
TE Gemma tutorial attempt#2 (#1839)
* add tutorial files and other local changes Signed-off-by:Sudhakar Singh <sudhakars@nvidia.com> * remove extraneous code for easy debu Signed-off-by:
Charlene Yang <8636796+cyanguwa@users.noreply.github.com> * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * changes to make quantizers work with fp8_calibration Signed-off-by:
pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by:
Showing
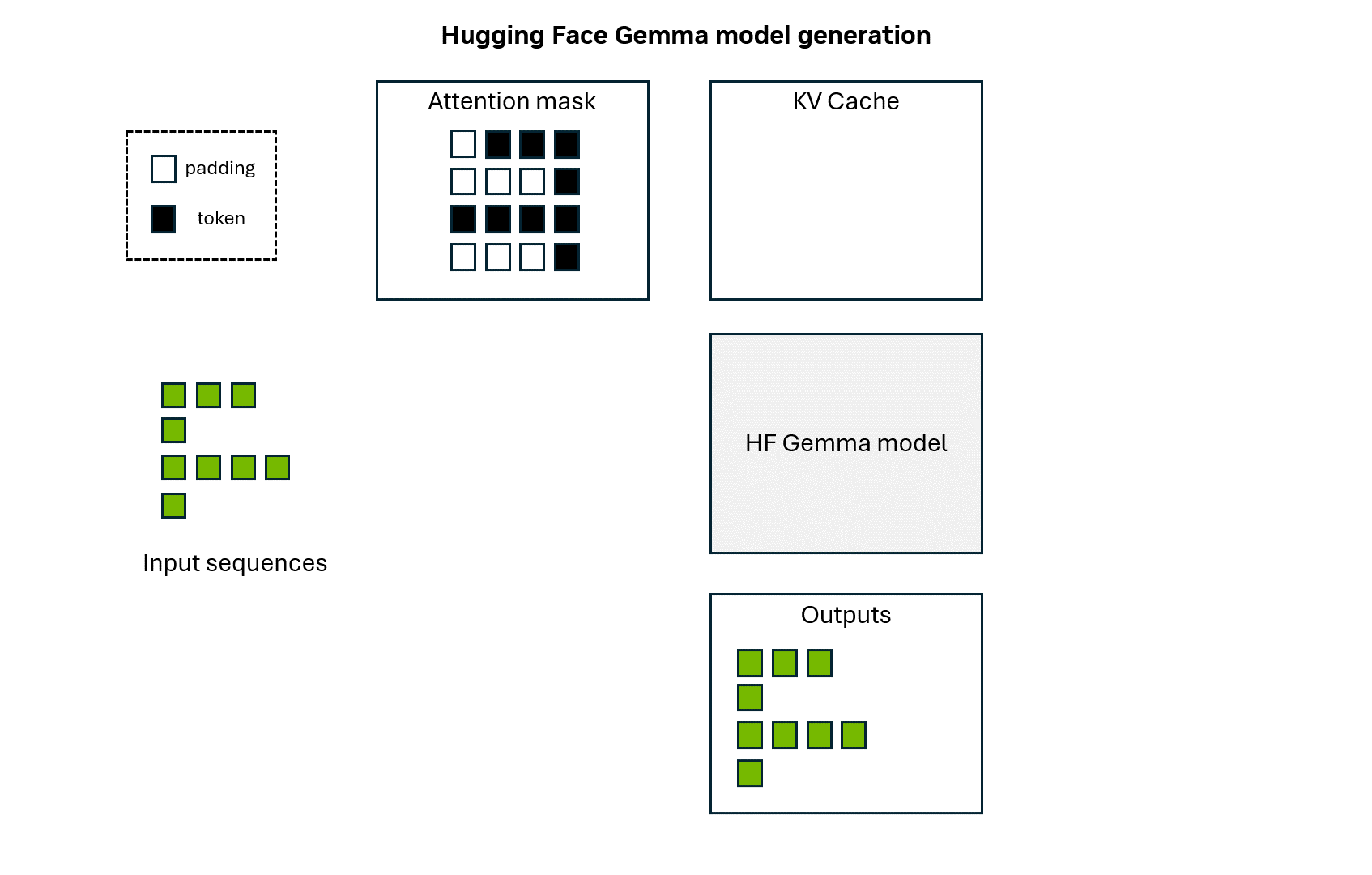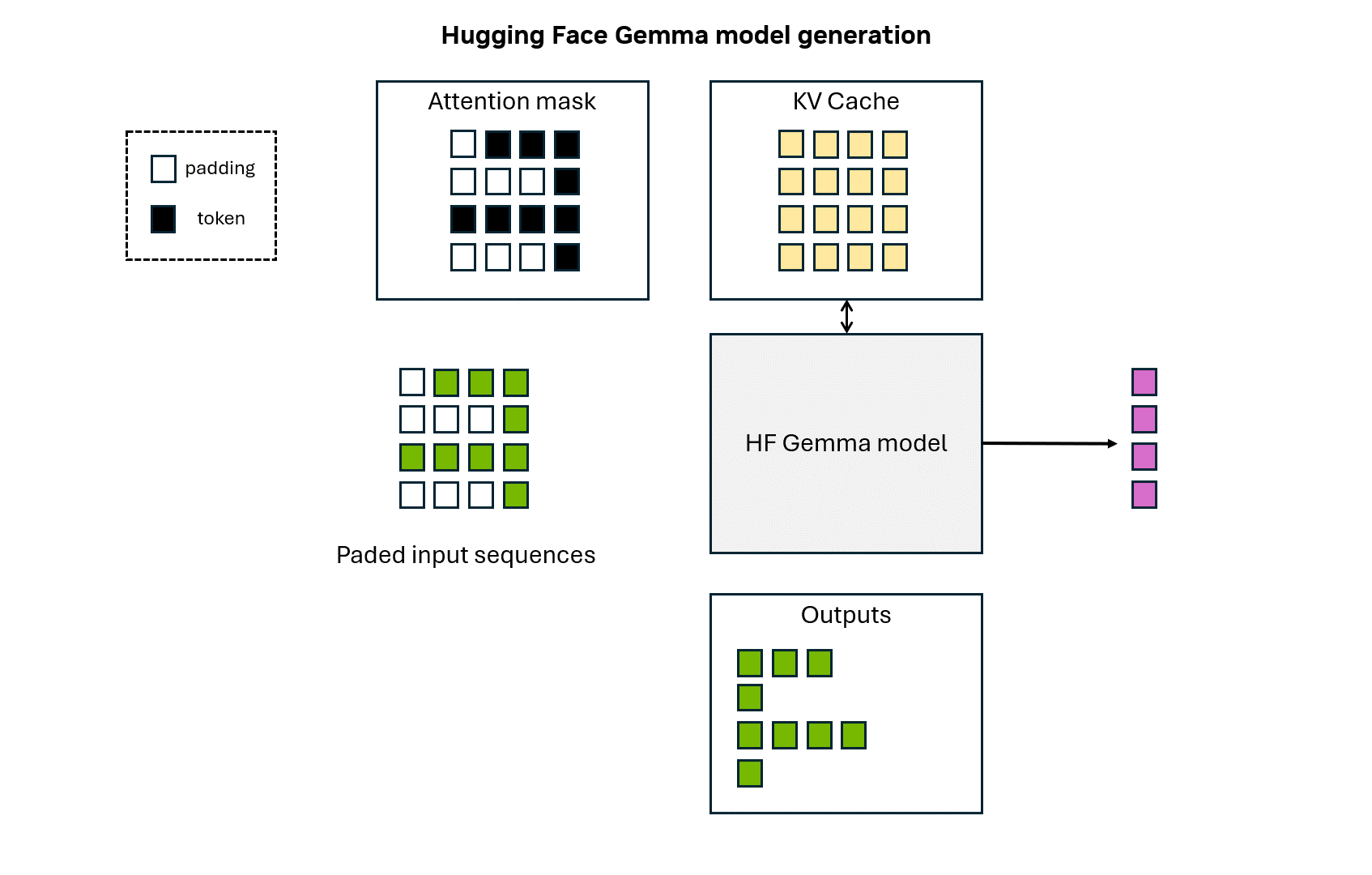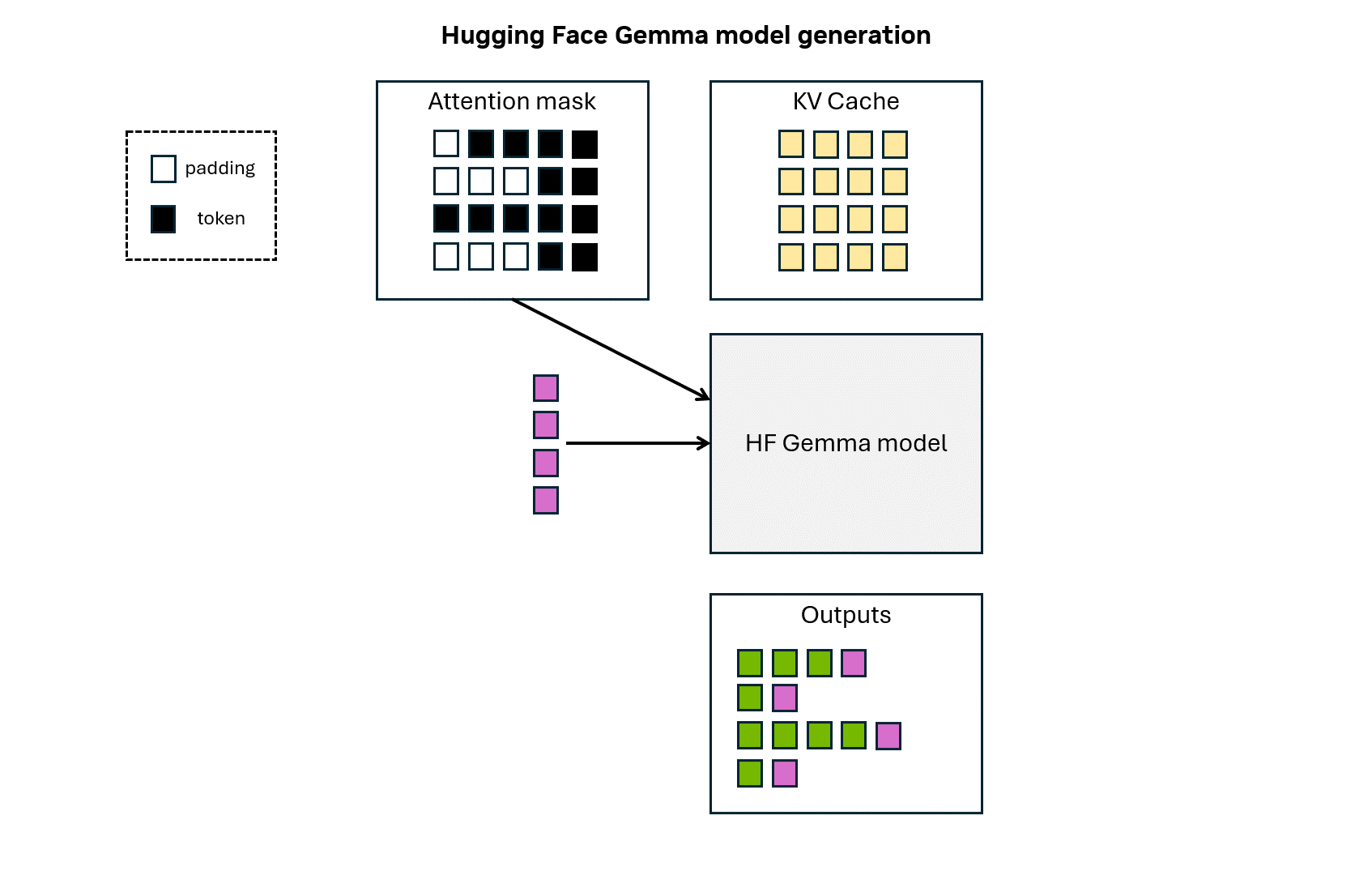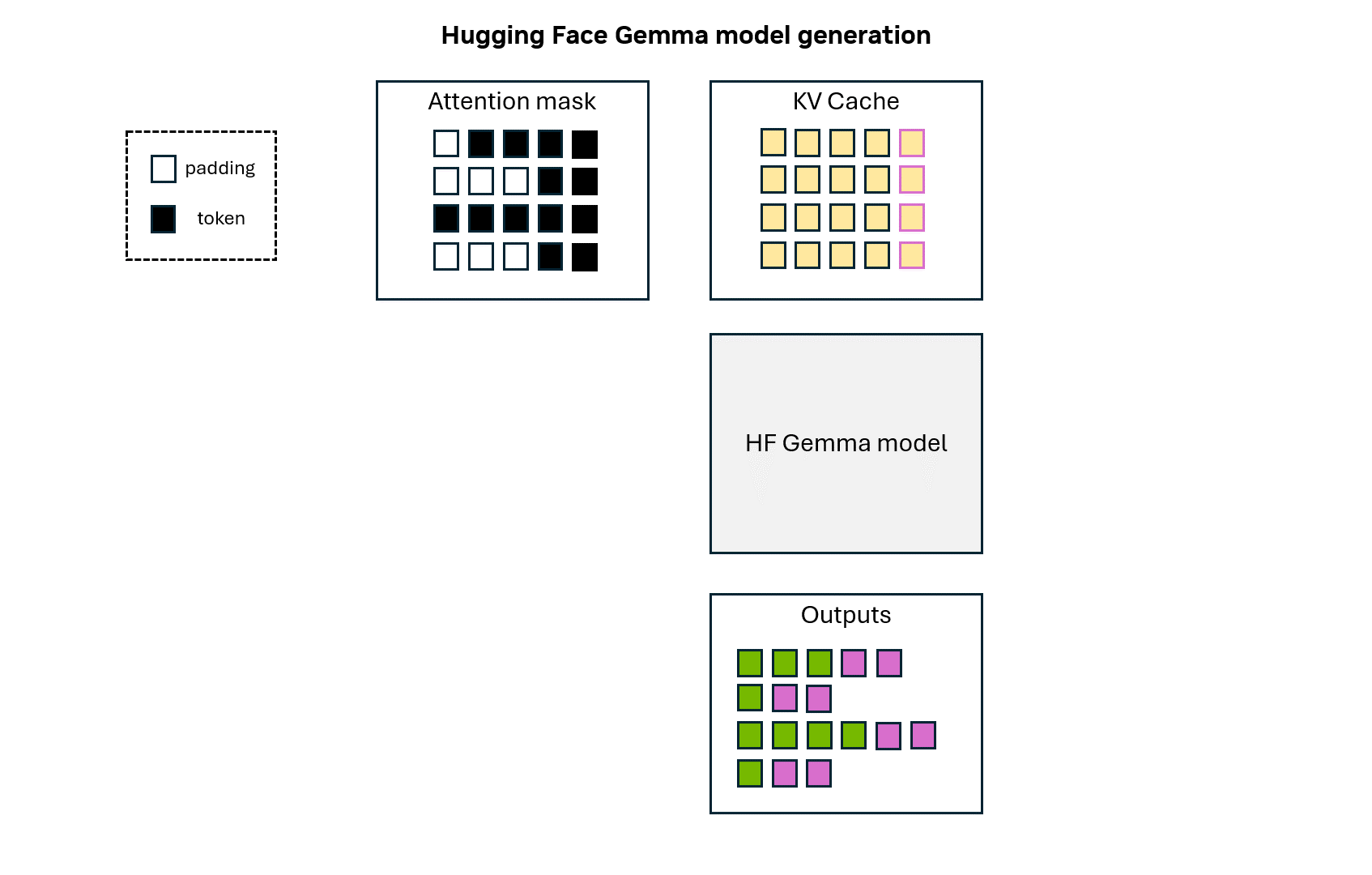
132 KB

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}