#users=1] = call_module[target=linear2](args = (%x,), kwargs = {})
+ %linear3 : [#users=1] = call_module[target=linear3](args = (%linear1,), kwargs = {})
+ %linear4 : [#users=1] = call_module[target=linear4](args = (%linear2,), kwargs = {})
+ %linear5 : [#users=1] = call_module[target=linear5](args = (%linear3,), kwargs = {})
+ return (linear4, linear5)
+ linear1 0
+ linear2 0
+ linear3 1
+ linear4 1
+ linear5 2
+ """
+ current_level = 0
+ nodes_to_process = []
+
+ top_nodes = get_top(graph)
+ for node in top_nodes:
+ node.bfs_level = current_level
+ nodes_to_process.extend(get_all_consumers(graph, node))
+
+ current_level += 1
+ while nodes_to_process:
+ new_process_list = []
+ for node in nodes_to_process:
+ if node.op == 'output':
+ continue
+ node.bfs_level = current_level
+ new_process_list.extend(get_all_consumers(graph, node))
+ nodes_to_process = new_process_list
+ current_level += 1
+
+
+def get_node_module(node) -> torch.nn.Module:
+ """
+ Find the module associated with the given node.
+ Args:
+ node (torch.fx.Node): a torch.fx.Node object in the fx computation graph
+ Returns:
+ torch.nn.Module: the module associated with the given node
+ """
+
+ assert node.graph.owning_module is not None, 'Cannot find the owning_module for node.graph, please make sure the graph is associated with a GraphModule object'
+ assert node.op == 'call_module', f'Expected node.op to be call_module, but found {node.op}'
+ module = node.graph.owning_module.get_submodule(node.target)
+ return module
+
diff --git a/colossalai/fx/profiler/__init__.py b/colossalai/fx/profiler/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8bcbde0eb23b806b7e37e407d57a962d8ff71573
--- /dev/null
+++ b/colossalai/fx/profiler/__init__.py
@@ -0,0 +1,18 @@
+from .._compatibility import is_compatible_with_meta
+
+if is_compatible_with_meta():
+ from .opcount import flop_mapping
+ from .profiler import profile_function, profile_method, profile_module
+ from .shard_utils import (
+ calculate_bwd_time,
+ calculate_fwd_in,
+ calculate_fwd_out,
+ calculate_fwd_time,
+ calculate_fwd_tmp,
+ )
+ from .tensor import MetaTensor
+else:
+ from .experimental import meta_profiler_function, meta_profiler_module, profile_function, profile_method, profile_module, calculate_fwd_in, calculate_fwd_tmp, calculate_fwd_out
+
+from .dataflow import GraphInfo
+from .memory_utils import activation_size, is_inplace, parameter_size
diff --git a/colossalai/fx/profiler/constants.py b/colossalai/fx/profiler/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..5763a46dc83f19dadefbebb32dbcf9a59578a2b3
--- /dev/null
+++ b/colossalai/fx/profiler/constants.py
@@ -0,0 +1,44 @@
+import torch
+
+__all__ = ['ALIAS_ATEN', 'INPLACE_NEW', 'INPLACE_MATH_ATEN', 'CLONE_ATEN', 'RELU_LIKE_OPS', 'RELU_LIKE_MOD']
+
+aten = torch.ops.aten
+
+ALIAS_ATEN = [
+ aten.detach.default,
+ aten.t.default,
+ aten.transpose.int,
+ aten.view.default,
+ aten._unsafe_view.default,
+ aten._reshape_alias.default,
+]
+
+INPLACE_NEW = [
+ aten.empty_like.default,
+ aten.new_empty_strided.default,
+]
+
+INPLACE_MATH_ATEN = [
+ aten.add_.Tensor,
+ aten.sub_.Tensor,
+ aten.div_.Tensor,
+ aten.div_.Scalar,
+ aten.mul_.Tensor,
+ aten.bernoulli_.float,
+]
+
+CLONE_ATEN = [
+ aten.clone.default,
+]
+
+# See illustrations in
+# https://github.com/hpcaitech/ColossalAI/blob/main/colossalai/fx/profiler/constants.py
+OUTPUT_SAVED_OPS = [
+ torch.nn.functional.relu,
+ torch.nn.functional.softmax,
+]
+
+OUTPUT_SAVED_MOD = [
+ torch.nn.ReLU,
+ torch.nn.Softmax,
+]
diff --git a/colossalai/fx/profiler/dataflow.py b/colossalai/fx/profiler/dataflow.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5e8880322b84f54e6c4742a821f4de76dfb664a
--- /dev/null
+++ b/colossalai/fx/profiler/dataflow.py
@@ -0,0 +1,141 @@
+from dataclasses import dataclass, field
+from enum import Enum
+from functools import partial
+from typing import Dict, List
+
+from torch.fx import Graph, Node
+
+from .._compatibility import compatibility
+from .memory_utils import activation_size, is_inplace
+
+
+class Phase(Enum):
+ FORWARD = 0
+ BACKWARD = 1
+ PLACEHOLDER = 2
+
+
+@compatibility(is_backward_compatible=True)
+@dataclass
+class GraphInfo:
+ """
+ GraphInfo is a dataclass for MetaInfo, which measures
+ the execution memory cost and FLOPs with `MetaTensor`.
+ The dataflow analysis is conducted on a single node of the FX graph.
+ ============================================================================
+ -------------------------------
+ | Node |
+ [fwd_in] are ---> | [fwd_in] [bwd_out] | <----- [bwd_out] is marks the memory for `grad_out`.
+ placeholders saved for | | \__________ | |
+ backward. | | \ | |
+ | [fwd_tmp] ------> [bwd_tmp] | <-----
+ | | \_________ | | [bwd_tmp] marks the peak memory
+ | / \ \ | | in backward pass.
+ [x] is not counted ---> | [x] [fwd_tmp] -> [bwd_tmp] | <-----
+ in [fwd_tmp] because | | \_____ | |
+ it is not saved for | | \ | |
+ backward. | [fwd_out] \ | | <----- [fwd_out] is [fwd_in] for the next node.
+ -------------------------------
+ ============================================================================
+ Attributes:
+ fwd_flop (int): The forward FLOPs of a certain node.
+ fwd_time (float): The real forward time (s) of a certain node.
+ bwd_flop (int): The backward FLOPs of a certain node.
+ bwd_time (float): The real backward time (s) of a certain node.
+ save_fwd_in (bool): The decision variable of whether to save the fwd_mem_out of parent nodes.
+ fwd_in (List): See the above illustration.
+ fwd_tmp (List): See the above illustration.
+ fwd_out (List): See the above illustration.
+ fwd_mem_tmp (int): See the above illustration.
+ fwd_mem_out (int): See the above illustration.
+ bwd_mem_tmp (int): See the above illustration.
+ bwd_mem_out (int): See the above illustration.
+ """
+
+ # TODO(super-dainiu): removed redundant items, currently all of them are necessary for development
+
+ fwd_flop: int = 0
+ fwd_time: float = 0.0
+ bwd_flop: int = 0
+ bwd_time: float = 0.0
+ save_fwd_in: bool = False
+ fwd_in: List = field(default_factory=list)
+ fwd_tmp: List = field(default_factory=list)
+ fwd_out: List = field(default_factory=list)
+ fwd_mem_tmp: int = 0
+ fwd_mem_out: int = 0
+ bwd_mem_tmp: int = 0
+ bwd_mem_out: int = 0
+
+
+def is_phase(n: Node, phase: Phase) -> bool:
+ assert 'phase' in n.meta, f'Node meta of {n} has no key `phase`!'
+ return n.meta['phase'] == phase
+
+
+@compatibility(is_backward_compatible=False)
+def autograd_graph_analysis(graph: Graph) -> GraphInfo:
+ """Analyze the autograd node dependencies and find out the memory usage.
+ Basically the input graph should have all nodes marked for keyword `phase`.
+ Nodes should have attribute `out` indicating the output of each node.
+ ============================================================================
+ Placeholder ----> p o <---- We need to keep track of grad out
+ |\________ |
+ ↓ ↘|
+ f --------> b
+ |\ \_____ ↑
+ | \ ↘ /
+ f f ----> b <---- Not every forward result needs to be saved for backward
+ | \____ ↑
+ ↘ ↘|
+ f ----> b <---- Backward can be freed as soon as it is required no more.
+ ↘ ↗
+ l
+ =============================================================================
+ Args:
+ graph (Graph): The autograd graph with nodes marked for keyword `phase`.
+
+ Returns:
+ graph_info (GraphInfo): Meta information for the dataflow.
+ """
+
+ def _peak_memory(deps: Dict[Node, int]):
+ peak_mem = 0
+ for k, v in deps.items():
+ if v > 0 and is_phase(k, Phase.BACKWARD) and not all(map(is_inplace, k.users)) and not is_inplace(k):
+ peak_mem += activation_size(k.meta['saved_tensor'])
+ if v <= float('-inf') and is_phase(k, Phase.FORWARD):
+ peak_mem -= activation_size(k.meta['saved_tensor'])
+ return peak_mem
+
+ # deps is used to track all the memory dependencies of the graph.
+ deps = {}
+ graph_info = GraphInfo()
+
+ for n in graph.nodes:
+ n: Node
+ deps[n] = len(n.users)
+ # A forward tensor who is marked `save` but is also
+ # an input to `Phase.FORWARD` should be saved during forward.
+ # If the tensor is a placeholder, then it belongs to `fwd_mem_in`.
+ # Any `fwd_mem_in` should be kept in memory even this function
+ # is checkpointed.
+ # Otherwise, the tensor belongs to `fwd_mem_tmp`. If we checkpoint
+ # the node, `fwd_mem_tmp` can be freed.
+ if is_phase(n, Phase.PLACEHOLDER):
+ graph_info.fwd_in += n.meta['saved_tensor']
+ if is_phase(n, Phase.FORWARD):
+ graph_info.fwd_tmp += n.meta['saved_tensor']
+ elif is_phase(n, Phase.BACKWARD):
+ if len(n.users):
+ graph_info.bwd_mem_tmp = max(graph_info.bwd_mem_tmp, _peak_memory(deps))
+ else:
+ # TODO: some of the bwd_mem_out might be model parameters.
+ # basically a backward node without user is a `grad_out` node
+ graph_info.bwd_mem_out += activation_size(n.meta['saved_tensor'])
+ for input_n in n.all_input_nodes:
+ if input_n in deps:
+ deps[input_n] -= 1
+ if deps[input_n] <= 0:
+ deps[input_n] = float('-inf')
+ return graph_info
diff --git a/colossalai/fx/profiler/experimental/__init__.py b/colossalai/fx/profiler/experimental/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5387981e1921497d27c2acee9ebf4e310c3add7
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/__init__.py
@@ -0,0 +1,5 @@
+from .profiler import profile_function, profile_method, profile_module
+from .profiler_function import *
+from .profiler_module import *
+from .registry import meta_profiler_function, meta_profiler_module
+from .shard_utils import calculate_fwd_in, calculate_fwd_out, calculate_fwd_tmp
diff --git a/colossalai/fx/profiler/experimental/constants.py b/colossalai/fx/profiler/experimental/constants.py
new file mode 100644
index 0000000000000000000000000000000000000000..57ff3fd91299b5bb8938125bf2d3243c9a9c4c2b
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/constants.py
@@ -0,0 +1,44 @@
+from operator import add, floordiv, getitem, mul, neg, pos, setitem, sub
+
+import torch
+
+__all__ = ['INPLACE_OPS', 'INPLACE_METHOD', 'NON_INPLACE_METHOD']
+
+# TODO fill out the inplace ops
+INPLACE_OPS = [
+ add,
+ sub,
+ mul,
+ floordiv,
+ neg,
+ pos,
+ getitem,
+ setitem,
+ getattr,
+ torch.Tensor.cpu,
+]
+
+# TODO: list all call_methods that are inplace here
+INPLACE_METHOD = [
+ 'transpose',
+ 'permute',
+ # TODO: reshape may return a copy of the data if the data is not contiguous
+ 'reshape',
+ 'dim',
+ 'flatten',
+ 'size',
+ 'view',
+ 'unsqueeze',
+ 'to',
+ 'type',
+ 'flatten',
+]
+
+# TODO: list all call_methods that are not inplace here
+NON_INPLACE_METHOD = [
+ 'chunk',
+ 'contiguous',
+ 'expand',
+ 'mean',
+ 'split',
+]
diff --git a/colossalai/fx/profiler/experimental/profiler.py b/colossalai/fx/profiler/experimental/profiler.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c545260e72b723bfa54beacfb20def3e758413f
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler.py
@@ -0,0 +1,172 @@
+from dataclasses import dataclass
+from typing import Any, Callable, Dict, Tuple
+
+import torch
+from torch.fx.node import Argument, Target
+
+from ..._compatibility import compatibility
+from ..memory_utils import activation_size
+from .constants import INPLACE_METHOD, INPLACE_OPS, NON_INPLACE_METHOD
+from .registry import meta_profiler_function, meta_profiler_module
+
+__all__ = ['profile_function', 'profile_module', 'profile_method']
+
+
+# this is for compatibility use
+@compatibility(is_backward_compatible=True)
+@dataclass
+class GraphInfo:
+ """
+ GraphInfo is a dataclass for MetaInfo, which measures
+ the execution memory cost and FLOPs with `MetaTensor`.
+ The dataflow analysis is conducted on a single node of the FX graph.
+ ============================================================================
+ -------------------------------
+ | Node |
+ [fwd_in] are ---> | [fwd_in] [bwd_out] | <----- [bwd_out] is marks the memory for `grad_out`
+ placeholders saved for | | \__________ | |
+ backward. | | \ | |
+ | [fwd_tmp] ------> [bwd_tmp] | <-----
+ | | \_________ | | [bwd_tmp] marks the peak memory
+ | / \ \ | | in backward pass.
+ [x] is not counted ---> | [x] [fwd_tmp] -> [bwd_tmp] | <-----
+ in [fwd_tmp] because | | | \_____ | |
+ it is not saved for | | | \ | |
+ backward. -------------------------------
+ ============================================================================
+ Attributes:
+ fwd_flop (int): The forward FLOPs of a certain node
+ bwd_flop (int): The backward FLOPs of a certain node.
+ fwd_mem_in (int): See the above illustration.
+ fwd_mem_tmp (int): See the above illustration.
+ bwd_mem_tmp (int): See the above illustration.
+ bwd_mem_out (int): See the above illustration.
+ """
+ fwd_flop: int = 0
+ bwd_flop: int = 0
+ fwd_mem_in: int = 0
+ fwd_mem_tmp: int = 0
+ bwd_mem_tmp: int = 0
+ bwd_mem_out: int = 0
+
+
+CALL_FUNCTION_MSG = \
+"""
+Colossal-AI hasn't supported profiling for {}, you might manually patch it with the following code.\n
+from colossalai.fx.profiler.experimental import meta_profiler_function
+@meta_profiler_function.register(YOUR_FUNCTION)
+def profile_YOUR_FUNCTION(input: torch.Tensor, *args) -> Tuple[int, int]:
+ flops = ...
+ macs = ...
+ return flops, macs
+"""
+CALL_METHOD_MSG = 'Please check if {} is an inplace method. If so, add target to INPLACE_METHOD={}. Otherwise, add target to NON_INPLACE_METHOD={}'
+CALL_MODULE_MSG = \
+"""
+Colossal-AI hasn't supported profiling for {}, you might manually patch it with the following code.\n
+from colossalai.fx.profiler.experimental import meta_profiler_module
+@meta_profiler_module.register(YOUR_MODULE)
+def profile_YOUR_MODULE(self: torch.nn.Module, input: torch.Tensor) -> Tuple[int, int]:
+ flops = ...
+ macs = ...
+ return flops, macs
+"""
+
+
+@compatibility(is_backward_compatible=True)
+def profile_function(target: 'Target') -> Callable:
+ """
+ Wrap a `call_function` node or `torch.nn.functional` in order to
+ record the memory cost and FLOPs of the execution.
+ Unfortunately, backward memory cost and FLOPs are estimated results.
+
+ Warnings:
+ You may only use tensors with `device=meta` for this wrapped function.
+ Only original `torch.nn.functional` are available.
+
+ Examples:
+ >>> input = torch.rand(100, 100, 100, 100, device='meta')
+ >>> func = torch.nn.functional.relu
+ >>> output, (fwd_flop, bwd_flop), (fwd_tmp, fwd_out, bwd_tmp, bwd_out) = profile_function(func)(input, inplace=False)
+ """
+
+ def f(*args: Tuple[Argument, ...], **kwargs: Dict[str, Any]) -> Any:
+ assert meta_profiler_function.has(target) or meta_profiler_function.has(
+ target.__name__), CALL_FUNCTION_MSG.format(target)
+
+ fwd_tmp = 0
+ fwd_out = 0
+ out = func(*args, **kwargs)
+ if target not in INPLACE_OPS and not kwargs.get('inplace', False):
+ fwd_out = activation_size(out)
+ if meta_profiler_function.has(target):
+ profiler = meta_profiler_function.get(target)
+ else:
+ profiler = meta_profiler_function.get(target.__name__)
+ fwd_flop, _ = profiler(*args, **kwargs)
+ return out, GraphInfo(fwd_flop, fwd_flop * 2, fwd_tmp, fwd_out, fwd_tmp + fwd_out, 0)
+
+ f.__name__ = target.__name__
+ func = target
+ return f
+
+
+@compatibility(is_backward_compatible=True)
+def profile_method(target: 'Target') -> Callable:
+ """
+ Wrap a `call_method` node
+ record the memory cost and FLOPs of the execution.
+
+ Warnings:
+ This is not fully implemented and you may follow the error message to debug.
+ """
+
+ def f(*args: Tuple[Argument, ...], **kwargs: Dict[str, Any]) -> Any:
+ # args[0] is the `self` object for this method call
+ self_obj, *args_tail = args
+
+ # execute the method and return the result
+ assert isinstance(target, str), f'{target} instance is not str.'
+
+ out = getattr(self_obj, target)(*args_tail, **kwargs)
+ assert target in INPLACE_METHOD + NON_INPLACE_METHOD, CALL_METHOD_MSG.format(
+ target, INPLACE_METHOD, NON_INPLACE_METHOD)
+ # call_method has no parameters and are MOSTLY(?) inplace, and has no FLOPs or MACs.
+ fwd_tmp = 0 if target in INPLACE_METHOD else activation_size(out)
+ fwd_out = 0 if target not in INPLACE_METHOD else activation_size(out)
+ return out, GraphInfo(0, 0, fwd_tmp, fwd_out, fwd_tmp + fwd_out, 0)
+
+ return f
+
+
+@compatibility(is_backward_compatible=True)
+def profile_module(module: torch.nn.Module) -> Callable:
+ """
+ Wrap a `call_module` node or `torch.nn` in order to
+ record the memory cost and FLOPs of the execution.
+
+ Warnings:
+ You may only use tensors with `device=meta` for this wrapped function.
+ Only original `torch.nn` are available.
+
+ Example:
+ >>> input = torch.rand(4, 3, 224, 224, device='meta')
+ >>> mod = torch.nn.Conv2d(3, 128, 3)
+ >>> output, (fwd_flop, bwd_flop), (fwd_tmp, fwd_out, bwd_tmp, bwd_out) = profile_module(mod)(input)
+ """
+
+ def f(*args: Tuple[Argument, ...], **kwargs: Dict[str, Any]) -> Any:
+ assert meta_profiler_module.has(type(module)), CALL_MODULE_MSG.format(type(module))
+
+ fwd_tmp = 0
+ fwd_out = 0
+ out = func(*args, **kwargs)
+ if getattr(module, 'inplace', False):
+ fwd_out = activation_size(out)
+ profiler = meta_profiler_module.get(type(module))
+ fwd_flop, _ = profiler(module, *args, **kwargs)
+ return out, GraphInfo(fwd_flop, fwd_flop * 2, fwd_tmp, fwd_out, fwd_tmp + fwd_out, 0)
+
+ f.__name__ = module.__class__.__name__
+ func = module.forward
+ return f
diff --git a/colossalai/fx/profiler/experimental/profiler_function/__init__.py b/colossalai/fx/profiler/experimental/profiler_function/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf77edba859ecc568a5010287b8797fc31bb6701
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_function/__init__.py
@@ -0,0 +1,8 @@
+from .activation_function import *
+from .arithmetic import *
+from .embedding import *
+from .linear import *
+from .normalization import *
+from .pooling import *
+from .python_ops import *
+from .torch_ops import *
diff --git a/colossalai/fx/profiler/experimental/profiler_function/activation_function.py b/colossalai/fx/profiler/experimental/profiler_function/activation_function.py
new file mode 100644
index 0000000000000000000000000000000000000000..a43aef063e197de12c23fc5a81fb13e8183eaae9
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_function/activation_function.py
@@ -0,0 +1,33 @@
+from typing import Tuple
+import torch
+from ..registry import meta_profiler_function
+
+# TODO: different activation has different FLOPs count, currently unused.
+_multiplier = {
+ torch.nn.functional.relu: 1,
+ torch.nn.functional.prelu: 4,
+ torch.nn.functional.sigmoid: 4,
+ torch.nn.functional.tanh: 5,
+ torch.nn.functional.leaky_relu: 3,
+ torch.nn.functional.elu: 4,
+ torch.nn.functional.relu6: 2,
+ torch.nn.functional.gelu: 9,
+ torch.nn.functional.hardswish: 5,
+ torch.nn.functional.hardsigmoid: 4,
+}
+
+
+@meta_profiler_function.register(torch.nn.functional.leaky_relu)
+@meta_profiler_function.register(torch.nn.functional.elu)
+@meta_profiler_function.register(torch.nn.functional.gelu)
+@meta_profiler_function.register(torch.nn.functional.relu6)
+@meta_profiler_function.register(torch.nn.functional.prelu)
+@meta_profiler_function.register(torch.nn.functional.relu)
+@meta_profiler_function.register(torch.nn.functional.sigmoid)
+@meta_profiler_function.register(torch.nn.functional.tanh)
+@meta_profiler_function.register(torch.nn.functional.hardswish)
+@meta_profiler_function.register(torch.nn.functional.hardsigmoid)
+def torch_nn_func_non_linear_act(input: torch.Tensor, inplace: bool = False) -> Tuple[int, int]:
+ flops = input.numel()
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_function/arithmetic.py b/colossalai/fx/profiler/experimental/profiler_function/arithmetic.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d1c8a8c6877fc12a7ad47b7b0103c309b8ed597
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_function/arithmetic.py
@@ -0,0 +1,90 @@
+# Copyright (c) Microsoft Corporation.
+
+# Licensed under the MIT License.
+import operator
+from functools import reduce
+from typing import Any, Optional, Tuple, Union
+
+import torch
+
+from ..registry import meta_profiler_function
+
+
+def _elementwise_flops_compute(input, other):
+ # copied from https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/profiling/flops_profiler/profiler.py#L763
+ if not torch.is_tensor(input):
+ if torch.is_tensor(other):
+ return reduce(operator.mul, other.shape), 0
+ else:
+ return 1, 0
+ elif not torch.is_tensor(other):
+ return reduce(operator.mul, input.shape), 0
+ else:
+ dim_input = len(input.shape)
+ dim_other = len(other.shape)
+ max_dim = max(dim_input, dim_other)
+
+ final_shape = []
+ for i in range(max_dim):
+ in_i = input.shape[i] if i < dim_input else 1
+ ot_i = other.shape[i] if i < dim_other else 1
+ if in_i > ot_i:
+ final_shape.append(in_i)
+ else:
+ final_shape.append(ot_i)
+ flops = reduce(operator.mul, final_shape)
+ return flops, 0
+
+
+@meta_profiler_function.register(torch.add)
+@meta_profiler_function.register(torch.eq)
+@meta_profiler_function.register(torch.sub)
+@meta_profiler_function.register(torch.mul)
+@meta_profiler_function.register(torch.floor_divide)
+@meta_profiler_function.register('add') # for built-in op +
+@meta_profiler_function.register('iadd') # for built-in op +=
+@meta_profiler_function.register('eq') # for built-in op =
+@meta_profiler_function.register('sub') # for built-in op -
+@meta_profiler_function.register('isub') # for built-in op -=
+@meta_profiler_function.register('mul') # for built-in op *
+@meta_profiler_function.register('imul') # for built-in op *=
+@meta_profiler_function.register('floordiv') # for built-in op //
+@meta_profiler_function.register('ifloordiv') # for built-in op //=
+def torch_add_like_ops(input: Any, other: Any, *, out: Optional[torch.Tensor] = None) -> Tuple[int, int]:
+ return _elementwise_flops_compute(input, other)
+
+
+@meta_profiler_function.register(torch.abs)
+def torch_elementwise_op(input: torch.Tensor, *, out: Optional[torch.Tensor] = None) -> Tuple[int, int]:
+ flops = input.numel()
+ macs = 0
+ return flops, macs
+
+
+@meta_profiler_function.register(torch.matmul)
+@meta_profiler_function.register('matmul') # for built-in op @
+@meta_profiler_function.register(torch.Tensor.matmul)
+def torch_matmul(input: torch.Tensor, other: torch.Tensor, *, out: Optional[torch.Tensor] = None) -> Tuple[int, int]:
+ macs = reduce(operator.mul, input.shape) * other.shape[-1]
+ flops = 2 * macs
+ return flops, macs
+
+
+@meta_profiler_function.register(torch.bmm)
+def torch_bmm(input: torch.Tensor, other: torch.Tensor, *, out: Optional[torch.Tensor] = None) -> Tuple[int, int]:
+ macs = reduce(operator.mul, input.shape) * other.shape[-1]
+ flops = 2 * macs
+ return flops, macs
+
+
+@meta_profiler_function.register(torch.var_mean)
+def torch_var_mean(input: torch.Tensor,
+ dim: Union[int, Tuple[int, ...]],
+ unbiased: Optional[bool] = True,
+ keepdim: Optional[bool] = False,
+ *,
+ out: Optional[torch.Tensor] = None) -> Tuple[int, int]:
+ assert out is None, 'saving to out is not supported yet'
+ flops = input.numel() * 3
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_function/embedding.py b/colossalai/fx/profiler/experimental/profiler_function/embedding.py
new file mode 100644
index 0000000000000000000000000000000000000000..d6e43d781b8b64ab78cf3299daba3df1d17a5420
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_function/embedding.py
@@ -0,0 +1,19 @@
+import torch
+from typing import Optional
+from ..registry import meta_profiler_function
+
+
+@meta_profiler_function.register(torch.nn.functional.embedding)
+def torch_nn_functional_embedding(
+ input: torch.Tensor,
+ weight: torch.Tensor,
+ padding_idx: Optional[int] = None,
+ max_norm: Optional[float] = None,
+ norm_type: float = 2.0,
+ scale_grad_by_freq: bool = False,
+ sparse: bool = False,
+) -> torch.Tensor:
+ # F.embedding is a dictionary lookup, so technically it has 0 FLOPs. (https://discuss.pytorch.org/t/correct-way-to-calculate-flops-in-model/67198/6)
+ flops = 0
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_function/linear.py b/colossalai/fx/profiler/experimental/profiler_function/linear.py
new file mode 100644
index 0000000000000000000000000000000000000000..01fe4c87137083db2458c560a88cc6faa0af377e
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_function/linear.py
@@ -0,0 +1,13 @@
+from typing import Tuple
+import torch
+from ..registry import meta_profiler_function
+
+
+@meta_profiler_function.register(torch.nn.functional.linear)
+def torch_nn_linear(input: torch.Tensor, weight: torch.Tensor, bias: torch.Tensor = None) -> Tuple[int, int]:
+ out_features = weight.shape[0]
+ macs = torch.numel(input) * out_features
+ flops = 2 * macs
+ if bias is not None:
+ flops += bias.numel()
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_function/normalization.py b/colossalai/fx/profiler/experimental/profiler_function/normalization.py
new file mode 100644
index 0000000000000000000000000000000000000000..c4ea508d70f80f33bbc8ae354e9743a4939d5e8c
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_function/normalization.py
@@ -0,0 +1,66 @@
+from typing import List, Optional, Tuple
+import torch
+from ..registry import meta_profiler_function
+
+
+@meta_profiler_function.register(torch.nn.functional.instance_norm)
+def torch_nn_func_instancenorm(
+ input: torch.Tensor,
+ running_mean: Optional[torch.Tensor] = None,
+ running_var: Optional[torch.Tensor] = None,
+ weight: Optional[torch.Tensor] = None,
+ bias: Optional[torch.Tensor] = None,
+ use_input_stats: bool = True,
+ momentum: float = 0.1,
+ eps: float = 1e-5,
+):
+ has_affine = weight is not None
+ flops = input.numel() * (5 if has_affine else 4)
+ macs = 0
+ return flops, macs
+
+
+@meta_profiler_function.register(torch.nn.functional.group_norm)
+def torch_nn_func_groupnorm(input: torch.Tensor,
+ num_groups: int,
+ weight: Optional[torch.Tensor] = None,
+ bias: Optional[torch.Tensor] = None,
+ eps: float = 1e-5) -> Tuple[int, int]:
+ has_affine = weight is not None
+ flops = input.numel() * (5 if has_affine else 4)
+ macs = 0
+ return flops, macs
+
+
+@meta_profiler_function.register(torch.nn.functional.layer_norm)
+def torch_nn_func_layernorm(
+ input: torch.Tensor,
+ normalized_shape: List[int],
+ weight: Optional[torch.Tensor] = None,
+ bias: Optional[torch.Tensor] = None,
+ eps: float = 1e-5,
+) -> Tuple[int, int]:
+ has_affine = weight is not None
+ flops = input.numel() * (5 if has_affine else 4)
+ macs = 0
+ return flops, macs
+
+
+@meta_profiler_function.register(torch.nn.functional.batch_norm)
+def torch_nn_func_batchnorm(
+ input: torch.Tensor,
+ running_mean: Optional[torch.Tensor],
+ running_var: Optional[torch.Tensor],
+ weight: Optional[torch.Tensor] = None,
+ bias: Optional[torch.Tensor] = None,
+ training: bool = False,
+ momentum: float = 0.1,
+ eps: float = 1e-5,
+) -> Tuple[int, int]:
+ has_affine = weight is not None
+ if training:
+ flops = input.numel() * (2 if has_affine else 1)
+ else:
+ flops = input.numel() * (5 if has_affine else 4)
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_function/pooling.py b/colossalai/fx/profiler/experimental/profiler_function/pooling.py
new file mode 100644
index 0000000000000000000000000000000000000000..a639f5ee83c1f4d2b75a3c120ea6ae3884fc422f
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_function/pooling.py
@@ -0,0 +1,22 @@
+from typing import Tuple, Union
+import torch
+from ..registry import meta_profiler_function
+
+
+@meta_profiler_function.register(torch.nn.functional.avg_pool1d)
+@meta_profiler_function.register(torch.nn.functional.avg_pool2d)
+@meta_profiler_function.register(torch.nn.functional.avg_pool3d)
+@meta_profiler_function.register(torch.nn.functional.max_pool1d)
+@meta_profiler_function.register(torch.nn.functional.max_pool2d)
+@meta_profiler_function.register(torch.nn.functional.max_pool3d)
+@meta_profiler_function.register(torch.nn.functional.adaptive_avg_pool1d)
+@meta_profiler_function.register(torch.nn.functional.adaptive_avg_pool2d)
+@meta_profiler_function.register(torch.nn.functional.adaptive_avg_pool3d)
+@meta_profiler_function.register(torch.nn.functional.adaptive_max_pool1d)
+@meta_profiler_function.register(torch.nn.functional.adaptive_max_pool2d)
+@meta_profiler_function.register(torch.nn.functional.adaptive_max_pool3d)
+def torch_nn_func_pooling(input: torch.Tensor, *args, **kwargs) -> Tuple[int, int]:
+ # all pooling could be considered as going over each input element only once (https://stackoverflow.com/a/67301217)
+ flops = input.numel()
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_function/python_ops.py b/colossalai/fx/profiler/experimental/profiler_function/python_ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e8561206ba0e7a874b202a31dd13a040533d1db
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_function/python_ops.py
@@ -0,0 +1,18 @@
+import operator
+from typing import Any, Tuple
+import torch
+from ..registry import meta_profiler_function
+
+
+@meta_profiler_function.register(operator.getitem)
+def operator_getitem(a: Any, b: Any) -> Tuple[int, int]:
+ flops = 0
+ macs = 0
+ return flops, macs
+
+
+@meta_profiler_function.register(getattr)
+def python_getattr(a: Any, b: Any) -> Tuple[int, int]:
+ flops = 0
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_function/torch_ops.py b/colossalai/fx/profiler/experimental/profiler_function/torch_ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..abdd7ad565ba237d7d6eab9e3c9b77d7afb10abf
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_function/torch_ops.py
@@ -0,0 +1,60 @@
+from functools import reduce
+import operator
+from typing import Any, Optional, Tuple
+import torch
+from ..registry import meta_profiler_function
+
+
+@meta_profiler_function.register(torch.arange)
+@meta_profiler_function.register(torch.finfo)
+@meta_profiler_function.register(torch.permute)
+@meta_profiler_function.register(torch.Tensor.permute)
+@meta_profiler_function.register(torch.Tensor.repeat)
+@meta_profiler_function.register(torch.index_select)
+@meta_profiler_function.register(torch.Tensor.index_select)
+@meta_profiler_function.register(torch.squeeze)
+@meta_profiler_function.register(torch.Tensor.squeeze)
+@meta_profiler_function.register(torch.unsqueeze)
+@meta_profiler_function.register(torch.Tensor.unsqueeze)
+@meta_profiler_function.register(torch.cat)
+@meta_profiler_function.register(torch.concat)
+@meta_profiler_function.register(torch.repeat_interleave)
+@meta_profiler_function.register(torch.Tensor.repeat_interleave)
+@meta_profiler_function.register(torch.flatten)
+@meta_profiler_function.register(torch.Tensor.flatten)
+@meta_profiler_function.register(torch.roll)
+@meta_profiler_function.register(torch.full)
+@meta_profiler_function.register(torch.Tensor.cpu)
+@meta_profiler_function.register(torch.Tensor.cuda)
+@meta_profiler_function.register(torch._assert)
+def torch_zero_flops_op(*args, **kwargs) -> Tuple[int, int]:
+ flops = 0
+ macs = 0
+ return flops, macs
+
+
+@meta_profiler_function.register(torch.where)
+def torch_where(condition: torch.Tensor, x: Any, y: Any) -> Tuple[int, int]:
+ # torch.where returns the broadcasted tensor of condition, x, and y,
+ # so hack it by using addition
+ flops = condition.numel()
+ macs = 0
+ return flops, macs
+
+
+@meta_profiler_function.register(torch.max)
+def torch_max(input: torch.Tensor,
+ dim: int = None,
+ keepdim: bool = False,
+ *,
+ out: Optional[torch.Tensor] = None) -> Tuple[int, int]:
+ macs = 0
+ assert out is None, 'assigning value to out is not supported yet'
+ if dim is not None:
+ shape = list(input.shape)
+ shape.pop(int(dim))
+ flops = reduce(operator.mul, shape), macs
+ return flops, macs
+ else:
+ flops = input.numel()
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_module/__init__.py b/colossalai/fx/profiler/experimental/profiler_module/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4fe646f3695e63d285b9a32530cd70f10187f34
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/__init__.py
@@ -0,0 +1,10 @@
+from .activation_function import *
+from .attention import *
+from .convolution import *
+from .dropout import *
+from .embedding import *
+from .linear import *
+from .normalization import *
+from .pooling import *
+from .rnn import *
+from .torch_op import *
diff --git a/colossalai/fx/profiler/experimental/profiler_module/activation_function.py b/colossalai/fx/profiler/experimental/profiler_module/activation_function.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ebf514ad2699cc4e71741b9c3e143cedcb63041
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/activation_function.py
@@ -0,0 +1,33 @@
+from typing import Tuple
+import torch
+from ..registry import meta_profiler_module
+
+# TODO: different activation has different FLOPs count, currently unused.
+_multiplier = {
+ torch.nn.ReLU: 1,
+ torch.nn.PReLU: 4,
+ torch.nn.Sigmoid: 4,
+ torch.nn.Tanh: 5,
+ torch.nn.LeakyReLU: 3,
+ torch.nn.ELU: 4,
+ torch.nn.ReLU6: 2,
+ torch.nn.GELU: 9,
+ torch.nn.Hardswish: 5,
+ torch.nn.Hardsigmoid: 4,
+}
+
+
+@meta_profiler_module.register(torch.nn.ELU)
+@meta_profiler_module.register(torch.nn.LeakyReLU)
+@meta_profiler_module.register(torch.nn.ReLU)
+@meta_profiler_module.register(torch.nn.GELU)
+@meta_profiler_module.register(torch.nn.Sigmoid)
+@meta_profiler_module.register(torch.nn.Tanh)
+@meta_profiler_module.register(torch.nn.ReLU6)
+@meta_profiler_module.register(torch.nn.PReLU)
+@meta_profiler_module.register(torch.nn.Hardswish)
+@meta_profiler_module.register(torch.nn.Hardsigmoid)
+def torch_nn_non_linear_act(self: torch.nn.Module, input: torch.Tensor) -> Tuple[int, int]:
+ flops = input.numel()
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_module/attention.py b/colossalai/fx/profiler/experimental/profiler_module/attention.py
new file mode 100644
index 0000000000000000000000000000000000000000..8daf74b232bf91d41933a2184e7b0c30d516d51a
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/attention.py
@@ -0,0 +1,81 @@
+from typing import Optional, Tuple
+import torch
+from ..registry import meta_profiler_module
+
+
+# TODO: This is hard to compute memory cost
+@meta_profiler_module.register(torch.nn.MultiheadAttention)
+def torch_nn_msa(self: torch.nn.MultiheadAttention,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ key_padding_mask: Optional[torch.Tensor] = None,
+ need_weights: bool = True,
+ attn_mask: Optional[torch.Tensor] = None,
+ average_attn_weights: bool = True) -> Tuple[int, int]:
+ if getattr(self, 'batch_first', False):
+ batch_size = query.shape[0]
+ len_idx = 1
+ else:
+ batch_size = query.shape[1]
+ len_idx = 0
+ dim_idx = 2
+
+ qdim = query.shape[dim_idx]
+ kdim = key.shape[dim_idx]
+ vdim = value.shape[dim_idx]
+
+ qlen = query.shape[len_idx]
+ klen = key.shape[len_idx]
+ vlen = value.shape[len_idx]
+
+ num_heads = self.num_heads
+ assert qdim == self.embed_dim
+
+ if self.kdim is None:
+ assert kdim == qdim
+ if self.vdim is None:
+ assert vdim == qdim
+
+ flops = 0
+ macs = 0
+
+ # Q scaling
+ flops += qlen * qdim
+
+ # Initial projections
+ flops += 2 * ((qlen * qdim * qdim) # QW
+ + (klen * kdim * kdim) # KW
+ + (vlen * vdim * vdim) # VW
+ )
+
+ macs += ((qlen * qdim * qdim) # QW
+ + (klen * kdim * kdim) # KW
+ + (vlen * vdim * vdim) # VW
+ )
+
+ if self.in_proj_bias is not None:
+ flops += (qlen + klen + vlen) * qdim
+
+ # attention heads: scale, matmul, softmax, matmul
+ qk_head_dim = qdim // num_heads
+ v_head_dim = vdim // num_heads
+
+ head_flops = (
+ 2 * (qlen * klen * qk_head_dim) # QK^T
+ + (qlen * klen) # softmax
+ + 2 * (qlen * klen * v_head_dim) # AV
+ )
+ head_macs = ((qlen * klen * qk_head_dim) # QK^T
+ + 2 * (qlen * klen * v_head_dim) # AV
+ )
+
+ flops += num_heads * head_flops
+ macs += num_heads * head_flops
+
+ # final projection, bias is always enabled
+ flops += qlen * vdim * (vdim + 1)
+
+ flops *= batch_size
+ macs *= batch_size
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_module/convolution.py b/colossalai/fx/profiler/experimental/profiler_module/convolution.py
new file mode 100644
index 0000000000000000000000000000000000000000..a4c15b91e611d5d1398eeb38ec5c106c2652749b
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/convolution.py
@@ -0,0 +1,157 @@
+# Copyright (c) Microsoft Corporation.
+
+# Licensed under the MIT License.
+import math
+import operator
+from functools import reduce
+from typing import Tuple
+
+import torch
+
+from ..registry import meta_profiler_module
+
+
+@meta_profiler_module.register(torch.nn.Conv1d)
+def torch_nn_conv1d(self: torch.nn.Conv1d, input: torch.Tensor) -> Tuple[int, int]:
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html
+ c_in, l_in = input.shape[-2:]
+ c_out = self.out_channels
+ l_out = math.floor((l_in + 2 * self.padding[0] - self.dilation[0] *
+ (self.kernel_size[0] - 1) - 1) / self.stride[0] + 1)
+ result_shape = input.shape[:-2] + (
+ c_out,
+ l_out,
+ )
+ macs_per_elem = reduce(operator.mul, self.kernel_size) * c_in // self.groups
+ num_elem = reduce(operator.mul, result_shape)
+ macs = macs_per_elem * num_elem
+ flops = 2 * macs
+ if self.bias is not None:
+ flops += num_elem
+ return flops, macs
+
+
+@meta_profiler_module.register(torch.nn.Conv2d)
+def torch_nn_conv2d(self: torch.nn.Conv2d, input: torch.Tensor) -> Tuple[int, int]:
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
+ c_in, h_in, w_in = input.shape[-3:]
+ c_out = self.out_channels
+ h_out = math.floor((h_in + 2 * self.padding[0] - self.dilation[0] *
+ (self.kernel_size[0] - 1) - 1) / self.stride[0] + 1)
+ w_out = math.floor((w_in + 2 * self.padding[1] - self.dilation[1] *
+ (self.kernel_size[1] - 1) - 1) / self.stride[1] + 1)
+ result_shape = input.shape[:-3] + (
+ c_out,
+ h_out,
+ w_out,
+ )
+ macs_per_elem = reduce(operator.mul, self.kernel_size) * c_in // self.groups
+ num_elem = reduce(operator.mul, result_shape)
+ macs = macs_per_elem * num_elem
+ flops = 2 * macs
+ if self.bias is not None:
+ flops += num_elem
+ return flops, macs
+
+
+@meta_profiler_module.register(torch.nn.Conv3d)
+def torch_nn_conv3d(self: torch.nn.Conv3d, input: torch.Tensor) -> Tuple[int, int]:
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.Conv3d.html
+ c_in, d_in, h_in, w_in = input.shape[-4:]
+ c_out = self.out_channels
+ d_out = math.floor((d_in + 2 * self.padding[0] - self.dilation[0] *
+ (self.kernel_size[0] - 1) - 1) / self.stride[0] + 1)
+ h_out = math.floor((h_in + 2 * self.padding[1] - self.dilation[1] *
+ (self.kernel_size[1] - 1) - 1) / self.stride[1] + 1)
+ w_out = math.floor((w_in + 2 * self.padding[2] - self.dilation[2] *
+ (self.kernel_size[2] - 1) - 1) / self.stride[2] + 1)
+ result_shape = input.shape[:-4] + (
+ c_out,
+ d_out,
+ h_out,
+ w_out,
+ )
+ macs_per_elem = reduce(operator.mul, self.kernel_size) * c_in // self.groups
+ num_elem = reduce(operator.mul, result_shape)
+ macs = macs_per_elem * num_elem
+ flops = 2 * macs
+ if self.bias is not None:
+ flops += num_elem
+ return flops, macs
+
+
+@meta_profiler_module.register(torch.nn.ConvTranspose1d)
+def torch_nn_convtranspose1d(self: torch.nn.ConvTranspose1d, input: torch.Tensor) -> Tuple[int, int]:
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose1d.html
+ c_in, l_in = input.shape[-2:]
+ c_out = self.out_channels
+ l_out = math.floor((l_in - 1) * self.stride[0] - 2 * self.padding[0] + self.dilation[0] *
+ (self.kernel_size[0] - 1) + self.output_padding[0] + 1)
+ result_shape = input.shape[:-2] + (
+ c_out,
+ l_out,
+ )
+ macs_per_elem = reduce(operator.mul, self.kernel_size) * c_in // self.groups
+ num_elem = reduce(
+ operator.mul, input.shape
+ ) # see https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/profiling/flops_profiler/profiler.py#L604
+ macs = macs_per_elem * num_elem
+ flops = 2 * macs
+ if self.bias is not None:
+ flops += reduce(operator.mul, result_shape)
+ return flops, macs
+
+
+@meta_profiler_module.register(torch.nn.ConvTranspose2d)
+def torch_nn_convtranspose2d(self: torch.nn.ConvTranspose2d, input: torch.Tensor) -> Tuple[int, int]:
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose2d.html
+ c_in, h_in, w_in = input.shape[-3:]
+ c_out = self.out_channels
+ h_out = math.floor((h_in - 1) * self.stride[0] - 2 * self.padding[0] + self.dilation[0] *
+ (self.kernel_size[0] - 1) + self.output_padding[0] + 1)
+ w_out = math.floor((w_in - 1) * self.stride[1] - 2 * self.padding[1] + self.dilation[1] *
+ (self.kernel_size[1] - 1) + self.output_padding[1] + 1)
+ result_shape = input.shape[:-3] + (
+ c_out,
+ h_out,
+ w_out,
+ )
+ macs_per_elem = reduce(operator.mul, self.kernel_size) * c_in // self.groups
+ num_elem = reduce(operator.mul, input.shape)
+ macs = macs_per_elem * num_elem
+ flops = 2 * macs
+ if self.bias is not None:
+ flops += reduce(operator.mul, result_shape)
+ return flops, macs
+
+
+@meta_profiler_module.register(torch.nn.ConvTranspose3d)
+def torch_nn_convtranspose3d(self: torch.nn.ConvTranspose3d, input: torch.Tensor) -> Tuple[int, int]:
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose3d.html
+ c_in, d_in, h_in, w_in = input.shape[-4:]
+ c_out = self.out_channels
+ d_out = math.floor((d_in - 1) * self.stride[0] - 2 * self.padding[0] + self.dilation[0] *
+ (self.kernel_size[0] - 1) + self.output_padding[0] + 1)
+ h_out = math.floor((h_in - 1) * self.stride[1] - 2 * self.padding[1] + self.dilation[1] *
+ (self.kernel_size[1] - 1) + self.output_padding[1] + 1)
+ w_out = math.floor((w_in - 1) * self.stride[2] - 2 * self.padding[2] + self.dilation[2] *
+ (self.kernel_size[2] - 1) + self.output_padding[2] + 1)
+ result_shape = input.shape[:-4] + (
+ c_out,
+ d_out,
+ h_out,
+ w_out,
+ )
+ macs_per_elem = reduce(operator.mul, self.kernel_size) * c_in // self.groups
+ num_elem = reduce(operator.mul, input.shape)
+ macs = macs_per_elem * num_elem
+ flops = 2 * macs
+ if self.bias is not None:
+ flops += reduce(operator.mul, result_shape)
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_module/dropout.py b/colossalai/fx/profiler/experimental/profiler_module/dropout.py
new file mode 100644
index 0000000000000000000000000000000000000000..417e0ed468637a5ce049ffa8137a73e5b266c971
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/dropout.py
@@ -0,0 +1,11 @@
+from typing import Tuple
+import torch
+from ..registry import meta_profiler_module
+
+
+@meta_profiler_module.register(torch.nn.Dropout)
+def torch_nn_dropout(self: torch.nn.Module, input: torch.Tensor) -> Tuple[int, int]:
+ # nn.Embedding is a dictionary lookup, so technically it has 0 FLOPs. (https://discuss.pytorch.org/t/correct-way-to-calculate-flops-in-model/67198/6)
+ flops = 0
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_module/embedding.py b/colossalai/fx/profiler/experimental/profiler_module/embedding.py
new file mode 100644
index 0000000000000000000000000000000000000000..a1ade5d3ad93845eec84ca543f0a9afaf5b7b7fd
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/embedding.py
@@ -0,0 +1,13 @@
+from typing import Tuple
+
+import torch
+
+from ..registry import meta_profiler_module
+
+
+@meta_profiler_module.register(torch.nn.Embedding)
+def torch_nn_embedding(self: torch.nn.Embedding, input: torch.Tensor) -> Tuple[int, int]:
+ # nn.Embedding is a dictionary lookup, so technically it has 0 FLOPs. (https://discuss.pytorch.org/t/correct-way-to-calculate-flops-in-model/67198/6)
+ flops = 0
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_module/linear.py b/colossalai/fx/profiler/experimental/profiler_module/linear.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1ffb6f244d2ed7d5764339d61fdb46f71ae59a2
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/linear.py
@@ -0,0 +1,14 @@
+from typing import Tuple
+import torch
+from ..registry import meta_profiler_module
+
+
+@meta_profiler_module.register(torch.nn.Linear)
+@meta_profiler_module.register(torch.nn.modules.linear.NonDynamicallyQuantizableLinear)
+def torch_nn_linear(self: torch.nn.Linear, input: torch.Tensor) -> Tuple[int, int]:
+ out_features = self.weight.shape[0]
+ macs = input.numel() * out_features
+ flops = 2 * macs
+ if self.bias is not None:
+ flops += self.bias.numel()
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_module/normalization.py b/colossalai/fx/profiler/experimental/profiler_module/normalization.py
new file mode 100644
index 0000000000000000000000000000000000000000..49e5e6fa5384b07412abe7ecc947d7963e88bd1a
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/normalization.py
@@ -0,0 +1,38 @@
+# Copyright (c) Microsoft Corporation.
+
+# Licensed under the MIT License.
+from typing import Tuple, Union
+
+import torch
+
+from ..registry import meta_profiler_module
+
+
+@meta_profiler_module.register(torch.nn.InstanceNorm1d)
+@meta_profiler_module.register(torch.nn.InstanceNorm2d)
+@meta_profiler_module.register(torch.nn.InstanceNorm3d)
+@meta_profiler_module.register(torch.nn.LayerNorm)
+@meta_profiler_module.register(torch.nn.GroupNorm)
+@meta_profiler_module.register(torch.nn.BatchNorm1d)
+@meta_profiler_module.register(torch.nn.BatchNorm2d)
+@meta_profiler_module.register(torch.nn.BatchNorm3d)
+def torch_nn_normalize(self: Union[torch.nn.LayerNorm, torch.nn.GroupNorm, torch.nn.BatchNorm1d, torch.nn.BatchNorm2d,
+ torch.nn.BatchNorm3d], input: torch.Tensor) -> Tuple[int, int]:
+ # adopted from https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/profiling/flops_profiler/profiler.py#L615
+ has_affine = self.weight is not None
+ if self.training:
+ flops = input.numel() * (2 if has_affine else 1)
+ else:
+ flops = input.numel() * (5 if has_affine else 4)
+ macs = 0
+ return flops, macs
+
+
+try:
+ import apex
+ meta_profiler_module.register(apex.normalization.FusedLayerNorm)(torch_nn_normalize)
+ meta_profiler_module.register(apex.normalization.FusedRMSNorm)(torch_nn_normalize)
+ meta_profiler_module.register(apex.normalization.MixedFusedLayerNorm)(torch_nn_normalize)
+ meta_profiler_module.register(apex.normalization.MixedFusedRMSNorm)(torch_nn_normalize)
+except (ImportError, AttributeError):
+ pass
diff --git a/colossalai/fx/profiler/experimental/profiler_module/pooling.py b/colossalai/fx/profiler/experimental/profiler_module/pooling.py
new file mode 100644
index 0000000000000000000000000000000000000000..e429ac3eea28055f42af2ea8f84663a5a6fd2a83
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/pooling.py
@@ -0,0 +1,22 @@
+from typing import Tuple
+import torch
+from ..registry import meta_profiler_module
+
+
+@meta_profiler_module.register(torch.nn.AvgPool1d)
+@meta_profiler_module.register(torch.nn.AvgPool2d)
+@meta_profiler_module.register(torch.nn.AvgPool3d)
+@meta_profiler_module.register(torch.nn.MaxPool1d)
+@meta_profiler_module.register(torch.nn.MaxPool2d)
+@meta_profiler_module.register(torch.nn.MaxPool3d)
+@meta_profiler_module.register(torch.nn.AdaptiveAvgPool1d)
+@meta_profiler_module.register(torch.nn.AdaptiveMaxPool1d)
+@meta_profiler_module.register(torch.nn.AdaptiveAvgPool2d)
+@meta_profiler_module.register(torch.nn.AdaptiveMaxPool2d)
+@meta_profiler_module.register(torch.nn.AdaptiveAvgPool3d)
+@meta_profiler_module.register(torch.nn.AdaptiveMaxPool3d)
+def torch_nn_pooling(self: torch.nn.Module, input: torch.Tensor) -> Tuple[int, int]:
+ # all pooling could be considered as going over each input element only once (https://stackoverflow.com/a/67301217)
+ flops = input.numel()
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_module/rnn.py b/colossalai/fx/profiler/experimental/profiler_module/rnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e733d6da9156db13b2bac35af63a52ad89ad5a3
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/rnn.py
@@ -0,0 +1,75 @@
+from functools import reduce
+import operator
+import torch
+from ..registry import meta_profiler_module
+from typing import Optional, Tuple, Union
+
+
+def _rnn_flops(flops: int, macs: int, module: torch.nn.RNNBase, w_ih: torch.Tensor,
+ w_hh: torch.Tensor) -> Tuple[int, int]:
+ # copied from https://github.com/sovrasov/flops-counter.pytorch/blob/master/ptflops/pytorch_ops.py
+
+ # matrix matrix mult ih state and internal state
+ macs += reduce(operator.mul, w_ih.shape)
+ flops += 2 * reduce(operator.mul, w_ih.shape)
+ # matrix matrix mult hh state and internal state
+ macs += reduce(operator.mul, w_hh.shape)
+ flops += 2 * reduce(operator.mul, w_hh.shape)
+ if isinstance(module, (torch.nn.RNN, torch.nn.RNNCell)):
+ # add both operations
+ flops += module.hidden_size
+ elif isinstance(module, (torch.nn.GRU, torch.nn.GRUCell)):
+ # hadamard of r
+ flops += module.hidden_size
+ # adding operations from both states
+ flops += module.hidden_size * 3
+ # last two hadamard product and add
+ flops += module.hidden_size * 3
+ elif isinstance(module, (torch.nn.LSTM, torch.nn.LSTMCell)):
+ # adding operations from both states
+ flops += module.hidden_size * 4
+ # two hadamard product and add for C state
+ flops += module.hidden_size * 3
+ # final hadamard
+ flops += module.hidden_size * 3
+ return flops, macs
+
+
+@meta_profiler_module.register(torch.nn.LSTM)
+@meta_profiler_module.register(torch.nn.GRU)
+@meta_profiler_module.register(torch.nn.RNN)
+def torch_nn_rnn(self: torch.nn.RNNBase, input: torch.Tensor, hx: Optional[torch.Tensor] = None) -> Tuple[int, int]:
+ flops = 0
+ macs = 0
+ for i in range(self.num_layers):
+ w_ih = self.__getattr__('weight_ih_l' + str(i))
+ w_hh = self.__getattr__('weight_hh_l' + str(i))
+ flops, macs = _rnn_flops(flops, macs, self, w_ih, w_hh)
+ if self.bias:
+ b_ih = self.__getattr__('bias_ih_l' + str(i))
+ b_hh = self.__getattr__('bias_hh_l' + str(i))
+ flops += reduce(operator.mul, b_ih) + reduce(operator.mul, b_hh)
+ flops *= reduce(operator.mul, input.shape[:2])
+ macs *= reduce(operator.mul, input.shape[:2])
+ if self.bidirectional:
+ flops *= 2
+ macs *= 2
+ return flops, macs
+
+
+@meta_profiler_module.register(torch.nn.LSTMCell)
+@meta_profiler_module.register(torch.nn.GRUCell)
+@meta_profiler_module.register(torch.nn.RNNCell)
+def torch_nn_rnn(self: torch.nn.RNNCellBase, input: torch.Tensor, hx: Optional[torch.Tensor] = None) -> Tuple[int, int]:
+ flops = 0
+ macs = 0
+ w_ih = self.__getattr__('weight_ih_l')
+ w_hh = self.__getattr__('weight_hh_l')
+ flops, macs = _rnn_flops(flops, macs, self, w_ih, w_hh)
+ if self.bias:
+ b_ih = self.__getattr__('bias_ih_l')
+ b_hh = self.__getattr__('bias_hh_l')
+ flops += reduce(operator.mul, b_ih) + reduce(operator.mul, b_hh)
+ flops *= input.shape[0]
+ macs *= input.shape[0]
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/profiler_module/torch_op.py b/colossalai/fx/profiler/experimental/profiler_module/torch_op.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3aed874eb10af76dc94e21b23c566178afe6264
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/profiler_module/torch_op.py
@@ -0,0 +1,11 @@
+import operator
+import torch
+from ..registry import meta_profiler_module
+from typing import Optional, Tuple, Union
+
+
+@meta_profiler_module.register(torch.nn.Flatten)
+def torch_nn_flatten(self: torch.nn.Flatten, input: torch.Tensor) -> Tuple[int, int]:
+ flops = 0
+ macs = 0
+ return flops, macs
diff --git a/colossalai/fx/profiler/experimental/registry.py b/colossalai/fx/profiler/experimental/registry.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d73bce321e43d7c1284bf4d78dbac2bc7c4abfc
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/registry.py
@@ -0,0 +1,25 @@
+class ProfilerRegistry:
+
+ def __init__(self, name):
+ self.name = name
+ self.store = {}
+
+ def register(self, source):
+
+ def wrapper(func):
+ self.store[source] = func
+ return func
+
+ return wrapper
+
+ def get(self, source):
+ assert source in self.store
+ target = self.store[source]
+ return target
+
+ def has(self, source):
+ return source in self.store
+
+
+meta_profiler_function = ProfilerRegistry(name='patched_functions_for_meta_profile')
+meta_profiler_module = ProfilerRegistry(name='patched_modules_for_meta_profile')
diff --git a/colossalai/fx/profiler/experimental/shard_utils.py b/colossalai/fx/profiler/experimental/shard_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e53ed0bf8ec657d8916d49c8c4b97f1d996010a
--- /dev/null
+++ b/colossalai/fx/profiler/experimental/shard_utils.py
@@ -0,0 +1,48 @@
+# for PyTorch 1.11 compatibility uses
+from typing import Dict, List, Tuple, Union
+
+import torch
+from torch.fx import GraphModule, Node
+
+from ..._compatibility import compatibility
+
+__all__ = ["calculate_fwd_in", "calculate_fwd_tmp", "calculate_fwd_out"]
+
+
+@compatibility(is_backward_compatible=True)
+def calculate_fwd_in(n: Node) -> bool:
+ """A helper function to calculate `fwd_in`
+
+ Args:
+ n (Node): a node from the graph
+
+ Returns:
+ save_fwd_in (bool): the result of `save_fwd_in`
+ """
+ return n.meta['save_fwd_in']
+
+
+@compatibility(is_backward_compatible=True)
+def calculate_fwd_tmp(n: Node) -> int:
+ """A helper function to calculate `fwd_tmp`
+
+ Args:
+ n (Node): a node from the graph
+
+ Returns:
+ fwd_tmp (int): the result of `fwd_tmp`
+ """
+ return n.meta["fwd_mem_tmp"]
+
+
+@compatibility(is_backward_compatible=True)
+def calculate_fwd_out(n: Node) -> int:
+ """A helper function to calculate `fwd_out`
+
+ Args:
+ n (Node): a node from the graph
+
+ Returns:
+ fwd_out (int): the result of `fwd_out`
+ """
+ return n.meta['fwd_mem_out']
diff --git a/colossalai/fx/profiler/memory_utils.py b/colossalai/fx/profiler/memory_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..6ccbcb01cdc14045fbdd4906f1fc6f2a5ad728db
--- /dev/null
+++ b/colossalai/fx/profiler/memory_utils.py
@@ -0,0 +1,71 @@
+from typing import Dict, List, Tuple, Union
+
+import torch
+from torch.fx import GraphModule, Node
+
+from .._compatibility import compatibility, is_compatible_with_meta
+
+__all__ = ['activation_size', 'parameter_size', 'is_inplace']
+
+
+@compatibility(is_backward_compatible=True)
+def activation_size(out: Union[torch.Tensor, Dict, List, Tuple, int]) -> int:
+ """Calculate activation size of a node.
+
+ Args:
+ activation (Union[torch.Tensor, Dict, List, Tuple, int]): The activation of a `torch.nn.Module` or `torch.nn.functional`.
+
+ Returns:
+ int: The activation size, unit is byte.
+ """
+ act_size = 0
+ if isinstance(out, torch.Tensor):
+ if out.is_quantized:
+ act_size += out.numel() * torch._empty_affine_quantized([], dtype=out.dtype).element_size()
+ else:
+ act_size += out.numel() * torch.tensor([], dtype=out.dtype).element_size()
+ elif isinstance(out, dict):
+ value_list = [v for _, v in out.items()]
+ act_size += activation_size(value_list)
+ elif isinstance(out, tuple) or isinstance(out, list) or isinstance(out, set):
+ for element in out:
+ act_size += activation_size(element)
+ return act_size
+
+
+@compatibility(is_backward_compatible=True)
+def parameter_size(mod: torch.nn.Module) -> int:
+ """Calculate parameter size of a node.
+
+ Args:
+ mod (torch.nn.Module): The target `torch.nn.Module`.
+
+ Returns:
+ int: The parameter size, unit is byte.
+ """
+ param_size = 0
+ for param in mod.parameters():
+ param_size += param.numel() * torch.tensor([], dtype=param.dtype).element_size()
+ return param_size
+
+
+def is_inplace(n: Node):
+ """Get the inplace argument from torch.fx.Node
+
+ Args:
+ node (Node): torch.fx.Node
+
+ Returns:
+ bool: indicates whether this op is inplace
+ """
+ inplace = False
+ if n.op == "call_function":
+ inplace = n.kwargs.get("inplace", False)
+ if is_compatible_with_meta():
+ from .constants import ALIAS_ATEN
+ if n.target in ALIAS_ATEN:
+ inplace = True
+ elif n.op == "call_module":
+ inplace = getattr(n.graph.owning_module.get_submodule(n.target), "inplace", False)
+
+ return inplace
diff --git a/colossalai/fx/profiler/opcount.py b/colossalai/fx/profiler/opcount.py
new file mode 100644
index 0000000000000000000000000000000000000000..ba090a2ec51bd7d1d83a6dd5d75c877c0708577f
--- /dev/null
+++ b/colossalai/fx/profiler/opcount.py
@@ -0,0 +1,374 @@
+# adopted from https://github.com/facebookresearch/fvcore/blob/main/fvcore/nn/jit_handles.py
+# ideas from https://pastebin.com/AkvAyJBw
+
+import operator
+from functools import partial, reduce
+from numbers import Number
+from typing import Any, Callable, List
+
+import torch
+from packaging import version
+
+aten = torch.ops.aten
+
+
+def matmul_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for matmul.
+ """
+ # Inputs should be a list of length 2.
+ # Inputs contains the shapes of two matrices.
+ input_shapes = [v.shape for v in inputs]
+ assert len(input_shapes) == 2, input_shapes
+
+ # There are three cases: 1) gemm, 2) gemv, 3) dot
+ if all(len(shape) == 2 for shape in input_shapes):
+ # gemm
+ assert input_shapes[0][-1] == input_shapes[1][-2], input_shapes
+ elif all(len(shape) == 1 for shape in input_shapes):
+ # dot
+ assert input_shapes[0][0] == input_shapes[1][0], input_shapes
+
+ # expand shape
+ input_shapes[0] = torch.Size([1, input_shapes[0][0]])
+ input_shapes[1] = torch.Size([input_shapes[1][0], 1])
+ else:
+ # gemv
+ if len(input_shapes[0]) == 1:
+ assert input_shapes[0][0] == input_shapes[1][-2], input_shapes
+ input_shapes.reverse()
+ else:
+ assert input_shapes[1][0] == input_shapes[0][-1], input_shapes
+
+ # expand the shape of the vector to [batch size, 1]
+ input_shapes[-1] = torch.Size([input_shapes[-1][-1], 1])
+ flops = reduce(operator.mul, input_shapes[0]) * input_shapes[-1][-1]
+ return flops
+
+
+def addmm_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for fully connected layers.
+ """
+ # Count flop for nn.Linear
+ # inputs is a list of length 3.
+ input_shapes = [v.shape for v in inputs[1:3]]
+ # input_shapes[0]: [batch size, input feature dimension]
+ # input_shapes[1]: [input feature dimension, output feature dimension]
+ assert len(input_shapes[0]) == 2, input_shapes[0]
+ assert len(input_shapes[1]) == 2, input_shapes[1]
+ batch_size, input_dim = input_shapes[0]
+ output_dim = input_shapes[1][1]
+ flops = batch_size * input_dim * output_dim
+ return flops
+
+
+def linear_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for the aten::linear operator.
+ """
+ # Inputs is a list of length 3; unlike aten::addmm, it is the first
+ # two elements that are relevant.
+ input_shapes = [v.shape for v in inputs[0:2]]
+ # input_shapes[0]: [dim0, dim1, ..., input_feature_dim]
+ # input_shapes[1]: [output_feature_dim, input_feature_dim]
+ assert input_shapes[0][-1] == input_shapes[1][-1]
+ flops = reduce(operator.mul, input_shapes[0]) * input_shapes[1][0]
+ return flops
+
+
+def bmm_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for the bmm operation.
+ """
+ # Inputs should be a list of length 2.
+ # Inputs contains the shapes of two tensor.
+ assert len(inputs) == 2, len(inputs)
+ input_shapes = [v.shape for v in inputs]
+ n, c, t = input_shapes[0]
+ d = input_shapes[-1][-1]
+ flops = n * c * t * d
+ return flops
+
+
+def baddbmm_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for the baddbmm(batch add and batch matmul) operation.
+ """
+ # Inputs = [input, batch1, batch2]
+ # out = input + batch1 x batch2
+ assert len(inputs) == 3, len(inputs)
+ n, c, t = inputs[1].shape
+ d = inputs[2].shape[-1]
+ flops = n * c * t * d
+ return flops
+
+
+def conv_flop_count(
+ x_shape: List[int],
+ w_shape: List[int],
+ out_shape: List[int],
+ transposed: bool = False,
+) -> Number:
+ """
+ Count flops for convolution. Note only multiplication is
+ counted. Computation for addition and bias is ignored.
+ Flops for a transposed convolution are calculated as
+ flops = (x_shape[2:] * prod(w_shape) * batch_size).
+ Args:
+ x_shape (list(int)): The input shape before convolution.
+ w_shape (list(int)): The filter shape.
+ out_shape (list(int)): The output shape after convolution.
+ transposed (bool): is the convolution transposed
+ Returns:
+ int: the number of flops
+ """
+ batch_size = x_shape[0]
+ conv_shape = (x_shape if transposed else out_shape)[2:]
+ flops = batch_size * reduce(operator.mul, w_shape) * reduce(operator.mul, conv_shape)
+ return flops
+
+
+def conv_flop_jit(inputs: List[Any], outputs: List[Any]):
+ """
+ Count flops for convolution.
+ """
+ x, w = inputs[:2]
+ x_shape, w_shape, out_shape = (x.shape, w.shape, outputs[0].shape)
+ transposed = inputs[6]
+
+ return conv_flop_count(x_shape, w_shape, out_shape, transposed=transposed)
+
+
+def transpose_shape(shape):
+ return [shape[1], shape[0]] + list(shape[2:])
+
+
+def conv_backward_flop_jit(inputs: List[Any], outputs: List[Any]):
+ grad_out_shape, x_shape, w_shape = [i.shape for i in inputs[:3]]
+ output_mask = inputs[-1]
+ fwd_transposed = inputs[7]
+ flop_count = 0
+
+ if output_mask[0]:
+ grad_input_shape = outputs[0].shape
+ flop_count += conv_flop_count(grad_out_shape, w_shape, grad_input_shape, not fwd_transposed)
+ if output_mask[1]:
+ grad_weight_shape = outputs[1].shape
+ flop_count += conv_flop_count(transpose_shape(x_shape), grad_out_shape, grad_weight_shape, fwd_transposed)
+
+ return flop_count
+
+
+def norm_flop_counter(affine_arg_index: int, input_arg_index: int) -> Callable:
+ """
+ Args:
+ affine_arg_index: index of the affine argument in inputs
+ """
+
+ def norm_flop_jit(inputs: List[Any], outputs: List[Any]) -> Number:
+ """
+ Count flops for norm layers.
+ """
+ # Inputs[0] contains the shape of the input.
+ input_shape = inputs[input_arg_index].shape
+
+ has_affine = inputs[affine_arg_index].shape is not None if hasattr(inputs[affine_arg_index],
+ 'shape') else inputs[affine_arg_index]
+ assert 2 <= len(input_shape) <= 5, input_shape
+ # 5 is just a rough estimate
+ flop = reduce(operator.mul, input_shape) * (5 if has_affine else 4)
+ return flop
+
+ return norm_flop_jit
+
+
+def batchnorm_flop_jit(inputs: List[Any], outputs: List[Any], training: bool = None) -> Number:
+ if training is None:
+ training = inputs[-3]
+ assert isinstance(training, bool), "Signature of aten::batch_norm has changed!"
+ if training:
+ return norm_flop_counter(1, 0)(inputs, outputs) # pyre-ignore
+ has_affine = inputs[1].shape is not None
+ input_shape = reduce(operator.mul, inputs[0].shape)
+ return input_shape * (2 if has_affine else 1)
+
+
+def elementwise_flop_counter(input_scale: float = 1, output_scale: float = 0) -> Callable:
+ """
+ Count flops by
+ input_tensor.numel() * input_scale + output_tensor.numel() * output_scale
+ Args:
+ input_scale: scale of the input tensor (first argument)
+ output_scale: scale of the output tensor (first element in outputs)
+ """
+
+ def elementwise_flop(inputs: List[Any], outputs: List[Any]) -> Number:
+ ret = 0
+ if input_scale != 0:
+ shape = inputs[0].shape
+ ret += input_scale * reduce(operator.mul, shape) if shape else 0
+ if output_scale != 0:
+ shape = outputs[0].shape
+ ret += output_scale * reduce(operator.mul, shape) if shape else 0
+ return ret
+
+ return elementwise_flop
+
+
+def zero_flop_jit(*args):
+ """
+ Count flops for zero flop layers.
+ """
+ return 0
+
+
+if version.parse(torch.__version__) >= version.parse('1.12.0') and version.parse(
+ torch.__version__) < version.parse('2.0.0'):
+ flop_mapping = {
+ # gemm, gemv and dot
+ aten.mm.default: matmul_flop_jit,
+ aten.mv.default: matmul_flop_jit,
+ aten.dot.default: matmul_flop_jit,
+ aten.matmul.default: matmul_flop_jit,
+ aten.addmm.default: addmm_flop_jit,
+ aten.bmm.default: bmm_flop_jit,
+ aten.baddbmm.default: baddbmm_flop_jit,
+
+ # convolution
+ aten.convolution.default: conv_flop_jit,
+ aten._convolution.default: conv_flop_jit,
+ aten.convolution_backward.default: conv_backward_flop_jit,
+
+ # normalization
+ aten.native_batch_norm.default: batchnorm_flop_jit,
+ aten.native_batch_norm_backward.default: batchnorm_flop_jit,
+ aten.cudnn_batch_norm.default: batchnorm_flop_jit,
+ aten.cudnn_batch_norm_backward.default: partial(batchnorm_flop_jit, training=True),
+ aten.native_layer_norm.default: norm_flop_counter(2, 0),
+ aten.native_layer_norm_backward.default: norm_flop_counter(2, 0),
+ aten.native_group_norm.default: norm_flop_counter(2, 0),
+ aten.native_group_norm_backward.default: norm_flop_counter(2, 0),
+
+ # pooling
+ aten.avg_pool1d.default: elementwise_flop_counter(1, 0),
+ aten.avg_pool2d.default: elementwise_flop_counter(1, 0),
+ aten.avg_pool2d_backward.default: elementwise_flop_counter(0, 1),
+ aten.avg_pool3d.default: elementwise_flop_counter(1, 0),
+ aten.avg_pool3d_backward.default: elementwise_flop_counter(0, 1),
+ aten.max_pool1d.default: elementwise_flop_counter(1, 0),
+ aten.max_pool2d.default: elementwise_flop_counter(1, 0),
+ aten.max_pool3d.default: elementwise_flop_counter(1, 0),
+ aten.max_pool1d_with_indices.default: elementwise_flop_counter(1, 0),
+ aten.max_pool2d_with_indices.default: elementwise_flop_counter(1, 0),
+ aten.max_pool2d_with_indices_backward.default: elementwise_flop_counter(0, 1),
+ aten.max_pool3d_with_indices.default: elementwise_flop_counter(1, 0),
+ aten.max_pool3d_with_indices_backward.default: elementwise_flop_counter(0, 1),
+ aten._adaptive_avg_pool2d.default: elementwise_flop_counter(1, 0),
+ aten._adaptive_avg_pool2d_backward.default: elementwise_flop_counter(0, 1),
+ aten._adaptive_avg_pool3d.default: elementwise_flop_counter(1, 0),
+ aten._adaptive_avg_pool3d_backward.default: elementwise_flop_counter(0, 1),
+ aten.embedding_dense_backward.default: elementwise_flop_counter(0, 1),
+ aten.embedding.default: elementwise_flop_counter(1, 0),
+ aten.upsample_nearest2d.vec: elementwise_flop_counter(0, 1),
+ aten.upsample_nearest2d_backward.vec: elementwise_flop_counter(0, 1),
+ }
+
+ elementwise_flop_aten = [
+ # basic op
+ aten.add.Tensor,
+ aten.add_.Tensor,
+ aten.div.Tensor,
+ aten.div_.Tensor,
+ aten.div.Scalar,
+ aten.div_.Scalar,
+ aten.mul.Tensor,
+ aten.mul.Scalar,
+ aten.mul_.Tensor,
+ aten.neg.default,
+ aten.pow.Tensor_Scalar,
+ aten.rsub.Scalar,
+ aten.sum.default,
+ aten.sum.dim_IntList,
+ aten.mean.dim,
+ aten.sub.Tensor,
+ aten.sub_.Tensor,
+ aten.exp.default,
+ aten.sin.default,
+ aten.cos.default,
+
+ # activation op
+ aten.hardswish.default,
+ aten.hardswish_.default,
+ aten.hardswish_backward.default,
+ aten.hardtanh.default,
+ aten.hardtanh_.default,
+ aten.hardtanh_backward.default,
+ aten.hardsigmoid_backward.default,
+ aten.hardsigmoid.default,
+ aten.gelu.default,
+ aten.gelu_backward.default,
+ aten.silu.default,
+ aten.silu_.default,
+ aten.silu_backward.default,
+ aten.sigmoid.default,
+ aten.sigmoid_backward.default,
+ aten._softmax.default,
+ aten._softmax_backward_data.default,
+ aten.relu_.default,
+ aten.relu.default,
+ aten.tanh.default,
+ aten.tanh_backward.default,
+ aten.threshold_backward.default,
+
+ # dropout
+ aten.native_dropout.default,
+ aten.native_dropout_backward.default,
+ ]
+ for op in elementwise_flop_aten:
+ flop_mapping[op] = elementwise_flop_counter(1, 0)
+
+ # TODO: this will be removed in future
+ zero_flop_aten = [
+ aten.as_strided.default,
+ aten.as_strided_.default,
+ aten.bernoulli_.float,
+ aten.cat.default,
+ aten.clone.default,
+ aten.copy_.default,
+ aten.detach.default,
+ aten.expand.default,
+ aten.empty_like.default,
+ aten.new_empty.default,
+ aten.new_empty_strided.default,
+ aten.ones_like.default,
+ aten._reshape_alias.default,
+ aten.select.int,
+ aten.select_backward.default,
+ aten.squeeze.dim,
+ aten.slice.Tensor,
+ aten.slice_backward.default,
+ aten.stack.default,
+ aten.split.Tensor,
+ aten.permute.default,
+ aten.t.default,
+ aten.transpose.int,
+ aten._to_copy.default,
+ aten.unsqueeze.default,
+ aten.unbind.int,
+ aten._unsafe_view.default,
+ aten.view.default,
+ aten.where.self,
+ aten.zero_.default,
+ aten.zeros_like.default,
+ aten.fill_.Scalar,
+ aten.stack.default
+ ] # yapf: disable
+
+ for op in zero_flop_aten:
+ flop_mapping[op] = zero_flop_jit
+
+else:
+ flop_mapping = {}
+ elementwise_flop_aten = {}
+ zero_flop_aten = {}
diff --git a/colossalai/fx/profiler/profiler.py b/colossalai/fx/profiler/profiler.py
new file mode 100644
index 0000000000000000000000000000000000000000..c87cd4321d31c59ebe369a2903b679a439fb4f96
--- /dev/null
+++ b/colossalai/fx/profiler/profiler.py
@@ -0,0 +1,409 @@
+import time
+from functools import partial
+from typing import Any, Callable, Dict, Tuple
+
+import torch
+from torch.fx import Graph, Node
+from torch.fx.node import Argument, Target
+from torch.nn.parameter import Parameter
+from torch.utils._pytree import tree_map
+
+from .._compatibility import compatibility
+from .constants import ALIAS_ATEN, OUTPUT_SAVED_MOD, OUTPUT_SAVED_OPS
+from .dataflow import GraphInfo, Phase, autograd_graph_analysis, is_phase
+from .memory_utils import activation_size, parameter_size
+from .opcount import flop_mapping
+from .tensor import MetaTensor
+
+__all__ = ['profile_function', 'profile_module', 'profile_method']
+
+# super-dainiu: this cache should be global, otherwise it cannot
+# track duplicated tensors between nodes
+cache = set()
+
+# a global identifier for inplace ops
+do_not_cache = False
+
+
+def normalize_tuple(x):
+ if not isinstance(x, tuple):
+ return (x,)
+ return x
+
+
+def is_autogradable(x):
+ return isinstance(x, torch.Tensor) and x.is_floating_point()
+
+
+def detach_variables(x):
+ if isinstance(x, torch.Tensor):
+ requires_grad = x.requires_grad
+ x = x.detach()
+ x.requires_grad = requires_grad
+
+ return x
+
+
+@compatibility(is_backward_compatible=True)
+def _profile_concrete(target: Callable, *args, **kwargs) -> Tuple[Tuple[Any, ...], GraphInfo]:
+ """Profile a Callable function with args and kwargs on concrete devices by https://github.com/Cypher30
+ To profile the actual forward memory, we first run target in the context torch.no_grad() to get
+ the fwd_mem_out, then we run target with grad enable to found the extra memory stored in the memory
+ by memory allocated minus the fwd_mem_out.
+ To profile the actual backward memory, we first make dummy gradient for torch.autograd.backward, then
+ find the bwd_mem_tmp with memory peak during the process minus bwd_mem_out(it is actually equal to size
+ of args and kwargs).
+ We also add time stamps to profile the real forward and backward time.
+
+ Args:
+ target (Callable): A Callable function
+ args (Any): Arguments
+ kwargs (Any): Arguments
+
+ Returns:
+ Tuple[Tuple[Any, ...], GraphInfo]: Output for next node & memory cost and real forward and backward
+ time.
+ """
+
+ graphinfo = GraphInfo()
+
+ # detach input from the graph
+ args = tree_map(detach_variables, args)
+ kwargs = tree_map(detach_variables, kwargs)
+ if isinstance(target, str):
+ # args[0] is the `self` object for this method call
+ self_obj, *args_tail = args
+
+ # calculate fwd_mem_out
+ mem_stamp0 = torch.cuda.memory_allocated()
+ with torch.no_grad():
+ out = getattr(self_obj, target)(*args_tail, **kwargs)
+ mem_stamp1 = torch.cuda.memory_allocated()
+ graphinfo.fwd_mem_out = mem_stamp1 - mem_stamp0
+ del out
+
+ # calculate fwd_mem_tmp & fwd_time
+ mem_stamp0 = torch.cuda.memory_allocated()
+ fwd_time0 = time.time()
+ out = getattr(self_obj, target)(*args_tail, **kwargs)
+ fwd_time1 = time.time()
+ graphinfo.fwd_time = fwd_time1 - fwd_time0
+ mem_stamp1 = torch.cuda.memory_allocated()
+ graphinfo.fwd_mem_tmp = mem_stamp1 - mem_stamp0 - graphinfo.fwd_mem_out
+
+ # calculate bwd_mem_tmp & bwd_time
+ grad_tensors = tree_map(lambda x: torch.ones_like(x) if isinstance(x, torch.Tensor) else None, out)
+ torch.cuda.reset_peak_memory_stats()
+ mem_stamp0 = torch.cuda.memory_allocated()
+ bwd_time0 = time.time()
+ torch.autograd.backward(out, grad_tensors=grad_tensors)
+ bwd_time1 = time.time()
+ graphinfo.bwd_time = bwd_time1 - bwd_time0
+ mem_stamp1 = torch.cuda.max_memory_allocated()
+
+ # calculate bwd memory stats
+ # NOTE: the module should add param to bwd_mem_out for bwd_mem_tmp calculation
+ graphinfo.bwd_mem_out = activation_size(args) + activation_size(kwargs)
+ graphinfo.bwd_mem_out += parameter_size(target.__self__) if hasattr(target.__self__, "parameters") else 0
+ graphinfo.bwd_mem_tmp = mem_stamp1 - mem_stamp0 - graphinfo.bwd_mem_out
+
+ else:
+ # calculate fwd_mem_out
+ mem_stamp0 = torch.cuda.memory_allocated()
+ with torch.no_grad():
+ out = target(*args, **kwargs)
+ mem_stamp1 = torch.cuda.memory_allocated()
+ graphinfo.fwd_mem_out = mem_stamp1 - mem_stamp0
+ del out
+
+ # calculate fwd_mem_tmp & fwd_time
+ mem_stamp0 = torch.cuda.memory_allocated()
+ fwd_time0 = time.time()
+ out = target(*args, **kwargs)
+ fwd_time1 = time.time()
+ graphinfo.fwd_time = fwd_time1 - fwd_time0
+ mem_stamp1 = torch.cuda.memory_allocated()
+ graphinfo.fwd_mem_tmp = mem_stamp1 - mem_stamp0 - graphinfo.fwd_mem_out
+
+ # calculate bwd_mem_tmp & bwd_time
+ grad_tensors = tree_map(lambda x: torch.ones_like(x) if isinstance(x, torch.Tensor) else None, out)
+ torch.cuda.reset_peak_memory_stats()
+ mem_stamp0 = torch.cuda.memory_allocated()
+ bwd_time0 = time.time()
+ torch.autograd.backward(out, grad_tensors=grad_tensors)
+ bwd_time1 = time.time()
+ graphinfo.bwd_time = bwd_time1 - bwd_time0
+ mem_stamp1 = torch.cuda.max_memory_allocated()
+
+ # calculate bwd memory stats
+ # NOTE: the module should add param to bwd_mem_out for bwd_mem_tmp calculation
+ graphinfo.bwd_mem_out = activation_size(args) + activation_size(kwargs)
+ graphinfo.bwd_mem_out += parameter_size(target.__self__) if hasattr(target.__self__, "parameters") else 0
+ graphinfo.bwd_mem_tmp = mem_stamp1 - mem_stamp0 - graphinfo.bwd_mem_out
+
+ return tree_map(detach_variables, out), graphinfo
+
+
+@compatibility(is_backward_compatible=False)
+def _profile_meta(target: Callable, *args, **kwargs) -> Tuple[Tuple[Any, ...], GraphInfo]:
+ """
+ Profile a Callable function with args and kwargs on meta devices.
+
+ Args:
+ target (Callable): A Callable function
+ args (Any): Argument
+ kwargs (Any): Argument
+
+ Returns:
+ out (Tuple[Any, ...]): The argument value that was retrieved.
+ meta_info (GraphInfo): The memory cost and FLOPs estimated with `MetaTensor`.
+ """
+ # This subgraph traces aten level ops inside one node.
+ subgraph = Graph()
+
+ # `flop_count`` serves as a global dictionary to store results.
+ flop_count = {
+ Phase.FORWARD: 0,
+ Phase.BACKWARD: 0,
+ }
+
+ # FlopTensor not only get the flop statistics of a single node,
+ # it also build a full autograd graph for this node.
+ # This makes sure we can analyze the dependencies of memory, and
+ # decide which forward intermediate results should be kept until
+ # backward is executed.
+ # Hopefully, this attempt will provide a better estimation of memory.
+ class FlopTensor(MetaTensor):
+
+ _node: Node = None
+
+ def __repr__(self):
+ if self.grad_fn:
+ return f"FlopTensor({self._tensor}, fake_device='{self.device}', size={tuple(self.shape)}, grad_fn={self.grad_fn})"
+ return f"FlopTensor({self._tensor}, fake_device='{self.device}', size={tuple(self.shape)}, requires_grad={self.requires_grad})"
+
+ @classmethod
+ def __torch_dispatch__(cls, func, types, args=(), kwargs=None):
+ args_node = tree_map(lambda x: x._node if isinstance(x, FlopTensor) else None, args)
+ kwargs_node = tree_map(lambda x: x._node if isinstance(x, FlopTensor) else None, kwargs)
+ node = subgraph.create_node('call_function', func, args_node, kwargs_node)
+
+ out = super().__torch_dispatch__(func, types, args, kwargs)
+
+ flop_count[phase] += flop_mapping[func](args, normalize_tuple(out))
+ node.meta['phase'] = phase
+
+ # super-dainiu: in `nn.MultiheadAttention` this weird thing occurs,
+ # i.e. `Phase.PLACEHOLDER` tensors are aliased and saved during
+ # `Phase.FORWARD`
+ if phase == Phase.FORWARD:
+ if all(map(partial(is_phase, phase=Phase.PLACEHOLDER), node.all_input_nodes)) and func in ALIAS_ATEN:
+ node.meta['phase'] = Phase.PLACEHOLDER
+
+ # TODO(yby): specify `saved_tensors` for backward memory estimation
+ node.meta['saved_tensor'] = []
+ if phase == Phase.BACKWARD:
+ node.meta['saved_tensor'] = normalize_tuple(out)
+
+ def wrap(x):
+ if isinstance(x, MetaTensor):
+ x = FlopTensor(x)
+ x._node = node
+ return x
+
+ out = tree_map(wrap, out)
+ return out
+
+ def wrap(x):
+ if isinstance(x, torch.Tensor):
+ x = FlopTensor(x)
+ if is_autogradable(x):
+ x.requires_grad_(True)
+ x._node = subgraph.create_node('placeholder',
+ 'placeholder', (subgraph._root,),
+ name=subgraph._graph_namespace.create_name('input', x._tensor))
+ x._node.meta['phase'] = Phase.PLACEHOLDER
+ x._node.meta['saved_tensor'] = []
+ return x
+
+ # Basically, we need to detach the args and kwargs from the outer graph.
+ args = tree_map(wrap, args)
+ kwargs = tree_map(wrap, kwargs)
+
+ def pack(x):
+ global cache, do_not_cache
+ if isinstance(x, FlopTensor) and not x._tensor.data_ptr() in cache:
+ tensor = x._tensor.detach()
+ tensor.data_ptr = x._tensor.data_ptr
+ x._node.meta['saved_tensor'] += [tensor]
+ if not do_not_cache:
+ cache.add(x._tensor.data_ptr())
+ return x
+
+ def unpack(x):
+ return x
+
+ # `phase` will mark the phase of autograd from outside scope.
+ phase = Phase.FORWARD
+ # mark saved tensors with saved_tensors_hooks
+ with torch.autograd.graph.saved_tensors_hooks(pack, unpack):
+ if isinstance(target, str):
+ # args[0] is the `self` object for this method call
+ self_obj, *args_tail = args
+ out = getattr(self_obj, target)(*args_tail, **kwargs)
+ else:
+ out = target(*args, **kwargs)
+
+ # If the output is not a floating point `torch.Tensor` or it does not
+ # requires grad, then we should not run backward for this node.
+ if all(map(lambda x: is_autogradable(x) and x.requires_grad, normalize_tuple(out))):
+ grad_out = [torch.zeros_like(t) for t in normalize_tuple(out)]
+ phase = Phase.BACKWARD
+ torch.autograd.backward(
+ out,
+ grad_out,
+ )
+
+ graph_info = autograd_graph_analysis(subgraph)
+ graph_info.fwd_flop, graph_info.bwd_flop = flop_count[Phase.FORWARD], flop_count[Phase.BACKWARD]
+
+ def extract_tensor(x: Any):
+ if isinstance(x, MetaTensor):
+ tensor = x._tensor.detach()
+ tensor.data_ptr = x._tensor.data_ptr
+ return tensor
+ if not isinstance(x, torch.finfo):
+ return x
+
+ graph_info.fwd_out = list(map(extract_tensor, normalize_tuple(out)))
+
+ def unwrap(x):
+ return MetaTensor(x) if isinstance(x, torch.Tensor) else x
+
+ return tree_map(unwrap, out), graph_info
+
+
+@compatibility(is_backward_compatible=True)
+def profile_function(target: 'Target', device: str = 'meta') -> Callable:
+ """
+ Wrap a `call_function` node or `torch.nn.functional` in order to
+ record the memory cost and FLOPs of the execution.
+
+ Warnings:
+ You may only use tensors with `device=meta` for this wrapped function.
+ Only original `torch.nn.functional` are available.
+
+ Examples:
+ >>> input = torch.rand(100, 100, 100, 100, device='meta')
+ >>> func = torch.nn.functional.relu
+ >>> output, meta_info = profile_function(func)(input)
+ """
+
+ def f(*args: Tuple[Argument, ...], **kwargs: Dict[str, Any]) -> Any:
+
+ # find the grad for parameter in args and kwargs
+ param_size = 0
+
+ def get_param_size(x):
+ nonlocal param_size
+ if isinstance(x, Parameter):
+ param_size += activation_size(x)
+
+ tree_map(get_param_size, args)
+ tree_map(get_param_size, kwargs)
+
+ # If there is an argument that this `call_function` is inplace, we should
+ # still run the profiling but discard some results regarding `target`
+ global do_not_cache
+
+ inplace = kwargs.get('inplace', False)
+ if target in OUTPUT_SAVED_OPS:
+ do_not_cache = True
+ if inplace:
+ do_not_cache = True
+ kwargs['inplace'] = False
+ if device == 'meta':
+ out, meta = _profile_meta(func, *args, **kwargs)
+ else:
+ out, meta = _profile_concrete(func, *args, **kwargs)
+ if inplace:
+ kwargs['inplace'] = True
+ meta.bwd_mem_tmp = 0
+ meta.bwd_mem_out = 0
+ do_not_cache = False
+
+ meta.bwd_mem_out -= param_size
+ return out, meta
+
+ f.__name__ = target.__name__
+ func = target
+ return f
+
+
+@compatibility(is_backward_compatible=True)
+def profile_method(target: 'Target', device: str = 'meta') -> Callable:
+ """
+ Wrap a `call_method` node
+ record the memory cost and FLOPs of the execution.
+ """
+
+ def f(*args: Tuple[Argument, ...], **kwargs: Dict[str, Any]) -> Any:
+ # execute the method and return the result
+ assert isinstance(target, str), f'{target} instance is not str.'
+ if device == 'meta':
+ out, meta = _profile_meta(target, *args, **kwargs)
+ else:
+ out, meta = _profile_concrete(target, *args, **kwargs)
+ return out, meta
+
+ return f
+
+
+@compatibility(is_backward_compatible=True)
+def profile_module(module: torch.nn.Module, device: str = 'meta') -> Callable:
+ """
+ Wrap a `call_module` node or `torch.nn` in order to
+ record the memory cost and FLOPs of the execution.
+
+ Warnings:
+ You may only use tensors with `device=meta` for this wrapped function.
+ Only original `torch.nn` are available.
+
+ Example:
+ >>> input = torch.rand(4, 3, 224, 224, device='meta')
+ >>> mod = torch.nn.Conv2d(3, 128, 3)
+ >>> output, meta_info = profile_module(mod)(input)
+ """
+
+ def f(*args: Tuple[Argument, ...], **kwargs: Dict[str, Any]) -> Any:
+
+ # calculate parameter size
+ param_size = parameter_size(module)
+
+ # If there is an argument that this `call_module` is inplace, we should
+ # still run the profiling but discard some results regarding `module`.
+ global do_not_cache
+
+ inplace = getattr(module, 'inplace', False)
+ if type(module) in OUTPUT_SAVED_MOD:
+ do_not_cache = True
+ if inplace:
+ do_not_cache = True
+ module.inplace = False
+ if device == 'meta':
+ out, meta = _profile_meta(func, *args, **kwargs)
+ else:
+ out, meta = _profile_concrete(func, *args, **kwargs)
+ if inplace:
+ module.inplace = True
+ meta.bwd_mem_tmp = 0
+ meta.bwd_mem_out = 0
+ do_not_cache = False
+
+ # grad for param will not be counted
+ meta.bwd_mem_out -= param_size
+ return out, meta
+
+ f.__name__ = module.__class__.__name__
+ func = module.forward
+ return f
diff --git a/colossalai/fx/profiler/shard_utils.py b/colossalai/fx/profiler/shard_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..34feefb4336ab4a7924f7023b6f887ba8610b25c
--- /dev/null
+++ b/colossalai/fx/profiler/shard_utils.py
@@ -0,0 +1,114 @@
+import torch
+from torch.fx import Node
+
+from .._compatibility import compatibility, is_compatible_with_meta
+from .memory_utils import activation_size
+
+if is_compatible_with_meta():
+ from .constants import OUTPUT_SAVED_MOD, OUTPUT_SAVED_OPS
+
+__all__ = ["calculate_fwd_in", "calculate_fwd_tmp", "calculate_fwd_out"]
+
+
+@compatibility(is_backward_compatible=False)
+def calculate_fwd_in(n: Node) -> int:
+ """A helper function to calculate `fwd_in` (with sharding spec)
+
+ Args:
+ n (Node): a node from the graph
+
+ Returns:
+ fwd_in (int): the result of `fwd_in`
+ """
+ # TODO(super-dainiu): should divide the memory by sharding spec
+ return activation_size(n.meta["fwd_in"])
+
+
+@compatibility(is_backward_compatible=False)
+def calculate_fwd_tmp(n: Node) -> int:
+ """A helper function to calculate `fwd_tmp` (with sharding spec)
+ Currently, `torch.nn.ReLU` behaves weirdly, so we have to patch it for accuracy.
+
+ Args:
+ n (Node): a node from the graph
+
+ Returns:
+ fwd_tmp (int): the result of `fwd_tmp`
+ """
+
+ # TODO(super-dainiu): should divide the memory by sharding spec
+ def is_relu_like_node(n: Node) -> bool:
+ """Check if a node is a ReLU-like node.
+ ReLU-like nodes have the following properties:
+ - They are either `call_function` or `call_module`
+ - Their output tensors are directly saved for backward
+ - Their input tensors are not saved for backward
+
+ An example is `torch.nn.functional.softmax` which has (forward + backward):
+ def forward(self, input_2):
+ _softmax_default = torch.ops.aten._softmax.default(input_2, None, None); input_2 = None
+ zeros_like_default = torch.ops.aten.zeros_like.default(_softmax_default, dtype = None, layout = None, device = None, pin_memory = None)
+ detach_default = torch.ops.aten.detach.default(_softmax_default); _softmax_default = None
+ _softmax_backward_data_default = torch.ops.aten._softmax_backward_data.default(zeros_like_default, detach_default, None, None); zeros_like_default = detach_default = None
+ detach_default_1 = torch.ops.aten.detach.default(_softmax_backward_data_default); _softmax_backward_data_default = None
+ detach_default_2 = torch.ops.aten.detach.default(detach_default_1); detach_default_1 = None
+
+ Args:
+ n (Node): A node from the graph
+
+ Returns:
+ bool: Whether the node is a ReLU-like node
+ """
+ if n.op == 'call_function':
+ return n.target in OUTPUT_SAVED_OPS
+ elif n.op == 'call_module':
+ return type(n.graph.owning_module.get_submodule(n.target)) in OUTPUT_SAVED_MOD
+ return False
+
+ if not is_relu_like_node(n):
+ return activation_size(n.meta["fwd_tmp"])
+ return 0
+
+
+@compatibility(is_backward_compatible=False)
+def calculate_fwd_out(n: Node) -> int:
+ """A helper function to calculate `fwd_out` (with sharding spec)
+
+ Args:
+ n (Node): a node from the graph
+
+ Returns:
+ fwd_out (int): the result of `fwd_out`
+ """
+
+ # TODO(super-dainiu): should divide the memory by sharding spec
+ def intersect(a, b):
+ return {k: a[k] for k in a if k in b}
+
+ fwd_in = dict()
+ for u in n.users:
+ fwd_in.update({x.data_ptr(): x for x in u.meta["fwd_in"] if isinstance(x, torch.Tensor)})
+ fwd_out = {x.data_ptr(): x for x in n.meta["fwd_out"] if isinstance(x, torch.Tensor)}
+ return activation_size(intersect(fwd_in, fwd_out))
+
+
+def calculate_fwd_time(n: Node) -> float:
+ """A helper function to calculate `fwd_time` (with sharding spec)
+ Args:
+ n (Node): a node from the graph
+ Returns:
+ fwd_time (float): the result of `fwd_time`
+ """
+ # TODO(super-dainiu): should divide the time by the number of GPUs as well as TFLOPs
+ return n.meta["fwd_time"]
+
+
+def calculate_bwd_time(n: Node) -> float:
+ """A helper function to calculate `bwd_time` (with sharding spec)
+ Args:
+ n (Node): a node from the graph
+ Returns:
+ bwd_time (float): the result of `bwd_time`
+ """
+ # TODO(super-dainiu): should divide the time by the number of GPUs as well as TFLOPs
+ return n.meta["bwd_time"]
diff --git a/colossalai/fx/profiler/tensor.py b/colossalai/fx/profiler/tensor.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ee5e5c47750c4bbc714987ce4bcae9f29e6ac71
--- /dev/null
+++ b/colossalai/fx/profiler/tensor.py
@@ -0,0 +1,137 @@
+import uuid
+
+import torch
+from torch.types import _bool, _device, _dtype
+from torch.utils._pytree import tree_flatten, tree_map
+
+from .._compatibility import compatibility
+from .constants import ALIAS_ATEN
+
+__all__ = ['MetaTensor']
+
+
+def set_data_ptr(x):
+ if isinstance(x, torch.Tensor):
+ if not x.data_ptr():
+ data_ptr = uuid.uuid4()
+ x.data_ptr = lambda: data_ptr
+
+
+@compatibility(is_backward_compatible=False)
+class MetaTensor(torch.Tensor):
+ """
+ A wrapping tensor that hacks `torch.autograd` without patching more `torch.ops.aten` ops.
+ `fake_device` is the device that `MetaTensor` is supposed to run on.
+ """
+
+ _tensor: torch.Tensor
+
+ @staticmethod
+ def __new__(cls, elem, fake_device=None):
+ # Avoid multiple wrapping
+ if isinstance(elem, MetaTensor):
+ fake_device = elem.device if fake_device is None else fake_device
+ elem = elem._tensor
+
+ # The wrapping tensor (MetaTensor) shouldn't hold any
+ # memory for the class in question, but it should still
+ # advertise the same device as before
+ r = torch.Tensor._make_wrapper_subclass(
+ cls,
+ elem.size(),
+ strides=elem.stride(),
+ storage_offset=elem.storage_offset(),
+ dtype=elem.dtype,
+ layout=elem.layout,
+ device=fake_device or (elem.device if elem.device.type != 'meta' else torch.device('cpu')),
+ requires_grad=elem.requires_grad) # deceive the frontend for aten selections
+ r._tensor = elem
+ # ...the real tensor is held as an element on the tensor.
+ if not r._tensor.is_meta:
+ r._tensor = r._tensor.to(torch.device('meta'))
+ # only tensor not on `meta` should be copied to `meta`
+ set_data_ptr(r._tensor)
+ return r
+
+ def __repr__(self):
+ if self.grad_fn:
+ return f"MetaTensor(..., size={tuple(self.shape)}, device='{self.device}', dtype={self.dtype}, grad_fn={self.grad_fn})"
+ return f"MetaTensor(..., size={tuple(self.shape)}, device='{self.device}', dtype={self.dtype})"
+
+ @classmethod
+ def __torch_dispatch__(cls, func, types, args=(), kwargs=None):
+ fake_device = None
+
+ def unwrap(x):
+ nonlocal fake_device
+ if isinstance(x, MetaTensor):
+ fake_device = x.device
+ x = x._tensor
+ elif isinstance(x, torch.Tensor):
+ fake_device = x.device
+ x = x.to(torch.device('meta'))
+ return x
+
+ args = tree_map(unwrap, args)
+ kwargs = tree_map(unwrap, kwargs)
+
+ if 'device' in kwargs:
+ fake_device = kwargs['device']
+ kwargs['device'] = torch.device('meta')
+
+ # run aten for backend=CPU but actually on backend=Meta
+ out = func(*args, **kwargs)
+
+ # here we keep the uuid of input because ALIAS_ATEN do not generate a physical copy
+ # of the input
+ if func in ALIAS_ATEN:
+ out.data_ptr = args[0].data_ptr
+
+ # Now, we want to continue propagating this tensor, so we rewrap Tensors in
+ # our custom tensor subclass
+ def wrap(x):
+ if isinstance(x, torch.Tensor):
+ nonlocal fake_device
+ if not x.is_meta:
+ x = x.to(torch.device('meta'))
+ return MetaTensor(x, fake_device=fake_device) if isinstance(x, torch.Tensor) else x
+
+ return tree_map(wrap, out)
+
+ def to(self, *args, **kwargs) -> torch.Tensor:
+ """An extension of `torch.Tensor.to()` to MetaTensor
+
+ Returns:
+ result (MetaTensor): MetaTensor
+
+ Usage:
+ >>> tensor = MetaTensor(torch.rand(10), fake_device='cuda:100')
+ >>> tensor.to(torch.uint8)
+ MetaTensor(tensor(..., device='meta', size=(10,), dtype=torch.uint8), fake_device='cuda:100')
+ >>> tensor.to(torch.device('cuda:42'))
+ MetaTensor(tensor(..., device='meta', size=(10,)), fake_device='cuda:42')
+ >>> tensor.to('vulkan')
+ MetaTensor(tensor(..., device='meta', size=(10,)), fake_device='vulkan')
+ """
+ # this imitates c++ function in the way of @overload
+ fake_device = None
+
+ def replace(x):
+ nonlocal fake_device
+ if isinstance(x, str) or isinstance(x, _device):
+ fake_device = x
+ return 'meta'
+ return x
+
+ elem = self._tensor.to(*tree_map(replace, args), **tree_map(replace, kwargs))
+ return MetaTensor(elem, fake_device=fake_device)
+
+ def cpu(self, *args, **kwargs):
+ if self.device.type == 'cpu':
+ return self.to(*args, **kwargs)
+ return self.to(*args, device='cpu', **kwargs)
+
+ def cuda(self, device=None, non_blocking=False):
+ if device is not None:
+ return self.to(device=device, non_blocking=non_blocking)
+ return self.to(device='cuda:0', non_blocking=non_blocking)
diff --git a/colossalai/fx/proxy.py b/colossalai/fx/proxy.py
new file mode 100644
index 0000000000000000000000000000000000000000..7317072c6298b66280810c48536eb22b7edca7f0
--- /dev/null
+++ b/colossalai/fx/proxy.py
@@ -0,0 +1,129 @@
+import operator
+from typing import Any, List, Union
+
+import torch
+from torch.fx.proxy import Attribute, Proxy
+
+from colossalai.fx.tracer.meta_patch import meta_patched_function
+
+__all__ = ['ColoProxy']
+
+
+class ColoProxy(Proxy):
+ """
+ ColoProxy is a proxy class which uses meta tensor to handle data-dependent control flow. The original torch.fx proxy
+ cannot be used to infer the condition statement, with this proxy, torch.fx can still run even with if statements.
+
+ Example::
+
+ proxy = tracer.create_proxy(...)
+ proxy.meta_data = torch.empty(4, 2, device='meta')
+ print(len(proxy)) # expect output 4
+
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.node._meta_data = None
+
+ @property
+ def meta_data(self):
+ return self.node._meta_data
+
+ @meta_data.setter
+ def meta_data(self, data: Any):
+ self.node._meta_data = data
+
+ @property
+ def has_meta_data(self):
+ return self._meta_data is not None
+
+ def _assert_meta_data_is_tensor(self):
+ assert torch.is_tensor(
+ self._meta_data) and self._meta_data.is_meta, f'Meta data is not a meta tensor for {self.node.name}'
+
+ def _assert_has_meta_data(self):
+ assert self._meta_data is not None, f'Meta data is not set for {self.node.name}'
+
+ def __len__(self):
+ self._assert_has_meta_data()
+ return len(self.meta_data)
+
+ def __int__(self):
+ self._assert_has_meta_data()
+ return int(self.meta_data)
+
+ def __float__(self):
+ self._assert_has_meta_data()
+ return float(self.meta_data)
+
+ def __bool__(self):
+ self._assert_has_meta_data()
+ return self.meta_data
+
+ def __getattr__(self, k):
+
+ return ColoAttribute(self, k)
+
+ def __contains__(self, key):
+ if self.node.op == "placeholder":
+ # this is used to handle like
+ # if x in kwargs
+ # we don't handle this case for now
+ return False
+ return super().__contains__(key)
+
+
+def extract_meta(*args, **kwargs):
+ """
+ This function is copied from _tracer_utils.py to avoid circular import issue.
+ """
+
+ def _convert(val):
+ if isinstance(val, ColoProxy):
+ return val.meta_data
+ elif isinstance(val, (list, tuple)):
+ return type(val)([_convert(ele) for ele in val])
+ return val
+
+ new_args = [_convert(val) for val in args]
+ new_kwargs = {k: _convert(v) for k, v in kwargs.items()}
+ return new_args, new_kwargs
+
+
+class ColoAttribute(ColoProxy):
+
+ def __init__(self, root, attr: str):
+ self.root = root
+ self.attr = attr
+ self.tracer = root.tracer
+ self._node = None
+
+ @property
+ def node(self):
+ if self._node is None:
+ proxy = self.tracer.create_proxy("call_function", getattr, (self.root, self.attr), {})
+ if not isinstance(proxy, ColoProxy):
+ meta_args, meta_kwargs = extract_meta(*(self.root, self.attr))
+ meta_out = getattr(*meta_args, **meta_kwargs)
+ proxy = ColoProxy(proxy.node)
+ proxy.meta_data = meta_out
+ self._node = proxy.node
+
+ return self._node
+
+ def __call__(self, *args, **kwargs):
+ proxy = self.tracer.create_proxy("call_method", self.attr, (self.root,) + args, kwargs)
+ if not isinstance(proxy, ColoProxy):
+ meta_args, meta_kwargs = extract_meta(*((self.root,) + args), **kwargs)
+ method = getattr(meta_args[0].__class__, self.attr)
+ if meta_patched_function.has(method):
+ meta_target = meta_patched_function.get(method)
+ elif meta_patched_function.has(method.__name__):
+ meta_target = meta_patched_function.get(method.__name__)
+ else:
+ meta_target = method
+ meta_out = meta_target(*meta_args, **meta_kwargs)
+ proxy = ColoProxy(proxy.node)
+ proxy.meta_data = meta_out
+ return proxy
diff --git a/colossalai/fx/tracer/__init__.py b/colossalai/fx/tracer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..590555ce38bf30fab0c575bb69f05af74c8d3802
--- /dev/null
+++ b/colossalai/fx/tracer/__init__.py
@@ -0,0 +1,5 @@
+from colossalai.fx.tracer.meta_patch.patched_function.python_ops import operator_getitem
+
+from ._meta_trace import meta_trace
+from ._symbolic_trace import symbolic_trace
+from .tracer import ColoTracer
diff --git a/colossalai/fx/tracer/_meta_trace.py b/colossalai/fx/tracer/_meta_trace.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c5abb81d271144ab666049d3ae2868cd9568497
--- /dev/null
+++ b/colossalai/fx/tracer/_meta_trace.py
@@ -0,0 +1,133 @@
+import torch
+from torch.fx import Graph, Node
+from torch.utils._pytree import tree_map
+
+
+def normalize_tuple(x):
+ if not isinstance(x, tuple):
+ return (x,)
+ return x
+
+
+def is_autogradable(x):
+ return isinstance(x, torch.Tensor) and x.is_floating_point()
+
+
+def meta_trace(module: torch.nn.Module, fake_device=None, *args, **kwargs) -> Graph:
+ """Trace forward and backward graph with MetaTensor
+
+ Args:
+ module (torch.nn.Module): The target module for tracing.
+
+ Returns:
+ graph (torch.fx.Graph): The computation graph.
+
+ Usage:
+ >>> import torchvision.models as tm
+ >>> model = tm.alexnet()
+ >>> graph = meta_trace(model, torch.rand(1000, 3, 224, 224))
+ >>> graph.print_tabular()
+ """
+ graph = Graph()
+ namespace = graph._graph_namespace
+
+ class MetaProxy(torch.Tensor):
+ """
+ A wrapping tensor that hacks `torch.autograd` without patching more `torch.ops.aten` ops.
+ """
+
+ _tensor: torch.Tensor
+ _node: Node
+
+ __slots__ = ['_tensor', '_node']
+
+ @staticmethod
+ def __new__(cls, tensor, fake_device=None, placeholder=False, name=None):
+ r = torch.Tensor._make_wrapper_subclass(
+ cls,
+ tensor.size(),
+ strides=tensor.stride(),
+ storage_offset=tensor.storage_offset(),
+ dtype=tensor.dtype,
+ layout=tensor.layout,
+ device=fake_device if fake_device is not None else tensor.device,
+ requires_grad=tensor.requires_grad) # deceive the frontend for aten selections
+ r._tensor = tensor
+ if placeholder:
+ if name is None:
+ name = 'input'
+ r._node = graph.create_node('placeholder',
+ 'placeholder', (graph._root,),
+ name=namespace.create_name(name, tensor))
+ # ...the real tensor is held as an element on the tensor.
+ if not r._tensor.is_meta:
+ r._tensor = r._tensor.to(torch.device('meta'))
+ return r
+
+ @classmethod
+ def __torch_dispatch__(cls, func, types, args=(), kwargs=None):
+
+ def unwrap(x):
+ nonlocal fake_device
+ if isinstance(x, MetaProxy):
+ fake_device = x.device
+ x = x._tensor
+ # assert not isinstance(x, MetaProxy)
+ elif isinstance(x, torch.Tensor):
+ fake_device = x.device
+ x = x.to(torch.device('meta'))
+ return x
+
+ def get_node(x):
+ if isinstance(x, torch.Tensor) and not hasattr(x, '_node'):
+ x = MetaProxy(x, placeholder=True, name='weight')
+ return x if not hasattr(x, '_node') else x._node
+
+ args_node = tree_map(get_node, args)
+ kwargs_node = tree_map(get_node, kwargs)
+ node = graph.create_node('call_function', func, args_node, kwargs_node)
+
+ if 'device' in kwargs:
+ fake_device = kwargs['device']
+ kwargs['device'] = torch.device('meta')
+
+ args = tree_map(unwrap, args)
+ kwargs = tree_map(unwrap, kwargs)
+
+ # run aten for backend=CPU but actually on backend=Meta
+ out = func(*args, **kwargs)
+
+ # Now, we want to continue propagating this tensor, so we rewrap Tensors in
+ # our custom tensor subclass
+ def wrap(x):
+ if isinstance(x, torch.Tensor):
+ nonlocal fake_device
+ if not x.is_meta:
+ x = x.to(torch.device('meta'))
+ return MetaProxy(
+ x, fake_device=fake_device) if isinstance(x, torch.Tensor) and not hasattr(x, '_tensor') else x
+
+ def set_node(x):
+ x._node = node
+
+ out = tree_map(wrap, out)
+ tree_map(set_node, out)
+
+ return out
+
+ def wrap(x):
+ return MetaProxy(x, fake_device=fake_device, placeholder=True) if isinstance(x, torch.Tensor) else x
+
+ args = tree_map(wrap, args)
+ kwargs = tree_map(wrap, kwargs)
+
+ out = module(*args, **kwargs)
+
+ for tensor in normalize_tuple(out):
+ if is_autogradable(tensor) and tensor.requires_grad:
+ grad = torch.empty_like(tensor._tensor, device=torch.device('meta')) if isinstance(
+ tensor, MetaProxy) else torch.empty_like(tensor, device=torch.device('meta'))
+ torch.autograd.backward(tensor,
+ MetaProxy(grad, fake_device=tensor.device, placeholder=True),
+ retain_graph=True)
+ return graph
diff --git a/colossalai/fx/tracer/_symbolic_trace.py b/colossalai/fx/tracer/_symbolic_trace.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c04eeace0ad97d1f6b9d0f962f363ef2ecd449b
--- /dev/null
+++ b/colossalai/fx/tracer/_symbolic_trace.py
@@ -0,0 +1,55 @@
+from typing import Any, Callable, Dict, Optional, Union
+
+import torch
+
+from colossalai.fx import ColoGraphModule
+from colossalai.fx._compatibility import compatibility
+
+from .tracer import ColoTracer
+
+
+@compatibility(is_backward_compatible=True)
+def symbolic_trace(
+ root: Union[torch.nn.Module, Callable[..., Any]],
+ concrete_args: Optional[Dict[str, Any]] = None,
+ meta_args: Optional[Dict[str, Any]] = None,
+ trace_act_ckpt=False,
+) -> ColoGraphModule:
+ """
+ Symbolic tracing API
+
+ Given an ``nn.Module`` or function instance ``root``, this function will return a ``ColoGraphModule``
+ constructed by recording operations seen while tracing through ``root``.
+
+ With ``meta_args``, we can trace the model that are untraceable subject to control flow. If specified using
+ ``meta_args`` only, the tracing can be done ahead of time.
+
+ Note that ``meta_args`` are kwargs, which contains the key of the argument's names and the value of the
+ argument's values.
+
+ Uses:
+ >>> model = ...
+
+ # if this works
+ >>> gm = symbolic_trace(model, concrete_args=concrete_args)
+
+ # else try this
+ >>> gm = symbolic_trace(model, concrete_args=concrete_args, meta_args={'x': torch.rand(1, 3, 224, 224, device='meta')})
+
+ Args:
+ root (Union[torch.nn.Module, Callable[..., Any]]): Module or function to be traced and converted
+ into a Graph representation.
+ concrete_args (Optional[Dict[str, Any]], optional): Concrete arguments to be used for tracing.
+ meta_args (Optional[Dict[str, Any]], optional): Inputs to be partially specialized, special for ``ColoTracer``.
+ Defaults to None.
+
+ Returns:
+ ColoGraphModule: A ``ColoGraphModule`` created from the recorded operations from ``root``.
+
+ Warnings:
+ This API is still under development and can incur some bugs. Feel free to report any bugs to the Colossal-AI team.
+
+ """
+ graph = ColoTracer(trace_act_ckpt=trace_act_ckpt).trace(root, concrete_args=concrete_args, meta_args=meta_args)
+ name = root.__class__.__name__ if isinstance(root, torch.nn.Module) else root.__name__
+ return ColoGraphModule(root, graph, name)
diff --git a/colossalai/fx/tracer/_tracer_utils.py b/colossalai/fx/tracer/_tracer_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..e160497a74444fd34eea50943eb0430875fe1252
--- /dev/null
+++ b/colossalai/fx/tracer/_tracer_utils.py
@@ -0,0 +1,52 @@
+from typing import Any, List, Union
+
+import torch
+
+from ..proxy import ColoAttribute, ColoProxy
+from .meta_patch import meta_patched_function, meta_patched_module
+
+__all__ = ['is_element_in_list', 'extract_meta']
+
+
+def is_element_in_list(elements: Union[List[Any], Any], list_: List[Any]):
+ if isinstance(elements, (tuple, list, set)):
+ for ele in elements:
+ if ele not in list_:
+ return False, ele
+ else:
+ if elements not in list_:
+ return False, elements
+
+ return True, None
+
+
+def extract_meta(*args, **kwargs):
+
+ def _convert(val):
+ if isinstance(val, ColoProxy):
+ return val.meta_data
+ elif isinstance(val, (list, tuple)):
+ return type(val)([_convert(ele) for ele in val])
+
+ return val
+
+ new_args = [_convert(val) for val in args]
+ new_kwargs = {k: _convert(v) for k, v in kwargs.items()}
+ return new_args, new_kwargs
+
+
+def compute_meta_data_for_functions_proxy(target, args, kwargs):
+ args_metas, kwargs_metas = extract_meta(*args, **kwargs)
+
+ # fetch patched function
+ if meta_patched_function.has(target):
+ meta_target = meta_patched_function.get(target)
+ elif meta_patched_function.has(target.__name__):
+ meta_target = meta_patched_function.get(target.__name__)
+ else:
+ meta_target = target
+ meta_out = meta_target(*args_metas, **kwargs_metas)
+ if isinstance(meta_out, torch.Tensor):
+ meta_out = meta_out.to(device="meta")
+
+ return meta_out
diff --git a/colossalai/fx/tracer/bias_addition_patch/__init__.py b/colossalai/fx/tracer/bias_addition_patch/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e724d6a22fa84ecd954a59ebc6eb9b8daa00a035
--- /dev/null
+++ b/colossalai/fx/tracer/bias_addition_patch/__init__.py
@@ -0,0 +1,2 @@
+from .patched_bias_addition_function import *
+from .patched_bias_addition_module import *
diff --git a/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/__init__.py b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..071bde4a5293e391d618973f803360deb4cd1b4c
--- /dev/null
+++ b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/__init__.py
@@ -0,0 +1,4 @@
+from .addbmm import Addbmm
+from .addmm import Addmm
+from .bias_addition_function import BiasAdditionFunc, LinearBasedBiasFunc, func_to_func_dict, method_to_func_dict
+from .linear import Linear
diff --git a/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/addbmm.py b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/addbmm.py
new file mode 100644
index 0000000000000000000000000000000000000000..859a19bf6241bbbf4061e0f7564975682527b8c2
--- /dev/null
+++ b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/addbmm.py
@@ -0,0 +1,75 @@
+import operator
+
+import torch
+import torch.nn.functional as F
+
+from ...registry import bias_addition_function, bias_addition_method
+from .bias_addition_function import LinearBasedBiasFunc
+
+
+@bias_addition_method.register(torch.Tensor.addbmm)
+@bias_addition_function.register(torch.addbmm)
+class Addbmm(LinearBasedBiasFunc):
+
+ def extract_kwargs_from_origin_func(self):
+ kwargs = {}
+ if 'beta' in self.kwargs:
+ kwargs['beta'] = self.kwargs['beta']
+ if 'alpha' in self.kwargs:
+ kwargs['alpha'] = self.kwargs['alpha']
+ return kwargs
+
+ def create_non_bias_func_proxy(self, input_proxy, other_proxy):
+ """
+ This method is used to create the non_bias_func proxy, the node created by this proxy will
+ compute the main computation, such as convolution, with bias option banned.
+ """
+ assert self.substitute_func == torch.bmm
+ node_kind = 'call_function'
+ node_target = self.substitute_func
+
+ node_args = (input_proxy, other_proxy)
+ # torch.bmm does not have any kwargs
+ node_kwargs = {}
+ non_bias_func_proxy = self.tracer.create_proxy(node_kind, node_target, node_args, node_kwargs)
+ return non_bias_func_proxy
+
+ def insert_sum_node(self, input_proxy, sum_dims=0):
+ '''
+ This method is used to sum the input_proxy through the sum_dims.
+ '''
+ node_kind = 'call_function'
+ node_target = torch.sum
+ node_args = (input_proxy, sum_dims)
+ node_kwargs = {}
+ sum_proxy = self.tracer.create_proxy(node_kind, node_target, node_args, node_kwargs)
+ return sum_proxy
+
+ def generate(self):
+ # The formula for addbmm is output = beta * input + alpha * (torch.bmm(b1, b2))
+
+ # doing the non-bias computation(temp_0 = torch.bmm(b1, b2))
+ non_bias_linear_func_proxy = self.create_non_bias_func_proxy(self.args[1], self.args[2])
+
+ # doing sum on the batch dimension(temp_1 = torch.sum(temp_0, 0))
+ sum_proxy = self.insert_sum_node(non_bias_linear_func_proxy)
+ kwargs = self.extract_kwargs_from_origin_func()
+
+ if 'beta' in kwargs:
+ beta = kwargs['beta']
+ # doing the multiplication with beta if it exists(temp_2 = beta * input)
+ beta_proxy = self.create_mul_node(self.args[0], beta)
+ else:
+ beta_proxy = self.args[0]
+
+ if 'alpha' in kwargs:
+ alpha = kwargs['alpha']
+ # doing the multiplication with alpha if it exists(temp_3 = alpha * temp_1)
+ alpha_proxy = self.create_mul_node(alpha, sum_proxy)
+ else:
+ alpha_proxy = sum_proxy
+
+ # doing the addition(temp_4 = temp_2 + temp_3)
+ bias_addition_proxy = self.create_bias_addition_proxy(alpha_proxy, beta_proxy)
+
+ return bias_addition_proxy
diff --git a/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/addmm.py b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/addmm.py
new file mode 100644
index 0000000000000000000000000000000000000000..fe7d8d07aac941028d7c682043b5af2bcdf2537a
--- /dev/null
+++ b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/addmm.py
@@ -0,0 +1,60 @@
+import operator
+
+import torch
+import torch.nn.functional as F
+
+from ...registry import bias_addition_function, bias_addition_method
+from .bias_addition_function import LinearBasedBiasFunc
+
+
+@bias_addition_method.register(torch.Tensor.addmm)
+@bias_addition_function.register(torch.addmm)
+class Addmm(LinearBasedBiasFunc):
+
+ def extract_kwargs_from_origin_func(self):
+ kwargs = {}
+ if 'beta' in self.kwargs:
+ kwargs['beta'] = self.kwargs['beta']
+ if 'alpha' in self.kwargs:
+ kwargs['alpha'] = self.kwargs['alpha']
+ return kwargs
+
+ def transpose_other_operand_for_linear(self, other_proxy):
+ '''
+ This method is used to transpose the other operand for linear function.
+ For example:
+ input = torch.rand(3, 4)
+ m1 = torch.rand(3, 5)
+ m2 = torch.rand(5, 4)
+ original_output = torch.addmm(input, m1, m2)
+ # To keep the computation graph consistent with the origin computation graph, we need to transpose the m2
+ # before we call the linear function.
+ new_output = torch.linear(m1, m2.transpose(0, 1)) + input
+ '''
+ node_kind = 'call_function'
+ node_target = torch.transpose
+ node_args = (other_proxy, 0, 1)
+ node_kwargs = {}
+ transpose_proxy = self.tracer.create_proxy(node_kind, node_target, node_args, node_kwargs)
+ return transpose_proxy
+
+ def generate(self):
+ transpose_proxy = self.transpose_other_operand_for_linear(self.args[2])
+ non_bias_linear_func_proxy = self.create_non_bias_func_proxy(self.args[1], transpose_proxy)
+ kwargs = self.extract_kwargs_from_origin_func()
+
+ if 'beta' in kwargs:
+ beta = kwargs['beta']
+ beta_proxy = self.create_mul_node(self.args[0], beta)
+ else:
+ beta_proxy = self.args[0]
+
+ if 'alpha' in kwargs:
+ alpha = kwargs['alpha']
+ alpha_proxy = self.create_mul_node(alpha, non_bias_linear_func_proxy)
+ else:
+ alpha_proxy = non_bias_linear_func_proxy
+
+ bias_addition_proxy = self.create_bias_addition_proxy(alpha_proxy, beta_proxy)
+
+ return bias_addition_proxy
diff --git a/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/bias_addition_function.py b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/bias_addition_function.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a3786332c08d9a3320ce4c7bee8221dd3d10abd
--- /dev/null
+++ b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/bias_addition_function.py
@@ -0,0 +1,115 @@
+import operator
+from abc import ABC, abstractmethod
+
+import torch
+import torch.nn.functional as F
+
+
+class BiasAdditionFunc(ABC):
+ """
+ This class is used to construct the restructure computation graph for
+ call_func node with bias addition inside.
+ """
+
+ def __init__(self, tracer, target, args, kwargs, substitute_func):
+ self.tracer = tracer
+ self.target = target
+ self.args = args
+ self.kwargs = kwargs
+ self.substitute_func = substitute_func
+
+ @abstractmethod
+ def extract_kwargs_from_origin_func(self):
+ """
+ This method is used to extract the kwargs for further graph transform.
+
+ For example:
+ The formula for torch.addmm is out = beta * input + alpha * (m1 @ m2)
+ The kwargs for addmm function is {beta=1, alpha=1, output=None}, then we need
+ to insert two more operator.mul nodes for the computation graph to compute the
+ final result.
+ """
+ pass
+
+ @abstractmethod
+ def generate(self):
+ """
+ This method is used to construct the whole restructure computation graph for call_func node with bias
+ addition inside.
+
+ A whole restructure computation graph will contain a weight node, a bias node, a non-bias addition computation node,
+ a bias reshape node if needed and a bias addition node.
+
+ Use torch.addmm as an example:
+ The origin node is:
+ %addmm: call_func[target=torch.addmm](args = (%input_1, m1, m2), kwargs = {beta=1, alpha=1})
+ Restructured graph is:
+ %transpose : [#users=1] = call_function[target=torch.transpose](args = (%m2, 0, 1), kwargs = {})
+ %linear : [#users=1] = call_function[target=torch._C._nn.linear](args = (%m1, %transpose), kwargs = {})
+ %mul : [#users=1] = call_function[target=operator.mul](args = (%input_1, 3), kwargs = {})
+ %mul_1 : [#users=1] = call_function[target=operator.mul](args = (2, %linear), kwargs = {})
+ %add : [#users=1] = call_function[target=operator.add](args = (%mul_1, %mul), kwargs = {})
+ """
+ pass
+
+ def create_mul_node(self, input_proxy, coefficent):
+ """
+ This method is used to create a coefficent node for the numerical correctness.
+ The formula for torch.addmm is out = beta * input + alpha * (m1 @ m2)
+ Therefore, we need to use this method insert two more operator.mul nodes for
+ the computation graph to compute the final result.
+ """
+ node_kind = 'call_function'
+ node_target = operator.mul
+ node_args = (
+ input_proxy,
+ coefficent,
+ )
+ node_kwargs = {}
+ mul_proxy = self.tracer.create_proxy(node_kind, node_target, node_args, node_kwargs)
+ return mul_proxy
+
+
+class LinearBasedBiasFunc(BiasAdditionFunc):
+ """
+ This class is used to construct the restructure computation graph for
+ call_func node based on F.linear.
+ """
+
+ def create_non_bias_func_proxy(self, input_proxy, other_proxy):
+ """
+ This method is used to create the non_bias_func proxy, the node created by this proxy will
+ compute the main computation, such as convolution, with bias option banned.
+ """
+ assert self.substitute_func == torch.nn.functional.linear
+ node_kind = 'call_function'
+ node_target = self.substitute_func
+
+ node_args = (input_proxy, other_proxy)
+ # non-bias linear does not have any kwargs
+ node_kwargs = {}
+ non_bias_func_proxy = self.tracer.create_proxy(node_kind, node_target, node_args, node_kwargs)
+ return non_bias_func_proxy
+
+ def create_bias_addition_proxy(self, non_bias_func_proxy, bias_proxy):
+ """
+ This method is used to create the bias_addition_proxy, the node created by this proxy will
+ compute the sum of non_bias_func result and bias with some reshape operation if needed.
+ """
+ bias_add_node_kind = 'call_function'
+ bias_add_node_target = operator.add
+ bias_add_args = (non_bias_func_proxy, bias_proxy)
+ bias_add_proxy = self.tracer.create_proxy(bias_add_node_kind, bias_add_node_target, tuple(bias_add_args), {})
+ return bias_add_proxy
+
+
+func_to_func_dict = {
+ torch.addmm: F.linear,
+ torch.addbmm: torch.bmm,
+ F.linear: F.linear,
+}
+
+method_to_func_dict = {
+ torch.Tensor.addmm: F.linear,
+ torch.Tensor.addbmm: torch.bmm,
+}
diff --git a/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/linear.py b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/linear.py
new file mode 100644
index 0000000000000000000000000000000000000000..e11ec0a364f1e5ee1445c97ae0c9b054d02bcfa2
--- /dev/null
+++ b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_function/linear.py
@@ -0,0 +1,25 @@
+import operator
+
+import torch
+import torch.nn.functional as F
+
+from ...registry import bias_addition_function
+from .bias_addition_function import LinearBasedBiasFunc
+
+
+@bias_addition_function.register(F.linear)
+class Linear(LinearBasedBiasFunc):
+
+ def extract_kwargs_from_origin_func(self):
+ assert 'bias' in self.kwargs
+ kwargs = {}
+ if 'bias' in self.kwargs:
+ kwargs['bias'] = self.kwargs['bias']
+ return kwargs
+
+ def generate(self):
+ non_bias_linear_func_proxy = self.create_non_bias_func_proxy(self.args[0], self.args[1])
+ kwargs = self.extract_kwargs_from_origin_func()
+ bias_addition_proxy = self.create_bias_addition_proxy(non_bias_linear_func_proxy, kwargs['bias'])
+
+ return bias_addition_proxy
diff --git a/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/__init__.py b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3823bb3e2a20e3963cc451459ec963a36eb1139
--- /dev/null
+++ b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/__init__.py
@@ -0,0 +1,3 @@
+from .bias_addition_module import *
+from .conv import *
+from .linear import *
diff --git a/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/bias_addition_module.py b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/bias_addition_module.py
new file mode 100644
index 0000000000000000000000000000000000000000..85f1553e304c9c45b2b8f1373e76e7023d452d47
--- /dev/null
+++ b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/bias_addition_module.py
@@ -0,0 +1,111 @@
+import operator
+from abc import ABC, abstractmethod
+
+import torch
+import torch.nn.functional as F
+
+
+class BiasAdditionModule(ABC):
+ """
+ This class is used to construct the restructure computation graph for
+ call_module node with bias addition inside.
+ """
+
+ def __init__(self, tracer, target, args, kwargs, substitute_func):
+ self.tracer = tracer
+ self.target = target
+ self.args = args
+ self.kwargs = kwargs
+ self.substitute_func = substitute_func
+ self.weight_proxy = self._create_weight_proxy()
+ self.bias_proxy = self._create_bias_proxy()
+
+ def _create_weight_proxy(self):
+ """
+ Create weight proxy, the node created by this proxy contains module weight.
+
+ Note: this function will be invoked during module initializing,
+ you should never call this function.
+ """
+ weight_node_kind = 'get_attr'
+ weight_node_target = self.target + '.weight'
+ weight_proxy = self.tracer.create_proxy(weight_node_kind, weight_node_target, (), {})
+ return weight_proxy
+
+ def _create_bias_proxy(self):
+ """
+ Create bias proxy, the node created by this proxy contains module bias.
+
+ Note: this function will be invoked during module initializing,
+ you should never call this function.
+ """
+ bias_node_kind = 'get_attr'
+ bias_node_target = self.target + '.bias'
+ bias_proxy = self.tracer.create_proxy(bias_node_kind, bias_node_target, (), {})
+ return bias_proxy
+
+ @abstractmethod
+ def extract_kwargs_from_mod(self):
+ """
+ This method is used to extract the kwargs for non-bias computation.
+
+ For example:
+ The kwargs for conv2d module is {} because the attributes like 'padding' or 'groups' are
+ considered during module initilizing. However, we need to consider those attributes as kwargs
+ in F.conv2d.
+ """
+ pass
+
+ def create_non_bias_func_proxy(self, input_proxy=None):
+ """
+ This method is used to create the non_bias_func proxy, the node created by this proxy will
+ compute the main computation, such as convolution, with bias option banned.
+ """
+ node_kind = 'call_function'
+ node_target = self.substitute_func
+ if input_proxy is None:
+ input_proxy = self.args[0]
+ node_args = (input_proxy, self.weight_proxy)
+ node_kwargs = self.extract_kwargs_from_mod()
+ non_bias_func_proxy = self.tracer.create_proxy(node_kind, node_target, node_args, node_kwargs)
+ return non_bias_func_proxy
+
+ def create_bias_addition_proxy(self, non_bias_func_proxy, bias_proxy):
+ """
+ This method is used to create the bias_addition_proxy, the node created by this proxy will
+ compute the sum of non_bias_func result and bias with some reshape operation if needed.
+ """
+ bias_add_node_kind = 'call_function'
+ bias_add_node_target = operator.add
+ bias_add_args = (non_bias_func_proxy, bias_proxy)
+ bias_add_proxy = self.tracer.create_proxy(bias_add_node_kind, bias_add_node_target, tuple(bias_add_args), {})
+ return bias_add_proxy
+
+ @abstractmethod
+ def generate(self):
+ """
+ This method is used to construct the whole restructure computation graph for call_module node with bias
+ addition inside.
+
+ A whole restructure computation graph will contain a weight node, a bias node, a non-bias addition computation node,
+ a bias reshape node if needed and a bias addition node.
+
+ Use Conv2d module as an example:
+ The origin node is:
+ %conv: call_module[target=conv](args = (%x,), kwargs = {})
+ Restructured graph is:
+ %conv_weight : [#users=1] = get_attr[target=conv.weight]
+ %conv_bias : [#users=1] = get_attr[target=conv.bias]
+ %conv2d : [#users=1] = call_function[target=torch.conv2d](args = (%x, %conv_weight), kwargs = {})
+ %view : [#users=1] = call_method[target=view](args = (%conv_bias, [1, -1, 1, 1]), kwargs = {})
+ %add : [#users=1] = call_function[target=operator.add](args = (%conv2d, %view), kwargs = {})
+ """
+ pass
+
+
+module_to_func_dict = {
+ torch.nn.Linear: F.linear,
+ torch.nn.Conv1d: F.conv1d,
+ torch.nn.Conv2d: F.conv2d,
+ torch.nn.Conv3d: F.conv3d,
+}
diff --git a/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/conv.py b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/conv.py
new file mode 100644
index 0000000000000000000000000000000000000000..4b6c82a74f57d213ba3d8b68863053ddd1aabf9d
--- /dev/null
+++ b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/conv.py
@@ -0,0 +1,56 @@
+import torch
+import torch.nn.functional as F
+from torch.nn.modules.utils import _pair, _reverse_repeat_tuple, _single, _triple
+
+from ...registry import bias_addition_module
+from .bias_addition_module import BiasAdditionModule
+
+
+@bias_addition_module.register(torch.nn.Conv1d)
+@bias_addition_module.register(torch.nn.Conv2d)
+@bias_addition_module.register(torch.nn.Conv3d)
+class BiasAdditionConv(BiasAdditionModule):
+
+ def extract_kwargs_from_mod(self):
+ root = self.tracer.root
+ conv_module = root.get_submodule(self.target)
+ kwarg_attributes = ['groups', 'dilation', 'stride']
+ non_bias_kwargs = {}
+ for attr_name in kwarg_attributes:
+ if hasattr(conv_module, attr_name):
+ non_bias_kwargs[attr_name] = getattr(conv_module, attr_name)
+ if conv_module.padding_mode != "zeros":
+ #TODO: non zeros mode requires some extra processing for input
+ conv_type = type(conv_module)
+ if conv_type == "torch.nn.Conv1d":
+ padding_element = _single(0)
+ elif conv_type == "torch.nn.Conv2d":
+ padding_element = _pair(0)
+ elif conv_type == "torch.nn.Conv3d":
+ padding_element = _triple(0)
+ non_bias_kwargs['padding'] = padding_element
+ else:
+ non_bias_kwargs['padding'] = getattr(conv_module, 'padding')
+
+ return non_bias_kwargs
+
+ def create_bias_reshape_proxy(self, dimensions):
+ """
+ This method is used to reshape the bias node in order to make bias and
+ output of non-bias convolution broadcastable.
+ """
+ bias_shape = [1] * (dimensions - 1)
+ bias_shape[0] = -1
+ bias_reshape_node_kind = 'call_method'
+ bias_reshape_node_target = 'view'
+ bias_reshape_node_args = (self.bias_proxy, torch.Size(bias_shape))
+ bias_reshape_proxy = self.tracer.create_proxy(bias_reshape_node_kind, bias_reshape_node_target,
+ bias_reshape_node_args, {})
+ return bias_reshape_proxy
+
+ def generate(self):
+ non_bias_conv_func_proxy = self.create_non_bias_func_proxy()
+ output_dims = non_bias_conv_func_proxy.meta_data.dim()
+ bias_reshape_proxy = self.create_bias_reshape_proxy(output_dims)
+ bias_addition_proxy = self.create_bias_addition_proxy(non_bias_conv_func_proxy, bias_reshape_proxy)
+ return bias_addition_proxy
diff --git a/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/linear.py b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/linear.py
new file mode 100644
index 0000000000000000000000000000000000000000..f6f7b6ddab401a637aa2b43b4dd8d2ce9193266e
--- /dev/null
+++ b/colossalai/fx/tracer/bias_addition_patch/patched_bias_addition_module/linear.py
@@ -0,0 +1,17 @@
+import torch
+import torch.nn.functional as F
+
+from ...registry import bias_addition_module
+from .bias_addition_module import BiasAdditionModule
+
+
+@bias_addition_module.register(torch.nn.Linear)
+class BiasAdditionLinear(BiasAdditionModule):
+
+ def extract_kwargs_from_mod(self):
+ return {}
+
+ def generate(self):
+ non_bias_linear_func_proxy = self.create_non_bias_func_proxy()
+ bias_addition_proxy = self.create_bias_addition_proxy(non_bias_linear_func_proxy, self.bias_proxy)
+ return bias_addition_proxy
diff --git a/colossalai/fx/tracer/experimental.py b/colossalai/fx/tracer/experimental.py
new file mode 100644
index 0000000000000000000000000000000000000000..88b65b6188fa67be33f7a15b55e7fd5d32d7c4cc
--- /dev/null
+++ b/colossalai/fx/tracer/experimental.py
@@ -0,0 +1,650 @@
+import enum
+import functools
+import inspect
+import operator
+from contextlib import contextmanager
+from typing import Any, Callable, Dict, List, Optional, Set, Tuple, Union
+
+import torch
+from torch.fx import Graph, Node, Proxy, Tracer
+from torch.utils._pytree import tree_map
+
+from colossalai.fx import ColoGraphModule, compatibility, is_compatible_with_meta
+from colossalai.fx.tracer._tracer_utils import extract_meta, is_element_in_list
+from colossalai.fx.tracer.bias_addition_patch import func_to_func_dict, method_to_func_dict, module_to_func_dict
+from colossalai.fx.tracer.registry import (
+ bias_addition_function,
+ bias_addition_method,
+ bias_addition_module,
+ meta_patched_function,
+ meta_patched_module,
+)
+
+if is_compatible_with_meta():
+ from colossalai.fx.profiler import MetaTensor
+
+Target = Union[Callable[..., Any], str]
+Argument = Optional[Union[Tuple[Any, ...], # actually Argument, but mypy can't represent recursive types
+ List[Any], # actually Argument
+ Dict[str, Any], # actually Argument
+ slice, # Slice[Argument, Argument, Argument], but slice is not a templated type in typing
+ 'Node',]]
+_CScriptMethod = ['add', 'mul', 'sub', 'div']
+_TorchNewMethod = [
+ "arange", "zeros", "zeros_like", "ones", "ones_like", "full", "full_like", "empty", "empty_like", "eye", "tensor",
+ "finfo"
+]
+_TensorPropertyMethod = ["dtype", "shape", "device", "requires_grad", "grad", "grad_fn", "data"]
+
+
+def _truncate_suffix(s: str):
+ import re
+ return re.sub(r'_\d+$', '', s)
+
+
+def default_device():
+ return torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
+
+
+@compatibility(is_backward_compatible=False)
+class ColoProxy(Proxy):
+
+ def __init__(self, *args, data=None, **kwargs):
+ super().__init__(*args, **kwargs)
+ self._meta_data = data
+
+ @property
+ def meta_data(self):
+ return self._meta_data
+
+ @meta_data.setter
+ def meta_data(self, args):
+ wrap_fn = lambda x: MetaTensor(x) if isinstance(x, torch.Tensor) else x
+ self._meta_data = tree_map(wrap_fn, args)
+
+ @classmethod
+ def __torch_function__(cls, orig_method, types, args=(), kwargs=None):
+ proxy = cls.from_torch_proxy(super().__torch_function__(orig_method, types, args, kwargs))
+ unwrap_fn = lambda p: p.meta_data if isinstance(p, ColoProxy) else p
+ kwargs = {} if kwargs is None else kwargs
+ if proxy.meta_data is None:
+ proxy.meta_data = orig_method(*tree_map(unwrap_fn, args), **tree_map(unwrap_fn, kwargs))
+ return proxy
+
+ @classmethod
+ def from_torch_proxy(cls, proxy: Proxy):
+ return cls(proxy.node, proxy.tracer)
+
+ def __repr__(self):
+ return f"ColoProxy({self.node.name}, meta_data={self.meta_data})"
+
+ def __len__(self):
+ return len(self.meta_data)
+
+ def __int__(self):
+ return int(self.meta_data)
+
+ def __index__(self):
+ try:
+ return int(self.meta_data)
+ except:
+ return torch.zeros(self.meta_data.shape, dtype=torch.bool).numpy().__index__()
+
+ def __float__(self):
+ return float(self.meta_data)
+
+ def __bool__(self):
+ return self.meta_data
+
+ def __getattr__(self, k):
+ return ColoAttribute(self, k, getattr(self._meta_data, k, None))
+
+ def __setitem__(self, key, value):
+ proxy = self.tracer.create_proxy('call_function', operator.setitem, (self, key, value), {})
+ proxy.meta_data = self._meta_data
+ return proxy
+
+ def __contains__(self, key):
+ if self.node.op == "placeholder":
+ # this is used to handle like
+ # if x in kwargs
+ # we don't handle this case for now
+ return False
+ return super().__contains__(key)
+
+ def __isinstancecheck__(self, type):
+ return isinstance(self.meta_data, type)
+
+ @property
+ def shape(self):
+ return self.meta_data.shape
+
+ @property
+ def ndim(self):
+ return self.meta_data.ndim
+
+ @property
+ def device(self):
+ proxy = self.tracer.create_proxy('call_function', getattr, (self, 'device'), {})
+ proxy.meta_data = self.meta_data.device
+ return proxy
+
+ @property
+ def dtype(self):
+ proxy = self.tracer.create_proxy('call_function', getattr, (self, 'dtype'), {})
+ proxy.meta_data = self.meta_data.dtype
+ return proxy
+
+ def to(self, *args, **kwargs):
+ return self.tracer.create_proxy('call_method', 'to', (self, *args), {**kwargs})
+
+ def cpu(self, *args, **kwargs):
+ return self.tracer.create_proxy('call_method', 'cpu', (self, *args), {**kwargs})
+
+ def cuda(self, *args, **kwargs):
+ return self.tracer.create_proxy('call_method', 'cuda', (self, *args), {**kwargs})
+
+
+@compatibility(is_backward_compatible=False)
+class ColoAttribute(ColoProxy):
+
+ def __init__(self, root, attr: str, data=None):
+ self.root = root
+ self.attr = attr
+ self.tracer = root.tracer
+ self._meta_data = data
+ self._node: Optional[Node] = None
+
+ @property
+ def node(self):
+ # the node for attributes is added lazily, since most will just be method calls
+ # which do not rely on the getitem call
+ if self._node is None:
+ self._node = self.tracer.create_proxy('call_function', getattr, (self.root, self.attr), {}).node
+ return self._node
+
+ def __call__(self, *args, **kwargs):
+ return self.tracer.create_proxy('call_method', self.attr, (self.root,) + args, kwargs)
+
+ def __repr__(self):
+ return f"ColoAttribute({self.node.name}, attr={self.attr})"
+
+
+@compatibility(is_backward_compatible=False)
+class ColoTracer(Tracer):
+
+ def __init__(self, trace_act_ckpt: bool = False, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self._disable_module_getattr = False
+ self.proxy_buffer_attributes = True
+
+ # whether the tracer will record the usage of torch.utils.checkpoint
+ self.trace_act_ckpt = trace_act_ckpt
+ # whether the current tracing occurs within the activation checkpoint functions
+ self.inside_torch_checkpoint_func = False
+ self.act_ckpt_region_count = 0
+
+ def proxy(self, node: Node) -> 'ColoProxy':
+ return ColoProxy(node, self)
+
+ def create_proxy(self,
+ kind: str,
+ target: Target,
+ args: Tuple[Any, ...],
+ kwargs: Dict[str, Any],
+ name: Optional[str] = None,
+ type_expr: Optional[Any] = None,
+ proxy_factory_fn: Callable[[Node], 'Proxy'] = None):
+
+ proxy: ColoProxy = super().create_proxy(kind, target, args, kwargs, name, type_expr, proxy_factory_fn)
+ unwrap_fn = lambda p: p.meta_data if isinstance(p, ColoProxy) else p
+ if kind == 'placeholder':
+ proxy.meta_data = self.meta_args[target] if target in self.meta_args else self.concrete_args.get(
+ _truncate_suffix(target), None)
+ elif kind == 'get_attr':
+ self._disable_module_getattr = True
+ try:
+ attr_itr = self.root
+ atoms = target.split(".")
+ for atom in atoms:
+ attr_itr = getattr(attr_itr, atom)
+ proxy.meta_data = attr_itr
+ finally:
+ self._disable_module_getattr = False
+ elif kind == 'call_function':
+ proxy.meta_data = target(*tree_map(unwrap_fn, args), **tree_map(unwrap_fn, kwargs))
+ elif kind == 'call_method':
+ self._disable_module_getattr = True
+ try:
+ if target == '__call__':
+ proxy.meta_data = unwrap_fn(args[0])(*tree_map(unwrap_fn, args[1:]), **tree_map(unwrap_fn, kwargs))
+ else:
+ if target not in _TensorPropertyMethod:
+ proxy._meta_data = getattr(unwrap_fn(args[0]), target)(*tree_map(unwrap_fn, args[1:]),
+ **tree_map(unwrap_fn, kwargs))
+ finally:
+ self._disable_module_getattr = False
+ elif kind == 'call_module':
+ mod = self.root.get_submodule(target)
+ self._disable_module_getattr = True
+ try:
+ proxy.meta_data = mod.forward(*tree_map(unwrap_fn, args), **tree_map(unwrap_fn, kwargs))
+ finally:
+ self._disable_module_getattr = False
+ return proxy
+
+ def create_node(self, *args, **kwargs) -> Node:
+ node = super().create_node(*args, **kwargs)
+
+ if self.inside_torch_checkpoint_func:
+ # annotate the activation checkpoint module
+ node.meta['activation_checkpoint'] = self.act_ckpt_region_count
+ return node
+
+ def trace(self,
+ root: torch.nn.Module,
+ concrete_args: Optional[Dict[str, torch.Tensor]] = None,
+ meta_args: Optional[Dict[str, torch.Tensor]] = None) -> Graph:
+
+ if meta_args is None:
+ meta_args = {}
+
+ if concrete_args is None:
+ concrete_args = {}
+
+ # check concrete and meta args have valid names
+ sig = inspect.signature(root.forward)
+ sig_names = set(sig.parameters.keys())
+ meta_arg_names = set(meta_args.keys())
+
+ # update concrete args with default values
+ non_meta_arg_names = sig_names - meta_arg_names
+ for k, v in sig.parameters.items():
+ if k in non_meta_arg_names and \
+ k not in concrete_args and \
+ v.default is not inspect.Parameter.empty:
+ concrete_args[k] = v.default
+
+ # get non concrete arg names
+ concrete_arg_names = set(concrete_args.keys())
+ non_concrete_arg_names = sig_names - concrete_arg_names
+
+ def _check_arg_name_valid(names):
+ success, element = is_element_in_list(names, sig_names)
+ if not success:
+ raise KeyError(
+ f"argument {element} is not found in the signature of {root.__class__.__name__}'s forward function")
+
+ _check_arg_name_valid(meta_arg_names)
+ _check_arg_name_valid(concrete_arg_names)
+
+ self.concrete_args = concrete_args
+ self.meta_args = meta_args
+
+ with _TorchTensorOverride(self), self.trace_activation_checkpoint(enabled=self.trace_act_ckpt):
+ self.graph = super().trace(root, concrete_args=concrete_args)
+ self.graph.lint()
+ return self.graph
+
+ @contextmanager
+ def trace_activation_checkpoint(self, enabled: bool):
+ if enabled:
+ orig_ckpt_func = torch.utils.checkpoint.CheckpointFunction
+
+ class PatchedCheckpointFunction(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, run_function, preserve_rng_state, *args):
+ # signal that the current tracing occurs within activaton checkpoint part
+ self.inside_torch_checkpoint_func = True
+ out = run_function(*args)
+ self.inside_torch_checkpoint_func = False
+ self.act_ckpt_region_count += 1
+ return out
+
+ @staticmethod
+ def backward(ctx: Any, *grad_outputs: Any) -> Any:
+ raise NotImplementedError(
+ "We do not implement the backward pass as we only trace the forward pass.")
+
+ # override the checkpoint function
+ torch.utils.checkpoint.CheckpointFunction = PatchedCheckpointFunction
+ yield
+
+ if enabled:
+ # recover the checkpoint function upon exit
+ torch.utils.checkpoint.CheckpointFunction = orig_ckpt_func
+
+ def _post_check(self, non_concrete_arg_names: Set[str]):
+ # This is necessary because concrete args are added as input to the traced module since
+ # https://github.com/pytorch/pytorch/pull/55888.
+ for node in self.graph.nodes:
+ if node.op == "placeholder":
+ # Removing default values for inputs as the forward pass will fail with them.
+ if node.target in non_concrete_arg_names:
+ node.args = ()
+ # Without this, torch.jit.script fails because the inputs type is Optional[torch.Tensor].
+ # It cannot infer on the attributes and methods the input should have, and fails.
+ node.type = torch.Tensor
+ # It is a concrete arg so it is not used and should be removed.
+ else:
+ if hasattr(torch.fx._symbolic_trace, "_assert_is_none"):
+ # Newer versions of torch.fx emit an assert statement
+ # for concrete arguments; delete those before we delete
+ # the concrete arg.
+ to_delete = []
+ for user in node.users:
+ if user.target == torch.fx._symbolic_trace._assert_is_none:
+ to_delete.append(user)
+ for user in to_delete:
+ self.graph.erase_node(user)
+
+ self.graph.erase_node(node)
+
+ # TODO: solves GraphModule creation.
+ # Without this, return type annotation "Tuple" is causing code execution failure.
+ if node.op == "output":
+ node.type = None
+ self.graph.lint()
+
+ def _module_getattr(self, attr, attr_val, parameter_proxy_cache):
+ if getattr(self, "_disable_module_getattr", False):
+ return attr_val
+
+ def maybe_get_proxy_for_attr(attr_val, collection_to_search, parameter_proxy_cache):
+ for n, p in collection_to_search:
+ if attr_val is p:
+ if n not in parameter_proxy_cache:
+ kwargs = {}
+ if 'proxy_factory_fn' in inspect.signature(self.create_proxy).parameters:
+ kwargs['proxy_factory_fn'] = (None if not self.param_shapes_constant else
+ lambda node: ColoProxy(self, node, n, attr_val))
+ val_proxy = self.create_proxy('get_attr', n, (), {}, **kwargs) # type: ignore[arg-type]
+ parameter_proxy_cache[n] = val_proxy
+ return parameter_proxy_cache[n]
+ return None
+
+ if self.proxy_buffer_attributes and isinstance(attr_val, torch.Tensor):
+ maybe_buffer_proxy = maybe_get_proxy_for_attr(attr_val, self.root.named_buffers(), parameter_proxy_cache)
+ if maybe_buffer_proxy is not None:
+ return maybe_buffer_proxy
+
+ if isinstance(attr_val, torch.nn.Parameter):
+ maybe_parameter_proxy = maybe_get_proxy_for_attr(attr_val, self.root.named_parameters(),
+ parameter_proxy_cache)
+ if maybe_parameter_proxy is not None:
+ return maybe_parameter_proxy
+
+ return attr_val
+
+
+@compatibility(is_backward_compatible=True)
+def symbolic_trace(
+ root: Union[torch.nn.Module, Callable[..., Any]],
+ concrete_args: Optional[Dict[str, Any]] = None,
+ meta_args: Optional[Dict[str, Any]] = None,
+ trace_act_ckpt=False,
+) -> ColoGraphModule:
+ if is_compatible_with_meta():
+ if meta_args is not None:
+ root.to(default_device())
+ wrap_fn = lambda x: MetaTensor(x, fake_device=default_device()) if isinstance(x, torch.Tensor) else x
+ graph = ColoTracer(trace_act_ckpt=trace_act_ckpt).trace(root,
+ concrete_args=concrete_args,
+ meta_args=tree_map(wrap_fn, meta_args))
+ root.cpu()
+ else:
+ graph = Tracer().trace(root, concrete_args=concrete_args)
+ else:
+ from .tracer import ColoTracer as OrigColoTracer
+ graph = OrigColoTracer(trace_act_ckpt=trace_act_ckpt).trace(root,
+ concrete_args=concrete_args,
+ meta_args=meta_args)
+ name = root.__class__.__name__ if isinstance(root, torch.nn.Module) else root.__name__
+ return ColoGraphModule(root, graph, name)
+
+
+@compatibility(is_backward_compatible=False)
+class _TorchTensorOverride(object):
+
+ def __init__(self, tracer: Tracer):
+ self.overrides = {}
+ self.tracer = tracer
+
+ def __enter__(self):
+
+ def wrap_tensor_method(target):
+
+ @functools.wraps(target)
+ def wrapper(*args, **kwargs):
+ is_proxy = any(isinstance(p, ColoProxy) for p in args) | any(
+ isinstance(p, ColoProxy) for p in kwargs.values())
+ if is_proxy:
+ # if the arg is a proxy, then need to record this function called on this proxy
+ # e.g. torch.ones(size) where size is an input proxy
+ self.tracer._disable_module_getattr = True
+ try:
+ proxy = self.tracer.create_proxy('call_function', target, args, kwargs)
+ finally:
+ self.tracer._disable_module_getattr = False
+ return proxy
+ else:
+ return target(*args, **kwargs)
+
+ return wrapper, target
+
+ self.overrides = {
+ target: wrap_tensor_method(getattr(torch, target))
+ for target in _TorchNewMethod
+ if callable(getattr(torch, target))
+ }
+ for name, (wrapper, orig) in self.overrides.items():
+ setattr(torch, name, wrapper)
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ for name, (wrapper, orig) in self.overrides.items():
+ setattr(torch, name, orig)
+
+
+def meta_prop_pass(gm: ColoGraphModule,
+ root: torch.nn.Module,
+ meta_args: Optional[Dict[str, Any]] = None,
+ concrete_args: Optional[Dict[str, torch.Tensor]] = None):
+
+ if meta_args is None:
+ meta_args = {}
+
+ if concrete_args is None:
+ concrete_args = {}
+
+ # check concrete and meta args have valid names
+ sig = inspect.signature(root.forward)
+ sig_names = set(sig.parameters.keys())
+ meta_arg_names = set(meta_args.keys())
+
+ # update concrete args with default values
+ non_meta_arg_names = sig_names - meta_arg_names
+ for k, v in sig.parameters.items():
+ if k in non_meta_arg_names and \
+ k not in concrete_args and \
+ v.default is not inspect.Parameter.empty:
+ concrete_args[k] = v.default
+
+ for node in gm.graph.nodes:
+ node._meta_data = _meta_data_computing(meta_args, concrete_args, root, node.op, node.target, node.args,
+ node.kwargs)
+
+
+def _meta_data_computing(meta_args, concrete_args, root, kind, target, args, kwargs):
+ unwrap_fn = lambda n: n._meta_data if isinstance(n, Node) else n
+ if kind == 'placeholder':
+ meta_out = meta_args[target] if target in meta_args else concrete_args.get(_truncate_suffix(target), None)
+ elif kind == 'get_attr':
+ attr_itr = root
+ atoms = target.split(".")
+ for atom in atoms:
+ attr_itr = getattr(attr_itr, atom)
+ meta_out = attr_itr
+ elif kind == 'call_function':
+ meta_out = target(*tree_map(unwrap_fn, args), **tree_map(unwrap_fn, kwargs))
+ elif kind == 'call_method':
+ if target == '__call__':
+ meta_out = unwrap_fn(args[0])(*tree_map(unwrap_fn, args[1:]), **tree_map(unwrap_fn, kwargs))
+ else:
+ if target not in _TensorPropertyMethod:
+ meta_out = getattr(unwrap_fn(args[0]), target)(*tree_map(unwrap_fn, args[1:]),
+ **tree_map(unwrap_fn, kwargs))
+ elif kind == 'call_module':
+ mod = root.get_submodule(target)
+ meta_out = mod.forward(*tree_map(unwrap_fn, args), **tree_map(unwrap_fn, kwargs))
+ else:
+ meta_out = None
+ return meta_out
+
+
+def _meta_data_computing_v0(meta_args, root, kind, target, args, kwargs):
+ if kind == "placeholder" and target in meta_args and meta_args[target].is_meta:
+ meta_out = meta_args[target]
+ return meta_out
+
+ if target in [getattr(torch, torch_func) for torch_func in _TorchNewMethod]:
+ # NOTE: tensor constructors in PyTorch define the `device` argument as
+ # *kwargs-only*. That is why this works. If you add methods to
+ # _TORCH_METHODS_TO_PATCH that do not define `device` as kwarg-only,
+ # this will break and you will likely see issues where we cannot infer
+ # the size of the output.
+ if "device" in kwargs:
+ kwargs["device"] = "meta"
+
+ try:
+ unwrap_fn = lambda n: n._meta_data if isinstance(n, Node) else n
+ args_metas = tree_map(unwrap_fn, args)
+ kwargs_metas = tree_map(unwrap_fn, kwargs)
+
+ if kind == "call_function":
+ # fetch patched function
+ if meta_patched_function.has(target):
+ meta_target = meta_patched_function.get(target)
+ elif meta_patched_function.has(target.__name__):
+ # use name for some builtin op like @ (matmul)
+ meta_target = meta_patched_function.get(target.__name__)
+ else:
+ meta_target = target
+
+ meta_out = meta_target(*args_metas, **kwargs_metas)
+
+ if isinstance(meta_out, torch.Tensor):
+ meta_out = meta_out.to(device="meta")
+ elif kind == "call_method":
+ method = getattr(args_metas[0].__class__, target)
+
+ # fetch patched method
+ if meta_patched_function.has(method):
+ meta_target = meta_patched_function.get(method)
+ else:
+ meta_target = method
+
+ meta_out = meta_target(*args_metas, **kwargs_metas)
+ elif kind == "call_module":
+ mod = root.get_submodule(target)
+ mod_type = type(mod)
+ if meta_patched_module.has(mod_type):
+ meta_out = meta_patched_module.get(mod_type)(mod, *args_metas, **kwargs_metas)
+ else:
+ meta_out = mod(*args_metas, **kwargs_metas)
+ elif kind == "get_attr":
+ attr_itr = root
+ atoms = target.split(".")
+ for atom in atoms:
+ attr_itr = getattr(attr_itr, atom)
+ if isinstance(attr_itr, torch.nn.parameter.Parameter):
+ meta_out = torch.nn.Parameter(attr_itr.to(device="meta"))
+ elif isinstance(attr_itr, torch.Tensor):
+ meta_out = attr_itr.to(device="meta")
+ else:
+ meta_out = attr_itr
+ else:
+ return None
+
+ except Exception as e:
+ raise RuntimeError(f"Could not compute metadata for {kind} target {target}: {e}")
+
+ return meta_out
+
+
+def bias_addition_pass(gm: ColoGraphModule, root_model: torch.nn.Module, meta_args: Optional[Dict[str, Any]] = None):
+ result_graph = Graph()
+ value_remap = {}
+ unwrap_fn = lambda n: n._meta_data if isinstance(n, Node) else n
+
+ for orig_node in gm.graph.nodes:
+ assert hasattr(orig_node, "_meta_data")
+ kind = orig_node.op
+ target = orig_node.target
+ args = orig_node.args
+ kwargs = orig_node.kwargs
+
+ args_metas = tree_map(unwrap_fn, args)
+ tracer = ColoTracer()
+ tracer.graph = Graph(tracer_cls=ColoTracer)
+ tracer.root = root_model
+
+ def wrap_fn(n):
+ if isinstance(n, Node):
+ proxy = ColoProxy(n, tracer)
+ proxy.meta_data = n._meta_data
+ return proxy
+ return n
+
+ args_proxy = tree_map(wrap_fn, args)
+ kwargs_proxy = tree_map(wrap_fn, kwargs)
+
+ handle = None
+ if kind == "call_function":
+ if bias_addition_function.has(target):
+ if target == torch.nn.functional.linear:
+ if 'bias' in kwargs and kwargs['bias'] is not None:
+ function_to_substitute = func_to_func_dict[target]
+ handle = bias_addition_function.get(target)(tracer, target, args_proxy, kwargs_proxy,
+ function_to_substitute)
+ else:
+ function_to_substitute = func_to_func_dict[target]
+ handle = bias_addition_function.get(target)(tracer, target, args_proxy, kwargs_proxy,
+ function_to_substitute)
+ elif bias_addition_function.has(target.__name__):
+ # use name for some builtin op like @ (matmul)
+ function_to_substitute = func_to_func_dict[target]
+ handle = bias_addition_function.get(target.__name__)(tracer, target, args_proxy, kwargs_proxy,
+ function_to_substitute)
+
+ elif kind == "call_method":
+ method = getattr(args_metas[0].__class__, target)
+ if bias_addition_method.has(method):
+ function_to_substitute = method_to_func_dict[method]
+ handle = bias_addition_method.get(method)(tracer, target, args_proxy, kwargs_proxy,
+ function_to_substitute)
+
+ elif kind == "call_module":
+ # if not hasattr(self, "orig_forward"):
+ # raise AttributeError(f"{self} does not have an attribute called orig_forward")
+ mod = gm.get_submodule(target)
+ mod_type = type(mod)
+ if bias_addition_module.has(mod_type) and mod.bias is not None:
+ function_to_substitute = module_to_func_dict[mod_type]
+ handle = bias_addition_module.get(mod_type)(tracer, target, args_proxy, kwargs_proxy,
+ function_to_substitute)
+
+ if handle is not None:
+ handle.generate()
+ for node_inserted in tracer.graph.nodes:
+ value_remap[node_inserted] = result_graph.node_copy(node_inserted, lambda n: value_remap[n])
+ last_node = value_remap[node_inserted]
+ value_remap[orig_node] = last_node
+ else:
+ value_remap[orig_node] = result_graph.node_copy(orig_node, lambda n: value_remap[n])
+
+ del tracer
+
+ gm.graph = result_graph
+ gm.recompile()
+ meta_prop_pass(gm, root_model, meta_args)
diff --git a/colossalai/fx/tracer/meta_patch/__init__.py b/colossalai/fx/tracer/meta_patch/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..192aef7a4ba0388a817c8146b55c41311faa577a
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/__init__.py
@@ -0,0 +1,2 @@
+from .patched_function import *
+from .patched_module import *
diff --git a/colossalai/fx/tracer/meta_patch/patched_function/__init__.py b/colossalai/fx/tracer/meta_patch/patched_function/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e00fdf6f5c328e4e92a3911094325ada2182c5f9
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_function/__init__.py
@@ -0,0 +1,6 @@
+from .activation_function import *
+from .arithmetic import *
+from .convolution import *
+from .embedding import *
+from .normalization import *
+from .torch_ops import *
diff --git a/colossalai/fx/tracer/meta_patch/patched_function/activation_function.py b/colossalai/fx/tracer/meta_patch/patched_function/activation_function.py
new file mode 100644
index 0000000000000000000000000000000000000000..12c42514895e61777f0dbb1c348206af7d0ac5ec
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_function/activation_function.py
@@ -0,0 +1,8 @@
+import torch
+
+from ...registry import meta_patched_function
+
+
+@meta_patched_function.register(torch.nn.functional.relu)
+def torch_nn_func_relu(input, inplace=False):
+ return torch.empty(input.shape, device='meta')
diff --git a/colossalai/fx/tracer/meta_patch/patched_function/arithmetic.py b/colossalai/fx/tracer/meta_patch/patched_function/arithmetic.py
new file mode 100644
index 0000000000000000000000000000000000000000..042b92c5847a4ed0d78d4acf068a0a5030fa7089
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_function/arithmetic.py
@@ -0,0 +1,95 @@
+import torch
+
+from ...registry import meta_patched_function
+
+
+@meta_patched_function.register(torch.matmul)
+@meta_patched_function.register('matmul') # for built-in op @
+def torch_matmul(input, other, *, out=None):
+ # copied from huggingface.utils.fx
+ d1 = input.dim()
+ d2 = other.dim()
+ shape = None
+ if d1 == 1 and d2 == 1:
+ shape = None
+ elif d1 == 2 and d2 == 2:
+ shape = (input.size(0), other.size(1))
+ elif d1 == 1 and d2 == 2:
+ shape = (other.size(1),)
+ elif d1 == 2 and d2 == 1:
+ shape = (input.size(0),)
+ else:
+ max_length = max(input.dim(), other.dim())
+ shape1 = list(input.shape)
+ shape2 = list(other.shape)
+ if d1 == 1:
+ shape1 = [1] + shape1
+ if d2 == 1:
+ shape2.append(1)
+ shape1 = [-1] * (max_length - d1) + list(input.shape)
+ shape2 = [-1] * (max_length - d2) + list(other.shape)
+ shape = []
+ for i in range(max_length):
+ shape.append(max(shape1[i], shape2[i]))
+ shape[-2] = shape1[-2]
+ shape[-1] = shape2[-1]
+ if d1 == 1:
+ shape.pop(-2)
+ if d2 == 1:
+ shape.pop(-1)
+ if shape is None:
+ return torch.tensor(0.0, device="meta")
+ return torch.empty(*shape, device="meta")
+
+
+@meta_patched_function.register(torch.abs)
+def torch_abs(input, *, out=None):
+ assert out is None, 'out is not supported yet'
+ return torch.empty(input.shape, device='meta')
+
+
+@meta_patched_function.register(torch.bmm)
+def torch_bmm(input, mat2, *, out=None):
+ if out is not None:
+ raise ValueError("Don't support in-place abs for MetaTensor analysis")
+ batch_size, n, m = input.shape
+ _, _, p = mat2.shape
+ return torch.empty(batch_size, n, p, device="meta")
+
+
+@meta_patched_function.register(torch.nn.functional.linear)
+def torch_linear(input, mat2, bias=None, *, out=None):
+ if out is not None:
+ raise ValueError("Don't support in-place abs for MetaTensor analysis")
+ output_shape = list(input.shape)
+ output_feature = list(mat2.shape)[0]
+ output_shape[-1] = output_feature
+ return torch.empty(*output_shape, device="meta")
+
+
+@meta_patched_function.register(torch.addbmm)
+@meta_patched_function.register(torch.Tensor.addbmm)
+def torch_addbmm(input, mat1, mat2, *, beta=1, alpha=1, out=None):
+ if out is not None:
+ raise ValueError("Don't support in-place abs for MetaTensor analysis")
+ _, n, _ = mat1.shape
+ _, _, p = mat2.shape
+ return torch.empty(n, p, device="meta")
+
+
+@meta_patched_function.register(torch.addmm)
+@meta_patched_function.register(torch.Tensor.addmm)
+def torch_addmm(input, mat1, mat2, *, beta=1, alpha=1, out=None):
+ if out is not None:
+ raise ValueError("Don't support in-place abs for MetaTensor analysis")
+ n, _ = mat1.shape
+ _, p = mat2.shape
+ return torch.empty(n, p, device="meta")
+
+
+@meta_patched_function.register(torch.var_mean)
+def torch_var_mean(input, dim, unbiased=True, keepdim=False, *, out=None):
+ assert out is None, 'saving to out is not supported yet'
+ var = torch.empty(1).squeeze(0).to('meta')
+ mean = torch.empty(1).squeeze(0).to('meta')
+ return var, mean
diff --git a/colossalai/fx/tracer/meta_patch/patched_function/convolution.py b/colossalai/fx/tracer/meta_patch/patched_function/convolution.py
new file mode 100644
index 0000000000000000000000000000000000000000..8500e5c82508195ca3ec8ebc99a33ad2a1b946ad
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_function/convolution.py
@@ -0,0 +1,180 @@
+import collections
+import math
+from itertools import repeat
+
+import torch
+
+from ...registry import meta_patched_function
+
+
+def _ntuple(n, name="parse"):
+
+ def parse(x):
+ if isinstance(x, collections.abc.Iterable):
+ return tuple(x)
+ return tuple(repeat(x, n))
+
+ parse.__name__ = name
+ return parse
+
+
+_single = _ntuple(1, "_single")
+_pair = _ntuple(2, "_pair")
+_triple = _ntuple(3, "_triple")
+
+
+def _extract_kwargs(kwargs):
+ if 'stride' in kwargs:
+ stride = kwargs['stride']
+ else:
+ stride = 1
+ # TODO: process str type padding
+ if 'padding' in kwargs:
+ padding = kwargs['padding']
+ else:
+ padding = 0
+ if 'dilation' in kwargs:
+ dilation = kwargs['dilation']
+ else:
+ dilation = 1
+ if 'output_padding' in kwargs:
+ output_padding = kwargs['output_padding']
+ else:
+ output_padding = 0
+
+ return stride, padding, dilation, output_padding
+
+
+@meta_patched_function.register(torch.nn.functional.conv1d)
+def torch_nn_functional_conv1d(input, weight, **kwargs):
+ stride, padding, dilation, _ = _extract_kwargs(kwargs)
+
+ stride = _single(stride)
+ padding = _single(padding)
+ dilation = _single(dilation)
+
+ kernel_size = weight.shape[2:]
+ l_in = input.shape[-1]
+ c_out = weight.shape[0]
+ l_out = math.floor((l_in + 2 * padding[0] - dilation[0] * (kernel_size[0] - 1) - 1) / stride[0] + 1)
+ result_shape = input.shape[:-2] + (
+ c_out,
+ l_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_function.register(torch.nn.functional.conv2d)
+def torch_nn_functional_conv2d(input, weight, **kwargs):
+ stride, padding, dilation, _ = _extract_kwargs(kwargs)
+
+ stride = _pair(stride)
+ padding = _pair(padding)
+ dilation = _pair(dilation)
+
+ kernel_size = weight.shape[2:]
+ h_in, w_in = input.shape[-2:]
+ c_out = weight.shape[0]
+ h_out = math.floor((h_in + 2 * padding[0] - dilation[0] * (kernel_size[0] - 1) - 1) / stride[0] + 1)
+ w_out = math.floor((w_in + 2 * padding[1] - dilation[1] * (kernel_size[1] - 1) - 1) / stride[1] + 1)
+ result_shape = input.shape[:-3] + (
+ c_out,
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_function.register(torch.nn.functional.conv3d)
+def torch_nn_functional_conv3d(input, weight, **kwargs):
+ stride, padding, dilation, _ = _extract_kwargs(kwargs)
+
+ stride = _triple(stride)
+ padding = _triple(padding)
+ dilation = _triple(dilation)
+
+ kernel_size = weight.shape[2:]
+ d_in, h_in, w_in = input.shape[-3:]
+ c_out = weight.shape[0]
+ d_out = math.floor((d_in + 2 * padding[0] - dilation[0] * (kernel_size[0] - 1) - 1) / stride[0] + 1)
+ h_out = math.floor((h_in + 2 * padding[1] - dilation[1] * (kernel_size[1] - 1) - 1) / stride[1] + 1)
+ w_out = math.floor((w_in + 2 * padding[2] - dilation[2] * (kernel_size[2] - 1) - 1) / stride[2] + 1)
+ result_shape = input.shape[:-4] + (
+ c_out,
+ d_out,
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_function.register(torch.nn.functional.conv_transpose1d)
+def torch_nn_functional_convtranspose1d(input, weight, **kwargs):
+ stride, padding, dilation, output_padding = _extract_kwargs(kwargs)
+
+ stride = _single(stride)
+ padding = _single(padding)
+ dilation = _single(dilation)
+ output_padding = _single(output_padding)
+
+ kernel_size = weight.shape[2:]
+ l_in = input.shape[-1]
+ c_out = weight.shape[1]
+ l_out = math.floor((l_in - 1) * stride[0] - 2 * padding[0] + dilation[0] * (kernel_size[0] - 1) +
+ output_padding[0] + 1)
+ result_shape = input.shape[:-2] + (
+ c_out,
+ l_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_function.register(torch.nn.functional.conv_transpose2d)
+def torch_nn_functional_convtranspose2d(input, weight, **kwargs):
+ stride, padding, dilation, output_padding = _extract_kwargs(kwargs)
+
+ stride = _pair(stride)
+ padding = _pair(padding)
+ dilation = _pair(dilation)
+ output_padding = _pair(output_padding)
+
+ kernel_size = weight.shape[2:]
+ h_in, w_in = input.shape[-2:]
+ c_out = weight.shape[1]
+ h_out = math.floor((h_in - 1) * stride[0] - 2 * padding[0] + dilation[0] * (kernel_size[0] - 1) +
+ output_padding[0] + 1)
+ w_out = math.floor((w_in - 1) * stride[1] - 2 * padding[1] + dilation[1] * (kernel_size[1] - 1) +
+ output_padding[1] + 1)
+ result_shape = input.shape[:-3] + (
+ c_out,
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_function.register(torch.nn.functional.conv_transpose3d)
+def torch_nn_functional_convtranspose3d(input, weight, **kwargs):
+ stride, padding, dilation, output_padding = _extract_kwargs(kwargs)
+
+ stride = _triple(stride)
+ padding = _triple(padding)
+ dilation = _triple(dilation)
+ output_padding = _triple(output_padding)
+
+ kernel_size = weight.shape[2:]
+ d_in, h_in, w_in = input.shape[-3:]
+ c_out = weight.shape[1]
+ d_out = math.floor((d_in - 1) * stride[0] - 2 * padding[0] + dilation[0] * (kernel_size[0] - 1) +
+ output_padding[0] + 1)
+ h_out = math.floor((h_in - 1) * stride[1] - 2 * padding[1] + dilation[1] * (kernel_size[1] - 1) +
+ output_padding[1] + 1)
+ w_out = math.floor((w_in - 1) * stride[2] - 2 * padding[2] + dilation[2] * (kernel_size[2] - 1) +
+ output_padding[2] + 1)
+ result_shape = input.shape[:-4] + (
+ c_out,
+ d_out,
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
diff --git a/colossalai/fx/tracer/meta_patch/patched_function/embedding.py b/colossalai/fx/tracer/meta_patch/patched_function/embedding.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d8d864ea29acd648f7f7097821c248655b0191e
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_function/embedding.py
@@ -0,0 +1,14 @@
+import torch
+
+from ...registry import meta_patched_function
+
+
+@meta_patched_function.register(torch.nn.functional.embedding)
+def torch_nn_functional_embedding(input,
+ weight,
+ padding_idx=None,
+ max_norm=None,
+ norm_type=2.0,
+ scale_grad_by_freq=False,
+ sparse=False):
+ return torch.empty(*input.shape, weight.shape[-1], device="meta")
diff --git a/colossalai/fx/tracer/meta_patch/patched_function/normalization.py b/colossalai/fx/tracer/meta_patch/patched_function/normalization.py
new file mode 100644
index 0000000000000000000000000000000000000000..e9e7eda6159c88ca3a82320c841360df87540c82
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_function/normalization.py
@@ -0,0 +1,20 @@
+import torch
+
+from ...registry import meta_patched_function
+
+
+@meta_patched_function.register(torch.nn.functional.layer_norm)
+def torch_nn_func_layernorm(input, normalized_shape, weight=None, bias=None, eps=1e-05):
+ return torch.empty(input.shape, device='meta')
+
+
+@meta_patched_function.register(torch.nn.functional.batch_norm)
+def torch_nn_func_batchnorm(input,
+ running_mean,
+ running_var,
+ weight=None,
+ bias=None,
+ training=False,
+ momentum=0.1,
+ eps=1e-05):
+ return torch.empty(input.shape, device='meta')
diff --git a/colossalai/fx/tracer/meta_patch/patched_function/python_ops.py b/colossalai/fx/tracer/meta_patch/patched_function/python_ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c171cb1099119de54b70b03097e1781880f2624
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_function/python_ops.py
@@ -0,0 +1,60 @@
+import operator
+
+import torch
+
+from colossalai.fx.proxy import ColoProxy
+
+from ...registry import meta_patched_function
+
+
+@meta_patched_function.register(operator.getitem)
+def operator_getitem(a, b):
+ # copied from huggingface.utils.fx
+ def to_concrete(t):
+ if isinstance(t, torch.Tensor):
+ concrete = torch.ones_like(t, device="cpu")
+ if concrete.dtype in [torch.float16, torch.float32, torch.float64, torch.int32]:
+ concrete = concrete.to(torch.int64)
+ return concrete
+ return t
+
+ def _slice_convert(slice_obj):
+ attrs = {'start': slice_obj.start, 'stop': slice_obj.stop, 'step': slice_obj.step}
+ new_attrs = _slice_attr_convert(attrs)
+ attr_dict_to_tuple = (new_attrs['start'], new_attrs['stop'], new_attrs['step'])
+ return slice(*attr_dict_to_tuple)
+
+ def _slice_attr_convert(attrs):
+ new_attrs = {}
+ for key, value in attrs.items():
+ if isinstance(value, ColoProxy):
+ new_attrs[key] = value.meta_data
+ else:
+ new_attrs[key] = value
+ return new_attrs
+
+ if isinstance(b, tuple):
+ b = list(b)
+ for index, element in enumerate(b):
+ if isinstance(element, slice):
+ b[index] = _slice_convert(element)
+ b = tuple(b)
+ elif isinstance(b, slice):
+ b = _slice_convert(b)
+
+ if isinstance(a, torch.Tensor):
+ # TODO: infer shape without performing the computation.
+ if isinstance(b, tuple):
+ b = tuple(map(to_concrete, b))
+ else:
+ b = to_concrete(b)
+ return operator.getitem(torch.empty_like(a, device="cpu"), b).to("meta")
+
+ if isinstance(a, ColoProxy):
+ # TODO: infer shape without performing the computation.
+ if isinstance(b, tuple):
+ b = tuple(map(to_concrete, b))
+ else:
+ b = to_concrete(b)
+ return operator.getitem(torch.empty_like(a.meta_data, device="cpu"), b).to("meta")
+ return operator.getitem(a, b)
diff --git a/colossalai/fx/tracer/meta_patch/patched_function/torch_ops.py b/colossalai/fx/tracer/meta_patch/patched_function/torch_ops.py
new file mode 100644
index 0000000000000000000000000000000000000000..b14ff10ce1377055ed7f3ab3025ee7c05c6a1657
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_function/torch_ops.py
@@ -0,0 +1,174 @@
+import torch
+
+from ...registry import meta_patched_function
+
+
+@meta_patched_function.register(torch.arange)
+def torch_arange(*args, **kwargs):
+ n = len(args)
+ step = 1
+ if n == 1:
+ start = 0
+ end = args[0]
+ elif n == 2:
+ start, end = args
+ else:
+ start, end, step = args
+ if isinstance(start, float):
+ start = int(start)
+ if isinstance(end, float):
+ start = int(end)
+ if isinstance(step, float):
+ step = int(step)
+ step = kwargs.get("step", step)
+ dtype = kwargs.get("dtype")
+ return torch.empty((end - start) // step, dtype=dtype, device="meta")
+
+
+@meta_patched_function.register(torch.finfo)
+def torch_finfo(*args):
+ return torch.finfo(*args)
+
+
+@meta_patched_function.register(torch.where)
+def torch_where(condition, x, y):
+ # torch.where returns the broadcasted tensor of condition, x, and y,
+ # so hack it by using addition
+ return condition.to(device="meta") + x.to(device="meta") + y.to(device="meta")
+
+
+@meta_patched_function.register(torch.Tensor.repeat)
+def torch_tensor_repeat(self, *sizes):
+ shape = list(self.shape)
+ for i, x in enumerate(sizes):
+ shape[i] *= x
+ return torch.empty(shape, device="meta")
+
+
+@meta_patched_function.register(torch.index_select)
+def torch_index_select(input, dim, index, *, out=None):
+ shape = list(input.shape)
+ shape[dim] = len(index)
+ return torch.empty(*shape, device="meta")
+
+
+@meta_patched_function.register(torch.Tensor.index_select)
+def torch_tensor_index_select(self, dim, index):
+ return torch_index_select(self, dim, index)
+
+
+@meta_patched_function.register(torch.squeeze)
+def torch_squeeze(input, dim=None):
+ shape = list(input.shape)
+ if dim is not None:
+ if dim < 0:
+ dim = input.dim() + dim
+ if shape[dim] == 1:
+ shape.pop(dim)
+ else:
+ new_shape = []
+ for dim_value in shape:
+ if dim_value == 1:
+ continue
+ new_shape.append(dim_value)
+ shape = new_shape
+ return torch.empty(shape, device="meta")
+
+
+@meta_patched_function.register(torch.Tensor.squeeze)
+def torch_tensor_squeeze(self, dim=None):
+ return torch_squeeze(self, dim)
+
+
+@meta_patched_function.register(torch.unsqueeze)
+def torch_unsqueeze(input, dim):
+ shape = list(input.shape)
+ if dim < 0:
+ dim = input.dim() + 1 + dim
+ shape.insert(dim, 1)
+ return torch.empty(shape, device="meta")
+
+
+@meta_patched_function.register(torch.Tensor.unsqueeze)
+def torch_tensor_unsqueeze(self, dim):
+ return torch_unsqueeze(self, dim)
+
+
+@meta_patched_function.register(torch.cat)
+def torch_cat(tensors, dim=None, axis=None, *, out=None):
+ if dim is None and axis is None:
+ dim = 0
+ if dim is None and axis is not None:
+ dim = axis
+ if dim < 0:
+ dim = tensors[0].dim() + dim
+ shapes = [t.shape for t in tensors]
+ shape = list(shapes[0])
+ concatenated_dim = sum(shape[dim] for shape in shapes)
+ final_shape = shape[:dim] + [concatenated_dim] + shape[dim + 1:]
+ return torch.empty(final_shape, device="meta")
+
+
+@meta_patched_function.register(torch.repeat_interleave)
+def torch_repeat_interleave(input, repeats, dim=None, output_size=None):
+ assert isinstance(repeats, int) or isinstance(repeats, torch.Tensor), \
+ "Argument 'repeats' should be of type 'torch.Tensor' or 'int'"
+
+ shape = list(input.shape) if dim is not None else [input.numel()]
+ dim = dim if dim is not None else 0
+ dim = input.dim() + dim if dim < 0 else dim
+
+ if isinstance(repeats, int):
+ shape[dim] = shape[dim] * repeats
+ elif isinstance(repeats, torch.Tensor):
+ shape[dim] = repeats.sum()
+ return torch.empty(shape, device="meta")
+
+
+@meta_patched_function.register(torch.Tensor.repeat_interleave)
+def torch_tensor_repeat_interleave(self, repeats, dim=None, *, output_size=None):
+ return torch_repeat_interleave(self, repeats, dim, output_size)
+
+
+@meta_patched_function.register(torch.roll)
+def torch_roll(input, shifts, dims=None):
+ return torch.empty(input.shape, device='meta')
+
+
+@meta_patched_function.register(torch.full)
+def torch_full(size, fill_value, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False):
+ assert out is None, 'assigning result to out is not supported yet'
+ return torch.empty(size, device='meta', dtype=dtype, layout=layout, requires_grad=requires_grad)
+
+
+@meta_patched_function.register(torch.max)
+def torch_max(input, dim=None, keepdim=False, *, out=None):
+ assert out is None, 'assigning value to out is not supported yet'
+ if dim is not None:
+ if isinstance(dim, int):
+ shape = list(input.shape)
+ shape.pop(dim)
+ if keepdim:
+ shape.insert(dim, 1)
+ return torch.empty(shape, device='meta', dtype=input.dtype), torch.empty(shape,
+ device='meta',
+ dtype=input.dtype)
+ elif isinstance(dim, torch.Tensor):
+ # when dim is a 0D or 1D tensor, it will maintain the same shape
+ num_dims = dim.dim()
+ if num_dims in [0, 1]:
+ return torch.empty_like(input, device='meta')
+ else:
+ raise ValueError(f"Expected dim to a 0D or 1D tensor but got {num_dims} dimensions")
+ else:
+ return torch.empty([], device='meta', dtype=input.dtype)
+
+
+@meta_patched_function.register(torch.Tensor.cpu)
+def torch_tensor_cpu(input):
+ return input.clone()
+
+
+@meta_patched_function.register(torch.Tensor.cuda)
+def torch_tensor_cuda(input, *args, **kwargs):
+ return input.clone()
diff --git a/colossalai/fx/tracer/meta_patch/patched_module/__init__.py b/colossalai/fx/tracer/meta_patch/patched_module/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e28e52585fffc193473a7c8270c103919cc63e0d
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_module/__init__.py
@@ -0,0 +1,7 @@
+from .activation_function import *
+from .convolution import *
+from .embedding import *
+from .linear import *
+from .normalization import *
+from .pooling import *
+from .rnn import *
\ No newline at end of file
diff --git a/colossalai/fx/tracer/meta_patch/patched_module/activation_function.py b/colossalai/fx/tracer/meta_patch/patched_module/activation_function.py
new file mode 100644
index 0000000000000000000000000000000000000000..d03da6588c1cbf56403dccc5989f4a4987b7e2a9
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_module/activation_function.py
@@ -0,0 +1,13 @@
+import torch
+
+from ...registry import meta_patched_module
+
+
+@meta_patched_module.register(torch.nn.ReLU)
+@meta_patched_module.register(torch.nn.Sigmoid)
+@meta_patched_module.register(torch.nn.GELU)
+@meta_patched_module.register(torch.nn.Tanh)
+@meta_patched_module.register(torch.nn.ReLU6)
+@meta_patched_module.register(torch.nn.PReLU)
+def torch_nn_non_linear_act(self, input):
+ return torch.empty(input.shape, device='meta')
diff --git a/colossalai/fx/tracer/meta_patch/patched_module/convolution.py b/colossalai/fx/tracer/meta_patch/patched_module/convolution.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf9f3487aac9f31ff799e3245132c40d643de64f
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_module/convolution.py
@@ -0,0 +1,113 @@
+import math
+
+import torch
+
+from ...registry import meta_patched_module
+
+
+@meta_patched_module.register(torch.nn.Conv1d)
+def torch_nn_conv1d(self, input):
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html#torch.nn.Conv1d
+ l_in = input.shape[-1]
+ c_out = self.out_channels
+ l_out = math.floor((l_in + 2 * self.padding[0] - self.dilation[0] *
+ (self.kernel_size[0] - 1) - 1) / self.stride[0] + 1)
+ result_shape = input.shape[:-2] + (
+ c_out,
+ l_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.Conv2d)
+def torch_nn_conv2d(self, input):
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html#torch.nn.Conv2d
+ h_in, w_in = input.shape[-2:]
+ c_out = self.out_channels
+ h_out = math.floor((h_in + 2 * self.padding[0] - self.dilation[0] *
+ (self.kernel_size[0] - 1) - 1) / self.stride[0] + 1)
+ w_out = math.floor((w_in + 2 * self.padding[1] - self.dilation[1] *
+ (self.kernel_size[1] - 1) - 1) / self.stride[1] + 1)
+ result_shape = input.shape[:-3] + (
+ c_out,
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.Conv3d)
+def torch_nn_conv3d(self, input):
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.Conv1d.html#torch.nn.Conv3d
+ d_in, h_in, w_in = input.shape[-3:]
+ c_out = self.out_channels
+ d_out = math.floor((d_in + 2 * self.padding[0] - self.dilation[0] *
+ (self.kernel_size[0] - 1) - 1) / self.stride[0] + 1)
+ h_out = math.floor((h_in + 2 * self.padding[1] - self.dilation[1] *
+ (self.kernel_size[1] - 1) - 1) / self.stride[1] + 1)
+ w_out = math.floor((w_in + 2 * self.padding[2] - self.dilation[2] *
+ (self.kernel_size[2] - 1) - 1) / self.stride[2] + 1)
+ result_shape = input.shape[:-4] + (
+ c_out,
+ d_out,
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.ConvTranspose1d)
+def torch_nn_convtranspose1d(self, input):
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose1d.html
+ l_in = input.shape[-1]
+ c_out = self.out_channels
+ l_out = math.floor((l_in - 1) * self.stride[0] - 2 * self.padding[0] + self.dilation[0] *
+ (self.kernel_size[0] - 1) + self.output_padding[0] + 1)
+ result_shape = input.shape[:-2] + (
+ c_out,
+ l_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.ConvTranspose2d)
+def torch_nn_convtranspose2d(self, input):
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose2d.html
+ h_in, w_in = input.shape[-2:]
+ c_out = self.out_channels
+ h_out = math.floor((h_in - 1) * self.stride[0] - 2 * self.padding[0] + self.dilation[0] *
+ (self.kernel_size[0] - 1) + self.output_padding[0] + 1)
+ w_out = math.floor((w_in - 1) * self.stride[1] - 2 * self.padding[1] + self.dilation[1] *
+ (self.kernel_size[1] - 1) + self.output_padding[1] + 1)
+ result_shape = input.shape[:-3] + (
+ c_out,
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.ConvTranspose3d)
+def torch_nn_convtranspose3d(self, input):
+ # the output shape is calculated using the formula stated
+ # at https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose3d.html
+ d_in, h_in, w_in = input.shape[-3:]
+ c_out = self.out_channels
+ d_out = math.floor((d_in - 1) * self.stride[0] - 2 * self.padding[0] + self.dilation[0] *
+ (self.kernel_size[0] - 1) + self.output_padding[0] + 1)
+ h_out = math.floor((h_in - 1) * self.stride[1] - 2 * self.padding[1] + self.dilation[1] *
+ (self.kernel_size[1] - 1) + self.output_padding[1] + 1)
+ w_out = math.floor((w_in - 1) * self.stride[2] - 2 * self.padding[2] + self.dilation[2] *
+ (self.kernel_size[2] - 1) + self.output_padding[2] + 1)
+ result_shape = input.shape[:-4] + (
+ c_out,
+ d_out,
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
diff --git a/colossalai/fx/tracer/meta_patch/patched_module/embedding.py b/colossalai/fx/tracer/meta_patch/patched_module/embedding.py
new file mode 100644
index 0000000000000000000000000000000000000000..999e33b17c1c7b442d2a6db73f957be4413f1fa1
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_module/embedding.py
@@ -0,0 +1,9 @@
+import torch
+
+from ...registry import meta_patched_module
+
+
+@meta_patched_module.register(torch.nn.Embedding)
+def torch_nn_embedding(self, input):
+ result_shape = input.shape + (self.embedding_dim,)
+ return torch.empty(result_shape, device='meta')
diff --git a/colossalai/fx/tracer/meta_patch/patched_module/linear.py b/colossalai/fx/tracer/meta_patch/patched_module/linear.py
new file mode 100644
index 0000000000000000000000000000000000000000..56f13bf97532e26770a0be7a4226ee69a2124ee5
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_module/linear.py
@@ -0,0 +1,10 @@
+import torch
+
+from ...registry import meta_patched_module
+
+
+@meta_patched_module.register(torch.nn.Linear)
+def torch_nn_linear(self, input):
+ last_dim = input.shape[-1]
+ assert last_dim == self.in_features, f'Expected hidden size {self.in_features} but got {last_dim} for the torch.nn.Linear patch'
+ return torch.empty(input.shape[:-1] + (self.out_features,), device="meta")
diff --git a/colossalai/fx/tracer/meta_patch/patched_module/normalization.py b/colossalai/fx/tracer/meta_patch/patched_module/normalization.py
new file mode 100644
index 0000000000000000000000000000000000000000..c21ff64cf3dec9baf357771fa0d15b341b413ac1
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_module/normalization.py
@@ -0,0 +1,31 @@
+import torch
+
+from ...registry import meta_patched_module
+
+
+@meta_patched_module.register(torch.nn.LayerNorm)
+@meta_patched_module.register(torch.nn.GroupNorm)
+@meta_patched_module.register(torch.nn.BatchNorm1d)
+@meta_patched_module.register(torch.nn.BatchNorm2d)
+@meta_patched_module.register(torch.nn.BatchNorm3d)
+def torch_nn_normalize(self, input):
+ # check shape
+ if isinstance(self, torch.nn.BatchNorm1d):
+ assert input.dim() in [2, 3]
+ elif isinstance(self, torch.nn.BatchNorm2d):
+ assert input.dim() == 4
+ elif isinstance(self, torch.nn.BatchNorm3d):
+ assert input.dim() == 5
+
+ # normalization maintain the same shape as the input
+ return input.clone()
+
+
+try:
+ import apex
+ meta_patched_module.register(apex.normalization.FusedLayerNorm)(torch_nn_normalize)
+ meta_patched_module.register(apex.normalization.FusedRMSNorm)(torch_nn_normalize)
+ meta_patched_module.register(apex.normalization.MixedFusedLayerNorm)(torch_nn_normalize)
+ meta_patched_module.register(apex.normalization.MixedFusedRMSNorm)(torch_nn_normalize)
+except (ImportError, AttributeError):
+ pass
diff --git a/colossalai/fx/tracer/meta_patch/patched_module/pooling.py b/colossalai/fx/tracer/meta_patch/patched_module/pooling.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ce23fbf7ac9368f4ec8496b252494e779fb5015
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_module/pooling.py
@@ -0,0 +1,202 @@
+import math
+
+import torch
+
+from ...registry import meta_patched_module
+
+
+@meta_patched_module.register(torch.nn.AvgPool1d)
+def torch_nn_avgpool1d(self, input):
+ num_dim = input.dim()
+ assert num_dim in [2, 3], f'expected the input to have 2 or 3 dimensions, but got {num_dim} dimensions'
+
+ l_in = input.shape[-1]
+
+ def _convert_int_to_list(item):
+ if isinstance(item, int):
+ return [item] * 1
+ else:
+ return item
+
+ padding = _convert_int_to_list(self.padding)
+ kernel_size = _convert_int_to_list(self.kernel_size)
+ stride = _convert_int_to_list(self.stride)
+
+ l_out = math.floor((l_in + 2 * padding[0] - kernel_size[0]) / stride[0] + 1)
+
+ result_shape = tuple(input.shape[:-1]) + (l_out,)
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.AvgPool2d)
+def torch_nn_avgpool2d(self, input):
+ num_dim = input.dim()
+ assert num_dim in [3, 4], f'expected the input to have 3 or 4 dimensions, but got {num_dim} dimensions'
+
+ h_in, w_in = input.shape[-2:]
+
+ def _convert_int_to_list(item):
+ if isinstance(item, int):
+ return [item] * 2
+ else:
+ return item
+
+ padding = _convert_int_to_list(self.padding)
+ kernel_size = _convert_int_to_list(self.kernel_size)
+ stride = _convert_int_to_list(self.stride)
+
+ h_out = math.floor((h_in + 2 * padding[0] - kernel_size[0]) / stride[0] + 1)
+ w_out = math.floor((w_in + 2 * padding[1] - kernel_size[1]) / stride[1] + 1)
+
+ result_shape = tuple(input.shape[:-2]) + (
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.AvgPool3d)
+def torch_nn_avgpool3d(self, input):
+ num_dim = input.dim()
+ assert num_dim in [4, 5], f'expected the input to have 4 or 5 dimensions, but got {num_dim} dimensions'
+
+ d_in, h_in, w_in = input.shape[-3:]
+
+ def _convert_int_to_list(item):
+ if isinstance(item, int):
+ return [item] * 3
+ else:
+ return item
+
+ padding = _convert_int_to_list(self.padding)
+ kernel_size = _convert_int_to_list(self.kernel_size)
+ stride = _convert_int_to_list(self.stride)
+
+ d_out = math.floor((d_in + 2 * padding[0] - kernel_size[0]) / stride[0] + 1)
+ h_out = math.floor((h_in + 2 * padding[1] - kernel_size[1]) / stride[1] + 1)
+ w_out = math.floor((w_in + 2 * padding[2] - kernel_size[2]) / stride[2] + 1)
+
+ result_shape = tuple(input.shape[:-3]) + (
+ d_out,
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.MaxPool1d)
+def torch_nn_maxpool1d(self, input):
+ num_dim = input.dim()
+ assert num_dim in [2, 3], f'expected the input to have 2 or 3 dimensions, but got {num_dim} dimensions'
+
+ l_in = input.shape[-1]
+
+ def _convert_int_to_list(item):
+ if isinstance(item, int):
+ return [item] * 1
+ else:
+ return item
+
+ padding = _convert_int_to_list(self.padding)
+ dilation = _convert_int_to_list(self.dilation)
+ kernel_size = _convert_int_to_list(self.kernel_size)
+ stride = _convert_int_to_list(self.stride)
+
+ l_out = math.floor((l_in + 2 * padding[0] - dilation[0] * (kernel_size[0] - 1) - 1) / stride[0] + 1)
+
+ result_shape = tuple(input.shape[:-1]) + (l_out,)
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.MaxPool2d)
+def torch_nn_maxpool2d(self, input):
+ num_dim = input.dim()
+ assert num_dim in [3, 4], f'expected the input to have 3 or 4 dimensions, but got {num_dim} dimensions'
+
+ h_in, w_in = input.shape[-2:]
+
+ def _convert_int_to_list(item):
+ if isinstance(item, int):
+ return [item] * 2
+ else:
+ return item
+
+ padding = _convert_int_to_list(self.padding)
+ dilation = _convert_int_to_list(self.dilation)
+ kernel_size = _convert_int_to_list(self.kernel_size)
+ stride = _convert_int_to_list(self.stride)
+
+ h_out = math.floor((h_in + 2 * padding[0] - dilation[0] * (kernel_size[0] - 1) - 1) / stride[0] + 1)
+ w_out = math.floor((w_in + 2 * padding[1] - dilation[1] * (kernel_size[1] - 1) - 1) / stride[1] + 1)
+
+ result_shape = tuple(input.shape[:-2]) + (
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.MaxPool3d)
+def torch_nn_maxpool3d(self, input):
+ num_dim = input.dim()
+ assert num_dim in [4, 5], f'expected the input to have 4 or 5 dimensions, but got {num_dim} dimensions'
+
+ d_in, h_in, w_in = input.shape[-3:]
+
+ def _convert_int_to_list(item):
+ if isinstance(item, int):
+ return [item] * 3
+ else:
+ return item
+
+ padding = _convert_int_to_list(self.padding)
+ dilation = _convert_int_to_list(self.dilation)
+ kernel_size = _convert_int_to_list(self.kernel_size)
+ stride = _convert_int_to_list(self.stride)
+
+ d_out = math.floor((d_in + 2 * padding[0] - dilation[0] * (kernel_size[0] - 1) - 1) / stride[0] + 1)
+ h_out = math.floor((h_in + 2 * padding[1] - dilation[1] * (kernel_size[1] - 1) - 1) / stride[1] + 1)
+ w_out = math.floor((w_in + 2 * padding[2] - dilation[2] * (kernel_size[2] - 1) - 1) / stride[2] + 1)
+
+ result_shape = tuple(input.shape[:-3]) + (
+ d_out,
+ h_out,
+ w_out,
+ )
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.AdaptiveAvgPool1d)
+@meta_patched_module.register(torch.nn.AdaptiveMaxPool1d)
+def torch_nn_adapative_pooling_1d(self, input):
+ assert input.dim() in [2, 3]
+ if isinstance(self.output_size, int):
+ output_size = (self.output_size,)
+ else:
+ output_size = self.output_size
+ result_shape = tuple(input.shape[:-1]) + output_size
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.AdaptiveAvgPool2d)
+@meta_patched_module.register(torch.nn.AdaptiveMaxPool2d)
+def torch_nn_adapative_pooling_2d(self, input):
+ assert input.dim() in [3, 4]
+ if isinstance(self.output_size, int):
+ output_size = (self.output_size,) * 2
+ else:
+ output_size = self.output_size
+ result_shape = tuple(input.shape[:-2]) + output_size
+ return torch.empty(result_shape, device='meta')
+
+
+@meta_patched_module.register(torch.nn.AdaptiveAvgPool3d)
+@meta_patched_module.register(torch.nn.AdaptiveMaxPool3d)
+def torch_nn_adapative_pooling_3d(self, input):
+ assert input.dim() in [4, 5]
+ if isinstance(self.output_size, int):
+ output_size = (self.output_size,) * 3
+ else:
+ output_size = self.output_size
+ result_shape = tuple(input.shape[:-3]) + output_size
+ return torch.empty(result_shape, device='meta')
diff --git a/colossalai/fx/tracer/meta_patch/patched_module/rnn.py b/colossalai/fx/tracer/meta_patch/patched_module/rnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..ee15ca34162e83612eb179e0cff066d9f06faf36
--- /dev/null
+++ b/colossalai/fx/tracer/meta_patch/patched_module/rnn.py
@@ -0,0 +1,16 @@
+from typing import Optional
+
+import torch
+
+from ...registry import meta_patched_module
+
+
+@meta_patched_module.register(torch.nn.GRU)
+@meta_patched_module.register(torch.nn.RNN)
+def torch_nn_rnn(self, input, hx):
+ assert input.shape[
+ -1] == self.input_size, f'Expected input to have input size {self.input_size} but got {input.shape[-1]} for the torch.nn.RNN patch'
+ assert hx.shape[
+ -1] == self.hidden_size, f'Expected hx to have hidden size {self.hidden_size} but got {hx.shape[-1]} for the torch.nn.RNN patch'
+ d = 2 if self.bidirectional else 1
+ return torch.empty(input.shape[:-1] + (self.hidden_size * d,), device="meta"), hx
diff --git a/colossalai/fx/tracer/registry.py b/colossalai/fx/tracer/registry.py
new file mode 100644
index 0000000000000000000000000000000000000000..12fc6de73d4435dea8ec58fa50b93a6070fd6254
--- /dev/null
+++ b/colossalai/fx/tracer/registry.py
@@ -0,0 +1,28 @@
+class PatchRegistry:
+
+ def __init__(self, name):
+ self.name = name
+ self.store = {}
+
+ def register(self, source):
+
+ def wrapper(func):
+ self.store[source] = func
+ return func
+
+ return wrapper
+
+ def get(self, source):
+ assert source in self.store
+ target = self.store[source]
+ return target
+
+ def has(self, source):
+ return source in self.store
+
+
+meta_patched_function = PatchRegistry(name='patched_functions_for_meta_execution')
+meta_patched_module = PatchRegistry(name='patched_modules_for_meta_execution')
+bias_addition_function = PatchRegistry(name='patched_function_for_bias_addition')
+bias_addition_module = PatchRegistry(name='patched_module_for_bias_addition')
+bias_addition_method = PatchRegistry(name='patched_method_for_bias_addition')
diff --git a/colossalai/fx/tracer/tracer.py b/colossalai/fx/tracer/tracer.py
new file mode 100644
index 0000000000000000000000000000000000000000..1ae31f9589756d4552f6c2247e0b71679625832b
--- /dev/null
+++ b/colossalai/fx/tracer/tracer.py
@@ -0,0 +1,558 @@
+#!/usr/bin/env python
+"""
+tracer.py:
+ Implemented a tracer which supports control flow and user-defined meta arguments.
+ The implementation is partly inspired HuggingFace's fx tracer
+"""
+import enum
+import functools
+import inspect
+import operator
+from contextlib import contextmanager
+from typing import Any, Dict, Optional
+
+import torch
+import torch.nn as nn
+from torch import Tensor
+from torch.fx import Node, Tracer
+from torch.fx.graph import Graph, magic_methods, reflectable_magic_methods
+from torch.fx.proxy import ParameterProxy, Proxy
+
+from ..proxy import ColoProxy
+from ._tracer_utils import compute_meta_data_for_functions_proxy, extract_meta, is_element_in_list
+from .bias_addition_patch import func_to_func_dict, method_to_func_dict, module_to_func_dict
+from .registry import (
+ bias_addition_function,
+ bias_addition_method,
+ bias_addition_module,
+ meta_patched_function,
+ meta_patched_module,
+)
+
+__all__ = ['ColoTracer']
+
+
+class TracerType(enum.Enum):
+ DEFAULT = 1
+ META = 2
+
+
+class ColoTracer(Tracer):
+ """
+ ColoTracer is a symbolic tracer designed to support dynamic control flow by using meta tensors for the `colossalai.fx` module.
+ This tracer is initialized in the same way as the original torch.fx.Tracer.
+
+ Usage::
+
+ class Model(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.linear1 = nn.Linear(10, 10)
+ self.linear2 = nn.Linear(10, 10)
+
+ def forward(self, x, y):
+ x1 = self.linear1(x)
+ y1 = self.linear2(y)
+
+ if x1.dim() == 2:
+ return x1 + y1
+ else:
+ return x1 - y1
+
+ model = Model()
+ tracer = ColoTracer()
+ graph = tracer.trace(model, concrete_args={'y': torch.rand(4, 10)}, meta_args={'x': torch.rand(4, 10, device='meta')})
+ """
+
+ def __init__(self, trace_act_ckpt: bool = False, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.tracer_type = TracerType.META
+ self.proxy_cls = ColoProxy
+
+ # whether the tracer will record the usage of torch.utils.checkpoint
+ self.trace_act_ckpt = trace_act_ckpt
+ # whether the current tracing occurs within the activation checkpoint functions
+ self.inside_torch_checkpoint_func = False
+ self.act_ckpt_region_count = 0
+
+ # Feature flag for proxying accesses to buffer values
+ proxy_buffer_attributes: bool = True
+
+ _TORCH_METHODS_TO_PATCH = ["arange", "zeros", "ones", "full", "full_like", "eye", "empty", "tensor", "finfo"]
+
+ def create_proxy(self, kind, target, args, kwargs, name=None, type_expr=None, proxy_factory_fn=None) -> ColoProxy:
+ """
+ Create a proxy for different kinds of operations.
+ """
+
+ if self.tracer_type == TracerType.DEFAULT:
+ # since meta_args is not given
+ # we just fall back to the original torch.fx.Tracer
+ proxy = super().create_proxy(kind, target, args, kwargs, name, type_expr, proxy_factory_fn)
+ return proxy
+
+ # if graph is traced for auto parallelism module, some extra node will be added during
+ # graph construction to deal with the compatability between bias addition and all reduce.
+
+ # if no extra manipulation is applied, we just pass the origin arguments to create_proxy function
+ # to create node on computation graph
+ origin_arguments = (kind, target, args, kwargs, name, type_expr, proxy_factory_fn)
+ # dispatch the arguments generator depending on the kind and target in origin arguments.
+ args_metas, _ = extract_meta(*args, **kwargs)
+ handle = None
+ if kind == "call_function":
+ if bias_addition_function.has(target):
+ if target == torch.nn.functional.linear:
+ if 'bias' in kwargs and kwargs['bias'] is not None:
+ function_to_substitute = func_to_func_dict[target]
+ handle = bias_addition_function.get(target)(self, target, args, kwargs, function_to_substitute)
+ else:
+ function_to_substitute = func_to_func_dict[target]
+ handle = bias_addition_function.get(target)(self, target, args, kwargs, function_to_substitute)
+ elif bias_addition_function.has(target.__name__):
+ # use name for some builtin op like @ (matmul)
+ function_to_substitute = func_to_func_dict[target]
+ handle = bias_addition_function.get(target.__name__)(self, target, args, kwargs, function_to_substitute)
+
+ elif kind == "call_method":
+ method = getattr(args_metas[0].__class__, target)
+ if bias_addition_method.has(method):
+ function_to_substitute = method_to_func_dict[method]
+ handle = bias_addition_method.get(method)(self, target, args, kwargs, function_to_substitute)
+
+ elif kind == "call_module":
+ if not hasattr(self, "orig_forward"):
+ raise AttributeError(f"{self} does not have an attribute called orig_forward")
+ self._disable_module_getattr = True
+ try:
+ mod = self.root.get_submodule(target)
+ mod_type = type(mod)
+ if bias_addition_module.has(mod_type) and mod.bias is not None:
+ function_to_substitute = module_to_func_dict[mod_type]
+ handle = bias_addition_module.get(mod_type)(self, target, args, kwargs, function_to_substitute)
+ finally:
+ self._disable_module_getattr = False
+
+ if handle is not None:
+ return handle.generate()
+
+ # create nodes using patched arguments
+ proxy = super().create_proxy(*origin_arguments)
+ proxy: ColoProxy
+ meta_out = self._meta_data_computing(
+ kind,
+ target,
+ args,
+ kwargs,
+ )
+ proxy.meta_data = meta_out
+
+ return proxy
+
+ def _module_getattr(self, attr, attr_val, parameter_proxy_cache):
+ if getattr(self, "_disable_module_getattr", False):
+ return attr_val
+ else:
+ # return super()._module_getattr(attr, attr_val, parameter_proxy_cache)
+ def maybe_get_proxy_for_attr(attr_val, collection_to_search, parameter_proxy_cache):
+ for n, p in collection_to_search:
+ if attr_val is p:
+ if n not in parameter_proxy_cache:
+ kwargs = {}
+ if "proxy_factory_fn" in inspect.signature(self.create_proxy).parameters:
+ kwargs["proxy_factory_fn"] = (None if not self.param_shapes_constant else
+ lambda node: ParameterProxy(self, node, n, attr_val))
+ val_proxy = self.create_proxy("get_attr", n, (), {}, **kwargs) # type: ignore[arg-type]
+ parameter_proxy_cache[n] = val_proxy
+ return parameter_proxy_cache[n]
+ return None
+
+ if isinstance(attr_val, torch.nn.Parameter):
+ maybe_parameter_proxy = maybe_get_proxy_for_attr(attr_val, self.root.named_parameters(),
+ parameter_proxy_cache)
+ if maybe_parameter_proxy is not None:
+ return maybe_parameter_proxy
+
+ if self.proxy_buffer_attributes and isinstance(attr_val, torch.Tensor):
+ maybe_buffer_proxy = maybe_get_proxy_for_attr(attr_val, self.root.named_buffers(),
+ parameter_proxy_cache)
+ if maybe_buffer_proxy is not None:
+ return maybe_buffer_proxy
+
+ return attr_val
+
+ def call_module(self, m, forward, args, kwargs):
+ self.orig_forward = forward
+ module_qualified_name = self.path_of_module(m)
+
+ # a leaf module is the torch.nn.Module subclasses starting with `torch.nn`
+ # which means customized modules are not leaf module by default
+ # if a customized or third-party module like apex.normalization.FusedRMSNorm is patched,
+ # we should treat it as leaf module as well
+ if meta_patched_module.has(m.__class__) or self.is_leaf_module(m, module_qualified_name):
+ return self.create_proxy('call_module', module_qualified_name, args, kwargs)
+ else:
+ return forward(*args, **kwargs)
+
+ def proxy(self, node) -> Proxy:
+ """
+ Returns a ColoProxy object.
+ """
+ return self.proxy_cls(node, self)
+
+ def _configure_tracer_type(self, tracer_type: TracerType):
+ if tracer_type == TracerType.DEFAULT:
+ self.proxy_cls = Proxy
+ self.tracer_type = TracerType.DEFAULT
+ elif tracer_type == TracerType.META:
+ self.proxy_cls = ColoProxy
+ self.tracer_type = TracerType.META
+ else:
+ raise ValueError(f"Unrecognised tracer type {tracer_type}")
+
+ def _meta_data_computing(self, kind, target, args, kwargs):
+
+ if kind == "placeholder" and target in self.meta_args and self.meta_args[target].is_meta:
+ meta_out = self.meta_args[target]
+ return meta_out
+
+ if target in self.orig_torch_tensor_methods:
+ # NOTE: tensor constructors in PyTorch define the `device` argument as
+ # *kwargs-only*. That is why this works. If you add methods to
+ # _TORCH_METHODS_TO_PATCH that do not define `device` as kwarg-only,
+ # this will break and you will likely see issues where we cannot infer
+ # the size of the output.
+ if "device" in kwargs:
+ kwargs["device"] = "meta"
+
+ try:
+ args_metas, kwargs_metas = extract_meta(*args, **kwargs)
+
+ if kind == "call_function":
+ # Our meta data will not record the nn.parameter.Parameter attribute。
+ # It works fine in most of the case, but it may cause some problems after
+ # the bias addition manipulation.
+ # Therefore, I need to record the nn.parameter.Parameter attribute for the operation
+ # added by the bias addition manipulation following the get_attr node.
+ convert_to_parameter = False
+ if target in (torch.transpose, torch.reshape) and isinstance(args_metas[0],
+ torch.nn.parameter.Parameter):
+ convert_to_parameter = True
+ # fetch patched function
+ if meta_patched_function.has(target):
+ meta_target = meta_patched_function.get(target)
+ elif meta_patched_function.has(target.__name__):
+ # use name for some builtin op like @ (matmul)
+ meta_target = meta_patched_function.get(target.__name__)
+ else:
+ meta_target = target
+
+ meta_out = meta_target(*args_metas, **kwargs_metas)
+ if isinstance(meta_out, torch.Tensor):
+ meta_out = meta_out.to(device="meta")
+ if convert_to_parameter:
+ meta_out = torch.nn.Parameter(meta_out)
+
+ elif kind == "call_method":
+ # Our meta data will not record the nn.parameter.Parameter attribute。
+ # It works fine in most of the case, but it may cause some problems after
+ # the bias addition manipulation.
+ # Therefore, I need to record the nn.parameter.Parameter attribute for the operation
+ # added by the bias addition manipulation following the get_attr node.
+ convert_to_parameter = False
+ if target in (torch.Tensor.view,) and isinstance(args_metas[0], torch.nn.parameter.Parameter):
+ convert_to_parameter = True
+ method = getattr(args_metas[0].__class__, target)
+
+ # fetch patched method
+ if meta_patched_function.has(method):
+ meta_target = meta_patched_function.get(method)
+ else:
+ meta_target = method
+
+ meta_out = meta_target(*args_metas, **kwargs_metas)
+ if convert_to_parameter:
+ meta_out = torch.nn.Parameter(meta_out)
+ elif kind == "call_module":
+ if not hasattr(self, "orig_forward"):
+ raise AttributeError(f"{self} does not have an attribute called orig_forward")
+ self._disable_module_getattr = True
+ try:
+ mod = self.root.get_submodule(target)
+ mod_type = type(mod)
+ if meta_patched_module.has(mod_type):
+ meta_out = meta_patched_module.get(mod_type)(mod, *args_metas, **kwargs_metas)
+ else:
+ meta_out = self.orig_forward(*args_metas, **kwargs_metas)
+ finally:
+ self._disable_module_getattr = False
+ elif kind == "get_attr":
+ self._disable_module_getattr = True
+ try:
+ attr_itr = self.root
+ atoms = target.split(".")
+ for atom in atoms:
+ attr_itr = getattr(attr_itr, atom)
+ if isinstance(attr_itr, torch.nn.parameter.Parameter):
+ meta_out = torch.nn.Parameter(attr_itr.to(device="meta"))
+ elif isinstance(attr_itr, torch.Tensor):
+ meta_out = attr_itr.to(device="meta")
+ else:
+ meta_out = attr_itr
+ finally:
+ self._disable_module_getattr = False
+ else:
+ return None
+
+ except Exception as e:
+ raise RuntimeError(f"Could not compute metadata for {kind} target {target}: {e}")
+
+ return meta_out
+
+ def trace(self,
+ root: nn.Module,
+ concrete_args: Optional[Dict[str, Tensor]] = None,
+ meta_args: Optional[Dict[str, Tensor]] = None) -> Graph:
+ """
+ Trace the forward computation graph using `torch.fx.Tracer`. This tracer enables data-dependent control flow.
+
+ Args:
+ root (nn.Module): a `nn.Module` object to trace the computation graph
+ meta_args (Optional[Dict[str, Tensor]]): the meta tensor arguments used to trace the computation graph.
+ These arguments are the sample data fed to the model during actual computation, but just converted to meta tensors.
+ concrete_args (Optional[Dict[str, Tensor]]): the concrete arguments that should not be treated as Proxies.
+ """
+ if meta_args is None:
+ meta_args = {}
+
+ if concrete_args is None:
+ concrete_args = {}
+
+ if len(meta_args) == 0:
+ self._configure_tracer_type(TracerType.DEFAULT)
+ else:
+ self._configure_tracer_type(TracerType.META)
+
+ # check concrete and meta args have valid names
+ sig = inspect.signature(root.forward)
+ sig_names = set(sig.parameters.keys())
+ meta_arg_names = set(meta_args.keys())
+
+ # update concrete args with default values
+ non_meta_arg_names = sig_names - meta_arg_names
+ for k, v in sig.parameters.items():
+ if k in non_meta_arg_names and \
+ k not in concrete_args and \
+ v.default is not inspect.Parameter.empty:
+ concrete_args[k] = v.default
+
+ # get non concrete arg names
+ concrete_arg_names = set(concrete_args.keys())
+ non_concrete_arg_names = sig_names - concrete_arg_names
+
+ def _check_arg_name_valid(names):
+ success, element = is_element_in_list(names, sig_names)
+ if not success:
+ raise KeyError(
+ f"argument {element} is not found in the signature of {root.__class__.__name__}'s forward function")
+
+ _check_arg_name_valid(meta_arg_names)
+ _check_arg_name_valid(concrete_arg_names)
+
+ # assign as attributed for late reference
+ def _check_kwargs(kwargs, should_be_meta: bool):
+ for k, v in kwargs.items():
+ if not should_be_meta:
+ assert not torch.is_tensor(v) or not v.is_meta, \
+ f'Expected the {k} not to be a meta tensor, please check the args passed to the tracer'
+ else:
+ assert v.is_meta == should_be_meta, \
+ f'Expected the is_meta attribute of {k} to be {should_be_meta}, but got {v.is_meta}, please check the args passed to the tracer'
+
+ _check_kwargs(concrete_args, should_be_meta=False)
+ _check_kwargs(meta_args, should_be_meta=True)
+
+ self.concrete_args = concrete_args
+ self.meta_args = meta_args
+
+ self.patched_torch_tensor_methods = {}
+ if self.tracer_type == TracerType.META:
+ # wrap the torch tensor constructing methods so that they are captured in the graph
+ self.patched_torch_tensor_methods = {
+ target: wrap_tensor_constructor_method(getattr(torch, target))
+ for target in self._TORCH_METHODS_TO_PATCH
+ }
+
+ # patch these methods to replace their original use
+ for name, (wrapper, orig) in self.patched_torch_tensor_methods.items():
+ setattr(torch, name, wrapper)
+
+ # cache these methods so that we can detect whether a method call
+ # should be patched during tracing
+ self.orig_torch_tensor_methods = [val[1] for val in self.patched_torch_tensor_methods.values()]
+
+ try:
+ # to track the usage of torch.utils.checkpoint
+ with self.trace_activation_checkpoint(enabled=self.trace_act_ckpt):
+ self.graph = super().trace(root, concrete_args=concrete_args)
+
+ finally:
+ # recover the patched methods
+ for name, (_, orig) in self.patched_torch_tensor_methods.items():
+ setattr(torch, name, orig)
+
+ if self.tracer_type == TracerType.DEFAULT:
+ return self.graph
+
+ # This is necessary because concrete args are added as input to the traced module since
+ # https://github.com/pytorch/pytorch/pull/55888.
+ for node in self.graph.nodes:
+ if node.op == "placeholder":
+ # Removing default values for inputs as the forward pass will fail with them.
+ if node.target in non_concrete_arg_names:
+ node.args = ()
+ # Without this, torch.jit.script fails because the inputs type is Optional[torch.Tensor].
+ # It cannot infer on the attributes and methods the input should have, and fails.
+ node.type = torch.Tensor
+ # It is a concrete arg so it is not used and should be removed.
+ else:
+ if hasattr(torch.fx._symbolic_trace, "_assert_is_none"):
+ # Newer versions of torch.fx emit an assert statement
+ # for concrete arguments; delete those before we delete
+ # the concrete arg.
+ to_delete = []
+ for user in node.users:
+ if user.target == torch.fx._symbolic_trace._assert_is_none:
+ to_delete.append(user)
+ for user in to_delete:
+ self.graph.erase_node(user)
+
+ self.graph.erase_node(node)
+
+ # TODO: solves GraphModule creation.
+ # Without this, return type annotation "Tuple" is causing code execution failure.
+ if node.op == "output":
+ node.type = None
+
+ return self.graph
+
+ @contextmanager
+ def trace_activation_checkpoint(self, enabled: bool):
+ if enabled:
+ orig_ckpt_func = torch.utils.checkpoint.CheckpointFunction
+
+ class PatchedCheckpointFunction(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, run_function, preserve_rng_state, *args):
+ # signal that the current tracing occurs within activaton checkpoint part
+ self.inside_torch_checkpoint_func = True
+ out = run_function(*args)
+ self.inside_torch_checkpoint_func = False
+ self.act_ckpt_region_count += 1
+ return out
+
+ @staticmethod
+ def backward(ctx: Any, *grad_outputs: Any) -> Any:
+ raise NotImplementedError(
+ "We do not implement the backward pass as we only trace the forward pass.")
+
+ # override the checkpoint function
+ torch.utils.checkpoint.CheckpointFunction = PatchedCheckpointFunction
+ yield
+
+ if enabled:
+ # recover the checkpoint function upon exit
+ torch.utils.checkpoint.CheckpointFunction = orig_ckpt_func
+
+ def create_node(self, *args, **kwargs) -> Node:
+ node = super().create_node(*args, **kwargs)
+
+ if self.inside_torch_checkpoint_func:
+ # annotate the activation checkpoint module
+ node.meta['activation_checkpoint'] = self.act_ckpt_region_count
+ return node
+
+
+def wrap_tensor_constructor_method(target):
+
+ def look_for_proxy(*args, **kwargs):
+ # find in pos vars
+ for arg in args:
+ if isinstance(arg, Proxy):
+ return arg
+ if isinstance(arg, (tuple, list)):
+ return look_for_proxy(*arg)
+
+ # find in keyword vars
+ for k, v in kwargs.items():
+ if isinstance(v, Proxy):
+ return v
+ if isinstance(v, (tuple, list)):
+ return look_for_proxy(*v)
+ return None
+
+ @functools.wraps(target)
+ def wrapper(*args, **kwargs):
+ proxy = look_for_proxy(*args, **kwargs)
+
+ if proxy is not None:
+ # if the arg is a proxy, then need to record this function called on this proxy
+ # e.g. torch.ones(size) where size is an input proxy
+ colo_proxy = proxy.tracer.create_proxy("call_function", target, args, kwargs)
+ if not isinstance(colo_proxy, ColoProxy):
+ meta_out = compute_meta_data_for_functions_proxy(target, args, kwargs)
+ colo_proxy = ColoProxy(proxy.node)
+ colo_proxy.meta_data = meta_out
+ return colo_proxy
+ else:
+ # this is called directly when the inputs do not contain proxy
+ # e.g. torch.ones(4) where the input is static
+ return target(*args, **kwargs)
+
+ return wrapper, target
+
+
+# Patched magic methods for ColoProxy, then tracer could record the magic_method like __sub__,
+# and add meta_data attribute to the created proxy.
+for method in magic_methods:
+
+ def _scope(method):
+
+ def impl(*args, **kwargs):
+
+ tracer = args[0].tracer
+ target = getattr(operator, method)
+ proxy = tracer.create_proxy('call_function', target, args, kwargs)
+ if not isinstance(proxy, ColoProxy):
+ meta_out = compute_meta_data_for_functions_proxy(target, args, kwargs)
+ proxy = ColoProxy(proxy.node)
+ proxy.meta_data = meta_out
+ return proxy
+
+ impl.__name__ = method
+ as_magic = f'__{method.strip("_")}__'
+ setattr(ColoProxy, as_magic, impl)
+
+ _scope(method)
+
+
+def _define_reflectable(orig_method_name):
+ method_name = f'__r{orig_method_name.strip("_")}__'
+
+ def impl(self, rhs):
+ target = getattr(operator, orig_method_name)
+ proxy = self.tracer.create_proxy('call_function', target, (rhs, self), {})
+ if not isinstance(proxy, ColoProxy):
+ meta_out = compute_meta_data_for_functions_proxy(target, *(rhs, self), {})
+ proxy = ColoProxy(proxy.node)
+ proxy.meta_data = meta_out
+ return proxy
+
+ impl.__name__ = method_name
+ impl.__qualname__ = method_name
+ setattr(ColoProxy, method_name, impl)
+
+
+for orig_method_name in reflectable_magic_methods:
+ _define_reflectable(orig_method_name)
diff --git a/colossalai/global_variables.py b/colossalai/global_variables.py
new file mode 100644
index 0000000000000000000000000000000000000000..61b31965e2e63d2119bfadba0d49478537c31fa7
--- /dev/null
+++ b/colossalai/global_variables.py
@@ -0,0 +1,56 @@
+from typing import Optional
+
+
+class TensorParallelEnv(object):
+ _instance = None
+
+ def __new__(cls, *args, **kwargs):
+ if cls._instance is None:
+ cls._instance = object.__new__(cls, *args, **kwargs)
+ return cls._instance
+
+ def __init__(self, *args, **kwargs):
+ self.load(*args, **kwargs)
+
+ def load(self,
+ mode: Optional[str] = None,
+ vocab_parallel: bool = False,
+ parallel_input_1d: bool = False,
+ summa_dim: int = None,
+ tesseract_dim: int = None,
+ tesseract_dep: int = None,
+ depth_3d: int = None,
+ input_group_3d=None,
+ weight_group_3d=None,
+ output_group_3d=None,
+ input_x_weight_group_3d=None,
+ output_x_weight_group_3d=None):
+ self.mode = mode
+ self.vocab_parallel = vocab_parallel
+ self.parallel_input_1d = parallel_input_1d
+ self.summa_dim = summa_dim
+ self.tesseract_dim = tesseract_dim
+ self.tesseract_dep = tesseract_dep
+ self.depth_3d = depth_3d
+ self.input_group_3d = input_group_3d
+ self.weight_group_3d = weight_group_3d
+ self.output_group_3d = output_group_3d
+ self.input_x_weight_group_3d = input_x_weight_group_3d
+ self.output_x_weight_group_3d = output_x_weight_group_3d
+
+ def save(self):
+ return dict(mode=self.mode,
+ vocab_parallel=self.vocab_parallel,
+ parallel_input_1d=self.parallel_input_1d,
+ summa_dim=self.summa_dim,
+ tesseract_dim=self.tesseract_dim,
+ tesseract_dep=self.tesseract_dep,
+ depth_3d=self.depth_3d,
+ input_group_3d=self.input_group_3d,
+ weight_group_3d=self.weight_group_3d,
+ output_group_3d=self.output_group_3d,
+ input_x_weight_group_3d=self.input_x_weight_group_3d,
+ output_x_weight_group_3d=self.output_x_weight_group_3d)
+
+
+tensor_parallel_env = TensorParallelEnv()
diff --git a/colossalai/initialize.py b/colossalai/initialize.py
new file mode 100644
index 0000000000000000000000000000000000000000..5d3f3e5530cbb71a6e88cd3726615c1b6b61a164
--- /dev/null
+++ b/colossalai/initialize.py
@@ -0,0 +1,470 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import argparse
+import os
+import pprint
+from pathlib import Path
+from typing import Callable, Dict, Iterable, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+from torch.nn.modules.loss import _Loss
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.optim.lr_scheduler import _LRScheduler
+from torch.optim.optimizer import Optimizer
+from torch.utils.data import DataLoader
+
+from colossalai.amp import AMP_TYPE, convert_to_amp
+from colossalai.amp.naive_amp import NaiveAMPModel
+from colossalai.builder.builder import build_gradient_handler
+from colossalai.context import Config, ConfigException, ParallelMode
+from colossalai.context.moe_context import MOE_CONTEXT
+from colossalai.core import global_context as gpc
+from colossalai.engine import Engine
+from colossalai.engine.gradient_accumulation import accumulate_gradient
+from colossalai.engine.schedule import (
+ InterleavedPipelineSchedule,
+ NonPipelineSchedule,
+ PipelineSchedule,
+ get_tensor_shape,
+)
+from colossalai.logging import get_dist_logger
+from colossalai.nn.optimizer.colossalai_optimizer import ColossalaiOptimizer
+from colossalai.utils import get_current_device, is_using_ddp, is_using_pp, is_using_sequence, sync_model_param
+from colossalai.utils.moe import sync_moe_model_param
+from colossalai.zero.legacy import ShardedOptimizerV2, convert_to_zero_v2
+from colossalai.zero.legacy.gemini.ophooks import BaseOpHook
+
+
+def get_default_parser():
+ """Reads user command line and uses an argument parser to parse the input arguments.
+ Input arguments include configuration, host, port, world size, local rank, backend for torch.distributed.
+
+ Returns:
+ Namespace: Returns the parser with the default arguments, the user may add customized arguments into this parser.
+ """
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--config', type=str, help='path to the config file')
+ parser.add_argument('--host', type=str, help='the master address for distributed training')
+ parser.add_argument('--port', type=int, help='the master port for distributed training')
+ parser.add_argument('--world_size', type=int, help='world size for distributed training')
+ parser.add_argument('--rank', type=int, help='rank for the default process group')
+ parser.add_argument('--local_rank', type=int, help='local rank on the node')
+ parser.add_argument('--backend', type=str, default='nccl', help='backend for distributed communication')
+ return parser
+
+
+def launch(config: Union[str, Path, Config, Dict],
+ rank: int,
+ world_size: int,
+ host: str,
+ port: int,
+ backend: str = 'nccl',
+ local_rank: int = None,
+ seed: int = 1024,
+ verbose: bool = True):
+ """This function first parses the configuration arguments, using :func:`parse_args()` in case one of the input
+ arguments are not given. Then initialize and set distributed environment by calling global_context's functions.
+
+ Args:
+ config (Union[str, dict, Config]): Config file or config file path are both acceptable
+ rank (int): Rank for the default process group
+ world_size (int): World size of the default process group
+ host (str): The master address for distributed training
+ port (str): The master port for distributed training
+ backend (str, optional): Backend for ``torch.distributed``, defaults to ``nccl``
+ local_rank (int, optional):
+ Rank for the process on the node and is used to set the default CUDA device,
+ defaults to None. If local_rank = None, the default device ordinal will be calculated automatically.
+ seed (int, optional): Specified random seed for every process. Defaults to 1024.
+ verbose (bool, optional): Whether to print logs. Defaults to True.
+
+ Raises:
+ Exception: Raise exception when config type is wrong
+ """
+ gpc.verbose = verbose
+
+ # set config
+ assert isinstance(config, (Config, str, Path, dict)), \
+ f'expected argument config to be Config, str or Path, but got {type(config)}'
+ if not isinstance(config, Config) and isinstance(config, dict):
+ config = Config(config)
+ if isinstance(config, (str, Path)):
+ config = Config.from_file(config)
+ gpc.load_config(config)
+
+ # init default process group
+ gpc.init_global_dist(rank, world_size, backend, host, port)
+
+ # init process groups for different parallel modes from config
+ gpc.init_parallel_groups()
+
+ # set cuda device
+ if torch.cuda.is_available():
+ # if local rank is not given, calculate automatically
+ gpc.set_device(local_rank)
+
+ # set the number of processes running on the same node
+ gpc.detect_num_processes_on_current_node()
+
+ gpc.set_seed(seed)
+
+ if verbose:
+ logger = get_dist_logger()
+ logger.info(
+ f'Distributed environment is initialized, '
+ f'data parallel size: {gpc.data_parallel_size}, pipeline parallel size: {gpc.pipeline_parallel_size}, '
+ f'tensor parallel size: {gpc.tensor_parallel_size}',
+ ranks=[0])
+
+
+def launch_from_slurm(config: Union[str, Path, Config, Dict],
+ host: str,
+ port: int,
+ backend: str = 'nccl',
+ seed: int = 1024,
+ verbose: bool = True):
+ """A wrapper for colossalai.launch for SLURM launcher by reading rank and world size from the environment variables
+ set by SLURM
+
+ Args:
+ config (Union[str, dict, Config]): Config file or config file path are both acceptable
+ host (str): The master address for distributed training
+ port (str): The master port for distributed training
+ backend (str, optional): Backend for ``torch.distributed``, defaults to ``nccl``
+ seed (int, optional): Specified random seed for every process. Defaults to 1024.
+ verbose (bool, optional): Whether to print logs. Defaults to True.
+ """
+ try:
+ rank = int(os.environ['SLURM_PROCID'])
+ world_size = int(os.environ['SLURM_NPROCS'])
+ except KeyError as e:
+ raise RuntimeError(
+ f"Could not find {e} in the SLURM environment, visit https://www.colossalai.org/ for more information on launching with SLURM"
+ )
+
+ launch(config=config,
+ rank=rank,
+ world_size=world_size,
+ host=host,
+ port=port,
+ backend=backend,
+ seed=seed,
+ verbose=verbose)
+
+
+def launch_from_openmpi(config: Union[str, Path, Config, Dict],
+ host: str,
+ port: int,
+ backend: str = 'nccl',
+ seed: int = 1024,
+ verbose: bool = True):
+ """A wrapper for colossalai.launch for OpenMPI launcher by reading rank and world size from the environment variables
+ set by OpenMPI
+
+ Args:
+ config (Union[str, dict, Config]): Config file or config file path are both acceptable
+ host (str): The master address for distributed training
+ port (str): The master port for distributed training
+ backend (str, optional): Backend for ``torch.distributed``, defaults to ``nccl``
+ seed (int, optional): Specified random seed for every process. Defaults to 1024.
+ verbose (bool, optional): Whether to print logs. Defaults to True.
+ """
+ try:
+ rank = int(os.environ['OMPI_COMM_WORLD_RANK'])
+ local_rank = int(os.environ['OMPI_COMM_WORLD_LOCAL_RANK'])
+ world_size = int(os.environ['OMPI_COMM_WORLD_SIZE'])
+ except KeyError as e:
+ raise RuntimeError(
+ f"Could not find {e} in the OpenMPI environment, visit https://www.colossalai.org/ for more information on launching with OpenMPI"
+ )
+
+ launch(config=config,
+ local_rank=local_rank,
+ rank=rank,
+ world_size=world_size,
+ host=host,
+ port=port,
+ backend=backend,
+ seed=seed,
+ verbose=verbose)
+
+
+def launch_from_torch(config: Union[str, Path, Config, Dict],
+ backend: str = 'nccl',
+ seed: int = 1024,
+ verbose: bool = True):
+ """A wrapper for colossalai.launch for torchrun or torch.distributed.launch by reading rank and world size
+ from the environment variables set by PyTorch
+
+ Args:
+ config (Union[str, dict, Config]): Config file or config file path are both acceptable
+ backend (str, optional): Backend for ``torch.distributed``, defaults to ``nccl``
+ seed (int, optional): Specified random seed for every process. Defaults to 1024.
+ verbose (bool, optional): Whether to print logs. Defaults to True.
+ """
+ try:
+ rank = int(os.environ['RANK'])
+ local_rank = int(os.environ['LOCAL_RANK'])
+ world_size = int(os.environ['WORLD_SIZE'])
+ host = os.environ['MASTER_ADDR']
+ port = int(os.environ['MASTER_PORT'])
+ except KeyError as e:
+ raise RuntimeError(
+ f"Could not find {e} in the torch environment, visit https://www.colossalai.org/ for more information on launching with torch"
+ )
+
+ launch(config=config,
+ local_rank=local_rank,
+ rank=rank,
+ world_size=world_size,
+ host=host,
+ port=port,
+ backend=backend,
+ seed=seed,
+ verbose=verbose)
+
+
+def initialize(model: nn.Module,
+ optimizer: Optimizer,
+ criterion: Optional[_Loss] = None,
+ train_dataloader: Optional[Iterable] = None,
+ test_dataloader: Optional[Iterable] = None,
+ lr_scheduler: Optional[_LRScheduler] = None,
+ ophooks: Optional[List[BaseOpHook]] = None,
+ verbose: bool = True) -> Tuple[Engine, DataLoader, DataLoader, _LRScheduler]:
+ """Core function to wrap the essential training components with our functionality based on the config which is
+ loaded into gpc.config.
+
+ Args:
+ model (:class:`torch.nn.Module` or Callbale): Your model instance or a function to build the model.
+ optimizer (:class:`torch.optim.optimizer.Optimizer` or :class:`Type[torch.optim.optimizer]`):
+ Your optimizer instance.
+ criterion (:class:`torch.nn.modules.loss._Loss`, optional): Your criterion instance.
+ train_dataloader (:class:`torch.utils.data.DataLoader`, optional): Dataloader for training.
+ test_dataloader (:class:`torch.utils.data.DataLoader`, optional): Dataloader for testing.
+ lr_scheduler (:class:`torch.nn.lr_scheduler._LRScheduler`, optional): Your lr scheduler instance, optional.
+ verbose (bool, optional): Whether to print logs.
+
+ Returns:
+ Tuple (engine, train_dataloader, test_dataloader, lr_scheduler):
+ A tuple of ``(engine, train_dataloader, test_dataloader, lr_scheduler)``
+ where only ``engine`` could not be None.
+ """
+ # get logger
+ logger = get_dist_logger()
+ gpc.verbose = verbose
+
+ # get config from gpc
+ config = gpc.config
+
+ # print config
+ if verbose:
+ logger.info(
+ f"\n========== Your Config ========\n"
+ f"{pprint.pformat(gpc.config)}\n"
+ f"================================\n",
+ ranks=[0])
+
+ # cudnn
+ cudnn_benchmark = config.get('cudnn_benchmark', False)
+ cudnn_deterministic = config.get('cudnn_deterministic', False)
+ torch.backends.cudnn.benchmark = cudnn_benchmark
+ torch.backends.cudnn.deterministic = cudnn_deterministic
+ if verbose:
+ logger.info(f"cuDNN benchmark = {cudnn_benchmark}, deterministic = {cudnn_deterministic}", ranks=[0])
+
+ # zero
+ use_zero = hasattr(gpc.config, 'zero')
+ if use_zero:
+ zero_cfg = gpc.config.get('zero', None)
+ if zero_cfg is not None:
+ cfg_ = zero_cfg.copy()
+ else:
+ cfg_ = {}
+ optimizer_config = zero_cfg.get('optimizer_config', None)
+ model_config = zero_cfg.get('model_config', None)
+ model, optimizer = convert_to_zero_v2(model,
+ optimizer,
+ model_config=model_config,
+ optimizer_config=optimizer_config)
+
+ logger.info("Initializing ZeRO model and optimizer finished!", ranks=[0])
+ else:
+ if isinstance(model, nn.Module):
+ # first sync model across dp ranks
+ model.to(get_current_device())
+ elif isinstance(model, Callable):
+ model = model().to(get_current_device())
+
+ # optimizer maybe a optimizer_cls
+ if isinstance(optimizer, Callable):
+ optimizer = optimizer(model.parameters())
+ logger.warning("Initializing an non ZeRO model with optimizer class")
+
+ if not use_zero:
+ if is_using_sequence():
+ sync_model_param(model, ParallelMode.SEQUENCE_DP)
+ elif MOE_CONTEXT.is_initialized:
+ sync_moe_model_param(model)
+ elif is_using_ddp():
+ sync_model_param(model, ParallelMode.DATA)
+ else:
+ logger.warning(
+ "The parameters of models is not automatically synchronized.\n"
+ "Please make sure that all parameters are the same in data parallel group.",
+ ranks=[0])
+
+ # check amp and zero
+ fp16_cfg = gpc.config.get('fp16', None)
+
+ if fp16_cfg is not None and fp16_cfg.mode is not None and use_zero:
+ raise ConfigException(
+ "It is not allowed to set fp16 and zero configuration in your config file at the same time")
+
+ # clip grad norm
+ clip_grad_norm = gpc.config.get('clip_grad_norm', 0.0)
+
+ # initialize amp
+ amp_mode = None
+ if fp16_cfg is not None and fp16_cfg.mode is not None:
+ cfg_ = fp16_cfg.copy()
+ amp_mode = cfg_.pop('mode')
+ if is_using_pp():
+ assert amp_mode == AMP_TYPE.NAIVE, 'Pipeline only support NaiveAMP currently'
+ if amp_mode == AMP_TYPE.NAIVE:
+ cfg_['clip_grad_norm'] = clip_grad_norm
+ model, optimizer, criterion = convert_to_amp(model=model,
+ optimizer=optimizer,
+ criterion=criterion,
+ mode=amp_mode,
+ amp_config=cfg_)
+
+ # get torch ddp config
+ torch_ddp_cfg = gpc.config.get('torch_ddp', dict())
+
+ # gradient handler
+ gradient_handler_cfg = gpc.config.get('gradient_handler', None)
+ if gradient_handler_cfg is None:
+ # if gradient handler is not specified in the configuration file,
+ # check in the following order
+ # 1. if optimizer is ZERO, then use zero grad handler
+ # 2. if dp size is larger than 1 and pipeline is not used, use pytorch ddp
+ # 3. if using pipeline and dp size larger than 1, use data parallel grad handler
+ if isinstance(optimizer, ShardedOptimizerV2):
+ gradient_handler_cfg = [dict(type='ZeROGradientHandler')]
+ if verbose:
+ logger.info(
+ "Training with zero is detected, ZeROGradientHandler is automatically "
+ "added even though not specified in the configuration",
+ ranks=[0])
+ elif is_using_ddp() and MOE_CONTEXT.is_initialized:
+ gradient_handler_cfg = [dict(type='MoeGradientHandler')]
+ if verbose:
+ logger.info(
+ "Data parallel training is detected with moe parallel, MoeGradientHandler is automatically "
+ "added even though not specified in the configuration",
+ ranks=[0])
+ elif is_using_sequence():
+ model = DDP(model,
+ process_group=gpc.get_group(ParallelMode.SEQUENCE_DP),
+ device_ids=[torch.cuda.current_device()],
+ **torch_ddp_cfg)
+ if verbose:
+ logger.info('Model is using torch.nn.parallel.DistributedDataParallel for Sequence Parallelism',
+ ranks=[0])
+ elif is_using_ddp() and not is_using_pp() and amp_mode != AMP_TYPE.NAIVE:
+ model = DDP(model,
+ process_group=gpc.get_group(ParallelMode.DATA),
+ device_ids=[torch.cuda.current_device()],
+ **torch_ddp_cfg)
+ if verbose:
+ logger.info('Model is using torch.nn.parallel.DistributedDataParallel for Data Parallelism', ranks=[0])
+ elif is_using_ddp():
+ gradient_handler_cfg = [dict(type='DataParallelGradientHandler')]
+ if verbose:
+ logger.info(
+ "Data parallel training is detected when using pipeline parallel, "
+ "DataParallelGradientHandler is automatically "
+ "added even though not specified in the configuration",
+ ranks=[0])
+ # add pipeline parallel gradient handler, if pipeline shared module is detected
+ for param in model.parameters():
+ if getattr(param, 'pipeline_shared_module_pg', None) is not None:
+ if gradient_handler_cfg is None:
+ gradient_handler_cfg = [dict(type='PipelineSharedModuleGradientHandler')]
+ else:
+ gradient_handler_cfg.append(dict(type='PipelineSharedModuleGradientHandler'))
+ if verbose:
+ logger.info(
+ "pipeline_shared_module is detected, PipelineSharedModuleGradientHandler is automatically "
+ "added even though not specified in the configuration",
+ ranks=[0])
+ break
+ else:
+ if not isinstance(gradient_handler_cfg, list):
+ raise ConfigException(
+ f"expected gradient_handler in the configuration file to be a list but got {type(gradient_handler_cfg)}"
+ )
+
+ # turn off sync buffer for NaiveAMPModel if using torch DDP and NaiveAMPModel at the same time
+ # to avoid duplicated buffer synchronization
+ if isinstance(model, DDP) and isinstance(model.module, NaiveAMPModel):
+ model.module.sync_buffer = False
+
+ # initialize schedule for engine
+ if is_using_pp():
+ tensor_shape = get_tensor_shape()
+ use_interleaved = hasattr(gpc.config, 'model') and hasattr(gpc.config.model, 'num_chunks')
+ if gpc.is_initialized(ParallelMode.PARALLEL_1D):
+ scatter_gather = True
+ else:
+ scatter_gather = False
+ if use_interleaved:
+ if isinstance(model, nn.Sequential):
+ model = nn.ModuleList([model])
+ schedule = InterleavedPipelineSchedule(gpc.config.NUM_MICRO_BATCHES,
+ gpc.config.model.num_chunks,
+ tensor_shape=tensor_shape,
+ scatter_gather_tensors=scatter_gather)
+ else:
+ schedule = PipelineSchedule(gpc.config.NUM_MICRO_BATCHES,
+ tensor_shape=tensor_shape,
+ scatter_gather_tensors=scatter_gather)
+ else:
+ schedule = NonPipelineSchedule()
+
+ if gradient_handler_cfg is None:
+ gradient_handlers = None
+ if verbose and not isinstance(model, DDP):
+ logger.warning(
+ "No PyTorch DDP or gradient handler is set up, please make sure you do not need "
+ "to all-reduce the gradients after a training step.",
+ ranks=[0])
+ else:
+ gradient_handlers = [build_gradient_handler(cfg, model, optimizer) for cfg in gradient_handler_cfg]
+
+ # check if optimizer is ColossalaiOptimizer
+ if not isinstance(optimizer, (ColossalaiOptimizer, ShardedOptimizerV2)):
+ optimizer = ColossalaiOptimizer(optim=optimizer)
+
+ # gradient accumulation
+ grad_accum_size = gpc.config.get('gradient_accumulation', None)
+ if grad_accum_size is not None:
+ optimizer, train_dataloader, gradient_handlers, lr_scheduler = accumulate_gradient(
+ model=model,
+ optimizer=optimizer,
+ dataloader=train_dataloader,
+ accumulate_size=grad_accum_size,
+ gradient_handlers=gradient_handlers,
+ lr_scheduler=lr_scheduler)
+ engine = Engine(model=model,
+ optimizer=optimizer,
+ criterion=criterion,
+ gradient_handlers=gradient_handlers,
+ clip_grad_norm=clip_grad_norm,
+ ophook_list=ophooks,
+ schedule=schedule)
+
+ return engine, train_dataloader, test_dataloader, lr_scheduler
diff --git a/colossalai/interface/__init__.py b/colossalai/interface/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c658e375146ae4f6f31f62a9e913ed16fbb0714
--- /dev/null
+++ b/colossalai/interface/__init__.py
@@ -0,0 +1,4 @@
+from .model import ModelWrapper
+from .optimizer import OptimizerWrapper
+
+__all__ = ['OptimizerWrapper', 'ModelWrapper']
diff --git a/colossalai/interface/model.py b/colossalai/interface/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..a067d7671ce7eaaa174aced664ec16461cd03034
--- /dev/null
+++ b/colossalai/interface/model.py
@@ -0,0 +1,25 @@
+import torch.nn as nn
+
+
+class ModelWrapper(nn.Module):
+ """
+ A wrapper class to define the common interface used by booster.
+
+ Args:
+ module (nn.Module): The model to be wrapped.
+ """
+
+ def __init__(self, module: nn.Module) -> None:
+ super().__init__()
+ self.module = module
+
+ def unwrap(self):
+ """
+ Unwrap the model to return the original model for checkpoint saving/loading.
+ """
+ if isinstance(self.module, ModelWrapper):
+ return self.module.unwrap()
+ return self.module
+
+ def forward(self, *args, **kwargs):
+ return self.module(*args, **kwargs)
diff --git a/colossalai/interface/optimizer.py b/colossalai/interface/optimizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..dd9acab17584a452ad430094ab7fed4b9e272efb
--- /dev/null
+++ b/colossalai/interface/optimizer.py
@@ -0,0 +1,121 @@
+from typing import Union
+
+import torch.nn as nn
+from torch import Tensor
+from torch.optim import Optimizer
+
+
+class OptimizerWrapper:
+ """
+ A standard interface for optimizers wrapped by the Booster.
+
+ Args:
+ optim (Optimizer): The optimizer to be wrapped.
+ """
+
+ def __init__(self, optim: Optimizer):
+ self.optim = optim
+
+ @property
+ def parameters(self):
+ params = []
+
+ for group in self.param_groups:
+ params += group['params']
+ return params
+
+ @property
+ def param_groups(self):
+ return self.optim.param_groups
+
+ @property
+ def defaults(self):
+ return self.optim.defaults
+
+ def add_param_group(self, *args, **kwargs):
+ return self.optim.add_param_group(*args, **kwargs)
+
+ def step(self, *args, **kwargs):
+ """
+ Performs a single optimization step.
+ """
+ return self.optim.step(*args, **kwargs)
+
+ def zero_grad(self, *args, **kwargs):
+ """
+ Clears the gradients of all optimized `torch.Tensor`.
+ """
+ self.optim.zero_grad(*args, **kwargs)
+
+ def backward(self, loss: Tensor, *args, **kwargs):
+ """
+ Performs a backward pass on the loss.
+ """
+ loss.backward(*args, **kwargs)
+
+ def state_dict(self):
+ """
+ Returns the optimizer state.
+ """
+ return self.optim.state_dict()
+
+ def load_state_dict(self, *args, **kwargs):
+ """
+ Loads the optimizer state.
+ """
+ self.optim.load_state_dict(*args, **kwargs)
+
+ def clip_grad_by_value(self, clip_value: float, *args, **kwargs) -> None:
+ """
+ Clips gradient of an iterable of parameters at specified min and max values.
+
+ Args:
+ clip_value (float or int): maximum allowed value of the gradients. Gradients are clipped in the range
+
+ Note:
+ In PyTorch Torch 2.0 and above, you can pass in foreach=True as kwargs to clip_grad_value_ to use the
+ faster implementation. Please refer to the PyTorch documentation for more details.
+ """
+ nn.utils.clip_grad_value_(self.parameters, clip_value, *args, **kwargs)
+
+ def clip_grad_by_norm(self,
+ max_norm: Union[float, int],
+ norm_type: Union[float, int] = 2.0,
+ error_if_nonfinite: bool = False,
+ *args,
+ **kwargs) -> Tensor:
+ """
+ Clips gradient norm of an iterable of parameters.
+
+ Args:
+ max_norm (float or int): max norm of the gradients
+ norm_type (float or int): type of the used p-norm. Can be ``'inf'`` for infinity norm.
+ error_if_nonfinite (bool): if True, an error is raised if the total norm is non-finite. Default: False
+
+ Note:
+ In PyTorch Torch 2.0 and above, you can pass in foreach=True as kwargs to clip_grad_norm_ to use the
+ faster implementation. Please refer to the PyTorch documentation for more details.
+ """
+ norm = nn.utils.clip_grad_norm_(self.parameters, max_norm, norm_type, error_if_nonfinite, *args, **kwargs)
+ return norm
+
+ def scale_loss(self, loss: Tensor):
+ """
+ Scales the loss for mixed precision training.
+
+ Note: Only available for optimizers with mixed precision training.
+
+ Args:
+ loss (Tensor): The loss to be scaled.
+ """
+ raise NotImplementedError(
+ "The method scale_loss is only available for optimizers with mixed precision training")
+
+ def unscale_grad(self):
+ """
+ Unscale the gradients for mixed precision training.
+
+ Note: Only available for optimizers with mixed precision training.
+ """
+ raise NotImplementedError(
+ "The method unscale_grad is only available for optimizers with mixed precision training")
diff --git a/colossalai/kernel/__init__.py b/colossalai/kernel/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8933fc0a3c2f122a37656b6facfd904e039c8cdd
--- /dev/null
+++ b/colossalai/kernel/__init__.py
@@ -0,0 +1,7 @@
+from .cuda_native import FusedScaleMaskSoftmax, LayerNorm, MultiHeadAttention
+
+__all__ = [
+ "LayerNorm",
+ "FusedScaleMaskSoftmax",
+ "MultiHeadAttention",
+]
diff --git a/colossalai/kernel/cuda_native/__init__.py b/colossalai/kernel/cuda_native/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..1d5a6ce495bdec0fe02475ed0bb3b3b67bb86b3c
--- /dev/null
+++ b/colossalai/kernel/cuda_native/__init__.py
@@ -0,0 +1,5 @@
+from .layer_norm import MixedFusedLayerNorm as LayerNorm
+from .multihead_attention import MultiHeadAttention
+from .scaled_softmax import FusedScaleMaskSoftmax, ScaledUpperTriangMaskedSoftmax
+
+__all__ = ['LayerNorm', 'MultiHeadAttention', 'FusedScaleMaskSoftmax', 'ScaledUpperTriangMaskedSoftmax']
diff --git a/colossalai/kernel/cuda_native/csrc/colossal_C_frontend.cpp b/colossalai/kernel/cuda_native/csrc/colossal_C_frontend.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..94f132521771bb18638d3a7edf03f7e4e14dcc27
--- /dev/null
+++ b/colossalai/kernel/cuda_native/csrc/colossal_C_frontend.cpp
@@ -0,0 +1,49 @@
+// modified from
+// https://github.com/NVIDIA/apex/blob/master/csrc/multi_tensor_adam.cu
+#include
+
+void multi_tensor_scale_cuda(int chunk_size, at::Tensor noop_flag,
+ std::vector> tensor_lists,
+ float scale);
+
+void multi_tensor_sgd_cuda(int chunk_size, at::Tensor noop_flag,
+ std::vector> tensor_lists,
+ float wd, float momentum, float dampening, float lr,
+ bool nesterov, bool first_run,
+ bool wd_after_momentum, float scale);
+
+void multi_tensor_adam_cuda(int chunk_size, at::Tensor noop_flag,
+ std::vector> tensor_lists,
+ const float lr, const float beta1,
+ const float beta2, const float epsilon,
+ const int step, const int mode,
+ const int bias_correction, const float weight_decay,
+ const float div_scale);
+
+void multi_tensor_lamb_cuda(int chunk_size, at::Tensor noop_flag,
+ std::vector> tensor_lists,
+ const float lr, const float beta1,
+ const float beta2, const float epsilon,
+ const int step, const int bias_correction,
+ const float weight_decay, const int grad_averaging,
+ const int mode, at::Tensor global_grad_norm,
+ const float max_grad_norm,
+ at::optional use_nvlamb_python);
+
+std::tuple multi_tensor_l2norm_cuda(
+ int chunk_size, at::Tensor noop_flag,
+ std::vector> tensor_lists,
+ at::optional per_tensor_python);
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("multi_tensor_scale", &multi_tensor_scale_cuda,
+ "Fused overflow check + scale for a list of contiguous tensors");
+ m.def("multi_tensor_sgd", &multi_tensor_sgd_cuda,
+ "Fused SGD optimizer for list of contiguous tensors");
+ m.def("multi_tensor_adam", &multi_tensor_adam_cuda,
+ "Compute and apply gradient update to parameters for Adam optimizer");
+ m.def("multi_tensor_lamb", &multi_tensor_lamb_cuda,
+ "Computes and apply update for LAMB optimizer");
+ m.def("multi_tensor_l2norm", &multi_tensor_l2norm_cuda,
+ "Computes L2 norm for a list of contiguous tensors");
+}
diff --git a/colossalai/kernel/cuda_native/csrc/compat.h b/colossalai/kernel/cuda_native/csrc/compat.h
new file mode 100644
index 0000000000000000000000000000000000000000..00066dc95475296168c799904dc595ed435d2b0a
--- /dev/null
+++ b/colossalai/kernel/cuda_native/csrc/compat.h
@@ -0,0 +1,10 @@
+// modified from https://github.com/NVIDIA/apex/blob/master/csrc/compat.h
+#ifndef TORCH_CHECK
+#define TORCH_CHECK AT_CHECK
+#endif
+
+#ifdef VERSION_GE_1_3
+#define DATA_PTR data_ptr
+#else
+#define DATA_PTR data
+#endif
\ No newline at end of file
diff --git a/colossalai/kernel/cuda_native/csrc/cpu_adam.cpp b/colossalai/kernel/cuda_native/csrc/cpu_adam.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..0ab250218da38f9ded00766d6546d73b918699fa
--- /dev/null
+++ b/colossalai/kernel/cuda_native/csrc/cpu_adam.cpp
@@ -0,0 +1,459 @@
+/*
+Copyright (c) Microsoft Corporation.
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE
+*/
+#include "cpu_adam.h"
+
+#include
+#include
+#include
+
+#include
+#include
+#include
+#include
+
+// C++ interface
+
+void Adam_Optimizer::Step_1(float *_params, float *grads, float *_exp_avg,
+ float *_exp_avg_sq, size_t _param_size,
+ bool param_half_precision, bool grad_half_precision,
+ float loss_scale) {
+ size_t rounded_size = 0;
+
+ float betta1_minus1 = 1 - _betta1;
+ float betta2_minus1 = 1 - _betta2;
+ float step_size = -1 * _alpha / _bias_correction1;
+ float w_decay = -1 * _alpha * _weight_decay;
+
+ __half *params_cast_h = NULL;
+ __half *grads_cast_h = NULL;
+
+ if (param_half_precision) {
+ params_cast_h = reinterpret_cast<__half *>(_params);
+ }
+ if (grad_half_precision) {
+ grads_cast_h = reinterpret_cast<__half *>(grads);
+ }
+
+#if defined(__AVX512__) or defined(__AVX256__) or defined(__AVX2__)
+ AVX_Data betta1_4;
+ betta1_4.data = SIMD_SET(_betta1);
+ AVX_Data betta2_4;
+ betta2_4.data = SIMD_SET(_betta2);
+
+ AVX_Data betta1_minus1_4;
+ betta1_minus1_4.data = SIMD_SET(betta1_minus1);
+ AVX_Data betta2_minus1_4;
+ betta2_minus1_4.data = SIMD_SET(betta2_minus1);
+
+ AVX_Data bias2_sqrt;
+ bias2_sqrt.data = SIMD_SET(_bias_correction2);
+
+ AVX_Data eps_4;
+ eps_4.data = SIMD_SET(_eps);
+
+ AVX_Data step_size_4;
+ step_size_4.data = SIMD_SET(step_size);
+
+ AVX_Data weight_decay_4;
+ if (_weight_decay > 0)
+ weight_decay_4.data =
+ (_adamw_mode ? SIMD_SET(w_decay) : SIMD_SET(_weight_decay));
+ rounded_size = ROUND_DOWN(_param_size, SIMD_WIDTH);
+
+ for (size_t t = 0; t < rounded_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > rounded_size) copy_size = rounded_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t i = t; i < offset; i += SIMD_WIDTH) {
+ AVX_Data grad_4;
+ if (grad_half_precision) {
+ grad_4.data = SIMD_LOAD_HALF(grads_cast_h + i);
+ } else {
+ grad_4.data = SIMD_LOAD(grads + i);
+ }
+ if (loss_scale > 0) {
+ AVX_Data loss_scale_vec;
+ loss_scale_vec.data = SIMD_SET(loss_scale);
+ grad_4.data = SIMD_DIV(grad_4.data, loss_scale_vec.data);
+ }
+ AVX_Data momentum_4;
+ momentum_4.data = SIMD_LOAD(_exp_avg + i);
+
+ AVX_Data variance_4;
+ variance_4.data = SIMD_LOAD(_exp_avg_sq + i);
+
+ AVX_Data param_4;
+ if (param_half_precision) {
+ param_4.data = SIMD_LOAD_HALF(params_cast_h + i);
+ } else {
+ param_4.data = SIMD_LOAD(_params + i);
+ }
+
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad_4.data = SIMD_FMA(param_4.data, weight_decay_4.data, grad_4.data);
+ }
+ momentum_4.data = SIMD_MUL(momentum_4.data, betta1_4.data);
+ momentum_4.data =
+ SIMD_FMA(grad_4.data, betta1_minus1_4.data, momentum_4.data);
+ variance_4.data = SIMD_MUL(variance_4.data, betta2_4.data);
+ grad_4.data = SIMD_MUL(grad_4.data, grad_4.data);
+ variance_4.data =
+ SIMD_FMA(grad_4.data, betta2_minus1_4.data, variance_4.data);
+ grad_4.data = SIMD_SQRT(variance_4.data);
+ grad_4.data = SIMD_FMA(grad_4.data, bias2_sqrt.data, eps_4.data);
+ grad_4.data = SIMD_DIV(momentum_4.data, grad_4.data);
+
+ if (_weight_decay > 0 && _adamw_mode) {
+ param_4.data =
+ SIMD_FMA(param_4.data, weight_decay_4.data, param_4.data);
+ }
+ param_4.data = SIMD_FMA(grad_4.data, step_size_4.data, param_4.data);
+
+ if (param_half_precision) {
+ SIMD_STORE_HALF((float *)(params_cast_h + i), param_4.data);
+ } else {
+ SIMD_STORE(_params + i, param_4.data);
+ }
+ SIMD_STORE(_exp_avg + i, momentum_4.data);
+ SIMD_STORE(_exp_avg_sq + i, variance_4.data);
+ }
+ }
+#endif
+ if (_param_size > rounded_size) {
+ for (size_t t = rounded_size; t < _param_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > _param_size) copy_size = _param_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t k = t; k < offset; k++) {
+ float grad = grad_half_precision ? (float)grads_cast_h[k] : grads[k];
+ if (loss_scale > 0) {
+ grad /= loss_scale;
+ }
+ float param =
+ param_half_precision ? (float)params_cast_h[k] : _params[k];
+ float momentum = _exp_avg[k];
+ float variance = _exp_avg_sq[k];
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad = param * _weight_decay + grad;
+ }
+ momentum = momentum * _betta1;
+ momentum = grad * betta1_minus1 + momentum;
+
+ variance = variance * _betta2;
+ grad = grad * grad;
+ variance = grad * betta2_minus1 + variance;
+
+ grad = sqrt(variance);
+ grad = grad * _bias_correction2 + _eps;
+ grad = momentum / grad;
+ if (_weight_decay > 0 && _adamw_mode) {
+ param += w_decay * param;
+ }
+ param = grad * step_size + param;
+
+ if (param_half_precision)
+ params_cast_h[k] = (__half)param;
+ else
+ _params[k] = param;
+ _exp_avg[k] = momentum;
+ _exp_avg_sq[k] = variance;
+ }
+ }
+ }
+}
+
+void Adam_Optimizer::Step_4(float *_params, float *grads, float *_exp_avg,
+ float *_exp_avg_sq, size_t _param_size,
+ bool param_half_precision, bool grad_half_precision,
+ float loss_scale) {
+ size_t rounded_size = 0;
+
+ __half *params_cast_h = NULL;
+ __half *grads_cast_h = NULL;
+ if (param_half_precision) {
+ params_cast_h = reinterpret_cast<__half *>(_params);
+ }
+ if (grad_half_precision) {
+ grads_cast_h = reinterpret_cast<__half *>(grads);
+ }
+
+#if defined(__AVX512__) or defined(__AVX256__) or defined(__AVX2__)
+ AVX_Data betta1_4;
+ betta1_4.data = SIMD_SET(_betta1);
+ AVX_Data betta2_4;
+ betta2_4.data = SIMD_SET(_betta2);
+
+ float betta1_minus1 = 1 - _betta1;
+ AVX_Data betta1_minus1_4;
+ betta1_minus1_4.data = SIMD_SET(betta1_minus1);
+ float betta2_minus1 = 1 - _betta2;
+ AVX_Data betta2_minus1_4;
+ betta2_minus1_4.data = SIMD_SET(betta2_minus1);
+
+ AVX_Data bias2_sqrt;
+ bias2_sqrt.data = SIMD_SET(_bias_correction2);
+
+ AVX_Data eps_4;
+ eps_4.data = SIMD_SET(_eps);
+
+ float step_size = -1 * _alpha / _bias_correction1;
+ AVX_Data step_size_4;
+ step_size_4.data = SIMD_SET(step_size);
+
+ float w_decay = -1 * _alpha * _weight_decay;
+ AVX_Data weight_decay_4;
+ if (_weight_decay > 0)
+ weight_decay_4.data =
+ (_adamw_mode ? SIMD_SET(w_decay) : SIMD_SET(_weight_decay));
+ rounded_size = ROUND_DOWN(_param_size, SIMD_WIDTH * 4);
+
+ for (size_t t = 0; t < rounded_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > rounded_size) copy_size = rounded_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t i = t; i < offset; i += SIMD_WIDTH * 4) {
+ AVX_Data grad_4[4];
+ AVX_Data momentum_4[4];
+ AVX_Data variance_4[4];
+ AVX_Data param_4[4];
+#pragma unroll 4
+ for (int j = 0; j < 4; j++) {
+ if (grad_half_precision) {
+ grad_4[j].data = SIMD_LOAD_HALF(grads_cast_h + i + SIMD_WIDTH * j);
+ } else {
+ grad_4[j].data = SIMD_LOAD(grads + i + SIMD_WIDTH * j);
+ }
+
+ if (loss_scale > 0) {
+ AVX_Data loss_scale_vec;
+ loss_scale_vec.data = SIMD_SET(loss_scale);
+ grad_4[j].data = SIMD_DIV(grad_4[j].data, loss_scale_vec.data);
+ }
+
+ momentum_4[j].data = SIMD_LOAD(_exp_avg + i + SIMD_WIDTH * j);
+ variance_4[j].data = SIMD_LOAD(_exp_avg_sq + i + SIMD_WIDTH * j);
+
+ if (param_half_precision) {
+ param_4[j].data = SIMD_LOAD_HALF(params_cast_h + i + SIMD_WIDTH * j);
+ } else {
+ param_4[j].data = SIMD_LOAD(_params + i + SIMD_WIDTH * j);
+ }
+
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad_4[j].data =
+ SIMD_FMA(param_4[j].data, weight_decay_4.data, grad_4[j].data);
+ }
+ momentum_4[j].data = SIMD_MUL(momentum_4[j].data, betta1_4.data);
+ momentum_4[j].data =
+ SIMD_FMA(grad_4[j].data, betta1_minus1_4.data, momentum_4[j].data);
+ variance_4[j].data = SIMD_MUL(variance_4[j].data, betta2_4.data);
+ grad_4[j].data = SIMD_MUL(grad_4[j].data, grad_4[j].data);
+ variance_4[j].data =
+ SIMD_FMA(grad_4[j].data, betta2_minus1_4.data, variance_4[j].data);
+ grad_4[j].data = SIMD_SQRT(variance_4[j].data);
+ grad_4[j].data = SIMD_FMA(grad_4[j].data, bias2_sqrt.data, eps_4.data);
+ grad_4[j].data = SIMD_DIV(momentum_4[j].data, grad_4[j].data);
+
+ if (_weight_decay > 0 && _adamw_mode) {
+ param_4[j].data =
+ SIMD_FMA(param_4[j].data, weight_decay_4.data, param_4[j].data);
+ }
+ param_4[j].data =
+ SIMD_FMA(grad_4[j].data, step_size_4.data, param_4[j].data);
+ if (param_half_precision) {
+ SIMD_STORE_HALF((float *)(params_cast_h + i + SIMD_WIDTH * j),
+ param_4[j].data);
+ } else {
+ SIMD_STORE(_params + i + SIMD_WIDTH * j, param_4[j].data);
+ }
+ SIMD_STORE(_exp_avg + i + SIMD_WIDTH * j, momentum_4[j].data);
+ SIMD_STORE(_exp_avg_sq + i + SIMD_WIDTH * j, variance_4[j].data);
+ }
+ }
+ }
+#endif
+ if (_param_size > rounded_size)
+ Step_1((param_half_precision ? (float *)(params_cast_h + rounded_size)
+ : _params + rounded_size),
+ (grad_half_precision ? (float *)(grads_cast_h + rounded_size)
+ : grads + rounded_size),
+ (_exp_avg + rounded_size), (_exp_avg_sq + rounded_size),
+ (_param_size - rounded_size), param_half_precision,
+ grad_half_precision, loss_scale);
+}
+
+void Adam_Optimizer::Step_8(float *_params, float *grads, float *_exp_avg,
+ float *_exp_avg_sq, size_t _param_size,
+ bool param_half_precision, bool grad_half_precision,
+ float loss_scale) {
+ size_t rounded_size = 0;
+ __half *params_cast_h = NULL;
+ __half *grads_cast_h = NULL;
+ if (param_half_precision) {
+ params_cast_h = reinterpret_cast<__half *>(_params);
+ }
+ if (grad_half_precision) {
+ grads_cast_h = reinterpret_cast<__half *>(grads);
+ }
+#if defined(__AVX512__) or defined(__AVX256__) or defined(__AVX2__)
+ AVX_Data betta1_4;
+ betta1_4.data = SIMD_SET(_betta1);
+ AVX_Data betta2_4;
+ betta2_4.data = SIMD_SET(_betta2);
+
+ float betta1_minus1 = 1 - _betta1;
+ AVX_Data betta1_minus1_4;
+ betta1_minus1_4.data = SIMD_SET(betta1_minus1);
+ float betta2_minus1 = 1 - _betta2;
+ AVX_Data betta2_minus1_4;
+ betta2_minus1_4.data = SIMD_SET(betta2_minus1);
+
+ AVX_Data bias2_sqrt;
+ bias2_sqrt.data = SIMD_SET(_bias_correction2);
+
+ AVX_Data eps_4;
+ eps_4.data = SIMD_SET(_eps);
+
+ float step_size = -1 * _alpha / _bias_correction1;
+ AVX_Data step_size_4;
+ step_size_4.data = SIMD_SET(step_size);
+
+ float w_decay = -1 * _alpha * _weight_decay;
+ AVX_Data weight_decay_4;
+ if (_weight_decay > 0)
+ weight_decay_4.data =
+ (_adamw_mode ? SIMD_SET(w_decay) : SIMD_SET(_weight_decay));
+ rounded_size = ROUND_DOWN(_param_size, SIMD_WIDTH * 8);
+
+ for (size_t t = 0; t < rounded_size; t += TILE) {
+ size_t copy_size = TILE;
+ if ((t + TILE) > rounded_size) copy_size = rounded_size - t;
+ size_t offset = copy_size + t;
+
+#pragma omp parallel for
+ for (size_t i = t; i < offset; i += SIMD_WIDTH * 8) {
+ AVX_Data grad_4[8];
+ AVX_Data momentum_4[8];
+ AVX_Data variance_4[8];
+ AVX_Data param_4[8];
+#pragma unroll 8
+ for (int j = 0; j < 8; j++) {
+ if (grad_half_precision) {
+ grad_4[j].data = SIMD_LOAD_HALF(grads_cast_h + i + SIMD_WIDTH * j);
+ } else {
+ grad_4[j].data = SIMD_LOAD(grads + i + SIMD_WIDTH * j);
+ }
+
+ if (loss_scale > 0) {
+ AVX_Data loss_scale_vec;
+ loss_scale_vec.data = SIMD_SET(loss_scale);
+ grad_4[j].data = SIMD_DIV(grad_4[j].data, loss_scale_vec.data);
+ }
+
+ momentum_4[j].data = SIMD_LOAD(_exp_avg + i + SIMD_WIDTH * j);
+ variance_4[j].data = SIMD_LOAD(_exp_avg_sq + i + SIMD_WIDTH * j);
+
+ if (param_half_precision) {
+ param_4[j].data = SIMD_LOAD_HALF(params_cast_h + i + SIMD_WIDTH * j);
+ } else {
+ param_4[j].data = SIMD_LOAD(_params + i + SIMD_WIDTH * j);
+ }
+
+ if (_weight_decay > 0 && !_adamw_mode) {
+ grad_4[j].data =
+ SIMD_FMA(param_4[j].data, weight_decay_4.data, grad_4[j].data);
+ }
+ momentum_4[j].data = SIMD_MUL(momentum_4[j].data, betta1_4.data);
+ momentum_4[j].data =
+ SIMD_FMA(grad_4[j].data, betta1_minus1_4.data, momentum_4[j].data);
+ variance_4[j].data = SIMD_MUL(variance_4[j].data, betta2_4.data);
+ grad_4[j].data = SIMD_MUL(grad_4[j].data, grad_4[j].data);
+ variance_4[j].data =
+ SIMD_FMA(grad_4[j].data, betta2_minus1_4.data, variance_4[j].data);
+ grad_4[j].data = SIMD_SQRT(variance_4[j].data);
+ grad_4[j].data = SIMD_FMA(grad_4[j].data, bias2_sqrt.data, eps_4.data);
+ grad_4[j].data = SIMD_DIV(momentum_4[j].data, grad_4[j].data);
+ if (_weight_decay > 0 && _adamw_mode) {
+ param_4[j].data =
+ SIMD_FMA(param_4[j].data, weight_decay_4.data, param_4[j].data);
+ }
+ param_4[j].data =
+ SIMD_FMA(grad_4[j].data, step_size_4.data, param_4[j].data);
+
+ if (param_half_precision) {
+ SIMD_STORE_HALF((float *)(params_cast_h + i + SIMD_WIDTH * j),
+ param_4[j].data);
+ } else {
+ SIMD_STORE(_params + i + SIMD_WIDTH * j, param_4[j].data);
+ }
+
+ SIMD_STORE(_exp_avg + i + (SIMD_WIDTH * j), momentum_4[j].data);
+ SIMD_STORE(_exp_avg_sq + i + (SIMD_WIDTH * j), variance_4[j].data);
+ }
+ }
+ }
+#endif
+ if (_param_size > rounded_size)
+ Step_4((param_half_precision ? (float *)(params_cast_h + rounded_size)
+ : _params + rounded_size),
+ (grad_half_precision ? (float *)(grads_cast_h + rounded_size)
+ : grads + rounded_size),
+ (_exp_avg + rounded_size), (_exp_avg_sq + rounded_size),
+ (_param_size - rounded_size), param_half_precision,
+ grad_half_precision, loss_scale);
+}
+
+void Adam_Optimizer::step(size_t step, float lr, float beta1, float beta2,
+ float epsilon, float weight_decay,
+ bool bias_correction, torch::Tensor ¶ms,
+ torch::Tensor &grads, torch::Tensor &exp_avg,
+ torch::Tensor &exp_avg_sq, float loss_scale) {
+ auto params_c = params.contiguous();
+ auto grads_c = grads.contiguous();
+ auto exp_avg_c = exp_avg.contiguous();
+ auto exp_avg_sq_c = exp_avg_sq.contiguous();
+
+ float *params_ptr = (float *)params_c.data_ptr();
+ float *grads_ptr = (float *)grads_c.data_ptr();
+ float *exp_avg_ptr = (float *)exp_avg_c.data_ptr();
+ float *exp_avg_sq_ptr = (float *)exp_avg_sq_c.data_ptr();
+
+ this->IncrementStep(step, beta1, beta2);
+ this->update_state(lr, epsilon, weight_decay, bias_correction);
+ this->Step_8(params_ptr, grads_ptr, exp_avg_ptr, exp_avg_sq_ptr,
+ params_c.numel(), (params.options().dtype() == at::kHalf),
+ (grads.options().dtype() == at::kHalf), loss_scale);
+}
+
+namespace py = pybind11;
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ py::class_(m, "CPUAdamOptimizer")
+ .def(py::init())
+ .def("step", &Adam_Optimizer::step);
+}
diff --git a/colossalai/kernel/cuda_native/csrc/cpu_adam.h b/colossalai/kernel/cuda_native/csrc/cpu_adam.h
new file mode 100644
index 0000000000000000000000000000000000000000..4247da94277518e438cbaf638de8eeaffbf26da5
--- /dev/null
+++ b/colossalai/kernel/cuda_native/csrc/cpu_adam.h
@@ -0,0 +1,164 @@
+/*
+Copyright (c) Microsoft Corporation.
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE
+*/
+#pragma once
+
+#include
+#include
+#include
+#include
+#include
+#include
+#if (__x86_64__ || __i386__)
+#include
+#include
+#endif
+
+#define ROUND_DOWN(size, step) ((size) & ~((step)-1))
+#define TILE (128 * 1024 * 1024)
+
+#if defined(__AVX512__) or defined(__AVX256__) or defined(__AVX2__)
+
+#if defined(__AVX512__)
+#define SIMD_WIDTH 16
+#define INTV __m256i
+#define SIMD_STORE(a, d) _mm512_storeu_ps(a, d)
+#define SIMD_LOAD(x) _mm512_loadu_ps(x)
+#define SIMD_SET(x) _mm512_set1_ps(x)
+#define SIMD_ADD(x, y) _mm512_add_ps(x, y)
+#define SIMD_MUL(x, y) _mm512_mul_ps(x, y)
+#define SIMD_FMA(x, y, c) _mm512_fmadd_ps(x, y, c)
+#define SIMD_SQRT(x) _mm512_sqrt_ps(x)
+#define SIMD_DIV(x, y) _mm512_div_ps(x, y)
+#define SIMD_LOAD_HALF(x) \
+ _mm512_cvtph_ps(_mm256_loadu_si256((const __m256i *)(x)))
+#define SIMD_STORE_HALF(x, d) \
+ _mm256_store_ps( \
+ x, _mm256_castsi256_ps(_mm512_cvtps_ph(d, _MM_FROUND_TO_NEAREST_INT)))
+
+#elif defined(__AVX256__) or defined(__AVX2__)
+#define SIMD_WIDTH 8
+#define INTV __m128i
+#define SIMD_STORE(a, d) _mm256_storeu_ps(a, d)
+#define SIMD_LOAD(x) _mm256_loadu_ps(x)
+#define SIMD_SET(x) _mm256_set1_ps(x)
+#define SIMD_ADD(x, y) _mm256_add_ps(x, y)
+#define SIMD_MUL(x, y) _mm256_mul_ps(x, y)
+#define SIMD_FMA(x, y, c) _mm256_fmadd_ps(x, y, c)
+#define SIMD_SQRT(x) _mm256_sqrt_ps(x)
+#define SIMD_DIV(x, y) _mm256_div_ps(x, y)
+#define SIMD_LOAD_HALF(x) _mm256_cvtph_ps(_mm_loadu_si128((const __m128i *)(x)))
+#define SIMD_STORE_HALF(x, d) \
+ _mm_store_ps( \
+ x, _mm_castsi128_ps(_mm256_cvtps_ph(d, _MM_FROUND_TO_NEAREST_INT)))
+
+#endif
+
+union AVX_Data {
+#if defined(__AVX512__)
+ __m512 data;
+#elif defined(__AVX256__) or defined(__AVX2__)
+ __m256 data;
+#endif
+ // float data_f[16];
+};
+
+#endif
+
+#define STEP(SPAN) \
+ void Step_##SPAN(float *_params, float *grads, float *_exp_avg, \
+ float *_exp_avg_sq, size_t _param_size, \
+ bool param_half_precision = false, \
+ bool grad_half_precision = false, float loss_scale = -1);
+
+class Adam_Optimizer {
+ public:
+ Adam_Optimizer(float alpha = 1e-3, float betta1 = 0.9, float betta2 = 0.999,
+ float eps = 1e-8, float weight_decay = 0,
+ bool adamw_mode = true)
+ : _alpha(alpha),
+ _betta1(betta1),
+ _betta2(betta2),
+ _eps(eps),
+ _weight_decay(weight_decay),
+ _betta1_t(1.0),
+ _betta2_t(1.0),
+ _step(0),
+ _adamw_mode(adamw_mode) {}
+ ~Adam_Optimizer() {}
+
+ STEP(1)
+ STEP(4)
+ STEP(8)
+ inline void IncrementStep(size_t step, float beta1, float beta2) {
+ if (beta1 != _betta1 || beta2 != _betta2) {
+ _step = step;
+ _betta1 = beta1;
+ _betta2 = beta2;
+ _betta1_t = std::pow(_betta1, step);
+ _betta2_t = std::pow(_betta2, step);
+ } else {
+ _step++;
+ if (_step != step) {
+ _betta1_t = std::pow(_betta1, step);
+ _betta2_t = std::pow(_betta2, step);
+ _step = step;
+ } else {
+ _betta1_t *= _betta1;
+ _betta2_t *= _betta2;
+ }
+ }
+ }
+ inline void update_state(float lr, float epsilon, float weight_decay,
+ bool bias_correction) {
+ _alpha = lr;
+ _eps = epsilon;
+ _weight_decay = weight_decay;
+
+ _bias_correction1 = 1.0f;
+ _bias_correction2 = 1.0f;
+ if (bias_correction == 1) {
+ _bias_correction1 = 1 - _betta1_t;
+ _bias_correction2 = 1 / sqrt(1 - _betta2_t);
+ }
+ }
+
+ void step(size_t step, float lr, float beta1, float beta2, float epsilon,
+ float weight_decay, bool bias_correction, torch::Tensor ¶ms,
+ torch::Tensor &grads, torch::Tensor &exp_avg,
+ torch::Tensor &exp_avg_sq, float loss_scale);
+
+ private:
+ float _alpha;
+ float _betta1;
+ float _betta2;
+ float _eps;
+ float _weight_decay;
+
+ float _betta1_t;
+ float _betta2_t;
+ size_t _step;
+
+ float _bias_correction1;
+ float _bias_correction2;
+
+ bool _adamw_mode;
+};
diff --git a/colossalai/kernel/cuda_native/csrc/kernels/cross_entropy.cu b/colossalai/kernel/cuda_native/csrc/kernels/cross_entropy.cu
new file mode 100644
index 0000000000000000000000000000000000000000..58d26235a9cc6954e9822119f215b9745b0a1684
--- /dev/null
+++ b/colossalai/kernel/cuda_native/csrc/kernels/cross_entropy.cu
@@ -0,0 +1,191 @@
+#include "block_reduce.h"
+#include "cuda_util.h"
+#include "kernels.h"
+#include "ls_cub.cuh"
+
+ls::cub::CachingDeviceAllocator g_allocator(true);
+
+template
+__global__ void ls_cross_entropy_fw_kernel(
+ const T *__restrict__ inputs, const int *__restrict__ targets,
+ float *__restrict__ outputs, float *__restrict__ nll_loss_outputs,
+ const int padding_idx, const float epsilon, const int vocab_size) {
+ /* step1: compute each thread's max_logit and sum_exp_logit, store in
+ * max_input, sum_exp_logit */
+ const int block_start = blockIdx.x * vocab_size;
+ const int left_idx = block_start + threadIdx.x;
+ const int right_idx = (blockIdx.x + 1) * vocab_size;
+ float max_input[1] = {REDUCE_FLOAT_INF_NEG};
+ float sum_logits[2] = {0.f, 0.f}; // logit and logit exp
+ int target_tid = targets[blockIdx.x];
+
+ if (target_tid == padding_idx) {
+ if (threadIdx.x == 0) {
+ nll_loss_outputs[blockIdx.x] = 0.f;
+ outputs[blockIdx.x] = 0.f;
+ }
+ return;
+ }
+
+ for (int i = left_idx; i < right_idx; i += blockDim.x) {
+ max_input[0] = fmaxf(max_input[0], static_cast(inputs[i]));
+ }
+ blockReduce(max_input);
+ __shared__ float s_max_input;
+ if (threadIdx.x == 0) {
+ s_max_input = max_input[0];
+ }
+ __syncthreads();
+
+ for (int i = left_idx; i < right_idx; i += blockDim.x) {
+ float logit = static_cast(inputs[i]) - s_max_input;
+ sum_logits[0] += logit;
+ sum_logits[1] += expf(logit);
+ }
+
+ blockReduce(sum_logits);
+ __shared__ float s_sum_logit;
+ __shared__ float s_sum_exp;
+ if (threadIdx.x == 0) {
+ s_sum_logit = sum_logits[0];
+ s_sum_exp = sum_logits[1];
+ }
+ __syncthreads();
+
+ float eps_i = epsilon / (vocab_size - 1);
+ if (threadIdx.x == 0) {
+ // neg_log_prob = log(sum(exp(x - x_max))) - (x - x_max)
+ float nll_loss = logf(s_sum_exp) -
+ static_cast(inputs[block_start + target_tid]) +
+ s_max_input;
+ nll_loss_outputs[blockIdx.x] = nll_loss;
+ float sum_nll_loss = vocab_size * logf(s_sum_exp) - s_sum_logit;
+ outputs[blockIdx.x] =
+ (1.f - epsilon - eps_i) * nll_loss + eps_i * sum_nll_loss;
+ }
+}
+
+template
+__global__ void ls_cross_entropy_bw_kernel(
+ const float *__restrict__ grad_outputs, const T *__restrict__ inputs,
+ const int *__restrict__ targets, T *__restrict__ grad_inputs,
+ const int padding_idx, const float epsilon, const int vocab_size) {
+ /* step1: compute each thread's max_logit and sum_exp_logit, store in
+ * max_input, sum_exp_logit */
+ const int block_start = blockIdx.x * vocab_size;
+ const int left_idx = block_start + threadIdx.x;
+ const int right_idx = (blockIdx.x + 1) * vocab_size;
+ float max_input[1] = {REDUCE_FLOAT_INF_NEG};
+ float sum_logits[1] = {0.f};
+ const float grad_out = static_cast(grad_outputs[0]);
+ int target_tid = targets[blockIdx.x];
+
+ if (target_tid == padding_idx) {
+ for (int i = left_idx; i < right_idx; i += blockDim.x) {
+ grad_inputs[i] = 0.f;
+ }
+ return;
+ }
+
+ for (int i = left_idx; i < right_idx; i += blockDim.x) {
+ max_input[0] = fmaxf(max_input[0], static_cast(inputs[i]));
+ }
+ blockReduce(max_input);
+ __shared__ float s_max_input;
+ if (threadIdx.x == 0) {
+ s_max_input = max_input[0];
+ }
+ __syncthreads();
+
+ for (int i = left_idx; i < right_idx; i += blockDim.x) {
+ float logit = static_cast(inputs[i]) - s_max_input;
+ sum_logits[0] += expf(logit);
+ }
+
+ blockReduce(sum_logits);
+ __shared__ float s_sum_exp;
+ if (threadIdx.x == 0) {
+ s_sum_exp = sum_logits[0];
+ }
+ __syncthreads();
+
+ float eps_i = epsilon / (vocab_size - 1);
+ float nll_weight = 1.0 - epsilon - eps_i;
+
+ for (int i = left_idx; i < right_idx; i += blockDim.x) {
+ float prob = expf(static_cast(inputs[i]) - s_max_input) / s_sum_exp;
+ float grad = 0;
+ grad += (vocab_size * prob - 1) * eps_i;
+ grad += prob * nll_weight;
+ if ((i - block_start) == target_tid) {
+ grad -= nll_weight;
+ }
+ grad_inputs[i] = grad_out * grad;
+ }
+}
+
+template
+void launch_cross_entropy_fw(const T *inputs_ptr, const int *targets_ptr,
+ float *outputs_ptr, float *nll_loss_ptr,
+ float *loss_buffer, const int padding_idx,
+ const float epsilon, const int batch_size,
+ const int seq_len, const int vocab_size,
+ cudaStream_t stream) {
+ int grid_dim = batch_size * seq_len;
+ float *nll_loss_buffer = loss_buffer + grid_dim;
+ ls_cross_entropy_fw_kernel<<>>(
+ inputs_ptr, targets_ptr, loss_buffer, nll_loss_buffer, padding_idx,
+ epsilon, vocab_size);
+
+ int num_items = grid_dim;
+ void *d_temp_storage = NULL;
+ size_t temp_storage_bytes = 0;
+ CHECK_GPU_ERROR(ls::cub::DeviceReduce::Sum(d_temp_storage, temp_storage_bytes,
+ loss_buffer, outputs_ptr,
+ num_items, stream));
+ CHECK_GPU_ERROR(
+ g_allocator.DeviceAllocate(&d_temp_storage, temp_storage_bytes));
+ CHECK_GPU_ERROR(ls::cub::DeviceReduce::Sum(d_temp_storage, temp_storage_bytes,
+ loss_buffer, outputs_ptr,
+ num_items, stream));
+ CHECK_GPU_ERROR(ls::cub::DeviceReduce::Sum(d_temp_storage, temp_storage_bytes,
+ nll_loss_buffer, nll_loss_ptr,
+ num_items, stream));
+ CHECK_GPU_ERROR(g_allocator.DeviceFree(d_temp_storage));
+}
+
+template void launch_cross_entropy_fw(
+ const float *inputs_ptr, const int *targets_ptr, float *outputs_ptr,
+ float *nll_loss_ptr, float *loss_buffer, const int padding_idx,
+ const float epsilon, const int batch_size, const int seq_len,
+ const int vocab_size, cudaStream_t stream);
+
+template void launch_cross_entropy_fw<__half>(
+ const __half *inputs_ptr, const int *targets_ptr, float *outputs_ptr,
+ float *nll_loss_ptr, float *loss_buffer, const int padding_idx,
+ const float epsilon, const int batch_size, const int seq_len,
+ const int vocab_size, cudaStream_t stream);
+
+template
+void launch_cross_entropy_bw(const float *grad_outputs_ptr, const T *inputs_ptr,
+ const int *targets_ptr, T *grad_inputs_ptr,
+ const int padding_idx, const float epsilon,
+ const int batch_size, const int seq_len,
+ const int vocab_size, cudaStream_t stream) {
+ int grid_dim = batch_size * seq_len;
+ ls_cross_entropy_bw_kernel<<>>(
+ grad_outputs_ptr, inputs_ptr, targets_ptr, grad_inputs_ptr, padding_idx,
+ epsilon, vocab_size);
+}
+
+template void launch_cross_entropy_bw(
+ const float *grad_outputs_ptr, const float *inputs_ptr,
+ const int *targets_ptr, float *grad_inputs_ptr, const int padding_idx,
+ const float epsilon, const int batch_size, const int seq_len,
+ const int vocab_size, cudaStream_t stream);
+
+template void launch_cross_entropy_bw<__half>(
+ const float *grad_outputs_ptr, const __half *inputs_ptr,
+ const int *targets_ptr, __half *grad_inputs_ptr, const int padding_idx,
+ const float epsilon, const int batch_size, const int seq_len,
+ const int vocab_size, cudaStream_t stream);
diff --git a/colossalai/kernel/cuda_native/csrc/kernels/cublas_wrappers.cu b/colossalai/kernel/cuda_native/csrc/kernels/cublas_wrappers.cu
new file mode 100644
index 0000000000000000000000000000000000000000..09f34763f9b292a05d1e7d7b2bddfd9b6367d781
--- /dev/null
+++ b/colossalai/kernel/cuda_native/csrc/kernels/cublas_wrappers.cu
@@ -0,0 +1,88 @@
+/* Copyright 2021 The LightSeq Team
+ Copyright Microsoft DeepSpeed
+ This file is adapted from Microsoft DeepSpeed
+ Licensed under the MIT License.
+*/
+#include "cublas_wrappers.h"
+
+int cublas_gemm_ex(cublasHandle_t handle, cublasOperation_t transa,
+ cublasOperation_t transb, int m, int n, int k,
+ const float *alpha, const float *beta, const float *A,
+ const float *B, float *C, cublasGemmAlgo_t algo) {
+ cublasStatus_t status =
+ cublasGemmEx(handle, transa, transb, m, n, k, (const void *)alpha,
+ (const void *)A, CUDA_R_32F, (transa == CUBLAS_OP_N) ? m : k,
+ (const void *)B, CUDA_R_32F, (transb == CUBLAS_OP_N) ? k : n,
+ (const void *)beta, C, CUDA_R_32F, m, CUDA_R_32F, algo);
+
+ if (status != CUBLAS_STATUS_SUCCESS) {
+ fprintf(stderr,
+ "!!!! kernel execution error. (m: %d, n: %d, k: %d, error: %d) \n",
+ m, n, k, (int)status);
+ return EXIT_FAILURE;
+ }
+ return 0;
+}
+
+int cublas_gemm_ex(cublasHandle_t handle, cublasOperation_t transa,
+ cublasOperation_t transb, int m, int n, int k,
+ const float *alpha, const float *beta, const __half *A,
+ const __half *B, __half *C, cublasGemmAlgo_t algo) {
+ cublasStatus_t status = cublasGemmEx(
+ handle, transa, transb, m, n, k, (const void *)alpha, (const void *)A,
+ CUDA_R_16F, (transa == CUBLAS_OP_N) ? m : k, (const void *)B, CUDA_R_16F,
+ (transb == CUBLAS_OP_N) ? k : n, (const void *)beta, (void *)C,
+ CUDA_R_16F, m, CUDA_R_32F, algo);
+
+ if (status != CUBLAS_STATUS_SUCCESS) {
+ fprintf(stderr,
+ "!!!! kernel execution error. (m: %d, n: %d, k: %d, error: %d) \n",
+ m, n, k, (int)status);
+ return EXIT_FAILURE;
+ }
+ return 0;
+}
+
+int cublas_strided_batched_gemm(cublasHandle_t handle, int m, int n, int k,
+ const float *alpha, const float *beta,
+ const float *A, const float *B, float *C,
+ cublasOperation_t op_A, cublasOperation_t op_B,
+ int stride_A, int stride_B, int stride_C,
+ int batch, cublasGemmAlgo_t algo) {
+ cublasStatus_t status = cublasGemmStridedBatchedEx(
+ handle, op_A, op_B, m, n, k, alpha, A, CUDA_R_32F,
+ (op_A == CUBLAS_OP_N) ? m : k, stride_A, B, CUDA_R_32F,
+ (op_B == CUBLAS_OP_N) ? k : n, stride_B, beta, C, CUDA_R_32F, m, stride_C,
+ batch, CUDA_R_32F, algo);
+
+ if (status != CUBLAS_STATUS_SUCCESS) {
+ fprintf(stderr,
+ "!!!! kernel execution error. (batch: %d, m: %d, n: %d, k: %d, "
+ "error: %d) \n",
+ batch, m, n, k, (int)status);
+ return EXIT_FAILURE;
+ }
+ return 0;
+}
+
+int cublas_strided_batched_gemm(cublasHandle_t handle, int m, int n, int k,
+ const float *alpha, const float *beta,
+ const __half *A, const __half *B, __half *C,
+ cublasOperation_t op_A, cublasOperation_t op_B,
+ int stride_A, int stride_B, int stride_C,
+ int batch, cublasGemmAlgo_t algo) {
+ cublasStatus_t status = cublasGemmStridedBatchedEx(
+ handle, op_A, op_B, m, n, k, alpha, A, CUDA_R_16F,
+ (op_A == CUBLAS_OP_N) ? m : k, stride_A, B, CUDA_R_16F,
+ (op_B == CUBLAS_OP_N) ? k : n, stride_B, beta, C, CUDA_R_16F, m, stride_C,
+ batch, CUDA_R_32F, algo);
+
+ if (status != CUBLAS_STATUS_SUCCESS) {
+ fprintf(stderr,
+ "!!!! kernel execution error. (m: %d, n: %d, k: %d, error: %d) \n",
+ m, n, k, (int)status);
+ return EXIT_FAILURE;
+ }
+
+ return 0;
+}
diff --git a/colossalai/kernel/cuda_native/csrc/kernels/cuda_util.cu b/colossalai/kernel/cuda_native/csrc/kernels/cuda_util.cu
new file mode 100644
index 0000000000000000000000000000000000000000..26efa2ad6f31632a4e7ceddd06745b067759bb43
--- /dev/null
+++ b/colossalai/kernel/cuda_native/csrc/kernels/cuda_util.cu
@@ -0,0 +1,170 @@
+#include
+#include
+
+
+#include "cuda_util.h"
+
+/* GPU function guard */
+std::string _cudaGetErrorString(cudaError_t error) {
+ return cudaGetErrorString(error);
+}
+
+std::string _cudaGetErrorString(cublasStatus_t error) {
+ switch (error) {
+ case CUBLAS_STATUS_SUCCESS:
+ return "CUBLAS_STATUS_SUCCESS";
+
+ case CUBLAS_STATUS_NOT_INITIALIZED:
+ return "CUBLAS_STATUS_NOT_INITIALIZED";
+
+ case CUBLAS_STATUS_ALLOC_FAILED:
+ return "CUBLAS_STATUS_ALLOC_FAILED";
+
+ case CUBLAS_STATUS_INVALID_VALUE:
+ return "CUBLAS_STATUS_INVALID_VALUE";
+
+ case CUBLAS_STATUS_ARCH_MISMATCH:
+ return "CUBLAS_STATUS_ARCH_MISMATCH";
+
+ case CUBLAS_STATUS_MAPPING_ERROR:
+ return "CUBLAS_STATUS_MAPPING_ERROR";
+
+ case CUBLAS_STATUS_EXECUTION_FAILED:
+ return "CUBLAS_STATUS_EXECUTION_FAILED";
+
+ case CUBLAS_STATUS_INTERNAL_ERROR:
+ return "CUBLAS_STATUS_INTERNAL_ERROR";
+
+ case CUBLAS_STATUS_NOT_SUPPORTED:
+ return "CUBLAS_STATUS_NOT_SUPPORTED";
+
+ case CUBLAS_STATUS_LICENSE_ERROR:
+ return "CUBLAS_STATUS_LICENSE_ERROR";
+ }
+ return "CUBLAS_UNKNOW";
+}
+
+template
+void check_gpu_error(T result, char const *const func, const char *const file,
+ int const line) {
+ if (result) {
+ throw std::runtime_error(std::string("[CUDA][ERROR] ") + +file + "(" +
+ std::to_string(line) +
+ "): " + (_cudaGetErrorString(result)) + "\n");
+ }
+}
+
+template void check_gpu_error(cudaError_t result,
+ char const *const func,
+ const char *const file,
+ int const line);
+template void check_gpu_error(cublasStatus_t result,
+ char const *const func,
+ const char *const file,
+ int const line);
+
+template
+void print_vec(const T *outv, std::string outn, int num_output_ele) {
+ std::cout << outn << ": ";
+ std::vector hout(num_output_ele, (T)0);
+ cudaMemcpy(hout.data(), outv, num_output_ele * sizeof(T),
+ cudaMemcpyDeviceToHost);
+ for (int i = 0; i < num_output_ele; i++) {
+ std::cout << hout[i] << ", ";
+ }
+ std::cout << std::endl;
+}
+
+template <>
+void print_vec<__half>(const __half *outv, std::string outn,
+ int num_output_ele) {
+ std::cout << outn << ": ";
+ std::vector<__half> hout(num_output_ele, (__half)0.f);
+ cudaMemcpy(hout.data(), outv, num_output_ele * sizeof(__half),
+ cudaMemcpyDeviceToHost);
+ for (int i = 0; i < num_output_ele; i++) {
+ std::cout << __half2float(hout[i]) << ", ";
+ }
+ std::cout << std::endl;
+}
+
+template void print_vec(const float *outv, std::string outn,
+ int num_output_ele);
+
+template void print_vec(const int *outv, std::string outn,
+ int num_output_ele);
+
+template void print_vec<__half>(const __half *outv, std::string outn,
+ int num_output_ele);
+
+template
+T *cuda_malloc(size_t ele_num) {
+ size_t byte_size = ele_num * sizeof(T);
+ T *pdata = nullptr;
+ CHECK_GPU_ERROR(cudaMalloc((void **)&pdata, byte_size));
+ return pdata;
+}
+
+template float *cuda_malloc(size_t ele_num);
+
+template __half *cuda_malloc<__half>(size_t ele_num);
+
+template uint8_t *cuda_malloc(size_t ele_num);
+
+void cuda_free(void *pdata) {
+ if (pdata != nullptr) {
+ cudaFree(pdata);
+ }
+}
+
+template
+struct _isnan {
+ __device__ bool operator()(T a) const { return isnan(a); }
+};
+
+template <>
+struct _isnan<__half> {
+ __device__ bool operator()(const __half a) const { return __hisnan(a); }
+};
+
+template
+struct _isinf {
+ __device__ bool operator()(T a) const { return isinf(a); }
+};
+
+template <>
+struct _isinf<__half> {
+ __device__ bool operator()(const __half a) const { return __hisinf(a); }
+};
+
+template
+void check_nan_inf(const T *data_ptr, int dsize, bool check_nan_inf,
+ std::string file, int line, cudaStream_t stream) {
+ // check_nan_inf = 0 for checking nan
+ // check_nan_inf = 1 for checking inf
+ bool res = false;
+ std::string msg = file + "(" + std::to_string(line) + "): ";
+ if (check_nan_inf) {
+ msg += "nan.";
+ res = thrust::transform_reduce(thrust::cuda::par.on(stream), data_ptr,
+ data_ptr + dsize, _isnan(), false,
+ thrust::logical_or());
+ } else {
+ msg += "inf.";
+ res = thrust::transform_reduce(thrust::cuda::par.on(stream), data_ptr,
+ data_ptr + dsize, _isinf(), false,
+ thrust::logical_or());
+ }
+ if (res) {
+ throw std::runtime_error(msg);
+ }
+ std::cout << msg << " [check pass]." << std::endl;
+}
+
+template void check_nan_inf(const float *data_ptr, int dsize,
+ bool check_nan_inf, std::string file,
+ int line, cudaStream_t stream);
+
+template void check_nan_inf<__half>(const __half *data_ptr, int dsize,
+ bool check_nan_inf, std::string file,
+ int line, cudaStream_t stream);
diff --git a/colossalai/kernel/cuda_native/csrc/kernels/dropout_kernels.cu b/colossalai/kernel/cuda_native/csrc/kernels/dropout_kernels.cu
new file mode 100644
index 0000000000000000000000000000000000000000..a39a6dae0f7fb6968e6ee65fde8db4bbc5d61ab0
--- /dev/null
+++ b/colossalai/kernel/cuda_native/csrc/kernels/dropout_kernels.cu
@@ -0,0 +1,1002 @@
+#include
+#include
+
+#include "kernels.h"
+
+#include
+
+
+namespace cg = cooperative_groups;
+
+curandStatePhilox4_32_10_t *curandstate;
+
+/**
+ * @brief element-wise activation function on device, like Relu, Gelu
+ *
+ * @tparam enum class ActivationType, kRelu, kGelu
+ * @tparam input type
+ * @param any shape of float and __half2
+ * @return same shape and type with input
+ */
+template
+__forceinline__ __device__ T activation_kernel(T x);
+
+template <>
+__device__ float activation_kernel(float x) {
+ float cdf =
+ 0.5f *
+ (1.0f + tanhf((0.7978845608028654f * (x + 0.044715f * x * x * x))));
+ return x * cdf;
+}
+
+template <>
+__device__ __half2
+activation_kernel(__half2 val) {
+ __half2 val_pow3 = __hmul2(val, __hmul2(val, val));
+ float2 tmp_pow = __half22float2(val_pow3);
+ float2 tmp = __half22float2(val);
+
+ tmp.x =
+ 0.5f *
+ (1.0f + tanhf((0.7978845608028654f * (tmp.x + 0.044715f * tmp_pow.x))));
+ tmp.y =
+ 0.5f *
+ (1.0f + tanhf((0.7978845608028654f * (tmp.y + 0.044715f * tmp_pow.y))));
+ return __hmul2(val, __float22half2_rn(tmp));
+}
+
+template <>
+__device__ float activation_kernel(float x) {
+ return fmaxf(x, 0);
+}
+
+template <>
+__device__ __half2
+activation_kernel(__half2 x) {
+ return __floats2half2_rn(fmaxf(0.f, __half2float(x.x)),
+ fmaxf(0.f, __half2float(x.y)));
+}
+
+/**
+ * @brief element-wise activation backward function on device
+ *
+ * @tparam enum class ActivationType
+ * @tparam input type
+ * @param any shape of float and __half2
+ * @return same shape of input
+ */
+template
+__forceinline__ __device__ T activation_bwd_kernel(T grad, T x);
+
+template <>
+__device__ float activation_bwd_kernel(float grad,
+ float x) {
+ const float sqrt_param = 0.79788456080286535587989211986876f;
+ const float mul_param = 0.044715;
+
+ float x2mul = x * x * mul_param;
+ float tan_h = tanhf(sqrt_param * (x + x * x2mul));
+ float dg1 = 0.5f * (1.0f + tan_h);
+ float dg2 = x * 0.5f * sqrt_param * (1 - tan_h * tan_h);
+ float dg3 = dg2 * 3 * x2mul;
+ return grad * (dg1 + dg2 + dg3);
+}
+
+template <>
+__device__ __half activation_bwd_kernel(
+ __half grad, __half x_half) {
+ float x = __half2float(x_half);
+ const float sqrt_param = 0.79788456080286535587989211986876f;
+ const float mul_param = 0.044715;
+
+ float x2mul = x * x * mul_param;
+ float tan_h = tanhf(sqrt_param * (x + x * x2mul));
+ float dg1 = 0.5f * (1.0f + tan_h);
+ float dg2 = x * 0.5f * sqrt_param * (1 - tan_h * tan_h);
+ float dg3 = dg2 * 3 * x2mul;
+ return grad * __float2half(dg1 + dg2 + dg3);
+}
+
+template <>
+__device__ float activation_bwd_kernel(float grad,
+ float x) {
+ return x > 0.f ? grad : 0.f;
+}
+
+template <>
+__device__ __half
+activation_bwd_kernel(__half grad, __half x) {
+ const __half half_zero = __float2half(0.f);
+ return x > half_zero ? grad : half_zero;
+}
+
+template <>
+__device__ __half2 activation_bwd_kernel(
+ __half2 grad2, __half2 x_half2) {
+ const __half half_zero = __float2half(0.f);
+ return __floats2half2_rn(x_half2.x > half_zero ? grad2.x : half_zero,
+ x_half2.y > half_zero ? grad2.y : half_zero);
+}
+
+/**
+ * @brief init curand states in global memory
+ *
+ * @thread grid_dim * block*dim to suuport any size of states
+ * @param state persistant curand states
+ * @param seed seed to init states
+ * @return void
+ */
+__global__ void curand_init_kernel(curandStatePhilox4_32_10_t *state,
+ int seed) {
+ /* Each thread gets same seed, a different sequence
+ number, no offset */
+ int id = threadIdx.x + blockIdx.x * blockDim.x;
+ curand_init(seed, id, 0, &state[id]);
+}
+
+void launch_curand_init(int total_count, int dim, cudaStream_t stream) {
+ cudaMalloc(&curandstate, total_count * sizeof(curandStatePhilox4_32_10_t));
+ int grid_dim = total_count >> 9;
+ curand_init_kernel<<>>(
+ curandstate, std::chrono::duration_cast(
+ std::chrono::system_clock::now().time_since_epoch())
+ .count());
+}
+
+/**
+ * @brief element-wise dropout, store dropped position in mask, it's not
+ * in-place
+ *
+ * @thread
+ * gridDim.x = total_count / 1024
+ * blockDim.x = 1024
+ *
+ * @param total_count total elements
+ * @param ratio drop ratio
+ * @param out any size of float and __half
+ * @param in same with out
+ * @param mask uint8 type, same size with out
+ * @param seed seed to curand
+ * @return void
+ */
+__global__ void ls_dropout_kernel(const int total_count, const float ratio,
+ float *__restrict__ out,
+ const float *__restrict__ in,
+ uint8_t *__restrict__ mask, const int seed) {
+ const float scale = 1.f / (1.f - ratio);
+ int i = blockIdx.x * blockDim.x + threadIdx.x;
+
+ if (i * 4 >= total_count) return;
+
+ curandStatePhilox4_32_10_t state;
+ curand_init(seed, i, 0, &state);
+ uint8_t m[4];
+
+ float4 *out4 = reinterpret_cast(out);
+ const float4 *data4 = reinterpret_cast(in);
+ uint32_t *mask4 = reinterpret_cast(mask);
+ float4 rand = curand_uniform4(&state);
+
+ m[0] = (uint8_t)(rand.x > ratio);
+ m[1] = (uint8_t)(rand.y > ratio);
+ m[2] = (uint8_t)(rand.z > ratio);
+ m[3] = (uint8_t)(rand.w > ratio);
+
+ uint32_t *m4 = reinterpret_cast(m);
+ mask4[i] = m4[0];
+
+ float4 input4 = data4[i];
+ float4 res4;
+ res4.x = input4.x * scale * m[0];
+ res4.y = input4.y * scale * m[1];
+ res4.z = input4.z * scale * m[2];
+ res4.w = input4.w * scale * m[3];
+ out4[i] = res4;
+}
+
+__global__ void ls_dropout_kernel(const int total_count, const float ratio,
+ __half *__restrict__ out,
+ const __half *__restrict__ in,
+ uint8_t *__restrict__ mask, const int seed) {
+ const float scale = 1.f / (1.f - ratio);
+
+ int i = blockIdx.x * blockDim.x + threadIdx.x;
+
+ if (i * 8 >= total_count) return;
+
+ curandStatePhilox4_32_10_t state;
+ curand_init(seed, i, 0, &state);
+
+ const float4 *vals_float4 = reinterpret_cast(in);
+ float4 *outs_float4 = reinterpret_cast(out);
+ uint64_t *mask8 = reinterpret_cast(mask);
+
+ uint8_t m[8];
+ float4 rand = curand_uniform4(&state);
+ m[0] = (uint8_t)(rand.x > ratio);
+ m[1] = (uint8_t)(rand.y > ratio);
+ m[2] = (uint8_t)(rand.z > ratio);
+ m[3] = (uint8_t)(rand.w > ratio);
+ rand = curand_uniform4(&state);
+ m[4] = (uint8_t)(rand.x > ratio);
+ m[5] = (uint8_t)(rand.y > ratio);
+ m[6] = (uint8_t)(rand.z > ratio);
+ m[7] = (uint8_t)(rand.w > ratio);
+ uint64_t *m8 = reinterpret_cast(m);
+ mask8[i] = *m8;
+
+ float4 val_float4 = vals_float4[i];
+ float4 out_float4;
+ __half2 *val_half2 = reinterpret_cast<__half2 *>(&val_float4);
+ __half2 *out_half2 = reinterpret_cast<__half2 *>(&out_float4);
+ __half2 scale_mask_1 = __floats2half2_rn(scale * m[0], scale * m[1]);
+ __half2 scale_mask_2 = __floats2half2_rn(scale * m[2], scale * m[3]);
+ __half2 scale_mask_3 = __floats2half2_rn(scale * m[4], scale * m[5]);
+ __half2 scale_mask_4 = __floats2half2_rn(scale * m[6], scale * m[7]);
+ out_half2[0] = __hmul2(val_half2[0], scale_mask_1);
+ out_half2[1] = __hmul2(val_half2[1], scale_mask_2);
+ out_half2[2] = __hmul2(val_half2[2], scale_mask_3);
+ out_half2[3] = __hmul2(val_half2[3], scale_mask_4);
+ outs_float4[i] = out_float4;
+}
+
+/**
+ * @brief element-wise dropout backward with dropout mask, it's
+ * not in-place
+ *
+ * @thread
+ * gridDim.x = total_count / 1024
+ * blockDim.x = 1024
+ *
+ * @param total_count total elements
+ * @param ratio drop ratio
+ * @param in any size of float and __half
+ * @param mask uint8 type, same size with in
+ * @return void
+ */
+__global__ void ls_dropout_bwd_kernel(const int total_count, const float ratio,
+ float *out, const float *in,
+ const uint8_t *__restrict__ mask) {
+ const float scale = 1.f / (1.f - ratio);
+ int i = blockIdx.x * blockDim.x + threadIdx.x;
+
+ if (i * 4 >= total_count) return;
+
+ uint8_t m[4];
+
+ float4 *out4 = reinterpret_cast(out);
+ const float4 *in4 = reinterpret_cast(in);
+ const uint32_t *mask4 = reinterpret_cast(mask);
+
+ uint32_t *m4 = reinterpret_cast(m);
+ m4[0] = mask4[i];
+
+ float4 input4 = in4[i];
+ float4 res4;
+ res4.x = input4.x * scale * static_cast(m[0]);
+ res4.y = input4.y * scale * static_cast(m[1]);
+ res4.z = input4.z * scale * static_cast(m[2]);
+ res4.w = input4.w * scale * static_cast(m[3]);
+ out4[i] = res4;
+}
+
+__global__ void ls_dropout_bwd_kernel(const int total_count, const float ratio,
+ __half *out, const __half *in,
+ const uint8_t *__restrict__ mask) {
+ const __half scale = 1.f / (1.f - ratio);
+
+ int i = blockIdx.x * blockDim.x + threadIdx.x;
+
+ if (i * 8 >= total_count) return;
+
+ float4 *out4 = reinterpret_cast(out);
+ const float4 *vals_float4 = reinterpret_cast(in);
+ const uint64_t *mask8 = reinterpret_cast(mask);
+
+ uint8_t m[8];
+ uint64_t *m8 = reinterpret_cast(m);
+ m8[0] = mask8[i];
+
+ float4 val_float4 = vals_float4[i];
+ float4 out_float4;
+ __half2 *val_half2 = reinterpret_cast<__half2 *>(&val_float4);
+ __half2 *out_half2 = reinterpret_cast<__half2 *>(&out_float4);
+ __half2 scale_mask_1 =
+ __halves2half2(scale * __float2half(m[0]), scale * __float2half(m[1]));
+ __half2 scale_mask_2 =
+ __halves2half2(scale * __float2half(m[2]), scale * __float2half(m[3]));
+ __half2 scale_mask_3 =
+ __halves2half2(scale * __float2half(m[4]), scale * __float2half(m[5]));
+ __half2 scale_mask_4 =
+ __halves2half2(scale * __float2half(m[6]), scale * __float2half(m[7]));
+ out_half2[0] = __hmul2(val_half2[0], scale_mask_1);
+ out_half2[1] = __hmul2(val_half2[1], scale_mask_2);
+ out_half2[2] = __hmul2(val_half2[2], scale_mask_3);
+ out_half2[3] = __hmul2(val_half2[3], scale_mask_4);
+ out4[i] = out_float4;
+}
+
+template <>
+void launch_ls_dropout(float *out, const float *vals, uint8_t *mask,
+ int total_count, float ratio, cudaStream_t stream,
+ bool backward) {
+ int grid_dim = total_count >> 12;
+ if (!backward) {
+ ls_dropout_kernel<<>>(
+ total_count, ratio, out, vals, mask,
+ std::chrono::duration_cast(
+ std::chrono::system_clock::now().time_since_epoch())
+ .count());
+ } else {
+ ls_dropout_bwd_kernel<<>>(total_count, ratio,
+ out, vals, mask);
+ }
+}
+
+template <>
+void launch_ls_dropout<__half>(__half *out, const __half *vals, uint8_t *mask,
+ int total_count, float ratio,
+ cudaStream_t stream, bool backward) {
+ int grid_dim = total_count >> 13;
+ if (!backward) {
+ ls_dropout_kernel<<>>(
+ total_count, ratio, out, vals, mask,
+ std::chrono::duration_cast(
+ std::chrono::system_clock::now().time_since_epoch())
+ .count());
+ } else {
+ ls_dropout_bwd_kernel<<>>(total_count, ratio,
+ out, vals, mask);
+ }
+}
+
+/**
+ * @brief fused bias, dropout, and residual at the end of Attention and FFN,
+ * store dropped position in mask, it's not in-place
+ *
+ * @thread
+ * gridDim.x = total_count / 1024
+ * blockDim.x = 1024
+ *
+ * @param total_count total elements
+ * @param ratio drop ratio
+ * @param out [batch_size, seq_len, hidden_size], float and __half
+ * @param in [batch_size, seq_len, hidden_size], float and __half
+ * @param mask [batch_size, seq_len, hidden_size], uint8 type
+ * @param bias [hidden_size], ffn bias
+ * @param residual [batch_size, seq_len, hidden_size], float and __half
+ * @param seed seed to curand
+ * @param hidden_size hidden size
+ * @return void
+ */
+__global__ void ls_dropout_res_bias_kernel(
+ const int total_count, const float ratio, float *__restrict__ out,
+ const float *__restrict__ in, uint8_t *__restrict__ mask,
+ const float *__restrict__ bias, const float *__restrict__ residual,
+ const int seed, const int hidden_size) {
+ const float scale = 1.f / (1.f - ratio);
+ int i = blockIdx.x * blockDim.x + threadIdx.x;
+
+ if (i * 4 >= total_count) return;
+
+ curandStatePhilox4_32_10_t state;
+ curand_init(seed, i, 0, &state);
+ uint8_t m[4];
+
+ float4 *out4 = reinterpret_cast(out);
+ const float4 *data4 = reinterpret_cast(in);
+ const float4 *residual4 = reinterpret_cast(residual);
+ const float4 *bias4 = reinterpret_cast(bias);
+ uint32_t *mask4 = reinterpret_cast(mask);
+ float4 rand = curand_uniform4(&state);
+
+ m[0] = static_cast(rand.x > ratio);
+ m[1] = static_cast(rand.y > ratio);
+ m[2] = static_cast(rand.z > ratio);
+ m[3] = static_cast(rand.w > ratio);
+
+ int bias_i = i % (hidden_size >> 2);
+ uint32_t *m4 = reinterpret_cast(m);
+ mask4[i] = m4[0];
+ const float4 input4 = data4[i];
+ const float4 b4 = __ldg(&bias4[bias_i]);
+ const float4 res4 = residual4[i];
+ float4 output4;
+
+ output4.x = (input4.x + b4.x) * scale * m[0] + res4.x;
+ output4.y = (input4.y + b4.y) * scale * m[1] + res4.y;
+ output4.z = (input4.z + b4.z) * scale * m[2] + res4.z;
+ output4.w = (input4.w + b4.w) * scale * m[3] + res4.w;
+
+ out4[i] = output4;
+}
+
+__global__ void ls_dropout_res_bias_kernel(
+ const int total_count, const float ratio, __half *__restrict__ out,
+ const __half *__restrict__ in, uint8_t *__restrict__ mask,
+ const __half *__restrict__ bias, const __half *__restrict__ residual,
+ const int seed, const int hidden_size) {
+ const __half scale = 1. / (1. - ratio);
+
+ int i = blockIdx.x * blockDim.x + threadIdx.x;
+
+ if (i * 8 >= total_count) return;
+
+ curandStatePhilox4_32_10_t state;
+ curand_init(seed, i, 0, &state);
+
+ const float4 *vals_float4 = reinterpret_cast(in);
+ float4 *outs_float4 = reinterpret_cast(out);
+ const float4 *residual4 = reinterpret_cast(residual);
+ const float4 *bias4 = reinterpret_cast(bias);
+ uint64_t *mask8 = reinterpret_cast(mask);
+
+ uint8_t m[8];
+ float4 rand = curand_uniform4(&state);
+ m[0] = static_cast(rand.x > ratio);
+ m[1] = static_cast(rand.y > ratio);
+ m[2] = static_cast(rand.z > ratio);
+ m[3] = static_cast(rand.w > ratio);
+ rand = curand_uniform4(&state);
+ m[4] = static_cast(rand.x > ratio);
+ m[5] = static_cast(rand.y > ratio);
+ m[6] = static_cast(rand.z > ratio);
+ m[7] = static_cast(rand.w > ratio);
+ uint64_t *m8 = reinterpret_cast(m);
+ mask8[i] = m8[0];
+
+ int bias_i = i % (hidden_size >> 3);
+ float4 val_float4 = vals_float4[i];
+ const float4 b4 = __ldg(&bias4[bias_i]);
+ const float4 res4 = residual4[i];
+ float4 out_float4;
+
+ __half2 *val_half2 = reinterpret_cast<__half2 *>(&val_float4);
+ __half2 *out_half2 = reinterpret_cast<__half2 *>(&out_float4);
+ const __half2 *b_half2 = reinterpret_cast(&b4);
+ const __half2 *res_half2 = reinterpret_cast(&res4);
+ __half2 scale_mask_1 =
+ __halves2half2(scale * __float2half(m[0]), scale * __float2half(m[1]));
+ __half2 scale_mask_2 =
+ __halves2half2(scale * __float2half(m[2]), scale * __float2half(m[3]));
+ __half2 scale_mask_3 =
+ __halves2half2(scale * __float2half(m[4]), scale * __float2half(m[5]));
+ __half2 scale_mask_4 =
+ __halves2half2(scale * __float2half(m[6]), scale * __float2half(m[7]));
+ out_half2[0] =
+ __hfma2(__hadd2(val_half2[0], b_half2[0]), scale_mask_1, res_half2[0]);
+ out_half2[1] =
+ __hfma2(__hadd2(val_half2[1], b_half2[1]), scale_mask_2, res_half2[1]);
+ out_half2[2] =
+ __hfma2(__hadd2(val_half2[2], b_half2[2]), scale_mask_3, res_half2[2]);
+ out_half2[3] =
+ __hfma2(__hadd2(val_half2[3], b_half2[3]), scale_mask_4, res_half2[3]);
+ outs_float4[i] = out_float4;
+}
+
+template <>
+void launch_ls_dropout_res_bias(float *out, const float *vals,
+ uint8_t *mask, const float *bias,
+ const float *residual, int total_count,
+ int dim, float ratio,
+ cudaStream_t stream) {
+ int grid_dim = total_count >> 12;
+ ls_dropout_res_bias_kernel<<>>(
+ total_count, ratio, out, vals, mask, bias, residual,
+ std::chrono::duration_cast(
+ std::chrono::system_clock::now().time_since_epoch())
+ .count(),
+ dim);
+}
+
+template <>
+void launch_ls_dropout_res_bias<__half>(__half *out, const __half *vals,
+ uint8_t *mask, const __half *bias,
+ const __half *residual, int total_count,
+ int dim, float ratio,
+ cudaStream_t stream) {
+ int grid_dim = total_count >> 13;
+ ls_dropout_res_bias_kernel<<>>(
+ total_count, ratio, out, vals, mask, bias, residual,
+ std::chrono::duration_cast(
+ std::chrono::system_clock::now().time_since_epoch())
+ .count(),
+ dim);
+}
+
+/**
+ * @brief fused bias and dropout backward at the end of Attention and FFN
+ *
+ * @thread
+ * gridDim.x = hidden_size / 8
+ * blockDim.x = 8
+ * blockDim.y = 1024 / 8 = 128
+ *
+ * @param row_size batch_size * seq_len
+ * @param ratio dropout ratio
+ * @param in_grad [batch_size, seq_len, hidden_size], input grad
+ * @param bias_grad [hidden_size], bias grad
+ * @param out_grad [batch_size, seq_len, hidden_size], output grad
+ * @param mask [batch_size, seq_len, hidden_size], dropout mask
+ * @param hidden_size
+ * @return void
+ */
+__global__ void ls_dropout_bias_bwd_kernel(
+ const int row_size, const float ratio, float *__restrict__ in_grad,
+ float *__restrict__ bias_grad, const float *__restrict__ out_grad,
+ const uint8_t *__restrict__ mask, const int hidden_size) {
+ const float scale = 1.f / (1.f - ratio);
+ // every block generate 8 bias result
+ __shared__ float tile[8][129];
+
+ cg::thread_block b = cg::this_thread_block();
+ cg::thread_block_tile g = cg::tiled_partition(b);
+
+ int col_idx = flat_2dim(blockIdx.x, threadIdx.x, 8);
+ int stride = hidden_size * 128;
+ float local_sum = 0;
+
+ int idx = flat_2dim(threadIdx.y, col_idx, hidden_size);
+ for (int r = threadIdx.y; r < row_size; r += 128) {
+ float val = out_grad[idx];
+ val *= scale * static_cast(mask[idx]);
+ local_sum += val;
+ in_grad[idx] = val;
+ idx += stride;
+ }
+
+ tile[threadIdx.x][threadIdx.y] = local_sum;
+ __syncthreads();
+
+ float sum = 0;
+ int tid = threadIdx.y * blockDim.x + threadIdx.x;
+ int x = tid >> 7;
+ int y = tid & (127);
+ if (y < 32) {
+#pragma unroll
+ for (int i = 0; i < 4; i++) {
+ sum += tile[x][y + i * 32];
+ }
+ }
+ __syncthreads();
+
+ for (int i = 1; i < 32; i <<= 1) sum += g.shfl_down(sum, i);
+
+ if (y == 0) tile[0][x] = sum;
+ __syncthreads();
+
+ if (threadIdx.x < 8) {
+ int pos = flat_2dim(blockIdx.x, threadIdx.x, 8);
+ bias_grad[pos] = tile[0][threadIdx.x];
+ }
+}
+
+__global__ void ls_dropout_bias_bwd_kernel(
+ const int row_size, const float ratio, __half *__restrict__ in_grad,
+ __half *__restrict__ bias_grad, const __half *__restrict__ out_grad,
+ const uint8_t *__restrict__ mask, const int hidden_size) {
+ const __half2 scale = __float2half2_rn(1.f / (1.f - ratio));
+ __shared__ __half2 tile[8][129];
+
+ cg::thread_block b = cg::this_thread_block();
+ cg::thread_block_tile g = cg::tiled_partition(b);
+
+ __half2 *in_grad2 = reinterpret_cast<__half2 *>(in_grad);
+ const __half2 *out_grad2 = reinterpret_cast(out_grad);
+ __half2 *bias_grad2 = reinterpret_cast<__half2 *>(bias_grad);
+
+ int col_idx = flat_2dim(blockIdx.x, threadIdx.x, 8);
+ int stride = hidden_size * 128;
+ __half2 local_sum = __float2half2_rn(0.f);
+
+ int idx = flat_2dim(threadIdx.y, col_idx, hidden_size);
+ for (int r = threadIdx.y; r < row_size; r += 128) {
+ __half2 val = out_grad2[idx];
+ __half2 m2 = __floats2half2_rn(mask[2 * idx], mask[2 * idx + 1]);
+ val *= scale * m2;
+ local_sum += val;
+ in_grad2[idx] = val;
+ idx += stride;
+ }
+
+ tile[threadIdx.x][threadIdx.y] = local_sum;
+ __syncthreads();
+
+ __half2 sum = __float2half2_rn(0.f);
+ int tid = threadIdx.y * blockDim.x + threadIdx.x;
+ int x = tid >> 7;
+ int y = tid & (127);
+ if (y < 32) {
+#pragma unroll
+ for (int i = 0; i < 4; i++) {
+ sum += tile[x][y + i * 32];
+ }
+ }
+ __syncthreads();
+
+ for (int i = 1; i < WARP_SIZE; i <<= 1) sum += g.shfl_down(sum, i);
+
+ if (y == 0) tile[0][x] = sum;
+ __syncthreads();
+
+ if (threadIdx.x < 8) {
+ int pos = flat_2dim(blockIdx.x, threadIdx.x, 8);
+ bias_grad2[pos] = tile[0][threadIdx.x];
+ }
+}
+
+template
+void launch_ls_dropout_bias_bwd(T *in_grad, T *bias_grad, const T *out_grad,
+ const uint8_t *mask, int row_size, int dim,
+ float ratio, cudaStream_t stream) {
+ dim3 grid_dim((dim - 1) / 8 + 1);
+ dim3 block_dim(8, 128);
+ ls_dropout_bias_bwd_kernel<<>>(
+ row_size, ratio, in_grad, bias_grad, out_grad, mask, dim);
+}
+
+template <>
+void launch_ls_dropout_bias_bwd(__half *in_grad, __half *bias_grad,
+ const __half *out_grad, const uint8_t *mask,
+ int row_size, int dim, float ratio,
+ cudaStream_t stream) {
+ dim >>= 1;
+ dim3 grid_dim((dim - 1) / 8 + 1);
+ dim3 block_dim(8, 128);
+ ls_dropout_bias_bwd_kernel<<>>(
+ row_size, ratio, in_grad, bias_grad, out_grad, mask, dim);
+}
+
+template void launch_ls_dropout_bias_bwd(float *in_grad, float *bias_grad,
+ const float *out_grad,
+ const uint8_t *mask, int row_size,
+ int dim, float ratio,
+ cudaStream_t stream);
+
+/**
+ * @brief fused bias, activation, and dropout at the end of first ffn
+ *
+ * @thread
+ * gridDim.x = hidden_size / 8
+ * blockDim.x = 8
+ * blockDim.y = 1024 / 8 = 128
+ *
+ * @tparam act_type activation function, like kRelu, kGelu
+ * @param total_count total elements
+ * @param ratio drop ratio
+ * @param out [batch_size, seq_len, hidden_size], float and __half
+ * @param in [batch_size, seq_len, hidden_size], float and __half
+ * @param mask [batch_size, seq_len, hidden_size], uint8 type
+ * @param bias [hidden_size], ffn bias
+ * @param seed seed to curand
+ * @param hidden_size
+ * @return void
+ */
+template
+__global__ void ls_dropout_act_bias_kernel(
+ const int total_count, const float ratio, float *__restrict__ out,
+ const float *__restrict__ in, uint8_t *__restrict__ mask,
+ const float *__restrict__ bias, const int seed, const int hidden_size) {
+ const float scale = 1.f / (1.f - ratio);
+ int i = blockIdx.x * blockDim.x + threadIdx.x;
+
+ if (i * 4 >= total_count) return;
+
+ curandStatePhilox4_32_10_t state;
+ curand_init(seed, i, 0, &state);
+ uint8_t m[4];
+
+ float4 *out4 = reinterpret_cast(out);
+ const float4 *data4 = reinterpret_cast(in);
+ const float4 *bias4 = reinterpret_cast(bias);
+ uint32_t *mask4 = reinterpret_cast(mask);
+ float4 rand = curand_uniform4(&state);
+
+ m[0] = (uint8_t)(rand.x > ratio);
+ m[1] = (uint8_t)(rand.y > ratio);
+ m[2] = (uint8_t)(rand.z > ratio);
+ m[3] = (uint8_t)(rand.w > ratio);
+
+ int bias_i = i % (hidden_size >> 2);
+ uint32_t *m4 = reinterpret_cast(m);
+ mask4[i] = m4[0];
+ const float4 input4 = data4[i];
+ const float4 b4 = __ldg(&bias4[bias_i]);
+ float4 output4;
+
+ output4.x =
+ activation_kernel(input4.x + b4.x) * scale * m[0];
+ output4.y =
+ activation_kernel(input4.y + b4.y) * scale * m[1];
+ output4.z =
+ activation_kernel(input4.z + b4.z) * scale * m[2];
+ output4.w =
+ activation_kernel(input4.w + b4.w) * scale * m[3];
+
+ out4[i] = output4;
+}
+
+template
+__global__ void ls_dropout_act_bias_kernel(
+ const int total_count, const float ratio, __half *__restrict__ out,
+ const __half *__restrict__ in, uint8_t *__restrict__ mask,
+ const __half *__restrict__ bias, const int seed, const int hidden_size) {
+ const float scale = 1.f / (1.f - ratio);
+
+ int i = blockIdx.x * blockDim.x + threadIdx.x;
+
+ if (i * 8 >= total_count) return;
+
+ curandStatePhilox4_32_10_t state;
+ curand_init(seed, i, 0, &state);
+
+ const float4 *vals_float4 = reinterpret_cast(in);
+ float4 *outs_float4 = reinterpret_cast(out);
+ const float4 *bias4 = reinterpret_cast(bias);
+ uint64_t *mask8 = reinterpret_cast(mask);
+
+ uint8_t m[8];
+ float4 rand = curand_uniform4(&state);
+ m[0] = (uint8_t)(rand.x > ratio);
+ m[1] = (uint8_t)(rand.y > ratio);
+ m[2] = (uint8_t)(rand.z > ratio);
+ m[3] = (uint8_t)(rand.w > ratio);
+ rand = curand_uniform4(&state);
+ m[4] = (uint8_t)(rand.x > ratio);
+ m[5] = (uint8_t)(rand.y > ratio);
+ m[6] = (uint8_t)(rand.z > ratio);
+ m[7] = (uint8_t)(rand.w > ratio);
+ uint64_t *m8 = reinterpret_cast(m);
+ mask8[i] = *m8;
+
+ int bias_i = i % (hidden_size >> 3);
+ float4 val_float4 = vals_float4[i];
+ const float4 b4 = __ldg(&bias4[bias_i]);
+ float4 out_float4;
+
+ __half2 *val_half2 = reinterpret_cast<__half2 *>(&val_float4);
+ __half2 *out_half2 = reinterpret_cast<__half2 *>(&out_float4);
+ const __half2 *b_half2 = reinterpret_cast(&b4);
+
+ __half2 scale_mask_1 = __floats2half2_rn(scale * m[0], scale * m[1]);
+ __half2 scale_mask_2 = __floats2half2_rn(scale * m[2], scale * m[3]);
+ __half2 scale_mask_3 = __floats2half2_rn(scale * m[4], scale * m[5]);
+ __half2 scale_mask_4 = __floats2half2_rn(scale * m[6], scale * m[7]);
+ out_half2[0] = __hmul2(
+ activation_kernel(__hadd2(val_half2[0], b_half2[0])),
+ scale_mask_1);
+ out_half2[1] = __hmul2(
+ activation_kernel(__hadd2(val_half2[1], b_half2[1])),
+ scale_mask_2);
+ out_half2[2] = __hmul2(
+ activation_kernel(__hadd2(val_half2[2], b_half2[2])),
+ scale_mask_3);
+ out_half2[3] = __hmul2(
+ activation_kernel(__hadd2(val_half2[3], b_half2[3])),
+ scale_mask_4);
+ outs_float4[i] = out_float4;
+}
+
+template <>
+void launch_ls_dropout_act_bias(
+ float *out, const float *vals, uint8_t *mask, const float *bias,
+ int total_count, int dim, float ratio, cudaStream_t stream) {
+ int grid_dim = total_count >> 10;
+ ls_dropout_act_bias_kernel
+
+