Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
OpenDAS
bitsandbytes
Commits
7f87ba83
Commit
7f87ba83
authored
Apr 01, 2023
by
Mitchell Wortsman
Browse files
cleaning and refactor
parent
30d21d58
Changes
32
Hide whitespace changes
Inline
Side-by-side
Showing
12 changed files
with
0 additions
and
723 deletions
+0
-723
tests/triton_tests/info_mlp_autocast_ln.jsonl
tests/triton_tests/info_mlp_autocast_ln.jsonl
+0
-23
tests/triton_tests/mlp.py
tests/triton_tests/mlp.py
+0
-64
tests/triton_tests/mlp_decomp_autocast.py
tests/triton_tests/mlp_decomp_autocast.py
+0
-166
tests/triton_tests/mlp_decomp_autocast_ln.py
tests/triton_tests/mlp_decomp_autocast_ln.py
+0
-165
tests/triton_tests/plot1.png
tests/triton_tests/plot1.png
+0
-0
tests/triton_tests/plot2.pdf
tests/triton_tests/plot2.pdf
+0
-0
tests/triton_tests/plot2.png
tests/triton_tests/plot2.png
+0
-0
tests/triton_tests/plot2.py
tests/triton_tests/plot2.py
+0
-69
tests/triton_tests/plot3.pdf
tests/triton_tests/plot3.pdf
+0
-0
tests/triton_tests/plot3.png
tests/triton_tests/plot3.png
+0
-0
tests/triton_tests/plot3.py
tests/triton_tests/plot3.py
+0
-193
tests/triton_tests/rowwise.py
tests/triton_tests/rowwise.py
+0
-43
No files found.
tests/triton_tests/info_mlp_autocast_ln.jsonl
deleted
100644 → 0
View file @
30d21d58
{"repeat": 32, "batch_size": 16384, "dim": 1024, "standard": 5.171686410903931, "my_standard": 5.839601159095764, "standard_compiled": 5.032263696193695, "sb": 4.89344447851181}
{"repeat": 32, "batch_size": 32768, "dim": 1024, "standard": 9.605035185813904, "my_standard": 10.910414159297943, "standard_compiled": 9.230785071849823, "sb": 9.128175675868988}
{"repeat": 32, "batch_size": 65536, "dim": 1024, "standard": 18.802084028720856, "my_standard": 21.311581134796143, "standard_compiled": 18.105976283550262, "sb": 17.489850521087646}
{"repeat": 32, "batch_size": 131072, "dim": 1024, "standard": 37.49683499336243, "my_standard": 42.40527004003525, "standard_compiled": 36.13145649433136, "sb": 34.58733111619949}
{"repeat": 32, "batch_size": 16384, "dim": 1280, "standard": 7.709823548793793, "my_standard": 8.290477097034454, "standard_compiled": 7.564418017864227, "sb": 6.8823546171188354}
{"repeat": 32, "batch_size": 32768, "dim": 1280, "standard": 14.64156061410904, "my_standard": 16.996942460536957, "standard_compiled": 14.4081711769104, "sb": 12.761622667312622}
{"repeat": 32, "batch_size": 65536, "dim": 1280, "standard": 31.40200674533844, "my_standard": 36.074504256248474, "standard_compiled": 30.981406569480896, "sb": 24.76389706134796}
{"repeat": 32, "batch_size": 131072, "dim": 1280, "standard": 56.93405121564865, "my_standard": 66.35250151157379, "standard_compiled": 56.07586354017258, "sb": 48.49743843078613}
{"repeat": 32, "batch_size": 16384, "dim": 1408, "standard": 9.188003838062286, "my_standard": 9.84550267457962, "standard_compiled": 9.006097912788391, "sb": 7.9473331570625305}
{"repeat": 32, "batch_size": 32768, "dim": 1408, "standard": 17.268165946006775, "my_standard": 18.64910125732422, "standard_compiled": 16.983114182949066, "sb": 14.70106840133667}
{"repeat": 32, "batch_size": 65536, "dim": 1408, "standard": 34.39047932624817, "my_standard": 36.69705241918564, "standard_compiled": 33.8401272892952, "sb": 29.188089072704315}
{"repeat": 32, "batch_size": 131072, "dim": 1408, "standard": 66.70494377613068, "my_standard": 71.27603143453598, "standard_compiled": 65.56134670972824, "sb": 55.6538850069046}
{"repeat": 32, "batch_size": 16384, "dim": 1664, "standard": 12.10707426071167, "my_standard": 12.931793928146362, "standard_compiled": 11.76995038986206, "sb": 10.228671133518219}
{"repeat": 32, "batch_size": 32768, "dim": 1664, "standard": 22.5130096077919, "my_standard": 23.962542414665222, "standard_compiled": 21.997176110744476, "sb": 18.89890432357788}
{"repeat": 32, "batch_size": 65536, "dim": 1664, "standard": 45.210108160972595, "my_standard": 47.94136434793472, "standard_compiled": 44.2262664437294, "sb": 37.37735003232956}
{"repeat": 32, "batch_size": 131072, "dim": 1664, "standard": 88.1955549120903, "my_standard": 93.6831533908844, "standard_compiled": 86.33609116077423, "sb": 71.23208791017532}
{"repeat": 32, "batch_size": 16384, "dim": 2048, "standard": 16.538940370082855, "my_standard": 17.607316374778748, "standard_compiled": 16.108587384223938, "sb": 14.030493795871735}
{"repeat": 32, "batch_size": 32768, "dim": 2048, "standard": 31.795650720596313, "my_standard": 33.57230871915817, "standard_compiled": 31.04180097579956, "sb": 25.971196591854095}
{"repeat": 32, "batch_size": 65536, "dim": 2048, "standard": 63.021354377269745, "my_standard": 66.8477788567543, "standard_compiled": 61.682507395744324, "sb": 50.138771533966064}
{"repeat": 32, "batch_size": 131072, "dim": 2048, "standard": 125.17062574625015, "my_standard": 133.60925763845444, "standard_compiled": 122.21191823482513, "sb": 98.40084612369537}
{"repeat": 32, "batch_size": 16384, "dim": 4096, "standard": 57.31645971536636, "my_standard": 60.84543466567993, "standard_compiled": 55.78199774026871, "sb": 45.43223977088928}
{"repeat": 32, "batch_size": 32768, "dim": 4096, "standard": 111.80306226015091, "my_standard": 119.0284714102745, "standard_compiled": 108.91905426979065, "sb": 85.4572057723999}
{"repeat": 32, "batch_size": 65536, "dim": 4096, "standard": 220.4471081495285, "my_standard": 233.0927476286888, "standard_compiled": 214.26431089639664, "sb": 163.30372542142868}
tests/triton_tests/mlp.py
deleted
100644 → 0
View file @
30d21d58
import
time
import
torch
import
torch.nn
as
nn
import
bitsandbytes.nn
as
bnn
from
bitsandbytes.nn.triton_based_modules
import
SwitchBackLinear
,
SwitchBackGlobalLinear
,
StandardLinear
def
construct_model
(
dim
,
layers
,
module
):
modules
=
[]
for
_
in
range
(
layers
):
modules
.
append
(
module
(
dim
,
4
*
dim
))
modules
.
append
(
module
(
4
*
dim
,
dim
))
return
nn
.
Sequential
(
*
modules
).
cuda
().
train
()
def
get_time
(
model
,
x
,
name
):
for
_
in
range
(
repeat
//
2
):
#with torch.cuda.amp.autocast():
out
=
model
(
x
)
#(2**16 * out.pow(2).mean()).backward()
torch
.
cuda
.
synchronize
()
start
=
time
.
time
()
for
_
in
range
(
repeat
):
# with torch.cuda.amp.autocast():
out
=
model
(
x
)
#(2**16 * out.pow(2).mean()).backward()
torch
.
cuda
.
synchronize
()
end
=
time
.
time
()
print
(
f
"time
{
name
}
:
{
(
end
-
start
)
/
repeat
*
1000
:.
3
f
}
ms"
)
if
__name__
==
'__main__'
:
torch
.
manual_seed
(
0
)
# hparams
repeat
=
16
dim
=
2048
layers
=
4
batch_size
=
2
sequence_length
=
2
**
15
# construct models
standard
=
construct_model
(
dim
,
layers
,
nn
.
Linear
).
half
()
my_standard
=
construct_model
(
dim
,
layers
,
StandardLinear
).
half
()
switchback
=
construct_model
(
dim
,
layers
,
SwitchBackLinear
).
half
()
switchback_global
=
construct_model
(
dim
,
layers
,
SwitchBackGlobalLinear
).
half
()
#bnb_8bitmixed = construct_model(dim, layers, bnn.Linear8bitLt)
# simulate forward pass
x
=
torch
.
randn
(
batch_size
*
sequence_length
,
dim
,
dtype
=
torch
.
float16
).
cuda
()
# get time for forward and backward
get_time
(
standard
,
x
,
"standard"
)
get_time
(
my_standard
,
x
,
"my_standard"
)
get_time
(
switchback
,
x
,
"switchback"
)
get_time
(
switchback_global
,
x
,
"switchback_global"
)
#get_time(bnb_8bitmixed, x, "bnb_8bitmixed")
tests/triton_tests/mlp_decomp_autocast.py
deleted
100644 → 0
View file @
30d21d58
import
torch
import
json
from
bitsandbytes.nn.triton_based_modules
import
SwitchBackGlobalMLP
,
SwitchBackGlobalLinear
,
StandardLinear
import
time
if
__name__
==
'__main__'
:
print
(
'Startin'
)
for
dim
in
[
1024
,
1280
,
1408
,
1664
,
2048
]:
for
batch
in
[
2
**
14
,
2
**
15
,
2
**
16
,
2
**
17
]:
if
dim
!=
4096
or
batch
!=
2
**
17
:
continue
x1
=
torch
.
randn
(
batch
,
dim
).
cuda
().
requires_grad_
(
True
)
d
=
2
standard
=
torch
.
nn
.
Sequential
(
torch
.
nn
.
Linear
(
dim
,
4
*
dim
),
torch
.
nn
.
GELU
(),
torch
.
nn
.
Linear
(
4
*
dim
,
dim
),
).
cuda
()
my_standard
=
torch
.
nn
.
Sequential
(
StandardLinear
(
dim
,
4
*
dim
),
torch
.
nn
.
GELU
(),
StandardLinear
(
4
*
dim
,
dim
),
).
cuda
()
fused_mlp
=
SwitchBackGlobalMLP
(
dim
,
4
*
dim
).
cuda
()
sb
=
torch
.
nn
.
Sequential
(
SwitchBackGlobalLinear
(
dim
,
4
*
dim
),
torch
.
nn
.
GELU
(),
SwitchBackGlobalLinear
(
4
*
dim
,
dim
),
).
cuda
()
standard_compiled
=
torch
.
compile
(
standard
)
print
(
'Model part 2'
)
repeat
=
32
info
=
{
'repeat'
:
repeat
,
'batch_size'
:
batch
,
'dim'
:
dim
}
# k = 'standard'
# for _ in range(repeat // 2):
# with torch.cuda.amp.autocast():
# out_standard = standard(x1)
# ((2 ** 16) * out_standard).abs().mean().backward()
# torch.cuda.synchronize()
# start = time.time()
# for _ in range(repeat):
# with torch.cuda.amp.autocast():
# out_standard = standard(x1)
# ((2 ** 16) * out_standard).abs().mean().backward()
# torch.cuda.synchronize()
# end = time.time()
# ms = (end - start) / repeat * 1000
# print(f"time {k}: {ms:.3f} ms")
# info[k] = ms
# x1.grad.zero_()
# k = 'my_standard'
# for _ in range(repeat // 2):
# with torch.cuda.amp.autocast():
# out_my_standard = my_standard(x1)
# ((2 ** 16) * out_my_standard).abs().mean().backward()
# torch.cuda.synchronize()
# start = time.time()
# for _ in range(repeat):
# with torch.cuda.amp.autocast():
# out_my_standard = my_standard(x1)
# ((2 ** 16) * out_my_standard).abs().mean().backward()
# torch.cuda.synchronize()
# end = time.time()
# ms = (end - start) / repeat * 1000
# print(f"time {k}: {ms:.3f} ms")
# info[k] = ms
# x1.grad.zero_()
# k = 'standard_compiled'
# for _ in range(repeat // 2):
# with torch.cuda.amp.autocast():
# out_standard_compiled = standard_compiled(x1)
# ((2 ** 16) * out_standard_compiled).abs().mean().backward()
# torch.cuda.synchronize()
# start = time.time()
# for _ in range(repeat):
# with torch.cuda.amp.autocast():
# out_standard_compiled = standard_compiled(x1)
# ((2 ** 16) * out_standard_compiled).abs().mean().backward()
# torch.cuda.synchronize()
# end = time.time()
# ms = (end - start) / repeat * 1000
# print(f"time {k}: {ms:.3f} ms")
# info[k] = ms
# x1.grad.zero_()
k
=
'sb'
for
_
in
range
(
repeat
//
2
):
with
torch
.
cuda
.
amp
.
autocast
():
out_sb
=
sb
(
x1
)
((
2
**
16
)
*
out_sb
).
abs
().
mean
().
backward
()
torch
.
cuda
.
synchronize
()
start
=
time
.
time
()
for
_
in
range
(
repeat
):
with
torch
.
cuda
.
amp
.
autocast
():
out_sb
=
sb
(
x1
)
((
2
**
16
)
*
out_sb
).
abs
().
mean
().
backward
()
torch
.
cuda
.
synchronize
()
end
=
time
.
time
()
ms
=
(
end
-
start
)
/
repeat
*
1000
print
(
f
"time
{
k
}
:
{
ms
:.
3
f
}
ms"
)
info
[
k
]
=
ms
info_json
=
json
.
dumps
(
info
)
with
open
(
"tests/triton_tests/info_mlp_autocast.jsonl"
,
"a"
)
as
file
:
file
.
write
(
info_json
+
"
\n
"
)
#exit()
# err_fused = (out_standard - out_fused).abs().mean()
# err_sb = (out_standard - out_sb).abs().mean()
# print('OUT', err_fused, err_sb)
# err_fused = (standard[d].weight.grad - fused_mlp.linear2.weight.grad).abs().mean()
# err_sb = (standard[d].weight.grad - sb[d].weight.grad).abs().mean()
# print('GW2', err_fused, err_sb)
# err_fused = (standard[0].weight.grad - fused_mlp.linear1.weight.grad).abs().mean()
# err_sb = (standard[0].weight.grad - sb[0].weight.grad).abs().mean()
# print('GW1', err_fused, err_sb)
# err_fused = (x1.grad - x2.grad).abs().mean()
# err_sb = (x1.grad - x3.grad).abs().mean()
# print('GX1', err_fused, err_sb)
# import pdb; pdb.set_trace()
# # NO GELU, ST GRADIENTS, EVERYTHING FINE.
tests/triton_tests/mlp_decomp_autocast_ln.py
deleted
100644 → 0
View file @
30d21d58
import
torch
import
json
from
bitsandbytes.nn.triton_based_modules
import
SwitchBackGlobalMLP
,
SwitchBackGlobalLinear
,
StandardLinear
import
time
if
__name__
==
'__main__'
:
print
(
'Startin'
)
for
dim
in
[
1024
,
1280
,
1408
,
1664
,
2048
]:
for
batch
in
[
2
**
14
,
2
**
15
,
2
**
16
,
2
**
17
]:
x1
=
torch
.
randn
(
batch
,
dim
).
cuda
().
requires_grad_
(
True
)
d
=
2
standard
=
torch
.
nn
.
Sequential
(
torch
.
nn
.
LayerNorm
(
dim
),
torch
.
nn
.
Linear
(
dim
,
4
*
dim
),
torch
.
nn
.
GELU
(),
torch
.
nn
.
Linear
(
4
*
dim
,
dim
),
).
cuda
()
my_standard
=
torch
.
nn
.
Sequential
(
torch
.
nn
.
LayerNorm
(
dim
),
StandardLinear
(
dim
,
4
*
dim
),
torch
.
nn
.
GELU
(),
StandardLinear
(
4
*
dim
,
dim
),
).
cuda
()
fused_mlp
=
SwitchBackGlobalMLP
(
dim
,
4
*
dim
).
cuda
()
sb
=
torch
.
nn
.
Sequential
(
torch
.
nn
.
LayerNorm
(
dim
),
SwitchBackGlobalLinear
(
dim
,
4
*
dim
),
torch
.
nn
.
GELU
(),
SwitchBackGlobalLinear
(
4
*
dim
,
dim
),
).
cuda
()
standard_compiled
=
torch
.
compile
(
standard
)
print
(
'Model part 2'
)
repeat
=
32
info
=
{
'repeat'
:
repeat
,
'batch_size'
:
batch
,
'dim'
:
dim
}
k
=
'standard'
for
_
in
range
(
repeat
//
2
):
with
torch
.
cuda
.
amp
.
autocast
():
out_standard
=
standard
(
x1
)
((
2
**
16
)
*
out_standard
).
abs
().
mean
().
backward
()
torch
.
cuda
.
synchronize
()
start
=
time
.
time
()
for
_
in
range
(
repeat
):
with
torch
.
cuda
.
amp
.
autocast
():
out_standard
=
standard
(
x1
)
((
2
**
16
)
*
out_standard
).
abs
().
mean
().
backward
()
torch
.
cuda
.
synchronize
()
end
=
time
.
time
()
ms
=
(
end
-
start
)
/
repeat
*
1000
print
(
f
"time
{
k
}
:
{
ms
:.
3
f
}
ms"
)
info
[
k
]
=
ms
x1
.
grad
.
zero_
()
k
=
'my_standard'
for
_
in
range
(
repeat
//
2
):
with
torch
.
cuda
.
amp
.
autocast
():
out_my_standard
=
my_standard
(
x1
)
((
2
**
16
)
*
out_my_standard
).
abs
().
mean
().
backward
()
torch
.
cuda
.
synchronize
()
start
=
time
.
time
()
for
_
in
range
(
repeat
):
with
torch
.
cuda
.
amp
.
autocast
():
out_my_standard
=
my_standard
(
x1
)
((
2
**
16
)
*
out_my_standard
).
abs
().
mean
().
backward
()
torch
.
cuda
.
synchronize
()
end
=
time
.
time
()
ms
=
(
end
-
start
)
/
repeat
*
1000
print
(
f
"time
{
k
}
:
{
ms
:.
3
f
}
ms"
)
info
[
k
]
=
ms
x1
.
grad
.
zero_
()
k
=
'standard_compiled'
for
_
in
range
(
repeat
//
2
):
with
torch
.
cuda
.
amp
.
autocast
():
out_standard_compiled
=
standard_compiled
(
x1
)
((
2
**
16
)
*
out_standard_compiled
).
abs
().
mean
().
backward
()
torch
.
cuda
.
synchronize
()
start
=
time
.
time
()
for
_
in
range
(
repeat
):
with
torch
.
cuda
.
amp
.
autocast
():
out_standard_compiled
=
standard_compiled
(
x1
)
((
2
**
16
)
*
out_standard_compiled
).
abs
().
mean
().
backward
()
torch
.
cuda
.
synchronize
()
end
=
time
.
time
()
ms
=
(
end
-
start
)
/
repeat
*
1000
print
(
f
"time
{
k
}
:
{
ms
:.
3
f
}
ms"
)
info
[
k
]
=
ms
x1
.
grad
.
zero_
()
k
=
'sb'
for
_
in
range
(
repeat
//
2
):
with
torch
.
cuda
.
amp
.
autocast
():
out_sb
=
sb
(
x1
)
((
2
**
16
)
*
out_sb
).
abs
().
mean
().
backward
()
torch
.
cuda
.
synchronize
()
start
=
time
.
time
()
for
_
in
range
(
repeat
):
with
torch
.
cuda
.
amp
.
autocast
():
out_sb
=
sb
(
x1
)
((
2
**
16
)
*
out_sb
).
abs
().
mean
().
backward
()
torch
.
cuda
.
synchronize
()
end
=
time
.
time
()
ms
=
(
end
-
start
)
/
repeat
*
1000
print
(
f
"time
{
k
}
:
{
ms
:.
3
f
}
ms"
)
info
[
k
]
=
ms
info_json
=
json
.
dumps
(
info
)
with
open
(
"tests/triton_tests/info_mlp_autocast_ln.jsonl"
,
"a"
)
as
file
:
file
.
write
(
info_json
+
"
\n
"
)
#exit()
# err_fused = (out_standard - out_fused).abs().mean()
# err_sb = (out_standard - out_sb).abs().mean()
# print('OUT', err_fused, err_sb)
# err_fused = (standard[d].weight.grad - fused_mlp.linear2.weight.grad).abs().mean()
# err_sb = (standard[d].weight.grad - sb[d].weight.grad).abs().mean()
# print('GW2', err_fused, err_sb)
# err_fused = (standard[0].weight.grad - fused_mlp.linear1.weight.grad).abs().mean()
# err_sb = (standard[0].weight.grad - sb[0].weight.grad).abs().mean()
# print('GW1', err_fused, err_sb)
# err_fused = (x1.grad - x2.grad).abs().mean()
# err_sb = (x1.grad - x3.grad).abs().mean()
# print('GX1', err_fused, err_sb)
# import pdb; pdb.set_trace()
# # NO GELU, ST GRADIENTS, EVERYTHING FINE.
tests/triton_tests/plot1.png
deleted
100644 → 0
View file @
30d21d58
119 KB
tests/triton_tests/plot2.pdf
deleted
100644 → 0
View file @
30d21d58
File deleted
tests/triton_tests/plot2.png
deleted
100644 → 0
View file @
30d21d58
50.8 KB
tests/triton_tests/plot2.py
deleted
100644 → 0
View file @
30d21d58
import
matplotlib.pyplot
as
plt
import
pandas
as
pd
import
numpy
as
np
import
os
import
matplotlib.gridspec
as
gridspec
cmap
=
plt
.
get_cmap
(
'cool'
)
if
__name__
==
'__main__'
:
fig
=
plt
.
figure
(
tight_layout
=
True
,
figsize
=
(
6
,
3.5
))
gs
=
gridspec
.
GridSpec
(
1
,
1
)
rdf
=
pd
.
read_json
(
'tests/triton_tests/info.jsonl'
,
lines
=
True
)
ax
=
fig
.
add_subplot
(
gs
[
0
,
0
])
# now plot the % speedup for different batch sizes
for
j
,
batch_size
in
enumerate
([
2
**
14
,
2
**
15
,
2
**
16
,
2
**
17
]):
all_xs
,
all_ys
=
[],
[]
for
k
,
marker
,
ls
,
color
,
name
in
[
(
'x_quantize_rowwise+g_quantize_rowwise+w_quantize_global+w_quantize_global_transpose+standard_gw+global_fwd+global_bwd'
,
'o'
,
'-'
,
'C4'
,
'SwitchBack int8 (total time)'
),
(
'x_quantize_rowwise+g_quantize_rowwise+w_quantize_global+w_quantize_global_transpose'
,
'o'
,
'-'
,
'C4'
,
'SwitchBack int8 (total time)'
),
]:
xs
,
ys
=
[],
[]
df
=
rdf
[
rdf
.
batch_size
==
batch_size
]
for
embed_dim
in
[
1024
,
1280
,
1408
,
1664
,
2048
,
4096
]:
df_
=
df
[
df
.
dim_in
==
embed_dim
]
df_
=
df_
[
df_
.
dim_out
==
embed_dim
*
4
]
xs
.
append
(
embed_dim
)
y_
=
0
for
k_
in
k
.
split
(
'+'
):
y_
+=
df_
[
k_
].
values
[
0
]
df_
=
df
[
df
.
dim_in
==
embed_dim
*
4
]
df_
=
df_
[
df_
.
dim_out
==
embed_dim
]
for
k_
in
k
.
split
(
'+'
):
y_
+=
df_
[
k_
].
values
[
0
]
ys
.
append
(
y_
*
0.5
)
all_xs
.
append
(
xs
)
all_ys
.
append
(
ys
)
color
=
cmap
(
j
*
0.25
)
real_ys
=
[
100
*
all_ys
[
1
][
i
]
/
all_ys
[
0
][
i
]
for
i
in
range
(
len
(
all_ys
[
0
]))]
markers
=
[
'^'
,
'v'
,
'P'
,
'o'
]
ax
.
plot
(
all_xs
[
0
],
real_ys
,
color
=
color
,
label
=
f
'batch * sequence length =
{
batch_size
}
'
,
marker
=
markers
[
j
],
markersize
=
5
if
marker
==
's'
else
5
)
ax
.
legend
()
ax
.
set_xlabel
(
'dim'
,
fontsize
=
13
)
ax
.
set_xscale
(
'log'
)
ax
.
grid
()
ax
.
set_ylabel
(
r
'% time occupied by quantize ops'
,
fontsize
=
12
)
ax
.
tick_params
(
axis
=
'x'
,
labelsize
=
11
)
ax
.
tick_params
(
axis
=
'y'
,
labelsize
=
11
)
ax
.
set_xticks
([
1024
,
2048
,
4096
])
ax
.
set_xticklabels
([
1024
,
2048
,
4096
])
ax
.
set_xticks
([],
minor
=
True
)
#ax.set_title(' Linear layer summary, varying dimensions', fontsize=10, loc='left', y=1.05, pad=-20)
plt
.
savefig
(
'tests/triton_tests/plot2.pdf'
,
bbox_inches
=
'tight'
)
tests/triton_tests/plot3.pdf
deleted
100644 → 0
View file @
30d21d58
File deleted
tests/triton_tests/plot3.png
deleted
100644 → 0
View file @
30d21d58
57 KB
tests/triton_tests/plot3.py
deleted
100644 → 0
View file @
30d21d58
import
matplotlib.pyplot
as
plt
import
pandas
as
pd
import
numpy
as
np
import
os
import
matplotlib.lines
as
mlines
import
matplotlib.gridspec
as
gridspec
cmap
=
plt
.
get_cmap
(
'cool'
)
if
__name__
==
'__main__'
:
fig
=
plt
.
figure
(
tight_layout
=
True
,
figsize
=
(
12
,
3.5
))
gs
=
gridspec
.
GridSpec
(
1
,
3
)
rdf1
=
pd
.
read_json
(
'tests/triton_tests/info_mlp_autocast_ln.jsonl'
,
lines
=
True
)
ax
=
fig
.
add_subplot
(
gs
[
0
,
0
])
# now plot the % speedup for different batch sizes
for
j
,
batch_size
in
enumerate
([
2
**
15
,
2
**
17
]):
#, 2**15, 2**17, 2**17]):
all_xs
,
all_ys
=
{},
{}
for
k
,
marker
,
ls
,
color
,
name
in
[
(
'standard_compiled'
,
'o'
,
'-'
,
'C0'
,
'standard compiled (total time)'
),
#('standard', 'o', '-', 'C1', 'standard (total time)'),
(
'my_standard'
,
'o'
,
'-'
,
'C2'
,
'my standard (total time)'
),
(
'sb'
,
'o'
,
'-'
,
'C4'
,
'SwitchBack int8 (total time)'
),
]:
xs
,
ys
=
[],
[]
df
=
rdf1
[
rdf1
.
batch_size
==
batch_size
]
for
embed_dim
in
[
1024
,
1280
,
1408
,
1664
,
2048
]:
df_
=
df
[
df
.
dim
==
embed_dim
]
xs
.
append
(
embed_dim
)
y_
=
0
for
k_
in
k
.
split
(
'+'
):
y_
+=
df_
[
k_
].
values
[
0
]
ys
.
append
(
y_
)
all_xs
[
k
]
=
xs
all_ys
[
k
]
=
ys
#ax.plot(xs, ys, color=color, label=f'batch * sequence length = {batch_size}', marker=marker, markersize=5 if marker=='s' else 5)
color
=
cmap
(
float
(
j
))
speedup_over_my_standard
=
[
-
100
*
(
all_ys
[
'sb'
][
i
]
-
all_ys
[
'my_standard'
][
i
])
/
all_ys
[
'my_standard'
][
i
]
for
i
in
range
(
len
(
all_ys
[
'my_standard'
]))]
speedup_over_compile
=
[
-
100
*
(
all_ys
[
'sb'
][
i
]
-
all_ys
[
'standard_compiled'
][
i
])
/
all_ys
[
'standard_compiled'
][
i
]
for
i
in
range
(
len
(
all_ys
[
'standard_compiled'
]))]
ax
.
plot
(
xs
,
speedup_over_my_standard
,
color
=
color
,
label
=
f
'batch * sequence length =
{
batch_size
}
'
,
marker
=
'o'
,
markersize
=
5
if
marker
==
's'
else
5
)
ax
.
plot
(
xs
,
speedup_over_compile
,
color
=
color
,
label
=
f
'batch * sequence length =
{
batch_size
}
'
,
marker
=
'o'
,
markersize
=
5
if
marker
==
's'
else
5
,
linestyle
=
'--'
)
#ax.legend()
ax
.
set_xlabel
(
'dim'
,
fontsize
=
13
)
ax
.
set_xscale
(
'log'
)
ax
.
grid
()
ax
.
set_ylabel
(
r
'% speedup'
,
fontsize
=
12
)
ax
.
tick_params
(
axis
=
'x'
,
labelsize
=
11
)
ax
.
tick_params
(
axis
=
'y'
,
labelsize
=
11
)
ax
.
set_xticks
([
1024
,
2048
])
ax
.
set_xticklabels
([
1024
,
2048
])
ax
.
set_xticks
([],
minor
=
True
)
ax
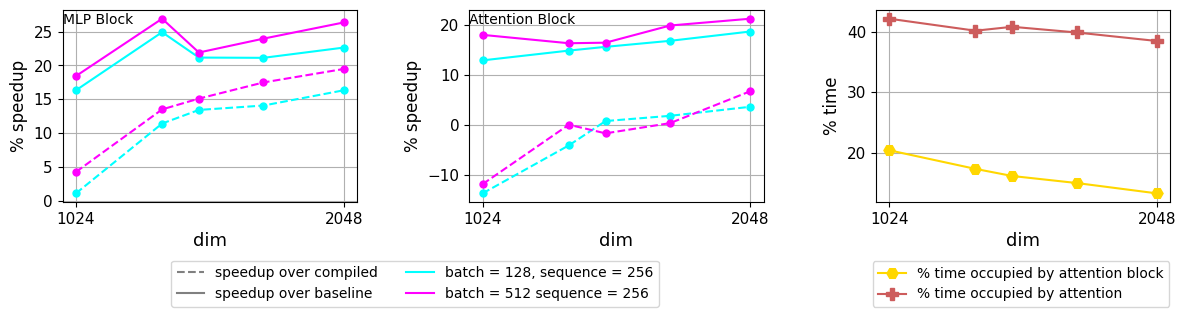
.
set_title
(
'MLP Block'
,
fontsize
=
10
,
loc
=
'left'
,
y
=
1.07
,
pad
=-
20
)
##########################################
rdf2
=
pd
.
read_json
(
'tests/triton_tests/attn_info_ln.jsonl'
,
lines
=
True
)
ax
=
fig
.
add_subplot
(
gs
[
0
,
1
])
for
j
,
batch_size
in
enumerate
([
2
**
15
,
2
**
17
]):
#, 2**15, 2**17, 2**17]):
all_xs
,
all_ys
=
{},
{}
for
k
,
marker
,
ls
,
color
,
name
in
[
(
'standard_compiled'
,
'o'
,
'-'
,
'C0'
,
'standard compiled (total time)'
),
#('standard', 'o', '-', 'C1', 'standard (total time)'),
(
'my_standard'
,
'o'
,
'-'
,
'C2'
,
'my standard (total time)'
),
(
'sb'
,
'o'
,
'-'
,
'C4'
,
'SwitchBack int8 (total time)'
),
]:
xs
,
ys
=
[],
[]
df
=
rdf2
[
rdf2
.
batch_size
==
batch_size
]
for
embed_dim
in
[
1024
,
1280
,
1408
,
1664
,
2048
]:
df_
=
df
[
df
.
dim
==
embed_dim
]
xs
.
append
(
embed_dim
)
y_
=
0
for
k_
in
k
.
split
(
'+'
):
y_
+=
df_
[
k_
].
values
[
0
]
ys
.
append
(
y_
)
all_xs
[
k
]
=
xs
all_ys
[
k
]
=
ys
#ax.plot(xs, ys, color=color, label=f'batch * sequence length = {batch_size}', marker=marker, markersize=5 if marker=='s' else 5)
color
=
cmap
(
float
(
j
))
speedup_over_my_standard
=
[
-
100
*
(
all_ys
[
'sb'
][
i
]
-
all_ys
[
'my_standard'
][
i
])
/
all_ys
[
'my_standard'
][
i
]
for
i
in
range
(
len
(
all_ys
[
'my_standard'
]))]
speedup_over_compile
=
[
-
100
*
(
all_ys
[
'sb'
][
i
]
-
all_ys
[
'standard_compiled'
][
i
])
/
all_ys
[
'standard_compiled'
][
i
]
for
i
in
range
(
len
(
all_ys
[
'standard_compiled'
]))]
ax
.
plot
(
xs
,
speedup_over_my_standard
,
color
=
color
,
label
=
f
'batch * sequence length =
{
batch_size
}
'
,
marker
=
'o'
,
markersize
=
5
if
marker
==
's'
else
5
)
ax
.
plot
(
xs
,
speedup_over_compile
,
color
=
color
,
label
=
f
'batch * sequence length =
{
batch_size
}
'
,
marker
=
'o'
,
markersize
=
5
if
marker
==
's'
else
5
,
linestyle
=
'--'
)
speedup_compiled
=
mlines
.
Line2D
([],
[],
linestyle
=
'--'
,
color
=
'gray'
,
label
=
'speedup over compiled'
)
speedup_baseline
=
mlines
.
Line2D
([],
[],
linestyle
=
'-'
,
color
=
'gray'
,
label
=
'speedup over baseline'
)
batch_size_4
=
mlines
.
Line2D
([],
[],
linestyle
=
'-'
,
color
=
cmap
(
0.
),
label
=
f
'batch =
{
int
(
2
**
15
//
256
)
}
, sequence =
{
256
}
'
)
batch_size_8
=
mlines
.
Line2D
([],
[],
linestyle
=
'-'
,
color
=
cmap
(
1.
),
label
=
f
'batch =
{
int
(
2
**
17
/
256
)
}
sequence =
{
256
}
'
)
# Create the legend with the proxy artists
# adjust plots so that they dont get squished by putting the legend under both
plt
.
subplots_adjust
(
left
=
0.2
)
plt
.
subplots_adjust
(
right
=
0.8
)
fig
.
legend
(
handles
=
[
speedup_compiled
,
speedup_baseline
,
batch_size_4
,
batch_size_8
],
ncol
=
2
,
loc
=
'upper center'
,
bbox_to_anchor
=
(
0.35
,
0.255
))
ax
.
set_xlabel
(
'dim'
,
fontsize
=
13
)
ax
.
set_xscale
(
'log'
)
ax
.
grid
()
ax
.
set_ylabel
(
r
'% speedup'
,
fontsize
=
12
)
ax
.
tick_params
(
axis
=
'x'
,
labelsize
=
11
)
ax
.
tick_params
(
axis
=
'y'
,
labelsize
=
11
)
ax
.
set_xticks
([
1024
,
2048
])
ax
.
set_xticklabels
([
1024
,
2048
])
ax
.
set_xticks
([],
minor
=
True
)
ax
.
set_title
(
'Attention Block'
,
fontsize
=
10
,
loc
=
'left'
,
y
=
1.07
,
pad
=-
20
)
##########################################
ax
=
fig
.
add_subplot
(
gs
[
0
,
2
])
for
j
,
batch_size
in
enumerate
([
2
**
15
]):
#, 2**15, 2**17, 2**17]):
all_xs
,
all_ys
=
{},
{}
for
k
,
marker
,
ls
,
color
,
name
,
b
in
[
(
'standard_compiled'
,
'o'
,
'-'
,
'C0'
,
'standard compiled (total time)'
,
False
),
(
'standard_compiled'
,
'o'
,
'-'
,
'C0'
,
'standard compiled (total time)'
,
True
),
#('standard', 'o', '-', 'C1', 'standard (total time)'),
#('my_standard', 'o', '-', 'C2', 'my standard (total time)'),
(
'attn'
,
'o'
,
'-'
,
'C4'
,
'SwitchBack int8 (total time)'
,
True
),
]:
rdf
=
rdf2
if
b
else
rdf1
xs
,
ys
=
[],
[]
df
=
rdf
[
rdf
.
batch_size
==
batch_size
]
for
embed_dim
in
[
1024
,
1280
,
1408
,
1664
,
2048
]:
df_
=
df
[
df
.
dim
==
embed_dim
]
xs
.
append
(
embed_dim
)
y_
=
0
for
k_
in
k
.
split
(
'+'
):
y_
+=
df_
[
k_
].
values
[
0
]
ys
.
append
(
y_
)
all_xs
[
k
+
str
(
int
(
b
))]
=
xs
all_ys
[
k
+
str
(
int
(
b
))]
=
ys
#ax.plot(xs, ys, color=color, label=f'batch * sequence length = {batch_size}', marker=marker, markersize=5 if marker=='s' else 5)
print
(
all_ys
.
keys
())
all_ys
[
'standard_compiled'
]
=
[
x
+
y
for
x
,
y
in
zip
(
all_ys
[
'standard_compiled0'
],
all_ys
[
'standard_compiled1'
])]
speedup_over_my_standard
=
[
100
*
all_ys
[
'attn1'
][
i
]
/
(
all_ys
[
'standard_compiled'
][
i
]
+
all_ys
[
'attn1'
][
i
])
for
i
in
range
(
len
(
all_ys
[
'standard_compiled'
]))]
ax
.
plot
(
xs
,
speedup_over_my_standard
,
color
=
'gold'
,
label
=
r
'% time occupied by attention'
,
marker
=
'H'
,
markersize
=
8
)
speedup_over_my_standard
=
[
100
*
all_ys
[
'standard_compiled1'
][
i
]
/
(
all_ys
[
'standard_compiled0'
][
i
]
+
all_ys
[
'standard_compiled1'
][
i
])
for
i
in
range
(
len
(
all_ys
[
'standard_compiled'
]))]
ax
.
plot
(
xs
,
speedup_over_my_standard
,
color
=
'indianred'
,
label
=
r
'% time occupied by attention block'
,
marker
=
'P'
,
markersize
=
8
)
ax
.
legend
(
bbox_to_anchor
=
(
1.02
,
-
0.27
))
ax
.
set_xlabel
(
'dim'
,
fontsize
=
13
)
ax
.
set_xscale
(
'log'
)
ax
.
grid
()
ax
.
set_ylabel
(
r
'% time'
,
fontsize
=
12
)
ax
.
tick_params
(
axis
=
'x'
,
labelsize
=
11
)
ax
.
tick_params
(
axis
=
'y'
,
labelsize
=
11
)
ax
.
set_xticks
([
1024
,
2048
])
ax
.
set_xticklabels
([
1024
,
2048
])
ax
.
set_xticks
([],
minor
=
True
)
plt
.
savefig
(
'tests/triton_tests/plot3.pdf'
,
bbox_inches
=
'tight'
)
tests/triton_tests/rowwise.py
deleted
100644 → 0
View file @
30d21d58
import
time
import
torch
import
torch
import
torch.nn
as
nn
import
bitsandbytes.nn
as
bnn
from
bitsandbytes.nn.triton_based_modules
import
SwitchBackLinear
,
SwitchBackGlobalLinear
from
bitsandbytes.nn.triton_utils.v0.quantize_rowwise_nogroup
import
quantize_rowwise_nogroup
# 256 * 256 * 4096 _> 0.7
# 256 * 128 * 8192 -> 10
if
__name__
==
'__main__'
:
torch
.
manual_seed
(
0
)
# hparams
repeat
=
16
dim
=
8192
layers
=
4
batch_size
=
256
*
128
# simulate forward pass
x
=
torch
.
randn
(
batch_size
,
dim
,
dtype
=
torch
.
float16
).
cuda
()
for
_
in
range
(
repeat
//
2
):
quantize_rowwise_nogroup
(
x
)
torch
.
cuda
.
synchronize
()
start
=
time
.
time
()
for
_
in
range
(
repeat
):
quantize_rowwise_nogroup
(
x
)
torch
.
cuda
.
synchronize
()
end
=
time
.
time
()
print
(
f
"time:
{
(
end
-
start
)
/
repeat
*
1000
:.
3
f
}
ms"
)
\ No newline at end of file
Prev
1
2
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}
{kind=link}